
Category Archives:图形编程
Raylib 这种立即模式的图形引擎如何呢?
最近 raylib 比较火,又是移植 web 又是移植掌机,看了眼 raylib 的例子代码,知道它为什么代码量那么少了,它甚至连一个显示对象树/场景树都没有实现,就是直接调用各种 draw 函数,和 ImGUI 一样属于 “立即模式”,这种模式做点简单的东西很舒服,对象一多一复杂就会比较麻烦:
那么这种每帧控制自己绘制的立即模式有啥问题呢?

如何在八叉树里寻找离某位置最近的点?
第一步:如果给定点 z 在八叉树包围盒内就从所属的最末端的子包围盒叶子节点开始,如果在八叉树外的话就从任意最靠近的叶子节点开始,先找一个最靠近 z 的候选点 A,如果叶子节点包围盒是空的,就递归向上,总之先找到第一个候选点 A。
第二步:以 z 为圆心,z 到 A 的距离为半径,做一个球体 S,把球体 S 同八叉树求交(离 z 最近的点一定落在这个球体范围内),筛选出有交集的叶子节点包围盒,然后迭代这些叶子节点包围盒里的点,一旦找到更近的就缩小球的范围,这样就能找到离 z 最近的点了。
如果要找前 k 个距离最近的点,你需要维护一个长度为 K 的优先队列(或者最大堆),在找到最近邻居的基础上,将兄弟节点邻近的候选点都填充到队列里,直到队列里装满 k 个点,此时以 z 为圆心,队列里第 k 个离 z 最近的点为半径,对八叉树做一次范围搜索(前 k 个点一定落在该范围内),搜索过程中不断更新优先队列并及时根据最新的第 k 个点离 z 的距离调整半径。
如何使用 C++ 写一个可编程软件渲染器?
今天你想用最新的 D3D12 画一个三角形,少说也要上千行代码了,对于初学者来讲,这个门槛是非常高的,太多干扰了,而一千多行代码,已经足够你重头实现一个简易版 D3D 了,为什么不呢?比起从图形 API 入门,不如从画点开始,同样一千行代码,却能让你对 GPU 的工作原理有一个直观的了解。
因此,为了让希望学习渲染的人更快入门,我开源了一个 C++ 实现可编程渲染管线的教程:
那么网上软件渲染器其实不少,这个 RenderHelp 和他们有什么区别么?区别有三:
第一:实现精简,没依赖,就是一个 RenderHelp.h 文件,单独 include 它就能编译了,不用复杂的工程,导入一堆源文件,vim/vscode 里设置个 gcc 命令行,F9 编译单文件即可。
第二:模型标准,计算精确,网上很多软渲染器实现有很多大大小小的问题:比如纹理不是透视正确的,比如邻接三角形的边没有处理正确,比如 Edge Equation 其实没用对,比如完全没有裁剪,比如到屏幕坐标的计算有误差,应该以像素点方框的中心对齐,结果他们对齐到左上角去了,导致模型动起来三角形边缘会有跳变的感觉,太多问题了,对于强迫症,画错个点都是难接受的,RenderHelp 采用标准模型,不画错一个点,不算错一处坐标。
第三:可读性高,全中文注释,一千多行代码 1/3 是注释,网上很多同类项目,属于作者自己的习作,重在实现,做完了事,注释量不足 5%,一串矩阵套矩阵的操作过去,连行说明都没有,你想搜索下相关概念,连个关键字都不知道。RenderHelp.h 是面向可读性编写的,虽然也比较小巧,但重点计算全部展开,每一处计算都有解释。某些代码其实可以提到外层运行更快些,但为了可读性,还是写到了相关位置上,便于理解。
渲染效果图片:

使用很简单,include 项目内的RenderHelp.h 即可,VS 和 PS 之间传参,主要使用一个ShaderContext 的结构体,里面都是一堆各种类型的 varying:
// 着色器上下文,由 VS 设置,再由渲染器按像素逐点插值后,供 PS 读取struct ShaderContext { std::map<int, float> varying_float; // 浮点数 varying 列表 std::map<int, Vec2f> varying_vec2f; // 二维矢量 varying 列表 std::map<int, Vec3f> varying_vec3f; // 三维矢量 varying 列表 std::map<int, Vec4f> varying_vec4f; // 四维矢量 varying 列表};外层需要提供给渲染器 VS 的函数指针,并在渲染器的 DrawPrimitive 函数进行顶点初始化时对三角形的三个顶点依次调用:
// 顶点着色器:因为是 C++ 编写,无需传递 attribute,传个 0-2 的顶点序号// 着色器函数直接在外层根据序号读取响应数据即可,最后需要返回一个坐标 pos// 各项 varying 设置到 output 里,由渲染器插值后传递给 PS typedef std::function<Vec4f(int index, ShaderContext &output)> VertexShader;每次调用时,渲染器会依次将三个顶点的编号 0, 1, 2 通过 index 字段传递给 VS 程序,方便从外部读取顶点数据。
渲染器对三角形内每个需要填充的点调用像素着色器:
// 像素着色器:输入 ShaderContext,需要返回 Vec4f 类型的颜色// 三角形内每个点的 input 具体值会根据前面三个顶点的 output 插值得到typedef std::function<Vec4f(ShaderContext &input)> PixelShader;像素着色程序返回的颜色会被绘制到 Frame Buffer 的对应位置。
完整例子很简单,只需要下面几行代码就能工作了:(点击 Read more 展开)
OpenGL / DirectX 如何在知道顶点的情况下得到像素位置?
DirectX 和 OpenGL 是如何得知对应屏幕空间对应的纹理坐标和顶点色的呢?一句话回答就是光栅化。具体一点,实现的话,一般有两种方法:Edge Walking 和 Edge Equation。
两个我都完整实现过,下面分别介绍下具体原理:
Edge Walking
基本上所有基于 CPU 的软件渲染器都使用 Edge Walking 进行求解,因为计算量少,但是逻辑又相对复杂一点,适合 CPU 计算。具体做法分为三个阶段:
第一阶段:拆分三角形,将一个三角形拆分成上下两个平底梯形(或者一个),每个梯形由左右两条边和上下两条水平线(上底,下底)表示。

普通三角形可以拆分成上下两个平底三角形,不管是上面的那一半还是下面的那一半,都可以用一个平底梯形来表示(即上底 y 值 和下底 y 值,以及左右两边的线段),这样再送入统一的逻辑中渲染具体某一个平底梯形。
第二阶段:按行迭代,然后以梯形为单位进行渲染,先从左右两条边开始,一行一行的往下迭代,每迭代一次,y坐标下移1像素,先根据左右两边线段的端点计算出左右两边线段与水平线 y 的交点:
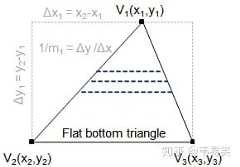
然后继续插值出左右两边交点的纹理坐标,RGB 值 之类的 varying 型变量,然后进入扫描线绘制阶段。
第三阶段:按像素迭代,有了上面步骤计算出来的一条水平线,以及左右端点的各种 varying 变量的值,那么就进入一个 draw_scanline 的紧凑循环,按点进行插值,相当于 fragment shader 干的事情。
计算 varying 变量插值的时候需要进行透视矫正,根据平面方程和透视投影公式,可以证明屏幕空间内的像素和 1/w 是线性相关的,而三维空间的 x / w, y / w, z / w 和屏幕空间也是线性相关的,也即各个 varying 变量按屏幕空间插值时需要先 / w,然后按照屏幕空间每迭代一个点时再除以最新的(1/w)就可以还原改点的真实 varying 变量值。
完整实现可以参考我写的 700 行软件渲染器:
而对于透视矫正的数学原理不清楚可以看《透视矫正原理》这篇文章。
上面是第一种方法。
Edge Equation
这个方法简单粗暴,虽然计算量较大,但是计算方法简洁而单一,适合 GPU 实现,即按照三角形外接矩形(或者屏幕上任意矩形),两层 for 循环迭代每一个一个像素,先走一遍 Edge Equation 判断是否再三角形范围内,如果否的话就跳出,如果是的话,使用插值方式得到各个 varying 变量的值(纹理坐标,RGB顶点色和法线等)。
由于没有像 Edge Walking 一样迭代左右两边的每个像素,所以插值使用了一种“重心坐标”的公式,直接参考三个顶点的位置和当前点重心坐标来插值:(点击 Read more 展开)
为什么图形学人才这么少?
图形学人才变少了,原因说起来很简单,就是锻炼的机会越来越少了呗,以前是家游戏公司都要研发自己的图形引擎,没有标准化,也没有成熟的商用引擎,更没有完善的开源引擎。
那么你但凡一家公司要做产品,势必要有一批人研发自己的引擎,大公司有时间自己慢慢搞全新的,中小公司没资源从头做,至少也要会修改 irrlicht 和 ogre,改着改着也就成自己的东西了,不想改也没关系,挖个拿着上家公司祖传源码的 “牛人” ,过来魔改一堆接口名称,一个新的引擎就诞生了。
那么你一个才毕业的应届生,即便以前从没碰过这一块,只要灵光点,是有很多机会接触到相关工作的,引擎要不断的升级,不断的开发周边工具,经过一个个项目的实战,总能不断成长,哪天碰到公司内外的新项目机会或者上面的人离职了,就能够把各大引擎按照自己的想法再抄一遍,再一不小心给新项目挖几个坑,有幸填完的话,一个新的图形学人才就这么锻炼出来了。然后进可以到大公司从事更专业的工作,退可以到中小公司当个“大牛”。
大公司肯定需要这样的人,发财的中小公司愿意两倍薪水挖这样的人,没发财的中小公司会意识到自己没发财很大原因是没有牛人导致图形效果不好,卡顿和崩溃。
所以人才得以上下流动,对应届生也能一步步的阶梯化成长。而现在就完全反过来了。
除了大公司外,98%的中小公司老板不愿意投资引擎,风险高,见效慢。而且关键是但凡一家外包美术公司,如果你用标准引擎,他们都能给你按标准格式输出各种素材,都能熟练使用标准引擎的各种上下游编辑器。游戏公司自己即便作出个引擎来。周边工具的缺失和非标准化所带来的成本是无可估量的。
作为游戏项目的技术团队,如果同时有公司内闭源引擎和 u3d,除非公司强制,或者前者特定领域下能秒杀后者,否则大部分时候都会选用u3d,因为于公而言,内部引擎文档匮乏,找人困难,培训时间长,找个有经验的人进来也要熟悉一半天。于私而言,自己花几年把经验积累到公司内部引擎上,换家公司,这些经验就白费了,人家需要的东西自己还很不熟,何必呢?
所以当有成熟引擎可用时,不论老板还是员工,因公还是因私,利益最大化的选择都是用现成的而非自研。
你可以说用同样引擎的游戏画面千篇一律,u3d做出来都像乐高玩具,ue34做出来画面看起来都很脏,cry做出来太刺眼,3A大作都有自己的引擎,所以画面才有自己的特点。
这说的没错,但是还有一个边际效应问题,现在不像过去做端游,手游夜游生命周期平均也就几个月,你能指望公司养你半年做引擎?而一款成熟的自研引擎无疑都是要成年计算的迭代时间和无数个项目的试错才可能成熟。游戏生命比过去缩短了三倍,然而引擎的研发周期和复杂度却增长了三倍,人员工资也上涨了三倍,相应整体投资风险也比过去也就高了二十七倍了。
所以除不差钱的大公司外,上到老板,下到项目组和上下游企业,都更愿意选择标准化的外部引擎而不是自研的话,原有的引擎团队的重要性就会降级,就会被打散或者重组,或者没有高薪资自然被分流。
那么一个毕业生,就再也难以有机会从事到相关工作中去了,没有真刀真枪的项目锤炼,没有百万用户终端上填过各种坑的技术,是很难有突破性成长的。
就算你有幸进入到了还有引擎团队的公司里去,你也会因为担心离开这里不好找对口的工作,而不得不考虑转方向的后路。
和以前任何一个图形程序员离职一堆公司疯抢的情况已经完全不同了,需求直接砍去了一大半。
当然,你特别牛的话就可以照样跳出三界外不在五行中,我讨论的大量普通水平的从业人员。而今天的牛人也是从过去普通水平的人里进化出来的。
而现在需求断了,导致人才流动的路径变窄,最终锻炼机会没了,三角循环,自然人才就少了。
256字节3D程序是如何实现3D引擎的呢?
网上有很多 256 个字节实现图形渲染的 “引擎”,他们的原理是什么呢?
- 全都不是基于正统3D引擎的多边形绘制,而是基于少数特定情况的简化版光线跟踪算法
- 只能渲染特定几种物体,并不能渲染通用物体。
- 无资源或者少资源(基本靠生成),重复
- 16位代码,COM格式的可执行(没有PE头,代码数据和栈都在一个段内,指针只有两字节)
- 尽可能用汇编来写
你自己花点时间也能做出来,
具体解释一下:
简化版的 raycasting,实现起来的代码量比通用的多边形绘制方法至少 N个量级。
基本的光线跟踪,在 320×200 的解析度下,从摄像机中心射出 320×200条光线,屏幕上每个点对应一条光线,首先碰撞到的物体的位置颜色,就是屏幕上这个点的颜色:

可以描述为下面这段代码:
for (int y = 0; y < 200; y++) { for (int x = 0; x < 320; x++) { DWORD color = RayCasting(x, y); DrawPixel(x, y, color); }}其中函数 RayCasting(x, y) 就是计算从视点开始穿过屏幕上 (x, y)这个点的射线。
所谓简化版的光线跟踪,是只需要实现特定物体,以及针对特定条件,比如早年游戏里面用的最多的实时光线跟踪绘制地形高度图的(比如三角洲特种部队,xxx直升飞机):

比如云风 2002年写过的文章:3D地表生成及渲染 (VOXEL)
实现上述效果的地形渲染,只需要 200多行 C 代码
使用标准三角形渲染这样的地形(软件渲染),代码少说也上千行了,使用标准的光线跟踪少说也要 500行左右。
3D 图形光栅化的透视校正问题
写了文章《如何写一个软件渲染器》以后,不少网友希望进一步解释背后的数学公式,询问以及自己加一个 phong 光照该如何加,本文将对透视纹理映射的插值原理做一个简单的解释,希望能帮助到大家:
透视纹理绘制发生在最后阶段,坐标已经完成 projection,剔除,裁剪了,然后顶点/w,开始批量绘制扫描线之前,这时候开始计算纹理的位置。
使用 w 还是用 z,关系不大,早年的 3D 引擎,直接 /z 的,只是后面标准化了以后,发现 w 更好用,可以同时表示透视投影和正交投影。同时顶点经过标准的 mvp 矩阵运算后,w 和 z 是承线性关系的,方便对 z/w 做 [0,1] 的 cvv 裁剪。你可以理解成 w 就是另外一个 z。以前屏幕坐标:
x' = x / z * d + Ay' = y / z * d + A现在是
x' = x / w * d + Ay' = y / w * d + A然后绘制纹理前,你需要先证明屏幕上两个点之间,1/w 承线性关系,即屏幕上两个点X1′, X2′ 之间任意取一点 X3’,他们的 (1/w) 值的变化比例相同,即在 t 取任意值有:
x3' = x1' + (x2' - x1') * t(1 / w3) = (1 / w1) + ((1 / w2) - (1 / w1)) * t再根据他们在同一个平面上,证明屏幕上两个点之间,u/w, v/w 承线性关系,即 t 取任意值有:
x3' = x1' + (x2' - x1') * t(u3 / w3) = (u1 / w1) + ((u2 / w2) - (u1 / w1)) * t(v3 / w3) = (v1 / w1) + ((v2 / w2) - (v1 / w1)) * t具体到代码里面的做法就是三角形的三个顶点 /w 以后,u 和 v 也同时/w,然后把w换成自己的倒数:w = 1 / w,及把顶点数据:
(x, y, z, w) + (u, v)变换成:
(x / w, y / w, z / w, 1 / w) + (u / w, v / w)然后用 1/w, u/w, v/w 进行屏幕空间插值,具体绘制某个点的时候,先从 1/w 求倒得到 w,然后乘以 u/w, v/w 得到 u, v,就可以了。
更进一步,可以证明,所有在三维空间里同 x,y,z 成线性关系的变量,不管是纹理坐标,顶点色或者法向还是其他,他们在屏幕空间里的插值规则都可以通过:插值前先 /w ,插值后要用时再 * w 得到具体值,然后我们把这类三维空间里同 x,y,z 成线性关系的变量统进行统一的批量处理,和 OpenGL 的 attribute,varying 处理方法相同。
相关阅读:
如何写一个软件渲染器
OpenGL / DirectX 如何在知道顶点的情况下得到像素位置?
还原被摄像机透视的纹理
如何用 OpenGL 封装一个 2D 引擎?
如何正确的使用 OpenGL “封装一个2D引擎” ?以下几个步骤:
1. 别用什么 glBegin/glEnd,至少写兼容GLES2代码,不然手机上跑不起来。
2. 用两个三角形的纹理拼凑出一个2D的图块出来,不是搞啥每个点自己画。
3. 2D图像库基本就是要把显示对象树给做出来就得了。
4. 每个显示对象除了自己外还有很多儿子节点。
5. 每个显示对象有一个变换矩阵,用来设置位置和角度还有缩放,最后是节点的显示效果。
6. 渲染的时候需要从远到近排序,并尽量归并相同效果(fs)及纹理。
7. 把常用纹理管理起来,提供资源加载,可以换进换出,提供类 LRU的机制。
8. 在此基础上提供一些动画(精灵)和场景控制的api,提供显示字体,即可。
最后推荐两个现成的轻量级2D引擎供阅读:
EJoy2D:GitHub – ejoy/ejoy2d: A 2D Graphics Engine for Mobile Game
就是这样。
计算机底层是如何访问显卡的?
以前 DOS下做游戏,操作系统除了磁盘和文件管理外基本不管事情,所有游戏都是直接操作显卡和声卡的,用不了什么驱动。
虽然没有驱动,但是硬件标准还是放在那里,VGA, SVGA, VESA, VESA2.0 之类的硬件标准,最起码,你只做320x200x256c的游戏,或者 ModeX 下 320x240x256c 的游戏的话,需要用到VGA和部分 SVGA标准,而要做真彩高彩,更高分辨率的游戏的话,就必须掌握 VESA的各项规范了。
翻几段以前写的代码演示下:
例子1: 初始化 VGA/VESA 显示模式
基本是参考 VGA的编程手册来做:
INT 10,0 - Set Video Mode AH = 00 AL = 00 40x25 B/W text (CGA,EGA,MCGA,VGA) = 01 40x25 16 color text (CGA,EGA,MCGA,VGA) = 02 80x25 16 shades of gray text (CGA,EGA,MCGA,VGA) = 03 80x25 16 color text (CGA,EGA,MCGA,VGA) = 04 320x200 4 color graphics (CGA,EGA,MCGA,VGA) = 05 320x200 4 color graphics (CGA,EGA,MCGA,VGA) = 06 640x200 B/W graphics (CGA,EGA,MCGA,VGA) = 07 80x25 Monochrome text (MDA,HERC,EGA,VGA) = 08 160x200 16 color graphics (PCjr) = 09 320x200 16 color graphics (PCjr) = 0A 640x200 4 color graphics (PCjr) = 0B Reserved (EGA BIOS function 11) = 0C Reserved (EGA BIOS function 11) = 0D 320x200 16 color graphics (EGA,VGA) = 0E 640x200 16 color graphics (EGA,VGA) = 0F 640x350 Monochrome graphics (EGA,VGA) = 10 640x350 16 color graphics (EGA or VGA with 128K) 640x350 4 color graphics (64K EGA) = 11 640x480 B/W graphics (MCGA,VGA) = 12 640x480 16 color graphics (VGA) = 13 320x200 256 color graphics (MCGA,VGA) = 8x EGA, MCGA or VGA ignore bit 7, see below = 9x EGA, MCGA or VGA ignore bit 7, see below - if AL bit 7=1, prevents EGA,MCGA & VGA from clearing display - function updates byte at 40:49; bit 7 of byte 40:87 (EGA/VGA Display Data Area) is set to the value of AL bit 7转换成代码的话,类似这样:
// enter standard graphic modeint display_enter_graph(int mode){ short hr = 0; union REGS r; memset(&r, 0, sizeof(r)); if (mode < 0x100) { r.w.ax = (short)mode; int386(0x10, &r, &r); r.h.ah = 0xf; int386(0x10, &r, &r); if (r.h.al != mode) hr = -1; } else { r.w.ax = 0x4f02; r.w.bx = (short)mode; int386(0x10, &r, &r); if (r.w.ax != 0x004f) hr = -1; } return hr;}
BasicBitmap:比 SDL/DirectDraw/GDI 更快的位图库
开源一个高性能位图库,之前对我的二维图形库pixellib 的部分代码进行了精简和重写,最终形成一个只包含两个文件(BasicBitmap.h, BasicBitmap.cpp)的图形基础库。
在今天 GPU 绘制横行天下的时候,任然有很多时候需要使用到纯 CPU实现的图形库,比如图像处理,视频预处理与合成,界面,以及GPU无法使用的情况(比如某个应用把gpu占满了,或者无法通过gpu做一些十分灵活的事情时),纹理处理,简单图片加载保存等。
支持 SSE2/AVX 优化,比 DirectDraw 快 40%(全系统内存绘制),比 SDL 快 10%,比GDI快 38%。如果你需要一个方便的高性能位图库,足够高性能的同时保证足够紧凑。
如果你有上述需求,那么你和我一样需要用到 BasicBitmap,只需要把 BasicBitmap.h/.cpp 两个文件拷贝到你的代码中即可。我正是为了这个目的编写了这两个文件。
项目地址
特性介绍
- 高度优化的 C++ 代码,可以在任意平台编译并运行
- 多重像素格式,从8位到32位:A8R8G8B8, R8G8B8, A4R4G4B4, R5G6B5, A8, 等.
- Blit (Bit Blt) ,包含透明和非透明的模式。
- 像素格式快速转换
- 使用不同的 Compositor 进行 Blending
- 使用不同的过滤器进行缩放(nearest, linear, bilinear)
- 高质量位图重采样(Bicubic/Box)
- 支持从内存或者文件直接读取 BMP/TGA 文件
- 支持从内存或者文件直接读取 PNG/JPEG 文件(Windows下)
- 保存图片为 BMP/PPM 文件
- 核心绘制函数可以被外部实现通过设置函数指针重载(比如 SSE2实现)
- 比 DirectDraw 快 40% 的性能进行绘制(打开 AVX/SSE2支持)
- 比 GDI 的 AlphaBlend 函数快34%的性能进行混色
- Self-contained, 不依赖任何其他第三方库
- 高度紧凑,只需要拷贝 BasicBitmap.h/.cpp 两个文件到你项目即可
Blit 性能比较
Full window (800×600) blitting (both opacity and transparent), compare to GDI/SDL/DirectDraw:
| 32 Bits Blit | Opacity | Transparent |
|---|---|---|
| BasicBitmap C++ | fps=2325 | fps=1368 |
| BasicBitmap AVX/SSE2 | fps=2904 | fps=2531 |
| GDI | fps=2333 | fps=1167 |
| SDL | fps=2671 | fps=1015 |
| DirectDraw | fps=2695 | fps=2090 |
Note: use BltFast with DirectDrawSurface7 in System Memory to perform Opacity & Transparent blit. BitBlt and TransparentBlt(msimg32.dll) are used in the GDI testing case.
| 16 Bits Blit | Opacity | Transparent |
|---|---|---|
| BasicBitmap C++ | fps=4494 | fps=1253 |
| BasicBitmap AVX/SSE2 | fps=9852 | fps=2909 |
| DirectDraw BltFast | fps=5889 | fps=861 |
Blitting performance in SDL & GDI are slower than DirectDraw, just compare to ddraw as well.
| 8 Bits Blit | Opacity | Transparent |
|---|---|---|
| BasicBitmap C++ | fps=11142 | fps=1503 |
| BasicBitmap AVX/SSE2 | fps=18181 | fps=5449 |
| DirectDraw BltFast | fps=14705 | fps=4832 |
DirectDrawSurface in Video Memory takes the benefit of hardware acceleration which is definitely faster than BasicBitmap. If you really need hardware acceleration, use OpenGL/DX as well.
BasicBitmap is a software implementation which aims to achieve the best performance in all other software implementations: like GDI/GDI+, SDL/DirectDraw in System Memory, for examples.
So just compare to DirectDrawSurface in System Memory. Use it in the condition that you only need a lightweight software solution: GUI/Cross Platform/hardware unavailable/image processing/video compositing, etc.
混色性能比较
| SRC OVER | FPS |
|---|---|
| BasicBitmap C++ | 594 |
| BasicBitmap SSE2 | 1731 |
| GDI (msimg32.dll) | 1137 |
note: 800×600 full window src-over blending vs GDI’s AlphaBlend function (in msimg32.dll).