
- HOME >
広告機械学習
交差検証法とは?種類やPythonの実装・ホールドアウト法との違いまでわかりやすく解説


- 交差検証法ってなに?
- どんな手法があるの?
- ホールドアウト法との違いは?
とお悩みではないですか?
本記事では、モデルの評価方法の1つとして重要な交差検証法について種類やPythonでの実装・ホールドアウト法との違いについてまで解説していきます。
交差検証法とはデータを等分し、それらのデータの1つをテストデータとして繰り返しテストを行うモデルの評価方法です。
本記事の信頼性

こんな悩みがある方読んで欲しい
- 交差検証法ってなに?
- 交差検証法の種類は?
- Pythonではどうやって実装するの?
- 交差検証法とホールドアウト法との違いは何?
月額980円で学べる!

交差検証法(Cross-Validation)とは
交差検証法(Cross-Validation)とは、データを複数に分割し、それらのデータで訓練とテストを繰り返すモデルの性能を評価するための手法の1つです。
モデルを学習する時、すべてのデータをモデルを作るための学習に使ってしまうとどうなるでしょうか。
学習したデータにしか適さないモデルになり、過学習になってしまいます。
過学習についてよく知らないという方は『過学習(Overfitting)とは?起こる原因から見分け方・対策方法までわかりやすく解説!』の記事をご参照ください。
交差検証法を用いることで、擬似的に未知のデータ(テストデータ)を作り出して、過学習になっていないか繰り返しテストを行います。
交差検証法を使って、作成したモデルが本当に未知のデータに対しても使えるのか判断しましょう。
交差検証法の3つの種類

交差検証法では、代表的な手法として以下の3つがあります。
- k分割交差検証
- 層化k分割交差検証
- LOOCV (Leave-One-Out Cross-Validation)
上記の3つにはそれぞれ特徴があり、使い分けが必要です。
それぞれ解説していきます。
k分割交差検証

k分割交差検証は、データをランダムにk個のグループに分け、1つをテストデータ、その他を訓練データとして学習をk回行い、そのk回分の学習を平均化するなどしてモデルを評価する手法です。
なんでk回も学習しないといけないの?
k回のテストを行うことで、すべてのグループが1度テストデータとなるテストがあるため、偏ったデータのグループがあっても影響力を下げられるメリットがあります。
例えば、年齢から身長を推測するモデルを作成することを考えましょう。
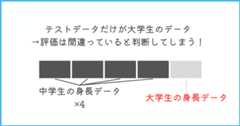
上記のような分割を行った時、訓練データは中学生のデータであるのに、テストデータは大学生のデータであるため、モデルが正確ではないと評価してしまいます。
そのため、テストをk回行い、k個分のテストから総合的な評価をすることで、例のようなデータの偏りによる悪影響を防ぐのがk分割交差検証なのです。
しかし、k回分テストを行うため、1回だけテストを行うことと比べて計算にかかるコストが大きくなってしまうので注意しておきましょう。
加えて、irisデータ(よく用いられるサンプルデータ)を使ったPythonのサンプルコードを以下に記載します。
コメントアウトでそれぞれの変数について書いているため、併せてご確認ください。
from sklearn.model_selection import KFoldfrom sklearn.datasets import load_irisfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score# サンプルデータをロードdata = load_iris()X, y = data.data, data.target# モデル# 今回は分類モデルのため、ロジスティック回帰を採用model = LogisticRegression()# 5分割交差検証を設定# n_splits:kの値,shuffle:ランダムにするかどうか,radom_state:乱数の設定を変えないための変数kfold = KFold(n_splits=5, shuffle=True, random_state=1)# それぞれのテストの正解率を格納するリストaccuracies = []# 5分割交差検証を実行for train_indices, test_indices in kfold.split(X): X_train, X_test = X[train_indices], X[test_indices] y_train, y_test = y[train_indices], y[test_indices] # モデルの学習 model.fit(X_train, y_train) # モデルを使ってデータを予測 y_pred = model.predict(X_test) # 正解率を算出 accuracy = accuracy_score(y_test, y_pred) accuracies.append(accuracy)# 各分割の正解率を表示for i, accuracy in enumerate(accuracies): print(f"Fold {i+1} accuracy: {accuracy}")# 平均正解率を計算して表示mean_accuracy = sum(accuracies) / len(accuracies)print(f"Mean accuracy: {mean_accuracy}")今回は正解率を評価指標として用いましたが、他にも適合率や再現率などさまざまな指標が存在します。
評価指標について詳しく知りたい方は『機械学習の評価指標はどう選ぶ?回帰、分類の評価指標をわかりやすく解説!』の記事をご参照ください。

層化k分割交差検証

層化k分割交差検証は、それぞれのグループごとのデータの分布を合わせてデータを分割する手法です。
普通のk分割交差検証はランダムにデータを分割して検証しますが、層化k分割交差検証は属性で層別に分けてから分割を行います。
そのため、特定のグループのデータが偏るということがなくなり、通常のk分割交差検証に比べて安定した評価を行えるのです。
特に分類を行うモデルの場合は、それぞれのクラスの割合が重要になるため、層化k分割交差検証が用いられやすいので覚えておきましょう。
以下に層化k分割交差検証を行うPythonコードを記載します。

基本的にはk分割交差検証と同じコードです。
from sklearn.model_selection import StratifiedKFoldfrom sklearn.datasets import load_irisfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score# サンプルデータをロードdata = load_iris()X, y = data.data, data.target# モデルmodel = LogisticRegression()# 層化5分割交差検証を設定skf =StratifiedKFold(n_splits=5, shuffle=True, random_state=1)accuracies = []# 層化5分割交差検証を実行for train_indices, test_indices in skf.split(X, y): X_train, X_test = X[train_indices], X[test_indices] y_train, y_test = y[train_indices], y[test_indices] model.fit(X_train, y_train) y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) accuracies.append(accuracy)# 各分割の正解率を表示for i, accuracy in enumerate(accuracies): print(f"Fold {i+1} accuracy: {accuracy}")# 平均正解率を計算して表示mean_accuracy = sum(accuracies) / len(accuracies)print(f"Mean accuracy: {mean_accuracy}")LOOCV (Leave-One-Out Cross-Validation)

LOOCVは、k分割交差検証を各グループ1つのデータで行う手法です。
例えば、5個のデータがあった時、LOOCVを用いると、5個のグループが作られ、評価が行われます。
データを一つずつ分割することによって、データを最大限活用できますが、計算コストが高くなってしまう点が注意です。
データ数が少ないときなどにLOOCVを活用するようにしましょう。
LOOCVをプログラミングで行う場合は、k分割交差検証のコードでkの値をデータ数と同じにして行いましょう。
データサイエンスを総復習するなら「スタアカ」がおすすめ!
交差検証法とホールドアウト法の違い
交差検証法とホールドアウト法の違いは、複数回のテストで評価を行うか、1回のテストで評価を行うかです。
ホールドアウト法とはデータを訓練データとテストデータの2つに分割し、1回のテストから評価を行う手法です。
まず、ホールドアウト法について詳しく知りたい方は『ホールドアウト法とは?Pythonの実装までをわかりやすく解説』の記事をご参照ください。
ホールドアウト法だと、もしデータにたまたま偏りがあった場合に適切な評価ができない可能性があります。
そのため、複数回のテストで安定した評価を得られる交差検証法を用いることをおすすめします。
しかし、交差検証法は計算コストが高くなるため、大規模なデータの場合やコストをかけたくない場合にはホールドアウト法による評価を行うことも検討に入れましょう。
まとめ
交差検証法は、モデルの評価方法として実際に用いられている重要な手法です。
交差検証法には以下の3つの種類があります。
- k分割交差検証
- 層化k分割交差検証
- LOOCV (Leave-One-Out Cross-Validation)
それぞれ特徴があるため、どの手法で評価するかはその時々によって変えてください。
また、交差検証法と並んでホールドアウト法がモデルの評価方法としてありますが、基本的には交差検証法を使用して、安定した評価を行いましょう。
ただし、交差検証法は計算コストがかかるため、計算コストを抑えたい場合はホールドアウト法を用いることがおすすめです。
交差検証法を使って、正確なモデルの評価を行いましょう!
- 機械学習の勉強がなかなか上手く進まない...
- 勉強していても全体像が見えてこない...
- 本当にデータサイエンティストになれるのかな...
と不安に感じてはいませんか?
そんな悩みをまるっと解決してくれるサービスが『スタアカ』です。
僕も利用している『スタアカ』のライトプランは月額980円で動画見放題でコスパ最強です。
「勉強の道しるべが欲しい!」「学習を効率的に進めたい」という方にはこの上ないサブスクです。
データサイエンスを学びたい方に最強のサブスク『スタアカ』を気軽に始めてみませんか?
「ちょっとでも興味がある」という方は、受講した感想も載せている記事もあわせてどうぞ。





おすすめ記事ランキング



commentコメントをキャンセル
関連記事

バイアスとバリアンスとは?意味やトレードオフ・分解について解説
バイアスとバリアンスはモデルの予測性能に大きく関わる重要な概念です。本記事では、バイアスとバリアンスのそれぞれの概要やトレードオフの関係、バイアス・バリアンス分解について解説していきます。

過学習(Overfitting)とは?起こる原因から見分け方・対策方法までわかりやすく解説!
過学習は学習のために用いたデータに過度に適合することで、未知のデータに対する予測精度が低くなってしまう現象です。今回の記事では、過学習の原因から見分け方・対策方法まで解説しています。

DBSCANとは?アルゴリズムやメリット、Pythonコードまで解説
DBSCANはデータの密度で判断してクラスタリングを行う手法です。本記事では、DBSCANのアルゴリズムやメリット、Pythonでの実装について解説していきます。

標準化(Standardization)とは?正規化との違いやPythonでのやり方をわかりやすく解説
標準化は、データの分布を正規分布に近い形にすることで異なる特徴量(変数)同士を比較できるようにするデータの前処理の手法の1つです。本記事では、標準化について、概要から正規化との違い、Pythonでのやり方まで解説していきます。

k近傍法(kNN)とは?仕組みからPythonでの実装までわかりやすく解説!
k近傍法はあるデータを分類するという場面で用いられる手法です。シンプルな仕組みであるため、理解しやすく実装も容易に行えます。今回はk近傍法について、仕組みや実用例、Pythonでの実装、メリット・デメリットについて解説していきます!











{kind=link}