
Category Archives:网络编程
异步事件模型的 Self-pipe trick
异步事件模型中有一个重要问题是,当你的 select/poll 循环陷入等待时,没有办法被另外一个线程被唤醒,这导致了一系列问题:
1)在没有 pselect/ppoll 的系统上,信号无法中断 select/poll 等待,得不到即时处理;
2)另一个线程投递过来的消息,由于 select/poll 等待,无法得到即时处理;
3)调短 select/poll 的超时时间也无济于事,poll 的超时精度最低 1ms,粗糙的程序可能影响不大,但精细的程序却很难接受这个超时;
4)有的系统上即便你传了 1ms 进去,可能会等待出 15ms 也很正常。
比如主线程告诉网络线程要发送一个数据,网络线程还在 select/poll 那里空等待,根本没有机会知道自己自己的消息队列里来了新消息;或者多个 select/poll 循环放在不同线程里,当一个 accept 了一个新连接想转移给另一个时,没有办法通知另一个醒来即时处理。
解决这个问题的方法就叫做 self-pipe trick,顾名思义,就是创建一个匿名管道,或者 socketpair,把它加入 select/poll 中,然后另外一个线程想要唤醒它的话,就是往这个管道或者 socketpair 里写一个字节就行了。
类似 java 的 nio 里的 selector 里面的notify() 函数,允许其他线程调用这个函数来唤醒等待中的一个 selector。
具体实现有几点要注意,首先是使用notify() 唤醒,不用每次调用notify() 都往管道/socketpair 里写一个字节,可以加锁检测,没写过才写,写过就不用写了:
// notify select/poll to wake upvoid poller_notify(CPoller *poller) { IMUTEX_LOCK(&poller->lock_pipe); if (poller->pipe_written == 0) { char dummy = 1; int hr = 0; #ifdef __unix hr = write(poller->pipe_writer_fd, &dummy, 1); #else hr = send(poller->pipe_writer_fd, &dummy, 1); #endif if (hr == 1) { poller->pipe_written = 1; } } IMUTEX_UNLOCK(&poller->lock_pipe);}大概类似这样,在非 Windows 下面把pipe() 创建的两个管道中的其中一个放到 select/poll 中,所以用write(),而 Windows 下的 select 不支持放入管道,只支持套接字,所以把两个相互连接的套接字里其中一个放入 select。
两个配对的管道命名为 reader/writer,加入 select 的是 reader,而唤醒时是向 writer 写一个字节,并且判断,如果写过就不再写了,避免不停 notify 导致管道爆掉,阻塞线程。
而作为网络线程的 select/poll 等待,每次被唤醒时,甭管有没有网络数据,都去做一次管道复位:
static void poller_pipe_reset(CPoller *poller) { IMUTEX_LOCK(&poller->lock_pipe); if (poller->pipe_written != 0) { char dummy = 0; int hr; #if __unix hr = read(poller->pipe_reader_fd, &dummy, 1); #else hr = recv(poller->pipe_reader_fd, &dummy, 1); #endif if (hr == 1) { poller->pipe_written = 0 } } IMUTEX_UNLOCK(&poller->lock_pipe);}每次 select/poll 醒来,都调用一下这个poller_pipe_reset(),这样确保管道里的数据被清空后,就可以复位pipe_written 标志了。
让后紧接着,处理完所有网络事件,就检查自己内部应用层的消息队列是否有其他消息投递过来,再去处理这些事件去;而其他线程想给这个线程发消息,也很简单,消息队列里塞一条,然后调用一下notify(),把该线程唤醒,让他可以马上去检查自己的消息队列。
主循环大概这样:
while (is_running) { // 1)调用 select/poll 等待网络事件,超时设置成 1ms-10ms; // 2)醒来后先处理所有网络事件; // 3)如果和上次等待之间超过 1毫秒,则马上处理所有时钟超时事件; // 4)检查自己消息队列,并处理新到来的事件。}差不多就是这样。
PS:有人说用 eventfd 也能实现类似效果,没错,但不能跨平台,只有 Linux 特有,而且还有一些坑,但 self-pipe trick 是跨平台的通用解决方案,不管你用 Windows / FreeBSD / Linux / Solaris 都可以使用这个功能。

WinSock 可以把 SOCKET 类型转换成 int 保存么?
在 Linux/Unix 等 posix 环境中,每个套接字都是一个文件描述符fd,类型是int,使用起来非常方便;但在 Win32 环境中是SOCKET 类型被定义成UINT_PTR ,是一个指针,在 x64 环境中一个SOCKET 占用 8 个字节。
那么是否能将SOCKET 类型强制转换成int 类型保存没?这样就能统一用int 在所有平台下表示套接字了,同时在 x64 环境下这样将 64 位的指针转换为 32 位的整数是否安全?
答案是可以的,下面将从三个方面说明一下。
Kernel Object
每个 SOCKET 背后其实都是一个指向 Kernel Object 的 Handle,而每个进程的 Handle 的数量是有限的,见 MSDN 的Kernel Objects:
Kernel object handles are process specific. That is, a process must either create the object or open an existing object to obtain a kernel object handle. The per-process limit on kernel handles is 2^24. However, handles are stored in the paged pool, so the actual number of handles you can create is based on available memory.
单进程不会超过 2^24 个,每个 Kernel Object 需要通过一个 Handle 来访问:

这些 Handle 保存于每个进程内位于低端地址空间的 Handle Table 表格,而这个 Handle Table 是连续的,见 MSDN 中的Handles and objects:
Each handle has an entry in an internally maintained table. Those entries contain the addresses of the resources, and the means to identify the resource type.
这个 Handle Table 表格对用户进程只读,对内核是可读写,在进程结束时,操作系统会扫描整个表格,给每个有效 Handle 背后指向的 Kernel Object 解引用,来做资源回收。
所以看似是UINT_PTR 指针的SOCKET 类型,其实也只是一个表格索引而已,这个 Handle Table 表格的项目有数量限的(最多 2^24 个元素),内容又是连续的,那当然可以用int 来保存。
开源案例
故此不少开源项目也会选择在 Windows 环境下将SOCKET 类型直接用int 来存储,比如著名的 openssl 在include/internal/sockets.h 里有解释:
/* * Even though sizeof(SOCKET) is 8, it's safe to cast it to int, because * the value constitutes an index in per-process table of limited size * and not a real pointer. And we also depend on fact that all processors * Windows run on happen to be two's-complement, which allows to * interchange INVALID_SOCKET and -1. */# define socket(d,t,p) ((int)socket(d,t,p))# define accept(s,f,l) ((int)accept(s,f,l))所以 openssl 不论什么平台,都将套接字看作int 来使用:
int SSL_set_fd(SSL *ssl, int fd);int SSL_set_rfd(SSL *ssl, int fd);int SSL_set_wfd(SSL *ssl, int fd);所以它的这些 API 设计,清一色的int 类型。
程序验证
道理前面都讲完了,下面写个程序验证一下:
WinSock 的 select 如何超过 64 个套接字限制?(三种方法)
在做跨平台网络编程时,Windows 下面能够对应 epoll/kevent 这类 reactor 事件模型的 API 只有一个 select,但是却有数量限制,一次传入 select 的 socket 数量不能超过FD_SETSIZE 个,而这个值是 64。
所以 java 里的 nio 的 select 在 Windows 也有同样的数量限制,很多移植 Windows 的服务程序,用了 reactor 模型的大多有这样一个限制,让人觉得 Windows 下的服务程序性能很弱。
那么这个数量限制对开发一个高并发的服务器显然是不够的,我们是否有办法突破这个限制呢?而 cygwin 这类用 Win32 API 模拟 posix API 的系统,又是如何模拟不受限制的 poll 调用呢?
当然可以,大概有三个方法让你绕过 64 个套接字的限制。
方法1:重定义 FD_SETSIZE
首先可以看 MSDN 中 winsock2 的select 帮助,这个FD_SETSIZE 是可以自定义的:
Four macros are defined in the header file Winsock2.h for manipulating and checking the descriptor sets. The variable FD_SETSIZE determines the maximum number of descriptors in a set. (The default value of FD_SETSIZE is 64, which can be modified by defining FD_SETSIZE to another value before including Winsock2.h.)
而在winsock2.h 中,可以看到这个值也是允许预先定义的:
#ifndef FD_SETSIZE#define FD_SETSIZE 64#endif只要你在 include 这个winsock2.h 之前,自定义了FD_SETSIZE,即可突破 64 的限制,比如在 cygwin 的 poll 实现poll.cc,开头就重定义了FD_SETSIZE:
#define FD_SETSIZE 16384 // lots of fds#include "winsup.h"#include <sys/poll.h>#include <sys/param.h>定义到了一个非常大的 16384,最多 16K 个套接字一起 select,然后 cygwin 后面继续用 select 来实现 posix 中 poll 函数的模拟。
这个方法问题不大,但有两个限制,第一是到底该定义多大的FD_SETSIZE 呢?定义大了废内存,每次 select 临时分配又一地内存碎片,定义少了又不够用;其次是程序不够 portable,头文件哪天忘记了换下顺序,或者代码拷贝到其它地方就没法运行。
因此我们有了更通用的方法2。
(点击 more/continue 继续)
Python 的 asyncio 网络性能比 C 写的 Redis 还好?
先前我做过一个 asyncio/gevent 的性能比较《性能测试:asyncio vs gevent vs native epoll》,今天修改了一下 asyncio 的测试程序的消息解析部分,改用 Protocol,发现它甚至比 redis 还快了:
安装依赖:
pip install hiredis uvloop编辑 echosvr.py 文件:
互联网技术比游戏后端技术领先十年吗?
最近时间线上又起了一场不大不小的论战,做互联网的人觉得游戏服务端发展很慢,同时互联网技术日新月异,似乎觉得互联网技术领先了游戏后端技术十年,这个结论显然是武断的,几位朋友也已经驳斥的很充分了,游戏服务端的同学实属没必要和这个互联网的人一般见识,本来就此打住也还挺好。
但最近两天事情似乎正在悄悄起变化,时间线上一直看到不停的有人跳出来,清一色的全在说互联网简单,什么做个电商不过就是 CRUD 的话也出来了,看的我也大跌眼镜,过犹不及吧。
今天更是又刷到有几位不管不顾就说什么游戏服务端领先互联网十年什么的,似乎这又要成为了另外一个极端了,那么有几点情况是不是也请正视一下:
1)游戏服务端足够复杂,但是发展太慢,祖传代码修修补补跑个十多年的不要太多。能用固然是好事,但没有新观念的引入,导致可用性和开发效率一直没有太多提升。
2)各自闭门造车,没有形成行业标准与合力,这个项目的代码,很难在另一个项目共享,相互之间缺少支持和协同。
3)互联网后端随便拎出一个服务来(包括各种 C/C++ 基建)大概率都没有游戏服务端复杂,但最近十年日新月异,形成了很强的互相组合互相增强的态势。
我上面指的是互联网基建项目,不是互联网 CRUD,互联网近十年的发展,让其整体可用性,效能,开发效率,都上了很多个台阶,不应一味忽视。
如果继续觉得游戏服务端领先互联网十年可以直接右转了,开放心态的话我也可以多聊一些(点击下方 more 阅读更多):
《原神》也在使用 KCP 加速游戏消息
最近看到米哈游《原神》的客户端安装文件里附带了 KCP 的 LICENSE:

于是找米哈游的同学求证了一下,果然他们在游戏里使用 KCP 来保证游戏消息可以以较低的延迟进行传输,这里还有一篇文章分析了原神使用 KCP 的具体细节:

文章见:https://forum.ragezone.com/f861/genshin-impact-private-server-1191004/index7.html
KCP 是我之前开源的一套低延迟可靠传输协议,能够有比 TCP/QUIC 更快的端到端传输效果,适合游戏、音视频以及各类延迟敏感的应用。
欢迎大家尝试:
目前使用 KCP 的商用项目包括不限于:
- 原神:米哈游的《原神》使用 KCP 降低游戏消息的传输耗时,提升操作的体验。
- SpatialOS: 大型多人分布式游戏服务端引擎,BigWorld 的后继者,使用 KCP 加速数据传输。
- 西山居:使用 KCP 进行游戏数据加速。
- CC:网易 CC 使用 kcp 加速视频推流,有效提高流畅性
- BOBO:网易 BOBO 使用 kcp 加速主播推流
- UU:网易 UU 加速器使用 KCP/KCPTUN 经行远程传输加速。
- 阿里云:阿里云的视频传输加速服务 GRTN 使用 KCP 进行音视频数据传输优化。
- 云帆加速:使用 KCP 加速文件传输和视频推流,优化了台湾主播推流的流畅度。
- 明日帝国:Game K17 的 《明日帝国》,使用 KCP 加速游戏消息,让全球玩家流畅联网
- 仙灵大作战:4399 的 MOBA游戏,使用 KCP 优化游戏同步
KCP 成功的运行在多个用户规模上亿的项目上,为他们提供了更加灵敏和丝滑网络体验。
新版瑞士军刀:socat
我在《用好你的瑞士军刀:netcat》中介绍过 nc 和它的几个实现(bsd, gnu, nmap),netcat 还有一个最重要的变种 socat (socket cat),值得花一篇完整的文章介绍一下,它不仅语义统一,功能灵活,除了完成 nc 能完成的所有任务外,还有很多实用的用法:
基本命令就是:
socat [参数] <地址1> <地址2>使用 socat 需要提供两个地址,然后 socat 做的事情就是把这两个地址的数据流串起来,把第左边地址的输出数据传给右边,同时又把右边输出的数据传到左边。
最简单的地址就是一个减号“-”,代表标准输入输出,而在命令行输入:
socat - - # 把标准输入和标准输出对接,输入什么显示什么就会对接标准输入和标准输出,你键盘敲什么屏幕上就显示什么,类似无参数的 cat 命令。除了减号地址外,socat 还支持:TCP,TCP-LISTEN,UDP,UDP-LISTEN,OPEN,EXEC,SOCKS,PROXY 等多种地址,用于端口监听、链接,文件和进程读写,代理桥接等等。
因此使用 socat 其实就是学习各类地址的定义及搭配方法,我们继续以实用例子开始。
网络测试
这个类似 nc 的连通性测试,两台主机到底网络能否联通:
socat - TCP-LISTEN:8080 # 终端1 上启动 server 监听 TCPsocat - TCP:localhost:8080 # 终端2 上启动 client 链接 TCP在终端 1 上输入第一行命令作为服务端,并在终端 2 上输入第二行命令作为客户端去链接。
联通后在终端2上随便输入点什么,就能显示在终端1上,反之亦然,因为两条命令都是把标准输入输出和网络串起来,因此把两个地址交换一下也是等价的:
socat TCP-LISTEN:8080 - # 终端1 上启动 server 监听 TCPsocat TCP:localhost:8080 - # 终端2 上启动 client 链接 TCP因为 socat 就是把左右两个地址的输入输出接在一起,因此颠倒左右两个地址影响不大,除非前面指明-u 或者-U 显示指明数据“从左到右”还是“从右到左”。
同 netcat 一样,如果客户端结束的话,服务端也会结束,但是 socat 还可以加额外参数:
socat - TCP-LISTEN:8080,fork,reuseaddr # 终端1 上启动 serversocat - TCP:localhost:8080 # 终端2 上启动 client服务端在TCP-LISTEN 地址后面加了 fork 的参数后,就能同时应答多个链接过来的客户端,每个客户端会 fork 一个进程出来进行通信,加上 reuseaddr 可以防止链接没断开玩无法监听的问题。
刚才也说了使用 socat 主要就是学习描述各种地址,那么想测试 UDP 的话修改一下就行:
socat - UDP-LISTEN:8080 # 终端1 上启动 server 监听 UDPsocat - UDP:localhost:8080 # 终端2 上启动 client 链接 UDP即可进行测试。
端口转发
在主机上监听一个 8080 端口,将 8080 端口所有流量转发给远程机器的 80 端口:
socat TCP-LISTEN:8080,fork,reuseaddr TCP:192.168.1.3:80那么连到这台机器上 8080 端口的所有链接,相当于链接了 192.168.1.3 这台机器的 80 端口,命令中交换左右两个地址一样是等价的。
(点击 Read more 展开)
支持 Win10 的网络环境模拟(丢包,延迟,带宽)
升级 Windows 10 以后,原来各种网络模拟软件都挂掉了,目前能用的就是只有clumsy:
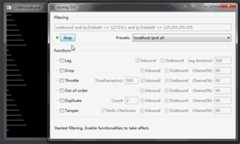
唯一问题是不支持模拟带宽,那么平时要模拟一些糟糕的网络情况的话,是不太方便的,而开虚拟机用 Linux tc 或者设置个远程 linux 网关又很蛋疼,于是我顺便给他加了个带宽模拟功能:

注意最下面的 “Bandwidth” 选项,打上勾的话,就能顺利限速了,注意上面的 Filtering 需要填写正确的 WinDivert 规则。
注意,统计包大小时用的是整个 IP 包的大小(包括各种协议头),所以你设置成 500 KB/s 的话,实际按 tcp 计算的下载速率会略小。
二进制下载:
想自己检查自己编译的话:
欢迎 PR。
用好你的瑞士军刀/netcat
Netcat 号称 TCP/IP 的瑞士军刀并非浪得虚名,以体积小(可执行 200KB)功能灵活而著称,在各大发行版中都默认安装,你可以用它来做很多网络相关的工作,熟练使用它可以不依靠其他工具做一些很有用的事情。
最初作者是叫做“霍比特人”的网友 Hobbithobbit@avian.org 于 1995 年在 UNIX 上以源代码的形式发布,Posix 版本的 netcat 主要有 GNU 版本的 netcat 和 OpenBSD 的 netcat 两者都可以在 debian/ubuntu 下面安装,但是 Windows 下面只有 GNU 版本的 port。
不管是程序员还是运维,熟悉这个命令都可以让很多工作事半功倍,然而网上基本 90% 的 netcat 文章说的都是老版本的 OpenBSD 的 netcat,已经没法在主流 linux 上使用了,所以我们先要检查版本:
在 debian/ubuntu 下面:
readlink -f $(which nc)看看,结果会有两种:
/bin/nc.traditional: 默认 GNU 基础版本,一般系统自带。/bin/nc.openbsd: openbsd 版本,强大很多。
都可以用apt-get install nc-traditional 或者apt-get install nc-openbsd 来选择安装。不管是 gnu 版本还是 openbsd 版本,都有新老的区别,主要是传送文件时 stdin 发生 EOF 了,老版本会自动断开,而新的 gnu/openbsd 还会一直连着,两年前 debian jessie 时统一升过级,导致网上的所有教程几乎同时失效。
下面主要以最新的 GNU 版本为主同时对照更强大的 openbsd 版本进行说明。
端口测试
你在服务器 A主机(192.168.1.2) 上面 8080 端口启动了一个服务,有没有通用的方法检测服务的 TCP 端口是否启动成功?或者在 B 主机上能不能正常访问该端口?
进一步,如果而 A 主机上用 netstat -an 发现端口成功监听了,你在 B 主机上的客户端却无法访问,那么到底是服务错误还是网络无法到达呢?我们当然可以在 B 主机上用 telnet 探测一下:
telnet 192.168.1.2 8080但 telnet 并不是专门做这事情的,还需要额外安装,所以我们在 B 主机上用 netcat:
nc -vz 192.168.1.2 8080即可,v 的意思是显示多点信息(verbose),z 代表不发送数据。那么如果 B 主机连不上 A 主机的 8080 端口,此时你就该检查网络和安全设置了,如果连的上那么再去查服务日志去。
nc 命令后面的 8080 可以写成一个范围进行扫描:
nc -v -v -w3 -z 192.168.1.2 8080-8083两次 -v 是让它报告更详细的内容,-w3 是设置扫描超时时间为 3 秒。
传输测试
你在配置 iptable 或者安全组策略,禁止了所有端口,但是仅仅开放了 8080 端口,你想测试一下该设置成功与否怎么测试?安装个 nginx 改下端口,外面再用 chrome 访问下或者 telnet/curl 测试下??还是 python -m 启动简单 http 服务 ?其实不用那么麻烦,在需要测试的 A 主机上:
nc -l -p 8080这样就监听了 8080 端口,然后在 B 主机上连接过去:
nc 192.168.1.2 8080两边就可以会话了,随便输入点什么按回车,另外一边应该会显示出来,注意,openbsd 版本 netcat 用了-l 以后可以省略-p 参数,写做:nc -l 8080 ,但在 GNU netcat 下面无法运行,所以既然推荐写法是加上-p 参数,两个版本都通用。
老版本的 nc 只要 CTRL+D 发送 EOF 就会断开,新版本一律要 CTRL+C 结束,不管是服务端还是客户端只要任意一边断开了,另一端也就结束了,但是 openbsd 版本的 nc 可以加一个 -k 参数让服务端持续工作。
那么你就可以先用 nc 监听 8080 端口,再远端检查可用,然后又再次随便监听个 8081 端口,远端检测不可用,说明你的安全策略配置成功了,完全不用安装任何累赘的服务。
(点击 Read more 展开)
如何在高丢包率的链路上建立低延迟连接?
这是其实通信领域的话题了,低延迟传输有上百种优化方式,上面说的那些冗余码只是很小一部分,不考虑信道容量的冗余编码系统都是在耍流氓,不用等到同信道内跑两套这样的协议你才会发现问题,一套协议再接近信道带宽容量限制时,就会出现指数上升的丢包率,所以不考虑带宽检测的冗余法就是一个残次品。
要系统的解决低延迟传输问题,需要同时在传输层,协议层,路由层,应用层几个方面着手:
传输层带外冗余:弱智重复法
设你要发送的数据为 x1-xn,你实际发送出去的包为 p1-pn,那么比如 Pn = [Xn, Xn-1, Xn-2],重复前面出现过的 1-2个数据,丢包了你可以随时恢复出来。
传输层带外冗余:异或法
每发四个包 x1-x4,你多发一个冗余包,内容为前面四个包的异或: R = x1 ^ x2 ^ x3 ^ x4,那么本组数据五个数据包(x1-x4, R)中任意丢失一个,都可以从其他四个异或得到。当然,不一定要四个包冗余一个,你可以根据情况和丢包率,两个包或者三个包冗余一个。
传输层带外冗余:解方程法
把每个数据包看成一个整数,要发送 x1-x4 四个包,并不直接发送x,而是将他们进行线性运算得到 y1-y7,然后发送出去:
A1 * x1 + B1 * x2 + C1 * x3 + D1 * x4 = y1 收到A2 * x1 + B2 * x2 + C2 * x3 + D2 * x4 = y2 收到A3 * x1 + B3 * x2 + C3 * x3 + D3 * x4 = y3 丢失A4 * x1 + B4 * x2 + C4 * x3 + D4 * x4 = y4 收到A5 * x1 + B5 * x2 + C5 * x3 + D5 * x4 = y5 丢失A6 * x1 + B6 * x2 + C6 * x3 + D6 * x4 = y6 收到A7 * x1 + B7 * x2 + C7 * x3 + D7 * x4 = y7 丢失接收方收到一组数据以后,发现y3, y5, y7丢失,得到:
A1 * x1 + B1 * x2 + C1 * x3 + D1 * x4 = y1 A2 * x1 + B2 * x2 + C2 * x3 + D2 * x4 = y2 A4 * x1 + B4 * x2 + C4 * x3 + D4 * x4 = y4 A6 * x1 + B6 * x2 + C6 * x3 + D6 * x4 = y6如果 y1-y7 在发送的过程中丢失了三个:y3, y5, y7 观察等式。变量任然有4个,参数也任然有四个A1, A2, A4, A6, B?, C?, D? 四个变量,四个等式,那么我们可以通过解方程求出x1-x4,这就是一个矩阵运算和求逆的过程,也就是俗称的 Read-Solomon 冗余码的基本原理(PS: shorthair/long hair 两个库写的很烂呀),实际传输时需要根据网络质量来选择每组数据和冗余包的比例。
传输层网络评估
需要一套比较强大的系统,实时评估当前网络质量(RTT, 丢包率,抖动值,可用带宽),为协议决策提供参考,比如这时一个带宽很大,延迟却很高的信道呢?还是带宽很小,延迟也很小的信道呢?不同的情况对应不同的策略,当前丢包是常规丢包?震荡性丢包?还是接近信道限制出现无可挽回的丢包?再根据当前协议出于什么情况?交互模式还是单向传输模式,来给出最佳的传输策略。不考虑这些情况的协议,都是比较弱智的(比如楼上提到的几种)。
协议层决策模型
根据不同的情况,来推导不同的数据包丢失后,对整体协议的影响,从而通过马科夫决策过程,来找到哪个包丢失的代价最大,以此来指导冗余包的生成过程:
