
Tag Archives:优化
定点数优化:性能成倍提升
定点数这玩意儿并不是什么新东西,早年 CPU 浮点性能不够,定点数技巧大量活跃于各类图形图像处理的热点路径中。今天 CPU 浮点上来了,但很多情况下整数仍然快于浮点,因此比如:libcario (gnome/quartz 后端)及 pixman 之类的很多库里你仍然找得到定点数的身影。那么今天我们就来看看使用定点数到底能快多少。
简单用一下的话,下面这几行宏就够了:
#define cfixed_from_int(i) (((cfixed)(i)) << 16)#define cfixed_from_float(x) ((cfixed)((x) * 65536.0f))#define cfixed_from_double(d) ((cfixed)((d) * 65536.0))#define cfixed_to_int(f) ((f) >> 16)#define cfixed_to_float(x) ((float)((x) / 65536.0f))#define cfixed_to_double(f) ((double)((f) / 65536.0))#define cfixed_const_1 (cfixed_from_int(1))#define cfixed_const_half (cfixed_const_1 >> 1)#define cfixed_const_e ((cfixed)(1))#define cfixed_const_1_m_e (cfixed_const_1 - cfixed_const_e)#define cfixed_frac(f) ((f) & cfixed_const_1_m_e)#define cfixed_floor(f) ((f) & (~cfixed_const_1_m_e))#define cfixed_ceil(f) (cfixed_floor((f) + 0xffff))#define cfixed_mul(x, y) ((cfixed)((((int64_t)(x)) * (y)) >> 16))#define cfixed_div(x, y) ((cfixed)((((int64_t)(x)) << 16) / (y)))#define cfixed_const_max ((int64_t)0x7fffffff)#define cfixed_const_min (-((((int64_t)1) << 31)))typedef int32_t cfixed;类型狂可以写成 inline 函数,封装狂可以封装成一系列 operator xx,如果需要更高的精度,可以将上面用int32_t 表示的16.16 定点数改为用int64_t 表示的32.32 定点数。
那么我们找个浮点数的例子优化一下吧,比如libyuv 中的 ARGBAffineRow_C 函数:
void ARGBAffineRow_C(const uint8_t* src_argb, int src_argb_stride, uint8_t* dst_argb, const float* uv_dudv, int width) { int i; // Render a row of pixels from source into a buffer. float uv[2]; uv[0] = uv_dudv[0]; uv[1] = uv_dudv[1]; for (i = 0; i < width; ++i) { int x = (int)(uv[0]); int y = (int)(uv[1]); *(uint32_t*)(dst_argb) = *(const uint32_t*)(src_argb + y * src_argb_stride + x * 4); dst_argb += 4; uv[0] += uv_dudv[2]; uv[1] += uv_dudv[3]; }}这个函数是干什么用的呢?给图像做仿射变换(affine transformation) 用的,比如 2D 图像库或者 ActionScript 中可以给 Bitmap 设置一个 3×3 的矩阵,然后让 Bitmap 按照该矩阵进行变换绘制:

基本上二维图像所有:缩放,旋转,扭曲都是通过仿射变换完成,这个函数就是从图像的起点(u, v)开始按照步长(du, dv)进行采样,放入临时缓存中,方便下一步一次性整行写入 frame buffer。
这个采样函数有几个特点:
- 运算简单:没有复杂的运算,计算无越界,不需要求什么 log/exp 之类的复杂函数。
- 范围可控:大部分图像长宽尺寸都在 32768 范围内,用 16.16 的定点数即可。
- 转换频繁:每个点的坐标都需要从浮点转换成整数,这个操作很费事。
适合用定点数简单重写一下:(点击 Read more 展开)

快除 255:到底能有多快?
真金不怕火炼,我先前在《C 语言有什么奇技淫巧?》中给出的整数快速除以 255 的公式:
#define div_255_fast(x) (((x) + (((x) + 257) >> 8)) >> 8)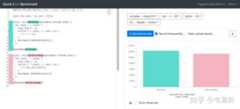
红色为 255 快除法的消耗时间,看他的测试好像也只快了那么一点,是这样的么?
并非如此,我们只要把测试用例中的 long long j 改成 int j 就有比较大的性能提升了:
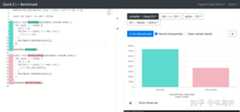
链接:http://quick-bench.com/t3Y2-b4isYIwnKwMaPQi3n9dmtQ
这才是真实的快除法性能。
原评测的作者其他地方都是用 int ,这里故意改成 64 位去和原始的 / 255 对齐,引入一个干扰项,得到一个比较慢的结果,到底是为了黑而黑呢?还是别的什么原因?
编译器生成的 / 255 方法是把 x / 255 换成定点数的 x * (1/255):
(点击 Read more 展开)
快速范围判断:再来一种新写法
C 语言的魔法数不胜数,我在《C 语言有什么奇技淫巧?》中过给快速范围判断的公式,将:
if (x >= minx && x <= maxx) ...改做:
if (((x - minx) | (maxx - x)) >= 0) ...能有一倍的性能提升,我也提到,如果你的数据 99% 都是超出范围的那继续用 && 最快。今天再给大家介绍另外一种新写法,它有更均衡的性能,并且在最坏的情况下,任然表现良好:
if ((unsigned)(x - minx) <= (unsigned)(maxx - minx)) ...该公式在各种测试数据中能有更均衡的表现,类型安全狂们可以写作:
if (((unsigned)x - (unsigned)minx) <= ((unsigned)maxx - (unsigned)minx)) ...利用单次无符号整数溢出来减少指令和分支,普通情况,这个公式性能照样快接近一倍:

链接:http://quick-bench.com/EbCR9psA3lUEhpn8bYLwVtJ-FWk
为什么说它综合性能最好呢?是不是只实用于某些特殊情况呢?普通情况如何?汇编指令有啥区别?理论依据是啥?是不是只有 x86 可以用,换个平台就不行呢?下面依次回答:
(点击 Read more 展开)
C 语言有什么奇技淫巧?
C 语言的技巧有很多,列一些和性能有关的:
快速范围判断
经常要批量判断某些值在不在范围内,如果 int 检测是 [0, N) 的话:
if (x >= 0 && x < N) ...众所周知,现代 CPU 优化,减分支是重要手段,上述两次判断可以简写为:
if (((unsigned int)x) < N) ...减少判断次数。如果 int 检测范围是 [minx, maxx] 这种更常见的形式的话,怎么办呢?
if (x >= minx && x <= maxx) ...可以继续用比特或操作继续减少判断次数:
if (( (x - minx) | (maxx - x) ) >= 0) ...如果语言警察们担心有符号整数回环是未定义行为的话,可以写成这样:
if ((int32_t)(((uint32_t)x - (uint32_t)minx) | ((uint32_t)maxx - (uint32_t)x)) > = 0) ...性能相同,但避开了有符号整数回环,改为无符号回环,合并后转为有符号判断最高位。
第一个 (x – minx) 如果 x < minx 的话,得到的结果 < 0 ,即高位为 1,第二个判断同理,如果超过范围,高位也为 1,两个条件进行比特或运算以后,只有两个高位都是 0 ,最终才为真,同理,多个变量范围判断整合:
if (( (x - minx) | (maxx - x) | (y - miny) | (maxy - y) ) >= 0) ...这样本来需要对 [x, y] 进行四次判断的,可以完全归并为一次判断,减少分支。
补充:加了个性能评测

性能提升 37%。快速范围判断还有第二个性能更均衡的版本:
if ((unsigned)(x - minx) <= (unsigned)(maxx - minx)) ...快速范围判断的原理和评测详细见:《快速范围判断:再来一种新写法》。
更好的循环展开
很多人提了 duff’s device ,按照 gcc 和标委会丧心病狂的程度,你们用这些 just works 的代码,不怕哪天变成未定义行为给一股脑优化掉了么?其实对于循环展开,可以有更优雅的写法:
#define CPU_LOOP_UNROLL_4X(actionx1, actionx2, actionx4, width) do { \ unsigned long __width = (unsigned long)(width); \ unsigned long __increment = __width >> 2; \ for (; __increment > 0; __increment--) { actionx4; } \ if (__width & 2) { actionx2; } \ if (__width & 1) { actionx1; } \} while (0)送大家个代替品,CPU_LOOP_UNROLL_4X,用于四次循环展开,用法是:
(点击 Read more 展开)
BasicBitmap:比 SDL/DirectDraw/GDI 更快的位图库
开源一个高性能位图库,之前对我的二维图形库pixellib 的部分代码进行了精简和重写,最终形成一个只包含两个文件(BasicBitmap.h, BasicBitmap.cpp)的图形基础库。
在今天 GPU 绘制横行天下的时候,任然有很多时候需要使用到纯 CPU实现的图形库,比如图像处理,视频预处理与合成,界面,以及GPU无法使用的情况(比如某个应用把gpu占满了,或者无法通过gpu做一些十分灵活的事情时),纹理处理,简单图片加载保存等。
支持 SSE2/AVX 优化,比 DirectDraw 快 40%(全系统内存绘制),比 SDL 快 10%,比GDI快 38%。如果你需要一个方便的高性能位图库,足够高性能的同时保证足够紧凑。
如果你有上述需求,那么你和我一样需要用到 BasicBitmap,只需要把 BasicBitmap.h/.cpp 两个文件拷贝到你的代码中即可。我正是为了这个目的编写了这两个文件。
项目地址
特性介绍
- 高度优化的 C++ 代码,可以在任意平台编译并运行
- 多重像素格式,从8位到32位:A8R8G8B8, R8G8B8, A4R4G4B4, R5G6B5, A8, 等.
- Blit (Bit Blt) ,包含透明和非透明的模式。
- 像素格式快速转换
- 使用不同的 Compositor 进行 Blending
- 使用不同的过滤器进行缩放(nearest, linear, bilinear)
- 高质量位图重采样(Bicubic/Box)
- 支持从内存或者文件直接读取 BMP/TGA 文件
- 支持从内存或者文件直接读取 PNG/JPEG 文件(Windows下)
- 保存图片为 BMP/PPM 文件
- 核心绘制函数可以被外部实现通过设置函数指针重载(比如 SSE2实现)
- 比 DirectDraw 快 40% 的性能进行绘制(打开 AVX/SSE2支持)
- 比 GDI 的 AlphaBlend 函数快34%的性能进行混色
- Self-contained, 不依赖任何其他第三方库
- 高度紧凑,只需要拷贝 BasicBitmap.h/.cpp 两个文件到你项目即可
Blit 性能比较
Full window (800×600) blitting (both opacity and transparent), compare to GDI/SDL/DirectDraw:
| 32 Bits Blit | Opacity | Transparent |
|---|---|---|
| BasicBitmap C++ | fps=2325 | fps=1368 |
| BasicBitmap AVX/SSE2 | fps=2904 | fps=2531 |
| GDI | fps=2333 | fps=1167 |
| SDL | fps=2671 | fps=1015 |
| DirectDraw | fps=2695 | fps=2090 |
Note: use BltFast with DirectDrawSurface7 in System Memory to perform Opacity & Transparent blit. BitBlt and TransparentBlt(msimg32.dll) are used in the GDI testing case.
| 16 Bits Blit | Opacity | Transparent |
|---|---|---|
| BasicBitmap C++ | fps=4494 | fps=1253 |
| BasicBitmap AVX/SSE2 | fps=9852 | fps=2909 |
| DirectDraw BltFast | fps=5889 | fps=861 |
Blitting performance in SDL & GDI are slower than DirectDraw, just compare to ddraw as well.
| 8 Bits Blit | Opacity | Transparent |
|---|---|---|
| BasicBitmap C++ | fps=11142 | fps=1503 |
| BasicBitmap AVX/SSE2 | fps=18181 | fps=5449 |
| DirectDraw BltFast | fps=14705 | fps=4832 |
DirectDrawSurface in Video Memory takes the benefit of hardware acceleration which is definitely faster than BasicBitmap. If you really need hardware acceleration, use OpenGL/DX as well.
BasicBitmap is a software implementation which aims to achieve the best performance in all other software implementations: like GDI/GDI+, SDL/DirectDraw in System Memory, for examples.
So just compare to DirectDrawSurface in System Memory. Use it in the condition that you only need a lightweight software solution: GUI/Cross Platform/hardware unavailable/image processing/video compositing, etc.
混色性能比较
| SRC OVER | FPS |
|---|---|
| BasicBitmap C++ | 594 |
| BasicBitmap SSE2 | 1731 |
| GDI (msimg32.dll) | 1137 |
note: 800×600 full window src-over blending vs GDI’s AlphaBlend function (in msimg32.dll).
内存拷贝优化(3)-深入优化
今天继续在原来内存拷贝代码上优化:
1. 修改了小内存方案:由原来64字节扩大为128字节,由 int 改为 xmm,小内存性能提升 80%
2. 修改了中内存方案:从4个xmm寄存器并行拷贝改为8个并行拷贝+prefetch,提升20%左右
3. 去除目标地址头部对齐的分支判断,用一次xmm拷贝完成目标对齐,性能替升10%。
4. 增加测试用例:为贴近实际,增加了随机访问,10MB空间内(绝对大于L2尺寸)随机位置和长度的测试
为避免随机数生成影响结果,提前生成随机数,最终平均性能达到gcc4.9配套标准库的2倍以上:
https://github.com/skywind3000/FastMemcpy
最新代码测试结果(可以对比老的表看新版本性能是否有所提升):
内存拷贝优化(2)-全尺寸拷贝优化
四年前写过一篇小内存拷贝优化:http://www.skywind.me/blog/archives/143 纠结了一下还是把全尺寸拷贝优化代码发布出来吧,没啥好保密的, 如今总结一下全尺寸内存拷贝优化的要点:
- 策略区别:64字节以内用小内存方案,64K以内用中尺寸方案,大于64K用大内存拷贝方案。
- 查表跳转:拷贝不同小尺寸内存,直接跳转到相应地址解除循环。
- 目标对齐:64字节以上拷贝的先用普通方法拷贝几个字节让目标地址对齐,好做后面的事情。
- 矢量拷贝:并行一次性读入N个矢量到 sse2 寄存器,再并行写出。
- 缓存预取:使用 prefetchnta ,提前预取数据,等到真的要用时数据已经到位。
- 内存直写:使用 movntdq 来直写内存,避免缓存污染。
如何设计一个内存分配器?
通常工程里不推荐自己写内存分配器,因为你费力写一个出来99%可能性没有内置的好,且内存出bug难调试
不过看书之余,你也可以动手自己试试,当个玩具写写玩玩:
1. 实现教科书上的内存分配器:
做一个链表指向空闲内存,分配就是取出一块来,改写链表,返回,释放就是放回到链表里面,并做好归并。注意做好标记和保护,避免二次释放,还可以花点力气在如何查找最适合大小的内存快的搜索上,减少内存碎片,有空你了还可以把链表换成伙伴算法,写着玩嘛。
2. 实现固定内存分配器:
即实现一个 FreeList,每个 FreeList 用于分配固定大小的内存块,比如用于分配 32字节对象的固定内存分配器,之类的。每个固定内存分配器里面有两个链表,OpenList 用于存储未分配的空闲对象,CloseList用于存储已分配的内存对象,那么所谓的分配就是从 OpenList 中取出一个对象放到 CloseList 里并且返回给用户,释放又是从 CloseList 移回到
OpenList。分配时如果不够,那么就需要增长 OpenList:申请一个大一点的内存块,切割成比如 64 个相同大小的对象添加到 OpenList中。这个固定内存分配器回收的时候,统一把先前向系统申请的内存块全部还给系统。
内存拷贝优化(1)-小内存拷贝优化
相信大家代码里有很多地方用到memcpy这个函数,相信这个函数的占用是不小的,有时优化了memcpy,能使整个项目的运行效率提升。通过适当的编码技巧,让我们的内存拷贝速度超过memcpy两倍,是可以实现的。 有人说memcpy还能优化么?不就是rep movsd么?CPU和内存之间的带宽是固定的,怎么可能优化呢?其实是普通的内存拷贝并没有发挥全部的带宽,很多被浪费掉了,比如要等到数据完全读取成功后再去写入,然后要写入成功后再去读取新的。而优化本身就是使这两者尽量的并行,发挥最大的带宽。
现代的内存拷贝都需要判断内存大小,并按照大小选择不同策略进行拷贝,比如大内存拷贝(超过cache大小),那么最好使用并行若干读取指令和写入指令,然后再并行写入,使得CPU前后结果依赖得以大大降低,并且使用缓冲预取,再CPU处理数据之前,就把数据放到离CPU最近的CACHE。这样已经可以比memcpy快很多了,如果再加上一些新指令的帮助,大内存拷贝会大大提速。
但是用同样的代码去拷贝小内存,因为额外的开销,难对齐的内存,准备工作一大堆,如果实际要拷贝的内存很小的话,这样的工作开销还比直接按照 dword复制慢很多。在VC10的memcpy实现中将内存按照128个字节大小进行区分,小于该大小的使用普通拷贝,大于该大小的使用普通SSE指令拷贝,而现在我们就要来挑战VC10的memcpy,本篇先叙述小内存拷贝部分。
适合拷贝64字节以内的数据量。原理很简单,LOOP UNROLL。rep movsb/movsd是靠不住的,小内存拷贝还是得展开循环。
废话不多说,代码贴上: