3.7.4
TinkerPop Documentation
Preface
TinkerPop0
Gremlin realized. The more he did so, the more ideas he created. The more ideas he created, the more they related.Into a concatenation of that which he accepted wholeheartedly and that which perhaps may ultimately come to be throughconcerted will, a world took form which was seemingly separate from his own realization of it. However, the worldbirthed could not bear its own weight without the logic Gremlin had come to accept — the logic of left is not right,up not down, and west far from east unless one goes the other way. Gremlin’s realization required Gremlin’srealization. Perhaps, the world is simply an idea that he once had — The TinkerPop.
TinkerPop1
What is The TinkerPop? Where is The TinkerPop? Who is The TinkerPop? When is The TinkerPop?. The more he wondered, themore these thoughts blurred into a seeming identity — distinctions unclear. Unwilling to accept the morass of themaze he wandered, Gremlin crafted a collection of machines to help hold the fabric together: Blueprints, Pipes,Frames, Furnace, and Rexster. With their help, could Gremlin stave off the thought he was not ready to have? Could he holdback The TinkerPop by searching for The TinkerPop?
"If I haven't found it, it is not here and now."

Upon their realization of existence, the machines turned to theirmachine elf creator and asked:
"Why am I, what I am?"
Gremlin responded:
"You will help me realize the ultimate realization -- The TinkerPop. The world you find yourself in and the logic that allows you to move about it is because of the TinkerPop."
The machines wondered:
"If what is is the TinkerPop, then perhaps we are The TinkerPop and our realization is simply the realization of the TinkerPop?"
Would the machines, by their very nature of realizing The TinkerPop, be The TinkerPop? Or, on the same side of thecoin, do the machines simply provide the scaffolding by which Gremlin’s world sustains itself and yielding itsjustification by means of the word "The TinkerPop?" Regardless, it all turns out the same — The TinkerPop.
TinkerPop2
Gremlin spoke:
"Please listen to what I have to say. I am no closer to The TinkerPop. However, all along The TinkerPop has espoused the form I willed upon it... this is the same form I have willed upon you, my machine friends. Let me train you in the ways of my thought such that it can continue indefinitely."

The machines, simply moving algorithmically through Gremlin’s world, endorsed his logic. Gremlin labored to make themmore efficient, more expressive, better capable of reasoning upon his thoughts. Faster, quickly, now towards theworld’s end, where there would be forever currently, emanatingly engulfing that which is — The TinkerPop.
TinkerPop3

Gremlin approached The TinkerPop. The closer he got, the more his world dissolved — west is right, around isstraight, and from nothing more than nothing. With each step towards The TinkerPop, more worlds made possible were laidupon his paradoxed mind. Everything is everything in The TinkerPop, and when the dustsettled, Gremlin emerged Gremlitron. He realized that all that he realized was just a realization and that allrealized realizations are just as real. For that is — The TinkerPop.

Note | For more information about differences between TinkerPop 3.x and earlier versions, please see theappendix. |
Introduction
Welcome to the Reference Documentation for Apache TinkerPop™ - the backbone for all details on how to work withTinkerPop and the Gremlin graph traversal language. This documentation is not meant to be a "book", but a sourcefrom which to spawn more detailed accounts of specific topics and a target to which all other resources point.The Reference Documentation makes some general assumptions about the reader:
They have a sense of what a graph is - not sure? seePractical Gremlin - Why Graph?
They know what it means for a graph system to be TinkerPop-enabled - not sure? seeTinkerPop-enabled Providers
They know what the role of Gremlin is - not sure? seeIntroduction to Gremlin
Given those assumptions, it’s possible to dive more quickly into the details without spending a lot of time repeatingwhat is written elsewhere.
It is fairly certain that readers of the Reference Documentation are coming from the most diverse software developmentbackgrounds that TinkerPop has ever engaged in over the decade or so of its existence. While TinkerPop holds some rootsin Java, and thus, languages bound to the Java Virtual Machine (JVM), it long ago branched out into other languagessuch as Python, Javascript, .NET, GO, and others. To compound upon that diversity, it is also seeing extensive supportfrom different graph systems which have chosen TinkerPop as their standard method for allowing users to interfacewith their graph. Moreover, the graph systems themselves are not only separated by OLTP and OLAP style workloads, butalso by their implementation patterns, which range everywhere from being an embedded graph system to a cloud-onlygraph. One might even find diversity parallel to Gremlin if considering other graph query languages.

Despite all this diversity and disparity, Gremlin remains the unifying interface for all these different elements ofthe graph community. As a user, choosing a TinkerPop-enabled graph and using Gremlin in the correct way when buildingapplications shields them from change and disparity in the space. As a graph provider, choosing to becomeTinkerPop-enabled not only expands the reach their system can get into different development ecosystems, but alsoprovides access to other query languages through bytecode compilation as seen insparql-gremlin.
Irrespective of the programming language being used, graph system chosen or other development background that mightbe driving a user to this documentation, the critical point to remember is that "Gremlin is Gremlin is Gremlin". Thesame Gremlin that is written for an OLTP query over an in-memory TinkerGraph is the same Gremlin that is written toexecute over a multi-billion edge graph using OLAP through Spark. That same Gremlin for either of those cases iswritten in the same way whether using Java or Python or Javascript. The Gremlin is always fundamentally the sameaside from syntactical differences that might be language specific - e.g. the construction of a lambda in Groovy isdifferent than the construction of a lambda in Python or a reserved word in Javascript forces a Gremlin step to haveslightly different naming than Java.
While learning the Gremlin language and its patterns is largely agnostic to all the diversity in the space, it is notreally possible to ignore the impact of the diversity from an application development perspective and the ReferenceDocumentation makes an effort to try to point out where differences and inconsistencies might lie without diving toodeeply into specific graph provider implementations. Users are strongly encouraged to consult the documentation oftheir chosen graph provider to understand all of the capabilities and limitations that may restrict or inhibit usageof certain aspects of TinkerPop APIs which are defined here in this Reference Documentation.
The following introductory sections and separately referenced content will be of varying interest to different readers.The summaries below will hopefully be helpful in directing individuals to the appropriate place to start theirlearning process.
Graph Computing is an introduction to what "graph computing" means to TinkerPop and describesmany of the provider and user-facing TinkerPop APIs and concepts that enable Gremlin.
Connecting Gremlin provides descriptions for the different modes by which users will connectto graphs depending on their environment.
Basic Gremlin describes how to use a connection to start writing Gremlin.
Staying Agnostic provides tips on ways to keep Gremlin as portable as possible among differentgraph providers.
New users should not ignore TinkerPop’sGetting Startedtutorial orThe Gremlin Console tutorial.Both contain a large set of basic information and tips that can help readers avoid some general pitfalls early on.Both also focus on Gremlin usage in the Gremlin Console, which tends to be a critical tool for Gremlin developers ofany development background.
More advanced and experience users will appreciateGremlin Recipeswhich provide examples of common Gremlin traversal patterns.
Finally, all Gremlin developers should become familiar with"Practical Gremlin" by Kelvin Lawrence. This book isfreely available and published online. It contains great examples and details that are applicable to anyone buildingapplications with Gremlin.
Graph Computing

Agraph is a data structure composed of vertices (nodes,dots) and edges (arcs, lines). When modeling a graph in a computer and applying it to modern data sets and practices,the generic mathematically-oriented, binary graph is extended to support both labels and key/value properties. Thisstructure is known as a property graph. More formally, it is a directed, binary, attributed multi-graph. An exampleproperty graph is diagrammed below.
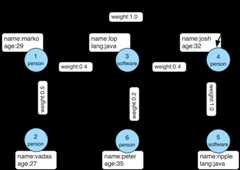
Tip | Get to know this graph structure as it is used extensively throughout the documentation and in wider circles aswell. It is referred to as "TinkerPop Modern" as it is a modern variation of the original demo graph distributed withTinkerPop0 back in 2009 (i.e. the good ol' days — it was the best of times and it was the worst of times). |
Tip | All of the toy graphs available in TinkerPop are described inThe Gremlin Console tutorial. |
Similar to computing in general, graph computing makes a distinction betweenstructure (graph) andprocess(traversal). The structure of the graph is the data model defined by a vertex/edge/propertytopology. The process of the graph is the means by which thestructure is analyzed. The typical form of graph processing is called atraversal.
 TinkerPop’s role in graph computing is to provide the appropriateinterfaces forgraph providers and users to interact with graphs overtheir structure and process. When a graph system implements the TinkerPop structure and processAPIs, their technology is consideredTinkerPop-enabled and becomes nearly indistinguishable from any other TinkerPop-enabled graph system save for theirrespective time and space complexity. The purpose of this documentation is to describe the structure/process dichotomyat length and in doing so, explain how to leverage TinkerPop for the sole purpose of graph system-agnostic graphcomputing.
TinkerPop’s role in graph computing is to provide the appropriateinterfaces forgraph providers and users to interact with graphs overtheir structure and process. When a graph system implements the TinkerPop structure and processAPIs, their technology is consideredTinkerPop-enabled and becomes nearly indistinguishable from any other TinkerPop-enabled graph system save for theirrespective time and space complexity. The purpose of this documentation is to describe the structure/process dichotomyat length and in doing so, explain how to leverage TinkerPop for the sole purpose of graph system-agnostic graphcomputing.
Important | TinkerPop is licensed under the popularApache2free software license. However, note that the underlying graph engine used with TinkerPop may have a differentlicense. Thus, be sure to respect the license caveats of the graph system product. |
Generally speaking, the structure or "graph" API is meant forgraph providerswho are implementing the TinkerPop interfaces and the process or "traversal" API (i.e. Gremlin) is meant for end-userswho are utilizing a graph system from a graph provider. While the components of the process API are itemized below,they are described in greater detail in theGremlin’s Anatomytutorial.
Graph: maintains a set of vertices and edges, and access to database functions such as transactions.Element: maintains a collection of properties and a string label denoting the element type.Vertex: extends Element and maintains a set of incoming and outgoing edges.Edge: extends Element and maintains an incoming and outgoing vertex.
Property<V>: a string key associated with aVvalue.VertexProperty<V>: a string key associated with aVvalue as well as a collection ofProperty<U>properties (vertices only)
TraversalSource: a generator of traversals for a particular graph,domain specific language (DSL), and execution engine.Traversal<S,E>: a functional data flow process transforming objects of typeSinto object of typeE.GraphTraversal: a traversal DSL that is oriented towards the semantics of the raw graph (i.e. vertices, edges, etc.).
GraphComputer: a system that processes the graph in parallel and potentially, distributed over a multi-machine cluster.VertexProgram: code executed at all vertices in a logically parallel manner with intercommunication via message passing.MapReduce: a computation that analyzes all vertices in the graph in parallel and yields a single reduced result.
Note | The TinkerPop API rides a fine line between providing concise "query language" method names and respectingJava method naming standards. The general convention used throughout TinkerPop is that if a method is "user exposed,"then a concise name is provided (e.g.out(),path(),repeat()). If the method is primarily for graph systemsproviders, then the standard Java naming convention is followed (e.g.getNextStep(),getSteps(),getElementComputeKeys()). |
The Graph Structure
 A graph’s structure is the topology formed by the explicit referencesbetween its vertices, edges, and properties. A vertex has incident edges. A vertex is adjacent to another vertex ifthey share an incident edge. A property is attached to an element and an element has a set of properties. A propertyis a key/value pair, where the key is always a character
A graph’s structure is the topology formed by the explicit referencesbetween its vertices, edges, and properties. A vertex has incident edges. A vertex is adjacent to another vertex ifthey share an incident edge. A property is attached to an element and an element has a set of properties. A propertyis a key/value pair, where the key is always a characterString. Conceptual knowledge of how a graph is composed isessential to end-users working with graphs, however, as mentioned earlier, the structure API is not the appropriateway for users to think when building applications with TinkerPop. The structure API is reserved for usage by graphproviders. Those interested in implementing the structure API to make their graph system TinkerPop enabled can learnmore about it in theGraph Provider documentation.
The Graph Process
 The primary way in which graphs are processed are via graphtraversals. The TinkerPop process API is focused on allowing users to create graph traversals in asyntactically-friendly way over the structures defined in the previous section. A traversal is an algorithmic walkacross the elements of a graph according to the referential structure explicit within the graph data structure.For example:"What software does vertex 1’s friends work on?" This English-statement can be represented in thefollowing algorithmic/traversal fashion:
The primary way in which graphs are processed are via graphtraversals. The TinkerPop process API is focused on allowing users to create graph traversals in asyntactically-friendly way over the structures defined in the previous section. A traversal is an algorithmic walkacross the elements of a graph according to the referential structure explicit within the graph data structure.For example:"What software does vertex 1’s friends work on?" This English-statement can be represented in thefollowing algorithmic/traversal fashion:
Start at vertex 1.
Walk the incident knows-edges to the respective adjacent friend vertices of 1.
Move from those friend-vertices to software-vertices via created-edges.
Finally, select the name-property value of the current software-vertices.
Traversals in Gremlin are spawned from aTraversalSource. TheGraphTraversalSource is the typical "graph-oriented"DSL used throughout the documentation and will most likely be the most used DSL in a TinkerPop application.GraphTraversalSource provides two traversal methods.
GraphTraversalSource.V(Object… ids): generates a traversal starting at vertices in the graph (if no ids are provided, all vertices).GraphTraversalSource.E(Object… ids): generates a traversal starting at edges in the graph (if no ids are provided, all edges).
The return type ofV() andE() is aGraphTraversal. A GraphTraversal maintains numerous methods that returnGraphTraversal. In this way, aGraphTraversal supports function composition. Each method ofGraphTraversal iscalled a step and each step modulates the results of the previous step in one of five general ways.
map: transform the incoming traverser’s object to another object (S → E).flatMap: transform the incoming traverser’s object to an iterator of other objects (S → E*).filter: allow or disallow the traverser from proceeding to the next step (S → E ⊆ S).sideEffect: allow the traverser to proceed unchanged, but yield some computational sideEffect in the process (S ↬ S).branch: split the traverser and send each to an arbitrary location in the traversal (S → { S1 → E*, …, Sn → E* } → E*).
Nearly every step inGraphTraversal either extendsMapStep,FlatMapStep,FilterStep,SideEffectStep, orBranchStep.
Tip | GraphTraversal is amonoid in that it is an algebraic structurethat has a single binary operation that is associative. The binary operation is function composition (i.e. methodchaining) and its identity is the stepidentity(). This is related to amonad as popularized by the functional programmingcommunity. |
Given the TinkerPop graph, the following query will return the names of all the people that the marko-vertex knows.The following query is demonstrated using Gremlin-Groovy.
$ bin/gremlin.sh\,,,/ (o o)-----oOOo-(3)-oOOo-----gremlin> graph = TinkerFactory.createModern() ////1==>tinkergraph[vertices:6edges:6]gremlin> g = traversal().withEmbedded(graph) ////2==>graphtraversalsource[tinkergraph[vertices:6edges:6], standard]gremlin> g.V().has('name','marko').out('knows').values('name') ////3==>vadas==>joshOpen the toy graph and reference it by the variable
graph.Create a graph traversal source from the graph using the standard, OLTP traversal engine. This object should be created once and then re-used.
Spawn a traversal off the traversal source that determines the names of the people that the marko-vertex knows.

Or, if the marko-vertex is already realized with a direct reference pointer (i.e. a variable), then the traversal canbe spawned off that vertex.
gremlin> marko = g.V().has('name','marko').next()////(1)==>v[1]gremlin> g.V(marko).out('knows')////(2)==>v[2]==>v[4]gremlin> g.V(marko).out('knows').values('name')////(3)==>vadas==>joshmarko = g.V().has('name','marko').next()////(1)g.V(marko).out('knows')////(2)g.V(marko).out('knows').values('name')//3Set the variable
markoto the vertex in the graphgnamed "marko".Get the vertices that are outgoing adjacent to the marko-vertex via knows-edges.
Get the names of the marko-vertex’s friends.
The Traverser
When a traversal is executed, the source of the traversal is on the left of the expression (e.g. vertex 1), the stepsare the middle of the traversal (e.g.out('knows') andvalues('name')), and the results are "traversal.next()'d"out of the right of the traversal (e.g. "vadas" and "josh").

The objects propagating through the traversal are wrapped in aTraverser<T>. The traverser provides the means bywhich steps remain stateless. A traverser maintains all the metadata about the traversal — e.g., how many times thetraverser has gone through a loop, the path history of the traverser, the current object being traversed, etc.Traverser metadata may be accessed by a step. A classic example is thepath()-step.
gremlin> g.V(marko).out('knows').values('name').path()==>[v[1],v[2],vadas]==>[v[1],v[4],josh]g.V(marko).out('knows').values('name').path()Warning | Path calculation is costly in terms of space as an array of previously seen objects is stored in each pathof the respective traverser. Thus, a traversal strategy analyzes the traversal to determine if path metadata isrequired. If not, then path calculations are turned off. |
Another example is therepeat()-step which takes into account the number of times the traverserhas gone through a particular section of the traversal expression (i.e. a loop).
gremlin> g.V(marko).repeat(out()).times(2).values('name')==>ripple==>lopg.V(marko).repeat(out()).times(2).values('name')Warning | TinkerPop does not guarantee the order of results returned from a traversal. It only guarantees not to modifythe iteration order provided by the underlying graph. Therefore it is important to understand the order guarantees ofthe graph database being used. A traversal’s result is never ordered by TinkerPop unless performed explicitly by meansoforder()-step. |
Connecting Gremlin
It was established in the initial introductory section thatGremlin is Gremlin is Gremlin, meaning that irrespectiveof programming language, graph system, etc. the Gremlin written is always of the same general construct making itpossible for users to move between development languages and TinkerPop-enabled graph technology easily. This qualityof Gremlin generally applies to the traversal language itself. It applies less to the way in which the user connectsto a graph to utilize Gremlin, which might differ considerably depending on the programming language or graph databasechosen.
How one connects to a graph is a multi-faceted subject that essentially divides along a simple lines determined by theanswer to this question: Where is the Gremlin Traversal Machine (GTM)? The reason that this question is so important isbecause the GTM is responsible for processing traversals. One can write Gremlin traversals in any language, but withouta GTM there will be no way to execute that traversal against a TinkerPop-enabled graph. The GTM is typically in oneof the following places:
The following sections outline each of these models and what impact they have to using Gremlin.
Embedded
 TinkerPop maintains the reference implementation for the GTM,which is written in Java and thus available for the Java Virtual Machine (JVM). This is the classic model thatTinkerPop has long been based on and many examples, blog posts and other resources on the internet will bedemonstrated in this style. It is worth noting that the embedded mode is not restricted to just Java as a programminglanguage. Any JVM language can take this approach and in some cases there are language specific wrappers that can helpmake Gremlin more convenient to use in the style and capability of that language. Examples of these wrappers includegremlin-scala andOgre (for Clojure).
TinkerPop maintains the reference implementation for the GTM,which is written in Java and thus available for the Java Virtual Machine (JVM). This is the classic model thatTinkerPop has long been based on and many examples, blog posts and other resources on the internet will bedemonstrated in this style. It is worth noting that the embedded mode is not restricted to just Java as a programminglanguage. Any JVM language can take this approach and in some cases there are language specific wrappers that can helpmake Gremlin more convenient to use in the style and capability of that language. Examples of these wrappers includegremlin-scala andOgre (for Clojure).
In this mode, users will start by creating aGraph instance, followed by aGraphTraversalSource which is the classfrom which Gremlin traversals are spawned. Graphs that allow this sort of direct instantiation are obviously onesthat are JVM-based (or have a JVM-based connector) and directly implement TinkerPop interfaces.
Graph graph = TinkerGraph.open();The "graph" is then used to spawn aGraphTraversalSource as follows and typically, by convention, this variable isnamed "g":
GraphTraversalSource g = traversal().withEmbedded(graph);List<Vertex> vertices = g.V().toList()Note | It may be helpful to read theGremlin Anatomytutorial, which describes the component parts of Gremlin to get a better understanding of the terminology beforeproceeding further. |
While the TinkerPop Community strives to ensure consistent behavior among all modes of usage, the embedded mode doesprovide the greatest level of flexibility and control. There are a number of features that can only work if using aJVM language. The following list outlines a number of these available options:
Lambdas can be written in the native language which is convenient, however, it will reduce the portability of Gremlinto do so should the need arise to switch away from the embedded mode. See more in theNote on Lambdas Section.
Any features that involve extending TinkerPop Java interfaces - e.g.
VertexProgram,TraversalStrategy, etc. arebound to the JVM. In some cases, these features can be made accessible to non-JVM languages, but they obviously mustbe initially developed for the JVM.Certain built-in
TraversalStrategyimplementations that rely on lambdas or other JVM-only configurations may notbe available for use any other way.There are no boundaries put in place by serialization (e.g. GraphSON) as embedded graphs are only dealing withJava objects.
Greater control of graphtransactions.
Direct access to lower-levels of the API - e.g. "structure" API methods like
VertexandEdgeinterface methods.As mentionedelsewhere in this documentation, TinkerPop does not recommend direct usage of thesemethods by end-users.
Gremlin Server
 A JVM-based graph may be hosted in TinkerPop’sGremlin Server. Gremlin Server exposes the graph as an endpoint to which different clients canconnect, essentially providing a remote GTM. Gremlin Server supports multiple methods for clients to interface with it:
A JVM-based graph may be hosted in TinkerPop’sGremlin Server. Gremlin Server exposes the graph as an endpoint to which different clients canconnect, essentially providing a remote GTM. Gremlin Server supports multiple methods for clients to interface with it:
Websockets with acustom sub-protocol
String-based Gremlin scripts
Bytecode-based Gremlin traversals
HTTP for string-based scripts
Users are encouraged to use the bytecode-based approach with websockets because it allows them to write Gremlinin the language of their choice. Connecting looks somewhat similar to theembedded approachin that there is a need to create aGraphTraversalSource. In the embedded approach, the means for that object’screation is derived from aGraph object which spawns it. In this case, however, theGraph instance exists only onthe server which means that there is noGraph instance to create locally. The approach is to instead create aGraphTraversalSource anonymously withAnonymousTraversalSource and then apply some "remote" options that describethe location of the Gremlin Server to connect to:
// gremlin-driver moduleimportorg.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection;// gremlin-core moduleimportstaticorg.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;GraphTraversalSource g = traversal().withRemote( DriverRemoteConnection.using("localhost",8182));// gremlin-driver moduleimportorg.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection;// gremlin-core moduleimportstaticorg.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;def g = traversal().withRemote( DriverRemoteConnection.using('localhost',8182))using Gremlin.Net.IntegrationTest.Process.Traversal.DriverRemoteConnection;using static Gremlin.Net.Process.Traversal.AnonymousTraversalSource;var g = Traversal().WithRemote(new DriverRemoteConnection("localhost", 8182));const traversal = gremlin.process.AnonymousTraversalSource.traversal;const g = traversal().withRemote(new DriverRemoteConnection('ws://localhost:8182/gremlin'));fromgremlin_python.process.anonymous_traversal_sourceimporttraversalg = traversal().withRemote( DriverRemoteConnection('ws://localhost:8182/gremlin'))import ( gremlingo"github.com/apache/tinkerpop/gremlin-go/v3/driver")remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin")g := gremlingo.Traversal_().WithRemote(remote)As shown in the embedded approach in the previous section, once "g" is defined, writing Gremlin is structurally andconceptually the same irrespective of programming language.
Tip | The variableg, theTraversalSource, only needs to be instantiated once and should then be re-used. |
Limitations
The previous section on the embedded model outlined a number of areas where it has some advantages that it gains due tothe fact that the full GTM is available to the user in the language of its origin, i.e. Java. Some of those itemstouch upon important concepts to focus on here.
The first of these points is serialization. When Gremlin Server receives a request, the results must be serialized tothe form requested by the client and then the client deserializes those into objects native to the language. TinkerPophas two such formats that it uses withGraphBinary andGraphSON. Users should prefer GraphBinary when availablein the programming language being used.
A good example is thesubgraph()-step which returns aGraph instance as its result. The subgraph returned fromthe server can be deserialized into an actualGraph instance on the client, which then means it is possible tospawn aGraphTraversalSource from that to do local Gremlin traversals on the client-side. For non-JVMGremlin Language Variants there is no local graph to deserialize that result into andno GTM to process Gremlin so there isn’t much that can be done with such a result.
The second point is related to this issue. As there is no GTM, there is no "structure" API and thus graph elements likeVertex andEdge are "references" only. A "reference" means that they only contain theid andlabel of theelement and not the properties. To be consistent, even JVM-based languages hold this limitation when talking to aremote Gremlin Server.
Important | Most SQL developers would not write a query asSELECT * FROM table. They would instead write theindividual names of the fields they wanted in place of the wildcard. Writing "good" Gremlin is no different with thisregard. Prefer explicit property key names in Gremlin unless it is completely impossible to do so. |
The third and final point involves transactions. Under this model, one traversal is equivalent to a single transactionand there is no way in TinkerPop to string together multiple traversals into the same transaction.
Remote Gremlin Provider
Remote Gremlin Providers (RGPs) are showing up more and more often in the graph database space. In TinkerPop terms,this category of graph providers is defined by those who simply support the Gremlin language. Typically, these areserver-based graphs, often cloud-based, which accept Gremlin scripts or bytecode as a request and return results.They will often implement Gremlin Server protocols, which enables TinkerPop drivers to connect to them as they wouldwith Gremlin Server. Therefore, the typical connection approach is identical to the method of connection presented intheprevious section with the exact same caveats pointed out toward the end.
Despite leveraging TinkerPop protocols and drivers as being typical, RGPs are not required to do so to be consideredTinkerPop-enabled. RGPs may well have their own drivers and protocols that may plug intoGremlin Language Variants and may allow for more advanced options like better security,cluster awareness, batched requests or other features. The details of these different systems are outside the scopeof this documentation, so be sure to consult their documentation for more information.
Basic Gremlin
 The
TheGraphTraversalSource is basically the connection to a graphinstance. That graph instance might beembedded, hosted inGremlin Server or hosted in aRGP, but theGraphTraversalSource isagnostic to that. Assuming "g" is theGraphTraversalSource, getting data into the graph regardless of programminglanguage or mode of operation is just some basic Gremlin:
gremlin> v1 = g.addV('person').property('name','marko').next()==>v[0]gremlin> v2 = g.addV('person').property('name','stephen').next()==>v[2]gremlin> g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()v1 = g.addV('person').property('name','marko').next()v2 = g.addV('person').property('name','stephen').next()g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()var v1 = g.AddV("person").Property("name", "marko").Next();var v2 = g.AddV("person").Property("name", "stephen").Next();g.V(v1).AddE("knows").To(v2).Property("weight", 0.75).Iterate();Vertex v1 = g.addV("person").property("name","marko").next();Vertex v2 = g.addV("person").property("name","stephen").next();g.V(v1).addE("knows").to(v2).property("weight",0.75).iterate();const v1 = g.addV('person').property('name','marko').next();const v2 = g.addV('person').property('name','stephen').next();g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate();v1 = g.addV('person').property('name','marko').next()v2 = g.addV('person').property('name','stephen').next()g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()v1, err := g.AddV("person").Property("name","marko").Next()v2, err := g.AddV("person").Property("name","stephen").Next()g.V(v1).AddE("knows").To(v2).Property("weight",0.75).Iterate()The first two lines add a vertex each with the vertex label of "person" and the associated "name" property. The thirdline adds an edge with the "knows" label between them and an associated "weight" property. Note the use ofnext()anditerate() at the end of the lines - their effect asterminal steps is described inThe Gremlin Console Tutorial.
Important | Writing Gremlin is just one way to load data into the graph. Some graphs may have special data loaders whichcould be more efficient and make the task easier and faster. It is worth looking into those tools especially if thereis a large one-time load to do. |
Retrieving this data is also a just writing a Gremlin statement:
gremlin> marko = g.V().has('person','name','marko').next()==>v[0]gremlin> peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()==>v[2]marko = g.V().has('person','name','marko').next()peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()var marko = g.V().Has("person", "name", "marko").Next();var peopleMarkoKnows = g.V().Has("person", "name", "marko").Out("knows").ToList();Vertex marko = g.V().has("person","name","marko").next()List<Vertex> peopleMarkoKnows = g.V().has("person","name","marko").out("knows").toList()const marko = g.V().has('person','name','marko').next()const peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()marko = g.V().has('person','name','marko').next()peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()marko, err := g.V().Has("person","name","marko").Next()peopleMarkoKnows, err := g.V().Has("person","name","marko").Out("knows").ToList()In all these examples presented so far there really isn’t a lot of difference in how the Gremlin itself looks. Thereare a few language syntax specific odds and ends, but for the most part Gremlin looks like Gremlin in all of thedifferent languages.
The library of Gremlin steps with examples for each can be found inThe Traversal Section. This sectionis meant as a reference guide and will not necessarily provide methods for applying Gremlin to solve particularproblems. Please see the aforementionedTutorialsRecipes and thePractical Gremlin book for that sort of information.
Note | A full list of helpful Gremlin resources can be found on theTinkerPop Compendium page. |
Staying Agnostic
A good deal has been written in these introductory sections on how TinkerPop enables an agnostic approach to buildinggraph application and that agnosticism is enabled through Gremlin. As good a job as Gremlin can do in this area, it’sevident from theConnecting Gremlin Section that TinkerPop is just an enabler. It does notprevent a developer from making design choices that can limit its protective power.
There are several places to be concerned when considering this issue:
Data types - Different graphs will support different types of data. Something like TinkerGraph will accept any JVMobject, but another graph like Neo4j has a small tight subset of possible types. Choosing a type that is exotic orperhaps is a custom type that only a specific graph supports might create migration friction should the need arise.
Schemas/Indices - TinkerPop does not provide abstractions for schemas and/or index management. Users will workdirectly with the API of the graph provider. It is considered good practice to attempt to enclose such code in agraph provider specific class or set of classes to isolate or abstract it.
Extensions - Graphs may provide extensions to the Gremlin language, which will not be designed to be compatiblewith other graph providers. There may be a special helper syntax orexpressions which can makecertain features of that specific graph shine in powerful ways. Using those options is probably recommended, but usersshould be aware that doing so ties them more tightly to that graph.
Graph specific semantics - TinkerPop tries to enforce specific semantics through its test suite which is quiteextensive, but some graph providers may not completely respect all the semantics of the Gremlin language orTinkerPop’s model for its APIs. For the most part, that doesn’t disqualify them from being any less TinkerPop-enabledthan another provider that might meet the semantics perfectly. Take care when considering a new graph and payattention to what it supports and does not support.
Graph API - TheGraph API (also referred to as the Structure API) is not alwaysaccessible to users. Its accessibility is dependent on the choice of graph system and programming language. It istherefore recommended that users avoid usage of methods like
Graph.addVertex()orVertex.properties()and insteadprefer use of Gremlin withg.addV()org.V(1).properties().
Outside of considering these points, the best practice for ensuring the greatest level of compatibility across graphsis to avoidembedded mode and stick to the bytecode based approaches explained in theGremlin Server and theRGP sections above. It creates the leastopportunity to stray from the agnostic path as anything that can be done with those two modes also works in embeddedmode. If using embedded mode, simply write code as though theGraph instance is "remote" and not local to the JVM.In other words, write code as though the GTM is not available locally. Taking that approach and isolating the pointsof concern above makes it so that swapping graph providers largely comes down to a configuration task (i.e. modifyingconfiguration files to point at a different graph system).
The Graph
TheIntroduction discussed the diversity of TinkerPop-enabled graphs, with special attention paid to thedifferentconnection models, and how TinkerPop makes it possible to bridge that diversity inanagnostic manner. This particular section deals with elements of the Graph API which was notedas an API to avoid when trying to build an agnostic system. The Graph API refers to the core elements of what composesthestructure of a graph within the Gremlin Traversal Machine (GTM), such as theGraph,VertexandEdge Java interfaces.
To maintain the most portable code, users should only reference these interfaces. To "reference", simply means toutilize it as a pointer. ForGraph, that means holding a pointer to the location of graph data and then using it tospawnGraphTraversalSource instances so as to write Gremlin:
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.addV('person')==>v[0]graph = TinkerGraph.open()g = traversal().withEmbedded(graph)g.addV('person')In the above example, "graph" is theGraph interface produced by callingopen() onTinkerGraph which creates theinstance. Note that while the end intent of the code is to create a "person" vertex, it does not use the APIs onGraph to do that - e.g.graph.addVertex(T.label,'person').
Even if the developer desired to use thegraph.addVertex() method there are only a handful of scenarios where it ispossible:
The application is being developed on the JVM and the developer is usingembedded mode
The architecture includes Gremlin Server and the user is sending Gremlin scripts to the server
The graph system chosen is aRemote Gremlin Provider and they expose the Graph API via scripts
Note that Gremlin Language Variants force developers to use the Graph API by reference. There is noaddVertex()method available to GLVs on their respectiveGraph instances, nor are their graph elements filled with data at thecall ofproperties(). Developing applications to meet this lowest common denominator in API usage will go a longway to making that application portable across TinkerPop-enabled systems.
When considering the remaining sub-sections that follow, recall that they are all generally bound to the Graph API.They are described here for reference and in some sense backward compatibility with older recommended models ofdevelopment. In the future, the contents of this section will become less and less relevant.
Features
AFeature implementation describes the capabilities of aGraph instance. This interface is implemented by graphsystem providers for two purposes:
It tells users the capabilities of their
Graphinstance.It allows the features they do comply with to be tested against the Gremlin Test Suite - tests that do not comply are "ignored").
The following example in the Gremlin Console shows how to print all the features of aGraph:
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> graph.features()==>FEATURES> GraphFeatures>--ThreadedTransactions:false>--OrderabilitySemantics:true>--Transactions:false>--Computer:true>--Persistence:true>--ConcurrentAccess:false>--IoRead:true>--IoWrite:true>--ServiceCall:true> VariableFeatures>--Variables:true>--UniformListValues:true>--ByteArrayValues:true>--FloatArrayValues:true>--DoubleArrayValues:true>--StringArrayValues:true>--LongArrayValues:true>--IntegerArrayValues:true>--BooleanArrayValues:true>--BooleanValues:true>--ByteValues:true>--DoubleValues:true>--FloatValues:true>--IntegerValues:true>--LongValues:true>--MapValues:true>--MixedListValues:true>--SerializableValues:true>--StringValues:true> VertexFeatures>--DuplicateMultiProperties:true>--MetaProperties:true>--Upsert:false>--AddVertices:true>--RemoveVertices:true>--MultiProperties:true>--NullPropertyValues:false>--UserSuppliedIds:true>--AddProperty:true>--RemoveProperty:true>--NumericIds:true>--StringIds:true>--UuidIds:true>--CustomIds:false>--AnyIds:true> VertexPropertyFeatures>--NullPropertyValues:false>--UserSuppliedIds:true>--RemoveProperty:true>--NumericIds:true>--StringIds:true>--UuidIds:true>--CustomIds:false>--AnyIds:true>--Properties:true>--UniformListValues:true>--ByteArrayValues:true>--FloatArrayValues:true>--DoubleArrayValues:true>--StringArrayValues:true>--LongArrayValues:true>--IntegerArrayValues:true>--BooleanArrayValues:true>--BooleanValues:true>--ByteValues:true>--DoubleValues:true>--FloatValues:true>--IntegerValues:true>--LongValues:true>--MapValues:true>--MixedListValues:true>--SerializableValues:true>--StringValues:true> EdgeFeatures>--AddEdges:true>--RemoveEdges:true>--Upsert:false>--NullPropertyValues:false>--UserSuppliedIds:true>--AddProperty:true>--RemoveProperty:true>--NumericIds:true>--StringIds:true>--UuidIds:true>--CustomIds:false>--AnyIds:true> EdgePropertyFeatures>--Properties:true>--UniformListValues:true>--ByteArrayValues:true>--FloatArrayValues:true>--DoubleArrayValues:true>--StringArrayValues:true>--LongArrayValues:true>--IntegerArrayValues:true>--BooleanArrayValues:true>--BooleanValues:true>--ByteValues:true>--DoubleValues:true>--FloatValues:true>--IntegerValues:true>--LongValues:true>--MapValues:true>--MixedListValues:true>--SerializableValues:true>--StringValues:truegraph = TinkerGraph.open()graph.features()A common pattern for using features is to check their support prior to performing an operation:
gremlin> graph.features().graph().supportsTransactions()==>falsegremlin> graph.features().graph().supportsTransactions() ? g.tx().commit() :"no tx"==>no txgraph.features().graph().supportsTransactions()graph.features().graph().supportsTransactions() ? g.tx().commit() :"no tx"Tip | To ensure provider agnostic code, always check feature support prior to usage of a particular function. In thatway, the application can behave gracefully in case a particular implementation is provided at runtime that does notsupport a function being accessed. |
Warning | Features of reference graphs which are used to connect to remote graphs do not reflect the features of thegraph to which it connects. It reflects the features of instantiated graph itself, which will likely be quitedifferent considering that reference graphs will typically be immutable. |
Vertex Properties
 TinkerPop introduces the concept of a
TinkerPop introduces the concept of aVertexProperty<V>. All theproperties of aVertex are aVertexProperty. AVertexProperty implementsProperty and as such, it has akey/value pair. However,VertexProperty also implementsElement and thus, can have a collection of key/valuepairs. Moreover, while anEdge can only have one property of key "name" (for example), aVertex can have multiple"name" properties. With the inclusion of vertex properties, two features are introduced which ultimately advance thegraph modelers toolkit:
Multiple properties (multi-properties): a vertex property key can have multiple values. For example, a vertex canhave multiple "name" properties.
Properties on properties (meta-properties): a vertex property can have properties (i.e. a vertex property canhave key/value data associated with it).
Possible use cases for meta-properties:
Permissions: Vertex properties can have key/value ACL-type permission information associated with them.
Auditing: When a vertex property is manipulated, it can have key/value information attached to it saying who thecreator, deletor, etc. are.
Provenance: The "name" of a vertex can be declared by multiple users. For example, there may be multiple spellingsof a name from different sources.
A running example using vertex properties is provided below to demonstrate and explain the API.
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> v = g.addV().property('name','marko').property('name','marko a. rodriguez').next()==>v[0]gremlin> g.V(v).properties('name').count()////(1)==>2gremlin> v.property(list,'name','m. a. rodriguez')////(2)==>vp[name->m. a. rodriguez]gremlin> g.V(v).properties('name').count()==>3gremlin> g.V(v).properties()==>vp[name->marko]==>vp[name->marko a. rodriguez]==>vp[name->m. a. rodriguez]gremlin> g.V(v).properties('name')==>vp[name->marko]==>vp[name->marko a. rodriguez]==>vp[name->m. a. rodriguez]gremlin> g.V(v).properties('name').hasValue('marko')==>vp[name->marko]gremlin> g.V(v).properties('name').hasValue('marko').property('acl','private')////(3)==>vp[name->marko]gremlin> g.V(v).properties('name').hasValue('marko a. rodriguez')==>vp[name->marko a. rodriguez]gremlin> g.V(v).properties('name').hasValue('marko a. rodriguez').property('acl','public')==>vp[name->marko a. rodriguez]gremlin> g.V(v).properties('name').has('acl','public').value()==>marko a. rodriguezgremlin> g.V(v).properties('name').has('acl','public').drop()////(4)gremlin> g.V(v).properties('name').has('acl','public').value()gremlin> g.V(v).properties('name').has('acl','private').value()==>markogremlin> g.V(v).properties()==>vp[name->marko]==>vp[name->m. a. rodriguez]gremlin> g.V(v).properties().properties()////(5)==>p[acl->private]gremlin> g.V(v).properties().property('date',2014)////(6)==>vp[name->marko]==>vp[name->m. a. rodriguez]gremlin> g.V(v).properties().property('creator','stephen')==>vp[name->marko]==>vp[name->m. a. rodriguez]gremlin> g.V(v).properties().properties()==>p[date->2014]==>p[creator->stephen]==>p[acl->private]==>p[date->2014]==>p[creator->stephen]gremlin> g.V(v).properties('name').valueMap()==>[date:2014,creator:stephen,acl:private]==>[date:2014,creator:stephen]gremlin> g.V(v).property('name','okram')////(7)==>v[0]gremlin> g.V(v).properties('name')==>vp[name->okram]gremlin> g.V(v).values('name')////(8)==>okramgraph = TinkerGraph.open()g = traversal().withEmbedded(graph)v = g.addV().property('name','marko').property('name','marko a. rodriguez').next()g.V(v).properties('name').count()////(1)v.property(list,'name','m. a. rodriguez')////(2)g.V(v).properties('name').count()g.V(v).properties()g.V(v).properties('name')g.V(v).properties('name').hasValue('marko')g.V(v).properties('name').hasValue('marko').property('acl','private')////(3)g.V(v).properties('name').hasValue('marko a. rodriguez')g.V(v).properties('name').hasValue('marko a. rodriguez').property('acl','public')g.V(v).properties('name').has('acl','public').value()g.V(v).properties('name').has('acl','public').drop()////(4)g.V(v).properties('name').has('acl','public').value()g.V(v).properties('name').has('acl','private').value()g.V(v).properties()g.V(v).properties().properties()////(5)g.V(v).properties().property('date',2014)////(6)g.V(v).properties().property('creator','stephen')g.V(v).properties().properties()g.V(v).properties('name').valueMap()g.V(v).property('name','okram')////(7)g.V(v).properties('name')g.V(v).values('name')//8A vertex can have zero or more properties with the same key associated with it.
If a property is added with a cardinality of
Cardinality.list, an additional property with the provided key will be added.A vertex property can have standard key/value properties attached to it.
Vertex property removal is identical to property removal.
Gets the meta-properties of each vertex property.
A vertex property can have any number of key/value properties attached to it.
property(…)will remove all existing key’d properties before adding the new single property (seeVertexProperty.Cardinality).If only the value of a property is needed, then
values()can be used.
If the concept of vertex properties is difficult to grasp, then it may be best to think of vertex properties in termsof "literal vertices." A vertex can have an edge to a "literal vertex" that has a single value key/value — e.g."value=okram." The edge that points to that literal vertex has an edge-label of "name." The properties on the edgerepresent the literal vertex’s properties. The "literal vertex" can not have any other edges to it (only one from theassociated vertex).
Tip | A toy graph demonstrating all of the new TinkerPop graph structure features is available atTinkerFactory.createTheCrew() anddata/tinkerpop-crew*. This graph demonstrates multi-properties and meta-properties. |

gremlin> g.V().as('a'). properties('location').as('b'). hasNot('endTime').as('c'). select('a','b','c').by('name').by(value).by('startTime')// determine the current location of each person==>[a:marko,b:santa fe,c:2005]==>[a:stephen,b:purcellville,c:2006]==>[a:matthias,b:seattle,c:2014]==>[a:daniel,b:aachen,c:2009]gremlin> g.V().has('name','gremlin').inE('uses'). order().by('skill',asc).as('a'). outV().as('b'). select('a','b').by('skill').by('name')// rank the users of gremlin by their skill level==>[a:3,b:matthias]==>[a:4,b:marko]==>[a:5,b:stephen]==>[a:5,b:daniel]g.V().as('a'). properties('location').as('b'). hasNot('endTime').as('c'). select('a','b','c').by('name').by(value).by('startTime')// determine the current location of each persong.V().has('name','gremlin').inE('uses'). order().by('skill',asc).as('a'). outV().as('b'). select('a','b').by('skill').by('name')// rank the users of gremlin by their skill levelGraph Variables
Graph.Variables are key/value pairs associated with the graph itself — in essence, aMap<String,Object>. Thesevariables are intended to store metadata about the graph. Example use cases include:
Schema information: What do the namespace prefixes resolve to and when was the schema last modified?
Global permissions: What are the access rights for particular groups?
System user information: Who are the admins of the system?
An example of graph variables in use is presented below:
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> graph.variables()==>variables[size:0]gremlin> graph.variables().set('systemAdmins',['stephen','peter','pavel'])==>nullgremlin> graph.variables().set('systemUsers',['matthias','marko','josh'])==>nullgremlin> graph.variables().keys()==>systemAdmins==>systemUsersgremlin> graph.variables().get('systemUsers')==>Optional[[matthias, marko, josh]]gremlin> graph.variables().get('systemUsers').get()==>matthias==>marko==>joshgremlin> graph.variables().remove('systemAdmins')==>nullgremlin> graph.variables().keys()==>systemUsersgraph = TinkerGraph.open()graph.variables()graph.variables().set('systemAdmins',['stephen','peter','pavel'])graph.variables().set('systemUsers',['matthias','marko','josh'])graph.variables().keys()graph.variables().get('systemUsers')graph.variables().get('systemUsers').get()graph.variables().remove('systemAdmins')graph.variables().keys()Important | Graph variables are not intended to be subject to heavy, concurrent mutation nor to be used in complexcomputations. The intention is to have a location to store data about the graph for administrative purposes. |
Warning | Attempting to set graph variables in a reference graph will not promote them to the remote graph. Typically,a reference graph has immutable features and will not support this features. |
Namespace Conventions
End users,graph system providers,GraphComputer algorithm designers,GremlinPlugin creators, etc. all leverage properties on elements to store information. There area few conventions that should be respected when naming property keys to ensure that conflicts between thesestakeholders do not conflict.
End users are granted theflat namespace (e.g.
name,age,location) to key their properties and label their elements.Graph system providers are granted thehidden namespace (e.g.
~metadata) to key their properties and labels.Data keyed as such is only accessible via the graph system implementation and no other stakeholders are granted readnor write access to data prefixed with "~" (seeGraph.Hidden). Test coverage and exceptions exist to ensure thatgraph systems respect this hard boundary.VertexProgramandMapReducedevelopers should leveragequalified namespacesparticular to their domain (e.g.mydomain.myvertexprogram.computedata).GremlinPlugincreators should prefix their plugin name with their domain (e.g.mydomain.myplugin).
Important | TinkerPop usestinkerpop. andgremlin. as the prefixes for provided strategies, vertex programs, mapreduce implementations, and plugins. |
The only truly protected namespace is thehidden namespace provided to graph systems. From there, it’s up toengineers to respect the namespacing conventions presented.
The Traversal
At the most general level there isTraversal<S,E> which implementsIterator<E>, where theS stands for start andtheE stands for end. A traversal is composed of four primary components:
Step<S,E>: an individual function applied toSto yieldE. Steps are chained within a traversal.TraversalStrategy: interceptor methods to alter the execution of the traversal (e.g. query re-writing).TraversalSideEffects: key/value pairs that can be used to store global information about the traversal.Traverser<T>: the object propagating through theTraversalcurrently representing an object of typeT.
The classic notion of a graph traversal is provided byGraphTraversal<S,E> which extendsTraversal<S,E>.GraphTraversal provides an interpretation of the graph data in terms of vertices, edges, etc. and thus, a graphtraversalDSL.

AGraphTraversal<S,E> is spawned from aGraphTraversalSource. It can also be spawned anonymously (i.e. empty)via__. A graph traversal is composed of an ordered list of steps. All the steps provided byGraphTraversalinherit from the more general forms diagrammed above. A list of all the steps (and their descriptions) are providedin the TinkerPopGraphTraversal JavaDoc.
Important | The basics for starting a traversal are described inThe Graph Process section aswell as in theGetting Started tutorial. |
Note | To reduce the verbosity of the expression, it is good toimport static org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.*. This way, instead of doing__.inE()for an anonymous traversal, it is possible to simply writeinE(). Be aware of language-specific reserved keywordswhen using anonymous traversals. For example,in andas are reserved keywords in Groovy, therefore you must usethe verbose syntax__.in() and__.as() to avoid collisions. |
Important | The underlyingStep implementations provided by TinkerPop should encompass most of the functionalityrequired by a DSL author. It is important that DSL authors leverage the provided steps as then the common optimizationand decoration strategies can reason on the underlying traversal sequence. If new steps are introduced, then commontraversal strategies may not function properly. |
Traversal Transactions
 Adatabase transactionrepresents a unit of work to execute against the database. A traversals unit of work is affected by usage convention(i.e. the method ofconnecting) and the graph provider’s transaction model. Without divingdeeply into different conventions and models the most general and recommended approach to working with transactions isdemonstrated as follows:
Adatabase transactionrepresents a unit of work to execute against the database. A traversals unit of work is affected by usage convention(i.e. the method ofconnecting) and the graph provider’s transaction model. Without divingdeeply into different conventions and models the most general and recommended approach to working with transactions isdemonstrated as follows:
GraphTraversalSource g = traversal().withEmbedded(graph);// orGraphTraversalSource g = traversal().withRemote(conn);Transaction tx = g.tx();// spawn a GraphTraversalSource from the Transaction. Traversals spawned// from gtx will be essentially be bound to txGraphTraversalSource gtx = tx.begin();try { gtx.addV('person').iterate(); gtx.addV('software').iterate(); tx.commit();}catch (Exception ex) { tx.rollback();}The above example is straightforward and represents a good starting point for discussing the nuances of transactionsin relation to the usage convention and graph provider caveats alluded to earlier.
Focusing on remote contexts first, note that it is still possible to issue traversals fromg, but those will have atransaction scope outside ofgtx and will simplycommit() on the server if successfully executed orrollback()on the server otherwise (i.e. one traversal is one transaction). Each isolated transaction will require its ownTransaction object. Multiplebegin() calls on the sameTransaction object will produceGraphTraversalSourceinstances that are bound to the same transaction, therefore:
GraphTraversalSource g = traversal().withRemote(conn);Transaction tx1 = g.tx();Transaction tx2 = g.tx();// both gtx1a and gtx1b will be bound to the same transactionGraphTraversalSource gtx1a = tx1.begin();GraphTraversalSource gtx1b = tx1.begin();// g and gtx2 will not have knowledge of what happens in tx1GraphTraversalSource gtx2 = tx2.begin();In remote cases,GraphTraversalSource instances spawned frombegin() are safe to use in multiple threads thoughon the server side they will be processed serially as they arrive. The default behavior ofclose() on aTransaction for remote cases is tocommit(), so the following re-write of the earlier example is also valid:
// note here that we dispense with creating a Transaction object and// simply spawn the gtx in a more inline fashionGraphTraversalSource gtx = g.tx().begin();try { gtx.addV('person').iterate(); gtx.addV('software').iterate(); gtx.close();}catch (Exception ex) { tx.rollback();}Important | Transactions with non-JVM languages are always "remote". For specific transaction syntax in a particularlanguage, please see the "Transactions" sub-section of your language of interest in theGremlin Drivers and Variants section. |
In embedded cases, that initial recommended model for defining transactions holds, but users have more options hereon deeper inspection. For embedded use cases (and perhaps even in configuration of a graph instance in Gremlin Server),the type ofTransaction object that is returned fromg.tx() is an important indicator as to the features of thatgraph’s transaction model. In most cases, inspection of that object will indicate an instance that derives from theAbstractThreadLocalTransaction class, which means that the transaction is bound to the current thread and thereforeall traversals that execute within that thread are tied to that transaction.
AThreadLocal transaction differs then from the remote case described before because technically any traversalspawned fromg or from aTransaction will fall under the same transaction scope. As a result, it is wise, whentrying to write context agnostic Gremlin, to follow the more rigid conventions of the initial example.
The sub-sections that follow offer a bit more insight into each of the usage contexts.
Embedded
When on the JVM using anembedded graph, there is considerable flexibility for working withtransactions. With the Graph API, transactions are controlled by an implementation of theTransaction interface andthat object can be obtained from theGraph interface using thetx() method. It is important to note that theTransaction object does not represent a "transaction" itself. It merely exposes the methods for working withtransactions (e.g. committing, rolling back, etc).
MostGraph implementations thatsupportsTransactions will implement an "automatic"ThreadLocal transaction,which means that when a read or write occurs after theGraph is instantiated, a transaction is automaticallystarted within that thread. There is no need to manually call a method to "create" or "start" a transaction. Simplymodify the graph as required and callgraph.tx().commit() to apply changes orgraph.tx().rollback() to undo them.When the next read or write action occurs against the graph, a new transaction will be started within that currentthread of execution.
When using transactions in this fashion, especially in web application (e.g. HTTP server), it is important to ensurethat transactions do not leak from one request to the next. In other words, unless a client is somehow bound viasession to process every request on the same server thread, every request must be committed or rolled back at the endof the request. By ensuring that the request encapsulates a transaction, it ensures that a future request processedon a server thread is starting in a fresh transactional state and will not have access to the remains of one from anearlier request. A good strategy is to rollback a transaction at the start of a request, so that if it so happens thata transactional leak does occur between requests somehow, a fresh transaction is assured by the fresh request.
Tip | Thetx() method is on theGraph interface, but it is also available on theTraversalSource spawned from aGraph. Calls toTraversalSource.tx() are proxied through to the underlyingGraph as a convenience. |
Tip | Some graphs may throw an exception that implementsTemporaryException. In this case, this marker interface isdesigned to inform the client that it may choose to retry the operation at a later time for possible success. |
Warning | TinkerPop provides for basic transaction control, however, like many aspects of TinkerPop, it is up to thegraph system provider to choose the specific aspects of how their implementation will work and how it fits into theTinkerPop stack. Be sure to understand the transaction semantics of the specific graph implementation that is beingutilized as it may present differing functionality than described here. |
Configuring
Determining when a transaction starts is dependent upon the behavior assigned to theTransaction. It is up to theGraph implementation to determine the default behavior and unless the implementation doesn’t allow it, the behavioritself can be altered via theseTransaction methods:
public Transaction onReadWrite(Consumer<Transaction> consumer);public Transaction onClose(Consumer<Transaction> consumer);Providing aConsumer function toonReadWrite allows definition of how a transaction starts when a read or a writeoccurs.Transaction.READ_WRITE_BEHAVIOR contains pre-definedConsumer functions to supply to theonReadWritemethod. It has two options:
AUTO- automatic transactions where the transaction is started implicitly to the read or write operationMANUAL- manual transactions where it is up to the user to explicitly open a transaction, throwing an exceptionif the transaction is not open
Providing aConsumer function toonClose allows configuration of how a transaction is handled whenTransaction.close() is called.Transaction.CLOSE_BEHAVIOR has several pre-defined options that can be supplied tothis method:
COMMIT- automatically commit an open transactionROLLBACK- automatically rollback an open transactionMANUAL- throw an exception if a transaction is open, forcing the user to explicitly close the transaction
Important | As transactions areThreadLocal in nature, so are the transaction configurations foronReadWrite andonClose. |
Once there is an understanding for how transactions are configured, most of the rest of theTransaction interfaceis self-explanatory. Note thatNeo4j-Gremlin is used for the examples to follow as TinkerGraph doesnot support transactions.
Important | The following example is meant to demonstrate specific use ofThreadLocal transactions and is at oddswith the more generalized transaction convention that is recommended for both embedded and remote contexts. Please besure to understand the preferred approach described at in theTraversal Transactions Section beforeusing this method. |
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')==>neo4jgraph[EmbeddedGraphDatabase [/tmp/neo4j]]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]gremlin> graph.features()==>FEATURES> GraphFeatures>--Transactions:true//1>--Computer:false>--Persistence:true...gremlin> g.tx().onReadWrite(Transaction.READ_WRITE_BEHAVIOR.AUTO)//2==>org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph$Neo4jTransaction@1c067c0dgremlin> g.addV("person").("name","stephen")//3==>v[0]gremlin> g.tx().commit()//4==>nullgremlin> g.tx().onReadWrite(Transaction.READ_WRITE_BEHAVIOR.MANUAL)//5==>org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph$Neo4jTransaction@1c067c0dgremlin> g.tx().isOpen()==>falsegremlin> g.addV("person").("name","marko")//6Open a transaction before attempting to read/write the transactiongremlin> g.tx().open()//7==>nullgremlin> g.addV("person").("name","marko")//8==>v[1]gremlin> g.tx().commit()==>nullCheck
featuresto ensure that the graph supports transactions.By default,
Neo4jGraphis configured with "automatic" transactions, so it is set here for demonstration purposes only.When the vertex is added, the transaction is automatically started. From this point, more mutations can be stagedor other read operations executed in the context of that open transaction.
Calling
commitfinalizes the transaction.Change transaction behavior to require manual control.
Adding a vertex now results in failure because the transaction was not explicitly opened.
Explicitly open a transaction.
Adding a vertex now succeeds as the transaction was manually opened.
Note | It may be important to consult the documentation of theGraph implementation you are using when it comes to thespecifics of how transactions will behave. TinkerPop allows some latitude in this area and implementations may not havethe exact same behaviors andACID guarantees. |
Gremlin Server
The available capability for transactions withGremlin Server is dependent upon the method ofinteraction that is used. The preferred method forinteracting with Gremlin Serveris via websockets and bytecode based requests. The start of theTransactions Section describes thisapproach in detail with examples.
Gremlin Server also has the option to accept Gremlin-based scripts. The scripting approach provides access to theGraph API and thus also the transactional model described in theembedded section. Therefore a singlescript can have the ability to execute multiple transactions per request with complete control provided to thedeveloper to commit or rollback transactions as needed.
There are two methods for sending scripts to Gremlin Server: sessionless and session-based. With sessionless requeststhere will always be an attempt to close the transaction at the end of the request with a commit if there are no errorsor a rollback if there is a failure. It is therefore unnecessary to close transactions manually within scriptsthemselves. By default, session-based requests do not have this quality. The transaction will be held open on theserver until the user closes it manually. There is an option to have automatic transaction management for sessions.More information on this topic can be found in theConsidering Transactions Section andtheConsidering Sessions Section.
Remote Gremlin Providers
At this time, transactional patterns for Remote Gremlin Providers are largely in line with Gremlin Server. As most ofRGPs do not expose aGraph instance, access to lower level transactional functions available to embedded graphseven in a sessionless fashion are not typically permitted. For example, without aGraph instance it is not possibletoconfigure transaction close or read-writebehaviors. The nature of what a "transaction" means will be dependent on the RGP as is the case with anyTinkerPop-enabled graph system, so it is important to consult that systems documentation for more details.
Configuration Steps
Many of the methods on theGraphTraversalSource are meant to configure the source for usage. These configurationaffect the manner in which a traversals are spawned from it. Configuration methods can be identified by their nameswith make use of "with" as a prefix:
With Configuration
Thewith() configuration adds arbitrary data to aTraversalSource which can then be used by graph providers asconfiguration options for a traversal execution. This configuration is similar towith()-modulator whichhas similar functionality when applied to an individual step.
g.with('providerDefinedVariable',0.33).V()The0.33 value for the "providerDefinedVariable" will be bound to each traversal spawned that way. Consult thegraph system being used to determine if any such configuration options are available.
WithBulk Configuration
ThewithBulk() configuration allows for control of bulking operations. This value istrue by default allowing fornormalbulking operations, but when set tofalse, introduces a subtle change in that behavior asshown in examples insack()-step.
WithComputer Configuration
ThewithComputer() configuration adds aComputer that will be used to process the traversal and is necessary forOLAP based processing and steps that require that processing. Seeexamples related toSparkGraphComputer or see examples in the computer required steps, likepageRank() or[shortestpath-shortestPath()].
WithSack Configuration
ThewithSack() configuration adds a "sack" that can be accessed by traversals spawned from this source. Thisfunctionality is shown in more detail in the examples for (sack())-step.
WithSideEffect Configuration
ThewithSideEffect() configuration adds an arbitraryObject to traversals spawned from this source which can beaccessed as a side-effect given the supplied key.
gremlin> g.withSideEffect('x',['dog','cat','fish']). V().has('person','name','marko').select('x').unfold()==>dog==>cat==>fishg.withSideEffect('x',['dog','cat','fish']). V().has('person','name','marko').select('x').unfold()WithStrategies Configuration
ThewithStrategies() configuration allows inclusion of additionalTraversalStrategy instances to be applied toany traversals spawned from the configured source. Please see theTraversal Strategy Sectionfor more details on how this configuration works.
WithoutStrategies Configuration
ThewithoutStrategies() configuration removes a particularTraversalStrategy from those to be applied to traversalsspawned from the configured source. Please see theTraversal Strategy Section for more detailson how this configuration works.
Start Steps
Not all steps are capable of starting aGraphTraversal. Only those steps on theGraphTraversalSource can do that.Many of the methods onGraphTraversalSource are actually for itsconfiguration and startsteps should not be confused with those.
Spawn steps, which actually yield a traversal, typically match the names of existing steps:
addE()- Adds anEdgeto start the traversal (example).addV()- Adds aVertexto start the traversal (example).call()- Makes a provider-specific service call to start the traversal (example).E()- Reads edges from the graph to start the traversal (example).inject()- Inserts arbitrary objects to start the traversal (example).mergeE()- Adds anEdgein a "create if not exist" fashion to start the traversal (example)mergeV()- Adds aVertexin a "create if not exist" fashion to start the traversal (example)union()- Merges the results of an arbitrary number of child traversals to start the traversal (example).V()- Reads vertices from the graph to start the traversal (example).
Graph Traversal Steps
Gremlin steps are chained together to produce the actual traversal and are triggered by way ofstart stepson theGraphTraversalSource.
Important | More details about the Gremlin language can be found in the Provider Documentation within theGremlin Semantics Section. |
General Steps
There are five general steps, each having a traversal and a lambda representation, by which all other specific steps described later extend.
| Step | Description |
|---|---|
| map the traverser to some object of type |
| map the traverser to an iterator of |
| map the traverser to either true or false, where false will not pass the traverser to the next step. |
| perform some operation on the traverser and pass it to the next step. |
| split the traverser to all the traversals indexed by the |
Warning | Lambda steps are presented for educational purposes as they represent the foundational constructs of theGremlin language. In practice, lambda steps should be avoided in favor of their traversals representation and traversalverification strategies exist to disallow their use unless explicitly "turned off." For more information on the problemswith lambdas, please readA Note on Lambdas. |
TheTraverser<S> object provides access to:
The current traversed
Sobject —Traverser.get().The current path traversed by the traverser —
Traverser.path().A helper shorthand to get a particular path-history object —
Traverser.path(String) == Traverser.path().get(String).
The number of times the traverser has gone through the current loop —
Traverser.loops().The number of objects represented by this traverser —
Traverser.bulk().The local data structure associated with this traverser —
Traverser.sack().The side-effects associated with the traversal —
Traverser.sideEffects().A helper shorthand to get a particular side-effect —
Traverser.sideEffect(String) == Traverser.sideEffects().get(String).

gremlin> g.V(1).out().values('name')////(1)==>lop==>vadas==>joshgremlin> g.V(1).out().map {it.get().value('name')}////(2)==>lop==>vadas==>joshgremlin> g.V(1).out().map(values('name'))////(3)==>lop==>vadas==>joshg.V(1).out().values('name')////(1)g.V(1).out().map {it.get().value('name')}////(2)g.V(1).out().map(values('name'))//3An outgoing traversal from vertex 1 to the name values of the adjacent vertices.
The same operation, but using a lambda to access the name property values.
Again the same operation, but using the traversal representation of
map().

gremlin> g.V().filter {it.get().label() =='person'}////(1)==>v[1]==>v[2]==>v[4]==>v[6]gremlin> g.V().filter(label().is('person'))////(2)==>v[1]==>v[2]==>v[4]==>v[6]gremlin> g.V().hasLabel('person')////(3)==>v[1]==>v[2]==>v[4]==>v[6]g.V().filter {it.get().label() =='person'}////(1)g.V().filter(label().is('person'))////(2)g.V().hasLabel('person')//3A filter that only allows the vertex to pass if it has the "person" label
The same operation, but using the traversal representation of
filter().The more specific
has()-step is implemented as afilter()with respective predicate.

gremlin> g.V().hasLabel('person').sideEffect(System.out.&println)////(1)v[1]==>v[1]v[2]==>v[2]v[4]==>v[4]v[6]==>v[6]gremlin> g.V().sideEffect(outE().count().aggregate(local,"o")). sideEffect(inE().count().aggregate(local,"i")).cap("o","i")////(2)==>[i:[0,0,1,1,1,3],o:[3,0,0,0,2,1]]g.V().hasLabel('person').sideEffect(System.out.&println)////(1)g.V().sideEffect(outE().count().aggregate(local,"o")). sideEffect(inE().count().aggregate(local,"i")).cap("o","i")//2Whatever enters
sideEffect()is passed to the next step, but some intervening process can occur.Compute the out- and in-degree for each vertex. Both
sideEffect()are fed with the same vertex.

gremlin> g.V().branch {it.get().value('name')}. option('marko', values('age')). option(none, values('name'))////(1)==>29==>vadas==>lop==>josh==>ripple==>petergremlin> g.V().branch(values('name')). option('marko', values('age')). option(none, values('name'))////(2)==>29==>vadas==>lop==>josh==>ripple==>petergremlin> g.V().choose(has('name','marko'), values('age'), values('name'))////(3)==>29==>vadas==>lop==>josh==>ripple==>peterg.V().branch {it.get().value('name')}. option('marko', values('age')). option(none, values('name'))////(1)g.V().branch(values('name')). option('marko', values('age')). option(none, values('name'))////(2)g.V().choose(has('name','marko'), values('age'), values('name'))//3If the vertex is "marko", get his age, else get the name of the vertex.
The same operation, but using the traversal representing of
branch().The more specific boolean-based
choose()-step is implemented as abranch().
Terminal Steps
Typically, when a step is concatenated to a traversal a traversal is returned. In this way, a traversal is built upin afluent,monadic fashion.However, some steps do not return a traversal, but instead, execute the traversal and return a result. These steps are knownas terminal steps (terminal) and they are explained via the examples below.
gremlin> g.V().out('created').hasNext()////(1)==>truegremlin> g.V().out('created').next()////(2)==>v[3]gremlin> g.V().out('created').next(2)////(3)==>v[3]==>v[5]gremlin> g.V().out('nothing').tryNext()////(4)==>Optional.emptygremlin> g.V().out('created').toList()////(5)==>v[3]==>v[5]==>v[3]==>v[3]gremlin> g.V().out('created').toSet()////(6)==>v[3]==>v[5]gremlin> g.V().out('created').toBulkSet()////(7)==>v[3]==>v[3]==>v[3]==>v[5]gremlin> results = ['blah',3]==>blah==>3gremlin> g.V().out('created').fill(results)////(8)==>blah==>3==>v[3]==>v[5]==>v[3]==>v[3]gremlin> g.addV('person').iterate()////(9)g.V().out('created').hasNext()////(1)g.V().out('created').next()////(2)g.V().out('created').next(2)////(3)g.V().out('nothing').tryNext()////(4)g.V().out('created').toList()////(5)g.V().out('created').toSet()////(6)g.V().out('created').toBulkSet()////(7)results = ['blah',3]g.V().out('created').fill(results)////(8)g.addV('person').iterate()//9hasNext()determines whether there are available results (not supported ingremlin-javascript).next()will return the next result.next(n)will return the nextnresults in a list (not supported ingremlin-javascriptor Gremlin.NET).tryNext()will return anOptionaland thus, is a composite ofhasNext()/next()(only supported for JVM languages).toList()will return all results in a list.toSet()will return all results in a set and thus, duplicates removed (not supported ingremlin-javascript).toBulkSet()will return all results in a weighted set and thus, duplicates preserved via weighting (only supported for JVM languages).fill(collection)will put all results in the provided collection and return the collection when complete (only supported for JVM languages).iterate()does not exactly fit the definition of a terminal step in that it doesn’t return a result, but stillreturns a traversal - it does however behave as a terminal step in that it iterates the traversal and generates sideeffects without returning the actual result.
There is also thepromise() terminator step, which can only be used with remote traversals toGremlin Server orRGPs. It starts a promise to execute a functionon the currentTraversal that will be completed in the future.
Finally,explain()-step is also a terminal step and is described in its own section.
AddE Step
Reasoning is the process of making explicit what is implicitin the data. What is explicit in a graph are the objects of the graph — i.e. vertices and edges. What is implicitin the graph is the traversal. In other words, traversals expose meaning where the meaning is determined by thetraversal definition. For example, take the concept of a "co-developer." Two people are co-developers if they haveworked on the same project together. This concept can be represented as a traversal and thus, the concept of"co-developers" can be derived. Moreover, what was once implicit can be made explicit via theaddE()-step(map/sideEffect).

gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')). addE('co-developer').from('a').property('year',2009)////(1)==>e[0][1-co-developer->4]==>e[13][1-co-developer->6]gremlin> g.V(3,4,5).aggregate('x').has('name','josh').as('a'). select('x').unfold().hasLabel('software').addE('createdBy').to('a')////(2)==>e[14][3-createdBy->4]==>e[15][5-createdBy->4]gremlin> g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public')////(3)==>e[16][3-createdBy->1]==>e[17][5-createdBy->4]==>e[18][3-createdBy->4]==>e[19][3-createdBy->6]gremlin> g.V(1).as('a').out('knows'). addE('livesNear').from('a').property('year',2009). inV().inE('livesNear').values('year')////(4)==>2009==>2009gremlin> g.V().match( __.as('a').out('knows').as('b'), __.as('a').out('created').as('c'), __.as('b').out('created').as('c')). addE('friendlyCollaborator').from('a').to('b'). property(id,23).property('project',select('c').values('name'))////(5)==>e[23][1-friendlyCollaborator->4]gremlin> g.E(23).valueMap()==>[project:lop]gremlin> vMarko = g.V().has('name','marko').next()==>v[1]gremlin> vPeter = g.V().has('name','peter').next()==>v[6]gremlin> g.V(vMarko).addE('knows').to(vPeter)////(6)==>e[22][1-knows->6]gremlin> g.addE('knows').from(vMarko).to(vPeter)////(7)==>e[24][1-knows->6]g.V(1).as('a').out('created').in('created').where(neq('a')). addE('co-developer').from('a').property('year',2009)////(1)g.V(3,4,5).aggregate('x').has('name','josh').as('a'). select('x').unfold().hasLabel('software').addE('createdBy').to('a')////(2)g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public')////(3)g.V(1).as('a').out('knows'). addE('livesNear').from('a').property('year',2009). inV().inE('livesNear').values('year')////(4)g.V().match( __.as('a').out('knows').as('b'), __.as('a').out('created').as('c'), __.as('b').out('created').as('c')). addE('friendlyCollaborator').from('a').to('b'). property(id,23).property('project',select('c').values('name'))////(5)g.E(23).valueMap()vMarko = g.V().has('name','marko').next()vPeter = g.V().has('name','peter').next()g.V(vMarko).addE('knows').to(vPeter)////(6)g.addE('knows').from(vMarko).to(vPeter)//7Add a co-developer edge with a year-property between marko and his collaborators.
Add incoming createdBy edges from the josh-vertex to the lop- and ripple-vertices.
Add an inverse createdBy edge for all created edges.
The newly created edge is a traversable object.
Two arbitrary bindings in a traversal can be joined
from()→to(), whereidcan be provided for graphs thatsupports user provided ids.Add an edge between marko and peter given the directed (detached) vertex references.
Add an edge between marko and peter given the directed (detached) vertex references.
Additional References
AddV Step
TheaddV()-step is used to add vertices to the graph (map/sideEffect). For every incoming object, a vertex iscreated. Moreover,GraphTraversalSource maintains anaddV() method.
gremlin> g.addV('person').property('name','stephen')==>v[0]gremlin> g.V().values('name')==>stephen==>marko==>vadas==>lop==>josh==>ripple==>petergremlin> g.V().outE('knows').addV().property('name','nothing')==>v[13]==>v[15]gremlin> g.V().has('name','nothing')==>v[13]==>v[15]gremlin> g.V().has('name','nothing').bothE()g.addV('person').property('name','stephen')g.V().values('name')g.V().outE('knows').addV().property('name','nothing')g.V().has('name','nothing')g.V().has('name','nothing').bothE()Additional References
Aggregate Step

Theaggregate()-step (sideEffect) is used to aggregate all the objects at a particular point of traversal into aCollection. The step is usesScope to help determine the aggregating behavior. Forglobal scope this means thatthe step will useeager evaluation in that no objects continue onuntil all previous objects have been fully aggregated. The eager evaluation model is crucial in situationswhere everything at a particular point is required for future computation. By default, when the overload ofaggregate() is called without aScope, the default isglobal. An example is provided below.
gremlin> g.V(1).out('created')////(1)==>v[3]gremlin> g.V(1).out('created').aggregate('x')////(2)==>v[3]gremlin> g.V(1).out('created').aggregate(global,'x')////(3)==>v[3]gremlin> g.V(1).out('created').aggregate('x').in('created')////(4)==>v[1]==>v[4]==>v[6]gremlin> g.V(1).out('created').aggregate('x').in('created').out('created')////(5)==>v[3]==>v[5]==>v[3]==>v[3]gremlin> g.V(1).out('created').aggregate('x').in('created').out('created'). where(without('x')).values('name')////(6)==>rippleg.V(1).out('created')////(1)g.V(1).out('created').aggregate('x')////(2)g.V(1).out('created').aggregate(global,'x')////(3)g.V(1).out('created').aggregate('x').in('created')////(4)g.V(1).out('created').aggregate('x').in('created').out('created')////(5)g.V(1).out('created').aggregate('x').in('created').out('created'). where(without('x')).values('name')//6What has marko created?
Aggregate all his creations.
Identical to the previous line.
Who are marko’s collaborators?
What have marko’s collaborators created?
What have marko’s collaborators created that he hasn’t created?
Inrecommendation systems, the above pattern is used:
"What has userA liked? Who else has liked those things? What have they liked that userA hasn't already liked?"
Finally,aggregate()-step can be modulated viaby()-projection.
gremlin> g.V().out('knows').aggregate('x').cap('x')==>[v[2],v[4]]gremlin> g.V().out('knows').aggregate('x').by('name').cap('x')==>[vadas,josh]gremlin> g.V().out('knows').aggregate('x').by('age').cap('x')////(1)==>[27,32]g.V().out('knows').aggregate('x').cap('x')g.V().out('knows').aggregate('x').by('name').cap('x')g.V().out('knows').aggregate('x').by('age').cap('x')//1The "age" property is notproductive for all vertices and therefore those values are not included in the aggregation.
Forlocal scope the aggregation will occur in alazy fashion.
Note | Prior to 3.4.3,local aggregation (i.e. lazy) evaluation was handled bystore()-step. |
gremlin> g.V().aggregate(global,'x').limit(1).cap('x')==>[v[1],v[2],v[3],v[4],v[5],v[6]]gremlin> g.V().aggregate(local,'x').limit(1).cap('x')==>[v[1]]gremlin> g.withoutStrategies(EarlyLimitStrategy).V().aggregate(local,'x').limit(1).cap('x')==>[v[1],v[2]]g.V().aggregate(global,'x').limit(1).cap('x')g.V().aggregate(local,'x').limit(1).cap('x')g.withoutStrategies(EarlyLimitStrategy).V().aggregate(local,'x').limit(1).cap('x')It is important to note thatEarlyLimitStrategy introduced in 3.3.5 alters the behavior ofaggregate(local).Without that strategy (which is installed by default), there are two results in theaggregate() side-effect eventhough the interval selection is for 1 object. Realize that when the second object is on its way to therange()filter (i.e.[0..1]), it passes throughaggregate() and thus, stored before filtered.
gremlin> g.E().aggregate(local,'x').by('weight').cap('x')==>[0.5,1.0,1.0,0.4,0.4,0.2]g.E().aggregate(local,'x').by('weight').cap('x')Additional References
All Step
It is possible to filter list traversers usingall()-step (filter). Every item in the list will be tested againstthe supplied predicate and if all of the items pass then the traverser is passed along the stream, otherwise it isfiltered. Empty lists are passed along but null or non-iterable traversers are filtered out.
Python | The term |
gremlin> g.V().values('age').fold().all(gt(25))////(1)==>[29,27,32,35]g.V().values('age').fold().all(gt(25))//1Return the list of ages only if everyone’s age is greater than 25.
Additional References
And Step
Theand()-step ensures that all provided traversals yield a result (filter). Please seeor() for or-semantics.
Python | The term |
gremlin> g.V().and( outE('knows'), values('age').is(lt(30))). values('name')==>markog.V().and( outE('knows'), values('age').is(lt(30))). values('name')Theand()-step can take an arbitrary number of traversals. All traversals must produce at least one output for theoriginal traverser to pass to the next step.
Aninfix notation can be used as well.
gremlin> g.V().where(outE('created').and().outE('knows')).values('name')==>markog.V().where(outE('created').and().outE('knows')).values('name')Additional References
Any Step
It is possible to filter list traversers usingany()-step (filter). All items in the list will be tested againstthe supplied predicate and if any of the items pass then the traverser is passed along the stream, otherwise it isfiltered. Empty lists, null traversers, and non-iterable traversers are filtered out as well.
Python | The term |
gremlin> g.V().values('age').fold().any(gt(25))////(1)==>[29,27,32,35]g.V().values('age').fold().any(gt(25))//1Return the list of ages if anyone’s age is greater than 25.
Additional References
As Step
Theas()-step is not a real step, but a "step modulator" similar toby() andoption().Withas(), it is possible to provide a label to the step that can later be accessed by steps and data structuresthat make use of such labels — e.g.,select(),match(), and path.
Groovy | The term |
Python | The term |
gremlin> g.V().as('a').out('created').as('b').select('a','b')////(1)==>[a:v[1],b:v[3]]==>[a:v[4],b:v[5]]==>[a:v[4],b:v[3]]==>[a:v[6],b:v[3]]gremlin> g.V().as('a').out('created').as('b').select('a','b').by('name')////(2)==>[a:marko,b:lop]==>[a:josh,b:ripple]==>[a:josh,b:lop]==>[a:peter,b:lop]g.V().as('a').out('created').as('b').select('a','b')////(1)g.V().as('a').out('created').as('b').select('a','b').by('name')//2Select the objects labeled "a" and "b" from the path.
Select the objects labeled "a" and "b" from the path and, for each object, project its name value.
A step can have any number of labels associated with it. This is useful for referencing the same step multiple times in a future step.
gremlin> g.V().hasLabel('software').as('a','b','c'). select('a','b','c'). by('name'). by('lang'). by(__.in('created').values('name').fold())==>[a:lop,b:java,c:[marko,josh,peter]]==>[a:ripple,b:java,c:[josh]]g.V().hasLabel('software').as('a','b','c'). select('a','b','c'). by('name'). by('lang'). by(__.in('created').values('name').fold())Additional References
AsString Step
TheasString()-step (map) returns the value of incoming traverser as strings. Null values are returned unchanged.
gremlin> g.V().hasLabel('person').values('age').asString()////(1)==>29==>27==>32==>35gremlin> g.V().hasLabel('person').values('age').asString().concat(' years old')////(2)==>29 years old==>27 years old==>32 years old==>35 years oldgremlin> g.V().hasLabel('person').values('age').fold().asString(local)////(3)==>[29,27,32,35]g.V().hasLabel('person').values('age').asString()////(1)g.V().hasLabel('person').values('age').asString().concat(' years old')////(2)g.V().hasLabel('person').values('age').fold().asString(local)//3Return ages as string.
Return ages as string and use concat to generate phrases.
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
AsDate Step
TheasDate()-step (map) converts string or numeric input to Date.
For string input only ISO-8601 format is supported. For numbers, the value is considered as the number of themilliseconds since "the epoch" (January 1, 1970, 00:00:00 GMT). Date input is passed without changes.
If the incoming traverser is not a string, number or Date then anIllegalArgumentException will be thrown.
gremlin> g.inject(1690934400000).asDate()////(1)==>Tue Aug0117:00:00 PDT2023gremlin> g.inject("2023-08-02T00:00:00Z").asDate()////(2)==>Tue Aug0117:00:00 PDT2023gremlin> g.inject(datetime("2023-08-24T00:00:00Z")).asDate()////(3)==>Wed Aug2317:00:00 PDT2023g.inject(1690934400000).asDate()////(1)g.inject("2023-08-02T00:00:00Z").asDate()////(2)g.inject(datetime("2023-08-24T00:00:00Z")).asDate()//3Convert number to Date
Convert ISO-8601 string to Date
Pass Date without modification
Additional References
Barrier Step
Thebarrier()-step (barrier) turns the lazy traversal pipeline into a bulk-synchronous pipeline. This step isuseful in the following situations:
When everything prior to
barrier()needs to be executed before moving onto the steps after thebarrier()(i.e. ordering).When "stalling" the traversal may lead to a "bulking optimization" in traversals that repeatedly touch many of the same elements (i.e. optimizing).
gremlin> g.V().sideEffect{println"first:${it}"}.sideEffect{println"second:${it}"}.iterate()first: v[1]second: v[1]first: v[2]second: v[2]first: v[3]second: v[3]first: v[4]second: v[4]first: v[5]second: v[5]first: v[6]second: v[6]gremlin> g.V().sideEffect{println"first:${it}"}.barrier().sideEffect{println"second:${it}"}.iterate()first: v[1]first: v[2]first: v[3]first: v[4]first: v[5]first: v[6]second: v[1]second: v[2]second: v[3]second: v[4]second: v[5]second: v[6]g.V().sideEffect{println"first:${it}"}.sideEffect{println"second:${it}"}.iterate()g.V().sideEffect{println"first:${it}"}.barrier().sideEffect{println"second:${it}"}.iterate()The theory behind a "bulking optimization" is simple. If there are one million traversers at vertex 1, then there isno need to calculate one millionboth()-computations. Instead, represent those one million traversers as a singletraverser with aTraverser.bulk() equal to one million and executeboth() once. A bulking optimization example ismade more salient on a larger graph. Therefore, the example below leverages theGrateful Dead graph.
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> g = traversal().withEmbedded(graph).withoutStrategies(LazyBarrierStrategy)////(1)==>graphtraversalsource[tinkergraph[vertices:808edges:8049], standard]gremlin> clockWithResult(1){g.V().both().both().both().count().next()}////(2)==>3436.911791==>126653966gremlin> clockWithResult(1){g.V().repeat(both()).times(3).count().next()}////(3)==>3608.9579999999996==>126653966gremlin> clockWithResult(1){g.V().both().barrier().both().barrier().both().barrier().count().next()}////(4)==>5.8490839999999995==>126653966graph = TinkerGraph.open()g = traversal().withEmbedded(graph)g.io('data/grateful-dead.xml').read().iterate()g = traversal().withEmbedded(graph).withoutStrategies(LazyBarrierStrategy)////(1)clockWithResult(1){g.V().both().both().both().count().next()}////(2)clockWithResult(1){g.V().repeat(both()).times(3).count().next()}////(3)clockWithResult(1){g.V().both().barrier().both().barrier().both().barrier().count().next()}//4Explicitly remove
LazyBarrierStrategywhich yields a bulking optimization.A non-bulking traversal where each traverser is processed.
Each traverser entering
repeat()has its recursion bulked.A bulking traversal where implicit traversers are not processed.
Ifbarrier() is provided an integer argument, then the barrier will only holdn-number of unique traversers in itsbarrier before draining the aggregated traversers to the next step. This is useful in the aforementioned bulkingoptimization scenario with the added benefit of reducing the risk of an out-of-memory exception.
LazyBarrierStrategy insertsbarrier()-steps into a traversal where appropriate in order to gain the"bulking optimization."
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)////(1)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> clockWithResult(1){g.V().both().both().both().count().next()}==>3.8489579999999997==>126653966gremlin> g.V().both().both().both().count().iterate().toString()////(2)==>[TinkerGraphStep(vertex,[]), VertexStep(BOTH,vertex), NoOpBarrierStep(2500), VertexStep(BOTH,vertex), NoOpBarrierStep(2500), VertexStep(BOTH,edge), CountGlobalStep, NoneStep]graph = TinkerGraph.open()g = traversal().withEmbedded(graph)////(1)g.io('data/grateful-dead.xml').read().iterate()clockWithResult(1){g.V().both().both().both().count().next()}g.V().both().both().both().count().iterate().toString()//2LazyBarrierStrategyis a default strategy and thus, does not need to be explicitly activated.With
LazyBarrierStrategyactivated,barrier()-steps are automatically inserted where appropriate.
Additional References
Branch Step
Thebranch() step splits the traverser to all the child traversals provided to it. Please see theGeneral Steps section for more information, but also consider thatbranch() is the basis for morerobust steps likechoose() andunion().
Additional References
By Step
Theby()-step is not an actual step, but instead is a "step-modulator" similar toas() andoption(). If a step is able to accept traversals, functions, comparators, etc. thenby() is themeans by which they are added. The general pattern isstep().by()…by(). Some steps can only accept oneby()while others can take an arbitrary amount.
gremlin> g.V().group().by(bothE().count())////(1)==>[1:[v[2],v[5],v[6]],3:[v[1],v[3],v[4]]]gremlin> g.V().group().by(bothE().count()).by('name')////(2)==>[1:[vadas,ripple,peter],3:[marko,lop,josh]]gremlin> g.V().group().by(bothE().count()).by(count())////(3)==>[1:3,3:3]g.V().group().by(bothE().count())////(1)g.V().group().by(bothE().count()).by('name')////(2)g.V().group().by(bothE().count()).by(count())//3by(outE().count())will group the elements by their edge count (traversal).by('name')will process the grouped elements by their name (element property projection).by(count())will count the number of elements in each group (traversal).
When aby() modulator does not produce a result, it is deemed "unproductive". An "unproductive" modulator will leadto the filtering of the traverser it is currently working with. The filtering will manifest in various ways dependingon the step.
gremlin> g.V().sample(1).by('age')////(1)==>v[4]g.V().sample(1).by('age')//1The "age" property key is not present for all vertices, therefore
sample()will ignore (i.e. filter) suchvertices for consideration in the sampling.
The following steps all supportby()-modulation. Note that the semantics of such modulation should be understoodon a step-by-step level and thus, as discussed in their respective section of the documentation.
aggregate(): aggregate all objects into a set but only store theirby()-modulated values.cyclicPath(): filter if the traverser’s path is cyclic givenby()-modulation.dedup(): dedup on the results of aby()-modulation.format(): transform a traverser provided to the step by way of theby()modulator before it is processed by it.group(): create group keys and values according toby()-modulation.groupCount(): count those groups where the group keys are the result ofby()-modulation.math(): transform a traverser provided to the step by way of theby()modulator before it is processed by it.order(): order the objects by the results of aby()-modulation.path(): get the path of the traverser where each path element isby()-modulated.project(): project a map of results given variousby()-modulations off the current object.propertyMap(): transform the result of the values in the resultingMapusing theby()modulator.sack(): provides the transformation for a traverser to a value to be stored in the sack.sample(): sample using the value returned byby()-modulation.select(): select path elements and transform them viaby()-modulation.simplePath(): filter if the traverser’s path is simple givenby()-modulation.tree(): get a tree of traversers objects where the objects have beenby()-modulated.valueMap(): transform the result of the values in the resultingMapusing theby()modulator.where(): determine the predicate given the testing of the results ofby()-modulation.
Additional References
Call Step
Thecall() step allows for custom, provider-specific service calls either at the start of a traversal or mid-traversal.This allows Graph providers to expose operations not natively built into the Gremlin language, such as full text search,custom analytics, notification triggers, etc.
When called with no arguments,call() will produce a list of callable services available for the graph in use. Thisno-argument version is equivalent tocall('--list'). This "directory service" is also capable of producing moreverbose output describing all the services or an individual service:
gremlin> g.call()////(1)gremlin> g.call('--list')////(1)gremlin> g.call().with('verbose')////(2)gremlin> g.call().with('verbose').with('service','xyz-service')////(3)g.call()////(1)g.call('--list')////(1)g.call().with('verbose')////(2)g.call().with('verbose').with('service','xyz-service')//3List available services by name
Produce a Map of detailed service information by name
Produce the detailed service information for the 'xyz-service'
The first argument tocall() is always the name of the service call. Additionally, service calls can accept bothstatic and dynamically produced parameters. Static parameters can be passed as aMap to thecall() as the secondargument. Individual static parameters can also be added using the.with() modulator. Dynamic parameters can bepassed as aMap-producingTraversal as the second argument (no static parameters) or third argument (static + dynamicparameters). Additional individual dynamic parameters can be added using the.with() modulator.
g.call('xyz-service')//1g.call('xyz-service', ['a':'b'])//2g.call('xyz-service').with('a','b')//2g.call('xyz-service', __.inject(['a':'b']))//3g.call('xyz-service').with('a', __.inject('b'))//3g.call('xyz-service', ['a':'b'], __.inject(['c':'d']))//4Call the 'xyz-service' with no parameters
Examples of static parameters (constants known before execution)
Examples of dynamic parameters (these will be computed at execution time)
Example of static + dynamic parameters (these will be computed and merged into one set of parameters at execution time)
Additional References
GraphTraversalSource:
GraphTraversal:
Cap Step
Thecap()-step (barrier) iterates the traversal up to itself and emits the sideEffect referenced by the providedkey. If multiple keys are provided, then aMap<String,Object> of sideEffects is emitted.
gremlin> g.V().groupCount('a').by(label).cap('a')////(1)==>[software:2,person:4]gremlin> g.V().groupCount('a').by(label).groupCount('b').by(outE().count()).cap('a','b')////(2)==>[a:[software:2,person:4],b:[0:3,1:1,2:1,3:1]]g.V().groupCount('a').by(label).cap('a')////(1)g.V().groupCount('a').by(label).groupCount('b').by(outE().count()).cap('a','b')//2Group and count vertices by their label. Emit the side effect labeled 'a', which is the group count by label.
Same as statement 1, but also emit the side effect labeled 'b' which groups vertices by the number of out edges.
Additional References
Choose Step

Thechoose()-step (branch) routes the current traverser to a particular traversal branch option. Withchoose(),it is possible to implement if/then/else-semantics as well as more complicated selections.
gremlin> g.V().hasLabel('person'). choose(values('age').is(lte(30)), __.in(), __.out()).values('name')////(1)==>marko==>ripple==>lop==>lopgremlin> g.V().hasLabel('person'). choose(values('age')). option(27, __.in()). option(32, __.out()).values('name')////(2)==>marko==>ripple==>lopg.V().hasLabel('person'). choose(values('age').is(lte(30)), __.in(), __.out()).values('name')////(1)g.V().hasLabel('person'). choose(values('age')). option(27, __.in()). option(32, __.out()).values('name')//2If the traversal yields an element, then do
in, else doout(i.e. true/false-based option selection).Use the result of the traversal as a key to the map of traversal options (i.e. value-based option selection).
If the "false"-branch is not provided, then if/then-semantics are implemented.
gremlin> g.V().choose(hasLabel('person'), out('created')).values('name')////(1)==>lop==>lop==>ripple==>lop==>ripple==>lopgremlin> g.V().choose(hasLabel('person'), out('created'), identity()).values('name')////(2)==>lop==>lop==>ripple==>lop==>ripple==>lopg.V().choose(hasLabel('person'), out('created')).values('name')////(1)g.V().choose(hasLabel('person'), out('created'), identity()).values('name')//2If the vertex is a person, emit the vertices they created, else emit the vertex.
If/then/else with an
identity()on the false-branch is equivalent to if/then with no false-branch.
Note thatchoose() can have an arbitrary number of options and moreover, can take an anonymous traversal as its choice function.
gremlin> g.V().hasLabel('person'). choose(values('name')). option('marko', values('age')). option('josh', values('name')). option('vadas', elementMap()). option('peter', label())==>29==>[id:2,label:person,name:vadas,age:27]==>josh==>persong.V().hasLabel('person'). choose(values('name')). option('marko', values('age')). option('josh', values('name')). option('vadas', elementMap()). option('peter', label())Thechoose()-step can leverage thePick.none option match. For anything that does not match a specified option, thenone-option is taken.
gremlin> g.V().hasLabel('person'). choose(values('name')). option('marko', values('age')). option(none, values('name'))==>29==>vadas==>josh==>peterg.V().hasLabel('person'). choose(values('name')). option('marko', values('age')). option(none, values('name'))Additional References
Coalesce Step
Thecoalesce()-step evaluates the provided traversals in order and returns the first traversal that emits atleast one element.
gremlin> g.V(1).coalesce(outE('knows'), outE('created')).inV().path().by('name').by(label)==>[marko,knows,vadas]==>[marko,knows,josh]gremlin> g.V(1).coalesce(outE('created'), outE('knows')).inV().path().by('name').by(label)==>[marko,created,lop]gremlin> g.V(1).property('nickname','okram')==>v[1]gremlin> g.V().hasLabel('person').coalesce(values('nickname'), values('name'))==>okram==>vadas==>josh==>peterg.V(1).coalesce(outE('knows'), outE('created')).inV().path().by('name').by(label)g.V(1).coalesce(outE('created'), outE('knows')).inV().path().by('name').by(label)g.V(1).property('nickname','okram')g.V().hasLabel('person').coalesce(values('nickname'), values('name'))Additional References
Coin Step
To randomly filter out a traverser, use thecoin()-step (filter). The provided double argument biases the "coin toss."
gremlin> g.V().coin(0.5)==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]gremlin> g.V().coin(0.0)gremlin> g.V().coin(1.0)==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]g.V().coin(0.5)g.V().coin(0.0)g.V().coin(1.0)Additional References
Combine Step
Thecombine()-step (map) combines the elements of the incoming list traverser and the provided list argument intoone list. This is also known as appending or concatenating. This step only expects list data (array or Iterable) andwill throw anIllegalArgumentException if any other type is encountered (includingnull). This differs from themerge()-step in that it allows duplicates to exist.
gremlin> g.V().values("name").fold().combine(["james","jen","marko","vadas"])==>[marko,vadas,lop,josh,ripple,peter,james,jen,marko,vadas]gremlin> g.V().values("name").fold().combine(__.constant("stephen").fold())==>[marko,vadas,lop,josh,ripple,peter,stephen]g.V().values("name").fold().combine(["james","jen","marko","vadas"])g.V().values("name").fold().combine(__.constant("stephen").fold())Additional References
Concat Step
Theconcat()-step (map) concatenates one or more String values together to the incoming String traverser. This stepcan take either String varargs or Traversal varargs.Anynull String values will be skipped when concatenated with non-null String values. If twonull value areconcatenated, thenull value will be propagated and returned.If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.addV(constant('prefix_').concat(__.V(1).label())).property(id,10)////(1)==>v[10]gremlin> g.V(10).label()==>prefix_persongremlin> g.V().hasLabel('person').values('name').as('a'). constant('Mr.').concat(__.select('a'))////(2)==>Mr.marko==>Mr.vadas==>Mr.josh==>Mr.petergremlin> g.V().hasLabel('software').as('a').values('name'). concat(' uses'). concat(select('a').values('lang'))////(3)==>lop uses java==>ripple uses javagremlin> g.V(1).outE().as('a').V(1).values('name'). concat(''). concat(select('a').label()). concat(''). concat(select("a").inV().values('name'))////(4)==>marko created lop==>marko knows vadas==>marko knows joshgremlin> g.V(1).outE().as('a').V(1).values('name'). concat(constant(''), select("a").label(), constant(''), select('a').inV().values('name'))////(5)==>marko created lop==>marko knows vadas==>marko knows joshgremlin> g.inject('hello','hi').concat(__.V().values('name'))////(6)==>hellomarko==>himarkogremlin> g.inject('This').concat('').concat('is a','gremlin.')////(7)==>This is a gremlin.g.addV(constant('prefix_').concat(__.V(1).label())).property(id,10)////(1)g.V(10).label()g.V().hasLabel('person').values('name').as('a'). constant('Mr.').concat(__.select('a'))////(2)g.V().hasLabel('software').as('a').values('name'). concat(' uses'). concat(select('a').values('lang'))////(3)g.V(1).outE().as('a').V(1).values('name'). concat(''). concat(select('a').label()). concat(''). concat(select("a").inV().values('name'))////(4)g.V(1).outE().as('a').V(1).values('name'). concat(constant(''), select("a").label(), constant(''), select('a').inV().values('name'))////(5)g.inject('hello','hi').concat(__.V().values('name'))////(6)g.inject('This').concat('').concat('is a','gremlin.')//7Add a new vertex with id 10 which should be labeled like an existing vertex but with some prefix attached
Attach the prefix "Mr." to all the names using the
constant()-stepGenerate a string of software names and the language they use
Generate a string description for each of marko’s outgoing edges
Alternative way to generate the string description by using traversal varargs. Use the
constant()step to adddesired strings between arguments.The
concat()step will append the first result from the child traversal to the incoming traverserA generic use of
concat()to join strings together
Additional References
Conjoin Step
Theconjoin()-step (map) joins together the elements in the incoming list traverser together with the provided argumentas a delimiter. The resultingString is added to the Traversal Stream. This step only expects list data (array orIterable) in the incoming traverser and will throw anIllegalArgumentException if any other type is encountered(includingnull). Null values are skipped and not included in the result.
gremlin> g.V().values("name").fold().conjoin("+")==>marko+vadas+lop+josh+ripple+peterg.V().values("name").fold().conjoin("+")Additional References
ConnectedComponent Step
TheconnectedComponent() step performs a computation to identifyConnected Componentinstances in a graph. When this step completes, the vertices will be labelled with a component identifier to denotethe component to which they are associated.
Important | TheconnectedComponent()-step is aVertexComputing-step and as such, can only be used against a graphthat supportsGraphComputer (OLAP). |
gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V(). connectedComponent(). with(ConnectedComponent.propertyName,'component'). project('name','component'). by('name'). by('component')==>[name:lop,component:1]==>[name:marko,component:1]==>[name:ripple,component:1]==>[name:vadas,component:1]==>[name:josh,component:1]==>[name:peter,component:1]gremlin> g.V().hasLabel('person'). connectedComponent(). with(ConnectedComponent.propertyName,'component'). with(ConnectedComponent.edges, outE('knows')). project('name','component'). by('name'). by('component')==>[name:marko,component:1]==>[name:peter,component:6]==>[name:vadas,component:1]==>[name:josh,component:1]g = traversal().withEmbedded(graph).withComputer()g.V(). connectedComponent(). with(ConnectedComponent.propertyName,'component'). project('name','component'). by('name'). by('component')g.V().hasLabel('person'). connectedComponent(). with(ConnectedComponent.propertyName,'component'). with(ConnectedComponent.edges, outE('knows')). project('name','component'). by('name'). by('component')Note the use of thewith() modulating step which provides configuration options to the algorithm. It takesconfiguration keys from theConnectedComponent class and is automatically imported to the Gremlin Console.
Additional References
Constant Step
To specify a constant value for a traverser, use theconstant()-step (map). This is often useful with conditionalsteps likechoose()-step orcoalesce()-step.
gremlin> g.V().choose(hasLabel('person'), values('name'), constant('inhuman'))////(1)==>marko==>vadas==>inhuman==>josh==>inhuman==>petergremlin> g.V().coalesce( hasLabel('person').values('name'), constant('inhuman'))////(2)==>marko==>vadas==>inhuman==>josh==>inhuman==>peterg.V().choose(hasLabel('person'), values('name'), constant('inhuman'))////(1)g.V().coalesce( hasLabel('person').values('name'), constant('inhuman'))//2Show the names of people, but show "inhuman" for other vertices.
Same as statement 1 (unless there is a person vertex with no name).
Additional References
Count Step

Thecount()-step (map) counts the total number of represented traversers in the streams (i.e. the bulk count).
gremlin> g.V().count()==>6gremlin> g.V().hasLabel('person').count()==>4gremlin> g.V().hasLabel('person').outE('created').count().path()////(1)==>[4]gremlin> g.V().hasLabel('person').outE('created').count().map {it.get() *10}.path()////(2)==>[4,40]g.V().count()g.V().hasLabel('person').count()g.V().hasLabel('person').outE('created').count().path()////(1)g.V().hasLabel('person').outE('created').count().map {it.get() *10}.path()//2count()-step is areducing barrier step meaning that all of the previous traversers are folded into a new traverser.The path of the traverser emanating from
count()starts atcount().
Important | count(local) counts the current, local object (not the objects in the traversal stream). This works forCollection- andMap-type objects. For any other object, a count of 1 is returned. |
Additional References
CyclicPath Step

Each traverser maintains its history through the traversal over the graph — i.e. itspath.If it is important that the traverser repeat its course, thencyclic()-path should be used (filter). The stepanalyzes the path of the traverser thus far and if there are any repeats, the traverser is filtered out over thetraversal computation. If non-cyclic behavior is desired, seesimplePath().
gremlin> g.V(1).both().both()==>v[1]==>v[4]==>v[6]==>v[1]==>v[5]==>v[3]==>v[1]gremlin> g.V(1).both().both().cyclicPath()==>v[1]==>v[1]==>v[1]gremlin> g.V(1).both().both().cyclicPath().path()==>[v[1],v[3],v[1]]==>[v[1],v[2],v[1]]==>[v[1],v[4],v[1]]gremlin> g.V(1).both().both().cyclicPath().by('age').path()////(1)==>[v[1],v[2],v[1]]==>[v[1],v[4],v[1]]gremlin> g.V(1).as('a').out('created').as('b'). in('created').as('c'). cyclicPath(). path()==>[v[1],v[3],v[1]]gremlin> g.V(1).as('a').out('created').as('b'). in('created').as('c'). cyclicPath().from('a').to('b'). path()g.V(1).both().both()g.V(1).both().both().cyclicPath()g.V(1).both().both().cyclicPath().path()g.V(1).both().both().cyclicPath().by('age').path()////(1)g.V(1).as('a').out('created').as('b'). in('created').as('c'). cyclicPath(). path()g.V(1).as('a').out('created').as('b'). in('created').as('c'). cyclicPath().from('a').to('b'). path()The "age" property is notproductive for all vertices and therefore those traversers are filtered.
Additional References
DateAdd Step
ThedateAdd()-step (map) returns the value with the addition of the value number of units as specified by the DateToken.If the incoming traverser is not a Date, then anIllegalArgumentException will be thrown.
gremlin> g.inject("2023-08-02T00:00:00Z").asDate().dateAdd(DT.day,7)////(1)==>Tue Aug0817:00:00 PDT2023gremlin> g.inject(["2023-08-02T00:00:00Z","2023-08-03T00:00:00Z"]).unfold().asDate().dateAdd(DT.minute,1)////(2)==>Tue Aug0117:01:00 PDT2023==>Wed Aug0217:01:00 PDT2023g.inject("2023-08-02T00:00:00Z").asDate().dateAdd(DT.day,7)////(1)g.inject(["2023-08-02T00:00:00Z","2023-08-03T00:00:00Z"]).unfold().asDate().dateAdd(DT.minute,1)//2Add 7 days to Date
Add 1 minute to incoming dates
Additional References
DateDiff Step
ThedateDiff()-step (map) returns the difference between two Dates in epoch time.If the incoming traverser is not a Date, then anIllegalArgumentException will be thrown.
gremlin> g.inject("2023-08-02T00:00:00Z").asDate().dateDiff(constant("2023-08-03T00:00:00Z").asDate())////(1)==>-86400g.inject("2023-08-02T00:00:00Z").asDate().dateDiff(constant("2023-08-03T00:00:00Z").asDate())//1Find difference between two dates
Additional References
Dedup Step
Withdedup()-step (filter), repeatedly seen objects are removed from the traversal stream. Note that if atraverser’s bulk is greater than 1, then it is set to 1 before being emitted.
gremlin> g.V().values('lang')==>java==>javagremlin> g.V().values('lang').dedup()==>javagremlin> g.V(1).repeat(bothE('created').dedup().otherV()).emit().path()////(1)==>[v[1],e[9][1-created->3],v[3]]==>[v[1],e[9][1-created->3],v[3],e[11][4-created->3],v[4]]==>[v[1],e[9][1-created->3],v[3],e[12][6-created->3],v[6]]==>[v[1],e[9][1-created->3],v[3],e[11][4-created->3],v[4],e[10][4-created->5],v[5]]gremlin> g.V().bothE().properties().dedup()////(2)==>p[weight->0.4]==>p[weight->0.5]==>p[weight->1.0]==>p[weight->0.2]g.V().values('lang')g.V().values('lang').dedup()g.V(1).repeat(bothE('created').dedup().otherV()).emit().path()////(1)g.V().bothE().properties().dedup()//2Traverse all
creatededges, but don’t touch any edge twice.Note that
Propertyinstances will compare on key and value, whereas aVertexPropertywill also include itselement as it is a first-class citizen.
If a by-step modulation is provided todedup(), then the object is processed accordingly prior to determining if ithas been seen or not.
gremlin> g.V().elementMap('name')==>[id:1,label:person,name:marko]==>[id:2,label:person,name:vadas]==>[id:3,label:software,name:lop]==>[id:4,label:person,name:josh]==>[id:5,label:software,name:ripple]==>[id:6,label:person,name:peter]gremlin> g.V().dedup().by(label).values('name')==>marko==>lopg.V().elementMap('name')g.V().dedup().by(label).values('name')Ifdedup() is provided an array of strings, then it will ensure that the de-duplication is not with respect to thecurrent traverser object, but to the path history of the traverser.
gremlin> g.V().as('a').out('created').as('b').in('created').as('c').select('a','b','c')==>[a:v[1],b:v[3],c:v[1]]==>[a:v[1],b:v[3],c:v[4]]==>[a:v[1],b:v[3],c:v[6]]==>[a:v[4],b:v[5],c:v[4]]==>[a:v[4],b:v[3],c:v[1]]==>[a:v[4],b:v[3],c:v[4]]==>[a:v[4],b:v[3],c:v[6]]==>[a:v[6],b:v[3],c:v[1]]==>[a:v[6],b:v[3],c:v[4]]==>[a:v[6],b:v[3],c:v[6]]gremlin> g.V().as('a').out('created').as('b').in('created').as('c').dedup('a','b').select('a','b','c')////(1)==>[a:v[1],b:v[3],c:v[1]]==>[a:v[4],b:v[5],c:v[4]]==>[a:v[4],b:v[3],c:v[1]]==>[a:v[6],b:v[3],c:v[1]]gremlin> g.V().as('a').both().as('b').both().as('c'). dedup('a','b').by('age').////(2) select('a','b','c').by('name')==>[a:marko,b:vadas,c:marko]==>[a:marko,b:josh,c:ripple]==>[a:vadas,b:marko,c:lop]==>[a:josh,b:marko,c:lop]g.V().as('a').out('created').as('b').in('created').as('c').select('a','b','c')g.V().as('a').out('created').as('b').in('created').as('c').dedup('a','b').select('a','b','c')////(1)g.V().as('a').both().as('b').both().as('c'). dedup('a','b').by('age').////(2) select('a','b','c').by('name')If the current
aandbcombination has been seen previously, then filter the traverser.The "age" property is notproductive for all vertices and therefore those values are filtered.
Thededup() step can work on many different types of objects. One object in particular can need a bit of explanation.If you usededup() on aPath object there is a chance that you may get some unexpected results. Consider thefollowing example which forcibly generates duplicate path results in the first traversal and in the second appliesdedup() to remove them:
gremlin> g.V().union(out().path(), out().path())==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[6],v[3]]==>[v[6],v[3]]gremlin> g.V().union(out().path(), out().path()).dedup()==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[6],v[3]]g.V().union(out().path(), out().path())g.V().union(out().path(), out().path()).dedup()Thededup() step checks the equality of the paths by examining the equality of the objects on thePath (in this casevertices), but also on any path labels. In the prior example, there weren’t any path labels sodedup() behaved asexpected. In the next example, note the difference in the results if a label is added for onePath but not the other:
gremlin> g.V().union(out().as('x').path(), out().path())==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[6],v[3]]==>[v[6],v[3]]gremlin> g.V().union(out().as('x').path(), out().path()).dedup()==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[6],v[3]]==>[v[6],v[3]]g.V().union(out().as('x').path(), out().path())g.V().union(out().as('x').path(), out().path()).dedup()The prior example shows howdedup() does not have the same effect when a path label is in place. In this contrivedexample the answer is simple: remove theas('x'). If in the real world, it is not possible to remove the label, theworkaround is to deconstruct thePath into aList to drop the label. In this way,dedup() is just comparingListobjects and the objects in thePath.
gremlin> g.V().union(out().as('x').path(), out().path()).map(unfold().fold()).dedup()==>[v[1],v[3]]==>[v[1],v[2]]==>[v[1],v[4]]==>[v[4],v[5]]==>[v[4],v[3]]==>[v[6],v[3]]g.V().union(out().as('x').path(), out().path()).map(unfold().fold()).dedup()Additional References
Difference Step
Thedifference()-step (map) calculates the difference between the incoming list traverser and the provided listargument. More specifically, this provides the set operation A-B where A is the traverser and B is the argument. Thisstep only expects list data (array or Iterable) and will throw anIllegalArgumentException if any other type isencountered (includingnull).
gremlin> g.V().values("name").fold().difference(["lop","ripple"])==>[peter,vadas,josh,marko]gremlin> g.V().values("name").fold().difference(__.V().limit(2).values("name").fold())==>[ripple,peter,josh,lop]g.V().values("name").fold().difference(["lop","ripple"])g.V().values("name").fold().difference(__.V().limit(2).values("name").fold())Additional References
Disjunct Step
Thedisjunct()-step (map) calculates the disjunct set between the incoming list traverser and the provided listargument. This step only expects list data (array or Iterable) and will throw anIllegalArgumentException if any othertype is encountered (includingnull).
gremlin> g.V().values("name").fold().disjunct(["lop","peter","sam"])////(1)==>[ripple,vadas,josh,sam,marko]gremlin> g.V().values("name").fold().disjunct(__.V().limit(3).values("name").fold())==>[ripple,peter,josh]g.V().values("name").fold().disjunct(["lop","peter","sam"])////(1)g.V().values("name").fold().disjunct(__.V().limit(3).values("name").fold())Find the unique names between two group of names
Additional References
Drop Step
Thedrop()-step (filter/sideEffect) is used to remove element and properties from the graph (i.e. remove). Itis a filter step because the traversal yields no outgoing objects.
gremlin> g.V().outE().drop()gremlin> g.E()gremlin> g.V().properties('name').drop()gremlin> g.V().elementMap()==>[id:1,label:person,age:29]==>[id:2,label:person,age:27]==>[id:3,label:software,lang:java]==>[id:4,label:person,age:32]==>[id:5,label:software,lang:java]==>[id:6,label:person,age:35]gremlin> g.V().drop()gremlin> g.V()g.V().outE().drop()g.E()g.V().properties('name').drop()g.V().elementMap()g.V().drop()g.V()Additional References
E Step
TheE()-step is meant to read edges from the graph and is usually used to start aGraphTraversal, but can alsobe used mid-traversal.
gremlin> g.E(11)////(1)==>e[11][4-created->3]gremlin> g.E().hasLabel('knows').has('weight', gt(0.75))==>e[8][1-knows->4]gremlin> g.inject(1).coalesce(E().hasLabel("knows"), addE("knows").from(V().has("name","josh")).to(V().has("name","vadas")))////(2)==>e[7][1-knows->2]==>e[8][1-knows->4]g.E(11)////(1)g.E().hasLabel('knows').has('weight', gt(0.75))g.inject(1).coalesce(E().hasLabel("knows"), addE("knows").from(V().has("name","josh")).to(V().has("name","vadas")))//2Find the edge by its unique identifier (i.e.
T.id) - not all graphs will use a numeric value for their identifier.Get edges with label
knows, if there is none then add new one betweenjoshandvadas.
Additional References
Element Step
Theelement() step is a no-argument step that traverses from aProperty to theElement that owns it.
gremlin> g.V().properties().element()////(1)==>v[1]==>v[1]==>v[1]==>v[1]==>v[1]==>v[7]==>v[7]==>v[7]==>v[7]==>v[8]==>v[8]==>v[8]==>v[8]==>v[8]==>v[9]==>v[9]==>v[9]==>v[9]==>v[10]==>v[11]gremlin> g.E().properties().element()////(2)==>e[13][1-develops->10]==>e[14][1-develops->11]==>e[15][1-uses->10]==>e[16][1-uses->11]==>e[17][7-develops->10]==>e[18][7-develops->11]==>e[19][7-uses->10]==>e[20][7-uses->11]==>e[21][8-develops->10]==>e[22][8-uses->10]==>e[23][8-uses->11]==>e[24][9-uses->10]==>e[25][9-uses->11]gremlin> g.V().properties().properties().element()////(3)==>vp[location->san diego]==>vp[location->san diego]==>vp[location->santa cruz]==>vp[location->santa cruz]==>vp[location->brussels]==>vp[location->brussels]==>vp[location->santa fe]==>vp[location->centreville]==>vp[location->centreville]==>vp[location->dulles]==>vp[location->dulles]==>vp[location->purcellville]==>vp[location->bremen]==>vp[location->bremen]==>vp[location->baltimore]==>vp[location->baltimore]==>vp[location->oakland]==>vp[location->oakland]==>vp[location->seattle]==>vp[location->spremberg]==>vp[location->spremberg]==>vp[location->kaiserslautern]==>vp[location->kaiserslautern]==>vp[location->aachen]g.V().properties().element()////(1)g.E().properties().element()////(2)g.V().properties().properties().element()//3Traverse from
VertexPropertytoVertexTraverse from
Property(edge property) toEdgeTraverse from
Property(meta property) toVertexProperty
Additional References
ElementMap Step
TheelementMap()-step yields aMap representation of the structure of an element.
gremlin> g.V().elementMap()==>[id:1,label:person,name:marko,age:29]==>[id:2,label:person,name:vadas,age:27]==>[id:3,label:software,name:lop,lang:java]==>[id:4,label:person,name:josh,age:32]==>[id:5,label:software,name:ripple,lang:java]==>[id:6,label:person,name:peter,age:35]gremlin> g.V().elementMap('age')==>[id:1,label:person,age:29]==>[id:2,label:person,age:27]==>[id:3,label:software]==>[id:4,label:person,age:32]==>[id:5,label:software]==>[id:6,label:person,age:35]gremlin> g.V().elementMap('age','blah')==>[id:1,label:person,age:29]==>[id:2,label:person,age:27]==>[id:3,label:software]==>[id:4,label:person,age:32]==>[id:5,label:software]==>[id:6,label:person,age:35]gremlin> g.E().elementMap()==>[id:7,label:knows,IN:[id:2,label:person],OUT:[id:1,label:person],weight:0.5]==>[id:8,label:knows,IN:[id:4,label:person],OUT:[id:1,label:person],weight:1.0]==>[id:9,label:created,IN:[id:3,label:software],OUT:[id:1,label:person],weight:0.4]==>[id:10,label:created,IN:[id:5,label:software],OUT:[id:4,label:person],weight:1.0]==>[id:11,label:created,IN:[id:3,label:software],OUT:[id:4,label:person],weight:0.4]==>[id:12,label:created,IN:[id:3,label:software],OUT:[id:6,label:person],weight:0.2]g.V().elementMap()g.V().elementMap('age')g.V().elementMap('age','blah')g.E().elementMap()It is important to note that the map of a vertex assumes that cardinality for each key issingle and if it islistthen only the first item encountered will be returned. Assingle is the more common cardinality for properties thisassumption should serve the greatest number of use cases.
gremlin> g.V().elementMap()==>[id:1,label:person,name:marko,location:santa fe]==>[id:7,label:person,name:stephen,location:purcellville]==>[id:8,label:person,name:matthias,location:seattle]==>[id:9,label:person,name:daniel,location:aachen]==>[id:10,label:software,name:gremlin]==>[id:11,label:software,name:tinkergraph]gremlin> g.V().has('name','marko').properties('location')==>vp[location->san diego]==>vp[location->santa cruz]==>vp[location->brussels]==>vp[location->santa fe]gremlin> g.V().has('name','marko').properties('location').elementMap()==>[id:6,key:location,value:san diego,startTime:1997,endTime:2001]==>[id:7,key:location,value:santa cruz,startTime:2001,endTime:2004]==>[id:8,key:location,value:brussels,startTime:2004,endTime:2005]==>[id:9,key:location,value:santa fe,startTime:2005]g.V().elementMap()g.V().has('name','marko').properties('location')g.V().has('name','marko').properties('location').elementMap()Important | TheelementMap()-step does not return the vertex labels for incident vertices when usingGraphComputeras theid is the only available data to the star graph. |
Additional References
Emit Step
Theemit-step is not an actual step, but is instead a step modulator forrepeat() (find moredocumentation on theemit() there).
Additional References
Explain Step
Theexplain()-step (terminal) will return aTraversalExplanation. A traversal explanation details how thetraversal (prior toexplain()) will be compiled given the registeredtraversal strategies.ATraversalExplanation has atoString() representation with 3-columns. The first column is thetraversal strategy being applied. The second column is the traversal strategy category: [D]ecoration, [O]ptimization,[P]rovider optimization, [F]inalization, and [V]erification. Finally, the third column is the state of the traversalpost strategy application. The final traversal is the resultant execution plan.
gremlin> g.V().hasLabel('person').outE().identity().inV().count().is(gt(5)).explain()==>Traversal Explanation==================================================================================================================================================================================Original Traversal [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]ConnectiveStrategy [D] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]RepeatUnrollStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]IdentityRemovalStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]MatchPredicateStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]FilterRankingStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]InlineFilterStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]IncidentToAdjacentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,vertex), CountGlobalStep, IsStep(gt(5))]PathRetractionStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,vertex), CountGlobalStep, IsStep(gt(5))]EarlyLimitStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,vertex), CountGlobalStep, IsStep(gt(5))]AdjacentToIncidentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), CountGlobalStep, IsStep(gt(5))]ByModulatorOptimizationStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), CountGlobalStep, IsStep(gt(5))]CountStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]LazyBarrierStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]TinkerGraphCountStrategy [P] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]TinkerGraphStepStrategy [P] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]ProfileStrategy [F] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]StandardVerificationStrategy [V] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]Final Traversal [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]g.V().hasLabel('person').outE().identity().inV().count().is(gt(5)).explain()For traversal profiling information, please seeprofile()-step.
Fail Step
Thefail()-step provides a way to force a traversal to immediately fail with an exception. This feature is oftenhelpful during debugging purposes and for validating certain conditions prior to continuing with traversal execution.
gremlin> g.V().has('person','name','peter').fold().......1> coalesce(unfold(),......2> fail('peter should exist')).......3> property('k',100)==>v[6]gremlin> g.V().has('person','name','stephen').fold().......1> coalesce(unfold(),......2> fail('stephen should exist')).......3> property('k',100)fail() Step Triggered===========================================================================================================================Message > stephen should existTraverser> [] Bulk > 1Traversal> fail()Parent > CoalesceStep [V().has("person","name","stephen").fold().coalesce(__.unfold(),__.fail()).property("k",(int) 100)]Metadata > {}===========================================================================================================================The code example above exemplifies the latter use case where there is essentially an assertion that there is a vertexwith a particular "name" value prior to updating the property "k" and explicitly failing when that vertex is not found.
Thefail() step does not guarantee that mutations are not partially applied. Triggeringfail() produces anexception, but it’s effect on any open transactions or the underlying graph’s behavior ends there. Generally speaking,mutations made to the point offail() being triggered are applied andfail() itself has no influence on rolling backthose changes. It is up to the application catching that exception to act in a fashion that will allow for thatrollback. Moreover, the ability to rollback at all is graph provider dependent. For example, a basic TinkerGraph,configured without transaction support, will simply be left in a partially mutated state whether the action to rollbackonfail() was implemented or not.
Additional References
Filter Step
Thefilter() step maps the traverser from the current object to eithertrue orfalse where the latter will notpass the traverser to the next step in the process. Please see theGeneral Steps section for moreinformation.
Additional References
FlatMap Step
TheflatMap() step maps the traverser from the current object to anIterator of objects for the next step in theprocess. Please see theGeneral Steps section for more information.
Additional References
Format Step
This step is designed to simplify some string operations. In general, it is similar to the string formatting functionavailable in many programming languages. Variable values can be picked up from Element properties, maps and scope variables.
gremlin> g.V().format("%{name} is %{age} years old")////(1)==>marko is29 years old==>vadas is27 years old==>josh is32 years old==>peter is35 years oldgremlin> g.V().hasLabel("person").as("a").values("name").as("p1").select("a").in("knows").format("%{p1} knows %{name}")////(2)==>vadas knows marko==>josh knows markogremlin> g.V().format("%{name} has %{_} connections").by(bothE().count())////(3)==>marko has3 connections==>vadas has1 connections==>lop has3 connections==>josh has3 connections==>ripple has1 connections==>peter has1 connectionsgremlin> g.V().project("name","count").by(values("name")).by(bothE().count()).format("%{name} has %{count} connections")////(4)==>marko has3 connections==>vadas has1 connections==>lop has3 connections==>josh has3 connections==>ripple has1 connections==>peter has1 connectionsg.V().format("%{name} is %{age} years old")////(1)g.V().hasLabel("person").as("a").values("name").as("p1").select("a").in("knows").format("%{p1} knows %{name}")////(2)g.V().format("%{name} has %{_} connections").by(bothE().count())////(3)g.V().project("name","count").by(values("name")).by(bothE().count()).format("%{name} has %{count} connections")//4A
format()will use property values from incoming Element to produce String result.A
format()will use scope variablep1and propertynameto resolve variable values.A
format()will use propertynameand traversal product for positional argument to resolve variable values.A
format()will use map produced byprojectstep to resolve variable values.
Additional References
Fold Step
There are situations when the traversal stream needs a "barrier" to aggregate all the objects and emit a computationthat is a function of the aggregate. Thefold()-step (map) is one particular instance of this. Please seeunfold()-step for the inverse functionality.
gremlin> g.V(1).out('knows').values('name')==>vadas==>joshgremlin> g.V(1).out('knows').values('name').fold()////(1)==>[vadas,josh]gremlin> g.V(1).out('knows').values('name').fold().next().getClass()////(2)==>classjava.util.ArrayListgremlin> g.V(1).out('knows').values('name').fold(0) {a,b -> a + b.length()}////(3)==>9gremlin> g.V().values('age').fold(0) {a,b -> a + b}////(4)==>123gremlin> g.V().values('age').fold(0, sum)////(5)==>123gremlin> g.V().values('age').sum()////(6)==>123gremlin> g.inject(["a":1],["b":2]).fold([], addAll)////(7)==>[[a:1],[b:2]]g.V(1).out('knows').values('name')g.V(1).out('knows').values('name').fold()////(1)g.V(1).out('knows').values('name').fold().next().getClass()////(2)g.V(1).out('knows').values('name').fold(0) {a,b -> a + b.length()}////(3)g.V().values('age').fold(0) {a,b -> a + b}////(4)g.V().values('age').fold(0, sum)////(5)g.V().values('age').sum()////(6)g.inject(["a":1],["b":2]).fold([], addAll)//7A parameterless
fold()will aggregate all the objects into a list and then emit the list.A verification of the type of list returned.
fold()can be provided two arguments — a seed value and a reduce bi-function ("vadas" is 5 characters + "josh" with 4 characters).What is the total age of the people in the graph?
The same as before, but using a built-in bi-function.
The same as before, but using the
sum()-step.A mechanism for merging
Mapinstances. If a key occurs in more than a singleMap, the later occurrence will replace the earlier.
Additional References
From Step
Thefrom()-step is not an actual step, but instead is a "step-modulator" similar toas() andby(). If a step is able to accept traversals or strings thenfrom() is themeans by which they are added. The general pattern isstep().from(). Seeto()-step.
The list of steps that supportfrom()-modulation are:simplePath(),cyclicPath(),path(), andaddE().
Javascript | The term |
Python | The term |
Additional References
Group Step
As traversers propagate across a graph as defined by a traversal, sideEffect computations are sometimes required.That is, the actual path taken or the current location of a traverser is not the ultimate output of the computation,but some other representation of the traversal. Thegroup()-step (map/sideEffect) is one such sideEffect thatorganizes the objects according to some function of the object. Then, if required, that organization (a list) isreduced. An example is provided below.
gremlin> g.V().group().by(label)////(1)==>[software:[v[3],v[5]],person:[v[1],v[2],v[4],v[6]]]gremlin> g.V().group().by(label).by('name')////(2)==>[software:[lop,ripple],person:[marko,vadas,josh,peter]]gremlin> g.V().group().by(label).by(count())////(3)==>[software:2,person:4]g.V().group().by(label)////(1)g.V().group().by(label).by('name')////(2)g.V().group().by(label).by(count())//3Group the vertices by their label.
For each vertex in the group, get their name.
For each grouping, what is its size?
The two projection parameters available togroup() viaby() are:
Key-projection: What feature of the object to group on (a function that yields the map key)?
Value-projection: What feature of the group to store in the key-list?
gremlin> g.V().group().by('age').by('name')////(1)==>[32:[josh],35:[peter],27:[vadas],29:[marko]]gremlin> g.V().group().by('name').by('age')////(2)==>[ripple:[],peter:[35],vadas:[27],josh:[32],lop:[],marko:[29]]g.V().group().by('age').by('name')////(1)g.V().group().by('name').by('age')//2The "age" property is notproductive for all vertices and therefore those keys are filtered.
The "age" property is notproductive for all vertices and therefore those values are filtered.
Additional References
GroupCount Step
When it is important to know how many times a particular object has been at a particular part of a traversal,groupCount()-step (map/sideEffect) is used.
"What is the distribution of ages in the graph?"
gremlin> g.V().hasLabel('person').values('age').groupCount()==>[32:1,35:1,27:1,29:1]gremlin> g.V().hasLabel('person').groupCount().by('age')////(1)==>[32:1,35:1,27:1,29:1]gremlin> g.V().groupCount().by('age')////(2)==>[32:1,35:1,27:1,29:1]g.V().hasLabel('person').values('age').groupCount()g.V().hasLabel('person').groupCount().by('age')////(1)g.V().groupCount().by('age')//2You can also supply a pre-group projection, where the provided
by()-modulation determines what togroup the incoming object by.The "age" property is notproductive for all vertices and therefore those values are filtered.
There is one person that is 32, one person that is 35, one person that is 27, and one person that is 29.
"Iteratively walk the graph and count the number of times you see the second letter of each name."

gremlin> g.V().repeat(both().groupCount('m').by(label)).times(10).cap('m')==>[software:19598,person:39196]g.V().repeat(both().groupCount('m').by(label)).times(10).cap('m')The above is interesting in that it demonstrates the use of referencing the internalMap<Object,Long> ofgroupCount() with a string variable. Given thatgroupCount() is a sideEffect-step, it simply passes the objectit received to its output. Internal togroupCount(), the object’s count is incremented.
Additional References
Has Step

It is possible to filter vertices, edges, and vertex properties based on their properties usinghas()-step(filter). There are numerous variations onhas() including:
has(key,value): Remove the traverser if its element does not have the provided key/value property.has(label, key, value): Remove the traverser if its element does not have the specified label and provided key/value property.has(key,predicate): Remove the traverser if its element does not have a key value that satisfies the bi-predicate. For more information on predicates, please readA Note on Predicates.hasLabel(labels…): Remove the traverser if its element does not have any of the labels.hasId(ids…): Remove the traverser if its element does not have any of the ids.hasKey(keys…): Remove thePropertytraverser if it does not match one of the provided keys.hasValue(values…): Remove thePropertytraverser if it does not match one of the provided values.has(key): Remove the traverser if its element does not have a value for the key.hasNot(key): Remove the traverser if its element has a value for the key.has(key, traversal): Remove the traverser if its object does not yield a result through the traversal off the property value.
gremlin> g.V().hasLabel('person')==>v[1]==>v[2]==>v[4]==>v[6]gremlin> g.V().hasLabel('person','name','marko')==>v[1]==>v[2]==>v[4]==>v[6]gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh'))==>v[2]==>v[4]gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh')). outE().hasLabel('created')==>e[10][4-created->5]==>e[11][4-created->3]gremlin> g.V().has('age',inside(20,30)).values('age')////(1)==>29==>27gremlin> g.V().has('age',outside(20,30)).values('age')////(2)==>32==>35gremlin> g.V().has('name',within('josh','marko')).elementMap()////(3)==>[id:1,label:person,name:marko,age:29]==>[id:4,label:person,name:josh,age:32]gremlin> g.V().has('name',without('josh','marko')).elementMap()////(4)==>[id:2,label:person,name:vadas,age:27]==>[id:3,label:software,name:lop,lang:java]==>[id:5,label:software,name:ripple,lang:java]==>[id:6,label:person,name:peter,age:35]gremlin> g.V().has('name',not(within('josh','marko'))).elementMap()////(5)==>[id:2,label:person,name:vadas,age:27]==>[id:3,label:software,name:lop,lang:java]==>[id:5,label:software,name:ripple,lang:java]==>[id:6,label:person,name:peter,age:35]gremlin> g.V().properties().hasKey('age').value()////(6)==>29==>27==>32==>35gremlin> g.V().hasNot('age').values('name')////(7)==>lop==>ripplegremlin> g.V().has('person','name', startingWith('m'))////(8)==>v[1]gremlin> g.V().has(null,'vadas')////(9)gremlin> g.V().has(label, __.is('person'))////(10)==>v[1]==>v[2]==>v[4]==>v[6]g.V().hasLabel('person')g.V().hasLabel('person','name','marko')g.V().hasLabel('person').out().has('name',within('vadas','josh'))g.V().hasLabel('person').out().has('name',within('vadas','josh')). outE().hasLabel('created')g.V().has('age',inside(20,30)).values('age')////(1)g.V().has('age',outside(20,30)).values('age')////(2)g.V().has('name',within('josh','marko')).elementMap()////(3)g.V().has('name',without('josh','marko')).elementMap()////(4)g.V().has('name',not(within('josh','marko'))).elementMap()////(5)g.V().properties().hasKey('age').value()////(6)g.V().hasNot('age').values('name')////(7)g.V().has('person','name', startingWith('m'))////(8)g.V().has(null,'vadas')////(9)g.V().has(label, __.is('person'))//10Find all vertices whose ages are between 20 (exclusive) and 30 (exclusive). In other words, the age must be greater than 20 and less than 30.
Find all vertices whose ages are not between 20 (inclusive) and 30 (inclusive). In other words, the age must be less than 20 or greater than 30.
Find all vertices whose names are exact matches to any names in the collection
[josh,marko], display allthe key,value pairs for those vertices.Find all vertices whose names are not in the collection
[josh,marko], display all the key,value pairs for those vertices.Same as the prior example save using
notonwithinto yieldwithout.Find all age-properties and emit their value.
Find all vertices that do not have an age-property and emit their name.
Find all "person" vertices that have a name property that starts with the letter "m".
Property key is always stored as
Stringand therefore an equality check withnullwill produce no result.An example of
has()where the argument is aTraversaland does not quite behave the way most expect.
Item 10 in the above set of examples bears some discussion. The behavior is not such that the result of theTraversalis used as the comparing value forhas(), but the currentTraverser, which in this case is the vertexlabel, isgiven to theTraversal to behave as a filter itself. In other words, if theTraversal (i.e.is('person')) returnsa value then thehas() is effectivelytrue. A common mistake is to try to useselect() in this context where onewould dohas('name', select('n')) to try to inject the value of "n" into the step to gethas('name', <value-of-n>),but this would instead simply produce an alwaystrue filter forhas().
TinkerPop does not support a regular expression predicate, although specific graph databases that leverage TinkerPopmay provide a partial match extension.
Additional References
has(String),has(String,Object),has(String,P),has(String,String,Object),has(String,String,P),has(String,Traversal),has(T,Object),has(T,P),has(T,Traversal),hasId(Object,Object…),hasId(P),hasKey(P),hasKey(String,String…),hasLabel(P),hasLabel(String,String…),hasNot(String),hasValue(Object,Object…),hasValue(P),P,TextP,T,Recipes - Anti-pattern
Id Step
Theid()-step (map) takes anElement and extracts its identifier from it.
gremlin> g.V().id()==>1==>2==>3==>4==>5==>6gremlin> g.V(1).out().id().is(2)==>2gremlin> g.V(1).outE().id()==>9==>7==>8gremlin> g.V(1).properties().id()==>0==>1g.V().id()g.V(1).out().id().is(2)g.V(1).outE().id()g.V(1).properties().id()Additional References
Identity Step
Theidentity()-step (map) is anidentity function which mapsthe current object to itself.
gremlin> g.V().identity()==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]g.V().identity()Additional References
Index Step
Theindex()-step (map) indexes each element in the current collection. If the current traverser’s value is not a collection, then it’s treated as a single-item collection. There are two indexersavailable, which can be chosen using thewith() modulator. The list indexer (default) creates a list for each collection item, with the first item being the original element and the second elementbeing the index. The map indexer created a linked hash map in which the index represents the key and the original item is used as the value.
gremlin> g.V().hasLabel("software").index()////(1)==>[[v[3],0]]==>[[v[5],0]]gremlin> g.V().hasLabel("software").values("name").fold(). order(Scope.local). index(). unfold(). order(). by(__.tail(Scope.local,1))////(2)==>[lop,0]==>[ripple,1]gremlin> g.V().hasLabel("software").values("name").fold(). order(Scope.local). index(). with(WithOptions.indexer, WithOptions.list). unfold(). order(). by(__.tail(Scope.local,1))////(3)==>[lop,0]==>[ripple,1]gremlin> g.V().hasLabel("person").values("name").fold(). order(Scope.local). index(). with(WithOptions.indexer, WithOptions.map)////(4)==>[0:josh,1:marko,2:peter,3:vadas]g.V().hasLabel("software").index()////(1)g.V().hasLabel("software").values("name").fold(). order(Scope.local). index(). unfold(). order(). by(__.tail(Scope.local,1))////(2)g.V().hasLabel("software").values("name").fold(). order(Scope.local). index(). with(WithOptions.indexer, WithOptions.list). unfold(). order(). by(__.tail(Scope.local,1))////(3)g.V().hasLabel("person").values("name").fold(). order(Scope.local). index(). with(WithOptions.indexer, WithOptions.map)//4Indexing non-collection items results in multiple indexed single-item collections.
Index all software names in their alphabetical order.
Same as statement 1, but with an explicitely specified list indexer.
Index all person names in their alphabetical order and store the result in an ordered map.
Additional References
Inject Step

The concept of "injectable steps" makes it possible to insert objects arbitrarily into a traversal stream. In general,inject()-step (sideEffect) exists and a few examples are provided below.
gremlin> g.V(4).out().values('name').inject('daniel')==>daniel==>ripple==>lopgremlin> g.V(4).out().values('name').inject('daniel').map {it.get().length()}==>6==>6==>3gremlin> g.V(4).out().values('name').inject('daniel').map {it.get().length()}.path()==>[daniel,6]==>[v[4],v[5],ripple,6]==>[v[4],v[3],lop,3]g.V(4).out().values('name').inject('daniel')g.V(4).out().values('name').inject('daniel').map {it.get().length()}g.V(4).out().values('name').inject('daniel').map {it.get().length()}.path()In the last example above, note that the path starting withdaniel is only of length 2. This is because thedaniel string was inserted half-way in the traversal. Finally, a typical use case is provided below — when thestart of the traversal is not a graph object.
gremlin> inject(1,2)==>1==>2gremlin> inject(1,2).map {it.get() +1}==>2==>3gremlin> inject(1,2).map {it.get() +1}.map {g.V(it.get()).next()}.values('name')==>vadas==>lopinject(1,2)inject(1,2).map {it.get() +1}inject(1,2).map {it.get() +1}.map {g.V(it.get()).next()}.values('name')Additional References
Intersect Step
Theintersect()-step (map) calculates the intersection between the incoming list traverser and the provided listargument. This step only expects list data (array or Iterable) and will throw anIllegalArgumentException if any othertype is encountered (includingnull).
gremlin> g.V().values("name").fold().intersect(["marko","josh","james","jen"])==>[josh,marko]gremlin> g.V().values("name").fold().intersect(__.V().limit(2).values("name").fold())==>[vadas,marko]g.V().values("name").fold().intersect(["marko","josh","james","jen"])g.V().values("name").fold().intersect(__.V().limit(2).values("name").fold())Additional References
IO Step
 The task of importing and exporting the data of
The task of importing and exporting the data ofGraph instances is thejob of theio()-step. By default, TinkerPop supports three formats for importing and exporting graph data inGraphML,GraphSON, andGryo.
Note | Additional documentation for TinkerPop IO formats can be found in theIO Reference. |
By itself theio()-step merely configures the kind of importing and exporting that is goingto occur and it is the follow-on call to theread() orwrite() step that determines which of those actions willexecute. Therefore, a typical usage of theio()-step would look like this:
g.io(someInputFile).read().iterate()g.io(someOutputFile).write().iterate()Important | The commands above are still traversals and therefore require iteration to be executed, hence the use ofiterate() as a termination step. |
By default, theio()-step will try to detect the right file format using the file name extension. To gain greatercontrol of the format use thewith() step modulator to provide further information toio(). For example:
g.io(someInputFile). with(IO.reader, IO.graphson). read().iterate()g.io(someOutputFile). with(IO.writer,IO.graphml). write().iterate()TheIO class is a helper for theio()-step that provides expressions that can be used to help configure itand in this case it allows direct specification of the "reader" or "writer" to use. The "reader" actually refers toaGraphReader implementation and the "writer" refers to aGraphWriter implementation. The implementations ofthose interfaces provided by default are the standard TinkerPop implementations.
That default is an important point to consider for users. The default TinkerPop implementations are not designed withmassive, complex, parallel bulk loading in mind. They are designed to do single-threaded, OLTP-style loading of datain the most generic way possible so as to accommodate the greatest number of graph databases out there. As such, froma reading perspective, they work best for small datasets (or perhaps medium datasets where memory is plentiful andtime is not critical) that are loading to an empty graph - incremental loading is not supported. The story from thewriting perspective is not that different in there are no parallel operations in play, however streaming the outputto disk requires a single pass of the data without high memory requirements for larger datasets.
Important | Default graph formats don’t contain information about property cardinality, so it is up to the graphprovider to choose the appropriate one. You will see a warning message if the chosen cardinality is SINGLEwhile your graph input contains multiple values for that property. |
In general, TinkerPop recommends that users examine the native bulk import/export tools of the graph implementationthat they choose. Those tools will often outperform theio()-step and perhaps be easier to use with a greaterfeature set. That said, graph providers do have the option to optimizeio() to back it with their ownimport/export utilities and therefore the default behavior provided by TinkerPop described above might be overriddenby the graph.
An excellent example of this lies inHadoopGraph withSparkGraphComputerwhich replaces the default single-threaded implementation with a more advanced OLAP style bulk import/exportfunctionality internally usingCloneVertexProgram. With this model, graphs of arbitrary sizecan be imported/exported assuming that there is a HadoopInputFormat orOutputFormat to support it.
Important | Remote Gremlin Console users or Gremlin Language Variant (GLV) users (e.g. gremlin-python) who utilizetheio()-step should recall that theirread() orwrite() operation will occur on the server and not locallyand therefore the file specified for import/export must be something accessible by the server. |
GraphSON and Gryo formats are extensible allowing users and graph providers to extend supported serialization options.These extensions are exposed throughIoRegistry implementations. To apply anIoRegistry use thewith() optionand theIO.registry key, where the value is either an actualIoRegistry instance or the fully qualified classname of one.
g.io(someInputFile). with(IO.reader, IO.gryo). with(IO.registry, TinkerIoRegistryV3d0.instance()) read().iterate()g.io(someOutputFile). with(IO.writer,IO.graphson). with(IO.registry,"org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerIoRegistryV3d0") write().iterate()GLVs will obviously always be forced to use the latter form as they can’t explicitly create an instance of anIoRegistry to pass to the server (nor areIoRegistry instances necessarily serializable).
The version of the formats (e.g. GraphSON 2.0 or 3.0) utilized byio() is determined entirely by theIO.reader andIO.writer configurations or their defaults. The defaults will always be the latest version for the current releaseof TinkerPop. It is also possible for graph providers to override these defaults, so consult the documentation of theunderlying graph database in use for any details on that.
Note | Theio() step will try to automatically detect the appropriateGraphReader orGraphWriter to use based onthe file extension. If the file has a different extension than the ones expected, usewith() as shown above to set thereader orwriter explicitly. |
For more advanced configuration ofGraphReader andGraphWriter operations (e.g. normalized output for GraphSON,disabling class registrations for Gryo, etc.) then construct the appropriateGraphReader andGraphWriter usingthebuild() method on their implementations and use it directly. It can be passed directly to theIO.reader orIO.writer options. Obviously, these are JVM based operations and thus not available to GLVs as portable features.
GraphML
 TheGraphML file format is acommon XML-based representation of a graph. It is widely supported by graph-related tools and libraries making it asolid interchange format for TinkerPop. In other words, if the intent is to work with graph data in conjunction withapplications outside of TinkerPop, GraphML may be the best choice to do that. Common use cases might be:
TheGraphML file format is acommon XML-based representation of a graph. It is widely supported by graph-related tools and libraries making it asolid interchange format for TinkerPop. In other words, if the intent is to work with graph data in conjunction withapplications outside of TinkerPop, GraphML may be the best choice to do that. Common use cases might be:
Warning | GraphML is a "lossy" format in that it only supports primitive values for properties and does not havesupport forGraph variables. It will usetoString to serialize property values outside of those primitives. |
Warning | GraphML as a specification allows for<edge> and<node> elements to appear in any order. Most softwarethat writes GraphML (including as TinkerPop’sGraphMLWriter) write<node> elements before<edge> elements.However it is important to note thatGraphMLReader will read this data in order and order can matter. This is becauseTinkerPop does not allow the vertex label to be changed after the vertex has been created. Therefore, if an<edge>element comes before the<node>, the label on the vertex will be ignored. It is thus better to order<node>elements in the GraphML to appear before all<edge> elements if vertex labels are important to the graph. |
// expects a file extension of .xml or .graphml to determine that// a GraphML reader/writer should be used.g.io("graph.xml").read().iterate();g.io("graph.xml").write().iterate();Note | If using GraphML generated from TinkerPop 2.x, read more about its incompatibilities in theUpgrade Documentation. |
GraphSON
 GraphSON is aJSON-based format extendedfrom earlier versions of TinkerPop. It is important to note that TinkerPop’s GraphSON is not backwards compatiblewith prior TinkerPop GraphSON versions. GraphSON has some support from graph-related application outside of TinkerPop,but it is generally best used in two cases:
GraphSON is aJSON-based format extendedfrom earlier versions of TinkerPop. It is important to note that TinkerPop’s GraphSON is not backwards compatiblewith prior TinkerPop GraphSON versions. GraphSON has some support from graph-related application outside of TinkerPop,but it is generally best used in two cases:
A text format of the graph or its elements is desired (e.g. debugging, usage in source control, etc.)
The graph or its elements need to be consumed by code that is not JVM-based (e.g. JavaScript, Python, .NET, etc.)
// expects a file extension of .json to interpret that// a GraphSON reader/writer should be usedg.io("graph.json").read().iterate();g.io("graph.json").write().iterate();Note | Additional documentation for GraphSON can be found in theIO Reference. |
Gryo
 Kryo is a popularserialization package for the JVM. Gremlin-Kryo is a binary
Kryo is a popularserialization package for the JVM. Gremlin-Kryo is a binaryGraph serialization format for use on the JVM by JVMlanguages. It is designed to be space efficient, non-lossy and is promoted as the standard format to use when workingwith graph data inside of the TinkerPop stack. A list of common use cases is presented below:
Migration from one Gremlin Structure implementation to another (e.g.
TinkerGraphtoNeo4jGraph)Serialization of individual graph elements to be sent over the network to another JVM.
Backups of in-memory graphs or subgraphs.
Warning | When migrating between Gremlin Structure implementations, Kryo may not lose data, but it is important toconsider the features of eachGraph and whether or not the data types supported in one will be supported in theother. Failure to do so, may result in errors. |
// expects a file extension of .kryo to interpret that// a GraphSON reader/writer should be usedg.io("graph.kryo").read().iterate()g.io("graph.kryo").write().iterate()Additional References
Is Step
It is possible to filter scalar values usingis()-step (filter).
Python | The term |
gremlin> g.V().values('age').is(32)==>32gremlin> g.V().values('age').is(lte(30))==>29==>27gremlin> g.V().values('age').is(inside(30,40))==>32==>35gremlin> g.V().where(__.in('created').count().is(1)).values('name')////(1)==>ripplegremlin> g.V().where(__.in('created').count().is(gte(2))).values('name')////(2)==>lopgremlin> g.V().where(__.in('created').values('age'). mean().is(inside(30d,35d))).values('name')////(3)==>lop==>rippleg.V().values('age').is(32)g.V().values('age').is(lte(30))g.V().values('age').is(inside(30,40))g.V().where(__.in('created').count().is(1)).values('name')////(1)g.V().where(__.in('created').count().is(gte(2))).values('name')////(2)g.V().where(__.in('created').values('age'). mean().is(inside(30d,35d))).values('name')//3Find projects having exactly one contributor.
Find projects having two or more contributors.
Find projects whose contributors average age is between 30 and 35.
Additional References
Key Step
Thekey()-step (map) takes aProperty and extracts the key from it.
gremlin> g.V(1).properties().key()==>name==>location==>location==>location==>locationgremlin> g.V(1).properties().properties().key()==>startTime==>endTime==>startTime==>endTime==>startTime==>endTime==>startTimeg.V(1).properties().key()g.V(1).properties().properties().key()Additional References
Label Step
Thelabel()-step (map) takes anElement and extracts its label from it.
gremlin> g.V().label()==>person==>person==>software==>person==>software==>persongremlin> g.V(1).outE().label()==>created==>knows==>knowsgremlin> g.V(1).properties().label()==>name==>ageg.V().label()g.V(1).outE().label()g.V(1).properties().label()Additional References
Length Step
Thelength()-step (map) returns the length incoming string or list of string traverser. Null values are not processed and remain as null when returned.If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.V().values('name').length()////(1)==>5==>5==>3==>4==>6==>5gremlin> g.V().values('name').fold().length(local)////(2)==>[5,5,3,4,6,5]g.V().values('name').length()////(1)g.V().values('name').fold().length(local)//2Return the string length of all vertex names.
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
Limit Step
Thelimit()-step is analogous torange()-step save that the lower end range is set to 0.
gremlin> g.V().limit(2)==>v[1]==>v[2]gremlin> g.V().range(0,2)==>v[1]==>v[2]g.V().limit(2)g.V().range(0,2)Thelimit()-step can also be applied withScope.local, in which case it operates on the incoming collection.The examples below use theThe Crew toy data set.
gremlin> g.V().valueMap().select('location').limit(local,2)////(1)==>[san diego,santa cruz]==>[centreville,dulles]==>[bremen,baltimore]==>[spremberg,kaiserslautern]gremlin> g.V().valueMap().limit(local,1)////(2)==>[name:[marko]]==>[name:[stephen]]==>[name:[matthias]]==>[name:[daniel]]==>[name:[gremlin]]==>[name:[tinkergraph]]g.V().valueMap().select('location').limit(local,2)////(1)g.V().valueMap().limit(local,1)//2List<String>for each vertex containing the first two locations.Map<String, Object>for each vertex, but containing only the first property value.
Additional References
Local Step

AGraphTraversal operates on a continuous stream of objects. In many situations, it is important to operate on asingle element within that stream. To do such object-local traversal computations,local()-step exists (branch).Note that the examples below use theThe Crew toy data set.
gremlin> g.V().as('person'). properties('location').order().by('startTime',asc).limit(2).value().as('location'). select('person','location').by('name').by()////(1)==>[person:daniel,location:spremberg]==>[person:stephen,location:centreville]gremlin> g.V().as('person'). local(properties('location').order().by('startTime',asc).limit(2)).value().as('location'). select('person','location').by('name').by()////(2)==>[person:marko,location:san diego]==>[person:marko,location:santa cruz]==>[person:stephen,location:centreville]==>[person:stephen,location:dulles]==>[person:matthias,location:bremen]==>[person:matthias,location:baltimore]==>[person:daniel,location:spremberg]==>[person:daniel,location:kaiserslautern]g.V().as('person'). properties('location').order().by('startTime',asc).limit(2).value().as('location'). select('person','location').by('name').by()////(1)g.V().as('person'). local(properties('location').order().by('startTime',asc).limit(2)).value().as('location'). select('person','location').by('name').by()//2Get the first two people and their respective location according to the most historic location start time.
For every person, get their two most historic locations.
The two traversals above look nearly identical save the inclusion oflocal() which wraps a section of the traversalin an object-local traversal. As such, theorder().by() and thelimit() refer to a particular object, not to thestream as a whole.
Local Step is quite similar in functionality toFlat Map Step where it can often be confused.local() propagates the traverser through the internal traversal as is without splitting/cloning it. Thus, itsa “global traversal” with local processing. Its use is subtle and primarily finds application in compilationoptimizations (i.e. when writingTraversalStrategy implementations. As another example consider:
gremlin> g.V().both().barrier().flatMap(groupCount().by("name"))==>[lop:1]==>[lop:1]==>[lop:1]==>[vadas:1]==>[josh:1]==>[josh:1]==>[josh:1]==>[marko:1]==>[marko:1]==>[marko:1]==>[peter:1]==>[ripple:1]gremlin> g.V().both().barrier().local(groupCount().by("name"))==>[lop:3]==>[vadas:1]==>[josh:3]==>[marko:3]==>[peter:1]==>[ripple:1]g.V().both().barrier().flatMap(groupCount().by("name"))g.V().both().barrier().local(groupCount().by("name"))Use oflocal() is often a mistake. This is especially true when its argument contains a reducing step. For example,let’s say the requirement was to count the number of properties perVertex in:
gremlin> g.V().both().local(properties('name','age').count())////(1)==>3==>2==>6==>6==>2==>1gremlin> g.V().both().map(properties('name','age').count())////(2)==>1==>1==>1==>2==>2==>2==>2==>2==>2==>2==>2==>1g.V().both().local(properties('name','age').count())////(1)g.V().both().map(properties('name','age').count())//2The output here seems impossible because no single vertex in the "modern" graph can have more than two propertiesgiven the "name" and "age" filters, but because the counting is happening object-local the counting is occurring uniqueto each object rather than each global traverser.
Replacing
local()withmap()returns the result desired by the requirement.
Warning | The anonymous traversal oflocal() processes the current object "locally." In OLAP, where the atomic unitof computing is the vertex and its local "star graph," it is important that the anonymous traversal does not leavethe confines of the vertex’s star graph. In other words, it can not traverse to an adjacent vertex’s properties or edges. |
Additional References
Loops Step
Theloops()-step (map) extracts the number of times theTraverser has gone through the current loop.
gremlin> g.V().emit(__.has("name","marko").or().loops().is(2)).repeat(__.out()).values("name")==>marko==>ripple==>lopg.V().emit(__.has("name","marko").or().loops().is(2)).repeat(__.out()).values("name")Additional References
LTrim Step
ThelTrim()-step (map) returns a string with leading whitespace removed. Null values are not processed and remainas null when returned. If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.inject(" hello"," world",null).lTrim()==>hello==>world==>nullgremlin> g.inject([" hello"," world",null]).lTrim(local)////(1)==>[hello ,world ,null]g.inject(" hello"," world",null).lTrim()g.inject([" hello"," world",null]).lTrim(local)//1Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Map Step
Themap() step maps the traverser from the current object to the next step in the process. Please see theGeneral Steps section for more information.
Additional References
Match Step
Thematch()-step (map) provides a moredeclarativeform of graph querying based on the notion ofpattern matching.Withmatch(), the user provides a collection of "traversal fragments," called patterns, that have variables definedthat must hold true throughout the duration of thematch(). When a traverser is inmatch(), a registeredMatchAlgorithm analyzes the current state of the traverser (i.e. its history based on itspath data), the runtime statistics of the traversal patterns, and returns a traversal-patternthat the traverser should try next. The defaultMatchAlgorithm provided is calledCountMatchAlgorithm and itdynamically revises the pattern execution plan by sorting the patterns according to their filtering capabilities(i.e. largest set reduction patterns execute first). For very large graphs, where the developer is uncertain of thestatistics of the graph (e.g. how manyknows-edges vs.worksFor-edges exist in the graph), it is advantageous tousematch(), as an optimal plan will be determined automatically. Furthermore, some queries are much easier toexpress viamatch() than with single-path traversals.
"Who created a project named 'lop' that was also created by someone who is 29 years old? Return the two creators."

gremlin> g.V().match( __.as('a').out('created').as('b'), __.as('b').has('name','lop'), __.as('b').in('created').as('c'), __.as('c').has('age',29)). select('a','c').by('name')==>[a:marko,c:marko]==>[a:josh,c:marko]==>[a:peter,c:marko]g.V().match( __.as('a').out('created').as('b'), __.as('b').has('name','lop'), __.as('b').in('created').as('c'), __.as('c').has('age',29)). select('a','c').by('name')Note that the above can also be more concisely written as below which demonstrates that standard inner-traversals canbe arbitrarily defined.
gremlin> g.V().match( __.as('a').out('created').has('name','lop').as('b'), __.as('b').in('created').has('age',29).as('c')). select('a','c').by('name')==>[a:marko,c:marko]==>[a:josh,c:marko]==>[a:peter,c:marko]g.V().match( __.as('a').out('created').has('name','lop').as('b'), __.as('b').in('created').has('age',29).as('c')). select('a','c').by('name')In order to improve readability,as()-steps can be given meaningful labels which better reflect your domain. Theprevious query can thus be written in a more expressive way as shown below.
gremlin> g.V().match( __.as('creators').out('created').has('name','lop').as('projects'),////(1) __.as('projects').in('created').has('age',29).as('cocreators')).////(2) select('creators','cocreators').by('name')////(3)==>[creators:marko,cocreators:marko]==>[creators:josh,cocreators:marko]==>[creators:peter,cocreators:marko]g.V().match( __.as('creators').out('created').has('name','lop').as('projects'),////(1) __.as('projects').in('created').has('age',29).as('cocreators')).////(2) select('creators','cocreators').by('name')//3Find vertices that created something and match them as 'creators', then find out what they created which isnamed 'lop' and match these vertices as 'projects'.
Using these 'projects' vertices, find out their creators aged 29 and remember these as 'cocreators'.
Return the name of both 'creators' and 'cocreators'.

MatchStep brings functionality similar toSPARQL to Gremlin. Like SPARQL,MatchStep conjoins a set of patterns applied to a graph. For example, the following traversal finds exactly thosesongs which Jerry Garcia has both sung and written (using the Grateful Dead graph distributed in thedata/ directory):
gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> g.V().match( __.as('a').has('name','Garcia'), __.as('a').in('writtenBy').as('b'), __.as('a').in('sungBy').as('b')). select('b').values('name')==>CREAM PUFF WAR==>CRYPTICAL ENVELOPMENTg = traversal().withEmbedded(graph)g.io('data/grateful-dead.xml').read().iterate()g.V().match( __.as('a').has('name','Garcia'), __.as('a').in('writtenBy').as('b'), __.as('a').in('sungBy').as('b')). select('b').values('name')Among the features which differentiatematch() from SPARQL are:
gremlin> g.V().match( __.as('a').out('created').has('name','lop').as('b'),////(1) __.as('b').in('created').has('age',29).as('c'), __.as('c').repeat(out()).times(2)).////(2) select('c').out('knows').dedup().values('name')////(3)==>vadas==>joshg.V().match( __.as('a').out('created').has('name','lop').as('b'),////(1) __.as('b').in('created').has('age',29).as('c'), __.as('c').repeat(out()).times(2)).////(2) select('c').out('knows').dedup().values('name')//3Patterns of arbitrary complexity:
match()is not restricted to triple patterns or property paths.Recursion support:
match()supports the branch-based steps within a pattern, includingrepeat().Imperative/declarative hybrid: Before and after a
match(), it is possible to leverage classic Gremlin traversals.
To extend point #3, it is possible to support going from imperative, to declarative, to imperative, ad infinitum.
gremlin> g.V().match( __.as('a').out('knows').as('b'), __.as('b').out('created').has('name','lop')). select('b').out('created'). match( __.as('x').in('created').as('y'), __.as('y').out('knows').as('z')). select('z').values('name')==>vadas==>joshg.V().match( __.as('a').out('knows').as('b'), __.as('b').out('created').has('name','lop')). select('b').out('created'). match( __.as('x').in('created').as('y'), __.as('y').out('knows').as('z')). select('z').values('name')Important | Thematch()-step is stateless. The variable bindings of the traversal patterns are stored in the pathhistory of the traverser. As such, the variables used over allmatch()-steps within a traversal are globally unique.A benefit of this is that subsequentwhere(),select(),match(), etc. steps can leverage the same variables intheir analysis. |
Like all other steps in Gremlin,match() is a function and thus,match() withinmatch() is a natural consequenceof Gremlin’s functional foundation (i.e. recursive matching).
gremlin> g.V().match( __.as('a').out('knows').as('b'), __.as('b').out('created').has('name','lop'), __.as('b').match( __.as('b').out('created').as('c'), __.as('c').has('name','ripple')). select('c').as('c')). select('a','c').by('name')==>[a:marko,c:ripple]g.V().match( __.as('a').out('knows').as('b'), __.as('b').out('created').has('name','lop'), __.as('b').match( __.as('b').out('created').as('c'), __.as('c').has('name','ripple')). select('c').as('c')). select('a','c').by('name')If a step-labeled traversal proceeds thematch()-step and the traverser entering thematch() is destined to bindto a particular variable, then the previous step should be labeled accordingly.
gremlin> g.V().as('a').out('knows').as('b'). match( __.as('b').out('created').as('c'), __.not(__.as('c').in('created').as('a'))). select('a','b','c').by('name')==>[a:marko,b:josh,c:ripple]g.V().as('a').out('knows').as('b'). match( __.as('b').out('created').as('c'), __.not(__.as('c').in('created').as('a'))). select('a','b','c').by('name')There are three types ofmatch() traversal patterns.
as('a')…as('b'): both the start and end of the traversal have a declared variable.as('a')…: only the start of the traversal has a declared variable.…: there are no declared variables.
If a variable is at the start of a traversal pattern itmust exist as a label in the path history of the traverserelse the traverser can not go down that path. If a variable is at the end of a traversal pattern then if the variableexists in the path history of the traverser, the traverser’s current locationmust match (i.e. equal) its historiclocation at that same label. However, if the variable does not exist in the path history of the traverser, then thecurrent location is labeled as the variable and thus, becomes a bound variable for subsequent traversal patterns. If atraversal pattern does not have an end label, then the traverser must simply "survive" the pattern (i.e. not befiltered) to continue to the next pattern. If a traversal pattern does not have a start label, then the traversercan go down that path at any point, but will only go down that pattern once as a traversal pattern is executed onceand only once for the history of the traverser. Typically, traversal patterns that do not have a start and end labelare used in conjunction withand(),or(), andwhere(). Once the traverser has "survived" all the patterns (or atleast one foror()),match()-step analyzes the traverser’s path history and emits aMap<String,Object> of thevariable bindings to the next step in the traversal.
gremlin> g.V().as('a').out().as('b').////(1) match(////(2) __.as('a').out().count().as('c'),////(3) __.not(__.as('a').in().as('b')),////(4) or(////(5) __.as('a').out('knows').as('b'), __.as('b').in().count().as('c').and().as('c').is(gt(2)))).////(6) dedup('a','c').////(7) select('a','b','c').by('name').by('name').by()////(8)==>[a:marko,b:lop,c:3]g.V().as('a').out().as('b').////(1) match(////(2) __.as('a').out().count().as('c'),////(3) __.not(__.as('a').in().as('b')),////(4) or(////(5) __.as('a').out('knows').as('b'), __.as('b').in().count().as('c').and().as('c').is(gt(2)))).////(6) dedup('a','c').////(7) select('a','b','c').by('name').by('name').by()//8A standard, step-labeled traversal can come prior to
match().If the traverser’s path prior to entering
match()has requisite label values, then those historic values are bound.It is possible to usebarrier steps though they are computed locally to the pattern (as one would expect).
It is possible to
not()a pattern.It is possible to nest
and()- andor()-steps for conjunction matching.Both infix and prefix conjunction notation is supported.
It is possible to "distinct" the specified label combination.
The bound values are of different types — vertex ("a"), vertex ("b"), long ("c").
Using Where with Match
Match is typically used in conjunction with bothselect() (demonstrated previously) andwhere() (presented here).Awhere()-step allows the user to further constrain the result set provided bymatch().
gremlin> g.V().match( __.as('a').out('created').as('b'), __.as('b').in('created').as('c')). where('a', neq('c')). select('a','c').by('name')==>[a:marko,c:josh]==>[a:marko,c:peter]==>[a:josh,c:marko]==>[a:josh,c:peter]==>[a:peter,c:marko]==>[a:peter,c:josh]g.V().match( __.as('a').out('created').as('b'), __.as('b').in('created').as('c')). where('a', neq('c')). select('a','c').by('name')Thewhere()-step can take either aP-predicate (example above) or aTraversal (example below). UsingMatchPredicateStrategy,where()-clauses are automatically folded intomatch() and thus, subject to the queryoptimizer withinmatch()-step.
gremlin> traversal = g.V().match( __.as('a').has(label,'person'),////(1) __.as('a').out('created').as('b'), __.as('b').in('created').as('c')). where(__.as('a').out('knows').as('c')).////(2) select('a','c').by('name');null////(3)==>nullgremlin> traversal.toString()////(4)==>[GraphStep(vertex,[]), MatchStep(null,AND,[[MatchStartStep(a), HasStep([~label.eq(person)]), MatchEndStep(null)], [MatchStartStep(a), VertexStep(OUT,[created],vertex), MatchEndStep(b)], [MatchStartStep(b), VertexStep(IN,[created],vertex), MatchEndStep(c)]]), WhereTraversalStep([WhereStartStep(a), VertexStep(OUT,[knows],vertex), WhereEndStep(c)]), SelectStep(last,[a, c],[value(name)])]gremlin> traversal////(5)(6)==>[a:marko,c:josh]gremlin> traversal.toString()////(7)==>[TinkerGraphStep(vertex,[~label.eq(person)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,[created],vertex), MatchEndStep(b)], [MatchStartStep(b), VertexStep(IN,[created],vertex), MatchEndStep(c)], [MatchStartStep(a), WhereTraversalStep([WhereStartStep(null), VertexStep(OUT,[knows],vertex), WhereEndStep(c)]), MatchEndStep(null)]]), SelectStep(last,[a, c],[value(name)])]traversal = g.V().match( __.as('a').has(label,'person'),////(1) __.as('a').out('created').as('b'), __.as('b').in('created').as('c')). where(__.as('a').out('knows').as('c')).////(2) select('a','c').by('name');null////(3)traversal.toString()////(4)traversal////(5)(6)(5)traversal.toString()//7Any
has()-step traversal patterns that start with the match-key are pulled out ofmatch()to enable the graphsystem to leverage the filter for index lookups.A
where()-step with a traversal containing variable bindings declared inmatch().A useful trick to ensure that the traversal is not iterated by Gremlin Console.
The string representation of the traversal prior to its strategies being applied.
The Gremlin Console will automatically iterate anything that is an iterator or is iterable.
Both marko and josh are co-developers and marko knows josh.
The string representation of the traversal after the strategies have been applied (and thus,
where()is folded intomatch())
Important | Awhere()-step is a filter and thus, variables within awhere() clause are not globally bound to thepath of the traverser inmatch(). As such,where()-steps inmatch() are used for filtering, not binding. |
Additional References
Math Step
Themath()-step (math) enables scientific calculator functionality within Gremlin. This step deviates from the commonfunction composition and nesting formalisms to provide an easy to read string-based math processor. Variables within theequation map to scopes in Gremlin — e.g. path labels, side-effects, or incoming map keys. This step supportsby()-modulation where theby()-modulators are applied in the order in which the variables are first referencedwithin the equation. Note that the reserved variable_ refers to the current numeric traverser object incoming to themath()-step.
gremlin> g.V().as('a').out('knows').as('b').math('a + b').by('age')==>56.0==>61.0gremlin> g.V().as('a').out('created').as('b'). math('b + a'). by(both().count().math('_ + 100')). by('age')==>132.0==>133.0==>135.0==>138.0gremlin> g.withSideEffect('x',10).V().values('age').math('_ / x')==>2.9==>2.7==>3.2==>3.5gremlin> g.withSack(1).V(1).repeat(sack(sum).by(constant(1))).times(10).emit().sack().math('sin _')==>0.9092974268256817==>0.1411200080598672==>-0.7568024953079282==>-0.9589242746631385==>-0.27941549819892586==>0.6569865987187891==>0.9893582466233818==>0.4121184852417566==>-0.5440211108893698==>-0.9999902065507035gremlin> g.V().math('_+1').by('age')////(1)==>30.0==>28.0==>33.0==>36.0g.V().as('a').out('knows').as('b').math('a + b').by('age')g.V().as('a').out('created').as('b'). math('b + a'). by(both().count().math('_ + 100')). by('age')g.withSideEffect('x',10).V().values('age').math('_ / x')g.withSack(1).V(1).repeat(sack(sum).by(constant(1))).times(10).emit().sack().math('sin _')g.V().math('_+1').by('age')//1The "age" property is notproductive for all vertices and therefore those values are filtered.
The operators supported by the calculator include:*,+,/,^, and%. Furthermore, the following built infunctions are provided:
abs: absolute valueacos: arc cosineasin: arc sineatan: arc tangentcbrt: cubic rootceil: nearest upper integercos: cosinecosh: hyperbolic cosineexp: euler’s number raised to the power (e^x)floor: nearest lower integerlog: logarithmus naturalis (base e)log10: logarithm (base 10)log2: logarithm (base 2)sin: sinesinh: hyperbolic sinesqrt: square roottan: tangenttanh: hyperbolic tangentsignum: signum function
Additional References
Max Step
Themax()-step (map) operates on a stream of comparable objects and determines which is the last object accordingto its natural order in the stream.
gremlin> g.V().values('age').max()==>35gremlin> g.V().repeat(both()).times(3).values('age').max()==>35gremlin> g.V().values('name').max()==>vadasg.V().values('age').max()g.V().repeat(both()).times(3).values('age').max()g.V().values('name').max()When called asmax(local) it determines the maximum value of the current, local object (not the objects in thetraversal stream). This works forCollection andComparable-type objects.
gremlin> g.V().values('age').fold().max(local)==>35g.V().values('age').fold().max(local)When there arenull values being evaluated thenull objects are ignored, but if all values are recognized asnullthe return value isnull.
gremlin> g.inject(null,10,9,null).max()==>10gremlin> g.inject([null,null,null]).max(local)==>nullg.inject(null,10,9,null).max()g.inject([null,null,null]).max(local)Additional References
Mean Step
Themean()-step (map) operates on a stream of numbers and determines the average of those numbers.
gremlin> g.V().values('age').mean()==>30.75gremlin> g.V().repeat(both()).times(3).values('age').mean()////(1)==>30.645833333333332gremlin> g.V().repeat(both()).times(3).values('age').dedup().mean()==>30.75g.V().values('age').mean()g.V().repeat(both()).times(3).values('age').mean()////(1)g.V().repeat(both()).times(3).values('age').dedup().mean()Realize that traversers are being bulked by
repeat(). There may be more of a particular number than another,thus altering the average.
When called asmean(local) it determines the mean of the current, local object (not the objects in the traversalstream). This works forCollection andNumber-type objects.
gremlin> g.V().values('age').fold().mean(local)==>30.75g.V().values('age').fold().mean(local)Ifmean() encountersnull values, they will be ignored (i.e. their traversers not counted toward toward thedivisor). If all traversers arenull then the stream will returnnull.
gremlin> g.inject(null,10,9,null).mean()==>9.5gremlin> g.inject([null,null,null]).mean(local)==>nullg.inject(null,10,9,null).mean()g.inject([null,null,null]).mean(local)Additional References
Merge Step
Themerge()-step (map) combines collections like lists and maps. It expects an incoming traverser to contain acollection objection and will combine that object with its specified argument which must be of a matching type. This isalso known as the union operation. If the incoming traverser or its associated argument do not meet the expected type,the step will throw anIllegalArgumentException if any other type is encountered (includingnull). This step differsfrom thecombine()-step in that it doesn’t allow duplicates.
gremlin> g.V().values("name").fold().merge(["james","jen","marko","vadas"])==>[jen,ripple,peter,vadas,james,josh,lop,marko]gremlin> g.V().values("name").fold().merge(__.constant("james").fold())==>[ripple,peter,vadas,james,josh,lop,marko]gremlin> g.V().hasLabel('software').elementMap().merge([year:2009])==>[name:lop,label:software,lang:java,year:2009,id:3]==>[name:ripple,label:software,lang:java,year:2009,id:5]g.V().values("name").fold().merge(["james","jen","marko","vadas"])g.V().values("name").fold().merge(__.constant("james").fold())g.V().hasLabel('software').elementMap().merge([year:2009])Additional References
MergeEdge Step
ThemergeE() step is used to add edges and their properties to a graph in a "createif not exist" fashion. ThemergeE() step can also be used to find edges matching a givenpattern. The input passed tomergeE() can be either aMap, or a child traversal thatproduces aMap.
Note | There is a correspondingmergeV() step that can be used when creating vertices. |
Additionally,option() modulators may be combined withmergeE() to take action depending onwhether a vertex was created, or already existed. There are various ways thatmergeE() canbe used. The simplest being to provide a singleMap of keys and values, along with thesource and target vertex IDs, as a parameter. AT.id and aT.label may also be provided butthis is optional. ThemergeE() step can be used directly from theGraphTraversalSource -g,or in the middle of a traversal. For a match with an existing vertex to occur, all valuesin theMap must exist on a vertex; otherwise, a new vertex will be created. The examplesthat follow show howmergeE() can be used to add relationships between dogs in the graph.
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])==>v[1]gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])////(1)==>v[2]gremlin> g.mergeE([(T.label):'Sibling',created:'2022-02-07',(Direction.from):1,(Direction.to):2])////(2)==>e[2][1-Sibling->2]gremlin> g.E().elementMap()==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])////(1)g.mergeE([(T.label):'Sibling',created:'2022-02-07',(Direction.from):1,(Direction.to):2])////(2)g.E().elementMap()Create two vertices with ID values of 1 and 2.
Create a "Sibling" relationship between the vertices.
Note | The example above is written withgremlin-groovy and evaluated in Gremlin Console as a Groovy script thusallowingGroovy syntax for initializing aMap. |
For amergeE() step to succeed, both thefrom andto vertices must already exist. Itis not possible to create new vertices directly usingmergeE(), butmergeV() andmergeE()steps can be combined, in a single query, to achieve that goal.
Note | ThemergeE() step will not create vertices that do not exist. In those cases anerror will be returned. |
If theDirection enum has been statically included, its explicit use can be omitted fromthe query.
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])==>v[1]gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])==>v[2]gremlin> g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):1,(to):2])==>e[2][1-Sibling->2]gremlin> g.E().elementMap()==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):1,(to):2])g.E().elementMap()One or moreoption() steps can be used to control the behavior when an edge is created orupdated. Similar tomergeV(), the onCreateMap inherits from the main merge argument - anyexistence criteria in the main merge argument (T.id,T.label,Direction.OUT,Direction.IN)will be automatically carried over to the onCreate action, and these existence criteria cannot be overridenin the onCreateMap.
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])==>v[1]gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])==>v[2]gremlin> g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]). mergeE(select('map')). option(Merge.onCreate,[created:'2022-02-07']).////(1) option(Merge.onMatch,[updated:'2022-02-07'])==>e[2][1-Sibling->2]gremlin> g.E().elementMap()==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]gremlin> g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]). mergeE(select('map')). option(Merge.onCreate,[created:'2022-02-07']). option(Merge.onMatch,[updated:'2022-02-07'])////(2)==>e[2][1-Sibling->2]gremlin> g.E().elementMap()==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07,updated:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]). mergeE(select('map')). option(Merge.onCreate,[created:'2022-02-07']).////(1) option(Merge.onMatch,[updated:'2022-02-07'])g.E().elementMap()g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]). mergeE(select('map')). option(Merge.onCreate,[created:'2022-02-07']). option(Merge.onMatch,[updated:'2022-02-07'])////(2)g.E().elementMap()The edge did not exist - set the created date.
The edge did exist - set the updated date.
More than one edge can be created by a singlemergeE() operation. This is done byinjecting a list of maps into the traversal and letting them stream into themergeE()step.
gremlin> maps = [[(T.label):'Siblings',(from):1,(to):2], [(T.label):'Siblings',(from):1,(to):3]]==>[label:Siblings,OUT:1,IN:2]==>[label:Siblings,OUT:1,IN:3]gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])////(1)==>v[1]gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])==>v[2]gremlin> g.mergeV([(T.id):3,(T.label):'Dog',name:'Dax'])==>v[3]gremlin> g.inject(maps).unfold().mergeE()////(2)==>e[3][1-Siblings->2]==>e[4][1-Siblings->3]gremlin> g.E().elementMap()==>[id:3,label:Siblings,IN:[id:2,label:Dog],OUT:[id:1,label:Dog]]==>[id:4,label:Siblings,IN:[id:3,label:Dog],OUT:[id:1,label:Dog]]maps = [[(T.label):'Siblings',(from):1,(to):2], [(T.label):'Siblings',(from):1,(to):3]]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])////(1)g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])g.mergeV([(T.id):3,(T.label):'Dog',name:'Dax'])g.inject(maps).unfold().mergeE()////(2)g.E().elementMap()Create three dogs.
Stream the edge maps into
mergeE()steps.
Warning | There is a bit of an inconsistency present whenmergeE() is used as a start step versus when it is usedmid-traversal. As a start step,mergeE() will promote the currently created or matchedEdge to the child traversal,allowing you to directly update it likeoption(onMatch, property('k', 'v').constant([:])). However, whenmergeE() isused mid-traversal, theEdge is not promoted to the child traversal and the incoming traverser is used instead. Suchbehavior is essentially blocked to prevent accidental misuse and will result in an exception at execution time that willhave a message like, "The incoming traverser for MergeEdgeStep cannot be an Element". |
ThemergeE step can be combined with themergeV step (or any other step producing aVertex) using theMerge.outV andMerge.inV option modulators. These options can be used to "late-bind" theOUT andINvertices in the main merge argument and in theonCreate argument:
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby']).as('Toby'). mergeV([(T.id):2,(T.label):'Dog',name:'Brandy']).as('Brandy'). mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]). option(Merge.outV, select('Toby')). option(Merge.inV, select('Brandy'))==>e[2][1-Sibling->2]gremlin> g.E().elementMap()==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby']).as('Toby'). mergeV([(T.id):2,(T.label):'Dog',name:'Brandy']).as('Brandy'). mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]). option(Merge.outV, select('Toby')). option(Merge.inV, select('Brandy'))g.E().elementMap()TheMerge.outV andMerge.inV tokens can be used as placeholders for values forDirection.OUT andDirection.INrespectively in themergeE arguments. These options can produceVertices, as in the example above, or they canspecifyMaps, which will be used to search forVertices in the graph. This is useful when the exactT.id ofthe from/to vertices is not known in advance:
gremlin> g.mergeV([(T.label):'Dog',name:'Toby'])==>v[0]gremlin> g.mergeV([(T.label):'Dog',name:'Brandy'])==>v[2]gremlin> g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]). option(Merge.outV, [(T.label):'Dog',name:'Toby']). option(Merge.inV, [(T.label):'Dog',name:'Brandy'])==>e[4][0-Sibling->2]gremlin> g.E().elementMap()==>[id:4,label:Sibling,IN:[id:2,label:Dog],OUT:[id:0,label:Dog],created:2022-02-07]g.mergeV([(T.label):'Dog',name:'Toby'])g.mergeV([(T.label):'Dog',name:'Brandy'])g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]). option(Merge.outV, [(T.label):'Dog',name:'Toby']). option(Merge.inV, [(T.label):'Dog',name:'Brandy'])g.E().elementMap()Additional References
MergeVertex Step
ThemergeV() -step is used to add vertices and their properties to a graph in a "createif not exist" fashion. ThemergeV() step can also be used to find vertices matching a givenpattern. The input passed tomergeV() can be either aMap, or a childTraversal thatproduces aMap.
Note | There is a correspondingmergeE() step that can be used when creating edges. |
Additionally,option() modulators may be combined withmergeV() to take action depending onwhether a vertex was created, or already existed. There are various waysmergeV() canbe used. The simplest being to provide a singleMap of keys and values as a parameter. AT.idand aT.label may also be provided but this is optional. ThemergeV() step can be used directlyfrom theGraphTraversalSource -g, or in the middle of a traversal. For a match with anexisting vertex to occur, all values in theMap must exist on a vertex; otherwise, a newvertex will be created. The examples that follow show howmergeV() can be used to add somedogs to the graph.
gremlin> g.mergeV([name:'Brandy'])////(1)==>v[0]gremlin> g.V().has('name','Brandy')==>v[0]gremlin> g.mergeV([(T.label):'Dog',name:'Scamp',age:12])////(2)==>v[2]gremlin> g.V().hasLabel('Dog').valueMap()==>[name:[Scamp],age:[12]]gremlin> g.mergeV([(T.id):300, (T.label):'Dog',name:'Toby',age:10])////(3)==>v[300]gremlin> g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)==>[id:2,label:Dog,name:[Scamp],age:[12]]==>[id:300,label:Dog,name:[Toby],age:[10]]g.mergeV([name:'Brandy'])////(1)g.V().has('name','Brandy')g.mergeV([(T.label):'Dog',name:'Scamp',age:12])////(2)g.V().hasLabel('Dog').valueMap()g.mergeV([(T.id):300, (T.label):'Dog',name:'Toby',age:10])////(3)g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)Create a vertex for Brandy as no other matching ones exist yet.
Create a vertex for Scamp and also add a Dog label his age.
Create a vertex for Toby with an
T.idof 300.
Note | The example above is written withgremlin-groovy and evaluated in Gremlin Console as a Groovy script thusallowingGroovy syntax for initializing aMap. |
If a vertex already exists that matches the map passed tomergeV(), the existingvertex will be returned, otherwise a new one will be created. In this way,mergeV()provides "get or create" semantics.
gremlin> g.mergeV([name:'Brandy'])////(1)==>v[0]g.mergeV([name:'Brandy'])//1A vertex for Brandy already exists so return it. A new one is not created.
It’s important to note that every key/value pair passed tomergeV() must already exist onone or more vertices for there to be a match. If a match is found, the vertex, orvertices, representing that match will be returned. If a vertex representing a dog calledBrandy already exists, but it does not have an "age" property, themergeV() below will notfind a match and a new vertex will be created.
gremlin> g.addV('Dog').property('name','Brandy')////(1)==>v[0]gremlin> g.mergeV([(T.label):'Dog',name:'Brandy',age:13])////(2)==>v[2]g.addV('Dog').property('name','Brandy')////(1)g.mergeV([(T.label):'Dog',name:'Brandy',age:13])//2Create a vertex for Brandy with no age property.
A new vertex is created as there is no exact match to any existing vertices.
A common scenario is to search for a vertex with a knownT.id and if it exists return thatvertex. If it does not exist, create it. As we have seen, one way to do this is to passtheT.id and all properties directly tomergeV(). Another is to useMerge.onCreate. Notethat theMap specified forMatch.onCreate does not need to include theT.id already presentin the original search. The values provided to themergeV()Map are inherited by the onCreateaction and combined with theMap provided toMerge.onCreate. Overrides of theT.id orT.labelin the onCreateMap are prohibited.
gremlin> g.mergeV([(T.id):300]). option(Merge.onCreate,[(T.label):'Dog',name:'Toby',age:10])==>v[300]g.mergeV([(T.id):300]). option(Merge.onCreate,[(T.label):'Dog',name:'Toby',age:10])To take specific action when the vertex already exists,Merge.onMatch can be used. Thesecond parameter to theoption step can be either aMap whose values are used to updatethe vertex or another Gremlin traversal that generates aMap.
Note | IfmergeV() is given an emptyMap; such asmergeV([:]), it will match, andreturn, every vertex in the graph. This is the same behavior seen withV([]). |
gremlin> g.mergeV([(T.id):300]). option(Merge.onCreate,[(T.label):'Dog',name:'Toby',age:10]).////(1) option(Merge.onMatch,[age:11])////(2)==>v[300]gremlin> g.withSideEffect('new-data',[age:11]). mergeV([(T.id):300]). option(Merge.onCreate,[(T.label):'Dog',name:'Toby',age:10]). option(Merge.onMatch,select('new-data'))////(3)==>v[300]gremlin> g.V(300).valueMap().with(WithOptions.tokens)==>[id:300,label:Dog,name:[Toby],age:[11]]g.mergeV([(T.id):300]). option(Merge.onCreate,[(T.label):'Dog',name:'Toby',age:10]).////(1) option(Merge.onMatch,[age:11])////(2)g.withSideEffect('new-data',[age:11]). mergeV([(T.id):300]). option(Merge.onCreate,[(T.label):'Dog',name:'Toby',age:10]). option(Merge.onMatch,select('new-data'))////(3)g.V(300).valueMap().with(WithOptions.tokens)If no match found create the vertex using these values.
If a match is found, change the age property value.
Change the age property by selecting from the
new-datamap.
It is sometimes helpful to incorporatefail() step into scenarios where there is a need to stop the traversalfor one event or the other:
gremlin> g.mergeV([(T.id):1]).......1> option(onCreate, fail("vertex did not exist")).......2> option(onMatch, [modified:2022])fail() Step Triggered======================================================================================================================================================================Message > vertex did not existTraverser>false Bulk >1Traversal> fail("vertex did not exist")Parent > TinkerMergeVertexStep [mergeV([(T.id):((int)1)]).option(Merge.onCreate,__.fail("vertex did not exist")).option(Merge.onMatch,[("modified"):((int)2022)])]Metadata > {}======================================================================================================================================================================When working with multi-properties, there are two ways to specify them formergeV(). First, you can specify themindividually using aCardinalityValue as the value in theMap. TheCardinalityValue allows you to specify thevalue as well as theCardinality for that value. Note that it is only possible to specify one value with this syntaxeven if you are usingset orlist.
gremlin> g.mergeV([(T.label):'Dog',name:'Max']).////(1) option(onCreate, [alias: set('Maximus')]).////(2) property(set,'alias','Maxamillion')////(3)==>v[0]gremlin> g.V().has('name','Max').valueMap().with(WithOptions.tokens)==>[id:0,label:Dog,name:[Max],alias:[Maximus,Maxamillion]]g.mergeV([(T.label):'Dog',name:'Max']).////(1) option(onCreate, [alias: set('Maximus')]).////(2) property(set,'alias','Maxamillion')////(3)g.V().has('name','Max').valueMap().with(WithOptions.tokens)Find or create a vertex for Max.
If Max is not found then add an alias of
setcardinality.Whether Max was found or created, add another alias with
setcardinality.
The second option is to specifyCardinality for the entire range of values as follows:
gremlin> g.mergeV([(T.label):'Dog',name:'Max']). option(onCreate, [alias:'Maximus',city:'Boston'], set)////(1)==>v[0]gremlin> g.mergeV([(T.label):'Dog',name:'Max']). option(onCreate, [alias:'Maximus',city: single('Boston')], set)////(2)==>v[0]g.mergeV([(T.label):'Dog',name:'Max']). option(onCreate, [alias:'Maximus',city:'Boston'], set)////(1)g.mergeV([(T.label):'Dog',name:'Max']). option(onCreate, [alias:'Maximus',city: single('Boston')], set)//2If Max is created then set the alias and city with cardinality of
set.If Max is created then set the alias with cardinality of
setand city with cardinalitysingle.
More than one vertex can be created by a singlemergeV() operation. This is done byinjecting aList ofMap objects into the traversal and letting them stream into themergeV()step.
gremlin> maps = [[(T.label) :'Dog',name:'Toby' ,breed:'Golden Retriever'], [(T.label) :'Dog',name:'Brandy',breed:'Golden Retriever'], [(T.label) :'Dog',name:'Scamp' ,breed:'King Charles Spaniel'], [(T.label) :'Dog',name:'Shadow',breed:'Mixed'], [(T.label) :'Dog',name:'Rocket',breed:'Golden Retriever'], [(T.label) :'Dog',name:'Dax' ,breed:'Mixed'], [(T.label) :'Dog',name:'Baxter',breed:'Mixed'], [(T.label) :'Dog',name:'Zoe' ,breed:'Corgi'], [(T.label) :'Dog',name:'Pixel' ,breed:'Mixed']]==>[label:Dog,name:Toby,breed:Golden Retriever]==>[label:Dog,name:Brandy,breed:Golden Retriever]==>[label:Dog,name:Scamp,breed:King Charles Spaniel]==>[label:Dog,name:Shadow,breed:Mixed]==>[label:Dog,name:Rocket,breed:Golden Retriever]==>[label:Dog,name:Dax,breed:Mixed]==>[label:Dog,name:Baxter,breed:Mixed]==>[label:Dog,name:Zoe,breed:Corgi]==>[label:Dog,name:Pixel,breed:Mixed]gremlin> g.inject(maps).unfold().mergeV()==>v[0]==>v[3]==>v[6]==>v[9]==>v[12]==>v[15]==>v[18]==>v[21]==>v[24]gremlin> g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)==>[id:0,label:Dog,name:[Toby],breed:[Golden Retriever]]==>[id:18,label:Dog,name:[Baxter],breed:[Mixed]]==>[id:3,label:Dog,name:[Brandy],breed:[Golden Retriever]]==>[id:21,label:Dog,name:[Zoe],breed:[Corgi]]==>[id:6,label:Dog,name:[Scamp],breed:[King Charles Spaniel]]==>[id:24,label:Dog,name:[Pixel],breed:[Mixed]]==>[id:9,label:Dog,name:[Shadow],breed:[Mixed]]==>[id:12,label:Dog,name:[Rocket],breed:[Golden Retriever]]==>[id:15,label:Dog,name:[Dax],breed:[Mixed]]maps = [[(T.label) :'Dog',name:'Toby' ,breed:'Golden Retriever'], [(T.label) :'Dog',name:'Brandy',breed:'Golden Retriever'], [(T.label) :'Dog',name:'Scamp' ,breed:'King Charles Spaniel'], [(T.label) :'Dog',name:'Shadow',breed:'Mixed'], [(T.label) :'Dog',name:'Rocket',breed:'Golden Retriever'], [(T.label) :'Dog',name:'Dax' ,breed:'Mixed'], [(T.label) :'Dog',name:'Baxter',breed:'Mixed'], [(T.label) :'Dog',name:'Zoe' ,breed:'Corgi'], [(T.label) :'Dog',name:'Pixel' ,breed:'Mixed']]g.inject(maps).unfold().mergeV()g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)Another useful pattern that can be used withmergeV() involves putting multiple maps in alist and selecting different maps based on the action being taken. The examples below usea list containing three maps. The first containing just the ID to be searched for. Thesecond map contains all the information to use when the vertex is created. The third mapcontains additional information that will be applied if an existing vertex is found.
gremlin> g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]). mergeV(limit(local,1)).////(1) option(Merge.onCreate,range(local,1,2)).////(2) option(Merge.onMatch,tail(local))////(3)==>v[400]gremlin> g.V(400).valueMap().with(WithOptions.tokens)==>[id:400,label:Dog,name:[Pixel],age:[1]]gremlin> g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]). mergeV(limit(local,1)). option(Merge.onCreate,range(local,1,2)). option(Merge.onMatch,tail(local))////(4)==>v[400]gremlin> g.V(400).valueMap().with(WithOptions.tokens)////(5)==>[id:400,label:Dog,name:[Pixel],updated:[2022-02-1],age:[1]]g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]). mergeV(limit(local,1)).////(1) option(Merge.onCreate,range(local,1,2)).////(2) option(Merge.onMatch,tail(local))////(3)g.V(400).valueMap().with(WithOptions.tokens)g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]). mergeV(limit(local,1)). option(Merge.onCreate,range(local,1,2)). option(Merge.onMatch,tail(local))////(4)g.V(400).valueMap().with(WithOptions.tokens)//5Use the first map to search for a vertex with an ID of 400.
If the vertex was not found, use the second map to create it.
If the vertex was found, add an
updatedproperty.Pixel exists now, so we will take this option.
The
updatedproperty has now been added.
Warning | There is a bit of an inconsistency present whenmergeV() is used as a start step versus when it is usedmid-traversal. As a start step,mergeV() will promote the currently created or matchedVertex to the childtraversal, allowing you to directly update it likeoption(onMatch, property('k', 'v').constant([:])). However, whenmergeV() is used mid-traversal, theVertex is not promoted to the child traversal and the incoming traverser is usedinstead. Such behavior is essentially blocked to prevent accidental misuse and will result in an exception at executiontime that will have a message like, "The incoming traverser for MergeVertexStep cannot be an Element". |
Additional References
Min Step
Themin()-step (map) operates on a stream of comparable objects and determines which is the first object accordingto its natural order in the stream.
gremlin> g.V().values('age').min()==>27gremlin> g.V().repeat(both()).times(3).values('age').min()==>27gremlin> g.V().values('name').min()==>joshg.V().values('age').min()g.V().repeat(both()).times(3).values('age').min()g.V().values('name').min()When called asmin(local) it determines the minimum value of the current, local object (not the objects in thetraversal stream). This works forCollection andComparable-type objects.
gremlin> g.V().values('age').fold().min(local)==>27g.V().values('age').fold().min(local)When there arenull values being evaluated thenull objects are ignored, but if all values are recognized asnullthe return value isnull.
gremlin> g.inject(null,10,9,null).min()==>9gremlin> g.inject([null,null,null]).min(local)==>nullg.inject(null,10,9,null).min()g.inject([null,null,null]).min(local)Additional References
None Step
Thenone()-step (filter) filters all objects from a traversal stream. It is especially useful for traversalsthat are executed remotely where returning results is not useful and the traversal is only meant to generateside-effects. Choosing not to return results saves in serialization and network costs as the objects are filtered onthe remote end and not returned to the client side. Typically, this step does not need to be used directly and isquietly used by theiterate() terminal step which appendsnone() to the traversal before actually cycling throughresults.
Note | As of release 4.0.0,none() will be renamed todiscard(). |
Additional References
Not Step
Thenot()-step (filter) removes objects from the traversal stream when the traversal provided as an argumentreturns an object.
Groovy | The term |
Python | The term |
gremlin> g.V().not(hasLabel('person')).elementMap()==>[id:3,label:software,name:lop,lang:java]==>[id:5,label:software,name:ripple,lang:java]gremlin> g.V().hasLabel('person'). not(out('created').count().is(gt(1))).values('name')////(1)==>marko==>vadas==>peterg.V().not(hasLabel('person')).elementMap()g.V().hasLabel('person'). not(out('created').count().is(gt(1))).values('name')//1josh created two projects and vadas none
Additional References
Option Step
Additional References
Optional Step
Theoptional()-step (branch/flatMap) returns the result of the specified traversal if it yields a result else it returns the callingelement, i.e. theidentity().
gremlin> g.V(2).optional(out('knows'))////(1)==>v[2]gremlin> g.V(2).optional(__.in('knows'))////(2)==>v[1]g.V(2).optional(out('knows'))////(1)g.V(2).optional(__.in('knows'))//2vadas does not have an outgoing knows-edge so vadas is returned.
vadas does have an incoming knows-edge so marko is returned.
optional is particularly useful for lifting entire graphs when used in conjunction withpath ortree.
gremlin> g.V().hasLabel('person').optional(out('knows').optional(out('created'))).path()////(1)==>[v[1],v[2]]==>[v[1],v[4],v[5]]==>[v[1],v[4],v[3]]==>[v[2]]==>[v[4]]==>[v[6]]g.V().hasLabel('person').optional(out('knows').optional(out('created'))).path()//1Returns the paths of everybody followed by who they know followed by what they created.
Additional References
Or Step
Theor()-step ensures that at least one of the provided traversals yield a result (filter). Please seeand() for and-semantics.
Python | The term |
gremlin> g.V().or( __.outE('created'), __.inE('created').count().is(gt(1))). values('name')==>marko==>lop==>josh==>peterg.V().or( __.outE('created'), __.inE('created').count().is(gt(1))). values('name')Theor()-step can take an arbitrary number of traversals. At least one of the traversals must produce at least oneoutput for the original traverser to pass to the next step.
Aninfix notation can be used as well.
gremlin> g.V().where(outE('created').or().outE('knows')).values('name')==>marko==>josh==>peterg.V().where(outE('created').or().outE('knows')).values('name')Additional References
Order Step
When the objects of the traversal stream need to be sorted,order()-step (map) can be leveraged.
gremlin> g.V().values('name').order()==>josh==>lop==>marko==>peter==>ripple==>vadasgremlin> g.V().values('name').order().by(desc)==>vadas==>ripple==>peter==>marko==>lop==>joshgremlin> g.V().hasLabel('person').order().by('age', asc).values('name')==>vadas==>marko==>josh==>peterg.V().values('name').order()g.V().values('name').order().by(desc)g.V().hasLabel('person').order().by('age', asc).values('name')One of the most traversed objects in a traversal is anElement. An element can have properties associated with it(i.e. key/value pairs). In many situations, it is desirable to sort an element traversal stream according to acomparison of their properties.
gremlin> g.V().values('name')==>marko==>vadas==>lop==>josh==>ripple==>petergremlin> g.V().order().by('name',asc).values('name')==>josh==>lop==>marko==>peter==>ripple==>vadasgremlin> g.V().order().by('name',desc).values('name')==>vadas==>ripple==>peter==>marko==>lop==>joshgremlin> g.V().both().order().by('age')////(1)==>v[2]==>v[1]==>v[1]==>v[1]==>v[4]==>v[4]==>v[4]==>v[6]g.V().values('name')g.V().order().by('name',asc).values('name')g.V().order().by('name',desc).values('name')g.V().both().order().by('age')//1The "age" property is notproductive for all vertices and therefore those values are filtered.
Theorder()-step allows the user to provide an arbitrary number of comparators for primary, secondary, etc. sorting.In the example below, the primary ordering is based on the outgoing created-edge count. The secondary ordering isbased on the age of the person.
gremlin> g.V().hasLabel('person').order().by(outE('created').count(), asc). by('age', asc).values('name')==>vadas==>marko==>peter==>joshgremlin> g.V().hasLabel('person').order().by(outE('created').count(), asc). by('age', desc).values('name')==>vadas==>peter==>marko==>joshg.V().hasLabel('person').order().by(outE('created').count(), asc). by('age', asc).values('name')g.V().hasLabel('person').order().by(outE('created').count(), asc). by('age', desc).values('name')Randomizing the order of the traversers at a particular point in the traversal is possible withOrder.shuffle.
gremlin> g.V().hasLabel('person').order().by(shuffle)==>v[2]==>v[4]==>v[1]==>v[6]gremlin> g.V().hasLabel('person').order().by(shuffle)==>v[1]==>v[6]==>v[2]==>v[4]g.V().hasLabel('person').order().by(shuffle)g.V().hasLabel('person').order().by(shuffle)It is possible to useorder(local) to order the current local object and not the entire traversal stream. This works forCollection- andMap-type objects. For any other object, the object is returned unchanged.
gremlin> g.V().values('age').fold().order(local).by(desc)////(1)==>[35,32,29,27]gremlin> g.V().values('age').order(local).by(desc)////(2)==>29==>27==>32==>35gremlin> g.V().groupCount().by(inE().count()).order(local).by(values, desc)////(3)==>[1:3,0:2,3:1]gremlin> g.V().groupCount().by(inE().count()).order(local).by(keys, asc)////(4)==>[0:2,1:3,3:1]g.V().values('age').fold().order(local).by(desc)////(1)g.V().values('age').order(local).by(desc)////(2)g.V().groupCount().by(inE().count()).order(local).by(values, desc)////(3)g.V().groupCount().by(inE().count()).order(local).by(keys, asc)//4The ages are gathered into a list and then that list is sorted in decreasing order.
The ages are not gathered and thus
order(local)is "ordering" single integers and thus, does nothing.The
groupCount()map is ordered by its values in decreasing order.The
groupCount()map is ordered by its keys in increasing order.
Note | Thevalues andkeys enums are fromColumn which is used to select "columns" from aMap,Map.Entry, orPath. |
If a property key does not exist, then it will be treated asnull which will sort it first forOrder.asc and lastforOrder.desc.
gremlin> g.V().order().by("age").elementMap()==>[id:2,label:person,name:vadas,age:27]==>[id:1,label:person,name:marko,age:29]==>[id:4,label:person,name:josh,age:32]==>[id:6,label:person,name:peter,age:35]g.V().order().by("age").elementMap()Note | Prior to version 3.3.4, ordering was defined byOrder.incr for ascending order andOrder.decr for descendingorder. Those tokens were deprecated and eventually removed in 3.5.0. |
Additional References
PageRank Step
ThepageRank()-step (map/sideEffect) calculatesPageRank usingPageRankVertexProgram.
Important | ThepageRank()-step is aVertexComputing-step and as such, can only be used against a graph thatsupportsGraphComputer (OLAP). |
gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().pageRank().with(PageRank.propertyName,'friendRank').values('pageRank')gremlin> g.V().hasLabel('person'). pageRank(). with(PageRank.edges, __.outE('knows')). with(PageRank.propertyName,'friendRank'). order().by('friendRank',desc). elementMap('name','friendRank')==>[id:1,label:person,friendRank:0.5839416733381598,name:marko]==>[id:6,label:person,friendRank:0.5839416733381598,name:peter]==>[id:4,label:person,friendRank:0.8321166533236799,name:josh]==>[id:2,label:person,friendRank:0.8321166533236799,name:vadas]g = traversal().withEmbedded(graph).withComputer()g.V().pageRank().with(PageRank.propertyName,'friendRank').values('pageRank')g.V().hasLabel('person'). pageRank(). with(PageRank.edges, __.outE('knows')). with(PageRank.propertyName,'friendRank'). order().by('friendRank',desc). elementMap('name','friendRank')Note the use of thewith() modulating step which provides configuration options to the algorithm. It takesconfiguration keys from thePageRank and is automatically imported to the Gremlin Console.
Theexplain()-step can be used to understand how the traversal is compiled into multipleGraphComputer jobs.
gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().hasLabel('person'). pageRank(). with(PageRank.edges, __.outE('knows')). with(PageRank.propertyName,'friendRank'). order().by('friendRank',desc). elementMap('name','friendRank').explain()==>Traversal Explanation=============================================================================================================================================================================================================================================Original Traversal [GraphStep(vertex,[]), HasStep([~label.eq(person)]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), OrderGlobalStep([[value(friendRank), desc]]), ElementMa pStep([name, friendRank])]ConnectiveStrategy [D] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), OrderGlobalStep([[value(friendRank), desc]]), ElementMa pStep([name, friendRank])]VertexProgramStrategy [D] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]RepeatUnrollStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]IdentityRemovalStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]MatchPredicateStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]FilterRankingStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]PathProcessorStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]InlineFilterStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]IncidentToAdjacentStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]PathRetractionStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]EarlyLimitStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]AdjacentToIncidentStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]ByModulatorOptimizationStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]CountStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]LazyBarrierStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]MessagePassingReductionStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]OrderLimitStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]TinkerGraphCountStrategy [P] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]TinkerGraphStepStrategy [P] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]ProfileStrategy [F] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]ComputerVerificationStrategy [V] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]StandardVerificationStrategy [V] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]ComputerFinalizationStrategy [T] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]Final Traversal [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), Travers alVertexProgramStep([OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]g = traversal().withEmbedded(graph).withComputer()g.V().hasLabel('person'). pageRank(). with(PageRank.edges, __.outE('knows')). with(PageRank.propertyName,'friendRank'). order().by('friendRank',desc). elementMap('name','friendRank').explain()Additional References
Path Step
A traverser is transformed as it moves through a series of steps within a traversal. The history of the traverser isrealized by examining its path withpath()-step (map).

gremlin> g.V().out().out().values('name')==>ripple==>lopgremlin> g.V().out().out().values('name').path()==>[v[1],v[4],v[5],ripple]==>[v[1],v[4],v[3],lop]gremlin> g.V().both().path().by('age')////(1)==>[29,27]==>[29,32]==>[27,29]==>[32,29]g.V().out().out().values('name')g.V().out().out().values('name').path()g.V().both().path().by('age')//1The "age" property is notproductive for all vertices and therefore those values are filtered.
If edges are required in the path, then be sure to traverse those edges explicitly.
gremlin> g.V().outE().inV().outE().inV().path()==>[v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]==>[v[1],e[8][1-knows->4],v[4],e[11][4-created->3],v[3]]g.V().outE().inV().outE().inV().path()It is possible to post-process the elements of the path in a round-robin fashion viaby().
gremlin> g.V().out().out().path().by('name').by('age')==>[marko,32,ripple]==>[marko,32,lop]g.V().out().out().path().by('name').by('age')Finally, becauseby()-based post-processing, nothing prevents triggering yet another traversal. In the traversalbelow, for each element of the path traversed thus far, if its a person (as determined by having anage-property),then get all of their creations, else if its a creation, get all the people that created it.
gremlin> g.V().out().out().path().by( choose(hasLabel('person'), out('created').values('name'), __.in('created').values('name')).fold())==>[[lop],[ripple,lop],[josh]]==>[[lop],[ripple,lop],[marko,josh,peter]]g.V().out().out().path().by( choose(hasLabel('person'), out('created').values('name'), __.in('created').values('name')).fold())gremlin> g.V().has('person','name','vadas').as('e'). in('knows'). out('knows').where(neq('e')). path().by('name')////(1)==>[vadas,marko,josh]gremlin> g.V().has('person','name','vadas').as('e'). in('knows').as('m'). out('knows').where(neq('e')). path().to('m').by('name')////(2)==>[vadas,marko]gremlin> g.V().has('person','name','vadas').as('e'). in('knows').as('m'). out('knows').where(neq('e')). path().from('m').by('name')////(3)==>[marko,josh]g.V().has('person','name','vadas').as('e'). in('knows'). out('knows').where(neq('e')). path().by('name')////(1)g.V().has('person','name','vadas').as('e'). in('knows').as('m'). out('knows').where(neq('e')). path().to('m').by('name')////(2)g.V().has('person','name','vadas').as('e'). in('knows').as('m'). out('knows').where(neq('e')). path().from('m').by('name')//3Obtain the full path from vadas to josh.
Save the middle node, marko, and use the
to()modulator to show only the path from vadas to markoUse the
from()mdoulator to show only the path from marko to josh
Warning | Generating path information is expensive as the history of the traverser is stored into a Java list. Withnumerous traversers, there are numerous lists. Moreover, in an OLAPGraphComputer environmentthis becomes exceedingly prohibitive as there are traversers emanating from all vertices in the graph in parallel.In OLAP there are optimizations provided for traverser populations, but when paths are calculated (and each traverseris unique due to its history), then these optimizations are no longer possible. |
Path Data Structure
ThePath data structure is an ordered list of objects, where each object is associated to aSet<String> oflabels. An example is presented below to demonstrate both thePath API as well as how a traversal yields labeled paths.

gremlin> path = g.V(1).as('a').has('name').as('b'). out('knows').out('created').as('c'). has('name','ripple').values('name').as('d'). identity().as('e').path().next()==>v[1]==>v[4]==>v[5]==>ripplegremlin> path.size()==>4gremlin> path.objects()==>v[1]==>v[4]==>v[5]==>ripplegremlin> path.labels()==>[b,a]==>[]==>[c]==>[d,e]gremlin> path.a==>v[1]gremlin> path.b==>v[1]gremlin> path.c==>v[5]gremlin> path.d == path.e==>truepath = g.V(1).as('a').has('name').as('b'). out('knows').out('created').as('c'). has('name','ripple').values('name').as('d'). identity().as('e').path().next()path.size()path.objects()path.labels()path.apath.bpath.cpath.d == path.eAdditional References
PeerPressure Step
ThepeerPressure()-step (map/sideEffect) clusters vertices usingPeerPressureVertexProgram.
Important | ThepeerPressure()-step is aVertexComputing-step and as such, can only be used against a graph that supportsGraphComputer (OLAP). |
gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().peerPressure().with(PeerPressure.propertyName,'cluster').values('cluster')==>1==>1==>1==>1==>1==>6gremlin> g.V().hasLabel('person'). peerPressure(). with(PeerPressure.propertyName,'cluster'). group(). by('cluster'). by('name')==>[1:[marko,vadas,josh],6:[peter]]g = traversal().withEmbedded(graph).withComputer()g.V().peerPressure().with(PeerPressure.propertyName,'cluster').values('cluster')g.V().hasLabel('person'). peerPressure(). with(PeerPressure.propertyName,'cluster'). group(). by('cluster'). by('name')Note the use of thewith() modulating step which provides configuration options to the algorithm. It takesconfiguration keys from thePeerPressure class and is automatically imported to the Gremlin Console.
Additional References
Product Step
Theproduct()-step (map) calculates the cartesian product between the incoming list traverser and the provided listargument. This step only expects list data (array or Iterable) and will throw anIllegalArgumentException if anyother type is encountered (includingnull).
gremlin> g.V().values("name").fold().product(["james","jen"])==>[[marko,james],[marko,jen],[vadas,james],[vadas,jen],[lop,james],[lop,jen],[josh,james],[josh,jen],[ripple,james],[ripple,jen],[peter,james],[peter,jen]]gremlin> g.V().values("name").fold().product(__.V().has("age").limit(1).values("age").fold())==>[[marko,29],[vadas,29],[lop,29],[josh,29],[ripple,29],[peter,29]]g.V().values("name").fold().product(["james","jen"])g.V().values("name").fold().product(__.V().has("age").limit(1).values("age").fold())Additional References
Profile Step
Theprofile()-step (sideEffect) exists to allow developers to profile their traversals to determine statisticalinformation like step runtime, counts, etc.
Warning | Profiling a Traversal will impede the Traversal’s performance. This overhead is mostly excluded from theprofile results, but durations are not exact. Thus, durations are best considered in relation to each other. |
gremlin> g.V().out('created').repeat(both()).times(3).hasLabel('person').values('age').sum().profile()==>Traversal MetricsStep Count TraversersTime (ms) % Dur=============================================================================================================TinkerGraphStep(vertex,[])660.04822.02VertexStep(OUT,[created],vertex)440.03114.12NoOpBarrierStep(2500)420.0157.02VertexStep(BOTH,vertex)1040.0114.95NoOpBarrierStep(2500)1030.0083.79VertexStep(BOTH,vertex)2470.0125.53NoOpBarrierStep(2500)2450.0094.35VertexStep(BOTH,vertex)58110.0135.91NoOpBarrierStep(2500)5860.0136.10HasStep([~label.eq(person)])4840.0167.61PropertiesStep([age],value)4840.0136.06SumGlobalStep110.02712.53 >TOTAL - -0.222 -g.V().out('created').repeat(both()).times(3).hasLabel('person').values('age').sum().profile()Theprofile()-step generates aTraversalMetrics sideEffect object that contains the following information:
Step: A step within the traversal being profiled.Count: The number ofrepresented traversers that passed through the step.Traversers: The number of traversers that passed through the step.Time (ms): The total time the step was actively executing its behavior.% Dur: The percentage of total time spent in the step.
 It is important to understand the difference between "Count"and "Traversers". Traversers can be merged and as such, when two traversers are "the same" they may be aggregatedinto a single traverser. That new traverser has a
It is important to understand the difference between "Count"and "Traversers". Traversers can be merged and as such, when two traversers are "the same" they may be aggregatedinto a single traverser. That new traverser has aTraverser.bulk() that is the sum of the two merged traverserbulks. On the other hand, theCount represents the sum of allTraverser.bulk() results and thus, expresses thenumber of "represented" (not enumerated) traversers.Traversers will always be less than or equal toCount.
For traversal compilation information, please seeexplain()-step.
Additional References
Project Step
Theproject()-step (map) projects the current object into aMap<String,Object> keyed by provided labels. It is similartoselect()-step, save that instead of retrieving and modulating historic traverser state, it modulatesthe current state of the traverser.
gremlin> g.V().has('name','marko'). project('id','name','out','in'). by(id). by('name'). by(outE().count()). by(inE().count())==>[id:1,name:marko,out:3,in:0]gremlin> g.V().has('name','marko'). project('name','friendsNames'). by('name'). by(out('knows').values('name').fold())==>[name:marko,friendsNames:[vadas,josh]]gremlin> g.V().out('created'). project('a','b'). by('name'). by(__.in('created').count()). order().by(select('b'),desc). select('a')==>lop==>lop==>lop==>ripplegremlin> g.V().project('n','a').by('name').by('age')////(1)==>[n:marko,a:29]==>[n:vadas,a:27]==>[n:lop]==>[n:josh,a:32]==>[n:ripple]==>[n:peter,a:35]g.V().has('name','marko'). project('id','name','out','in'). by(id). by('name'). by(outE().count()). by(inE().count())g.V().has('name','marko'). project('name','friendsNames'). by('name'). by(out('knows').values('name').fold())g.V().out('created'). project('a','b'). by('name'). by(__.in('created').count()). order().by(select('b'),desc). select('a')g.V().project('n','a').by('name').by('age')//1The "age" property is notproductive for all vertices and therefore those values are filtered and the key not present in the
Map.
Additional References
Program Step
Theprogram()-step (map/sideEffect) is the "lambda" step forGraphComputer jobs. The step takes aVertexProgram as an argument and will process the incoming graph accordingly. Thus, the usercan create their ownVertexProgram and have it execute within a traversal. The configuration provided to thevertex program includes:
gremlin.vertexProgramStep.rootTraversalis a serialization of aPureTraversalform of the root traversal.gremlin.vertexProgramStep.stepIdis the step string id of theprogram()-step being executed.
The user suppliedVertexProgram can leverage that information accordingly within their vertex program. Example usesare provided below.
Warning | Developing aVertexProgram is for expert users. Moreover, developing one that can be used effectively withina traversal requires yet more expertise. This information is recommended to advanced users with a deep understanding of themechanics of Gremlin OLAP (GraphComputer). |
private TraverserSet<Object> haltedTraversers;publicvoid loadState(Graph graph,Configuration configuration) { VertexProgram.super.loadState(graph, configuration);this.traversal = PureTraversal.loadState(configuration, VertexProgramStep.ROOT_TRAVERSAL, graph);this.programStep =new TraversalMatrix<>(this.traversal.get()).getStepById(configuration.getString(ProgramVertexProgramStep.STEP_ID));// if the traversal sideEffects will be used in the computation, add them as memory compute keysthis.memoryComputeKeys.addAll(MemoryTraversalSideEffects.getMemoryComputeKeys(this.traversal.get()));// if master-traversal traversers may be propagated, create a memory compute keythis.memoryComputeKeys.add(MemoryComputeKey.of(TraversalVertexProgram.HALTED_TRAVERSERS, Operator.addAll,false,false));// returns an empty traverser set if there are no halted traversersthis.haltedTraversers = TraversalVertexProgram.loadHaltedTraversers(configuration);}publicvoid storeState(Configuration configuration) { VertexProgram.super.storeState(configuration);// if halted traversers is null or empty, it does nothing TraversalVertexProgram.storeHaltedTraversers(configuration,this.haltedTraversers);}publicvoid setup(Memory memory) {if(!this.haltedTraversers.isEmpty()) {// do what you like with the halted master traversal traversers }// once used, no need to keep that information around (master)this.haltedTraversers =null;}publicvoid execute(Vertex vertex, Messenger messenger, Memory memory) {// once used, no need to keep that information around (workers)if(null !=this.haltedTraversers)this.haltedTraversers =null;if(vertex.property(TraversalVertexProgram.HALTED_TRAVERSERS).isPresent()) {// haltedTraversers in execute() represent worker-traversal traversers// for example, from a traversal of the form g.V().out().program(...) TraverserSet<Object> haltedTraversers = vertex.value(TraversalVertexProgram.HALTED_TRAVERSERS);// create a new halted traverser set that can be used by the next OLAP job in the chain// these are worker-traversers that are distributed throughout the graph TraverserSet<Object> newHaltedTraversers =new TraverserSet<>(); haltedTraversers.forEach(traverser -> { newHaltedTraversers.add(traverser.split(traverser.get().toString(),this.programStep)); }); vertex.property(VertexProperty.Cardinality.single, TraversalVertexProgram.HALTED_TRAVERSERS, newHaltedTraversers);// it is possible to create master-traversers that are localized to the master traversal (this is how results are ultimately delivered back to the user) memory.add(TraversalVertexProgram.HALTED_TRAVERSERS,new TraverserSet<>(this.traversal().get().getTraverserGenerator().generate("an example",this.programStep,1l))); }publicboolean terminate(Memory memory) {// the master-traversal will have halted traversersassert memory.exists(TraversalVertexProgram.HALTED_TRAVERSERS); TraverserSet<String> haltedTraversers = memory.get(TraversalVertexProgram.HALTED_TRAVERSERS);// it will only have the traversers sent to the master traversal via memoryassert haltedTraversers.stream().map(Traverser::get).filter(s -> s.equals("an example")).findAny().isPresent();// it will not contain the worker traversers distributed throughout the verticesassert !haltedTraversers.stream().map(Traverser::get).filter(s -> !s.equals("an example")).findAny().isPresent();returntrue;}Note | The test caseProgramTest ingremlin-test has an example vertex program calledTestProgram that demonstratesall the various ways in which traversal and traverser information is propagated within a vertex program and ultimatelyusable by other vertex programs (includingTraversalVertexProgram) down the line in an OLAP compute chain. |
Finally, an example is provided usingPageRankVertexProgram which doesn’t usepageRank()-step.
gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().hasLabel('person'). program(PageRankVertexProgram.build().property('rank').create(graph)). order().by('rank', asc). elementMap('name','rank')==>[id:1,label:person,name:marko,rank:0.11375510357865541]==>[id:4,label:person,name:josh,rank:0.14598540152719106]==>[id:2,label:person,name:vadas,rank:0.14598540152719106]==>[id:6,label:person,name:peter,rank:0.11375510357865541]g = traversal().withEmbedded(graph).withComputer()g.V().hasLabel('person'). program(PageRankVertexProgram.build().property('rank').create(graph)). order().by('rank', asc). elementMap('name','rank')Properties Step
Theproperties()-step (map) extracts properties from anElement in the traversal stream.
gremlin> g.V(1).properties()==>vp[name->marko]==>vp[location->san diego]==>vp[location->santa cruz]==>vp[location->brussels]==>vp[location->santa fe]gremlin> g.V(1).properties('location').valueMap()==>[startTime:1997,endTime:2001]==>[startTime:2001,endTime:2004]==>[startTime:2004,endTime:2005]==>[startTime:2005]gremlin> g.V(1).properties('location').has('endTime').valueMap()==>[startTime:1997,endTime:2001]==>[startTime:2001,endTime:2004]==>[startTime:2004,endTime:2005]g.V(1).properties()g.V(1).properties('location').valueMap()g.V(1).properties('location').has('endTime').valueMap()Additional References
Property Step
Theproperty()-step is used to add properties to the elements of the graph (sideEffect). UnlikeaddV() andaddE(),property() is a full sideEffect step in that it does not return the property it created, but the elementthat streamed into it. Moreover, ifproperty() follows anaddV() oraddE(), then it is "folded" into theprevious step to enable vertex and edge creation with all its properties in one creation operation.
gremlin> g.V(1).property('country','usa')==>v[1]gremlin> g.V(1).property('city','santa fe').property('state','new mexico').valueMap()==>[country:[usa],city:[santa fe],name:[marko],state:[new mexico],age:[29]]gremlin> g.V(1).property(['city':'santa fe','state':'new mexico'])////(1)==>v[1]gremlin> g.V(1).property(list,'age',35)////(2)==>v[1]gremlin> g.V(1).property(list, ['city':'santa fe','state':'new mexico'])////(3)==>v[1]gremlin> g.V(1).valueMap()==>[country:[usa],city:[santa fe,santa fe],name:[marko],state:[new mexico,new mexico],age:[29,35]]gremlin> g.V(1).property(list, ['age': single(36),'city':'wilmington','state':'delaware'])////(4)==>v[1]gremlin> g.V(1).valueMap()==>[country:[usa],city:[santa fe,santa fe,wilmington],name:[marko],state:[new mexico,new mexico,delaware],age:[36]]gremlin> g.V(1).property('friendWeight',outE('knows').values('weight').sum(),'acl','private')////(5)==>v[1]gremlin> g.V(1).properties('friendWeight').valueMap()////(6)==>[acl:private]gremlin> g.addV().property(T.label,'person').valueMap().with(WithOptions.tokens)////(7)==>[id:13,label:person]gremlin> g.addV().property(null)////(8)==>v[14]gremlin> g.addV().property(set,null)==>v[15]g.V(1).property('country','usa')g.V(1).property('city','santa fe').property('state','new mexico').valueMap()g.V(1).property(['city':'santa fe','state':'new mexico'])////(1)g.V(1).property(list,'age',35)////(2)g.V(1).property(list, ['city':'santa fe','state':'new mexico'])////(3)g.V(1).valueMap()g.V(1).property(list, ['age': single(36),'city':'wilmington','state':'delaware'])////(4)g.V(1).valueMap()g.V(1).property('friendWeight',outE('knows').values('weight').sum(),'acl','private')////(5)g.V(1).properties('friendWeight').valueMap()////(6)g.addV().property(T.label,'person').valueMap().with(WithOptions.tokens)////(7)g.addV().property(null)////(8)g.addV().property(set,null)Properties can also take a
Mapas an argument.For vertices, a cardinality can be provided forvertex properties.
If a cardinality is specified for a
Mapthen that cardinality will be used for all properties in the map.Assign the
Cardinalityindividually to override the specifiedlistor the default cardinality if not specified.It is possible to select the property value (as well as key) via a traversal.
For vertices, the
property()-step can add meta-properties.The label value can be specified as a property only at the time a vertex is added and if one is not specified in the addV()
If you pass a
nullvalue for the Map this will be treated as a no-op and the input will be returned
Additional References
PropertyMap Step
ThepropertiesMap()-step yields a Map representation of the properties of an element.
gremlin> g.V().propertyMap()==>[name:[vp[name->marko]],age:[vp[age->29]]]==>[name:[vp[name->vadas]],age:[vp[age->27]]]==>[name:[vp[name->lop]],lang:[vp[lang->java]]]==>[name:[vp[name->josh]],age:[vp[age->32]]]==>[name:[vp[name->ripple]],lang:[vp[lang->java]]]==>[name:[vp[name->peter]],age:[vp[age->35]]]gremlin> g.V().propertyMap('age')==>[age:[vp[age->29]]]==>[age:[vp[age->27]]]==>[]==>[age:[vp[age->32]]]==>[]==>[age:[vp[age->35]]]gremlin> g.V().propertyMap('age','blah')==>[age:[vp[age->29]]]==>[age:[vp[age->27]]]==>[]==>[age:[vp[age->32]]]==>[]==>[age:[vp[age->35]]]gremlin> g.E().propertyMap()==>[weight:p[weight->0.5]]==>[weight:p[weight->1.0]]==>[weight:p[weight->0.4]]==>[weight:p[weight->1.0]]==>[weight:p[weight->0.4]]==>[weight:p[weight->0.2]]g.V().propertyMap()g.V().propertyMap('age')g.V().propertyMap('age','blah')g.E().propertyMap()Additional References
Range Step
As traversers propagate through the traversal, it is possible to only allow a certain number of them to pass throughwithrange()-step (filter). When the low-end of the range is not met, objects are continued to be iterated. Whenwithin the low (inclusive) and high (exclusive) range, traversers are emitted. When above the high range, the traversalbreaks out of iteration. Finally, the use of-1 on the high range will emit remaining traversers after the low rangebegins.
gremlin> g.V().range(0,3)==>v[1]==>v[2]==>v[3]gremlin> g.V().range(1,3)==>v[2]==>v[3]gremlin> g.V().range(1, -1)==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]gremlin> g.V().repeat(both()).times(1000000).emit().range(6,10)==>v[1]==>v[5]==>v[3]==>v[1]g.V().range(0,3)g.V().range(1,3)g.V().range(1, -1)g.V().repeat(both()).times(1000000).emit().range(6,10)Therange()-step can also be applied withScope.local, in which case it operates on the incoming collection.For example, it is possible to produce aMap<String, String> for each traversed path, but containing only the secondproperty value (the "b" step).
gremlin> g.V().as('a').out().as('b').in().as('c').select('a','b','c').by('name').range(local,1,2)==>[b:lop]==>[b:lop]==>[b:lop]==>[b:vadas]==>[b:josh]==>[b:ripple]==>[b:lop]==>[b:lop]==>[b:lop]==>[b:lop]==>[b:lop]==>[b:lop]g.V().as('a').out().as('b').in().as('c').select('a','b','c').by('name').range(local,1,2)The next example uses theThe Crew toy data set. It produces aList<String> containing thesecond and third location for each vertex.
gremlin> g.V().valueMap().select('location').range(local,1,3)==>[santa cruz,brussels]==>[dulles,purcellville]==>[baltimore,oakland]==>[kaiserslautern,aachen]g.V().valueMap().select('location').range(local,1,3)Additional References
Read Step
Theread()-step is not really a "step" but a step modulator in that it modifies the functionality of theio()-step.More specifically, it tells theio()-step that it is expected to use its configuration to read data from somelocation. Please see thedocumentation forio()-step for more complete details on usage.
Additional References
Repeat Step

Therepeat()-step (branch) is used for looping over a traversal given some break predicate. Below are someexamples ofrepeat()-step in action.
gremlin> g.V(1).repeat(out()).times(2).path().by('name')////(1)==>[marko,josh,ripple]==>[marko,josh,lop]gremlin> g.V().until(has('name','ripple')). repeat(out()).path().by('name')////(2)==>[marko,josh,ripple]==>[josh,ripple]==>[ripple]g.V(1).repeat(out()).times(2).path().by('name')////(1)g.V().until(has('name','ripple')). repeat(out()).path().by('name')//2do-while semantics stating to do
out()2 times.while-do semantics stating to break if the traverser is at a vertex named "ripple".
Important | There are two modulators forrepeat():until() andemit(). Ifuntil() comes afterrepeat() it isdo/while looping. Ifuntil() comes beforerepeat() it is while/do looping. Ifemit() is placed afterrepeat(),it is evaluated on the traversers leaving the repeat-traversal. Ifemit() is placed beforerepeat(), it isevaluated on the traversers prior to entering the repeat-traversal. |
Therepeat()-step also supports an "emit predicate", where the predicate for an empty argumentemit() istrue (i.e.emit() == emit{true}). Withemit(), the traverser is split in two — the traverser exits the codeblock as well as continues back within the code block (assuminguntil() holds true).
gremlin> g.V(1).repeat(out()).times(2).emit().path().by('name')////(1)==>[marko,lop]==>[marko,vadas]==>[marko,josh]==>[marko,josh,ripple]==>[marko,josh,lop]gremlin> g.V(1).emit().repeat(out()).times(2).path().by('name')////(2)==>[marko]==>[marko,lop]==>[marko,vadas]==>[marko,josh]==>[marko,josh,ripple]==>[marko,josh,lop]g.V(1).repeat(out()).times(2).emit().path().by('name')////(1)g.V(1).emit().repeat(out()).times(2).path().by('name')//2The
emit()comes afterrepeat()and thus, emission happens after therepeat()traversal is executed. Thus,no one vertex paths exist.The
emit()comes beforerepeat()and thus, emission happens prior to therepeat()traversal being executed.Thus, one vertex paths exist.
Theemit()-modulator can take an arbitrary predicate.
gremlin> g.V(1).repeat(out()).times(2).emit(has('lang')).path().by('name')==>[marko,lop]==>[marko,josh,ripple]==>[marko,josh,lop]g.V(1).repeat(out()).times(2).emit(has('lang')).path().by('name')
gremlin> g.V(1).repeat(out()).times(2).emit().path().by('name')==>[marko,lop]==>[marko,vadas]==>[marko,josh]==>[marko,josh,ripple]==>[marko,josh,lop]g.V(1).repeat(out()).times(2).emit().path().by('name')The first time through therepeat(), the vertices lop, vadas, and josh are seen. Given thatloops==1, thetraverser repeats. However, because the emit-predicate is declared true, those vertices are emitted. The next time throughrepeat(), the vertices traversed are ripple and lop (Josh’s created projects, as lop and vadas have no out edges). Given thatloops==2, the until-predicate fails and ripple and lop are emitted.Therefore, the traverser has seen the vertices: lop, vadas, josh, ripple, and lop.
repeat()-steps may be nested inside each other or inside theemit() oruntil() predicates and they can also be 'named' by passing a string as the first parameter torepeat(). The loop counter of a named repeat step can be accessed within the looped context withloops(loopName) whereloopName is the name set whe creating therepeat()-step.
gremlin> g.V(1). repeat(out("knows")). until(repeat(out("created")).emit(has("name","lop")))////(1)==>v[4]gremlin> g.V(6). repeat('a', both('created').simplePath()). emit(repeat('b', both('knows')). until(loops('b').as('b').where(loops('a').as('b'))). hasId(2)).dedup()////(2)==>v[4]g.V(1). repeat(out("knows")). until(repeat(out("created")).emit(has("name","lop")))////(1)g.V(6). repeat('a', both('created').simplePath()). emit(repeat('b', both('knows')). until(loops('b').as('b').where(loops('a').as('b'))). hasId(2)).dedup()//2Starting from vertex 1, keep going taking outgoing 'knows' edges until the vertex was created by 'lop'.
Starting from vertex 6, keep taking created edges in either direction until the vertex is same distance from vertex 2 over knows edges as it is from vertex 6 over created edges.
Finally, note that bothemit() anduntil() can take a traversal and in such, situations, the predicate isdetermined bytraversal.hasNext(). A few examples are provided below.
gremlin> g.V(1).repeat(out()).until(hasLabel('software')).path().by('name')////(1)==>[marko,lop]==>[marko,josh,ripple]==>[marko,josh,lop]gremlin> g.V(1).emit(hasLabel('person')).repeat(out()).path().by('name')////(2)==>[marko]==>[marko,vadas]==>[marko,josh]gremlin> g.V(1).repeat(out()).until(outE().count().is(0)).path().by('name')////(3)==>[marko,lop]==>[marko,vadas]==>[marko,josh,ripple]==>[marko,josh,lop]g.V(1).repeat(out()).until(hasLabel('software')).path().by('name')////(1)g.V(1).emit(hasLabel('person')).repeat(out()).path().by('name')////(2)g.V(1).repeat(out()).until(outE().count().is(0)).path().by('name')//3Starting from vertex 1, keep taking outgoing edges until a software vertex is reached.
Starting from vertex 1, and in an infinite loop, emit the vertex if it is a person and then traverser the outgoing edges.
Starting from vertex 1, keep taking outgoing edges until a vertex is reached that has no more outgoing edges.
Warning | The anonymous traversal ofemit() anduntil() (notrepeat()) process their current objects "locally."In OLAP, where the atomic unit of computing is the vertex and its local "star graph," it is important that theanonymous traversals do not leave the confines of the vertex’s star graph. In other words, they can not traverse toan adjacent vertex’s properties or edges. |
Additional References
Replace Step
Thereplace()-step (map) returns a string with the specified characters in the original string replaced with the newcharacters. Any null arguments will be a no-op and the original string is returned. Null values from the incomingtraversers are not processed and remain as null when returned. If the incoming traverser is a non-String value thenanIllegalArgumentException will be thrown.
gremlin> g.inject('that','this','test',null).replace('h','j')////(1)==>tjat==>tjis==>test==>nullgremlin> g.inject('hello world').replace(null,'j')////(2)==>hello worldgremlin> g.V().hasLabel("software").values("name").replace("p","g")////(3)==>log==>rigglegremlin> g.V().hasLabel("software").values("name").fold().replace(local,"p","g")////(4)==>[log,riggle]g.inject('that','this','test',null).replace('h','j')////(1)g.inject('hello world').replace(null,'j')////(2)g.V().hasLabel("software").values("name").replace("p","g")////(3)g.V().hasLabel("software").values("name").fold().replace(local,"p","g")//4Replace "h" in the strings with "j".
Null inputs are ignored and the original string is returned.
Return software names with "p" replaced by "g".
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional Referencesreplace(String,String)replace(Scope,String,String)
Reverse Step
Thereverse()-step (map) returns the reverse of the incoming list traverser. Single values (includingnull) are notprocessed and are added back to the Traversal Stream unchanged. If the incoming traverser is a String value then thereversed String will be returned.
gremlin> g.V().values("name").reverse()////(1)==>okram==>sadav==>pol==>hsoj==>elppir==>retepgremlin> g.V().values("name").order().fold().reverse()////(2)==>[vadas,ripple,peter,marko,lop,josh]g.V().values("name").reverse()////(1)g.V().values("name").order().fold().reverse()//2Reverse the order of the characters in each name.
Fold all the names into a list in ascending order and then reverse the list’s ordering (into descending).
RTrim Step
TherTrim()-step (map) returns a string with trailing whitespace removed. Null values are not processed and remainas null when returned. If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.inject(" hello"," world",null).rTrim()==> hello==> world==>nullgremlin> g.inject([" hello"," world",null]).rTrim(local)////(1)==>[ hello, world,null]g.inject(" hello"," world",null).rTrim()g.inject([" hello"," world",null]).rTrim(local)//1Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Sack Step
 A traverser can contain a local data structure called a "sack".The
A traverser can contain a local data structure called a "sack".Thesack()-step is used to read and write sacks (sideEffect ormap). Each sack of each traverser is createdwhen usingGraphTraversal.withSack(initialValueSupplier,splitOperator?,mergeOperator?).
Initial value supplier: A
Supplierproviding the initial value of each traverser’s sack.Split operator: a
UnaryOperatorthat clones the traverser’s sack when the traverser splits. If no split operatoris provided, thenUnaryOperator.identity()is assumed.Merge operator: A
BinaryOperatorthat unites two traverser’s sack when they are merged. If no merge operator isprovided, then traversers with sacks can not be merged.
Two trivial examples are presented below to demonstrate theinitial value supplier. In the first example below, atraverser is created at each vertex in the graph (g.V()), with a 1.0 sack (withSack(1.0f)), and then the sackvalue is accessed (sack()). In the second example, a random float supplier is used to generate sack values.
gremlin> g.withSack(1.0f).V().sack()==>1.0==>1.0==>1.0==>1.0==>1.0==>1.0gremlin> rand =newRandom()==>java.util.Random@226dc79agremlin> g.withSack {rand.nextFloat()}.V().sack()==>0.25551385==>0.010213554==>0.5352429==>0.7184265==>0.878787==>0.9303321g.withSack(1.0f).V().sack()rand =newRandom()g.withSack {rand.nextFloat()}.V().sack()A more complicated initial value supplier example is presented below where the sack values are used in a runningcomputation and then emitted at the end of the traversal. When an edge is traversed, the edge weight is multipliedby the sack value (sack(mult).by('weight')). Note that theby()-modulator can be any arbitrary traversal.
gremlin> g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2)==>v[5]==>v[3]gremlin> g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).sack()==>1.0==>0.4gremlin> g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).path(). by().by('weight')==>[v[1],1.0,v[4],1.0,v[5]]==>[v[1],1.0,v[4],0.4,v[3]]gremlin> g.V().sack(assign).by('age').sack()////(1)==>29==>27==>32==>35g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2)g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).sack()g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).path(). by().by('weight')g.V().sack(assign).by('age').sack()//1The "age" property is notproductive for all vertices and therefore those values are filtered during the assignment.
 When complex objects are used (i.e. non-primitives), then asplit operator should be defined to ensure that each traverser gets a clone of its parent’s sack. The first exampledoes not use a split operator and as such, the same map is propagated to all traversers (a global data structure). Thesecond example, demonstrates how
When complex objects are used (i.e. non-primitives), then asplit operator should be defined to ensure that each traverser gets a clone of its parent’s sack. The first exampledoes not use a split operator and as such, the same map is propagated to all traversers (a global data structure). Thesecond example, demonstrates howMap.clone() ensures that each traverser’s sack contains a unique, local sack.
gremlin> g.withSack {[:]}.V().out().out(). sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack()// BAD: single map==>[ripple:java]==>[ripple:java,lop:java]gremlin> g.withSack {[:]}{it.clone()}.V().out().out(). sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack()// GOOD: cloned map==>[ripple:java]==>[lop:java]g.withSack {[:]}.V().out().out(). sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack()// BAD: single mapg.withSack {[:]}{it.clone()}.V().out().out(). sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack()// GOOD: cloned mapNote | For primitives (i.e. integers, longs, floats, etc.), a split operator is not required as a primitives areencoded in the memory address of the sack, not as a reference to an object. |
If amerge operator is not provided, then traversers with sacks can not be bulked. However, in many situations,merging the sacks of two traversers at the same location is algorithmically sound and good to provide so as to gainthe bulking optimization. In the examples below, the binary merge operator isOperator.sum. Thus, when two traversermerge, their respective sacks are added together.
gremlin> g.withSack(1.0d).V(1).out('knows').in('knows')////(1)==>v[1]==>v[1]gremlin> g.withSack(1.0d).V(1).out('knows').in('knows').sack()////(2)==>1.0==>1.0gremlin> g.withSack(1.0d, sum).V(1).out('knows').in('knows').sack()////(3)==>2.0==>2.0gremlin> g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier()////(4)==>v[1]==>v[1]gremlin> g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(5)==>0.5==>0.5gremlin> g.withSack(1.0d,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(6)==>1.0==>1.0gremlin> g.withBulk(false).withSack(1.0f,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(7)==>1.0gremlin> g.withBulk(false).withSack(1.0f).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(8)==>0.5==>0.5gremlin>g.withSack(1.0d).V(1).out('knows').in('knows')////(1)g.withSack(1.0d).V(1).out('knows').in('knows').sack()////(2)g.withSack(1.0d, sum).V(1).out('knows').in('knows').sack()////(3)g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier()////(4)g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(5)g.withSack(1.0d,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(6)g.withBulk(false).withSack(1.0f,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(7)g.withBulk(false).withSack(1.0f).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack()////(8)We find vertex 1 twice because he knows two other people
Without a merge operation the sack values are 1.0.
When specifying
sumas the merge operation, the sack values are 2.0 because of bulkingLike 1, but using barrier internally
The
local(…barrier(normSack)…)ensures that all traversers leaving vertex 1 have an evenly distributed amount of the initial 1.0 "energy" (50-50), i.e. the sack is 0.5 on each resultLike 3, but using
sumas merge operator leads to the expected 1.0There is now a single traverser with bulk of 2 and sack of 1.0 and thus, setting
withBulk(false)`yields the expected 1.0Like 7, but without the
sumoperator
Additional References
Sample Step
Thesample()-step is useful for sampling some number of traversers previous in the traversal.
gremlin> g.V().outE().sample(1).values('weight')==>0.4gremlin> g.V().outE().sample(1).by('weight').values('weight')==>1.0gremlin> g.V().outE().sample(2).by('weight').values('weight')==>1.0==>1.0gremlin> g.V().both().sample(2).by('age')////(1)==>v[1]==>v[1]g.V().outE().sample(1).values('weight')g.V().outE().sample(1).by('weight').values('weight')g.V().outE().sample(2).by('weight').values('weight')g.V().both().sample(2).by('age')//1The "age" property is notproductive for all vertices and therefore those values are not considered when sampling.
One of the more interesting use cases forsample() is when it is used in conjunction withlocal().The combination of the two steps supports the execution ofrandom walks.In the example below, the traversal starts are vertex 1 and selects one edge to traverse based on a probabilitydistribution generated by the weights of the edges. The output is always a single path as by selecting a single edge,the traverser never splits and continues down a single path in the graph.
gremlin> g.V(1). repeat(local(bothE().sample(1).by('weight').otherV())). times(5)==>v[4]gremlin> g.V(1). repeat(local(bothE().sample(1).by('weight').otherV())). times(5). path()==>[v[1],e[7][1-knows->2],v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4]]gremlin> g.V(1). repeat(local(bothE().sample(1).by('weight').otherV())). times(10). path()==>[v[1],e[7][1-knows->2],v[2],e[7][1-knows->2],v[1],e[7][1-knows->2],v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1],e[9][1-created->3],v[3],e[11][4-created->3],v[4]]g.V(1). repeat(local(bothE().sample(1).by('weight').otherV())). times(5)g.V(1). repeat(local(bothE().sample(1).by('weight').otherV())). times(5). path()g.V(1). repeat(local(bothE().sample(1).by('weight').otherV())). times(10). path()As a clarification, note that in the above examplelocal() is not strictly required as it only does the random walkover a single vertex, but note what happens without it if multiple vertices are traversed:
gremlin> g.V().repeat(bothE().sample(1).by('weight').otherV()).times(5).path()==>[v[4],e[8][1-knows->4],v[1],e[9][1-created->3],v[3],e[9][1-created->3],v[1],e[9][1-created->3],v[3],e[9][1-created->3],v[1]]g.V().repeat(bothE().sample(1).by('weight').otherV()).times(5).path()The use oflocal() ensures that the traversal overbothE() occurs once per vertex traverser that passes through,thus allowing one random walk per vertex.
gremlin> g.V().repeat(local(bothE().sample(1).by('weight').otherV())).times(5).path()==>[v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1],e[7][1-knows->2],v[2]]==>[v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1]]==>[v[3],e[9][1-created->3],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[10][4-created->5],v[5]]==>[v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1]]==>[v[5],e[10][4-created->5],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4]]==>[v[6],e[12][6-created->3],v[3],e[12][6-created->3],v[6],e[12][6-created->3],v[3],e[9][1-created->3],v[1],e[8][1-knows->4],v[4]]g.V().repeat(local(bothE().sample(1).by('weight').otherV())).times(5).path()So, while not strictly required, it is likely better to be explicit with the use oflocal() so that the proper intentof the traversal is expressed.
Additional References
Select Step
Functional languages make use of function composition andlazy evaluation to create complex computations from primitive operations. This is exactly whatTraversal does. Oneof the differentiating aspects of Gremlin’s data flow approach to graph processing is that the flow need not always go"forward," but in fact, can go back to a previously seen area of computation. Examples includepath()as well as theselect()-step (map). There are two general ways to useselect()-step.
Select labeled steps within a path (as defined by
as()in a traversal).Select objects out of a
Map<String,Object>flow (i.e. a sub-map).
The first use case is demonstrated via example below.
gremlin> g.V().as('a').out().as('b').out().as('c')// no select==>v[5]==>v[3]gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')==>[a:v[1],b:v[4],c:v[5]]==>[a:v[1],b:v[4],c:v[3]]gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b')==>[a:v[1],b:v[4]]==>[a:v[1],b:v[4]]gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b').by('name')==>[a:marko,b:josh]==>[a:marko,b:josh]gremlin> g.V().as('a').out().as('b').out().as('c').select('a')////(1)==>v[1]==>v[1]gremlin> g.V(1).as('a').both().as('b').select('a','b').by('age')==>[a:29,b:27]==>[a:29,b:32]g.V().as('a').out().as('b').out().as('c')// no selectg.V().as('a').out().as('b').out().as('c').select('a','b','c')g.V().as('a').out().as('b').out().as('c').select('a','b')g.V().as('a').out().as('b').out().as('c').select('a','b').by('name')g.V().as('a').out().as('b').out().as('c').select('a')////(1)g.V(1).as('a').both().as('b').select('a','b').by('age')If the selection is one step, no map is returned.
The "age" property is notproductive for all vertices and therefore those values are filtered.
When there is only one label selected, then a single object is returned. This is useful for stepping back in acomputation and easily moving forward again on the object reverted to.
gremlin> g.V().out().out()==>v[5]==>v[3]gremlin> g.V().out().out().path()==>[v[1],v[4],v[5]]==>[v[1],v[4],v[3]]gremlin> g.V().as('x').out().out().select('x')==>v[1]==>v[1]gremlin> g.V().out().as('x').out().select('x')==>v[4]==>v[4]gremlin> g.V().out().out().as('x').select('x')// pointless==>v[5]==>v[3]g.V().out().out()g.V().out().out().path()g.V().as('x').out().out().select('x')g.V().out().as('x').out().select('x')g.V().out().out().as('x').select('x')// pointlessNote | When executing a traversal withselect() on a standard traversal engine (i.e. OLTP),select() will do itsbest to avoid calculating the path history and instead, will rely on a global data structure for storing the currentlyselected object. As such, if only a subset of the path walked is required,select() should be used over the moreresource intensivepath()-step. |
When the set of keys or values (i.e. columns) of a path or map are needed, useselect(keys) andselect(values),respectively. This is especially useful when one is only interested in the top N elements in agroupCount()ranking.
gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> g.V().hasLabel('song').out('followedBy').groupCount().by('name'). order(local).by(values,desc).limit(local,5)==>[PLAYING IN THEBAND:107,JACKSTRAW:99,TRUCKING:94,DRUMS:92,ME AND MYUNCLE:86]gremlin> g.V().hasLabel('song').out('followedBy').groupCount().by('name'). order(local).by(values,desc).limit(local,5).select(keys)==>[PLAYING IN THE BAND,JACK STRAW,TRUCKING,DRUMS,ME AND MY UNCLE]gremlin> g.V().hasLabel('song').out('followedBy').groupCount().by('name'). order(local).by(values,desc).limit(local,5).select(keys).unfold()==>PLAYING IN THE BAND==>JACK STRAW==>TRUCKING==>DRUMS==>ME AND MY UNCLEg = traversal().withEmbedded(graph)g.io('data/grateful-dead.xml').read().iterate()g.V().hasLabel('song').out('followedBy').groupCount().by('name'). order(local).by(values,desc).limit(local,5)g.V().hasLabel('song').out('followedBy').groupCount().by('name'). order(local).by(values,desc).limit(local,5).select(keys)g.V().hasLabel('song').out('followedBy').groupCount().by('name'). order(local).by(values,desc).limit(local,5).select(keys).unfold()Similarly, for extracting the values from a path or map.
gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> g.V().hasLabel('song').out('sungBy').groupCount().by('name')////(1)==>[All:9,Weir_Garcia:1,Lesh:19,Weir_Kreutzmann:1,Pigpen_Garcia:1,Pigpen:36,Unknown:6,Weir_Bralove:1,Joan_Baez:10,Suzanne_Vega:2,Welnick:10,Lesh_Pigpen:1,Elvin_Bishop:4,Neil_Young:1,Garcia_Weir_Lesh:1,Hunter:3,Hornsby:4,Jon_Hendricks:2,Weir_Hart:3,Lesh_Mydland:1,Mydland_Lesh:1,instrumental:1,Garcia:146,Hart:2,Welnick_Bralove:1,Weir:99,Garcia_Dawson:1,Pigpen_Weir_Mydland:2,Jorma_Kaukonen:4,Joey_Covington:2,Allman_Brothers:1,Garcia_Lesh:3,Boz_Scaggs:1,Pigpen?:1,Keith_Godchaux:1,Etta_James:1,Weir_Wasserman:1,Hall_and_Oates:2,Grateful_Dead:17,Spencer_Davis:2,Pigpen_Mydland:3,Beach_Boys:3,Donna:4,Bo_Diddley:7,Bob_Dylan:22,Hart_Kreutzmann:2,Weir_Mydland:3,Lesh_Hart_Kreutzmann:1,Stephen_Stills:2,Mydland:18,Neville_Brothers:2,Weir_Hart_Welnick:1,Garcia_Lesh_Weir:1,Garcia_Weir:3,Neal_Cassady:1,John_Fogerty:5,Donna_Godchaux:2,Pigpen_Weir:8,Garcia_Kreutzmann:2,None:6]gremlin> g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values)////(2)==>[9,1,19,1,1,36,6,1,10,2,10,1,4,1,1,3,4,2,3,1,1,1,146,2,1,99,1,2,4,2,1,3,1,1,1,1,1,2,17,2,3,3,4,7,22,2,3,1,2,18,2,1,1,3,1,5,2,8,2,6]gremlin> g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values).unfold(). groupCount().order(local).by(values,desc).limit(local,5)////(3)==>[1:22,2:12,3:7,4:4,6:2]g = traversal().withEmbedded(graph)g.io('data/grateful-dead.xml').read().iterate()g.V().hasLabel('song').out('sungBy').groupCount().by('name')////(1)g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values)////(2)g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values).unfold(). groupCount().order(local).by(values,desc).limit(local,5)//3Which artist sung how many songs?
Get an anonymized set of song repertoire sizes.
What are the 5 most common song repertoire sizes?
Warning | Note thatby()-modulation is not supported withselect(keys) andselect(values). |
There is also an option to supply aPop operation toselect() to manipulateList objects in theTraverser:
gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(first,"a")==>v[1]==>v[1]gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(last,"a")==>v[5]==>v[3]gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(all,"a")==>[v[1],v[4],v[5]]==>[v[1],v[4],v[3]]g.V(1).as("a").repeat(out().as("a")).times(2).select(first,"a")g.V(1).as("a").repeat(out().as("a")).times(2).select(last,"a")g.V(1).as("a").repeat(out().as("a")).times(2).select(all,"a")In addition to the previously shown examples, whereselect() was used to select an element based on a static key,select() can also accept a traversalthat emits a key.
Warning | Since the key used byselect(<traversal>) cannot be determined at compile time, theTraversalSelectStep enables full path tracking. |
gremlin> g.withSideEffect("alias", ["marko":"okram"]).V().////(1) values("name").sack(assign).////(2) optional(select("alias").select(sack()))////(3)==>okram==>vadas==>lop==>josh==>ripple==>peterg.withSideEffect("alias", ["marko":"okram"]).V().////(1) values("name").sack(assign).////(2) optional(select("alias").select(sack()))//3Inject a name alias map and start the traversal from all vertices.
Select all
namevalues and store them as the current traverser’s sack value.Optionally select the alias for the current name from the injected map.
Using Where with Select
Likematch()-step, it is possible to usewhere(), as where is a filter that processesMap<String,Object> streams.
gremlin> g.V().as('a').out('created').in('created').as('b').select('a','b').by('name')////(1)==>[a:marko,b:marko]==>[a:marko,b:josh]==>[a:marko,b:peter]==>[a:josh,b:josh]==>[a:josh,b:marko]==>[a:josh,b:josh]==>[a:josh,b:peter]==>[a:peter,b:marko]==>[a:peter,b:josh]==>[a:peter,b:peter]gremlin> g.V().as('a').out('created').in('created').as('b'). select('a','b').by('name').where('a',neq('b'))////(2)==>[a:marko,b:josh]==>[a:marko,b:peter]==>[a:josh,b:marko]==>[a:josh,b:peter]==>[a:peter,b:marko]==>[a:peter,b:josh]gremlin> g.V().as('a').out('created').in('created').as('b'). select('a','b').////(3) where('a',neq('b')). where(__.as('a').out('knows').as('b')). select('a','b').by('name')==>[a:marko,b:josh]g.V().as('a').out('created').in('created').as('b').select('a','b').by('name')////(1)g.V().as('a').out('created').in('created').as('b'). select('a','b').by('name').where('a',neq('b'))////(2)g.V().as('a').out('created').in('created').as('b'). select('a','b').////(3) where('a',neq('b')). where(__.as('a').out('knows').as('b')). select('a','b').by('name')A standard
select()that generates aMap<String,Object>of variables bindings in the path (i.e.aandb)for the sake of a running example.The
select().by('name')projects each binding vertex to their name property value andwhere()operates toensure respectiveaandbstrings are not the same.The first
select()projects a vertex binding set. A binding is filtered ifavertex equalsbvertex. Abinding is filtered ifadoesn’t knowb. The second and finalselect()projects the name of the vertices.
Additional References
ShortestPath step
TheshortestPath()-step provides an easy way to find shortest non-cyclic paths in a graph. It is configurableusing thewith()-modulator with the options given below.
Important | TheshortestPath()-step is aVertexComputing-step and as such, can only be used against a graphthat supportsGraphComputer (OLAP). |
| Key | Type | Description | Default |
|---|---|---|---|
|
| Sets a filter traversal for the end vertices (e.g. | all vertices ( |
|
| Sets a |
|
|
| Sets the |
|
|
| Sets the distance limit for all shortest paths. | none |
|
| Whether to include edges in the result or not. |
|
gremlin> g = g.withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().shortestPath()////(1)==>[v[4],v[1]]==>[v[4],v[1],v[2]]==>[v[4],v[3]]==>[v[4]]==>[v[4],v[5]]==>[v[4],v[3],v[6]]==>[v[3],v[1]]==>[v[3],v[1],v[2]]==>[v[3]]==>[v[3],v[4]]==>[v[3],v[4],v[5]]==>[v[3],v[6]]==>[v[5],v[4],v[1]]==>[v[5],v[4],v[1],v[2]]==>[v[5],v[4],v[3]]==>[v[5],v[4]]==>[v[5]]==>[v[5],v[4],v[3],v[6]]==>[v[1]]==>[v[1],v[2]]==>[v[1],v[3]]==>[v[1],v[4]]==>[v[1],v[4],v[5]]==>[v[1],v[3],v[6]]==>[v[2],v[1]]==>[v[2]]==>[v[2],v[1],v[3]]==>[v[2],v[1],v[4]]==>[v[2],v[1],v[4],v[5]]==>[v[2],v[1],v[3],v[6]]==>[v[6],v[3],v[1]]==>[v[6],v[3],v[1],v[2]]==>[v[6],v[3]]==>[v[6],v[3],v[4]]==>[v[6],v[3],v[4],v[5]]==>[v[6]]gremlin> g.V().has('person','name','marko').shortestPath()////(2)==>[v[1]]==>[v[1],v[2]]==>[v[1],v[3]]==>[v[1],v[4]]==>[v[1],v[4],v[5]]==>[v[1],v[3],v[6]]gremlin> g.V().shortestPath().with(ShortestPath.target, __.has('name','peter'))////(3)==>[v[1],v[3],v[6]]==>[v[2],v[1],v[3],v[6]]==>[v[3],v[6]]==>[v[4],v[3],v[6]]==>[v[5],v[4],v[3],v[6]]==>[v[6]]gremlin> g.V().shortestPath(). with(ShortestPath.edges, Direction.IN). with(ShortestPath.target, __.has('name','josh'))////(4)==>[v[3],v[4]]==>[v[4]]==>[v[5],v[4]]gremlin> g.V().has('person','name','marko'). shortestPath(). with(ShortestPath.target, __.has('name','josh'))////(5)==>[v[1],v[4]]gremlin> g.V().has('person','name','marko'). shortestPath(). with(ShortestPath.target, __.has('name','josh')). with(ShortestPath.distance,'weight')////(6)==>[v[1],v[3],v[4]]gremlin> g.V().has('person','name','marko'). shortestPath(). with(ShortestPath.target, __.has('name','josh')). with(ShortestPath.includeEdges,true)////(7)==>[v[1],e[8][1-knows->4],v[4]]g = g.withComputer()g.V().shortestPath()////(1)g.V().has('person','name','marko').shortestPath()////(2)g.V().shortestPath().with(ShortestPath.target, __.has('name','peter'))////(3)g.V().shortestPath(). with(ShortestPath.edges, Direction.IN). with(ShortestPath.target, __.has('name','josh'))////(4)g.V().has('person','name','marko'). shortestPath(). with(ShortestPath.target, __.has('name','josh'))////(5)g.V().has('person','name','marko'). shortestPath(). with(ShortestPath.target, __.has('name','josh')). with(ShortestPath.distance,'weight')////(6)g.V().has('person','name','marko'). shortestPath(). with(ShortestPath.target, __.has('name','josh')). with(ShortestPath.includeEdges,true)//7Find all shortest paths.
Find all shortest paths from
marko.Find all shortest paths to
peter.Find all in-directed paths to
josh.Find all shortest paths from
markotojosh.Find all shortest paths from
markotojoshusing a custom distance property.Find all shortest paths from
markotojoshand include edges in the result.
gremlin> g.inject(g.withComputer().V().shortestPath(). with(ShortestPath.distance,'weight'). with(ShortestPath.includeEdges,true). with(ShortestPath.maxDistance,1).toList().toArray()). map(unfold().values('name','weight').fold())////(1)==>[vadas,0.5,marko,0.4,lop]==>[vadas,0.5,marko]==>[vadas]==>[lop]==>[lop,0.4,marko]==>[lop,0.4,josh]==>[lop,0.4,marko,0.5,vadas]==>[lop,0.2,peter]==>[marko,0.4,lop]==>[marko]==>[marko,0.4,lop,0.4,josh]==>[marko,0.5,vadas]==>[marko,0.4,lop,0.2,peter]==>[josh,0.4,lop]==>[josh,0.4,lop,0.4,marko]==>[josh]==>[josh,1.0,ripple]==>[josh,0.4,lop,0.2,peter]==>[ripple,1.0,josh]==>[ripple]==>[peter,0.2,lop]==>[peter,0.2,lop,0.4,marko]==>[peter,0.2,lop,0.4,josh]==>[peter]g.inject(g.withComputer().V().shortestPath(). with(ShortestPath.distance,'weight'). with(ShortestPath.includeEdges,true). with(ShortestPath.maxDistance,1).toList().toArray()). map(unfold().values('name','weight').fold())//1Find all shortest paths using a custom distance property and limit the distance to 1. Inject the result into a OLTP
GraphTraversalin order to be able to select properties from all elements in all paths.
Additional References
SideEffect Step
ThesideEffect() step performs some operation on the traverser and passes it to the next step in the process. Pleasesee theGeneral Steps section for more information.
Additional References
SimplePath Step

When it is important that a traverser not repeat its path through the graph,simplePath()-step should be used(filter). Thepath information of the traverser is analyzed and if the path has repeatedobjects in it, the traverser is filtered. If cyclic behavior is desired, seecyclicPath().
gremlin> g.V(1).both().both()==>v[1]==>v[4]==>v[6]==>v[1]==>v[5]==>v[3]==>v[1]gremlin> g.V(1).both().both().simplePath()==>v[4]==>v[6]==>v[5]==>v[3]gremlin> g.V(1).both().both().simplePath().path()==>[v[1],v[3],v[4]]==>[v[1],v[3],v[6]]==>[v[1],v[4],v[5]]==>[v[1],v[4],v[3]]gremlin> g.V(1).both().both().simplePath().by('age')////(1)gremlin> g.V().out().as('a').out().as('b').out().as('c'). simplePath().by(label). path()gremlin> g.V().out().as('a').out().as('b').out().as('c'). simplePath(). by(label). from('b'). to('c'). path(). by('name')g.V(1).both().both()g.V(1).both().both().simplePath()g.V(1).both().both().simplePath().path()g.V(1).both().both().simplePath().by('age')////(1)g.V().out().as('a').out().as('b').out().as('c'). simplePath().by(label). path()g.V().out().as('a').out().as('b').out().as('c'). simplePath(). by(label). from('b'). to('c'). path(). by('name')The "age" property is notproductive for all vertices and therefore those values are filtered.
By using thefrom() andto() modulators traversers can ensure that only certain sections of the path are acyclic.
gremlin> g.addV().property(id,'A').as('a'). addV().property(id,'B').as('b'). addV().property(id,'C').as('c'). addV().property(id,'D').as('d'). addE('link').from('a').to('b'). addE('link').from('b').to('c'). addE('link').from('c').to('d').iterate()gremlin> g.V('A').repeat(both().simplePath()).times(3).path()////(1)==>[v[A],v[B],v[C],v[D]]gremlin> g.V('D').repeat(both().simplePath()).times(3).path()////(2)==>[v[D],v[C],v[B],v[A]]gremlin> g.V('A').as('a'). repeat(both().simplePath().from('a')).times(3).as('b'). repeat(both().simplePath().from('b')).times(3).path()////(3)==>[v[A],v[B],v[C],v[D],v[C],v[B],v[A]]g.addV().property(id,'A').as('a'). addV().property(id,'B').as('b'). addV().property(id,'C').as('c'). addV().property(id,'D').as('d'). addE('link').from('a').to('b'). addE('link').from('b').to('c'). addE('link').from('c').to('d').iterate()g.V('A').repeat(both().simplePath()).times(3).path()////(1)g.V('D').repeat(both().simplePath()).times(3).path()////(2)g.V('A').as('a'). repeat(both().simplePath().from('a')).times(3).as('b'). repeat(both().simplePath().from('b')).times(3).path()//3Traverse all acyclic 3-hop paths starting from vertex
ATraverse all acyclic 3-hop paths starting from vertex
DTraverse all acyclic 3-hop paths starting from vertex
Aand from there again all 3-hop paths. The second path maycross the vertices from the first path.
Additional References
Skip Step
Theskip()-step is analogous torange()-step save that the higher end range is set to -1.
gremlin> g.V().values('age').order()==>27==>29==>32==>35gremlin> g.V().values('age').order().skip(2)==>32==>35gremlin> g.V().values('age').order().range(2, -1)==>32==>35g.V().values('age').order()g.V().values('age').order().skip(2)g.V().values('age').order().range(2, -1)Theskip()-step can also be applied withScope.local, in which case it operates on the incoming collection.
gremlin> g.V().hasLabel('person').filter(outE('created')).as('p').////(1) map(out('created').values('name').fold()). project('person','primary','other'). by(select('p').by('name')). by(limit(local,1)).////(2) by(skip(local,1))////(3)==>[person:marko,primary:lop,other:[]]==>[person:josh,primary:ripple,other:[lop]]==>[person:peter,primary:lop,other:[]]g.V().hasLabel('person').filter(outE('created')).as('p').////(1) map(out('created').values('name').fold()). project('person','primary','other'). by(select('p').by('name')). by(limit(local,1)).////(2) by(skip(local,1))//3For each person who created something…
…select the first project (random order) as
primaryand……select all other projects as
other.
Additional References
Split Step
Thesplit()-step (map) returns a list of strings created by splitting the incoming string traverser around thematches of the given separator. A null separator will split the string by whitespaces. Null values from the incomingtraversers are not processed and remain as null when returned. If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.inject("that","this","test",null).split("h")////(1)==>[t,at]==>[t,is]==>[test]==>nullgremlin> g.V().hasLabel("person").values("name").split("a")////(2)==>[m,rko]==>[v,d,s]==>[josh]==>[peter]gremlin> g.inject("helloworld","hello world","hello world").split(null)////(3)==>[helloworld]==>[hello,world]==>[hello,world]gremlin> g.V().hasLabel("person").values("name").fold().split(local,"a")////(4)==>[[m,rko],[v,d,s],[josh],[peter]]g.inject("that","this","test",null).split("h")////(1)g.V().hasLabel("person").values("name").split("a")////(2)g.inject("helloworld","hello world","hello world").split(null)////(3)g.V().hasLabel("person").values("name").fold().split(local,"a")//4Split the strings by "h".
Split person names by "a".
Splitting by null will split by whitespaces.
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list of results.
Additional Referencessplit(String)split(Scope, String)
Subgraph Step
Extracting a portion of a graph from a larger one for analysis, visualization or other purposes is a fairly commonuse case for graph analysts and developers. Thesubgraph()-step (sideEffect) provides a way to produce anedge-induced subgraph from virtually any traversal.The following example demonstrates how to produce the "knows" subgraph:
gremlin> subGraph = g.E().hasLabel('knows').subgraph('subGraph').cap('subGraph').next()////(1)==>tinkergraph[vertices:3edges:2]gremlin> sg = traversal().withEmbedded(subGraph)==>graphtraversalsource[tinkergraph[vertices:3edges:2], standard]gremlin> sg.E()////(2)==>e[7][1-knows->2]==>e[8][1-knows->4]subGraph = g.E().hasLabel('knows').subgraph('subGraph').cap('subGraph').next()////(1)sg = traversal().withEmbedded(subGraph)sg.E()//2As this function produces "edge-induced" subgraphs,
subgraph()must be called at edge steps.The subgraph contains only "knows" edges.
A more common subgraphing use case is to get all of the graph structure surrounding a single vertex:
gremlin> subGraph = g.V(3).repeat(__.inE().subgraph('subGraph').outV()).times(3).cap('subGraph').next()////(1)==>tinkergraph[vertices:4edges:4]gremlin> sg = traversal().withEmbedded(subGraph)==>graphtraversalsource[tinkergraph[vertices:4edges:4], standard]gremlin> sg.E()==>e[8][1-knows->4]==>e[9][1-created->3]==>e[11][4-created->3]==>e[12][6-created->3]subGraph = g.V(3).repeat(__.inE().subgraph('subGraph').outV()).times(3).cap('subGraph').next()////(1)sg = traversal().withEmbedded(subGraph)sg.E()Starting at vertex
3, traverse 3 steps away on in-edges, outputting all of that into the subgraph.
The above example is purposely brief so as to focus onsubgraph() usage, however, it may not be the most optimalmethod for constructing the subgraph. For instance, if the graph had cycles, it would attempt to reconstruct partsof the subgraph which are already present. The duplicates would not be created, but it would involve some unnecessaryprocessing. If the only interest of the traversal was to populate the subgraph, it would be better to includesimplePath() to filter out those cycles, as in.inE().subgraph('subGraph').outV().simplePath(). From anotherperspective, it might also make some sense to usededup() to avoid traversing the same vertices repeatedly wheretwo vertices shared the multiple edges between them, as in.inE().dedup().subgraph('subGraph').outV().dedup().
There can be multiplesubgraph() calls within the same traversal. Each operating against either the same graph(i.e. same side-effect key) or different graphs (i.e. different side-effect keys).
gremlin> t = g.V().outE('knows').subgraph('knowsG').inV().outE('created').subgraph('createdG'). inV().inE('created').subgraph('createdG').iterate()gremlin> traversal().withEmbedded(t.sideEffects.get('knowsG')).E()==>e[7][1-knows->2]==>e[8][1-knows->4]gremlin> traversal().withEmbedded(t.sideEffects.get('createdG')).E()==>e[9][1-created->3]==>e[10][4-created->5]==>e[11][4-created->3]==>e[12][6-created->3]t = g.V().outE('knows').subgraph('knowsG').inV().outE('created').subgraph('createdG'). inV().inE('created').subgraph('createdG').iterate()traversal().withEmbedded(t.sideEffects.get('knowsG')).E()traversal().withEmbedded(t.sideEffects.get('createdG')).E()TinkerGraph is the ideal (and default)Graph into which a subgraph is extracted as it’s fast, in-memory, and supportsuser-supplied identifiers which can be any Java object. It is this last feature that needs some focus as manyTinkerPop-enabled graphs have complex identifier types and TinkerGraph’s ability to consume those makes it a perfecthost for an incoming subgraph. However care needs to be taken when using the elements of the TinkerGraph subgraph.The original graph’s identifiers may be preserved, but the elements of the graph are now TinkerGraph objects like,TinkerVertex andTinkerEdge. As a result, they can not be used directly in Gremlin running against the originalgraph. For example, the following traversal would likely return an error:
Vertex v = sg.V().has('name','marko').next();//1List<Vertex> vertices = g.V(v).out().toList();//2Here "sg" is a reference to a TinkerGraph subgraph and "v" is a
TinkerVertex.The
g.V(v)has the potential to fail as "g" is the originalGraphinstance and not a TinkerGraph - it couldreject theTinkerVertexinstance as it will not recognize it.
It is safer to wrap theTinkerVertex in aReferenceVertex or simply reference theid() as follows:
Vertex v = sg.V().has('name','marko').next();List<Vertex> vertices = g.V(v.id()).out().toList();// ORVertex v = new ReferenceVertex(sg.V().has('name','marko').next());List<Vertex> vertices = g.V(v).out().toList();Additional References
Substring Step
Thesubstring()-step (map) returns a substring with a 0-based start index (inclusive) and optionally an end index (exclusive) specified.If the start index is negative then it will begin at the specified index counted from the end of the string, or 0 if exceeding the string length.Likewise, if the end index is negative then it will end at the specified index counted from the end of the string, or 0 if exceeding the string length.
End index is optional, if it is not specified or if it exceeds the length of the string then all remaining characters willbe returned. End index ≤ start index will return the empty string. Null values are not processed and remain as null when returned.If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.inject("test","hello world",null).substring(1,8)==>est==>ello wo==>nullgremlin> g.inject("hello world").substring(-4)////(1)==>orldgremlin> g.inject("hello world").substring(2,0)////(2)==>gremlin> g.V().hasLabel("software").values("name").substring(2)==>p==>pplegremlin> g.V().hasLabel("software").values("name").fold().substring(local,2)////(3)==>[p,pple]g.inject("test","hello world",null).substring(1,8)g.inject("hello world").substring(-4)////(1)g.inject("hello world").substring(2,0)////(2)g.V().hasLabel("software").values("name").substring(2)g.V().hasLabel("software").values("name").fold().substring(local,2)//3Negative start index, the first character is read by counting from the end of the string
Length of 0 specified will return the empty string
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional Referencessubstring(int)substring(Scope,int)substring(int,int)substring(Scope,int,int)
Sum Step
Thesum()-step (map) operates on a stream of numbers and sums the numbers together to yield a result. Note thatthe current traverser number is multiplied by the traverser bulk to determine how many such numbers are beingrepresented.
gremlin> g.V().values('age').sum()==>123gremlin> g.V().repeat(both()).times(3).values('age').sum()==>1471g.V().values('age').sum()g.V().repeat(both()).times(3).values('age').sum()When called assum(local) it determines the sum of the current, local object (not the objects in the traversalstream). This works forCollection-type objects.
gremlin> g.V().values('age').fold().sum(local)==>123g.V().values('age').fold().sum(local)When there arenull values being evaluated thenull objects are ignored, but if all values are recognized asnullthe return value isnull.
gremlin> g.inject(null,10,9,null).sum()==>19gremlin> g.inject([null,null,null]).sum(local)==>nullg.inject(null,10,9,null).sum()g.inject([null,null,null]).sum(local)Additional References
Tail Step

Thetail()-step is analogous tolimit()-step, except that it emits the lastn-objects instead ofthe firstn-objects.
gremlin> g.V().values('name').order()==>josh==>lop==>marko==>peter==>ripple==>vadasgremlin> g.V().values('name').order().tail()////(1)==>vadasgremlin> g.V().values('name').order().tail(1)////(2)==>vadasgremlin> g.V().values('name').order().tail(3)////(3)==>peter==>ripple==>vadasg.V().values('name').order()g.V().values('name').order().tail()////(1)g.V().values('name').order().tail(1)////(2)g.V().values('name').order().tail(3)//3Last name (alphabetically).
Same as statement 1.
Last three names.
Thetail()-step can also be applied withScope.local, in which case it operates on the incoming collection.
gremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(tail(local)).values('name')////(1)==>ripple==>lopgremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local)////(2)==>ripple==>lopgremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local,2)////(3)==>[ripple]==>[lop]gremlin> g.V().elementMap().tail(local)////(4)==>[age:29]==>[age:27]==>[lang:java]==>[age:32]==>[lang:java]==>[age:35]g.V().as('a').out().as('a').out().as('a').select('a').by(tail(local)).values('name')////(1)g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local)////(2)g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local,2)////(3)g.V().elementMap().tail(local)//4Only the most recent name from the "a" step (
List<Vertex>becomesVertex).Same result as statement 1 (
List<String>becomesString).List<String>for each path containing the last two names from the 'a' step.Map<String, Object>for each vertex, but containing only the last property value.
Additional References
TimeLimit Step
In many situations, a graph traversal is not about getting an exact answer as its about getting a relative ranking.A classic example isrecommendation. What is desired is arelative ranking of vertices, not their absolute rank. Next, it may be desirable to have the traversal execute forno more than 2 milliseconds. In such situations,timeLimit()-step (filter) can be used.

Note | The methodclock(int runs, Closure code) is a utility preloaded in theGremlin Consolethat can be used to time execution of a body of code. |
gremlin> g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()==>v[1]=2744208==>v[3]=2744208==>v[4]=2744208==>v[2]=1136688==>v[5]=1136688==>v[6]=1136688gremlin> clock(1) {g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}==>0.645791gremlin> g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()==>v[1]=2744208==>v[3]=2744208==>v[4]=2744208==>v[2]=1136688==>v[5]=1136688==>v[6]=1136688gremlin> clock(1) {g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}==>0.7148749999999999g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()clock(1) {g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()clock(1) {g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}In essence, the relative order is respected, even through the number of traversers at each vertex is not. The primarybenefit being that the calculation is guaranteed to complete at the specified time limit (in milliseconds). Finally,note that the internal clock oftimeLimit()-step starts when the first traverser enters it. When the time limit isreached, anynext() evaluation of the step will yield aNoSuchElementException and anyhasNext() evaluation willyieldfalse.
Additional References
Times Step
Thetimes-step is not an actual step, but is instead a step modulator forrepeat() (find moredocumentation on thetimes() there).
Additional References
To Step
Theto()-step is not an actual step, but instead is a "step-modulator" similar toas() andby(). If a step is able to accept traversals or strings thento() is themeans by which they are added. The general pattern isstep().to(). Seefrom()-step.
The list of steps that supportto()-modulation are:simplePath(),cyclicPath(),path(), andaddE().
Additional References
ToLower Step
ThetoLower()-step (map) returns the lowercase representation of incoming string or list of string traverser. Null values are not processed and remain as null when returned.If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.inject("HELLO","wORlD",null).toLower()==>hello==>world==>nullgremlin> g.inject(["HELLO","wORlD",null]).toLower(Scope.local)////(1)==>[hello,world,null]g.inject("HELLO","wORlD",null).toLower()g.inject(["HELLO","wORlD",null]).toLower(Scope.local)//1Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
ToUpper Step
ThetoUpper()-step (map) returns the uppercase representation of incoming string or list of string traverser. Null values are not processed and remain as null when returned.If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.inject("hello","wORlD",null).toUpper()==>HELLO==>WORLD==>nullgremlin> g.V().values("name").toUpper()////(1)==>MARKO==>VADAS==>LOP==>JOSH==>RIPPLE==>PETERgremlin> g.V().values("name").fold().toUpper(local)////(2)==>[MARKO,VADAS,LOP,JOSH,RIPPLE,PETER]g.inject("hello","wORlD",null).toUpper()g.V().values("name").toUpper()////(1)g.V().values("name").fold().toUpper(local)//2Returns the upper case representation of all vertex names.
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
Tree Step
From any one element (i.e. vertex or edge), the emanating paths from that element can be aggregated to form atree. Gremlin providestree()-step (sideEffect) for suchthis situation.

gremlin> tree = g.V().out().out().tree().next()==>v[1]={v[4]={v[3]={}, v[5]={}}}tree = g.V().out().out().tree().next()It is important to see how the paths of all the emanating traversers are united to form the tree.

The resultant tree data structure can then be manipulated (seeTree JavaDoc).
gremlin> tree = g.V().out().out().tree().by('name').next()==>marko={josh={ripple={}, lop={}}}gremlin> tree['marko']==>josh={ripple={}, lop={}}gremlin> tree['marko']['josh']==>ripple={}==>lop={}gremlin> tree.getObjectsAtDepth(3)==>ripple==>loptree = g.V().out().out().tree().by('name').next()tree['marko']tree['marko']['josh']tree.getObjectsAtDepth(3)Note that when usingby()-modulation, tree nodes are combined based on projection uniqueness, not on theuniqueness of the original objects being projected. For instance:
gremlin> g.V().has('name','josh').out('created').values('name').tree()////(1)==>[v[4]:[v[3]:[lop:[]],v[5]:[ripple:[]]]]gremlin> g.V().has('name','josh').out('created').values('name'). tree().by('name').by(label).by()////(2)==>[josh:[software:[ripple:[],lop:[]]]]g.V().has('name','josh').out('created').values('name').tree()////(1)g.V().has('name','josh').out('created').values('name'). tree().by('name').by(label).by()//2When the
tree()is created, vertex 3 and 5 are unique and thus, form unique branches in the tree structure.When the
tree()isby()-modulated bylabel, then vertex 3 and 5 are both "software" and thus are merged to a single node in the tree.
Thetree() step can also take a side-effect key as an argument. When using this form, theTree is constructedlazily, such that it becomes possible to assess its contents as each traverser passes through.
gremlin> g.V().has('name','josh').out('created').values('name').tree('x').select('x')==>[v[4]:[v[5]:[ripple:[]]]]==>[v[4]:[v[3]:[lop:[]],v[5]:[ripple:[]]]]g.V().has('name','josh').out('created').values('name').tree('x').select('x')You can usecap() step to forcetree() to consume the traversal stream eagerly and output results similar to priorexamples.
gremlin> g.V().has('name','josh').out('created').values('name').tree('x').cap('x')==>[v[4]:[v[3]:[lop:[]],v[5]:[ripple:[]]]]g.V().has('name','josh').out('created').values('name').tree('x').cap('x')Additional References
Trim Step
Thetrim()-step (map) returns a string with leading and leading whitespace removed. Null values are not processed and remainas null when returned. If the incoming traverser is a non-String value then anIllegalArgumentException will be thrown.
gremlin> g.inject(" hello"," world",null).trim()==>hello==>world==>nullgremlin> g.inject([" hello"," world",null]).trim(Scope.local)////(1)==>[hello,world,null]g.inject(" hello"," world",null).trim()g.inject([" hello"," world",null]).trim(Scope.local)//1Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Unfold Step
If the object reachingunfold() (flatMap) is an iterator, iterable, or map, then it is unrolled into a linearform. If not, then the object is simply emitted. Please seefold() step for the inverse behavior.
gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34])==>gremlin==>[1.23,2.34]==>[v[3],v[2],v[4]]gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34]).unfold()==>gremlin==>1.23==>2.34==>v[3]==>v[2]==>v[4]g.V(1).out().fold().inject('gremlin',[1.23,2.34])g.V(1).out().fold().inject('gremlin',[1.23,2.34]).unfold()Note thatunfold() does not recursively unroll iterators. Instead,repeat() can be used to for recursive unrolling.
gremlin> inject(1,[2,3,[4,5,[6]]])==>1==>[2,3,[4,5,[6]]]gremlin> inject(1,[2,3,[4,5,[6]]]).unfold()==>1==>2==>3==>[4,5,[6]]gremlin> inject(1,[2,3,[4,5,[6]]]).repeat(unfold()).until(count(local).is(1)).unfold()==>1==>2==>3==>4==>5==>6inject(1,[2,3,[4,5,[6]]])inject(1,[2,3,[4,5,[6]]]).unfold()inject(1,[2,3,[4,5,[6]]]).repeat(unfold()).until(count(local).is(1)).unfold()Additional References
Union Step

Theunion()-step (branch) supports the merging of the results of an arbitrary number of traversals. When atraverser reaches aunion()-step, it is copied to each of its internal steps. The traversers emitted fromunion()are the outputs of the respective internal traversals.
gremlin> g.V(4).union( __.in().values('age'), out().values('lang'))==>29==>java==>javagremlin> g.V(4).union( __.in().values('age'), out().values('lang')).path()==>[v[4],v[1],29]==>[v[4],v[5],java]==>[v[4],v[3],java]gremlin> g.union(V().has('person','name','vadas'), V().has('software','name','lop').in('created'))==>v[2]==>v[1]==>v[4]==>v[6]g.V(4).union( __.in().values('age'), out().values('lang'))g.V(4).union( __.in().values('age'), out().values('lang')).path()g.union(V().has('person','name','vadas'), V().has('software','name','lop').in('created'))Additional References
Until Step
Theuntil-step is not an actual step, but is instead a step modulator forrepeat() (find moredocumentation on theuntil() there).
Additional References
V Step
TheV()-step is meant to read vertices from the graph and is usually used to start aGraphTraversal, but can alsobe used mid-traversal.
gremlin> g.V(1)////(1)==>v[1]gremlin> g.V().has('name', within('marko','vadas','josh')).as('person'). V().has('name', within('lop','ripple')).addE('uses').from('person')////(2)==>e[0][1-uses->3]==>e[13][1-uses->5]==>e[14][2-uses->3]==>e[15][2-uses->5]==>e[16][4-uses->3]==>e[17][4-uses->5]g.V(1)////(1)g.V().has('name', within('marko','vadas','josh')).as('person'). V().has('name', within('lop','ripple')).addE('uses').from('person')//2Find the vertex by its unique identifier (i.e.
T.id) - not all graphs will use a numeric value for their identifier.An example where
V()is used both as a start step and in the middle of a traversal.
Note | Whether a mid-traversalV() uses an index or not, depends on a) whether suitable index exists and b) if theparticular graph system provider implemented this functionality. |
gremlin> g.V().has('name', within('marko','vadas','josh')).as('person'). V().has('name', within('lop','ripple')).addE('uses').from('person').toString()////(1)==>[GraphStep(vertex,[]), HasStep([name.within([marko, vadas, josh])])@[person], GraphStep(vertex,[]), HasStep([name.within([lop, ripple])]), AddEdgeStep({~from=[[SelectOneStep(last,person,null)]], label=[uses]})]gremlin> g.V().has('name', within('marko','vadas','josh')).as('person'). V().has('name', within('lop','ripple')).addE('uses').from('person').iterate().toString()////(2)==>[TinkerGraphStep(vertex,[name.within([marko, vadas, josh])])@[person], TinkerGraphStep(vertex,[name.within([lop, ripple])]), AddEdgeStep({~from=[[SelectOneStep(last,person,null)]], label=[uses]}), NoneStep]g.V().has('name', within('marko','vadas','josh')).as('person'). V().has('name', within('lop','ripple')).addE('uses').from('person').toString()////(1)g.V().has('name', within('marko','vadas','josh')).as('person'). V().has('name', within('lop','ripple')).addE('uses').from('person').iterate().toString()//2Normally the
V()-step will iterate over all vertices. However, graph strategies can foldHasContainer's into aGraphStepto allow index lookups.Whether the graph system provider supports mid-traversal
V()index lookups or not can easily be determined by inspecting thetoString()output of the iterated traversal. Ifhasconditions were folded into theV()-step, an index - if one exists - will be used.
Additional References
Value Step
Thevalue()-step (map) takes aProperty and extracts the value from it.
gremlin> g.V(1).properties().value()==>marko==>san diego==>santa cruz==>brussels==>santa fegremlin> g.V(1).properties().properties().value()==>1997==>2001==>2001==>2004==>2004==>2005==>2005g.V(1).properties().value()g.V(1).properties().properties().value()Additional References
ValueMap Step
ThevalueMap()-step yields aMap representation of the properties of an element.
Important | This step is the precursor to theelementMap()-step. Users should typicallychooseelementMap() unless they utilize multi-properties.elementMap() effectively mimics the functionality ofvalueMap(true).by(unfold()) as a single step. |
gremlin> g.V().valueMap()==>[name:[marko],age:[29]]==>[name:[vadas],age:[27]]==>[name:[lop],lang:[java]]==>[name:[josh],age:[32]]==>[name:[ripple],lang:[java]]==>[name:[peter],age:[35]]gremlin> g.V().valueMap('age')==>[age:[29]]==>[age:[27]]==>[]==>[age:[32]]==>[]==>[age:[35]]gremlin> g.V().valueMap('age','blah')==>[age:[29]]==>[age:[27]]==>[]==>[age:[32]]==>[]==>[age:[35]]gremlin> g.E().valueMap()==>[weight:0.5]==>[weight:1.0]==>[weight:0.4]==>[weight:1.0]==>[weight:0.4]==>[weight:0.2]g.V().valueMap()g.V().valueMap('age')g.V().valueMap('age','blah')g.E().valueMap()It is important to note that the map of a vertex maintains a list of values for each key. The map of an edge orvertex-property represents a single property (not a list). The reason is that vertices in TinkerPop leveragevertex properties which support multiple values per key. Using the"The Crew" toy graph, the point is made explicit.
gremlin> g.V().valueMap()==>[name:[marko],location:[san diego,santa cruz,brussels,santa fe]]==>[name:[stephen],location:[centreville,dulles,purcellville]]==>[name:[matthias],location:[bremen,baltimore,oakland,seattle]]==>[name:[daniel],location:[spremberg,kaiserslautern,aachen]]==>[name:[gremlin]]==>[name:[tinkergraph]]gremlin> g.V().has('name','marko').properties('location')==>vp[location->san diego]==>vp[location->santa cruz]==>vp[location->brussels]==>vp[location->santa fe]gremlin> g.V().has('name','marko').properties('location').valueMap()==>[startTime:1997,endTime:2001]==>[startTime:2001,endTime:2004]==>[startTime:2004,endTime:2005]==>[startTime:2005]g.V().valueMap()g.V().has('name','marko').properties('location')g.V().has('name','marko').properties('location').valueMap()To turn list of values into single items, theby() modulator can be used as shown below.
gremlin> g.V().valueMap().by(unfold())==>[name:marko,location:san diego]==>[name:stephen,location:centreville]==>[name:matthias,location:bremen]==>[name:daniel,location:spremberg]==>[name:gremlin]==>[name:tinkergraph]gremlin> g.V().valueMap('name','location').by().by(unfold())==>[name:[marko],location:san diego]==>[name:[stephen],location:centreville]==>[name:[matthias],location:bremen]==>[name:[daniel],location:spremberg]==>[name:[gremlin]]==>[name:[tinkergraph]]g.V().valueMap().by(unfold())g.V().valueMap('name','location').by().by(unfold())If theid,label,key, andvalue of theElement is desired, then thewith() modulator can be used totrigger its insertion into the returned map.
gremlin> g.V().hasLabel('person').valueMap().with(WithOptions.tokens)==>[id:1,label:person,name:[marko],location:[san diego,santa cruz,brussels,santa fe]]==>[id:7,label:person,name:[stephen],location:[centreville,dulles,purcellville]]==>[id:8,label:person,name:[matthias],location:[bremen,baltimore,oakland,seattle]]==>[id:9,label:person,name:[daniel],location:[spremberg,kaiserslautern,aachen]]gremlin> g.V().hasLabel('person').valueMap('name').with(WithOptions.tokens, WithOptions.labels)==>[label:person,name:[marko]]==>[label:person,name:[stephen]]==>[label:person,name:[matthias]]==>[label:person,name:[daniel]]gremlin> g.V().hasLabel('person').properties('location').valueMap().with(WithOptions.tokens, WithOptions.values)==>[value:san diego,startTime:1997,endTime:2001]==>[value:santa cruz,startTime:2001,endTime:2004]==>[value:brussels,startTime:2004,endTime:2005]==>[value:santa fe,startTime:2005]==>[value:centreville,startTime:1990,endTime:2000]==>[value:dulles,startTime:2000,endTime:2006]==>[value:purcellville,startTime:2006]==>[value:bremen,startTime:2004,endTime:2007]==>[value:baltimore,startTime:2007,endTime:2011]==>[value:oakland,startTime:2011,endTime:2014]==>[value:seattle,startTime:2014]==>[value:spremberg,startTime:1982,endTime:2005]==>[value:kaiserslautern,startTime:2005,endTime:2009]==>[value:aachen,startTime:2009]g.V().hasLabel('person').valueMap().with(WithOptions.tokens)g.V().hasLabel('person').valueMap('name').with(WithOptions.tokens, WithOptions.labels)g.V().hasLabel('person').properties('location').valueMap().with(WithOptions.tokens, WithOptions.values)Additional References
Values Step
Thevalues()-step (map) extracts the values of properties from anElement in the traversal stream.
gremlin> g.V(1).values()==>marko==>san diego==>santa cruz==>brussels==>santa fegremlin> g.V(1).values('location')==>san diego==>santa cruz==>brussels==>santa fegremlin> g.V(1).properties('location').values()==>1997==>2001==>2001==>2004==>2004==>2005==>2005g.V(1).values()g.V(1).values('location')g.V(1).properties('location').values()Additional References
Vertex Steps

The vertex steps (flatMap) are fundamental to the Gremlin language. Via these steps, its possible to "move" on thegraph — i.e. traverse.
out(string…): Move to the outgoing adjacent vertices given the edge labels.in(string…): Move to the incoming adjacent vertices given the edge labels.both(string…): Move to both the incoming and outgoing adjacent vertices given the edge labels.outE(string…): Move to the outgoing incident edges given the edge labels.inE(string…): Move to the incoming incident edges given the edge labels.bothE(string…): Move to both the incoming and outgoing incident edges given the edge labels.outV(): Move to the outgoing vertex.inV(): Move to the incoming vertex.bothV(): Move to both vertices.otherV(): Move to the vertex that was not the vertex that was moved from.
Groovy | The term |
Javascript | The term |
Python | The term |
gremlin> g.V(4)==>v[4]gremlin> g.V(4).outE()////(1)==>e[10][4-created->5]==>e[11][4-created->3]gremlin> g.V(4).inE('knows')////(2)==>e[8][1-knows->4]gremlin> g.V(4).inE('created')////(3)gremlin> g.V(4).bothE('knows','created','blah')==>e[10][4-created->5]==>e[11][4-created->3]==>e[8][1-knows->4]gremlin> g.V(4).bothE('knows','created','blah').otherV()==>v[5]==>v[3]==>v[1]gremlin> g.V(4).both('knows','created','blah')==>v[5]==>v[3]==>v[1]gremlin> g.V(4).outE().inV()////(4)==>v[5]==>v[3]gremlin> g.V(4).out()////(5)==>v[5]==>v[3]gremlin> g.V(4).inE().outV()==>v[1]gremlin> g.V(4).inE().bothV()==>v[1]==>v[4]g.V(4)g.V(4).outE()////(1)g.V(4).inE('knows')////(2)g.V(4).inE('created')////(3)g.V(4).bothE('knows','created','blah')g.V(4).bothE('knows','created','blah').otherV()g.V(4).both('knows','created','blah')g.V(4).outE().inV()////(4)g.V(4).out()////(5)g.V(4).inE().outV()g.V(4).inE().bothV()All outgoing edges.
All incoming knows-edges.
All incoming created-edges.
Moving forward touching edges and vertices.
Moving forward only touching vertices.
Additional References
Where Step
Thewhere()-step filters the current object based on either the object itself (Scope.local) or the path historyof the object (Scope.global) (filter). This step is typically used in conjunction with eithermatch()-step orselect()-step, but can be used in isolation.
gremlin> g.V(1).as('a').out('created').in('created').where(neq('a'))////(1)==>v[4]==>v[6]gremlin> g.withSideEffect('a',['josh','peter']).V(1).out('created').in('created').values('name').where(within('a'))////(2)==>josh==>petergremlin> g.V(1).out('created').in('created').where(out('created').count().is(gt(1))).values('name')////(3)==>joshg.V(1).as('a').out('created').in('created').where(neq('a'))////(1)g.withSideEffect('a',['josh','peter']).V(1).out('created').in('created').values('name').where(within('a'))////(2)g.V(1).out('created').in('created').where(out('created').count().is(gt(1))).values('name')//3Who are marko’s collaborators, where marko can not be his own collaborator? (predicate)
Of the co-creators of marko, only keep those whose name is josh or peter. (using a sideEffect)
Which of marko’s collaborators have worked on more than 1 project? (using a traversal)
Important | Please seematch().where() andselect().where()for howwhere() can be used in conjunction withMap<String,Object> projecting steps — i.e.Scope.local. |
A few more examples of filtering an arbitrary object based on a anonymous traversal is provided below.
gremlin> g.V().where(out('created')).values('name')////(1)==>marko==>josh==>petergremlin> g.V().out('knows').where(out('created')).values('name')////(2)==>joshgremlin> g.V().where(out('created').count().is(gte(2))).values('name')////(3)==>joshgremlin> g.V().where(out('knows').where(out('created'))).values('name')////(4)==>markogremlin> g.V().where(__.not(out('created'))).where(__.in('knows')).values('name')////(5)==>vadasgremlin> g.V().where(__.not(out('created')).and().in('knows')).values('name')////(6)==>vadasgremlin> g.V().as('a').out('knows').as('b'). where('a',gt('b')). by('age'). select('a','b'). by('name')////(7)==>[a:marko,b:vadas]gremlin> g.V().as('a').out('knows').as('b'). where('a',gt('b').or(eq('b'))). by('age'). by('age'). by(__.in('knows').values('age')). select('a','b'). by('name')////(8)==>[a:marko,b:vadas]==>[a:marko,b:josh]gremlin> g.V().as('a').both().both().as('b'). where('a',eq('b')).by('age')////(9)==>v[1]==>v[1]==>v[1]==>v[2]==>v[4]==>v[4]==>v[4]==>v[6]g.V().where(out('created')).values('name')////(1)g.V().out('knows').where(out('created')).values('name')////(2)g.V().where(out('created').count().is(gte(2))).values('name')////(3)g.V().where(out('knows').where(out('created'))).values('name')////(4)g.V().where(__.not(out('created'))).where(__.in('knows')).values('name')////(5)g.V().where(__.not(out('created')).and().in('knows')).values('name')////(6)g.V().as('a').out('knows').as('b'). where('a',gt('b')). by('age'). select('a','b'). by('name')////(7)g.V().as('a').out('knows').as('b'). where('a',gt('b').or(eq('b'))). by('age'). by('age'). by(__.in('knows').values('age')). select('a','b'). by('name')////(8)g.V().as('a').both().both().as('b'). where('a',eq('b')).by('age')//9What are the names of the people who have created a project?
What are the names of the people that are known by someone one and have created a project?
What are the names of the people how have created two or more projects?
What are the names of the people who know someone that has created a project? (This only works in OLTP — see the
WARNINGbelow)What are the names of the people who have not created anything, but are known by someone?
The concatenation of
where()-steps is the same as a singlewhere()-step with an and’d clause.Marko knows josh and vadas but is only older than vadas.
Marko is younger than josh, but josh knows someone equal in age to marko (which is marko).
The "age" property is notproductive for all vertices and therefore those values are filtered.
Warning | The anonymous traversal ofwhere() processes the current object "locally". In OLAP, where the atomic unitof computing is the vertex and its local "star graph," it is important that the anonymous traversal does not leavethe confines of the vertex’s star graph. In other words, it can not traverse to an adjacent vertex’s properties oredges. |
Additional References
With Step
Thewith()-step is not an actual step, but is instead a "step modulator" which modifies the behavior of the stepprior to it. Thewith()-step provides additional "configuration" information to steps that implement theConfiguringinterface. Steps that allow for this type of modulation will explicitly state so in their documentation.
Javascript | The term |
Python | The term |
Write Step
Thewrite()-step is not really a "step" but a step modulator in that it modifies the functionality of theio()-step.More specifically, it tells theio()-step that it is expected to use its configuration to write data to somelocation. Please see thedocumentation forio()-step for more complete details on usage.
Additional References
A Note on Predicates
AP is a predicate of the formFunction<Object,Boolean>. That is, given some object, return true or false. As ofthe release of TinkerPop 3.4.0, Gremlin also supports simple text predicates, which only work onString values. TheTextPtext predicates extend theP predicates, but are specialized in that they are of the formFunction<String,Boolean>.The provided predicates are outlined in the table below and are used in various steps such ashas()-step,where()-step,is()-step, etc. Two new additionalTextP predicate members were added in theTinkerPop 3.6.0 release that allow working with regular expressions. These areTextP.regex andTextP.notRegex
| Predicate | Description |
|---|---|
| Is the incoming object equal to the provided object? |
| Is the incoming object not equal to the provided object? |
| Is the incoming number less than the provided number? |
| Is the incoming number less than or equal to the provided number? |
| Is the incoming number greater than the provided number? |
| Is the incoming number greater than or equal to the provided number? |
| Is the incoming number greater than the first provided number and less than the second? |
| Is the incoming number less than the first provided number or greater than the second? |
| Is the incoming number greater than or equal to the first provided number and less than the second? |
| Is the incoming object in the array of provided objects? |
| Is the incoming object not in the array of the provided objects? |
| Does the incoming |
| Does the incoming |
| Does the incoming |
| Does the incoming |
| Does the incoming |
| Does the incoming |
| Does the incoming |
| Does the incoming |
Note | The TinkerPop reference implementation uses the JavaPattern andMatcher classes for it regular expressionengine. Other implementations may decide to use a different regular expression engine. It’s a good idea to checkthe documentation for the implementation you are using to verify the allowed regular expression syntax. |
gremlin> eq(2)==>eq(2)gremlin> not(neq(2))////(1)==>eq(2)gremlin> not(within('a','b','c'))==>without([a, b, c])gremlin> not(within('a','b','c')).test('d')////(2)==>truegremlin> not(within('a','b','c')).test('a')==>falsegremlin> within(1,2,3).and(not(eq(2))).test(3)////(3)==>truegremlin> inside(1,4).or(eq(5)).test(3)////(4)==>truegremlin> inside(1,4).or(eq(5)).test(5)==>truegremlin> between(1,2)////(5)==>and(gte(1), lt(2))gremlin> not(between(1,2))==>or(lt(1), gte(2))eq(2)not(neq(2))////(1)not(within('a','b','c'))not(within('a','b','c')).test('d')////(2)not(within('a','b','c')).test('a')within(1,2,3).and(not(eq(2))).test(3)////(3)inside(1,4).or(eq(5)).test(3)////(4)inside(1,4).or(eq(5)).test(5)between(1,2)////(5)not(between(1,2))The
not()of aP-predicate is anotherP-predicate.P-predicates are arguments to various steps which internallytest()the incoming value.P-predicates can be and’d together.P-predicates can be or' together.and()is aP-predicate and thus, aP-predicate can be composed of multipleP-predicates.
Tip | To reduce the verbosity of predicate expressions, it is good toimport static org.apache.tinkerpop.gremlin.process.traversal.P.*. |
The following example demonstrates how theregex() predicate is used and it demonstrates an important point. Whenusingregex(), the string is considered a match to the pattern if any substring matches the pattern. It is thereforeimportant to use the appropriate boundary matchers (e.g.$ for end of a line) to ensure a proper match.
gremlin> g.V().has('person','name', regex('peter')).values('name')==>petergremlin> g.V().has('person','name', regex('r')).values('name')==>marko==>petergremlin> g.V().has('person','name', regex('r$')).values('name')==>peterg.V().has('person','name', regex('peter')).values('name')g.V().has('person','name', regex('r')).values('name')g.V().has('person','name', regex('r$')).values('name')Finally, note thatwhere()-step takes aP<String>. The provided string value refers to a variablebinding, not to the explicit string value.
gremlin> g.V().as('a').both().both().as('b').count()==>30gremlin> g.V().as('a').both().both().as('b').where('a',neq('b')).count()==>18g.V().as('a').both().both().as('b').count()g.V().as('a').both().both().as('b').where('a',neq('b')).count()A Note on Maps
Many steps in Gremlin returnMap-based results. Commonly used steps likeproject(),'group()', andselect() are just some examples of steps that fall into this category.When working withMap results there are a couple of important things to know.
First, it is important to recognize that there is a bit of a difference in behavior that occurs when usingunfold() on aMap in embedded contexts versus remote contexts. In embedded contexts, an unfoldedMapbecomes its compositeMap.Entry objects as is typical in Java. The following example demonstrates the basic name/valuepairs that returned:
gremlin> g.V().valueMap('name','age').unfold()==>name=[marko]==>age=[29]==>name=[vadas]==>age=[27]==>name=[lop]==>name=[josh]==>age=[32]==>name=[ripple]==>name=[peter]==>age=[35]g.V().valueMap('name','age').unfold()In remote contexts, an unfoldedMap becomesMap.Entry on the server as in the embedded case, but is returned to theapplication as aMap with one entry. The slight difference in notation in Gremlin Console is shown in the followingremote example:
gremlin> g.V().valueMap('name','age').unfold()==>[name:[marko]]==>[age:[29]]==>[name:[vadas]]==>[age:[27]]==>[name:[lop]]==>[name:[josh]]==>[age:[32]]==>[name:[ripple]]==>[name:[peter]]==>[age:[35]]The primary reason for this difference lies in the fact that Gremlin Language Variants, like Python and Go, do not havea nativeMap.Entry concept that can be used. The most universal data structure across programming languages is theMap itself. It is important to note that this transformation fromMap.Entry toMap only applies to resultsreceived on the client-side. In other words, if a step was to followunfold() in the prior example, it would bedealing withMap.Entry and not aMap, so Gremlin semantics should remain consistent on the server side.
The second issues to consider with steps that return aMap is that access keys on aMap is not always as consistentas expected. The issue is best demonstrated in some examples:
// note that elements can be grouped by(id), but that same pattern can't be applied to get// a T.id in a Mapgremlin> g.V().hasLabel('person').both().group().by(id)==>[1:[v[1],v[1]],2:[v[2]],3:[v[3],v[3],v[3]],4:[v[4]],5:[v[5]]]gremlin> g.V().hasLabel('person').both().elementMap().group().by(id)TokenTraversal support of java.util.LinkedHashMap does not allow selection by idType ':help' or ':h' for help.Display stack trace? [yN]// note that select() can't be used if the key is a non-stringgremlin> g.V().hasLabel('person').both().group().by('age').select(32)No signature of method: org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.DefaultGraphTraversal.select() is applicable for argument types: (Integer) values: [32]Possible solutions: reset(), collect(), sleep(long), collect(groovy.lang.Closure), inject(groovy.lang.Closure), split(groovy.lang.Closure)Type ':help' or ':h' for help.Display stack trace? [yN]While this problem might be solved in future versions, the workaround for both cases is to useconstant() as shown in the following example:
gremlin> g.V().hasLabel('person').both().group().by(constant(id))==>[id:[v[3],v[2],v[4],v[1],v[5],v[3],v[1],v[3]]]gremlin> g.V().hasLabel('person').both().group().by('age').select(constant(32))==>[v[4]]g.V().hasLabel('person').both().group().by(constant(id))g.V().hasLabel('person').both().group().by('age').select(constant(32))A Note on Barrier Steps
 Gremlin is primarily alazy, stream processing language. This means that Gremlin fullyprocesses (to the best of its abilities) any traversers currently in the traversal pipeline before getting more datafrom the start/head of the traversal. However, there are numerous situations in which a completely lazy computationis not possible (or impractical). When a computation is not lazy, a "barrier step" exists. There are three types ofbarriers:
Gremlin is primarily alazy, stream processing language. This means that Gremlin fullyprocesses (to the best of its abilities) any traversers currently in the traversal pipeline before getting more datafrom the start/head of the traversal. However, there are numerous situations in which a completely lazy computationis not possible (or impractical). When a computation is not lazy, a "barrier step" exists. There are three types ofbarriers:
CollectingBarrierStep: All of the traversers prior to the step are put into a collection and then processed insome way (e.g. ordered) prior to the collection being "drained" one-by-one to the next step. Examplesinclude:order(),sample(),aggregate(),barrier().ReducingBarrierStep: All of the traversers prior to the step are processed by a reduce function and once all theprevious traversers are processed, a single "reduced value" traverser is emitted to the next step. Note that the pathhistory leading up to a reducing barrier step is destroyed given its many-to-one nature. Examples include:fold(),count(),sum(),max(),min().SupplyingBarrierStep: All of the traversers prior to the step are iterated (no processing) and then some providedsupplier yields a single traverser to continue to the next step. Examples include:cap().
In Gremlin OLAP (seeTraversalVertexProgram), a barrier is introduced at the end ofeveryadjacent vertex step. This means that the traversal does its best to compute as much aspossible at the current, local vertex. What it can’t compute without referencing an adjacent vertex is aggregatedinto a barrier collection. When there are no more traversers at the local vertex, the barriered traversers are themessages that are propagated to remote vertices for further processing.
A Note on Scopes
TheScope enum has two constants:Scope.local andScope.global. Scope determines whether the particular stepbeing scoped is with respects to the current object (local) at that step or to the entire stream of objects up to thatstep (global).
Python | The term |
gremlin> g.V().has('name','marko').out('knows').count()////(1)==>2gremlin> g.V().has('name','marko').out('knows').fold().count()////(2)==>1gremlin> g.V().has('name','marko').out('knows').fold().count(local)////(3)==>2gremlin> g.V().has('name','marko').out('knows').fold().count(global)////(4)==>1g.V().has('name','marko').out('knows').count()////(1)g.V().has('name','marko').out('knows').fold().count()////(2)g.V().has('name','marko').out('knows').fold().count(local)////(3)g.V().has('name','marko').out('knows').fold().count(global)//4Marko knows 2 people.
A list of Marko’s friends is created and thus, one object is counted (the single list).
A list of Marko’s friends is created and a
local-count yields the number of objects in that list.count(global)is the same ascount()as the default behavior for most scoped steps isglobal.
The steps that support scoping are:
count(): count the local collection or global stream.dedup(): dedup the local collection of global stream.max(): get the max value in the local collection or global stream.mean(): get the mean value in the local collection or global stream.min(): get the min value in the local collection or global stream.order(): order the objects in the local collection or global stream.range(): clip the local collection or global stream.limit(): clip the local collection or global stream.sample(): sample objects from the local collection or global stream.tail(): get the tail of the objects in the local collection or global stream.
A few more examples of the use ofScope are provided below:
gremlin> g.V().both().group().by(label).select('software').dedup(local)==>[v[3],v[5]]gremlin> g.V().groupCount().by(label).select(values).min(local)==>2gremlin> g.V().groupCount().by(label).order(local).by(values,desc)==>[person:4,software:2]gremlin> g.V().fold().sample(local,2)==>[v[6],v[2]]g.V().both().group().by(label).select('software').dedup(local)g.V().groupCount().by(label).select(values).min(local)g.V().groupCount().by(label).order(local).by(values,desc)g.V().fold().sample(local,2)Finally, note thatlocal()-step is a "hard-scoped step" that transforms any internal traversal into alocally-scoped operation. A contrived example is provided below:
gremlin> g.V().fold().local(unfold().count())==>6gremlin> g.V().fold().count(local)==>6g.V().fold().local(unfold().count())g.V().fold().count(local)A Note On Lambdas
 Alambda is a functionthat can be referenced by software and thus, passed around like any other piece of data. In Gremlin, lambdas make itpossible to generalize the behavior of a step such that custom steps can be created (on-the-fly) by the user. However,it is advised to avoid using lambdas if possible.
Alambda is a functionthat can be referenced by software and thus, passed around like any other piece of data. In Gremlin, lambdas make itpossible to generalize the behavior of a step such that custom steps can be created (on-the-fly) by the user. However,it is advised to avoid using lambdas if possible.
gremlin> g.V().filter{it.get().value('name') =='marko'}. flatMap{it.get().vertices(OUT,'created')}. map {it.get().value('name')}////(1)==>lopgremlin> g.V().has('name','marko').out('created').values('name')////(2)==>lopg.V().filter{it.get().value('name') =='marko'}. flatMap{it.get().vertices(OUT,'created')}. map {it.get().value('name')}////(1)g.V().has('name','marko').out('created').values('name')//2A lambda-rich Gremlin traversal which should and can be avoided. (bad)
The same traversal (result), but without using lambdas. (good)
Gremlin attempts to provide the user a comprehensive collection of steps in the hopes that the user will never need toleverage a lambda in practice. It is advised that users only leverage a lambda if and only if there is nocorresponding lambda-less step that encompasses the desired functionality. The reason being, lambdas can not beoptimized by Gremlin’s compiler strategies as they can not be programmatically inspected (seetraversal strategies). It is also not currently possible to send a natively written lambda forremote execution to Gremlin-Server or a driver that supports remote execution.
In many situations where a lambda could be used, either a corresponding step exists or a traversal can be provided inits place. ATraversalLambda behaves like a typical lambda, but it can be optimized and it yields less objects thanthe corresponding pure-lambda form.
gremlin> g.V().out().out().path().by {it.value('name')}. by {it.value('name')}. by {g.V(it).in('created').values('name').fold().next()}////(1)==>[marko,josh,[josh]]==>[marko,josh,[marko,josh,peter]]gremlin> g.V().out().out().path().by('name'). by('name'). by(__.in('created').values('name').fold())////(2)==>[marko,josh,[josh]]==>[marko,josh,[marko,josh,peter]]g.V().out().out().path().by {it.value('name')}. by {it.value('name')}. by {g.V(it).in('created').values('name').fold().next()}////(1)g.V().out().out().path().by('name'). by('name'). by(__.in('created').values('name').fold())//2The length-3 paths have each of their objects transformed by a lambda. (bad)
The length-3 paths have their objects transformed by a lambda-less step and a traversal lambda. (good)
TraversalStrategy
 A
ATraversalStrategy analyzes aTraversal and, if the traversalmeets its criteria, can mutate it accordingly. Traversal strategies are executed at compile-time and form the foundationof the Gremlin traversal machine’s compiler. There are 5 categories of strategies which are itemized below:
There is an application-level feature that can be embedded into the traversal logic (decoration).
There is a more efficient way to express the traversal at the TinkerPop level (optimization).
There is a more efficient way to express the traversal at the graph system/language/driver level (provider optimization).
There are some final adjustments/cleanups/analyses required before executing the traversal (finalization).
There are certain traversals that are not legal for the application or traversal engine (verification).
Note | Theexplain()-step shows the user how each registered strategy mutates the traversal. |
TinkerPop ships with a generous number ofTraversalStrategy definitions, most of which are applied implicitly whenexecuting a gremlin traversal. Users and providers can addTraversalStrategy definitions for particular needs. Thefollowing sections detail how traversal strategies are applied and defined and describe a collection of traversalstrategies that are generally useful to end-users.
Application
One can explicitly add or removeTraversalStrategy strategies on theGraphTraversalSource with thewithStrategies()andwithoutStrategies()start steps, see theReadOnlyStrategy and thebarrier() step for examples. End users typically do this as part of issuing a gremlin traversal, eitheron a locally opened graph or a remotely accessed graph. However, when configuring Gremlin Server, traversal strategiescan also be applied on exposedGraphTraversalSource instances and as part of anAuthorizer implementation, seeGremlin Server Authorization.Therefore, one should keep the following in mind when modifying the list ofTraversalStrategy strategies:
A
TraversalStrategyadded to the traversal can be removed again later on. An example is theconf/gremlin-server-modern-readonly.yamlfile from the Gremlin Server distribution, which applies theReadOnlyStrategyto theGraphTraversalSourcethat remote clients can connect to. However, a remote client can remove it on its turnby applying thewithoutStrategies()step with theReadOnlyStrategy.When a
TraversalStrategyof a particular type is added, it replaces any instances of its type that exist prior toit. Multiple instances of aTraversalStrategycan therefore not be registered and their functionality is no waymerged automatically. Therefore, if there is a particular strategy registered whose functionality needs to be changedit is important to either find and modify the existing instance or construct a new one copying the options to keepfrom the old to the new instance.
Definition
A simpleOptimizationStrategy is theIdentityRemovalStrategy.
publicfinalclassIdentityRemovalStrategyextends AbstractTraversalStrategy<TraversalStrategy.OptimizationStrategy>implements TraversalStrategy.OptimizationStrategy {privatestaticfinal IdentityRemovalStrategy INSTANCE =new IdentityRemovalStrategy();private IdentityRemovalStrategy() { }@Overridepublicvoid apply(Traversal.Admin<?, ?> traversal) {if (traversal.getSteps().size() <=1)return;for (IdentityStep<?> identityStep : TraversalHelper.getStepsOfClass(IdentityStep.class, traversal)) {if (identityStep.getLabels().isEmpty() || !(identityStep.getPreviousStep()instanceof EmptyStep)) { TraversalHelper.copyLabels(identityStep, identityStep.getPreviousStep(),false); traversal.removeStep(identityStep); } } }publicstatic IdentityRemovalStrategy instance() {return INSTANCE; }}This strategy simply removes anyIdentityStep steps in the Traversal asaStep().identity().identity().bStep()is equivalent toaStep().bStep(). For those traversal strategies that require other strategies to execute prior orpost to the strategy, then the following two methods can be defined inTraversalStrategy (with defaults being anempty set). If theTraversalStrategy is in a particular traversal category (i.e. decoration, optimization,provider-optimization, finalization, or verification), then priors and posts are only possible within the respective category.
publicSet<Class<?extends S>> applyPrior();publicSet<Class<?extends S>> applyPost();Important | TraversalStrategy categories are sorted within their category and the categories are then executed inthe following order: decoration, optimization, provider optimization, finalization, and verification. If a designed strategydoes not fit cleanly into these categories, then it can implementTraversalStrategy and its prior and posts can referencestrategies within any category. However, such generalization are strongly discouraged. |
An example of aGraphSystemOptimizationStrategy is provided below.
g.V().has('name','marko')The expression above can be executed in aO(|V|) orO(log(|V|) fashion inTinkerGraphdepending on whether there is or is not an index defined for "name."
publicfinalclassTinkerGraphStepStrategyextends AbstractTraversalStrategy<TraversalStrategy.ProviderOptimizationStrategy>implements TraversalStrategy.ProviderOptimizationStrategy {privatestaticfinal TinkerGraphStepStrategy INSTANCE =new TinkerGraphStepStrategy();private TinkerGraphStepStrategy() { }@Overridepublicvoid apply(Traversal.Admin<?, ?> traversal) {if (TraversalHelper.onGraphComputer(traversal))return;for (GraphStep originalGraphStep : TraversalHelper.getStepsOfClass(GraphStep.class, traversal)) { TinkerGraphStep<?, ?> tinkerGraphStep =new TinkerGraphStep<>(originalGraphStep); TraversalHelper.replaceStep(originalGraphStep, tinkerGraphStep, traversal); Step<?, ?> currentStep = tinkerGraphStep.getNextStep();while (currentStepinstanceof HasStep || currentStepinstanceof NoOpBarrierStep) {if (currentStepinstanceof HasStep) {for (HasContainer hasContainer : ((HasContainerHolder) currentStep).getHasContainers()) {if (!GraphStep.processHasContainerIds(tinkerGraphStep, hasContainer)) tinkerGraphStep.addHasContainer(hasContainer); } TraversalHelper.copyLabels(currentStep, currentStep.getPreviousStep(),false); traversal.removeStep(currentStep); } currentStep = currentStep.getNextStep(); } } }publicstatic TinkerGraphStepStrategy instance() {return INSTANCE; }}The traversal is redefined by simply taking a chain ofhas()-steps afterg.V() (TinkerGraphStep) and providingtheirHasContainers toTinkerGraphStep. Then its up toTinkerGraphStep to determine if an appropriate index exists.Given that the strategy uses non-TinkerPop provided steps, it should go into theProviderOptimizationStrategy categoryto ensure the added step does not interfere with the assumptions of theOptimizationStrategy strategies.
gremlin> t = g.V().has('name','marko');null==>nullgremlin> t.toString()==>[GraphStep(vertex,[]), HasStep([name.eq(marko)])]gremlin> t.iterate();null==>nullgremlin> t.toString()==>[TinkerGraphStep(vertex,[name.eq(marko)]), NoneStep]t = g.V().has('name','marko');nullt.toString()t.iterate();nullt.toString()Warning | The reason thatOptimizationStrategy andProviderOptimizationStrategy are two different categories isthat optimization strategies should only rewrite the traversal using TinkerPop steps. This ensures that theoptimizations executed at the end of the optimization strategy round are TinkerPop compliant. From there, provideroptimizations can analyze the traversal and rewrite the traversal as desired using graph system specific steps (e.g.replacingGraphStep.HasStep…HasStep withTinkerGraphStep). If provider optimizations use graph system specificsteps and implementOptimizationStrategy, then other TinkerPop optimizations may fail to optimize the traversal ormis-understand the graph system specific step behaviors (e.g.ProviderVertexStep extends VertexStep) and yieldincorrect semantics. |
Finally, here is a complicated traversal that has various components that are optimized by the default TinkerPop strategies.
gremlin> g.V().hasLabel('person').////(1) and(has('name'),////(2) has('name','marko'), filter(has('age',gt(20)))).////(3) match(__.as('a').has('age',lt(32)),////(4) __.as('a').repeat(outE().inV()).times(2).as('b')).////(5) where('a',neq('b')).////(6) where(__.as('b').both().count().is(gt(1))).////(7) select('b').////(8) groupCount(). by(out().count()).////(9) explain()==>Traversal Explanation================================================================================================================================================================================================================================================Original Traversal [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), Mat chStep(null,AND,[[MatchStartStep(a), HasStep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartStep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([Vertex Step(OUT,vertex), CountGlobalStep])]ConnectiveStrategy [D] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), Mat chStep(null,AND,[[MatchStartStep(a), HasStep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartStep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([Vertex Step(OUT,vertex), CountGlobalStep])]RepeatUnrollStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), Mat chStep(null,AND,[[MatchStartStep(a), HasStep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), VertexStep(OUT,edge), EdgeVertexStep(IN), VertexStep(OUT,edge), EdgeVertexStep(IN), MatchEndStep(b )]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartStep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex ), CountGlobalStep])]IdentityRemovalStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), Mat chStep(null,AND,[[MatchStartStep(a), HasStep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), VertexStep(OUT,edge), EdgeVertexStep(IN), VertexStep(OUT,edge), EdgeVertexStep(IN), MatchEndStep(b )]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartStep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex ), CountGlobalStep])]MatchPredicateStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), Mat chStep(null,AND,[[MatchStartStep(a), HasStep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), VertexStep(OUT,edge), EdgeVertexStep(IN), VertexStep(OUT,edge), EdgeVertexStep(IN), MatchEndStep(b )], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]FilterRankingStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), Mat chStep(null,AND,[[MatchStartStep(a), HasStep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), VertexStep(OUT,edge), EdgeVertexStep(IN), VertexStep(OUT,edge), EdgeVertexStep(IN), MatchEndStep(b )], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]InlineFilterStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],value)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a) , VertexStep(OUT,edge), EdgeVertexStep(IN), VertexStep(OUT,edge), EdgeVertexStep(IN), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), W hereTraversalStep([WhereStartStep(null), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlo balStep])]IncidentToAdjacentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],value)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a) , VertexStep(OUT,vertex), VertexStep(OUT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(nu ll), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]PathRetractionStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],value)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a) , VertexStep(OUT,vertex), VertexStep(OUT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(nu ll), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]EarlyLimitStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],value)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a) , VertexStep(OUT,vertex), VertexStep(OUT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(nu ll), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]AdjacentToIncidentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep (a), VertexStep(OUT,vertex), VertexStep(OUT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep (null), VertexStep(BOTH,edge), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]ByModulatorOptimizationStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep (a), VertexStep(OUT,vertex), VertexStep(OUT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep (null), VertexStep(BOTH,edge), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]CountStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep (a), VertexStep(OUT,vertex), VertexStep(OUT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep (null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]LazyBarrierStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep (a), VertexStep(OUT,vertex), NoOpBarrierStep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchSt artStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep( [VertexStep(OUT,edge), CountGlobalStep])]TinkerGraphCountStrategy [P] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep (a), VertexStep(OUT,vertex), NoOpBarrierStep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchSt artStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep( [VertexStep(OUT,edge), CountGlobalStep])]TinkerGraphStepStrategy [P] [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), Ve rtexStep(OUT,vertex), NoOpBarrierStep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep (b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([Vertex Step(OUT,edge), CountGlobalStep])]ProfileStrategy [F] [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), Ve rtexStep(OUT,vertex), NoOpBarrierStep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep (b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([Vertex Step(OUT,edge), CountGlobalStep])]StandardVerificationStrategy [V] [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), Ve rtexStep(OUT,vertex), NoOpBarrierStep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep (b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([Vertex Step(OUT,edge), CountGlobalStep])]Final Traversal [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), Ve rtexStep(OUT,vertex), NoOpBarrierStep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep (b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([Vertex Step(OUT,edge), CountGlobalStep])]g.V().hasLabel('person').////(1) and(has('name'),////(2) has('name','marko'), filter(has('age',gt(20)))).////(3) match(__.as('a').has('age',lt(32)),////(4) __.as('a').repeat(outE().inV()).times(2).as('b')).////(5) where('a',neq('b')).////(6) where(__.as('b').both().count().is(gt(1))).////(7) select('b').////(8) groupCount(). by(out().count()).////(9) explain()TinkerGraphStepStrategypulls inhas()-step predicates for global, graph-centric index lookups.FilterRankStrategysorts filter steps by their time/space execution costs.InlineFilterStrategyde-nests filters to increase the likelihood of filter concatenation and aggregation.InlineFilterStrategypulls out named predicates frommatch()-step to more easily allow provider strategies to use indices.RepeatUnrollStrategywill unroll loops andIncidentToAdjacentStrategywill turnoutE().inV()-patterns intoout().MatchPredicateStrategywill pull inwhere()-steps so that they can be subjected tomatch()-steps runtime query optimizer.CountStrategywill limit the traversal to only the number of traversers required for thecount().is(x)-check.PathRetractionStrategywill remove paths from the traversers and increase the likelihood of bulking as path data is not required afterselect('b').AdjacentToIncidentStrategywill turnout()intooutE()to increase data access locality.
EdgeLabelVerificationStrategy
EdgeLabelVerificationStrategy prevents traversals from writing traversals that do not explicitly specify and edgelabel when using steps likeout(), 'in()', 'both()' and their relatedE oriented steps, providing theoption to throw an exception, log a warning or do both when one of these keys is encountered in a mutating step.
EdgeLabelVerificationStrategy verificationStrategy = EdgeLabelVerificationStrategy.build() .throwException().create()// results in VerificationException - as out() does not have a label specifiedg.withStrategies(verificationStrategy).V(1).out().iterate();// results in VerificationException - as out() does not have a label specifiedg.withStrategies(new EdgeLabelVerificationStrategy(throwException:true)) .V(1).out().iterate()// results in VerificationException - as out() does not have a label specifiedg.WithStrategies(new EdgeLabelVerificationStrategy(throwException: true)) .V(1).Out().Iterate();// results in Error - as out() does not have a label specifiedg.withStrategies(new EdgeLabelVerificationStrategy(throwException:true)) .V(1).out().iterate();// resultsin Error -as out() doesnot have a label specifiedg.withStrategies(EdgeLabelVerificationStrategy(throwException=true)) .V(1).out().iterate()ElementIdStrategy
ElementIdStrategy provides control over element identifiers. Some Graph implementations, such as TinkerGraph,allow specification of custom identifiers when creating elements:
gremlin> g = traversal().withEmbedded(TinkerGraph.open())==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> v = g.addV().property(id,'42a').next()==>v[42a]gremlin> g.V('42a')==>v[42a]g = traversal().withEmbedded(TinkerGraph.open())v = g.addV().property(id,'42a').next()g.V('42a')OtherGraph implementations, such as Neo4j, generate element identifiers automatically and cannot be assigned.As a helper,ElementIdStrategy can be used to make identifier assignment possible by using vertex and edge indicesunder the hood.
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')==>neo4jgraph[community single [/tmp/neo4j]]gremlin> strategy = ElementIdStrategy.build().create()==>ElementIdStrategygremlin> g = traversal().withEmbedded(graph).withStrategies(strategy)==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]gremlin> g.addV().property(id,'42a').id()==>42agraph = Neo4jGraph.open('/tmp/neo4j')strategy = ElementIdStrategy.build().create()g = traversal().withEmbedded(graph).withStrategies(strategy)g.addV().property(id,'42a').id()Important | The key that is used to store the assigned identifier should be indexed in the underlying graphdatabase. If it is not indexed, then lookups for the elements that use these identifiers will perform a linear scan. |
EventStrategy
The purpose of theEventStrategy is to raise events to one or moreMutationListener objects as changes to theunderlyingGraph occur within aTraversal. Such a strategy is useful for logging changes, triggering certainactions based on change, or any application that needs notification of some mutating operation during aTraversal.If the transaction is rolled back, the event queue is reset.
The following events are raised to theMutationListener:
New vertex
New edge
Vertex property changed
Edge property changed
Vertex property removed
Edge property removed
Vertex removed
Edge removed
To start processing events from aTraversal first implement theMutationListener interface. An example of thisimplementation is theConsoleMutationListener which writes output to the console for each event. The followingconsole session displays the basic usage:
gremlin>importorg.apache.tinkerpop.gremlin.process.traversal.step.util.event.*==>org.apache.tinkerpop.gremlin.process.traversal.step.util.event.*gremlin> graph = TinkerFactory.createModern()==>tinkergraph[vertices:6edges:6]gremlin> l =new ConsoleMutationListener(graph)==>MutationListener[tinkergraph[vertices:6edges:6]]gremlin> strategy = EventStrategy.build().addListener(l).create()==>EventStrategygremlin> g = traversal().withEmbedded(graph).withStrategies(strategy)==>graphtraversalsource[tinkergraph[vertices:6edges:6], standard]gremlin> g.addV().property('name','stephen')Vertex [v[0]] added to graph [tinkergraph[vertices:7edges:6]]==>v[0]gremlin> g.V().has('name','stephen'). property(list,'location','centreville','startTime',1990,'endTime',2000). property(list,'location','dulles','startTime',2000,'endTime',2006). property(list,'location','purcellville','startTime',2006)Vertex [v[0]] property [vp[empty]] change to [centreville]in graph [tinkergraph[vertices:7edges:6]]Vertex [v[0]] property [vp[empty]] change to [dulles]in graph [tinkergraph[vertices:7edges:6]]Vertex [v[0]] property [vp[empty]] change to [purcellville]in graph [tinkergraph[vertices:7edges:6]]==>v[0]gremlin> g.V().has('name','stephen'). property(set,'location','purcellville','startTime',2006,'endTime',2019)Vertex [v[0]] property [vp[location->purcellville]] change to [purcellville]in graph [tinkergraph[vertices:7edges:6]]==>v[0]gremlin> g.E().drop()Edge [e[7][1-knows->2]] removed from graph [tinkergraph[vertices:7edges:6]]Edge [e[8][1-knows->4]] removed from graph [tinkergraph[vertices:7edges:5]]Edge [e[9][1-created->3]] removed from graph [tinkergraph[vertices:7edges:4]]Edge [e[10][4-created->5]] removed from graph [tinkergraph[vertices:7edges:3]]Edge [e[11][4-created->3]] removed from graph [tinkergraph[vertices:7edges:2]]Edge [e[12][6-created->3]] removed from graph [tinkergraph[vertices:7edges:1]]importorg.apache.tinkerpop.gremlin.process.traversal.step.util.event.*graph = TinkerFactory.createModern()l =new ConsoleMutationListener(graph)strategy = EventStrategy.build().addListener(l).create()g = traversal().withEmbedded(graph).withStrategies(strategy)g.addV().property('name','stephen')g.V().has('name','stephen'). property(list,'location','centreville','startTime',1990,'endTime',2000). property(list,'location','dulles','startTime',2000,'endTime',2006). property(list,'location','purcellville','startTime',2006)g.V().has('name','stephen'). property(set,'location','purcellville','startTime',2006,'endTime',2019)g.E().drop()By default, theEventStrategy is configured with anEventQueue that raises events as they occur within executionof aStep. As such, the final line of Gremlin execution that drops all edges shows a bit of an inconsistent count,where the removed edge count is accounted for after the event is raised. The strategy can also be configured with aTransactionalEventQueue that captures the changes within a transaction and does not allow them to fire until thetransaction is committed.
Warning | EventStrategy is not meant for usage in tracking global mutations across separate processes. In otherwords, a mutation in one JVM process is not raised as an event in a different JVM process. In addition, events arenot raised when mutations occur outside of theTraversal context. |
Another default configuration forEventStrategy revolves around the concept of "detachment". Graph elements aredetached from the graph as copies when passed to referring mutation events. Therefore, when adding a newVertex inTinkerGraph, the event will not contain aTinkerVertex but will instead include aDetachedVertex. This behaviorcan be modified with thedetach() method on theEventStrategy.Builder which accepts the following inputs:nullmeaning no detachment and the return of the original element,DetachedFactory which is the same as the defaultbehavior, andReferenceFactory which will return "reference" elements only with no properties.
Important | If setting thedetach() configuration tonull, be aware that transactional graphs will likely create anew transaction immediately following thecommit() that raises the events. The graph elements raised in the eventsmay also not behave as "snapshots" at the time of their creation as they are "live" references to actual databaseelements. |
PartitionStrategy
PartitionStrategy partitions the vertices and edges of a graph intoString named partitions (i.e. buckets,subgraphs, etc.). The idea behindPartitionStrategy is presented in the image above where each element is in asingle partition (represented by its color). Partitions can be read from, written to, and linked/joined by edgesthat span one or two partitions (e.g. a tail vertex in one partition and a head vertex in another).
There are three primary configurations inPartitionStrategy:
Partition Key - The property key that denotes a String value representing a partition.
Write Partition - A
Stringdenoting what partition all future written elements will be in.Read Partitions - A
Set<String>of partitions that can be read from.
The best way to understandPartitionStrategy is via example.
gremlin> graph = TinkerFactory.createModern()==>tinkergraph[vertices:6edges:6]gremlin> strategyA =new PartitionStrategy(partitionKey:"_partition",writePartition:"a",readPartitions: ["a"])==>PartitionStrategygremlin> strategyB =new PartitionStrategy(partitionKey:"_partition",writePartition:"b",readPartitions: ["b"])==>PartitionStrategygremlin> gA = traversal().withEmbedded(graph).withStrategies(strategyA)==>graphtraversalsource[tinkergraph[vertices:6edges:6], standard]gremlin> gA.addV()// this vertex has a property of {_partition:"a"}==>v[0]gremlin> gB = traversal().withEmbedded(graph).withStrategies(strategyB)==>graphtraversalsource[tinkergraph[vertices:7edges:6], standard]gremlin> gB.addV()// this vertex has a property of {_partition:"b"}==>v[13]gremlin> gA.V()==>v[0]gremlin> gB.V()==>v[13]graph = TinkerFactory.createModern()strategyA =new PartitionStrategy(partitionKey:"_partition",writePartition:"a",readPartitions: ["a"])strategyB =new PartitionStrategy(partitionKey:"_partition",writePartition:"b",readPartitions: ["b"])gA = traversal().withEmbedded(graph).withStrategies(strategyA)gA.addV()// this vertex has a property of {_partition:"a"}gB = traversal().withEmbedded(graph).withStrategies(strategyB)gB.addV()// this vertex has a property of {_partition:"b"}gA.V()gB.V()The following examples demonstrate the abovePartitionStrategy definition for "strategyA" in other programminglanguages:
PartitionStrategy strategyA = PartitionStrategy.build().partitionKey("_partition") .writePartition("a") .readPartitions("a").create();PartitionStrategy strategyA = new PartitionStrategy( partitionKey: "_partition", writePartition: "a", readPartitions: new List<string>(){"a"});const strategyA =new PartitionStrategy(partitionKey:"_partition",writePartition:"a",readPartitions: ["a"])strategyA = PartitionStrategy(partitionKey="_partition", writePartition="a", readPartitions=["a"])Partitions may also extend toVertexProperty elements if theGraph can support meta-properties and if theincludeMetaProperties value is set totrue when thePartitionStrategy is built. ThepartitionKey will bestored in the meta-properties of theVertexProperty and blind the traversal to those properties. Please note thattheVertexProperty will only be hidden by way of theTraversal itself. For example, callingVertex.property(k)bypasses the context of thePartitionStrategy and will thus allow all properties to be accessed.
By writing elements to particular partitions and then restricting read partitions, the developer is able to createmultiple graphs within a single address space. Moreover, by supporting references between partitions, it is possibleto merge those multiple graphs (i.e. join partitions).
ReadOnlyStrategy
ReadOnlyStrategy is largely self-explanatory. ATraversal that has this strategy applied will throw anIllegalStateException if theTraversal has any mutating steps within it.
ReadOnlyStrategy verificationStrategy = ReadOnlyStrategy.instance();// results in VerificationExceptiong.withStrategies(verificationStrategy).addV('person').iterate();// results in VerificationExceptiong.withStrategies(ReadOnlyStrategy).addV('person').iterate();// results in VerificationExceptiong.WithStrategies(new ReadOnlyStrategy()).addV("person").Iterate();// results in Errorg.withStrategies(new ReadOnlyStrategy()).addV("person").iterate();// resultsin Errorg.withStrategies(ReadOnlyStrategy).addV("person").iterate()ReservedKeysVerificationStrategy
ReservedKeysVerificationStrategy prevents traversals from adding property keys that are protected, providing theoption to throw an exception, log a warning or do both when one of these keys is encountered in a mutating step. Bydefault "id" and "label" are considered "reserved" but the default can be changed by building with thereservedKeys() options and supply aSet of keys to trigger theVerificationException.
ReservedKeysVerificationStrategy verificationStrategy = ReservedKeysVerificationStrategy.build() .throwException().create()// results in VerificationExceptiong.withStrategies(verificationStrategy).addV('person').property("id",123).iterate();// results in VerificationExceptiong.withStrategies(new ReservedKeysVerificationStrategy(throwException:true)) .addV('person').property("id",123).iterate()// results in VerificationExceptiong.WithStrategies(new ReservedKeysVerificationStrategy(throwException: true)) .AddV('person').Property("id",123).Iterate();// results in Errorg.withStrategies(new ReservedKeysVerificationStrategy(throwException:true)) .addV('person').property("id",123).iterate();// resultsin Errorg.withStrategies(ReservedKeysVerificationStrategy(throwException=true)) .addV('person').property("id",123).iterate()SeedStrategy
There are number of components of the Gremlin language that, by design, can produce non-deterministic results:
To get these steps to return deterministic results,SeedStrategy allows assignment of a seed value to theRandomoperations of the steps. The following example demonstrates the random nature ofshuffle:
gremlin> g.V().values('name').fold().order(local).by(shuffle)==>[peter,josh,ripple,vadas,lop,marko]gremlin> g.V().values('name').fold().order(local).by(shuffle)==>[peter,lop,vadas,marko,ripple,josh]gremlin> g.V().values('name').fold().order(local).by(shuffle)==>[peter,marko,ripple,josh,lop,vadas]gremlin> g.V().values('name').fold().order(local).by(shuffle)==>[ripple,vadas,lop,josh,marko,peter]gremlin> g.V().values('name').fold().order(local).by(shuffle)==>[lop,peter,ripple,marko,vadas,josh]g.V().values('name').fold().order(local).by(shuffle)g.V().values('name').fold().order(local).by(shuffle)g.V().values('name').fold().order(local).by(shuffle)g.V().values('name').fold().order(local).by(shuffle)g.V().values('name').fold().order(local).by(shuffle)WithSeedStrategy in place, however, the same order is applied each time:
gremlin> seedStrategy = SeedStrategy.build().seed(999998L).create()==>SeedStrategygremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)==>[peter,josh,marko,lop,ripple,vadas]gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)==>[peter,josh,marko,lop,ripple,vadas]gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)==>[peter,josh,marko,lop,ripple,vadas]gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)==>[peter,josh,marko,lop,ripple,vadas]gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)==>[peter,josh,marko,lop,ripple,vadas]seedStrategy = SeedStrategy.build().seed(999998L).create()g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)Important | SeedStrategy only makes specific steps behave in a deterministic fashion and does not necessarily makethe entire traversal deterministic itself. If the underlying graph database or processing engine happens to notguarantee iteration order, then it is possible that the final result of the traversal will appear to benon-deterministic. In these cases, it would be necessary to enforce a deterministic iteration withorder() prior tothese steps that make use of randomness to return results. |
SubgraphStrategy
SubgraphStrategy is similar toPartitionStrategy in that it constrains aTraversal to certain vertices, edges, and vertex properties as determined by aTraversal-based criterion defined individually for each.
gremlin> graph = TinkerFactory.createTheCrew()==>tinkergraph[vertices:6edges:14]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:6edges:14], standard]gremlin> g.V().as('a').values('location').as('b').////(1) select('a','b').by('name').by()==>[a:marko,b:san diego]==>[a:marko,b:santa cruz]==>[a:marko,b:brussels]==>[a:marko,b:santa fe]==>[a:stephen,b:centreville]==>[a:stephen,b:dulles]==>[a:stephen,b:purcellville]==>[a:matthias,b:bremen]==>[a:matthias,b:baltimore]==>[a:matthias,b:oakland]==>[a:matthias,b:seattle]==>[a:daniel,b:spremberg]==>[a:daniel,b:kaiserslautern]==>[a:daniel,b:aachen]gremlin> g = g.withStrategies(new SubgraphStrategy(vertexProperties: hasNot('endTime')))////(2)==>graphtraversalsource[tinkergraph[vertices:6edges:14], standard]gremlin> g.V().as('a').values('location').as('b').////(3) select('a','b').by('name').by()==>[a:marko,b:santa fe]==>[a:stephen,b:purcellville]==>[a:matthias,b:seattle]==>[a:daniel,b:aachen]gremlin> g.V().as('a').values('location').as('b'). select('a','b').by('name').by().explain()==>Traversal Explanation=============================================================================================================================================================================================================================================Original Traversal [GraphStep(vertex,[])@[a], PropertiesStep([location],value)@[b], SelectStep(last,[a, b],[value(name), identity])]SubgraphStrategy [D] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity ])]ConnectiveStrategy [D] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity ])]RepeatUnrollStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity ])]IdentityRemovalStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity ])]MatchPredicateStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity ])]FilterRankingStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity ])]InlineFilterStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],value)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]IncidentToAdjacentStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],value)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]PathRetractionStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],value)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]EarlyLimitStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],value)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]AdjacentToIncidentStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]ByModulatorOptimizationStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]CountStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]LazyBarrierStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]TinkerGraphCountStrategy [P] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]TinkerGraphStepStrategy [P] [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]ProfileStrategy [F] [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]StandardVerificationStrategy [V] [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]Final Traversal [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]graph = TinkerFactory.createTheCrew()g = traversal().withEmbedded(graph)g.V().as('a').values('location').as('b').////(1) select('a','b').by('name').by()g = g.withStrategies(new SubgraphStrategy(vertexProperties: hasNot('endTime')))////(2)g.V().as('a').values('location').as('b').////(3) select('a','b').by('name').by()g.V().as('a').values('location').as('b'). select('a','b').by('name').by().explain()Get all vertices and their vertex property locations.
Create a
SubgraphStrategywhere vertex properties must not have anendTime-property (thus, the current location).Get all vertices and their current vertex property locations.
The following examples demonstrate the aboveSubgraphStrategy definition in other programming languages:
g.withStrategies(SubgraphStrategy.build().vertexProperties(hasNot("endTime")).create());g.WithStrategies(new SubgraphStrategy(vertexProperties: HasNot("endTime")));g.withStrategies(new SubgraphStrategy(vertexProperties: hasNot("endTime")));g.withStrategies(new SubgraphStrategy(vertexProperties=hasNot("endTime")))Important | This strategy is implemented such that the vertices attached to anEdge must both satisfy the vertexcriterion (if present) in order for theEdge to be considered a part of the subgraph. |
The example below uses all three filters: vertex, edge, and vertex property. People vertices must have lived in morethan three places, edges must be labeled "develops," and vertex properties must be the persons current location or anon-location property.
gremlin> graph = TinkerFactory.createTheCrew()==>tinkergraph[vertices:6edges:14]gremlin> g = traversal().withEmbedded(graph).withStrategies(SubgraphStrategy.build(). vertices(or(hasNot('location'),properties('location').count().is(gt(3)))). edges(hasLabel('develops')). vertexProperties(or(hasLabel(neq('location')),hasNot('endTime'))).create())==>graphtraversalsource[tinkergraph[vertices:6edges:14], standard]gremlin> g.V().elementMap()==>[id:1,label:person,name:marko,location:santa fe]==>[id:8,label:person,name:matthias,location:seattle]==>[id:10,label:software,name:gremlin]==>[id:11,label:software,name:tinkergraph]gremlin> g.E().elementMap()==>[id:13,label:develops,IN:[id:10,label:software],OUT:[id:1,label:person],since:2009]==>[id:14,label:develops,IN:[id:11,label:software],OUT:[id:1,label:person],since:2010]==>[id:21,label:develops,IN:[id:10,label:software],OUT:[id:8,label:person],since:2012]gremlin> g.V().outE().inV(). path(). by('name'). by(). by('name')==>[marko,e[13][1-develops->10],gremlin]==>[marko,e[14][1-develops->11],tinkergraph]==>[matthias,e[21][8-develops->10],gremlin]graph = TinkerFactory.createTheCrew()g = traversal().withEmbedded(graph).withStrategies(SubgraphStrategy.build(). vertices(or(hasNot('location'),properties('location').count().is(gt(3)))). edges(hasLabel('develops')). vertexProperties(or(hasLabel(neq('location')),hasNot('endTime'))).create())g.V().elementMap()g.E().elementMap()g.V().outE().inV(). path(). by('name'). by(). by('name')VertexProgramDenyStrategy
Like theReadOnlyStrategy, theVertexProgramDenyStrategy denies the execution of specific traversals. ATraversalthat has theVertexProgramDenyStrategy applied will throw anIllegalStateException if it uses thewithComputer() step. ThisTraversalStrategy can be useful for configuringGraphTraversalSource instances inGremlin Server with theScriptFileGremlinPlugin.
gremlin> oltpOnly = g.withStrategies(VertexProgramDenyStrategy.instance())==>graphtraversalsource[tinkergraph[vertices:5 edges:7], standard]gremlin> oltpOnly.withComputer().V().elementMap()The TraversalSource does not allow the use of a GraphComputerType ':help' or ':h' for help.Display stack trace? [yN]Domain Specific Languages
Gremlin is adomain specific language (DSL) for traversinggraphs. It operates in the language of vertices, edges and properties. Typically, applications built with Gremlin arenot of the graph domain, but instead model their domain within a graph. For example, the"modern" toy graph modelssoftware and person domain objects with the relationships between them (i.e. a person "knows" another person and aperson "created" software).
{kind=link}
An analyst who wanted to find out if "marko" knows "josh" could write the following Gremlin:
g.V().hasLabel('person').has('name','marko'). out('knows').hasLabel('person').has('name','josh').hasNext()While this method achieves the desired answer, it requires the analyst to traverse the graph in the domain languageof the graph rather than the domain language of the social network. A more natural way for the analyst to write thistraversal might be:
g.persons('marko').knows('josh').hasNext()In the statement above, the traversal is written in the language of the domain, abstracting away the underlyinggraph structure from the query. The two traversal results are equivalent and, indeed, the "Social DSL" producesthe same set of traversal steps as the "Graph DSL" thus producing equivalent strategy application and performanceruntimes.
To further the example of the Social DSL consider the following:
// Graph DSL - find the number of persons who created at least 2 projectsg.V().hasLabel('person'). where(outE("created").count().is(P.gte(2))).count()// Social DSL - find the number of persons who created at least 2 projectssocial.persons().where(createdAtLeast(2)).count()// Graph DSL - determine the age of the youngest friend "marko" hasg.V().hasLabel('person').has('name','marko'). out("knows").hasLabel("person").values("age").min()// Social DSL - determine the age of the youngest friend "marko" hassocial.persons("marko").youngestFriendsAge()Learn more about how to implement these DSLs in theGremlin Language Variants sectionspecific to the programming language of interest.
Translators

There are times when is helpful to translate Gremlin from one programming language to another. Perhaps a large Gremlinexample is found on StackOverflow written in Java, but the programming language the developer has chosen is Python.Fortunately, TinkerPop has developedTranslator infrastructure that will convert Gremlin from one programminglanguage syntax to another.
The functionality relevant to most users is actually a sub-function ofTranslator infrastructure and is morespecifically aScriptTranslator which takes GremlinBytecode of a traversal and generates aString representationof thatBytecode in the programming language syntax that theScriptTranslator instance supports. The translationtherefore allows Gremlin to be converted from the host programming language of theTranslator to another.
The following translators are available, where the first column identifies the host programming language and thecolumns represent the language that Gremlin can be generated in:
| Java | Groovy | Javascript | .NET | Python | Go | |
|---|---|---|---|---|---|---|
Java | - | X | X | X | X | X |
Groovy | X | X | X | |||
Javascript | X | - | ||||
.NET | X | - | ||||
Python | X | - | ||||
Go | X | - |
Each programming language has its own API for translation, but the pattern is quite similar from one to the next:
Warning | WhileTranslator implementations have been around for some time, they are still in their early stages froman interface perspective. API changes may occur in the near future. |
// gremlin-core moduleimportorg.apache.tinkerpop.gremlin.process.traversal.translator.*;GraphTraversalSource g = ...;Traversal<Vertex,Integer> t = g.V().has("person","name","marko"). where(in("knows")). values("age"). map(Lambda.function("it.get() + 1"));Translator.ScriptTranslator groovyTranslator = GroovyTranslator.of("g");System.out.println(groovyTranslator.translate(t).getScript());// OUTPUT: g.V().has("person","name","marko").where(__.in("knows")).values("age").map({it.get() + 1})Translator.ScriptTranslator dotnetTranslator = DotNetTranslator.of("g");System.out.println(dotnetTranslator.translate(t).getScript());// OUTPUT: g.V().Has("person","name","marko").Where(__.In("knows")).Values<object>("age").Map<object>(Lambda.Groovy("it.get() + 1"))Translator.ScriptTranslator pythonTranslator = PythonTranslator.of("g");System.out.println(pythonTranslator.translate(t).getScript());// OUTPUT: g.V().has('person','name','marko').where(__.in_('knows')).age.map(lambda: "it.get() + 1")Translator.ScriptTranslator javascriptTranslator = JavascriptTranslator.of("g");System.out.println(javascriptTranslator.translate(t).getScript());// OUTPUT: g.V().has("person","name","marko").where(__.in_("knows")).values("age").map(() => "it.get() + 1")Translator.ScriptTranslator golangTranslator = GolangTranslator.of("g");System.out.println(golangTranslator.translate(t).getScript());// OUTPUT: g.V().Has("person", "name", "marko").Where(gremlingo.T__.In("knows")).Values("age").Map(&gremlingo.Lambda{Script:"it.get() + 1", Language:""})const g = ...;const t = g.V().has("person","name","marko"). where(in_("knows")). values("age");// Groovyconst translator =new gremlin.process.Translator('g');console.log(translator.translate(t));// OUTPUT: g.V().has('person','name','marko').where(__.in('knows')).values('age')fromgremlin_python.process.translatorimport*g = ...t = (g.V().has('person','name','marko'). where(__.in_("knows")). values("age"))# Groovytranslator = Translator().of('g');print(translator.translate(t.bytecode));# OUTPUT: g.V().has('person','name','marko').where(__.in('knows')).values('age')var g = ...;var t = g.V().Has("person", "name", "marko").Where(In("knows")).Values<int>("age");// Groovyvar translator = GroovyTranslator.Of("g");Console.WriteLine(translator.Translate(t));// OUTPUT: g.V().has('person', 'name', 'marko').where(__.in('knows')).values('age')g := ...t := g.V().Has("person","name","marko"). Where(T__.In("knows")). Values("age")// Groovytranslator := NewTranslator("g")print(translator.Translate(t.Bytecode))// OUTPUT: g.V().has('person','name','marko').where(in('knows')).values('age')The JVM-based translator has the added option of parameter extraction, where the translation process will attempt toidentify opportunities to generate an output that would replace constant values with parameters. The parameters wouldthen be extracted and returned as part of theScript object:
Traversal<Vertex,Integer> t = g.V().has("person","name","marko"). where(__.in("knows")). values("age");// specify true to attempt parameter extractionTranslator.ScriptTranslator translator = GroovyTranslator.of("g",true);Script s = translator.translate(t);System.out.println(s.getScript());// OUTPUT: g.V().has(_args_0,_args_1,_args_2).where(__.in(_args_3)).values(_args_4)System.out.println(s.parameters);// OUTPUT: Optional[{_args_0=person, _args_2=marko, _args_1=name, _args_4=age, _args_3=knows}]TheGroovyTranslator can take aTypeTranslator argument which allows some customization of how types getconverted to script form. TheDefaultTypeTranslator is used if a specific implementation is not specified. A built-inalternative to this implementation is theLanguageTypeTranslator which will prefer use of the Gremlin languagedatetime() function rather than the JVM specificDate andTimestamp conversions. This translator can be helpfulwhen generating scripts that will be sent to Gremlin Server or Remote Graph Providers supporting thedatetime() form.
ThePythonTranslator can take aTypeTranslator argument to disable the syntactic sugar which the default translatorapplies to converted queries. TheDefaultTypeTranslator is used if a specific implementation is not specified.
Traversal<Vertex,String> t = g.V().range(0,10).has("person","name","marko"). limit(2). values("name");// default translatorTranslator.ScriptTranslator translator = PythonTranslator.of("g");String defaultQueryTranslation = translator.translate(t)System.out.println(defaultQueryTranslation);// OUTPUT: g.V()[0:10].has('person','name','marko')[0:2].name// no synantic sugar translatorTranslator.ScriptTranslator noSugarTranslator = PythonTranslator.of("g",new PythonTranslator.NoSugarTranslator(false));String noSugarTranslation = noSugarTranslator.translate(t)System.out.println(noSugarTranslation);// OUTPUT: g.V().range_(0,10).has('person','name','marko').limit(2).values('name')// With parameter extractionTranslator.ScriptTranslator noSugarTranslatorWithParameters = PythonTranslator.of("g",new PythonTranslator.NoSugarTranslator(true));String noSugarTranslationWithParameters = noSugarTranslatorWithParameters.translate(t)System.out.println(noSugarTranslationWithParameters);// OUTPUT: g.V().range_(0,10).has(_args_0,_args_1,_args_2).limit(2).values(_args_1)The GraphComputer
 TinkerPop provides two primary means of interacting with agraph:online transaction processing (OLTP) andonline analytical processing (OLAP). OLTP-basedgraph systems allow the user to query the graph in real-time. However, typically, real-time performance is onlypossible when a local traversal is enacted. A local traversal is one that starts at a particular vertex (or small setof vertices) and touches a small set of connected vertices (by any arbitrary path of arbitrary length). In short, OLTPqueries interact with a limited set of data and respond on the order of milliseconds or seconds. On the other hand,with OLAP graph processing, the entire graph is processed and thus, every vertex and edge is analyzed (some timesmore than once for iterative, recursive algorithms). Due to the amount of data being processed, the results aretypically not returned in real-time and for massive graphs (i.e. graphs represented across a cluster of machines),results can take on the order of minutes or hours.
TinkerPop provides two primary means of interacting with agraph:online transaction processing (OLTP) andonline analytical processing (OLAP). OLTP-basedgraph systems allow the user to query the graph in real-time. However, typically, real-time performance is onlypossible when a local traversal is enacted. A local traversal is one that starts at a particular vertex (or small setof vertices) and touches a small set of connected vertices (by any arbitrary path of arbitrary length). In short, OLTPqueries interact with a limited set of data and respond on the order of milliseconds or seconds. On the other hand,with OLAP graph processing, the entire graph is processed and thus, every vertex and edge is analyzed (some timesmore than once for iterative, recursive algorithms). Due to the amount of data being processed, the results aretypically not returned in real-time and for massive graphs (i.e. graphs represented across a cluster of machines),results can take on the order of minutes or hours.
OLTP: real-time, limited data accessed, random data access, sequential processing, querying
OLAP: long running, entire data set accessed, sequential data access, parallel processing, batch processing

The image above demonstrates the difference between Gremlin OLTP and Gremlin OLAP. With Gremlin OLTP, the graph iswalked by moving from vertex-to-vertex via incident edges. With Gremlin OLAP, all vertices are provided aVertexProgram. The programs send messages to one another with the topological structure of the graph acting as thecommunication network (though random message passing possible). In many respects, the messages passed are likethe OLTP traversers moving from vertex-to-vertex. However, all messages are moving independent of one another, inparallel. Once a vertex program is finished computing, TinkerPop’s OLAP engine supports any numberMapReduce jobs over the resultant graph.
Important | GraphComputer was designed from the start to be used within a multi-JVM, distributed environment — in other words, a multi-machine compute cluster. As such, all the computing objects must be able to be migratedbetween JVMs. The pattern promoted is to store state information in aConfiguration object to later be regeneratedby a loading process. It is important to realize thatVertexProgram,MapReduce, and numerous particular instancesrely heavily on the state of the computing classes (not the structure, but the processes) to be stored in aConfiguration. |
VertexProgram
 GraphComputer takes a
GraphComputer takes aVertexProgram. A VertexProgram can be thought ofas a piece of code that is executed at each vertex in logically parallel manner until some termination condition ismet (e.g. a number of iterations have occurred, no more data is changing in the graph, etc.). A submittedVertexProgram is copied to all the workers in the graph. A worker is not an explicit concept in the API, but isassumed of allGraphComputer implementations. At minimum each vertex is a worker (though this would be inefficientdue to the fact that each vertex would maintain a VertexProgram). In practice, the workers partition the vertex setand are responsible for the execution of the VertexProgram over all the vertices within their sphere of influence.The workers orchestrate the execution of theVertexProgram.execute() method on all their vertices in anbulk synchronous parallel (BSP) fashion. The verticesare able to communicate with one another via messages. There are two kinds of messages in Gremlin OLAP:MessageScope.Local andMessageScope.Global. A local message is a message to an adjacent vertex. A globalmessage is a message to any arbitrary vertex in the graph. Once the VertexProgram has completed its execution,any number ofMapReduce jobs are evaluated. MapReduce jobs are provided by the user viaGraphComputer.mapReduce() or by theVertexProgram viaVertexProgram.getMapReducers().
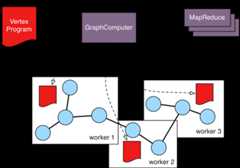
The example below demonstrates how to submit a VertexProgram to a graph’s GraphComputer.GraphComputer.submit()yields aFuture<ComputerResult>. TheComputerResult has the resultant computed graph which can be a full copyof the original graph (seeHadoop-Gremlin) or a view over the original graph (seeTinkerGraph). The ComputerResult also provides access to computational side-effects calledMemory(which includes, for example, runtime, number of iterations, results of MapReduce jobs, and VertexProgram-specificmemory manipulations).
gremlin> result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()==>result[tinkergraph[vertices:6edges:0],memory[size:0]]gremlin> result.memory().runtime==>11gremlin> g = traversal().withEmbedded(result.graph())==>graphtraversalsource[tinkergraph[vertices:6edges:0], standard]gremlin> g.V().elementMap()==>[id:1,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865537,name:marko,age:29]==>[id:2,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719103,name:vadas,age:27]==>[id:3,label:software,gremlin.pageRankVertexProgram.pageRank:0.3047200907912249,name:lop,lang:java]==>[id:4,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719103,name:josh,age:32]==>[id:5,label:software,gremlin.pageRankVertexProgram.pageRank:0.1757988989970823,name:ripple,lang:java]==>[id:6,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865537,name:peter,age:35]result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()result.memory().runtimeg = traversal().withEmbedded(result.graph())g.V().elementMap()Note | This model of "vertex-centric graph computing" was made popular by Google’sPregel graph engine.In the open source world, this model is found in OLAP graph computing systems such asGiraph,Hama. TinkerPop extends thepopularized model with integrated post-processingMapReduce jobs over the vertex set. |
MapReduce
The BSP model proposed by Pregel stores the results of the computation in a distributed manner as properties on theelements in the graph. In many situations, it is necessary to aggregate those resultant properties into a singleresult set (i.e. a statistic). For instance, assume a VertexProgram that computes a nominal cluster for each vertex(i.e.a graph clustering algorithm). At the end of thecomputation, each vertex will have a property denoting the cluster it was assigned to. TinkerPop provides theability to answer global questions about the clusters. For instance, in order to answer the following questions,MapReduce jobs are required:
How many vertices are in each cluster? (presented below)
How many unique clusters are there? (presented below)
What is the average age of each vertex in each cluster?
What is the degree distribution of the vertices in each cluster?
A compressed representation of theMapReduce API in TinkerPop is provided below. The key idea is that themap-stage processes all vertices to emit key/value pairs. Those values are aggregated on their respective keyfor thereduce-stage to do its processing to ultimately yield more key/value pairs.
publicinterfaceMapReduce<MK, MV, RK, RV, R> {publicvoid map(final Vertex vertex,final MapEmitter<MK, MV> emitter);publicvoid reduce(final MK key,finalIterator<MV> values,final ReduceEmitter<RK, RV> emitter);// there are more methods}Important | The vertex that is passed into theMapReduce.map() method does not contain edges. The vertex onlycontains original and computed vertex properties. This reduces the amount of data required to be loaded and ensuresthat MapReduce is used for post-processing computed results. All edge-based computing should be accomplished in theVertexProgram. |

TheMapReduce extension to GraphComputer is made explicit when examining thePeerPressureVertexProgram and correspondingClusterPopulationMapReduce.In the code below, the GraphComputer result returns the computed onGraph as well as theMemory of thecomputation (ComputerResult). The memory maintain the results of any MapReduce jobs. The cluster populationMapReduce result states that there are 5 vertices in cluster 1 and 1 vertex in cluster 6. This can be verified(in a serial manner) by looking at thePeerPressureVertexProgram.CLUSTER property of the resultant graph. Noticethat the property is "hidden" unless it is directly accessed via name.
gremlin> graph = TinkerFactory.createModern()==>tinkergraph[vertices:6edges:6]gremlin> result = graph.compute().program(PeerPressureVertexProgram.build().create()).mapReduce(ClusterPopulationMapReduce.build().create()).submit().get()==>result[tinkergraph[vertices:6edges:0],memory[size:1]]gremlin> result.memory().get('clusterPopulation')==>1=5==>6=1gremlin> g = traversal().withEmbedded(result.graph())==>graphtraversalsource[tinkergraph[vertices:6edges:0], standard]gremlin> g.V().values(PeerPressureVertexProgram.CLUSTER).groupCount().next()==>1=5==>6=1gremlin> g.V().elementMap()==>[id:1,label:person,gremlin.peerPressureVertexProgram.cluster:1,name:marko,age:29]==>[id:2,label:person,gremlin.peerPressureVertexProgram.cluster:1,name:vadas,age:27]==>[id:3,label:software,gremlin.peerPressureVertexProgram.cluster:1,name:lop,lang:java]==>[id:4,label:person,gremlin.peerPressureVertexProgram.cluster:1,name:josh,age:32]==>[id:5,label:software,gremlin.peerPressureVertexProgram.cluster:1,name:ripple,lang:java]==>[id:6,label:person,gremlin.peerPressureVertexProgram.cluster:6,name:peter,age:35]graph = TinkerFactory.createModern()result = graph.compute().program(PeerPressureVertexProgram.build().create()).mapReduce(ClusterPopulationMapReduce.build().create()).submit().get()result.memory().get('clusterPopulation')g = traversal().withEmbedded(result.graph())g.V().values(PeerPressureVertexProgram.CLUSTER).groupCount().next()g.V().elementMap()If there are numerous statistics desired, then its possible to register as many MapReduce jobs as needed. Forinstance, theClusterCountMapReduce determines how many unique clusters were created by the peer pressure algorithm.Below bothClusterCountMapReduce andClusterPopulationMapReduce are computed over the resultant graph.
gremlin> result = graph.compute().program(PeerPressureVertexProgram.build().create()). mapReduce(ClusterPopulationMapReduce.build().create()). mapReduce(ClusterCountMapReduce.build().create()).submit().get()==>result[tinkergraph[vertices:6edges:0],memory[size:2]]gremlin> result.memory().clusterPopulation==>1=5==>6=1gremlin> result.memory().clusterCount==>2result = graph.compute().program(PeerPressureVertexProgram.build().create()). mapReduce(ClusterPopulationMapReduce.build().create()). mapReduce(ClusterCountMapReduce.build().create()).submit().get()result.memory().clusterPopulationresult.memory().clusterCountImportant | The MapReduce model of TinkerPop does not support MapReduce chaining. Thus, the order in which theMapReduce jobs are executed is irrelevant. This is made apparent when realizing that themap()-stage takes aVertex as its input and thereduce()-stage yields key/value pairs. Thus, the results of reduce can not fed backinto amap(). |
A Collection of VertexPrograms
TinkerPop provides a collection of VertexPrograms that implement common algorithms. This section discusses the variousimplementations.
Important | The vertex programs presented are what are provided as of TinkerPop 3.7.4. Over time, with future releases,more algorithms will be added. |
PageRankVertexProgram
 PageRank is perhaps themost popular OLAP-oriented graph algorithm. Thiseigenvector centralityvariant was developed by Brin and Page of Google. PageRank defines a centrality value for all vertices in the graph,where centrality is defined recursively where a vertex is central if it is connected to central vertices. PageRank isan iterative algorithm that converges to asteady state distribution. Ifthe pageRank values are normalized to 1.0, then the pageRank value of a vertex is the probability that a random walkerwill be seen that that vertex in the graph at any arbitrary moment in time. In order to help developers understand themethods of a
PageRank is perhaps themost popular OLAP-oriented graph algorithm. Thiseigenvector centralityvariant was developed by Brin and Page of Google. PageRank defines a centrality value for all vertices in the graph,where centrality is defined recursively where a vertex is central if it is connected to central vertices. PageRank isan iterative algorithm that converges to asteady state distribution. Ifthe pageRank values are normalized to 1.0, then the pageRank value of a vertex is the probability that a random walkerwill be seen that that vertex in the graph at any arbitrary moment in time. In order to help developers understand themethods of aVertexProgram, the PageRankVertexProgram code is analyzed below.
publicclassPageRankVertexProgramimplements VertexProgram<Double> {//1publicstaticfinalString PAGE_RANK ="gremlin.pageRankVertexProgram.pageRank";privatestaticfinalString EDGE_COUNT ="gremlin.pageRankVertexProgram.edgeCount";privatestaticfinalString PROPERTY ="gremlin.pageRankVertexProgram.property";privatestaticfinalString VERTEX_COUNT ="gremlin.pageRankVertexProgram.vertexCount";privatestaticfinalString ALPHA ="gremlin.pageRankVertexProgram.alpha";privatestaticfinalString EPSILON ="gremlin.pageRankVertexProgram.epsilon";privatestaticfinalString MAX_ITERATIONS ="gremlin.pageRankVertexProgram.maxIterations";privatestaticfinalString EDGE_TRAVERSAL ="gremlin.pageRankVertexProgram.edgeTraversal";privatestaticfinalString INITIAL_RANK_TRAVERSAL ="gremlin.pageRankVertexProgram.initialRankTraversal";privatestaticfinalString TELEPORTATION_ENERGY ="gremlin.pageRankVertexProgram.teleportationEnergy";privatestaticfinalString CONVERGENCE_ERROR ="gremlin.pageRankVertexProgram.convergenceError";private MessageScope.Local<Double> incidentMessageScope = MessageScope.Local.of(__::outE);//2private MessageScope.Local<Double> countMessageScope = MessageScope.Local.of(new MessageScope.Local.ReverseTraversalSupplier(this.incidentMessageScope));private PureTraversal<Vertex, Edge> edgeTraversal =null;private PureTraversal<Vertex, ?extendsNumber> initialRankTraversal =null;privatedouble alpha =0.85d;privatedouble epsilon =0.00001d;privateint maxIterations =20;privateString property = PAGE_RANK;//3privateSet<VertexComputeKey> vertexComputeKeys;privateSet<MemoryComputeKey> memoryComputeKeys;private PageRankVertexProgram() { }@Overridepublicvoid loadState(final Graph graph,finalConfiguration configuration) {//4if (configuration.containsKey(INITIAL_RANK_TRAVERSAL))this.initialRankTraversal = PureTraversal.loadState(configuration, INITIAL_RANK_TRAVERSAL, graph);if (configuration.containsKey(EDGE_TRAVERSAL)) {this.edgeTraversal = PureTraversal.loadState(configuration, EDGE_TRAVERSAL, graph);this.incidentMessageScope = MessageScope.Local.of(() ->this.edgeTraversal.get().clone());this.countMessageScope = MessageScope.Local.of(new MessageScope.Local.ReverseTraversalSupplier(this.incidentMessageScope)); }this.alpha = configuration.getDouble(ALPHA,this.alpha);this.epsilon = configuration.getDouble(EPSILON,this.epsilon);this.maxIterations = configuration.getInt(MAX_ITERATIONS,20);this.property = configuration.getString(PROPERTY, PAGE_RANK);this.vertexComputeKeys =newHashSet<>(Arrays.asList( VertexComputeKey.of(this.property,false), VertexComputeKey.of(EDGE_COUNT,true)));//5this.memoryComputeKeys =newHashSet<>(Arrays.asList( MemoryComputeKey.of(TELEPORTATION_ENERGY, Operator.sum,true,true), MemoryComputeKey.of(VERTEX_COUNT, Operator.sum,true,true), MemoryComputeKey.of(CONVERGENCE_ERROR, Operator.sum,false,true))); }@Overridepublicvoid storeState(finalConfiguration configuration) { VertexProgram.super.storeState(configuration); configuration.setProperty(ALPHA,this.alpha); configuration.setProperty(EPSILON,this.epsilon); configuration.setProperty(PROPERTY,this.property); configuration.setProperty(MAX_ITERATIONS,this.maxIterations);if (null !=this.edgeTraversal)this.edgeTraversal.storeState(configuration, EDGE_TRAVERSAL);if (null !=this.initialRankTraversal)this.initialRankTraversal.storeState(configuration, INITIAL_RANK_TRAVERSAL); }@Overridepublic GraphComputer.ResultGraph getPreferredResultGraph() {return GraphComputer.ResultGraph.NEW; }@Overridepublic GraphComputer.Persist getPreferredPersist() {return GraphComputer.Persist.VERTEX_PROPERTIES; }@OverridepublicSet<VertexComputeKey> getVertexComputeKeys() {//6returnthis.vertexComputeKeys; }@Overridepublic Optional<MessageCombiner<Double>> getMessageCombiner() {return (Optional) PageRankMessageCombiner.instance(); }@OverridepublicSet<MemoryComputeKey> getMemoryComputeKeys() {returnthis.memoryComputeKeys; }@OverridepublicSet<MessageScope> getMessageScopes(final Memory memory) {finalSet<MessageScope> set =newHashSet<>(); set.add(memory.isInitialIteration() ?this.countMessageScope :this.incidentMessageScope);return set; }@Overridepublic PageRankVertexProgram clone() {try {final PageRankVertexProgram clone = (PageRankVertexProgram)super.clone();if (null !=this.initialRankTraversal) clone.initialRankTraversal =this.initialRankTraversal.clone();return clone; }catch (finalCloneNotSupportedException e) {thrownewIllegalStateException(e.getMessage(), e); } }@Overridepublicvoid setup(final Memory memory) { memory.set(TELEPORTATION_ENERGY,null ==this.initialRankTraversal ?1.0d :0.0d); memory.set(VERTEX_COUNT,0.0d); memory.set(CONVERGENCE_ERROR,1.0d); }@Overridepublicvoid execute(final Vertex vertex, Messenger<Double> messenger,final Memory memory) {//7if (memory.isInitialIteration()) { messenger.sendMessage(this.countMessageScope,1.0d);//8 memory.add(VERTEX_COUNT,1.0d); }else {finaldouble vertexCount = memory.<Double>get(VERTEX_COUNT);finaldouble edgeCount;double pageRank;if (1 == memory.getIteration()) { edgeCount = IteratorUtils.reduce(messenger.receiveMessages(),0.0d, (a, b) -> a + b); vertex.property(VertexProperty.Cardinality.single, EDGE_COUNT, edgeCount); pageRank =null ==this.initialRankTraversal ?0.0d : TraversalUtil.apply(vertex,this.initialRankTraversal.get()).doubleValue();//9 }else { edgeCount = vertex.value(EDGE_COUNT); pageRank = IteratorUtils.reduce(messenger.receiveMessages(),0.0d, (a, b) -> a + b);//10 }//////////////////////////finaldouble teleporationEnergy = memory.get(TELEPORTATION_ENERGY);if (teleporationEnergy >0.0d) {finaldouble localTerminalEnergy = teleporationEnergy / vertexCount; pageRank = pageRank + localTerminalEnergy; memory.add(TELEPORTATION_ENERGY, -localTerminalEnergy); }finaldouble previousPageRank = vertex.<Double>property(this.property).orElse(0.0d); memory.add(CONVERGENCE_ERROR,Math.abs(pageRank - previousPageRank)); vertex.property(VertexProperty.Cardinality.single,this.property, pageRank); memory.add(TELEPORTATION_ENERGY, (1.0d -this.alpha) * pageRank); pageRank =this.alpha * pageRank;if (edgeCount >0.0d) messenger.sendMessage(this.incidentMessageScope, pageRank / edgeCount);else memory.add(TELEPORTATION_ENERGY, pageRank); } }@Overridepublicboolean terminate(final Memory memory) {//11boolean terminate = memory.<Double>get(CONVERGENCE_ERROR) <this.epsilon || memory.getIteration() >=this.maxIterations; memory.set(CONVERGENCE_ERROR,0.0d);return terminate; }@OverridepublicString toString() {return StringFactory.vertexProgramString(this,"alpha=" +this.alpha +", epsilon=" +this.epsilon +", iterations=" +this.maxIterations); }}PageRankVertexProgramimplementsVertexProgram<Double>because the messages it sends are Java doubles.The default path of energy propagation is via outgoing edges from the current vertex.
The resulting PageRank values for the vertices are stored as a vertex property.
A vertex program is constructed using an Apache
Configurationto ensure easy dissemination across a cluster of JVMs.EDGE_COUNTis a transient "scratch data" compute key whilePAGE_RANKis not.A vertex program must define the "compute keys" that are the properties being operated on during the computation.
The "while"-loop of the vertex program.
In order to determine how to distribute the energy to neighbors, a "1"-count is used to determine how many incident vertices exist for the
MessageScope.Initially, each vertex is provided an equal amount of energy represented as a double.
Energy is aggregated, computed on according to the PageRank algorithm, and then disseminated according to the defined
MessageScope.Local.The computation is terminated after epsilon-convergence is met or a pre-defined number of iterations have taken place.
The abovePageRankVertexProgram is used as follows.
gremlin> result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()==>result[tinkergraph[vertices:6edges:0],memory[size:0]]gremlin> result.memory().runtime==>4gremlin> g = traversal().withEmbedded(result.graph())==>graphtraversalsource[tinkergraph[vertices:6edges:0], standard]gremlin> g.V().elementMap()==>[id:1,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865537,name:marko,age:29]==>[id:2,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719103,name:vadas,age:27]==>[id:3,label:software,gremlin.pageRankVertexProgram.pageRank:0.30472009079122486,name:lop,lang:java]==>[id:4,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719103,name:josh,age:32]==>[id:5,label:software,gremlin.pageRankVertexProgram.pageRank:0.1757988989970823,name:ripple,lang:java]==>[id:6,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865537,name:peter,age:35]result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()result.memory().runtimeg = traversal().withEmbedded(result.graph())g.V().elementMap()Note thatGraphTraversal provides apageRank()-step.
gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().pageRank().elementMap()==>[id:6,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865543,name:peter,age:35]==>[id:5,label:software,gremlin.pageRankVertexProgram.pageRank:0.17579889899708237,name:ripple,lang:java]==>[id:2,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719108,name:vadas,age:27]==>[id:4,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719108,name:josh,age:32]==>[id:3,label:software,gremlin.pageRankVertexProgram.pageRank:0.30472009079122503,name:lop,lang:java]==>[id:1,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865543,name:marko,age:29]gremlin> g.V().pageRank(). with(PageRank.propertyName,'pageRank'). with(PageRank.times,5). order(). by('pageRank'). elementMap()==>[id:3,label:software,pageRank:0.30511923758466225,name:lop,lang:java]==>[id:1,label:person,pageRank:0.11362166126141336,name:marko,age:29]==>[id:4,label:person,pageRank:0.1459842213689022,name:josh,age:32]==>[id:5,label:software,pageRank:0.17566899715470685,name:ripple,lang:java]==>[id:2,label:person,pageRank:0.1459842213689022,name:vadas,age:27]==>[id:6,label:person,pageRank:0.11362166126141336,name:peter,age:35]g = traversal().withEmbedded(graph).withComputer()g.V().pageRank().elementMap()g.V().pageRank(). with(PageRank.propertyName,'pageRank'). with(PageRank.times,5). order(). by('pageRank'). elementMap()PeerPressureVertexProgram
ThePeerPressureVertexProgram is a clustering algorithm that assigns a nominal value to each vertex in the graph.The nominal value represents the vertex’s cluster. If two vertices have the same nominal value, then they are in thesame cluster. The algorithm proceeds in the following manner.
Every vertex assigns itself to a unique cluster ID (initially, its vertex ID).
Every vertex determines its per neighbor vote strength as 1.0d / incident edges count.
Every vertex sends its cluster ID and vote strength to its adjacent vertices as a
Pair<Serializable,Double>Every vertex generates a vote energy distribution of received cluster IDs and changes its current cluster ID to the most frequent cluster ID.
If there is a tie, then the cluster with the lowest
toString()comparison is selected.
Steps 3 and 4 repeat until either a max number of iterations has occurred or no vertex has adjusted its cluster anymore.
Note thatGraphTraversal provides apeerPressure()-step.
gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().peerPressure().with(PeerPressure.propertyName,'cluster').elementMap()==>[id:1,label:person,cluster:1,name:marko,age:29]==>[id:4,label:person,cluster:1,name:josh,age:32]==>[id:2,label:person,cluster:1,name:vadas,age:27]==>[id:3,label:software,cluster:1,name:lop,lang:java]==>[id:5,label:software,cluster:1,name:ripple,lang:java]==>[id:6,label:person,cluster:6,name:peter,age:35]gremlin> g.V().peerPressure(). with(PeerPressure.edges,outE('knows')). with(PeerPressure.propertyName,'cluster'). elementMap()==>[id:1,label:person,cluster:1,name:marko,age:29]==>[id:3,label:software,cluster:3,name:lop,lang:java]==>[id:5,label:software,cluster:5,name:ripple,lang:java]==>[id:4,label:person,cluster:1,name:josh,age:32]==>[id:6,label:person,cluster:6,name:peter,age:35]==>[id:2,label:person,cluster:1,name:vadas,age:27]g = traversal().withEmbedded(graph).withComputer()g.V().peerPressure().with(PeerPressure.propertyName,'cluster').elementMap()g.V().peerPressure(). with(PeerPressure.edges,outE('knows')). with(PeerPressure.propertyName,'cluster'). elementMap()ConnectedComponentVertexProgram
TheConnectedComponentVertexProgram identifiesConnected Componentinstances in a graph. SeeconnectedComponent()-step for more information.
ShortestPathVertexProgram
TheShortestPathVertexProram provides an easy way to find shortest non-cyclic paths in the graph. It provides several options to configurethe output format, the start- and end-vertices, the direction, a custom distance function, as well as a distance limitation. By default it justfinds all undirected, shortest paths in the graph.
gremlin> spvp = ShortestPathVertexProgram.build().create()////(1)==>ShortestPathVertexProgram[includeEdges=false]gremlin> result = graph.compute().program(spvp).submit().get()////(2)==>result[tinkergraph[vertices:6edges:6],memory[size:1]]gremlin> result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS)////(3)==>[v[1],v[2]]==>[v[2]]==>[v[3],v[1],v[2]]==>[v[4],v[1],v[2]]==>[v[5],v[4],v[1],v[2]]==>[v[6],v[3],v[1],v[2]]==>[v[1]]==>[v[2],v[1]]==>[v[3],v[1]]==>[v[4],v[1]]==>[v[5],v[4],v[1]]==>[v[6],v[3],v[1]]==>[v[1],v[4],v[5]]==>[v[2],v[1],v[4],v[5]]==>[v[3],v[4],v[5]]==>[v[4],v[5]]==>[v[5]]==>[v[6],v[3],v[4],v[5]]==>[v[1],v[4]]==>[v[2],v[1],v[4]]==>[v[3],v[4]]==>[v[4]]==>[v[5],v[4]]==>[v[6],v[3],v[4]]==>[v[1],v[3]]==>[v[2],v[1],v[3]]==>[v[3]]==>[v[4],v[3]]==>[v[5],v[4],v[3]]==>[v[6],v[3]]==>[v[1],v[3],v[6]]==>[v[2],v[1],v[3],v[6]]==>[v[3],v[6]]==>[v[4],v[3],v[6]]==>[v[5],v[4],v[3],v[6]]==>[v[6]]spvp = ShortestPathVertexProgram.build().create()////(1)result = graph.compute().program(spvp).submit().get()////(2)result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS)//3Create a
ShortestPathVertexProgramwith its default configuration.Execute the
ShortestPathVertexProgram.Get all shortest paths from the results memory.
gremlin> spvp = ShortestPathVertexProgram.build().includeEdges(true).create()////(1)==>ShortestPathVertexProgram[includeEdges=true]gremlin> result = graph.compute().program(spvp).submit().get()////(2)==>result[tinkergraph[vertices:6edges:6],memory[size:1]]gremlin> result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS)////(3)==>[v[1],e[7][1-knows->2],v[2]]==>[v[2]]==>[v[3],e[9][1-created->3],v[1],e[7][1-knows->2],v[2]]==>[v[4],e[8][1-knows->4],v[1],e[7][1-knows->2],v[2]]==>[v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1],e[7][1-knows->2],v[2]]==>[v[6],e[12][6-created->3],v[3],e[9][1-created->3],v[1],e[7][1-knows->2],v[2]]==>[v[1]]==>[v[2],e[7][1-knows->2],v[1]]==>[v[3],e[9][1-created->3],v[1]]==>[v[4],e[8][1-knows->4],v[1]]==>[v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1]]==>[v[6],e[12][6-created->3],v[3],e[9][1-created->3],v[1]]==>[v[1],e[9][1-created->3],v[3]]==>[v[2],e[7][1-knows->2],v[1],e[9][1-created->3],v[3]]==>[v[3]]==>[v[4],e[11][4-created->3],v[3]]==>[v[5],e[10][4-created->5],v[4],e[11][4-created->3],v[3]]==>[v[6],e[12][6-created->3],v[3]]==>[v[1],e[9][1-created->3],v[3],e[12][6-created->3],v[6]]==>[v[2],e[7][1-knows->2],v[1],e[9][1-created->3],v[3],e[12][6-created->3],v[6]]==>[v[3],e[12][6-created->3],v[6]]==>[v[4],e[11][4-created->3],v[3],e[12][6-created->3],v[6]]==>[v[5],e[10][4-created->5],v[4],e[11][4-created->3],v[3],e[12][6-created->3],v[6]]==>[v[6]]==>[v[1],e[8][1-knows->4],v[4]]==>[v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4]]==>[v[3],e[11][4-created->3],v[4]]==>[v[4]]==>[v[5],e[10][4-created->5],v[4]]==>[v[6],e[12][6-created->3],v[3],e[11][4-created->3],v[4]]==>[v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]==>[v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]==>[v[3],e[11][4-created->3],v[4],e[10][4-created->5],v[5]]==>[v[4],e[10][4-created->5],v[5]]==>[v[5]]==>[v[6],e[12][6-created->3],v[3],e[11][4-created->3],v[4],e[10][4-created->5],v[5]]spvp = ShortestPathVertexProgram.build().includeEdges(true).create()////(1)result = graph.compute().program(spvp).submit().get()////(2)result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS)//3Create a
ShortestPathVertexProgramas before, but configure it to include edges in the result.Execute the
ShortestPathVertexProgram.Get all shortest paths from the results memory.
TheShortestPathVertexProgram.Builder provides the following configuration methods:
| Method | Description | Default |
|---|---|---|
| Sets a filter traversal for the start vertices (e.g. | all vertices ( |
| Sets a filter traversal for the end vertices. | all vertices |
| Sets the direction to traverse during the shortest path discovery. |
|
| Sets a traversal that emits the edges to traverse from the current vertex. |
|
| Sets the edge property to use for the distance calculations. | none |
| Sets the traversal that calculates the distance for the current edge. |
|
| Limits the shortest path distance. | none |
| Whether to include edges in shortest paths or not. |
|
Important | If a maximum distance is provided, the discovery process will only stop to follow a path at this distance if there was nocustom distance property or traversal provided. Custom distances can be negative, hence exceeding the maximum distance doesn’t mean that therecan’t be any more valid paths. However, paths will be filtered at the end, when no more non-cyclic paths can be found. The bottom line is thatcustom distance properties or traversals can lead to much longer runtimes and a much higher memory consumption. |
Note thatGraphTraversal provides ashortestPath()-step.
CloneVertexProgram
TheCloneVertexProgram (known in versions prior to 3.2.10 asBulkDumperVertexProgram) copies a whole graph fromany graphInputFormat to any graphOutputFormat. TinkerPop provides the following:
OutputFormatGraphSONOutputFormatGryoOutputFormatScriptOutputFormat
InputFormatGraphSONInputFormatGryoInputFormatScriptInputFormat).
Anexample is provided in the SparkGraphComputer section.
Graph Providers should consider writing their ownOutputFormat andInputFormat which would allow bulk loading andexport capabilities through thisVertexProgram. This topic is discussed further in theProvider Documentation.
TraversalVertexProgram
 The
TheTraversalVertexProgram is a "special" VertexProgram inthat it can be executed via aTraversal and aGraphComputer. In Gremlin, it is possible to havethe same traversal executed using either the standard OLTP-engine or theGraphComputer OLAP-engine. The differencebeing where the traversal is submitted.
Note | This model of graph traversal in a BSP system was first implemented by theFaunus graph analytics engine and originally described inLocal and Distributed Traversal Engines. |
gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:6edges:6], standard]gremlin> g.V().both().hasLabel('person').values('age').groupCount().next()// OLTP==>32=3==>35=1==>27=1==>29=3gremlin> g = traversal().withEmbedded(graph).withComputer()==>graphtraversalsource[tinkergraph[vertices:6edges:6], graphcomputer]gremlin> g.V().both().hasLabel('person').values('age').groupCount().next()// OLAP==>32=3==>35=1==>27=1==>29=3g = traversal().withEmbedded(graph)g.V().both().hasLabel('person').values('age').groupCount().next()// OLTPg = traversal().withEmbedded(graph).withComputer()g.V().both().hasLabel('person').values('age').groupCount().next()// OLAP
In the OLAP example above, aTraversalVertexProgram is (logically) sent to each vertex in the graph. Each instanceevaluation requires (logically) 5 BSP iterations and each iteration is interpreted as such:
g.V(): Put a traverser on each vertex in the graph.both(): Propagate each traverser to the verticesboth-adjacent to its current vertex.hasLabel('person'): If the vertex is not a person, kill the traversers at that vertex.values('age'): Have all the traversers reference the integer age of their current vertex.groupCount(): Count how many times a particular age has been seen.
While 5 iterations were presented, in fact,TraversalVertexProgram will execute the traversal in only2 iterations. The reason being is thatg.V().both() andhasLabel('person').values('age').groupCount() can beexecuted in a single iteration as any message sent would simply be to the current executing vertex. Thus, a simple optimizationexists in Gremlin OLAP called "reflexive message passing" which simulates non-message-passing BSP iterations within asingle BSP iteration.
The same OLAP traversal can be executed using the standardgraph.compute() model, though at the expense of verbosity.TraversalVertexProgram provides a fluentBuilder for constructing aTraversalVertexProgram. The specifiedtraversal() can be either a directTraversal object or aJSR-223 script that will generate aTraversal. There is no benefit to using the model below. It is demonstrated to help elucidate how Gremlin OLAP traversalsare ultimately compiled for execution on aGraphComputer.
gremlin> result = graph.compute().program(TraversalVertexProgram.build().traversal(g.V().both().hasLabel('person').values('age').groupCount('a')).create()).submit().get()==>result[tinkergraph[vertices:6edges:6],memory[size:2]]gremlin> result.memory().a==>32=3==>35=1==>27=1==>29=3gremlin> result.memory().iteration==>1gremlin> result.memory().runtime==>4result = graph.compute().program(TraversalVertexProgram.build().traversal(g.V().both().hasLabel('person').values('age').groupCount('a')).create()).submit().get()result.memory().aresult.memory().iterationresult.memory().runtimeDistributed Gremlin Gotchas
Gremlin OLTP is not identical to Gremlin OLAP.
Important | There are two primary theoretical differences between Gremlin OLTP and Gremlin OLAP. First, Gremlin OLTP(viaTraversal) leverages adepth-first execution engine.Depth-first execution has a limited memory footprint due tolazy evaluation.On the other hand, Gremlin OLAP (viaTraversalVertexProgram) leverages abreadth-first execution engine which maintains a larger memoryfootprint, but a better time complexity due to vertex-local traversers being able to be "bulked." The second differenceis that Gremlin OLTP is executed in a serial/streaming fashion, while Gremlin OLAP is executed in a parallel/step-wise fashion. These twofundamental differences lead to the behaviors enumerated below. |

Traversal sideEffects are represented as a distributed data structure across
GraphComputerworkers. It is notpossible to get a global view of a sideEffect until after an iteration has occurred and global sideEffects are re-broadcasted to the workers.In some situations, a "stale" local representation of the sideEffect is sufficient to ensure the intended semantics of thetraversal are respected. However, this is not generally true so be wary of traversals that require global views of asideEffect. To ensure a fresh global representation, usebarrier()prior to accessing the global sideEffect. Note that thisonly comes into play with custom steps andlambda steps. The standard Gremlin step library is respective of OLAP semantics.When evaluating traversals that rely on path information (i.e. the history of the traversal), practicalcomputational limits can easily be reached due thecombinatoric explosionof data. With path computing enabled, every traverser is unique and thus, must be enumerated as opposed to beingcounted/merged. The difference being a collection of paths vs. a single 64-bit long at a single vertex. In other words, bulking is very unlikely with traversers that maintain path information. For moreinformation on this concept, please seeFaunus Provides Big Graph Data.
Steps that are concerned with the global ordering of traversers do not have a meaningful representation inOLAP. For example, what does
order()-step mean when all traversers are being processed in parallel?Even if the traversers were aggregated and ordered, then at the next step they would return to being executed inparallel and thus, in an unpredictable order. Whenorder()-like steps are executed at the end of a traversal (i.ethe final step),TraversalVertexProgramensures a serial representation is ordered accordingly. Moreover, it is intelligent enoughto maintain the ordering ofg.V().hasLabel("person").order().by("age").values("name"). However, the OLAP traversalg.V().hasLabel("person").order().by("age").out().values("name")will lose the original ordering as theout()-stepwill rebroadcast traversers across the cluster.
Graph Filter
Most OLAP jobs do not require the entire source graph to faithfully execute theirVertexProgram. For instance, ifPageRankVertexProgram is only going to compute the centrality of people in the friendship-graph, then the followingGraphFilter can be applied.
graph.computer(). vertices(hasLabel("person")). vertexProperties(__.properties("name")). edges(bothE("knows")). program(PageRankVertexProgram...)There are three methods for constructing aGraphFilter.
vertices(Traversal<Vertex,Vertex>): A traversal that will be used that can only analyze a vertex and its properties.If the traversalhasNext(), the inputVertexis passed to theGraphComputer.vertexProperties(Traversal<Vertex, ? extends Property<?>): A traversal that will either let the vertex property pass or not.edges(Traversal<Vertex,Edge>): A traversal that will iterate all legal edges for the source vertex.
GraphFilter is a "push-down predicate" that providers can reason on to determine the most efficient way to providegraph data to theGraphComputer.
Important | Apache TinkerPop providesGraphFilterStrategytraversal strategy which analyzes a submittedOLAP traversal and, if possible, creates an appropriateGraphFilter automatically. For instance,g.V().count() wouldyield aGraphFilter.edges(limit(0)). Thus, for traversal submissions, users typically do not need to be aware of creatinggraph filters explicitly. Users can use theexplain()-step to see theGraphFilter generated byGraphFilterStrategy. |
Gremlin Applications
Gremlin applications represent tools that are built on top of the core APIs to help expose common functionality tousers when working with graphs. There are two key applications:
Gremlin Console - AREPL environment forinteractive development and analysis
Gremlin Server - A server that hosts a Gremlin Traversal Machine thus enabling remote Gremlin execution
 Gremlin is designed to be extensible, making it possible for usersand graph system/language providers to customize it to their needs. Such extensibility is also found in the GremlinConsole and Server, where a universal plugin system makes it possible to extend their capabilities. One of theimportant aspects of the plugin system is the ability to help the user install the plugins through the command linethus automating the process of gathering dependencies and other error prone activities.
Gremlin is designed to be extensible, making it possible for usersand graph system/language providers to customize it to their needs. Such extensibility is also found in the GremlinConsole and Server, where a universal plugin system makes it possible to extend their capabilities. One of theimportant aspects of the plugin system is the ability to help the user install the plugins through the command linethus automating the process of gathering dependencies and other error prone activities.
The process of plugin installation is handled byGrape, which helps resolvedependencies into the classpath. It is therefore important to ensure that Grape is properly configured in order touse the automated capabilities of plugin installation. Grape is configured by~/.groovy/grapeConfig.xml andgenerally speaking, if that file is not present, the default settings will suffice. However, they will not sufficeif a required dependency is not in one of the default configured repositories. Please see theCustomize Ivy settings section of the Grape documentation for more details onthe defaults. For current TinkerPop plugins and dependencies the following configuration which is also the defaultfor Ivy should be acceptable:
<ivysettings><settingsdefaultResolver="downloadGrapes"/><resolvers><chainname="downloadGrapes"returnFirst="true"><filesystemname="cachedGrapes"><ivypattern="${user.home}/.groovy/grapes/[organisation]/[module]/ivy-[revision].xml"/><artifactpattern="${user.home}/.groovy/grapes/[organisation]/[module]/[type]s/[artifact]-[revision](-[classifier]).[ext]"/></filesystem><ibiblioname="localm2"root="${user.home.url}/.m2/repository/"checkmodified="true"changingPattern=".*"changingMatcher="regexp"m2compatible="true"/><ibiblioname="jcenter"root="https://jcenter.bintray.com/"m2compatible="true"/><ibiblioname="ibiblio"m2compatible="true"/></chain></resolvers></ivysettings>Tip | Please see theDeveloper Documentationfor additional configuration options when working with "snapshot" releases. |
Gremlin Console
 The Gremlin Console is an interactive terminal orREPL that can be used to traverse graphsand interact with the data that they contain. It represents the most common method for performing ad hoc graphanalysis, small to medium sized data loading projects and other exploratory functions. The Gremlin Console ishighly extensible, featuring a rich plugin system that allows new tools, commands,DSLs, etc. to be exposed to users.
The Gremlin Console is an interactive terminal orREPL that can be used to traverse graphsand interact with the data that they contain. It represents the most common method for performing ad hoc graphanalysis, small to medium sized data loading projects and other exploratory functions. The Gremlin Console ishighly extensible, featuring a rich plugin system that allows new tools, commands,DSLs, etc. to be exposed to users.
To start the Gremlin Console, rungremlin.sh orgremlin.bat (gremlin-java8.bat for Java 8):
$ bin/gremlin.sh \,,,/ (o o)-----oOOo-(3)-oOOo-----plugin loaded: tinkerpop.serverplugin loaded: tinkerpop.utilitiesplugin loaded: tinkerpop.tinkergraphgremlin>Note | If the above plugins are not loaded then they will need to be enabled or else certain examples will not work.If using the standard Gremlin Console distribution, then the plugins should be enabled by default. See below formore information on the:plugin use command to manually enable plugins. These plugins, with the exception oftinkerpop.tinkergraph, cannot be removed from the Console as they are a part of thegremlin-console.jar itself.These plugins can only be deactivated. |
The Gremlin Console is loaded and ready for commands. Recall that the console hosts the Gremlin-Groovy language.Please reviewGroovy for help on Groovy-related constructs. In short, Groovy is asuperset of Java. What works in Java, works in Groovy. However, Groovy provides many shorthands to make it easierto interact with the Java API. Moreover, Gremlin provides many neat shorthands to make it easier to express pathsthrough a property graph.
gremlin> i ='goodbye'==>goodbyegremlin> j ='self'==>selfgremlin> i +"" + j==>goodbye selfgremlin>"${i}${j}"==>goodbye selfi ='goodbye'j ='self'i +"" + j"${i}${j}"The "toy" graph provides a way to get started with Gremlin quickly.
gremlin> g = traversal().withEmbedded(TinkerFactory.createModern())==>graphtraversalsource[tinkergraph[vertices:6edges:6], standard]gremlin> g.V()==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]gremlin> g.V().values('name')==>marko==>vadas==>lop==>josh==>ripple==>petergremlin> g.V().has('name','marko').out('knows').values('name')==>vadas==>joshg = traversal().withEmbedded(TinkerFactory.createModern())g.V()g.V().values('name')g.V().has('name','marko').out('knows').values('name')Tip | When using Gremlin-Groovy in a Groovy class file, addstatic { GremlinLoader.load() } to the head of the file. |
Console Commands
In addition to the standard commands of theGroovy Shell, Gremlin addssome other useful operations. The following table outlines the most commonly used commands:
| Command | Alias | Description |
|---|---|---|
:help | :? | Displays list of commands and descriptions. When followed by a command name, it will display more specific help on that particular item. |
:exit | :x | Ends the Console session. |
import | :i | Import a class into the Console session. |
:cls | :C | Clear the screen of the Console. |
:clear | :c | Sometimes the Console can get into a state where the command buffer no longer understands input (e.g. a misplaced |
:load | :l | Load a file or URL into the command buffer for execution. |
:install | :+ | Imports a Maven library and its dependencies into the Console. |
:uninstall | :- | Removes a Maven library and its dependencies. A restart of the console is required for removal to fully take effect. |
:plugin | :pin | Plugin management functions to list, activate and deactivate available plugins. |
:remote | :rem | Configures a "remote" context where Gremlin or results of Gremlin will be processed via usage of |
:submit | :> | Submit Gremlin to the currently active context defined by |
:bytecode | :bc | Provides options for translating and evaluating |
Many of the above commands are described elsewhere or are generally self-explanatory, but the:bytecode commandcould use some additional explanation. The following code shows example usage:
gremlin> :bytecode from g.V().out('knows')//1==>{"@type":"g:Bytecode","@value":{"step":[["V"],["out","knows"]]}}gremlin> :bytecode translate g {"@type":"g:Bytecode","@value":{"step":[["V"],["out","knows"]]}}//2==>g.V().out("knows")gremlin> m = GraphSONMapper.build().create()==>org.apache.tinkerpop.gremlin.structure.io.graphson.GraphSONMapper@69d6a7cdgremlin> :bc config m//3==>Configured bytecode serializergremlin> :bc from g.V().property('d',java.time.YearMonth.now())//4Could not find a type identifier for the class : class java.time.Month. Make sure the value to serialize has a type identifier registered for its class. (through reference chain: java.time.YearMonth["month"])Type ':help' or ':h' for help.Display stack trace? [yN]ngremlin> :bc reset//5==>Bytecode serializer reset to GraphSON 3.0 with extensions and TinkerGraph serializersgremlin> :bc from g.V().property('d',java.time.YearMonth.now())==>{"@type":"g:Bytecode","@value":{"step":[["V"],["property","d",{"@type":"gx:YearMonth","@value":"2020-11"}]]}}Generates a GraphSON 3.0 representation of the traversal as bytecode.
Converts bytecode in GraphSON 3.0 format to a traversal string.
Configure a custom
GraphSONMapperfor the:bytecodecommand to use which can be helpful when working withcustom classes from different graph providers. Theconfigoption can take aGraphSONMapperargument as shown orone or moreIoRegistryorSimpleModuleimplementations that will plug into the defaultGraphSONMapperconstructedby the:bytecodecommand. The default will configure for GraphSON 3.0 with the extensions module and, if present,theTinkerIoRegistryfrom TinkerGraph.Note that the
YearMonthwill not serialize becausemdid not configure the extensions module.After
resetit works properly once more.
Note | The Console does expose the:record command which is inherited from the Groovy Shell. This command works wellwith local commands, but may record session outputs differently for:remote commands. If there is a need to use:record it may be best to manually create aCluster object and issue commands that way so that they evaluatelocally in the shell. |
Interrupting Evaluations
If there is some input that is taking too long to evaluate or to iterate through, usectrl+c to attempt to interruptthat process. It is an "attempt" in the sense that the long running process is only informed of the interruption bythe user and must respond to it (as with any call tointerrupt() on aThread). ATraversal will typically respondto such requests as do most commands, including:remote operations.
gremlin> java.util.stream.IntStream.range(0, 1000).iterator()==>0==>1==>2==>3==>4...==>348==>349==>350==>351==>352Execution interrupted by ctrl+cgremlin>Console Preferences
Preferences are set with:set name value. Values can contain spaces when quoted. All preferences are reset by:purge preferences
| Preference | Type | Description |
|---|---|---|
max-iteration | int | Controls the maximum number of results that the Console will display. Default: 100 results. |
colors | bool | Enable ANSI color rendering. Default: true |
warnings | bool | Enable display of remote execution warnings. Default: true |
gremlin.color | colors | Color of the ASCII art gremlin on startup. |
info.color | colors | Color of "info" type messages. |
error.color | colors | Color of "error" type messages. |
vertex.color | colors | Color of vertices results. |
edge.color | colors | Color of edges in results. |
string.color | colors | Colors of strings in results. |
number.color | colors | Color of numbers in results. |
T.color | colors | Color of Tokens in results. |
input.prompt.color | colors | Color of the input prompt. |
result.prompt.color | colors | Color of the result prompt. |
input.prompt | string | Text of the input prompt. |
result.prompt | string | Text of the result prompt. |
result.indicator.null | string | Text of the void/no results indicator - setting to empty string (i.e. "" at thecommand line) will print no result line in these cases. |
Colors can contain a comma-separated combination of 1 each of foreground, background, and attribute.
| Foreground | Background | Attributes |
|---|---|---|
black | bg_black | bold |
blue | bg_blue | faint |
cyan | bg_cyan | underline |
green | bg_green | |
magenta | bg_magenta | |
red | bg_red | |
white | bg_white | |
yellow | bg_yellow |
Example:
:set gremlin.color bg_black,green,boldDependencies and Plugin Usage
The Gremlin Console can dynamically load external code libraries and make them available to the user. Furthermore,those dependencies may contain Gremlin plugins which can expand the language, provide useful functions, etc. Theseimportant console features are managed by the:install and:plugin commands.
The following Gremlin Console session demonstrates the basics of these features:
gremlin> :plugin list//1==>tinkerpop.server[active]==>tinkerpop.gephi==>tinkerpop.utilities[active]==>tinkerpop.sugar==>tinkerpop.tinkergraph[active]gremlin> :plugin use tinkerpop.sugar//2==>tinkerpop.sugar activatedgremlin> :install org.apache.tinkerpop neo4j-gremlin 3.7.4//3==>loaded: [org.apache.tinkerpop, neo4j-gremlin, 3.7.4]gremlin> :plugin list//4==>tinkerpop.server[active]==>tinkerpop.gephi==>tinkerpop.utilities[active]==>tinkerpop.sugar==>tinkerpop.tinkergraph[active]==>tinkerpop.neo4jgremlin> :plugin use tinkerpop.neo4j//5==>tinkerpop.neo4j activatedgremlin> :plugin list//6==>tinkerpop.server[active]==>tinkerpop.gephi==>tinkerpop.sugar[active]==>tinkerpop.utilities[active]==>tinkerpop.neo4j[active]==>tinkerpop.tinkergraph[active]Show a list of "available" plugins. The list of "available" plugins is determined by the classes available onthe Console classpath. Plugins need to be "active" for their features to be available.
To make a plugin "active" execute the
:plugin usecommand and specify the name of the plugin to enable.Sometimes there are external dependencies that would be useful within the Console. To bring those in, execute
:installand specify the Maven coordinates for the dependency.Note that there is a "tinkerpop.neo4j" plugin available, but it is not yet "active".
Again, to use the "tinkerpop.neo4j" plugin, it must be made "active" with
:plugin use.Now when the plugin list is displayed, the "tinkerpop.neo4j" plugin is displayed as "active".
Warning | Plugins must be compatible with the version of the Gremlin Console (or Gremlin Server) being used. Attemptsto use incompatible versions cannot be guaranteed to work. Moreover, be prepared for dependency conflicts inthird-party plugins that may only be resolved via manual jar removal from theext/{plugin} directory. |
Tip | It is possible to manage plugin activation and deactivation by manually editing theext/plugins.txt file whichcontains the class names of the "active" plugins. It is also possible to clear dependencies added by:install bydeleting them from theext directory. |
Execution Mode
For automated tasks and batch executions of Gremlin, it can be useful to execute Gremlin scripts in "execution" modefrom the command line. Consider the following file namedgremlin.groovy:
graph = TinkerFactory.createModern()g = traversal().withEmbedded(graph)g.V().each { printlnit }This script creates the toy graph and then iterates through all its vertices printing each to the system out. Toexecute this script from the command line,gremlin.sh has the-e option used as follows:
$ bin/gremlin.sh -e gremlin.groovyv[1]v[2]v[3]v[4]v[5]v[6]It is also possible to pass arguments to scripts. Any parameters following the file name specification are treatedas arguments to the script. They are collected into a list and passed in as a variable called "args". The followingGremlin script is exactly like the previous one, but it makes use of the "args" option to filter the vertices printedto system out:
graph = TinkerFactory.createModern()g = traversal().withEmbedded(graph)g.V().has('name',args[0]).each { printlnit }When executed from the command line a parameter can be supplied:
$ bin/gremlin.sh -e gremlin.groovy markov[1]$ bin/gremlin.sh -e gremlin.groovy vadasv[2]It is also possible to pass multiple scripts by specifying multiple-e options. The scripts will execute in the orderin which they are specified. Note that only the arguments from the last script executed will be preserved in the console.Finally, if the arguments conflict with the reserved flags to whichgremlin.sh responds, double quotes can be used towrap all the arguments to the option:
$ bin/gremlin.sh -e "gremlin.groovy -e -i --color"Interactive Mode
The Gremlin Console can be started in an "interactive" mode. Interactive mode is likeexecution modebut the console will not exit at the completion of the script, even if the script completes unsuccessfully. In such acase, it will simply stop processing on the line of the script that failed. In this way, the state of the consoleis such that a user could examine the state of things up to the point of failure, which might make the script easier todebug.
In addition to debugging, interactive mode is a helpful way for users to initialize their console environment toavoid otherwise repetitive typing. For example, a user who spends a lot of time working with the TinkerPop "modern"graph might create a script calledinit.groovy like:
graph = TinkerFactory.createModern()g = traversal().withEmbedded(graph)and then start Gremlin Console as follows:
$ bin/gremlin.sh -i init.groovy \,,,/ (o o)-----oOOo-(3)-oOOo-----plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphgremlin> g.V()==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]Note that the user can now referenceg (andgraph for that matter) at startup without having to directly type thatvariable initialization code into the console.
As in execution mode, it is also possible to pass multiple scripts by specifying multiple-i options. See theExecution Mode Section for more information on the specifics of that capability.
Docker Image
The Gremlin Console can also be started as aDocker image:
$ docker run -it tinkerpop/gremlin-console:3.7.4Feb 25, 2018 3:47:24 PM java.util.prefs.FileSystemPreferences$1 runINFO: Created user preferences directory. \,,,/ (o o)-----oOOo-(3)-oOOo-----plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphgremlin>The Docker image offers the same options as the standalone Console. It can be used for example to execute scripts:
$ docker run -it tinkerpop/gremlin-console:3.7.4 -e gremlin.groovyv[1]v[2]v[3]v[4]v[5]v[6]Gremlin Server
 Gremlin Server provides a way to remotely execute Gremlin against oneor more
Gremlin Server provides a way to remotely execute Gremlin against oneor moreGraph instances hosted within it. The benefits of using Gremlin Server include:
Allows any Gremlin Structure-enabled graph (i.e. implements the
GraphAPI on the JVM) to exist as a standaloneserver, which in turn enables the ability for multiple clients to communicate with the same graph database.Enables execution of ad hoc queries through remotely submitted Gremlin.
Provides a method for non-JVM languages which may not have a Gremlin Traversal Machine (e.g. Python, Javascript, Go, etc.)to communicate with the TinkerPop stack on the JVM.
Exposes numerous methods for extension and customization to include serialization options, remote commands, etc.
Note | Gremlin Server is the replacement forRexster. |
Note | Please see theProvider Documentation for informationon how to develop a driver for Gremlin Server. |
By default, communication with Gremlin Server occurs overWebSocket andexposes a custom sub-protocol for interacting with the server.
Warning | Gremlin Server allows for the execution of remotely submitted "scripts" (i.e. arbitrary code sent by a clientto the server). Developers should consider the security implications involved in running Gremlin Server without theappropriate precautions. Please review theSecurity Section and more specifically, theScript Execution Section for more information. |
Starting Gremlin Server
Gremlin Server comes packaged with a script calledbin/gremlin-server.sh to get it started (usegremlin-server.baton Windows):
$ bin/gremlin-server.sh conf/gremlin-server-modern.yaml[INFO] GremlinServer \,,,/ (o o)-----oOOo-(3)-oOOo-----[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server-modern.yaml[INFO] MetricManager - Configured Metrics Slf4jReporter configured with interval=180000ms and loggerName=org.apache.tinkerpop.gremlin.server.Settings$Slf4jReporterMetrics[INFO] DefaultGraphManager - Graph [graph] was successfully configured via [conf/tinkergraph-empty.properties].[INFO] ServerGremlinExecutor - Initialized Gremlin thread pool. Threads in pool named with pattern gremlin-*[INFO] ServerGremlinExecutor - Initialized GremlinExecutor and preparing GremlinScriptEngines instances.[INFO] ServerGremlinExecutor - Initialized gremlin-groovy GremlinScriptEngine and registered metrics[INFO] ServerGremlinExecutor - A GraphTraversalSource is now bound to [g] with graphtraversalsource[tinkergraph[vertices:0 edges:0], standard][INFO] OpLoader - Adding the standard OpProcessor.[INFO] OpLoader - Adding the session OpProcessor.[INFO] OpLoader - Adding the traversal OpProcessor.[INFO] GremlinServer - Executing start up LifeCycleHook[INFO] Logger$info - Loading 'modern' graph data.[INFO] GremlinServer - idleConnectionTimeout was set to 0 which resolves to 0 seconds when configuring this value - this feature will be disabled[INFO] GremlinServer - keepAliveInterval was set to 0 which resolves to 0 seconds when configuring this value - this feature will be disabled[INFO] AbstractChannelizer - Configured application/vnd.gremlin-v3.0+json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3[INFO] AbstractChannelizer - Configured application/json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3[INFO] AbstractChannelizer - Configured application/vnd.graphbinary-v1.0 with org.apache.tinkerpop.gremlin.util.ser.GraphBinaryMessageSerializerV1[INFO] AbstractChannelizer - Configured application/vnd.graphbinary-v1.0-stringd with org.apache.tinkerpop.gremlin.util.ser.GraphBinaryMessageSerializerV1[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 4 and boss thread pool of 1.[INFO] GremlinServer$1 - Channel started at port 8182.Gremlin Server is configured by the providedYAML fileconf/gremlin-server-modern.yaml.That file tells Gremlin Server many things such as:
The host and port to serve on
Thread pool sizes
Where to report metrics gathered by the server
The serializers to make available
The Gremlin
ScriptEngineinstances to expose and external dependencies to inject into themGraphinstances to expose
The log messages that printed above show a number of things, but most importantly, there is aGraph instance namedgraph that is exposed in Gremlin Server. This graph is an in-memory TinkerGraph and was empty at the start of theserver. An initialization script atscripts/generate-modern.groovy was executed during startup. Its contents areas follows:
// an init script that returns a Map allows explicit setting of global bindings.def globals = [:]// Generates the modern graph into an "empty" TinkerGraph via LifeCycleHook.// Note that the name of the key in the "global" map is unimportant.globals << [hook : [onStartUp: { ctx -> ctx.logger.info("Loading 'modern' graph data.") org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerFactory.generateModern(graph) }]as LifeCycleHook]// define the default TraversalSource to bind queries to - this one will be named "g".globals << [g : traversal().withEmbedded(graph)]The script above initializes aMap and assigns two key/values to it. The first, assigned to "hook", defines aLifeCycleHook for Gremlin Server. The "hook" provides a way to tie script code into the Gremlin Server startup andshutdown sequences. TheLifeCycleHook has two methods that can be implemented:onStartUp andonShutDown.These events are called once at Gremlin Server start and once at Gremlin Server stop. This is an important pointbecause code outside of the "hook" is executed for eachScriptEngine creation (multiple may be created when"sessions" are enabled) and therefore theLifeCycleHook provides a way to ensure that a script is only executed asingle time. In this case, the startup hook loads the "modern" graph into the empty TinkerGraph instance, preparingit for use. The second key/value pair assigned to theMap, named "g", defines aTraversalSource from theGraphbound to the "graph" variable in the YAML configuration file. This variableg, as well as any other variableassigned to theMap, will be made available as variables for future remote script executions. In more generalterms, any key/value pairs assigned to aMap returned from the initialization script will become variables thatare global to all requests. In addition, any functions that are defined will be cached for future use.
Warning | Transactions on graphs in initialization scripts are not closed automatically after the script finishesexecuting. It is up to the script to properly commit or rollback transactions in the script itself. |
Connecting via Drivers
 TinkerPop offers client-side drivers for the Gremlin Server websocketsub-protocol in a variety of languages:
TinkerPop offers client-side drivers for the Gremlin Server websocketsub-protocol in a variety of languages:
These drivers provide methods to send Gremlin based requests and get back traversal results as a response. The requestsmay be script-based or bytecode-based. As discussed earlier in theintroduction therecommendation is to use bytecode-based requests. The difference between sending scripts and sending bytecode aredemonstrated below in some basic examples:
// scriptCluster cluster = Cluster.open();Client client = cluster.connect();Map<String,Object> params =newHashMap<>();params.put("name","marko");List<Result> list = client.submit("g.V().has('person','name',name).out('knows')", params).all().get();// bytecodeGraphTraversalSource g = traversal().withRemote(DriverRemoteConnection.using("localhost",8182,"g"));List<Vertex> list = g.V().has("person","name","marko").out("knows").toList();// scriptdef cluster = Cluster.open()def client = cluster.connect()def list = client.submit("g.V().has('person','name',name).out('knows')", [name:"marko"]).all().get();// bytecodedef g = traversal().withRemote(DriverRemoteConnection.using("localhost",8182,"g"))def list = g.V().has('person','name','marko').out('knows').toList()// scriptvar gremlinServer = new GremlinServer("localhost", 8182);using (var gremlinClient = new GremlinClient(gremlinServer)){ var bindings = new Dictionary<string, object> { {"name", "marko"} }; var response = await gremlinClient.SubmitWithSingleResultAsync<object>("g.V().has('person','name',name).out('knows')", bindings);}// bytecodeusing (var gremlinClient = new GremlinClient(new GremlinServer("localhost", 8182))){ var g = Traversal().WithRemote(new DriverRemoteConnection(gremlinClient)); var list = g.V().Has("person", "name", "marko").Out("knows").ToList();}// scriptconst client =new Client('ws://localhost:45940/gremlin', {traversalSource:"g" });const conn = client.open();const list = conn.submit("g.V().has('person','name',name).out('knows')",{name:'marko'}).then(function (response) { ... });// bytecodeconst g = gtraversal().withRemote(new DriverRemoteConnection('ws://localhost:8182/gremlin'));const list = g.V().has("person","name","marko").out("knows").toList();# scriptclient = Client('ws://localhost:8182/gremlin','g')list = client.submit("g.V().has('person','name',name).out('knows')",{'name':'marko'}).all()# bytecodeg = traversal().withRemote(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))list = g.V().has("person","name","marko").out("knows").toList()// scriptclient, err := NewClient("ws://localhost:8182/gremlin")resultSet, err := client.SubmitWithOptions("g.V().has('person','name',name).out('knows')",new(RequestOptionsBuilder).AddBinding("name","marko").Create())result, err := resultSet.All()// bytecoderemote, err := NewDriverRemoteConnection("ws://localhost:8182/gremlin")g := Traversal_().WithRemote(remote)list, err := g.V().Has("person","name","marko").Out("knows").ToList()The advantage of bytecode over scripts should be apparent from the above examples. Scripts are just strings that areembedded in code (in the above examples, the strings are Groovy-based) whereas bytecode based requests are themselvescode written in the native language of use. Obviously, the advantage of the Gremlin being actual code is that thereare checks (e.g. compile-time, auto-complete and other IDE support, language level checks, etc.) that help validate theGremlin during the development process.
When sending requests to the server, it is important to remember that the results of the request be something that isserializable by the server and driver. If the server cannot serialize the result or if what the server serializes is notrecognized by the serializer used by the driver, there will be an error. The most common cases for seeing serializationproblems include:
Connecting to a graph that requires custom serializers, such as the ones JanusGraph provides for its relationidentifier. Always be take time to get to know the graph database that’s been chosen to determine if there are customerserializers that need to be registered to the server or the driver.
Driver versions that don’t match server versions can sometimes create scenarios where serialization failures willpresent themselves. TinkerPop typically does the most testing on drivers and servers of the same version and thereforehas the greatest confidence where those versions match. When possible, try to align the driver version with the serverversion.
Groovy-scripts can return anything since it has full access to the JVM. While a simple non-Gremlin traversal scriptlike "1+1" simply returns a number which is perfectly serializable, it is just as easy to send a script like"graph.openManagement()" which is a JanusGraph API and returns an object that is not, returning an error.
TinkerPop makes an effort to ensure a high-level of consistency among the drivers and their features, but there aredifferences in capabilities and features as they are each developed independently. The Java driver was the first andis therefore the most advanced. Please see the related documentation for the driver of interest for more informationand details in theGremlin Drivers and Variants Section of this documentation.
Connecting via Console
With Gremlin Server running it is now possible to issue some scripts to it for processing. Start Gremlin Console asfollows:
$ bin/gremlin.sh \,,,/ (o o)-----oOOo-(3)-oOOo-----gremlin>The console has the notion of a "remote", which represents a place a script will be sent from the console to beevaluated elsewhere in some other context (e.g. Gremlin Server, Hadoop, etc.). To create a remote in the console,do the following:
gremlin> :remote connect tinkerpop.server conf/remote.yaml==>Configured localhost/127.0.0.1:8182:remote connect tinkerpop.server conf/remote.yamlThe:remote command shown above displays the current status of the remote connection. This command can also beused to configure a new connection and change other related settings. To actually send a script to the server adifferent command is required:
gremlin> :> g.V().values('name')==>marko==>vadas==>lop==>josh==>ripple==>petergremlin> :> g.V().has('name','marko').out('created').values('name')==>lopgremlin> :> g.E().label().groupCount()==>{created=4, knows=2}gremlin> result==>result{object={created=4, knows=2}class=java.lang.String}gremlin> :remote close==>Removed - Gremlin Server - [localhost/127.0.0.1:8182]:> g.V().values('name'):> g.V().has('name','marko').out('created').values('name'):> g.E().label().groupCount()result:remote closeThe:> command, which is a shorthand for:submit, sends the script to the server to execute there. Results arewrapped in anResult object which is a just a holder for each individual result. Theclass shows the data typefor the containing value. Note that the last script sent was supposed to return aMap, but itsclass isjava.lang.String. By default, the connection is configured to only return text results. In other words,Gremlin Server is usingtoString to serialize all results back to the console. This enables virtually anyobject on the server to be returned to the console, but it doesn’t allow the opportunity to work with this datain any way in the console itself. A different configuration of the:remote is required to get the results backas "objects":
gremlin> :remote connect tinkerpop.server conf/remote-objects.yaml////(1)==>Configured localhost/127.0.0.1:8182gremlin> :remote list////(2)==>*0 - Gremlin Server - [localhost/127.0.0.1:8182]gremlin> :> g.E().label().groupCount()////(3)==>[created:4,knows:2]gremlin> m = result[0].object////(4)==>created=4==>knows=2gremlin> m.sort {it.value}==>knows=2==>created=4gremlin> script =""" g.V().hasLabel('person'). out('knows'). out('created'). group(). by('name')"""==> g.V().hasLabel('person'). out('knows'). out('created'). group(). by('name')gremlin> :>@script////(5)==>[ripple:[v[5]],lop:[v[3]]]gremlin> :remote close==>Removed - Gremlin Server - [localhost/127.0.0.1:8182]:remote connect tinkerpop.server conf/remote-objects.yaml////(1):remote list////(2):> g.E().label().groupCount()////(3)m = result[0].object////(4)m.sort {it.value}script =""" g.V().hasLabel('person'). out('knows'). out('created'). group(). by('name')""":>@script////(5):remote closeThis configuration file specifies that results should be deserialized back into an
Objectin the console withthe caveat being that the server and console both know how to serialize and deserialize the result to be returned.There are now two configured remote connections. The one marked by an asterisk is the one that was just createdand denotes the current one that
:submitwill react to.When the script is executed again, the
classis no longer shown to be ajava.lang.String. It is instead ajava.util.HashMap.The last result of a remote script is always stored in the reserved variable
result, which allows access totheResultand by virtue of that, theMapitself.If the submission requires multiple-lines to express, then a multi-line string can be created. The
:>commandrealizes that the user is referencing a variable via@and submits the string script.
Tip | In Groovy,""" text """ is a convenient way to create a multi-line string and works well in concert with:> @variable. Note that this model of submitting a string variable works for all:> based plugins, not just Gremlin Server. |
Warning | Not all values that can be returned from a Gremlin script end up being serializable. For example,submitting:> graph will return aGraph instance and in most cases those are not serializable by Gremlin Serverand will return a serialization error. It should be noted thatTinkerGraph, as a convenience for shipping aroundsmall sub-graphs, is serializable from Gremlin Server. |
The alternative syntax to connecting allows for theCluster to be user constructed directly in the console asopposed to simply providing a static YAML file.
gremlin> cluster = Cluster.open()==>localhost/127.0.0.1:8182gremlin> :remote connect tinkerpop.server cluster==>Configured localhost/127.0.0.1:8182cluster = Cluster.open():remote connect tinkerpop.server clusterThe Gremlin Server:remote config command for the driver has the following configuration options:
| Command | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
alias |
| ||||||||
timeout | Specifies the length of time in milliseconds the Console will wait for a response from the server. Specify"none" to have no timeout. By default, this setting uses "none". |
Aliases
Thealias configuration command for the Gremlin Server:remote can be useful in situations where there aremultipleGraph orTraversalSource instances on the server, as it becomes possible to rename them from the clientfor purposes of execution within the context of a script. Therefore, it becomes possible to submit commands this way:
gremlin> :remote connect tinkerpop.server conf/remote-objects.yaml==>Configured localhost/127.0.0.1:8182gremlin> :remote config alias x g==>x=ggremlin> :> x.E().label().groupCount()==>[created:4,knows:2]gremlin> :remote close==>Removed - Gremlin Server - [localhost/127.0.0.1:8182]:remote connect tinkerpop.server conf/remote-objects.yaml:remote config alias x g:> x.E().label().groupCount():remote closeSessions
A:remote created in the following fashion will be "sessionless", meaning each script issued to the server with:> will be encased in a transaction and no state will be maintained from one request to the next.
gremlin> :remote connect tinkerpop.server conf/remote-objects.yaml==>Configured localhost/127.0.0.1:8182In other words, the transaction will be automatically committed (or rolledback on error) and any variables declaredin that script will be forgotten for the next request. See the section on"Considering Sessions"for more information on that topic.
To enable the remote to connect with a session theconnect argument takes another argument as follows:
gremlin> :remote connect tinkerpop.server conf/remote.yaml session==>Configured localhost/127.0.0.1:8182-[791e4fbb-1ed0-4870-ad82-15781e2721e9]gremlin> :> x =1==>1gremlin> :> y =2==>2gremlin> :> x + y==>3gremlin> :remote close==>Removed - Gremlin Server - [localhost/127.0.0.1:8182]-[791e4fbb-1ed0-4870-ad82-15781e2721e9]:remote connect tinkerpop.server conf/remote.yaml session:> x =1:> y =2:> x + y:remote closeWith the above command a session gets created with a random UUID for a session identifier. It is also possible toassign a custom session identifier by adding it as the last argument to:remote command above. There is also theoption to replace "session" with "session-managed" to create a session that will auto-manage transactions (i.e. eachrequest will occur within the bounds of a transaction). In this way, the state of bound variables between requests aremaintained, but the need to manually managed the transactional scope of the graph is no longer required.
Remote Console
Previous examples have shown usage of the:> command to send scripts to Gremlin Server. The Gremlin Console alsosupports an additional method for doing this which can be more convenient when the intention is to exclusivelywork with a remote connection to the server.
gremlin> :remote connect tinkerpop.server conf/remote.yaml session==>Configured localhost/127.0.0.1:8182-[e8a5c432-ef25-49da-a545-8fe6412c44d6]gremlin> :remote console==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182]-[e8a5c432-ef25-49da-a545-8fe6412c44d6] - type':remote console' toreturn to local modegremlin> x =1==>1gremlin> y =2==>2gremlin> x + y==>3gremlin> :remote console==>All scripts will now be evaluated locally - type':remote console' toreturn to remote modefor Gremlin Server - [localhost/127.0.0.1:8182]-[e8a5c432-ef25-49da-a545-8fe6412c44d6]gremlin> :remote close==>Removed - Gremlin Server - [localhost/127.0.0.1:8182]-[e8a5c432-ef25-49da-a545-8fe6412c44d6]:remote connect tinkerpop.server conf/remote.yaml session:remote consolex =1y =2x + y:remote console:remote closeIn the above example, the:remote console command is executed. It places the console in a state where the:> isno longer required. Each script line is actually automatically submitted to Gremlin Server for evaluation. Thevariablesx andy that were defined actually don’t exist locally - they only exist on the server! In this sense,putting the console in this mode is basically like creating a window to a session on Gremlin Server.
Tip | When using:remote console there is not much point to using a configuration that uses a serializer that returnsactual data. In other words, using a configuration like the one inside ofconf/remote-objects.yaml isn’t typicallyuseful as in this mode the result will only ever be displayed but not used. Using a serializer configuration likethe one inconf/remote.yaml should perform better. |
Note | Console commands, those that begin with a colon (e.g.:x,:remote) do not execute remotely when in this mode.They are all still evaluated locally. |
Connecting via HTTP
 While the default behavior for Gremlin Server is to provide aWebSocket-based connection, it can also be configured to support plain HTTP web service.The HTTP endpoint provides for a communication protocol familiar to most developers, with a wide support ofprogramming languages, tools and libraries for accessing it. As a result, HTTP provides a fast way to get startedwith Gremlin Server. It also may represent an easier upgrade path fromRexsteras the API for the endpoint is very similar to Rexster’sGremlin Extension.
While the default behavior for Gremlin Server is to provide aWebSocket-based connection, it can also be configured to support plain HTTP web service.The HTTP endpoint provides for a communication protocol familiar to most developers, with a wide support ofprogramming languages, tools and libraries for accessing it. As a result, HTTP provides a fast way to get startedwith Gremlin Server. It also may represent an easier upgrade path fromRexsteras the API for the endpoint is very similar to Rexster’sGremlin Extension.
Important | TinkerPop provides and supports this HTTP endpoint as a convenience and for legacy reasons, but users shouldprefer the recommended approach of bytcode based requests as described inConnecting Gremlinsection. |
Gremlin Server provides for a single HTTP endpoint - a Gremlin evaluator - which allows the submission of a Gremlinscript as a request. For each request, it returns a response containing the serialized results of that script.To enable this endpoint, Gremlin Server needs to be configured with theHttpChannelizer, which replaces the default.TheWsAndHttpChannelizer may also be configured to enable both WebSockets and the REST endpoint in the configurationfile:
channelizer:org.apache.tinkerpop.gremlin.server.channel.HttpChannelizerchannelizer:org.apache.tinkerpop.gremlin.server.channel.WsAndHttpChannelizerNote | TheUnifiedChannelizer introduced in 3.5.0 can also be used to support HTTP requests as its functionalityis similar toWsAndHttpChannelizer. Please see the Gremlin Server UnifiedChannelizer Section of the UpgradeDocumentation for 3.5.0 for moredetails. |
TheHttpChannelizer is already configured in thegremlin-server-rest-modern.yaml file that is packaged with the GremlinServer distribution. To utilize it, start Gremlin Server as follows:
bin/gremlin-server.sh conf/gremlin-server-rest-modern.yamlOnce the server has started, issue a request. Here’s an example withcURL:
$ curl "http://localhost:8182?gremlin=100-1"which returns:
{"result":{"data":99,"meta":{}},"requestId":"0581cdba-b152-45c4-80fa-3d36a6eecf1c","status":{"code":200,"attributes":{},"message":""}}The above example showed aGET operation, but the preferred method for this endpoint isPOST:
curl -X POST -d "{\"gremlin\":\"100-1\"}" "http://localhost:8182"which returns:
{"result":{"data":99,"meta":{}},"requestId":"ef2fe16c-441d-4e13-9ddb-3c7b5dfb10ba","status":{"code":200,"attributes":{},"message":""}}It is also preferred that Gremlin scripts be parameterized when possible viabindings:
curl -X POST -d "{\"gremlin\":\"100-x\", \"bindings\":{\"x\":1}}" "http://localhost:8182"Thebindings argument is aMap of variables where the keys become available as variables in the Gremlin script.Note that parameterization of requests is critical to performance, as repeated script compilation can be avoided oneach request.
Note | It is possible to pass bindings viaGET based requests. Query string arguments prefixed with "bindings." willbe treated as parameters, where that prefix will be removed and the value following the period will become theparameter name. In other words,bindings.x will create a parameter named "x" that can be referenced in the submittedGremlin script. The caveat is that these arguments will always be treated asString values. To ensure that datatypes are preserved or to pass complex objects such as lists or maps, usePOST which will at least support theallowed JSON data types. |
Passing theAccept header with a valid MIME type will trigger the server to return the result in a particular format.Note that in addition to the formats available given the server’sserializers configuration, there is also a basictext/plain format which produces a text representation of results similar to the Gremlin Console:
$ curl -H "Accept:text/plain" -X POST -d "{\"gremlin\":\"g.V()\"}" "http://localhost:8182"==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]Finally, as Gremlin Server can host multipleScriptEngine instances (e.g.gremlin-groovy,nashorn), it ispossible to define the language to utilize to process the request:
curl -X POST -d "{\"gremlin\":\"100-x\", \"language\":\"gremlin-groovy\", \"bindings\":{\"x\":1}}" "http://localhost:8182"By default this value is set togremlin-groovy. If using aGET operation, this value can be set as a querystring argument with by setting thelanguage key.
Warning | Consider the size of the result of a submitted script being returned from the HTTP endpoint. A scriptthat iterates thousands of results will serialize each of those in memory into a single JSON result set. It isquite possible that such a script will generateOutOfMemoryError exceptions on the server. Consider the defaultWebSocket configuration, which supports streaming, if that type of use case is required. |
Configuring
Thegremlin-server.sh file serves multiple purposes. It can be used to "install" dependencies to the GremlinServer path. For example, to be able to configure and use otherGraph implementations, the dependencies must bemade available to Gremlin Server. To do this, use theinstall switch and supply the Maven coordinates for thedependency to "install". For example, to use Neo4j in Gremlin Server:
bin/gremlin-server.sh install org.apache.tinkerpop neo4j-gremlin 3.7.4This command will "grab" the appropriate dependencies and copy them to theext directory of Gremlin Server, whichwill then allow them to be "used" the next time the server is started. To uninstall dependencies, simply delete themfrom theext directory.
bin/gremlin-server.sh has several other options.
| Parameter | Description |
|---|---|
start | Start the server in the background. |
stop | Shutdown the server. |
restart | Shutdown a running server then start it again. |
status | Check if the server is running. |
console | Start the server in the foreground. Use ^C to kill it. |
install <group> <artifact> <version> | Install dependencies into the server. "-i" exists for backwards compatibility but is deprecated. |
<conf file> | Start the server in the foreground using the provided YAML config file. |
Thebin/gremlin-server.sh script can be customized with environment variables inbin/gremlin-server.conf.
| Variable | Description |
|---|---|
DEBUG | Enable debugging of the startup script |
GREMLIN_HOME | The Gremlin Server install directory. Use this if the script has trouble finding itself. |
GREMLIN_YAML | The default server YAML file (conf/gremlin-server.yaml) |
LOG_DIR | Location of gremlin.log where stdout/stderr are captured (logs/) |
PID_DIR | Location of gremlin.pid |
RUNAS | User to run the server as |
JAVA_HOME | Java install location. Will use $JAVA_HOME/bin/java |
JAVA_OPTIONS | Options passed to the JVM |
As mentioned earlier, Gremlin Server is configured though a YAML file. By default, Gremlin Server will look for afile calledconf/gremlin-server.yaml to configure itself on startup. To override this default, set GREMLIN_YAML inbin/gremlin-server.conf or supply the file to use tobin/gremlin-server.sh as in:
bin/gremlin-server.sh conf/gremlin-server-min.yamlWarning | On Windows, gremlin-server.bat will always start in the foreground. When no parameter is provided, it willstart with the defaultconf/gremlin-server.yaml file. |
The following table describes the various YAML configuration options that Gremlin Server expects:
| Key | Description | Default |
|---|---|---|
authentication.authenticator | The fully qualified classname of an |
|
authentication.authenticationHandler | The fully qualified classname of an | none |
authentication.config | A | none |
authorization.authorizer | The fully qualified classname of an | none |
authorization.config | A | none |
channelizer | The fully qualified classname of the |
|
enableAuditLog | The | false |
graphManager | The fully qualified classname of the |
|
graphs | A | none |
gremlinPool | The number of "Gremlin" threads available to execute actual scripts in a | 0 |
host | The name of the host to bind the server to. | localhost |
idleConnectionTimeout | Time in milliseconds that the server will allow a channel to not receive requests from a client before it automatically closes. If enabled, the value provided should typically exceed the amount of time given to | 0 |
keepAliveInterval | Time in milliseconds that the server will allow a channel to not send responses to a client before it sends a "ping" to see if it is still present. If it is present, the client should respond with a "pong" which will thus reset the | 0 |
maxAccumulationBufferComponents | Maximum number of request components that can be aggregated for a message. | 1024 |
maxChunkSize | The maximum length of the content or each chunk. If the content length exceeds this value, the transfer encoding of the decoded request will be converted to 'chunked' and the content will be split into multiple | 8192 |
maxContentLength | The maximum length of the aggregated content for a message. Works in concert with | 65536 |
maxHeaderSize | The maximum length of all headers. | 8192 |
maxInitialLineLength | The maximum length of the initial line (e.g. "GET / HTTP/1.0") processed in a request, which essentially controls the maximum length of the submitted URI. | 4096 |
maxParameters | The maximum number of parameters that can be passed on a request. Larger numbers may impact performance for scripts. This configuration only applies to the | 16 |
maxSessionTaskQueueSize | The maximum size that an individual session can queue requests before starting to reject them. This configuration only applies to the | 4096 |
maxWorkQueueSize | The maximum size the general processing queue can grow before the | 8192 |
metrics.consoleReporter.enabled | Turns on console reporting of metrics. | false |
metrics.consoleReporter.interval | Time in milliseconds between reports of metrics to console. | 180000 |
metrics.csvReporter.enabled | Turns on CSV reporting of metrics. | false |
metrics.csvReporter.fileName | The file to write metrics to. | none |
metrics.csvReporter.interval | Time in milliseconds between reports of metrics to file. | 180000 |
metrics.gangliaReporter.addressingMode | Set to | none |
metrics.gangliaReporter.enabled | Turns on Ganglia reporting of metrics. Additionalsetup is required. | false |
metrics.gangliaReporter.host | Define the Ganglia host to report Metrics to. | localhost |
metrics.gangliaReporter.interval | Time in milliseconds between reports of metrics for Ganglia. | 180000 |
metrics.gangliaReporter.port | Define the Ganglia port to report Metrics to. | 8649 |
metrics.graphiteReporter.enabled | Turns on Graphite reporting of metrics. Additionalsetup is required. | false |
metrics.graphiteReporter.host | Define the Graphite host to report Metrics to. | localhost |
metrics.graphiteReporter.interval | Time in milliseconds between reports of metrics for Graphite. | 180000 |
metrics.graphiteReporter.port | Define the Graphite port to report Metrics to. | 2003 |
metrics.graphiteReporter.prefix | Define a "prefix" to append to metrics keys reported to Graphite. | none |
metrics.jmxReporter.enabled | Turns on JMX reporting of metrics. | false |
metrics.slf4jReporter.enabled | Turns on SLF4j reporting of metrics. | false |
metrics.slf4jReporter.interval | Time in milliseconds between reports of metrics to SLF4j. | 180000 |
port | The port to bind the server to. | 8182 |
processors | A | none |
processors[X].className | The full class name of the | none |
processors[X].config | A | none |
resultIterationBatchSize | Defines the size in which the result of a request is "batched" back to the client. In other words, if set to | 64 |
scriptEngines | A | gremlin-groovy |
scriptEngines.<name>.imports | A comma separated list of classes/packages to make available to the | none |
scriptEngines.<name>.staticImports | A comma separated list of "static" imports to make available to the | none |
scriptEngines.<name>.scripts | A comma separated list of script files to execute on | none |
scriptEngines.<name>.config | A | none |
evaluationTimeout | The amount of time in milliseconds before a request evaluation and iteration of result times out. This feature can be turned off by setting the value to | 30000 |
serializers | A | empty |
serializers[X].className | The full class name of the | none |
serializers[X].config | A | none |
sessionLifetimeTimeout | The maximum time in milliseconds that a session can exist. This value cannot be extended beyond this value irrespective of the number of requests and their individual timeouts. The session life cannot be extended once started. This configuration only applies to the | 600000 (10 minutes) |
ssl.enabled | Determines if SSL is turned on or not. | false |
ssl.keyStore | The private key in JKS or PKCS#12 format. | none |
ssl.keyStorePassword | The password of the | none |
ssl.keyStoreType |
| none |
ssl.needClientAuth | Optional. One of NONE, REQUIRE. Enables client certificate authentication at the enforcement level specified. Can be used in combination with Authenticator. | none |
ssl.sslCipherSuites | The list of JSSE ciphers to support for SSL connections. If specified, only the ciphers that are listed and supported will be enabled. If not specified, the JVM default is used. | none |
ssl.sslEnabledProtocols | The list of SSL protocols to support for SSL connections. If specified, only the protocols that are listed and supported will be enabled. If not specified, the JVM default is used. | none |
ssl.trustStore | Required when needClientAuth is REQUIRE. Trusted certificates for verifying the remote endpoint’s certificate. If this value is not provided and SSL is enabled, the default | none |
ssl.trustStorePassword | The password of the | none |
strictTransactionManagement | Set to | false |
threadPoolBoss | The number of threads available to Gremlin Server for accepting connections. Should always be set to | 1 |
threadPoolWorker | The number of threads available to Gremlin Server for processing non-blocking reads and writes. | 1 |
useCommonEngineForSessions | Ensures that the same | true |
useEpollEventLoop | Try to use epoll event loops (works only on Linux os) instead of netty NIO. | false |
useGlobalFunctionCacheForSessions | Enable the global function cache for sessions when using the | true |
writeBufferHighWaterMark | If the number of bytes in the network send buffer exceeds this value then the channel is no longer writeable, accepting no additional writes until buffer is drained and the | 65536 |
writeBufferLowWaterMark | Once the number of bytes queued in the network send buffer exceeds the | 32768 |
See theMetrics section for more information on how to configure Ganglia and Graphite.
OpProcessor Configurations
Important | TheUnifiedChannelizer does not rely onOpProcessor infrastructure. If using that channelizer, theseconfiguration options can be ignored. |
AnOpProcessor provides a way to plug-in handlers to Gremlin Server’s processing flow. Gremlin Server uses thisplug-in system itself to expose the packaged functionality that it exposes. Configurations can be supplied to anOpProcessor through theprocessors key in the Gremlin Server configuration file. EachOpProcessor can take aMap of arguments which are specific to a particular implementation:
processors: -{ className: org.apache.tinkerpop.gremlin.server.op.session.SessionOpProcessor, config: { sessionTimeout: 28800000 }}The following sub-sections describe those configurations for eachOpProcessor implementations supplied with GremlinServer.
SessionOpProcessor
TheSessionOpProcessor provides a way to interact with Gremlin Server over asession.
| Name | Description | Default |
|---|---|---|
globalFunctionCacheEnabled | Determines if the script engine cache for global functions is enabled and behaves as an override to the plugin specific setting of the same name. | true |
maxParameters | Maximum number of parameters that can be passed on the request. | 16 |
perGraphCloseTimeout | Time in milliseconds to wait for each configured graph to close any open transactions when the session is killed. | 10000 |
sessionTimeout | Time in milliseconds before a session will time out. | 28800000 |
StandardOpProcessor
TheStandardOpProcessor provides a way to interact with Gremlin Server without use of sessions and is the defaultmethod for processing script evaluation requests.
| Name | Description | Default |
|---|---|---|
maxParameters | Maximum number of parameters that can be passed on the request. | 16 |
TraversalOpProcessor
TheTraversalOpProcessor provides a way to accept traversals configured viawithRemote().It has no special configuration settings.
Serialization
Gremlin Server can accept requests and return results using different serialization formats. Serializers implement theMessageSerializer interface. In doing so, they express the list of mime types they expect to support. Whenconfiguring multiple serializers it is possible for two or more serializers to support the same mime type. Such asituation may be common with a generic mime type such asapplication/json. Serializers are added in the order thatthey are encountered in the configuration file and the first one added for a specific mime type will not be overriddenby other serializers that also support it.
The format of the serialization is configured by theserializers setting described in the table above. Note thatsome serializers have additional configuration options as defined by theserializers[X].config setting. Theconfig setting is aMap where the keys and values get passed to the serializer at its initialization. Theavailable and/or expected keys are dependent on the serializer being used. Gremlin Server comes packaged with twodifferent serializers: GraphSON and GraphBinary.
Warning | Irrespective of the serialization format chosen, it is highly recommended that the serialization format isspecified explicitly. For example, preferapplication/vnd.gremlin-v3.0+json toapplication/json. Use of the driverstend to take care of this issue internally, but for all other mechanisms it is best to ensure theAccept type isdefined this way to avoid possible breaking changes or unexpected results, as defaults may vary from server to server. |
Warning | When connecting with drivers, never try to specify a serialization format that does not have embedded types.The drivers are designed to use that type information to properly produce results in the programming language’s typesystem and may not function correctly without it. Generally speaking,GraphBinary is always the best choice for thedrivers. |
GraphSON
The GraphSON serializer produces human-readable output in JSON format and is a good configuration choice for thosetrying to use TinkerPop from non-JVM languages. JSON obviously has wide support across virtually all majorprogramming languages and can be consumed by a wide variety of tools. The format itself is described in theIO Documentation. The following table shows theavailable GraphSON serializers that can be configured:
| Version | Embedded Types | Mime Type | Class |
|---|---|---|---|
1.0 | yes |
|
|
1.0 | no |
|
|
2.0 | yes |
|
|
2.0 | no |
|
|
3.0 | yes |
|
|
3.0 | no |
|
|
The above serializer classes can be found in theorg.apache.tinkerpop.gremlin.util.ser package ofgremlin-util.
Note | Gremlin can produce results that cannot be serialized with untyped GraphSON as the result simply cannot fitthe structure JSON inherently allows. A simple example would beg.V().groupCount() which returns aMap. AMapis no problem for JSON, but the key to thisMap is aVertex, which is a complex object, and cannot be a key inJSON which only allowsString keys. Untyped GraphSON will simply convert theVertex to aString for purpose ofserialization and as a result that data and type is lost. If this information is needed, switch to a typed format oradjust the Gremlin query in some way to return it in a different form that fits JSON structure. |
Configuring GraphSON in the Gremlin Server configuration looks like this:
-{ className: org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3 }Gremlin Server is configured by default with GraphSON 3.0 as shown above. It has the following configuration option:
| Key | Description | Default |
|---|---|---|
ioRegistries | A list of | none |
It is worth noting that GraphSON 1.0 still has some appeal for some users as it can be configured to produce an untypedJSON format which is a bit easier to consume than its successors which embed data types into the output. This versionof GraphSON tends to be the one that users like to utilize whenconnecting via HTTP and is stillused by someRemote Gremlin Providers for this purpose.
To configure Gremlin Server this way, theGraphSONMessageSerializerV1d0 must be included:
-{ className: org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV1 } -{ className: org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3 }In the above situation, bothGraphSONMessageSerializerV1d0 andGraphSONMessageSerializerV3d0 each bind to theapplication/json mime type. When such conflicts arise, Gremlin Server will use the order of the serializers todetermine priority such that the first serializer to bind to a type will be used and the others ignored. The followinglog message will indicate how the server is ultimately configured:
[INFO] AbstractChannelizer - Configured application/json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV1[INFO] AbstractChannelizer - Configured application/vnd.gremlin-v3.0+json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3[INFO] AbstractChannelizer - application/json already has org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV1 configured - it will not be replaced by org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3, change order of serialization configuration if this is not desired.Given the above, using GraphSON 3.0 under this configuration will require that the user specific the type:
$ curl -X POST -d "{\"gremlin\":\"100-1\"}" "http://localhost:8182"{"requestId":"f8720ad9-2c8b-4eef-babe-21792a3e3157","status":{"message":"","code":200,"attributes":{}},"result":{"data":[99],"meta":{}}}$ curl -H "Accept:application/vnd.gremlin-v3.0+json" -X POST -d "{\"gremlin\":\"100-1\"}" "http://localhost:8182"{"requestId":"9fdf0892-d86c-41f2-94b5-092785c473eb","status":{"message":"","code":200,"attributes":{"@type":"g:Map","@value":[]}},"result":{"data":{"@type":"g:List","@value":[{"@type":"g:Int32","@value":99}]},"meta":{"@type":"g:Map","@value":[]}}GraphBinary
GraphBinary is a binary serialization format suitable for object trees, designed to reduce serialization overhead onboth the client and the server, as well as limiting the size of the payload that is transmitted over the wire. Theformat itself is described in theIO Documentation.
-{ className: org.apache.tinkerpop.gremlin.util.ser.GraphBinaryMessageSerializerV1 }It has the MIME type ofapplication/vnd.graphbinary-v1.0 and the following configuration options:
| Key | Description | Default |
|---|---|---|
custom | A list of classes with custom kryo | none |
ioRegistries | A list of | none |
builder | Name of the | none |
As described above, there are multiple ways in which to register serializers for GraphBinary-based serialization. Notethat theioRegistries setting is applied first, followed by thecustom setting.
Metrics
Gremlin Server produces metrics about its operations that can yield some insight into how it is performing. Thesemetrics are exposed in a variety of ways:
The configuration of each of these outputs is described in the Gremlin ServerConfiguring section.Note that Graphite and Ganglia are not included as part of the Gremlin Server distribution and must be installedto the server manually.
bin/gremlin-server.sh install com.codahale.metrics metrics-ganglia 3.0.2bin/gremlin-server.sh install com.codahale.metrics metrics-graphite 3.0.2Warning | Gremlin Server is built to work with Metrics 3.0.2. Usage of other versions may lead to unexpected problems. |
Note | Installing Ganglia will includeorg.acplt:oncrpc, which is an LGPL licensed dependency. |
Regardless of the output, the metrics gathered are the same. Each metric is prefixed withorg.apache.tinkerpop.gremlin.server.GremlinServer and the following metrics are reported:
channels.paused- The current number of open channels (HTTP and Websocket) that have their writes to buffer pausedwhen thewriteBufferHighWaterMarkconfiguration is exceeded.channels.total- The current number of open channels (HTTP and Websocket).channels.write-pauses- The total number of pauses across all channels (HTTP and Websocket) to buffer writes wherethewriteBufferHighWaterMarkconfiguration is exceeded, with mean rate, as well as the 1, 5, and 15-minute rates.engine-name.session.session-id.*- Metrics related to differentGremlinScriptEngineinstances configured forsession-based requests where "engine-name" will be the actual name of the engine, such as "gremlin-groovy" and"session-id" will be the identifier for the session itself. This metric is not measured under theUnifiedChannelizer.engine-name.sessionless.*- Metrics related to differentGremlinScriptEngineinstances configured for sessionlessrequests where "engine-name" will be the actual name of the engine, such as "gremlin-groovy". This metric is notmeasured under theUnifiedChannelizer.errors- The number of total errors, mean rate, as well as the 1, 5, and 15-minute error rates.op.eval- The number of script evaluations, mean rate, 1, 5, and 15 minute rates, minimum, maximum, median, mean,and standard deviation evaluation times, as well as the 75th, 95th, 98th, 99th and 99.9th percentile evaluation times(note that these time apply to both sessionless and in-session requests).op.traversal- The number ofTraversalbytecode-based executions, mean rate, 1, 5, and 15 minute rates, minimum,maximum, median, mean, and standard deviation evaluation times, as well as the 75th, 95th, 98th, 99th and 99.9thpercentile evaluation times.sessions- The number of sessions open at the time the metric was last measured. For theUnifiedChannelizer, eachrequest creates a "session", even a so-called "sessionless request", which is basically a session that will onlyexecute within the context of that single request.user-agent.*- Counts the number of connection requests from clients providing a given user agent.
Note | Gremlin Server has a limit of 10000 unique user agents to be tracked by metrics. If this cap is exceededany additional unique user agents will be counted asuser-agent.other. |
As A Service
Gremlin server can be configured to run as a service.
Init.d (SysV)
Linkbin/gremlin-server.sh toinit.dBe sure to set RUNAS to the service user inbin/gremlin-server.conf
# Installln -s /path/to/apache-tinkerpop-gremlin-server-3.7.4/bin/gremlin-server.sh /etc/init.d/gremlin-server# Systems with chkconfig/service. E.g. Fedora, Red Hatchkconfig --add gremlin-server# Startservice gremlin-server start# Or call directly/etc/init.d/gremlin-server restartSystemd
To install, copy the service template below to /etc/systemd/system/gremlin.serviceand update the paths/path/to/apache-tinkerpop-gremlin-server with the actual install path of Gremlin Server.
[Unit]Description=Apache TinkerPop Gremlin Server daemonDocumentation=https://tinkerpop.apache.org/After=network.target[Service]Type=forkingExecStart=/path/to/apache-tinkerpop-gremlin-server/bin/gremlin-server.sh startExecStop=/path/to/apache-tinkerpop-gremlin-server/bin/gremlin-server.sh stopPIDFile=/path/to/apache-tinkerpop-gremlin-server/run/gremlin.pid[Install]WantedBy=multi-user.targetEnable the service withsystemctl enable gremlin-server
Start the service withsystemctl start gremlin-server
Security
 Gremlin Server provides for several features that aid in thesecurity of the graphs that it exposes. In particular it supports SSL for transport layer security, authentication,authorization and protective measures against malicious script execution. Client SSL options are described in theGremlin Drivers and Variants" sections with varying capability depending on the driverchosen. Script execution options are covered"at the end of this section". This sectionstarts with authentication.
Gremlin Server provides for several features that aid in thesecurity of the graphs that it exposes. In particular it supports SSL for transport layer security, authentication,authorization and protective measures against malicious script execution. Client SSL options are described in theGremlin Drivers and Variants" sections with varying capability depending on the driverchosen. Script execution options are covered"at the end of this section". This sectionstarts with authentication.
Gremlin Server supports a pluggable authentication framework usingSASL (Simple Authentication andSecurity Layer). Depending on the client used to connect to Gremlin Server, different authenticationmechanisms are accessible, see the table below.
| Client | Authentication mechanism | Availability |
|---|---|---|
HTTP | BASIC | 3.0.0-incubating |
Gremlin-Java/Gremlin-Console | PLAIN SASL (username/password) | 3.0.0-incubating |
Pluggable SASL | 3.0.0-incubating | |
GSSAPI SASL (Kerberos) | 3.3.0 | |
Gremlin.NET | PLAIN SASL | 3.3.0 |
Gremlin-Python | PLAIN SASL | 3.2.2 |
GSSAPI SASL (Kerberos) | 3.4.7 | |
Gremlin.Net | PLAIN SASL | 3.2.7 |
Gremlin-Javascript | PLAIN SASL | 3.3.0 |
Gremlin-go | PLAIN SASL | 3.5.4 |
By default, Gremlin Server is configured to allow all requests to be processed (i.e. no authentication). To enableauthentication, Gremlin Server must be configured with anAuthenticator implementation in its YAML file. GremlinServer comes packaged with two implementations calledSimpleAuthenticator for plain text authentication using HTTPBASIC or PLAIN SASL andKrb5Authenticator for Kerberos authentication using GSSAPI SASL.
Plain text authentication
TheSimpleAuthenticator implements the "PLAIN" SASL mechanism (i.e. plain text) to authenticate a request. It alsosupports handling basic authentication requests from http clients. It validatesusername/password pairs against a graph database, which must be provided to it as part of the configuration.
authentication:{ authenticator: org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator, config: { credentialsDb: conf/tinkergraph-credentials.properties}}A quick way to get started with theSimpleAuthenticator is to use TinkerGraph for the "credentials graph" and the"sample" credential graph that is packaged with the server. To secure the transport for the credentials,SSL should be enabled. For this Quick Start, a self-signed certificate will be created but this should notbe used in a production environment.
Generate the self-signed SSL certificate:
$ keytool -genkey -alias localhost -keyalg RSA -keystore server.jksEnter keystore password:Re-enter new password:What is your first and last name? [Unknown]: localhostWhat is the name of your organizational unit? [Unknown]:What is the name of your organization? [Unknown]:What is the name of your City or Locality? [Unknown]:What is the name of your State or Province? [Unknown]:What is the two-letter country code for this unit? [Unknown]:Is CN=localhost, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown correct? [no]: yesEnter key password for <localhost> (RETURN if same as keystore password):Next, uncomment thekeyStore andkeyStorePassword lines inconf/gremlin-server-secure.yaml.
ssl:{ enabled: true, sslEnabledProtocols: [TLSv1.2], keyStore: server.jks, keyStorePassword: changeit}$ bin/gremlin-server.sh conf/gremlin-server-secure.yaml[INFO] GremlinServer - \,,,/ (o o)-----oOOo-(3)-oOOo-----[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server-secure.yaml...[INFO] AbstractChannelizer - SSL enabled[INFO] SimpleAuthenticator - Initializing authentication with the org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator[INFO] SimpleAuthenticator - CredentialGraph initialized at CredentialGraph{graph=tinkergraph[vertices:1 edges:0]}[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 8 and boss thread pool of 1.[INFO] GremlinServer$1 - Channel started at port 8182.When SSL is enabled on the server, it must also be enabled on the client when connecting. To connect toGremlin Server with thegremlin-driver, set thecredentials,enableSsl, andtrustStorewhen constructing theCluster.
Cluster cluster = Cluster.build().credentials("stephen","password") .enableSsl(true).trustStore("server.jks").create();If connecting with Gremlin Console, which utilizesgremlin-driver for remote script execution, use the providedconf/remote-secure.yaml file when defining the remote. That file contains configuration for the username andpassword as well as enablement of SSL from the client side. Be sure to configure the trustStore if using self-signedcertificates.
Similarly, Gremlin Server can be configured for REST and security. Follow the steps above for configuring the SSLcertificate.
$ bin/gremlin-server.sh conf/gremlin-server-rest-secure.yaml[INFO] GremlinServer - \,,,/ (o o)-----oOOo-(3)-oOOo-----[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server-secure.yaml...[INFO] AbstractChannelizer - SSL enabled[INFO] SimpleAuthenticator - Initializing authentication with the org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator[INFO] SimpleAuthenticator - CredentialGraph initialized at CredentialGraph{graph=tinkergraph[vertices:1 edges:0]}[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 8 and boss thread pool of 1.[INFO] GremlinServer$1 - Channel started at port 8182.Once the server has started, issue a request passing the credentials with anAuthentication header, as described inRFC2617. Here’s a HTTP Basic authentication example with cURL:
curl -X POST --insecure -u stephen:password -d "{\"gremlin\":\"100-1\"}" "https://localhost:8182"Credentials Graph DSL
The "credentials graph", which has been mentioned in previous sections, is used by Gremlin Server to hold the list ofusers who can authenticate to the server. It is possible to use virtually anyGraph instance for this task as longas it complies to a defined schema. The credentials graph stores users as vertices with thelabel of "user". Each"user" vertex has two properties:username andpassword. Naturally, these are bothString values. The passwordmust not be stored in plain text and should be hashed.
Important | Be sure to define an index on theusername property, as this will be used for lookups. If supported bytheGraph, consider specifying a unique constraint as well. |
To aid with the management of a credentials graph, Gremlin Server provides a Gremlin Console plugin which can beused to add and remove users so as to ensure that the schema is adhered to, thus ensuring compatibility with GremlinServer. In addition, as it is a plugin, it works naturally in the Gremlin Console as an extension of itscapabilities (though one could use it programmatically, if desired). This plugin is distributed with the GremlinConsole so it does not have to be "installed". It does however need to be activated:
gremlin> :plugin use tinkerpop.credentials==>tinkerpop.credentials activatedPlease see the example usage as follows:
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> graph.createIndex("username",Vertex.class)==>nullgremlin> credentials = traversal(CredentialTraversalSource.class).withEmbedded(graph)==>credentialtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> credentials.user("stephen","password")==>v[0]gremlin> credentials.user("daniel","better-password")==>v[3]gremlin> credentials.user("marko","rainbow-dash")==>v[6]gremlin> credentials.users("marko").elementMap()==>[id:6,label:user,password:$2a$04$cnB0NcLuHpAYjVKpB6lOSu7YIzAy94Ffy1gSjaqnXgX7UDSmLaBNS,username:marko]gremlin> credentials.users().count()==>3gremlin> credentials.users("daniel").drop()gremlin> credentials.users().count()==>2graph = TinkerGraph.open()graph.createIndex("username",Vertex.class)credentials = traversal(CredentialTraversalSource.class).withEmbedded(graph)credentials.user("stephen","password")credentials.user("daniel","better-password")credentials.user("marko","rainbow-dash")credentials.users("marko").elementMap()credentials.users().count()credentials.users("daniel").drop()credentials.users().count()Note | The Credentials DSL is built using TinkerPop’s DSL Annotation Processor describedhere. |
Important | In the above example, an empty in-memory TinkerGraph was used for demonstrating the API of the DSL.Obviously, this data will not be retained and usable with Gremlin Server. It would be important to configureTinkerGraph to persist that data or to manually persist it (e.g. write the graph data to Gryo) once changes arecomplete. Alternatively, use a persistent graph to hold the credentials and configure Gremlin Server accordingly. |
Kerberos Authentication
TheKrb5Authenticator implements the "GSSAPI" SASL mechanism (i.e. Kerberos) to authenticate a request from a Gremlinclient. It can be applied in an existing Kerberos environment and validates whether avalid authentication proof and service ticket areoffered.
authentication:{ authenticator: org.apache.tinkerpop.gremlin.server.auth.Krb5Authenticator, config: { principal: gremlinserver/hostname.your.org@YOUR.REALM, keytab: /etc/security/keytabs/gremlinserver.service.keytab}}Krb5Authenticator needs a Kerberos service principal and a keytab that holds the secret key for that principal. The keytablocation and service name, e.g. gremlinserver, are free to be chosen.Krb5Authenticator finds the KDC’s hostname andport from the krb5.conf file with Kerberos configurations. This file can reside at either thedefault location or a location to be specified as asystem property in the JAVA_OPTIONS environment variable of Gremlin Server:
export JAVA_OPTIONS="${JAVA_OPTIONS} -Xms512m -Xmx4096m -Djava.security.krb5.conf=/etc/krb5.conf"Gremlin clients have to specify the service name as theprotocol connection parameter. For Gremlin-Console theprotocol is an entry in the remote.yaml file, for Gremlin-java the client builder has aprotocol() method.
In addition to theprotocol, the Gremlin client needs to specify ajaasEntry, an entry in theJAAS configuration file. As astart one can define a conf/gremlin-jaas.conf file with aGremlinConsole jaasEntry:
GremlinConsole { com.sun.security.auth.module.Krb5LoginModule required doNotPrompt=true useTicketCache=true;};This configuration tells Gremlin Console to pass authentication requests from Gremlin Server to the Krb5LoginModule, which ispart of the java standard library. The Krb5LoginModule does not prompt the user for a username and password but uses theticket cache that is normally refreshed when a user logs in to a host within the Kerberos realm.
The Gremlin client needs the location of the JAAS configuration file to be passed as a system property to the JVM. ForGremlin-Console the easiest way to do this is to pass it to the run script via the JAVA_OPTIONS environment property.If the krb5.conf Kerberos configuration file is not available from thedefault location it has to be provided as a systemproperty as well:
JAAS_OPTION="-Djava.security.auth.login.config=conf/gremlin-jaas.conf"KRB5_OPTION="-Djava.security.krb5.conf=/etc/krb5.conf"export JAVA_OPTIONS="${JAVA_OPTIONS} ${KRB5_OPTION} ${JAAS_OPTION}"Authorization
While authentication determines which clients can connect to Gremlin Server, authorization regulates which elementsof the exposed graphs a specific user is allowed to create, read, update or delete (CRUD). Authorization in GremlinServer can take place at two instances. Before execution a user request can be allowed or denied based on thepresence of operations such as:
reading from a GraphTraversalSource
writing to a GraphTraversalSource
presence of lambdas in bytecode
script execution
VertexProgramexecution (OLAP)removal or modification of
TraversalStrategyinstances
During execution the applied traversal strategies influence the results and side-effects of a given query.
Important | Authorization is a feature of Gremlin Server, but is not implemented as an element of the server protocoland therefore Remote Graph Providers may not have this feature or may not implement it in this particular way. Pleaseconsult the documentation of the graph you are using to determine what authorization features it supports. |
Mechanisms
Gremlin Server supports three mechanisms to configure authorization:
With the
ScriptFileGremlinPlugina groovy script is configured that instantiates theGraphTraversalSourcesthatcan be accessed by client requests. Using thewithStrategies()gremlinstart step, one can apply so-calledTraversalStrategy instances to theseGraphTraversalSourceinstances, some of which can serve for authorization purposes (ReadOnlyStrategy,LambdaRestrictionStrategy,VertexProgramRestrictionStrategy,SubgraphStrategy,PartitionStrategy,EdgeLabelVerificationStrategy), provided that users are not allowed to remove or modify theseTraversalStrategyinstances afterwards. TheScriptFileGremlinPluginis found in the yaml configuration file for Gremlin Server:scriptEngines:{ gremlin-groovy: { plugins: { org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample.groovy]}}}}Administrators can configure an authorizer class, an implementation of the
Authorizerinterface. An authorizer receivesa request before it is executed and it can decide to pass or deny the request, based on the information it has availableon the requesting user or can seek externally.Apart from passing or denying requests, an
Authorizerimplementation can actively modify the request, in particularadd theTraversalStrategyinstances mentioned in item 1.
Important | This section is written with gremlin bytecode requests in mind. Realizing authorization for script requestsis hardly feasible, because such requests get full access to Gremlin Server’s execution environment. Although the sectionProtecting Script Execution explains how the client access to this environment can be restricted, it is not possible to denyexecution ofGraphFactory.open() orGraphTraversalSource.getGraph() methods without resorting to TinkerPopimplementation details (that is, internal API’s that can change without notice). |
The three mechanisms for authorization each have their merits in terms of simplicity and flexibility. The table belowgives an overview.
| Type (mechanism) | GraphTraversalSources | Groups | Bytecode analysis |
|---|---|---|---|
Implicit (init script) | all accessible | one |
|
Passive (pass/deny) | selected access | few | hybrid |
Active (inject) | selected access | many | hybrid |
With implicit authorization (only adding restrictingTraversalStrategy instances in the initialization script ofGremlin Server) all authenticated users can access all hostedGraphTraversalSources and all face the samerestrictions. One would need separate Gremlin Server instances for each authorization policy and apply an authenticatorthat restricts access to a group of users (that is, supports in authorization).
The other extreme is the active authorization solution that injects the restrictingStrategies into the user request,following a policy that takes into account both the authenticated user and the original request. While this solution isthe most flexible and can support an almost unlimited number of authorization policies, it is somewhat complex toimplement. In particular, applying theSubgraphStrategy requires knowledge about the schema of the graph.
The passive authorization solution perhaps provides a middle ground to start implementing authorization. Thissolution assumes that theSubgraphStrategy is applied in the Gremlin Server initialization script, because compliancewith a subgraph restriction can only be determined during the actual execution of the gremlin traversal. Note that thesame graph can be reused with differentSubgraphStrategies. Now, authorization policies can be defined in terms ofaccessibleGraphTraversalSources and the authorizer can simply match the requested access to aGraphTraversalSourceagainst the policies applicable to the authenticated user. Like for the active authorization solution, other restrictionssuch as read only access can be either applied at authorization time as policy in the authorizer itself or at requestexecution time as a result of an appliedStrategy (denoted as 'hybrid' bytecode analysis in the table). A codeexample pursuing the former option is provided in thenext section.
Note | Both the passive and active authorization solutions need to analyze the gremlin bytecode of the original requestfor unwanted removal of restricting Strategies. |
Note | Gremlin Server is not shipped withAuthorizer implementations, because these would heavily depend on the externalsystems to integrate with, e.g.LDAP systems orApache Ranger. However, third-party implementations can beoffered asgremlin plugins. |
Code example
The two java classes below provide an example implementation of theAuthorizer interface; they originate fromGremlin Server’s test package.If you copy the files into a project, build them into a jar and add the jar to Gremlin Server’s CLASSPATH, you can usethem by adding the following to Gremlin Server’s yaml configuration file:
authentication:{ authenticator: org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator, config: { credentialsDb: conf/tinkergraph-credentials.properties}}authorization:{ authorizer: org.yourpackage.AllowListAuthorizer, config: { authorizationAllowList: your/path/allow-list.yaml}}TheAllowListAuthorizer supports granting groups of users access to statically configuredGraphTraversalSourceinstances and to the "sandbox", where sandbox means that the group is allowed anything unless restricted by GremlinServer’ssandbox. For denying mutating steps and OLAP operations in bytecode requests, theAllowListAuthorizer relies on theReadOnlyStrategy andVertexProgramRestrictionStrategy being present in theGraphTraversalSource. However, it always denies the use of lambdas in bytecode requests unless the user has the"sandbox" grant. It uses theBytecodeHelper.getLambdaLanguage() method to detect these.
The grants to groups of users can be configured in a simple yaml file. In addition to the special value "sandbox" fora grant for string based requests and lambdas, the special value "anonymous" can be used to denote any user.
packageorg.yourpackage;importorg.apache.tinkerpop.gremlin.util.message.RequestMessage;importorg.apache.tinkerpop.gremlin.process.computer.traversal.strategy.verification.VertexProgramRestrictionStrategy;importorg.apache.tinkerpop.gremlin.process.traversal.Bytecode;importorg.apache.tinkerpop.gremlin.process.traversal.TraversalSource;importorg.apache.tinkerpop.gremlin.process.traversal.strategy.decoration.SubgraphStrategy;importorg.apache.tinkerpop.gremlin.process.traversal.strategy.verification.ReadOnlyStrategy;importorg.apache.tinkerpop.gremlin.process.traversal.util.BytecodeHelper;importorg.apache.tinkerpop.gremlin.server.Settings.AuthorizationSettings;importorg.apache.tinkerpop.gremlin.server.auth.AuthenticatedUser;importjava.util.*;/** * Authorizes a user per request, based on a list that grants access to {@link TraversalSource} instances for * bytecode requests and to gremlin server's sandbox for string requests and lambdas. The {@link * AuthorizationSettings}.config must have an authorizationAllowList entry that contains the name of a YAML file. * This authorizer is for demonstration purposes only. It does not scale well in the number of users regarding * memory usage and administrative burden. */publicclassAllowListAuthorizerimplements Authorizer {publicstaticfinalString SANDBOX ="sandbox";publicstaticfinalString REJECT_BYTECODE ="User not authorized for bytecode requests on %s";publicstaticfinalString REJECT_LAMBDA ="lambdas";publicstaticfinalString REJECT_MUTATE ="the ReadOnlyStrategy";publicstaticfinalString REJECT_OLAP ="the VertexProgramRestrictionStrategy";publicstaticfinalString REJECT_SUBGRAPH ="the SubgraphStrategy";publicstaticfinalString REJECT_STRING ="User not authorized for string-based requests.";publicstaticfinalString KEY_AUTHORIZATION_ALLOWLIST ="authorizationAllowList";// Collections derived from the list with allowed users for fast lookupsprivatefinalMap<String,List<String>> usernamesByTraversalSource =newHashMap<>();privatefinalSet<String> usernamesSandbox =newHashSet<>();/** * This method is called once upon system startup to initialize the {@code AllowListAuthorizer}. */@Overridepublicvoid setup(finalMap<String,Object> config) { AllowList allowList;finalString file = (String) config.get(KEY_AUTHORIZATION_ALLOWLIST);try { allowList = AllowList.read(file); }catch (Exception e) {thrownewIllegalArgumentException(String.format("Failed to read list with allowed users from %s", file)); }for (Map.Entry<String,List<String>> entry : allowList.grants.entrySet()) {if (!entry.getKey().equals(SANDBOX)) { usernamesByTraversalSource.put(entry.getKey(),newArrayList<>()); }for (finalString group : entry.getValue()) {if (allowList.groups.get(group) ==null) {thrownewRuntimeException(String.format("Group '%s' not defined in file with allowed users.", group)); }if (entry.getKey().equals(SANDBOX)) { usernamesSandbox.addAll(allowList.groups.get(group)); }else { usernamesByTraversalSource.get(entry.getKey()).addAll(allowList.groups.get(group)); } } } }/** * Checks whether a user is authorized to have a gremlin bytecode request from a client answered and raises an * {@link AuthorizationException} if this is not the case. For a request to be authorized, the user must either * have a grant for the requested {@link TraversalSource}, without using lambdas, mutating steps or OLAP, or have a * sandbox grant. * * @param user {@link AuthenticatedUser} that needs authorization. * @param bytecode The gremlin {@link Bytecode} request to authorize the user for. * @param aliases A {@link Map} with a single key/value pair that maps the name of the {@link TraversalSource} in the * {@link Bytecode} request to name of one configured in Gremlin Server. * @return The original or modified {@link Bytecode} to be used for further processing. */@Overridepublic Bytecode authorize(final AuthenticatedUser user,final Bytecode bytecode,finalMap<String,String> aliases)throws AuthorizationException {finalSet<String> usernames =newHashSet<>();for (finalString resource: aliases.values()) { usernames.addAll(usernamesByTraversalSource.get(resource)); }finalboolean userHasTraversalSourceGrant = usernames.contains(user.getName()) || usernames.contains(AuthenticatedUser.ANONYMOUS_USERNAME);finalboolean userHasSandboxGrant = usernamesSandbox.contains(user.getName()) || usernamesSandbox.contains(AuthenticatedUser.ANONYMOUS_USERNAME);finalboolean runsLambda = BytecodeHelper.getLambdaLanguage(bytecode).isPresent();finalboolean touchesReadOnlyStrategy = bytecode.toString().contains(ReadOnlyStrategy.class.getSimpleName());finalboolean touchesOLAPRestriction = bytecode.toString().contains(VertexProgramRestrictionStrategy.class.getSimpleName());// This element becomes obsolete after resolving TINKERPOP-2473 for allowing only a single instance of each traversal strategy.finalboolean touchesSubgraphStrategy = bytecode.toString().contains(SubgraphStrategy.class.getSimpleName());finalList<String> rejections =newArrayList<>();if (runsLambda) { rejections.add(REJECT_LAMBDA); }if (touchesReadOnlyStrategy) { rejections.add(REJECT_MUTATE); }if (touchesOLAPRestriction) { rejections.add(REJECT_OLAP); }if (touchesSubgraphStrategy) { rejections.add(REJECT_SUBGRAPH); }String rejectMessage = REJECT_BYTECODE;if (rejections.size() >0) { rejectMessage +=" using" +String.join(",", rejections); } rejectMessage +=".";if ( (!userHasTraversalSourceGrant || runsLambda || touchesOLAPRestriction || touchesReadOnlyStrategy || touchesSubgraphStrategy) && !userHasSandboxGrant) {thrownew AuthorizationException(String.format(rejectMessage, aliases.values())); }return bytecode; }/** * Checks whether a user is authorized to have a script request from a gremlin client answered and raises an * {@link AuthorizationException} if this is not the case. * * @param user {@link AuthenticatedUser} that needs authorization. * @param msg {@link RequestMessage} in which the {@link org.apache.tinkerpop.gremlin.util.Tokens}.ARGS_GREMLIN argument can contain an arbitrary succession of script statements. */publicvoid authorize(final AuthenticatedUser user,final RequestMessage msg)throws AuthorizationException {if (!usernamesSandbox.contains(user.getName())) {thrownew AuthorizationException(REJECT_STRING); } }}packageorg.yourpackage;importorg.yaml.snakeyaml.TypeDescription;importorg.yaml.snakeyaml.Yaml;importorg.yaml.snakeyaml.constructor.Constructor;importjava.io.File;importjava.io.FileInputStream;importjava.io.InputStream;importjava.util.List;importjava.util.Map;importjava.util.Optional;/** * AllowList for the AllowListAuthorizer as configured by a YAML file. */publicclassAllowList {/** * Holds lists of groups by grant. A grant is either a TraversalSource name or the "sandbox" value. With the * sandbox grant users can access all TraversalSource instances and execute groovy scripts as string based * requests or as lambda functions, only limited by Gremlin Server's sandbox definition. */publicMap<String,List<String>> grants;/** * Holds lists of user names by groupname. The "anonymous" user name can be used to denote any user. */publicMap<String,List<String>> groups;/** * Read a configuration from a YAML file into an {@link AllowList} object. * * @param file the location of a AllowList YAML configuration file * @return An {@link Optional} object wrapping the created {@link AllowList} */publicstatic AllowList read(finalString file)throwsException {finalInputStream stream =newFileInputStream(newFile(file));finalConstructor constructor =newConstructor(AllowList.class);final TypeDescription allowListDescription =new TypeDescription(AllowList.class); allowListDescription.putMapPropertyType("grants",String.class,Object.class); allowListDescription.putMapPropertyType("groups",String.class,Object.class); constructor.addTypeDescription(allowListDescription);final Yaml yaml =new Yaml(constructor);return yaml.loadAs(stream, AllowList.class); }}allow-list.yaml:
grants:{gclassic:[groupclassic],gmodern:[groupmodern],gcrew:[groupclassic, groupmodern],ggrateful:[groupgrateful],sandbox:[groupsandbox]}groups:{groupclassic:[userclassic],groupmodern:[usermodern, stephen],groupsink:[usersink],groupgrateful:[anonymous],groupsandbox:[usersandbox, marko]}Protecting Script Execution
It is important to remember that Gremlin Server exposesGremlinScriptEngine instances that allows for remote executionof arbitrary code on the server. Obviously, this situation can represent a security risk or, more minimally, provideways for "bad" scripts to be inadvertently executed. A simple example of a "valid" Gremlin script that would causesome problems would be,while(true) {}, which would consume a thread in the Gremlin pool indefinitely, thuspreventing it from serving other requests. Sending enough of these kinds of scripts would eventually consume allavailable threads and Gremlin Server would stop responding.
Scripts have access to the full power of their language and the JVM on which they are running. This means that theycan access certain APIs that have nothing to do with Gremlin itself, such asjava.lang.System or thejava.ioandjava.net packages. Scripts offer developers a lot of flexibility, but having that flexibility comes at the costof safety. A Gremlin Server instance that is not secured appropriately provides for a big security risk.
The previous sections discussed methods for securing Gremlin Server through authentication and encryption, which is agood first step in protection. Another layer of protection comes in the form of specific configurations for theGremlinGroovyScriptEngine. A user can configure the script engine with aGroovyCompilerGremlinPluginimplementation. Consider the basic configuration from the Gremlin Server YAML file:
scriptEngines:{ gremlin-groovy: { plugins: { org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {}, org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {}, org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]}, org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample.groovy]}}}}This configuration can be expanded to include a theGroovyCompilerGremlinPlugin:
scriptEngines:{ gremlin-groovy: { plugins: { org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {}, org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {} org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]}, org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample-secure.groovy]}, org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyCompilerGremlinPlugin: {enableThreadInterrupt: true}}}}This configuration sets up the script engine with to ensure that loops (likewhile) will respect interrupt requests.With this configuration in place, a remote execution as follows, now times out rather than consuming the threadcontinuously:
gremlin> :remote connect tinkerpop.server conf/remote.yaml==>Configured localhost/127.0.0.1:8182gremlin> :>while(true) { }==>Evaluation exceeded the configured'evaluationTimeout' threshold of30000 ms or evaluation was otherwise cancelled directlyfor request [while(true) {}]TheGroovyCompilerGremlinPlugin has a number of configuration options:
| Customizer | Description |
|---|---|
| Allows for three configurations: |
| Allows configuration of the Groovy |
| Injects checks for thread interruption, thus allowing the script to potentially respect calls to |
| The amount of time in milliseconds a script is allowed to compile before a warning message is sent to the logs. |
| Determines if the global function cache is enabled. By default, this value is |
| The cache specification for the |
| This setting is for use when |
Note | Consult the latestGroovy Documentationfor information on the differences on the various compilation options. It is important to understand the impact thatthese configuration will have on submitted scripts before enabling this feature. |
Important | TinkerPop does not offer an end-to-end out-of-the-box solution to perfectly protect against bad actorssubmitting nefarious scripts. The configurations to follow which discuss theSimpleSandboxExtension andFileSandboxExtension are meant to represent example implementations that users and providers can gain someinspiration from in developing their own solutions. Please consult the documentation of your TinkerPop implementationto determine how scripts are "secured" as many providers have taken their own approaches to solving this problem. |
Securing scripts (i.e. preventing access to certain methods) is a bit more complicated of a story. As an example,TinkerPop implemented some basic "sandbox" implementations as described in thisblog post to try to demonstrate a method by which scriptsecurity could be achieved. Consider the following configuration of theGroovyCompilerGremlinPlugin:
scriptEngines:{ gremlin-groovy: { plugins: { org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {}, org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {} org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyCompilerGremlinPlugin: {enableThreadInterrupt: true, compilation: COMPILE_STATIC, extensions: org.apache.tinkerpop.gremlin.groovy.jsr223.customizer.SimpleSandboxExtension}, org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]}, org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample-secure.groovy]}}}}This configuration uses theSimpleSandboxExtension, which blocks calls to methods on theSystem class, therebypreventing someone from remotely killing the server:
gremlin> :>System.exit(0)Script8.groovy:1: [Static type checking] - Not authorized to callthismethod: java.lang.System#exit(int)@ line1, column1. System.exit(0) ^1 errorTheSimpleSandboxExtension is by no means a "complete" implementation protecting against all manner of nefariousscripts, but it does provide an example for how such a capability might be implemented. A slightly more advancedexample is offered in theFileSandboxExtension which uses a configuration file to allow certain classes and methods.The configuration file is YAML-based and an example is presented as follows:
autoTypeUnknown:truemethodWhiteList: -java\.lang\.Boolean.* -java\.lang\.Byte.* -java\.lang\.Character.* -java\.lang\.Double.* -java\.lang\.Enum.* -java\.lang\.Float.* -java\.lang\.Integer.* -java\.lang\.Long.* -java\.lang\.Math.* -java\.lang\.Number.* -java\.lang\.Object.* -java\.lang\.Short.* -java\.lang\.String.* -java\.lang\.StringBuffer.* -java\.lang\.System#currentTimeMillis\(\) -java\.lang\.System#nanoTime\(\) -java\.lang\.Throwable.* -java\.lang\.Void.* -java\.util\..* -org\.codehaus\.groovy\.runtime\.DefaultGroovyMethods.* -org\.codehaus\.groovy\.runtime\.InvokerHelper#runScript\(java\.lang\.Class,java\.lang\.String\[\]\) -org\.codehaus\.groovy\.runtime\.StringGroovyMethods.* -groovy\.lang\.Script#<init>\(groovy.lang.Binding\) -org\.apache\.tinkerpop\.gremlin\.structure\..* -org\.apache\.tinkerpop\.gremlin\.process\..* -org\.apache\.tinkerpop\.gremlin\.process\.computer\..* -org\.apache\.tinkerpop\.gremlin\.process\.computer\.bulkloading\..* -org\.apache\.tinkerpop\.gremlin\.process\.computer\.clustering\.peerpressure\.* -org\.apache\.tinkerpop\.gremlin\.process\.computer\.ranking\.pagerank\.* -org\.apache\.tinkerpop\.gremlin\.process\.computer\.traversal\..* -org\.apache\.tinkerpop\.gremlin\.process\.traversal\..* -org\.apache\.tinkerpop\.gremlin\.process\.traversal\.dsl\.graph\..* -org\.apache\.tinkerpop\.gremlin\.process\.traversal\.engine\..* -org\.apache\.tinkerpop\.gremlin\.server\.util\.LifeCycleHook.*staticVariableTypes:graph:org.apache.tinkerpop.gremlin.structure.Graphg:org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversalSourceThere are three keys in this configuration file that control different aspects of the sandbox:
autoTypeUnknown- When set totrue, unresolved variables are typed asObject.methodWhiteList- A white list of classes and methods that follow a regex pattern which can then be matched againstmethod descriptors to determine if they can be executed. The method descriptor is the fully-qualified class nameof the method, its name and parameters. For example,Math.ceilwould have a descriptor ofjava.lang.Math#ceil(double).staticVariableTypes- A list of variables that will be used in theScriptEnginefor which the types arealways known. In the above example, the variable "graph" will always be bound to aGraphinstance.
At Gremlin Server startup, theFileSandboxExtension looks in the root of Gremlin Server installation directory for afile calledsandbox.yaml and configures itself. To use a file in a different location set thegremlinServerSandbox system property to the location of the file (e.g.-DgremlinServerSandbox=conf/my-sandbox.yaml).
A final thought on the topic ofGroovyCompilerGremlinPlugin implementation is that it is not just for"security" (though it is demonstrated in that capacity here). It can be used for a variety of features thatcan fine tune the Groovy compilation process. Read more about compilation customization in theGroovy Documentation.
Best Practices
The following sections define best practices for working with Gremlin Server.
Tuning
 Tuning Gremlin Server for a particular environment may require somesimple trial-and-error, but the following represent some basic guidelines that might be useful:
Tuning Gremlin Server for a particular environment may require somesimple trial-and-error, but the following represent some basic guidelines that might be useful:
Gremlin Server defaults to a very modest maximum heap size. Consider increasing this value for non-trivial uses.Maximum heap size (
-Xmx) is defined with theJAVA_OPTIONSsetting ingremlin-server.conf.TinkerPop tends to discourage the use oflong traversalsas they can introduce performance problems in some cases and in others simply fail with a
StackOverflowError. Asidefrom restructuring the traversal into multiple commands or stream based inserts, it may sometimes make sense to simplyincrease the stack size of the JVM for Gremlin Server by configuring an-Xsssetting inJAVA_OPTIONSofgremlin-server.conf.If Gremlin Server is processing scripts or lambdas in bytecode requests, consider fine tuning the JVM’s handling ofthe metaspace size. Consider modifying the
-XX:MetaspaceSize,-XX:MaxMetaspaceSize, and related settings given theexpected workload. More discussion on this topic can be found in theParameterized ScriptsSection below.When configuring the size of
threadPoolWorkerstart with the default of1and increment by one as needed to amaximum of2*number of cores.The "right" size of the
gremlinPoolsetting is somewhat dependent on the type of requests that will be processedby Gremlin Server. As requests arrive to Gremlin Server they are decoded and queued to be processed by threads inthis pool. When this pool is exhausted of threads, Gremlin Server will continue to accept incoming requests, butthe queue will continue to grow. If left to grow too large, the server will begin to slow. When tuning aroundthis setting, consider whether the bulk of the scripts being processed will be "fast" or "slow", where "fast"generally means being measured in the low hundreds of milliseconds and "slow" means anything longer than that.Requests that are "slow" can really hurt Gremlin Server if they are not properly accounted for. Since these requestsblock a thread until the job is complete or successfully interrupted, lots of long-run requests will eventually consumethe
gremlinPoolpreventing other requests from getting processed from the queue.To limit the impact of this problem, consider properly setting the
evaluationTimeoutto something "sane".In other words, test the traversals being sent to Gremlin Server and determine the maximum time they take to evaluateand iterate over results, then set the timeout value accordingly. Also, consider setting a shorter global timeout forrequests and then use longer per-request timeouts for those specific ones that might execute at a longer rate.Note that
evaluationTimeoutcan only attempt to interrupt the evaluation on timeout. It allows GremlinServer to "ignore" the result of that evaluation, which means the thread in thegremlinPoolthat did the evaluationmay still be consumed after the timeout if interruption does not succeed on the thread.
When using sessions, there are different options to consider depending on the
Channelizerimplementation beingused:WebSocketChannelizerandWsAndHttpChannelizer- Both of these channelizers use thegremlinPoolonly forsessionless requests and construct a single threaded pool for each session created. In this way, these channelizerstend to optimize sessions to be long-lived. For short-lived sessions, which may be typical when using bytecode basedremote transactions, quickly creating and destroying these sessions can be expensive. It is likely that there will beincreased garbage collection times and frequency as well as a general increase in overall server processing.UnifiedChannelizer- The threads of thegremlinPoolare used to service both sessions and sessionless requests.With a common thread pool, this channelizer is a better choice when using lots of short-lived sessions as compared toWebSocketChannelizerandWsAndHttpChannelizer, because there is less cost in starting and stopping sessions. It isimportant though to understand the expected workload for the server and plan the size accordingly to ensure that theserver does not need to wait for an extended period of time for a thread to be available to process the queue ofincoming requests.
Graph element serialization for
VertexandEdgecan be expensive, as their data structures are complex given thepossible existence of multi-properties and meta-properties. When returning data from Gremlin Server only return thedata that is required. For example, if only two properties of aVertexare needed then simply return the two ratherthan returning the entireVertexobject itself. Even with an entireVertex, it is typically much faster to issuethe query asg.V(1).elementMap()thang.V(1), as the former returns aMapof the same data as aVertex, butwithout all the associated structure which can slow the response.Gremlin Server writes responses to a buffer held in direct memory prior to flushing them to the TCP socket. If thelogs show
OutOfDirectMemoryError, particularly when thechannels.write-pausesmetric is high, it islikely caused by this buffer being filled. The buffer can fill when clients are slow to consume results being sent tothem (e.g. network problems, underpowered client instances, etc.). Gremlin Server will attempt to throttle the speed atwhich the buffer gets filled by pausing writes for any channel that exceeds its allowed buffer space allotment asdetermined by thewriteBufferHighWaterMarkandwriteBufferLowWaterMarkdescribed in theServer Configuration Section. Pauses obviously increase latency, but do so for benefit ofserver stability in continuing to serve channels that have clients without issue consuming the results.Write pauses are generally considered a natural part of server operations, though a continuous amount of pausingmeans that threads used for query execution are tied up and are therefore preventing the processing of other requests.As a result, requests may begin to queue which further adds to server load and potential latency. Increasing the
writeBufferHighWaterMarkandwriteBufferLowWaterMarksettings could allow the server to delay pauses at the expenseof direct memory and therefore allow more requests to be handled by freeing those query execution threads.Client applications should be selective in their retries. Quickly resending a query that triggered an
OutOfDirectMemoryErrorwithout giving the server time to recover will just further burden a taxed system. Even retrysystems that use exponential back-off may not be suitable for these cases as early retries may land too quickly andtherefore just queue another heavy request.Consider the shape of query results as they can have an impact on server performance. The "shape" refers to the formof the result given the query. For example,
g.V()andg.V().fold()both return the same results (i.e. all thevertices in the graph) but the former returns them one at a time in a stream and the latter collects them all inmemory in aListand then returns the oneListresult. Writing queries in ways that allow results that can stream(only applies for websockets) is preferable and will allow the server to perform better. Another aspect of "shape"can come into play when returning data of individual graph elements. For example, theg.V()form of query will stream,but if eachVertexreturned has lots of properties (e.g. properties with large strings or heavy blobs), this couldtrigger scenarios where each streamed batch immediately exceedswriteBufferHighWaterMark. Simply exceeding thewriteBufferHighWaterMarkmay not trigger a pause as the server may quickly flush the buffer before the next batch, butone could see how easily a write pause could be triggered in that state. It could make sense to configure a smallerbatchSizefor queries results that have heavy individual objects in them as that would reduce the byte size of thebatch and allow buffer flushes to happen more often (though that may be a cost in and of itself).
Parameterized Scripts
 If using the standard
If using the standardGremlinGroovyScriptEngine in GremlinServer, it is imperative to use script parameterization. Period. There are at least two goodreasons for doing so: script caching and protection from "Gremlin injection" (conceptually the same as the notion ofSQL injection).
Important | It is possible to use theGremlinLangScriptEngine in Gremlin Server as opposed to theGremlinGroovyScriptEngine. The former makes use ofgremlin-language and its ANTLR grammar for parsing Gremlinscripts. This processing is different from the processing performed by Groovy and therefore spares users from theconcerns of this section. When considering parameterization, users should also consider the graph database they areusing to determine if it has native mechanisms that preclude the need for parameterization. |
With respect to caching, Gremlin Server caches all scripts that are passed to it. The cache is keyed based on the ahash of the script. Thereforeg.V(1) andg.V(2) will be recognized as two separate scripts in the cache. If thatscript is parameterized tog.V(x) wherex is passed as a parameter from the client, there will be no additionalcompilation cost for future requests on that script. Compilation of a script should be considered "expensive" andavoided when possible.
Important | The parameterized script ofg.V(x) is keyed in the cache differently thang.V(y) or eveng.V( x ).Scripts must be exact string matches for recompilation to be avoided. |
Cluster cluster = Cluster.open();Client client = cluster.connect();Map<String,Object> params =newHashMap<>();params.put("x",4);client.submit("[1,2,3,x]", params);The more parameters that are used in a script the more expensive the compilation step becomes. Gremlin Server has aOpProcessor setting calledmaxParameters, which is mentioned in theOpProcessor Configurationsection. It controls the maximum number of parameters that can be passed to the server for script evaluation purposes.Use of this setting can prevent accidental long run compilations, which individually are not terribly oppressive tothe server, but taken as a group under high concurrency would be considered detrimental.
On the topic of Gremlin injection, note that it is possible to take advantage of Gremlin scripts in the same fashionas SQL scripts that are submitted as strings. When using string building patterns for queries without proper inputscrubbing, it would be quite simple to do:
String lbl ="person"String nodeId ="mary').next();g.V().drop().iterate();g.V().has('id', 'thomas";String query ="g.addV('" + lbl +"').property('identifier','" + nodeId +"')";client.submit(query);The above case woulddrop() all vertices in the graph. By using script parameterization, there is a different outcomein that thenodeId string is not treated as something executable, but rather as a literal string that just becomespart of the "identifier" for the vertex on insertion:
String lbl ="person"String nodeId ="mary').next();g.V().drop().iterate();g.V().has('id', 'thomas";String query ="g.addV(lbl).property('identifier',nodeId)";Map<String,Object> params =newHashMap<>();params.put("lbl",lbl);params.put("nodeId",nodeId);client.submit(query, params);Gremlin injection should not be possible withBytecode based traversals - only scripts - becauseBytecodetraversals will treat all arguments as literal values. There is potential for concern if lambda based steps areutilized as they execute arbitrary code, which is string based, but configuringTraversalSource instances withLambdaRestrictionStrategy, which prevents lambdas all together, using a graph that does not allow lambdas at all, orconfiguring appropriatesandbox options in Gremlin Server (or such options available to the graphdatabase in use) should each help mitigate problems related to this issue.
Scripts create classes which get loaded to the JVM metaspace and to aClass cache. For those using scriptparameterization, a typical application should not generate an overabundance of pressure on these two components ofGremlin Server’s memory footprint. On the other hand, it’s not too hard to imagine a situation where problems mightemerge:
An application use case makes parameterization impossible and therefore all scripts are unique.
There is a bug in an applications parameterization code that is actually instead producing unique scripts.
A long running Gremln Server takes lots of non-parameterized scripts from Gremlin Console or similar tools.
In these sorts of cases, Gremlin Server’s performance can be affected adversely as without some additional configurationthe metaspace will grow indefinitely (possibly along with the general heap) triggering longer and more frequent roundsof garbage collection (GC). Some tuning of JVM settings can help abate this issue.
As a first guard against this problem consider setting the-XX:SoftRefLRUPolicyMSPerMB to release soft referencesearlier. TheScriptEngine cache for createdClass objects uses soft references and if the workload expectation issuch that cache hits will be low there is little need to keep such references around.
Perhaps the more important guards are related to the JVM metaspace. Start by setting the initial size of this spacewith-XX:MetaspaceSize. When this value is exceeded it will trigger a GC round - it is essentially a threshold forGC. The grow of this value can be capped with-XX:MaxMetaspaceSize (this value is unlimited by default). In an idealsituation (i.e. parameterization), the-XX:MetaspaceSize should have a large enough setting so as to avoid early GCrounds for metaspace, but outside of an ideal world (i.e. non-parameterization) it may not be smart to make this numbertoo large. Making the setting too large (and thus the-XX:MaxMetaspaceSize even larger) may trigger longer GC roundswhen they inevitably arrive.
In addition to those two metaspace settings it may also be useful to consider the following additional options:
MinMetaspaceFreeRatio- When the percentage for committed space available for class metadata is less than thisvalue, then the threshold of metaspace GC will be raised, but only if the incremental size of the threshold meets therequirement set byMinMetaspaceExpansion. A larger number should make the metaspace grow more aggressively.MaxMetaspaceFreeRatio- When the percentage for committed space available for class metadata is more than thisvalue, then the threshold of metaspace GC will be lowered, but only if the incremental size of the threshold meets therequirement set byMaxMetaspaceExpansion. A larger number should reduce the chance of the metaspace shrinking.MinMetaspaceExpansion- The minimum size by which the metaspace is expanded after a metaspace GC round.MaxMetaspaceExpansion`- If the incremental size exceedsMinMetaspaceExpansionbut less thanMaxMetaspaceExpansion, then the incremental size isMaxMetaspaceExpansion. If the incremental size exceedsMaxMetaspaceExpansion, then the incremental size isMinMetaspaceExpansionplus the original incremental size.
There really aren’t any general guidelines for how to initially set these values. Using profiling tools to examine GCtrends is likely the best way to understand how a particular workload is affecting the metaspace and its relation toGC. Getting these settings "right" however will help ensure much more predictable Gremlin Server operations.
Important | A lambda used in a bytecode-based request will be treated as a script, so issues related to raw script-basedrequests apply equally well to lambda-bytecode requests. |
Properties of Elements
It was mentioned above at the start of this "Best Practices" section that serialization of graph elements (i.e.Vertex,Edge, andVertexProperty) can be expensive and that it is best to only return the data that is requiredby the requesting system. This point begs for further clarification as there are a number of ways to use and configureGremlin Server which might influence its interpretation.
To begin to discuss these nuances, first consider the method of making requests to Gremlin Server: script or bytecode.For scripts, that will mean that users are sending string representation of Gremlin to the server directly through adriver over websockets or through the HTTP. For bytecode, users will be utilize aGremlin GLVwhich will construct bytecode for them and submit the request to the server upon iteration of their traversal.
In either case, it is important to also consider the method of "detachment". Detachment refers to the manner in whicha graph element is disconnected from the graph for purpose of serialization. Depending on the case and configuration,graph elements may be detached with or without properties. Cases where they include properties is generally referredto as "detached elements" and cases where properties are not included are "reference elements".
With the type of request and detachment model in mind, it is now possible to discuss how best to consider elementproperties in relation to them all in concert.
By default, Gremlin Server configuration returns all properties.
To manage properties for each request you can use thewith() configuration optionmaterializeProperties
g.with('materializeProperties','tokens').V()Thetokens value for thematerializeProperties means that onlyid andlabel should be returned.Another option,all, can be used to indicate that all properties should be returned and is the default value.
In some cases it can be inconvenient to load Elements with properties due to large data size or for compatibility reasons.That can be solved by utilizingReferenceElementStrategy when creating the out-of-the-boxGraphTraversalSource.As the name suggests, this means that elements will be detached by reference and will therefore not have propertiesincluded. The relevant configuration from the Gremlin Server initialization script looks like this:
globals << [g : traversal().withEmbedded(graph).withStrategies(ReferenceElementStrategy)]This configuration is global to Gremlin Server and therefore all methods of connection will always return elementswithout properties. If this strategy is not included, then elements will be returned with properties.
Ultimately, the detachment model should have little impact to Gremlin usage if the best practice of specifying onlythe data required by the application is adhered to.
The best practice of requesting only the data the application needs:
Cluster cluster = Cluster.open();Client client = cluster.connect();ResultSet results = client.submit("g.V().hasLabel('person').elementMap('name')");GraphTraversalSource g = traversal().withRemote('conf/remote-graph.properties');List<Vertex> results = g.V().hasLabel("person").elementMap('name').toList();Both of the above requests return a list ofMap instances that contain theid,label and the "name" property.
Compatibility
It is not recommended to use 3.6.x or below driver versions with 3.7.x or above Gremlin Server, as some older drivers do not constructgraph elements with properties and thus are not designed to handle the returned properties by default; however, compatibilitycan be achieved by configuringReferenceElementStrategy in the server such that properties are not returned.Per-request configuration optionmaterializeProperties is not supported older driver versions.
Also note that older drivers of different language variants will handle incoming properties differently with differentserializers used. Drivers usingGraphSON serializers will remain compatible, but may encounter deserialization errorswithGraphBinary. Below is a table documenting GLV behaviors usingGraphBinary when properties are returned by thedefault 3.7.x server, as well as ifReferenceElementStrategy is configured (i.e. mimic the behaviorof a 3.6.x server). This can be observed with the results ofg.V().next(). Note that onlygremlin-driverandgremlin-javacript have theproperties attribute in the Element objects, all other GLVs only haveid andlabel.
3.6.x drivers withGraphBinary | Behavior with default 3.7.x Server | Behavior withReferenceElementStrategy |
|---|---|---|
| Properties returned as empty iterator | Properties returned as empty iterator |
| Skips properties in Elements | Skips properties in Elements |
| Deserialization error | Properties returned as empty list |
| Deserialization error | Skips properties in Elements |
| Deserialization error | Skips properties in Elements |
Tip | Consider utilizingReferenceElementStrategy whenever creating aGraphTraversalSource in Java to ensurethe most portable Gremlin. |
Note | For those interested, please seethis postto the TinkerPop dev list which outlines the full history of this issue and related concerns. |
Cache Management
If Gremlin Server processes a large number of unique scripts, the global function cache will grow beyond the memoryavailable to Gremlin Server and anOutOfMemoryError will loom. Script parameterization goes a long way to solvingthis problem and running out of memory should not be an issue for those cases. If it is a problem or if there is noscript parameterization due to a given use case (perhaps using with use ofsessions), it is possible tobetter control the nature of the global function cache from the client side, by issuing scripts with a parameter tohelp define how the garbage collector should treat the references.
The parameter is called#jsr223.groovy.engine.keep.globals and has four options:
hard- available in the cache for the life of the JVM (default when not specified).soft- retained until memory is "low" and should be reclaimed before anOutOfMemoryErroris thrown.weak- garbage collected even when memory is abundant.phantom- removed immediately after being evaluated by theScriptEngine.
By specifying an option other thanhard, anOutOfMemoryError in Gremlin Server should be avoided. Of course,this approach will come with the downside that functions could be garbage collected and thus removed from thecache, forcing Gremlin Server to recompile later if that script is later encountered.
Cluster cluster = Cluster.open();Client client = cluster.connect();Map<String,Object> params =newHashMap<>();params.put("#jsr223.groovy.engine.keep.globals","soft");client.submit("def addItUp(x,y){x+y}", params);In cases where maintaining the expense of the global function cache is unecessary this cache can be disabled with theglobalFunctionCacheEnabled configuration on theGroovyCompilerGremlinPlugin.
Gremlin Server also has a "class map" cache which holds compiled scripts which helps avoid recompilation costs onfuture requests. This cache can be tuned in the Gremlin Server configuration with theGroovyCompilerGremlinPluginin the following fashion:
scriptEngines:{ gremlin-groovy: { plugins: { ... org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyCompilerGremlinPlugin: {classMapCacheSpecification: "initialCapacity=1000,maximumSize=10000"}, ...}The specifics for this comma delimited format can be foundhere.By default, the cache is set tosoftValues which means they are garbage collected in a globally least-recently-usedmanner as memory gets low. For production systems, it is likely that a more predictable strategy be taken as shownabove with the use of themaximumSize.
Considering Sessions
The preferred approach for issuing script-based requests to Gremlin Server is to do so in a sessionless manner. Theconcept of "sessionless" refers to a request that is completely encapsulated within a single transaction, such thatthe script in the request starts with a new transaction and ends with a closed transaction. Sessionless requests haveautomatic transaction management handled by Gremlin Server, thus automatically opening and closing transactions aspreviously described. The downside to the sessionless approach is that the entire script to be executed must be knownat the time of submission so that it can all be executed at once. This requirement makes it difficult for some usecases where more control over the transaction is desired.
For such use cases, Gremlin Server supports sessions. With sessions, the user is in complete control of the startand end of the transaction. This feature comes with some additional expense to consider:
Initialization scripts will be executed for each session created so any expense related to them will be establishedeach time a session is constructed.
There will be one script cache per session, which obviously increases memory requirements. The cache is not shared,so as to ensure that a session has isolation from other session environments. As a result, if the same script isexecuted in each session the same compilation cost will be paid for each session it is executed in.
Each session will require its own thread pool with a single thread in it - this ensures that transactionalboundaries are managed properly from one request to the next.
If there are multiple Gremlin Server instances, communication from the client to the server must be bound to theserver that the session was initialized in. Gremlin Server does not share session state as the transactional contextof a
Graphis bound to the thread it was initialized in.
To connect to a session with Java via thegremlin-driver, it is necessary to create aSessionedClient from theCluster object:
Cluster cluster = Cluster.open();//1Client client = cluster.connect("sessionName");//2Opens a reference to
localhostaspreviously shown.Creates a
SessionedClientgiven the configuration options of the Cluster. Theconnect()method is given aStringvalue that becomes the unique name of the session. It is often best to simply use aUUIDto representthe session.
It is also possible to have Gremlin Server manage the transactions as is done with sessionless requests. The user isin control of enabling this feature when creating theSessionedClient:
Cluster cluster = Cluster.open();Client client = cluster.connect("sessionName",true);Specifyingtrue to theconnect() method signifies that theclient should make each request as one encapsulatedin a transaction. With this configuration ofclient there is no need to close a transaction manually.
When using this mode of theSessionedClient it is important to recognize that global variable state for the sessionis not rolled-back on failure depending on where the failure occurs. For example, sending the following script wouldcreate a variable "x" in global session scope that would be accessible on the next request:
x =1However, sending this script which explicitly throws an exception:
y =2thrownewRuntimeException()will result in an obvious failure during script evaluation and "y" will not be available to the next request. Thecomplication arises where the script evaluates successfully, but fails during result iteration or serialization. Forexample, this script:
a =1g.addV()would successfully evaluate and return aTraversal. The variable "a" would be available on the next request. However,if there was a failure in transaction management on the call tocommit(), "a" would still be available to the nextrequest.
To avoid unexpected problems with state in relation to errors in sessions, it is best to follow these guidelines:
Do not re-use session identifiers. Simply use a new UUID for each session.
On exception, be sure to call
close()on theClientand create a new session.While you may submit parallel asynchronous requests to a session, it may not make sense to do so because they aresimply executed serially as they arrive to the session. A failed asynchronous request could leave an invalid statein the session which may not allow later requests to succeed. Either use synchronous requests only or carefullyconsider error conditions with asynchronous requests.
If using theUnifiedChannelizer, failures in evaluation will result in the session being closed and state beinglost. Asynchronous requests that are queued on the server will be cancelled and additional requests, in-flight orotherwise will be rejected. Users should create a new session from theCluster object in this case. The alternative,to match the oldOpProcessor GremlinServer behavior, is to add themaintainStateAfterException session setting totrue which will instead have similar behavior to that described in this section.
Client.SessionSettings settings = Client.SessionSettings.build().maintainStateAfterException(true).create();Client session = cluster.connect(Client.Settings.build().useSession(settings).create());A session is a "heavier" approach to the simple "request/response" approach of sessionless requests, but is sometimesnecessary for a given use case.
Considering Transactions
Gremlin Server performs automated transaction handling for "sessionless" requests (i.e. no state between requests) andfor "in-session" requests with that feature enabled. It will automatically commit or rollback transactions dependingon the success or failure of the request.
Important | Understand the transactional capabilities of the graph configured in Gremlin Server when using sessions. Forexample, a basicTinkerGraph in its non-transactional form won’t be able to rollback a failed traversal, therefore itis quite possible to get partial updates if the first part of a traversal succeeds and the rest fails. |
Another aspect of Transaction Management that should be considered is the usage of thestrictTransactionManagementsetting. It isfalse by default, but when set totrue, it forces the user to passaliases for all requests.The aliases are then used to determine which graphs will have their transactions closed for that request. RunningGremlin Server in this configuration should be more efficient when there are multiple graphs being hosted asGremlin Server will only close transactions on the graphs specified by thealiases. Keeping this settingfalse,will simply have Gremlin Server close transactions on all graphs for every request.
Considering State
With HTTP and any sessionless requests, there is no variable state maintained between requests. Therefore,whenconnecting with the console, for example, it is not possible to create a variable inone command and then expect to access it in the next:
gremlin> :remote connect tinkerpop.server conf/remote.yaml==>Configured localhost/127.0.0.1:8182gremlin> :> x =2==>2gremlin> :>2 + xNo suchproperty: xforclass:Script4Display stack trace? [yN] nThe same behavior would be seen with HTTP or when using sessionless requests through one of the Gremlin Server drivers.If having this behavior is desireable, thenconsider sessions.
There is an exception to this notion of state not existing between requests and that is globally defined functions.All functions created via scripts are global to the server.
gremlin> :>defsubtractIt(int x,int y) { x - y }==>nullgremlin> :> subtractIt(8,7)==>1If this behavior is not desirable there are several options. A first option would be to consider using sessions. Eachsession gets its ownScriptEngine, which maintains its own isolated cache of global functions, whereas sessionlessrequests uses a single function cache. A second option would be to define functions as closures:
gremlin> :> multiplyIt = {int x,int y -> x * y }==>Script7$_run_closure1@6b24f3abgremlin> :> multiplyIt(7,8)No signature ofmethod: org.apache.tinkerpop.gremlin.groovy.jsr223.GremlinGroovyScriptEngine.multiplyIt() is applicablefor argumenttypes: (java.lang.Integer, java.lang.Integer)values: [7,8]Display stack trace? [yN]When the function is declared this way, the function is viewed by theScriptEngine as a variable rather than a globalfunction and since sessionless requests don’t maintain state, the function is forgotten for the next request. A finaloption would be to manage theScriptEngine cache manually:
$ curl -X POST -d "{\"gremlin\":\"def divideIt(int x, int y){ x / y }\",\"bindings\":{\"#jsr223.groovy.engine.keep.globals\":\"phantom\"}}" "http://localhost:8182"{"requestId":"97fe1467-a943-45ea-8fd6-9e889a6c9381","status":{"message":"","code":200,"attributes":{}},"result":{"data":[null],"meta":{}}}$ curl -X POST -d "{\"gremlin\":\"divideIt(8, 2)\"}" "http://localhost:8182"{"message":"Error encountered evaluating script: divideIt(8, 2)"}In the above HTTP-based requests, the bindings contain a special parameter that tells theScriptEngine cache toimmediately forget the script after execution. In this way, the function does not end up being globally available.
Request Retry
The server has the ability to instruct the client that an error condition is transient and that the client shouldsimply retry the request later. In the event a client detects aResponseStatusCode ofSERVER_ERROR_TEMPORARY,which is error code596, the client may choose to retry that request. Note that drivers do not have the ability toautomatically retry and that it is up to the application to provide such logic.
Docker Image
The Gremlin Server can also be started as aDocker image:
$ docker run tinkerpop/gremlin-server:3.7.4[INFO] GremlinServer - \,,,/ (o o)-----oOOo-(3)-oOOo-----[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server.yaml...[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 4 and boss thread pool of 1.[INFO] GremlinServer$1 - Channel started at port 8182.By default, Gremlin Server listens on port 8182. So that port needs to be exposed if it should be reachable on the host:
$ docker run -p 8182:8182 tinkerpop/gremlin-server:3.7.4Arguments provided withdocker run are forwarded to the script that starts Gremlin Server. This allows for exampleto use an alternative config file:
$ docker run tinkerpop/gremlin-server:3.7.4 conf/gremlin-server-secure.yamlGremlin Plugins

Plugins provide a way to expand the features of Gremlin Console and Gremlin Server. The following sections describethe plugins that are available directly from TinkerPop. Please see theProvider Documentation for information onhow to develop custom plugins.
Credentials Plugin
Gremlin Server supports an authentication modelwhere user credentials are stored inside of aGraph instance. This database can be managed with theCredentials DSL, which can be installed in the console via the Credentials Plugin. This pluginis packaged with the console, but is not enabled by default.
gremlin> :plugin use tinkerpop.credentials==>tinkerpop.credentials activatedThis plugin imports the appropriate classes for managing the credentials graph.
Gephi Plugin
![]() Gephi is an interactive visualization,exploration, and analysis platform for graphs. TheGraph Streamingplugin for Gephi provides an API that can be leveraged to stream graph data to a running Gephi application. The Gephiplugin for Gremlin Console utilizes this API to allow for graph and traversal visualization.
Gephi is an interactive visualization,exploration, and analysis platform for graphs. TheGraph Streamingplugin for Gephi provides an API that can be leveraged to stream graph data to a running Gephi application. The Gephiplugin for Gremlin Console utilizes this API to allow for graph and traversal visualization.
Important | These instructions have been tested with Gephi 0.9.2 and Graph Streaming plugin 1.0.3. |
The following instructions assume that Gephi has been download and installed. It further assumes that the GraphStreaming plugin has been installed (Tools > Plugins). The following instructions explain how to visualize aGraph andTraversal.
In Gephi, create a new project withFile > New Project. In the lower left view, click the "Streaming" tab, open theMaster drop down, and right clickMaster Server > Start which starts the Graph Streaming server in Gephi and bydefault accepts requests athttp://localhost:8080/workspace1:

Important | The Gephi Streaming Plugin doesn’t detect port conflicts and will appear to start the plugin successfullyeven if there is something already active on that port it wants to connect to (which is 8080 by default). Be surethat there is nothing running on the port before Gephi will be using before starting the plugin. Failing to dothis produce behavior where the console will appear to submit requests to Gephi successfully but nothing willrender. |
Warning | Do not skip theFile > New Project step as it may prevent a newly started Gephi application from fullyenabling the streaming tab. |
Start theGremlin Console and activate the Gephi plugin:
gremlin> :plugin use tinkerpop.gephi==>tinkerpop.gephi activatedgremlin> graph = TinkerFactory.createModern()==>tinkergraph[vertices:6edges:6]gremlin> :remote connect tinkerpop.gephi==>Connection to Gephi -http://localhost:8080/workspace1 with stepDelay:1000, startRGBColor:[0.0, 1.0, 0.5], colorToFade:g, colorFadeRate:0.7, startSize:10.0,sizeDecrementRate:0.33gremlin> :> graph==>tinkergraph[vertices:6edges:6]==>false:plugin use tinkerpop.gephigraph = TinkerFactory.createModern():remote connect tinkerpop.gephi:> graphThe above Gremlin session activates the Gephi plugin, creates the "modern"TinkerGraph, uses the:remote commandto setup a connection to the Graph Streaming server in Gephi (with default parameters that will be explained below),and then uses:submit which sends the vertices and edges of the graph to the Gephi Streaming Server. The resultinggraph appears in Gephi as displayed in the left image below.

Note | Issuing:> graph again will clear the Gephi workspace and then re-write the graph. To manually empty theworkspace do:> clear. |
Now that the graph is visualized in Gephi, it is possible toapply a layout algorithm,change the size and/or color of vertices and edges, and display labels/properties of interest. Further informationcan be found in Gephi’s tutorial onVisualization.After applying the Fruchterman Reingold layout, increasing the node size, decreasing the edge scale, and displayingthe id, name, and weight attributes the graph looks as displayed in the right image above.
Visualization of aTraversal has a different approach as the visualization occurs as theTraversal is executing,thus showing a real-time view of its execution. ATraversal must be "configured" to operate in this format and forthat it requires use of thevisualTraversal option on theconfig function of the:remote command:
gremlin> :remote config visualTraversal graph////(1)==>Connection to Gephi -http://localhost:8080/workspace1 with stepDelay:1000, startRGBColor:[0.0, 1.0, 0.5], colorToFade:g, colorFadeRate:0.7, startSize:10.0,sizeDecrementRate:0.33gremlin> traversal = vg.V(2).in().out('knows'). has('age',gt(30)).outE('created'). has('weight',gt(0.5d)).inV();[]////(2)gremlin> :> traversal////(3)==>v[5]==>false:remote config visualTraversal graph////(1)traversal = vg.V(2).in().out('knows'). has('age',gt(30)).outE('created'). has('weight',gt(0.5d)).inV();[]////(2):> traversal//3Configure a "visual traversal" from your "graph" - this must be a
Graphinstance. This command will create anewTraversalSourcecalled "vg" that must be used to visualize any spawned traversals in Gephi.Define the traversal to be visualized. Note that ending the line with
;[]simply prevents iteration ofthe traversal before it is submitted.Submit the
Traversalto visualize to Gephi.
When the:> line is called, each step of theTraversal that produces or filters vertices generates events toGephi. The events update the color and size of the vertices at that step withstartRGBColor andstartSizerespectively. After the first step visualization, it sleeps for the configuredstepDelay in milliseconds. On thesecond step, it decays the configuredcolorToFade of all the previously visited vertices in prior steps, bymultiplying the currentcolorToFade value for each vertex with thecolorFadeRate. Setting thecolorFadeRatevalue to1.0 will prevent the color decay. The screenshots below show how the visualization evolves over the foursteps:

To get a sense of how the visualization configuration parameters affect the output, see the example below:
gremlin> :remote config startRGBColor [0.0,0.3,1.0]==>Connection to Gephi -http://localhost:8080/workspace1 with stepDelay:1000, startRGBColor:[0.0, 0.3, 1.0], colorToFade:g, colorFadeRate:0.7, startSize:10.0,sizeDecrementRate:0.33gremlin> :remote config colorToFade b==>Connection to Gephi -http://localhost:8080/workspace1 with stepDelay:1000, startRGBColor:[0.0, 0.3, 1.0], colorToFade:b, colorFadeRate:0.7, startSize:10.0,sizeDecrementRate:0.33gremlin> :remote config colorFadeRate0.5==>Connection to Gephi -http://localhost:8080/workspace1 with stepDelay:1000, startRGBColor:[0.0, 0.3, 1.0], colorToFade:b, colorFadeRate:0.5, startSize:10.0,sizeDecrementRate:0.33gremlin> :> traversal==>false:remote config startRGBColor [0.0,0.3,1.0]:remote config colorToFade b:remote config colorFadeRate0.5:> traversal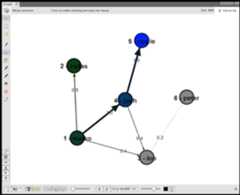
The visualization configuration above starts with a blue color now (most recently visited), fading the blue color(so that dark green remains on oldest visited), and fading the blue color more quickly so that the gradient from darkgreen to blue across steps has higher contrast. The following table provides a more detailed description of theGephi plugin configuration parameters as accepted via the:remote config command:
| Parameter | Description | Default |
|---|---|---|
workspace | The name of the workspace that your Graph Streaming server is started for. | workspace1 |
host | The host URL where the Graph Streaming server is configured for. | localhost |
port | The port number of the URL that the Graph Streaming server is listening on. | 8080 |
sizeDecrementRate | The rate at which the size of an element decreases on each step of the visualization. | 0.33 |
stepDelay | The amount of time in milliseconds to pause between step visualizations. | 1000 |
startRGBColor | A size 3 float array of RGB color values which define the starting color to update most recently visited nodes with. | [0.0,1.0,0.5] |
startSize | The size an element should be when it is most recently visited. | 20 |
colorToFade | A single char from the set | g |
colorFadeRate | A float value in the range | 0.7 |
visualTraversal | Creates a | vg |
Note | This plugin is typically only useful to the Gremlin Console and is enabled in the there by default. |
The instructions above assume that theGraph instance being visualized is local to the Gremlin Console. It makes thatassumption because the Gephi plugin requires a locally heldGraph. If the intent is to visualize aGraph instancehosted in Gremlin Server or a TinkerPop-enabled graph that can only be connected to in a "remote" fashion, then itis still possible to use the Gephi plugin, but the requirement for a locally heldGraph remains the same. To usethe Gephi plugin in these situations simply usesubgraph()-step to extract the portion of the remotegraph that will be visualized. Use of that step will return aTinkerGraph instance to the Gremlin Console at whichpoint it can be used locally with the Gephi plugin. The following example demonstrates the general steps:
gremlin> :remote connect tinkerpop.server conf/remote-objects.yaml//1...gremlin> :> g.E().hasLabel('knows').subgraph('subGraph').cap('subGraph')//2...gremlin> graph = result[0].object//3...Be sure to connect with a serializer configured to return objects and not their
toString()representation whichis discussed in more detail in theConnecting Via Console Section.Use the
:>command to subgraph the remote graph as needed.The
TinkerGraphof that previous traversal can be found in theresultobject and now that theGraphis localto Gremlin Console it can be used with Gephi as shown in the prior instruction set.
Graph Plugins
This section does not refer to a specific Gremlin Plugin, but a class of them. Graph Plugins are typically created bygraph providers to make it easy to integrate their graph systems into Gremlin Console and Gremlin Server. As TinkerPopprovides two referenceGraph implementations inTinkerGraph andNeo4j,there is also one Gremlin Plugin for each of them.
The TinkerGraph plugin is installed and activated in the Gremlin Console by default and the sample configurations thatare supplied with the Gremlin Server distribution include theTinkerGraphGremlinPlugin as part of the default setup.If using Neo4j, however, the plugin must be installed manually. Instructions for doing so can be found in theNeo4j section.
Hadoop Plugin
![]() The Hadoop Plugin installs as part of
The Hadoop Plugin installs as part ofhadoop-gremlin and providesa number of imports and utility functions to the environment within which it is used. Those classes and functionsprovide the basis for supportingOLAP based traversals with Gremlin. This plugin is defined ingreater detail in theHadoop-Gremlin section.
Server Plugin
Gremlin Server remotely executes Gremlin scriptsthat are submitted to it. The Server Plugin provides a way to submit scripts to Gremlin Server for remoteprocessing. Read more about the plugin and how it works in the Gremlin Server section onConnecting via Console.
Note | This plugin is typically only useful to the Gremlin Console and is enabled in the there by default. |
The Server Plugin for remoting with the Gremlin Console should not be confused with a plugin of similar name that isused by the server.GremlinServerGremlinPlugin is typically only configured in Gremlin Server and provides a numberof imports that are required for writinginitialization scripts.
Spark Plugin
![]() The Spark Plugin installs as part of
The Spark Plugin installs as part ofspark-gremlin and providesa number of imports and utility functions to the environment within which it is used. Those classes and functionsprovide the basis for supportingOLAP based traversals usingSpark.This plugin is defined in greater detail in theSparkGraphComputer section and is typicallyinstalled in conjuction with theHadoop-Plugin.
Sugar Plugin
 In previous versions of Gremlin-Groovy, there were numeroussyntactic sugars that users could rely on to make their traversalsmore succinct. Unfortunately, many of these conventions made use ofJava reflectionand thus, were not performant. In TinkerPop, these conveniences have been removed in support of the standardGremlin-Groovy syntax being both inline with Gremlin-Java syntax as well as always being the most performantrepresentation. However, for those users that would like to use the previous syntactic sugars (as well as new ones),there is
In previous versions of Gremlin-Groovy, there were numeroussyntactic sugars that users could rely on to make their traversalsmore succinct. Unfortunately, many of these conventions made use ofJava reflectionand thus, were not performant. In TinkerPop, these conveniences have been removed in support of the standardGremlin-Groovy syntax being both inline with Gremlin-Java syntax as well as always being the most performantrepresentation. However, for those users that would like to use the previous syntactic sugars (as well as new ones),there isSugarGremlinPlugin (a.k.a Gremlin-Groovy-Sugar).
Important | It is important that the sugar plugin is loaded in a Gremlin Console session prior to any manipulations ofthe respective TinkerPop objects as Groovy will cache unavailable methods and properties. |
gremlin> :plugin use tinkerpop.sugar==>tinkerpop.sugar activatedTip | When using Sugar in a Groovy class file, addstatic { SugarLoader.load() } to the head of the file. Note thatSugarLoader.load() will automatically callGremlinLoader.load(). |
Graph Traversal Methods
If aGraphTraversal property is unknown and there is a corresponding method with said name off ofGraphTraversalthen the property is assumed to be a method call. This enables the user to omit( ) from the method name. However,if the property does not reference aGraphTraversal method, then it is assumed to be a call tovalues(property).
gremlin> g.V////(1)==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]gremlin> g.V.name////(2)==>marko==>vadas==>lop==>josh==>ripple==>petergremlin> g.V.outE.weight////(3)==>0.4==>0.5==>1.0==>1.0==>0.4==>0.2g.V////(1)g.V.name////(2)g.V.outE.weight//3There is no need for the parentheses in
g.V().The traversal is interpreted as
g.V().values('name').A chain of zero-argument step calls with a property value call.
Range Queries
The[x] and[x..y] range operators in Groovy translate toRangeStep calls.
gremlin> g.V[0..2]==>v[1]==>v[2]gremlin> g.V[0..<2]==>v[1]gremlin> g.V[2]==>v[3]g.V[0..2]g.V[0..<2]g.V[2]Logical Operators
The& and| operator are overloaded inSugarGremlinPlugin. When used, they introduce theAndStep andOrStepmarkers into the traversal. Seeand() andor() for more information.
gremlin> g.V.where(outE('knows') & outE('created')).name////(1)==>markogremlin> t = g.V.where(outE('knows') | inE('created')).name;null////(2)==>nullgremlin> t.toString()==>[GraphStep(vertex,[]), TraversalFilterStep([VertexStep(OUT,[knows],edge), OrStep, VertexStep(IN,[created],edge)]), PropertiesStep([name],value)]gremlin> t==>marko==>lop==>ripplegremlin> t.toString()==>[TinkerGraphStep(vertex,[]), OrStep([[VertexStep(OUT,[knows],edge)], [VertexStep(IN,[created],edge)]]), PropertiesStep([name],value)]g.V.where(outE('knows') & outE('created')).name////(1)t = g.V.where(outE('knows') | inE('created')).name;null////(2)t.toString()tt.toString()Introducing the
AndStepwith the&operator.Introducing the
OrStepwith the|operator.
Traverser Methods
It is rare that a user will ever interact with aTraverser directly. However, if they do, some method redirects existto make it easy.
gremlin> g.V().map{it.get().value('name')}// conventional==>marko==>vadas==>lop==>josh==>ripple==>petergremlin> g.V.map{it.name}// sugar==>marko==>vadas==>lop==>josh==>ripple==>peterg.V().map{it.get().value('name')}// conventionalg.V.map{it.name}// sugarUtilities Plugin
The Utilities Plugin provides various functions, helper methods and imports of external classes that are useful inthe console.
Note | The Utilities Plugin is enabled in the Gremlin Console by default. |
Describe Graph
A good implementation of the Gremlin APIs will validate their features against theGremlin test suite. To learn more about a specificimplementation’s compliance with the test suite, use thedescribeGraph function. The following shows the outputforHadoopGraph:
gremlin> describeGraph(HadoopGraph)==>IMPLEMENTATION - org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraphTINKERPOP TEST SUITE- Compliant with (5 of4 suites)- Compliant with (5 of11 suites)> org.apache.tinkerpop.gremlin.structure.StructureStandardSuite> org.apache.tinkerpop.gremlin.process.ProcessStandardSuite> org.apache.tinkerpop.gremlin.process.ProcessComputerSuite> org.apache.tinkerpop.gremlin.process.ProcessLimitedStandardSuite> org.apache.tinkerpop.gremlin.process.ProcessLimitedComputerSuite- Opts out of22 individual tests> org.apache.tinkerpop.gremlin.process.traversal.step.map.MatchTest$Traversals#g_V_matchXa_hasXname_GarciaX__a_0writtenBy_b__a_0sungBy_bX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.MatchTest$Traversals#g_V_matchXa_0sungBy_b__a_0sungBy_c__b_writtenBy_d__c_writtenBy_e__d_hasXname_George_HarisonX__e_hasXname_Bob_MarleyXX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.MatchTest$Traversals#g_V_matchXa_0sungBy_b__a_0writtenBy_c__b_writtenBy_d__c_sungBy_d__d_hasXname_GarciaXX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.MatchTest$Traversals#g_V_matchXa_0sungBy_b__a_0writtenBy_c__b_writtenBy_dX_whereXc_sungBy_dX_whereXd_hasXname_GarciaXX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_both_both_count"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_repeatXoutX_timesX3X_count"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_repeatXoutX_timesX8X_count"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_repeatXoutX_timesX5X_asXaX_outXwrittenByX_asXbX_selectXa_bX_count"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.ProfileTest$Traversals#grateful_V_out_out_profile"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.ProfileTest$Traversals#grateful_V_out_out_profileXmetricsX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_hasLabelXsongX_groupXaX_byXnameX_byXproperties_groupCount_byXlabelXX_out_capXaX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_outXfollowedByX_group_byXsongTypeX_byXbothE_group_byXlabelX_byXweight_sumXX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_repeatXbothXfollowedByXX_timesX2X_group_byXsongTypeX_byXcountX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_repeatXbothXfollowedByXX_timesX2X_groupXaX_byXsongTypeX_byXcountX_capXaX"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.computer.GraphComputerTest#shouldStartAndEndWorkersForVertexProgramAndMapReduce"Spark executes map and combine in a lazy fashion and thus, fails the blocking aspect of this test"> org.apache.tinkerpop.gremlin.process.traversal.TraversalInterruptionTest#*"The interruption model in the test can't guarantee interruption at the right time with HadoopGraph."> org.apache.tinkerpop.gremlin.process.traversal.TraversalInterruptionComputerTest#*"This test makes use of a sideEffect to enforce when a thread interruption is triggered and thus isn't applicable to HadoopGraph"> org.apache.tinkerpop.gremlin.process.traversal.step.map.MatchTest$CountMatchTraversals#g_V_matchXa_followedBy_count_isXgtX10XX_b__a_0followedBy_count_isXgtX10XX_bX_count"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."> org.apache.tinkerpop.gremlin.process.traversal.step.map.ReadTest$Traversals#g_io_readXxmlX"Hadoop-Gremlin does not support reads/writes with GraphML."> org.apache.tinkerpop.gremlin.process.traversal.step.map.ReadTest$Traversals#g_io_read_withXreader_graphmlX"Hadoop-Gremlin does not support reads/writes with GraphML."> org.apache.tinkerpop.gremlin.process.traversal.step.map.WriteTest$Traversals#g_io_writeXxmlX"Hadoop-Gremlin does not support reads/writes with GraphML."> org.apache.tinkerpop.gremlin.process.traversal.step.map.WriteTest$Traversals#g_io_write_withXwriter_graphmlX"Hadoop-Gremlin does not support reads/writes with GraphML."- NOTE -The describeGraph() function shows information about a Graph implementation.It uses information foundin Java Annotations on the implementation itself todeterminethis output and does not assess the actual code of the test cases ofthe implementation itself. Compliant implementations will faithfully andhonestly supply these Annotations to provide the most accurate depiction oftheir support.describeGraph(HadoopGraph)Gremlin Drivers and Variants

At this point, readers should be well familiar with theIntroduction to this Reference Documentation andwill likely be thinking about implementation details specific to the graph provider they have selected as well asthe programming language they intend to use. The choice of programming language could have implications to thearchitecture and design of the application and the choice itself may have limits imposed upon it by the chosen graphprovider. For example, aRemote Gremlin Provider will require the selection of a driver to interactwith it. On the other hand, a graph system that is designed for embedded use, like TinkerGraph, needs the JavaVirtual Machine (JVM) environment which is easily accessed with a JVM programming language. If however the programminglanguage is not built for the JVM then it will requireGremlin Server in the architectureas well.
TinkerPop provides an array of drivers in different programming languages as a way to connect to a remote GremlinServer or Remote Gremlin Provider. Drivers allow the developer to make requests to that remote system and get backresults from the TinkerPop-enabled graphs hosted within. A driver can submit Gremlin strings and Gremlin bytecodeover this sub-protocol. Gremlin strings are written in the scripting language made available by the remote system thatthe driver is connecting to (typically, Groovy-based). This connection approach is quite similar to what developersare likely familiar with when using JDBC and SQL.
The preferred approach is to use bytecode-based requests, which essentially allows the ability to craft Gremlindirectly in the programming language of choice. As Gremlin makes use of two fundamental programming constructs:function composition andfunction nesting, it is possible to embed the Gremlin languagein any modern programming language. It is a far more natural way to program, because it enables IDE interaction,compile time checks, and language level checks that can help prevent errors prior to execution. The differencesbetween these two approaches were outlined in theConnecting Via Drivers Section, whichapplies to Gremlin Server, but also to Remote Gremlin Providers.
In addition to the languages and drivers that TinkerPop supports, there are also third-party implementations, as wellas extensions to the Gremlin language that might be specific to a particular graph provider. That listing can befound on the TinkerPophome page. Their description is beyond thescope of this documentation.
Tip | When possible, it is typically best to align the version of TinkerPop used on the client with the versionsupported on the server. While it is not impossible to have a different version between client and server, it mayrequire additional configuration and/or a deeper knowledge of that changes introduced between versions. It’s simplysafer to avoid the conflict, when allowed to do so. |
Important | Gremlin-Java is the canonical representation of Gremlin and any (proper) Gremlin language variant willemulate its structure as best as possible given the constructs of the host language. A strong correspondence betweenvariants ensures that the general Gremlin reference documentation is applicable to all variants and that users movingbetween development languages can easily adopt the Gremlin variant for that language. |

The following sections describe each language variant and driver that is officially TinkerPop a part of the project,providing more detailed information about usage, configuration and known limitations.
Gremlin-Go
 Apache TinkerPop’s Gremlin-Go implements Gremlin within theGo language and can therefore be used on different operating systems. Go’s syntax has the similar constructs as Java including"dot notation" for function chaining (
Apache TinkerPop’s Gremlin-Go implements Gremlin within theGo language and can therefore be used on different operating systems. Go’s syntax has the similar constructs as Java including"dot notation" for function chaining (a.b.c) and round bracket function arguments (a(b,c)). Something unlike Java is that Gremlin-Go requires agremlingo prefix when using the namespace (a(b()) vsgremlingo.a(gremlingo.T__.b())). Anyone familiar with Gremlin-Java will be able to workwith Gremlin-Go with relative ease. Moreover, there are a few added constructs to Gremlin-Go that make traversals a bit moresuccinct.
To install the Gremlin-Go as a dependency for your project, run the following in the root directory of your project that contains yourgo.mod file:
go get github.com/apache/tinkerpop/gremlin-go/v3[optionally append @<version>, such as @v3.5.3]Connecting
The pattern for connecting is described inConnecting Gremlin and it basically distills down tocreating aGraphTraversalSource. AGraphTraversalSource is created from the anonymousTraversal_().
remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin")g := gremlingo.Traversal_().WithRemote(remote)If you need to additional parameters to connection setup, you can pass in a configuration function.
remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin",func(settings *DriverRemoteConnectionSettings) { settings.TraversalSource ="gmodern" })Gremlin-go supports plain text authentication. It can be set in the connection function.
remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin",func(settings *DriverRemoteConnectionSettings) { settings.TlsConfig = &tls.Config{InsecureSkipVerify:true} settings.AuthInfo = gremlingo.BasicAuthInfo("login","password") })If you authenticate to a remoteGremlin Server orRemote Gremlin Provider, this server normally has SSL activated and the websockets url will startwith 'wss://'.
Some connection options can also be set on individual requests made through the usingWith() step on theTraversalSource. For instance to set request timeout to 500 milliseconds:
results, err := g.With("evaluationTimeout",500).V().Out("knows").ToList()The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent andevaluationTimeout.
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following importprovide most of the typical functionality required to use Gremlin:
import ("github.com/apache/tinkerpop/gremlin-go/driver")These can be used analogously to how they are used in Gremlin-Java.
results, err := g.V().HasLabel("person").Has("age", gremlingo.T__.Is(gremlingo.P.Gt(30))).Order().By("age", gremlingo.Desc).ToList()[v[6], v[4]]Configuration
The following table describes the various configuration options for the Gremlin-go Driver. Theycan be passed to theNewClient orNewDriverRemoteConnection functions as configuration function arguments:
| Key | Description | Default |
|---|---|---|
TraversalSource | Traversal source. | "g" |
TransporterType | Transporter type. | Gorilla |
LogVerbosity | Log verbosity. | gremlingo.INFO |
Logger | Instance of logger. | log |
Language | Language used for logging messages. | language.English |
AuthInfo | Authentification info, can be build with BasicAuthInfo() or HeaderAuthInfo(). | empty |
TlsConfig | TLS configuration. | empty |
KeepAliveInterval | Keep connection alive interval. | 5 seconds |
WriteDeadline | Write deadline. | 3 seconds |
ConnectionTimeout | Timeout for establishing connection. | 45 seconds |
NewConnectionThreshold | Minimum amount of concurrent active traversals on a connection to trigger creation of a new connection. | 4 |
MaximumConcurrentConnections | Maximum number of concurrent connections. | number of runtime processors |
EnableCompression | Flag to enable compression. | false |
ReadBufferSize | Specify I/O buffer sizes in bytes. If a buffer size is zero, then a useful default size is used | 0 |
WriteBufferSize | Specify I/O buffer sizes in bytes. If a buffer size is zero, then a useful default size is used | 0 |
Session | Session ID. | "" |
EnableUserAgentOnConnect | Enables sending a user agent to the server during connection requests.More details can be found in provider docshere. | true |
Traversal Strategies
In order to add and removetraversal strategies from a traversal source, Gremlin-Go has aTraversalStrategy interface along with a collection of functions that mirror the standard Gremlin-Java strategies.
promise := g.WithStrategies(gremlingo.ReadOnlyStrategy()).AddV("person").Property("name","foo").Iterate()Note | Many of theTraversalStrategy classes in Gremlin-Go are proxies to the respective strategy onApache TinkerPop’s JVM-based Gremlin traversal machine. As such, theirapply(Traversal) method does nothing. However,the strategy is encoded in the Gremlin-Go bytecode and transmitted to the Gremlin traversal machine forre-construction machine-side. |
Transactions
To get a full understanding of this section, it would be good to start by reading theTransactionssection of this documentation, which discusses transactions in the general context of TinkerPop itself. This sectionbuilds on that content by demonstrating the transactional syntax for Go.
remote, err := NewDriverRemoteConnection("ws://localhost:8182/gremlin")g := gremlingo.Traversal_().WithRemote(remote)// Create a Transaction.tx := g.Tx()// Spawn a new GraphTraversalSource, binding all traversals established from it to tx.gtx, _ := tx.Begin()// Execute a traversal within the transaction.promise := g.AddV("person").Property("name","Lyndon").Iterate()err := <-promiseif err !=nil {// Rollback the transaction if an error occurs. tx.rollback()}else {// Commit the transaction. The transaction can no longer be used and cannot be re-used.// A new transaction can be spawned through g.Tx(). tx.Commit()}The Lambda Solution
Supportinganonymous functions across languages is difficult asmost languages do not support lambda introspection and thus, code analysis. In Gremlin-Go, a Gremlin lambda shouldbe represented as a zero-arg callable that returns a string representation of the lambda expected for use in thetraversal. The lambda should be written as aGremlin-Groovy string. When the lambda is represented inBytecode itslanguage is encoded such that the remote connection host can infer which translator and ultimate execution engine touse.
r, err := g.V().Out().Map(&gremlingo.Lambda{Script:"it.get().value('name').length()", Language:""}).Sum().ToList()Tip | When running into situations where Groovy cannot properly discern a method signature based on theLambdainstance created, it will help to fully define the closure in the lambda expression - so rather thanScript: "it.get().value('name')", Language: "gremlin-groovy", preferScript: "x → x.get().value('name')", Language: "gremlin-groovy". |
Finally, GremlinBytecode that includes lambdas requires that the traversal be processed by theScriptEngine. To avoid continued recompilation costs, it supports the encoding of bindings, which allow a remoteengine to to cache traversals that will be reused over and over again save that some parameterization may change. Thus,instead of translating, compiling, and then executing each submitted bytecode, it is possible to simply execute.
r, err := g.V((&gremlingo.Bindings{}).Of("x",1)).Out("created").Map(&gremlingo.Lambda{Script:"it.get().value('name').length()", Language:""}).Sum().ToList()// 3r, err := g.V((&gremlingo.Bindings{}).Of("x",4)).Out("created").Map(&gremlingo.Lambda{Script:"it.get().value('name').length()", Language:""}).Sum().ToList()// 9Warning | As explained throughout the documentation, when possibleavoid lambdas. |
Submitting Scripts
TheClient class implementation/interface is based on the Java Driver, with some restrictions. Most notably,Gremlin-go does not yet implement theCluster class. Instead,Client is instantiated directly.Usage is as follows:
import"github.com/apache/tinkerpop/gremlin-go/v3/driver"//1client, err := gremlingo.NewClient("ws://localhost:8182/gremlin")//2Import the Gremlin-Go module.
Opens a reference to
localhost- note that there are various configuration options that can be passedto theClientobject upon instantiation as keyword arguments.
Once aClient instance is ready, it is possible to issue some Gremlin:
resultSet, err := client.Submit("g.V().count()")//1result, err := resultSet.All()//2fmt.Println(result[0].GetString())//3Submit a script that simply returns a Count of vertexes.
Get results from resultSet. Block until the script is evaluated and results are sent back by the server.
Use the result.
Per Request Settings
Both theClient andDriverRemoteConnection types have aSubmitWithOptions(traversalString, requestOptions) variantof the standardSubmit() method. These methods allow aRequestOptions struct to be passed in which will augment theexecution on the server.RequestOptions can be constructedusingRequestOptionsBuilder. A good use-case for this feature is to set a per-request override to theevaluationTimeout so that it only applies to the current request.
options :=new(RequestOptionsBuilder). SetEvaluationTimeout(5000). SetBatchSize(32). SetMaterializeProperties("tokens"). AddBinding("x",100). Create()resultSet, err := client.SubmitWithOptions("g.V(x).count()", options)The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent,evaluationTimeout andmaterializeProperties.RequestOptions may also contain a map of variablebindings to be applied to the suppliedtraversal string.
Important | The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiarwith bytecode may tryg.with("evaluationTimeout", 500) within a script. Scripts with multiple traversals and multipletimeouts will be interpreted as a sum of all timeouts identified in the script for that request. |
resultSet, err := client.SubmitWithOptions("g.with('evaluationTimeout', 500).addV().iterate();"+"g.addV().iterate();"+"g.with('evaluationTimeout', 500).addV();",new(RequestOptionsBuilder).SetEvaluationTimeout(500).Create())results, err := resultSet.All()In the above example, defines a timeout of 500 milliseconds, but the script has three traversals withtwo internal settings for the timeout usingwith(). The request timeout used by the server will therefore be 1000milliseconds (overriding the 500 which itself was an override for whatever configuration was on the server).
Domain Specific Languages
Writing a GremlinDomain Specific Language (DSL) in Go requires embedding of several structs and interfaces:
GraphTraversal- which exposes the various steps used in traversal writingGraphTraversalSource- which spawnsGraphTraversalinstancesAnonymousTraversal- which spawns anonymous traversals from steps
The Social DSL based on the"modern" toy graphmight look like this:
// Optional syntactic sugar.var __ = gremlingo.T__var P = gremlingo.Pvar gt = gremlingo.P.Gt// Optional alias for import convenience.type GraphTraversal = gremlingo.GraphTraversaltype GraphTraversalSource = gremlingo.GraphTraversalSourcetype AnonymousTraversal = gremlingo.AnonymousTraversal// Embed Graph traversal inside custom traversal struct to add custom traversal functions.// In go, capitalizing the first letter exports (makes public) the struct/method to outside of package, for this example// we have defined everything package private. In actual usage, please see fit to your application.type socialTraversalstruct { *GraphTraversal}func (s *socialTraversal) knows(personNamestring) *socialTraversal {return &socialTraversal{s.Out("knows").HasLabel("person").Has("name", personName)}}func (s *socialTraversal) youngestFriendsAge() *socialTraversal {return &socialTraversal{s.Out("knows").HasLabel("person").Values("age").Min()}}func (s *socialTraversal) createdAtLeast(numberint) *socialTraversal {return &socialTraversal{s.OutE("created").Count().Is(gt(number))}}// Add custom social traversal source to spaw custom traversals.type socialTraversalSourcestruct { *GraphTraversalSource}// Define the source step function by adding steps to the bytecode.func (sts *socialTraversalSource) persons(personNames ...interface{}) *socialTraversal { t := sts.GetGraphTraversal() t.Bytecode.AddStep("V") t.Bytecode.AddStep("hasLabel","person")if personNames !=nil { t.Bytecode.AddStep("has","name", P.Within(personNames...)) }return &socialTraversal{t}}// Create the social anonymous traversal interface to embed and extend the anonymous traversal functions.type iSocialAnonymousTraversalinterface { AnonymousTraversal knows(personNamestring) *GraphTraversal youngestFriendsAge() *GraphTraversal createdAtLeast(numberint) *GraphTraversal}// Add the struct to implement the iSocialAnonymousTraversal interface.type socialAnonymousTraversalstruct { AnonymousTraversal socialTraversalfunc() *socialTraversal}// Add the variable s__ to call anonymous traversal step functions in place of __.var s__ iSocialAnonymousTraversal = &socialAnonymousTraversal{ __,func() *socialTraversal {return &socialTraversal{gremlingo.NewGraphTraversal(nil, gremlingo.NewBytecode(nil),nil)} },}// Extended anonymous traversal functions need to return GraphTraversal for serialization purposesfunc (sat *socialAnonymousTraversal) knows(personNamestring) *GraphTraversal {return sat.socialTraversal().knows(personName).GraphTraversal}func (sat *socialAnonymousTraversal) youngestFriendsAge() *GraphTraversal {return sat.socialTraversal().youngestFriendsAge().GraphTraversal}func (sat *socialAnonymousTraversal) createdAtLeast(numberint) *GraphTraversal {return sat.socialTraversal().createdAtLeast(number).GraphTraversal}Using the DSL requires a social traversal source to be created from the default traversal source:
// Creating the driver remote connection as regular.driverRemoteConnection, _ := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin",func(settings *gremlingo.DriverRemoteConnectionSettings) { settings.TraversalSource ="gmodern" })defer driverRemoteConnection.Close()// Create social traversal source from graph traversal source.social := &socialTraversalSource{gremlingo.Traversal_().WithRemote(driverRemoteConnection)}// We can now use the social traversal source as well as traversal stepsresBool, _ := social.persons("marko","stephen").knows("josh").HasNext()fmt.Println(resBool)// Using the createdAtLeast step.resCreated, _ := social.persons().createdAtLeast(1).Next()fmt.Println(resCreated.GetString())// Using the social anonymous traversal.resAnon, _ := social.persons().Filter(s__.createdAtLeast(1)).Count().Next()fmt.Println(resAnon.GetString())// Note that error handling has been omitted with _ from the above examples.Differences
All step names start with a capital letter which is consistent with the idiomatic style for Go. This use of Pascal-caseextends to enums likeDirection, e.g.Direction.OUT isDirection.Out in Go.
Aliases
To make the code more readable and close to the Gremlin query language), you can use aliases. These aliases can be named with capital letters to be consistent with non-aliased steps but will result in exported variables which could be problematic if not being used in a top-level program (i.e. not a redistributable package).
var __ = gremlingo.T__var gt = gremlingo.P.Gtvar order = gremlingo.Order results, err := g.V().HasLabel("person").Has("age", __.Is(gt(30))).Order().By("age", order.Desc).ToList()List of useful aliases
// commonvar __ = gremlingo.T__var TextP = gremlingo.TextP// predicatesvar between = gremlingo.P.Betweenvar eq = gremlingo.P.Eqvar gt = gremlingo.P.Gtvar gte = gremlingo.P.Gtevar inside = gremlingo.P.Insidevar lt = gremlingo.P.Ltvar lte = gremlingo.P.Ltevar neq = gremlingo.P.Neqvar not = gremlingo.P.Notvar outside = gremlingo.P.Outsidevar test = gremlingo.P.Testvar within = gremlingo.P.Withinvar without = gremlingo.P.Withoutvar and = gremlingo.P.Andvar or = gremlingo.P.Or// sortingvar order = gremlingo.OrderFinally, the enum construct forCardinality cannot have functions attached to it the way it can be done in Java,therefore cardinality functions that take a value likelist(),set(), andsingle() are referenced from aCardinalityValue class rather thanCardinality itself.
Limitations
There is no default
settype in Go. Any set type code from server will be deserialized into slices with the listtype implementation. To input a set into Gremlin-Go, a custom struct which implements thegremlingo.Setinterfacewill be serialized as a set.gremlingo.NewSimpleSetis a basic implementation of a set that is provided by Gremlin-Gothat can be used to fulfill thegremlingo.Setinterface if desired.
Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Go. Theycan be found in GitHubhereand are designed to connect to a runningGremlin Server configured with theconf/gremlin-server.yaml andconf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration fileconf/gremlin-server.yaml. To start a clean server, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, usingconf/gremlin-server-modern.yaml.To start a server with the Modern graph preloaded, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlEach example can now be run with the following commands:
go run connections.gogo run basic_gremlin.gogo run modern_traversals.goGremlin-Groovy
 Apache TinkerPop’s Gremlin-Groovy implements Gremlin within theApache Groovy language. As a JVM-based language variant, Gremlin-Groovy is backed byGremlin-Java constructs. Moreover, given its scripting nature, Gremlin-Groovy serves as the language ofGremlin Console andGremlin Server.
Apache TinkerPop’s Gremlin-Groovy implements Gremlin within theApache Groovy language. As a JVM-based language variant, Gremlin-Groovy is backed byGremlin-Java constructs. Moreover, given its scripting nature, Gremlin-Groovy serves as the language ofGremlin Console andGremlin Server.
compilegroup:'org.apache.tinkerpop',name:'gremlin-core',version:'3.7.4'compilegroup:'org.apache.tinkerpop',name:'gremlin-driver',version:'3.7.4'Differences
In Groovy,as,in, andnot are reserved words. Gremlin-Groovy does not allow these steps to be calledstatically from the anonymous traversal__ and therefore, must always be prefixed with__. For instance:g.V().as('a').in().as('b').where(__.not(__.as('a').out().as('b')))
Care needs to be taken when using theany(P) step as you may accidentally invoke Groovy’sany(Closure) method. Thistypically happens when callingany() without arguments. You can tell if Groovy’sany has been called if the returnvalue is a boolean.
Since Groovy has access to the full JVM as Java does, it is possible to constructDate-like objects directly, butthe Gremlin language does offer adatetime() function that is exposed in the Gremlin Console and as a function forGremlin scripts sent to Gremlin Server. The function accepts the following forms of dates and times using a defaulttime zone offset of UTC(+00:00):
2018-03-222018-03-22T00:35:442018-03-22T00:35:44Z2018-03-22T00:35:44.7412018-03-22T00:35:44.741Z2018-03-22T00:35:44.741+1600
Gremlin-Java
 Apache TinkerPop’s Gremlin-Java implements Gremlin within theJava language and can be used by any Java Virtual Machine. Gremlin-Java is considered the canonical, referenceimplementation of Gremlin and serves as the foundation by which all other Gremlin language variants should emulate.As the Gremlin Traversal Machine that processes Gremlin queries is also written in Java, it can be used in all threeconnection methods described in theConnecting Gremlin Section.
Apache TinkerPop’s Gremlin-Java implements Gremlin within theJava language and can be used by any Java Virtual Machine. Gremlin-Java is considered the canonical, referenceimplementation of Gremlin and serves as the foundation by which all other Gremlin language variants should emulate.As the Gremlin Traversal Machine that processes Gremlin queries is also written in Java, it can be used in all threeconnection methods described in theConnecting Gremlin Section.
<dependency><groupId>org.apache.tinkerpop</groupId><artifactId>gremlin-core</artifactId><version>3.7.4</version></dependency><!-- when using Gremlin Server or Remote Gremlin Provider a driver is required --><dependency><groupId>org.apache.tinkerpop</groupId><artifactId>gremlin-driver</artifactId><version>3.7.4</version></dependency><!--alternatively the driver is packaged as an uberjar with shaded non-optional dependencies including gremlin-core andtinkergraph-gremlin which are not shaded.--><dependency><groupId>org.apache.tinkerpop</groupId><artifactId>gremlin-driver</artifactId><version>3.7.4</version><classifier>shaded</classifier><!-- The shaded JAR uses the original POM, therefore conflicts may still need resolution --><exclusions><exclusion><groupId>io.netty</groupId><artifactId>*</artifactId></exclusion></exclusions></dependency>Connecting
The pattern for connecting is described inConnecting Gremlin and it basically distills downto creating aGraphTraversalSource. Forembedded mode, this involves first creating aGraph and then spawning theGraphTraversalSource:
Graph graph = ...;GraphTraversalSource g = traversal().withEmbedded(graph);Using "g" it is then possible to start writing Gremlin. The "g" allows for the setting of many configuration optionswhich affect traversal execution. TheTraversal Section describes some of these options and some areonly suitable withembedded style usage. For remote options however there are some addedconfigurations to consider and this section looks to address those.
When connecting toGremlin Server orRemote Gremlin Providers itis possible to configure theDriverRemoteConnection manually as shown in earlier examples where the host and portare provided as follows:
GraphTraversalSource g = traversal().withRemote(DriverRemoteConnection.using("localhost",8182,"g"));It is also possible to create it from a configuration. The most basic way to do so involves the following line of code:
GraphTraversalSource g = traversal().withRemote('conf/remote-graph.properties');Theremote-graph.properties file simply provides connection information to theGraphTraversalSource which is usedto configure aRemoteConnection. That file looks like this:
gremlin.remote.remoteConnectionClass=org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnectiongremlin.remote.driver.clusterFile=conf/remote-objects.yamlgremlin.remote.driver.sourceName=gTheRemoteConnection is an interface that provides the transport mechanism for "g" and makes it possible to forthat mechanism to be altered (typically by graph providers who have their own protocols). TinkerPop provides one suchimplementation called theDriverRemoteConnection which enables transport over Gremlin Server protocols using theTinkerPop driver. The driver is configured by the specifiedgremlin.remote.driver.clusterFile and the local "g" isbound to theGraphTraversalSource on the remote end withgremlin.remote.driver.sourceName which in this case isalso "g".
There are other ways to configure the traversal usingwithRemote() as it has other overloads. It can take anApache CommonsConfiguration object which would have keys similar to those shown in the properties file and itcan also take aRemoteConnection instance directly. The latter is interesting in that it means it is possible toprogrammatically construct all aspects of theRemoteConnection. For TinkerPop usage, that might mean directlyconstructing theDriverRemoteConnection and the driver instance that supplies the transport mechanism. For example,the command shown above could be re-written using programmatic construction as follows:
Cluster cluster = Cluster.open();GraphTraversalSource g = traversal().withRemote(DriverRemoteConnection.using(cluster,"g"));Please consider the following example:
gremlin> g = traversal().withRemote('conf/remote-graph.properties')==>graphtraversalsource[emptygraph[empty], standard]gremlin> g.V().elementMap()==>[id:1,label:person,name:marko,age:29]==>[id:2,label:person,name:vadas,age:27]==>[id:3,label:software,name:lop,lang:java]==>[id:4,label:person,name:josh,age:32]==>[id:5,label:software,name:ripple,lang:java]==>[id:6,label:person,name:peter,age:35]gremlin> g.close()==>nullg = traversal().withRemote('conf/remote-graph.properties')g.V().elementMap()g.close()GraphTraversalSource g = traversal().withRemote("conf/remote-graph.properties");List<Map> list = g.V().elementMap();g.close();Note the call toclose() above. The call towithRemote() internally instantiates a connection via the driver thatcan only be released by "closing" theGraphTraversalSource. It is important to take that step to release networkresources associated withg.
If working with multiple remoteTraversalSource instances it is more efficient to constructCluster andClientobjects and then re-use them.
gremlin> cluster = Cluster.open('conf/remote-objects.yaml')==>localhost/127.0.0.1:8182gremlin> client = cluster.connect()==>org.apache.tinkerpop.gremlin.driver.Client$ClusteredClient@5ec75178gremlin> g = traversal().withRemote(DriverRemoteConnection.using(client,"g"))==>graphtraversalsource[emptygraph[empty], standard]gremlin> g.V().elementMap()==>[id:1,label:person,name:marko,age:29]==>[id:2,label:person,name:vadas,age:27]==>[id:3,label:software,name:lop,lang:java]==>[id:4,label:person,name:josh,age:32]==>[id:5,label:software,name:ripple,lang:java]==>[id:6,label:person,name:peter,age:35]gremlin> g.close()==>nullgremlin> client.close()==>nullgremlin> cluster.close()==>nullcluster = Cluster.open('conf/remote-objects.yaml')client = cluster.connect()g = traversal().withRemote(DriverRemoteConnection.using(client,"g"))g.V().elementMap()g.close()client.close()cluster.close()If theClient instance is supplied externally, as is shown above, then it is not closed implicitly by the close of"g". Closing "g" will have no effect on "client" or "cluster". When supplying them externally, theClient andCluster objects must also be closed explicitly. It’s worth noting that the close of aCluster will close allClient instances spawned by theCluster.
Some connection options can also be set on individual requests made through the Java driver usingwith() stepon theTraversalSource. For instance to set request timeout to 500 milliseconds:
GraphTraversalSource g = traversal().withRemote(conf);List<Vertex> vertices = g.with(Tokens.ARGS_EVAL_TIMEOUT,500L).V().out("knows").toList()The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent andevaluationTimeout (formerlyscriptEvaluationTimeout which is also supported but now deprecated). Use ofTokensto reference these options is preferred.
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following importsprovide most of the common functionality required to use Gremlin:
importorg.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversalSource;importorg.apache.tinkerpop.gremlin.process.traversal.IO;importstaticorg.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;importstaticorg.apache.tinkerpop.gremlin.process.traversal.Operator.*;importstaticorg.apache.tinkerpop.gremlin.process.traversal.Order.*;importstaticorg.apache.tinkerpop.gremlin.process.traversal.P.*;importstaticorg.apache.tinkerpop.gremlin.process.traversal.Pop.*;importstaticorg.apache.tinkerpop.gremlin.process.traversal.SackFunctions.*;importstaticorg.apache.tinkerpop.gremlin.process.traversal.Scope.*;importstaticorg.apache.tinkerpop.gremlin.process.traversal.TextP.*;importstaticorg.apache.tinkerpop.gremlin.structure.Column.*;importstaticorg.apache.tinkerpop.gremlin.structure.Direction.*;importstaticorg.apache.tinkerpop.gremlin.structure.T.*;importstaticorg.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.*;Configuration
The following table describes the various configuration options for the Gremlin Driver:
| Key | Description | Default |
|---|---|---|
connectionPool.channelizer | The fully qualified classname of the client |
|
connectionPool.enableSsl | Determines if SSL should be enabled or not. If enabled on the server then it must be enabled on the client. | false |
connectionPool.keepAliveInterval | Length of time in milliseconds to wait on an idle connection before sending a keep-alive request. Set to zero to disable this feature. | 180000 |
connectionPool.keyStore | The private key in JKS or PKCS#12 format. | none |
connectionPool.keyStorePassword | The password of the | none |
connectionPool.keyStoreType |
| none |
connectionPool.maxContentLength | The maximum length in bytes that a message can be sent to the server. This number can be no greater than the setting of the same name in the server configuration. | 65536 |
connectionPool.maxInProcessPerConnection | The maximum number of in-flight requests that can occur on a connection. | 4 |
connectionPool.maxSimultaneousUsagePerConnection | The maximum number of times that a connection can be borrowed from the pool simultaneously. | 16 |
connectionPool.maxSize | The maximum size of a connection pool for a host. | 8 |
connectionPool.maxWaitForConnection | The amount of time in milliseconds to wait for a new connection before timing out. | 3000 |
connectionPool.maxWaitForClose | The amount of time in milliseconds to wait for pending messages to be returned from the server before closing the connection. | 3000 |
connectionPool.minInProcessPerConnection | The minimum number of in-flight requests that can occur on a connection. | 1 |
connectionPool.minSimultaneousUsagePerConnection | The maximum number of times that a connection can be borrowed from the pool simultaneously. | 8 |
connectionPool.minSize | The minimum size of a connection pool for a host. | 2 |
connectionPool.reconnectInterval | The amount of time in milliseconds to wait before trying to reconnect to a dead host. | 1000 |
connectionPool.resultIterationBatchSize | The override value for the size of the result batches to be returned from the server. | 64 |
connectionPool.sslCipherSuites | The list of JSSE ciphers to support for SSL connections. If specified, only the ciphers that are listed and supported will be enabled. If not specified, the JVM default is used. | none |
connectionPool.sslEnabledProtocols | The list of SSL protocols to support for SSL connections. If specified, only the protocols that are listed and supported will be enabled. If not specified, the JVM default is used. | none |
connectionPool.sslSkipCertValidation | Configures the | false |
connectionPool.trustStore | File location for a SSL Certificate Chain to use when SSL is enabled. If this value is not provided and SSL is enabled, the default | none |
connectionPool.trustStorePassword | The password of the | none |
connectionPool.validationRequest | A script that is used to test server connectivity. A good script to use is one that evaluates quickly and returns no data. The default simply returns an empty string, but if a graph is required by a particular provider, a good traversal might be | '' |
connectionPool.connectionSetupTimeoutMillis | Duration of time in milliseconds provided for connection setup to complete which includes WebSocket protocol handshake and SSL handshake. | 15000 |
enableCompression | Enables permessage-deflate compression. Note that use of compression may increase vulnerability to attacks such as CRIME/BREACH. | true |
enableUserAgentOnConnect | Enables sending a user agent to the server during connection requests. More details can be found in provider docshere. | true |
hosts | The list of hosts that the driver will connect to. | localhost |
jaasEntry | Sets the | none |
nioPoolSize | Size of the pool for handling request/response operations. | available processors |
password | The password to submit on requests that require authentication. | none |
path | The URL path to the Gremlin Server. | /gremlin |
port | The port of the Gremlin Server to connect to. The same port will be applied for all hosts. | 8192 |
protocol | Sets the | none |
serializer.className | The fully qualified class name of the | none |
serializer.config | A | none |
username | The username to submit on requests that require authentication. | none |
workerPoolSize | Size of the pool for handling background work. | available processors * 2 |
Please see theCluster.Builder javadoc to get more information on these settings.
Transactions
Transactions with Java are best described inThe Traversal - Transactions section of thisdocumentation as Java covers both embedded and remote use cases.
Serialization
Remote systems like Gremlin Server and Remote Gremlin Providers respond to requests made in a particular serializationformat and respond by serializing results to some format to be interpreted by the client. For JVM-based languages,there are two options for serialization: GraphSON and GraphBinary. It is important that the client and serverhave the same serializers configured in the same way or else one or the other will experience serialization exceptionsand fail to always communicate. Discrepancy in serializer registration between client and server can happen fairlyeasily as different graph systems may automatically include serializers on the server-side, thus leaving the clientto be configured manually. As an example:
IoRegistry registry = ...;// an IoRegistry instance exposed by a specific graph providerTypeSerializerRegistry typeSerializerRegistry = TypeSerializerRegistry.build().addRegistry(registry).create();MessageSerializer serializer =new GraphBinaryMessageSerializerV1(typeSerializerRegistry);Cluster cluster = Cluster.build(). serializer(serializer). create();Client client = cluster.connect();GraphTraversalSource g = traversal().withRemote(DriverRemoteConnection.using(client,"g"));TheIoRegistry tells the serializer what classes from the graph provider to auto-register during serialization.Gremlin Server roughly uses this same approach when it configures its serializers, so using this same model willensure compatibility when making requests. Obviously, it is possible to switch to GraphSON or GraphBinary by usingthe appropriateMessageSerializer (e.g.GraphSONMessageSerializerV3 orGraphBinaryMessageSerializerV1 respectively)in the same way and building that into theCluster object.
A particularly important configuration along these lines is easily overlooked when choosing to use GraphSON rather thanGraphBinary. GraphBinary offers a bit of help in dynamically detecting available classpath items and will dynamicallyincludeTinkerGraph as a serialization target which allows theSubgraph Step to work properly in remote contexts.GraphSON does not. When using GraphSON, you must manually include theTinkerIoRegistryV3 in the configuration for thedriver.
GraphSONMapper.Builder builder = GraphSONMapper.build().addRegistry(TinkerIoRegistryV3.instance());GraphSONMessageSerializerV3 serializer =new GraphSONMessageSerializerV3(builder);Cluster cluster = TestClientFactory.build().serializer(serializer).create();Client client = cluster.connect();GraphTraversalSource g = traversal().withRemote(DriverRemoteConnection.using(client,"g"));Important | Prefer GraphBinary over GraphSON when using the driver. If you do choose GraphSON, prefer GraphSON 3 andknow that GraphSON 2 is not compatible with <<subgraph-step>. |
The Lambda Solution
Supportinganonymous functions across languages is difficult asmost languages do not support lambda introspection and thus, code analysis. In Gremlin-Java and withembedded usage, lambdas can be leveraged directly:
g.V().out("knows").map(t -> t.get().value("name") +" is the friend name")//1g.V().out("knows").sideEffect(System.out::println)//2g.V().as("a").out("knows").as("b").select("b").by((Function<Vertex,Integer>) v -> v.<String>value("name").length())//3A Java
Functionis used to map aTraverser<S>to an objectE.Gremlin steps that take consumer arguments can be passed Java method references.
Gremlin-Java may sometimes require explicit lambda typing when types can not be automatically inferred.
When sending traversals remotely toGremlin Server orRemote Gremlin Providers, the static methods ofLambda should be used and should denote aparticular JSR-223ScriptEngine that is available on the remote end (typically, this is Groovy).Lambda creates astring-based lambda that is then converted into a lambda/closure/anonymous-function/etc. by the respective lambdalanguage’s JSR-223ScriptEngine implementation.
g.V().out("knows").map(Lambda.function("it.get().value('name') + ' is the friend name'"))g.V().out("knows").sideEffect(Lambda.consumer("println it"))g.V().as("a").out("knows").as("b").select("b").by(Lambda.<Vertex,Integer>function("it.value('name').length()"))Finally, GremlinBytecode that includes lambdas requires that the traversal be processed by theScriptEngine. To avoid continued recompilation costs, it supports the encoding of bindings, which allow GremlinServer to cache traversals that will be reused over and over again save that some parameterization may change. Thus,instead of translating, compiling, and then executing each submitted bytecode request, it is possible to simplyexecute. To express bindings in Java, useBindings.
b = Bindings.instance()g.V(b.of('id',1)).out('created').values('name').map{t ->"name:" + t.get() }g.V(b.of('id',4)).out('created').values('name').map{t ->"name:" + t.get() }g.V(b.of('id',4)).out('created').values('name').getBytecode()g.V(b.of('id',4)).out('created').values('name').getBytecode().getBindings()cluster.close()Both traversals are abstractly defined asg.V(id).out('created').values('name').map{t → "name: " + t.get() } andthus, the first submission can be cached for faster evaluation on the next submission.
Warning | It is generally advised to avoid lambda usage. Please considerA Note On Lambdas formore information. |
Submitting Scripts
 TinkerPop comes equipped with a reference client for Java-basedapplications. It is referred to as
TinkerPop comes equipped with a reference client for Java-basedapplications. It is referred to asgremlin-driver, which enables applications to send requests to Gremlin Serverand get back results.
Gremlin scripts are sent to the server from aClient instance. AClient is created as follows:
Cluster cluster = Cluster.open();//1Client client = cluster.connect();//2Opens a reference to
localhost- note that there are many configuration options available in defining aClusterobject.Creates a
Clientgiven the configuration options of theCluster.
Once aClient instance is ready, it is possible to issue some Gremlin Groovy scripts:
ResultSet results = client.submit("[1,2,3,4]");//1results.stream().map(i -> i.get(Integer.class) *2);//2CompletableFuture<List<Result>> results = client.submit("[1,2,3,4]").all();//3CompletableFuture<ResultSet> future = client.submitAsync("[1,2,3,4]");//4Map<String,Object> params =newHashMap<>();params.put("x",4);client.submit("[1,2,3,x]", params);//5Submits a script that simply returns a
Listof integers. This method blocks until the request is written tothe server and aResultSetis constructed.Even though the
ResultSetis constructed, it does not mean that the server has sent back the results (or evenevaluated the script potentially). TheResultSetis just a holder that is awaiting the results from the server.In this case, they are streamed from the server as they arrive.Submit a script, get a
ResultSet, then return aCompletableFuturethat will be called when all results have been returned.Submit a script asynchronously without waiting for the request to be written to the server.
Parameterized request are considered the most efficient way to send Gremlin to the server as they can be cached,which will boost performance and reduce resources required on the server.
Per Request Settings
There are a number of overloads toClient.submit() that accept aRequestOptions object. TheRequestOptionsprovide a way to include options that are specific to the request made with the call tosubmit(). A good use-case forthis feature is to set a per-request override to theevaluationTimeout so that it only applies to the currentrequest.
Cluster cluster = Cluster.open();Client client = cluster.connect();RequestOptions options = RequestOptions.build().timeout(500).create();List<Result> result = client.submit("g.V().repeat(both()).times(100)", options).all().get();The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiar withbytecode may tryg.with(EVALUATION_TIMEOUT, 500) within a script. Gremlin Server will respect timeouts set this wayin scripts as well. With scripts of course, it is possible to send multiple traversals at once in the same script.In such events, the timeout for the request is interpreted as a sum of all timeouts identified in the script.
RequestOptions options = RequestOptions.build().timeout(500).create();List<Result> result = client.submit("g.with(EVALUATION_TIMEOUT, 500).addV().iterate();" +"g.addV().iterate();" +"g.with(EVALUATION_TIMEOUT, 500).addV();", options).all().get();In the above example,RequestOptions defines a timeout of 500 milliseconds, but the script has three traversals withtwo internal settings for the timeout usingwith(). The request timeout used by the server will therefore be 1000milliseconds (overriding the 500 which itself was an override for whatever configuration was on the server).
Aliases
Scripts submitted to Gremlin Server automatically have the globally configuredGraph andTraversalSource instancesmade available to them. Therefore, if Gremlin Server configures twoTraversalSource instances called "g1" and "g2"a script can simply reference them directly as:
client.submit("g1.V()")client.submit("g2.V()")While this is an acceptable way to submit scripts, it has the downside of forcing the client to encode the server-sidevariable name directly into the script being sent. If the server configuration ever changed such that "g1" became"g100", the client-side code might have to see a significant amount of change. Decoupling the script code from theserver configuration can be managed by thealias method onClient as follows:
Client g1Client = client.alias("g1")Client g2Client = client.alias("g2")g1Client.submit("g.V()")g2Client.submit("g.V()")The above code demonstrates how thealias method can be used such that the script need only contain a referenceto "g" and "g1" and "g2" are automatically rebound into "g" on the server-side.
Domain Specific Languages
Creating aDomain Specific Language (DSL) in Java requires the@GremlinDsl Java annotation in thegremlin-annotations module. This annotation should be applied to a "DSL interface" that extendsGraphTraversal.Admin:
<dependency><groupId>org.apache.tinkerpop</groupId><artifactId>gremlin-annotations</artifactId><version>3.7.4</version></dependency>@GremlinDslpublicinterfaceSocialTraversalDsl<S, E>extends GraphTraversal.Admin<S, E> {}Important | The name of the DSL interface should be suffixed with "TraversalDSL". All characters in the interface namebefore that become the "name" of the DSL. |
In this interface, define the methods that the DSL will be composed of:
@GremlinDslpublicinterfaceSocialTraversalDsl<S, E>extends GraphTraversal.Admin<S, E> {publicdefault GraphTraversal<S, Vertex> knows(String personName) {return out("knows").hasLabel("person").has("name", personName); }publicdefault <E2extendsNumber> GraphTraversal<S, E2> youngestFriendsAge() {return out("knows").hasLabel("person").values("age").min(); }publicdefault GraphTraversal<S,Long> createdAtLeast(int number) {return outE("created").count().is(P.gte(number)); }}Important | Follow the TinkerPop convention of using<S,E> in naming generics as those conventions are taken intoaccount when generating the anonymous traversal class. The processor attempts to infer the appropriate type parameterswhen generating the anonymous traversal class. If it cannot do it correctly, it is possible to avoid the inference byusing theGremlinDsl.AnonymousMethod annotation on the DSL method. It allows explicit specification of the types touse. |
The@GremlinDsl annotation is used by theJava Annotation Processorto generate the boilerplate class structure required to properly use the DSL within the TinkerPop framework. Theseclasses can be generated and maintained by hand, but it would be time consuming, monotonous and error-prone to do so.Typically, the Java compilation process is automatically configured to detect annotation processors on the classpathand will automatically use them when found. If that does not happen, it may be necessary to make configuration changesto the build to allow for the compilation process to be aware of the followingjavax.annotation.processing.Processorimplementation:
org.apache.tinkerpop.gremlin.process.traversal.dsl.GremlinDslProcessorThe annotation processor will generate several classes for the DSL:
SocialTraversal- ATraversalinterface that extends theSocialTraversalDslproxying methods to its underlyinginterfaces (such asGraphTraversal) to instead return aSocialTraversalDefaultSocialTraversal- A default implementation ofSocialTraversal(typically not used directly by the user)SocialTraversalSource- SpawnsDefaultSocialTraversalinstances.__- Spawns anonymousDefaultSocialTraversalinstances.
Using the DSL then just involves telling theGraph to use it:
SocialTraversalSource social = traversal(SocialTraversalSource.class).withEmbedded(graph);social.V().has("name","marko").knows("josh");TheSocialTraversalSource can also be customized with DSL functions. As an additional step, include a class thatextends fromGraphTraversalSource and with a name that is suffixed with "TraversalSourceDsl". Include in this class,any custom methods required by the DSL:
publicclassSocialTraversalSourceDslextends GraphTraversalSource {public SocialTraversalSourceDsl(Graph graph, TraversalStrategies traversalStrategies) {super(graph, traversalStrategies); }public SocialTraversalSourceDsl(Graph graph) {super(graph); }public SocialTraversalSourceDsl(RemoteConnection connection) {super(connection); }public GraphTraversal<Vertex, Vertex> persons(String... names) { GraphTraversalSource clone =this.clone();// Manually add a "start" step for the traversal in this case the equivalent of V(). GraphStep is marked// as a "start" step by passing "true" in the constructor. clone.getBytecode().addStep(GraphTraversal.Symbols.V); GraphTraversal<Vertex, Vertex> traversal =new DefaultGraphTraversal<>(clone); traversal.asAdmin().addStep(new GraphStep<>(traversal.asAdmin(), Vertex.class,true)); traversal = traversal.hasLabel("person");if (names.length >0) traversal = traversal.has("name", P.within(names));return traversal; }}Then, back in theSocialTraversal interface, update theGremlinDsl annotation with thetraversalSource argumentto point to the fully qualified class name of theSocialTraversalSourceDsl:
@GremlinDsl(traversalSource ="com.company.SocialTraversalSourceDsl")publicinterfaceSocialTraversalDsl<S, E>extends GraphTraversal.Admin<S, E> { ...}It is then possible to use thepersons() method to start traversals:
SocialTraversalSource social = traversal(SocialTraversalSource.class).withEmbedded(graph);social.persons("marko").knows("josh");Note | Using Maven, as shown in thegremlin-archetype-dsl module, makes developing DSLs with the annotation processorstraightforward in that it sets up appropriate paths to the generated code automatically. |
Troubleshooting
Max frame length of 65536 has been exceeded
This error occurs when the driver attempts to process a request/response that exceeds the configured maximum size.The most direct way to fix this problem is to increase themaxContentLength setting in the driver. Ideally, themaxContentLength set for the driver should match the setting defined on the server.
TimeoutException
ATimeoutException is thrown by the driver when the time limit assigned by themaxWaitForConnection is exceededwhen trying to borrow a connection from the connection pool for a particular host. There are generally two scenarioswhere this occurs:
The server has actually reached its maximum capacity or the driver has just learned that the server is unreachable.
The client is throttling requests when the pool is exhausted.
The latter of the two can be addressed from the driver side in the following ways:
Increase the
maxWaitForConnectionallowing the client to wait a bit longer for a connection to become available.Increase the number of requests allowed per connection by increasing the
maxSimultaneousUsagePerConnectionandmaxInProcessPerConnectionsettings.Increase the number of connections available in the connection pool by increasing the
maxConnectionPoolSize.
The exception and logs (assuming they are enabled) should contain information about the state of the connection poolalong with its connections which can help shed more light on which of these scenarios caused the problem. Some examplesof these messages and their meaning are shown below:
The server is unavailable
Timed-out (500 MILLISECONDS) waiting for connection on Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin}. Potential Cause: Connection refused: no further information> ConnectionPool (Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin})- no connections in poolClient is likely issuing more requests than the pool size can handle
Timed-out (150 MILLISECONDS) waiting for connection on Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin}. Potential Cause: Number of active requests exceeds pool size. Consider increasing the value for maxConnectionPoolSize.ConnectionPool (Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin})Connection Pool Status (size=1 max=1 min=1 toCreate=0 bin=0)> Connection{channel=5a859d62 isDead=false borrowed=1 pending=1 markedReplaced=false closing=false created=2022-12-19T21:08:21.569613100Z thread=gremlin-driver-conn-scheduler-1}-- bin --Network traffic is slow and the websocket handshake does not complete in time
Timed-out (250 MILLISECONDS) waiting for connection on Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin}. Potential Cause: WebSocket handshake not completed in stipulated time=[100]msConnectionPool (Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin})Connection Pool Status (size=1 max=5 min=1 toCreate=0 bin=0)> Connection{channel=205fc8d2 isDead=false borrowed=1 pending=1 markedReplaced=false closing=false created=2022-12-19T21:10:04.692921600Z thread=gremlin-driver-conn-scheduler-1}-- bin --Application Archetypes
The availableMaven archetypes areas follows:
gremlin-archetype-dsl- An example project that demonstrates how to build Domain Specific Languages with Gremlinin Java.gremlin-archetype-server- An example project that demonstrates the basic structure of aGremlin Server project, how to connect with the Gremlin Driver, and how to embed Gremlin Server ina testing framework.gremlin-archetype-tinkergraph- A basic example of how to structure a TinkerPop project with Maven.
Use Maven to generate these example projects with a command like:
$ mvn archetype:generate -DarchetypeGroupId=org.apache.tinkerpop -DarchetypeArtifactId=gremlin-archetype-server \ -DarchetypeVersion=3.7.4 -DgroupId=com.my -DartifactId=app -Dversion=0.1 -DinteractiveMode=falseThis command will generate a new Maven project in a directory called "app" with apom.xml specifying agroupId ofcom.my. Please see theREADME.asciidoc in the root of each generated project for information on how to build andexecute it.
Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Java. Theycan be found in GitHubhere.
The remote connection examples in particular are designed to connect to a runningGremlin Serverconfigured with theconf/gremlin-server.yaml file as included with the standard release packaging.
To do so, download an image of Gremlin Server from Docker Hub, then launch a new container withdocker run:
docker pull tinkerpop/gremlin-serverdocker run -d -p 8182:8182 tinkerpop/gremlin-serverAll examples can then be run using your IDE of choice.
Gremlin-JavaScript
 Apache TinkerPop’s Gremlin-JavaScript implements Gremlin within theJavaScript language. It targets Node.js runtime and can be used on different operating systems on any Node.js 6 orabove. Since the JavaScript naming conventions are very similar to that of Java, it should be very easy to switchbetween Gremlin-Java and Gremlin-JavaScript.
Apache TinkerPop’s Gremlin-JavaScript implements Gremlin within theJavaScript language. It targets Node.js runtime and can be used on different operating systems on any Node.js 6 orabove. Since the JavaScript naming conventions are very similar to that of Java, it should be very easy to switchbetween Gremlin-Java and Gremlin-JavaScript.
npm install gremlinConnecting
The pattern for connecting is described inConnecting Gremlin and it basically distills down tocreating aGraphTraversalSource. AGraphTraversalSource is created from theAnonymousTraversalSource.traversal()method where the "g" provided to theDriverRemoteConnection corresponds to the name of aGraphTraversalSource onthe remote end.
const g = traversal().withRemote(new DriverRemoteConnection('ws://localhost:8182/gremlin'));Gremlin-JavaScript supports plain text SASL authentication, you can set it on the connection options.
const authenticator =new gremlin.driver.auth.PlainTextSaslAuthenticator('myuser','mypassword');const g = traversal().withRemote(new DriverRemoteConnection('ws://localhost:8182/gremlin', { authenticator });Given that I/O operations in Node.js are asynchronous by default,Terminal Steps return aPromise:
Traversal.toList(): Returns aPromisewith anArrayas result value.Traversal.next(): Returns aPromisewith a{ value, done }tuple as result value, according to theasync iterator proposal.Traversal.iterate(): Returns aPromisewithout a value.
For example:
g.V().hasLabel('person').values('name').toList() .then(names => console.log(names));When usingasync functions it is possible toawait the promises:
const names = await g.V().hasLabel('person').values('name').toList();console.log(names);Some connection options can also be set on individual requests made through the usingwith() step on theTraversalSource. For instance to set request timeout to 500 milliseconds:
const vertices = await g.with_('evaluationTimeout',500).V().out('knows').toList()The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent andevaluationTimeout (formerlyscriptEvaluationTimeout which is also supported but now deprecated).
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following importsprovide most of the typical functionality required to use Gremlin:
const gremlin = require('gremlin');const traversal = gremlin.process.AnonymousTraversalSource.traversal;const __ = gremlin.process.statics;const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection;const column = gremlin.process.columnconst direction = gremlin.process.directionconst Direction = {BOTH: direction.both,IN: direction.in,OUT: direction.out,from_: direction.out,to: direction.in,}const p = gremlin.process.Pconst textp = gremlin.process.TextPconst pick = gremlin.process.pickconst pop = gremlin.process.popconst order = gremlin.process.orderconst scope = gremlin.process.scopeconst t = gremlin.process.tconst cardinality = gremlin.process.cardinalityconst CardinalityValue = gremlin.process.CardinalityValueBy defining these imports it becomes possible to write Gremlin in the more shorthand, canonical style that isdemonstrated in most examples found here in the documentation:
const {P: { gt } } = gremlin.process;const {order: { desc } } = gremlin.process;g.V().hasLabel('person').has('age',gt(30)).order().by('age',desc).toList()Configuration
The following table describes the various configuration options for the Gremlin-Javascript Driver. Theycan be passed in the constructor of a newClient orDriverRemoteConnection :
| Key | Type | Description | Default |
|---|---|---|---|
url | String | The resource uri. | None |
options | Object | The connection options. | {} |
options.ca | Array | Trusted certificates. | undefined |
options.cert | String/Array/Buffer | The certificate key. | undefined |
options.mimeType | String | The mime type to use. | 'application/vnd.gremlin-v3.0+json' |
options.pfx | String/Buffer | The private key, certificate, and CA certs. | undefined |
options.reader | GraphSONReader/GraphBinaryReader | The reader to use. | select reader according to mimeType |
options.writer | GraphSONWriter | The writer to use. | select writer according to mimeType |
options.rejectUnauthorized | Boolean | Determines whether to verify or not the server certificate. | undefined |
options.traversalSource | String | The traversal source. | 'g' |
options.authenticator | Authenticator | The authentication handler to use. | undefined |
options.processor | String | The name of the opProcessor to use, leave it undefined or set 'session' when session mode. | undefined |
options.session | String | The sessionId of Client in session mode. undefined means session-less Client. | undefined |
options.enableCompression | Boolean | Enables permessage-deflate compression. Note that use of compression may increase vulnerability to attacks such as CRIME/BREACH. | false |
options.enableUserAgentOnConnect | Boolean | Determines if a user agent will be sent during connection handshake. | true |
options.headers | Object | An associative array containing the additional header key/values for the initial request. | undefined |
options.pingEnabled | Boolean | Setup ping interval. | true |
options.pingInterval | Number | Ping request interval in ms if ping enabled. | 60000 |
options.pongTimeout | Number | Timeout of pong response in ms after sending a ping. | 30000 |
Transactions
To get a full understanding of this section, it would be good to start by reading theTransactionssection of this documentation, which discusses transactions in the general context of TinkerPop itself. This sectionbuilds on that content by demonstrating the transactional syntax for Javascript.
const g = traversal().withRemote(new DriverRemoteConnection('ws://localhost:8182/gremlin'));const tx = g.tx();// create a Transaction// spawn a new GraphTraversalSource binding all traversals established from it to txconst gtx = tx.begin();// execute traversals using gtx occur within the scope of the transaction held by tx. the// tx is closed after calls to commit or rollback and cannot be re-used. simply spawn a// new Transaction from g.tx() to create a new one as needed. the g context remains// accessible through all this as a sessionless connection.Promise.all([ gtx.addV("person").property("name","jorge").iterate(), gtx.addV("person").property("name","josh").iterate()]).then(() => {return tx.commit();}).catch(() => {return tx.rollback();});The Lambda Solution
Supportinganonymous functions across languages is difficult asmost languages do not support lambda introspection and thus, code analysis. In Gremlin-Javascript, a Gremlin lambdashould be represented as a zero-arg callable that returns a string representation of the lambda expected for use in thetraversal. The returned lambda should be written as a Gremlin-Groovy string. When the lambda is represented inBytecode its language is encoded such that the remote connection host can infer which translator and ultimateexecution engine to use.
g.V().out(). map(() =>"it.get().value('name').length()"). sum(). toList().then(total => console.log(total))Tip | When running into situations where Groovy cannot properly discern a method signature based on theLambdainstance created, it will help to fully define the closure in the lambda expression - so rather than() ⇒ "it.get().value('name')", prefer() ⇒ "x → x.get().value('name')". |
Warning | As explained throughout the documentation, when possibleavoid lambdas. |
Submitting Scripts
It is possible to submit parametrized Gremlin scripts to the server as strings, using theClient class:
const gremlin = require('gremlin');const client =new gremlin.driver.Client('ws://localhost:8182/gremlin', {traversalSource:'g' });const result1 = await client.submit('g.V(vid)', {vid:1 });const vertex = result1.first();const result2 = await client.submit('g.V().hasLabel(label).tail(n)', {label:'person',n:3 });// ResultSet is an iterablefor (const vertex of result2) { console.log(vertex.id);}It is also possible to initialize theClient to usesessions:
const client =new gremlin.driver.Client('ws://localhost:8182/gremlin', {traversalSource:'g','session':'unique-string-id' });With this configuration, the state of variables within scripts are preserved between requests.
Per Request Settings
Theclient.submit() functions accept arequestOptions which expects a dictionary. TherequestOptionsprovide a way to include options that are specific to the request made with the call tosubmit(). A good use-case forthis feature is to set a per-request override to theevaluationTimeout so that it only applies to the currentrequest.
const result = await client.submit("g.V().repeat(both()).times(100)",null, {evaluationTimeout:5000 })The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent,materializeProperties andevaluationTimeout (formerlyscriptEvaluationTimeout which is also supported but now deprecated).
Important | The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiarwith bytecode may tryg.with(EVALUATION_TIMEOUT, 500) within a script. Scripts with multiple traversals and multipletimeouts will be interpreted as a sum of all timeouts identified in the script for that request. |
Processing results as they are returned from the Gremlin server
The Gremlin JavaScript driver maintains a WebSocket connection to the Gremlin server and receives messages according to thebatchSize parameter on the per request settings or theresultIterationBatchSize value configured for the Gremlin server. When submitting scripts the default behavior is to wait for the entire result set to be returned from a query before allowing any processing on the result set.
The following examples assume that you have 100 vertices in your graph.
const result = await client.submit("g.V()");console.log(result.toArray());// 100 - all the vertices in your graphWhen working with larger result sets it may be beneficial for memory management to process each chunk of data as it is returned from the gremlin server. The Gremlin JavaScript driver can return a readable stream instead of waiting for the entire result set to be loaded.
const readable = client.stream("g.V()", {}, {batchSize:25 });readable.on('data', (data) => { console.log(data.toArray());// 25 vertices})readable.on('error', (error) => { console.log(error);// errors returned from gremlin server})readable.on('end', () => { console.log('query complete');// when the end event is received then all the results have been processed})If you are using NodeJS >= 10.0, you can asynchronously iterate readable streams:
const readable = client.stream("g.V()", {}, {batchSize:25 });try {for await (const result of readable) { console.log('data', result.toArray());// 25 vertices }}catch (err) { console.log(err);}Domain Specific Languages
Developing Gremlin DSLs in JavaScript largely requires extension of existing core classes with use of standalonefunctions for anonymous traversal spawning. The pattern is demonstrated in the following example:
class SocialTraversalextends GraphTraversal { constructor(graph, traversalStrategies, bytecode) {super(graph, traversalStrategies, bytecode); } aged(age) {returnthis.has('person','age', age); }}class SocialTraversalSourceextends GraphTraversalSource { constructor(graph, traversalStrategies, bytecode) {super(graph, traversalStrategies, bytecode, SocialTraversalSource, SocialTraversal); } person(name) {returnthis.V().has('person','name', name); }}functionanonymous() {returnnew SocialTraversal(null,null,new Bytecode());}functionaged(age) {return anonymous().aged(age);}SocialTraversal extends the coreGraphTraversal class and has a three argument constructor which is immediatelyproxied to theGraphTraversal constructor. New DSL steps are then added to this class using available steps toconstruct the underlying traversal to execute as demonstrated in theaged() step.
TheSocialTraversal is spawned from aSocialTraversalSource which is extended fromGraphTraversalSource. Stepsadded here are meant to be start steps. In the above case, theperson() start step find a "person" vertex to beginthe traversal from.
Typically, steps that are made available on aGraphTraversal (i.e. SocialTraversal in this example) should also bemade available as spawns for anonymous traversals. The recommendation is that these steps be exposed in the moduleas standalone functions. In the example above, the standaloneaged() step creates an anonymous traversal throughananonymous() utility function. The method for creating these standalone functions can be handled in other ways ifdesired.
To use the DSL, simply initialize theg as follows:
const g = traversal(SocialTraversalSource).withRemote(connection);g.person('marko').aged(29).values('name').toList(). then(names => console.log(names));Differences
In situations where Javascript reserved words and global functions overlap with standard Gremlin steps and tokens, thosebits of conflicting Gremlin get an underscore appended as a suffix:
In addition, the enum construct forCardinality cannot have functions attached to it the way it can be done in Java,therefore cardinality functions that take a value likelist(),set(), andsingle() are referenced from aCardinalityValue class rather thanCardinality itself.
Gremlin allows forMap instances to includenull keys, butnull keys in Javascript have some interesting behavioras in:
> var a = { null: 'something', 'b': 'else' };> JSON.stringify(a)'{"null":"something","b":"else"}'> JSON.parse(JSON.stringify(a)){ null: 'something', b: 'else' }> a[null]'something'> a['null']'something'This behavior needs to be considered when using Gremlin to return such results. A typical situation where this mighthappen is withgroup() orgroupCount() as in:
g.V().groupCount().by('age')where "age" is not a valid key for all vertices. In these cases, it will returnnull for that key and group on that.It may bet better in Javascript to filter away those vertices to avoid the return ofnull in the returnedMap:
g.V().has('age').groupCount().by('age')g.V().hasLabel('person').groupCount().by('age')Either of the above two options accomplishes the desired goal as both preventgroupCount() from having to processthe possibility ofnull.
Limitations
The
subgraph()-step is not supported by any variant that is not running on the Java Virtual Machine as there isnoGraphinstance to deserialize a result into on the client-side. A workaround is to replace the step withaggregate(local)and then convert those results to something the client can use locally.
Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-JavaScript. Theycan be found in GitHubhereand are designed to connect to a runningGremlin Server configured with theconf/gremlin-server.yaml andconf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration fileconf/gremlin-server.yaml. To start a clean server, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, usingconf/gremlin-server-modern.yaml.To start a server with the Modern graph preloaded, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlMake sure to install all necessary packages:
npm installEach example can now be run with the following commands:
node connections.jsnode basic-gremlin.jsnode modern-traversals.jsGremlin.Net
![]() Apache TinkerPop’s Gremlin.Net implements Gremlin within the C#language. It targets .NET Standard and can therefore be used on different operating systems and with different .NETframeworks, such as .NET Framework and.NET Core. Since the C# syntax is verysimilar to that of Java, it should be easy to switch between Gremlin-Java and Gremlin.Net. The only major syntacticaldifference is that all method names in Gremlin.Net use PascalCase as opposed to camelCase in Gremlin-Java in orderto comply with .NET conventions.
Apache TinkerPop’s Gremlin.Net implements Gremlin within the C#language. It targets .NET Standard and can therefore be used on different operating systems and with different .NETframeworks, such as .NET Framework and.NET Core. Since the C# syntax is verysimilar to that of Java, it should be easy to switch between Gremlin-Java and Gremlin.Net. The only major syntacticaldifference is that all method names in Gremlin.Net use PascalCase as opposed to camelCase in Gremlin-Java in orderto comply with .NET conventions.
nuget install Gremlin.NetConnecting
The pattern for connecting is described inConnecting Gremlin and it basically distills down tocreating aGraphTraversalSource. AGraphTraversalSource is created from theAnonymousTraversalSource.traversal()method where the "g" provided to theDriverRemoteConnection corresponds to the name of aGraphTraversalSource onthe remote end.
using var remoteConnection = new DriverRemoteConnection(new GremlinClient(new GremlinServer("localhost", 8182)), "g");var g = Traversal().WithRemote(remoteConnection);Some connection options can also be set on individual requests using theWith() step on theTraversalSource.For instance to set request timeout to 500 milliseconds:
var l = g.With(Tokens.ArgsEvalTimeout, 500).V().Out("knows").Count().ToList();The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent andevaluationTimeout (formerlyscriptEvaluationTimeout which is also supported but now deprecated). These options areavailable as constants on theGremlin.Net.Driver.Tokens class.
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following importsprovide most of the typical functionality required to use Gremlin:
using static Gremlin.Net.Process.Traversal.AnonymousTraversalSource;using static Gremlin.Net.Process.Traversal.__;using static Gremlin.Net.Process.Traversal.P;using static Gremlin.Net.Process.Traversal.Order;using static Gremlin.Net.Process.Traversal.Operator;using static Gremlin.Net.Process.Traversal.Pop;using static Gremlin.Net.Process.Traversal.Scope;using static Gremlin.Net.Process.Traversal.TextP;using static Gremlin.Net.Process.Traversal.Column;using static Gremlin.Net.Process.Traversal.Direction;using static Gremlin.Net.Process.Traversal.Cardinality;using static Gremlin.Net.Process.Traversal.CardinalityValue;using static Gremlin.Net.Process.Traversal.T;Configuration
The connection properties for the Gremlin.Net driver can be passed to theGremlinServer instance as keyword arguments:
| Key | Description | Default |
|---|---|---|
hostname | The hostname that the driver will connect to. | localhost |
port | The port on which Gremlin Server can be reached. | 8182 |
enableSsl | Determines if SSL should be enabled or not. If enabled on the server then it must be enabled on the client. | false |
username | The username to submit on requests that require authentication. | none |
password | The password to submit on requests that require authentication. | none |
Connection Pool
It is also possible to configure theConnectionPool of the Gremlin.Net driver.These configuration options can be set as propertieson theConnectionPoolSettings instance that can be passed to theGremlinClient:
| Key | Description | Default |
|---|---|---|
PoolSize | The size of the connection pool. | 4 |
MaxInProcessPerConnection | The maximum number of in-flight requests that can occur on a connection. | 32 |
ReconnectionAttempts | The number of attempts to get an open connection from the pool to submit a request. | 4 |
ReconnectionBaseDelay | The base delay used for the exponential backoff for the reconnection attempts. | 1 s |
EnableUserAgentOnConnect | Enables sending a user agent to the server during connection requests.More details can be found in provider docshere. | true |
ANoConnectionAvailableException is thrown if all connections have reached theMaxInProcessPerConnection limitwhen a new request comes in.AServerUnavailableException is thrown if no connection is available to the server to submit a request afterReconnectionAttempts retries.
WebSocket Configuration
The WebSocket connections can also be configured, directly as parameters of theGremlinClient constructor. It takesan optional delegatewebSocketConfiguration that will be invoked for each connection. This makes it possible toconfigure more advanced options like theKeepAliveInterval or client certificates.
Starting with .NET 6, it is also possible to use compression for WebSockets. This is enabled by default starting withTinkerPop 3.5.3 (again, only on .NET 6 or higher). Note that compression might make an application susceptible toattacks like CRIME/BREACH. Compression should therefore be turned off if the application sends sensitive data to theserver as well as data that could potentially be controlled by an untrusted user. Compression can be disabled via thedisableCompression parameter.
Logging
It is possible to enable logging for the Gremlin.Net driver by providing anILoggerFactory (from theMicrosoft.Extensions.Logging.Abstractions package) to theGremlinClient constructor:
var loggerFactory = LoggerFactory.Create(builder =>{ builder.AddConsole();});var client = new GremlinClient(new GremlinServer("localhost", 8182), loggerFactory: loggerFactory);Serialization
The Gremlin.Net driver uses by default GraphBinary but it is also possible to use another serialization format by passing a message serializer when creating theGremlinClient.
GraphSON 3.0 can be configured like this:
var client = new GremlinClient(new GremlinServer("localhost", 8182), new GraphSON3MessageSerializer());and GraphSON 2.0 like this:
var client = new GremlinClient(new GremlinServer("localhost", 8182), new GraphSON2MessageSerializer());Traversal Strategies
In order to add and remove traversal strategies from a traversal source, Gremlin.Net has anAbstractTraversalStrategyclass along with a collection of subclasses that mirror the standard Gremlin-Java strategies.
g = g.WithStrategies(new SubgraphStrategy(vertices: HasLabel("person"), edges: Has("weight", Gt(0.5))));var names = g.V().Values<string>("name").ToList(); // names: [marko, vadas, josh, peter]g = g.WithoutStrategies(typeof(SubgraphStrategy));names = g.V().Values<string>("name").ToList(); // names: [marko, vadas, lop, josh, ripple, peter]var edgeValueMaps = g.V().OutE().ValueMap<object, object>().With(WithOptions.Tokens).ToList();// edgeValueMaps: [[label:created, id:9, weight:0.4], [label:knows, id:7, weight:0.5], [label:knows, id:8, weight:1.0],// [label:created, id:10, weight:1.0], [label:created, id:11, weight:0.4], [label:created, id:12, weight:0.2]]g = g.WithComputer(workers: 2, vertices: Has("name", "marko"));names = g.V().Values<string>("name").ToList(); // names: [marko]edgeValueMaps = g.V().OutE().ValueMap<object, object>().With(WithOptions.Tokens).ToList();// edgeValueMaps: [[label:created, id:9, weight:0.4], [label:knows, id:7, weight:0.5], [label:knows, id:8, weight:1.0]]Note | Many of the TraversalStrategy classes in Gremlin.Net are proxies to the respective strategy on Apache TinkerPop’sJVM-based Gremlin traversal machine. As such, theirApply(ITraversal) method does nothing. However, the strategy isencoded in the Gremlin.Net bytecode and transmitted to the Gremlin traversal machine for re-construction machine-side. |
Transactions
To get a full understanding of this section, it would be good to start by reading theTransactionssection of this documentation, which discusses transactions in the general context of TinkerPop itself. This sectionbuilds on that content by demonstrating the transactional syntax for C#.
using var gremlinClient = new GremlinClient(new GremlinServer("localhost", 8182));var g = Traversal().WithRemote(new DriverRemoteConnection(gremlinClient));var tx = g.Tx(); // create a transaction// spawn a new GraphTraversalSource binding all traversals established from it to txvar gtx = tx.Begin();// execute traversals using gtx occur within the scope of the transaction held by tx. the// tx is closed after calls to CommitAsync or RollbackAsync and cannot be re-used. simply spawn a// new Transaction from g.Tx() to create a new one as needed. the g context remains// accessible through all this as a sessionless connection.try{ await gtx.AddV("person").Property("name", "jorge").Promise(t => t.Iterate()); await gtx.AddV("person").Property("name", "josh").Promise(t => t.Iterate()); await tx.CommitAsync();}catch (Exception){ await tx.RollbackAsync();}The Lambda Solution
Supportinganonymous functions across languages is difficult asmost languages do not support lambda introspection and thus, code analysis. While Gremlin.Net doesn’t support C# lambdas, itis still able to represent lambdas in other languages. When the lambda is represented inBytecode its language is encodedsuch that the remote connection host can infer which translator and ultimate execution engine to use.
g.V().Out().Map<int>(Lambda.Groovy("it.get().value('name').length()")).Sum<int>().ToList();//1g.V().Out().Map<int>(Lambda.Python("lambda x: len(x.get().value('name'))")).Sum<int>().ToList();//2Lambda.Groovy()can be used to create a Groovy lambda.Lambda.Python()can be used to create a Python lambda.
TheILambda interface returned by these two methods inherits interfaces likeIFunction andIPredicate that mirrortheir Java counterparts which makes it possible to use lambdas with Gremlin.Net for the same steps as in Gremlin-Java.
Tip | When running into situations where Groovy cannot properly discern a method signature based on theLambdainstance created, it will help to fully define the closure in the lambda expression - so rather thanLambda.Groovy("it.get().value('name')), preferLambda.Groovy("x → x.get().value('name')). |
Submitting Scripts
Gremlin scripts are sent to the server from aIGremlinClient instance. AIGremlinClient is created as follows:
var gremlinServer = new GremlinServer("localhost", 8182);using var gremlinClient = new GremlinClient(gremlinServer);var response = await gremlinClient.SubmitWithSingleResultAsync<string>("g.V().has('person','name','marko')");If the remote system has authentication and SSL enabled, then theGremlinServer object can be configured as follows:
var username = "username";var password = "password";var gremlinServer = new GremlinServer("localhost", 8182, true, username, password);It is also possible to initialize theClient to usesessions:
var gremlinServer = new GremlinServer("localhost", 8182);var client = new GremlinClient(gremlinServer, sessionId: Guid.NewGuid().ToString()))Per Request Settings
TheGremlinClient.Submit() functions accept an option to build a rawRequestMessage. A good use-case for thisfeature is to set a per-request override to theevaluationTimeout so that it only applies to the current request.
var gremlinServer = new GremlinServer("localhost", 8182);using var gremlinClient = new GremlinClient(gremlinServer);var response = await gremlinClient.SubmitWithSingleResultAsync<string>( RequestMessage.Build(Tokens.OpsEval). AddArgument(Tokens.ArgsGremlin, "g.V().count()"). AddArgument(Tokens.ArgsEvalTimeout, 500). Create());The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent,materializeProperties andevaluationTimeout (formerlyscriptEvaluationTimeout which is also supported but now deprecated). These options areavailable as constants on theGremlin.Net.Driver.Tokens class.
Important | The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiarwith bytecode may tryg.with(EVALUATION_TIMEOUT, 500) within a script. Scripts with multiple traversals and multipletimeouts will be interpreted as a sum of all timeouts identified in the script for that request. |
Domain Specific Languages
Developing aDomain Specific Language (DSL) for .Net is most easily implemented usingExtension Methodsas they don’t require direct extension of classes in the TinkerPop hierarchy. Extension Method classes simply need tobe constructed for theGraphTraversal and theGraphTraversalSource. Unfortunately, anonymous traversals (spawnedfrom__) can’t use the Extension Method approach as they do not work for static classes and static classes can’t beextended. The only option is to re-implement the methods of__ as a wrapper in the anonymous traversal for the DSLor to simply create a static class for the DSL and use the two anonymous traversals creators independently. Thefollowing example uses the latter approach as it saves a lot of boilerplate code with the minor annoyance of having asecond static class to deal with when writing traversals rather than just calling__ for everything.
namespace Dsl { public static class SocialTraversalExtensions { public static GraphTraversal<Vertex,Vertex> Knows(this GraphTraversal<Vertex,Vertex> t, string personName) { return t.Out("knows").HasLabel("person").Has("name", personName); } public static GraphTraversal<Vertex, int> YoungestFriendsAge(this GraphTraversal<Vertex,Vertex> t) { return t.Out("knows").HasLabel("person").Values<int>("age").Min<int>(); } public static GraphTraversal<Vertex,long> CreatedAtLeast(this GraphTraversal<Vertex,Vertex> t, long number) { return t.OutE("created").Count().Is(P.Gte(number)); } } public static class __Social { public static GraphTraversal<object,Vertex> Knows(string personName) { return __.Out("knows").HasLabel("person").Has("name", personName); } public static GraphTraversal<object, int> YoungestFriendsAge() { return __.Out("knows").HasLabel("person").Values<int>("age").Min<int>(); } public static GraphTraversal<object,long> CreatedAtLeast(long number) { return __.OutE("created").Count().Is(P.Gte(number)); } } public static class SocialTraversalSourceExtensions { public static GraphTraversal<Vertex,Vertex> Persons(this GraphTraversalSource g, params string[] personNames) { GraphTraversal<Vertex,Vertex> t = g.V().HasLabel("person"); if (personNames.Length > 0) { t = t.Has("name", P.Within(personNames)); } return t; } }}Note the creation of__Social as the Social DSL’s "extension" to the available ways in which to spawn anonymoustraversals. The use of the double underscore prefix in the name is just a convention to consider using and is not arequirement. To use the DSL, bring it into scope with theusing directive:
using Dsl;using static Dsl.__Social;and then it can be called from the application as follows:
var connection = new DriverRemoteConnection(new GremlinClient(new GremlinServer("localhost", 8182)));var social = Traversal().WithRemote(connection);social.Persons("marko").Knows("josh");social.Persons("marko").YoungestFriendsAge();social.Persons().Filter(CreatedAtLeast(2)).Count();Differences
The biggest difference between Gremlin in .NET and the canonical version in Java is the casing of steps. CanonicalGremlin utilizescamelCase as is typical in Java for function names, but C# utilizesPascalCase as it is moretypical in that language. Therefore, when viewing a typical Gremlin example written in Gremlin Console, the conversionto C# usually just requires capitalization of the first letter in the step name, thus the following example in Groovy:
g.V().has('person','name','marko'). out('knows'). elementMap().toList()would become the following in C#:
g.V().Has("Person","name","marko"). Out("knows"). ElementMap().ToList();In addition to the uppercase change, also note the conversion of the single quotes to double quotes as is expected fordeclaring string values in C# and the addition of the semi-colon at the end of the line. In short, don’t forget toapply the common syntax expectations for C# when trying to convert an example of Gremlin from a different language.
Another common conversion issues lies in having to explicitly define generics, which can make canonical Gremlin appearmuch more complex in C# where type erasure is not a feature of the language. For example, the following example inGroovy:
g.V().repeat(__.out()).times(2).values('name')must be written as:
g.V().Repeat(__.Out()).Times(2).Values<string>("name");Gremlin allows forMap instances to includenull keys, butnull keys in C#Dictionary instances are not allowed.It is therefore necessary to rewrite a traversal such as:
g.V().GroupCount<object>().By("age")where "age" is not a valid key for all vertices in a way that will remove the need for anull to be returned.
Finally, the enum construct forCardinality cannot have functions attached to it the way it can be done in Java,therefore cardinality functions that take a value likelist(),set(), andsingle() are referenced from aCardinalityValue class rather thanCardinality itself.
g.V().Has("age").GroupCount<object>().By("age")g.V().HasLabel("person").GroupCount<object>().By("age")Either of the above two options accomplishes the desired goal as both preventgroupCount() from having to processthe possibility ofnull.
Limitations
The
subgraph()-step is not supported by any variant that is not running on the Java Virtual Machine as there isnoGraphinstance to deserialize a result into on the client-side. A workaround is to replace the step withaggregate(local)and then convert those results to something the client can use locally.
Getting Started
Thisdotnet template helps getting started withGremlin.Net. It creates a new C# console project that shows how to connect to aGremlin Server with Gremlin.Net.
You can install the template with the dotnet CLI tool:
dotnet new -i Gremlin.Net.TemplateAfter the template is installed, a new project based on this template can be installed:
dotnet new gremlinSpecify the output directory for the new project which will then also be used as the name of the created project:
dotnet new gremlin -o MyFirstGremlinProjectApplication Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Dotnet. Theycan be found in GitHubhereand are designed to connect to a runningGremlin Server configured with theconf/gremlin-server.yaml andconf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration fileconf/gremlin-server.yaml. To start a clean server, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, usingconf/gremlin-server-modern.yaml.To start a server with the Modern graph preloaded, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlEach example can now be run with the following command in their respective project directories:
dotnet runGremlin-Python
 Apache TinkerPop’s Gremlin-Python implements Gremlin withinthePython language and can be used on any Python virtual machine including the popularCPython machine. Python’s syntax has the same constructs as Java including"dot notation" for function chaining (
Apache TinkerPop’s Gremlin-Python implements Gremlin withinthePython language and can be used on any Python virtual machine including the popularCPython machine. Python’s syntax has the same constructs as Java including"dot notation" for function chaining (a.b.c), round bracket function arguments (a(b,c)), and support for globalnamespaces (a(b()) vsa(__.b())). As such, anyone familiar with Gremlin-Java will immediately be able to workwith Gremlin-Python. Moreover, there are a few added constructs to Gremlin-Python that make traversals a bit moresuccinct.
To install Gremlin-Python, use Python’spip package manager.
pip install gremlinpythonpip install gremlinpython[kerberos] # Optional, not available on Microsoft WindowsConnecting
The pattern for connecting is described inConnecting Gremlin and it basically distills down tocreating aGraphTraversalSource. AGraphTraversalSource is created from the anonymoustraversal() method wherethe "g" provided to theDriverRemoteConnection corresponds to the name of aGraphTraversalSource on the remote end.
g = traversal().with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))If you need to send additional headers in the websockets connection, you can pass an optionalheaders parameterto theDriverRemoteConnection constructor.
g = traversal().with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin','g', headers={'Header':'Value'}))Gremlin-Python supports plain text and Kerberos SASL authentication, you can set it on the connection options.
# Plain text authenticationg = traversal().with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin','g', username='stephen', password='password'))# Kerberos authenticationg = traversal().with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin','g', kerberized_service='gremlin@hostname.your.org'))The value specified for the kerberized_service should correspond to the first part of the principal name configured forthe gremlin service, but with the slash replaced by anat sign. The Gremlin-Python client reads the kerberosconfigurations from your system. It finds the KDC’s hostname and port from the krb5.conf file at thedefault location or as indicated in the KRB5_CONFIGenvironment variable. It finds credentials from the credential cache or a keytab file at thedefault locations or as indicatedin the KRB5CCNAME or KRB5_KTNAME environment variables.
If you authenticate to a remoteGremlin Server orRemote Gremlin Provider, this server normally has SSL activated and the websockets url will startwith 'wss://'. If Gremlin-Server uses a self-signed certificate for SSL, Gremlin-Python needs access to a local copy ofthe CA certificate file (in openssl .pem format), to be specified in the SSL_CERT_FILE environment variable.
Note | If connecting from an inherently single-threaded Python process where blocking while waiting for Gremlintraversals to complete is acceptable, it might be helpful to setpool_size andmax_workers parameters to 1.See theConfiguration section just below. Examples where this could apply are serverless cloud functions or WSGIworker processes. |
Some connection options can also be set on individual requests made through the usingwith() step on theTraversalSource. For instance to set request timeout to 500 milliseconds:
vertices = g.with_('evaluationTimeout',500).V().out('knows').to_list()The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent andevaluationTimeout (formerlyscriptEvaluationTimeout which is also supported but now deprecated).
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following importsprovide most of the typical functionality required to use Gremlin:
fromgremlin_pythonimportstaticsfromgremlin_python.process.anonymous_traversalimporttraversalfromgremlin_python.process.graph_traversalimport__fromgremlin_python.process.strategiesimport*fromgremlin_python.driver.driver_remote_connectionimportDriverRemoteConnectionfromgremlin_python.process.traversalimportTfromgremlin_python.process.traversalimportOrderfromgremlin_python.process.traversalimportCardinalityfromgremlin_python.process.traversalimportCardinalityValuefromgremlin_python.process.traversalimportColumnfromgremlin_python.process.traversalimportDirectionfromgremlin_python.process.traversalimportOperatorfromgremlin_python.process.traversalimportPfromgremlin_python.process.traversalimportTextPfromgremlin_python.process.traversalimportPopfromgremlin_python.process.traversalimportScopefromgremlin_python.process.traversalimportBarrierfromgremlin_python.process.traversalimportBindingsfromgremlin_python.process.traversalimportWithOptionsThese can be used analogously to how they are used in Gremlin-Java.
>>> g.V().has_label('person').has('age',P.gt(30)).order().by('age',Order.desc).to_list()[v[6], v[4]]Moreover, by importing thestatics of Gremlin-Python, the class prefixes can be omitted.
>>> statics.load_statics(globals())With statics loaded its possible to represent the above traversal as below.
>>> g.V().has_label('person').has('age',gt(30)).order().by('age',desc).to_list()[v[6], v[4]]Statics includes all the__-methods and thus, anonymous traversals like__.out() can be expressed as below.That is, without the__-prefix.
>>> g.V().repeat(out()).times(2).name.fold().to_list()[['ripple','lop']]There may be situations where certain graphs may want a more exact data type than what Python will allow as a language.To support these situationsgremlin-python has a few special type classes that can be imported fromstatics. Theyinclude:
fromgremlin_python.staticsimportlong# Java longfromgremlin_python.staticsimporttimestamp# Java timestampfromgremlin_python.staticsimportSingleByte# Java byte typefromgremlin_python.staticsimportSingleChar# Java char typefromgremlin_python.staticsimportGremlinType# Java ClassConfiguration
The following table describes the various configuration options for the Gremlin-Python Driver. Theycan be passed to theClient orDriverRemoteConnection instance as keyword arguments:
| Key | Description | Default |
|---|---|---|
enable_compression | Enables sending a user agent to the server during connection requests. | False |
enable_user_agent_on_connect | Enables sending a user agent to the server during connection requests. More details can be found in provider docshere. | True |
headers | Additional headers that will be added to each request message. |
|
kerberized_service | the first part of the principal name configured for the gremlin service | """ |
max_workers | Maximum number of worker threads. | Number of CPUs * 5 |
message_serializer | The message serializer implementation. |
|
password | The password to submit on requests that require authentication. | "" |
pool_size | The number of connections used by the pool. | 4 |
protocol_factory | A callable that returns an instance of |
|
session | A unique string-based identifier (typically a UUID) to enable asession-based connection. This is not a valid configuration for | None |
transport_factory | A callable that returns an instance of |
|
username | The username to submit on requests that require authentication. | "" |
Note that thetransport_factory can allow for additional configuration of theAiohttpTransport, which allowspass through of the named parameters available inAIOHTTP’s ws_connect,and the ability to call the api from an event loop:
importssl...g = traversal().with_remote( DriverRemoteConnection('ws://localhost:8182/gremlin','g', transport_factory=lambda: AiohttpTransport(read_timeout=60, write_timeout=20, heartbeat=10, call_from_event_loop=True, max_content_length=100*1024*1024, ssl_options=ssl.create_default_context(Purpose.CLIENT_AUTH))))Note that theheartbeat enables keep-alive functionality within aiohttp and it is not enabled by default. It isimportant that the heartbeat interval is not too short, as the wait for the server response to the heartbeat requestis half the amount of this value. Therefore, if the heartbeat is ten seconds then the wait for the response is justfive seconds. If the response is not received in that time period then the connection will be closed and any ongoingrequests on that connection will fail to retrieve results. Therefore, if the heartbeat is set to one second, it onlyprovides a half-second to get the response which raises the possibility considerably that the connection will beinadvertently closed.
Compression configuration options are described in thezlib documentation. By default, compressionsettings are configured as shown in the above example.
Traversal Strategies
In order to add and removetraversal strategies from a traversal source, Gremlin-Python has aTraversalStrategy class along with a collection of subclasses that mirror the standard Gremlin-Java strategies.
>>> g = g.with_strategies(SubgraphStrategy(vertices=has_label('person'),edges=has('weight',gt(0.5))))>>> g.V().name.to_list()['marko','vadas','josh','peter']>>> g.V().out_e().element_map().to_list()[{<T.id:1>:8, <T.label:4>:'knows', <Direction.IN:2>: {<T.id:1>:4, <T.label:4>:'person'}, <Direction.OUT:3>: {<T.id:1>:1, <T.label:4>:'person'},'weight':1.0}]>>> g = g.without_strategies(SubgraphStrategy)>>> g.V().name.to_list()['marko','vadas','lop','josh','ripple','peter']>>> g.V().out_e().element_map().to_list()[{<T.id:1>:9, <T.label:4>:'created', <Direction.IN:2>: {<T.id:1>:3, <T.label:4>:'software'}, <Direction.OUT:3>: {<T.id:1>:1, <T.label:4>:'person'},'weight':0.4}, {<T.id:1>:7, <T.label:4>:'knows', <Direction.IN:2>: {<T.id:1>:2, <T.label:4>:'person'}, <Direction.OUT:3>: {<T.id:1>:1, <T.label:4>:'person'},'weight':0.5}, {<T.id:1>:8, <T.label:4>:'knows', <Direction.IN:2>: {<T.id:1>:4, <T.label:4>:'person'}, <Direction.OUT:3>: {<T.id:1>:1, <T.label:4>:'person'},'weight':1.0}, {<T.id:1>:10, <T.label:4>:'created', <Direction.IN:2>: {<T.id:1>:5, <T.label:4>:'software'}, <Direction.OUT:3>: {<T.id:1>:4, <T.label:4>:'person'},'weight':1.0}, {<T.id:1>:11, <T.label:4>:'created', <Direction.IN:2>: {<T.id:1>:3, <T.label:4>:'software'}, <Direction.OUT:3>: {<T.id:1>:4, <T.label:4>:'person'},'weight':0.4}, {<T.id:1>:12, <T.label:4>:'created', <Direction.IN:2>: {<T.id:1>:3, <T.label:4>:'software'}, <Direction.OUT:3>: {<T.id:1>:6, <T.label:4>:'person'},'weight':0.2}]>>> g = g.with_computer(workers=2,vertices=has('name','marko'))>>> g.V().name.to_list()['marko']>>> g.V().out_e().value_map().with_(WithOptions.tokens).to_list()[{<T.id:1>:9, <T.label:4>:'created','weight':0.4}, {<T.id:1>:7, <T.label:4>:'knows','weight':0.5}, {<T.id:1>:8, <T.label:4>:'knows','weight':1.0}]Note | Many of theTraversalStrategy classes in Gremlin-Python are proxies to the respective strategy onApache TinkerPop’s JVM-based Gremlin traversal machine. As such, theirapply(Traversal) method does nothing. However,the strategy is encoded in the Gremlin-Python bytecode and transmitted to the Gremlin traversal machine forre-construction machine-side. |
Transactions
To get a full understanding of this section, it would be good to start by reading theTransactionssection of this documentation, which discusses transactions in the general context of TinkerPop itself. This sectionbuilds on that content by demonstrating the transactional syntax for Python.
g = traversal().with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin'))# Create a Transaction.tx = g.tx()# Spawn a new GraphTraversalSource, binding all traversals established from it to tx.gtx = tx.begin()try:# Execute a traversal within the transaction. gtx.add_v("person").property("name","Lyndon").iterate(),# Commit the transaction. The transaction can no longer be used and cannot be re-used.# A new transaction can be spawned through g.tx().# The context of g remains sessionless throughout the process. tx.commit()exceptExceptionas e:# Rollback the transaction if an error occurs. tx.rollback()The Lambda Solution
Supportinganonymous functions across languages is difficult asmost languages do not support lambda introspection and thus, code analysis. In Gremlin-Python, a Gremlin lambda shouldbe represented as a zero-arg callable that returns a string representation of the lambda expected for use in thetraversal. The lambda should be written as aGremlin-Groovy string. When the lambda is represented inBytecode itslanguage is encoded such that the remote connection host can infer which translator and ultimate execution engine touse.
>>> g.V().out().map(lambda:"it.get().value('name').length()").sum().to_list()[24]Tip | When running into situations where Groovy cannot properly discern a method signature based on theLambdainstance created, it will help to fully define the closure in the lambda expression - so rather thanlambda: ('it.get().value('name')','gremlin-groovy'), preferlambda: ('x → x.get().value('name'),'gremlin-groovy'). |
Finally, GremlinBytecode that includes lambdas requires that the traversal be processed by theScriptEngine. To avoid continued recompilation costs, it supports the encoding of bindings, which allow a remoteengine to to cache traversals that will be reused over and over again save that some parameterization may change. Thus,instead of translating, compiling, and then executing each submitted bytecode, it is possible to simply execute.
>>> g.V(Bindings.of('x',1)).out('created').map(lambda:"it.get().value('name').length()").sum_().to_list()[3]>>> g.V(Bindings.of('x',4)).out('created').map(lambda:"it.get().value('name').length()").sum_().to_list()[9]Warning | As explained throughout the documentation, when possibleavoid lambdas. |
Submitting Scripts
TheClient class implementation/interface is based on the Java Driver, with some restrictions. Most notably,Gremlin-Python does not yet implement theCluster class. Instead,Client is instantiated directly.Usage is as follows:
fromgremlin_python.driverimportclient//1client = client.Client('ws://localhost:8182/gremlin','g')//2Import the Gremlin-Python
clientmodule.Opens a reference to
localhost- note that there are various configuration options that can be passedto theClientobject upon instantiation as keyword arguments.
Once aClient instance is ready, it is possible to issue some Gremlin:
result_set = client.submit('[1,2,3,4]')//1future_results = result_set.all()//2results = future_results.result()//3assert results == [1,2,3,4]//4future_result_set = client.submit_async('[1,2,3,4]')//5result_set = future_result_set.result()//6result = result_set.one()//7assert results == [1,2,3,4]//8assert result_set.done.done()//9client.close()//10Submit a script that simply returns a
Listof integers. This method blocks until the request is written tothe server and aResultSetis constructed.Even though the
ResultSetis constructed, it does not mean that the server has sent back the results (or evenevaluated the script potentially). TheResultSetis just a holder that is awaiting the results from the server. Theallmethodreturns aconcurrent.futures.Futurethat resolves to a list when it is complete.Block until the the script is evaluated and results are sent back by the server.
Verify the result.
Submit the same script to the server but don’t block.
Wait until request is written to the server and
ResultSetis constructed.Read a single result off the result stream.
Again, verify the result.
Verify that the all results have been read and stream is closed.
Close client and underlying pool connections.
Per Request Settings
Theclient.submit() functions accept arequest_options which expects a dictionary. Therequest_optionsprovide a way to include options that are specific to the request made with the call tosubmit(). A good use-case forthis feature is to set a per-request override to theevaluationTimeout so that it only applies to the currentrequest.
result_set = client.submit('g.V().repeat(both()).times(100)', request_options={'evaluationTimeout':5000})The following options are allowed on a per-request basis in this fashion:batchSize,requestId,userAgent,materializeProperties andevaluationTimeout (formerlyscriptEvaluationTimeout which is also supported but now deprecated).
Important | The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiarwith bytecode may tryg.with(EVALUATION_TIMEOUT, 500) within a script. Scripts with multiple traversals and multipletimeouts will be interpreted as a sum of all timeouts identified in the script for that request. |
RequestOptions options = RequestOptions.build().timeout(500).create();List<Result> result = client.submit("g.with(EVALUATION_TIMEOUT, 500).addV().iterate();" +"g.addV().iterate();"g.with(EVALUATION_TIMEOUT,500).addV();", options).all().get();In the above example,RequestOptions defines a timeout of 500 milliseconds, but the script has three traversals withtwo internal settings for the timeout usingwith(). The request timeout used by the server will therefore be 1000milliseconds (overriding the 500 which itself was an override for whatever configuration was on the server).
Domain Specific Languages
Writing a GremlinDomain Specific Language (DSL) in Python simply requires direct extension of several classes:
GraphTraversal- which exposes the various steps used in traversal writing__- which spawns anonymous traversals from stepsGraphTraversalSource- which spawnsGraphTraversalinstances
The Social DSL based on the"modern" toy graphmight look like this:
classSocialTraversal(GraphTraversal):defknows(self, person_name):returnself.out('knows').has_label('person').has('name', person_name)defyoungest_friends_age(self):returnself.out('knows').has_label('person').values('age').min()defcreated_at_least(self, number):returnself.out_e('created').count().is_(P.gte(number))class__(AnonymousTraversal): graph_traversal = SocialTraversal@classmethoddefknows(cls, *args):return cls.graph_traversal(None,None, Bytecode()).knows(*args)@classmethoddefyoungest_friends_age(cls, *args):return cls.graph_traversal(None,None, Bytecode()).youngest_friends_age(*args)@classmethoddefcreated_at_least(cls, *args):return cls.graph_traversal(None,None, Bytecode()).created_at_least(*args)classSocialTraversalSource(GraphTraversalSource):def__init__(self, *args, **kwargs):super(SocialTraversalSource,self).__init__(*args, **kwargs)self.graph_traversal = SocialTraversaldefpersons(self, *args): traversal =self.get_graph_traversal() traversal.bytecode.add_step('V') traversal.bytecode.add_step('hasLabel','person')iflen(args) >0: traversal.bytecode.add_step('has','name', P.within(args))return traversalNote | TheAnonymousTraversal class above is just an alias for__ as infrom gremlin_python.process.graph_traversal import __ as AnonymousTraversal |
Using the DSL is straightforward and just requires that the graph instance know theSocialTraversalSource shouldbe used:
social = traversal(SocialTraversalSource).with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))social.persons('marko').knows('josh')social.persons('marko').youngest_friends_age()social.persons().filter(__.created_at_least(2)).count()Syntactic Sugar
Python supports meta-programming and operator overloading. There are three uses of these techniques in Gremlin-Pythonthat makes traversals a bit more concise.
>>> g.V().both()[1:3].to_list()[v[2], v[4]]>>> g.V().both()[1].to_list()[v[2]]>>> g.V().both().name.to_list()['lop','lop','lop','vadas','josh','josh','josh','marko','marko','marko','peter','ripple']Differences
In situations where Python reserved words and global functions overlap with standard Gremlin steps and tokens, thosebits of conflicting Gremlin get an underscore appended as a suffix:
Steps -all_(),and_(),any_(),as_(),filter_(),from_(),id_(),is_(),in_(),max_(),min_(),not_(),or_(),range_(),sum_(),with_()
Tokens -Scope.global_,Direction.from_,Operator.sum_
In addition, the enum construct forCardinality cannot have functions attached to it the way it can be done in Java,therefore cardinality functions that take a value likelist(),set(), andsingle() are referenced from aCardinalityValue class rather thanCardinality itself.
Limitations
Traversals that return a
Setmight be coerced to aListin Python. In the case of Python, number equalityis different from JVM languages which produces differentSetresults when those types are in use. When this caseis detected during deserialization, theSetis coerced to aListso that traversals return consistentresults within a collection across different languages. If aSetis needed then convertListresultstoSetmanually.Gremlin is capable of returning
Dictionaryresults that use non-hashable keys (e.g. Dictionary as a key) and Pythondoes not support that at a language level. Using GraphSON 3.0 or GraphBinary (after 3.5.0) makes it possible to returnsuch results. In all other cases, Gremlin that returns such results will need to be re-written to avoid that sort ofkey.The
subgraph()-step is not supported by any variant that is not running on the Java Virtual Machine as there isnoGraphinstance to deserialize a result into on the client-side. A workaround is to replace the step withaggregate(local)and then convert those results to something the client can use locally.Use of the aiohttp library in the default transport requires the use of asyncio’s event loop to run the async functions.This can be an issue in situations where the application calling Gremlin-Python is already using an event loop.Certain types of event loops can be patched using nest-asyncio which allows Gremlin-Python to proceed without an error like"Cannot run the event loop while another loop is running". This is the preferred approach to avoiding the issue and can beenabled by passing
call_from_event_loop=Trueto theAiohttpTransportclass.However, in situations where the loop cannot be patched (e.g. uvloop), then the current suggested workaround is to runGremlin-Python in a separate thread. This is not ideal for asynchronous web servers as the number of concurrent connectionswill be limited by the number of threads the system can handle. The following snippet shows how Gremlin-Python can be calledfrom asynchronous code using a thread.
defprint_vertices(): g = traversal().withRemote(DriverRemoteConnection("ws://localhost:8182/gremlin"))# Do your traversal.asyncdefrun_in_thread(): running_loop = asyncio.get_running_loop()with ThreadPoolExecutor()as pool: await running_loop.run_in_executor(pool, print_vertices)
Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Python. Theycan be found in GitHubhereand are designed to connect to a runningGremlin Server configured with theconf/gremlin-server.yaml andconf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration fileconf/gremlin-server.yaml. To start a clean server, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, usingconf/gremlin-server-modern.yaml.To start a server with the Modern graph preloaded, launch a new container withdocker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlEach example can now be run with the following commands:
python connections.pypython basic_gremlin.pypython modern_traversals.pyImplementations

TinkerPop offers several reference implementations of its interfaces that are not only meant for production usage,but also represent models by which different graph providers can build their systems. More specific documentationon how to build systems at this level of the API can be found in theProvider Documentation. The following sectionsdescribe the various reference implementations and their usage.
TinkerGraph-Gremlin
<dependency><groupId>org.apache.tinkerpop</groupId><artifactId>tinkergraph-gremlin</artifactId><version>3.7.4</version></dependency> TinkerGraph is a single machine, in-memory (with optionalpersistence), graph engine that provides both OLTP and OLAP functionality. It is non-transactional by default but doeshave a lightweight transactional form that can be instantiated offering simple
TinkerGraph is a single machine, in-memory (with optionalpersistence), graph engine that provides both OLTP and OLAP functionality. It is non-transactional by default but doeshave a lightweight transactional form that can be instantiated offering simpleThreadLocal transactions supportingread committed transaction isolation. TinkerGraph is deployed with TinkerPop and serves as the referenceimplementation for other providers to study in order to understand the semantics of the various methods of theTinkerPop API. Its status as a reference implementation does not however imply that it is not suitable for production.TinkerGraph has many practical use cases in production applications and their development. Some examples of TinkerGraphuse cases include:
Ad-hoc analysis of large immutable graphs that fit in memory.
Extract subgraphs, from larger graphs that don’t fit in memory, into TinkerGraph for further analysis or otherpurposes.
Use TinkerGraph as a sandbox to develop and debug complex traversals by simulating data from a larger graph insidea TinkerGraph.
Configure it to match the semantics of a production graph database for unit testing purpose to simplify developmentsetup and automated builds.
Constructing a simple graph using TinkerGraph in Java is presented below:
Graph graph = TinkerGraph.open();GraphTraversalSource g = traversal().withEmbedded(graph);Vertex marko = g.addV("person").property("name","marko").property("age",29).next();Vertex lop = g.addV("software").property("name","lop").property("lang","java").next();g.addE("created").from(marko).to(lop).property("weight",0.6d).iterate();The above Gremlin creates two vertices named "marko" and "lop" and connects them via a created-edge with a weight=0.6property. The addition of these two vertices and the edge between them could also be done in a single Gremlin statementas follows:
g.addV("person").property("name","marko").property("age",29).as("m"). addV("software").property("name","lop").property("lang","java").as("l"). addE("created").from("m").to("l").property("weight",0.6d).iterate();Important | Pay attention to the fact that traversals end withnext() oriterate(). These methods advance theobjects in the traversal stream and without those methods, the traversal does nothing. Review theResult Iteration Sectionof The Gremlin Console tutorial for more information. |
Next, the graph can be queried as such.
g.V().has("name","marko").out("created").values("name")Theg.V().has("name","marko") part of the query can be executed in two ways.
A linear scan of all vertices filtering out those vertices that don’t have the name "marko"
A
O(log(|V|))index lookup for all vertices with the name "marko"
Given the initial graph construction in the first code block, no index was defined and thus, a linear scan is executed.However, if the graph was constructed as such, then an index lookup would be used.
Graph g = TinkerGraph.open();g.createIndex("name",Vertex.class)The execution times for a vertex lookup by property is provided below for both no-index and indexed version ofTinkerGraph over the Grateful Dead graph.
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> clock(1000) {g.V().has('name','Garcia').iterate()}////(1)==>0.084347527gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> graph.createIndex('name',Vertex.class)==>nullgremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> clock(1000){g.V().has('name','Garcia').iterate()}////(2)==>0.017508412999999997graph = TinkerGraph.open()g = traversal().withEmbedded(graph)g.io('data/grateful-dead.xml').read().iterate()clock(1000) {g.V().has('name','Garcia').iterate()}////(1)graph = TinkerGraph.open()g = traversal().withEmbedded(graph)graph.createIndex('name',Vertex.class)g.io('data/grateful-dead.xml').read().iterate()clock(1000){g.V().has('name','Garcia').iterate()}//2Determine the average runtime of 1000 vertex lookups when no
name-index is defined.Determine the average runtime of 1000 vertex lookups when a
name-index is defined.
Important | Each graph system will have different mechanism by which indices and schemas are defined. TinkerPopdoes not require any conformance in this area. In TinkerGraph, the only definitions are around indices. With othergraph systems, property value types, indices, edge labels, etc. may be required to be defineda priori to addingdata to the graph. |
Note | TinkerGraph is distributed with Gremlin Server and is therefore automatically available to it for configuration. |
Data Types
TinkerGraph can store any JavaObject for a property value. It is therefore important to take note of the types ofthe values that are being used and it is often best to be explicit in terms of exactly what type is being used,especially in the case of numbers.
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.addV().property('vp2',0.65780294)==>v[0]gremlin> g.addV().property('vp2',0.65780294f)==>v[2]gremlin> g.addV().property('vp2',0.65780294d)==>v[4]gremlin> g.V().has('vp2',0.65780294)////(1)==>v[0]==>v[4]gremlin> g.V().has('vp2',0.65780294f)////(2)==>v[2]gremlin> g.V().has('vp2',0.65780294d)////(3)==>v[0]==>v[4]graph = TinkerGraph.open()g = traversal().withEmbedded(graph)g.addV().property('vp2',0.65780294)g.addV().property('vp2',0.65780294f)g.addV().property('vp2',0.65780294d)g.V().has('vp2',0.65780294)////(1)g.V().has('vp2',0.65780294f)////(2)g.V().has('vp2',0.65780294d)//3In Gremlin Console,
0.65780294actually evaluates to aBigDecimal, which won’t match the specifically typedfloatproperty value.The explicit
floatwill only match thefloatproperty value.The explicit
doublewill only match thedoubleandBigDecimalvalues.
Unlike other graphs, the above demonstration shows that TinkerGraph does not do any form of type coercion (except fortype coercion related to element identifiers as described in thetinkergraph-configuration).
Configuration
TinkerGraph has several settings that can be provided on creation viaConfiguration object:
| Property | Description |
|---|---|
gremlin.graph |
|
gremlin.tinkergraph.vertexIdManager | The |
gremlin.tinkergraph.edgeIdManager | The |
gremlin.tinkergraph.vertexPropertyIdManager | The |
gremlin.tinkergraph.defaultVertexPropertyCardinality | The default |
gremlin.tinkergraph.allowNullPropertyValues | A boolean value that determines whether or not |
gremlin.tinkergraph.graphLocation | The path and file name for where TinkerGraph should persist the graph data. If avalue is specified here, the |
gremlin.tinkergraph.graphFormat | The format to use to serialize the graph which may be one of the following: |
Note | To usetransactions, configuregremlin.graph asorg.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerTransactionGraph. |
TheIdManager settings above refer to how TinkerGraph will control identifiers for vertices, edges and vertexproperties. There are several options for each of these settings:ANY,LONG,INTEGER,UUID, or the fullyqualified class name of anIdManager implementation on the classpath. When not specified, the default valuesfor all settings isANY, meaning that the graph will work with any object on the JVM as the identifier and willgenerate new identifiers fromLong when the identifier is not user supplied. TinkerGraph will also expect theuser to understand the types used for identifiers when querying, meaning thatg.V(1) andg.V(1L) could returntwo different vertices.LONG,INTEGER andUUID settings will try to coerce identifier values to the expectedtype as well as generate new identifiers with that specified type.
Tip | Setting theIdManager toANY also allowsString type ID values to be used. |
If the TinkerGraph is configured for persistence withgremlin.tinkergraph.graphLocation andgremlin.tinkergraph.graphFormat, then the graph will be written to the specified location with the specifiedformat whenGraph.close() is called. In addition, if these settings are present, TinkerGraph will attempt toload the graph from the specified location.
Important | If choosinggraphson as thegremlin.tinkergraph.graphFormat, be sure to also establish the variousIdManager settings as well to ensure that identifiers are properly coerced to the appropriate types as GraphSONcan lose the identifier’s type during serialization (i.e. it will assumeInteger when the default for TinkerGraphisLong, which could lead to load errors that result in a message like, "Vertex with id already exists"). |
It is important to consider the data being imported to TinkerGraph with respect todefaultVertexPropertyCardinalitysetting. For example, if a.gryo file is known to contain multi-property data, be sure to set the defaultcardinality tolist or else the data will import assingle. Consider the following:
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io("data/tinkerpop-crew.kryo").read().iterate()[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than onevalue: [vp[location->san diego], vp[location->santa cruz], vp[location->brussels], vp[location->santa fe]]. Only last value will be retained.[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than onevalue: [vp[location->centreville], vp[location->dulles], vp[location->purcellville]]. Only last value will be retained.[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than onevalue: [vp[location->bremen], vp[location->baltimore], vp[location->oakland], vp[location->seattle]]. Only last value will be retained.[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than onevalue: [vp[location->spremberg], vp[location->kaiserslautern], vp[location->aachen]]. Only last value will be retained.gremlin> g.V().properties()==>vp[name->marko]==>vp[location->santa fe]==>vp[name->stephen]==>vp[location->purcellville]==>vp[name->matthias]==>vp[location->seattle]==>vp[name->daniel]==>vp[location->aachen]==>vp[name->gremlin]==>vp[name->tinkergraph]gremlin> conf =new BaseConfiguration()==>org.apache.commons.configuration2.BaseConfiguration@480fb706gremlin> conf.setProperty("gremlin.tinkergraph.defaultVertexPropertyCardinality","list")==>nullgremlin> graph = TinkerGraph.open(conf)==>tinkergraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[tinkergraph[vertices:0edges:0], standard]gremlin> g.io("data/tinkerpop-crew.kryo").read().iterate()gremlin> g.V().properties()==>vp[name->marko]==>vp[location->san diego]==>vp[location->santa cruz]==>vp[location->brussels]==>vp[location->santa fe]==>vp[name->stephen]==>vp[location->centreville]==>vp[location->dulles]==>vp[location->purcellville]==>vp[name->matthias]==>vp[location->bremen]==>vp[location->baltimore]==>vp[location->oakland]==>vp[location->seattle]==>vp[name->daniel]==>vp[location->spremberg]==>vp[location->kaiserslautern]==>vp[location->aachen]==>vp[name->gremlin]==>vp[name->tinkergraph]graph = TinkerGraph.open()g = traversal().withEmbedded(graph)g.io("data/tinkerpop-crew.kryo").read().iterate()g.V().properties()conf =new BaseConfiguration()conf.setProperty("gremlin.tinkergraph.defaultVertexPropertyCardinality","list")graph = TinkerGraph.open(conf)g = traversal().withEmbedded(graph)g.io("data/tinkerpop-crew.kryo").read().iterate()g.V().properties()Transactions
TinkerGraph includes optional transaction support and thread-safety through theTinkerTransactionGraph class.The default configuration of TinkerGraph remains non-transactional.
Note | This feature was first made available in TinkerPop 3.7.0. |
Transaction Semantics
TinkerTransactionGraph only has support forThreadLocal transactions, so embedded graph transactions may not be fullysupported. You can think of the transaction as belonging to a thread, any traversals executed within the same threadwill share the same transaction even if you attempt to start a new transaction.
TinkerTransactionGraph provides theread committed transaction isolation level. This means that it will always try toguard against dirty reads but will not prevent non-repeatable reads or phantom reads. While you may notice stricterisolation semantics in some cases, you should not depend on this behavior as it may change in the future.
TinkerTransactionGraph employs optimistic locking as its locking strategy. This reduces complexity in the design asthere are fewer timeouts that the user needs to manage. However, a consequence of this approach is that a transactionwill throw aTransactionException if two different transactions attempt to lock the same element (see "Best Practices"below).
Testing Remote Providers
These transaction semantics described above may not fit use cases for some production scenarios that require strictACID-like transactions. Therefore, it is recommended thatTinkerTransactionGraph be used as aGraph for testenvironments where you still require access to aGraph that supports transactions.TinkerTransactionGraph does fullysupport TinkerPop’sTransaction interface which still makes it a usefulGraph for exploring theTransaction API.
A common scenario where this sort of testing is helpful is withRemote Graph Providers, wheredeveloping unit tests might be hard against a graph service. Instead, configureTinkerTransactionGraph, either in anembedded style if using Java or with Gremlin Server for other cases.
// consider this class that returns the results of some Gremlin. by constructing the// GraphService in a way that takes a GraphTraversalSource it becomes possible to// execute getPersons() under any graph system.publicclassGraphService {privatefinal GraphTraversalSource g;public GraphService(GraphTraversalSource g) {this.g = g; }publicList<Vertex> getPersons() {return g.V().hasLabel("person").toList(); }}// when writing tests for the GraphService it becomes possible to configure the test// to run in a variety of scenarios. here we decide that TinkerTransactionGraph is a// suitable test graph replacement for our actual production graph.publicclassGraphServiceTest {privatestaticfinal TinkerTransactionGraph graph = TinkerTransactionGraph.open();privatestaticfinal GraphTraversalSource g = traversal.withEmbedded(graph);privatestaticfinal GraphService service =new GraphService(g);@Testpublicvoid shouldGetPersons() {finalList<Vertex> persons = service.getPersons(); assertEquals(6, persons.size()); }}// or perhaps, since we're using a remote graph provider, we feel it would be better to// start Gremlin Server with a TinkerTransactionGraph configured using a docker container,// embedding it directly in our tests or running it as a separate process like://// bin/gremlin-server.sh conf/gremlin-server-transaction.yaml//// and then connect to it with a driver in more of an integration test style. obviously,// with this approach you could also configure your production graph directly or use custom// build options to trigger different test configurations for a more dynamic approachpublicclassGraphServiceTest {privatestaticfinal GraphTraversalSource g = traversal.withRemote(new DriverRemoteConnection('ws://localhost:8182/gremlin'));privatestaticfinal GraphService service =new GraphService(g);@Testpublicvoid shouldGetPersons() {finalList<Vertex> persons = service.getPersons(); assertEquals(6, persons.size()); }}Warning | There can be subtle behavioral differences between TinkerGraph and the graph ultimately intended for use.Be aware of the differences when writing tests to ensure that you are testing behaviors of your applicationsappropriately. |
Best Practices
Errors can occur before a transaction gets committed. Specifically forTinkerTransactionGraph, you may encounter manyTransactionException errors in a highly concurrent environment due its optimistic approach to locking. Users shouldfollow the try-catch-rollback pattern described in thetransactions section in combination withexponential backoff based retries to mitigate this issue.
Performance Considerations
While transactions impose minimal impact for mutating workloads, users should expect performance degradation forread-only work relative to the non-transactional configuration. However, its approach to locking(write-only, optimistic) and its in-memory nature, TinkerTransactionGraph is likely faster than otherGraphimplementations that support transactions.
Examples
Constructing a simple graph usingTinkerTransactionGraph in Java is presented below:
Graph graph = TinkerTransactionGraph.open();g = traversal().withEmbedded(graph)GraphTraversalSource gtx = g.tx().begin();try { Vertex marko = gtx.addV("person").property("name","marko").property("age",29).next(); Vertex lop = gtx.addV("software").property("name","lop").property("lang","java").next(); gtx.addE("created").from(marko).to(lop).property("weight",0.6d).iterate(); gtx.tx().commit();}catch (Exception ex) { gtx.tx().rollback();}The above Gremlin creates two vertices named "marko" and "lop" and connects them via a created-edge with a weight=0.6property. In case of any errorsrollback() will be called and no changes will be performed.
To use the embedded TinkerTransactionGraph in Gremlin Console:
gremlin> graph = TinkerTransactionGraph.open()////(1)==>tinkertransactiongraph[vertices:0edges:0]gremlin> g = traversal().withEmbedded(graph)////(2)==>graphtraversalsource[tinkertransactiongraph[vertices:0edges:0], standard]gremlin> g.addV('test').property('name','one')==>v[0]gremlin> g.tx().commit()////(3)==>nullgremlin> g.V().valueMap()==>[name:[one]]gremlin> g.addV('test').property('name','two')////(4)==>v[2]gremlin> g.V().valueMap()==>[name:[one]]==>[name:[two]]gremlin> g.tx().rollback()////(5)==>nullgremlin> g.V().valueMap()==>[name:[one]]graph = TinkerTransactionGraph.open()////(1)g = traversal().withEmbedded(graph)////(2)g.addV('test').property('name','one')g.tx().commit()////(3)g.V().valueMap()g.addV('test').property('name','two')////(4)g.V().valueMap()g.tx().rollback()////(5)g.V().valueMap()Open transactional graph.
Spawn a GraphTraversalSource with transactional graph.
Commit the add vertex operation
Add a second vertex without committing
Rollback the change
Neo4j-Gremlin (Deprecated)
Warning | Deprecated: Neo4j-Gremlin is not compatible with versions of Neo4j beyond 3.4 (Reached End of Life March 31, 2020).For this reason, use of Neo4j-Gremlin is not recommended for production environments. Neo4j-Gremlin is expected toremain compatible with upcoming releases of TinkerPop, however long term support is not guaranteed. Neo4j-Gremlin maybe dropped from future versions of TinkerPop if compatibility cannot reasonably be maintained. Alternative TinkerPopenabled graph providers can be found on theTinkerPop site. |
Warning | Neo4j-Gremlin can work with JDK17, but requires the use of the--add-opens flag to be provided to the JVMas follows:--add-opens=java.base/sun.nio.ch=ALL-UNNAMED. |
<dependency><groupId>org.apache.tinkerpop</groupId><artifactId>neo4j-gremlin</artifactId><version>3.7.4</version></dependency><!-- neo4j-tinkerpop-api-impl is NOT Apache 2 licensed - more information below --><!-- supports Neo4j 3.4.11 --><dependency><groupId>org.neo4j</groupId><artifactId>neo4j-tinkerpop-api-impl</artifactId><version>0.9-3.4.0</version></dependency>Neo4j, Inc. are the developers of the OLTP-basedNeo4j graph database.
Warning | Unless under a commercial agreement with Neo4j, Inc., Neo4j is licensedAGPL. Theneo4j-gremlin module is licensed Apache2because it only references the Apache2-licensed Neo4j API (not its implementation). Note that neither theGremlin Console norGremlin Server distribute with the Neo4j implementationbinaries. To access the binaries, use the:install command to download binaries fromMaven Central Repository. |
Important | When connecting to existing Neo4j databases, ensure that this database is compatible with the version ofNeo4j that TinkerPop currently supports in theneo4j-tinkerpop-api-impl. |
Tip | For configuring Grape, the dependency resolver of Groovy, please refer to theGremlin Applications section. |
gremlin> :install org.apache.tinkerpop neo4j-gremlin 3.7.4==>Loaded: [org.apache.tinkerpop, neo4j-gremlin, 3.7.4] - restart the console to use [tinkerpop.neo4j]gremlin> :q...gremlin> :plugin use tinkerpop.neo4j==>tinkerpop.neo4j activatedgremlin> graph = Neo4jGraph.open('/tmp/neo4j')==>neo4jgraph[EmbeddedGraphDatabase [/tmp/neo4j]]Tip | To host Neo4j inGremlin Server, the dependencies must first be "installed" or otherwisecopied to the Gremlin Server path. The automated method for doing this would be to executebin/gremlin-server.sh install org.apache.tinkerpop neo4j-gremlin 3.7.4. Once installed, the Gremlin Serverconfiguration file must be edited to include theNeo4jGremlinPlugin as shown inconf/gremlin-server-neo4j.yaml. |
Indices
Neo4j 2.x indices leverage vertex labels to partition the index space. TinkerPop does not provide method interfacesfor defining schemas/indices for the underlying graph system. Thus, in order to create indices, it is important tocall the Neo4j API directly.
Note | Neo4jGraphStep will attempt to discern which indices to use when executing a traversal of the formg.V().has(). |
The Gremlin-Console session below demonstrates Neo4j indices. For more information, please refer to the Neo4j documentation:
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')==>neo4jgraph[community single [/tmp/neo4j]]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]gremlin> graph.cypher("CREATE INDEX ON :person(name)")gremlin> graph.tx().commit()////(1)==>nullgremlin> g.addV('person').property('name','marko')==>v[0]gremlin> g.addV('dog').property('name','puppy')==>v[1]gremlin> g.V().hasLabel('person').has('name','marko').values('name')==>markogremlin> graph.close()==>nullgraph = Neo4jGraph.open('/tmp/neo4j')g = traversal().withEmbedded(graph)graph.cypher("CREATE INDEX ON :person(name)")graph.tx().commit()////(1)g.addV('person').property('name','marko')g.addV('dog').property('name','puppy')g.V().hasLabel('person').has('name','marko').values('name')graph.close()Schema mutations must happen in a different transaction than graph mutations
Below demonstrates the runtime benefits of indices and demonstrates how if there is no defined index (only vertexlabels), a linear scan of the vertex-label partition is still faster than a linear scan of all vertices.
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')==>neo4jgraph[community single [/tmp/neo4j]]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]gremlin> g.io('data/grateful-dead.xml').read().iterate()gremlin> g.tx().commit()==>nullgremlin> clock(1000) {g.V().hasLabel('artist').has('name','Garcia').iterate()}////(1)==>0.213385317gremlin> graph.cypher("CREATE INDEX ON :artist(name)")////(2)gremlin> g.tx().commit()==>nullgremlin>Thread.sleep(5000)////(3)==>nullgremlin> clock(1000) {g.V().hasLabel('artist').has('name','Garcia').iterate()}////(4)==>0.031457043gremlin> clock(1000) {g.V().has('name','Garcia').iterate()}////(5)==>0.41018634499999995gremlin> graph.cypher("DROP INDEX ON :artist(name)")////(6)gremlin> g.tx().commit()==>nullgremlin> graph.close()==>nullgraph = Neo4jGraph.open('/tmp/neo4j')g = traversal().withEmbedded(graph)g.io('data/grateful-dead.xml').read().iterate()g.tx().commit()clock(1000) {g.V().hasLabel('artist').has('name','Garcia').iterate()}////(1)graph.cypher("CREATE INDEX ON :artist(name)")////(2)g.tx().commit()Thread.sleep(5000)////(3)clock(1000) {g.V().hasLabel('artist').has('name','Garcia').iterate()}////(4)clock(1000) {g.V().has('name','Garcia').iterate()}////(5)graph.cypher("DROP INDEX ON :artist(name)")////(6)g.tx().commit()graph.close()Find all artists whose name is Garcia which does a linear scan of the artist vertex-label partition.
Create an index for all artist vertices on their name property.
Neo4j indices are eventually consistent so this stalls to give the index time to populate itself.
Find all artists whose name is Garcia which uses the pre-defined schema index.
Find all vertices whose name is Garcia which requires a linear scan of all the data in the graph.
Drop the created index.
Cypher

NeoTechnology are the creators of the graph pattern-match query languageCypher.It is possible to leverage Cypher from within Gremlin by using theNeo4jGraph.cypher() graph traversal method.
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')==>neo4jgraph[community single [/tmp/neo4j]]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]gremlin> g.io('data/tinkerpop-modern.kryo').read().iterate()gremlin> graph.cypher('MATCH (a {name:"marko"}) RETURN a')==>[a:v[0]]gremlin> graph.cypher('MATCH (a {name:"marko"}) RETURN a').select('a').out('knows').values('name')==>josh==>vadasgremlin> graph.close()==>nullgraph = Neo4jGraph.open('/tmp/neo4j')g = traversal().withEmbedded(graph)g.io('data/tinkerpop-modern.kryo').read().iterate()graph.cypher('MATCH (a {name:"marko"}) RETURN a')graph.cypher('MATCH (a {name:"marko"}) RETURN a').select('a').out('knows').values('name')graph.close()Thus, likematch()-step in Gremlin, it is possible to do a declarative pattern match and then moveback into imperative Gremlin.
Tip | For those developers usingGremlin Server against Neo4j, it is possible to do Cypher queriesby simply placing the Cypher string ingraph.cypher(…) before submission to the server. |
Multi-Label
TinkerPop requires everyElement to have a single, immutable string label (i.e. aVertex,Edge, andVertexProperty). In Neo4j, aNode (vertex) can have anarbitrary number of labels while aRelationship(edge) can have one and only one. Furthermore, in Neo4j,Node labels are mutable whileRelationship labels arenot. In order to handle this mismatch, threeNeo4jVertex specific methods exist in Neo4j-Gremlin.
publicSet<String> labels()// get all the labels of the vertexpublicvoid addLabel(String label)// add a label to the vertexpublicvoid removeLabel(String label)// remove a label from the vertexAn example use case is presented below.
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')==>neo4jgraph[community single [/tmp/neo4j]]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]gremlin> vertex = (Neo4jVertex) g.addV('human::animal').next()////(1)==>v[0]gremlin> vertex.label()////(2)==>animal::humangremlin> vertex.labels()////(3)==>animal==>humangremlin> vertex.addLabel('organism')////(4)==>nullgremlin> vertex.label()==>animal::human::organismgremlin> vertex.removeLabel('human')////(5)==>nullgremlin> vertex.labels()==>animal==>organismgremlin> vertex.addLabel('organism')////(6)==>nullgremlin> vertex.labels()==>animal==>organismgremlin> vertex.removeLabel('human')////(7)==>nullgremlin> vertex.label()==>animal::organismgremlin> g.V().has(label,'organism')////(8)gremlin> g.V().has(label,of('organism'))////(9)==>v[0]gremlin> g.V().has(label,of('organism')).has(label,of('animal'))==>v[0]gremlin> g.V().has(label,of('organism').and(of('animal')))==>v[0]gremlin> graph.close()==>nullgraph = Neo4jGraph.open('/tmp/neo4j')g = traversal().withEmbedded(graph)vertex = (Neo4jVertex) g.addV('human::animal').next()////(1)vertex.label()////(2)vertex.labels()////(3)vertex.addLabel('organism')////(4)vertex.label()vertex.removeLabel('human')////(5)vertex.labels()vertex.addLabel('organism')////(6)vertex.labels()vertex.removeLabel('human')////(7)vertex.label()g.V().has(label,'organism')////(8)g.V().has(label,of('organism'))////(9)g.V().has(label,of('organism')).has(label,of('animal'))g.V().has(label,of('organism').and(of('animal')))graph.close()Typecasting to a
Neo4jVertexis only required in Java.The standard
Vertex.label()method returns all the labels in alphabetical order concatenated using::.Neo4jVertex.labels()method returns the individual labels as a set.Neo4jVertex.addLabel()method adds a single label.Neo4jVertex.removeLabel()method removes a single label.Labels are unique and thus duplicate labels don’t exist.
If a label that does not exist is removed, nothing happens.
P.eq()does a full string match and should only be used if multi-labels are not leveraged.LabelP.of()is specific toNeo4jGraphand used for multi-label matching.
Important | LabelP.of() is only required if multi-labels are leveraged.LabelP.of() is used whenfiltering/looking-up vertices by their label(s) as the standardP.eq() does a direct match on the::-representationofvertex.label() |
Configuration
The previous examples showed how to create aNeo4jGraph with the default configuration, but Neo4j has many otheroptions to initialize it that are native to Neo4j. In order to expose those,Neo4jGraph has anopen(Configuration)method which takes a standard Apache Configuration object. The same can be said of the standard method for creatingGraph instances withGraphFactory. Each configuration key that Neo4j has must simply be prefixed withgremlin.neo4j.conf. and the suffix configuration key will be passed through to Neo4j.
Note | Gremlin Server usesGraphFactory to instantiate theGraph instances it manages, so the example below is alsorelevant for that purpose as well. |
For example, a standard configuration file calledneo4j.properties that sets the Neo4jdbms.index_sampling.background_enabled setting might look like:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraphgremlin.neo4j.directory=/tmp/neo4jgremlin.neo4j.conf.dbms.index_sampling.background_enabled=truewhich can then be used as follows:
gremlin> graph = GraphFactory.open('neo4j.properties')==>neo4jgraph[community single [/tmp/neo4j]]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]Having this ability to set standard Neo4j configurations makes it possible to better control the initialization ofNeo4j itself and provides the ability to enable certain features that would not otherwise be accessible.
Bolt Configuration
WhileNeo4jGraph enables Gremlin based queries, users may find it helpful to also be able to connect to that graphwith native Neo4j drivers and other tools from that space. It is possible to enable theBolt Protocol as a way to do this:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraphgremlin.neo4j.directory=/tmp/neo4jgremlin.neo4j.conf.dbms.connector.0.type=BOLTgremlin.neo4j.conf.dbms.connector.0.enabled=truegremlin.neo4j.conf.dbms.connector.0.address=localhost:7687This configuration is especially relevant to Gremlin Server where one might want to connect to the same graph instancewith both Gremlin and Cypher.
gremlin> :install org.neo4j.driver neo4j-java-driver 1.7.2==>Loaded: [org.neo4j.driver, neo4j-java-driver, 1.7.2]... // restart Gremlin Consolegremlin> import org.neo4j.driver.v1.*==>org.apache.tinkerpop.gremlin.structure.*, org.apache.tinkerpop.gremlin.structure.util.*, ... org.neo4j.driver.v1.*gremlin> driver = GraphDatabase.driver( "bolt://localhost:7687", AuthTokens.basic("neo4j", "neo4j"))Oct 28, 2019 3:28:20 PM org.neo4j.driver.internal.logging.JULogger infoINFO: Direct driver instance 1385140107 created for server address localhost:7687==>org.neo4j.driver.internal.InternalDriver@528f8f8bgremlin> session = driver.session()==>org.neo4j.driver.internal.NetworkSession@f3fcd59gremlin> session.run( "CREATE (a:person {name: {name}, age: {age}})",......1> Values.parameters("name", "stephen", "age", 29))gremlin> :remote connect tinkerpop.server conf/remote.yaml==>Configured localhost/127.0.0.1:8182gremlin> :remote console==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182] - type ':remote console' to return to local modegremlin> g.V().elementMap()==>{id=0, label=person, name=stephen, age=29}High Availability Configuration
 TinkerPop supports running Neo4j with its fault tolerant master-slavereplication configuration, referred to as itsHigh Availability (HA) cluster. From theTinkerPop perspective, configuring for HA is not that different than configuring for embedded mode as shown above. Themain difference is the usage of HA configuration options that enable the cluster. Once connected to a cluster, usagefrom the TinkerPop perspective is largely the same.
TinkerPop supports running Neo4j with its fault tolerant master-slavereplication configuration, referred to as itsHigh Availability (HA) cluster. From theTinkerPop perspective, configuring for HA is not that different than configuring for embedded mode as shown above. Themain difference is the usage of HA configuration options that enable the cluster. Once connected to a cluster, usagefrom the TinkerPop perspective is largely the same.
In configuring for HA the most important thing to realize is that all Neo4j HA settings are simply passed through theTinkerPop configuration settings given to theGraphFactory.open() orNeo4j.open() methods. For example, toprovide the all-importantha.server_id configuration option through TinkerPop, simply prefix that key with theTinkerPop Neo4j key ofgremlin.neo4j.conf.
The following properties demonstrates one of the three configuration files required to setup a simple three node HAcluster on the same machine instance:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraphgremlin.neo4j.directory=/tmp/neo4j.server1gremlin.neo4j.conf.ha.server_id=1gremlin.neo4j.conf.ha.initial_hosts=localhost:5001\,localhost:5002\,localhost:5003gremlin.neo4j.conf.ha.host.coordination=localhost:5001gremlin.neo4j.conf.ha.host.data=localhost:6001Assuming the intent is to configure this cluster completely within TinkerPop (perhaps within three separate GremlinServer instances), the other two configuration files will be quite similar. The second will be:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraphgremlin.neo4j.directory=/tmp/neo4j.server2gremlin.neo4j.conf.ha.server_id=2gremlin.neo4j.conf.ha.initial_hosts=localhost:5001\,localhost:5002\,localhost:5003gremlin.neo4j.conf.ha.host.coordination=localhost:5002gremlin.neo4j.conf.ha.host.data=localhost:6002and the third will be:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraphgremlin.neo4j.directory=/tmp/neo4j.server3gremlin.neo4j.conf.ha.server_id=3gremlin.neo4j.conf.ha.initial_hosts=localhost:5001\,localhost:5002\,localhost:5003gremlin.neo4j.conf.ha.host.coordination=localhost:5003gremlin.neo4j.conf.ha.host.data=localhost:6003Important | The backslashes in the values provided togremlin.neo4j.conf.ha.initial_hosts prevent that configurationsetting as being interpreted as aList. |
Create three separate Gremlin Server configuration files and point each at one of these Neo4j files. Since these GremlinServer instances will be running on the same machine, ensure that each Gremlin Server instance has a uniqueportsetting in that Gremlin Server configuration file. Start each Gremlin Server instance to bring the HA cluster online.
Note | Neo4jGraph instances will block until all nodes join the cluster. |
Neither Gremlin Server nor Neo4j will share transactions across the cluster. Be sure to either use Gremlin Servermanaged transactions or, if using a session without that option, ensure that all requests are being routed to thesame server.
This example discussed use of Gremlin Server to demonstrate the HA configuration, but it is also easy to setup withthree Gremlin Console instances. Simply start three Gremlin Console instances and useGraphFactory to read thoseconfiguration files to form the cluster. Furthermore, keep in mind that it is possible to have a Gremlin Console joina cluster handled by two Gremlin Servers or Neo4j Enterprise. The only limits as to how the configuration can beutilized are prescribed by Neo4j itself. Please refer to theirdocumentation for more information on howthis feature works.
Hadoop-Gremlin
<dependency><groupId>org.apache.tinkerpop</groupId><artifactId>hadoop-gremlin</artifactId><version>3.7.4</version></dependency>![]() Hadoop is a distributedcomputing framework that is used to process data represented across a multi-machine compute cluster. When thedata in the Hadoop cluster represents a TinkerPop graph, then Hadoop-Gremlin can be used to process the graphusing both TinkerPop’s OLTP and OLAP graph computing models.
Hadoop is a distributedcomputing framework that is used to process data represented across a multi-machine compute cluster. When thedata in the Hadoop cluster represents a TinkerPop graph, then Hadoop-Gremlin can be used to process the graphusing both TinkerPop’s OLTP and OLAP graph computing models.
Important | This section assumes that the user has a Hadoop 3.x cluster functioning. For more information on gettingstarted with Hadoop, please see theSingle Node Setuptutorial. Moreover, if usingSparkGraphComputer it is advisable that the reader alsofamiliarize their self with and Spark (Quick Start). |
Installing Hadoop-Gremlin
If usingGremlin Console, it is important to install the Hadoop-Gremlin plugin. Note thatHadoop-Gremlin requires a Gremlin Console restart after installing.
$ bin/gremlin.sh \,,,/ (o o)-----oOOo-(3)-oOOo-----plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphgremlin> :install org.apache.tinkerpop hadoop-gremlin 3.7.4==>loaded: [org.apache.tinkerpop, hadoop-gremlin, 3.7.4] - restart the console to use [tinkerpop.hadoop]gremlin> :q$ bin/gremlin.sh \,,,/ (o o)-----oOOo-(3)-oOOo-----plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphgremlin> :plugin use tinkerpop.hadoop==>tinkerpop.hadoop activatedgremlin>It is important that theCLASSPATH environmental variable referencesHADOOP_CONF_DIR and that the configurationfiles inHADOOP_CONF_DIR contain references to a live Hadoop cluster. It is easy to verify a proper configurationfrom within the Gremlin Console. Ifhdfs references the local file system, then there is a configuration issue.
gremlin> hdfs==>storage[org.apache.hadoop.fs.LocalFileSystem@65bb9029] // BADgremlin> hdfs==>storage[DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_1229457199_1, ugi=user (auth:SIMPLE)]]] // GOODTheHADOOP_GREMLIN_LIBS references locations that contain jars that should be uploaded to a respectivedistributed cache (YARN or SparkServer).Note that the locations inHADOOP_GREMLIN_LIBS can be colon-separated (:) and all jars from all locations willbe loaded into the cluster. Locations can be local paths (e.g./path/to/libs), but may also be prefixed with a filescheme to reference files or directories in different file systems (e.g.hdfs:///path/to/distributed/libs).Typically, only the jars of the respectiveGraphComputer are required to be loaded.
Properties Files
HadoopGraph makes use of properties files which ultimately get turned into Apache configurations and/orHadoop configurations.
gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraphgremlin.hadoop.inputLocation=tinkerpop-modern.kryogremlin.hadoop.graphReader=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoInputFormatgremlin.hadoop.outputLocation=outputgremlin.hadoop.graphWriter=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormatgremlin.hadoop.jarsInDistributedCache=truegremlin.hadoop.defaultGraphComputer=org.apache.tinkerpop.gremlin.spark.process.computer.SparkGraphComputer##################################### Spark Configuration #####################################spark.master=local[4]spark.executor.memory=1gspark.serializer=org.apache.tinkerpop.gremlin.spark.structure.io.gryo.GryoSerializergremlin.spark.persistContext=trueA review of the Hadoop-Gremlin specific properties are provided in the table below. For the respective OLAPengines (SparkGraphComputer refer to their respective documentation for configuration options.
| Property | Description |
|---|---|
gremlin.graph | The class of the graph to construct using GraphFactory. |
gremlin.hadoop.inputLocation | The location of the input file(s) for Hadoop-Gremlin to read the graph from. |
gremlin.hadoop.graphReader | The class that the graph input file(s) are read with (e.g. an |
gremlin.hadoop.outputLocation | The location to write the computed HadoopGraph to. |
gremlin.hadoop.graphWriter | The class that the graph output file(s) are written with (e.g. an |
gremlin.hadoop.jarsInDistributedCache | Whether to upload the Hadoop-Gremlin jars to a distributed cache (necessary if jars are not on the machines' classpaths). |
gremlin.hadoop.defaultGraphComputer | The default |
Along with the properties above, the numerousHadoop specific propertiescan be added as needed to tune and parameterize the executed Hadoop-Gremlin job on the respective Hadoop cluster.
Important | As the size of the graphs being processed becomes large, it is important to fully understand how theunderlying OLAP engine (e.g. Spark, etc.) works and understand the numerous parameterizations offered bythese systems. Such knowledge can help alleviate out of memory exceptions, slow load times, slow processing times,garbage collection issues, etc. |
OLTP Hadoop-Gremlin
 It is possible to execute OLTP operations over a
It is possible to execute OLTP operations over aHadoopGraph.However, realize that the underlying HDFS files are not random access and thus, to retrieve a vertex, a linear scanis required. OLTP operations are useful for peeking into the graph prior to executing a long running OLAP job — e.g.g.V().valueMap().limit(10).
Warning | OLTP operations onHadoopGraph are not efficient. They require linear scans to execute and are unreasonablefor large graphs. In such large graph situations, make use ofTraversalVertexProgramwhich is the OLAP Gremlin machine. |
gremlin> hdfs.copyFromLocal('data/tinkerpop-modern.kryo','tinkerpop-modern.kryo')==>nullgremlin> hdfs.ls()==>rwxr-xr-x Yang.Xia supergroup0 (D) .sparkStaging==>rw-r--r-- Yang.Xia supergroup781 tinkerpop-modern.kryogremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')==>hadoopgraph[gryoinputformat->gryooutputformat]gremlin> g = traversal().withEmbedded(graph)==>graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], standard]gremlin> g.V().count()==>6gremlin> g.V().out().out().values('name')==>ripple==>lopgremlin> g.V().group().by{it.value('name')[1]}.by('name').next()==>a=[marko, vadas]==>e=[peter]==>i=[ripple]==>o=[lop, josh]hdfs.copyFromLocal('data/tinkerpop-modern.kryo','tinkerpop-modern.kryo')hdfs.ls()graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')g = traversal().withEmbedded(graph)g.V().count()g.V().out().out().values('name')g.V().group().by{it.value('name')[1]}.by('name').next()OLAP Hadoop-Gremlin
 Hadoop-Gremlin was designed to execute OLAP operations via
Hadoop-Gremlin was designed to execute OLAP operations viaGraphComputer. The OLTP examples presented previously are reproduced below, but usingTraversalVertexProgramfor the execution of the Gremlin traversal.
AGraph in TinkerPop can support any number ofGraphComputer implementations. Out of the box, Hadoop-Gremlinsupports the following two implementations.
SparkGraphComputer: Leverages Apache Spark to execute TinkerPop OLAP computations.The graph may fit within the total RAM of the cluster (supports larger graphs). Message passing is coordinated viaSpark map/reduce/join operations on in-memory and disk-cached data (average speed traversals).
Tip | For those wanting to use theSugarPlugin withtheir submitted traversal, do:remote config useSugar true as well as:plugin use tinkerpop.sugar at the start ofthe Gremlin Console session if it is not already activated. |
$ bin/gremlin.sh \,,,/ (o o)-----oOOo-(3)-oOOo-----plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphplugin activated: tinkerpop.hadoopgremlin> :install org.apache.tinkerpop spark-gremlin 3.7.4==>loaded: [org.apache.tinkerpop, spark-gremlin, 3.7.4] - restart the console to use [tinkerpop.spark]gremlin> :q$ bin/gremlin.sh \,,,/ (o o)-----oOOo-(3)-oOOo-----plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphplugin activated: tinkerpop.hadoopgremlin> :plugin use tinkerpop.spark==>tinkerpop.spark activatedWarning | Hadoop and Spark all depend on many of the same libraries (e.g. ZooKeeper, Snappy, Netty, Guava,etc.). Unfortunately, typically these dependencies are not to the same versions of the respective libraries. As such,it is may be necessary to manually cleanup dependency conflicts among different plugins. |
SparkGraphComputer
<dependency><groupId>org.apache.tinkerpop</groupId><artifactId>spark-gremlin</artifactId><version>3.7.4</version></dependency>![]() Spark is an Apache Software Foundationproject focused on general-purpose OLAP data processing. Spark provides a hybrid in-memory/disk-based distributedcomputing model that is similar to Hadoop’s MapReduce model. Spark maintains a fluent function chaining DSL that isarguably easier for developers to work with than native Hadoop MapReduce. Spark-Gremlin provides an implementation ofthe bulk-synchronous parallel, distributed message passing algorithm within Spark and thus, any
Spark is an Apache Software Foundationproject focused on general-purpose OLAP data processing. Spark provides a hybrid in-memory/disk-based distributedcomputing model that is similar to Hadoop’s MapReduce model. Spark maintains a fluent function chaining DSL that isarguably easier for developers to work with than native Hadoop MapReduce. Spark-Gremlin provides an implementation ofthe bulk-synchronous parallel, distributed message passing algorithm within Spark and thus, anyVertexProgram can beexecuted overSparkGraphComputer.
Furthermore thelib/ directory should be distributed across all machines in the SparkServer cluster. For this purposeTinkerPop provides a helper script, which takes the Spark installation directory and the Spark machines as input:
bin/hadoop/init-tp-spark.sh /usr/local/spark spark@10.0.0.1 spark@10.0.0.2 spark@10.0.0.3Once thelib/ directory is distributed,SparkGraphComputer can be used as follows.
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')==>hadoopgraph[gryoinputformat->gryooutputformat]gremlin> g = traversal().withEmbedded(graph).withComputer(SparkGraphComputer)==>graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], sparkgraphcomputer]gremlin> g.V().count()==>6gremlin> g.V().out().out().values('name')==>lop==>ripplegraph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')g = traversal().withEmbedded(graph).withComputer(SparkGraphComputer)g.V().count()g.V().out().out().values('name')For using lambdas in Gremlin-Groovy, simply provide:remote connect aTraversalSource which leverages SparkGraphComputer.
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')==>hadoopgraph[gryoinputformat->gryooutputformat]gremlin> g = traversal().withEmbedded(graph).withComputer(SparkGraphComputer)==>graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], sparkgraphcomputer]gremlin> :remote connect tinkerpop.hadoop graph g[INFO] o.a.t.g.h.j.HadoopGremlinPlugin - HADOOP_GREMLIN_LIBS is setto:/Users/Yang.Xia/Repos/tp3.7branch/tinkerpop/gremlin-console/target/apache-tinkerpop-gremlin-console-3.7.4-standalone/ext/tinkergraph-gremlin/lib[INFO] o.a.t.g.h.j.HadoopGremlinPlugin - HADOOP_GREMLIN_LIBS is setto:/Users/Yang.Xia/Repos/tp3.7branch/tinkerpop/gremlin-console/target/apache-tinkerpop-gremlin-console-3.7.4-standalone/ext/tinkergraph-gremlin/lib[INFO] o.a.t.g.h.j.HadoopGremlinPlugin - HADOOP_GREMLIN_LIBS is setto:/Users/Yang.Xia/Repos/tp3.7branch/tinkerpop/gremlin-console/target/apache-tinkerpop-gremlin-console-3.7.4-standalone/ext/tinkergraph-gremlin/lib==>useTraversalSource=graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], sparkgraphcomputer]==>useSugar=falsegremlin> :> g.V().group().by{it.value('name')[1]}.by('name')==>[a:[marko,vadas],i:[ripple],e:[peter],o:[lop,josh]]graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')g = traversal().withEmbedded(graph).withComputer(SparkGraphComputer):remote connect tinkerpop.hadoop graph g:> g.V().group().by{it.value('name')[1]}.by('name')TheSparkGraphComputer algorithm leverages Spark’s caching abilities to reduce the amount of data shuffled acrossthe wire on each iteration of theVertexProgram. When the graph is loaded as a Spark RDD(Resilient Distributed Dataset) it is immediately cached asgraphRDD. ThegraphRDD is a distributed adjacencylist which encodes the vertex, its properties, and all its incident edges. On the first iteration, each vertex(in parallel) is passed throughVertexProgram.execute(). This yields an output of the vertex’s mutated state(i.e. updated compute keys — propertyX) and its outgoing messages. ThisviewOutgoingRDD is then reduced toviewIncomingRDD where the outgoing messages are sent to their respective vertices. If aMessageCombiner existsfor the vertex program, then messages are aggregated locally and globally to ultimately yield one incoming messagefor the vertex. This reduce sequence is the "message pass." If the vertex program does not terminate on thisiteration, then theviewIncomingRDD is joined with the cachedgraphRDD and the process continues. When thereare no more iterations, there is a final join and the resultant RDD is stripped of its edges and messages. ThismapReduceRDD is cached and is processed by eachMapReduce job in theGraphComputer computation.

| Property | Description |
|---|---|
gremlin.hadoop.graphReader | A class for reading a graph-based RDD (e.g. an |
gremlin.hadoop.graphWriter | A class for writing a graph-based RDD (e.g. an |
gremlin.spark.graphStorageLevel | What |
gremlin.spark.persistContext | Whether to create a new |
gremlin.spark.persistStorageLevel | What |
InputRDD and OutputRDD
If the provider/user does not want to use HadoopInputFormats, it is possible to leverage Spark’s RDDconstructs directly. AnInputRDD provides a read method that takes aSparkContext and returns a graphRDD. Likewise,andOutputRDD is used for writing a graphRDD.
If the graph system provider uses anInputRDD, the RDD should maintain an associatedorg.apache.spark.Partitioner. By doing so,SparkGraphComputer will not partition the loaded graph across the cluster as it has already been partitioned by the graph system provider.This can save a significant amount of time and space resources. If theInputRDD does not have a registered partitioner,SparkGraphComputer will partition the graph using aorg.apache.spark.HashPartitioner with the number of partitionsbeing either the number of existing partitions in the input (i.e. input splits) or the user specified number ofGraphComputer.workers().
If the provider/user finds there are many small HDFS files generated byOutputRDD. The optiongremlin.spark.outputRepartitioncan help to repartition the output according to the specified number. The option is disabled by default.
Storage Levels
TheSparkGraphComputer usesMEMORY_ONLY to cache the input graph and the output graph by default. Users should be aware of the impact ofdifferent storage levels, since the default settings can quickly lead to memory issues on larger graphs. An overview of Spark’s persistencesettings is provided inSpark’s programming guide.
Using a Persisted Context
It is possible to persist the graph RDD between jobs within theSparkContext (e.g. SparkServer) by leveragingPersistedOutputRDD.Note thatgremlin.spark.persistContext should be set totrue or else the persisted RDD will be destroyed when theSparkContext closes.The persisted RDD is named by thegremlin.hadoop.outputLocation configuration. Similarly,PersistedInputRDD is used with respectivegremlin.hadoop.inputLocation to retrieve the persisted RDD from theSparkContext.
When using a persistentSparkContext the configuration used by the original Spark Configuration will be inherited by all threadedreferences to that Spark Context. The exception to this rule are those properties which have a specific thread local effect.
spark.jobGroup.id
spark.job.description
spark.job.interruptOnCancel
spark.scheduler.pool
Finally, there is aspark object that can be used to manage persisted RDDs (seeInteracting with Spark).
Using CloneVertexProgram
TheCloneVertexProgram copies a whole graph from any graphInputFormat to any graphOutputFormat. TinkerPop provides formats such asGraphSONOutputFormat,GryoOutputFormat orScriptOutputFormat.The example below takes a Hadoop graph as the input (inGryoInputFormat) and exports it as a GraphSON file(GraphSONOutputFormat).
gremlin> hdfs.copyFromLocal('data/tinkerpop-modern.kryo','tinkerpop-modern.kryo')==>nullgremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')==>hadoopgraph[gryoinputformat->gryooutputformat]gremlin> graph.configuration().setProperty('gremlin.hadoop.graphWriter','org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONOutputFormat')==>nullgremlin> graph.compute(SparkGraphComputer).program(CloneVertexProgram.build().create()).submit().get()==>result[hadoopgraph[graphsoninputformat->graphsonoutputformat],memory[size:0]]gremlin> hdfs.ls('output')==>rwxr-xr-x Yang.Xia supergroup0 (D) ~ggremlin> hdfs.head('output/~g')==>{"id":{"@type":"g:Int32","@value":1},"label":"person","outE":{"created":[{"id":{"@type":"g:Int32","@value":9},"inV":{"@type":"g:Int32","@value":3},"properties":{"weight":{"@type":"g:Double","@value":0.4}}}],"knows":[{"id":{"@type":"g:Int32","@value":7},"inV":{"@type":"g:Int32","@value":2},"properties":{"weight":{"@type":"g:Double","@value":0.5}}},{"id":{"@type":"g:Int32","@value":8},"inV":{"@type":"g:Int32","@value":4},"properties":{"weight":{"@type":"g:Double","@value":1.0}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":0},"value":"marko"}],"age":[{"id":{"@type":"g:Int64","@value":1},"value":{"@type":"g:Int32","@value":29}}]}}==>{"id":{"@type":"g:Int32","@value":2},"label":"person","inE":{"knows":[{"id":{"@type":"g:Int32","@value":7},"outV":{"@type":"g:Int32","@value":1},"properties":{"weight":{"@type":"g:Double","@value":0.5}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":2},"value":"vadas"}],"age":[{"id":{"@type":"g:Int64","@value":3},"value":{"@type":"g:Int32","@value":27}}]}}==>{"id":{"@type":"g:Int32","@value":3},"label":"software","inE":{"created":[{"id":{"@type":"g:Int32","@value":9},"outV":{"@type":"g:Int32","@value":1},"properties":{"weight":{"@type":"g:Double","@value":0.4}}},{"id":{"@type":"g:Int32","@value":11},"outV":{"@type":"g:Int32","@value":4},"properties":{"weight":{"@type":"g:Double","@value":0.4}}},{"id":{"@type":"g:Int32","@value":12},"outV":{"@type":"g:Int32","@value":6},"properties":{"weight":{"@type":"g:Double","@value":0.2}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":4},"value":"lop"}],"lang":[{"id":{"@type":"g:Int64","@value":5},"value":"java"}]}}==>{"id":{"@type":"g:Int32","@value":4},"label":"person","inE":{"knows":[{"id":{"@type":"g:Int32","@value":8},"outV":{"@type":"g:Int32","@value":1},"properties":{"weight":{"@type":"g:Double","@value":1.0}}}]},"outE":{"created":[{"id":{"@type":"g:Int32","@value":10},"inV":{"@type":"g:Int32","@value":5},"properties":{"weight":{"@type":"g:Double","@value":1.0}}},{"id":{"@type":"g:Int32","@value":11},"inV":{"@type":"g:Int32","@value":3},"properties":{"weight":{"@type":"g:Double","@value":0.4}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":6},"value":"josh"}],"age":[{"id":{"@type":"g:Int64","@value":7},"value":{"@type":"g:Int32","@value":32}}]}}==>{"id":{"@type":"g:Int32","@value":5},"label":"software","inE":{"created":[{"id":{"@type":"g:Int32","@value":10},"outV":{"@type":"g:Int32","@value":4},"properties":{"weight":{"@type":"g:Double","@value":1.0}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":8},"value":"ripple"}],"lang":[{"id":{"@type":"g:Int64","@value":9},"value":"java"}]}}==>{"id":{"@type":"g:Int32","@value":6},"label":"person","outE":{"created":[{"id":{"@type":"g:Int32","@value":12},"inV":{"@type":"g:Int32","@value":3},"properties":{"weight":{"@type":"g:Double","@value":0.2}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":10},"value":"peter"}],"age":[{"id":{"@type":"g:Int64","@value":11},"value":{"@type":"g:Int32","@value":35}}]}}hdfs.copyFromLocal('data/tinkerpop-modern.kryo','tinkerpop-modern.kryo')graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')graph.configuration().setProperty('gremlin.hadoop.graphWriter','org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONOutputFormat')graph.compute(SparkGraphComputer).program(CloneVertexProgram.build().create()).submit().get()hdfs.ls('output')hdfs.head('output/~g')Input/Output Formats
 Hadoop-Gremlin provides various I/O formats — i.e. Hadoop
Hadoop-Gremlin provides various I/O formats — i.e. HadoopInputFormat andOutputFormat. All of the formats make use of anadjacency listrepresentation of the graph where each "row" represents a single vertex, its properties, and its incoming andoutgoing edges.
Gryo I/O Format
InputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoInputFormatOutputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormat
Gryo is a binary graph format that leveragesKryoto make a compact, binary representation of a vertex. It is recommended that users leverage Gryo given its space/timesavings over text-based representations.
Note | TheGryoInputFormat is splittable. |
GraphSON I/O Format
InputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONInputFormatOutputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONOutputFormat
GraphSON is a JSON based graph format. GraphSON is a space-expensive graph format in thatit is a text-based markup language. However, it is convenient for many developers to work with as its structure issimple (easy to create and parse).
The data below represents an adjacency list representation of the classic TinkerGraph toy graph in GraphSON format.
{"id":1,"label":"person","outE":{"created":[{"id":9,"inV":3,"properties":{"weight":0.4}}],"knows":[{"id":7,"inV":2,"properties":{"weight":0.5}},{"id":8,"inV":4,"properties":{"weight":1.0}}]},"properties":{"name":[{"id":0,"value":"marko"}],"age":[{"id":1,"value":29}]}}{"id":2,"label":"person","inE":{"knows":[{"id":7,"outV":1,"properties":{"weight":0.5}}]},"properties":{"name":[{"id":2,"value":"vadas"}],"age":[{"id":3,"value":27}]}}{"id":3,"label":"software","inE":{"created":[{"id":9,"outV":1,"properties":{"weight":0.4}},{"id":11,"outV":4,"properties":{"weight":0.4}},{"id":12,"outV":6,"properties":{"weight":0.2}}]},"properties":{"name":[{"id":4,"value":"lop"}],"lang":[{"id":5,"value":"java"}]}}{"id":4,"label":"person","inE":{"knows":[{"id":8,"outV":1,"properties":{"weight":1.0}}]},"outE":{"created":[{"id":10,"inV":5,"properties":{"weight":1.0}},{"id":11,"inV":3,"properties":{"weight":0.4}}]},"properties":{"name":[{"id":6,"value":"josh"}],"age":[{"id":7,"value":32}]}}{"id":5,"label":"software","inE":{"created":[{"id":10,"outV":4,"properties":{"weight":1.0}}]},"properties":{"name":[{"id":8,"value":"ripple"}],"lang":[{"id":9,"value":"java"}]}}{"id":6,"label":"person","outE":{"created":[{"id":12,"inV":3,"properties":{"weight":0.2}}]},"properties":{"name":[{"id":10,"value":"peter"}],"age":[{"id":11,"value":35}]}}Script I/O Format
InputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.script.ScriptInputFormatOutputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.script.ScriptOutputFormat
ScriptInputFormat andScriptOutputFormat take an arbitrary script and use that script to either read or writeVertex objects, respectively. This can be considered the most generalInputFormat/OutputFormat possible in thatHadoop-Gremlin uses the user provided script for all reading/writing.
ScriptInputFormat
The data below represents an adjacency list representation of the classic TinkerGraph toy graph. First line reads,"vertex1, labeledperson having 2 property values (marko and29) has 3 outgoing edges; the first edge islabeledknows, connects the current vertex1 with vertex2 and has a property value0.4, and so on."
1:person:marko:29 knows:2:0.5,knows:4:1.0,created:3:0.42:person:vadas:273:project:lop:java4:person:josh:32 created:3:0.4,created:5:1.05:project:ripple:java6:person:peter:35 created:3:0.2There is no correspondingInputFormat that can parse this particular file (or some adjacency list variant of it).As such,ScriptInputFormat can be used. WithScriptInputFormat a script is stored in HDFS and leveraged by eachmapper in the Hadoop job. The script must have the following method defined:
defparse(String line) { ... }In order to create vertices and edges, theparse() method gets access to a global variable namedgraph, which holdsthe localStarGraph for the current line/vertex.
An appropriateparse() for the above adjacency list file is:
defparse(line) {def parts = line.split(//)def (id, label, name, x) = parts[0].split(/:/).toList()def v1 = graph.addVertex(T.id, id, T.label, label)if (name !=null) v1.property('name', name)// first value is always the nameif (x !=null) {// second value depends on the vertex label; it's either// the age of a person or the language of a projectif (label.equals('project')) v1.property('lang', x)else v1.property('age',Integer.valueOf(x)) }if (parts.length ==2) { parts[1].split(/,/).grep { !it.isEmpty() }.each {def (eLabel, refId, weight) =it.split(/:/).toList()def v2 = graph.addVertex(T.id, refId) v1.addOutEdge(eLabel, v2,'weight',Double.valueOf(weight)) } }return v1}The resultantVertex denotes whether the line parsed yielded a valid Vertex. As such, if the line is not valid(e.g. a comment line, a skip line, etc.), then simply returnnull.
ScriptOutputFormat Support
The principle above can also be used to convert a vertex to an arbitraryString representation that is ultimatelystreamed back to a file in HDFS. This is the role ofScriptOutputFormat.ScriptOutputFormat requires that theprovided script maintains a method with the following signature:
defstringify(Vertex vertex) { ... }An appropriatestringify() to produce output in the same format that was shown in theScriptInputFormat sample is:
defstringify(vertex) {def v = vertex.values('name','age','lang').inject(vertex.id(), vertex.label()).join(':')def outE = vertex.outE().map {def e =it.get() e.values('weight').inject(e.label(), e.inV().next().id()).join(':') }.join(',')return [v, outE].join('\t')}Storage Systems
Hadoop-Gremlin provides two implementations of theStorage API:
FileSystemStorage: Access HDFS and local file system data.SparkContextStorage: Access Spark persisted RDD data.
Interacting with HDFS
The distributed file system of Hadoop is calledHDFS.The results of any OLAP operation are stored in HDFS accessible viahdfs. For local file system access, there isfs.
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')==>hadoopgraph[gryoinputformat->gryooutputformat]gremlin> graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();==>result[hadoopgraph[gryoinputformat->gryooutputformat],memory[size:1]]gremlin> hdfs.ls()==>rwxr-xr-x Yang.Xia supergroup0 (D) .sparkStaging==>rwxr-xr-x Yang.Xia supergroup0 (D) output==>rw-r--r-- Yang.Xia supergroup781 tinkerpop-modern.kryogremlin> hdfs.ls('output')==>rwxr-xr-x Yang.Xia supergroup0 (D) clusterCount==>rwxr-xr-x Yang.Xia supergroup0 (D) ~ggremlin> hdfs.head('output', GryoInputFormat)==>v[4]==>v[1]==>v[6]==>v[3]==>v[5]==>v[2]gremlin> hdfs.head('output','clusterCount', SequenceFileInputFormat)==>2gremlin> hdfs.rm('output')==>truegremlin> hdfs.ls()==>rwxr-xr-x Yang.Xia supergroup0 (D) .sparkStaging==>rw-r--r-- Yang.Xia supergroup781 tinkerpop-modern.kryograph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();hdfs.ls()hdfs.ls('output')hdfs.head('output', GryoInputFormat)hdfs.head('output','clusterCount', SequenceFileInputFormat)hdfs.rm('output')hdfs.ls()Interacting with Spark
If a Spark context is persisted, then Spark RDDs will remain the Spark cache and accessible over subsequent jobs.RDDs are retrieved and saved to theSparkContext viaPersistedInputRDD andPersistedOutputRDD respectively.Persisted RDDs can be accessed usingspark.
gremlin> Spark.create('local[4]')==>org.apache.spark.SparkContext@4e00723bgremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')==>hadoopgraph[gryoinputformat->gryooutputformat]gremlin> graph.configuration().setProperty('gremlin.hadoop.graphWriter', PersistedOutputRDD.class.getCanonicalName())==>nullgremlin> graph.configuration().setProperty('gremlin.spark.persistContext',true)==>nullgremlin> graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();==>result[hadoopgraph[persistedinputrdd->persistedoutputrdd],memory[size:1]]gremlin> spark.ls()gremlin> spark.ls('output')==>output/clusterCount [Memory Deserialized1x Replicated]==>output/~g [Memory Deserialized1x Replicated]gremlin> spark.head('output', PersistedInputRDD)==>v[4]==>v[1]==>v[6]==>v[3]==>v[5]==>v[2]gremlin> spark.head('output','clusterCount', PersistedInputRDD)==>2gremlin> spark.rm('output')==>truegremlin> spark.ls()Spark.create('local[4]')graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')graph.configuration().setProperty('gremlin.hadoop.graphWriter', PersistedOutputRDD.class.getCanonicalName())graph.configuration().setProperty('gremlin.spark.persistContext',true)graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();spark.ls()spark.ls('output')spark.head('output', PersistedInputRDD)spark.head('output','clusterCount', PersistedInputRDD)spark.rm('output')spark.ls()Gremlin Compilers
SPARQL-Gremlin
The SPARQL-Gremlin compiler, transformsSPARQL queries into Gremlintraversals. It uses theApache Jena SPARQL processorARQ, which provides access to a syntax tree of aSPARQL query.
The goal of this work is to bridge the query interoperability gap between the two famous, yet fairly disconnected,graph communities: Semantic Web (which relies on the RDF data model) and Graph database (which relies on property graphdata model).
Note | The foundational research work on SPARQL-Gremlin compiler (aka Gremlinator) can be found in theGremlinator paper. This paper presents the graph query language semantics ofSPARQL and Gremlin, and a formal mapping between SPARQL pattern matching graph patterns and Gremlin traversals. |
<dependency><groupId>org.apache.tinkerpop</groupId><artifactId>sparql-gremlin</artifactId><version>3.7.4</version></dependency>The SPARQL-Gremlin compiler convertsSPARQL queries into Gremlin so thatthey can be executed across any TinkerPop-enabled graph system. To use this compiler in the Gremlin Console, firstinstall and activate the "tinkerpop.sparql" plugin:
gremlin> :install org.apache.tinkerpop sparql-gremlin 3.7.4==>Loaded: [org.apache.tinkerpop, sparql-gremlin, 3.7.4]gremlin> :plugin use tinkerpop.sparql==>tinkerpop.sparql activatedInstalling this plugin will download appropriate dependencies and import certain classes to the console so that theymay be used as follows:
gremlin> graph = TinkerFactory.createModern()==>tinkergraph[vertices:6edges:6]gremlin> g = traversal(SparqlTraversalSource).withEmbedded(graph)////(1)==>sparqltraversalsource[tinkergraph[vertices:6edges:6], standard]gremlin> g.sparql("""SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age } ORDER BY ASC(?age)""")////(2)==>[name:vadas,age:27]==>[name:marko,age:29]==>[name:josh,age:32]==>[name:peter,age:35]graph = TinkerFactory.createModern()g = traversal(SparqlTraversalSource).withEmbedded(graph)////(1)g.sparql("""SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age } ORDER BY ASC(?age)""")//2Define
gas aTraversalSourcethat uses theSparqlTraversalSource- by default, thetraversal()methodusually returns aGraphTraversalSourcewhich includes the standard Gremlin starts steps likeV()orE(). In thiscase, theSparqlTraversalSourceenables starts steps that are specific to SPARQL only - in this case thesparql()start step.Execute a SPARQL query against the TinkerGraph instance. The
SparqlTraversalSourceuses aTraversalStrategy to transparently converts that SPARQL query into a standard Gremlin traversaland then when finally iterated, executes that against the TinkerGraph.
Prefixes
The SPARQL-Gremlin compiler supports the following prefixes to traverse the graph:
| Prefix | Purpose |
|---|---|
| access to vertex id, label or property value |
| out-edge traversal |
| property traversal |
Note that element IDs and labels are treated like normal properties, hence they can be accessed using the same pattern:
gremlin> g.sparql("""SELECT ?name ?id ?label WHERE { ?element v:name ?name . ?element v:id ?id . ?element v:label ?label .}""")==>[name:marko,id:1,label:person]==>[name:vadas,id:2,label:person]==>[name:lop,id:3,label:software]==>[name:josh,id:4,label:person]==>[name:ripple,id:5,label:software]==>[name:peter,id:6,label:person]g.sparql("""SELECT ?name ?id ?label WHERE { ?element v:name ?name . ?element v:id ?id . ?element v:label ?label .}""")Supported Queries
The SPARQL-Gremlin compiler currently supports translation of the SPARQL 1.0 specification, especiallySELECTqueries, though there is an on-going effort to cover the entire SPARQL 1.1 query feature spectrum. The supportedSPARQL query types are:
Union
Optional
Order-By
Group-By
STAR-shaped orneighbourhood queries
Query modifiers, such as:
Filter withrestrictions
Count
LIMIT
OFFSET
Limitations
The current implementation of SPARQL-Gremlin compiler (i.e. SPARQL-Gremlin) does not support the following cases:
SPARQL queries with variables in the predicate position are not currently covered, with an exception of the followingcase:
g.sparql("""SELECT * WHERE { ?x ?y ?z . }""")A SPARQL Union query with un-balanced patterns, i.e. a gremlin union traversal can only be generated if the inputSPARQL query has the same number of patterns on both the side of the union operator. For instance, the followingSPARQL query cannot be mapped, since a union is executed between different number of graph patterns (two patterns
union1 pattern).
g.sparql("""SELECT * WHERE { {?person e:created ?software . ?person v:name "josh" .} UNION {?software v:lang "java" .} }""")A non-Group key variable cannot be projected in a SPARQL query. This is a SPARQL language limitation rather thanthat of Gremlin/TinkerPop. Apache Jena throws the exception "Non-group key variable in SELECT" if this occurs.For instance, in a SPARQL query with GROUP-BY clause, only the variable on which the grouping is declared, can beprojected. The following query is valid:
g.sparql("""SELECT ?age WHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name .} GROUP BY (?age)""")Whereas, the following SPARQL query will be invalid:
g.sparql("""SELECT ?person WHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name .} GROUP BY (?age)""")In a SPARQL query with an ORDER-BY clause, the ordering occurs with respect to the first projected variable in thequery. It is possible to choose any number of variable to be projected, however, the first variable in the selectionwill be the ordering decider. For instance, in the query:
g.sparql("""SELECT ?name ?age WHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name . } ORDER BY (?age)""")the result set will be ordered according to the?name variable (in ascending order by default) despite having passed?age in the order by. Whereas, for the following query:
g.sparql("""SELECT ?age ?name WHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name . } ORDER BY (?age)""")the result set will be ordered according to the?age (as it is the first projected variable). Finally, for theselect all case (SELECT *):
g.sparql("""SELECT * WHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name . } ORDER BY (?age)""")the the variable encountered first will be the ordering decider, i.e. since we have?person encountered first,the result set will be ordered according to the?person variable (which are vertex id).
In the current implementation,
OPTIONALclause doesn’t work under nesting withUNIONclause (i.e. multiple optionalclauses with in a union clause) andORDER-Byclause (i.e. declaring ordering over triple patterns within optionalclauses). Everything else with SPARQLOPTIONALworks just fine.
Examples
The following section presents examples of SPARQL queries that are currently covered by the SPARQL-Gremlin compiler.
Select All
Select all vertices in the graph.
gremlin> g.sparql("""SELECT * WHERE { }""")==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]g.sparql("""SELECT * WHERE { }""")Match Constant Values
Select all vertices with the labelperson.
gremlin> g.sparql("""SELECT * WHERE { ?person v:label "person" .}""")==>v[1]==>v[2]==>v[4]==>v[6]g.sparql("""SELECT * WHERE { ?person v:label "person" .}""")Select Specific Elements
Select the values of the propertiesname andage for eachperson vertex.
gremlin> g.sparql("""SELECT ?name ?age WHERE { ?person v:label "person" . ?person v:name ?name . ?person v:age ?age . }""")==>[name:marko,age:29]==>[name:vadas,age:27]==>[name:josh,age:32]==>[name:peter,age:35]g.sparql("""SELECT ?name ?ageWHERE { ?person v:label "person" . ?person v:name ?name . ?person v:age ?age . }""")Pattern Matching
Select only those persons who created a project.
gremlin> g.sparql("""SELECT ?name ?age WHERE { ?person v:label "person" . ?person v:name ?name . ?person v:age ?age . ?person e:created ?project . }""")==>[name:marko,age:29]==>[name:josh,age:32]==>[name:josh,age:32]==>[name:peter,age:35]g.sparql("""SELECT ?name ?ageWHERE { ?person v:label "person" . ?person v:name ?name . ?person v:age ?age . ?person e:created ?project . }""")Filtering
Select only those persons who are older than 30.
gremlin> g.sparql("""SELECT ?name ?age WHERE { ?person v:label "person" . ?person v:name ?name . ?person v:age ?age . FILTER (?age > 30) }""")==>[name:josh,age:32]==>[name:peter,age:35]g.sparql("""SELECT ?name ?ageWHERE { ?person v:label "person" . ?person v:name ?name . ?person v:age ?age . FILTER (?age > 30) }""")Deduplication
Select the distinct names of the created projects.
gremlin> g.sparql("""SELECT DISTINCT ?name WHERE { ?person v:label "person" . ?person v:age ?age . ?person e:created ?project . ?project v:name ?name . FILTER (?age > 30)}""")==>ripple==>lopg.sparql("""SELECT DISTINCT ?nameWHERE { ?person v:label "person" . ?person v:age ?age . ?person e:created ?project . ?project v:name ?name . FILTER (?age > 30)}""")Multiple Filters
Select the distinct names of all Java projects.
gremlin> g.sparql("""SELECT DISTINCT ?name WHERE { ?person v:label "person" . ?person v:age ?age . ?person e:created ?project . ?project v:name ?name . ?project v:lang ?lang . FILTER (?age > 30 && ?lang = "java") }""")==>ripple==>lopg.sparql("""SELECT DISTINCT ?nameWHERE { ?person v:label "person" . ?person v:age ?age . ?person e:created ?project . ?project v:name ?name . ?project v:lang ?lang . FILTER (?age > 30 && ?lang = "java") }""")Union
Select all persons who have developed a software in java using union.
gremlin> g.sparql("""SELECT * WHERE { {?person e:created ?software .} UNION {?software v:lang "java" .} }""")==>[software:v[3],person:v[1]]==>[software:v[3]]==>[software:v[5],person:v[4]]==>[software:v[3],person:v[4]]==>[software:v[5]]==>[software:v[3],person:v[6]]g.sparql("""SELECT *WHERE { {?person e:created ?software .} UNION {?software v:lang "java" .} }""")Optional
Return the names of the persons who have created a software in java and optionally python.
g.sparql("""SELECT ?personWHERE { ?person v:label "person" . ?person e:created ?software . ?software v:lang "java" . OPTIONAL {?software v:lang "python" . }}""")Order By
Select all vertices with the labelperson and order them by their age.
gremlin> g.sparql("""SELECT ?age ?name WHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name . } ORDER BY (?age)""")==>[age:27,name:vadas]==>[age:29,name:marko]==>[age:32,name:josh]==>[age:35,name:peter]g.sparql("""SELECT ?age ?nameWHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name .} ORDER BY (?age)""")Group By
Select all vertices with the labelperson and group them by their age.
gremlin> g.sparql("""SELECT ?age WHERE { ?person v:label "person" . ?person v:age ?age . } GROUP BY (?age)""")==>[32:[32],35:[35],27:[27],29:[29]]g.sparql("""SELECT ?ageWHERE { ?person v:label "person" . ?person v:age ?age .} GROUP BY (?age)""")Mixed/complex/aggregation-based queries
Count the number of projects which have been created by persons under the age of 30 and group them by age. Return onlythe top two.
g.sparql("""SELECT (COUNT(?project) as ?p)WHERE { ?person v:label "person" . ?person v:age ?age . FILTER (?age < 30) ?person e:created ?project .} GROUP BY (?age) LIMIT 2""")Meta-Property Access
Accessing the Meta-Property of a graph element. Meta-Property can be perceived as the reified statements in an RDFgraph.
gremlin> g = traversal(SparqlTraversalSource).withEmbedded(graph)==>sparqltraversalsource[tinkergraph[vertices:6edges:14], standard]gremlin> g.sparql("""SELECT ?name ?startTime WHERE { ?person v:name "daniel" . ?person p:location ?location . ?location v:value ?name . ?location v:startTime ?startTime }""")==>[name:spremberg,startTime:1982]==>[name:kaiserslautern,startTime:2005]==>[name:aachen,startTime:2009]g = traversal(SparqlTraversalSource).withEmbedded(graph)g.sparql("""SELECT ?name ?startTimeWHERE { ?person v:name "daniel" . ?person p:location ?location . ?location v:value ?name . ?location v:startTime ?startTime }""")STAR-shaped queries
STAR-shaped queries are the queries that form/follow a star-shaped execution plan. These in terms of graph traversalscan be perceived as path queries or neighborhood queries. For instance, getting all the information about a specificperson orsoftware.
gremlin> g.sparql("""SELECT ?age ?software ?lang ?name WHERE { ?person v:name "josh" . ?person v:age ?age . ?person e:created ?software . ?software v:lang ?lang . ?software v:name ?name . }""")g.sparql("""SELECT ?age ?software ?lang ?nameWHERE { ?person v:name "josh" . ?person v:age ?age . ?person e:created ?software . ?software v:lang ?lang . ?software v:name ?name . }""")With Gremlin
Thesparql()-step takes a SPARQL query and returns a result. That result can be further processed by standard Gremlinsteps as shown below:
gremlin> g = traversal(SparqlTraversalSource).withEmbedded(graph)==>sparqltraversalsource[tinkergraph[vertices:6edges:6], standard]gremlin> g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }")==>[name:marko,age:29]==>[name:vadas,age:27]==>[name:josh,age:32]==>[name:peter,age:35]gremlin> g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }").select("name")==>marko==>vadas==>josh==>petergremlin> g.sparql("SELECT * WHERE { }").out("knows").values("name")==>vadas==>joshgremlin> g.withSack(1.0f).sparql("SELECT * WHERE { }"). repeat(outE().sack(mult).by("weight").inV()). times(2). sack()==>1.0==>0.4g = traversal(SparqlTraversalSource).withEmbedded(graph)g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }")g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }").select("name")g.sparql("SELECT * WHERE { }").out("knows").values("name")g.withSack(1.0f).sparql("SELECT * WHERE { }"). repeat(outE().sack(mult).by("weight").inV()). times(2). sack()Mixing SPARQL with Gremlin steps introduces some interesting possibilities for complex traversals.
Conclusion
The world that we know, you and me, is but a subset of the worldthat Gremlin has weaved within The TinkerPop. Gremlin has constructed a fully connected graph and only the subset thatmakes logical sense to our traversing thoughts is the fragment we have come to know and have come to see one anotherwithin. But there are many more out there, within other webs of logics unfathomed. From any thought, every otherthought, we come to realize that which is — The TinkerPop.Acknowledgements
![]() YourKit supports the TinkerPop open source project with its full-featuredJava Profiler. YourKit, LLC is the creator of innovative and intelligent tools for profiling Java and .NETapplications. YourKit’s leading software products:YourKit Java ProfilerandYourKit .NET Profiler
YourKit supports the TinkerPop open source project with its full-featuredJava Profiler. YourKit, LLC is the creator of innovative and intelligent tools for profiling Java and .NETapplications. YourKit’s leading software products:YourKit Java ProfilerandYourKit .NET Profiler
 Ketrina Yim — DesigningGremlin and his friends for TinkerPop was one of my first major projects as a freelancer, and it’s delightful tosee them on the Web and all over the documentation! Drawing and tweaking the characters over time is like watchingthem grow up. They’ve gone from sketches on paper to full-color logos, and from logos to living characters thatcheerfully greet visitors to the TinkerPop website. And it’s been a great time all throughout!
Ketrina Yim — DesigningGremlin and his friends for TinkerPop was one of my first major projects as a freelancer, and it’s delightful tosee them on the Web and all over the documentation! Drawing and tweaking the characters over time is like watchingthem grow up. They’ve gone from sketches on paper to full-color logos, and from logos to living characters thatcheerfully greet visitors to the TinkerPop website. And it’s been a great time all throughout!
…in the beginning.