WO2022151505A1 - Neural network quantization method and apparatus, and computer-readable storage medium - Google Patents
Neural network quantization method and apparatus, and computer-readable storage mediumDownload PDFInfo
- Publication number
- WO2022151505A1 WO2022151505A1PCT/CN2021/072577CN2021072577WWO2022151505A1WO 2022151505 A1WO2022151505 A1WO 2022151505A1CN 2021072577 WCN2021072577 WCN 2021072577WWO 2022151505 A1WO2022151505 A1WO 2022151505A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- matrix
- bits
- elements
- neural network
- target
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0495—Quantised networks; Sparse networks; Compressed networks
Definitions
- the present applicationrelates to the technical field of neural network quantification, and in particular, to a neural network quantification method, apparatus, and computer-readable storage medium.
- Neural network quantizationrefers to quantizing a full-precision neural network into a low-precision, high-accuracy neural network, so that the low-precision, high-accuracy neural network can be deployed in smartphones, drones, tablet computers, wearable devices, etc. On electronic devices with low power consumption and weak computing power.
- the current neural network quantization algorithmis mainly mixed-bit quantization, that is, the middle layer of the neural network is quantized into low bits, and the input layer and the output layer are quantized into higher bits, so that the number of bits at each level of the quantized neural network is different. , the number of bits at each level of the quantized neural network will lead to difficulties in the design of artificial intelligence chips, high design costs, high power consumption, and low utilization.
- the embodiments of the present applicationprovide a neural network quantification method, device, and computer-readable storage medium, which aim to reduce the amount of computation for running the neural network and reduce the design complexity of chips required for running the neural network.
- an embodiment of the present applicationprovides a neural network quantization method, including:
- the target neural networkincludes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer;
- the first activation matrix and the first weight matrix of the input layerare quantized, so that the elements in the quantized first activation matrix and the first weight matrix are represented by the binary number of the target number of bits;
- the second activation matrix and the second weight matrix of the intermediate layerare quantized, so that the elements in the quantized second activation matrix and the second weight matrix are all represented by the binary number of the target number of bits;
- the third activation matrix and the third weight matrix of the output layerare quantized, so that the elements in the quantized third activation matrix and the third weight matrix are both represented by binary numbers of the target number of bits.
- an embodiment of the present applicationfurther provides a neural network quantization device, the control terminal includes a memory and a processor; the memory is used to store a computer program;
- the processoris configured to execute the computer program and implement the following steps when executing the computer program:
- the target neural networkincludes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer;
- the first activation matrix and the first weight matrix of the input layerare quantized, so that the elements in the quantized first activation matrix and the first weight matrix are represented by the binary number of the target number of bits;
- the second activation matrix and the second weight matrix of the intermediate layerare quantized, so that the elements in the quantized second activation matrix and the second weight matrix are all represented by the binary number of the target number of bits;
- the third activation matrix and the third weight matrix of the output layerare quantized, so that the elements in the quantized third activation matrix and the third weight matrix are both represented by binary numbers of the target number of bits.
- embodiments of the present applicationfurther provide a computer-readable storage medium, where the computer-readable storage medium stores a computer program, and when the computer program is executed by a processor, the processor implements the above-mentioned Steps of a neural network quantization method.
- Embodiments of the present applicationprovide a neural network quantization method, device, and computer-readable storage medium.
- quantizing the elements in the activation matrix and weight matrix of the input layer, output layer, and intermediate layer of the target neural network to be quantized as Representing with the same low-bit binary numbercan reduce the amount of computation for running the quantized neural network, and can also reduce the design complexity of the chip required to run the neural network, which greatly improves the user experience.
- FIG. 1is a schematic flowchart of steps of a neural network quantization method provided in an embodiment of the present application
- Fig. 2is the schematic flow chart of substeps of the neural network quantization method in Fig. 1;
- Fig. 3is the substep schematic flow chart of the neural network quantization method in Fig. 1;
- FIG. 4is a schematic block diagram of the structure of a neural network quantization apparatus provided by an embodiment of the present application.
- FIG. 5is a schematic block diagram of the structure of a neural network quantization device provided by an embodiment of the present application.
- Neural network quantizationrefers to quantizing a full-precision neural network into a low-precision, high-accuracy neural network, so that the low-precision, high-accuracy neural network can be deployed on smartphones, drones, tablet computers, wearable devices, etc. On electronic devices with low power consumption and weak computing power.
- the current neural network quantization algorithmis mainly mixed-bit quantization, that is, the middle layer of the neural network is quantized into low bits, and the input layer and the output layer are quantized into higher bits, so that the number of bits at each level of the quantized neural network is different. , the number of bits at each level of the quantized neural network will lead to difficulties in the design of artificial intelligence chips, high design costs, high power consumption, and low utilization.
- the embodiments of the present applicationprovide a neural network quantization method, device, and computer-readable storage medium.
- the elementsare all quantized into binary numbers with the same low-bit number, which can reduce the computational complexity of running the quantized neural network, and also reduce the design complexity of the chips required to run the neural network, greatly improving the user experience. .
- the neural network quantification methodcan be applied to a terminal device or a server, and the terminal device includes a mobile phone, a tablet computer, a notebook computer, a PC computer, etc., and the server can be a single server, or it can be composed of multiple A server cluster consisting of servers.
- the followingtakes the neural network quantization method applied to the server as an example for explanation.
- FIG. 1is a schematic flowchart of steps of a neural network quantization method provided by an embodiment of the present application.
- the neural network quantization methodincludes steps S101 to S104.
- Step S101Obtain a target neural network to be quantified, wherein the target neural network includes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer.
- the target neural networkincludes at least one of the following: a convolutional neural network, a recurrent convolutional neural network, and a deep convolutional neural network.
- the servercan obtain the target neural network to be quantified from the local memory, or can be obtained from an external storage device.
- the target neural network to be quantifiedcan also be obtained from the cloud, which is not specifically limited in this application.
- the input layer of the target neural networkmay include a first number of neurons
- the output layer of the target neural networkmay include a second number of neurons
- the intermediate layer of the target neural networkmay include a third number of neurons
- the first number of neurons , the second quantity, and the third quantitymay be set based on actual conditions, which are not specifically limited in this embodiment of the present application.
- Step S102Quantize the first activation matrix and the first weight matrix of the input layer, so that the elements in the quantized first activation matrix and the first weight matrix are both represented by binary numbers of the target number of bits.
- the target number of bitscan be set by the user, which is not specifically limited in this embodiment of the present application.
- the elements in the first activation matrixare represented by binary numbers of the first bit number, and the elements in the first weight matrix are represented by the second bit number.
- the binary number representation of the number, the first bit number and the second bit numbercan be the same or different, the first bit number and the second bit number are both greater than or equal to the target bit number, and the difference between the first bit number and the target bit number
- the quotient ofis an integer multiple of 2
- the quotient between the second number of bits and the target number of bitsis an integer multiple of 2.
- the first number of bitsis 8, the second number of bits is 8, and the target number of bits is 4.
- the first number of bitsis 8, the second number of bits is 4 bits, and the target number of bits is 4.
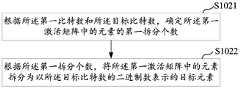
- quantizing the first activation matrix of the input layermay include sub-steps S1021 to S1022.
- Sub-step S1021Determine a first split number of elements in the first activation matrix according to the first number of bits and the target number of bits.
- the quotient of the first number of bits and the target number of bitsis determined, and the quotient of the first number of bits and the target number of bits is determined as the first split number of elements in the first activation matrix. For example, if the first number of bits is 8 and the target number of bits is 4, then the quotient of the first number of bits and the target number of bits is 2. Therefore, the first number of splits of elements in the first activation matrix is 2, and for example , the first number of bits is 16, and the target number of bits is 4, then the quotient of the first number of bits and the target number of bits is 4. Therefore, the first split number of elements in the first activation matrix is 4.
- Sub-step S1022According to the first split number, split the elements in the first activation matrix into target elements represented by the binary number of the target number of bits.
- the elements in the first activation matrixmay be split into target elements represented by binary numbers of the target number of bits based on the sequential indexing method and according to the first split number. For example, if the first number of bits is 8, the target number of bits is 4, and the first number of splits is 2, if an element in the first activation matrix is 10101001, then the element 10101001 in the first activation matrix can be split For the element represented by the high four-bit binary number 1010 and the low four-bit binary number 1001, the element 10101001 in the first activation matrix can also be split into the middle four-bit binary number 1010 and the head and tail four-bit binary number 1001. element.
- quantizing the first weight matrix of the input layermay include sub-steps S1023 to S1025.
- Sub-step S1023Determine a second split number of elements in the first weight matrix according to the second number of bits and the target number of bits.
- the quotient of the second number of bits and the target number of bitsis determined, and the quotient of the second number of bits and the target number of bits is determined as the second split number of elements in the first weight matrix. For example, if the second number of bits is 8 and the target number of bits is 4, the quotient of the second number of bits and the target number of bits is 2. Therefore, the second number of splits of elements in the first weight matrix is 2, and for example , the second number of bits is 16, and the target number of bits is 4, then the quotient of the second number of bits and the target number of bits is 4. Therefore, the second split number of elements in the first weight matrix is 4.
- Sub-step S1024According to the second split number, split the elements in the first weight matrix into elements represented by the binary numbers of the target number of bits to obtain a first target weight matrix.
- the ratio of the total number of first elements of the first weight matrix after quantization to the total number of second elements of the first weight matrix before quantizationis equal to the number of second splits, that is, the total number of first elements of the first target weight matrix and the number of The ratio of the total number of second elements of a weight matrix is equal to the number of second splits.
- the second number of bitsis 8 and the target number of bits is 4, then the second number of splits is 2, so the total number of first elements of the first target weight matrix is twice the total number of second elements of the first weight matrix, For another example, if the second number of bits is 16 and the target number of bits is 4, then the second number of splits is 4, so the total number of first elements of the first target weight matrix is 4 times the total number of second elements of the first weight matrix .
- the second number of bitsis 8
- the target number of bitsis 4, and the second number of splits is 2.
- the element 11001010 in the first weight matrixcan be split
- the element 11001010 in the first weight matrixcan also be split into the middle four-bit binary number 0010 and the head and tail four-bit binary numbers The element represented by 1110.
- Sub-step S1025Initialize the elements in the first target weight matrix that are represented by binary numbers of the target number of bits.
- the initializationincludes any one of random initialization and constant initialization.
- Step S103Quantize the second activation matrix and the second weight matrix of the intermediate layer, so that the elements in the quantized second activation matrix and the second weight matrix are both represented by the binary numbers of the target number of bits.
- the elements in the second activation matrixare represented by the binary numbers of the third bit number
- the elements in the second weight matrixare represented by the binary numbers of the fourth bit number
- the third bit number and the fourth bit numbercan be the same or can be Not the same
- the third bit number and the fourth bit numberare both greater than or equal to the target number of bits
- the quotient between the third bit number and the target number of bitsis an integer multiple of 2
- the quotient between the third bit number and the target number of bitsis an integer multiple of 2.
- the third number of bitsis 4, the fourth number of bits is 4, and the target number of bits is 4.
- the third number of bitsis 8, the fourth number of bits is 4 bits, and the target number of bits is 4.
- Step S104Quantize the third activation matrix and the third weight matrix of the output layer, so that the elements in the quantized third activation matrix and the third weight matrix are both represented by binary numbers of the target number of bits.
- the elements in the third activation matrixare represented by the binary numbers of the fifth bit number
- the elements in the third weight matrixare represented by the binary numbers of the sixth bit number
- the fifth bit number and the sixth bit numbermay be the same or may be Not the same
- the fifth and sixth bitsare both greater than or equal to the target number of bits
- the quotient between the fifth and the target number of bitsis an integer multiple of 2
- the quotient between the sixth and the target number of bitsis an integer multiple of 2.
- the number of fifth bitsis 8, the number of sixth bits is 4, and the number of target bits is 4
- the number of fifth bitsis 16, the number of sixth bits is 8 bits
- the number of target bitsis 4.
- the output result of the quantized output layeris represented by the binary number of the target number of bits, and the precision is low.
- the first matrix corresponding to the output result of the quantized output layeris obtained, that is, the first matrix corresponding to the output result of the quantized output layer is obtained.
- the matrix methodmay be: obtaining a third matrix corresponding to the input information of the output layer, and performing a convolution operation on the third matrix and the quantized third weight matrix to obtain a first matrix corresponding to the output result of the output layer; A matrix is quantized to obtain a second matrix corresponding to the output result of the output layer.
- the elements in the first matrixare represented by the binary numbers of the target number of bits, and the elements in the second matrix are all represented by the binary numbers of the sixth bit number.
- the accuracy of the output layercan be improved by representing the output of the output layer as a high-bit binary number.
- the sixth bit number and the target bit numberdetermine the number of spliced binary numbers of the elements in the first matrix, that is, determine the quotient of the sixth bit number and the target bit number, and compare the sixth bit number with the target number of bits.
- the quotient of the number of bitsis determined as the splicing number of the binary numbers of the elements in the first matrix; the splicing binary number of the splicing numbers of the elements in the first matrix is determined; the splicing of the splicing numbers of the elements in the first matrix
- the binary numbersare spliced to obtain a second matrix including elements represented by binary numbers of the sixth bit number.
- the sixth bit numberis 8 and the target bit number is 4, the quotient of the sixth bit number and the target bit number is 2. Therefore, the number of spliced binary numbers of the elements in the first matrix is 2.
- the two concatenated binary numbers of the elements in the first matrixare 1001 and 0111 respectively, then the concatenated binary number 1001 and the concatenated binary number 0111 are concatenated to obtain the element represented by the binary number 10010111 or 01111001.
- the neural network quantization method provided by the above embodimentby quantizing the elements in the activation matrix and the weight matrix of the input layer, output layer and intermediate layer of the target neural network to be quantized into binary numbers with the same low bit number, It can reduce the calculation amount of running the quantized neural network, and also can reduce the design complexity of the chip required for running the neural network, which greatly improves the user experience.
- FIG. 4is a schematic structural block diagram of a neural network quantization apparatus provided by an embodiment of the present application.
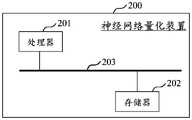
- the neural network quantization apparatus 200includes a processor 201 and a memory 202, and the processor 201 and the memory 202 are connected by a bus 203, such as an I2C (Inter-integrated Circuit) bus.
- a bus 203such as an I2C (Inter-integrated Circuit) bus.
- the processor 201may be a micro-controller unit (Micro-controller Unit, MCU), a central processing unit (Central Processing Unit, CPU), or a digital signal processor (Digital Signal Processor, DSP) or the like.
- MCUMicro-controller Unit
- CPUCentral Processing Unit
- DSPDigital Signal Processor
- the memory 202may be a Flash chip, a read-only memory (ROM, Read-Only Memory) magnetic disk, an optical disk, a U disk, or a removable hard disk, or the like.
- ROMRead-Only Memory
- the memory 202may be a Flash chip, a read-only memory (ROM, Read-Only Memory) magnetic disk, an optical disk, a U disk, or a removable hard disk, or the like.
- the processor 201is used for running the computer program stored in the memory 202, and implements the following steps when executing the computer program:
- the target neural networkincludes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer;
- the first activation matrix and the first weight matrix of the input layerare quantized, so that the elements in the quantized first activation matrix and the first weight matrix are represented by the binary number of the target number of bits;
- the second activation matrix and the second weight matrix of the intermediate layerare quantized, so that the elements in the quantized second activation matrix and the second weight matrix are all represented by the binary number of the target number of bits;
- the third activation matrix and the third weight matrix of the output layerare quantized, so that the elements in the quantized third activation matrix and the third weight matrix are all represented by binary numbers of the target number of bits.
- the target neural networkincludes at least one of the following: a convolutional neural network, a recurrent convolutional neural network, and a deep convolutional neural network.
- the elements in the first activation matrixare represented by binary numbers of a first number of bits, the first number of bits is greater than the target number of bits, and the first number of bits is the same as the target number of bits.
- the quotient between numbersis an integer multiple of 2.
- the elements in the first activation matrixare represented by a binary number of a first bit number, and when the processor quantizes the first activation matrix of the input layer, the processor is configured to:
- the elements in the first activation matrixare split into target elements represented by binary numbers of the target number of bits.
- the elements in the first weight matrixare represented by binary numbers of a second bit number, and the second bit number is greater than or equal to the target bit number, and the processor implements the input When the first weight matrix of the layer is quantized, it is used to achieve:
- the elements in the first weight matrixare split into elements represented by the binary numbers of the target number of bits to obtain a first target weight matrix
- the initializationincludes any one of random initialization and constant initialization.
- the ratio of the total number of first elements of the first weight matrix after quantization to the total number of second elements of the first weight matrix before quantizationis equal to the second number of divisions.
- the elements in the third weight matrix before quantizationare represented by a binary number of a sixth bit number, and the sixth bit number is greater than the target bit number, and the processor implements the After the third activation matrix and the third weight matrix of the output layer are quantized, they are also used to achieve:
- the first matrixis quantized to obtain a second matrix corresponding to the output result of the output layer, and the elements in the second matrix are all represented by binary numbers of the sixth bit number.
- the processorwhen the processor is implemented to quantize the first matrix to obtain the second matrix corresponding to the output result of the output layer, it is used to implement:
- the sixth bit number and the target bit numberdetermine the number of spliced binary numbers of the elements in the first matrix
- the spliced binary numbers of the spliced numbers of the elements in the first matrixare spliced to obtain a second matrix including elements all represented by the binary numbers of the sixth bit number.
- the processorwhen the processor acquires the first matrix corresponding to the output result of the output layer, the processor is configured to:
- a convolution operationis performed on the third matrix and the quantized third weight matrix to obtain a first matrix corresponding to the output result of the output layer.
- FIG. 5is a schematic structural block diagram of a neural network quantization device provided by an embodiment of the present application.
- the neural network quantization apparatus 300includes a neural network quantization apparatus 310 .
- the neural network quantization device 310may be the neural network quantization device in FIG. 4 .
- the neural network quantification device 300may be a terminal device or a server.
- Embodiments of the present applicationfurther provide a computer-readable storage medium, where a computer program is stored in the computer-readable storage medium, the computer program includes program instructions, and the processor executes the program instructions, so as to realize the provision of the above embodiments.
- the steps of the neural network quantization methodare described in detail below.
- the computer-readable storage mediummay be an internal storage unit of the neural network quantization device described in any of the foregoing embodiments, such as a hard disk or a memory of the neural network quantization device.
- the computer-readable storage mediumcan also be an external storage device of the neural network quantification device, such as a plug-in hard disk equipped on the neural network quantification device, a smart memory card (Smart Media Card, SMC), a secure digital ( Secure Digital, SD) card, flash memory card (Flash Card), etc.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
Translated fromChinese本申请涉及神经网络量化技术领域,尤其涉及一种神经网络量化方法、装置及计算机可读存储介质。The present application relates to the technical field of neural network quantification, and in particular, to a neural network quantification method, apparatus, and computer-readable storage medium.
神经网络量化是指将全精度的神经网络量化为低精度、高准确率的神经网络,使得低精度、高准确率的神经网络可以部署在智能手机、无人机、平板电脑、可穿戴设备等功耗低、算力弱的电子设备上。然而,目前的神经网络量化算法主要是混合比特量化,即将神经网络的中间层量化为低比特,将输入层和输出层量化为较高比特,使得量化后的神经网络的各层级的比特数不同,量化后的神经网络的各层级的比特数不同会导致人工智能芯片设计困难、设计成本较高、功耗较高、利用率较低等问题。Neural network quantization refers to quantizing a full-precision neural network into a low-precision, high-accuracy neural network, so that the low-precision, high-accuracy neural network can be deployed in smartphones, drones, tablet computers, wearable devices, etc. On electronic devices with low power consumption and weak computing power. However, the current neural network quantization algorithm is mainly mixed-bit quantization, that is, the middle layer of the neural network is quantized into low bits, and the input layer and the output layer are quantized into higher bits, so that the number of bits at each level of the quantized neural network is different. , the number of bits at each level of the quantized neural network will lead to difficulties in the design of artificial intelligence chips, high design costs, high power consumption, and low utilization.
发明内容SUMMARY OF THE INVENTION
基于此,本申请实施例提供了一种神经网络量化方法、装置及计算机可读存储介质,旨在减少运行神经网络的计算量,降低运行神经网络所需的芯片的设计复杂度。Based on this, the embodiments of the present application provide a neural network quantification method, device, and computer-readable storage medium, which aim to reduce the amount of computation for running the neural network and reduce the design complexity of chips required for running the neural network.
第一方面,本申请实施例提供了一种神经网络量化方法,包括:In a first aspect, an embodiment of the present application provides a neural network quantization method, including:
获取待量化的目标神经网络,其中,所述目标神经网络包括输入层、输出层和中间层,所述输入层与所述中间层连接,所述中间层与所述输出层连接;obtaining a target neural network to be quantified, wherein the target neural network includes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer;
对所述输入层的第一激活矩阵和第一权重矩阵进行量化,使得量化后的第一激活矩阵和第一权重矩阵中的元素均以目标比特数的二进制数表示;The first activation matrix and the first weight matrix of the input layer are quantized, so that the elements in the quantized first activation matrix and the first weight matrix are represented by the binary number of the target number of bits;
对所述中间层的第二激活矩阵和第二权重矩阵进行量化,使得量化后的第二激活矩阵和第二权重矩阵中的元素均以所述目标比特数的二进制数表示;The second activation matrix and the second weight matrix of the intermediate layer are quantized, so that the elements in the quantized second activation matrix and the second weight matrix are all represented by the binary number of the target number of bits;
对所述输出层的第三激活矩阵和第三权重矩阵进行量化,使得量化后的第三激活矩阵和第三权重矩阵中的元素均以所述目标比特数的二进制数表示。The third activation matrix and the third weight matrix of the output layer are quantized, so that the elements in the quantized third activation matrix and the third weight matrix are both represented by binary numbers of the target number of bits.
第二方面,本申请实施例还提供了一种神经网络量化装置,所述控制终端包括存储器和处理器;所述存储器用于存储计算机程序;In a second aspect, an embodiment of the present application further provides a neural network quantization device, the control terminal includes a memory and a processor; the memory is used to store a computer program;
所述处理器,用于执行所述计算机程序并在执行所述计算机程序时,实现如下步骤:The processor is configured to execute the computer program and implement the following steps when executing the computer program:
获取待量化的目标神经网络,其中,所述目标神经网络包括输入层、输出层和中间层,所述输入层与所述中间层连接,所述中间层与所述输出层连接;obtaining a target neural network to be quantified, wherein the target neural network includes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer;
对所述输入层的第一激活矩阵和第一权重矩阵进行量化,使得量化后的第一激活矩阵和第一权重矩阵中的元素均以目标比特数的二进制数表示;The first activation matrix and the first weight matrix of the input layer are quantized, so that the elements in the quantized first activation matrix and the first weight matrix are represented by the binary number of the target number of bits;
对所述中间层的第二激活矩阵和第二权重矩阵进行量化,使得量化后的第二激活矩阵和第二权重矩阵中的元素均以所述目标比特数的二进制数表示;The second activation matrix and the second weight matrix of the intermediate layer are quantized, so that the elements in the quantized second activation matrix and the second weight matrix are all represented by the binary number of the target number of bits;
对所述输出层的第三激活矩阵和第三权重矩阵进行量化,使得量化后的第三激活矩阵和第三权重矩阵中的元素均以所述目标比特数的二进制数表示。The third activation matrix and the third weight matrix of the output layer are quantized, so that the elements in the quantized third activation matrix and the third weight matrix are both represented by binary numbers of the target number of bits.
第三方面,本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如上所述的神经网络量化方法的步骤。In a third aspect, embodiments of the present application further provide a computer-readable storage medium, where the computer-readable storage medium stores a computer program, and when the computer program is executed by a processor, the processor implements the above-mentioned Steps of a neural network quantization method.
本申请实施例提供了一种神经网络量化方法、装置及计算机可读存储介质,通过将待量化的目标神经网络的输入层、输出层和中间层的激活矩阵和权重矩阵中的元素均量化为以相同的低比特数的二进制数表示,可以减少运行量化后的神经网络的计算量,也可以降低运行神经网络所需的芯片的设计复杂度,极大的提高了用户体验。Embodiments of the present application provide a neural network quantization method, device, and computer-readable storage medium. By quantizing the elements in the activation matrix and weight matrix of the input layer, output layer, and intermediate layer of the target neural network to be quantized as Representing with the same low-bit binary number can reduce the amount of computation for running the quantized neural network, and can also reduce the design complexity of the chip required to run the neural network, which greatly improves the user experience.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not limiting of the present application.
为了更清楚地说明本申请实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to explain the technical solutions of the embodiments of the present application more clearly, the following briefly introduces the accompanying drawings used in the description of the embodiments. For those of ordinary skill, other drawings can also be obtained from these drawings without any creative effort.
图1是本申请实施例提供的一种神经网络量化方法的步骤示意流程图;1 is a schematic flowchart of steps of a neural network quantization method provided in an embodiment of the present application;
图2是图1中的神经网络量化方法的子步骤示意流程图;Fig. 2 is the schematic flow chart of substeps of the neural network quantization method in Fig. 1;
图3是图1中的神经网络量化方法的子步骤示意流程图;Fig. 3 is the substep schematic flow chart of the neural network quantization method in Fig. 1;
图4是本申请实施例提供的一种神经网络量化装置的结构示意性框图;4 is a schematic block diagram of the structure of a neural network quantization apparatus provided by an embodiment of the present application;
图5是本申请实施例提供的一种神经网络量化设备的结构示意性框图。FIG. 5 is a schematic block diagram of the structure of a neural network quantization device provided by an embodiment of the present application.
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清 楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present application. Obviously, the described embodiments are part of the embodiments of the present application, rather than all of the embodiments. Based on the embodiments in the present application, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present application.
附图中所示的流程图仅是示例说明,不是必须包括所有的内容和操作/步骤,也不是必须按所描述的顺序执行。例如,有的操作/步骤还可以分解、组合或部分合并,因此实际执行的顺序有可能根据实际情况改变。The flowcharts shown in the figures are for illustration only, and do not necessarily include all contents and operations/steps, nor do they have to be performed in the order described. For example, some operations/steps can also be decomposed, combined or partially combined, so the actual execution order may be changed according to the actual situation.
下面结合附图,对本申请的一些实施方式作详细说明。在不冲突的情况下,下述的实施例及实施例中的特征可以相互组合。Some embodiments of the present application will be described in detail below with reference to the accompanying drawings. The embodiments described below and features in the embodiments may be combined with each other without conflict.
神经网络量化是指将全精度的神经网络量化为低精度、高准确率的神经网络,使得低精度、高准确率的神经网络可以部署在智能手机、无人机、平板电脑、可穿戴设备等功耗低、算力弱的电子设备上。然而,目前的神经网络量化算法主要是混合比特量化,即将神经网络的中间层量化为低比特,将输入层和输出层量化为较高比特,使得量化后的神经网络的各层级的比特数不同,量化后的神经网络的各层级的比特数不同会导致人工智能芯片设计困难、设计成本较高、功耗较高、利用率较低等问题。Neural network quantization refers to quantizing a full-precision neural network into a low-precision, high-accuracy neural network, so that the low-precision, high-accuracy neural network can be deployed on smartphones, drones, tablet computers, wearable devices, etc. On electronic devices with low power consumption and weak computing power. However, the current neural network quantization algorithm is mainly mixed-bit quantization, that is, the middle layer of the neural network is quantized into low bits, and the input layer and the output layer are quantized into higher bits, so that the number of bits at each level of the quantized neural network is different. , the number of bits at each level of the quantized neural network will lead to difficulties in the design of artificial intelligence chips, high design costs, high power consumption, and low utilization.
为解决上述问题,本申请实施例提供了一种神经网络量化方法、装置及计算机可读存储介质,通过将待量化的目标神经网络的输入层、输出层和中间层的激活矩阵和权重矩阵中的元素均量化为以相同的低比特数的二进制数表示,可以减少运行量化后的神经网络的计算量,也可以降低运行神经网络所需的芯片的设计复杂度,极大的提高了用户体验。In order to solve the above problems, the embodiments of the present application provide a neural network quantization method, device, and computer-readable storage medium. The elements are all quantized into binary numbers with the same low-bit number, which can reduce the computational complexity of running the quantized neural network, and also reduce the design complexity of the chips required to run the neural network, greatly improving the user experience. .
可选的,该神经网络量化方法可以应用于终端设备,也可以应用服务器,该终端设备包括手机、平板电脑、笔记本电脑和PC电脑等,该服务器可以是单台的服务器,也可以是由多台服务器组成的服务器集群。以下以神经网络量化方法应用于服务器为例进行解释说明。Optionally, the neural network quantification method can be applied to a terminal device or a server, and the terminal device includes a mobile phone, a tablet computer, a notebook computer, a PC computer, etc., and the server can be a single server, or it can be composed of multiple A server cluster consisting of servers. The following takes the neural network quantization method applied to the server as an example for explanation.
请参阅图1,图1是本申请实施例提供的一种神经网络量化方法的步骤示意流程图。Please refer to FIG. 1. FIG. 1 is a schematic flowchart of steps of a neural network quantization method provided by an embodiment of the present application.
如图1所示,该神经网络量化方法包括步骤S101至步骤S104。As shown in FIG. 1 , the neural network quantization method includes steps S101 to S104.
步骤S101、获取待量化的目标神经网络,其中,所述目标神经网络包括输入层、输出层和中间层,所述输入层与所述中间层连接,所述中间层与所述输出层连接。Step S101: Obtain a target neural network to be quantified, wherein the target neural network includes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer.
其中,目标神经网络包括如下至少一种:卷积神经网络、循环卷积神经网络、深度卷积神经网络,服务器可以从本地存储器中获取待量化的目标神经网 络,也可以从外部存储设备中获取待量化的目标神经网络,还可以从云端获取待量化的目标神经网络,本申请对此不做具体限定。The target neural network includes at least one of the following: a convolutional neural network, a recurrent convolutional neural network, and a deep convolutional neural network. The server can obtain the target neural network to be quantified from the local memory, or can be obtained from an external storage device. The target neural network to be quantified can also be obtained from the cloud, which is not specifically limited in this application.
其中,目标神经网络的输入层可以包括第一数量的神经元,目标神经网络的输出层可以包括第二数量的神经元,目标神经网络的中间层可以包括第三数量的神经元,第一数量、第二数量和第三数量可基于实际情况进行设置,本申请实施例对此不做具体限定。The input layer of the target neural network may include a first number of neurons, the output layer of the target neural network may include a second number of neurons, and the intermediate layer of the target neural network may include a third number of neurons, the first number of neurons , the second quantity, and the third quantity may be set based on actual conditions, which are not specifically limited in this embodiment of the present application.
步骤S102、对所述输入层的第一激活矩阵和第一权重矩阵进行量化,使得量化后的第一激活矩阵和第一权重矩阵中的元素均以目标比特数的二进制数表示。Step S102: Quantize the first activation matrix and the first weight matrix of the input layer, so that the elements in the quantized first activation matrix and the first weight matrix are both represented by binary numbers of the target number of bits.
其中,该目标比特数可由用户自行设置,本申请实施例对此不做具体限定,第一激活矩阵中的元素以第一比特数的二进制数表示,第一权重矩阵中的元素以第二比特数的二进制数表示,第一比特数与第二比特数可以相同,也可以不相同,第一比特数和第二比特数均大于或等于目标比特数,第一比特数与目标比特数之间的商为2的整数倍,第二比特数与目标比特数之间的商为2的整数倍。例如,第一比特数为8,第二比特数为8,目标比特数为4,又例如,第一比特数为8,第二比特数为4比特,目标比特数为4。The target number of bits can be set by the user, which is not specifically limited in this embodiment of the present application. The elements in the first activation matrix are represented by binary numbers of the first bit number, and the elements in the first weight matrix are represented by the second bit number. The binary number representation of the number, the first bit number and the second bit number can be the same or different, the first bit number and the second bit number are both greater than or equal to the target bit number, and the difference between the first bit number and the target bit number The quotient of is an integer multiple of 2, and the quotient between the second number of bits and the target number of bits is an integer multiple of 2. For example, the first number of bits is 8, the second number of bits is 8, and the target number of bits is 4. In another example, the first number of bits is 8, the second number of bits is 4 bits, and the target number of bits is 4.
在一实施例中,如图2所示,对输入层的第一激活矩阵进行量化可以包括子步骤S1021至S1022。In one embodiment, as shown in FIG. 2, quantizing the first activation matrix of the input layer may include sub-steps S1021 to S1022.
子步骤S1021、根据所述第一比特数和所述目标比特数,确定所述第一激活矩阵中的元素的第一拆分个数。Sub-step S1021: Determine a first split number of elements in the first activation matrix according to the first number of bits and the target number of bits.
确定第一比特数与目标比特数的商,并将第一比特数与目标比特数的商确定为第一激活矩阵中的元素的第一拆分个数。例如,第一比特数为8,目标比特数为4,则第一比特数与目标比特数的商为2,因此,第一激活矩阵中的元素的第一拆分个数为2,又例如,第一比特数为16,目标比特数为4,则第一比特数与目标比特数的商为4,因此,第一激活矩阵中的元素的第一拆分个数为4。The quotient of the first number of bits and the target number of bits is determined, and the quotient of the first number of bits and the target number of bits is determined as the first split number of elements in the first activation matrix. For example, if the first number of bits is 8 and the target number of bits is 4, then the quotient of the first number of bits and the target number of bits is 2. Therefore, the first number of splits of elements in the first activation matrix is 2, and for example , the first number of bits is 16, and the target number of bits is 4, then the quotient of the first number of bits and the target number of bits is 4. Therefore, the first split number of elements in the first activation matrix is 4.
子步骤S1022、根据所述第一拆分个数,将所述第一激活矩阵中的元素拆分为以所述目标比特数的二进制数表示的目标元素。Sub-step S1022: According to the first split number, split the elements in the first activation matrix into target elements represented by the binary number of the target number of bits.
其中,可以基于顺序索引法,根据第一拆分个数,将第一激活矩阵中的元素拆分为以目标比特数的二进制数表示的目标元素。例如,第一比特数为8,目标比特数为4,第一拆分个数为2,设第一激活矩阵中的某个元素为10101001,则可以将第一激活矩阵中的元素10101001拆分为以高四位二进制数1010和低四位二进制数1001表示的元素,也可以将第一激活矩阵中的元素10101001拆 分为以中间四位二进制数1010和头尾四位二进制数1001表示的元素。The elements in the first activation matrix may be split into target elements represented by binary numbers of the target number of bits based on the sequential indexing method and according to the first split number. For example, if the first number of bits is 8, the target number of bits is 4, and the first number of splits is 2, if an element in the first activation matrix is 10101001, then the element 10101001 in the first activation matrix can be split For the element represented by the high four-bit binary number 1010 and the low four-bit binary number 1001, the element 10101001 in the first activation matrix can also be split into the middle four-bit binary number 1010 and the head and tail four-bit binary number 1001. element.
在一实施例中,如图3所示,对输入层的第一权重矩阵进行量化可以包括子步骤S1023至S1025。In one embodiment, as shown in FIG. 3 , quantizing the first weight matrix of the input layer may include sub-steps S1023 to S1025.
子步骤S1023、根据所述第二比特数和所述目标比特数,确定所述第一权重矩阵中的元素的第二拆分个数。Sub-step S1023: Determine a second split number of elements in the first weight matrix according to the second number of bits and the target number of bits.
确定第二比特数与目标比特数的商,并将第二比特数与目标比特数的商确定为第一权重矩阵中的元素的第二拆分个数。例如,第二比特数为8,目标比特数为4,则第二比特数与目标比特数的商为2,因此,第一权重矩阵中的元素的第二拆分个数为2,又例如,第二比特数为16,目标比特数为4,则第二比特数与目标比特数的商为4,因此,第一权重矩阵中的元素的第二拆分个数为4。The quotient of the second number of bits and the target number of bits is determined, and the quotient of the second number of bits and the target number of bits is determined as the second split number of elements in the first weight matrix. For example, if the second number of bits is 8 and the target number of bits is 4, the quotient of the second number of bits and the target number of bits is 2. Therefore, the second number of splits of elements in the first weight matrix is 2, and for example , the second number of bits is 16, and the target number of bits is 4, then the quotient of the second number of bits and the target number of bits is 4. Therefore, the second split number of elements in the first weight matrix is 4.
子步骤S1024、根据所述第二拆分个数,将所述第一权重矩阵中的元素拆分为以所述目标比特数的二进制数表示的元素,得到第一目标权重矩阵。Sub-step S1024: According to the second split number, split the elements in the first weight matrix into elements represented by the binary numbers of the target number of bits to obtain a first target weight matrix.
其中,量化后的第一权重矩阵的第一元素总数与量化前的第一权重矩阵的第二元素总数的比值等于第二拆分个数,即第一目标权重矩阵的第一元素总数与第一权重矩阵的第二元素总数的比值等于第二拆分个数。例如,第二比特数为8,目标比特数为4,则第二拆分个数为2,因此第一目标权重矩阵的第一元素总数是第一权重矩阵的第二元素总数的2倍,又例如,第二比特数为16,目标比特数为4,则第二拆分个数为4,因此第一目标权重矩阵的第一元素总数是第一权重矩阵的第二元素总数的4倍。The ratio of the total number of first elements of the first weight matrix after quantization to the total number of second elements of the first weight matrix before quantization is equal to the number of second splits, that is, the total number of first elements of the first target weight matrix and the number of The ratio of the total number of second elements of a weight matrix is equal to the number of second splits. For example, if the second number of bits is 8 and the target number of bits is 4, then the second number of splits is 2, so the total number of first elements of the first target weight matrix is twice the total number of second elements of the first weight matrix, For another example, if the second number of bits is 16 and the target number of bits is 4, then the second number of splits is 4, so the total number of first elements of the first target weight matrix is 4 times the total number of second elements of the first weight matrix .
例如,第二比特数为8,目标比特数为4,第二拆分个数为2,设第一权重矩阵中的某个元素为11001010,则可以将第一权重矩阵中的元素11001010拆分为以高四位二进制数1100表示的元素和以低四位二进制数1010表示的元素,也可以将第一权重矩阵中的元素11001010拆分为中间四位二进制数0010和头尾四位二进制数1110表示的元素。For example, the second number of bits is 8, the target number of bits is 4, and the second number of splits is 2. If an element in the first weight matrix is 11001010, then the element 11001010 in the first weight matrix can be split For the element represented by the high four-bit binary number 1100 and the element represented by the low four-bit binary number 1010, the element 11001010 in the first weight matrix can also be split into the middle four-bit binary number 0010 and the head and tail four-bit binary numbers The element represented by 1110.
子步骤S1025、对所述第一目标权重矩阵中的以所述目标比特数的二进制数表示的元素进行初始化。Sub-step S1025: Initialize the elements in the first target weight matrix that are represented by binary numbers of the target number of bits.
通过对第一目标权重矩阵中的元素进行初始化,可以重新确定第一目标权重矩阵中的元素的具体数值,方便后续对量化后的神经网络进行迭代训练。其中,该初始化包括随机初始化和常数初始化中的任一项。By initializing the elements in the first target weight matrix, the specific values of the elements in the first target weight matrix can be re-determined, which facilitates subsequent iterative training of the quantized neural network. Wherein, the initialization includes any one of random initialization and constant initialization.
步骤S103、对所述中间层的第二激活矩阵和第二权重矩阵进行量化,使得量化后的第二激活矩阵和第二权重矩阵中的元素均以所述目标比特数的二进制数表示。Step S103: Quantize the second activation matrix and the second weight matrix of the intermediate layer, so that the elements in the quantized second activation matrix and the second weight matrix are both represented by the binary numbers of the target number of bits.
其中,第二激活矩阵中的元素以第三比特数的二进制数表示,第二权重矩阵中的元素以第四比特数的二进制数表示,第三比特数与第四比特数可以相同,也可以不相同,第三比特数与第四比特数均大于或等于目标比特数,第三比特数与目标比特数之间的商为2的整数倍,第三比特数与目标比特数之间的商为2的整数倍。例如,第三比特数为4,第四比特数为4,目标比特数为4,又例如,第三比特数为8,第四比特数为4比特,目标比特数为4。可以理解的是,对中间层的第二激活矩阵和第二权重矩阵进行量化的具体实现过程可以参照前述对输入层的第一激活矩阵和第一权重矩阵进行量化的详细描述,此处不做赘述。The elements in the second activation matrix are represented by the binary numbers of the third bit number, and the elements in the second weight matrix are represented by the binary numbers of the fourth bit number, and the third bit number and the fourth bit number can be the same or can be Not the same, the third bit number and the fourth bit number are both greater than or equal to the target number of bits, the quotient between the third bit number and the target number of bits is an integer multiple of 2, and the quotient between the third bit number and the target number of bits is an integer multiple of 2. For example, the third number of bits is 4, the fourth number of bits is 4, and the target number of bits is 4. In another example, the third number of bits is 8, the fourth number of bits is 4 bits, and the target number of bits is 4. It can be understood that the specific implementation process of quantizing the second activation matrix and the second weight matrix of the intermediate layer can refer to the foregoing detailed description of the quantization of the first activation matrix and the first weight matrix of the input layer, which is not described here. Repeat.
步骤S104、对所述输出层的第三激活矩阵和第三权重矩阵进行量化,使得量化后的第三激活矩阵和第三权重矩阵中的元素均以所述目标比特数的二进制数表示。Step S104: Quantize the third activation matrix and the third weight matrix of the output layer, so that the elements in the quantized third activation matrix and the third weight matrix are both represented by binary numbers of the target number of bits.
其中,第三激活矩阵中的元素以第五比特数的二进制数表示,第三权重矩阵中的元素以第六比特数的二进制数表示,第五比特数与第六比特数可以相同,也可以不相同,第五比特数与第六比特数均大于或等于目标比特数,第五比特数与目标比特数之间的商为2的整数倍,第六比特数与目标比特数之间的商为2的整数倍。例如,第五比特数为8,第六比特数为4,目标比特数为4,又例如,第五比特数为16,第六比特数为8比特,目标比特数为4。可以理解的是,对输出层的第三激活矩阵和第三权重矩阵进行量化的具体实现过程可以参照前述对输入层的第一激活矩阵和第一权重矩阵进行量化的详细描述,此处不做赘述。The elements in the third activation matrix are represented by the binary numbers of the fifth bit number, and the elements in the third weight matrix are represented by the binary numbers of the sixth bit number, and the fifth bit number and the sixth bit number may be the same or may be Not the same, the fifth and sixth bits are both greater than or equal to the target number of bits, the quotient between the fifth and the target number of bits is an integer multiple of 2, and the quotient between the sixth and the target number of bits is an integer multiple of 2. For example, the number of fifth bits is 8, the number of sixth bits is 4, and the number of target bits is 4; for another example, the number of fifth bits is 16, the number of sixth bits is 8 bits, and the number of target bits is 4. It can be understood that the specific implementation process of quantizing the third activation matrix and the third weight matrix of the output layer can refer to the foregoing detailed description of the quantization of the first activation matrix and the first weight matrix of the input layer, which is not described here. Repeat.
在一实施例中,对目标神经网络的输入层、中间层和输出层进行量化后,量化后的输出层的输出结果是以目标比特数的二进制数表示的,精度较低,因此,为解决上述问题,在对目标神经网络的输入层、中间层和输出层进行量化后,获取量化后的输出层的输出结果对应的第一矩阵,即获取量化后的输出层的输出结果对应的第一矩阵的方式可以为:获取输出层的输入信息对应的第三矩阵,并对第三矩阵和量化后的第三权重矩阵进行卷积运算,得到输出层的输出结果对应的第一矩阵;对第一矩阵进行量化,得到输出层的输出结果对应的第二矩阵。其中,第一矩阵中的元素以目标比特数的二进制数表示,第二矩阵中的元素均以第六比特数的二进制数表示。通过将输出层的输出结果以高比特数的二进制数表示,可以提高输出层的精度。In one embodiment, after quantizing the input layer, the middle layer and the output layer of the target neural network, the output result of the quantized output layer is represented by the binary number of the target number of bits, and the precision is low. For the above problem, after quantizing the input layer, intermediate layer and output layer of the target neural network, the first matrix corresponding to the output result of the quantized output layer is obtained, that is, the first matrix corresponding to the output result of the quantized output layer is obtained. The matrix method may be: obtaining a third matrix corresponding to the input information of the output layer, and performing a convolution operation on the third matrix and the quantized third weight matrix to obtain a first matrix corresponding to the output result of the output layer; A matrix is quantized to obtain a second matrix corresponding to the output result of the output layer. Wherein, the elements in the first matrix are represented by the binary numbers of the target number of bits, and the elements in the second matrix are all represented by the binary numbers of the sixth bit number. The accuracy of the output layer can be improved by representing the output of the output layer as a high-bit binary number.
示例性的,根据第六比特数和目标比特数,确定第一矩阵中的元素的二进 制数的拼接个数,即确定第六比特数与目标比特数的商,并将第六比特数与目标比特数的商确定为第一矩阵中的元素的二进制数的拼接个数;确定第一矩阵中的元素的拼接个数的拼接二进制数;对第一矩阵中的各元素的拼接个数的拼接二进制数进行拼接,得到包括均以第六比特数的二进制数表示的元素的第二矩阵。例如,第六比特数为8,目标比特数为4,则第六比特数与目标比特数的商为2,因此,第一矩阵中的元素的二进制数的拼接个数为2,设确定的第一矩阵中的元素的2个拼接二进制数分别为1001与0111,则将拼接二进制数1001与拼接二进制数0111进行拼接,得到以二进制数10010111或者01111001表示的元素。Exemplarily, according to the sixth bit number and the target bit number, determine the number of spliced binary numbers of the elements in the first matrix, that is, determine the quotient of the sixth bit number and the target bit number, and compare the sixth bit number with the target number of bits. The quotient of the number of bits is determined as the splicing number of the binary numbers of the elements in the first matrix; the splicing binary number of the splicing numbers of the elements in the first matrix is determined; the splicing of the splicing numbers of the elements in the first matrix The binary numbers are spliced to obtain a second matrix including elements represented by binary numbers of the sixth bit number. For example, if the sixth bit number is 8 and the target bit number is 4, the quotient of the sixth bit number and the target bit number is 2. Therefore, the number of spliced binary numbers of the elements in the first matrix is 2. The two concatenated binary numbers of the elements in the first matrix are 1001 and 0111 respectively, then the concatenated binary number 1001 and the concatenated binary number 0111 are concatenated to obtain the element represented by the binary number 10010111 or 01111001.
上述实施例提供的神经网络量化方法,通过将待量化的目标神经网络的输入层、输出层和中间层的激活矩阵和权重矩阵中的元素均量化为以相同的低比特数的二进制数表示,可以减少运行量化后的神经网络的计算量,也可以降低运行神经网络所需的芯片的设计复杂度,极大的提高了用户体验。The neural network quantization method provided by the above embodiment, by quantizing the elements in the activation matrix and the weight matrix of the input layer, output layer and intermediate layer of the target neural network to be quantized into binary numbers with the same low bit number, It can reduce the calculation amount of running the quantized neural network, and also can reduce the design complexity of the chip required for running the neural network, which greatly improves the user experience.
请参阅图4,图4是本申请实施例提供的一种神经网络量化装置的结构示意性框图。Please refer to FIG. 4. FIG. 4 is a schematic structural block diagram of a neural network quantization apparatus provided by an embodiment of the present application.
如图4所示,该神经网络量化装置200包括处理器201和存储器202,处理器201和存储器202通过总线203连接,该总线203比如为I2C(Inter-integrated Circuit)总线。As shown in FIG. 4 , the neural
具体地,处理器201可以是微控制单元(Micro-controller Unit,MCU)、中央处理单元(Central Processing Unit,CPU)或数字信号处理器(Digital Signal Processor,DSP)等。Specifically, the
具体地,存储器202可以是Flash芯片、只读存储器(ROM,Read-Only Memory)磁盘、光盘、U盘或移动硬盘等。Specifically, the
其中,所述处理器201用于运行存储在存储器202中的计算机程序,并在执行所述计算机程序时实现如下步骤:Wherein, the
获取待量化的目标神经网络,其中,所述目标神经网络包括输入层、输出层和中间层,所述输入层与所述中间层连接,所述中间层与所述输出层连接;obtaining a target neural network to be quantified, wherein the target neural network includes an input layer, an output layer and an intermediate layer, the input layer is connected to the intermediate layer, and the intermediate layer is connected to the output layer;
对所述输入层的第一激活矩阵和第一权重矩阵进行量化,使得量化后的第一激活矩阵和第一权重矩阵中的元素均以目标比特数的二进制数表示;The first activation matrix and the first weight matrix of the input layer are quantized, so that the elements in the quantized first activation matrix and the first weight matrix are represented by the binary number of the target number of bits;
对所述中间层的第二激活矩阵和第二权重矩阵进行量化,使得量化后的第二激活矩阵和第二权重矩阵中的元素均以所述目标比特数的二进制数表示;The second activation matrix and the second weight matrix of the intermediate layer are quantized, so that the elements in the quantized second activation matrix and the second weight matrix are all represented by the binary number of the target number of bits;
对所述输出层的第三激活矩阵和第三权重矩阵进行量化,使得量化后的第 三激活矩阵和第三权重矩阵中的元素均以所述目标比特数的二进制数表示。The third activation matrix and the third weight matrix of the output layer are quantized, so that the elements in the quantized third activation matrix and the third weight matrix are all represented by binary numbers of the target number of bits.
在一实施例中,所述目标神经网络包括如下至少一种:卷积神经网络、循环卷积神经网络、深度卷积神经网络。In an embodiment, the target neural network includes at least one of the following: a convolutional neural network, a recurrent convolutional neural network, and a deep convolutional neural network.
在一实施例中,所述第一激活矩阵中的元素以第一比特数的二进制数表示,所述第一比特数大于所述目标比特数,且所述第一比特数与所述目标比特数之间的商为2的整数倍。In one embodiment, the elements in the first activation matrix are represented by binary numbers of a first number of bits, the first number of bits is greater than the target number of bits, and the first number of bits is the same as the target number of bits. The quotient between numbers is an integer multiple of 2.
在一实施例中,所述第一激活矩阵中的元素以第一比特数的二进制数表示,所述处理器在实现对所述输入层的第一激活矩阵进行量化时,用于实现:In an embodiment, the elements in the first activation matrix are represented by a binary number of a first bit number, and when the processor quantizes the first activation matrix of the input layer, the processor is configured to:
根据所述第一比特数和所述目标比特数,确定所述第一激活矩阵中的元素的第一拆分个数;Determine the first split number of elements in the first activation matrix according to the first number of bits and the target number of bits;
根据所述第一拆分个数,将所述第一激活矩阵中的元素拆分为以所述目标比特数的二进制数表示的目标元素。According to the first split number, the elements in the first activation matrix are split into target elements represented by binary numbers of the target number of bits.
在一实施例中,所述第一权重矩阵中的元素以第二比特数的二进制数表示,所述第二比特数大于或等于所述目标比特数,所述处理器在实现对所述输入层的第一权重矩阵进行量化时,用于实现:In one embodiment, the elements in the first weight matrix are represented by binary numbers of a second bit number, and the second bit number is greater than or equal to the target bit number, and the processor implements the input When the first weight matrix of the layer is quantized, it is used to achieve:
根据所述第二比特数和所述目标比特数,确定所述第一权重矩阵中的元素的第二拆分个数;According to the second number of bits and the target number of bits, determine the second split number of elements in the first weight matrix;
根据所述第二拆分个数,将所述第一权重矩阵中的元素拆分为以所述目标比特数的二进制数表示的元素,得到第一目标权重矩阵;According to the second split number, the elements in the first weight matrix are split into elements represented by the binary numbers of the target number of bits to obtain a first target weight matrix;
对所述第一目标权重矩阵中的以所述目标比特数的二进制数表示的元素进行初始化。Initializing the elements in the first target weight matrix represented by the binary numbers of the target number of bits.
在一实施例中,所述初始化包括随机初始化和常数初始化中的任一项。In one embodiment, the initialization includes any one of random initialization and constant initialization.
在一实施例中,量化后的所述第一权重矩阵的第一元素总数与量化前的所述第一权重矩阵的第二元素总数的比值等于所述第二拆分个数。In one embodiment, the ratio of the total number of first elements of the first weight matrix after quantization to the total number of second elements of the first weight matrix before quantization is equal to the second number of divisions.
在一实施例中,量化前的所述第三权重矩阵中的元素以第六比特数的二进制数表示,所述第六比特数大于所述目标比特数,所述处理器在实现对所述输出层的第三激活矩阵和第三权重矩阵进行量化之后,还用于实现:In an embodiment, the elements in the third weight matrix before quantization are represented by a binary number of a sixth bit number, and the sixth bit number is greater than the target bit number, and the processor implements the After the third activation matrix and the third weight matrix of the output layer are quantized, they are also used to achieve:
获取所述输出层的输出结果对应的第一矩阵,其中,所述第一矩阵中的元素以所述目标比特数的二进制数表示;obtaining the first matrix corresponding to the output result of the output layer, wherein the elements in the first matrix are represented by the binary number of the target number of bits;
对所述第一矩阵进行量化,得到所述输出层的输出结果对应的第二矩阵,所述第二矩阵中的元素均以所述第六比特数的二进制数表示。The first matrix is quantized to obtain a second matrix corresponding to the output result of the output layer, and the elements in the second matrix are all represented by binary numbers of the sixth bit number.
在一实施例中,所述处理器在实现对所述第一矩阵进行量化,得到所述输 出层的输出结果对应的第二矩阵时,用于实现:In one embodiment, when the processor is implemented to quantize the first matrix to obtain the second matrix corresponding to the output result of the output layer, it is used to implement:
根据所述第六比特数和所述目标比特数,确定所述第一矩阵中的元素的二进制数的拼接个数;According to the sixth bit number and the target bit number, determine the number of spliced binary numbers of the elements in the first matrix;
确定所述第一矩阵中的元素的所述拼接个数的拼接二进制数;Determine the splicing binary number of the described splicing number of elements in the first matrix;
对所述第一矩阵中的各元素的所述拼接个数的拼接二进制数进行拼接,得到包括均以所述第六比特数的二进制数表示的元素的第二矩阵。The spliced binary numbers of the spliced numbers of the elements in the first matrix are spliced to obtain a second matrix including elements all represented by the binary numbers of the sixth bit number.
在一实施例中,所述处理器在实现获取所述输出层的输出结果对应的第一矩阵时,用于实现:In one embodiment, when the processor acquires the first matrix corresponding to the output result of the output layer, the processor is configured to:
获取所述输出层的输入信息对应的第三矩阵;obtaining a third matrix corresponding to the input information of the output layer;
对所述第三矩阵和量化后的所述第三权重矩阵进行卷积运算,得到所述输出层的输出结果对应的第一矩阵。A convolution operation is performed on the third matrix and the quantized third weight matrix to obtain a first matrix corresponding to the output result of the output layer.
需要说明的是,所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的神经网络量化装置的具体工作过程,可以参考前述神经网络量化方法实施例中的对应过程,在此不再赘述。It should be noted that those skilled in the art can clearly understand that, for the convenience and brevity of description, for the specific working process of the neural network quantization device described above, reference may be made to the corresponding process in the foregoing embodiments of the neural network quantization method. This will not be repeated here.
请参阅图5,图5是本申请实施例提供的一种神经网络量化设备的结构示意性框图。Please refer to FIG. 5. FIG. 5 is a schematic structural block diagram of a neural network quantization device provided by an embodiment of the present application.
如图5所示,神经网络量化设备300包括神经网络量化装置310。其中,神经网络量化装置310可以为图4中的神经网络量化装置。神经网络量化设备300可以是终端设备,也可以是服务器。As shown in FIG. 5 , the neural
需要说明的是,所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的神经网络量化设备的具体工作过程,可以参考前述神经网络量化方法实施例中的对应过程,在此不再赘述。It should be noted that those skilled in the art can clearly understand that, for the convenience and brevity of the description, for the specific working process of the neural network quantization device described above, reference may be made to the corresponding process in the foregoing embodiments of the neural network quantization method. This will not be repeated here.
本申请实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序中包括程序指令,所述处理器执行所述程序指令,实现上述实施例提供的神经网络量化方法的步骤。Embodiments of the present application further provide a computer-readable storage medium, where a computer program is stored in the computer-readable storage medium, the computer program includes program instructions, and the processor executes the program instructions, so as to realize the provision of the above embodiments. The steps of the neural network quantization method.
其中,所述计算机可读存储介质可以是前述任一实施例所述的神经网络量化设备的内部存储单元,例如所述神经网络量化设备的硬盘或内存。所述计算机可读存储介质也可以是所述神经网络量化设备的外部存储设备,例如所述神经网络量化设备上配备的插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)等。The computer-readable storage medium may be an internal storage unit of the neural network quantization device described in any of the foregoing embodiments, such as a hard disk or a memory of the neural network quantization device. The computer-readable storage medium can also be an external storage device of the neural network quantification device, such as a plug-in hard disk equipped on the neural network quantification device, a smart memory card (Smart Media Card, SMC), a secure digital ( Secure Digital, SD) card, flash memory card (Flash Card), etc.
应当理解,在此本申请说明书中所使用的术语仅仅是出于描述特定实施例的目的而并不意在限制本申请。如在本申请说明书和所附权利要求书中所使用 的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。It should be understood that the terms used in the specification of the present application herein are for the purpose of describing particular embodiments only and are not intended to limit the present application. As used in this specification and the appended claims, the singular forms "a," "an," and "the" are intended to include the plural forms unless the context clearly dictates otherwise.
还应当理解,在本申请说明书和所附权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。It will also be understood that, as used in this specification and the appended claims, the term "and/or" refers to and including any and all possible combinations of one or more of the associated listed items.
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以权利要求的保护范围为准。The above are only specific embodiments of the present application, but the protection scope of the present application is not limited thereto. Any person skilled in the art can easily think of various equivalents within the technical scope disclosed in the present application. Modifications or substitutions shall be covered by the protection scope of this application. Therefore, the protection scope of the present application shall be subject to the protection scope of the claims.
Claims (21)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2021/072577WO2022151505A1 (en) | 2021-01-18 | 2021-01-18 | Neural network quantization method and apparatus, and computer-readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2021/072577WO2022151505A1 (en) | 2021-01-18 | 2021-01-18 | Neural network quantization method and apparatus, and computer-readable storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022151505A1true WO2022151505A1 (en) | 2022-07-21 |
Family
ID=82446810
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2021/072577CeasedWO2022151505A1 (en) | 2021-01-18 | 2021-01-18 | Neural network quantization method and apparatus, and computer-readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2022151505A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024216624A1 (en)* | 2023-04-21 | 2024-10-24 | Robert Bosch Gmbh | Training deep neural networks with 4-bit integers |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109190754A (en)* | 2018-08-30 | 2019-01-11 | 北京地平线机器人技术研发有限公司 | Quantitative model generation method, device and electronic equipment |
| CN110413255A (en)* | 2018-04-28 | 2019-11-05 | 北京深鉴智能科技有限公司 | Artificial neural network method of adjustment and device |
| CN111105017A (en)* | 2019-12-24 | 2020-05-05 | 北京旷视科技有限公司 | Neural network quantization method and device and electronic equipment |
| CN112189216A (en)* | 2019-08-29 | 2021-01-05 | 深圳市大疆创新科技有限公司 | Data processing method and device |
- 2021
- 2021-01-18WOPCT/CN2021/072577patent/WO2022151505A1/ennot_activeCeased
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110413255A (en)* | 2018-04-28 | 2019-11-05 | 北京深鉴智能科技有限公司 | Artificial neural network method of adjustment and device |
| CN109190754A (en)* | 2018-08-30 | 2019-01-11 | 北京地平线机器人技术研发有限公司 | Quantitative model generation method, device and electronic equipment |
| CN112189216A (en)* | 2019-08-29 | 2021-01-05 | 深圳市大疆创新科技有限公司 | Data processing method and device |
| CN111105017A (en)* | 2019-12-24 | 2020-05-05 | 北京旷视科技有限公司 | Neural network quantization method and device and electronic equipment |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024216624A1 (en)* | 2023-04-21 | 2024-10-24 | Robert Bosch Gmbh | Training deep neural networks with 4-bit integers |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI830938B (en) | Method and system of quantizing artificial neural network and artificial neural network apparatus | |
| US11249721B2 (en) | Multiplication circuit, system on chip, and electronic device | |
| US12254398B2 (en) | Sparse machine learning acceleration | |
| US11853594B2 (en) | Neural network computing chip and computing method | |
| CN110520870A (en) | Flexible hardware for high-throughput vector dequantization with dynamic vector length and codebook size | |
| WO2021135715A1 (en) | Image compression method and apparatus | |
| US10452717B2 (en) | Technologies for node-degree based clustering of data sets | |
| CN111985632A (en) | Decompression apparatus and control method thereof | |
| WO2018107383A1 (en) | Neural network convolution computation method and device, and computer-readable storage medium | |
| WO2021081854A1 (en) | Convolution operation circuit and convolution operation method | |
| CN111353598A (en) | Neural network compression method, electronic device and computer readable medium | |
| JP7233636B2 (en) | Data quantization processing method, device, electronic device and storage medium | |
| WO2020001401A1 (en) | Operation method and apparatus for network layer in deep neural network | |
| CN116601585A (en) | Data type aware clock gating | |
| CN113255922A (en) | Quantum entanglement quantization method and device, electronic device and computer readable medium | |
| CN111860841A (en) | Optimization method, device, terminal and storage medium for quantitative model | |
| CN118194954B (en) | Training method and device for neural network model, electronic equipment and storage medium | |
| WO2021073638A1 (en) | Method and apparatus for running neural network model, and computer device | |
| CN115511071A (en) | Model training method and device and readable storage medium | |
| US12346789B2 (en) | System and method for execution of inference models across multiple data processing systems | |
| WO2022151505A1 (en) | Neural network quantization method and apparatus, and computer-readable storage medium | |
| CN105630999A (en) | Data compressing method and device of server | |
| CN111177479B (en) | Method and device for acquiring feature vector of node in relational network graph | |
| CN109740730B (en) | Operation method, device and related product | |
| WO2025055033A1 (en) | Method and device for artificial intelligence computing, and medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | Ref document number:21918705 Country of ref document:EP Kind code of ref document:A1 | |
| NENP | Non-entry into the national phase | Ref country code:DE | |
| 122 | Ep: pct application non-entry in european phase | Ref document number:21918705 Country of ref document:EP Kind code of ref document:A1 |