
Category Archives:人工智能
kNN 的花式用法
kNN (k-nearest neighbors)作为一个入门级模型,因为既简单又可靠,对非线性问题支持良好,虽然需要保存所有样本,但是仍然活跃在各个领域中,并提供比较稳健的识别结果。
说到这里也许你会讲,kNN 我知道啊,不就是在特征空间中找出最靠近测试样本的 k 个训练样本,然后判断大多数属于某一个类别,那么将它识别为该类别。
这就是书上/网络上大部分介绍 kNN 的说辞,如果仅仅如此,我也不用写这篇文章了。事实上,kNN 用的好,它真能用出一朵花来,越是基础的东西越值得我们好好玩玩,不是么?
第一种:分类
避免有人不知道,还是简单回顾下 kNN 用于分类的基本思想。

针对测试样本 Xu,想要知道它属于哪个分类,就先 for 循环所有训练样本找出离 Xu 最近的 K 个邻居(k=5),然后判断这 K个邻居中,大多数属于哪个类别,就将该类别作为测试样本的预测结果,如上图有4个邻居是圆形,1是方形,那么判断 Xu 的类别为 “圆形”。
第二种:回归
根据样本点,描绘出一条曲线,使得到样本点的误差最小,然后给定任意坐标,返回该曲线上的值,叫做回归。那么 kNN 怎么做回归呢?

如何实现和优化 SVM(支持向量机)?
学习 SVM 的最好方法是实现一个 SVM,可讲理论的很多,讲实现的太少了。
假设你已经读懂了 SVM 的原理,并了解公式怎么推导出来的,比如到这里:

SVM 的问题就变成:求解一系列满足约束的 alpha 值,使得上面那个函数可以取到最小值。然后记录下这些非零的 alpha 值和对应样本中的 x 值和 y 值,就完成学习了,然后预测的时候用:
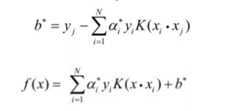
上面的公式计算出 f(x) ,如果返回值 > 0 那么是 +1 类别,否则是 -1 类别,先把这一步怎么来的,为什么这么来找篇文章读懂,不然你会做的一头雾水。
那么剩下的 SVM 实现问题就是如何求解这个函数的极值。方法有很多,我们先找个起点,比如 Platt 的 SMO 算法,它后面有伪代码描述怎么快速求解 SVM 的各个系数。
第一步:实现传统的 SMO 算法
现在大部分的 SVM 开源实现,源头都是 platt 的 smo 算法,读完他的文章和推导,然后照着伪代码写就行了,核心代码没几行:
如何实现传统神经网络?
传统神经网络最早我 2008 年我用 C 实现过一版,当时打算用它来炒股,结果一塌糊涂,不过程序是调试通顺了,主要实现了四个模块:
- 神经元:存储权重和激励函数,能够根据输入矢量计算出单一输出值。
- 层:由多个神经元组成一个层,不同层的输入输出可以串起来。
- 网络:由多个层串起来的网络结构。
- 训练:BP 算法训练每层上不同神经元的权重。
今年拿出来整理了一下,补写了很多注释,并又照着 C 版本实现了一个 Python 版本的(非 numpy 实现),没用 numpy,因为我觉得 numpy 矩阵套矩阵一串操作猛如虎,看起来会比较头疼,就用基础类型写清楚每步运算会更清晰一些。
项目地址:
包含两个实现,C 和 Python,神经网络的正向推理是很简单的,就是一路乘加调函数,直接看代码和注释问题不大;但要看懂后面的训练代码,会碰到 BP 算法这个难点,说白了就是要理解什么是链式求导:

感觉讲的最清楚的就是 cs231n 的:
先前看过很多其它二手内容云里雾里讲半天,真的很难明白,但 cs231n 的视频,顺着一步步从最后推导过来,一下就能让你明白怎么回事情,建议找这节课的视频出来看一看。
看懂 Lecture 4,回过头来看代码也就可以对照一下,这些公式具体是怎么落到代码上的了。
Python 版本末尾有一段测试程序,训练和测试 XOR 计算,经过几轮训练,神经网络能够轻松的计算出 XOR 的结果来,但你可以试试,将前面随机数初始化权重那里注释掉,然后你就发现所有计算结果都是 0.5 了。
为什么呢?因为神经网络不像其它类似 kNN 或者 SVM 的模型,SVM 得到的是解析解,而神经网络目前的 BP 算法得到的只是近似数值解,很容易就陷入局部最优解里出不来,所以必须初始化随机数,初始化的不同,训练结果也有细微差异。
而 SVM 根本就不需要随机数初始化系数 C,全部用 0 初始化就行,最终得到的都是唯一最优的解析解,所以从理论模型上来讲,SVM 的确更漂亮,但不得不说,神经网络这个中医,很多时候还是挺管用的。
相关阅读:
行为树的疑问
关于行为树的实现,我在网上看到几个实现版本都对节点规划了running状态,表示节点的动作未执行完毕,每次执行时从上次未执行完毕的节点开始执行而跳过之前已经执行完毕的节点。
问题在于,处于同一selector节点下的子节点,位置越靠前的节点优先级是越高的,如果因为running恢复机制而跳过了已经执行完毕的节点,岂不是无法实现“打断”现有逻辑的需求?
我想问,节点running状态的引入是为了解决什么问题?为什么不每次都top-down执行所有节点?
游戏中AI常用工具分析
BehaviorTree:国内很多正式商用项目确实用了,不管 RTS,还是 RPG,而且用的还行,毕竟写 AI 一大半时间在调试上,有图形化的界面,调试起来更方便点,有的项目策划可以直接来写 AI。值得花时间封装的东西,你做出一套来,以后其他项目都可以用,但是两个人一个多月的时间是最起码的。
一个人写一个 GUI 编辑器,另一个人写 BehaviorTree 的运行时,用你们熟悉的语言来写。包括若干基类,运行跟踪,状态单步,以及可以脱离游戏环境的调试方式。如果找到称手的 AI 框架,拿过来, 比如你可以评估下 U3D 的 BehaviorTree 的库和编辑器是否可以,能否集成到你的项目?我自己没有用过,我们用自己之前的一个实现。
NaviMesh:大部分情况最好不用,现在国内大部分游戏都是显示 3D,但是内部数据还是 2D 的,比如地图,还是用的格子,在这种情况下,引入 NaviMesh 会逼迫你客户端使用全 3D 数据结构,并且逼迫你服务端从2D计算升级到3D计算,主要是 NaviMesh 实现起来起码也要一个多月,然后要调试很久。
如何实现移动设备的通用手势识别?
移动设备多用手势进行输入,用户通过手指在屏幕上画出一个特定符号,计算机识别出来后给予响应的反应,要比让用户点击繁琐的按钮为直接和有趣,而如果为每种手势编写一段识别代码的话是件得不偿失的事情。如何设计一种通用的手势识别算法来完成上面的事情呢? 我们可以模仿笔记识别方法,实现一个简单的笔画识别模块,流程如下:
第一步:手势归一化
1. 手指按下时开始记录轨迹点,每划过一个新的点就记录到手势描述数组guesture中,直到手指离开屏幕。
2. 将gesture数组里每个点的x,y坐标最大值与最小值求出中上下左右的边缘,求出该手势路径点的覆盖面积。
3. 手势坐标归一化:以手势中心点为原点,将gesture里顶点归一化到 -1<=x<=1, -1<=y<=1空间中。
4. 数组长度归一化:将手势路径按照长度均匀划分成32段,用共32个新顶点替换guestue里的老顶点。
第二步:手势相似度
1. 手势点乘:
g1 * g2 = g1.x1*g2.x1 + g1.y1*g2.y1 + … + g1.x32*g2.x32 + g1.y32*g2.y322. 手势相似:
相似度(g1, g2) = g1 * g2 / sqrt(g1 * g1 + g2 * g2)由此我们可以根据两个手势的相似度算成一个分数score。用户输入了一个手势g,我们回合手势样本中的所有样本g1-gn打一次相似度分数,然后求出相似度最大的那个样本gm并且该分数大于某个特定阀值(比如0.8),即可以判断用户输入g相似于手势样本 gm !
TINY-GOBANG 最精简的五子棋人机对战
国庆没事,想看看最少多少行可以写一个人机对战起来游戏,于是有了这个 Python 版五子棋人机对战,仅仅几百行:
https://github.com/skywind3000/gobang
主要算法:min/max,博弈树搜索,alpha/beta 剪枝
下面是代码(点击 More/continue 展开)
体育竞技游戏的团队AI
很多人问游戏AI该怎么做?随着游戏类型的多元化,非 MMO或者卡牌的游戏越来越多,对AI的需求也越来越强了。而市面上关于 AI的书,网上找得到的文章,也都流于一些只言片语的认识,理论化的套路,和一些简单的 DEMO,离真正的项目差距甚远,无法前后衔接成一条线,更无法真正落地到编码。
国内真正做过游戏AI的少之又少,东拉西扯的人很多,真正做过项目的人很少,因为国内主要以MMO为主,RTS比较少,体育竞技类游戏更少,而从AI的难度上来看,应该是:MMO < FPS < RTS < 体育竞技。作为实际开发过AI的人,给大家科普一下,什么叫做硬派AI。
硬派游戏AI,不是虚无缥缈的神经网络,用神经网络其实是一个黑洞,把问题一脚踢给计算机,认为我只要训练它,它就能解决一切问题的懒人想法。更不是遗传算法和模糊逻辑,你想想以前8位机,16位机上就能有比较激烈对抗的足球游戏、篮球游戏,那么差的处理器能做这些计算么? 硬派游戏AI,就是状态机和行为树。状态机是基本功,行为树可选(早年AI没行为树这东西,大家都是hard code的)。大部分人说到这里也就没了,各位读完还是无法写代码。因为没有把最核心的三个问题讲清楚,即:分层状态机、决策支持系统、以及团队角色分配。下面以我之前做的篮球AI为例,简单叙述一下:何为分层状态机? 每个人物身上,有三层状态机:基础层状态机、行为层状态机、角色层状态机。每一层状态机解决一个层次的复杂度,并对上层提供接口,上层状态机通过设置下层状态机的目标实现更复杂的逻辑。
- 基础状态机:直接控制角色动画和绘制、提供基础的动作实现,为上层提供支持。
- 行为状态机:实现分解动作,躲避跑、直线移动、原地站立、要球、传球、射球、追球、打人、跳。
- 角色状态机:实现更复杂的逻辑,比如防射球、篮板等都是由N次直线运动+跳跃或者打人完成。


关于路径搜索算法的实用性优化
**关于路径搜索算法的实用性优化 **
UESTC 20013080 林 伟 2002.9.12
介绍:本文阐述对著名的路径搜索算法 A* 算法的重要改进,使之更实用于大规模,高效率,多阻塞,模糊求解的任务中。希望本文起一个抛砖引玉的作用,使读者能举一反三。
这里所提及的 A* 算法在许多领域内得到广泛的应用,比如我们熟悉的即时战略游戏正是利用这个算法来实现路径搜索的。但是人工智能的书上只是说,却很少有实现的例子,理论与实际差距太大,一些专业人士也曾经书写过代码,但代码的优点在于说明算法,而在效率与实用性方面就有些欠缺。
A* 是启发试搜索加动态规划。具体实现依靠两个队列 Open 队列和 Close 队列。从一点开始探走几个相邻的格子如果可以移动且当前移动为起点到哪个格子的历 史最佳方法则把那个格子按照估价值从小到大插入 Open 队列里面,几个方向试探结素后取出估价值最小的节点放入Close再从这里开始试探几个相邻的方向 同样放入 Open 队列里面,放入 Open 的条件是 1. 这步在地图上面是可以移动的,2. 这步所在节点在 Open 里面并不存在,3. 从起点到这步的实际距离 比这点的历史最小距离还短满足这三个条件就把节点放入Open队列。具体的算法网友们已经描述的再清楚不过了大致算法如下:
WHILE TRUE BEGIN1. 把 S 点加入 OPEN 队列(按该点到 E 点的距离排序 + 走过的步数从小到大排序) 2. 排序队列 OPEN 队列中距离最小的第一个点出列,并保存入 CLOSE 队列中 3. 从出列的点出发,分别向 4 个(或 8 个)方向中的一个各走出一步 4. 估算第 3 步所走到位置到目标点的距离,并把该位置按估价距离从小到大排序后并放入 OPEN 中 5. 如果该点从四个方向上都不能移动,则把该点从 CLOSE 队列中删除 6. 从目标点回溯树,直到树根则可以找到最佳路径,并保存在 PATH 中 END图表1:A* 路径搜索算法流程
具体实现和详细算法可以看代码http://www.skywind.me/maker/qfind_c.htm (其中 sort_queue 和 store_queue 是 open 和close 队列)
我觉得要使它可以胜任即时战略游戏第一点要改的就是规定搜寻的规模,即限制 close_queue 的大小,一旦超过大小而并没有到达终点,则取一个搜寻过的最接近终点的点(从它到终点的估价距离最短)作为搜索的终点。而一旦 Open 队列空了无法取出节点时搜索结束没有找到终点,此时还是按照上面的方法找一个最接近终点的点代替终点。
这样搜索就不会漫无边际地进行下去了。上面的程序大家稍微观察就会发现几处影响速度的致命地方,启发试搜索是不变的,而看程序每次加入取出两个队列时都要进行繁琐的内存分配,这是项耗费时间的工作,其次需要检查是否在队列中,这点也是很慢的,最后就是保存动态规划数据(历史最短距离)的数组进行还原,并且每次寻路都要还原若大的数组,这是无法接受的。 我所说的优化是从数据结构入手解决上面的问题让 Open / Close 两队列处理时不再涉及内存分配问题,首先建立一个与地图上面每个节点一一对应的节点数组Node[maph][mapw]; Node 里面有一个指针 Next 和Father ,Next 指相所在队列的下一个节点,Father 指向它的父节点。