
Tag Archives:机器学习
kNN 的花式用法
kNN (k-nearest neighbors)作为一个入门级模型,因为既简单又可靠,对非线性问题支持良好,虽然需要保存所有样本,但是仍然活跃在各个领域中,并提供比较稳健的识别结果。
说到这里也许你会讲,kNN 我知道啊,不就是在特征空间中找出最靠近测试样本的 k 个训练样本,然后判断大多数属于某一个类别,那么将它识别为该类别。
这就是书上/网络上大部分介绍 kNN 的说辞,如果仅仅如此,我也不用写这篇文章了。事实上,kNN 用的好,它真能用出一朵花来,越是基础的东西越值得我们好好玩玩,不是么?
第一种:分类
避免有人不知道,还是简单回顾下 kNN 用于分类的基本思想。

针对测试样本 Xu,想要知道它属于哪个分类,就先 for 循环所有训练样本找出离 Xu 最近的 K 个邻居(k=5),然后判断这 K个邻居中,大多数属于哪个类别,就将该类别作为测试样本的预测结果,如上图有4个邻居是圆形,1是方形,那么判断 Xu 的类别为 “圆形”。
第二种:回归
根据样本点,描绘出一条曲线,使得到样本点的误差最小,然后给定任意坐标,返回该曲线上的值,叫做回归。那么 kNN 怎么做回归呢?

如何实现和优化 SVM(支持向量机)?
学习 SVM 的最好方法是实现一个 SVM,可讲理论的很多,讲实现的太少了。
假设你已经读懂了 SVM 的原理,并了解公式怎么推导出来的,比如到这里:

SVM 的问题就变成:求解一系列满足约束的 alpha 值,使得上面那个函数可以取到最小值。然后记录下这些非零的 alpha 值和对应样本中的 x 值和 y 值,就完成学习了,然后预测的时候用:
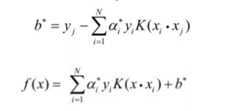
上面的公式计算出 f(x) ,如果返回值 > 0 那么是 +1 类别,否则是 -1 类别,先把这一步怎么来的,为什么这么来找篇文章读懂,不然你会做的一头雾水。
那么剩下的 SVM 实现问题就是如何求解这个函数的极值。方法有很多,我们先找个起点,比如 Platt 的 SMO 算法,它后面有伪代码描述怎么快速求解 SVM 的各个系数。
第一步:实现传统的 SMO 算法
现在大部分的 SVM 开源实现,源头都是 platt 的 smo 算法,读完他的文章和推导,然后照着伪代码写就行了,核心代码没几行:
如何实现传统神经网络?
传统神经网络最早我 2008 年我用 C 实现过一版,当时打算用它来炒股,结果一塌糊涂,不过程序是调试通顺了,主要实现了四个模块:
- 神经元:存储权重和激励函数,能够根据输入矢量计算出单一输出值。
- 层:由多个神经元组成一个层,不同层的输入输出可以串起来。
- 网络:由多个层串起来的网络结构。
- 训练:BP 算法训练每层上不同神经元的权重。
今年拿出来整理了一下,补写了很多注释,并又照着 C 版本实现了一个 Python 版本的(非 numpy 实现),没用 numpy,因为我觉得 numpy 矩阵套矩阵一串操作猛如虎,看起来会比较头疼,就用基础类型写清楚每步运算会更清晰一些。
项目地址:
包含两个实现,C 和 Python,神经网络的正向推理是很简单的,就是一路乘加调函数,直接看代码和注释问题不大;但要看懂后面的训练代码,会碰到 BP 算法这个难点,说白了就是要理解什么是链式求导:

感觉讲的最清楚的就是 cs231n 的:
先前看过很多其它二手内容云里雾里讲半天,真的很难明白,但 cs231n 的视频,顺着一步步从最后推导过来,一下就能让你明白怎么回事情,建议找这节课的视频出来看一看。
看懂 Lecture 4,回过头来看代码也就可以对照一下,这些公式具体是怎么落到代码上的了。
Python 版本末尾有一段测试程序,训练和测试 XOR 计算,经过几轮训练,神经网络能够轻松的计算出 XOR 的结果来,但你可以试试,将前面随机数初始化权重那里注释掉,然后你就发现所有计算结果都是 0.5 了。
为什么呢?因为神经网络不像其它类似 kNN 或者 SVM 的模型,SVM 得到的是解析解,而神经网络目前的 BP 算法得到的只是近似数值解,很容易就陷入局部最优解里出不来,所以必须初始化随机数,初始化的不同,训练结果也有细微差异。
而 SVM 根本就不需要随机数初始化系数 C,全部用 0 初始化就行,最终得到的都是唯一最优的解析解,所以从理论模型上来讲,SVM 的确更漂亮,但不得不说,神经网络这个中医,很多时候还是挺管用的。
相关阅读: