kanayamaのブログ
twitter: @tkanayama_
この広告は、90日以上更新していないブログに表示しています。
「施策デザインのための機械学習入門」を完全に理解したサトシくんがポケモン捕獲アルゴリズムを実装する話
@tkanayama_です。先日、「施策デザインのための機械学習入門*1」をご恵贈いただきました。
そこで本の内容を引用しつつ、学んだことをポケモンを題材に実践する*2ことにより、自らの理解を定着させるとともに本の良さをお伝えできればと思います。
プロローグ
サトシくんはデータサイエンスに強みを持ったポケモントレーナーです。
この世界では、ポケモンを捕獲することによりもらえる謝礼金がポケモントレーナーの重要な収入源の一つとなっています。ポケモンを捕まえて博士に送ると、ポケモン研究への協力金として謝礼金を受け取ることができます*3。
すなわち、以下のような表がポケモントレーナーに与えられているものとします。(データの全体はGitHubから確認できます。)
| 図鑑番号 | 名前 | 捕獲難度(数字が大きいほど捕獲が難しい)*4 | 謝礼金(ポケ円)*5 |
|---|---|---|---|
| 1 | フシギダネ | 210 | 1,600 |
| 2 | フシギソウ | 210 | 4,358 |
| ・・・ | ・・・ | ・・・ | ・・・ |
| 25 | ピカチュウ | 65 | 1,785 |
| ・・・ | ・・・ | ・・・ | ・・・ |
| 150 | ミュウツー | 252 | 47,333 |
| 151 | ミュウ | 210 | 24,414 |
ポケモンの捕獲に使えるボールはモンスターボールからマスターボールまで4種類あり、それぞれのボールは価格と性能が異なっています。ポケモントレーナーは、ポケモンに対してこれらいずれかのボールを投げる、もしくは何もせず「逃げる」という選択肢を取ることができます。表にまとめると以下のようになります。
| アクション名 | コスト(ポケ円) | 捕獲しやすさ |
|---|---|---|
| 逃げる | 0 | 必ず捕まえられない |
| モンスターボールを投げる | 100 | 捕まえにくい |
| スーパーボールを投げる | 500 | やや捕まえやすい |
| ハイパーボールを投げる | 2,000 | とても捕まえやすい |
| マスターボールを投げる | 10,000 | 必ず捕まえられる |
サトシくんはこれらの定性的・定量的な情報を頼りに、収益をできるだけ大きくする必要があります。さもなくば、ポケモントレーナーとして生計を立てていくのは難しいでしょう。
以下では簡単のため、ポケモンとの対面1回につき捕獲チャンスは1回のみとします。捕獲に失敗したら、また次のポケモンと対面することになります。次に現れるポケモンは、同じ種類のポケモンかもしれないし、違う種類かもしれません。(2021/09/15追記:どのポケモンと対面するかは適当な確率分布によって決まりますが、ポケモントレーナー側はこの分布を制御できないものとします。つまり、ピカチュウと会いたいからといってピカチュウがいそうな場所だけをウロウロするようなことはできません。)

ストーリー編
第1章 感銘
サトシくんはこれまで、どのポケモンにどのボールを使うかを勘と経験によって決めていました。しかし、「施策デザインのための機械学習入門」(以下、同書)に心を打たれ、機械学習を効果的に利用することによって収益増を狙いたいと考えました。
同書によると、「機械学習実践のためのフレームワーク」として以下の6つのステップが提言されています。
- KPIを設定する
- データの観測構造をモデル化する
- 解くべき問題を特定する
- 観測データのみを用いて問題を解く方法を考える
- 機械学習モデルを学習する
- 施策を導入する
そこで、サトシくんはこのステップに忠実に従って機械学習施策を実践していくことにしました。
step1. KPIの設定
サトシくんは、同書の例として出てきた「広告クリック回数最大化」のKPIを参考にして、今回のKPIを「ポケモン捕獲回数最大化」とすることにしました。つまり、一定の回数ポケモンと対面したとき、ポケモンをできるだけたくさん捕まえることをKPIとします。
step2. データの観測構造をモデル化する
データの観測構造として今回注意しなければならない点は、「1回の対面に対して、1つのアクションに対する結果しか観測することができない」という点です。例えば、目の前にピカチュウが現れたとして、モンスターボールを投げたとします。その結果、「捕まった」or「捕まらなかった」のデータを得ることができます。しかし、「ではスーパーボールを投げたらどういう結果になったのか?」というデータは決して得ることはできません。
この点に注意して、サトシくんはデータ収集を行うことにしました。同書を完全に理解しているサトシくんは、同書に書いてあった一文「決定的な意思決定モデルから得られたログデータに対してIPS推定量を使う場合、(中略)バイアスに対処できません。」を思い出しました。そこでサトシくんは以下のように、ポケモンの謝礼金に応じたルールベースかつ確率的なアルゴリズムに基づいた意思決定モデルを定義し、これを用いてデータを収集することにしました。
if 謝礼金 >10000円:# マスターボールを投げやすい {逃げる:10%, モンスター:10%, スーパー:10%, ハイパー:20%, マスター:50%}elif 謝礼金 >2000円:# ハイパーボールを投げやすい {逃げる:5%, モンスター:20%, スーパー:30%, ハイパー:40%, マスター:5%}elif 謝礼金 >500円:# スーパーボールを投げやすい {逃げる:10%, モンスター:30%, スーパー:50%, ハイパー:5%, マスター:5%}elif 謝礼金 >100円:# モンスターボールを投げやすい {逃げる:40%, モンスター:40%, スーパー:10%, ハイパー:5%, マスター:5%}else:# 逃げるを選択しやすい {逃げる:80%, モンスター:5%, スーパー:5%, ハイパー:5%, マスター:5%}
これにより、
- 完全にランダムな行動選択ではないので、データ収集段階でもある程度損害を抑えられる
- 確率的なアルゴリズムなので、あとあと意思決定モデルを学習する際にバイアスを取り除きやすい
の両方を満たすことを狙っています。
結果として、以下のような形式のログデータが収集できました。
| timestamp | ポケモン | 選んだアクション | 捕獲できたか? |
|---|---|---|---|
| 2021-08-21T12:34:56+09:00 | ピカチュウ | 逃げる | できなかった |
| ・・・ | ・・・ | ・・・ | ・・・ |
| 2021-08-28T00:55:21+09:00 | イーブイ | モンスターボールを投げる | できた |
step3. 解くべき問題を特定する
同書の内容を全て頭に刻み込んでいるサトシくんは、同書で紹介されている意思決定モデルの定式化をそのまま使えそうだと考えました。すなわち、以下を目的関数として最大化します。
]
同書では広告のクリック回数最大化を例として、 がユーザーの特徴量、
がどの広告をユーザーに表示するかを決める意思決定モデル、
がユーザーが広告をクリックしたかをどうかを表す2値確率変数としています。これを今回の例に応用すると、
をポケモンの特徴量、
をポケモンに対してどのアクションを取るか決める意思決定モデル、
をポケモンが捕まったかどうかを表す2値確率変数と見なせば良さそうです。
step4. 観測データのみを用いて問題を解く方法を考える
さて、最適化すべき目的関数が決まったところで、手元にあるデータを用いて実際にボールの投げ分けを最適化する方法を検討していきます。step2でも考察した通り、今回の問題の難しい点は、「新たに学習しようとしている意思決定モデルの出力がデータ収集用意思決定モデルの出力と異なっていた場合、それを直接学習に利用することができない」という点です。
そこで、同書を毎晩枕元に置いて寝ているサトシくんは、同書で紹介されているIPS推定量を用いてバイアスを取り除いた近似を行うことにしました。具体的には、以下の目的関数を最適化します。
ここで、 はデータ収集に用いた意思決定モデルです。つまり、単純に手元のデータから捕獲確率を経験確率として計算して目的関数とするのではなく、データ収集に用いた意思決定モデルの出力の逆数で重み付けした値を目的関数とするということです*6。
step5.機械学習モデルを学習する
ここまでくれば、あとは目的関数を最大化するように意思決定モデルを学習するだけです。サトシくんは、意思決定モデル をニューラルネットワークでモデル化しました。また、特徴量
としてポケモンの捕獲難易度と謝礼金額を用いました。そして、手元のデータを用いて学習を行いました。
step6. 施策を導入する
一刻も早く新しいアルゴリズムを試したいサトシくんは早速、今回学習した意思決定モデルに基づいて捕獲をしに出かけました。これで、圧倒的に収益が改善したはずです。
サトシくんは、ポケモンと1,000回の対面を終えた後、ワクワクしながら収益計算してみました。すると…
| 対面回数 | 通算収益 |
|---|---|
| 1,000回 | マイナス261万ポケ円 |
なんということでしょう、大赤字です…!サトシくんは膝から崩れ落ちました。
第2章 絶望
なぜこんなことが起きてしまったのでしょう?サトシくんは、今までの過程を遡って、原因を考えてみました。
- step5で意思決定モデルをニューラルネットワークでモデル化したのが悪かった?LightGBMを使ったほうがよかったのか?
- step4でIPS推定量でバイアスを取り除く方法が間違っていた?
- step3でKPIを意思決定モデルの目的関数として定式化する方法が間違っていた?
- step2で考慮できていないデータの観測構造があった?
様々な可能性が考えられます。そこでサトシくんは原因を究明するために、学習した意思決定モデルがどんなポケモンに対してどのアクションを選択したかを可視化し、衝撃の結果を目の当たりにしました。

なんと、全ての対面でマスターボールが選択されていたのです(!)
(ここで、各プロットはポケモンとの対面を表しており、意思決定モデルが選択したアクションを色で表現しています。また、横軸はポケモンの捕獲難易度、縦軸はそのポケモンを捕まえた場合の謝礼金額を表しています。また、マスターボールの販売価格である10,000ポケ円を表す横線を引いています。)
第3章 反省
なぜこのようなことが起きてしまったのか、サトシくんはついに気づきました。step1で設定したKPIがそもそも誤っていたのです。step1でサトシくんは、「ポケモン捕獲回数を最大化すること」をKPIとして掲げましたが、サトシくんが本当に最大化したかったのは「ポケモンを捕獲することによる収益を最大化すること」です。ポケモン捕獲回数を最大化するするようにモデル化して学習したら、当然お金に糸目をつけずにマスターボールを投げ続ける意思決定モデルが出来上がってしまいます。
サトシくんは、そもそも解くべき問題設定を誤ると、その後の工程がいかに正しかったとしても意味がないということを痛感すると同時に、本を一読しただけで完全に理解した気になっていたことに対して大いに反省しました。
第4章 再起
さて、今回の失敗で261万ポケ円を失ってしまったサトシくんですが、ここでめげないのがサトシくんの良いところです。サトシくんは今回の反省を踏まえて、改めて意思決定モデルを学習することにしました。
step1(再) KPIの設定
今回はサトシくんの真の関心ごとを素直にKPIにすることにしました。具体的には、「(もらえる謝礼金の総額)- (ボールの購入に使った総額)」すなわち収益を最大化することをKPIとします。
step2(再) データの観測構造をモデル化する
このstepは前述のstep2と同じです。すなわち、「1回の対面に対して、1つのアクションに対する結果しか観測することができない」ということに注意しつつ、確率的な意思決定モデルを用いてデータを収集しました。
step3(再) 解くべき問題を特定する
さきほどのstep3では、以下を目的関数として最大化しました。
]
ここで、はポケモンの特徴量、
は意思決定モデル、
はポケモンが捕まったかどうかを表す2値確率変数でした。これを、今回再設定したKPIに沿うように拡張します。
今回最大化したいのは捕まえるポケモン数ではなく、収益です。そこで、以下のように目的関数に変更を加えます。
]
ここで、
です。
が1(つまり捕獲できた)である場合は「謝礼金額 - コスト」が収益となり、
が0(つまり捕獲できなかった)である場合はコストがそのまま損失になることを表しています。
これなら、step1(再) で設定したKPIを直接最適化する目的関数になっているので、良さそうです。
step4(再) 観測データのみを用いて問題を解く方法を考える
次に、この目的関数を手元にあるデータで最適化する方法を考えます。このstepも先ほどのstep4と同様にIPS推定量を用いると以下のように表現できます。
はデータ収集に用いた意思決定モデルです。先ほどのstep4との違いは、ポケモンが捕まったかどうを表す確率変数
に対して報酬金額と価格を考慮するように補正を行ったのみです。
step5(再)機械学習モデルを学習する
次に、目的関数を最大化するように機械学習モデルを学習していきます。サトシくんは、意思決定モデル を再度ニューラルネットワークでモデル化しました。
その後、先ほどと同じ失敗を繰り返さないよう、今度は実戦投入前にバリデーションデータを用いて性能評価を行うことにしました。性能評価にも、IPS推定量を用いました。
比較対象とするモデルとして、以下のようなサトシくん渾身の決定的なルールベースモデルを用いました。
if 謝礼金 >10000円: マスターボールを投げるelif 謝礼金 >2000円: ハイパーボールを投げるelif 謝礼金 >500円: スーパーボールを投げるelif 謝礼金 >100円: モンスターボールを投げるelse: 逃げる
その結果、以下のように新たに学習した意思決定モデルの性能がルールベースモデルの性能を上回ることが確認できました(IPWと書かれている方が今回新たに学習したモデルです)。
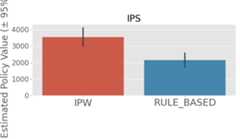
また、考察のために、新たに学習した意思決定モデルの出力を可視化しました。

先ほどの可視化と同様に、各プロットはポケモンとの対面1回を表しており、意思決定モデルが選択したアクションを色で表現しています。また、横軸はポケモンの捕獲難易度、縦軸はそのポケモンを捕まえた場合の謝礼金額を表しています。例えば、右上の外れ値はミュウツーを表しています。
ここから、例えば以下のようなことが読み取れます。
- 捕獲難易度が高くかつ謝礼金が10,000円を超えるポケモンは、マスターボールを使っても元が取れるのでマスターボールで確実に捕まえるのが良い(下図の赤枠)。
- 一方で、捕獲難易度は高いが謝礼金が10,000円を下回るポケモンは、コスパが悪いので「逃げる」を選択するのが良い(下図の青枠)。

サトシくんの作ったルールベースモデルと比べると、この「逃げる」の使い方の違いが大きな差を生んでいる可能性が示唆されました。
step6(再) 施策を導入する
サトシくんは、今回学習した意思決定モデル、および比較のためのルールベースモデルに基づいて実際のフィールドでA/Bテストを行い*7、性能を評価しました。
| モデル | 対面回数 | 1対面あたりの収益 |
|---|---|---|
| ルールベース | 1,000回 | 2,249ポケ円 |
| 今回学習した意思決定モデル | 1,000回 | 3,609ポケ円 |
結果、1対面あたり1,000ポケ円以上の収益改善を行うことができました。
第5章 俺たちの戦いはこれからだ!
サトシくんは今回の経験から、解くべき問題を正しく設定する重要さを学びました。また、アルゴリズムを実戦投入する前に、オフ方策評価や挙動を可視化することの重要さも同時に学びました。
サトシくんは、今後も「施策デザインのための機械学習入門」をバイブルにしながら、新しく学習した意思決定モデルを用いてデータを収集し、そのデータを用いてさらに高性能な意思決定モデルを開発していくことでしょう。
TO BE CONTINUED...
実装編
ここからは、上記のストーリー編を作成するにあたって実装した内容を解説していきます。実装の全貌はGitHubにて公開しています。
実装は、同書でも紹介されているOpen Bandit Pipline を用いて行いました。シミュレーションデータを生成して実験を行ったので、以下ではサトシくん目線ではなく神様目線で語っていることに注意してください。
準備
まず、各アクションを定義していきます。今回取りうるアクションは5種類で、それぞれにperformance (捕まえやすさ)とcost (ボールの販売価格)という属性を持たせます。
@dataclassclassAction: label:str performance:int cost:intACTIONS: List[Action] = [ Action(label='逃げる', performance=-math.inf, cost=0), Action(label='モンスターボールを投げる', performance=50, cost=100), Action(label='スーパーボールを投げる', performance=100, cost=500), Action(label='ハイパーボールを投げる', performance=200, cost=2000), Action(label='マスターボールを投げる', performance=math.inf, cost=10000),]
また、各ポケモンの捕まえやすさや謝礼金 を取得するためにポケモン図鑑クラスも作っておきます。
# ポケモンの捕獲難度と謝礼金を教えてくれるポケモン図鑑クラスclassPokemonZukan:def__init__(self) ->None: self._data = pd.read_csv('resources/input/pokemon.csv', index_col='id')defget_capture_dificulty(self, pokemon_id:int) ->int:return self._data.loc[pokemon_id]['capture_dificulty']defget_reward(self, pokemon_id:int) ->int:return self._data.loc[pokemon_id]['reward']defget_name(self, pokemon_id:int) ->str:return self._data.loc[pokemon_id]['name']
擬似データの生成
擬似データの生成には、Open Bandit PiplineのSyntheticBanditDataset を用いました。以下のように、今回の状況に合わせてreward_function とbehavior_policy を定義してSyntheticBanditDatasetに与えるだけです(簡単ですね!)。reward_function は各アクションを取った時にポケモンが捕まる確率を返し、behavior_policy はストーリー編のstep2で定義したデータ収集用の意思決定モデルの出力を返すように定義しておきます。
def_reward_function( context: np.ndarray, action_context: np.ndarray, random_state: Optional[int] =None,) -> np.ndarray:# 省略# 各アクションを取った時にポケモンが捕まる確率を返すreturn capture_probabilitiesdef_behavior_policy( context: np.ndarray, action_context: np.ndarray, random_state: Optional[int] =None,) -> np.ndarray:# 省略# データ収集用の意思決定モデルの出力を返すreturn policydataset = SyntheticBanditDataset( n_actions=len(ACTIONS), dim_context=1,# pokemon_idの元になるfloat値を生成する reward_function=_reward_function, behavior_policy_function=_behavior_policy, random_state=615, )
ただし、SyntheticBanditDataset は今回のストーリーのような離散値の報酬を生成することができないので、以下のように後処理を行なっています。
def_update_reward(data: BanditFeedback) -> BanditFeedback: rewards = data['context'][:,2] costs = np.array([ACTIONS[action_id].costfor action_idin data['action'].flatten()]) data['reward'] = rewards * data['reward'] - costsreturn datadef_post_process(data: BanditFeedback) -> BanditFeedback:# .... data = _update_reward(data)# ...return datatraining_data = _post_process(dataset.obtain_batch_bandit_feedback(n_rounds=50000))validation_data = _post_process(dataset.obtain_batch_bandit_feedback(n_rounds=5000))test_data = _post_process(dataset.obtain_batch_bandit_feedback(n_rounds=1000))
意思決定モデルの学習
同書で紹介されているIPWLearner では、今回のストーリーのように報酬が負の値を取る場合に上手く学習することができません。そこで、報酬が負の場合にも柔軟に対応できるモデルであるNNPolicyLearner を用います*8。使い方はIPWLearnerとほぼ同じで、先ほど生成したデータを用いてfitし、predictするだけです。
classIPWModel(BaseModel):def__init__(self) ->None: self._model = NNPolicyLearner( n_actions=len(ACTIONS), dim_context=2, off_policy_objective=IPS().estimate_policy_value_tensor, random_state=615 ) self._scaler = StandardScaler()deffit(self, data: BanditFeedback) ->None: context = data["context"][:,1:] self._scaler.fit(context) scaled_context = self._scaler.transform(context) self._model.fit( context=scaled_context, action=data['action'], reward=data['reward'], pscore=data['pscore'], )defpredict(self, context: np.ndarray) -> np.ndarray: scaled_context = self._scaler.transform(context[:,1:])return self._model.predict(context=scaled_context)
モデルのオフ方策評価
Open Bandit Piplineを使えば、モデルのオフ方策評価も非常にシンプルに記述できます。OffPolicyEvaluation にバリデーションデータと使用する推定量を入れて初期化し、visualize_off_policy_estimates_of_multiple_policies を呼ぶだけです。
ope = OffPolicyEvaluation( bandit_feedback=validation_data,# バリデーションデータ ope_estimators=[IPS(estimator_name="IPS")]# 使用する推定量 ) ope.visualize_off_policy_estimates_of_multiple_policies( policy_name_list=list(action_choices.keys()), action_dist_list=list(action_choices.values()), random_state=12345, fig_dir=Path('./resources/output/'),)plt.clf()
モデルの真の性能の評価
真の性能はSyntheticBanditDataset のcalc_ground_truth_policy_value 関数に、テストデータのexpected_rewardと各意思決定モデルの出力を渡してやることで計算できます。
# 現状calc_ground_truth_policy_valueがSyntheticBanditDatasetのinstance methodになっているので、SyntheticBanditDatasetを適当な初期値でinstance化している。ground_truth_score = SyntheticBanditDataset(2).calc_ground_truth_policy_value(expected_reward=test_data['expected_reward'], action_dist=action_choice)
まとめ
この記事では、「施策デザインのための機械学習入門」の内容を、架空のストーリーを通して実践してみました。実際に手を動かしてみることによってさらに理解を深めることができました。今後、この本で学んだことを実務にも取り入れていきたいです。
また、Open Bandit Piplineを用いて手軽に実験を行うことができました。みなさんもぜひ使ってみてください。
この記事を読んだ方はこんな記事も読んでいます(多分)
- 「ポケモンを題材に因果推論を実践してみる」
- 「ポケモンを題材に「SQLアンチパターン」を実践してみる」
- データサイエンスや機械学習からは離れますが、こちらも本の内容を踏まえてストーリー形式で実践しています。
*1:施策デザインのための機械学習入門〜データ分析技術のビジネス活用における正しい考え方 -- 齋藤 優太, 安井 翔太
*2:この記事を含め、私が何度か書いているポケモンのブログ記事はいわゆる二次創作に相当すると考えられ、著作権に対して注意を払う必要があります。任天堂はゲーム内の動画や静止画に対するガイドラインにて、ガイドラインの範囲内で適切な動画や静止画の共有サイトに投稿することを許可しています。一方、本ブログ記事のような形式の二次創作に対しては、任天堂および株式会社ポケモンから明確なガイドラインは公表されていないようでした。そこで、本ブログ記事は収益性を持たないこと・ポケモンを貶める意図はないことを明言した上で、権利者に要求された場合は速やかに記事の公開を停止することをここに宣言します。
*3:「ポケモンを売ることでお金をもらえます」という説明が一番シンプルではあるのですが、ポケモンに値段をつけて売買することはポケモンの世界観に反するので、「ポケモン研究への協力金」というストーリーをひねり出しました。
*4:捕獲難度はポケモンWikiの捕捉率一覧 の大小を逆転させたものを用いています。
*5:謝礼金の金額は、赤緑青ピカチュウ攻略サイト の合計種族値を40で割ってから4乗したものを用いています。これにより、「強いポケモンほど謝礼金が大きい」かつ「ポケモンの種類によってそれなりに金額に違いがある」が成り立つようにしています。
*6: の期待値が元の目的関数
に一致することは同書で丁寧に解説されています 。
*7:ポケモン捕獲のA/Bテストってどうやるんでしょうね。ここでは、ポケモンと対面するたびにコインを投げてどちらのモデルを用いるか決めていたと考えてください。
*8:ただし、NNPolicyLearnerは近々破壊的な変更が入る予定があるようなので注意してください。今回私はv0.4.1で実装しました。
