
Category Archives:编程技术
Rust 适合开发游戏吗?
Rust 并不适合开发游戏,它更擅长有明确定义,边界清晰的项目,这样你类型体操一遍做完问题不大,比如重构个已经十年没变过的 C 模块,但游戏领域并没有明确的定义,策划案不停修改,你的代码不但要求快速迭代还要求不停重构,那么类型体操在这过程中就变成锁死你的紧箍咒。
参考文章:3 年写了 10 万行代码开发者吐槽:当初用 Rust 是被忽悠了
这里解释一下,为什么当项目没有明确定义时,rust 为啥会显得笨拙?因为此时不但需求会随时间变来变去,更要命的是你没有一份十年没变过的 C 代码做参考,对项目整体实现缺乏全局的认识,只有自底向上的方法不断尝试和修正自己,不段反思和改进中上层代码,才能像盲人摸象那样逐步认清楚整个世界因该是啥样。
而此时类型体操会在这时勒得你喘不过气来,一个之前需要横着用的变量现在需要竖着用了,你思来想去发现你完全没办像其他语言那样改成法竖着用了,于是你只有引入更大范围的重写才能解决问题,你觉得这样很难受,去 rust 社区寻求帮助,但发现他们并不会帮助你真的解决语言问题,只会一个劲的指责你 “你觉得痛苦正是因为你对 rust 不熟悉导致的” 或者 “rust 逼迫你更大范围重写正是逼你尽早写出更好的代码”,他们这么说在定义清晰的项目里的确没问题,越早重构越好,但在定义不清晰的项目上里存在大量中间设计,你今天改成这样,八成不是最终形态,隔几天可能还要改,而此时 rust 却逼迫你每次都提前费精力进行更大范围的重写,即使这时完全没必要的,过两天就不需要的,他也不许你像其他语言那样用快速实现的方式应对新的中间状态,等需求稳定了,技术方案也收敛的情况下再进行迭代和完善,然后你就抓狂了!
网友 FENG DONG:项目没有明确定义时候,需要设计 cost function,然后让代码沿着 gradient 演进。但 Rust 不是一种可微的语言。
网友 Aaltonen:游戏开发是 “巨型可变状态球” (giant balls of mutable state),需求像 gradient descent 一样逐步演进,但 Rust 的借用检查器(borrow checker)和所有权模型强制你 “一次性想好”,导致小改动引发大重构。
那么 Rust 适合开发游戏引擎么?我只能说 depends,主要到了现在也没啥 rust 开发游戏引擎的成功例子啊,一天到晚到处搞营销的 rust 游戏引擎 bevy 基本上类似个玩具,到现在都没啥靠谱的商业游戏案例,顶多几个独立小游戏之类,而且它要求用 rust 来写业务逻辑,这个上面已经论述过,它并不适合开发游戏业务逻辑;

GCC 利用未定义行为进行优化正确么?
说实话,编译器是否该利用 Undefined Behavior 进行优化目前都还是一个争议话题,主要是 gcc 开了个坏头,不予余力的在默认参数下利用 UB 来优化,举个例子,C 语言里带符号整数溢出是未定义行为,编译器应该假设它实际上以某种方式定义了:
int foo(unsigned char c) { int value = 2147483600; value += c; if (value < 2147483600) bar(); return value;}但利用这个 UB 进行优化的编译器会认为,既然 x 不会是负数,那么 value < 2147483600 就永远不会发生,所以整个 if 语句以及后面的 bar() 调用将可以被忽略,变成:
int foo(unsigned char c) { int value = 2147483600; value += c; return value;}这其实是一种很危险的做法,因为 C 语言可以跨越各种 CPU 架构编程,当年标准定义时,CPU 架构的差异比今天还大,在处理上面这类问题时,即便在今天,不同的架构结果并不一定相同,比如有的平台用补码表示负数,所以溢出了就会变成 -2147483648,而碰到反码或者原码表示负数的架构下,溢出了可能就变成 0 或者其它,所以一些事情根本就没法具体定义,必须留给具体编译器具体平台去处理。
Undefined Behavior 并不是说代码这么写是错的,相反他们都是语法正确的代码,真是错的应该就编译错误了,而是标准留个编译器实现者以自由,不去做限制,让他们根据实际平台,根据自己实现情况自行选择实现方式,而某些编译器实现选择利用它来进行优化了,那么如果本来就想利用特定平台的特性完成某些特定功能时,所以这类代码将没法写了。
关于这个问题,有个 X 友说的很准确,这里贴下译文(原文贴后面):
亲爱的 C 程序员们,既然你们似乎无法阅读关于你们编程语言的文档,让我为你们解释一下什么是未定义行为,更重要的是它不是什么。
引用 C 标准:
未定义行为:本国际标准未做任何强制要求的行为。(Undefined behavior: behavior for which this International Standard imposes no requirements)
这意味着标准并没有规定某些表达式该如何表现,编译器的创造者们可以自由选择他们想要的行为,例如:
- 使编译失败
- 删除有问题的表达式并继续编译
- 发送给你的前任一条“我想你了”的消息
- 将你的票投给一个 XX 主义政党
- 甚至定义该行为(以平台特定的方式或非特定方式)
即,编译器的职责是合理处理未定义行为的情况。C 标准并没有对编译器作者提出挑战,这不是 “尽情发挥,给我惊喜”,它仅仅是对某些表达式没有施加限制,因为给予编译器作者自由选择其解决方案是合情合理的,因为这可能依赖于平台。
未定义行为并不是关于“被禁止的表达式”,它仅仅是语法上正确的 C 代码,而 C 标准对此并不关心。
到目前为止,这一切都是合理的。
在处理未定义行为时,编译器作者有多种选择:
- 偏向一致的语义
- 偏向性能
- 偏向实现的简单性
- …
正确的答案总是 “默认优先语义而非性能”。可以有破坏语义的优化,但这些优化应该通过适当的编译选项来启用,以便那些知道自己在做什么的人(或至少在继续破坏代码之前,编译器会得到明确的同意)使用。
(点击 more/continue 继续阅读)
库代码中是否应该检查 malloc 的返回值?
现在网上有很多似是而非的观点,比如 malloc 失败不用处理,直接退出,这样的经验看似很聪明,实际却很局限,比如:
1)嵌入式设备:不是所有设备都能有一个强大的全功能的操作系统,也不是所有设备都能有虚拟内存功能。
2)长时间运行的程序,内存虽然够,但由于碎片,会导致没有连续足够大的线性地址进而分配失败,32 位程序特别明显。
3)管理员对某类进程设置过内存限制,比如某类要起很多个的进程,那么设置一下内存限制是一个很正常的操作。
4)程序通过容器运行,事先给定了最大内存用量。
5)操作系统 overcommit 选项被管理员关闭。
所以说 malloc 失败不用检测,大多数是明确知道自己运行环境的某一类程序,比如上层业务,比如 CRUD,比如你就是做个增删改查,知道自己运行于一台标准的 linux 服务器,那么确实无需多处理,崩了也就崩了;或者你的程序严重依赖 malloc 三行代码一次分配,那么即使恢复出来估计你也很难往下走,不如乘早崩溃,免得祸害他人。
上面这些情况确实可以简单粗暴处理,但如果你开发一些基础库,你没办法决定自己是会运行在一台标准服务器上还是某个小设备里,那么上面的经验就完全失效了。
比如你开发一个类似 libjpeg 的图象编解码库,你没法假定运行环境,那么 malloc 失败时,你是该自作主张直接 assert 强退掉呢?还是该先把分配了一半的各种资源释放干净,然后向上层返回错误码,由上层决定怎么处理比较好呢?比如上层可选择:1)报错退出;2)释放部分缓存后再运行;3)降级运行,比如图象编码使用 low profile 再运行一遍。
你作为图象编码库需要经常分配一些比较大块的内存,你这里失败了,不代表上层无法继续分配内存处理后续任务对不对?上层内存里有很多图片 cache 用于加速图片显示,你这里失败了,上层感知到,直接从 cache 里回收一波,内存就又有了,对不对?图象视频编码根据资源消耗高低都有 high profile, low profile 的运行模式,你 high profile 内存不够了报告上层,上层视情况还可以选择再用 low profile 跑一遍对不对?
就是上层什么都不做,只在检测到你的返回值时在日志里记录一行内存不够再退出,你也得给上层一个选择的权利,而不是不管不顾,直接退掉;所以,你一个库碰到这类问题还是要自己处理干净把错误返回给上层,让上层来判断该如何处理更恰当一些。
再一种是需要精细控制内存的应用层业务,比如自己主动管理多个内存池,栈上的池不够了就应该到堆上的堆上池分配,堆上池分配不了就应该回收,回收不了就向操作系统要新的,这种情况也不能一概而论。
那么是不是说所有的 malloc 都要去处理 NULL 返回?当然不是,这里强调的是你既然选择用 C 语言了,脑袋里要有根弦,知道这个问题需要分情况处理,区分得了哪些代码重要,哪些代码不重要;哪些代码要什么力道去写,写到多深,这样即使某些业务模块懒得处理了,不处理 NULL 或者写个 assert 也没问题,但如果头脑里没这跟弦,不知道不同层次的代码需要不同的力道去写,一概无脑的不处理或者 assert,那么这样的代码写多了,只会越写越笨。
性能测试:asyncio vs gevent vs native epoll
测试一下 python 的 asyncio 和 gevent 的性能,再和同等 C 程序对比一下,先安装依赖:
pip3 install hiredis gevent如果是 Linux 的话,可以选择安装 uvloop 的包,可以测试加速 asyncio 的效果。
测试程序:echo_bench_gevent.py
import sysimport geventimport gevent.monkeyimport hiredisfrom gevent.server import StreamServergevent.monkey.patch_all()d = {}def process(req): # only support get/set cmd = req[0].lower() if cmd == b'set': d[req[1]] = req[2] return b"+OK\r\n" elif cmd == b'get': v = d.get(req[1]) if v is None: return b'$-1\r\n' else: return b'$1\r\n1\r\n' else: print(cmd) raise NotImplementedError() return b''def handle(sock, addr): reader = hiredis.Reader() while True: buf = sock.recv(4096) if not buf: return reader.feed(buf) while True: req = reader.gets() if not req: break sock.sendall(process(req)) return 0print('serving on 0.0.0.0:5000')server = StreamServer(('0.0.0.0', 5000), handle)server.serve_forever()测试程序:echo_bench_asyncio.py
(点击 Read more 展开)
别被忽悠了 Lua 数组真的也可以从 0 开始索引?
先前我说 Lua 数组从 1 开始不太爽,很多人来纠正我说也可以从 0 开始,比如:
local m = { [0] = 100, 101, 102, 103 }然后访问时 m[0] 也可以正常访问到第 0 个元素,所以 “Lua 给你充分自由度,让你可以从任意下标索引数组”,貌似好像说的很有道理,但是不是这样呢?
我们先用# 符号打印下上面数组的长度:
print('size', #m)输出是:3 ,而不是实际元素个数 4,因为# 就是从 1 开始数起的,所以如果你代码里用了 m[0] ,你也需要额外方式计算长度,同时保证用到这个数组的其他代码也遵从这样计算。
还有一个问题,使用ipairs 遍历的时候,m[0] 不会被遍历进去:
for i, j in ipairs(m) do print(i, '->', j)end输出是:
1 -> 1012 -> 1023 -> 103看到没,你的 m[0] 没了,即便你写了个 m[0] = 100 ,再ipairs 那里也不认,Lua 没把他算在整数索引范围。那么如果你创建一个数组从 0 开始索引的话,你就要通知所有用你数组的人,既不能用# 也不能用ipairs 来遍历,这种沟通成本和后续无穷的麻烦,你愿意接受吗?
那么你说,我们不用ipairs ,改用pairs 来遍历行不行?行,你可以这么写:
for i, j in pairs(m) do print(i, '->', j)end但数组从 0 开始的话,0 元素没有保存在 array part 里,会导致遍历顺序不一样(因为优先遍历 array part),上面代码的输出是:
1 -> 1012 -> 1023 -> 1030 -> 100看到没,先遍历的 1-3(他们在 array part 里),最后再遍历 hash part 里 0。你喜欢这样的无序遍历的数组么?还是继续坚持 for i = 0, N-1 do 来自己遍历,并通知你的同事这样才能保持顺序。
最后一个问题是,一个 table 中 1-n 的连续整数索引都会被保存到 array part 里,而其他会被保存到 hash part 里,不管是检索还是遍历,都会优先到 array part 里用 O(1) 的方式检索,不行再到 hash part 用非 O(1) 的方式同其他 key 一起检索,那么你 m[0] 是游离在 array part 外的键,不但遍历顺序靠后,没和其他元素放一起,每次检索还有额外代价。
因此 Lua 支持数组从 0 开始索引么?只能说允许你这么用,但是语言层面并不提供足够的支持。
那么又会有人混淆视听的说:“从 1 开始也挺好的啊,我有着并没用什么问题”,但他们是不是忘记了 Lua 是嵌入式语言,要依靠宿主 C 语言提供运行环境,数组从 1 开始的话,和 C 语言宿主存在一个换算的关系,两边都写得话,一会从 0 一会从 1 ,引入了额外的负担,不留神就 BUG 了。
—
扩展阅读:还有觉得从 1 开始更合理的点这里
为什么 C 语言数组是从 0 开始计数的?
C 语言等大多数编程语言的数组从 0 开始而不从 1 开始,有两个原因:
第一:地址计算更方便
C 语言从 0 开始的话,array[i] 的地址就正好是:
(array + i)如果是从 1 开始的话,就是
(array + i - 1)多一次计算,性能受影响,再扩展到二维数组的话 array[i][j] 从 0 开始的地址是:
(array + i * N + j)多整洁,而从 1 开始要变成
(array + (i - 1) * N + (j - 1))更繁琐。并且用 1 开始的话,同一个地址用 “指针+偏移”寻址和用 “数组+下标” 寻址还不能统一,经常要换算,何必呢?
第二:计算机硬件系统就是从 0 开始寻址的
物理内存地址寻址,端口寻址都是从 0 开始的,比如 32 位电脑的内存,地址范围就是:
[0, 2 ^ 32 - 1]刚好用一个 32 位整数就能表达,而如果内存从 1 开始寻址,那么 32 位电脑的地址范围就会变成:
[1, 2 ^ 32]那么最高地址 2 ^ 32 就需要一个 33 位的整数才能表达了,纯粹浪费资源。
其他的端口地址,DMA 通道等也都遵从这个从 0 开始的原则,那么用 3 比特表示 DMA 通道的话,更好可以表达 8 个通道 (0 – 7),而从 1 开始的话,同样 3 比特就只能表达 7 个通道了(1 – 7),一样是在浪费资源。
所以贴近系统的语言自然选择遵从硬件设定,除了第一条说的寻址计算更简单外,也能和计算机系统保持一致性,同时还能统一指针寻址和数组寻址的用户体验。
Dijkstra 解释过编程语言这么做的原因只是遵从硬件设计:
The decision taken by the language specification & compiler-designers is based on the decision made by computer system-designers to start count at 0.
所以 C 语言数组从零开始,目的在于:1)性能更好;2)统一数组和指针寻址;3)遵从硬件寻址法。
除此之外还有一些理论上的原因。
第三:数学上的原因
除去数组索引外,Dijkstra 主张一切计数应该从 0 开始,并且写了一篇文章解释:
(点击 more/continue 继续)
用 Lazarus 做界面合适吗?
也许你没留意,很多你经常用的桌面软件是用 Lazarus 开发的。
作为 Delphi 的开源替代品,我一直是比较喜欢 Lazarus 的,虽然有些小众。技术有两种,有些是用来挣钱养家,用来赶进度大规模集团作战的;还有一类是出于兴趣,单纯觉得好玩,会不自觉的有空就翻出来当爱好的,比如 Lazarus 就是一个很好玩的玩具。
因此不用成天纠结 “谁是 GUI 天下第一” 之类内卷的问题,抱着轻松和评测+鉴赏的心情了解下或许也不错。
在此之前,得先说两句 Delphi,姚冬老师,知乎编程板块无人不知,给了 Delphi 这样的评价:
Delphi 是神作,它在 RAD(快速应用开发)领域长时间没有对手,直到BS架构取代CS架构。Delphi 的特点就是简单、开发快,单纯就写个基本可用的应用来说,可能至今都没有比他更快的。
为啥作为国内最早使用 Qt 的人,却会给 Delphi 那么高的评价呢?中小应用开发 “至今没有比他更快的技术”这么高的评价,必然是有原因的,无独有偶,另一位 Qt 大神也发表示过对 Delphi 继承者 Lazarus 的喜爱:

Delphi 的继承人有两个,第一个是 C# Winform,几乎是把 Delphi 的整个开发模式迁移过去了;第二个就是 Lazarus。你用 C# Winform 没有任何问题,但 Lazarus 作为另外一个选择,它有其不可替代性:
- 免费开源,跨平台,支持:Windows, Linux, macOS, FreeBSD。
- Native 语言做 GUI 更加硬朗:更快响应,更低内存占用,不易破解。
- 高度还原 Delphi 开发方式,控件丰富。
Lazarus 使用 Free Pascal 和 Free VCL (LCL) 基本做到和 Delphi 项目源代码级别的兼容了,喜欢 Delphi 开发的,迁移 Lazarus 基本上都很容易,配张图感受下:

看看上边那一排丰富的控件,左边熟悉的控件属性面板,是的,原汁原味的 Delphi/BCB 的感觉。
Lazarus 在 2012 年发布 1.0 后在 Source Forge 上到 2020 年累计突破了 400 万的下载次数,持续迭代了多个版本后,于 2022 年发布了 2.2.0 版本,比前作更加稳定和完善。Lazarus 免费并且开源,允许用于商业开发的,这意味着你不需要花几万元购买 DELPHI 或者 VS 就可以开发商业应用。
(点击 more/continue 继续)
给 Qt5 引入 C# / Delphi 的 Anchor Layout
在前文用 MFC 写 GUI 程序是一种什么样的体验? 中提过 Anchor Layout 可以很简单的设定让控件跟随窗口四条边大小变化的策略:

比如右下角的两个按钮,设置的 anchor 是 “right,bottom” 他们在窗口扩大缩小时,会跟右和下两条边保持恒定距离,左上角的文字是 “left,top” 的 anchor,他会保持恒定的左边距和上边距,中间文字框的 anchor 是四个方向的 “left,top,right,bottom” 他会和窗口四条边框保持相同边距,因此会随窗口扩大而扩大。
这种布局方式最早是 Delphi / C++ Builder 引入的,非常简单实用,后来被 C# Winform 原封不动的抄了过去,而 QtWidgets 里用了另一套规则,虽然用起来更精细了,却没有 anchor layout 这么简单直白。
虽然 QtQuick 和 QGraphicsItem 里面也支持 anchor 布局,不过原生的 QtWidgets 里并没有支持,所以我写了两行代码解决了这个问题,只需要在窗体的 resizeEvent() 里调用下 AnchorLayout 类的 update() 方法,就能将所有子控件中包含 “anchor” 属性的 geometry 全部按照 c# 规则更新:(点击 Read more 展开)
用 MFC 写 GUI 程序是一种什么样的体验?
本文来自知乎问题:MFC、WTL、WPF、wxWidgets、Qt、GTK 各有什么特点?
感觉我说了太多 Qt 的事情了,今天只说一下 MFC ,到底过时在哪里,都在说 “MFC 就是 xxx” 类似的话,我来补充点细节,增加点感性认识,到底 MFC 过时在哪里?想要用好 MFC 可以怎么办?
虽然 MFC 也有 DIALOG 的设计器,似乎可以拖一下控件,做个 hello world, 计算器之类的好像也很简单,但是稍微复杂那么一点就麻烦了,比如布局,MFC 里的控件只能设置绝对坐标和大小,那么如果你的窗口扩大或者缩小了,想自动改变内部特定控件的大小和位置怎么办?比如 C# 里随便设置一下各个控件的 docking 和 anchor 就能:
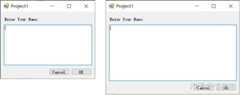
C# 里给控件设置 docking/anchor:窗口变大变小后就能自动调整控件的位置和大小
就能让某些控件随窗口变大而移动,某些控件随窗口变大而变大,而某些控件不变,这在任何 GUI 库里都是最基础的功能,都可以在设计器里点两下就做到的事情,MFC 却需要重载 WM_SIZE, WM_SIZING 消息来自己写代码每次手工计算所有控件的新坐标和大小,想写的通用点,还得上千行的代码,枚举所有子控件,根据额外信息重新计算位置大小,虽然 2015 的 MFC 里加了一个半成品的布局信息,但是基本没用,你在 MFC 的设计器里拖控件,都是写死坐标和大小的。(点击 Read more 展开)
怎么样打包 pyqt 应用才是最佳方案?
早先看一堆人说 PyQt 打包麻烦,部署困难的,打出来的包大(几十兆起步),而且启动贼慢,其实 Python+PyQt 打包非常容易,根本不需要用什么 PyInstaller,我手工打包出来的纯 Python 环境只有 5MB,加上 PyQt 也才 14MB。
很多人用 PyInstaller 喜欢加一个 -F 参数,打包成一个单文件:
这样的单文件看起来似乎很爽,其实他们不知道,这其实是一个自解压程序,每次运行时需要把自己解压到 temp 目录,然后再去用实际的方式运行一遍解压出来的东西:
Process Explorer 把雷达图标拖动到 pyqt_hello.exe 的窗口上,可以看到有两个 pyqt_hello.exe 的文件,外面那个是你打包出来的,里面那个才是真正的程序(虽然可执行都是一个),看看它下面依赖的 python310.dll 是在哪里?这不就是一个临时解压出来的目录么:
看到没?这就是你 PyInstaller 打包出来的 30MB 的程序,每次运行都要临时解压出 71MB 的文件,运行完又删除了,那么如果打包出来的可执行有 100MB,每次运行都要释放出 200-300 MB 的东西出来,所以为什么 PyInstaller 出来的单文件运行那么慢的原因除了每次要解压外,还有杀毒软件碰到新的二进制都要扫描一遍,你每次新增一堆 .dll , .pyd, .exe,每次都要扫描,不慢可能么?
其实 PyInstaller 如果不打包成单文件可执行(-F 参数),用起来问题不大,唯一不足有两个,首先是很多动态库其实我没用比如上面的 socket, ssl, QtQuick 等,但都被打包的时候打进去了,大小会偏大;其次是目录看起来很乱,上百个文件一个目录,找主程序都找不到。
正确的打包姿势
当然是手工打包,现在 Python 3.5 以后,官方都会发布一个嵌入式 Python 包:
链接在这里:Python Release Python 3.8.10
(点击 more/continue 继续)