




この記事は毎週必ず記事がでるテックブログLoglass Tech Blog Sprint の79週目の記事です!
2年間連続達成まで残り27週となりました!
昨今、データエンジニアリングの重要性が高まるなか、データレイクハウスという言葉を聞く機会が増えてきました。一方で、BI、DWH、データレイクといった分野は、色のついた商用製品であったり大規模な技術スタックになったりと気軽に触りにくい印象があったりもして個人的に最近はあまり触れてこなかった分野でした(15年程前はだいぶBI製品にお世話になりましたが)。
でも、実はかじってみると美味しい、単なる食わず嫌いだったかもしれません。この記事では前半にデータレイクハウスを概観しつつ後半に軽くハンズオンしてみたいと思います。チョイスは、最も使われるフォーマットであるApache Parquet 、S3 Tables の元となっているApache Iceberg 、Amazon Athena のエンジンになっているApache Trino です。
データレイクハウス ?
データレイクハウスにはどう変遷していったのでしょうか。バズワードなのでしょうか。
データ分析といえばまずDWH(データウェアハウス)です。各種システムからデータを抽出し、一元的に整理・管理することで分析を可能にする仕組みです(部門別など特化した要件に絞ったデータマートというワードもあったりします)。しかし、DWHではあらかじめ定義されたスキーマに従うため、非構造化データや新しい種類のデータを柔軟に取り込む余地がありませんでした。
この課題を解消しようと生まれたのがデータレイクという考え方です。生データをそのまま格納しておき、必要に応じて後から加工・分析することで、柔軟性を高める手法です。ただし、いざ大量にデータを溜め込むと、どのファイルが何のデータなのかや、バージョン管理・メタデータ管理などが追いつかず、データレイクでは大量のファイルがあるだけで整理されていない状態 に陥ることもありました。
そして、こうした問題を解消し、DWHのようなデータ管理・クエリ性能と、データレイクのような柔軟性・拡張性を両立させようというのがデータレイクハウスです。オブジェクトストレージ上のデータをテーブル管理(スキーマ管理やトランザクション、バージョニングなど)できる仕組みを導入し、SQLベースで効率的な分析やクエリを実行できるようにします。
すごくよさそうです。
データレイクハウスを構成するレイヤー
データレイクハウスは以下の4レイヤーで整理されます。それぞれに技術の選択肢があり特性や状況に応じて組み合わせてシステムを構成します。ベンダーロックインされにくいとも言えそうです。
| レイヤー | 概要 |
|---|---|
| Compute Engine | 保存したデータへ実際にクエリを投げ、集計・分析を行うエンジン。SQLベースのI/Fを備えているものが多い |
| Table Format | ストレージ上のファイル群を“テーブル”として認識・操作 できるよう管理する技術。スナップショット管理やスキーマの進化、ACIDトランザクションなどをサポート |
| File Format | 保存したデータをどの形式で管理するか。列指向フォーマットの Parquet は支持を得ているが、ORC や Avro なども。従来のCSVやJSONも該当 |
| Object Storage | 大量のファイルを分散管理するストレージ。スケーラブルかつ低コストなクラウド上のストレージを主に想定する。 |
特にストレージとエンジンの分離 は大きな特徴とされています。もう少し見ていきましょう。最下位の Object Storage レイヤーは、 Amazon S3、GCS、ADLS なので割愛しますが、上位3レイヤーを少し掘り下げてみます。
File Format – Parquet
いわゆるファイルなのでCSVやJSONなどと同列ですが、Avro、ORC、Parquetなどがデータレイクハウスでは選択肢に上がるようです。その中でも、Parquet(パーケ、パルケ)は支持を得ています。特に次の2点を押さえておくと良さそうです。
列指向フォーマット(カラムナー)
Parquetの大きな特徴は、データを“列ごと”にまとめて保存することです。従来の行指向(例:CSV)は1行単位でデータが並ぶことに対して、Parquetは1列ごとにデータを固めて保存する ため、分析における「特定カラムだけ集計したい」というケースにおいて、不要なカラムを読み飛ばし、クエリが高速化しやすいというメリットがあります。
列ごとにまとめることは似通ったデータが偏ることでもあるため圧縮の効率も上がります。I/Oコストの低減にもつながるため、クエリだけでなくデータ保存もより高速になります。
統計情報のメタデータ
Parquetファイルはフッタに「スキーマ情報」「各カラムの統計情報」「Row Group(データブロック)の情報」などを格納します。たとえば、
- カラムの物理型・論理型(INT, STRING など)
- それぞれのRow Groupのオフセット、圧縮方式、圧縮後サイズ
- カラム統計量(min/max, nullカウントなど)
公式サイトでは以下の図で表現されています。
Parquet の内部をよく知るには、以下の記事が非常に参考になります。
https://mrasu.hatenablog.jp/entry/2024/09/22/190000
このファイル単位のメタデータに加えて、次の Table Format レイヤーではファイル群をまとめてテーブルとしてのメタデータを管理し、より高度な機能を提供可能にしています。
Table Format – Iceberg
テーブルフォーマットは、オブジェクトストレージ上の複数のファイルを仮想的にテーブルとして扱い、いわゆるACIDトランザクションやスナップショット管理、スキーマの変更管理、パーティショニングなどをサポートします。代表的なテーブルフォーマットには、Apache Iceberg, Delta Lake, Apache Hudi などがあります。
この中でも、Amazon S3 Tables に組み込まれた Iceberg(アイスバーグ)をピックアップして、その特徴を見てみましょう。
https://aws.amazon.com/jp/about-aws/whats-new/2024/12/amazon-s3-tables-apache-iceberg-tables-analytics-workloads/
スキーマ管理とその変更管理、パーティショニング
Iceberg は、テーブルスキーマの追加・削除や型変更など、スキーマが変化するケースにも柔軟に対応できます。さらに、パーティショニングの定義を後から見直して変えていくことも可能でより効率的な分割とクエリ最適化が行えます。たとえば、これまで「月」でパーティションしていたけど、今後は「日」でパーティションしていく、といったことに柔軟に対応できます。
スナップショットによるバージョン管理
Iceberg は、テーブルの状態をスナップショットとして記録する仕組みを持っています。各スナップショットはどのファイルがテーブルに含まれているかのメタデータを持ち、スナップショットを切り替えるだけで「テーブルの特定時点の状態」に簡単にアクセスできます。これをタイムトラベルと呼ぶこともあり、過去のバージョンにクエリを投げて分析することが可能です。
ACIDトランザクション
データの更新や削除などを複数のクライアントが同時に実行する場合、整合性を保つにはトランザクションが必要となります。Icebergはアトミックなコミットを実現しており、一貫性のあるテーブルの状態を維持できます。従来のデータレイクが苦手としていたレコード単位のアップサート(更新/挿入/削除)も実現可能です。
マニフェストファイル
テーブルの情報は、マニフェスト(Manifest) と呼ばれるメタデータファイルで管理されます。マニフェストには、
- 対象となるデータファイル(例:Parquet)の一覧
- 各ファイルに含まれる行数や統計情報(min/maxなど)
が記載され、上位レイヤーとなるクエリエンジンがクエリを最適化する手がかりになります。Icebergはこのマニフェストを通じて分散環境でも一貫性をもってテーブルを扱えるように設計されています。
Iceberg は以下のイメージで紹介されることが多いです。Iceberg Catalog と metadata layer が Iceberg の持ち物です。

Icebergのようなテーブルフォーマットレイヤーによって、ファイルベースのデータレイクの柔軟性とともにデータベースのような堅牢性を持ち合わせる ことが可能になっています。
Iceberg についても、紹介しきれない分も含めていくつも素敵な記事が存在します。
https://bering.hatenadiary.com/entry/2023/09/24/175953
https://note.com/bunsekiya_tech/n/n18795b8d032a
書籍もよいですね。輪読記事もあります。
https://learning.oreilly.com/library/view/apache-iceberg-the/9781098148614/
https://zenn.dev/dataheroes/articles/iceberg-the-definitive-guide-summary
Compute Engine – Trino
データを「Parquet」形式で保存し、「Iceberg」を使ってテーブルとして管理する仕組みを見てきましたが、それらのデータに実際にクエリを投げて分析を行うためのレイヤーである Compute Engine が別に必要です。データレイクハウスでは、大量のデータをスケーラブルに読み取り・集計・分析するための Compute Engine(a.k.a. クエリエンジン、分散処理エンジン)は、その実現のために複数のワーカーで並列分散処理を行い、高速にSQLクエリを実行できるようにする役割を担います。Spark、Hive、Flink、Trino などが代表的な選択肢です。
Trino は、もともと Meta(Facebook)で開発された分散SQLエンジン「Presto」をルーツとしています。Amazon Athena にも組み込まれていたりします。
「データレイク上のファイルにSQLを投げる」だけでなく、RDBやNoSQLなど他のデータソースとも連携し、フェデレーテッドクエリ (複数のデータソースを横断するクエリ) を実行できることは大きな特徴です。ここは後半のハンズオンで試してみます。
Trinoの主な特徴
- 多種多様なコネクター: データレイク(例:S3 + Parquet + Iceberg)だけでなく、MySQL、PostgreSQL、MongoDB、Elasticsearch などのデータソースも単一の SQL で横断的にクエリできます。
- 高いパフォーマンスと低レイテンシ: メモリベースの処理を重視したアーキテクチャで、特にインタラクティブなクエリに強いです。大規模データに対してもスケールアウトすることで応答速度を維持できます。
- 標準SQL互換性: ほぼ標準 SQL に準拠した構文をサポートするため、RDB のクエリ経験者が比較的スムーズに移行できます。
- カタログへの対応: Iceberg のカタログなどを参照し、そこからテーブル定義を読み込み、クエリを投げられます。データレイクハウス環境では、Iceberg と Trino を組み合わせることで、バージョン管理やACIDトランザクション管理を実現できます。
データがどこにあっても、単一のSQLクエリで、大規模に並列に処理できるというのは非常に魅力的です。また、データの投入もできるのでETL/ELTとしての役割を担うことも可能です。
コントリビューターの TreasureData 竹添さんの情報発信は要ウォッチです。
https://takezoe.hatenablog.com/
網羅された書籍もあります。
https://learning.oreilly.com/library/view/trino-the-definitive/9781098137229/
ハンズオン
ここまでで、「Parquet」+「Iceberg」+「Trino」というレイクハウスの主要コンポーネントが揃いました。後半では、実際にどのように構築・利用するのか、簡単なハンズオンを通じて体験していきましょう。ハンズオンはParquet + Iceberg + Trino とPostgreSQL を組み合わせたミニマムなものです。流れは以下のとおりです。
- Trino + Iceberg のセットアップ
- Iceberg テーブルの作成 & メタデータの探索
- PostgreSQL への接続確認
- Trino 上でのデータ投入とファイル確認
- Trino で SQL クエリを実行
- Trino のコンソールを閲覧
全体像は以下のとおりです。

1. Trino + Iceberg のセットアップ
まずはTrino 単体でIceberg を使う最小構成を作ります。Iceberg は「テーブルフォーマット」なので、Trino のプラグインとして読み込み、Iceberg のメタデータはApache Polaris に格納することにします。
いくつかのカタログをみていく中で、Apaceh Polaris の getting-started/trino がよさそうでしたので、そちらに沿ってセットアップしていきます。RESTカタログが今度の主流になりそうというのもあります。Polaris はまだ Incubating フェーズですので今後はセットアップがもっと容易になっていくことでしょう。
(余談)カタログ技術選択の変遷
カタログの実装にはいくつかの種類があることは認識していましたが、予想外に苦戦しました。その変遷を残しておきます。分かる人にはすぐわかりそうですが初見殺しでした。笑
- まず最も単純な Hadoop カタログ。これはTrino ではスタンドアロンのHadoopカタログはサポートされていないようです。Spark だったらスッといけたのかも知れません。
- 次に Trino のデフォルトである Hive カタログ。Out-of-the-boxで利用できる Docker イメージのようなものはなく、個人で作られているものを試しました。更にバックエンドに MySQL かPostgreSQL の接続が必要でしたが接続パラメータがうまく渡せず、ここで断念しました。
- JDBC カタログは容易そうでしたので試してみました。PostgreSQL に接続はしたのですが、テーブル作成は手動で行うようでした。また、サポート範囲が限定されているようでした。
- 結局、REST カタログの Apaceh Polaris にたどり着きました。最初の判断では、まだ Incubating フェーズのようだったので優先度を落としていましたが結局一番容易でした。公式 Docker イメージはまだなかったので最初は躊躇したのですが Gradle のビルドでつまづきはありませんでした。Java21 がローカルに必要になります。
Polaris の Docker イメージのビルド
ここの手順は、Polaris の Getting Started の Trino の README のとおりです。
https://github.com/apache/polaris/blob/main/getting-started/trino/README.md
まず、リポジトリをクローンし Gradle でビルドします。そのため、Java21 が必要です(Temurinでなくても構いません)のでインストールしておきます。
brewinstall--cask temurin@21git clone git@github.com:apache/polaris.gitcd polaris./gradlew clean :polaris-quarkus-server:assemble -Dquarkus.container-image.build=true --no-build-cacheREADME のとおり docker コマンドdocker run -p 8181:8181 -p 8182:8182 apache/polaris:latest で立ち上げ可能ですが、Getting Started の設定を利用しましょう。ディレクトリを移動します。
cd getting-started/trinoDocker Compose に PostgreSQL 設定を追加
docker-compose.yml に PostgreSQL の設定を追加してしまいます。PostgreSQL 自身と、Trino からの接続設定です。
services:polaris:image: apache/polaris:latest (中略)create-polaris-catalog:image: curlimages/curl (中略)trino:image: trinodb/trino:latest (中略)postgres:image: postgres:15container_name: postgresenvironment:POSTGRES_USER: postgresPOSTGRES_PASSWORD: postgresports:-"5432:5432"trino-config/catalog 配下にiceberg.properties がありますが、postgres.properties ファイルを追加します。ディレクトリ配下のファイルは自動で読み込まれます。
connector.name=postgresqlconnection-url=jdbc:postgresql://postgres:5432/postgresconnection-user=postgresconnection-password=postgresDocker 起動
起動できればOKです。設定が誤っていると数秒後に Trino は停止します。その場合はdocker logs trino-trino-1 -n 100 などのコマンドでログを見てみましょう。
docker-compose up-d2. Iceberg テーブルの作成
Trino で Iceberg カタログを確認
Trino CLI をローカルにインストールして接続できるようですが、今回は直接接続してみます。先程のREADME と同様の内容ですが以下のように接続します。
dockerexec-it trino-trino-1 trinotrino> プロンプトが表示されます。SHOW CATALOGS クエリを流したときにiceberg とpostgres が存在していれば、ここまでは成功です。
SHOW CATALOGS;-- Catalog-- ----------- iceberg # ココ!-- postgres # ココ!-- system-- (2 rows)Iceberg スキーマ作成
iceberg には、information_schema しか存在しないためスキーマmy_schema を作成します。
SHOW SCHEMASFROM iceberg;-- Schema-- ---------------------- information_schema-- (1 row)CREATESCHEMA iceberg.my_iceberg;SHOW SCHEMASFROM iceberg;-- Schema-- ---------------------- information_schema-- my_schema-- (2 rows)Iceberg テーブルの作成
つづいてテーブルを作成します。単価数量 をイメージしたデータです。
USE iceberg.my_schema;CREATETABLE sales( sales_idBIGINT, product_idVARCHAR, quantityINT, sold_atTIMESTAMP)WITH(format='PARQUET');SHOW TABLES; やDESCRIBE sales; で作成結果を確認できます。
3. PostgreSQL への接続確認とテーブル作成
上記で同時に起動したpostgres コンテナに対して、Trino からアクセスするための設定を行います。
Trino で Postgres 接続を確認
先程の再掲になりますが、Iceberg と同様にカタログとして見えています。
SHOW CATALOGS;-- Catalog-- ----------- iceberg # ココ!-- postgres # ココ!-- system-- (2 rows)スキーマが正常に見えれば接続確認は完了です。デフォルトの public スキーマを使うことにしましょう。たとえば、docker stop postgres と打った後に以下のSQLを実行するとError listing schemas for catalog postgres: The connection attempt failed. というエラーが発生します。Trino側はそのままでPostgres側のコンテナを再起動すれば接続は回復します。
SHOW SCHEMASFROM postgres;-- Schema-- ---------------------- information_schema-- pg_catalog-- public-- (3 rows)Trino 経由でテーブルを作成
ここでは単価明細 を保存するテーブルを作ってみます。Iceberg のときと同様に Trino から作成することができます。
USE postgres.public;CREATETABLE price( product_idVARCHAR(50), unit_priceINT, updated_atTIMESTAMP);4. Trino 上でのデータ投入とファイル確認
次にデータを投入します。ここでは最もシンプルなINSERT分の発行にとどめます。実ユースケースでは外部からのデータロードになることも多いかと思います。
Iceberg へデータ投入
USE iceberg.my_schema;INSERTINTO sales(sales_id, product_id, quantity, sold_at)VALUES(1,'A',10,TIMESTAMP'2025-01-01 12:00:00'),(2,'B',5,TIMESTAMP'2025-01-02 15:30:00');PostgreSQL へデータ投入
USE postgres.public;INSERTINTO price(product_id, unit_price, updated_at)VALUES('A',100,TIMESTAMP'2025-01-01 00:00:00'),('B',200,TIMESTAMP'2025-01-01 00:00:00'),...('Z',999,TIMESTAMP'2025-01-01 00:00:00');Iceberg ファイルの確認
ここで Iceberg のメタデータおよびデータがどう保存されているか確認してみましょう。コンテナ内でls -al /tmp/polaris/my_schema (docker exec -it trino-trino-1 ls tmp/polaris/my_schema) などを実行すると、******.avro といったファイルが生成されているのを確認できます。これらがIceberg のメタデータを担っています。
私のローカルでは以下のようになっていました。ここで polaris は、iceberg.properties におけるiceberg.rest-catalog.warehouse=polaris 、my_schema は先程つくったものです。salesテーブルのデータが parquet で保存され、Iceberg のメタデータが avro ファイルで保存されていることがわかります。統計情報も stats ファイルとして保存されています。スナップショット snap があるのは初期の0件時点、INSERTした時点であると思われます。
/tmp/polaris/my_schema/sales-e313c1e08edc4839a49efed7b9f05cab ├─ data │ └─ 20250219_140658_00019_ttn3u-4e92fb92-8113-4813-99c7-5a693aab20e8.parquet └─ metadata ├─ 20250219_140658_00019_ttn3u-e5b2ac25-4447-4e06-8232-e06f79713c9c.stats ├─ 37917472-757c-4371-b600-3dd4044464c3-m0.avro ├─ snap-1364046597548053223-1-37917472-757c-4371-b600-3dd4044464c3.avro └─ snap-3844773239724659248-1-bfdf93d0-fcf3-44bc-8a6b-6b33cde7962a.avro5. Trino で SQL クエリを実行
最後に、Iceberg とPostgreSQL を横断するクエリを Trino で試してみます。
USE iceberg.my_schema;SELECT s.sales_id, s.product_id, s.quantity, p.unit_price,(s.quantity* p.unit_price)AS total_amount, s.sold_atFROM salesAS sJOIN postgres.public.priceAS pON s.product_id= p.product_idORDERBY s.sales_idLIMIT20;上記のように、Iceberg で管理されたsales テーブル、PostgreSQL で管理されたprice テーブルを1つのSQLでシームレスに結合できるのがフェデレーティッドクエリと呼ばれるものです。
6. Trino のコンソールを閲覧
最後にせっかくなので、Trino の管理コンソールを覗いてみましょう。8080ポートに usernname:admin で入れると思います。
open http://localhost:8080/まず、ホーム画面
下に一覧されているクエリのあるひとつの Query Plan 画面
その Stage Performance タブ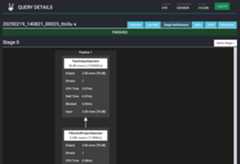
なんかとても使えそうですね。
!ハンズオンの最後ですが、ポート8080の管理コンソールはPolarisではなく、Trinoのものでした。失礼しました(2025-03-07訂正)
まとめ
長くなってしまいましたが、データレイクハウスの概念からハンズオンまでをまとめてみました。DWH時代で止まっていた知識を15年ぐらいアップデートできました。ハンズオンは基本的なものでしたが、中のデータファイルやメタデータファイルを見ていくとおもしろいですね。また今後、もう少し性能の傾向や複雑なユースケースへの対応を検証してみたいものです。
データレイクハウスは、非常にホットな領域であるとともに「もっと小回り必要じゃね?」と一石を投じられている記事を最近見かけました。こういった動向も気になります。
https://www.pracdata.io/p/the-rise-of-single-node-processing
最後ですが、この書籍も程よくまとまっておりおすすめです。
https://learning.oreilly.com/library/view/practical-lakehouse-architecture/9781098153007/

バッジを受け取った著者にはZennから現金やAmazonギフトカードが還元されます。
Discussion
