
Tag Archives:算法
kNN 的花式用法
kNN (k-nearest neighbors)作为一个入门级模型,因为既简单又可靠,对非线性问题支持良好,虽然需要保存所有样本,但是仍然活跃在各个领域中,并提供比较稳健的识别结果。
说到这里也许你会讲,kNN 我知道啊,不就是在特征空间中找出最靠近测试样本的 k 个训练样本,然后判断大多数属于某一个类别,那么将它识别为该类别。
这就是书上/网络上大部分介绍 kNN 的说辞,如果仅仅如此,我也不用写这篇文章了。事实上,kNN 用的好,它真能用出一朵花来,越是基础的东西越值得我们好好玩玩,不是么?
第一种:分类
避免有人不知道,还是简单回顾下 kNN 用于分类的基本思想。

针对测试样本 Xu,想要知道它属于哪个分类,就先 for 循环所有训练样本找出离 Xu 最近的 K 个邻居(k=5),然后判断这 K个邻居中,大多数属于哪个类别,就将该类别作为测试样本的预测结果,如上图有4个邻居是圆形,1是方形,那么判断 Xu 的类别为 “圆形”。
第二种:回归
根据样本点,描绘出一条曲线,使得到样本点的误差最小,然后给定任意坐标,返回该曲线上的值,叫做回归。那么 kNN 怎么做回归呢?

如何实现和优化 SVM(支持向量机)?
学习 SVM 的最好方法是实现一个 SVM,可讲理论的很多,讲实现的太少了。
假设你已经读懂了 SVM 的原理,并了解公式怎么推导出来的,比如到这里:

SVM 的问题就变成:求解一系列满足约束的 alpha 值,使得上面那个函数可以取到最小值。然后记录下这些非零的 alpha 值和对应样本中的 x 值和 y 值,就完成学习了,然后预测的时候用:
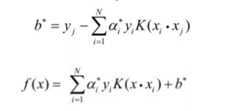
上面的公式计算出 f(x) ,如果返回值 > 0 那么是 +1 类别,否则是 -1 类别,先把这一步怎么来的,为什么这么来找篇文章读懂,不然你会做的一头雾水。
那么剩下的 SVM 实现问题就是如何求解这个函数的极值。方法有很多,我们先找个起点,比如 Platt 的 SMO 算法,它后面有伪代码描述怎么快速求解 SVM 的各个系数。
第一步:实现传统的 SMO 算法
现在大部分的 SVM 开源实现,源头都是 platt 的 smo 算法,读完他的文章和推导,然后照着伪代码写就行了,核心代码没几行:
如何实现传统神经网络?
传统神经网络最早我 2008 年我用 C 实现过一版,当时打算用它来炒股,结果一塌糊涂,不过程序是调试通顺了,主要实现了四个模块:
- 神经元:存储权重和激励函数,能够根据输入矢量计算出单一输出值。
- 层:由多个神经元组成一个层,不同层的输入输出可以串起来。
- 网络:由多个层串起来的网络结构。
- 训练:BP 算法训练每层上不同神经元的权重。
今年拿出来整理了一下,补写了很多注释,并又照着 C 版本实现了一个 Python 版本的(非 numpy 实现),没用 numpy,因为我觉得 numpy 矩阵套矩阵一串操作猛如虎,看起来会比较头疼,就用基础类型写清楚每步运算会更清晰一些。
项目地址:
包含两个实现,C 和 Python,神经网络的正向推理是很简单的,就是一路乘加调函数,直接看代码和注释问题不大;但要看懂后面的训练代码,会碰到 BP 算法这个难点,说白了就是要理解什么是链式求导:

感觉讲的最清楚的就是 cs231n 的:
先前看过很多其它二手内容云里雾里讲半天,真的很难明白,但 cs231n 的视频,顺着一步步从最后推导过来,一下就能让你明白怎么回事情,建议找这节课的视频出来看一看。
看懂 Lecture 4,回过头来看代码也就可以对照一下,这些公式具体是怎么落到代码上的了。
Python 版本末尾有一段测试程序,训练和测试 XOR 计算,经过几轮训练,神经网络能够轻松的计算出 XOR 的结果来,但你可以试试,将前面随机数初始化权重那里注释掉,然后你就发现所有计算结果都是 0.5 了。
为什么呢?因为神经网络不像其它类似 kNN 或者 SVM 的模型,SVM 得到的是解析解,而神经网络目前的 BP 算法得到的只是近似数值解,很容易就陷入局部最优解里出不来,所以必须初始化随机数,初始化的不同,训练结果也有细微差异。
而 SVM 根本就不需要随机数初始化系数 C,全部用 0 初始化就行,最终得到的都是唯一最优的解析解,所以从理论模型上来讲,SVM 的确更漂亮,但不得不说,神经网络这个中医,很多时候还是挺管用的。
相关阅读:
基础优化-最不坏的哈希表
哈希表性能优化的方法有很多,比如:
- 使用双 hash 检索冲突
- 使用开放+封闭混合寻址法组织哈希表
- 使用跳表快速定位冲突
- 使用 LRU 缓存最近访问过的键值,不管表内数据多大,短时内访问的总是那么几个
- 使用更好的分配器来管理 key_value_pair 这个节点对象
上面只要随便选两条你都能得到一个比 unordered_map 快不少的哈希表,类似的方法还有很多,比如使用除以质数来归一化哈希值(x86下性能最好,整数除法非常快,但非x86就不行了,arm还没有整数除法指令,要靠软件模拟,代价很大)。
哈希表最大的问题就是过分依赖哈希函数得到一个正态分布的哈希值,特别是开放寻址法(内存更小,速度更快,但是更怕哈希冲突),一旦冲突多了,或者 load factor 上去了,性能就急剧下降。
Python 的哈希表就是开放寻址的,速度是快了,但是面对哈希碰撞攻击时,挂的也是最惨的,早先爆出的哈希碰撞漏洞,攻击者可以通过哈希碰撞来计算成千上万的键值,导致 Python / Php / Java / V8 等一大批语言写成的服务完全瘫痪。
后续 Python 推出了修正版本,解决方案是增加一个哈希种子,用随机数来初始化它,这都不彻底,开放寻址法对hash函数的好坏仍然高度敏感,碰到特殊的数据,性能下降很厉害。
经过最近几年的各种事件,让人们不得不把目光从“如何实现个更快的哈希表”转移到 “如何实现一个最不坏的哈希表”来,以这个新思路重新思考 hash 表的设计。
哈希表定位主要靠下面一个操作:
index_pos = hash(key) % index_size;来决定一个键值到底存储在什么地方,虽然 hash(key) 返回的数值在 0-0xffffffff 之前,但是索引表是有大小限制的,在 hash 值用 index_size 取模以后,大量不同哈希值取模后可能得到相同的索引位置,所以即使哈希值不一样最终取模后还是会碰撞。
第一种思路是尽量避免冲突,比如双哈希,比如让索引大小 index_size 保持质数式增长,但是他们都太过依赖于哈希函数本身;所以第二种思路是把注意力放在碰撞发生了该怎么处理上,比如多层哈希,开放+封闭混合寻址法,跳表,封闭寻址+平衡二叉树。
优化方向
今天我们就来实现一下最后一种,也是最彻底的做法:封闭寻址+平衡二叉树,看看最终性能如何?能否达到我们的要求?实现起来有哪些坑?其原理简单说起来就是,将原来封闭寻址的链表,改为平衡二叉树:
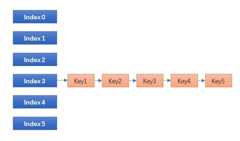
传统的封闭寻址哈希表,也是 Linux / STL 等大部分哈希表的实现,碰到碰撞时链表一长就挂掉,所谓哈希表+平衡二叉树就是:
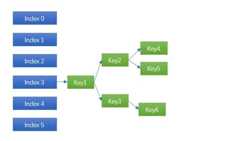
将原来的链表(有序或者无序)换成平衡二叉树,这是复杂度最高的做法,同时也是最可靠的做法。发生碰撞时能将时间复杂度由 O(N) 降低到 O(logN),10个节点,链表的复杂度就是 10,而使用平衡二叉树的复杂度是 3;100个节点前者的时间是100,后者只有6.6 越往后差距约明显。
面临问题
树表混合结构(哈希表+平衡二叉树)的方法,Hash table – Wikipedia 上面早有说明,之所以一直没有进入各大语言/SDK的主流实现主要有四个问题:
- 比起封闭寻址(STL,Java)来讲,节点少时,维持平衡(旋转等)会比有序链表更慢。
- 比起开放寻址(python,v8实现)来讲,内存不紧凑,缓存不够友好。
- 占用更多内存:一个平衡二叉树节点需要更多指针。
- 设计比其他任何哈希表都要复杂。
所以虽然早就有人提出,但是一直都是一个边缘方法,并未进入主流实现。而最近两年随着各大语言暴露出来的各种哈希碰撞攻击,和原有设计基本无力应对坏一些的情况,于是又开始寻求这种树表混合结构是否还有优化的空间。
先来解决第一个问题,如果二叉树节点只有3-5个,那还不如使用有序链表,这是公认的事实,Java 8 最新实现的树表混合结构里,引入了一个 TREEIFY_THRESHOLD = 8 的常量,同一个索引内(或者叫同一个桶/slot/bucket内),冲突键值小于 8 的,使用链表,大于这个阈值时当前 index 内所有节点进行树化操作(treeify)。
Java 8 靠这个方法有效的解决了第一个问题和第三个问题,最终代替了原有 java4-7 一直在使用的 HashMap 老实现,那么我们要使用 Java 8 的方法么?
不用,今天我们换种实现。
AVL/RBTREE 实际比较
网上对 AVL被批的很惨,认为性能不如 rbtree,这里给 AVL 树平反昭雪。最近优化了一下我之前的 AVL 树,总体跑的和 linux 的 rbtree 一样快了:

他们都比 std::map 快很多(即便使用动态内存分配,为每个新插入节点临时分配个新内存)。
项目代码在:skywind3000/avlmini
其他 AVL/RBTREE 评测也有类似的结论,见:STL AVL Map
谣言1:RBTREE的平均统计性能比 AVL 好
统计下来一千万个节点插入 AVL 共旋转 7053316 次(先左后右算两次),RBTREE共旋转 5887217 次,RBTREE看起来少是吧?应该很快?但是别忘了 RBTREE 再平衡的操作除了旋转外还有再着色,每次再平衡噼里啪啦的改一片颜色,父亲节点,叔叔,祖父,兄弟节点都要访问一圈,这些都是代价,再者平均树高比 AVL 高也成为各项操作的成本。
谣言2:RBTREE 一般情况只比 AVL 高一两层,这个代价忽略不计
纯粹谣言,随便随机一下,一百万个节点的 RBTREE 树高27,和一千万个节点的 AVL树相同,而一千万个节点的 RBTREE 树高 33,比 AVL 多了 6 层,这还不是最坏情况,最坏情况 AVL 只有 1.440 * log(n + 2) – 0.328, 而 RBTREE 是 2 * log(n + 1),也就是说同样100万个节点,AVL最坏情况是 28 层,rbtree 最坏可以到 39 层。
谣言3:AVL树删除节点是需要回溯到根节点
我以前也是这么写 AVL 树的,后来发现根据 AVL 的定义,可以做出两个推论,再平衡向上回溯时:
插入更新时:如当前节点的高度没有改变,则上面所有父节点的高度和平衡也不会改变。
删除更新时:如当前节点的高度没有改变且平衡值在 [-1, 1] 区间,则所有父节点的高度和平衡都不会改变。
根据这两个推论,AVL的插入和删除大部分时候只需要向上回溯一两个节点即可,范围十分紧凑。
谣言4:虽然二者插入一万个节点总时间类似,但是rbtree树更平均,avl有时很快,有时慢很多,rbtree 只需要旋转两次重新染色就行了,比 avl 平均
完全说反了,avl是公认的比rbtree平均的数据结构,插入时间更为平均,rbtree才是不均衡,有时候直接插入就返回了(上面是黑色节点),有时候插入要染色几个节点但不旋转,有时候还要两次旋转再染色然后递归到父节点。该说法最大的问题是以为 rbtree 插入节点最坏情况是两次旋转加染色,可是忘记了一条,需要向父节点递归,比如:当前节点需要旋转两次重染色,然后递归到父节点再旋转两次重染色,再递归到父节点的父节点,直到满足 rbtree 的5个条件。这种说法直接把递归给搞忘记了,翻翻看 linux 的 rbtree 代码看看,再平衡时那一堆的 while 循环是在干嘛?不就是向父节点递归么?avl和rbtree 插入和删除的最坏情况都需要递归到根节点,都可能需要一路旋转上去,否则你设想下,假设你一直再树的最左边插入1000个新节点,每次都想再局部转两次染染色,而不去调整整棵树,不动根节点,可能么?只是说整个过程avl更加平均而已。
比较结论
如何实现移动设备的通用手势识别?
移动设备多用手势进行输入,用户通过手指在屏幕上画出一个特定符号,计算机识别出来后给予响应的反应,要比让用户点击繁琐的按钮为直接和有趣,而如果为每种手势编写一段识别代码的话是件得不偿失的事情。如何设计一种通用的手势识别算法来完成上面的事情呢? 我们可以模仿笔记识别方法,实现一个简单的笔画识别模块,流程如下:
第一步:手势归一化
1. 手指按下时开始记录轨迹点,每划过一个新的点就记录到手势描述数组guesture中,直到手指离开屏幕。
2. 将gesture数组里每个点的x,y坐标最大值与最小值求出中上下左右的边缘,求出该手势路径点的覆盖面积。
3. 手势坐标归一化:以手势中心点为原点,将gesture里顶点归一化到 -1<=x<=1, -1<=y<=1空间中。
4. 数组长度归一化:将手势路径按照长度均匀划分成32段,用共32个新顶点替换guestue里的老顶点。
第二步:手势相似度
1. 手势点乘:
g1 * g2 = g1.x1*g2.x1 + g1.y1*g2.y1 + … + g1.x32*g2.x32 + g1.y32*g2.y322. 手势相似:
相似度(g1, g2) = g1 * g2 / sqrt(g1 * g1 + g2 * g2)由此我们可以根据两个手势的相似度算成一个分数score。用户输入了一个手势g,我们回合手势样本中的所有样本g1-gn打一次相似度分数,然后求出相似度最大的那个样本gm并且该分数大于某个特定阀值(比如0.8),即可以判断用户输入g相似于手势样本 gm !
快速可靠协议-KCP
简介
KCP是一个快速可靠协议,能以比 TCP浪费10%-20%的带宽的代价,换取平均延迟降低 30%-40%,且最大延迟降低三倍的传输效果。纯算法实现,并不负责底层协议(如UDP)的收发,需要使用者自己定义下层数据包的发送方式,以 callback的方式提供给 KCP。 连时钟都需要外部传递进来,内部不会有任何一次系统调用。
整个协议只有 ikcp.h, ikcp.c两个源文件,可以方便的集成到用户自己的协议栈中。也许你实现了一个P2P,或者某个基于 UDP的协议,而缺乏一套完善的ARQ可靠协议实现,那么简单的拷贝这两个文件到现有项目中,稍微编写两行代码,即可使用。
技术特性
TCP是为流量设计的(每秒内可以传输多少KB的数据),讲究的是充分利用带宽。而 KCP是为流速设计的(单个数据包从一端发送到一端需要多少时间),以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度。TCP信道是一条流速很慢,但每秒流量很大的大运河,而KCP是水流湍急的小激流。KCP有正常模式和快速模式两种,通过以下策略达到提高流速的结果:
RTO翻倍vs不翻倍:
TCP超时计算是RTOx2,这样连续丢三次包就变成RTOx8了,十分恐怖,而KCP启动快速模式后不x2,只是x1.5(实验证明1.5这个值相对比较好),提高了传输速度。
选择性重传 vs 全部重传:
TCP丢包时会全部重传从丢的那个包开始以后的数据,KCP是选择性重传,只重传真正丢失的数据包。
快速重传:
发送端发送了1,2,3,4,5几个包,然后收到远端的ACK: 1, 3, 4, 5,当收到ACK3时,KCP知道2被跳过1次,收到ACK4时,知道2被跳过了2次,此时可以认为2号丢失,不用等超时,直接重传2号包,大大改善了丢包时的传输速度。
延迟ACK vs 非延迟ACK:
TCP为了充分利用带宽,延迟发送ACK(NODELAY都没用),这样超时计算会算出较大 RTT时间,延长了丢包时的判断过程。KCP的ACK是否延迟发送可以调节。
UNA vs ACK+UNA:
ARQ模型响应有两种,UNA(此编号前所有包已收到,如TCP)和ACK(该编号包已收到),光用UNA将导致全部重传,光用ACK则丢失成本太高,以往协议都是二选其一,而 KCP协议中,除去单独的 ACK包外,所有包都有UNA信息。
非退让流控:
KCP正常模式同TCP一样使用公平退让法则,即发送窗口大小由:发送缓存大小、接收端剩余接收缓存大小、丢包退让及慢启动这四要素决定。但传送及时性要求很高的小数据时,可选择通过配置跳过后两步,仅用前两项来控制发送频率。以牺牲部分公平性及带宽利用率之代价,换取了开着BT都能流畅传输的效果。
基本使用
体育竞技游戏的团队AI
很多人问游戏AI该怎么做?随着游戏类型的多元化,非 MMO或者卡牌的游戏越来越多,对AI的需求也越来越强了。而市面上关于 AI的书,网上找得到的文章,也都流于一些只言片语的认识,理论化的套路,和一些简单的 DEMO,离真正的项目差距甚远,无法前后衔接成一条线,更无法真正落地到编码。
国内真正做过游戏AI的少之又少,东拉西扯的人很多,真正做过项目的人很少,因为国内主要以MMO为主,RTS比较少,体育竞技类游戏更少,而从AI的难度上来看,应该是:MMO < FPS < RTS < 体育竞技。作为实际开发过AI的人,给大家科普一下,什么叫做硬派AI。
硬派游戏AI,不是虚无缥缈的神经网络,用神经网络其实是一个黑洞,把问题一脚踢给计算机,认为我只要训练它,它就能解决一切问题的懒人想法。更不是遗传算法和模糊逻辑,你想想以前8位机,16位机上就能有比较激烈对抗的足球游戏、篮球游戏,那么差的处理器能做这些计算么? 硬派游戏AI,就是状态机和行为树。状态机是基本功,行为树可选(早年AI没行为树这东西,大家都是hard code的)。大部分人说到这里也就没了,各位读完还是无法写代码。因为没有把最核心的三个问题讲清楚,即:分层状态机、决策支持系统、以及团队角色分配。下面以我之前做的篮球AI为例,简单叙述一下:何为分层状态机? 每个人物身上,有三层状态机:基础层状态机、行为层状态机、角色层状态机。每一层状态机解决一个层次的复杂度,并对上层提供接口,上层状态机通过设置下层状态机的目标实现更复杂的逻辑。
- 基础状态机:直接控制角色动画和绘制、提供基础的动作实现,为上层提供支持。
- 行为状态机:实现分解动作,躲避跑、直线移动、原地站立、要球、传球、射球、追球、打人、跳。
- 角色状态机:实现更复杂的逻辑,比如防射球、篮板等都是由N次直线运动+跳跃或者打人完成。

[业余土制] 简易网络库 easenet
1. 跨平台网络库
2. 异步事件:kevent, iocp, epoll, poll, select封装
3. 内存管理:SlabPlus
4. 可靠协议:类tcp纯协议实现,包括重传机制,窗口管理,流量控制,拥塞处理。
5. 多种工具:缓存池,环状缓存,高性能hashmap等。
代码贴上: 项目地址:http://code.google.com/p/easenet/
[业余土制] SlabPlus内存分配算法
原理叙述:
我也来介绍一种内存管理方面的优化算法:怎样才能根除内存碎片?有且只有如下办法:1. 只分配不释放,2. 只分配固定大小内存,3. 不分配内存,虽然,仍不妨碍我们再一次回顾各种常用的分配策略,以发掘一些新的思路:
前提:下面提及的分配技巧并不能说是“最快的”,也不能说是“最小碎片的”,但是可以保证,不管系统运行多长时间,不管分配多大内存,碎片比例趋于恒定,同时分配时间为常数(unit interval):
最后将讨论一些更进一步的优化技巧(如果愿意大量增加代码行数的话),看看在分配内存方面,哪些我们值得努力,哪些不值得我们努力。
现代的内存分配算法,需要顾及以下几个特性:
1) 缓存命中:现今的计算机体系,优秀的缓存策略对一个系统而言异常重要,一些写的不太注意的分配器,容易忽略该特性,前分配一块内存,后分配一块内存,大大增加了缓存的失效。
2) 总线平衡:大部分缓存管理都是提供 2^n字节大小的内存机制,并且所分配地址也是以 2^n字节进行对齐,比如我们有一个 packfile对象有400多个字节,将使用 512字节的缓存分配器,并且按照 512字节进行对齐,但是问题在于,大部分时候我们都在访问该对象的头30个字节,因此在(0-30) mod 512的地方,也就是在以512字节为分割的缓存线周围集中了大量的压力,在现今的大部分普通的缓存芯片上将出现总线失衡bus-overbalance。
3) 页面归还:何时向系统请求页面,何时归还系统页面,很多分配器只向系统不停的申请页面,却并不考虑提供保证能够正常不断的归还系统页面的机制。
4) 多核优化:尽管多核技术现在才逐渐在PC上推广,但我们的服务器很早就已经开始使用双核或者四核的架构,分配器如何尽量避免在不同核间产生的等待,是分配器效率优化的一个前提。
以下几点内容有助于优化我们的分配器: