WO2025121815A1 - Method, server, and storage medium for processing voice command - Google Patents
Method, server, and storage medium for processing voice commandDownload PDFInfo
- Publication number
- WO2025121815A1 WO2025121815A1PCT/KR2024/019481KR2024019481WWO2025121815A1WO 2025121815 A1WO2025121815 A1WO 2025121815A1KR 2024019481 WKR2024019481 WKR 2024019481WWO 2025121815 A1WO2025121815 A1WO 2025121815A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- content
- output device
- attribute information
- voice command
- identifying
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images























Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
Definitions
- the present disclosurerelates to a method, a server, and a storage medium for processing a voice command to play content.
- An AI-based voice command processing agentcan perform a function associated with an intent corresponding to a voice command based on a text corresponding to a user's voice command.
- the voice command processing agentcan confirm the keyword "Banana Papa” based on the text "Play Banana Papa” corresponding to the voice command, and can confirm that the intent is "play content (e.g., video or music)".
- the voice agentcan confirm an output device capable of performing the confirmed intent of "play content”.
- the voice agentcan output data causing the confirmed output device to play content associated with the keyword "Banana Papa".
- the output device receiving the datacan play content associated with the keyword "Banana Papa". In this way, content can be played based on the voice command.
- a method for processing a voice commandmay be provided.
- the methodmay include an operation of confirming that an analysis result of the voice command is intended for content playback.
- the methodmay include an operation of confirming at least one attribute information of content associated with the voice command.
- the methodmay include an operation of confirming at least one output device capable of reproducing the content.
- the methodmay include an operation of confirming a first output device for reproducing the content among the at least one output device based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device.
- the methodmay include an operation of performing at least one operation for reproducing the content by the first output device.
- a storage mediumstoring at least one computer-readable instruction may be provided.
- the at least one instructionwhen executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one output device capable of playing back the content.
- the at least one operationmay include an operation of determining a first output device for playing back the content, based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include performing at least one operation for reproduction of the content by the first output device.
- an electronic devicemay include a memory storing at least one instruction.
- the electronic devicemay include one or more processors, including processing circuitry.
- the at least one instructionwhen executed by the one or more processors, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one output device capable of playing back the content.
- the at least one operationmay include an operation of identifying a first output device for playing back the content among the at least one output device, based on at least a portion of at least one attribute information of the content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include an operation of performing at least one operation for playing back the content by the first output device.
- a method for processing a voice commandmay be provided.
- the methodmay include an operation of confirming that an analysis result of a voice command provided by an electronic device reproducing first content is intended to change a playback device of the first content.
- the methodmay include an operation of confirming at least one attribute information of content associated with the voice command based on the confirmation that the analysis result of the voice command is intended to change a playback device of the first content.
- the methodmay include an operation of confirming at least one output device capable of reproducing the first content.
- the methodmay include an operation of confirming a first output device for reproducing the first content among the at least one output device based on at least a part of the at least one attribute information of the first content and a playback history of at least a part of the at least one output device.
- the methodmay include an operation of performing at least one operation for stopping playback of the first content by the electronic device and reproducing the first content by the first output device.
- a storage medium storing at least one computer-readable instructionmay be provided.
- the at least one instructionwhen executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command provided by the electronic device reproducing first content is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one output device capable of reproducing the first content.
- the at least one operationmay include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
- an electronic devicemay include a memory storing at least one instruction.
- the electronic devicemay include one or more processors, including processing circuitry.
- the at least one instructionwhen executed by the one or more processors, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command provided by an electronic device reproducing a first content is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one output device capable of reproducing the first content.
- the at least one operationmay include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
- FIG. 1is a block diagram of an electronic device within a network environment, according to one embodiment.
- FIG. 2is a block diagram of a system for controlling an external electronic device according to one embodiment.
- FIG. 3ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 3bis a diagram illustrating a method for identifying an output device based on at least one property of content and playback history.
- FIG. 3cis a diagram illustrating a method for identifying an output device based on at least one property of content and playback history.
- FIG. 3Dis a diagram illustrating a method for identifying an output device based on at least one property of content and playback history.
- FIG. 3eis a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 4is a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 5is a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 6ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 6bis a drawing for explaining a screen for selecting one of a plurality of output device candidates according to one embodiment.
- FIG. 6cis a drawing for explaining a screen for selecting one of a plurality of output device candidates according to one embodiment.
- FIG. 7ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 7bis a diagram illustrating a method for selecting one of a plurality of output device candidates according to one embodiment.
- FIG. 8ais a flowchart illustrating a method for checking attribute information of content according to one embodiment.
- FIG. 8bis a flowchart illustrating a method for checking attribute information of content according to one embodiment.
- FIG. 9ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 9bis a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 9cis a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 10ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 10bis a diagram for explaining a change in an entity that plays content according to one embodiment.
- FIG. 10cis a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 11ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- FIG. 11bis a drawing for explaining a playback history according to one embodiment.
- FIG. 1is a block diagram of an electronic device (101) in a network environment (100) according to one embodiment.
- the electronic device (101)may communicate with the electronic device (102) via a first network (198) (e.g., a short-range wireless communication network), or may communicate with the electronic device (104) or a server (108) via a second network (199) (e.g., a long-range wireless communication network).
- the electronic device (101)may communicate with the electronic device (104) via the server (108).
- the electronic device (101)may include a processor (120), a memory (130), an input module (150), an audio output module (155), a display module (160), an audio module (170), a sensor module (176), an interface (177), a connection terminal (178), a haptic module (179), a camera module (180), a power management module (188), a battery (189), a communication module (190), a subscriber identification module (196), or an antenna module (197).
- the electronic device (101)may omit at least one of these components (e.g., the connection terminal (178)), or may have one or more other components added.
- some of these componentse.g., the sensor module (176), the camera module (180), or the antenna module (197) may be integrated into one component (e.g., the display module (160)).
- the processor (120)may control at least one other component (e.g., a hardware or software component) of an electronic device (101) connected to the processor (120) by executing, for example, software (e.g., a program (140)), and may perform various data processing or calculations.
- the processor (120)may store a command or data received from another component (e.g., a sensor module (176) or a communication module (190)) in a volatile memory (132), process the command or data stored in the volatile memory (132), and store result data in a nonvolatile memory (134).
- the processor (120)may include a main processor (121) (e.g., a central processing unit or an application processor) or an auxiliary processor (123) (e.g., a graphics processing unit, a neural processing unit (NPU), an image signal processor, a sensor hub processor, or a communication processor) that can operate independently or together with the main processor (121).
- a main processor (121)e.g., a central processing unit or an application processor
- an auxiliary processor (123)e.g., a graphics processing unit, a neural processing unit (NPU), an image signal processor, a sensor hub processor, or a communication processor
- the auxiliary processor (123)may be configured to use less power than the main processor (121) or to be specialized for a given function.
- the auxiliary processor (123)may be implemented separately from the main processor (121) or as a part thereof.
- the auxiliary processor (123)may control at least a portion of functions or states associated with at least one of the components of the electronic device (101) (e.g., the display module (160), the sensor module (176), or the communication module (190)), for example, while the main processor (121) is in an inactive (e.g., sleep) state, or together with the main processor (121) while the main processor (121) is in an active (e.g., application execution) state.
- the auxiliary processor (123)e.g., an image signal processor or a communication processor
- the auxiliary processor (123)may include a hardware structure specialized for processing artificial intelligence models.
- the artificial intelligence modelsmay be generated through machine learning. Such learning may be performed, for example, in the electronic device (101) on which artificial intelligence is performed, or may be performed through a separate server (e.g., server (108)).
- the learning algorithmmay include, for example, supervised learning, unsupervised learning, semi-supervised learning, or reinforcement learning, but is not limited to the examples described above.
- the artificial intelligence modelmay include a plurality of artificial neural network layers.
- the artificial neural networkmay be one of a deep neural network (DNN), a convolutional neural network (CNN), a recurrent neural network (RNN), a restricted Boltzmann machine (RBM), a deep belief network (DBN), a bidirectional recurrent deep neural network (BRDNN), deep Q-networks, or a combination of two or more of the above, but is not limited to the examples described above.
- the artificial intelligence modelmay additionally or alternatively include a software structure.
- the memory (130)can store various data used by at least one component (e.g., processor (120) or sensor module (176)) of the electronic device (101).
- the datacan include, for example, software (e.g., program (140)) and input data or output data for commands related thereto.
- the memory (130)can include volatile memory (132) or nonvolatile memory (134).
- the program (140)may be stored as software in memory (130) and may include, for example, an operating system (142), middleware (144), or an application (146).
- the input module (150)can receive commands or data to be used in a component of the electronic device (101) (e.g., a processor (120)) from an external source (e.g., a user) of the electronic device (101).
- the input module (150)can include, for example, a microphone, a mouse, a keyboard, a key (e.g., a button), or a digital pen (e.g., a stylus pen).
- the audio output module (155)can output an audio signal to the outside of the electronic device (101).
- the audio output module (155)can include, for example, a speaker or a receiver.
- the speakercan be used for general purposes such as multimedia playback or recording playback.
- the receivercan be used to receive an incoming call. According to one embodiment, the receiver can be implemented separately from the speaker or as a part thereof.
- the display module (160)can visually provide information to an external party (e.g., a user) of the electronic device (101).
- the display module (160)can include, for example, a display, a holographic device, or a projector and a control circuit for controlling the device.
- the display module (160)can include a touch sensor configured to detect a touch, or a pressure sensor configured to measure the intensity of a force generated by the touch.
- the audio module (170)can convert sound into an electrical signal, or vice versa, convert an electrical signal into sound. According to one embodiment, the audio module (170) can obtain sound through an input module (150), or output sound through an audio output module (155), or an external electronic device (e.g., an electronic device (102)) (e.g., a speaker or a headphone) directly or wirelessly connected to the electronic device (101).
- an electronic devicee.g., an electronic device (102)
- a speaker or a headphonedirectly or wirelessly connected to the electronic device (101).
- the sensor module (176)can detect an operating state (e.g., power or temperature) of the electronic device (101) or an external environmental state (e.g., user state) and generate an electric signal or data value corresponding to the detected state.
- the sensor module (176)can include, for example, a gesture sensor, a gyro sensor, a barometric pressure sensor, a magnetic sensor, an acceleration sensor, a grip sensor, a proximity sensor, a color sensor, an IR (infrared) sensor, a biometric sensor, a temperature sensor, a humidity sensor, or an illuminance sensor.
- the interface (177)may support one or more designated protocols that may be used to directly or wirelessly connect the electronic device (101) with an external electronic device (e.g., the electronic device (102)).
- the interface (177)may include, for example, a high definition multimedia interface (HDMI), a universal serial bus (USB) interface, an SD card interface, or an audio interface.
- HDMIhigh definition multimedia interface
- USBuniversal serial bus
- SD card interfaceSecure Digital Card
- connection terminal (178)may include a connector through which the electronic device (101) may be physically connected to an external electronic device (e.g., the electronic device (102)).
- the connection terminal (178)may include, for example, an HDMI connector, a USB connector, an SD card connector, or an audio connector (e.g., a headphone connector).
- the haptic module (179)can convert an electrical signal into a mechanical stimulus (e.g., vibration or movement) or an electrical stimulus that a user can perceive through a tactile or kinesthetic sense.
- the haptic module (179)can include, for example, a motor, a piezoelectric element, or an electrical stimulation device.
- the camera module (180)can capture still images and moving images.
- the camera module (180)can include one or more lenses, image sensors, image signal processors, or flashes.
- the power management module (188)can manage power supplied to the electronic device (101).
- the power management module (188)can be implemented as, for example, at least a part of a power management integrated circuit (PMIC).
- PMICpower management integrated circuit
- the battery (189)can power at least one component of the electronic device (101).
- the battery (189)can include, for example, a non-rechargeable primary battery, a rechargeable secondary battery, or a fuel cell.
- the communication module (190)may support establishment of a direct (e.g., wired) communication channel or a wireless communication channel between the electronic device (101) and an external electronic device (e.g., the electronic device (102), the electronic device (104), or the server (108)), and performance of communication through the established communication channel.
- the communication module (190)may operate independently from the processor (120) (e.g., the application processor) and may include one or more communication processors that support direct (e.g., wired) communication or wireless communication.
- the communication module (190)may include a wireless communication module (192) (e.g., a cellular communication module, a short-range wireless communication module, or a GNSS (global navigation satellite system) communication module) or a wired communication module (194) (e.g., a local area network (LAN) communication module or a power line communication module).
- a wireless communication module (192)e.g., a cellular communication module, a short-range wireless communication module, or a GNSS (global navigation satellite system) communication module
- a wired communication module (194)e.g., a local area network (LAN) communication module or a power line communication module.
- a corresponding communication modulemay communicate with an external electronic device (104) via a first network (198) (e.g., a short-range communication network such as Bluetooth, wireless fidelity (WiFi) direct, or infrared data association (IrDA)) or a second network (199) (e.g., a long-range communication network such as a legacy cellular network, a 5G network, a next-generation communication network, the Internet, or a computer network (e.g., a LAN or WAN)).
- a first network (198)e.g., a short-range communication network such as Bluetooth, wireless fidelity (WiFi) direct, or infrared data association (IrDA)
- a second network (199)e.g., a long-range communication network such as a legacy cellular network, a 5G network, a next-generation communication network, the Internet, or a computer network (e.g., a LAN or WAN)
- a computer networke.g.,
- the wireless communication module (192)may use subscriber information (e.g., an international mobile subscriber identity (IMSI)) stored in the subscriber identification module (196) to identify or authenticate the electronic device (101) within a communication network such as the first network (198) or the second network (199).
- subscriber informatione.g., an international mobile subscriber identity (IMSI)
- IMSIinternational mobile subscriber identity
- the wireless communication module (192)can support a 5G network and next-generation communication technology after a 4G network, for example, NR access technology (new radio access technology).
- the NR access technologycan support high-speed transmission of high-capacity data (eMBB (enhanced mobile broadband)), terminal power minimization and connection of multiple terminals (mMTC (massive machine type communications)), or high reliability and low latency (URLLC (ultra-reliable and low-latency communications)).
- eMBBenhanced mobile broadband
- mMTCmassive machine type communications
- URLLCultra-reliable and low-latency communications
- the wireless communication module (192)can support, for example, a high-frequency band (e.g., mmWave band) to achieve a high data transmission rate.
- a high-frequency bande.g., mmWave band
- the wireless communication module (192)may support various technologies for securing performance in a high-frequency band, such as beamforming, massive multiple-input and multiple-output (MIMO), full dimensional MIMO (FD-MIMO), array antenna, analog beam-forming, or large scale antenna.
- the wireless communication module (192)may support various requirements specified in an electronic device (101), an external electronic device (e.g., an electronic device (104)), or a network system (e.g., a second network (199)).
- the wireless communication module (192)can support a peak data rate (e.g., 20 Gbps or more) for eMBB realization, a loss coverage (e.g., 164 dB or less) for mMTC realization, or a U-plane latency (e.g., 0.5 ms or less for downlink (DL) and uplink (UL) each, or 1 ms or less for round trip) for URLLC realization.
- a peak data ratee.g., 20 Gbps or more
- a loss coveragee.g., 164 dB or less
- U-plane latencye.g., 0.5 ms or less for downlink (DL) and uplink (UL) each, or 1 ms or less for round trip
- the antenna module (197)can transmit or receive signals or power to or from the outside (e.g., an external electronic device).
- the antenna module (197)can include an antenna including a radiator formed of a conductor or a conductive pattern formed on a substrate (e.g., a PCB).
- the antenna module (197)can include a plurality of antennas (e.g., an array antenna).
- at least one antenna suitable for a communication method used in a communication network, such as the first network (198) or the second network (199)can be selected from the plurality of antennas by, for example, the communication module (190).
- a signal or powercan be transmitted or received between the communication module (190) and the external electronic device through the selected at least one antenna.
- another componente.g., a radio frequency integrated circuit (RFIC)
- RFICradio frequency integrated circuit
- the antenna module (197)can form a mmWave antenna module.
- the mmWave antenna modulecan include a printed circuit board, an RFIC positioned on or adjacent a first side (e.g., a bottom side) of the printed circuit board and capable of supporting a designated high-frequency band (e.g., a mmWave band), and a plurality of antennas (e.g., an array antenna) positioned on or adjacent a second side (e.g., a top side or a side) of the printed circuit board and capable of transmitting or receiving signals in the designated high-frequency band.
- a first sidee.g., a bottom side
- a plurality of antennase.g., an array antenna
- At least some of the above componentsmay be connected to each other and exchange signals (e.g., commands or data) with each other via a communication method between peripheral devices (e.g., a bus, GPIO (general purpose input and output), SPI (serial peripheral interface), or MIPI (mobile industry processor interface)).
- peripheral devicese.g., a bus, GPIO (general purpose input and output), SPI (serial peripheral interface), or MIPI (mobile industry processor interface)).
- commands or datamay be transmitted or received between the electronic device (101) and an external electronic device (104) via a server (108) connected to a second network (199).
- Each of the external electronic devices (102, or 104)may be the same or a different type of device as the electronic device (101).
- all or part of the operations executed in the electronic device (101)may be executed in one or more of the external electronic devices (102, 104, or 108). For example, when the electronic device (101) is to perform a certain function or service automatically or in response to a request from a user or another device, the electronic device (101) may, instead of or in addition to executing the function or service itself, request one or more external electronic devices to perform at least a part of the function or service.
- One or more external electronic devices that have received the requestmay execute at least a part of the requested function or service, or an additional function or service related to the request, and transmit the result of the execution to the electronic device (101).
- the electronic device (101)may process the result as it is or additionally and provide it as at least a part of a response to the request.
- cloud computing, distributed computing, mobile edge computing (MEC), or client-server computing technologymay be used.
- the electronic device (101)may provide an ultra-low latency service by using, for example, distributed computing or mobile edge computing.
- the external electronic device (104)may include an IoT (Internet of Things) device.
- the server (108)may be an intelligent server using machine learning and/or a neural network.
- the external electronic device (104) or the server (108)may be included in the second network (199).
- the electronic device (101)can be applied to intelligent services (e.g., smart home, smart city, smart car, or healthcare) based on 5G communication technology and IoT-related technology.
- FIG. 2is a block diagram of a system for controlling an external electronic device according to one embodiment.
- the electronic device (101)may transmit and/or receive data to and from a server (108).
- the server (108)may include a voice command processing server (200) and/or an IoT server (240).
- the voice command processing server (200) and the IoT server (240)are implemented to be included in a single entity, the server (108), and at least one of the voice command processing server (200) and the IoT server (240) may not be included in a single server (108).
- the voice command processing server (200) and the IoT server (240)may both be implemented as different entities.
- the voice command processing server (200)may be implemented to include the IoT server (240), or the voice command processing server (200) may be implemented to support the functions performed by the IoT server (240) described in the present disclosure.
- the IoT server (240)may be implemented to include the voice command processing server (200), or the IoT server (240) may be implemented to support the functions performed by the voice command processing server (200) described in the present disclosure.
- the server (108)may include at least one processor.
- the at least one processormay include a central processing unit (CPU), a graphic processing unit (GPU), an NPU, an FPGA (field programmable gate array), an ASIC, and/or a SoC (system on chip), and there is no limitation on the form of implementation thereof.
- one operation performed by the server (108)may be performed by any one of the at least one processor (e.g., a CPU, a GPU, an NPU, an FPGA, an ASIC, and/or an SoC), or by a linkage of two or more processors.
- the plurality of operations performed by the server (108)may be performed by at least one processor (e.g., a CPU, a GPU, an NPU, an FPGA, an ASIC, and/or a SoC), or some of the plurality of operations may be performed by one processor and some of the operations may be performed by another processor.
- the server (108)may include at least one memory storing at least one instruction.
- the at least one memorymay include volatile memory and/or non-volatile memory, and there is no limitation on the form of implementation thereof.
- the at least one instructionwhen executed by the at least one processor, may cause the server (108) to perform at least one operation (e.g., at least some of the operations performed by the server (108) described herein).
- An instruction causing the performance of one operation or multiple operations performed by the server (108)may be stored in one physically independent memory, or may be stored distributed across multiple memories.
- the voice command processing server (200)may process a voice command provided from a voice command processing client (230) of the electronic device (101) and perform at least one operation corresponding to the intention of the voice command.
- the electronic device (101)may execute the voice command processing client (230).
- the electronic device (101)may obtain a user voice through a microphone and obtain a voice command based on the user voice.
- the voice commandmay be an acoustic signal, or a signal in which an acoustic signal is pre-processed (e.g., noise removed and/or amplified), but there is no limitation.
- the voice command processing client (230)may provide the pre-processed acoustic signal to the server (108) as a voice command. If the voice command processing client (230) supports the preprocessing function and the ASR (auto speech recognition) function, the electronic device (101) can provide the text identified based on the application of the ASR function to the acoustic signal as a voice command to the voice command processing server (200). If the voice command processing client (230) supports even the NLU (natural language understanding) function, the electronic device (101) can also provide the natural language understanding result identified by applying the NLU function to the text as a voice command to the server (108).
- ASRauto speech recognition
- the voice command processing client (230)can support at least some of the plurality of functions for voice command processing, and the voice command provided from the electronic device (101) to the server (108) can be set based on the supported functions.
- at least some of the functions performed by the server (108) (or at least one entity included in the server (108)) described in the present disclosuremay also be performed by the electronic device (101) that receives the user's voice.
- all of the operations performed by the server (108)may also be performed by the electronic device (101), which may be referred to as on-device voice command processing.
- at least some of the functions performed by the electronic device (101) described in the present disclosuremay also be performed by the server (108) (or at least one entity included in the server (108).
- the voice command processing server (200)can process (e.g., ASR and/or NLU) a voice command provided from the voice command processing client (230).
- the voice command processing server (200)can execute (or include) at least one module (211, 212, 213, 220).
- the ASR module (211)can provide, for example, a text corresponding to an acoustic signal.
- the NLU module (212)can provide a natural language understanding result corresponding to the text.
- the TTS module (213)can provide a signal (e.g., an acoustic signal) for a voice output corresponding to the text.
- the voice command processing server (200)can process a voice command provided from the electronic device (101) and provide a natural language understanding result.
- the voice command processing client (230) executed by the electronic device (101)the ASR module (211) and/or the NLU module (212) may not be utilized.
- the natural language understanding resultmay include, for example, keywords and/or intents, but there is no limitation on the form of implementation thereof.
- the keywordsmay include, for example, parameters and/or slots, but there is no limitation on the method of implementation thereof.
- the output device verification module (220)can be provided with a natural language understanding result.
- the output device verification module (220)can include, for example, a content property verification module (221), an output device selection module (222), a function execution command module (223), a playback history management module (224), and/or a playback history database (225), but is not limited thereto.
- the content property verification module (221)can verify at least one property corresponding to a keyword included in the natural language understanding result.
- the keywordcan be, for example, a word associated with content included in a voice command (for example, a title, a genre, an artist, copyright information, a review rating, but is not limited thereto).
- At least one property of the contentcan include, for example, a genre, a title, a review rating, copyright information, and/or artist-related information, but is not limited thereto.
- the playback history database (225)can store a playback history of at least one output device (251, 252, 253).
- the playback historymay include, but is not limited to, the playback time of the content that was played, the corresponding intent, a keyword, at least one attribute information of the corresponding content, information for identifying an output device that played the corresponding content, and/or playback management information.
- the output device selection module (222)can check a content attribute corresponding to a keyword provided from the content attribute verification module.
- the output device selection module (222)can check the playback history from the playback history DB.
- the output device selection module (222)can select at least one output device (251, 252, 253) capable of playing the content based on the content attribute corresponding to the keyword and the playback history from the playback history DB.
- the function execution command module (223)may provide a command to the electronic device (101) and/or the selected output device (e.g., the first output device (251)) (e.g., via the IoT server (240) or directly) to cause the selected output device (e.g., the first output device (251)) to play the content.
- the function execution command module (223)may provide, but is not limited to, parameters for intent and/or execution (or, may be named as slots).
- the function execution command module (223)may also generate a response to be provided to the user (NLG: natural language generation).
- the playback history management module (224)may store information on playback of the content by the selected output device in the playback history database (225) through the above-described process, and/or update information in the playback history database (225).
- the IoT server (240)may transmit and/or receive data to and from at least one output device (251, 252, 253) registered in connection with an account of a user who has accessed the electronic device (101), for example.
- the IoT server (240)may provide the current status (e.g., whether it is connected to the IoT server (240)) and/or capability (e.g., the type of content that can be played, but is not limited) of the at least one registered output device (251, 252, 253) to the voice command processing server (200), but is not limited thereto.
- the voice command processing server (200)may identify an output device capable of playing content based on the current status and/or capability of the at least one output device (251, 252, 253).
- the IoT server (240)may provide a control command to the at least one output device (251, 252, 253), for example.
- a part of at least one output device (251, 252, 253)may be directly or indirectly connected to the IoT server (240).
- a control commandmay be provided through an intermediate device (e.g., a mobile device), and sound output may be performed by an output device (e.g., an earset connected to a mobile device) connected to the intermediate device.
- the at least one output device (251, 252, 253) that receives a control command from the IoT server (240)may perform at least one operation corresponding to the control command, for example, playing content.
- the at least one output device (251, 252, 253)may provide a result (e.g., whether success or failure, but there is no limitation) after performing the at least one operation to the IoT server (240).
- the IoT server (240)may provide the result of the performance to the voice command processing server (200).
- the voice command processing server (200)can store the performance result in the playback history database (225). The performance result may be used for subsequent output device selection.
- FIG. 3Ais a flowchart for explaining a method for processing a voice command according to one embodiment.
- the embodiment of FIG. 3Awill be explained with reference to FIGS. 3B, 3C, and 3D.
- FIGS. 3B, 3C, and 3Dare drawings for explaining a method for identifying an output device based on at least one property of content and a playback history.
- each operationmay be performed sequentially, but is not necessarily performed sequentially. For example, the order of each operation may be changed, and at least two operations may be performed in parallel.
- the server (108)may, in operation 301, determine that the analysis result of the voice command is intended to play content. For example, referring to the embodiment of FIG. 3b, the server (108) may determine the voice command (350) of “play Banana Papa.” Based on the natural language understanding result of the voice command (350) of “play Banana Papa,” the server (108) may determine that the keyword of the voice command (350) is “banana papa” and that the intent of the voice command (350) is “play content.”
- the server (108), in operation 303,can verify at least one attribute information of the content associated with the voice command (350).
- the at least one attribute informationmay include, for example, at least one attribute of the content, a genre, a title, a review rating, copyright information, and/or artist-related information, but is not limited thereto.
- the server (108), in operation 305can verify at least one output device (e.g., output device (251, 252, 253)) capable of playing the content.
- the server (108)can verify at least one output device (e.g., output device (251, 252, 253)) capable of playing the content based on whether at least one output device registered in response to the user's account is connected to the server (108) and/or its capability (e.g., a type of content that can be played, but is not limited thereto), but there is no limitation on the verification method.
- at least one output devicee.g., output device (251, 252, 253
- its capabilitye.g., a type of content that can be played, but is not limited thereto
- the server (108), in operation 307,may identify a first output device (251) (e.g., a living room speaker (355) of FIG. 3B) for playing back the content among the at least one output device based on at least a portion of at least one attribute information of the content and a playback history of at least a portion of the at least one output device (251, 252, 253).
- the server (108)may identify, for example, a playback history (225a) such as FIG. 3B.
- the playback history (225a)may be arranged, for example, in the order of the playback time (331) of the content, but there is no limitation.
- the playback history (225a)may include, for example, a playback time (331) of the content, an intent (332), a keyword (333), at least one attribute information (334, 335, 336) of the corresponding content, information (337) for identifying an output device that played back the corresponding content, and/or playback management information (338), but is not limited thereto.
- the playback time (331) of the content of the first sub-playback history (341)may be "July 22, 2023 10:00".
- the intent (332) of the first sub-playback history (341)may be "Play music", which is an example of content playback.
- the intent (332)may be, for example, an intent of a natural language understanding result that caused the playback of the corresponding content, but is not limited thereto.
- the keyword (333) of the first sub-playback history (341)may be "grape".
- the keyword (333)may be a keyword of a natural language understanding result that caused content playback, but there is no limitation.
- the genre information (334)which is an example of attribute information of the corresponding content of the first sub-playback history (341)
- the artist information (335)which is an example of attribute information of the corresponding content of the first sub-playback history (341) may be "grape".
- the title information (336)which is an example of attribute information of the corresponding content of the first sub-playback history (341), may be "grape".
- the information (337) for identifying the output device that played the corresponding content of the first sub-playback history (341)may be "mobile”.
- the playback management information (338) of the first sub-playback history (341)may be "additional”.
- the playback management information (338)may be set as “additional” based on the start of playback of the corresponding content, but there is no limitation.
- other sub-playback histories (342, 343, 344, 345, 346, 347)may be stored in the playback history database (225).
- the content of the title "Grapes”may be started to be played by "mobile” at 10:00 on July 22, 2023.
- the output device that performs playback of the content of the title “Grapes”may be changed from “mobile” to "living room speaker” at 10:01 on July 22, 2023.
- the second sub-playback history (342)may be generated and stored.
- Information (337) for identifying the output device of the second sub-playback history (342)may be "living room speaker”, and playback management information (338) may be "change”.
- playback of the content titled "Grapes"may end at 10:05 on July 22, 2023.
- a third sub-playback history (343)may be generated and stored.
- Information (337) for identifying the output device of the third sub-playback history (343)may be "living room speaker”, and playback management information (338) may be "media end”.
- the playback time (331) of the content of the 4th sub-playback history (344)may be "July 22, 2023 10:05".
- the intent (332) of the 4th sub-playback history (344)may be "Play music", which is an example of content playback.
- the intent (332)may be, for example, the intent of the natural language understanding result that caused the playback of the corresponding content, but is not limited thereto.
- the keyword (333) of the 4th sub-playback history (344)may be "banana papa”.
- the genre information (334)which is an example of the attribute information of the corresponding content of the 4th sub-playback history (344), may be "nursery rhyme".
- the artist information (335), which is an example of the attribute information of the corresponding content of the 4th sub-playback history (344),may be "grapefruit".
- the title information (336), which is an example of the attribute information of the corresponding content of the 4th sub-playback history (344),may be "Banana Papa.”
- the information (337) for identifying the output device that reproduced the corresponding content of the 4th sub-playback history (344)may be "mobile.”
- the playback management information (338) of the 4th sub-playback history (344)may be "addition.” "Addition" may mean that the playback history by the output device for the corresponding content is added, but there is no limitation.
- “change”may mean a change of the playback device, but there is no limitation.
- “end”may mean the end of the playback of the corresponding content, but there is no limitation.
- the content of the title “Banana Papa”may be started to be played by "mobile” at 10:05 on July 22, 2023.
- an output device for performing playback of content with the title of "Banana Papa”may be changed from “mobile” to "living room speaker” at 10:06 on July 23, 2023.
- a fifth sub-playback history (345)may be generated and stored.
- Information (337) for identifying an output device of the fifth sub-playback history (345)may be "living room speaker”
- playback management information (338)may be "change”.
- a sixth sub-playback history (346)may be generated and stored.
- Information (337) for identifying an output device of the third sub-playback history (346)may be "living room speaker", and playback management information (338) may be "media end”.
- the playback time (331) of the content of the 7th sub-playback history (347)may be "July 23, 2023 10:14".
- the intent (332) of the 7th sub-playback history (347)may be "Play music", which is an example of content playback.
- the keyword (333) of the 7th sub-playback history (347)may be "Rocket".
- the genre information (334), which is an example of the attribute information of the corresponding content of the 7th sub-playback history (347),may be "Rock”.
- the artist information (335), which is an example of the attribute information of the corresponding content of the 7th sub-playback history (347),may be "PatentRock”.
- the title information (336), which is an example of the attribute information of the corresponding content of the 7th sub-playback history (347),may be "Rocket”.
- the information (337) for identifying the output device that reproduced the corresponding content of the 7th sub-playback history (347)may be "in-room speaker”.
- the reproduction management information (338) of the 7th sub-playback history (347)may be "additional”.
- the server (108)can confirm the intention of "content playback” and the keyword of "Banana Papa” as a result of the natural language understanding of the voice command (350) of "play Banana Papa”.
- the server (108)can confirm the attribute information (351) of the content associated with the keyword.
- the server (108)can confirm the attribute information (351) based on, for example, a linkage with an entity that supports NER (named entity recognition) and/or an entity that manages an LLM (large language model), but there is no limitation on the method of confirmation.
- the attribute information (351) of the contentcan be, for example, genre information (352) of "Children's Song", artist information (353) of “Grapes”, and title information (354) of "Banana Papa", but there is no limitation on the type thereof.
- the server (108)can confirm the sub-playback history corresponding to the attribute information (351) of the content by referring to the playback history (225a). For example, it can be confirmed that the genre information (334), the artist information (335), and the title information (336) of the sub-playback history (344, 345, 346) are identical to the genre information (352), the artist information (353), and the title information (354) of the attribute information (351) of the content.
- one of the output devices“mobile” and “living room speaker,” corresponding to the sub-playback history (341, 342, 343) can be confirmed as the output device.
- the server (108)can select one of them based on, for example, a user’s selection, a specified rule, and/or an inference result of an artificial intelligence model, which will be described later.
- a specified rulemay be to determine a corresponding device as an output device after a change in an output device for content playback.
- the server (108)may identify "living room speaker” as an output device based on the fact that "living room speaker” is a corresponding device after a change in content playback, but this is merely exemplary.
- the living room speaker (355)is selected.
- the genre information (334) and the artist information (335) of the sub playback history (341, 342, 343)are identical to the genre information (352), the artist information (335), and the title information (336) of the attribute information (351) of the content.
- the output device corresponding to the sub playback history (341, 342, 343)may also be identified as a candidate for the output device.
- an output device of a sub-playback history (344, 345, 346) having a relatively larger number of attribute information identical to the attribute information (351) of the contentmay be identified as a candidate for the output device, and an output device of a sub-playback history (341, 342, 343) having a relatively smaller number of attribute information may not be identified as a candidate for the output device, but there is no limitation.
- the server (108)may preferentially consider specific attribute information (e.g., genre information (352)) over other attribute information, but there is no limitation.
- specific attribute informatione.g., genre information (352)
- an output device that most recently played the content among a plurality of output devices that played the contentmay be selected.
- the server (108), in operation 309,may perform at least one operation for reproduction of content by the first output device (251) (e.g., the living room speaker (355) of FIG. 3b).
- the server (108)may provide data to the first output device (251) that causes output of the content (e.g., content having a title of "Banana Papa”).
- the server (108)may provide data to cause transmission of data for reproduction of the content to another external electronic device that may access a source providing the content (e.g., content having a title of "Banana Papa") or that stores the content.
- the external electronic devicemay establish a communication connection with the first output device (251) based on the received data, and may provide data for reproduction of the content to the first output device (251) based on the established communication connection.
- the first output device (251)may also reproduce content based on data for content reproduction received based on a communication connection.
- the server (108)may also update the playback history (225a) based on the completion of content playback.
- the server (108)can verify the voice command (360) of "play jingle bells.”
- the server (108)can verify attribute information (361) of content associated with the voice command (360) (or keyword).
- the attribute information (361)may be, for example, genre information (362) of "children's songs,” artist information (363) of "XXY,” and title information (364) of "jingle bells.”
- the server (108)can verify sub-play history (341, 342, 343, 344, 345, 346) having genre information (334) corresponding to the genre information (362) of "children's songs.”
- the server (108)can check the output devices, “mobile” and “living room speaker”, corresponding to the sub-play history (341,342,343,344,345,346).
- the server (108)can select the living room speaker (365), for example, based on the user’s selection, a specified rule, and/or the inference result of the AI model.
- the server (108)can perform at least one operation to cause the content of the title “Jingle Bells” to be played by the living room speaker (365).
- the server (108)can verify the voice command (370) of "Play Hostile.”
- the server (108)can verify attribute information (371) of content associated with the voice command (370) (or keyword).
- the attribute information (371)may be, for example, genre information (372) of "Rock,” artist information (373) of "Pamtera,” and title information (374) of "Hostile.”
- the server (108)can verify sub-play history (347) having genre information (334) corresponding to the genre information (372) of "Rock.”
- the server (108)can verify "room speaker,” which is an output device corresponding to the sub-play history (347).
- the server (108)may perform at least one action that causes the content of the title “Hostile” to be played by the in-room speaker (375).
- FIG. 3eis a flowchart illustrating a method for processing a voice command according to one embodiment.
- the server (108)may, at operation 391, determine that the analysis result of the voice command is intended for content playback.
- the server (108), at operation 393,may determine a category (or, may be named a cluster or a group) corresponding to the content associated with the voice command.
- Table 1is an example of a category corresponding to the content.
- the category of Table 1may be set based on genre information, but this is exemplary, and there is no limitation on the type and/or number of attribute information for distinguishing the category.
- the server (108)may confirm a category corresponding to the content based on information such as Table 1, and/or confirm a category corresponding to the content based on clustering, and there is no limitation on the confirmation method.
- Category-related informationsuch as Table 1 may be generated (or confirmed) based on, for example, K-means clustering, and/or a knowledge graph, but there is no limitation on the method. Meanwhile, it is merely exemplary that the category is classified by genre as in Table 1, and those skilled in the art will understand that the category may be classified based on other content attributes other than the category.
- the server (108), in operation 395,can identify at least one output device capable of playing back the content.
- the server (108), based on the category and at least some of the playback history of the at least one output devicecan identify a first output device for playing back the content among the at least one output device.
- a category by playback historycan be identified based on genre information of the playback history, or the playback history can be implemented such that information about the category is included.
- the server (108), based on the playback historycan identify the first output device that played back the content of the corresponding category, or can identify the first output device among candidates for a plurality of output devices.
- the server (108)can perform at least one operation for playing back the content by the first output device.
- FIG. 4is a flowchart illustrating a method for processing a voice command according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the electronic device (101)may obtain a voice command in operation 401.
- the electronic device (101)may provide the voice command to the server (108) in operation 403.
- the voice commandmay be implemented as an acoustic signal, a text in which the acoustic signal is changed, and/or a natural language understanding result for the text, as described above, and there is no limitation on the implementation thereof.
- the NLU module (212) included in the server (108)may determine, in operation 405, that the voice command is intended for content playback. Those skilled in the art will understand that if the electronic device (101) provides a voice command including a natural language understanding result, the operation by the NLU module (212) may be omitted.
- the NLU module (212)may provide content-related information in operation 407.
- the content-related informationmay include, for example, keywords and/or intent (for example, intent to play content), but is not limited thereto.
- the output device verification module (220)can verify at least one property of the content in operation 409. For example, the output device verification module (220) can verify at least one property of the content based on, but not limited to, an inquiry to an entity supporting NER and/or an entity managing LLM.
- the output device verification module (220)can verify a playback history of at least one output device in operation 411.
- the output device verification module (220)can verify a first output device based on at least a portion of the at least one property of the content and at least a portion of the playback history in operation 413. For example, the first output device can be verified based on at least a portion of the at least one property of the content corresponding (same and/or similar) to at least a portion of the content property in the playback history of the first output device.
- the output device identification module (220)may, in operation 415, provide data causing content playback to the first output device (251).
- the output device identification module (220)may, for example, provide the data to the first output device (251) via the IoT server (240), but this is exemplary and those skilled in the art will understand that the data may be transmitted without the intermediation of the IoT server (240).
- the first datamay include at least one command, a keyword, and/or at least one attribute of the identified content to achieve the intent of “content playback”, but there is no limitation on the implementation form thereof.
- the first output device (251)may, in operation 417, play back the content based on the received first data.
- the first output device (251)may download information for playing back the content and play it back by connecting to the source of the content based on information included in the first data, or may play back content that has been stored in advance.
- the first output device (251)may establish a connection with an external electronic device (e.g., the electronic device (101) or another IoT device) that can access the content, and may receive and play back data that can play back the content based on the established connection.
- an external electronic devicee.g., the electronic device (101) or another IoT device
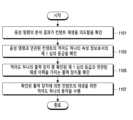
- FIG. 5is a flowchart illustrating a method for processing a voice command according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the electronic device (101)may obtain a voice command in operation 501.
- the electronic device (101)may provide the voice command to the server (108) in operation 503.
- the NLU module (212) included in the server (108)may confirm that the voice command is intended for content playback in operation 505.
- the NLU module (212)may provide content-related information in operation 507.
- the output device verification module (220)may confirm at least one property of the content in operation 509.
- the output device verification module (220)may confirm a playback history of at least one output device in operation 511.
- the output device verification module (220)may confirm a first output device based on at least a portion of at least one property of the content and at least a portion of the playback history in operation 513.
- the output device verification module (220)may, in operation 515, provide second data that causes transmission of first data for content playback to the electronic device (101) that provided the voice command. For example, the output device verification module (220) may verify whether the first output device (251) supports a function of establishing a communication connection with the electronic device (101), receiving data for content playback through the communication connection, and/or supporting a content playback function based on the received data, and may select the first output device (251) based on supporting at least one of the functions (which may be referred to as a wireless audio output function).
- the output device verification module (220)may select the first output device (251) by verifying whether the first output device (251) supports the wireless audio output function and additionally whether the first output device (251) can establish a communication connection with the electronic device (101). For example, the output device verification module (220) can verify whether the electronic device (101) is located in the space where the first output device (251) is placed based on information provided from the IoT server (240), and can verify whether wireless sound output is currently possible based on the verification result. Alternatively, the output device verification module (220) can receive a list of connectable devices verified based on short-range communication from the electronic device (101), and can verify whether the first output device (251) is currently capable of wireless sound output based on the list, and there is no limitation on the verification method.
- the electronic device (101)can establish a communication connection with the first output device (251) based on the received second data in operation 517. Meanwhile, those skilled in the art will understand that if the electronic device (101) has already established a communication connection with the first output device (251), the procedure for establishing the communication connection may be omitted.
- the second datamay include, for example, information for identifying the first output device (251), information for requesting establishment of a communication connection with the first output device (251), and/or information associated with content for which playback is requested, but there is no limitation in its implementation.
- the electronic device (101)can establish a communication connection with the first output device (251) based on the received second data in operation 517.
- the communication connectionmay be established based on, for example, short-range wireless communication, but is not limited thereto, and there is no limitation in its establishment method.
- the electronic device (101)may provide first data for content reproduction through a communication connection in operation 519.
- the electronic device (101)may reproduce content, and may enable content reproduction by the first output device (251) by setting the output device of the reproduced content to the first output device (251), but there is no limitation.
- the electronic device (101)may provide only data for content reproduction to the first output device (251) without reproducing the content, and thus enable content reproduction by the first output device (251).
- FIG. 6ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- Fig. 6ais a drawing for describing a screen for selecting one of a plurality of output device candidates according to one embodiment.
- FIG. 6cis a drawing for explaining a screen for selecting one of a plurality of output device candidates according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the electronic device (101)may obtain a voice command in operation 601.
- the electronic device (101)may provide the voice command to the server (108) in operation 603.
- the NLU module (212) included in the server (108)may confirm that the voice command is intended for content playback in operation 605.
- the NLU module (212)may provide content-related information in operation 607.
- the output device verification module (220)may confirm at least one property of the content in operation 609.
- the output device verification module (220)may confirm a playback history of at least one output device in operation 611.
- the output device verification module (220)may confirm output device candidates based on at least a portion of the at least one property and at least a portion of the playback history in operation 613. For example, as in FIG.
- the genre information (352) of the attribute (351) of the contentmay be confirmed as "Children's Song". Accordingly, "mobile” and “living room speaker” corresponding to the sub-play histories (341, 342, 343, 344, 345, 346) that include "Children's Song” in the genre information (333) may be confirmed as output device candidates.
- the output device confirmation module (220)may, in operation 615, provide data for expressing the output device candidates to the electronic device (101) that provided the voice command.
- the electronic device (101)may, in operation 617, express the output device candidates based on the received data. For example, as in FIG. 6b, the electronic device (101) may provide a pop-up window (631) on the screen (630) being displayed.
- the pop-up window (631)may include text intended to induce selection of an output device capable of playing the content.
- the pop-up window (631)may include at least one object (632, 633, 634).
- the at least one object (632, 633, 634)may be expressed as a UI element, a UI object, an icon, text, an image, a visual element, a visual component, an avatar, a thumbnail, an animation, a key, and/or a button, but there is no limitation on the expression method.
- At least one object (632, 633, 634)may include text that can identify each of the plurality of output device candidates, but there is no limitation on the way in which it is expressed.
- the electronic device (101)may replace or additionally provide identification information for the plurality of output device candidates and a voice response to select one of them, as a replacement for the pop-up window (631).
- the usermay select (for example, by tapping or inputting an additional voice command, but there is no limitation) one of the at least one object (632, 633, 634).
- the electronic device (101)may provide data related to the user selection to the output device confirmation module (220).
- the electronic device (101)may provide a pop-up window (631) as in FIG. 6C based on the received data.
- an additional object (636) providing a countdown animation effectmay be expressed on an object (632) that is one of the objects (632, 633, 634) corresponding to a plurality of output device candidates.
- the additional object (636)may be expressed as being placed on an object (632) corresponding to an output device having the highest priority among the output device candidates, for example. For example, in FIG.
- “Living Room TV”, “My tab S8”, and “My S23+”may be set as output device candidates, and since “Living Room TV” has the highest priority, the additional object (636) may be expressed as being placed on an object (632) corresponding to “Living Room TV”.
- the prioritymay be set based on a specified rule, and/or may be determined based on an inference result (e.g., a confidence score, but not limited to) of an artificial intelligence model (e.g., an artificial intelligence model based on a neural network, linear regression, and/or a support vector machine, but not limited to).
- the specified rulemay include a rule that a higher priority is given to a content property as the number of times the content property has been played increases.
- the specified rulemay include a rule that a higher priority is given to a content property as the time of playing the content property is closer to the most recent time.
- the specified rulemay include a rule that a higher priority is given to an output device after the change when the output device for playing the content property has been changed.
- the priority for each of the output device candidatesmay be determined based on the result of applying each rule (e.g., a score for setting the priority) (e.g., based on a sum or a weighted sum).
- the prioritymay be set based on the inference results of the AI model of each output device candidate.
- the AI modelmay be trained to receive, for example, at least one attribute of the output device and the content as input and output a fitness (or score).
- the AI modelmay be LLM, but there is no limitation on its implementation.
- the additional object (636)may be represented by the text “3” in the embodiment of FIG. 6c, for example. Over time, the text “3” may be sequentially changed to the texts “2”, “1”, and “0”, thereby expressing an animation effect of a countdown. Based on the expression of the text “0”, the electronic device (101) may determine that the output device corresponding to the object (632) associated with the location of the additional object (636) has been selected. The electronic device (101) may then, in operation 621, provide data related to the user selection to the output device identification module (220). Again, referring to operation 6a, the output device identification module (220) may, in operation 623, identify the first output device (251) based on the received data.
- the output device verification module (220)may, at operation 625, provide data to the first output device (251) that causes content playback.
- the output device verification module (220)may, for example, provide the data to the first output device (251) via the IoT server (240), but it will be understood by those skilled in the art that this is exemplary and that the data may be transmitted without the intermediation of the IoT server (240).
- the first output device (251), at operation 627,may play back the content based on the received data. Meanwhile, as another example, as described in FIG. 5, it will be understood by those skilled in the art that the output device verification module (220) may provide second data that causes transmission of the first data for content playback to the electronic device (101).
- FIG. 7ais a flowchart illustrating a method for processing a voice command according to one embodiment. The embodiment of FIG. 7a will be described with reference to FIG. 7b.
- FIG. 7bis a diagram illustrating a method for selecting one of a plurality of output device candidates according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may, in operation 701, confirm that the analysis result of the voice command is intended to play content. For example, the server (108) may confirm the voice command of "play Banana Papa.” Based on the natural language understanding result of the voice command of "play Banana Papa,” the server (108) may confirm that the keyword of the voice command is "banana papa” and the intent of the voice command (350) is "play content.” In operation 703, the server (108) may confirm at least one attribute information of the content associated with the voice command (350). In operation 705, the server (108) may confirm at least one output device capable of playing the content.
- the server (108), in operation 707,can identify candidates for output devices for playing back the content among the at least one output device based on at least a part of at least one attribute information of the content and at least a part of the playback history of at least one output device. For example, it is assumed that genre information of "Children's Song", artist information of "Pododo”, and title information of "Banana Papa” are identified as at least one attribute information of the keyword of "Banana Papa”. For example, the server (108) can identify sub-playback information (341, 342, 343, 344, 345, 346) having genre information (731) including "Children's Song".
- the server (108)can identify sub-playback information (341, 342, 343, 344, 345, 346) having artist information (732) including artist information of "Pododo". For example, the server (108) can check sub-playback information (344, 345, 346) having artist information (733) of "Banana Papa.” The server (108) can check the mobile (734) and living room speaker (735) corresponding to the sub-playback information (341, 342, 343, 344, 345, 346) as output device candidates.
- the server (108)may, in operation 709, identify a first output device among the output device candidates based on at least one rule and/or an artificial intelligence model.
- the server (108)may perform at least one operation for reproduction of content by the first output device.
- the specified rulemay include a rule that a higher priority is given to a content property as the number of times the content property is reproduced increases.
- the specified rulemay include a rule that a higher priority is given to a content property as the time of reproduction of the content property is closer to a recent time.
- the specified rulemay include a rule that, when an output device for reproduction of the content property is changed, a higher priority is given to an output device after the change.
- the priority of each of the output device candidatesmay be determined based on the result of applying each rule (e.g., a score for setting priorities) (e.g., based on a sum or a weighted sum).
- the server (108)may set the priority of the living room speaker (735) to be higher than that of the mobile (734) based on the specified rule, based on the fact that the playback subject of the content titled “Banana Papa” has changed from the mobile (734) to the living room speaker (735).
- the server (108)may determine the living room speaker (735) with a relatively high priority as the output device to play the content. Meanwhile, as described above, the priority may also be set based on the inference result of the artificial intelligence model of each of the output device candidates. According to the above, the server (108) may determine any one of the multiple output device candidates without the user’s selection.
- FIG. 8ais a flowchart illustrating a method for checking attribute information of content according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may, in operation 801, determine that the analysis result of the voice command is intended to play content.
- the server (108)may, in operation 803, determine a keyword.
- the server (108)may determine that the keyword of the voice command is "banana papa" and the intent of the voice command is "play content” based on the natural language understanding result for the voice command "play banana papa.”
- the server (108)may inquire about at least one attribute information corresponding to the keyword to an entity supporting NER (named entity recognition) (for example, it may be named a NER (named entity recognition) server, but there is no limitation thereon).
- NERnamed entity recognition
- the entity supporting NERmay be implemented to be included in the server (108), for example, or may be implemented as a separate entity from the server (108), and there is no limitation in the implementation method thereof.
- the server (108), in operation 807,may receive at least one attribute information corresponding to the keyword from an entity supporting NER as a response to the inquiry.
- Table 2is an example of a response provided from an entity supporting NER according to one embodiment.
- NERmay be performed, for example, as at least a part of an NLU operation, or may be performed independently of an NLU operation, and there is no limitation on the implementation of the performance.
- a response to an inquirymay include identification information ("Id") of the corresponding message.
- the responsemay include a domain related to the corresponding content (for example, "music” in Table 2).
- the responsemay include an entity related to the corresponding content (for example, “song” in Table 2).
- the responsemay include a keyword related to the corresponding content (for example, expressed as “textname” in Table 2, and its value may be "banana papa”).
- the responsemay include artist information as attribute information of the corresponding content (for example, expressed as “artist_name”, “artist_Id", and “type” in Table 2, and its values may be “ ⁇ ", "1703695", and "artist”).
- the responsemay include, as attribute information of the corresponding content, album information including the content (for example, expressed as "album_name” and “album_id” in Table 2, the values of which may be “All About Bananas” and “10269480”).
- the responsemay include, as attribute information of the corresponding content, genre information (for example, expressed as “genre” in Table 2, the value of which may be “kids”).
- the responsemay include, as attribute information of the corresponding content, rank information (for example, expressed as “genre_rank” and “rank” in Table 2, the values of which may be “4" and "1487”).
- the responsemay include information about an entity supporting NER (or a source referenced by the entity) (e.g., “streameverything.com” in Table 2).
- the server (108)may extract at least one attribute information from the response and, using the at least one attribute information extracted as described above, identify an output device to play the content.
- FIG. 8bis a flowchart illustrating a method for checking attribute information of content according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108), in operation 811,may determine that the analysis result of the voice command is intended to play content.
- the server (108), in operation 813may determine a keyword.
- the server (108), based on the natural language understanding result for the voice command of "play banana papa”,may determine that the keyword of the voice command is "banana papa" and the intent of the voice command is "play content”.
- the server (108)may provide prompting information for inquiring about at least one attribute information corresponding to the keyword to an entity managing an LLM (large language model).
- the entity managing the LLMmay be implemented to be included in the server (108), for example, or may be implemented as a separate entity from the server (108), and there is no limitation on the implementation method thereof.
- the server (108), in operation 817may receive at least one attribute information corresponding to the keyword from the entity managing the LLM as a response to the inquiry.
- Table 3is an example of prompting information with an LLM according to one embodiment.
- Table 3may be default prompting information, and the server (108) may insert a keyword into "OOO" of Table 3 to provide the corresponding information to the entity managing the LLM.
- the server (108)may receive a response corresponding to the prompting information of Table 3, for example.
- the prompting informationmay include, for example, a sentence that inquires about at least one attribute information (e.g., genre, artist, title, author information, and review information).
- the prompting informationmay also include, for example, a sentence that requests a response in a format that can be processed without performing additional NLU on the server (108).
- FIG. 9ais a flowchart illustrating a method for processing a voice command according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may obtain a voice command at operation 901.
- the server (108)may verify at least one property of the content at operation 903.
- the server (108)may verify at operation 905 whether an output device having a playback history corresponding to at least one property of the content exists. Based on the existence of an output device having a playback history corresponding to at least one property of the content (905-Yes), the server (108) may perform at least one operation for playback of the content by the verified output device at operation 907.
- the server (108)may select one of the output devices based on user selection, a specified rule, and/or an artificial intelligence inference result.
- the server (108)may, in operation 909, perform at least one operation for playback of the content by the electronic device (101) that acquired the user voice.
- the server (108)may cause the electronic device (101) to play the content by providing at least one command for playback of the identified content to the electronic device (101).
- the content playback by the electronic device (101)may not only mean the content playback by the audio output module (155) and/or the display module (160) included in the electronic device (101), but may also mean the content playback by an audio output device (for example, but not limited to, a wired earphone, a TWS (true wireless stereo) earphone, a Bluetooth-based speaker) connected to the electronic device (101).
- the server (108)may also update the playback history by adding the sub-playback history in which content is played by the electronic device (101) to the existing playback history.
- FIG. 9bis a flowchart illustrating a method for processing a voice command according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may obtain a voice command at operation 921.
- the server (108)may verify at least one property of the content at operation 923.
- the server (108)may verify at operation 925 whether an output device having a playback history corresponding to at least one property of the content exists. Based on the existence of an output device having a playback history corresponding to at least one property of the content (925-Yes), the server (108) may verify at operation 927 whether the verified output device is capable of playing back the content. For example, if the verified output device is not connected to the server (108) (e.g., is offline), data for playing back the content may not be provided to the output device.
- the server (108)may, in operation 929, perform at least one operation for playing the content by the identified output device. As described above, based on the existence of multiple output device candidates corresponding to at least one attribute of the content, those skilled in the art will understand that the server (108) may select any one of the output devices based on a user selection, a specified rule, and/or an artificial intelligence inference result.
- the server (108)may, in operation 931, perform at least one operation for playing the content by another output device corresponding to the identified output device.
- the server (108)e.g., the IoT server (240)
- the server (108)can manage the arrangement location of the output device.
- the server (108)can perform at least one operation for playing content by an output device arranged in the same space as the identified output device.
- the server (108)can perform at least one operation for playing content by an output device with a next priority for the identified output device.
- the server (108)can ask the user about other output device candidates and perform at least one operation for playing content by an output device selected based on the user's selection. Based on the absence of an output device having a playback history corresponding to at least one attribute of the content (925-No), the server (108) may, in operation 933, perform at least one operation for playback of the content by the electronic device (101) that acquired the user voice.
- FIG. 9cis a flowchart illustrating a method for processing a voice command according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may obtain a voice command at operation 941.
- the server (108)may verify at least one property of the content at operation 943.
- the server (108)may verify at operation 945 whether an output device having a playback history corresponding to at least one property of the content exists. Based on the existence of an output device having a playback history corresponding to at least one property of the content (945-Yes), the server (108) may verify at operation 947 that the verified output device is already playing another content.
- the server (108)may verify whether the verified output device can change the playback content. For example, whether the verified output device can change the playback content may be set in advance by a user.
- the server (108)may additionally ask the user whether to change the playback content, and based on the response thereto, determine whether the identified output device can change the playback content. Based on the identified output device being able to change the playback content (949-Yes), the server (108) may, in operation 951, perform at least one operation for changing the playback of the content by the identified output device.
- the server (108)may, for example, command to stop playback of the existing content and play the identified content, or may command only playback of the content without a stop command. Based on the identified output device being unable to change the playback content (949-No), the server (108) may, in operation 953, perform at least one operation for playing the content by another output device corresponding to the identified output device.
- the server (108)may, in operation 955, perform at least one operation for playback of the content by the electronic device (101) that acquired the user voice.
- FIG. 10Ais a flowchart illustrating a method for processing a voice command according to one embodiment. The embodiment of FIG. 10A will be described with reference to FIG. 10B.
- FIG. 10bis a diagram for explaining a change in an entity that plays content according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may, in operation 1001, determine that the analysis result of the voice command provided from the electronic device (101) is a change in the content playback output device.
- the electronic device (101)may play the first content (e.g., title: Banana Papa, artist: Grape Do).
- the electronic device (101)may provide a screen (e.g., may be an application execution screen for content playback, but is not limited thereto) (1030) indicating that the first content is played.
- the screen (1030)may include, for example, information about the title of the first content (1031) and/or information about the artist of the first content (1032), but is not limited thereto in its implementation.
- the electronic device (101)may obtain a user voice (1042) from a user (1041).
- the user voice (1042)may be "Play Banana Papa on another device.”
- the electronic device (101)may provide a voice command corresponding to the user voice (1042) to a voice command processing server (200).
- the voice commandmay include an acoustic signal, text, and/or a natural language understanding result corresponding to the user voice (1042), as described above, but there is no limitation on the form of its implementation.
- the server (108)e.g., the voice processing server (200)
- may determine that the intent of the voice commandis "change the content playback output device" and the keyword may be "Banana Papa.”
- the server (108)may, at operation 1003, identify at least one attribute information of the content associated with the voice command.
- the server (108), at operation 1005,may identify at least one output device capable of playing the content.
- the server (108)may identify a first output device (251) for playing the content among the at least one output device based on at least a portion of the at least one attribute information of the content and at least a portion of the playback history of the at least one output device.
- the server (108)may perform at least one operation for playing the content by the first output device (251). For example, in the example of FIG.
- the server (108)may provide data causing the content to be played to the first output device (251).
- the server (108)may command the electronic device (101) to stop playing the content.
- the provision of data to the first output device (251)is exemplary.
- the server (108)may provide the electronic device (101) with data that causes transmission of data for playing the content, and the electronic device (101) may transmit data for playing the content to the first output device (251) based on this.
- the first output device (251)may be implemented to play the corresponding content from the beginning, but this is exemplary.
- the first output device (251)may be implemented to play the corresponding content from the point in time at which the electronic device (101) stopped playing, for example.
- FIG. 10cis a flowchart illustrating a method for processing a voice command according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may, in operation 1041, check for an event of changing a playback output device for content being played on the electronic device (101).
- the confirmation of the intention to change a playback output device in the voice command described in FIG. 10Amay be an example of an event.
- the eventmay be set as the electronic device (101) entering a designated location.
- the usermay set the content being output to be played by another output device based on the electronic device (101) entering the user's house. Accordingly, the occurrence of the event may be notified to the server (108) based on the confirmation that the electronic device (101) has entered the designated location.
- the output devicemay be determined based on attribute information of the content being played on the electronic device (101).
- the output deviceneeds to be determined based on the deliberation level, which is one of the attribute information of the content.
- Content with an adult ratingis preferably not played on an output device that can be viewed by minors, and may be preferably played on an output device set for personal use.
- the server (108), in operation 1043may check at least one attribute information of the content associated with the voice command.
- the server (108), in operation 1045may check at least one output device that can play the content.
- the server (108), in operation 1047,may check a first output device (251) for playing the content among the at least one output device based on at least a part of the at least one attribute information of the content and at least a part of the playback history of the at least one output device.
- the server (108), in operation 1049,may perform at least one operation for playing the content by the first output device (251).
- FIG. 11ais a flowchart illustrating a method for processing a voice command according to one embodiment. The embodiment of FIG. 11a will be described with reference to FIG. 11b.
- FIG. 11bis a drawing for explaining a playback history according to one embodiment.
- the operationsmay be performed sequentially, but are not necessarily performed sequentially.
- the order of the operationsmay be changed, and at least two operations may be performed in parallel.
- the server (108)may, in operation 1101, confirm that the analysis result of the voice command is intended for content playback.
- the server (108)may confirm a first review grade as at least one attribute information of the content associated with the voice command.
- the server (108)may confirm an output device having a playback history associated with the confirmed first review grade among at least one output device.
- the server (108)may perform at least one operation for playback of the content by the confirmed output device.
- the server (108)may manage a playback history (1125) as in FIG. 11B .
- the playback history (1125)may be arranged, for example, in the order of the playback time (1131) of the content, but is not limited thereto.
- the playback history (1125)may include, for example, a playback time (1131) of the content, a keyword (1132), at least one attribute information (1133, 1134, 1135, 1136) of the content, information for identifying an output device that played the content (1137), and/or playback management information (1138), but is not limited thereto.
- the attribute information of the content of the playback history (1125)may further include a review rating (1136).
- the server (108)may confirm, for example, that the review rating of the sub-playback histories (1141, 1142, 1143) is "15 years old" and that the review rating of the sub-playback histories (1144, 1145, 1146) is "18 years old".
- the server (108)can confirm that the output devices corresponding to the sub-play history (1141, 1142, 1143) corresponding to the deliberation rating of, for example, "15 years old" are “mobile” and "projector".
- the server (108)can confirm that the output devices corresponding to the sub-play history (1144, 1145, 1146) corresponding to the deliberation rating of, for example, "18 years old” are “mobile” and "TV in my room”.
- the server (108)can confirm, for example, the voice command of "play horror mansion”.
- the server (108)can confirm that the keyword of the voice command is "horror mansion" and the intent is "play content”.
- the server (108)can confirm at least one attribute information of the content associated with the keyword of "horror mansion”.
- the server (108)may, for example, refer to the sub-play history (1144, 1145, 1146) having the rating of "18 years old” based on the rating of "Horror Mansion” being "18 years old".
- the server (108)may identify "mobile” and "home TV” as output devices of the sub-play history (1144, 1145, 1146) as candidates for the output device.
- the server (108)may identify "home TV” among the candidates as the output device based on a specified rule (e.g., a rule that gives a higher priority to a device after a content playback change).
- the server (108)may give (or manage) a higher priority to the attribute information of the "rating" than to other attribute information.
- the server (108)may primarily select an output device based on the "review rating", and may be set to select an output device based on other attribute information when an output device is not identified based on the "review rating" and/or multiple output devices are identified, but this is exemplary.
- the server (108)may, for example, give a relatively higher priority to attribute information other than the "review rating”.
- the server (108)may be set to assign a weight to each attribute information and select an output device based on the sum of the weights confirmed based on whether the attribute information of the identified content corresponds to the attribute information in the playback history.
- the weights corresponding to each attribute informationmay also be determined based on the priority of the attribute information, but there is no limitation.
- the server (108)may ask the user whether to play the content through the identified output device before the content with the "review rating" of "18 years old" is played. If the response to the inquiry result is positive, the server (108) may be configured to perform at least one action for playback of the content by the identified output device.
- the server (108)may manage public output devices and personal output devices separately.
- the server (108)may select a personal output device when the content has a designated rating (e.g., adult), and may select a public output device when the content has a non-designated rating.
- a designated ratinge.g., adult
- a public output devicewhen the content has a non-designated rating.
- the public output devices and personal output devicesmay be managed separately, for example, based on user settings or based on analysis results of their placement locations.
- a method for processing a voice commandmay be provided.
- the methodmay include an operation of confirming that an analysis result of the voice command is intended for content playback.
- the methodmay include an operation of confirming at least one attribute information of content associated with the voice command.
- the methodmay include an operation of confirming at least one output device capable of reproducing the content.
- the methodmay include an operation of confirming a first output device for reproducing the content among the at least one output device based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device.
- the methodmay include an operation of performing at least one operation for reproducing the content by the first output device.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying, based on at least a portion of the reproduction history, at least one first content reproduced by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying the first output device as an output device for reproducing the content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical.
- the act of performing at least one operation for reproduction of the content by the first output devicemay include the act of providing, to the first output device, first data that causes reproduction of the content.
- the act of performing at least one operation for reproduction of the content by the first output devicemay include the act of providing second data to an external electronic device capable of communicating with the first output device, the second data causing transmission of data for reproduction of the content.
- the operation of identifying a first output device for reproducing the content among the at least one output devicemay include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and at least a portion of the reproduction history.
- the operation of identifying a first output device for reproducing the content among the at least one output devicemay include identifying the first output device as an output device for reproducing the content based on identifying information about a user's selection of the first output device among the plurality of output devices.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and the reproduction history.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include identifying the first output device among the plurality of output devices as an output device for reproducing the content based on at least one rule and/or an artificial intelligence model.
- At least one attribute information of the contentmay include a genre of the content, a title of the content, a review rating of the content, authorship information of the content, and/or artist-related information of the content.
- the operation of verifying at least one attribute information of the content associated with the voice commandmay include an operation of inquiring about the at least one attribute information of the content to an entity supporting named entity recognition (NER).
- the operation of verifying the at least one attribute information of the content associated with the voice commandmay include an operation of verifying the at least one attribute information provided from an entity supporting NER.
- the operation of verifying at least one attribute information of the content associated with the voice commandmay include the operation of providing prompting information for inquiring about the at least one attribute information of the content to an entity managing a large language model (LLM).
- the operation of verifying at least one attribute information of the content associated with the voice commandmay include the operation of verifying the at least one attribute information provided from the entity managing the LLM.
- the methodmay further include receiving, from an entity managing the at least one output device, information for identifying the at least one output device and/or the playback history of the at least one output device.
- the operation of identifying the at least one output device capable of playing the contentmay include identifying the at least one output device based on the information for identifying the at least one output device.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying, based on at least a portion of the reproduction history, at least one second content reproduced by a second output device, different from the first output device among the at least one output device, and at least one second attribute information corresponding to each of the at least one second content.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying whether the second output device can reproduce the content based on the identity of at least a portion of the at least one second attribute information and at least a portion of the at least one attribute information of the content.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying the first output device corresponding to the second output device as an output device for reproducing the content based on the identification that the second output device cannot reproduce the content.
- the operation of identifying a first output device among the at least one output device for playing back the contentmay include an operation of identifying, based on the playback history, at least one first content played back by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content.
- the operation of identifying a first output device among the at least one output device for playing back the contentmay include an operation of identifying whether the first output device is playing back other content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical.
- the operation of identifying a first output device among the at least one output device for playing back the contentmay include an operation of identifying, based on identifying that the first output device is playing back the other content, whether the first output device can stop playing back the other content and play back the content.
- the operation of identifying a first output device for reproducing the content among the at least one output devicemay include an operation of identifying the first output device as an output device for reproducing the content based on determining that the first output device can stop reproducing the other content and reproduce the content.
- a storage mediumstoring at least one computer-readable instruction may be provided.
- the at least one instructionwhen executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one output device capable of playing back the content.
- the at least one operationmay include an operation of determining a first output device for playing back the content, based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include performing at least one operation for reproduction of the content by the first output device.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying, based on at least a portion of the reproduction history, at least one first content reproduced by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying the first output device as an output device for reproducing the content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical.
- the act of performing at least one operation for reproduction of the content by the first output devicemay include the act of providing second data to an external electronic device capable of communicating with the first output device, the second data causing transmission of data for reproduction of the content.
- the operation of identifying a first output device for reproducing the content among the at least one output devicemay include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and at least a portion of the reproduction history.
- the operation of identifying a first output device for reproducing the content among the at least one output devicemay include identifying the first output device as an output device for reproducing the content based on identifying information about a user's selection of the first output device among the plurality of output devices.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and the reproduction history.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include identifying the first output device among the plurality of output devices as an output device for reproducing the content based on at least one rule and/or an artificial intelligence model.
- At least one attribute information of the contentmay include a genre of the content, a title of the content, a review rating of the content, authorship information of the content, and/or artist-related information of the content.
- the operation of verifying at least one attribute information of the content associated with the voice commandmay include an operation of inquiring about the at least one attribute information of the content to an entity supporting NER.
- the operation of verifying at least one attribute information of the content associated with the voice commandmay include an operation of verifying the at least one attribute information provided from the entity supporting NER.
- the operation of verifying at least one attribute information of the content associated with the voice commandmay include the operation of providing prompting information for inquiring about the at least one attribute information of the content to an entity managing an LLM.
- the operation of verifying at least one attribute information of the content associated with the voice commandmay include the operation of verifying the at least one attribute information provided from the entity managing the LLM.
- the at least one operationmay further include receiving, from an entity managing the at least one output device, information for identifying the at least one output device and/or the playback history of the at least one output device.
- the operation of identifying the at least one output device capable of playing the contentmay include identifying the at least one output device based on the information for identifying the at least one output device.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying, based on at least a portion of the reproduction history, at least one second content reproduced by a second output device, different from the first output device among the at least one output device, and at least one second attribute information corresponding to each of the at least one second content.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying whether the second output device can reproduce the content based on the identity of at least a portion of the at least one second attribute information and at least a portion of the at least one attribute information of the content.
- the operation of identifying a first output device among the at least one output device for reproducing the contentmay include an operation of identifying the first output device corresponding to the second output device as an output device for reproducing the content based on the identification that the second output device cannot reproduce the content.
- the operation of identifying a first output device among the at least one output device for playing back the contentmay include an operation of identifying, based on the playback history, at least one first content played back by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content.
- the operation of identifying a first output device among the at least one output device for playing back the contentmay include an operation of identifying whether the first output device is playing back other content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical.
- the operation of identifying a first output device among the at least one output device for playing back the contentmay include an operation of identifying, based on identifying that the first output device is playing back the other content, whether the first output device can stop playing back the other content and play back the content.
- the operation of identifying a first output device for reproducing the content among the at least one output devicemay include an operation of identifying the first output device as an output device for reproducing the content based on determining that the first output device can stop reproducing the other content and reproduce the content.
- an electronic devicemay include a memory storing at least one instruction.
- the electronic devicemay include one or more processors, including processing circuitry.
- the at least one instructionwhen executed by the one or more processors, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content.
- the at least one operationmay include an operation of determining at least one output device capable of playing back the content.
- the at least one operationmay include an operation of identifying a first output device for playing back the content among the at least one output device, based on at least a portion of at least one attribute information of the content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include an operation of performing at least one operation for playing back the content by the first output device.
- a method for processing a voice commandmay be provided.
- the methodmay include an operation of confirming that an analysis result of a voice command provided by an electronic device reproducing first content is intended to change a playback device of the first content.
- the methodmay include an operation of confirming at least one attribute information of content associated with the voice command based on the confirmation that the analysis result of the voice command is intended to change a playback device of the first content.
- the methodmay include an operation of confirming at least one output device capable of reproducing the first content.
- the methodmay include an operation of confirming a first output device for reproducing the first content among the at least one output device based on at least a part of the at least one attribute information of the first content and a playback history of at least a part of the at least one output device.
- the methodmay include an operation of performing at least one operation for stopping playback of the first content by the electronic device and reproducing the first content by the first output device.
- a storage medium storing at least one computer-readable instructionmay be provided.
- the at least one instructionwhen executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command provided by the electronic device reproducing first content is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one output device capable of reproducing the first content.
- the at least one operationmay include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
- an electronic devicemay include a memory storing at least one instruction.
- the electronic devicemay include one or more processors, including processing circuitry.
- the at least one instructionwhen executed by the one or more processors, may cause the electronic device to perform at least one operation.
- the at least one operationmay include an operation of determining that an analysis result of a voice command provided by an electronic device reproducing a first content is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content.
- the at least one operationmay include an operation of determining at least one output device capable of reproducing the first content.
- the at least one operationmay include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device.
- the at least one operationmay include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
- the electronic devicemay be a variety of devices.
- the electronic devicemay include, for example, a portable communication device (e.g., a smartphone), a computer device, a portable multimedia device, a portable medical device, a camera, a wearable device, or a home appliance device.
- a portable communication devicee.g., a smartphone
- a computer devicee.g
- first, second, or first or secondmay be used merely to distinguish one component from another, and do not limit the components in any other respect (e.g., importance or order).
- a componente.g., a first
- another componente.g., a second
- functionallye.g., a third component
- moduleused in the embodiments of this document may include a unit implemented in hardware, software or firmware, and may be used interchangeably with terms such as logic, logic block, component, or circuit, for example.
- a modulemay be an integrally configured component or a minimum unit of the component or a part thereof that performs one or more functions.
- a modulemay be implemented in the form of an application-specific integrated circuit (ASIC).
- ASICapplication-specific integrated circuit
- One embodiment of the present documentmay be implemented as software (e.g., a program (140)) including one or more instructions stored in a storage medium (e.g., an internal memory (136) or an external memory (138)) readable by a machine (e.g., an electronic device (101)).
- a processore.g., a processor (120)
- the machinee.g., the electronic device (101)
- the one or more instructionsmay include code generated by a compiler or code executable by an interpreter.
- the machine-readable storage mediummay be provided in the form of a non-transitory storage medium.
- 'non-transitory'simply means that the storage medium is a tangible device and does not contain signals (e.g. electromagnetic waves), and the term does not distinguish between cases where data is stored semi-permanently or temporarily on the storage medium.
- the method according to one embodiment disclosed in the present documentmay be provided as included in a computer program product.
- the computer program productmay be traded between a seller and a buyer as a commodity.
- the computer program productmay be distributed in the form of a machine-readable storage medium (e.g., a compact disc read only memory (CD-ROM)), or may be distributed online (e.g., downloaded or uploaded) via an application store (e.g., Play StoreTM) or directly between two user devices (e.g., smart phones).
- an application storee.g., Play StoreTM
- at least a part of the computer program productmay be at least temporarily stored or temporarily generated in a machine-readable storage medium, such as a memory of a manufacturer's server, a server of an application store, or an intermediary server.
- each componente.g., a module or a program of the above-described components may include one or more entities, and some of the entities may be separated and arranged in another component.
- one or more of the components or operations of the above-described componentsmay be omitted, or one or more other components or operations may be added.
- the plurality of componentse.g., a module or a program
- the integrated componentmay perform one or more functions of each of the components of the plurality of components identically or similarly to those performed by the corresponding component of the plurality of components before the integration.
- the operations performed by the module, the program, or another componentmay be executed sequentially, in parallel, repeatedly, or heuristically, or one or more of the operations may be executed in a different order, omitted, or one or more other operations may be added.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
Description
Translated fromKorean본 개시는, 컨텐트를 재생하는 음성 명령을 처리하기 위한 방법, 서버, 및 저장 매체에 관한 것이다.The present disclosure relates to a method, a server, and a storage medium for processing a voice command to play content.
인공지능 기반의 음성 명령 처리 에이전트(agent)는, 사용자의 음성 명령에 대응하는 텍스트에 기반하여, 음성 명령에 대응하는 의도와 연관된 기능을 수행할 수 있다. 예를 들어, 음성 명령 처리 에이전트는, 음성 명령에 대응하는 "바나나 파파 재생해줘"라는 텍스트가 확인됨에 기반하여, "바나나 파파"의 키워드를 확인할 수 있으며, 그 의도가 "컨텐트(예를 들어, 동영상 또는 음악)의 재생"임을 확인할 수 있다. 예를 들어, 음성 에이전트는, 확인된 의도인 "컨텐트의 재생"을 수행할 수 있는, 출력 장치를 확인할 수 있다. 음성 에이전트는, 확인된 출력 장치로 하여금 "바나나 파파"의 키워드와 연관된 컨텐트를 재생하도록 야기하는 데이터를 출력할 수 있다. 데이터를 수신한 출력 장치는, "바나나 파파"의 키워드와 연관된 컨텐트를 재생할 수 있다. 이와 같이, 음성 명령에 기반하여, 컨텐트가 재생될 수 있다.An AI-based voice command processing agent can perform a function associated with an intent corresponding to a voice command based on a text corresponding to a user's voice command. For example, the voice command processing agent can confirm the keyword "Banana Papa" based on the text "Play Banana Papa" corresponding to the voice command, and can confirm that the intent is "play content (e.g., video or music)". For example, the voice agent can confirm an output device capable of performing the confirmed intent of "play content". The voice agent can output data causing the confirmed output device to play content associated with the keyword "Banana Papa". The output device receiving the data can play content associated with the keyword "Banana Papa". In this way, content can be played based on the voice command.
상술한 정보는 본 문서에 대한 이해를 돕기 위한 목적으로 하는 배경 기술(related art)로서 제공될 수 있다. 상술한 내용 중 어느 것도 본 문서와 관련된 종래 기술(prior art)로서 주장되거나, 종래 기술을 결정하는데 사용될 수 없다.The above information may be provided as related art to aid in understanding this document. None of the above is claimed to be prior art related to this document or can be used to determine prior art.
일 실시예에 따라서, 음성 명령을 처리하는 방법이 제공될 수 있다. 상기 방법은, 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a method for processing a voice command may be provided. The method may include an operation of confirming that an analysis result of the voice command is intended for content playback. The method may include an operation of confirming at least one attribute information of content associated with the voice command. The method may include an operation of confirming at least one output device capable of reproducing the content. The method may include an operation of confirming a first output device for reproducing the content among the at least one output device based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device. The method may include an operation of performing at least one operation for reproducing the content by the first output device.
일 실시예에 따라서, 컴퓨터로 독출 가능한 적어도 하나의 인스트럭션을 저장하는 저장 매체가 제공될 수 있다. 상기 적어도 하나의 인스트럭션은 전자 장치의 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a storage medium storing at least one computer-readable instruction may be provided. The at least one instruction, when executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command is intended to play back content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content. The at least one operation may include an operation of determining at least one output device capable of playing back the content. The at least one operation may include an operation of determining a first output device for playing back the content, based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device. The at least one operation may include performing at least one operation for reproduction of the content by the first output device.
일 실시예에 따라서, 전자 장치는, 적어도 하나의 인스트럭션을 저장하는 메모리를 포함할 수 있다. 상기 전자 장치는 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들을 포함할 수 있다. 상기 적어도 하나의 인스트럭션은 상기 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, an electronic device may include a memory storing at least one instruction. The electronic device may include one or more processors, including processing circuitry. The at least one instruction, when executed by the one or more processors, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command is intended to play back content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content. The at least one operation may include an operation of determining at least one output device capable of playing back the content. The at least one operation may include an operation of identifying a first output device for playing back the content among the at least one output device, based on at least a portion of at least one attribute information of the content and a playback history of at least a portion of the at least one output device. The at least one operation may include an operation of performing at least one operation for playing back the content by the first output device.
일 실시예에 따라서, 음성 명령을 처리하는 방법이 제공될 수 있다. 상기 방법은, 제 1 컨텐트를 재생하는 전자 장치에 의하여 제공되는 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 제 1 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 제 1 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 전자 장치에 의한 상기 제 1 컨텐트의 재생의 중단 및 상기 제 1 출력 장치에 의한 상기 제 1 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a method for processing a voice command may be provided. The method may include an operation of confirming that an analysis result of a voice command provided by an electronic device reproducing first content is intended to change a playback device of the first content. The method may include an operation of confirming at least one attribute information of content associated with the voice command based on the confirmation that the analysis result of the voice command is intended to change a playback device of the first content. The method may include an operation of confirming at least one output device capable of reproducing the first content. The method may include an operation of confirming a first output device for reproducing the first content among the at least one output device based on at least a part of the at least one attribute information of the first content and a playback history of at least a part of the at least one output device. The method may include an operation of performing at least one operation for stopping playback of the first content by the electronic device and reproducing the first content by the first output device.
일 실시예에 따라서, 컴퓨터로 독출 가능한 적어도 하나의 인스트럭션을 저장하는 저장 매체가 제공될 수 있다. 상기 적어도 하나의 인스트럭션은 전자 장치의 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 제 1 컨텐트를 재생하는 전자 장치에 의하여 제공되는 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 전자 장치에 의한 상기 제 1 컨텐트의 재생의 중단 및 상기 제 1 출력 장치에 의한 상기 제 1 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a storage medium storing at least one computer-readable instruction may be provided. The at least one instruction, when executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command provided by the electronic device reproducing first content is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one output device capable of reproducing the first content. The at least one operation may include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device. The at least one operation may include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
일 실시예에 따라서, 전자 장치는, 적어도 하나의 인스트럭션을 저장하는 메모리를포함할 수 있다. 상기 전자 장치는, 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들을 포함할 수 있다. 상기 적어도 하나의 인스트럭션은 상기 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 제 1 컨텐트를 재생하는 전자 장치에 의하여 제공되는 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 전자 장치에 의한 상기 제 1 컨텐트의 재생의 중단 및 상기 제 1 출력 장치에 의한 상기 제 1 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, an electronic device may include a memory storing at least one instruction. The electronic device may include one or more processors, including processing circuitry. The at least one instruction, when executed by the one or more processors, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command provided by an electronic device reproducing a first content is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one output device capable of reproducing the first content. The at least one operation may include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device. The at least one operation may include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
도 1은, 일 실시예들에 따른, 네트워크 환경 내의 전자 장치의 블록도이다.FIG. 1 is a block diagram of an electronic device within a network environment, according to one embodiment.
도 2는 일 실시예에 따른 외부 전자 장치의 제어를 위한 시스템의 블록도이다.FIG. 2 is a block diagram of a system for controlling an external electronic device according to one embodiment.
도 3a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 3a is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 3b는, 컨텐트의 적어도 하나의 속성 및 재생 이력에 기반한 출력 장치를 확인하기 위한 방법을 설명하기 위한 도면들이다.FIG. 3b is a diagram illustrating a method for identifying an output device based on at least one property of content and playback history.
도 3c는, 컨텐트의 적어도 하나의 속성 및 재생 이력에 기반한 출력 장치를 확인하기 위한 방법을 설명하기 위한 도면들이다.FIG. 3c is a diagram illustrating a method for identifying an output device based on at least one property of content and playback history.
도 3d는, 컨텐트의 적어도 하나의 속성 및 재생 이력에 기반한 출력 장치를 확인하기 위한 방법을 설명하기 위한 도면들이다.FIG. 3D is a diagram illustrating a method for identifying an output device based on at least one property of content and playback history.
도 3e는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 3e is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 4는, 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 4 is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 5는, 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 5 is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 6a는, 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 6a is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 6b는 일 실시예에 따른 복수 개의 출력 장치 후보들 중 어느 하나를 선택하기 위한 화면을 설명하기 위한 도면이다.FIG. 6b is a drawing for explaining a screen for selecting one of a plurality of output device candidates according to one embodiment.
도 6c는 일 실시예에 따른 복수 개의 출력 장치 후보들 중 어느 하나를 선택하기 위한 화면을 설명하기 위한 도면이다.FIG. 6c is a drawing for explaining a screen for selecting one of a plurality of output device candidates according to one embodiment.
도 7a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 7a is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 7b는 일 실시예에 따른 복수 개의 출력 장치 후보들 중 어느 하나를 선택하기 위한 방법을 설명하기 위한 도면이다.FIG. 7b is a diagram illustrating a method for selecting one of a plurality of output device candidates according to one embodiment.
도 8a는 일 실시예에 따른 컨텐트의 속성 정보를 확인하는 방법을 설명하기 위한 흐름도이다.FIG. 8a is a flowchart illustrating a method for checking attribute information of content according to one embodiment.
도 8b는 일 실시예에 따른 컨텐트의 속성 정보를 확인하는 방법을 설명하기 위한 흐름도이다.FIG. 8b is a flowchart illustrating a method for checking attribute information of content according to one embodiment.
도 9a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 9a is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 9b는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 9b is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 9c는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 9c is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 10a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 10a is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 10b는 일 실시예에 따른 컨텐트를 재생하는 엔티티의 변경을 설명하기 위한 도면이다.FIG. 10b is a diagram for explaining a change in an entity that plays content according to one embodiment.
도 10c는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 10c is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 11a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 11a is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 11b는, 일 실시예에 따른 재생 이력을 설명하기 위한 도면이다.FIG. 11b is a drawing for explaining a playback history according to one embodiment.
이하에서는 도면을 참조하여 본 개시의 실시예에 대하여 본 개시가 속하는 기술 분야에서 통상의 지식을 가진 자가 용이하게 실시할 수 있도록 상세히 설명한다. 그러나 본 개시는 여러 가지 상이한 형태로 구현될 수 있으며 여기에서 설명하는 실시예에 한정되지 않는다. 도면의 설명과 관련하여, 동일하거나 유사한 구성요소에 대해서는 동일하거나 유사한 참조 부호가 사용될 수 있다. 또한, 도면 및 관련된 설명에서는, 잘 알려진 기능 및 구성에 대한 설명이 명확성과 간결성을 위해 생략될 수 있다.Hereinafter, embodiments of the present disclosure will be described in detail with reference to the drawings so that those skilled in the art can easily implement the present disclosure. However, the present disclosure may be implemented in various different forms and is not limited to the embodiments described herein. In connection with the description of the drawings, the same or similar reference numerals may be used for the same or similar components. In addition, in the drawings and related descriptions, descriptions of well-known functions and configurations may be omitted for clarity and conciseness.
도 1은, 일 실시예들에 따른, 네트워크 환경(100) 내의 전자 장치(101)의 블록도이다. 도 1을 참조하면, 네트워크 환경(100)에서 전자 장치(101)는 제 1 네트워크(198)(예: 근거리 무선 통신 네트워크)를 통하여 전자 장치(102)와 통신하거나, 또는 제 2 네트워크(199)(예: 원거리 무선 통신 네트워크)를 통하여 전자 장치(104) 또는 서버(108)와 통신할 수 있다. 일실시예에 따르면, 전자 장치(101)는 서버(108)를 통하여 전자 장치(104)와 통신할 수 있다. 일실시예에 따르면, 전자 장치(101)는 프로세서(120), 메모리(130), 입력 모듈(150), 음향 출력 모듈(155), 디스플레이 모듈(160), 오디오 모듈(170), 센서 모듈(176), 인터페이스(177), 연결 단자(178), 햅틱 모듈(179), 카메라 모듈(180), 전력 관리 모듈(188), 배터리(189), 통신 모듈(190), 가입자 식별 모듈(196), 또는 안테나 모듈(197)을 포함할 수 있다. 어떤 실시예에서는, 전자 장치(101)에는, 이 구성요소들 중 적어도 하나(예: 연결 단자(178))가 생략되거나, 하나 이상의 다른 구성요소가 추가될 수 있다. 어떤 실시예에서는, 이 구성요소들 중 일부들(예: 센서 모듈(176), 카메라 모듈(180), 또는 안테나 모듈(197))은 하나의 구성요소(예: 디스플레이 모듈(160))로 통합될 수 있다.FIG. 1 is a block diagram of an electronic device (101) in a network environment (100) according to one embodiment. Referring to FIG. 1, in the network environment (100), the electronic device (101) may communicate with the electronic device (102) via a first network (198) (e.g., a short-range wireless communication network), or may communicate with the electronic device (104) or a server (108) via a second network (199) (e.g., a long-range wireless communication network). According to one embodiment, the electronic device (101) may communicate with the electronic device (104) via the server (108). According to one embodiment, the electronic device (101) may include a processor (120), a memory (130), an input module (150), an audio output module (155), a display module (160), an audio module (170), a sensor module (176), an interface (177), a connection terminal (178), a haptic module (179), a camera module (180), a power management module (188), a battery (189), a communication module (190), a subscriber identification module (196), or an antenna module (197). In some embodiments, the electronic device (101) may omit at least one of these components (e.g., the connection terminal (178)), or may have one or more other components added. In some embodiments, some of these components (e.g., the sensor module (176), the camera module (180), or the antenna module (197)) may be integrated into one component (e.g., the display module (160)).
프로세서(120)는, 예를 들면, 소프트웨어(예: 프로그램(140))를 실행하여 프로세서(120)에 연결된 전자 장치(101)의 적어도 하나의 다른 구성요소(예: 하드웨어 또는 소프트웨어 구성요소)를 제어할 수 있고, 다양한 데이터 처리 또는 연산을 수행할 수 있다. 일실시예에 따르면, 데이터 처리 또는 연산의 적어도 일부로서, 프로세서(120)는 다른 구성요소(예: 센서 모듈(176) 또는 통신 모듈(190))로부터 수신된 명령 또는 데이터를 휘발성 메모리(132)에 저장하고, 휘발성 메모리(132)에 저장된 명령 또는 데이터를 처리하고, 결과 데이터를 비휘발성 메모리(134)에 저장할 수 있다. 일실시예에 따르면, 프로세서(120)는 메인 프로세서(121)(예: 중앙 처리 장치 또는 어플리케이션 프로세서) 또는 이와는 독립적으로 또는 함께 운영 가능한 보조 프로세서(123)(예: 그래픽 처리 장치, 신경망 처리 장치(NPU: neural processing unit), 이미지 시그널 프로세서, 센서 허브 프로세서, 또는 커뮤니케이션 프로세서)를 포함할 수 있다. 예를 들어, 전자 장치(101)가 메인 프로세서(121) 및 보조 프로세서(123)를 포함하는 경우, 보조 프로세서(123)는 메인 프로세서(121)보다 저전력을 사용하거나, 지정된 기능에 특화되도록 설정될 수 있다. 보조 프로세서(123)는 메인 프로세서(121)와 별개로, 또는 그 일부로서 구현될 수 있다.The processor (120) may control at least one other component (e.g., a hardware or software component) of an electronic device (101) connected to the processor (120) by executing, for example, software (e.g., a program (140)), and may perform various data processing or calculations. According to one embodiment, as at least a part of the data processing or calculations, the processor (120) may store a command or data received from another component (e.g., a sensor module (176) or a communication module (190)) in a volatile memory (132), process the command or data stored in the volatile memory (132), and store result data in a nonvolatile memory (134). According to one embodiment, the processor (120) may include a main processor (121) (e.g., a central processing unit or an application processor) or an auxiliary processor (123) (e.g., a graphics processing unit, a neural processing unit (NPU), an image signal processor, a sensor hub processor, or a communication processor) that can operate independently or together with the main processor (121). For example, when the electronic device (101) includes a main processor (121) and an auxiliary processor (123), the auxiliary processor (123) may be configured to use less power than the main processor (121) or to be specialized for a given function. The auxiliary processor (123) may be implemented separately from the main processor (121) or as a part thereof.
보조 프로세서(123)는, 예를 들면, 메인 프로세서(121)가 인액티브(예: 슬립) 상태에 있는 동안 메인 프로세서(121)를 대신하여, 또는 메인 프로세서(121)가 액티브(예: 어플리케이션 실행) 상태에 있는 동안 메인 프로세서(121)와 함께, 전자 장치(101)의 구성요소들 중 적어도 하나의 구성요소(예: 디스플레이 모듈(160), 센서 모듈(176), 또는 통신 모듈(190))와 관련된 기능 또는 상태들의 적어도 일부를 제어할 수 있다. 일실시예에 따르면, 보조 프로세서(123)(예: 이미지 시그널 프로세서 또는 커뮤니케이션 프로세서)는 기능적으로 관련 있는 다른 구성요소(예: 카메라 모듈(180) 또는 통신 모듈(190))의 일부로서 구현될 수 있다. 일실시예에 따르면, 보조 프로세서(123)(예: 신경망 처리 장치)는 인공지능 모델의 처리에 특화된 하드웨어 구조를 포함할 수 있다. 인공지능 모델은 기계 학습을 통해 생성될 수 있다. 이러한 학습은, 예를 들어, 인공지능이 수행되는 전자 장치(101) 자체에서 수행될 수 있고, 별도의 서버(예: 서버(108))를 통해 수행될 수도 있다. 학습 알고리즘은, 예를 들어, 지도형 학습(supervised learning), 비지도형 학습(unsupervised learning), 준지도형 학습(semi-supervised learning) 또는 강화 학습(reinforcement learning)을 포함할 수 있으나, 전술한 예에 한정되지 않는다. 인공지능 모델은, 복수의 인공 신경망 레이어들을 포함할 수 있다. 인공 신경망은 심층 신경망(DNN: deep neural network), CNN(convolutional neural network), RNN(recurrent neural network), RBM(restricted boltzmann machine), DBN(deep belief network), BRDNN(bidirectional recurrent deep neural network), 심층 Q-네트워크(deep Q-networks) 또는 상기 중 둘 이상의 조합 중 하나일 수 있으나, 전술한 예에 한정되지 않는다. 인공지능 모델은 하드웨어 구조 이외에, 추가적으로 또는 대체적으로, 소프트웨어 구조를 포함할 수 있다.The auxiliary processor (123) may control at least a portion of functions or states associated with at least one of the components of the electronic device (101) (e.g., the display module (160), the sensor module (176), or the communication module (190)), for example, while the main processor (121) is in an inactive (e.g., sleep) state, or together with the main processor (121) while the main processor (121) is in an active (e.g., application execution) state. In one embodiment, the auxiliary processor (123) (e.g., an image signal processor or a communication processor) may be implemented as a part of another functionally related component (e.g., a camera module (180) or a communication module (190)). In one embodiment, the auxiliary processor (123) (e.g., a neural network processing device) may include a hardware structure specialized for processing artificial intelligence models. The artificial intelligence models may be generated through machine learning. Such learning may be performed, for example, in the electronic device (101) on which artificial intelligence is performed, or may be performed through a separate server (e.g., server (108)). The learning algorithm may include, for example, supervised learning, unsupervised learning, semi-supervised learning, or reinforcement learning, but is not limited to the examples described above. The artificial intelligence model may include a plurality of artificial neural network layers. The artificial neural network may be one of a deep neural network (DNN), a convolutional neural network (CNN), a recurrent neural network (RNN), a restricted Boltzmann machine (RBM), a deep belief network (DBN), a bidirectional recurrent deep neural network (BRDNN), deep Q-networks, or a combination of two or more of the above, but is not limited to the examples described above. In addition to the hardware structure, the artificial intelligence model may additionally or alternatively include a software structure.
메모리(130)는, 전자 장치(101)의 적어도 하나의 구성요소(예: 프로세서(120) 또는 센서 모듈(176))에 의해 사용되는 다양한 데이터를 저장할 수 있다. 데이터는, 예를 들어, 소프트웨어(예: 프로그램(140)) 및, 이와 관련된 명령에 대한 입력 데이터 또는 출력 데이터를 포함할 수 있다. 메모리(130)는, 휘발성 메모리(132) 또는 비휘발성 메모리(134)를 포함할 수 있다.The memory (130) can store various data used by at least one component (e.g., processor (120) or sensor module (176)) of the electronic device (101). The data can include, for example, software (e.g., program (140)) and input data or output data for commands related thereto. The memory (130) can include volatile memory (132) or nonvolatile memory (134).
프로그램(140)은 메모리(130)에 소프트웨어로서 저장될 수 있으며, 예를 들면, 운영 체제(142), 미들 웨어(144) 또는 어플리케이션(146)을 포함할 수 있다.The program (140) may be stored as software in memory (130) and may include, for example, an operating system (142), middleware (144), or an application (146).
입력 모듈(150)은, 전자 장치(101)의 구성요소(예: 프로세서(120))에 사용될 명령 또는 데이터를 전자 장치(101)의 외부(예: 사용자)로부터 수신할 수 있다. 입력 모듈(150)은, 예를 들면, 마이크, 마우스, 키보드, 키(예: 버튼), 또는 디지털 펜(예: 스타일러스 펜)을 포함할 수 있다.The input module (150) can receive commands or data to be used in a component of the electronic device (101) (e.g., a processor (120)) from an external source (e.g., a user) of the electronic device (101). The input module (150) can include, for example, a microphone, a mouse, a keyboard, a key (e.g., a button), or a digital pen (e.g., a stylus pen).
음향 출력 모듈(155)은 음향 신호를 전자 장치(101)의 외부로 출력할 수 있다. 음향 출력 모듈(155)은, 예를 들면, 스피커 또는 리시버를 포함할 수 있다. 스피커는 멀티미디어 재생 또는 녹음 재생과 같이 일반적인 용도로 사용될 수 있다. 리시버는 착신 전화를 수신하기 위해 사용될 수 있다. 일실시예에 따르면, 리시버는 스피커와 별개로, 또는 그 일부로서 구현될 수 있다.The audio output module (155) can output an audio signal to the outside of the electronic device (101). The audio output module (155) can include, for example, a speaker or a receiver. The speaker can be used for general purposes such as multimedia playback or recording playback. The receiver can be used to receive an incoming call. According to one embodiment, the receiver can be implemented separately from the speaker or as a part thereof.
디스플레이 모듈(160)은 전자 장치(101)의 외부(예: 사용자)로 정보를 시각적으로 제공할 수 있다. 디스플레이 모듈(160)은, 예를 들면, 디스플레이, 홀로그램 장치, 또는 프로젝터 및 해당 장치를 제어하기 위한 제어 회로를 포함할 수 있다. 일실시예에 따르면, 디스플레이 모듈(160)은 터치를 감지하도록 설정된 터치 센서, 또는 상기 터치에 의해 발생되는 힘의 세기를 측정하도록 설정된 압력 센서를 포함할 수 있다.The display module (160) can visually provide information to an external party (e.g., a user) of the electronic device (101). The display module (160) can include, for example, a display, a holographic device, or a projector and a control circuit for controlling the device. According to one embodiment, the display module (160) can include a touch sensor configured to detect a touch, or a pressure sensor configured to measure the intensity of a force generated by the touch.
오디오 모듈(170)은 소리를 전기 신호로 변환시키거나, 반대로 전기 신호를 소리로 변환시킬 수 있다. 일실시예에 따르면, 오디오 모듈(170)은, 입력 모듈(150)을 통해 소리를 획득하거나, 음향 출력 모듈(155), 또는 전자 장치(101)와 직접 또는 무선으로 연결된 외부 전자 장치(예: 전자 장치(102))(예: 스피커 또는 헤드폰)를 통해 소리를 출력할 수 있다.The audio module (170) can convert sound into an electrical signal, or vice versa, convert an electrical signal into sound. According to one embodiment, the audio module (170) can obtain sound through an input module (150), or output sound through an audio output module (155), or an external electronic device (e.g., an electronic device (102)) (e.g., a speaker or a headphone) directly or wirelessly connected to the electronic device (101).
센서 모듈(176)은 전자 장치(101)의 작동 상태(예: 전력 또는 온도), 또는 외부의 환경 상태(예: 사용자 상태)를 감지하고, 감지된 상태에 대응하는 전기 신호 또는 데이터 값을 생성할 수 있다. 일실시예에 따르면, 센서 모듈(176)은, 예를 들면, 제스처 센서, 자이로 센서, 기압 센서, 마그네틱 센서, 가속도 센서, 그립 센서, 근접 센서, 컬러 센서, IR(infrared) 센서, 생체 센서, 온도 센서, 습도 센서, 또는 조도 센서를 포함할 수 있다.The sensor module (176) can detect an operating state (e.g., power or temperature) of the electronic device (101) or an external environmental state (e.g., user state) and generate an electric signal or data value corresponding to the detected state. According to one embodiment, the sensor module (176) can include, for example, a gesture sensor, a gyro sensor, a barometric pressure sensor, a magnetic sensor, an acceleration sensor, a grip sensor, a proximity sensor, a color sensor, an IR (infrared) sensor, a biometric sensor, a temperature sensor, a humidity sensor, or an illuminance sensor.
인터페이스(177)는 전자 장치(101)가 외부 전자 장치(예: 전자 장치(102))와 직접 또는 무선으로 연결되기 위해 사용될 수 있는 하나 이상의 지정된 프로토콜들을 지원할 수 있다. 일실시예에 따르면, 인터페이스(177)는, 예를 들면, HDMI(high definition multimedia interface), USB(universal serial bus) 인터페이스, SD카드 인터페이스, 또는 오디오 인터페이스를 포함할 수 있다.The interface (177) may support one or more designated protocols that may be used to directly or wirelessly connect the electronic device (101) with an external electronic device (e.g., the electronic device (102)). In one embodiment, the interface (177) may include, for example, a high definition multimedia interface (HDMI), a universal serial bus (USB) interface, an SD card interface, or an audio interface.
연결 단자(178)는, 그를 통해서 전자 장치(101)가 외부 전자 장치(예: 전자 장치(102))와 물리적으로 연결될 수 있는 커넥터를 포함할 수 있다. 일실시예에 따르면, 연결 단자(178)는, 예를 들면, HDMI 커넥터, USB 커넥터, SD 카드 커넥터, 또는 오디오 커넥터(예: 헤드폰 커넥터)를 포함할 수 있다.The connection terminal (178) may include a connector through which the electronic device (101) may be physically connected to an external electronic device (e.g., the electronic device (102)). According to one embodiment, the connection terminal (178) may include, for example, an HDMI connector, a USB connector, an SD card connector, or an audio connector (e.g., a headphone connector).
햅틱 모듈(179)은 전기적 신호를 사용자가 촉각 또는 운동 감각을 통해서 인지할 수 있는 기계적인 자극(예: 진동 또는 움직임) 또는 전기적인 자극으로 변환할 수 있다. 일실시예에 따르면, 햅틱 모듈(179)은, 예를 들면, 모터, 압전 소자, 또는 전기 자극 장치를 포함할 수 있다.The haptic module (179) can convert an electrical signal into a mechanical stimulus (e.g., vibration or movement) or an electrical stimulus that a user can perceive through a tactile or kinesthetic sense. According to one embodiment, the haptic module (179) can include, for example, a motor, a piezoelectric element, or an electrical stimulation device.
카메라 모듈(180)은 정지 영상 및 동영상을 촬영할 수 있다. 일실시예에 따르면, 카메라 모듈(180)은 하나 이상의 렌즈들, 이미지 센서들, 이미지 시그널 프로세서들, 또는 플래시들을 포함할 수 있다.The camera module (180) can capture still images and moving images. According to one embodiment, the camera module (180) can include one or more lenses, image sensors, image signal processors, or flashes.
전력 관리 모듈(188)은 전자 장치(101)에 공급되는 전력을 관리할 수 있다. 일실시예에 따르면, 전력 관리 모듈(188)은, 예를 들면, PMIC(power management integrated circuit)의 적어도 일부로서 구현될 수 있다.The power management module (188) can manage power supplied to the electronic device (101). According to one embodiment, the power management module (188) can be implemented as, for example, at least a part of a power management integrated circuit (PMIC).
배터리(189)는 전자 장치(101)의 적어도 하나의 구성요소에 전력을 공급할 수 있다. 일실시예에 따르면, 배터리(189)는, 예를 들면, 재충전 불가능한 1차 전지, 재충전 가능한 2차 전지 또는 연료 전지를 포함할 수 있다.The battery (189) can power at least one component of the electronic device (101). In one embodiment, the battery (189) can include, for example, a non-rechargeable primary battery, a rechargeable secondary battery, or a fuel cell.
통신 모듈(190)은 전자 장치(101)와 외부 전자 장치(예: 전자 장치(102), 전자 장치(104), 또는 서버(108)) 간의 직접(예: 유선) 통신 채널 또는 무선 통신 채널의 수립, 및 수립된 통신 채널을 통한 통신 수행을 지원할 수 있다. 통신 모듈(190)은 프로세서(120)(예: 어플리케이션 프로세서)와 독립적으로 운영되고, 직접(예: 유선) 통신 또는 무선 통신을 지원하는 하나 이상의 커뮤니케이션 프로세서를 포함할 수 있다. 일실시예에 따르면, 통신 모듈(190)은 무선 통신 모듈(192)(예: 셀룰러 통신 모듈, 근거리 무선 통신 모듈, 또는 GNSS(global navigation satellite system) 통신 모듈) 또는 유선 통신 모듈(194)(예: LAN(local area network) 통신 모듈, 또는 전력선 통신 모듈)을 포함할 수 있다. 이들 통신 모듈 중 해당하는 통신 모듈은 제 1 네트워크(198)(예: 블루투스, WiFi(wireless fidelity) direct 또는 IrDA(infrared data association)와 같은 근거리 통신 네트워크) 또는 제 2 네트워크(199)(예: 레거시 셀룰러 네트워크, 5G 네트워크, 차세대 통신 네트워크, 인터넷, 또는 컴퓨터 네트워크(예: LAN 또는 WAN)와 같은 원거리 통신 네트워크)를 통하여 외부의 전자 장치(104)와 통신할 수 있다. 이런 여러 종류의 통신 모듈들은 하나의 구성요소(예: 단일 칩)로 통합되거나, 또는 서로 별도의 복수의 구성요소들(예: 복수 칩들)로 구현될 수 있다. 무선 통신 모듈(192)은 가입자 식별 모듈(196)에 저장된 가입자 정보(예: 국제 모바일 가입자 식별자(IMSI))를 이용하여 제 1 네트워크(198) 또는 제 2 네트워크(199)와 같은 통신 네트워크 내에서 전자 장치(101)를 확인 또는 인증할 수 있다.The communication module (190) may support establishment of a direct (e.g., wired) communication channel or a wireless communication channel between the electronic device (101) and an external electronic device (e.g., the electronic device (102), the electronic device (104), or the server (108)), and performance of communication through the established communication channel. The communication module (190) may operate independently from the processor (120) (e.g., the application processor) and may include one or more communication processors that support direct (e.g., wired) communication or wireless communication. According to one embodiment, the communication module (190) may include a wireless communication module (192) (e.g., a cellular communication module, a short-range wireless communication module, or a GNSS (global navigation satellite system) communication module) or a wired communication module (194) (e.g., a local area network (LAN) communication module or a power line communication module). Among these communication modules, a corresponding communication module may communicate with an external electronic device (104) via a first network (198) (e.g., a short-range communication network such as Bluetooth, wireless fidelity (WiFi) direct, or infrared data association (IrDA)) or a second network (199) (e.g., a long-range communication network such as a legacy cellular network, a 5G network, a next-generation communication network, the Internet, or a computer network (e.g., a LAN or WAN)). These various types of communication modules may be integrated into a single component (e.g., a single chip) or implemented as multiple separate components (e.g., multiple chips). The wireless communication module (192) may use subscriber information (e.g., an international mobile subscriber identity (IMSI)) stored in the subscriber identification module (196) to identify or authenticate the electronic device (101) within a communication network such as the first network (198) or the second network (199).
무선 통신 모듈(192)은 4G 네트워크 이후의 5G 네트워크 및 차세대 통신 기술, 예를 들어, NR 접속 기술(new radio access technology)을 지원할 수 있다. NR 접속 기술은 고용량 데이터의 고속 전송(eMBB(enhanced mobile broadband)), 단말 전력 최소화와 다수 단말의 접속(mMTC(massive machine type communications)), 또는 고신뢰도와 저지연(URLLC(ultra-reliable and low-latency communications))을 지원할 수 있다. 무선 통신 모듈(192)은, 예를 들어, 높은 데이터 전송률 달성을 위해, 고주파 대역(예: mmWave 대역)을 지원할 수 있다. 무선 통신 모듈(192)은 고주파 대역에서의 성능 확보를 위한 다양한 기술들, 예를 들어, 빔포밍(beamforming), 거대 배열 다중 입출력(massive MIMO(multiple-input and multiple-output)), 전차원 다중입출력(FD-MIMO: full dimensional MIMO), 어레이 안테나(array antenna), 아날로그 빔형성(analog beam-forming), 또는 대규모 안테나(large scale antenna)와 같은 기술들을 지원할 수 있다. 무선 통신 모듈(192)은 전자 장치(101), 외부 전자 장치(예: 전자 장치(104)) 또는 네트워크 시스템(예: 제 2 네트워크(199))에 규정되는 다양한 요구사항을 지원할 수 있다. 일실시예에 따르면, 무선 통신 모듈(192)은 eMBB 실현을 위한 Peak data rate(예: 20Gbps 이상), mMTC 실현을 위한 손실 Coverage(예: 164dB 이하), 또는 URLLC 실현을 위한 U-plane latency(예: 다운링크(DL) 및 업링크(UL) 각각 0.5ms 이하, 또는 라운드 트립 1ms 이하)를 지원할 수 있다.The wireless communication module (192) can support a 5G network and next-generation communication technology after a 4G network, for example, NR access technology (new radio access technology). The NR access technology can support high-speed transmission of high-capacity data (eMBB (enhanced mobile broadband)), terminal power minimization and connection of multiple terminals (mMTC (massive machine type communications)), or high reliability and low latency (URLLC (ultra-reliable and low-latency communications)). The wireless communication module (192) can support, for example, a high-frequency band (e.g., mmWave band) to achieve a high data transmission rate. The wireless communication module (192) may support various technologies for securing performance in a high-frequency band, such as beamforming, massive multiple-input and multiple-output (MIMO), full dimensional MIMO (FD-MIMO), array antenna, analog beam-forming, or large scale antenna. The wireless communication module (192) may support various requirements specified in an electronic device (101), an external electronic device (e.g., an electronic device (104)), or a network system (e.g., a second network (199)). According to one embodiment, the wireless communication module (192) can support a peak data rate (e.g., 20 Gbps or more) for eMBB realization, a loss coverage (e.g., 164 dB or less) for mMTC realization, or a U-plane latency (e.g., 0.5 ms or less for downlink (DL) and uplink (UL) each, or 1 ms or less for round trip) for URLLC realization.
안테나 모듈(197)은 신호 또는 전력을 외부(예: 외부의 전자 장치)로 송신하거나 외부로부터 수신할 수 있다. 일실시예에 따르면, 안테나 모듈(197)은 서브스트레이트(예: PCB) 위에 형성된 도전체 또는 도전성 패턴으로 이루어진 방사체를 포함하는 안테나를 포함할 수 있다. 일실시예에 따르면, 안테나 모듈(197)은 복수의 안테나들(예: 어레이 안테나)을 포함할 수 있다. 이런 경우, 제 1 네트워크(198) 또는 제 2 네트워크(199)와 같은 통신 네트워크에서 사용되는 통신 방식에 적합한 적어도 하나의 안테나가, 예를 들면, 통신 모듈(190)에 의하여 상기 복수의 안테나들로부터 선택될 수 있다. 신호 또는 전력은 상기 선택된 적어도 하나의 안테나를 통하여 통신 모듈(190)과 외부의 전자 장치 간에 송신되거나 수신될 수 있다. 어떤 실시예에 따르면, 방사체 이외에 다른 부품(예: RFIC(radio frequency integrated circuit))이 추가로 안테나 모듈(197)의 일부로 형성될 수 있다.The antenna module (197) can transmit or receive signals or power to or from the outside (e.g., an external electronic device). According to one embodiment, the antenna module (197) can include an antenna including a radiator formed of a conductor or a conductive pattern formed on a substrate (e.g., a PCB). According to one embodiment, the antenna module (197) can include a plurality of antennas (e.g., an array antenna). In this case, at least one antenna suitable for a communication method used in a communication network, such as the first network (198) or the second network (199), can be selected from the plurality of antennas by, for example, the communication module (190). A signal or power can be transmitted or received between the communication module (190) and the external electronic device through the selected at least one antenna. According to some embodiments, in addition to the radiator, another component (e.g., a radio frequency integrated circuit (RFIC)) can be additionally formed as a part of the antenna module (197).
일 실시예에 따르면, 안테나 모듈(197)은 mmWave 안테나 모듈을 형성할 수 있다. 일실시예에 따르면, mmWave 안테나 모듈은 인쇄 회로 기판, 상기 인쇄 회로 기판의 제 1 면(예: 아래 면)에 또는 그에 인접하여 배치되고 지정된 고주파 대역(예: mmWave 대역)을 지원할 수 있는 RFIC, 및 상기 인쇄 회로 기판의 제 2 면(예: 윗 면 또는 측 면)에 또는 그에 인접하여 배치되고 상기 지정된 고주파 대역의 신호를 송신 또는 수신할 수 있는 복수의 안테나들(예: 어레이 안테나)을 포함할 수 있다.In one embodiment, the antenna module (197) can form a mmWave antenna module. In one embodiment, the mmWave antenna module can include a printed circuit board, an RFIC positioned on or adjacent a first side (e.g., a bottom side) of the printed circuit board and capable of supporting a designated high-frequency band (e.g., a mmWave band), and a plurality of antennas (e.g., an array antenna) positioned on or adjacent a second side (e.g., a top side or a side) of the printed circuit board and capable of transmitting or receiving signals in the designated high-frequency band.
상기 구성요소들 중 적어도 일부는 주변 기기들간 통신 방식(예: 버스, GPIO(general purpose input and output), SPI(serial peripheral interface), 또는 MIPI(mobile industry processor interface))을 통해 서로 연결되고 신호(예: 명령 또는 데이터)를 상호간에 교환할 수 있다.At least some of the above components may be connected to each other and exchange signals (e.g., commands or data) with each other via a communication method between peripheral devices (e.g., a bus, GPIO (general purpose input and output), SPI (serial peripheral interface), or MIPI (mobile industry processor interface)).
일 실시예에 따르면, 명령 또는 데이터는 제 2 네트워크(199)에 연결된 서버(108)를 통해서 전자 장치(101)와 외부의 전자 장치(104)간에 송신 또는 수신될 수 있다. 외부의 전자 장치(102, 또는 104) 각각은 전자 장치(101)와 동일한 또는 다른 종류의 장치일 수 있다. 일실시예에 따르면, 전자 장치(101)에서 실행되는 동작들의 전부 또는 일부는 외부의 전자 장치들(102, 104, 또는 108) 중 하나 이상의 외부의 전자 장치들에서 실행될 수 있다. 예를 들면, 전자 장치(101)가 어떤 기능이나 서비스를 자동으로, 또는 사용자 또는 다른 장치로부터의 요청에 반응하여 수행해야 할 경우에, 전자 장치(101)는 기능 또는 서비스를 자체적으로 실행시키는 대신에 또는 추가적으로, 하나 이상의 외부의 전자 장치들에게 그 기능 또는 그 서비스의 적어도 일부를 수행하라고 요청할 수 있다. 상기 요청을 수신한 하나 이상의 외부의 전자 장치들은 요청된 기능 또는 서비스의 적어도 일부, 또는 상기 요청과 관련된 추가 기능 또는 서비스를 실행하고, 그 실행의 결과를 전자 장치(101)로 전달할 수 있다. 전자 장치(101)는 상기 결과를, 그대로 또는 추가적으로 처리하여, 상기 요청에 대한 응답의 적어도 일부로서 제공할 수 있다. 이를 위하여, 예를 들면, 클라우드 컴퓨팅, 분산 컴퓨팅, 모바일 에지 컴퓨팅(MEC: mobile edge computing), 또는 클라이언트-서버 컴퓨팅 기술이 이용될 수 있다. 전자 장치(101)는, 예를 들어, 분산 컴퓨팅 또는 모바일 에지 컴퓨팅을 이용하여 초저지연 서비스를 제공할 수 있다. 다른 실시예에 있어서, 외부의 전자 장치(104)는 IoT(internet of things) 기기를 포함할 수 있다. 서버(108)는 기계 학습 및/또는 신경망을 이용한 지능형 서버일 수 있다. 일실시예에 따르면, 외부의 전자 장치(104) 또는 서버(108)는 제 2 네트워크(199) 내에 포함될 수 있다. 전자 장치(101)는 5G 통신 기술 및 IoT 관련 기술을 기반으로 지능형 서비스(예: 스마트 홈, 스마트 시티, 스마트 카, 또는 헬스 케어)에 적용될 수 있다.In one embodiment, commands or data may be transmitted or received between the electronic device (101) and an external electronic device (104) via a server (108) connected to a second network (199). Each of the external electronic devices (102, or 104) may be the same or a different type of device as the electronic device (101). In one embodiment, all or part of the operations executed in the electronic device (101) may be executed in one or more of the external electronic devices (102, 104, or 108). For example, when the electronic device (101) is to perform a certain function or service automatically or in response to a request from a user or another device, the electronic device (101) may, instead of or in addition to executing the function or service itself, request one or more external electronic devices to perform at least a part of the function or service. One or more external electronic devices that have received the request may execute at least a part of the requested function or service, or an additional function or service related to the request, and transmit the result of the execution to the electronic device (101). The electronic device (101) may process the result as it is or additionally and provide it as at least a part of a response to the request. For this purpose, for example, cloud computing, distributed computing, mobile edge computing (MEC), or client-server computing technology may be used. The electronic device (101) may provide an ultra-low latency service by using, for example, distributed computing or mobile edge computing. In another embodiment, the external electronic device (104) may include an IoT (Internet of Things) device. The server (108) may be an intelligent server using machine learning and/or a neural network. According to one embodiment, the external electronic device (104) or the server (108) may be included in the second network (199). The electronic device (101) can be applied to intelligent services (e.g., smart home, smart city, smart car, or healthcare) based on 5G communication technology and IoT-related technology.
도 2는 일 실시예에 따른 외부 전자 장치의 제어를 위한 시스템의 블록도이다.FIG. 2 is a block diagram of a system for controlling an external electronic device according to one embodiment.
일 실시예에 따라서, 전자 장치(101)는, 서버(108)와 데이터를 송신 및/또는 수신할 수 있다. 서버(108)는, 음성 명령 처리 서버(200) 및/또는 IoT 서버(240)를 포함할 수 있다. 여기에서, 음성 명령 처리 서버(200) 및 IoT 서버(240)가 하나의 엔티티인 서버(108)에 포함되도록 구현되는 것은 단순히 예시적인 것으로, 음성 명령 처리 서버(200) 및 IoT 서버(240) 중 어느 적어도 하나가 하나의 서버(108)에 포함되지 않을 수도 있다. 예를 들어, 음성 명령 처리 서버(200) 및 IoT 서버(240)가 모두 다른 엔티티들로서 구현될 수도 있다. 또는, 음성 명령 처리 서버(200)가 IoT 서버(240)를 포함하도록 구현되거나, 음성 명령 처리 서버(200)가 본 개시에서 기술되는 IoT 서버(240)가 수행하는 기능을 지원하도록 구현될 수 있다. 또는, IoT 서버(240)가 음성 명령 처리 서버(200)를 포함하도록 구현되거나, IoT 서버(240)가 본 개시에서 기술되는 음성 명령 처리 서버(200)가 수행하는 기능을 지원하도록 구현될 수 있다. 서버(108)는, 적어도 하나의 프로세서를 포함할 수 있다. 적어도 하나의 프로세서는, CPU(central processing uinit), GPU(graphic processing unit), NPU, FPGA(field programmable gate array), ASIC, 및/또는 SoC(system on chip)를 포함할 수 있으며, 그 구현 형태에는 제한이 없다. 예를 들어, 실시예에 따라서 서버(108)에 의하여 수행되는 하나의 동작은, 적어도 하나의 프로세서(예를 들어, CPU, GPU, NPU, FPGA, ASIC, 및/또는 SoC) 중 어느 하나에 의하여 수행되거나, 또는 둘 이상의 프로세서의 연계에 의하여 수행될 수 있다. 예를 들어, 실시예에 따라서 서버(108)에 의하여 수행되는 복수의 동작들은, 적어도 하나의 프로세서(예를 들어, CPU, GPU, NPU, FPGA, ASIC, 및/또는 SoC) 중 어느 하나에 의하여 수행되거나, 또는 복수 개의 동작들 중 일부가 어느 하나의 프로세서에 의하여 수행되고 나머지 일부가 다른 프로세서에 의하여 수행될 수도 있다. 예를 들어, 서버(108)는, 적어도 하나의 인스트럭션을 저장하는 적어도 하나의 메모리를 포함할 수 있다. 적어도 하나의 메모리는, 휘발성 메모리 및/또는 비-휘발성 메모리를 포함할 수 있으며, 그 구현 형태에는 제한이 없다. 적어도 하나의 인스트럭션은, 적어도 하나의 프로세서에 의하여 실행 시에, 서버(108)로 하여금 적어도 하나의 동작(예를 들어, 본 개시에서 설명되는 서버(108)에 의하여 수행되는 동작들 중 적어도 일부)을 수행하도록 야기할 수 있다. 서버(108)에 의하여 수행되는 하나의 동작 또는 복수 개의 동작들의 수행을 야기하도록 하는 인스트럭션은, 하나의 물리적으로 독립된 메모리에 저장되거나, 또는 복수 개의 메모리들에 분산되어 저장될 수도 있다.According to one embodiment, the electronic device (101) may transmit and/or receive data to and from a server (108). The server (108) may include a voice command processing server (200) and/or an IoT server (240). Here, it is merely exemplary that the voice command processing server (200) and the IoT server (240) are implemented to be included in a single entity, the server (108), and at least one of the voice command processing server (200) and the IoT server (240) may not be included in a single server (108). For example, the voice command processing server (200) and the IoT server (240) may both be implemented as different entities. Alternatively, the voice command processing server (200) may be implemented to include the IoT server (240), or the voice command processing server (200) may be implemented to support the functions performed by the IoT server (240) described in the present disclosure. Alternatively, the IoT server (240) may be implemented to include the voice command processing server (200), or the IoT server (240) may be implemented to support the functions performed by the voice command processing server (200) described in the present disclosure. The server (108) may include at least one processor. The at least one processor may include a central processing unit (CPU), a graphic processing unit (GPU), an NPU, an FPGA (field programmable gate array), an ASIC, and/or a SoC (system on chip), and there is no limitation on the form of implementation thereof. For example, according to an embodiment, one operation performed by the server (108) may be performed by any one of the at least one processor (e.g., a CPU, a GPU, an NPU, an FPGA, an ASIC, and/or an SoC), or by a linkage of two or more processors. For example, according to an embodiment, the plurality of operations performed by the server (108) may be performed by at least one processor (e.g., a CPU, a GPU, an NPU, an FPGA, an ASIC, and/or a SoC), or some of the plurality of operations may be performed by one processor and some of the operations may be performed by another processor. For example, the server (108) may include at least one memory storing at least one instruction. The at least one memory may include volatile memory and/or non-volatile memory, and there is no limitation on the form of implementation thereof. The at least one instruction, when executed by the at least one processor, may cause the server (108) to perform at least one operation (e.g., at least some of the operations performed by the server (108) described herein). An instruction causing the performance of one operation or multiple operations performed by the server (108) may be stored in one physically independent memory, or may be stored distributed across multiple memories.
일 실시예에 따라서, 음성 명령 처리 서버(200)는, 전자 장치(101)의 음성 명령 처리 클라이언트(230)로부터 제공되는 음성 명령을 처리하여, 음성 명령의 의도에 대응하는 적어도 하나의 동작을 수행할 수 있다. 전자 장치(101)는, 음성 명령 처리 클라이언트(230)를 실행할 수 있다. 전자 장치(101)는, 마이크를 통하여 사용자 음성을 획득하여, 이에 기반하여 음성 명령을 획득할 수 있다. 예를 들어, 음성 명령은, 어쿠스틱(acoustic) 신호, 또는 어쿠스틱 신호가 전처리(pre-processing)(예를 들어, 잡음 제거 및/또는 증폭)된 신호일 수 있으나, 제한은 없다. 음성 명령 처리 클라이언트(230)가, 전처리 기능을 지원하는 경우에는, 전처리된 어쿠스틱 신호를, 음성 명령으로서 서버(108)로 제공할 수 있다. 음성 명령 처리 클라이언트(230)가, 전처리 기능 및 ASR(auto speech recognition) 기능을 지원하는 경우에는, 전자 장치(101)는, 어쿠스틱 신호에 대한 ASR 기능 적용에 기반하여 확인된 텍스트를 음성 명령으로서 음성 명령 처리 서버(200)로 제공할 수 있다. 음성 명령 처리 클라이언트(230)가, NLU(natural language understanding) 기능까지 지원하는 경우, 전자 장치(101)는, 텍스트에 대한 NLU 기능을 적용함으로서 확인되는 자연어 이해 결과를 음성 명령으로서, 서버(108)로 제공할 수도 있다. 상술한 바와 같이, 음성 명령 처리 클라이언트(230)는, 음성 명령 처리를 위한 복수의 기능들 중 적어도 일부를 지원할 수 있으며, 전자 장치(101)로부터 서버(108)로 제공되는 음성 명령은 지원되는 기능에 기반하여 설정될 수 있음을 당업자는 이해할 것이다. 한편, 구현에 따라서, 본 개시에서 설명되는 서버(108)(또는, 서버(108)에 포함되는 적어도 하나의 엔티티)에 의하여 수행되는 기능 중 적어도 일부가, 사용자 음성을 수신하는 전자 장치(101)에 의하여 수행될 수도 있다. 구현에 따라서, 서버(108)에 의한 동작들 전체가 전자 장치(101)에 의하여 수행될 수도 있으며, 이를 온-디바이스 음성 명령 처리로 명명할 수도 있다. 한편, 구현에 따라서, 본 개시에서 설명되는 전자 장치(101)에 의하여 수행되는 기능 중 적어도 일부가, 서버(108)(또는, 서버(108)에 포함되는 적어도 하나의 엔티티)에 의하여 수행될 수도 있다.According to one embodiment, the voice command processing server (200) may process a voice command provided from a voice command processing client (230) of the electronic device (101) and perform at least one operation corresponding to the intention of the voice command. The electronic device (101) may execute the voice command processing client (230). The electronic device (101) may obtain a user voice through a microphone and obtain a voice command based on the user voice. For example, the voice command may be an acoustic signal, or a signal in which an acoustic signal is pre-processed (e.g., noise removed and/or amplified), but there is no limitation. If the voice command processing client (230) supports a pre-processing function, it may provide the pre-processed acoustic signal to the server (108) as a voice command. If the voice command processing client (230) supports the preprocessing function and the ASR (auto speech recognition) function, the electronic device (101) can provide the text identified based on the application of the ASR function to the acoustic signal as a voice command to the voice command processing server (200). If the voice command processing client (230) supports even the NLU (natural language understanding) function, the electronic device (101) can also provide the natural language understanding result identified by applying the NLU function to the text as a voice command to the server (108). As described above, those skilled in the art will understand that the voice command processing client (230) can support at least some of the plurality of functions for voice command processing, and the voice command provided from the electronic device (101) to the server (108) can be set based on the supported functions. Meanwhile, depending on the implementation, at least some of the functions performed by the server (108) (or at least one entity included in the server (108)) described in the present disclosure may also be performed by the electronic device (101) that receives the user's voice. Depending on the implementation, all of the operations performed by the server (108) may also be performed by the electronic device (101), which may be referred to as on-device voice command processing. Meanwhile, depending on the implementation, at least some of the functions performed by the electronic device (101) described in the present disclosure may also be performed by the server (108) (or at least one entity included in the server (108).
일 실시예에 따라서, 음성 명령 처리 서버(200)는, 음성 명령 처리 클라이언트(230)로부터의 제공되는 음성 명령을 처리(예를 들어, ASR 및/또는 NLU)할 수 있다. 예를 들어, 음성 명령 처리 서버(200)는, 적어도 하나의 모듈(211,212,213,220)을 실행(또는, 포함)할 수 있다. ASR 모듈(211)은, 예를 들어 어쿠스틱 신호에 대응하는 텍스트를 제공 수 있다. NLU 모듈(212)은, 텍스트에 대응하는 자연어 이해 결과를 제공할 수 있다. TTS 모듈(213)은, 텍스트에 대응하는 음성 출력을 위한 신호(예를 들어, 어쿠스틱 신호)를 제공할 수 있다. 예를 들어, 음성 명령 처리 서버(200)는, 전자 장치(101)로부터 제공되는 음성 명령을 처리하여, 자연어 이해 결과를 제공할 수 있다. 한편, 상술한 바와 같이, 전자 장치(101)가 실행하는 음성 명령 처리 클라이언트(230)가 지원하는 기능에 따라, ASR 모듈(211) 및/또는 NLU 모듈(212)이 이용되지 않을 수도 있음을 당업자는 이해할 것이다. 자연어 이해 결과는, 예를 들어 키워드 및/또는 의도를 포함할 수 있으나, 그 구현 형식에는 제한이 없다. 키워드는, 예를 들어 파라미터 및/또는 슬롯을 포함할 수도 있으나, 그 구현 방식에는 제한이 없다.According to one embodiment, the voice command processing server (200) can process (e.g., ASR and/or NLU) a voice command provided from the voice command processing client (230). For example, the voice command processing server (200) can execute (or include) at least one module (211, 212, 213, 220). The ASR module (211) can provide, for example, a text corresponding to an acoustic signal. The NLU module (212) can provide a natural language understanding result corresponding to the text. The TTS module (213) can provide a signal (e.g., an acoustic signal) for a voice output corresponding to the text. For example, the voice command processing server (200) can process a voice command provided from the electronic device (101) and provide a natural language understanding result. Meanwhile, as described above, those skilled in the art will understand that, depending on the function supported by the voice command processing client (230) executed by the electronic device (101), the ASR module (211) and/or the NLU module (212) may not be utilized. The natural language understanding result may include, for example, keywords and/or intents, but there is no limitation on the form of implementation thereof. The keywords may include, for example, parameters and/or slots, but there is no limitation on the method of implementation thereof.
출력 장치 확인 모듈(220)은, 자연어 이해 결과를 제공받을 수 있다. 출력 장치 확인 모듈(220)은, 예를 들어 컨텐트 속성 확인 모듈(221), 출력 장치 선택 모듈(222), 기능 수행 명령 모듈(223), 재생 이력 관리 모듈(224), 및/또는 재생 이력 데이터베이스(225)를 포함할 수 있으나, 제한은 없다. 예를 들어, 컨텐트 속성 확인 모듈(221)은, 자연어 이해 결과에 포함되는 키워드에 대응하는 적어도 하나의 속성을 확인할 수 있다. 키워드는, 예를 들어 음성 명령에 포함된 컨텐트와 연관된 단어(예를 들어, 타이틀, 장르, 아티스트, 저작 정보, 심의 등급일 수 있으나 제한이 없음)일 수 있다. 예를 들어, 컨텐트의 적어도 하나의 속성은, 장르, 타이틀, 심의 등급, 저작 정보, 및/또는 아티스트 관련 정보를 포함할 수 있으나, 제한은 없다. 재생 이력 데이터베이스(225)에는, 적어도 하나의 출력 장치(251,252,253)의 재생 이력이 저장될 수 있다. 예를 들어, 재생 이력은, 재생되었던 컨텐트의 재생 시각, 대응하는 의도, 키워드, 해당 컨텐트의 적어도 하나의 속성 정보, 해당 컨텐트를 재생한 출력 장치의 식별을 위한 정보, 및/또는 재생 관리 정보를 포함할 수 있으나, 제한은 없다. 출력 장치 선택 모듈(222)은, 컨텐트 속성 확인 모듈로부터 제공되는 키워드에 대응하는 컨텐트 속성을 확인할 수 있다. 출력 장치 선택 모듈(222)은, 재생 이력 DB로부터 재생 이력을 확인할 수 있다. 출력 장치 선택 모듈(222)은, 키워드에 대응하는 컨텐트 속성 및 재생 이력 DB로부터 재생 이력에 기반하여, 컨텐트를 재생 가능한 적어도 하나의 출력 장치(251,252,253)를 선택할 수 있다. 기능 수행 명령 모듈(223)은, 선택된 출력 장치(예를 들어, 제 1 출력 장치(251))가 컨텐트를 재생하도록 하는 명령을 전자 장치(101) 및/또는 선택된 출력 장치(예를 들어, 제 1 출력 장치(251))(예를 들어, IoT 서버(240)를 통하거나, 또는 직접)로 제공할 수 있다. 하나의 예에서, 기능 수행 명령 모듈(223)은, 의도 및/또는 실행을 위한 파라미터(또는, 슬롯(slot)으로 명명될 수도 있음)를 제공할 수 있으나, 제한은 없다. 기능 수행 명령 모듈(223)은, 사용자에게 제공할 응답을 생성(NLG: natural language generation)할 수도 있다. 재생 이력 관리 모듈(224)은, 상술한 과정을 통하여 컨텐트의 선택된 출력 장치에 의한 재생에 대한 정보를 재생 이력 데이터베이스(225)에 저장할 수 있거나, 및/또는 재생 이력 데이터베이스(225)의 정보를 갱신할 수도 있다.The output device verification module (220) can be provided with a natural language understanding result. The output device verification module (220) can include, for example, a content property verification module (221), an output device selection module (222), a function execution command module (223), a playback history management module (224), and/or a playback history database (225), but is not limited thereto. For example, the content property verification module (221) can verify at least one property corresponding to a keyword included in the natural language understanding result. The keyword can be, for example, a word associated with content included in a voice command (for example, a title, a genre, an artist, copyright information, a review rating, but is not limited thereto). For example, at least one property of the content can include, for example, a genre, a title, a review rating, copyright information, and/or artist-related information, but is not limited thereto. The playback history database (225) can store a playback history of at least one output device (251, 252, 253). For example, the playback history may include, but is not limited to, the playback time of the content that was played, the corresponding intent, a keyword, at least one attribute information of the corresponding content, information for identifying an output device that played the corresponding content, and/or playback management information. The output device selection module (222) can check a content attribute corresponding to a keyword provided from the content attribute verification module. The output device selection module (222) can check the playback history from the playback history DB. The output device selection module (222) can select at least one output device (251, 252, 253) capable of playing the content based on the content attribute corresponding to the keyword and the playback history from the playback history DB. The function execution command module (223) may provide a command to the electronic device (101) and/or the selected output device (e.g., the first output device (251)) (e.g., via the IoT server (240) or directly) to cause the selected output device (e.g., the first output device (251)) to play the content. In one example, the function execution command module (223) may provide, but is not limited to, parameters for intent and/or execution (or, may be named as slots). The function execution command module (223) may also generate a response to be provided to the user (NLG: natural language generation). The playback history management module (224) may store information on playback of the content by the selected output device in the playback history database (225) through the above-described process, and/or update information in the playback history database (225).
일 실시예에 따라서, IoT 서버(240)는, 예를 들어, 전자 장치(101)에 기반하여 접속한 사용자의 계정에 연동되어 등록된 적어도 하나의 출력 장치(251,252,253)와 데이터를 송신 및/또는 수신할 수 있다. IoT 서버(240)는, 등록된 적어도 하나의 출력 장치(251,252,253)의 현재 상태(예를 들어, IoT 서버(240)에 연결된 상태인지 여부) 및/또는 능력(capability)(예를 들어, 재생할 수 있는 컨텐트의 타입일 수 있지만 제한이 없음)을, 음성 명령 처리 서버(200)로 제공할 수 있으나 제한은 없다. 음성 명령 처리 서버(200)는, 적어도 하나의 출력 장치(251,252,253)의 현재 상태 및/또는 능력에 기반하여, 컨텐트를 재생할 수 있는 출력 장치를 확인할 수 있다. IoT 서버(240)는, 예를 들어 적어도 하나의 출력 장치(251,252,253)에 제어 명령을 제공할 수 있다. 예를 들어, 적어도 하나의 출력 장치(251,252,253)의 일부는 IoT 서버(240)에 직접적으로 또는 간접적으로 연결될 수 있다. 적어도 하나의 출력 장치(251,252,253)가, 간접적으로 연결되어 있을 경우, 제어 명령은 중간 장치(예: 모바일 장치)를 통해 제공될 수 있으며, 사운드 출력은 중간 장치에 연결된 출력 장치(예: 모바일 장치에 연결된 이어셋)에서 수행될 수도 있다. IoT 서버(240)로부터 제어 명령을 수신한 적어도 하나의 출력 장치(251,252,253)는, 제어 명령에 대응하는 적어도 하나의 동작, 예를 들어 컨텐트의 재생을 수행할 수도 있다. 적어도 하나의 출력 장치(251,252,253)는, 적어도 하나의 동작을 수행한 이후의 결과(예를 들어, 성공 또는 실패 여부일 수 있지만 제한이 없음)를 IoT 서버(240)로 제공할 수도 있다. IoT 서버(240)는, 수행 결과를 음성 명령 처리 서버(200)로 제공할 수 있다. 음성 명령 처리 서버(200)는, 수행 결과를 재생 이력 데이터베이스(225)에 저장할 수 있다. 해당 수행 결과는, 이후의 출력 장치 선택에 이용될 수도 있다.According to one embodiment, the IoT server (240) may transmit and/or receive data to and from at least one output device (251, 252, 253) registered in connection with an account of a user who has accessed the electronic device (101), for example. The IoT server (240) may provide the current status (e.g., whether it is connected to the IoT server (240)) and/or capability (e.g., the type of content that can be played, but is not limited) of the at least one registered output device (251, 252, 253) to the voice command processing server (200), but is not limited thereto. The voice command processing server (200) may identify an output device capable of playing content based on the current status and/or capability of the at least one output device (251, 252, 253). The IoT server (240) may provide a control command to the at least one output device (251, 252, 253), for example. For example, a part of at least one output device (251, 252, 253) may be directly or indirectly connected to the IoT server (240). When at least one output device (251, 252, 253) is indirectly connected, a control command may be provided through an intermediate device (e.g., a mobile device), and sound output may be performed by an output device (e.g., an earset connected to a mobile device) connected to the intermediate device. The at least one output device (251, 252, 253) that receives a control command from the IoT server (240) may perform at least one operation corresponding to the control command, for example, playing content. The at least one output device (251, 252, 253) may provide a result (e.g., whether success or failure, but there is no limitation) after performing the at least one operation to the IoT server (240). The IoT server (240) may provide the result of the performance to the voice command processing server (200). The voice command processing server (200) can store the performance result in the playback history database (225). The performance result may be used for subsequent output device selection.
도 3a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다. 도 3a의 실시예는, 도 3b, 도 3c, 및 도 3d를 참조하여 설명하도록 한다. 도 3b, 도 3c, 및 도 3d는, 컨텐트의 적어도 하나의 속성 및 재생 이력에 기반한 출력 장치를 확인하기 위한 방법을 설명하기 위한 도면들이다. 이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.FIG. 3A is a flowchart for explaining a method for processing a voice command according to one embodiment. The embodiment of FIG. 3A will be explained with reference to FIGS. 3B, 3C, and 3D. FIGS. 3B, 3C, and 3D are drawings for explaining a method for identifying an output device based on at least one property of content and a playback history. In the following embodiments, each operation may be performed sequentially, but is not necessarily performed sequentially. For example, the order of each operation may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 301 동작에서, 음성 명령의 분석 결과가 컨텐트 재생을 의도함을 확인할 수 있다. 예를 들어, 도 3b의 실시예를 참조하면, 서버(108)는, "바나나 파파 틀어줘"의 음성 명령(350)을 확인할 수 있다. 서버(108)는, "바나나 파파 틀어줘"의 음성 명령(350)에 대한 자연어 이해 결과에 기반하여, 음성 명령(350)의 키워드가 "바나나 파파"이며, 음성 명령(350)의 의도가 "컨텐트 재생"임을 확인할 수 있다.According to one embodiment, the server (108) may, in
서버(108)는, 303 동작에서, 음성 명령(350)과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인할 수 있다. 적어도 하나의 속성 정보는, 예를 들어 컨텐트의 적어도 하나의 속성은, 장르, 타이틀, 심의 등급, 저작 정보, 및/또는 아티스트 관련 정보를 포함할 수 있으나, 제한은 없다. 하나의 예에서, 서버(108)는, 305 동작에서, 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치(예를 들어, 출력 장치(251,252,253))를 확인할 수 있다. 서버(108)는, 사용자의 계정에 대응하여 등록된 적어도 하나의 출력 장치의 서버(108)로의 연결 여부 및/또는 능력(예를 들어, 재생할 수 있는 컨텐트의 타입일 수 있지만 제한이 없음)에 기반하여, 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치(예를 들어, 출력 장치(251,252,253))를 확인할 수 있으나, 그 확인 방식에는 제한이 없다.The server (108), in
일 실시예에 따라서, 서버(108)는, 307 동작에서, 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 적어도 하나의 출력 장치(251,252,253) 중 적어도 일부의 재생 이력에 기반하여, 적어도 하나의 출력 장치 중 컨텐트를 재생하기 위한 제 1 출력 장치(251)(예를 들어, 도 3b의 거실 스피커(355))를 확인할 수 있다. 서버(108)는, 예를 들어 도 3b와 같은 재생 이력(225a)을 확인할 수 있다. 예를 들어, 도 3b를 참조하면, 재생 이력(225a)은, 예를 들어 컨텐트의 재생 시각(331)의 순서에 따라 정렬될 수 있으나, 제한이 없다. 재생 이력(225a)은, 예를 들어 컨텐트의 재생 시각(331), 의도(332), 키워드(333), 해당 컨텐트의 적어도 하나의 속성 정보(334,335,336), 해당 컨텐트를 재생한 출력 장치의 식별을 위한 정보(337), 및/또는 재생 관리 정보(338)를 포함할 수 있으나, 제한은 없다. 예를 들어, 제 1 서브 재생 이력(341)의 컨텐트의 재생 시각(331)은, "2023년 07월 22일 10:00"일 수 있다. 예를 들어, 제 1 서브 재생 이력(341)의 의도(332)는, 컨텐트 재생의 예시인 "Play music"일 수 있다. 의도(332)는, 예를 들어 해당 컨텐트 재생을 야기한 자연어 이해 결과의 의도일 수 있으나 제한은 없다. 예를 들어, 제 1 서브 재생 이력(341)의 키워드(333)는, "포도도"일 수 있다. 예를 들어, 키워드(333)는, 컨텐트 재생을 야기한 자연어 이해 결과의 키워드일 수 있으나 제한은 없다. 예를 들어, 제 1 서브 재생 이력(341)의 해당 컨텐트의 속성 정보의 예시인 장르 정보(334)는, "동요, 애니메이션"일 수 있다. 예를 들어, 제 1 서브 재생 이력(341)의 해당 컨텐트의 속성 정보의 예시인 아티스트 정보(335)는, "포도도"일 수 있다. 예를 들어, 제 1 서브 재생 이력(341)의 해당 컨텐트의 속성 정보의 예시인 타이틀 정보(336)는, "포도도"일 수 있다. 예를 들어, 제 1 서브 재생 이력(341)의 해당 컨텐트를 재생한 출력 장치의 식별을 위한 정보(337)는, "모바일"일 수 있다. 예를 들어, 제 1 서브 재생 이력(341)의 재생 관리 정보(338)는, "추가"일 수 있다. 예를 들어, 해당 컨텐트의 재생이 개시됨에 기반하여, 재생 관리 정보(338)가 "추가"로서 설정될 수 있으나, 제한은 없다. 예를 들어, 다른 서브 재생 이력(342,343,344,345,346,347)이 재생 이력 데이터베이스(225)에 저장될 수 있다. 예를 들어, "포도도"의 타이틀의 컨텐트가 2023년 07월 22일 10:00에 "모바일"에 의하여 재생이 개시될 수 있다. 한편, "포도도"의 타이틀의 컨텐트의 재생을 수행하는 출력 장치가, 2023년 07월 22일 10:01에 "모바일"로부터 "거실 스피커"로 변경될 수 있다. 이에 따라, 제 2 서브 재생 이력(342)이 생성되어 저장될 수 있다. 제 2 서브 재생 이력(342)의 출력 장치의 식별을 위한 정보(337)가 "거실 스피커"이며, 재생 관리 정보(338)가 "변경"일 수 있다. 한편, "포도도"의 타이틀의 컨텐트의 재생이 2023년 07월 22일 10:05에 종료될 수 있다. 이에 따라, 제 3 서브 재생 이력(343)이 생성되어 저장될 수 있다. 제 3 서브 재생 이력(343)의 출력 장치의 식별을 위한 정보(337)가 "거실 스피커"이며, 재생 관리 정보(338)가 "미디어 종료"일 수 있다.According to one embodiment, the server (108), in
예를 들어, 제 4 서브 재생 이력(344)의 컨텐트의 재생 시각(331)은, "2023년 07월 22일 10:05"일 수 있다. 예를 들어, 제 4 서브 재생 이력(344)의 의도(332)는, 컨텐트 재생의 예시인 "Play music"일 수 있다. 의도(332)는, 예를 들어 해당 컨텐트 재생을 야기한 자연어 이해 결과의 의도일 수 있으나 제한은 없다. 예를 들어, 제 4 서브 재생 이력(344)의 키워드(333)는, "바나나 파파"일 수 있다. 예를 들어, 제 4 서브 재생 이력(344)의 해당 컨텐트의 속성 정보의 예시인 장르 정보(334)는, "동요"일 수 있다. 예를 들어, 제 4 서브 재생 이력(344)의 해당 컨텐트의 속성 정보의 예시인 아티스트 정보(335)는, "포도도"일 수 있다. 예를 들어, 제 4 서브 재생 이력(344)의 해당 컨텐트의 속성 정보의 예시인 타이틀 정보(336)는, "바나나 파파"일 수 있다. 예를 들어, 제 4 서브 재생 이력(344)의 해당 컨텐트를 재생한 출력 장치의 식별을 위한 정보(337)는, "모바일"일 수 있다. 예를 들어, 제 4 서브 재생 이력(344)의 재생 관리 정보(338)는, "추가"일 수 있다. "추가"는, 해당 컨텐트에 대한 출력 장치에 의한 재생 이력이 추가됨을 의미할 수 있으나, 제한은 없다. 한편, "변경"은, 재생 장치의 변경을 의미할 수 있으나, 제한은 없다. 한편, "종료"는 해당 컨텐트의 재생의 종료를 의미할 수 있으나 제한은 없다. 예를 들어, "바나나 파파"의 타이틀의 컨텐트가 2023년 07월 22일 10:05에 "모바일"에 의하여 재생이 개시될 수 있다. 한편, "바나나 파파"의 타이틀의 컨텐트의 재생을 수행하는 출력 장치가, 2023년 07월 23일 10:06에 "모바일"로부터 "거실 스피커"로 변경될 수 있다. 이에 따라, 제 5 서브 재생 이력(345)이 생성되어 저장될 수 있다. 제 5 서브 재생 이력(345)의 출력 장치의 식별을 위한 정보(337)가 "거실 스피커"이며, 재생 관리 정보(338)가 "변경"일 수 있다. 한편, "바나나 파파"의 타이틀의 컨텐트의 재생이 2023년 07월 23일 10:10에 종료될 수 있다. 이에 따라, 제 6 서브 재생 이력(346)이 생성되어 저장될 수 있다. 제 3 서브 재생 이력(346)의 출력 장치의 식별을 위한 정보(337)가 "거실 스피커"이며, 재생 관리 정보(338)가 "미디어 종료"일 수 있다. 한편, 제 7 서브 재생 이력(347)의 컨텐트의 재생 시각(331)은, "2023년 07월 23일 10:14"일 수 있다. 예를 들어, 제 7 서브 재생 이력(347)의 의도(332)는, 컨텐트 재생의 예시인 "Play music"일 수 있다. 예를 들어, 제 7 서브 재생 이력(347)의 키워드(333)는, "Rocket"일 수 있다. 예를 들어, 제 7 서브 재생 이력(347)의 해당 컨텐트의 속성 정보의 예시인 장르 정보(334)는, "Rock"일 수 있다. 예를 들어, 제 7 서브 재생 이력(347)의 해당 컨텐트의 속성 정보의 예시인 아티스트 정보(335)는, "PatentRock"일 수 있다. 예를 들어, 제 7 서브 재생 이력(347)의 해당 컨텐트의 속성 정보의 예시인 타이틀 정보(336)는, "Rocket"일 수 있다. 예를 들어, 제 7 서브 재생 이력(347)의 해당 컨텐트를 재생한 출력 장치의 식별을 위한 정보(337)는, "내방 스피커"일 수 있다. 예를 들어, 제 7 서브 재생 이력(347)의 재생 관리 정보(338)는, "추가"일 수 있다.For example, the playback time (331) of the content of the 4th sub-playback history (344) may be "July 22, 2023 10:05". For example, the intent (332) of the 4th sub-playback history (344) may be "Play music", which is an example of content playback. The intent (332) may be, for example, the intent of the natural language understanding result that caused the playback of the corresponding content, but is not limited thereto. For example, the keyword (333) of the 4th sub-playback history (344) may be "banana papa". For example, the genre information (334), which is an example of the attribute information of the corresponding content of the 4th sub-playback history (344), may be "nursery rhyme". For example, the artist information (335), which is an example of the attribute information of the corresponding content of the 4th sub-playback history (344), may be "grapefruit". For example, the title information (336), which is an example of the attribute information of the corresponding content of the 4th sub-playback history (344), may be "Banana Papa." For example, the information (337) for identifying the output device that reproduced the corresponding content of the 4th sub-playback history (344) may be "mobile." For example, the playback management information (338) of the 4th sub-playback history (344) may be "addition." "Addition" may mean that the playback history by the output device for the corresponding content is added, but there is no limitation. Meanwhile, "change" may mean a change of the playback device, but there is no limitation. Meanwhile, "end" may mean the end of the playback of the corresponding content, but there is no limitation. For example, the content of the title "Banana Papa" may be started to be played by "mobile" at 10:05 on July 22, 2023. Meanwhile, an output device for performing playback of content with the title of "Banana Papa" may be changed from "mobile" to "living room speaker" at 10:06 on July 23, 2023. Accordingly, a fifth sub-playback history (345) may be generated and stored. Information (337) for identifying an output device of the fifth sub-playback history (345) may be "living room speaker", and playback management information (338) may be "change". Meanwhile, playback of content with the title of "Banana Papa" may be terminated at 10:10 on July 23, 2023. Accordingly, a sixth sub-playback history (346) may be generated and stored. Information (337) for identifying an output device of the third sub-playback history (346) may be "living room speaker", and playback management information (338) may be "media end". Meanwhile, the playback time (331) of the content of the 7th sub-playback history (347) may be "July 23, 2023 10:14". For example, the intent (332) of the 7th sub-playback history (347) may be "Play music", which is an example of content playback. For example, the keyword (333) of the 7th sub-playback history (347) may be "Rocket". For example, the genre information (334), which is an example of the attribute information of the corresponding content of the 7th sub-playback history (347), may be "Rock". For example, the artist information (335), which is an example of the attribute information of the corresponding content of the 7th sub-playback history (347), may be "PatentRock". For example, the title information (336), which is an example of the attribute information of the corresponding content of the 7th sub-playback history (347), may be "Rocket". For example, the information (337) for identifying the output device that reproduced the corresponding content of the 7th sub-playback history (347) may be "in-room speaker". For example, the reproduction management information (338) of the 7th sub-playback history (347) may be "additional".
상술한 바와 같이, 서버(108)는, "바나나 파파 틀어줘"의 음성 명령(350)의 자연어 이해 결과로서, "컨텐트 재생"의 의도 및 "바나나 파파"의 키워드를 확인할 수 있다. 서버(108)는, 키워드와 연관된 컨텐트의 속성 정보(351)를 확인할 수 있다. 후술할 것으로, 서버(108)는, 예를 들어 NER(named entity recognition)을 지원하는 엔티티 및/또는 LLM(large language model)을 관리하는 엔티티와의 연계에 기반하여, 속성 정보(351)를 확인할 수 있으나, 그 확인 방식에는 제한이 없다. 컨텐트의 속성 정보(351)는, 예를 들어, "동요"의 장르 정보(352), "포도도"의 아티스트 정보(353) 및 "바나나 파파"의 타이틀 정보(354)일 수 있으나, 그 종류에는 제한이 없다. 서버(108)는, 재생 이력(225a)을 참조하여, 컨텐트의 속성 정보(351)에 대응하는 서브 재생 이력을 확인할 수 있다. 예를 들어, 서브 재생 이력(344,345,346)의 장르 정보(334), 아티스트 정보(335) 및 타이틀 정보(336)이, 컨텐트의 속성 정보(351)의 장르 정보(352), 아티스트 정보(353) 및 타이틀 정보(354)와 동일함이 확인될 수 있다. 적어도 하나의 속성 정보가 동일함에 기반하여, 서브 재생 이력(341,342,343)에 대응하는 출력 장치인 "모바일" 및 "거실 스피커"중 어느 하나를 출력 장치로서 확인할 수 있다. 예를 들어, 복수 개의 출력 장치들이 확인된 경우에는, 서버(108)는, 예를 들어 사용자의 선택, 지정된 규칙, 및/또는 인공지능 모델의 추론 결과에 기반하여, 어느 하나를 선택할 수도 있으며, 이에 대하여서는 후술하도록 한다. 예를 들어, 지정된 규칙이, 컨텐트 재생을 위한 출력 장치의 변경 이후에 대응하는 장치를, 출력 장치로 결정하는 것일 수 있다. 이 경우, 서버(108)는, "거실 스피커"가 컨텐트 재생 변경 이후에 대응하는 장치임에 기반하여, "거실 스피커"를 출력 장치로서 확인할 수 있으나, 이는 단순히 예시적인 것이다. 도 3b의 실시예에서는, 예를 들어, 거실 스피커(355)가 선택된 것을 상정하도록 한다. 한편, 서브 재생 이력(341,342,343)의 장르 정보(334) 및 아티스트 정보(335)가 컨텐트의 속성 정보(351)의 장르 정보(352), 아티스트 정보(335) 및 타이틀 정보(336)와 동일함이 확인될 수 있다. 하나의 예에서는, 적어도 하나의 속성 정보가 동일함에 기반하여, 서브 재생 이력(341,342,343)에 대응하는 출력 장치 또한 출력 장치의 후보로서 확인될 수 있다. 또는, 다른 예에서는, 컨텐트의 속성 정보(351)와 동일한 속성 정보의 개수가 상대적으로 더 큰 서브 재생 이력(344,345,346)의 출력 장치는 출력 장치의 후보로서 확인되고, 그 개수가 상대적으로 더 작은 서브 재생 이력(341,342,343)의 출력 장치는 출력 장치의 후보로서 확인되지 않을 수도 있으나, 제한은 없다. 하나의 예에서, 서버(108)는, 특정 속성 정보(예를 들어, 장르 정보(352))를, 다른 속성 정보보다 우선적으로 고려할 수도 있으나, 제한은 없다. 하나의 예에서, 컨텐트를 재생한 복수 개의 출력 장치들 중 가장 최근에 해당 컨텐트를 재생한 출력 장치가 선택될 수도 있다.As described above, the server (108) can confirm the intention of "content playback" and the keyword of "Banana Papa" as a result of the natural language understanding of the voice command (350) of "play Banana Papa". The server (108) can confirm the attribute information (351) of the content associated with the keyword. As will be described later, the server (108) can confirm the attribute information (351) based on, for example, a linkage with an entity that supports NER (named entity recognition) and/or an entity that manages an LLM (large language model), but there is no limitation on the method of confirmation. The attribute information (351) of the content can be, for example, genre information (352) of "Children's Song", artist information (353) of "Grapes", and title information (354) of "Banana Papa", but there is no limitation on the type thereof. The server (108) can confirm the sub-playback history corresponding to the attribute information (351) of the content by referring to the playback history (225a). For example, it can be confirmed that the genre information (334), the artist information (335), and the title information (336) of the sub-playback history (344, 345, 346) are identical to the genre information (352), the artist information (353), and the title information (354) of the attribute information (351) of the content. Based on the identicalness of at least one piece of attribute information, one of the output devices, “mobile” and “living room speaker,” corresponding to the sub-playback history (341, 342, 343) can be confirmed as the output device. For example, when a plurality of output devices are confirmed, the server (108) can select one of them based on, for example, a user’s selection, a specified rule, and/or an inference result of an artificial intelligence model, which will be described later. For example, a specified rule may be to determine a corresponding device as an output device after a change in an output device for content playback. In this case, the server (108) may identify "living room speaker" as an output device based on the fact that "living room speaker" is a corresponding device after a change in content playback, but this is merely exemplary. In the embodiment of FIG. 3b, for example, it is assumed that the living room speaker (355) is selected. Meanwhile, it may be confirmed that the genre information (334) and the artist information (335) of the sub playback history (341, 342, 343) are identical to the genre information (352), the artist information (335), and the title information (336) of the attribute information (351) of the content. In one example, based on the identity of at least one piece of attribute information, the output device corresponding to the sub playback history (341, 342, 343) may also be identified as a candidate for the output device. Alternatively, in another example, an output device of a sub-playback history (344, 345, 346) having a relatively larger number of attribute information identical to the attribute information (351) of the content may be identified as a candidate for the output device, and an output device of a sub-playback history (341, 342, 343) having a relatively smaller number of attribute information may not be identified as a candidate for the output device, but there is no limitation. In one example, the server (108) may preferentially consider specific attribute information (e.g., genre information (352)) over other attribute information, but there is no limitation. In one example, an output device that most recently played the content among a plurality of output devices that played the content may be selected.
서버(108)는, 309 동작에서, 제 1 출력 장치(251)(예를 들어, 도 3b의 거실 스피커(355))에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 서버(108)는, 제 1 출력 장치(251)로, 컨텐트(예를 들어, "바나나 파파"의 타이틀을 가지는 컨텐트)의 출력을 야기하는 데이터를 제공할 수 있다. 또는, 예를 들어, 서버(108)는, 컨텐트(예를 들어, "바나나 파파"의 타이틀을 가지는 컨텐트)를 제공하는 소스에 접근할 수 있거나, 또는 해당 컨텐트를 저장하는 다른 외부 전자 장치로, 컨텐트 재생을 위한 데이터의 송신을 야기하도록 하는 데이터를 제공할 수도 있다. 이 경우, 외부 전자 장치는, 수신한 데이터에 기반하여, 제 1 출력 장치(251)와 통신 연결을 수립할 수 있으며, 수립된 통신 연결에 기반하여 컨텐트 재생을 위한 데이터를 제 1 출력 장치(251)로 제공할 수도 있다. 제 1 출력 장치(251)는, 통신 연결에 기반하여 수신된 컨텐트 재생을 위한 데이터에 기반하여, 컨텐트를 재생할 수도 있다.The server (108), in
서버(108)는, 컨텐트 재생이 완료됨에 기반하여, 재생 이력(225a)를 업데이트할 수도 있다.The server (108) may also update the playback history (225a) based on the completion of content playback.
한편, 도 3c를 참조하면, 서버(108)는, "징글벨 틀어줘"의 음성 명령(360)을 확인할 수 있다. 서버(108)는, 음성 명령(360)(또는, 키워드)과 연관된 컨텐트의 속성 정보(361)를 확인할 수 있다. 속성 정보(361)는, 예를 들어 "동요"의 장르 정보(362), "XXY"의 아티스트 정보(363) 및 "징글벨"의 타이틀 정보(364)일 수 있다. 서버(108)는, "동요"의 장르 정보(362)에 대응하는, 장르 정보(334)를 가지는 서브 재생 이력(341,342,343,344,345,346)을 확인할 수 있다. 서버(108)는, 서브 재생 이력(341,342,343,344,345,346)에 대응하는 출력 장치인 "모바일" 및 "거실 스피커"를 확인할 수 있다. 서버(108)는, 예를 들어, 사용자의 선택, 지정된 규칙, 및/또는 AI 모델의 추론 결과에 기반하여, 거실 스피커(365)를 선택할 수 있다. 서버(108)는, 거실 스피커(365)에 의하여 "징글벨"의 타이틀의 컨텐트의 재생을 야기하도록 하는 적어도 하나의 동작을 수행할 수 있다.Meanwhile, referring to FIG. 3c, the server (108) can verify the voice command (360) of "play jingle bells." The server (108) can verify attribute information (361) of content associated with the voice command (360) (or keyword). The attribute information (361) may be, for example, genre information (362) of "children's songs," artist information (363) of "XXY," and title information (364) of "jingle bells." The server (108) can verify sub-play history (341, 342, 343, 344, 345, 346) having genre information (334) corresponding to the genre information (362) of "children's songs." The server (108) can check the output devices, “mobile” and “living room speaker”, corresponding to the sub-play history (341,342,343,344,345,346). The server (108) can select the living room speaker (365), for example, based on the user’s selection, a specified rule, and/or the inference result of the AI model. The server (108) can perform at least one operation to cause the content of the title “Jingle Bells” to be played by the living room speaker (365).
한편, 도 3d를 참조하면, 서버(108)는, "Hostile 틀어줘"의 음성 명령(370)을 확인할 수 있다. 서버(108)는, 음성 명령(370)(또는, 키워드)과 연관된 컨텐트의 속성 정보(371)를 확인할 수 있다. 속성 정보(371)는, 예를 들어 "Rock"의 장르 정보(372), "Pamtera"의 아티스트 정보(373) 및 "Hostile"의 타이틀 정보(374)일 수 있다. 서버(108)는, "Rock"의 장르 정보(372)에 대응하는, 장르 정보(334)를 가지는 서브 재생 이력(347)을 확인할 수 있다. 서버(108)는, 서브 재생 이력(347)에 대응하는 출력 장치인 "내방 스피커"를 확인할 수 있다. 서버(108)는, 내방 스피커(375)에 의하여 "Hostile"의 타이틀의 컨텐트의 재생을 야기하도록 하는 적어도 하나의 동작을 수행할 수 있다.Meanwhile, referring to FIG. 3d, the server (108) can verify the voice command (370) of "Play Hostile." The server (108) can verify attribute information (371) of content associated with the voice command (370) (or keyword). The attribute information (371) may be, for example, genre information (372) of "Rock," artist information (373) of "Pamtera," and title information (374) of "Hostile." The server (108) can verify sub-play history (347) having genre information (334) corresponding to the genre information (372) of "Rock." The server (108) can verify "room speaker," which is an output device corresponding to the sub-play history (347). The server (108) may perform at least one action that causes the content of the title “Hostile” to be played by the in-room speaker (375).
도 3e는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 3e is a flowchart illustrating a method for processing a voice command according to one embodiment.
일 실시예에 따라서, 서버(108)는, 391 동작에서, 음성 명령의 분석 결과가 컨텐트 재생을 의도함을 확인할 수 있다. 서버(108)는, 393 동작에서, 음성 명령과 연관된 컨텐트에 대응하는 카테고리(category)(또는, 클러스터(cluster), 또는 그룹(group)으로 명명될 수도 있음)를 확인할 수 있다. 예를 들어, 표 1은, 컨텐트에 대응하는 카테고리의 예시이다.According to one embodiment, the server (108) may, at

예를 들어, 표 1의 카테고리는, 장르 정보에 기반하여 설정될 수 있으나, 이는 예시적인 것이며, 카테고리를 구분하기 위한 속성 정보의 종류 및/또는 개수에는 제한이 없다. 예를 들어, 서버(108)는, 표 1과 같은 정보에 기반하여 컨텐트에 대응하는 카테고리를 확인하거나, 및/또는 클러스터링(clustering)에 기반하여 컨텐트에 대응하는 카테고리를 확인할 수도 있으며, 그 확인 방식에 제한이 없다. 표 1과 같은 카테고리 관련 정보는, 예를 들어 K-means 클러스터링, 및/또는 지식 그래프(knowledge graph)에 기반하여 생성(또는, 확인)될 수 있으나, 그 방식에는 제한이 없다. 한편, 카테고리가 표 1과 같이 장르에 의하여 분류되는 것은 단순히 예시적인 것으로, 카테고리 이외의 다른 컨텐트 속성에 기반하여 카테고리가 분류될 수도 있음을 당업자는 이해할 것이다.For example, the category of Table 1 may be set based on genre information, but this is exemplary, and there is no limitation on the type and/or number of attribute information for distinguishing the category. For example, the server (108) may confirm a category corresponding to the content based on information such as Table 1, and/or confirm a category corresponding to the content based on clustering, and there is no limitation on the confirmation method. Category-related information such as Table 1 may be generated (or confirmed) based on, for example, K-means clustering, and/or a knowledge graph, but there is no limitation on the method. Meanwhile, it is merely exemplary that the category is classified by genre as in Table 1, and those skilled in the art will understand that the category may be classified based on other content attributes other than the category.
서버(108)는, 395 동작에서, 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인할 수 있다. 서버(108)는, 397 동작에서, 카테고리 및 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 적어도 하나의 출력 장치 중 컨텐트를 재생하기 위한 제 1 출력 장치를 확인할 수 있다. 예를 들어, 재생 이력의 장르 정보에 기반하여 재생 이력 별 카테고리가 확인될 수 있거나, 또는 재생 이력에 카테고리에 대한 정보가 포함되도록 구현될 수도 있다. 서버(108)는, 재생 이력에 기반하여, 해당 카테고리의 컨텐트를 재생한 제 1 출력 장치를 확인하거나, 또는 복수 개의 출력 장치의 후보들 중 제 1 출력 장치를 확인할 수 있다. 서버(108)는, 399 동작에서, 제 1 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다.The server (108), in
도 4는, 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 4 is a flowchart illustrating a method for processing a voice command according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 전자 장치(101)는, 401 동작에서, 음성 명령을 획득할 수 있다. 전자 장치(101)는, 403 동작에서, 음성 명령을 서버(108)로 제공할 수 있다. 음성 명령은, 상술한 바와 같이, 어쿠스틱 신호, 어쿠스틱 신호가 변화된 텍스트, 및/또는 텍스트에 대한 자연어 이해 결과로 구현될 수 있으며, 그 구현에 제한이 없다. 서버(108)에 포함된 NLU 모듈(212)은, 405 동작에서, 음성 명령이 컨텐트 재생을 의도한 것임을 확인할 수 있다. 만약, 전자 장치(101)가 자연어 이해 결과를 포함하는 음성 명령을 제공한 경우에는, NLU 모듈(212)에 의한 동작이 생략될 수도 있음을 당업자는 이해할 것이다. NLU 모듈(212)은, 407 동작에서, 컨텐트 관련 정보를 제공할 수 있다. 컨텐트 관련 정보는, 예를 들어 키워드 및/또는 의도(예를 들어, 컨텐트 재생 의도)를 포함할 수 있으나, 제한은 없다. 출력 장치 확인 모듈(220)은, 409 동작에서, 컨텐트의 적어도 하나의 속성을 확인할 수 있다. 예를 들어, 출력 장치 확인 모듈(220)은, NER을 지원하는 엔티티 및/또는 LLM을 관리하는 엔티티에 문의함에 기반하여, 컨텐트의 적어도 하나의 속성을 확인할 수 있으나, 제한은 없다. 출력 장치 확인 모듈(220)은, 411 동작에서, 적어도 하나의 출력 장치의 재생 이력을 확인할 수 있다. 출력 장치 확인 모듈(220)은, 413 동작에서, 컨텐트의 적어도 하나의 속성 중 적어도 일부 및 재생 이력의 적어도 일부에 기반하여, 제 1 출력 장치를 확인할 수 있다. 예를 들어, 컨텐트의 적어도 하나의 속성 중 적어도 일부가, 제 1 출력 장치의 재생 이력 내의 컨텐트 속성의 적어도 일부와 대응(동일 및/또는 유사)함에 기반하여, 제 1 출력 장치를 확인할 수 있다.According to one embodiment, the electronic device (101) may obtain a voice command in operation 401. The electronic device (101) may provide the voice command to the server (108) in
일 실시예에 따라서, 출력 장치 확인 모듈(220)은, 415 동작에서, 컨텐트 재생을 야기하는 데이터를 제 1 출력 장치(251)로 제공할 수 있다. 출력 장치 확인 모듈(220)은, 예를 들어 IoT 서버(240)를 통하여, 데이터를 제 1 출력 장치(251)로 제공할 수 있으나, 이는 예시적인 것으로 IoT 서버(240)의 중계 없이 데이터가 전달될 수도 있음을 당업자는 이해할 것이다. 예를 들어, 제 1 데이터는, "컨텐트 재생"의 의도를 달성하기 위한 적어도 하나의 명령, 키워드, 및/또는 확인된 컨텐트의 적어도 하나의 속성을 포함할 수 있으나, 그 구현 형태에는 제한이 없다. 제 1 출력 장치(251)는, 417 동작에서, 수신된 제 1 데이터에 기반하여 컨텐트를 재생할 수 있다. 예를 들어, 제 1 출력 장치(251)는, 제 1 데이터에 포함된 정보에 기반하여, 해당 컨텐트의 소스(source)로 접속함으로써, 제 컨텐트 재생을 위한 정보를 다운로드받아 재생을 수행할 수 있거나, 또는 미리 저장된 컨텐트를 재생할 수도 있다. 또는, 제 1 출력 장치(251)는, 해당 컨텐트에 대한 접속이 가능한 외부 전자 장치(예를 들어, 전자 장치(101) 또는 또 다른 IoT 장치)와 연결을 수립할 수 있으며, 수립된 연결에 기반하여 컨텐트를 재생할 수 있는 데이터를 수신하여 재생할 수도 있으며, 컨텐트의 재생 방식에는 제한이 없다.According to one embodiment, the output device identification module (220) may, in
도 5는, 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 5 is a flowchart illustrating a method for processing a voice command according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 전자 장치(101)는, 501 동작에서, 음성 명령을 획득할 수 있다. 전자 장치(101)는, 503 동작에서, 음성 명령을 서버(108)로 제공할 수 있다. 서버(108)에 포함된 NLU 모듈(212)은, 505 동작에서, 음성 명령이 컨텐트 재생을 의도한 것임을 확인할 수 있다. NLU 모듈(212)은, 507 동작에서, 컨텐트 관련 정보를 제공할 수 있다. 출력 장치 확인 모듈(220)은, 509 동작에서, 컨텐트의 적어도 하나의 속성을 확인할 수 있다. 출력 장치 확인 모듈(220)은, 511 동작에서, 적어도 하나의 출력 장치의 재생 이력을 확인할 수 있다. 출력 장치 확인 모듈(220)은, 513 동작에서, 컨텐트의 적어도 하나의 속성 중 적어도 일부 및 재생 이력의 적어도 일부에 기반하여, 제 1 출력 장치를 확인할 수 있다. 출력 장치 확인 모듈(220)은, 515 동작에서, 음성 명령을 제공하였던 전자 장치(101)로, 컨텐트 재생을 위한 제 1 데이터의 송신을 야기하는 제 2 데이터를 제공할 수 있다. 예를 들어, 출력 장치 확인 모듈(220)은, 제 1 출력 장치(251)가, 전자 장치(101)과의 통신 연결 수립, 통신 연결을 통한 컨텐트 재생을 위한 데이터 수신, 및/또는 수신된 데이터에 기반한 컨텐트 재생 기능을 지원하는지 여부를 확인할 수 있으며, 해당 적어도 하나의 기능(이를, 무선 음향 출력 기능이라 명명할 수도 있음)을 지원함에 기반하여 제 1 출력 장치(251)를 선택할 수 있다. 출력 장치 확인 모듈(220)은, 제 1 출력 장치(251)가 무선 음향 출력 기능을 지원하며, 추가적으로 제 1 출력 장치(251)가 전자 장치(101)와 통신 연결을 수립할 수 있는지를 확인하여 제 1 출력 장치(251)를 선택할 수도 있다. 예를 들어, 출력 장치 확인 모듈(220)은, IoT 서버(240)로부터 제공되는 정보에 기반하여 제 1 출력 장치(251)가 배치된 공간에 전자 장치(101)가 위치하는지 여부를 확인할 수 있으며, 확인 결과에 따라 현재 무선 음향 출력이 가능한지 여부를 확인할 수 있다. 또는, 출력 장치 확인 모듈(220)은, 전자 장치(101)로부터 근거리 통신에 기반하여 확인된 연결 가능한 장치 리스트를 수신할 수도 있으며, 이에 기반하여 제 1 출력 장치(251)가 현재 무선 음향 출력이 가능한지 여부를 확인할 수도 있으며, 그 확인 방식에 제한이 없다.According to one embodiment, the electronic device (101) may obtain a voice command in
전자 장치(101)는, 517 동작에서, 수신된 제 2 데이터에 기반하여, 제 1 출력 장치(251)와의 통신 연결을 수립할 수 있다. 한편, 전자 장치(101)가, 제 1 출력 장치(251)와 통신 연결을 이미 수립한 경우에는, 통신 연결의 수립 절차는 생략될 수도 있음을 당업자는 이해할 것이다. 제 2 데이터는, 예를 들어 제 1 출력 장치(251)를 식별하기 위한 정보, 제 1 출력 장치(251)와의 통신 연결 수립을 요청하는 정보, 및/또는 재생이 요청되는 컨텐트와 연관된 정보를 포함할 수 있으나, 그 구현에는 제한이 없다. 전자 장치(101)는, 517 동작에서, 수신된 제 2 데이터에 기반하여, 제 1 출력 장치(251)와의 통신 연결을 수립할 수 있다. 통신 연결은, 예를 들어 근거리 무선 통신에 기반하여 수립될 수 있으나, 이에 제한되지 않으며, 그 수립 방식에는 제한이 없다. 전자 장치(101)는, 519 동작에서, 통신 연결을 통하여 컨텐트 재생을 위한 제 1 데이터를 제공할 수 있다. 예를 들어, 전자 장치(101)는, 컨텐트를 재생할 수 있으며, 재생된 컨텐트의 출력 장치를 제 1 출력 장치(251)로 설정함으로써, 제 1 출력 장치(251)에 의한 컨텐트 재생이 가능할 수 있으나, 제한은 없다. 또는, 전자 장치(101)는, 컨텐트를 재생하지 않고, 컨텐트 재생을 위한 데이터만을 제 1 출력 장치(251)로 제공할 수도 있으며, 이에 따라 제 1 출력 장치(251)에 의한 컨텐트 재생이 가능할 수도 있다.The electronic device (101) can establish a communication connection with the first output device (251) based on the received second data in
도 6a는, 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 6a is a flowchart illustrating a method for processing a voice command according to one embodiment.
도 6a의 실시예는, 도 6b 및 도 6c를 참조하여 설명하도록 한다. 도 6b는 일 실시예에 따른 복수 개의 출력 장치 후보들 중 어느 하나를 선택하기 위한 화면을 설명하기 위한 도면이다.The embodiment of Fig. 6a will be described with reference to Figs. 6b and 6c. Fig. 6b is a drawing for describing a screen for selecting one of a plurality of output device candidates according to one embodiment.
도 6c는 일 실시예에 따른 복수 개의 출력 장치 후보들 중 어느 하나를 선택하기 위한 화면을 설명하기 위한 도면이다.FIG. 6c is a drawing for explaining a screen for selecting one of a plurality of output device candidates according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 전자 장치(101)는, 601 동작에서, 음성 명령을 획득할 수 있다. 전자 장치(101)는, 603 동작에서, 음성 명령을 서버(108)로 제공할 수 있다. 서버(108)에 포함된 NLU 모듈(212)은, 605 동작에서, 음성 명령이 컨텐트 재생을 의도한 것임을 확인할 수 있다. NLU 모듈(212)은, 607 동작에서, 컨텐트 관련 정보를 제공할 수 있다. 출력 장치 확인 모듈(220)은, 609 동작에서, 컨텐트의 적어도 하나의 속성을 확인할 수 있다. 출력 장치 확인 모듈(220)은, 611 동작에서, 적어도 하나의 출력 장치의 재생 이력을 확인할 수 있다. 출력 장치 확인 모듈(220)은, 613 동작에서, 적어도 하나의 속성 중 적어도 일부 및 재생 이력의 적어도 일부에 기반하여, 출력 장치 후보들을 확인할 수 있다. 예를 들어, 도 3b에서와 같이, 컨텐트의 속성(351)의 장르 정보(352)가 "동요"인 것으로 확인될 수 있다. 이에 따라, 장르 정보(333)에 "동요"가 포함된 서브 재생 이력들(341,342,343,344,345,346)에 대응하는 "모바일", "거실 스피커"가 출력 장치 후보들로서 확인될 수 있다. 츨력 장치 확인 모듈(220)은, 615 동작에서, 출력 장치 후보들을 표현하기 위한 데이터를 음성 명령을 제공하였던 전자 장치(101)로 제공할 수 있다. 전자 장치(101)는, 617 동작에서, 수신된 데이터에 기반하여 출력 장치 후보들을 표현할 수 있다. 예를 들어, 도 6b에서와 같이, 전자 장치(101)는, 표시 중인 화면(630) 상에 팝업 윈도우(631)를 제공할 수 있다. 한편, 팝업 윈도우(631)의 표현은 단순히 예시적인 것으로, 팝업 윈도우(631) 이외에도 다양한 표현 방식, 예를 들어 화면 전환이 가능할 수도 있음을 당업자는 이해할 것이다. 팝업 윈도우(631)에는, 컨텐트를 재생할 수 있는 출력 장치의 선택을 유도하는 취지의 텍스트가 포함될 수 있다. 팝업 윈도우(631)에는, 적어도 하나의 오브젝트(632,633,634)가 포함될 수 있다. 적어도 하나의 오브젝트(632,633,634)는, UI 엘리먼트(element), UI 오브젝트, 아이콘(icon), 텍스트(text), 이미지(image), 비주얼 엘리먼트(visual element), 비주얼 컴포넌트(visual component), 아바타(avatar), 섬네일(thumbnail), 애니메이션(animation), 키(key) 및/또는 버튼(button)으로 표현될 수 있으나, 그 표현 방식에는 제한이 없다. 적어도 하나의 오브젝트(632,633,634)는, 각각 복수 개의 출력 장치 후보들 각각을 식별할 수 있는 텍스트를 포함할 수 있으나, 그 표현 방식에는 제한이 없다. 한편, 전자 장치(101)는, 복수 개의 출력 장치 후보들에 대한 식별 정보 및 이 중 하나를 선택하라는 취지의 음성 응답을, 팝업 윈도우(631)를 대체하거나, 또는 추가적으로 제공할 수도 있다. 사용자는, 적어도 하나의 오브젝트(632,633,634) 중 어느 하나를 선택(예를 들어, 탭, 또는 추가 음성 명령 입력일 수 있으나 제한이 없음)할 수 있다. 전자 장치(101)는, 621 동작에서, 사용자 선택과 관련된 데이터를 출력 장치 확인 모듈(220)로 제공할 수 있다.According to one embodiment, the electronic device (101) may obtain a voice command in
또는, 전자 장치(101)는, 수신된 데이터에 기반하여, 도 6c와 같은 팝업 윈도우(631)를 제공할 수 있다. 도 6c에서는, 복수 개의 출력 장치 후보들에 대응하는 오브젝트들(632,633,634) 중 어느 하나인 오브젝트(632) 상에 카운트다운의 애니메이션 효과를 제공하는 추가 오브젝트(636)이 표현될 수 있다. 추가 오브젝트(636)는, 예를 들어 출력 장치 후보들 중 최상위의 우선 순위를 가지는 출력 장치에 대응하는 오브젝트(632) 상에 배치되는 것과 같이 표현될 수 있다. 예를 들어, 도 6c에서는, "거실 TV", "My tab S8", "My S23+"가 출력 장치 후보들로 설정될 수 있으며, 이 중 "거실 TV"가 가장 높은 우선 순위를 가짐에 따라, 추가 오브젝트(636)가 "거실 TV"에 대응하는 오브젝트(632) 상에 배치되는 것과 같이 표현될 수 있다. 우선 순위는, 지정된 규칙에 기반하여 설정되거나, 및/또는 인공지능 모델(예를 들어, 뉴럴 네트워크 기반의 인공지능 모델, 선형 회귀, 및/또는 서포트 벡터 머신일 수 있으나 제한이 없음)의 추론(inference) 결과(예를 들어, confidence score일 수 있으나 제한이 없음)에 기반하여 결정될 수 있다. 예를 들어, 지정된 규칙은, 해당 컨텐트 속성을 재생한 횟수가 많을수록 더 높은 우선 순위가 부여되는 규칙을 포함할 수 있다. 예를 들어, 지정된 규칙은, 해당 컨텐트 속성을 재생한 시점이 최근 시점에 가까울수록 더 높은 우선 순위가 부여되는 규칙을 포함할 수 있다. 예를 들어, 지정된 규칙은, 해당 컨텐트 속성에 대한 재생을 위한 출력 장치가 변경된 경우, 변경 이후의 출력 장치에 대하여 더 높은 우선 순위가 부여되는 규칙을 포함할 수 있다. 한편, 지정된 규칙의 종류 및/또는 개수에는 제한이 없다. 규칙이 복수 개인 경우, 각 규칙 적용 결과(예를 들어, 우선 순위 설정을 위한 스코어)에 기반하여(예를 들어, 합계 또는 가중치 합에 기반하여), 출력 장치 후보들 각각에 대한 우선 순위가 결정될 수 있다. 예를 들어, 우선 순위는, 각 출력 장치 후보들의 인공지능 모델의 추론 결과에 기반하여 설정될 수도 있다. 인공지능 모델은, 예를 들어 출력 장치 및 컨텐트의 적어도 하나의 속성을 입력으로서 수신하고, 적합도(또는, 스코어)를 출력하도록 트레이닝될 수 있다. 예를 들어, 인공지능 모델은, LLM일수도 있으나, 그 구현에는 제한이 없다.Alternatively, the electronic device (101) may provide a pop-up window (631) as in FIG. 6C based on the received data. In FIG. 6C, an additional object (636) providing a countdown animation effect may be expressed on an object (632) that is one of the objects (632, 633, 634) corresponding to a plurality of output device candidates. The additional object (636) may be expressed as being placed on an object (632) corresponding to an output device having the highest priority among the output device candidates, for example. For example, in FIG. 6C, “Living Room TV”, “My tab S8”, and “My S23+” may be set as output device candidates, and since “Living Room TV” has the highest priority, the additional object (636) may be expressed as being placed on an object (632) corresponding to “Living Room TV”. The priority may be set based on a specified rule, and/or may be determined based on an inference result (e.g., a confidence score, but not limited to) of an artificial intelligence model (e.g., an artificial intelligence model based on a neural network, linear regression, and/or a support vector machine, but not limited to). For example, the specified rule may include a rule that a higher priority is given to a content property as the number of times the content property has been played increases. For example, the specified rule may include a rule that a higher priority is given to a content property as the time of playing the content property is closer to the most recent time. For example, the specified rule may include a rule that a higher priority is given to an output device after the change when the output device for playing the content property has been changed. Meanwhile, there is no limitation on the type and/or number of the specified rules. When there are multiple rules, the priority for each of the output device candidates may be determined based on the result of applying each rule (e.g., a score for setting the priority) (e.g., based on a sum or a weighted sum). For example, the priority may be set based on the inference results of the AI model of each output device candidate. The AI model may be trained to receive, for example, at least one attribute of the output device and the content as input and output a fitness (or score). For example, the AI model may be LLM, but there is no limitation on its implementation.
추가 오브젝트(636)는, 예를 들어 도 6c의 실시예에서는 "3"의 텍스트로 표현될 수 있다. 시간의 흐름에 따라, "3"의 텍스트는, "2", "1", "0"의 텍스트로 순차적으로 변경될 수 있으며, 이에 따라 카운트다운의 애니메이션 효과가 표현될 수 있다. "0"의 텍스트가 표현됨에 기반하여, 전자 장치(101)는, 추가 오브젝트(636)가 위치와 연관된 오브젝트(632)에 대응하는 출력 장치가 선택된 것으로 확인할 수 있다. 전자 장치(101)는, 이에 621 동작에서, 사용자 선택과 관련된 데이터를 출력 장치 확인 모듈(220)로 제공할 수 있다. 다시, 6a를 참조하면, 출력 장치 확인 모듈(220)은, 623 동작에서, 수신된 데이터에 기반하여, 제 1 출력 장치(251)를 확인할 수 있다. 출력 장치 확인 모듈(220)은, 625 동작에서, 컨텐트 재생을 야기하도록 하는 데이터를 제 1 출력 장치(251)로 제공할 수 있다. 출력 장치 확인 모듈(220)은, 예를 들어 IoT 서버(240)를 통하여, 데이터를 제 1 출력 장치(251)로 제공할 수 있으나, 이는 예시적인 것으로 IoT 서버(240)의 중계 없이 데이터가 전달될 수도 있음을 당업자는 이해할 것이다. 제 1 출력 장치(251)는, 627 동작에서, 수신된 데이터에 기반하여 컨텐트를 재생할 수 있다. 한편, 다른 예에서는, 도 5에서 설명한 바와 같이, 출력 장치 확인 모듈(220)은, 컨텐트 재생을 위한 제 1 데이터의 송신을 야기하는 제 2 데이터를 전자 장치(101)로 제공할 수도 있음을 당업자는 이해할 것이다.The additional object (636) may be represented by the text “3” in the embodiment of FIG. 6c, for example. Over time, the text “3” may be sequentially changed to the texts “2”, “1”, and “0”, thereby expressing an animation effect of a countdown. Based on the expression of the text “0”, the electronic device (101) may determine that the output device corresponding to the object (632) associated with the location of the additional object (636) has been selected. The electronic device (101) may then, in
도 7a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다. 도 7a의 실시예는, 도 7b를 참조하여 설명하도록 한다.FIG. 7a is a flowchart illustrating a method for processing a voice command according to one embodiment. The embodiment of FIG. 7a will be described with reference to FIG. 7b.
도 7b는 일 실시예에 따른 복수 개의 출력 장치 후보들 중 어느 하나를 선택하기 위한 방법을 설명하기 위한 도면이다.FIG. 7b is a diagram illustrating a method for selecting one of a plurality of output device candidates according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 701 동작에서, 음성 명령의 분석 결과가 컨텐트 재생을 의도함을 확인할 수 있다. 예를 들어, 서버(108)는, "바나나 파파 틀어줘"의 음성 명령을 확인할 수 있다. 서버(108)는, "바나나 파파 틀어줘"의 음성 명령에 대한 자연어 이해 결과에 기반하여, 음성 명령의 키워드가 "바나나 파파"이며, 음성 명령(350)의 의도가 "컨텐트 재생"임을 확인할 수 있다. 서버(108)는, 703 동작에서, 음성 명령(350)과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인할 수 있다. 서버(108)는, 705 동작에서, 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인할 수 있다. 서버(108)는, 707 동작에서, 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 적어도 하나의 출력 장치 중 컨텐트를 재생하기 위한 출력 장치 후보들을 확인할 수 있다. 예를 들어, "바나나 파파"의 키워드의 적어도 하나의 속성 정보로서, "동요"의 장르 정보, "포도도"의 아티스트 정보, "바나나 파파"의 타이틀 정보가 확인된 것을 상정하도록 한다. 예를 들어, 서버(108)는, "동요"가 포함된 장르 정보(731)를 가지는 서브 재생 정보들(341,342,343,344,345,346)을 확인할 수 있다. 예를 들어, 서버(108)는, "포도도"의 아티스트 정보가 포함된 아티스트 정보(732)를 가지는 서브 재생 정보들(341,342,343,344,345,346)을 확인할 수 있다. 예를 들어, 서버(108)는, "바나나 파파"의 아티스트 정보(733)를 가지는 서브 재생 정보들(344,345,346)을 확인할 수 있다. 서버(108)는, 해당 서브 재생 정보들(341,342,343,344,345,346)에 대응하는 모바일(734) 및 거실 스피커(735)를, 출력 장치 후보들로 확인할 수 있다.According to one embodiment, the server (108) may, in
다시, 도 7a를 참조하면, 서버(108)는, 709 동작에서, 적어도 하나의 규칙 및/또는 인공지능 모델에 기반하여, 출력 장치 후보들 중 제 1 출력 장치를 확인할 수 있다. 서버(108)는, 711 동작에서, 제 1 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 지정된 규칙은, 해당 컨텐트 속성을 재생한 횟수가 많을수록 더 높은 우선 순위가 부여되는 규칙을 포함할 수 있다. 예를 들어, 지정된 규칙은, 해당 컨텐트 속성을 재생한 시점이 최근 시점에 가까울수록 더 높은 우선 순위가 부여되는 규칙을 포함할 수 있다. 예를 들어, 지정된 규칙은, 해당 컨텐트 속성에 대한 재생을 위한 출력 장치가 변경된 경우, 변경 이후의 출력 장치에 대하여 더 높은 우선 순위가 부여되는 규칙을 포함할 수 있다. 한편, 지정된 규칙의 종류 및/또는 개수에는 제한이 없다. 규칙이 복수 개인 경우, 각 규칙 적용 결과(예를 들어, 우선 순위 설정을 위한 스코어)에 기반하여(예를 들어, 합계 또는 가중치 합에 기반하여), 출력 장치 후보들 각각에 대한 우선 순위가 결정될 수 있다. 예를 들어, 도 7b를 참조하면, 서버(108)는, "바나나 파파"의 타이틀의 컨텐트의 재생 주체가 모바일(734)로부터 거실 스피커(735)로 변경됨에 기반하여, 지정된 규칙에 근거하여, 거실 스피커(735)의 우선 순위를 모바일(734)의 우선 순위보다 높게 설정할 수 있다. 예를 들어, 서버(108)는, 상대적으로 높은 우선 순위를 가지는 거실 스피커(735)를 컨텐트를 재생할 출력 장치로서 결정할 수 있다. 한편, 상술한 바와 같이, 우선 순위는, 각 출력 장치 후보들의 인공지능 모델의 추론 결과에 기반하여 설정될 수도 있다. 상술한 바에 따라서, 서버(108)는, 복수 개의 출력 장치 후보들 중 어느 하나를, 사용자의 선택 없이 결정할 수도 있다.Again, referring to FIG. 7A, the server (108) may, in
도 8a는 일 실시예에 따른 컨텐트의 속성 정보를 확인하는 방법을 설명하기 위한 흐름도이다.FIG. 8a is a flowchart illustrating a method for checking attribute information of content according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 801 동작에서, 음성 명령의 분석 결과가 컨텐트 재생을 의도함을 확인할 수 있다. 서버(108)는, 803 동작에서, 키워드를 확인할 수 있다. 예를 들어, 서버(108)는, "바나나 파파 틀어줘"의 음성 명령에 대한 자연어 이해 결과에 기반하여, 음성 명령의 키워드가 "바나나 파파"이며, 음성 명령의 의도가 "컨텐트 재생"임을 확인할 수 있다. 서버(108)는, 805 동작에서, 키워드에 대응하는 적어도 하나의 속성 정보를, NER(named entity recognition)을 지원하는 엔티티(예를 들어, NER(named entity recognition) 서버라 명명될 수 있지만 제한이 없음)에 문의할 수 있다. NER을 지원하는엔티티는, 예를 들어 서버(108)에 포함되도록 구현되거나, 또는 서버(108)와 별개의 엔티티로서 구현될 수도 있으며, 그 구현 방식에는 제한이 없다. 서버(108)는, 807 동작에서, 문의에 대한 응답으로서, NER을 지원하는 엔티티로부터 키워드에 대응하는 적어도 하나의 속성 정보를 수신할 수 있다. 예를 들어, 표 2는, 일 실시예에 따른 NER을 지원하는 엔티티로부터 제공되는 응답의 예시이다. NER은, 예를 들어 NLU 동작의 적어도 일부로서 수행될 수 있거나, 또는 NLU 동작과는 독립적으로 수행될 수도 있으며, 그 수행 구현에는 제한이 없다.According to one embodiment, the server (108) may, in

표 2에서와 같이, 문의에 대한 응답은, 해당 메시지의 식별 정보("Id")를 포함할 수 있다. 응답은, 해당 컨텐트와 관련된 도메인(예를 들어, 표 2에서는 "music")을 포함할 수 있다. 응답은, 해당 컨텐트와 관련된 엔티티(예를 들어, 표 2에서는 "song")을 포함할 수 있다. 응답은, 해당 컨텐트와 관련된 키워드(예를 들어, 표 2에서는 "textname"으로 표현되며, 그 값은 "바나나 파파"일 수 있음)을 포함할 수 있다. 응답은, 해당 컨텐트의 속성 정보로서, 아티스트 정보(예를 들어, 표 2에서는 "artist_name", "artist_Id", "type"으로 표현되며, 그 값은 "포도도", "1703695", "artist"일 수 있음)을 포함할 수 있다. 응답은, 해당 컨텐트의 속성 정보로서, 컨텐트가 수록된 앨범 정보(예를 들어, 표 2에서는 "album_name", "album_id"로 표현되며, 그 값은 "바나나의 모든것", "10269480" 일 수 있음)을 포함할 수 있다. 응답은, 해당 컨텐트의 속성 정보로서, 장르 정보(예를 들어, 표 2에서는 "genre"로 표현되며, 그 값은 "kids" 일 수 있음)을 포함할 수 있다. 응답은, 해당 컨텐트의 속성 정보로서, 순위 정보(예를 들어, 표 2에서는 "genre_rank" 및 "rank"로 표현되며, 그 값은 "4", "1487" 일 수 있음)을 포함할 수 있다. 응답은, NER을 지원하는 엔티티(또는, 엔티티가 참조한 소스(source))의 정보(예를 들어, 표 2에서는 "streameverything.com"을 포함할 수 있다. 서버(108)는, 응답으로부터 적어도 하나의 속성 정보를 추출할 수 있으며, 상술한 바와 같이 추출된 적어도 하나의 속성 정보를 이용하여 컨텐트를 재생할 출력 장치를 확인할 수 있다.As shown in Table 2, a response to an inquiry may include identification information ("Id") of the corresponding message. The response may include a domain related to the corresponding content (for example, "music" in Table 2). The response may include an entity related to the corresponding content (for example, "song" in Table 2). The response may include a keyword related to the corresponding content (for example, expressed as "textname" in Table 2, and its value may be "banana papa"). The response may include artist information as attribute information of the corresponding content (for example, expressed as "artist_name", "artist_Id", and "type" in Table 2, and its values may be "포도도", "1703695", and "artist"). The response may include, as attribute information of the corresponding content, album information including the content (for example, expressed as "album_name" and "album_id" in Table 2, the values of which may be "All About Bananas" and "10269480"). The response may include, as attribute information of the corresponding content, genre information (for example, expressed as "genre" in Table 2, the value of which may be "kids"). The response may include, as attribute information of the corresponding content, rank information (for example, expressed as "genre_rank" and "rank" in Table 2, the values of which may be "4" and "1487"). The response may include information about an entity supporting NER (or a source referenced by the entity) (e.g., “streameverything.com” in Table 2). The server (108) may extract at least one attribute information from the response and, using the at least one attribute information extracted as described above, identify an output device to play the content.
도 8b는 일 실시예에 따른 컨텐트의 속성 정보를 확인하는 방법을 설명하기 위한 흐름도이다.FIG. 8b is a flowchart illustrating a method for checking attribute information of content according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 811 동작에서, 음성 명령의 분석 결과가 컨텐트 재생을 의도함을 확인할 수 있다. 서버(108)는, 813 동작에서, 키워드를 확인할 수 있다. 예를 들어, 서버(108)는, "바나나 파파 틀어줘"의 음성 명령에 대한 자연어 이해 결과에 기반하여, 음성 명령의 키워드가 "바나나 파파"이며, 음성 명령의 의도가 "컨텐트 재생"임을 확인할 수 있다. 서버(108)는, 815 동작에서, 키워드에 대응하는 적어도 하나의 속성 정보를 문의하기 위한 프롬프팅 정보를, LLM(large language model)을 관리하는 엔티티에 제공할 수 있다. LLM을 관리하는 엔티티는, 예를 들어 서버(108)에 포함되도록 구현되거나, 또는 서버(108)와 별개의 엔티티로서 구현될 수도 있으며, 그 구현 방식에는 제한이 없다. 서버(108)는, 817 동작에서, 문의에 대한 응답으로서, LLM을 관리하는 엔티티로부터 키워드에 대응하는 적어도 하나의 속성 정보를 수신할 수 있다. 예를 들어, 표 3은, 일 실시예에 따른 LLM과의 프롬프팅 정보의 예시이다.According to one embodiment, the server (108), in

예를 들어, 표 3은 디폴트 프롬프팅 정보일 수 있으며, 서버(108)는, 표 3의 "OOO"내에 키워드를 삽입하여, LLM을 관리하는 엔티티에 해당 정보를 제공할 수 있다. 서버(108)는, 예를 들어 표 3의 프롬프팅 정보에 대응하는 답변을 수신할 수 있다. 프롬프팅 정보는, 예를 들어, 적어도 하나의 속성 정보(예를 들어, 장르, 아티스트, 타이틀, 저작 정보, 및 심의 정보)을 문의하는 취지의 문장을 포함할 수 있다. 프롬프팅 정보는, 예를 들어 서버(108)에서 추가적인 NLU를 수행하지 않고 처리가능한 형식으로의 답변을 요청하는 취지의 문장을 포함할 수도 있다.For example, Table 3 may be default prompting information, and the server (108) may insert a keyword into "OOO" of Table 3 to provide the corresponding information to the entity managing the LLM. The server (108) may receive a response corresponding to the prompting information of Table 3, for example. The prompting information may include, for example, a sentence that inquires about at least one attribute information (e.g., genre, artist, title, author information, and review information). The prompting information may also include, for example, a sentence that requests a response in a format that can be processed without performing additional NLU on the server (108).
도 9a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 9a is a flowchart illustrating a method for processing a voice command according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 901 동작에서, 음성 명령을 획득할 수 있다. 서버(108)는, 903 동작에서, 컨텐트의 적어도 하나의 속성을 확인할 수 있다. 서버(108)는, 905 동작에서, 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재하는지 여부를 확인할 수 있다. 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재함에 기반하여(905-예), 서버(108)는, 907 동작에서, 확인된 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 상술한 바와 같이, 컨텐트의 적어도 하나의 속성에 대응하는 복수 개의 출력 장치 후보들이 존재하는 것으로 확인됨에 기반하여, 서버(108)는, 사용자 선택, 지정된 규칙, 및/또는 인공지능 추론 결과에 기반하여, 어느 하나의 출력 장치를 선택할 수도 있음을 당업자는 이해할 것이다. 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재함지 않음에 기반하여(905-아니오), 서버(108)는, 909 동작에서, 사용자 음성을 획득한 전자 장치(101)에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 서버(108)는, 전자 장치(101)에, 확인된 컨텐트의 재생을 위한 적어도 하나의 명령을 제공함으로써, 전자 장치(101)로 하여금 컨텐트를 재생하도록 할 수 있다. 여기에서, 전자 장치(101)에 의한 컨텐트 재생은, 전자 장치(101)에 포함된 음향 출력 모듈(155) 및/또는 디스프레이 모듈(160)에 의한 컨텐트 재생을 의미할 뿐만 아니라, 전자 장치(101)에 유선 또는 무선으로 연결된 음향 출력 장치(예를 들어, 유선 이어폰, TWS(ture wireless stereo) 이어폰, 블루투스 기반 스피커일 수 있지만 제한이 없음)에 의한 컨텐트 재생도 의미할 수도 있음을 당업자는 이해할 것이다. 서버(108)는, 전자 장치(101)에 의하여 컨텐트가 재생된 서브 재생 이력을 기존 재생 이력에 추가함으로써, 재생 이력을 업데이트할 수도 있다.According to one embodiment, the server (108) may obtain a voice command at
도 9b는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 9b is a flowchart illustrating a method for processing a voice command according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 921 동작에서, 음성 명령을 획득할 수 있다. 서버(108)는, 923 동작에서, 컨텐트의 적어도 하나의 속성을 확인할 수 있다. 서버(108)는, 925 동작에서, 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재하는지 여부를 확인할 수 있다. 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재함에 기반하여(925-예), 서버(108)는, 927 동작에서, 확인된 출력 장치가 컨텐트 재생이 가능한 상태인지 여부를 확인할 수 있다. 예를 들어, 확인된 출력 장치가, 서버(108)에 연결되어 있지 않은 상태라면(예를 들어, 오프라인 상태라면), 출력 장치로 컨텐트 재생을 위한 데이터가 제공이 불가능할 수 있다. 또는, 확인된 출력 장치가, 현재 다른 컨텐트를 재생 중인 상태라면, 출력 장치로 컨텐트 재생을 위한 데이터가 제공이 불가능할 수도 있다. 한편, 상술한 오프라인 상태, 또는 다른 컨텐트를 재생하는 상태는 단순히 예시적인 것으로, 출력 장치가 컨텐트를 재생할 수 없는 상태의 예시에는 제한이 없다. 확인된 출력 장치가 컨텐트 재생이 가능한 상태임에 기반하여(927-예), 서버(108)는, 929 동작에서, 확인된 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 상술한 바와 같이, 컨텐트의 적어도 하나의 속성에 대응하는 복수 개의 출력 장치 후보들이 존재하는 것으로 확인됨에 기반하여, 서버(108)는, 사용자 선택, 지정된 규칙, 및/또는 인공지능 추론 결과에 기반하여, 어느 하나의 출력 장치를 선택할 수도 있음을 당업자는 이해할 것이다. 확인된 출력 장치가 컨텐트 재생이 가능하지 않은 상태임에 기반하여(927-아니오), 서버(108)는, 931 동작에서, 확인된 출력 장치에 대응하는 다른 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 서버(108)(예를 들어, IoT 서버(240))는, 출력 장치의 배치 위치를 관리할 수 있다. 예를 들어, 확인된 출력 장치가 현재 컨텐트 재생이 가능하지 않은 상태인 경우, 서버(108)는, 확인된 출력 장치와 동일한 공간에 배치되는 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 확인된 출력 장치가 현재 컨텐트 재생이 가능하지 않은 상태인 경우, 서버(108)는, 확인된 출력 장치의 우선 순위에 대한 차순위 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 확인된 출력 장치가 현재 컨텐트 재생이 가능하지 않은 상태인 경우, 서버(108)는, 사용자에게 다른 출력 장치 후보들을 문의할 수 있으며, 이에 대한 사용자 선택에 기반하여 선택된 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재함지 않음에 기반하여(925-아니오), 서버(108)는, 933 동작에서, 사용자 음성을 획득한 전자 장치(101)에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수도 있다.According to one embodiment, the server (108) may obtain a voice command at
도 9c는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 9c is a flowchart illustrating a method for processing a voice command according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 941 동작에서, 음성 명령을 획득할 수 있다. 서버(108)는, 943 동작에서, 컨텐트의 적어도 하나의 속성을 확인할 수 있다. 서버(108)는, 945 동작에서, 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재하는지 여부를 확인할 수 있다. 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재함에 기반하여(945-예), 서버(108)는, 947 동작에서, 확인된 출력 장치가 이미 다른 컨텐트를 재생 중임을 확인할 수 있다. 서버(108)는, 949 동작에서, 확인된 출력 장치가 재생 컨텐트를 변경할 수 있는지 여부를 확인할 수 있다. 예를 들어, 확인된 출력 장치가 재생 컨텐트를 변경 가능한지에 대하여 미리 사용자에 의하여 설정될 수 있다. 예를 들어, 서버(108)는, 추가적으로 사용자에게 재생 컨텐트 변경 여부를 문의할 수 있으며, 이에 대한 응답에 기반하여 확인된 출력 장치가 재생 컨텐트를 변경할 수 있는지 여부를 확인할 수 있다. 확인된 출력 장치가 재생 컨텐트를 변경할 수 있음에 기반하여(949-예), 서버(108)는, 951 동작에서, 확인된 출력 장치에 의한 컨텐트 재생 변경을 위한 적어도 하나의 동작을 수행할 수 있다. 서버(108)는, 예를 들어 기존 컨텐트 재생 중단 및 확인된 컨텐트 재생을 명령하거나, 또는 중단 명령 없이 컨텐트 재생만을 명령할 수도 있다. 확인된 출력 장치가 재생 컨텐트를 변경할 수 없음에 기반하여(949-아니오), 서버(108)는, 953 동작에서, 확인된 출력 장치에 대응하는 다른 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 확인된 출력 장치에 대응하는 다른 출력 장치에 대하여서는, 도 9b를 참조하여 설명하였으므로, 여기에서의 그 설명이 반복되지는 않는다. 컨텐트의 적어도 하나의 속성에 대응하는 재생 이력을 가지는 출력 장치가 존재함지 않음에 기반하여(945-아니오), 서버(108)는, 955 동작에서, 사용자 음성을 획득한 전자 장치(101)에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수도 있다.According to one embodiment, the server (108) may obtain a voice command at
도 10a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다. 도 10a의 실시예는, 도 10b를 참조하여 설명하도록 한다.FIG. 10A is a flowchart illustrating a method for processing a voice command according to one embodiment. The embodiment of FIG. 10A will be described with reference to FIG. 10B.
도 10b는 일 실시예에 따른 컨텐트를 재생하는 엔티티의 변경을 설명하기 위한 도면이다.FIG. 10b is a diagram for explaining a change in an entity that plays content according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 1001 동작에서, 전자 장치(101)로부터 제공되는 음성 명령의 분석 결과가 컨텐트 재생 출력 장치의 변경임을 확인할 수 있다. 예를 들어, 도 10b를 참조하면, 전자 장치(101)는, 제 1 컨텐트(예를 들어, 타이틀: 바나나 파파, 아티스트: 포도도)를 재생할 수 있다. 전자 장치(101)는, 제 1 컨텐트를 재생함을 나타내는 화면(예를 들어, 컨텐트 재생을 위한 어플리케이션 실행 화면일 수 있지만 제한이 없음)(1030)을 제공할 수 있다. 화면(1030)에는, 예를 들어 제 1 컨텐트의 타이틀에 대한 정보(1031) 및/또는 제 1 컨텐트의 아티스트에 대한 정보(1032)가 포함될 수 있으나, 그 구현에는 제한이 없다. 제 1 컨텐트를 재생하는 중, 전자 장치(101)는, 사용자(1041)로부터터의 사용자 음성(1042)을 획득할 수 있다. 예를 들어, 사용자 음성(1042)은, "바나나 파파를 다른 장치로 틀어줘"일 수 있다. 전자 장치(101)는, 사용자 음성(1042)에 대응하는 음성 명령을 음성 명령 처리 서버(200)로 제공할 수 있다. 음성 명령은, 상술한 바와 같이, 사용자 음성(1042)에 대응하는 어쿠스틱 신호, 텍스트, 및/또는 자연어 이해 결과를 포함할 수 있으나, 그 구현 형태에는 제한이 없다. 서버(108)(예를 들어, 음성 처리 서버(200))는, 음성 명령의 의도가 "컨텐트 재생 출력 장치의 변경"이고, 키워드는 "바나나 파파"일 수 있다.According to one embodiment, the server (108) may, in
다시, 도 10a를 참조하면, 서버(108)는, 1003 동작에서, 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인할 수 있다. 서버(108)는, 1005 동작에서, 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인할 수 있다. 서버(108)는, 1007 동작에서, 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 적어도 하나의 출력 장치 중 컨텐트를 재생하기 위한 제 1 출력 장치(251)를 확인할 수 있다. 서버(108)는, 1009 동작에서, 제 1 출력 장치(251)에 의한 컨텐트 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 도 10b의 예시에서는, 서버(108)(예를 들어, IoT 서버(240))가, 제 1 출력 장치(251)로 컨텐트 재생을 야기하는 데이터를 제공할 수 있다. 이 경우, 서버(108)는, 구현에 따라서, 전자 장치(101)에는, 컨텐트의 재생을 중단할 것을 명령할 수도 있다. 한편, 제 1 출력 장치(251)로의 데이터의 제공은 예시적인 것이다. 상술한 바와 같이, 서버(108)는, 전자 장치(101)로, 컨텐트 재생을 위한 데이터의 송신을 야기하는 데이터를 제공할 수도 있으며, 전자 장치(101)는 이에 기반하여 제 1 출력 장치(251)로 컨텐트 재생을 위한 데이터를 송신할 수도 있다. 예를 들어, 제 1 출력 장치(251)는, 해당 컨텐트를 처음부터 재생하도록 구현될 수 있으나, 이는 예시적인 것이다. 제 1 출력 장치(251)는, 예를 들어 해당 컨텐트를 전자 장치(101)가 재생을 중단한 시점부터 재생하도록 구현될 수 있다.Again, referring to FIG. 10A, the server (108) may, at
도 10c는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다.FIG. 10c is a flowchart illustrating a method for processing a voice command according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 1041 동작에서, 전자 장치(101)에서 재생되는 컨텐트에 대한 재생 출력 장치의 변경 이벤트를 확인할 수 있다. 도 10a에서 설명된 음성 명령 내의 재생 출력 장치의 변경 의도의 확인은, 이벤트의 하나의 예시일 수 있다. 예를 들어, 이벤트는, 전자 장치(101)가 지정된 장소에 진입하는 것으로 설정될 수도 있다. 예를 들어, 사용자는, 전자 장치(101)가, 사용자의 집에 진입함에 기반하여, 출력 중인 컨텐트를 다른 출력 장치에 의하여 재생되도록 설정할 수도 있다. 이에 따라, 전자 장치(101)가 지정된 장소에 진입함을 확인함에 기반하여, 이벤트 발생을 서버(108)로 알릴 수도 있다. 한편, 전자 장치(101)에서 재생 중인 컨텐트의 속성 정보에 따라서, 출력 장치가 결정될 수도 있다. 예를 들어, 사용자의 프라이버시 보호의 측면에서, 컨텐트의 속성 정보 중 하나인 심의 등급에 따라서, 출력 장치가 결정될 필요가 있다. 심의 등급이 성인용인 컨텐트는, 청소년이 시청 가능한 출력 장치에서 재생되지 않는 것이 바람직하며, 개인용으로 설정된 출력 장치에서 재생되는 것이 바람직할 수 있다. 서버(108)는, 1043 동작에서, 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인할 수 있다. 서버(108)는, 1045 동작에서, 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인할 수 있다. 서버(108)는, 1047 동작에서, 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 적어도 하나의 출력 장치 중 컨텐트를 재생하기 위한 제 1 출력 장치(251)를 확인할 수 있다. 서버(108)는, 1049 동작에서, 제 1 출력 장치(251)에 의한 컨텐트 재생을 위한 적어도 하나의 동작을 수행할 수 있다.According to one embodiment, the server (108) may, in
도 11a는 일 실시예에 따른 음성 명령을 처리하기 위한 방법을 설명하기 위한 흐름도이다. 도 11a의 실시예는, 도 11b를 참조하여 설명하도록 한다.FIG. 11a is a flowchart illustrating a method for processing a voice command according to one embodiment. The embodiment of FIG. 11a will be described with reference to FIG. 11b.
도 11b는, 일 실시예에 따른 재생 이력을 설명하기 위한 도면이다.FIG. 11b is a drawing for explaining a playback history according to one embodiment.
이하 실시예에서 각 동작들은 순차적으로 수행될 수도 있으나, 반드시 순차적으로 수행되는 것은 아니다. 예를 들어, 각 동작들의 순서가 변경될 수도 있으며, 적어도 두 동작들이 병렬적으로 수행될 수도 있다.In the following embodiments, the operations may be performed sequentially, but are not necessarily performed sequentially. For example, the order of the operations may be changed, and at least two operations may be performed in parallel.
일 실시예에 따라서, 서버(108)는, 1101 동작에서, 음성 명령의 분석 결과가 컨텐트 재생을 의도함을 확인할 수 있다. 서버(108)는, 1103 동작에서, 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보로서의 제 1 심의 등급을 확인할 수 있다. 서버(108)는, 1105 동작에서, 적어도 하나의 출력 장치 중 확인된 제 1 심의 등급과 연관된 재생 이력을 가지는 출력 장치를 확인할 수 있다. 서버(108)는, 1107 동작에서, 확인된 출력 장치에 의한 컨텐트의 재생을 위한 적어도 하나의 동작을 수행할 수 있다. 예를 들어, 서버(108)는, 도 11b에서와 같은 재생 이력(1125)을 관리할 수 있다. 재생 이력(1125)은, 예를 들어 컨텐트의 재생 시각(1131)의 순서에 따라 정렬될 수 있으나, 제한이 없다. 재생 이력(1125)은, 예를 들어 컨텐트의 재생 시각(1131), 키워드(1132), 해당 컨텐트의 적어도 하나의 속성 정보(1133,1134,1135,1136), 해당 컨텐트를 재생한 출력 장치의 식별을 위한 정보(1137), 및/또는 재생 관리 정보(1138)를 포함할 수 있으나, 제한은 없다. 도 3b에서 설명되었던 재생 이력(225a)과 비교하여, 재생 이력(1125)의 컨텐트의 속성 정보에 심의 등급(1136)이 더 포함될 수 있다. 서버(108)는, 예를 들어 서브 재생 이력(1141,1142,1143)의 심의 등급이 "15세"이며, 서브 재생 이력(1144,1145,1146)의 심의 등급이 "18세"임을 확인할 수 있다. 서버(108)는, 예를 들어 "15세"의 심의 등급에 대응하는 서브 재생 이력(1141,1142,1143)에 대응하는 출력 장치가 "모바일" 및 "프로젝터"임을 확인할 수 있다. 서버(108)는, "18세"의 심의 등급에 대응하는 서브 재생 이력(1144,1145,1146)에 대응하는 출력 장치가 "모바일" 및 "내방 TV"임을 확인할 수 있다. 서버(108)는, 예를 들어 "공포 맨션 재생해줘"의 음성 명령을 확인할 수 있다. 서버(108)는, 음성 명령의 키워드가 "공포 맨션"이고, 의도가 "컨텐트 재생"임을 확인할 수 있다. 서버(108)는, "공포 맨션"의 키워드와 연관된 컨텐트의 적어도 하나의 속성 정보를 확인할 수 있다. 예를 들어, "공포 맨션"의 심의 등급이 "18세"임을, 적어도 하나의 속성 정보로서 확인될 수 있다. 서버(108)는, 예를 들어, "공포 맨션"의 심의 등급이 "18세"임에 기반하여, "18세"의 심의 등급을 가지는 서브 재생 이력(1144,1145,1146)을 참조할 수 있다. 서버(108)는, 서브 재생 이력(1144,1145,1146)의 출력 장치인 "모바일" 및 "내방 TV"를 출력 장치의 후보들로서 확인할 수 있다. 예를 들어, 서버(108)는, 지정된 규칙(예를 들어, 컨텐트 재생 변경 이후의 장치에 더 높은 우선 순위를 부여하는 규칙)에 기반하여, 후보들 중 "내방 TV"를 출력 장치로서 확인할 수 있다. 하나의 예에서, 서버(108)는, "심의 등급"의 속성 정보에 다른 속성 정보보다 더 높은 우선 순위를 부여(또는, 관리)할 수 있다. 예를 들어, 서버(108)는, 일차적으로 "심의 등급"에 기반하여 출력 장치를 선택할 수 있으며, "심의 등급"에 기반하여 출력 장치가 확인되지 않거나, 및/또는 복수 개의 출력 장치가 확인되는 경우에 다른 속성 정보에 기반하여 출력 장치를 선택하도록 설정될 수도 있으나, 이는 예시적인 것이다. 서버(108)는, 예를 들어 "심의 등급"이 아닌 다른 속성 정보에 상대적으로 높은 우선 순위를 부여할 수도 있다. 또는, 서버(108)는, 각 속성 정보 별로 가중치를 부여하며, 확인된 컨텐트의 속성 정보들 및 재생 이력 내의 속성 정보들의 대응 여부에 기반한 확인되는 가중치 합에 기반하여 출력 장치를 선택하도록 설정될 수도 있다. 이 경우, 속성 정보들의 우선 순위에 기반하여 속성 정보들 각각에 대응하는 가중치들도 결정될 수도 있으나, 제한은 없다. 또는, 서버(108)는, "심의 등급"이 "18세"인 컨텐트가 재생되기 이전에는, 해당 컨텐트를 확인된 출력 장치를 통하여 재생할 지 여부를 사용자에게 문의할 수 있다. 문의 결과에 대한 응답이 긍정적인 경우에, 서버(108)는, 확인된 출력 장치에 의한 컨텐트 재생을 위한 적어도 하나의 동작을 수행하도록 설정될 수도 있다.According to one embodiment, the server (108) may, in
예를 들어, 서버(108)는, 공용 출력 장치 및 개인용 출력 장치를 구별하여 관리할 수도 있다. 서버(108)는, 컨텐트의 심의 등급이 지정된 등급(예를 들어, 성인용)인 경우에는 개인용 출력 장치를 선택하고, 컨텐트의 심의 등급이 지정된 등급이 아닌 경우에는 공용 출력 장치를 선택할 수도 있다. 공용 출력 장치 및 개인용 출력 장치는, 예를 들어 사용자 설정에 따라 구분 관리되거나, 그 배치위치에 대한 분석 결과에 기반하여 구분 관리될 수도 있음을 당업자는 이해할 것이다.For example, the server (108) may manage public output devices and personal output devices separately. The server (108) may select a personal output device when the content has a designated rating (e.g., adult), and may select a public output device when the content has a non-designated rating. Those skilled in the art will understand that the public output devices and personal output devices may be managed separately, for example, based on user settings or based on analysis results of their placement locations.
일 실시예에 따라서, 음성 명령을 처리하는 방법이 제공될 수 있다. 상기 방법은, 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a method for processing a voice command may be provided. The method may include an operation of confirming that an analysis result of the voice command is intended for content playback. The method may include an operation of confirming at least one attribute information of content associated with the voice command. The method may include an operation of confirming at least one output device capable of reproducing the content. The method may include an operation of confirming a first output device for reproducing the content among the at least one output device based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device. The method may include an operation of performing at least one operation for reproducing the content by the first output device.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 재생 이력의 적어도 일부에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 출력 장치가 재생한 적어도 하나의 제 1 컨텐트 및 상기 적어도 하나의 제 1 컨텐트 각각에 대응하는 적어도 하나의 제 1 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 적어도 하나의 제 1 속성 정보의 적어도 일부와, 상기 컨텐트의 상기 적어도 하나의 속성 정보 중 적어도 일부가 동일함에 기반하여, 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying, based on at least a portion of the reproduction history, at least one first content reproduced by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content. The operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying the first output device as an output device for reproducing the content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical.
일 실시예에 따라서, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작은, 상기 제 1 출력 장치로, 상기 컨텐트의 재생을 야기하도록 하는 제 1 데이터를 제공하는 동작을 포함할 수 있다.According to one embodiment, the act of performing at least one operation for reproduction of the content by the first output device may include the act of providing, to the first output device, first data that causes reproduction of the content.
일 실시예에 따라서, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작은, 상기 제 1 출력 장치와 통신이 가능한 외부 전자 장치로, 상기 컨텐트의 재생을 위한 데이터의 송신을 야기하도록 하는 제 2 데이터를 제공하는 동작을 포함할 수 있다.According to one embodiment, the act of performing at least one operation for reproduction of the content by the first output device may include the act of providing second data to an external electronic device capable of communicating with the first output device, the second data causing transmission of data for reproduction of the content.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보의 적어도 일부 및 상기 재생 이력의 적어도 일부에 기반하여, 복수 개의 출력 장치의 후보들을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 복수 개의 출력 장치들 중 상기 제 1 출력 장치에 대한 사용자의 선택에 대한 정보를 확인함에 기반하여, 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device for reproducing the content among the at least one output device may include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and at least a portion of the reproduction history. The operation of identifying a first output device for reproducing the content among the at least one output device may include identifying the first output device as an output device for reproducing the content based on identifying information about a user's selection of the first output device among the plurality of output devices.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보의 적어도 일부 및 상기 재생 이력에 기반하여, 복수 개의 출력 장치의 후보들을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 적어도 하나의 규칙 및/또는 인공지능 모델에 기반하여, 상기 복수 개의 출력 장치들 중 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for reproducing the content may include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and the reproduction history. The operation of identifying a first output device among the at least one output device for reproducing the content may include identifying the first output device among the plurality of output devices as an output device for reproducing the content based on at least one rule and/or an artificial intelligence model.
일 실시예에 따라서, 상기 컨텐트의 적어도 하나의 속성 정보는, 상기 컨텐트의 장르, 상기 컨텐트의 타이틀, 상기 컨텐트의 심의 등급, 상기 컨텐트의 저작 정보, 및/또는 상기 컨텐트의 아티스트 관련 정보를 포함할 수 있다.According to one embodiment, at least one attribute information of the content may include a genre of the content, a title of the content, a review rating of the content, authorship information of the content, and/or artist-related information of the content.
일 실시예에 따라서, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보를 NER(named entity recognition)을 지원하는 엔티티에 문의하는 동작을 포함할 수 있다. 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 NER을 지원하는 엔티티로부터 제공되는 상기 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of verifying at least one attribute information of the content associated with the voice command may include an operation of inquiring about the at least one attribute information of the content to an entity supporting named entity recognition (NER). The operation of verifying the at least one attribute information of the content associated with the voice command may include an operation of verifying the at least one attribute information provided from an entity supporting NER.
일 실시예에 따라서, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보를 문의하기 위한 프롬프팅 정보를, 거대 언어 모델(large language model: LLM)을 관리하는 엔티티에 제공하는 동작을 포함할 수 있다. 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 LLM을 관리하는 엔티티로부터 제공되는 상기 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of verifying at least one attribute information of the content associated with the voice command may include the operation of providing prompting information for inquiring about the at least one attribute information of the content to an entity managing a large language model (LLM). The operation of verifying at least one attribute information of the content associated with the voice command may include the operation of verifying the at least one attribute information provided from the entity managing the LLM.
일 실시예에 따라서, 상기 방법은, 상기 적어도 하나의 출력 장치를 관리하는 엔티티로부터, 상기 적어도 하나의 출력 장치를 식별하기 위한 정보 및/또는 상기 적어도 하나의 출력 장치의 상기 재생 이력을 수신하는 동작을 더 포함할 수 있다. 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작은, 상기 적어도 하나의 출력 장치를 식별하기 위한 정보에 기반하여, 상기 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다.According to one embodiment, the method may further include receiving, from an entity managing the at least one output device, information for identifying the at least one output device and/or the playback history of the at least one output device. The operation of identifying the at least one output device capable of playing the content may include identifying the at least one output device based on the information for identifying the at least one output device.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 재생 이력의 적어도 일부에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 출력 장치와 상이한 제 2 출력 장치가 재생한 적어도 하나의 제 2 컨텐트 및 상기 적어도 하나의 제 2 컨텐트 각각에 대응하는 적어도 하나의 제 2 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 적어도 하나의 제 2 속성 정보의 적어도 일부와, 상기 컨텐트의 상기 적어도 하나의 속성 정보 중 적어도 일부가 동일함에 기반하여, 상기 제 2 출력 장치가 상기 컨텐트를 재생 가능한지 여부를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 제 2 출력 장치가 상기 컨텐트를 재생 불가능함을 확인함에 기반하여, 상기 제 2 출력 장치에 대응하는 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying, based on at least a portion of the reproduction history, at least one second content reproduced by a second output device, different from the first output device among the at least one output device, and at least one second attribute information corresponding to each of the at least one second content. The operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying whether the second output device can reproduce the content based on the identity of at least a portion of the at least one second attribute information and at least a portion of the at least one attribute information of the content. The operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying the first output device corresponding to the second output device as an output device for reproducing the content based on the identification that the second output device cannot reproduce the content.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 출력 장치가 재생한 적어도 하나의 제 1 컨텐트 및 상기 적어도 하나의 제 1 컨텐트 각각에 대응하는 적어도 하나의 제 1 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 적어도 하나의 제 1 속성 정보의 적어도 일부와, 상기 컨텐트의 상기 적어도 하나의 속성 정보 중 적어도 일부가 동일함에 기반하여, 상기 제 1 출력 장치가 다른 컨텐트를 재생 중인지 여부를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 제 1 출력 장치가 상기 다른 컨텐트를 재생 중인 것을 확인함에 기반하여, 상기 제 1 출력 장치가 상기 다른 컨텐트의 재생을 중단하고 상기 컨텐트를 재생할 수 있는지 여부를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 제 1 출력 장치가 상기 다른 컨텐트의 재생을 중단하고 상기 컨텐트를 재생할 수 있는 것으로 확인됨에 기반하여, 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for playing back the content may include an operation of identifying, based on the playback history, at least one first content played back by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content. The operation of identifying a first output device among the at least one output device for playing back the content may include an operation of identifying whether the first output device is playing back other content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical. The operation of identifying a first output device among the at least one output device for playing back the content may include an operation of identifying, based on identifying that the first output device is playing back the other content, whether the first output device can stop playing back the other content and play back the content. The operation of identifying a first output device for reproducing the content among the at least one output device may include an operation of identifying the first output device as an output device for reproducing the content based on determining that the first output device can stop reproducing the other content and reproduce the content.
일 실시예에 따라서, 컴퓨터로 독출 가능한 적어도 하나의 인스트럭션을 저장하는 저장 매체가 제공될 수 있다. 상기 적어도 하나의 인스트럭션은 전자 장치의 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a storage medium storing at least one computer-readable instruction may be provided. The at least one instruction, when executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command is intended to play back content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content. The at least one operation may include an operation of determining at least one output device capable of playing back the content. The at least one operation may include an operation of determining a first output device for playing back the content, based on at least a portion of the at least one attribute information of the content and a playback history of at least a portion of the at least one output device. The at least one operation may include performing at least one operation for reproduction of the content by the first output device.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 재생 이력의 적어도 일부에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 출력 장치가 재생한 적어도 하나의 제 1 컨텐트 및 상기 적어도 하나의 제 1 컨텐트 각각에 대응하는 적어도 하나의 제 1 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 적어도 하나의 제 1 속성 정보의 적어도 일부와, 상기 컨텐트의 상기 적어도 하나의 속성 정보 중 적어도 일부가 동일함에 기반하여, 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying, based on at least a portion of the reproduction history, at least one first content reproduced by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content. The operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying the first output device as an output device for reproducing the content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical.
일 실시예에 따라서, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작은, 상기 제 1 출력 장치로, 상기 컨텐트의 재생을 야기하도록 하는 제 1 데이터를 제공하는 동작을 포함할 수 있다.According to one embodiment, the act of performing at least one operation for reproduction of the content by the first output device may include the act of providing, to the first output device, first data that causes reproduction of the content.
일 실시예에 따라서, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작은, 상기 제 1 출력 장치와 통신이 가능한 외부 전자 장치로, 상기 컨텐트의 재생을 위한 데이터의 송신을 야기하도록 하는 제 2 데이터를 제공하는 동작을 포함할 수 있다.According to one embodiment, the act of performing at least one operation for reproduction of the content by the first output device may include the act of providing second data to an external electronic device capable of communicating with the first output device, the second data causing transmission of data for reproduction of the content.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보의 적어도 일부 및 상기 재생 이력의 적어도 일부에 기반하여, 복수 개의 출력 장치의 후보들을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 복수 개의 출력 장치들 중 상기 제 1 출력 장치에 대한 사용자의 선택에 대한 정보를 확인함에 기반하여, 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device for reproducing the content among the at least one output device may include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and at least a portion of the reproduction history. The operation of identifying a first output device for reproducing the content among the at least one output device may include identifying the first output device as an output device for reproducing the content based on identifying information about a user's selection of the first output device among the plurality of output devices.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보의 적어도 일부 및 상기 재생 이력에 기반하여, 복수 개의 출력 장치의 후보들을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 적어도 하나의 규칙 및/또는 인공지능 모델에 기반하여, 상기 복수 개의 출력 장치들 중 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for reproducing the content may include identifying candidates of a plurality of output devices based on at least a portion of the at least one attribute information of the content and the reproduction history. The operation of identifying a first output device among the at least one output device for reproducing the content may include identifying the first output device among the plurality of output devices as an output device for reproducing the content based on at least one rule and/or an artificial intelligence model.
일 실시예에 따라서, 상기 컨텐트의 적어도 하나의 속성 정보는, 상기 컨텐트의 장르, 상기 컨텐트의 타이틀, 상기 컨텐트의 심의 등급, 상기 컨텐트의 저작 정보, 및/또는 상기 컨텐트의 아티스트 관련 정보를 포함할 수 있다.According to one embodiment, at least one attribute information of the content may include a genre of the content, a title of the content, a review rating of the content, authorship information of the content, and/or artist-related information of the content.
일 실시예에 따라서, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보를 NER을 지원하는 엔티티에 문의하는 동작을 포함할 수 있다. 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 NER을 지원하는 엔티티로부터 제공되는 상기 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of verifying at least one attribute information of the content associated with the voice command may include an operation of inquiring about the at least one attribute information of the content to an entity supporting NER. The operation of verifying at least one attribute information of the content associated with the voice command may include an operation of verifying the at least one attribute information provided from the entity supporting NER.
일 실시예에 따라서, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 컨텐트의 상기 적어도 하나의 속성 정보를 문의하기 위한 프롬프팅 정보를, LLM을 관리하는 엔티티에 제공하는 동작을 포함할 수 있다. 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작은, 상기 LLM을 관리하는 엔티티로부터 제공되는 상기 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of verifying at least one attribute information of the content associated with the voice command may include the operation of providing prompting information for inquiring about the at least one attribute information of the content to an entity managing an LLM. The operation of verifying at least one attribute information of the content associated with the voice command may include the operation of verifying the at least one attribute information provided from the entity managing the LLM.
일 실시예에 따라서, 상기 적어도 하나의 동작은, 상기 적어도 하나의 출력 장치를 관리하는 엔티티로부터, 상기 적어도 하나의 출력 장치를 식별하기 위한 정보 및/또는 상기 적어도 하나의 출력 장치의 상기 재생 이력을 수신하는 동작을 더 포함할 수 있다. 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작은, 상기 적어도 하나의 출력 장치를 식별하기 위한 정보에 기반하여, 상기 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다.According to one embodiment, the at least one operation may further include receiving, from an entity managing the at least one output device, information for identifying the at least one output device and/or the playback history of the at least one output device. The operation of identifying the at least one output device capable of playing the content may include identifying the at least one output device based on the information for identifying the at least one output device.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 재생 이력의 적어도 일부에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 출력 장치와 상이한 제 2 출력 장치가 재생한 적어도 하나의 제 2 컨텐트 및 상기 적어도 하나의 제 2 컨텐트 각각에 대응하는 적어도 하나의 제 2 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 적어도 하나의 제 2 속성 정보의 적어도 일부와, 상기 컨텐트의 상기 적어도 하나의 속성 정보 중 적어도 일부가 동일함에 기반하여, 상기 제 2 출력 장치가 상기 컨텐트를 재생 가능한지 여부를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 제 2 출력 장치가 상기 컨텐트를 재생 불가능함을 확인함에 기반하여, 상기 제 2 출력 장치에 대응하는 상기 제 1 출력 장치 를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying, based on at least a portion of the reproduction history, at least one second content reproduced by a second output device, different from the first output device among the at least one output device, and at least one second attribute information corresponding to each of the at least one second content. The operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying whether the second output device can reproduce the content based on the identity of at least a portion of the at least one second attribute information and at least a portion of the at least one attribute information of the content. The operation of identifying a first output device among the at least one output device for reproducing the content may include an operation of identifying the first output device corresponding to the second output device as an output device for reproducing the content based on the identification that the second output device cannot reproduce the content.
일 실시예에 따라서, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 출력 장치가 재생한 적어도 하나의 제 1 컨텐트 및 상기 적어도 하나의 제 1 컨텐트 각각에 대응하는 적어도 하나의 제 1 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 적어도 하나의 제 1 속성 정보의 적어도 일부와, 상기 컨텐트의 상기 적어도 하나의 속성 정보 중 적어도 일부가 동일함에 기반하여, 상기 제 1 출력 장치가 다른 컨텐트를 재생 중인지 여부를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 제 1 출력 장치가 상기 다른 컨텐트를 재생 중인 것을 확인함에 기반하여, 상기 제 1 출력 장치가 상기 다른 컨텐트의 재생을 중단하고 상기 컨텐트를 재생할 수 있는지 여부를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작은, 상기 제 1 출력 장치가 상기 다른 컨텐트의 재생을 중단하고 상기 컨텐트를 재생할 수 있는 것으로 확인됨에 기반하여, 상기 제 1 출력 장치를 상기 컨텐트를 재생하기 위한 출력 장치로서 확인하는 동작을 포함할 수 있다.According to one embodiment, the operation of identifying a first output device among the at least one output device for playing back the content may include an operation of identifying, based on the playback history, at least one first content played back by the first output device among the at least one output device and at least one first attribute information corresponding to each of the at least one first content. The operation of identifying a first output device among the at least one output device for playing back the content may include an operation of identifying whether the first output device is playing back other content based on at least a portion of the at least one first attribute information and at least a portion of the at least one attribute information of the content being identical. The operation of identifying a first output device among the at least one output device for playing back the content may include an operation of identifying, based on identifying that the first output device is playing back the other content, whether the first output device can stop playing back the other content and play back the content. The operation of identifying a first output device for reproducing the content among the at least one output device may include an operation of identifying the first output device as an output device for reproducing the content based on determining that the first output device can stop reproducing the other content and reproduce the content.
일 실시예에 따라서, 전자 장치는, 적어도 하나의 인스트럭션을 저장하는 메모리를 포함할 수 있다. 전자 장치는, 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들을 포함할 수 있다. 상기 적어도 하나의 인스트럭션은 상기 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령의 분석 결과가 컨텐트 재생을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 출력 장치에 의한 상기 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, an electronic device may include a memory storing at least one instruction. The electronic device may include one or more processors, including processing circuitry. The at least one instruction, when executed by the one or more processors, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command is intended to play back content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command, based on determining that the analysis result of the voice command is intended to play back content. The at least one operation may include an operation of determining at least one output device capable of playing back the content. The at least one operation may include an operation of identifying a first output device for playing back the content among the at least one output device, based on at least a portion of at least one attribute information of the content and a playback history of at least a portion of the at least one output device. The at least one operation may include an operation of performing at least one operation for playing back the content by the first output device.
일 실시예에 따라서, 음성 명령을 처리하는 방법이 제공될 수 있다. 상기 방법은, 제 1 컨텐트를 재생하는 전자 장치에 의하여 제공되는 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 제 1 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 제 1 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 방법은, 상기 전자 장치에 의한 상기 제 1 컨텐트의 재생의 중단 및 상기 제 1 출력 장치에 의한 상기 제 1 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a method for processing a voice command may be provided. The method may include an operation of confirming that an analysis result of a voice command provided by an electronic device reproducing first content is intended to change a playback device of the first content. The method may include an operation of confirming at least one attribute information of content associated with the voice command based on the confirmation that the analysis result of the voice command is intended to change a playback device of the first content. The method may include an operation of confirming at least one output device capable of reproducing the first content. The method may include an operation of confirming a first output device for reproducing the first content among the at least one output device based on at least a part of the at least one attribute information of the first content and a playback history of at least a part of the at least one output device. The method may include an operation of performing at least one operation for stopping playback of the first content by the electronic device and reproducing the first content by the first output device.
일 실시예에 따라서, 컴퓨터로 독출 가능한 적어도 하나의 인스트럭션을 저장하는 저장 매체가 제공될 수 있다. 상기 적어도 하나의 인스트럭션은 전자 장치의 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 제 1 컨텐트를 재생하는 전자 장치에 의하여 제공되는 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 전자 장치에 의한 상기 제 1 컨텐트의 재생의 중단 및 상기 제 1 출력 장치에 의한 상기 제 1 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, a storage medium storing at least one computer-readable instruction may be provided. The at least one instruction, when executed by one or more processors including processing circuitry of the electronic device, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command provided by the electronic device reproducing first content is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one output device capable of reproducing the first content. The at least one operation may include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device. The at least one operation may include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
일 실시예에 따라서, 전자 장치는, 적어도 하나의 인스트럭션을 저장하는 메모리를 포함할 수 있다. 전자 장치는, 프로세싱 회로(processing circuitry)를 포함하는, 하나 또는 이상의 프로세서들을 포함할 수 있다. 상기 적어도 하나의 인스트럭션은 상기 하나 또는 이상의 프로세서들에 의하여 실행 시에, 상기 전자 장치로 하여금 적어도 하나의 동작을 수행하도록 야기할 수 있다. 상기 적어도 하나의 동작은, 제 1 컨텐트를 재생하는 전자 장치에 의하여 제공되는 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 음성 명령의 분석 결과가 상기 제 1 컨텐트의 재생 장치의 변경을 의도한 것을 확인함에 기반하여, 상기 음성 명령과 연관된 컨텐트의 적어도 하나의 속성 정보를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트를 재생할 수 있는 적어도 하나의 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 제 1 컨텐트의 적어도 하나의 속성 정보의 적어도 일부 및 상기 적어도 하나의 출력 장치 중 적어도 일부의 재생 이력에 기반하여, 상기 적어도 하나의 출력 장치 중 상기 제 1 컨텐트를 재생하기 위한 제 1 출력 장치를 확인하는 동작을 포함할 수 있다. 상기 적어도 하나의 동작은, 상기 전자 장치에 의한 상기 제 1 컨텐트의 재생의 중단 및 상기 제 1 출력 장치에 의한 상기 제 1 컨텐트의 재생을 위한 적어도 하나의 동작을 수행하는 동작을 포함할 수 있다.According to one embodiment, an electronic device may include a memory storing at least one instruction. The electronic device may include one or more processors, including processing circuitry. The at least one instruction, when executed by the one or more processors, may cause the electronic device to perform at least one operation. The at least one operation may include an operation of determining that an analysis result of a voice command provided by an electronic device reproducing a first content is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one attribute information of content associated with the voice command based on determining that the analysis result of the voice command is intended to change a playback device of the first content. The at least one operation may include an operation of determining at least one output device capable of reproducing the first content. The at least one operation may include an operation of identifying a first output device for playing back the first content among the at least one output device based on at least a portion of at least one attribute information of the first content and a playback history of at least a portion of the at least one output device. The at least one operation may include an operation of stopping playback of the first content by the electronic device and performing at least one operation for playing back the first content by the first output device.
본 문서에 개시된 일 실시예들에 따른 전자 장치는 다양한 형태의 장치가 될 수 있다. 전자 장치는, 예를 들면, 휴대용 통신 장치(예: 스마트폰), 컴퓨터 장치, 휴대용 멀티미디어 장치, 휴대용 의료 기기, 카메라, 웨어러블 장치, 또는 가전 장치를 포함할 수 있다. 본 문서의 실시예에 따른 전자 장치는 전술한 기기들에 한정되지 않는다.The electronic device according to the embodiments disclosed in this document may be a variety of devices. The electronic device may include, for example, a portable communication device (e.g., a smartphone), a computer device, a portable multimedia device, a portable medical device, a camera, a wearable device, or a home appliance device. The electronic device according to the embodiments of this document is not limited to the above-described devices.
본 문서의 일 실시예들 및 이에 사용된 용어들은 본 문서에 기재된 기술적 특징들을 특정한 실시예들로 한정하려는 것이 아니며, 해당 실시예의 다양한 변경, 균등물, 또는 대체물을 포함하는 것으로 이해되어야 한다. 도면의 설명과 관련하여, 유사한 또는 관련된 구성요소에 대해서는 유사한 참조 부호가 사용될 수 있다. 아이템에 대응하는 명사의 단수 형은 관련된 문맥상 명백하게 다르게 지시하지 않는 한, 상기 아이템 한 개 또는 복수 개를 포함할 수 있다. 본 문서에서, "A 또는 B", "A 및 B 중 적어도 하나", "A 또는 B 중 적어도 하나", "A, B 또는 C", "A, B 및 C 중 적어도 하나", 및 "A, B, 또는 C 중 적어도 하나"와 같은 문구들 각각은 그 문구들 중 해당하는 문구에 함께 나열된 항목들 중 어느 하나, 또는 그들의 모든 가능한 조합을 포함할 수 있다. "제 1", "제 2", 또는 "첫째" 또는 "둘째"와 같은 용어들은 단순히 해당 구성요소를 다른 해당 구성요소와 구분하기 위해 사용될 수 있으며, 해당 구성요소들을 다른 측면(예: 중요성 또는 순서)에서 한정하지 않는다. 어떤(예: 제 1) 구성요소가 다른(예: 제 2) 구성요소에, "기능적으로" 또는 "통신적으로"라는 용어와 함께 또는 이런 용어 없이, "커플드" 또는 "커넥티드"라고 언급된 경우, 그것은 상기 어떤 구성요소가 상기 다른 구성요소에 직접적으로(예: 유선으로), 무선으로, 또는 제 3 구성요소를 통하여 연결될 수 있다는 것을 의미한다.The embodiments of this document and the terminology used herein are not intended to limit the technical features described in this document to specific embodiments, but should be understood to include various modifications, equivalents, or substitutes of the embodiments. In connection with the description of the drawings, similar reference numerals may be used for similar or related components. The singular form of a noun corresponding to an item may include one or more of the items, unless the context clearly dictates otherwise. In this document, each of the phrases "A or B", "at least one of A and B", "at least one of A or B", "A, B, or C", "at least one of A, B, and C", and "at least one of A, B, or C" can include any one of the items listed together in the corresponding phrase, or all possible combinations thereof. Terms such as "first", "second", or "first" or "second" may be used merely to distinguish one component from another, and do not limit the components in any other respect (e.g., importance or order). When a component (e.g., a first) is referred to as "coupled" or "connected" to another (e.g., a second) component, with or without the terms "functionally" or "communicatively," it means that the component can be connected to the other component directly (e.g., wired), wirelessly, or through a third component.
본 문서의 일 실시예들에서 사용된 용어 "모듈"은 하드웨어, 소프트웨어 또는 펌웨어로 구현된 유닛을 포함할 수 있으며, 예를 들면, 로직, 논리 블록, 부품, 또는 회로와 같은 용어와 상호 호환적으로 사용될 수 있다. 모듈은, 일체로 구성된 부품 또는 하나 또는 그 이상의 기능을 수행하는, 상기 부품의 최소 단위 또는 그 일부가 될 수 있다. 예를 들면, 일실시예에 따르면, 모듈은 ASIC(application-specific integrated circuit)의 형태로 구현될 수 있다.The term "module" used in the embodiments of this document may include a unit implemented in hardware, software or firmware, and may be used interchangeably with terms such as logic, logic block, component, or circuit, for example. A module may be an integrally configured component or a minimum unit of the component or a part thereof that performs one or more functions. For example, according to one embodiment, a module may be implemented in the form of an application-specific integrated circuit (ASIC).
본 문서의 일 실시예들은 기기(machine)(예: 전자 장치(101)) 의해 읽을 수 있는 저장 매체(storage medium)(예: 내장 메모리(136) 또는 외장 메모리(138))에 저장된 하나 이상의 명령어들을 포함하는 소프트웨어(예: 프로그램(140))로서 구현될 수 있다. 예를 들면, 기기(예: 전자 장치(101))의 프로세서(예: 프로세서(120))는, 저장 매체로부터 저장된 하나 이상의 명령어들 중 적어도 하나의 명령을 호출하고, 그것을 실행할 수 있다. 이것은 기기가 상기 호출된 적어도 하나의 명령어에 따라 적어도 하나의 기능을 수행하도록 운영되는 것을 가능하게 한다. 상기 하나 이상의 명령어들은 컴파일러에 의해 생성된 코드 또는 인터프리터에 의해 실행될 수 있는 코드를 포함할 수 있다. 기기로 읽을 수 있는 저장 매체는, 비일시적(non-transitory) 저장 매체의 형태로 제공될 수 있다. 여기서, '비일시적'은 저장 매체가 실재(tangible)하는 장치이고, 신호(signal)(예: 전자기파)를 포함하지 않는다는 것을 의미할 뿐이며, 이 용어는 데이터가 저장 매체에 반영구적으로 저장되는 경우와 임시적으로 저장되는 경우를 구분하지 않는다.One embodiment of the present document may be implemented as software (e.g., a program (140)) including one or more instructions stored in a storage medium (e.g., an internal memory (136) or an external memory (138)) readable by a machine (e.g., an electronic device (101)). For example, a processor (e.g., a processor (120)) of the machine (e.g., the electronic device (101)) may call at least one instruction among the one or more instructions stored from the storage medium and execute it. This enables the machine to operate to perform at least one function according to the at least one called instruction. The one or more instructions may include code generated by a compiler or code executable by an interpreter. The machine-readable storage medium may be provided in the form of a non-transitory storage medium. Here, 'non-transitory' simply means that the storage medium is a tangible device and does not contain signals (e.g. electromagnetic waves), and the term does not distinguish between cases where data is stored semi-permanently or temporarily on the storage medium.
일 실시예에 따르면, 본 문서에 개시된 일 실시예들에 따른 방법은 컴퓨터 프로그램 제품(computer program product)에 포함되어 제공될 수 있다. 컴퓨터 프로그램 제품은 상품으로서 판매자 및 구매자 간에 거래될 수 있다. 컴퓨터 프로그램 제품은 기기로 읽을 수 있는 저장 매체(예: compact disc read only memory(CD-ROM))의 형태로 배포되거나, 또는 어플리케이션 스토어(예: 플레이 스토어TM)를 통해 또는 두 개의 사용자 장치들(예: 스마트 폰들) 간에 직접, 온라인으로 배포(예: 다운로드 또는 업로드)될 수 있다. 온라인 배포의 경우에, 컴퓨터 프로그램 제품의 적어도 일부는 제조사의 서버, 어플리케이션 스토어의 서버, 또는 중계 서버의 메모리와 같은 기기로 읽을 수 있는 저장 매체에 적어도 일시 저장되거나, 임시적으로 생성될 수 있다.According to one embodiment, the method according to one embodiment disclosed in the present document may be provided as included in a computer program product. The computer program product may be traded between a seller and a buyer as a commodity. The computer program product may be distributed in the form of a machine-readable storage medium (e.g., a compact disc read only memory (CD-ROM)), or may be distributed online (e.g., downloaded or uploaded) via an application store (e.g., Play StoreTM) or directly between two user devices (e.g., smart phones). In the case of online distribution, at least a part of the computer program product may be at least temporarily stored or temporarily generated in a machine-readable storage medium, such as a memory of a manufacturer's server, a server of an application store, or an intermediary server.
일 실시예들에 따르면, 상기 기술한 구성요소들의 각각의 구성요소(예: 모듈 또는 프로그램)는 단수 또는 복수의 개체들을 포함할 수 있으며, 복수의 개체들 중 일부는 다른 구성요소에 분리 배치될 수도 있다. 일 실시예들에 따르면, 전술한 해당 구성요소들 중 하나 이상의 구성요소들 또는 동작들이 생략되거나, 또는 하나 이상의 다른 구성요소들 또는 동작들이 추가될 수 있다. 대체적으로 또는 추가적으로, 복수의 구성요소들(예: 모듈 또는 프로그램)은 하나의 구성요소로 통합될 수 있다. 이런 경우, 통합된 구성요소는 상기 복수의 구성요소들 각각의 구성요소의 하나 이상의 기능들을 상기 통합 이전에 상기 복수의 구성요소들 중 해당 구성요소에 의해 수행되는 것과 동일 또는 유사하게 수행할 수 있다. 일 실시예들에 따르면, 모듈, 프로그램 또는 다른 구성요소에 의해 수행되는 동작들은 순차적으로, 병렬적으로, 반복적으로, 또는 휴리스틱하게 실행되거나, 상기 동작들 중 하나 이상이 다른 순서로 실행되거나, 생략되거나, 또는 하나 이상의 다른 동작들이 추가될 수 있다.According to one embodiment, each component (e.g., a module or a program) of the above-described components may include one or more entities, and some of the entities may be separated and arranged in another component. According to one embodiment, one or more of the components or operations of the above-described components may be omitted, or one or more other components or operations may be added. Alternatively or additionally, the plurality of components (e.g., a module or a program) may be integrated into one component. In this case, the integrated component may perform one or more functions of each of the components of the plurality of components identically or similarly to those performed by the corresponding component of the plurality of components before the integration. According to one embodiment, the operations performed by the module, the program, or another component may be executed sequentially, in parallel, repeatedly, or heuristically, or one or more of the operations may be executed in a different order, omitted, or one or more other operations may be added.
Claims (15)
Translated fromKoreanApplications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2023-0176172 | 2023-12-07 | ||
| KR20230176172 | 2023-12-07 | ||
| KR10-2023-0187327 | 2023-12-20 | ||
| KR1020230187327AKR20250087394A (en) | 2023-12-07 | 2023-12-20 | Method for processing voice command, server and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025121815A1true WO2025121815A1 (en) | 2025-06-12 |
Family
ID=95980234
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/KR2024/019481PendingWO2025121815A1 (en) | 2023-12-07 | 2024-12-02 | Method, server, and storage medium for processing voice command |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2025121815A1 (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101832648B1 (en)* | 2014-10-09 | 2018-02-26 | 구글 엘엘씨 | Hotword detection on multiple devices |
| KR20180133526A (en)* | 2016-06-11 | 2018-12-14 | 애플 인크. | Intelligent device mediation and control |
| KR102095250B1 (en)* | 2016-02-22 | 2020-04-01 | 소노스 인코포레이티드 | Voice control method of media playback system |
| KR102360589B1 (en)* | 2016-06-27 | 2022-02-08 | 아마존 테크놀로지스, 인크. | Systems and methods for routing content to related output devices |
- 2024
- 2024-12-02WOPCT/KR2024/019481patent/WO2025121815A1/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101832648B1 (en)* | 2014-10-09 | 2018-02-26 | 구글 엘엘씨 | Hotword detection on multiple devices |
| KR102095250B1 (en)* | 2016-02-22 | 2020-04-01 | 소노스 인코포레이티드 | Voice control method of media playback system |
| KR102422270B1 (en)* | 2016-02-22 | 2022-07-18 | 소노스 인코포레이티드 | Audio response playback |
| KR20180133526A (en)* | 2016-06-11 | 2018-12-14 | 애플 인크. | Intelligent device mediation and control |
| KR102360589B1 (en)* | 2016-06-27 | 2022-02-08 | 아마존 테크놀로지스, 인크. | Systems and methods for routing content to related output devices |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2020180008A1 (en) | Method for processing plans having multiple end points and electronic device applying the same method | |
| WO2025121815A1 (en) | Method, server, and storage medium for processing voice command | |
| WO2023177079A1 (en) | Server and electronic device for processing user speech on basis of synthetic vector, and operating method thereof | |
| WO2023048379A1 (en) | Server and electronic device for processing user utterance, and operation method thereof | |
| WO2022216059A1 (en) | Electronic device and method for providing personalized audio information | |
| WO2022203374A1 (en) | Method for providing voice assistant service, and electronic device for supporting same | |
| WO2022191395A1 (en) | Apparatus for processing user command, and operating method therefor | |
| WO2025089659A1 (en) | Electronic device and image generation method based on speech data using same | |
| WO2025058316A1 (en) | Method for utilizing voice assistant based on conversation context and electronic device therefor | |
| WO2025150684A1 (en) | Electronic device for summarizing text content according to format and operation method therefor | |
| WO2025058265A1 (en) | Electronic device for processing voice command and operating method thereof | |
| WO2025121752A1 (en) | Electronic device and method for processing user utterance | |
| KR20250087394A (en) | Method for processing voice command, server and storage medium | |
| WO2025058324A1 (en) | Method for providing content according to user intent, and electronic device therefor | |
| WO2025143646A1 (en) | Electronic device, and method for providing user interface for user queries based on category by using same | |
| WO2025080098A1 (en) | Electronic device and method for processing user utterance | |
| WO2025183328A1 (en) | Electronic device for processing user speech, operating method thereof, and computer-readable recording medium | |
| WO2025193001A1 (en) | Method for providing video, electronic device for supporting same, and storage medium | |
| WO2025058408A1 (en) | Method for providing result of user utterance and electronic device therefor | |
| WO2024058597A1 (en) | Electronic device and user utterance processing method | |
| WO2024029850A1 (en) | Method and electronic device for processing user utterance on basis of language model | |
| WO2025127369A1 (en) | Electronic device, method, and computer-readable storage medium for changing style of text | |
| WO2025100783A1 (en) | Method for providing notification and electronic device therefor | |
| WO2025023722A1 (en) | Electronic device and method for processing user utterance | |
| WO2025095359A1 (en) | Electronic device, method, and storage medium for controlling iot device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | Ref document number:24901001 Country of ref document:EP Kind code of ref document:A1 |