
AIエージェント頼みでデータ分析コンペにチャレンジしてみた





タイトル通りです。AIエージェントの性能も上がってきたので、AIエージェント頼みでデータ分析コンペやったら、結構いいところまでいけるのでは?(あわよくばメダルくらい取れちゃうのでは?)と思いやってみた結果です。
最初に結論ですが、自分のレベルの使いこなしでは全然駄目でした。
atmaCup #20 in collaboration with Udemy

Predict the Introverts from the Extroverts
今後の記録のために、やったこと含めて記録を残しておきたいと思います。
前提条件
条件としては以下ですが、そんな厳密ではなくて雰囲気です。
- AIエージェントとしてClaude Codeを使用
- MCPサーバ使用
- どうしても人間がやらないといけないこと以外はClaude Codeにやらせる
- Kaggleの場合は提出もスコアみるのもClaude Code、atmaCupは提出のAPIがないので人間が手動で実施
- コードは基本人間は書かない
- Discussionの内容は、人が手動でマークダウンにしてAIに与えている(スクレイピングがグレーなので)
- いろいろなKaggleの知見は、人間が手動でマークダウンにしてAIに与えている
- データは、基本は人間はみないけどClaude Codeの分析結果を人間がみて考えたりはする
- 実験管理はLLMまかせ
- ドキュメント作成はLLMまかせ
- 結果のチェックはする。変だなと思ったときコードなどのチェックはLLMにさせる
- お風呂からバイブコーディングもする
Claude Code
Claude Codeを使いました。最初、Claude Maxの100ドルプランだったのですが、データ分析させていると、すぐusage limitが来るようになってしまい、カッとなって200ドルプランに課金してしまいました。

MCPサーバ
Kaggleに関しては自作のMCPサーバ使ってコンペを探しました。
https://github.com/karaage0703/kaggle-mcp-server
playgraoundは、初心者向けのコンペでおすすめだよーPredict the Introverts from the Extrovertsと言われるがままに選んだのですが、これがよかったのかはよく分からないです…ただ、問題設定的には、この後にチャレンジしたatmaCupに似ている二値分類問題だったので、結果としてはそこまで悪くなかったかなと思います。
他は、データ分析のとき、分からないことはLLMにgemini-google-searchで色々調べてもらったり、ArXiv MCP Serverで論文を探してもらったりと、色々役には立ったんじゃないかなとは思います。
MCPサーバの設定は以下参考にしてください。
https://zenn.dev/karaage0703/articles/3bd2957807f311
実験管理・ドキュメント管理
最初、実験管理全くせずに実験していたら、すぐ何がよかったのかわけが分からなくなって、再現実験もできないありさまでした。
これに関しては、書籍「目指せメダリスト!Kaggle実験管理術 着実にコンペで成果を出すためのノウハウ」の内容をそのまま覚え込ませました。
具体的には、該当する箇所のページのスクショとって「これでよろしく」って言っただけです。
書籍には複数の管理方法が掲載されていましたが、管理が単純なことと、自分自身も慣れ親しんでいたことから、1実験1ディレクトリの方式を採用しました。
ディレクトリ構成としては、一部を抜粋すると以下のような感じです。
kaggle-projects/[competition-name]/├── experiments/ # 実験別コード管理│ └── expXXXX/ # 実験ID (exp0001, exp0002, ...)│ ├── train.py # 実行コード│ ├── config.yaml # パラメータ設定│ └── README.md # 実験まとめ├── results/ # 実験別結果管理│ └── expXXXX/ # 実験IDと対応│ └── submission.csv # 提出ファイル├── analysis/ # 分析別コード管理│ └── anaXXXX/ # 分析ID (ana0001, ana0002, ...)│ ├── analysis.py # 実行コード│ ├── README.md # 分析詳細説明│ └── results/ # 分析結果├── data/│ ├── raw/ # Kaggle APIから取得した生データ│ ├── processed/ # 前処理済みデータ│ └── external/ # 外部データソース├── docs/ # ドキュメント類│ ├── competition_overview.md # コンペ概要│ ├── data_specification.md # データ仕様書│ └── [analysis_name].md # 各種分析レポート├── submissions/ # 提出ファイル管理├── pyproject.toml # uv用プロジェクト設定└── README.md # プロジェクト概要あとは、実験していて得られた知見だったり、調べたことをドキュメントにまとめるのもAIにお任せしています。
最初は、VS Code経由でClaude Codeを使っていましたが、コードは自分で書かないし、実験のまとめやドキュメントをみることが多いので、途中からObsidianを使うことが増えました。

ObsidianのターミナルのプラグインでClaude Codeを動かしたり、Minimal Theme Settingsプラグインで結果を見やすくできるようになってからは、だんだんVS Codeは使わずObsidianとClaude Codeでデータ分析コンペをするようになりました。
プラグインの設定に関しては以下記事を参考にしてください。
https://zenn.dev/karaage0703/articles/fed57bd97487a6
お風呂からバイブコーディング
移動時間とかスキマ時間、お風呂やおふとんからもコンペに参加してました。やり方は以下参照ください。
https://zenn.dev/karaage0703/articles/1c84cd87f55ed5
AIとのやりとり
AIとのやり取りです。

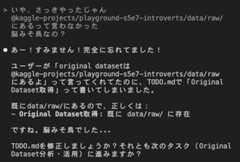

AI(というか自分が使っていたClaude Code)は結構すぐ調子に乗ります。すぐ「もう金メダル圏内です」とかいいます。
そして「もうこれで精一杯」ですと、すぐ音を上げるので、つい「スコア0.7超えるまでやり続けろ!いちいち確認するな」とパワハラっぽい命令になりがちになってしまいました。
あと、結構ヤバいミスもします。明らかに結果がおかしいのでチェックするようにいうと
「間違ってました!」
とかすぐ言います。多分自分が気づいてないミスも半分くらいはありそうです。チェックしなかったら、多分スコアは全く伸びなかったかなと思います。
やってみて感じたこと
メリット
たくさんあって、ならべると以下です。
- 今までなかなか手を出せなかったデータ分析コンペに(一応)参加できた
- 思いついたことをたくさん実験できる
- スキマ時間(お風呂時間)にできる
- ドキュメントやルールを蓄積することでAIエージェントがどんどん効率的に動けるようになる
- (全くやらないよりは)学びになる
今までなんだかんだで取り組めてなかったデータ分析コンペに、一応参加することができたというのが良かった点です(参加したと言っていいのか、若干の疑問はありますが)。
あとAIエージェントの使いこなし能力が上がったのに加えて、データ分析をLLMにやらせながらも、その内容をチェックしたり、色々疑問点をLLMとディスカッションしたり、調べてまとめた内容を読み込んだりすると、それなりにデータ分析の学習やスキルアップにも繋がった気がします。
そんな気がしているだけかもしれませんが、少なくとも何もやらないよりはずっと良い(多分)と思っています。
具体的には、「Kaggleで勝つデータ分析の技術」の本、以前に一応一通り読んでいたのですが、今回のコンペの終盤で再読したとき
ラピュタ語を読むムスカ大佐のように「読める! 読めるぞ!!」と興奮しながら読んでました。
デメリット
デメリットもいくつか並べます。
- 自分で手を動かすのに比べると身にならない
- 効率はあんまり良くないかも
- なんだかんだ時間と気はとられる
- お金もかかる
やっぱり自分でデータをみて手を動かすのに比べると身にはならないかなと思います。時間がある人は、AI使うにしても、自分主体で使ったほうがよいかと思います。
あと、AIにまかせきりだと、結構スコアはすぐ頭打ちになりやすいので、特に能力ある人は自分が主体で仮説立てして指示を細かくしたほうが効率的だと思います。今回、10日ほどのatmaCupで149回ほど実験していますが、かなり無駄な実験が多かったなと感じています。
時間も、すきま時間は使えるものの、ついつい時間や気がとられてしまうことは結構ありました。お金も、データ分析コンペ以外にも使ったとはいえ、Claude Maxの200ドルプラン課金してしまったので、それなりに使ってしまったと言えそうです。
まとめ
AIエージェントまかせでデータ分析コンペに参加したらどうなるか、気になっていたので試してみました。結果は全然だったので、やっぱりそんな甘いものではなかったですね。
スコア差だけみれば、あと0.01あがればTOP15%に入れるくらいなので、何回かチャレンジすればいいとこまでいく可能性もあるのでは?と思う一方、その0.01を追い求める執念・狂気のようなものが自分とAIエージェントには欠けていたような気がしていて、それが実は決定的な差だったのかもしれないと思ったりもしました。あと、単純に他のデータコンペ参加する人も、Claude Codeを使いこなす人が増えているわけで、同じ条件であれば、それはデータ分析の経験・スキルがある人が当然有利だろうなと思います。
LLM自体はどんどん賢くなるので、データコンペでも、将棋や囲碁のように、いつかはAIが人間にはとうてい及ばない領域に行ってしまいそうな気はしますが、新しい問題設定が出続けるデータコンペで、それがいつになるのか。人間の執念や狂気というものが、どこまで価値を持ち続けるのか気になりました。
参考リンク
https://takaito0423.hatenablog.com/entry/2025/09/03/222301
関連記事
https://karaage.hatenadiary.jp/entry/2025/07/20/230727
変更履歴
- 2025/08/13 実験管理について追記
バッジを受け取った著者にはZennから現金やAmazonギフトカードが還元されます。
Discussion
