WO2022022667A1 - Gene screening-based alcohol tolerance prediction system - Google Patents
Gene screening-based alcohol tolerance prediction systemDownload PDFInfo
- Publication number
- WO2022022667A1 WO2022022667A1PCT/CN2021/109457CN2021109457WWO2022022667A1WO 2022022667 A1WO2022022667 A1WO 2022022667A1CN 2021109457 WCN2021109457 WCN 2021109457WWO 2022022667 A1WO2022022667 A1WO 2022022667A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- drinking
- data
- user
- gene
- module
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/60—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to nutrition control, e.g. diets
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/04—Forecasting or optimisation specially adapted for administrative or management purposes, e.g. linear programming or "cutting stock problem"
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
Definitions
- the inventionrelates to the technical field of biological genes, in particular to a system for predicting alcohol consumption based on genetic screening.
- alcoholAfter alcohol enters the human body, it enters the blood circulation directly through the biofilm through the oral cavity, esophagus, stomach, intestine and other organs, and is quickly transported to various tissues and organs of the body for metabolism and utilization.
- Alcohol metabolismis mainly completed by two enzymes (alcohol dehydrogenase and aldehyde dehydrogenase), and the difference in drinking ability (alcohol amount) between individuals is mainly determined by the activities of these two enzymes, and the activity of the enzymes is determined by the gene In the final analysis, the amount of alcohol a person can drink is determined by genetics.
- the present inventionaims to solve one of the technical problems in the above technologies at least to a certain extent.
- the purpose of the present inventionis to propose a drinking quantity prediction system based on genetic screening, which provides a drinking quantity judgment standard, quantifies an individual's drinking ability, and gives a more intuitive and valuable alcohol quantity evaluation and drinking according to the user's physical condition. Recommendations to improve user experience.
- the embodiment of the present inventionproposes a system for predicting alcohol consumption based on genetic screening, including:
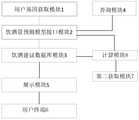
- the user gene acquisition moduleis used to obtain the user's genetic data
- the drinking volume prediction model interface moduleis connected with the user gene acquisition module, and inputs the user's genetic data into the drinking volume prediction model to predict the drinking volume of the user, and obtains the first prediction result of the drinking volume;
- a drinking suggestion database moduleconnected with the drinking quantity prediction model interface module, and used for giving drinking suggestions according to the first prediction result of the drinking quantity of the user;
- a query moduleconnected with the interface module of the drinking volume prediction model, and used for querying the relationship between the drinking volume-related genes, the drinking rank and the drinking volume, and the drinking advice corresponding to the drinking tier in the drinking volume prediction model;
- the display moduleis connected with the drinking suggestion database module, and is used for displaying the user's genetic data, the prediction result of drinking amount, and the drinking suggestion.
- the user's genetic datais obtained, and the user's genetic data is input into the alcohol consumption prediction model to predict the user's alcohol consumption, wherein the alcohol consumption prediction model adopts a decision tree classification model Construct, get the first prediction result of drinking amount, give drinking suggestion according to the first prediction result of user's drinking amount through the drinking suggestion database module, and finally display the user's genetic data, the predicted result of drinking amount, and drinking suggestion through the display module , according to the user's physical condition, it will give more intuitive and valuable alcohol evaluation and drinking suggestions to improve the user's experience.
- the query moduleis used to query the relationship between alcohol consumption-related genes, drinking grades and alcohol consumption, and drinking recommendations corresponding to drinking grades based on the alcohol consumption prediction model. related information.
- the user gene acquisition moduleincludes:
- a first obtaining moduleused to obtain the saliva of the user
- a first processing moduleconnected to the first acquisition module, for extracting DNA from the saliva of the user, and performing gene sequencing on the extracted DNA;
- the second processing moduleis connected to the first processing module, and is used to perform bioinformatics analysis after gene sequencing, obtain the genotype of the specified site, and format the genotype data of the specified site rs1229984 and rs671.
- the alcohol consumption prediction modelis constructed by selecting a machine learning model, including:
- the acquiring genetic data of the sample and formatting the genetic dataincludes:
- S23Process the gene data after gene sequencing to obtain the genotype of the locus related to the alcohol consumption of each sample;
- genetic locus screeningis performed on the genetic data of the formatted sample, including:
- the methodfurther includes: a user terminal, connected to the display module, for receiving relevant data information sent by the display module to facilitate viewing by the user.
- a second obtaining moduleconfigured to obtain second information that affects the drinking amount of the user, the second information including: disease history, drinking type, drinking degree, and drinking frequency;
- the calculation moduleis connected with the interface module of the drinking volume prediction model, the second acquisition module, and the drinking recommendation database module, and is used for calculating the drinking volume according to the first prediction result and the second information according to a preset algorithm The second prediction result of ;
- the drinking suggestion database moduleis further configured to give drinking suggestions according to the second prediction result of the drinking amount of the user.
- the preset algorithmincludes:
- V 1A ⁇ c
- Ais the drinking volume (ml) output by the alcohol volume prediction model based on the user's genetic data
- cis the preset alcohol concentration (%vol) in the alcohol volume prediction model
- V 2V 1 ⁇ d ⁇ t ⁇ f
- dis the correlation coefficient between the user's disease history and drinking amount
- tis the correlation coefficient between drinking type and drinking amount
- fis the correlation coefficient between drinking frequency and drinking amount
- cuis the drinking degree input by the user.
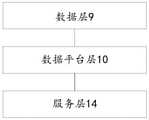
- the genetic screening-based alcohol consumption prediction systemuses SOA system architecture; including:
- the data layeris used to obtain user data according to the data source
- a data platform layerconnected to the data layer, for providing a development environment for data management
- the service layerconnected with the data platform layer, is used for receiving data information sent by the data platform, and providing services for data consumers according to the data information.
- FIG. 1is a block diagram of a genetic screening-based alcohol consumption prediction system according to an embodiment of the present invention
- FIG. 2is a block diagram of a user gene acquisition module according to an embodiment of the present invention.
- FIG. 3is a flowchart of a method for constructing a drinking quantity prediction model according to an embodiment of the present invention
- FIG. 4is a flowchart of processing genetic data of a sample according to an embodiment of the present invention.
- Fig. 5is a flow chart of the screening of genetic loci related to alcohol consumption according to an embodiment of the present invention.
- FIG. 6is a block diagram of a genetic screening-based alcohol consumption prediction system according to yet another embodiment of the present invention.
- FIG. 7is a block diagram of an SOA system architecture according to an embodiment of the present invention.
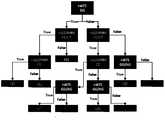
- FIG. 8is a schematic diagram of a decision tree of drinking quantity-related genes and drinking rank according to an embodiment of the present invention.
- User gene acquisition module 1first acquisition module 11, first processing module 12, second processing module 13, drinking quantity prediction model interface module 2, drinking suggestion database module 3, query module 4, display module 5, user terminal 6,
- the second acquisition module 7the calculation module 8 , the data layer 9 , the data platform layer 10 , and the service layer 14 .
- the followingdescribes a system for predicting the amount of alcohol consumption based on genetic screening proposed in an embodiment of the present invention with reference to FIG. 1 to FIG. 8 .
- Fig. 1is a block diagram of a system for predicting alcohol consumption based on genetic screening according to an embodiment of the present invention; as shown in Fig. 1, an embodiment of the present invention proposes a system for predicting alcohol consumption based on genetic screening, including:
- User gene acquisition module 1used to acquire the user's genetic data
- the drinking volume prediction model interface module 2is connected to the user gene acquisition module 1, and inputs the user's genetic data into the drinking volume prediction model to predict the drinking volume of the user, and obtains the first prediction result of the drinking volume;
- the drinking suggestion database module 3is connected with the drinking quantity prediction model interface module 2, and is used for giving drinking suggestions according to the first prediction result of the drinking quantity of the user;
- a query module 4connected with the drinking volume prediction model interface module 2, is used to query the relationship between the drinking volume-related genes, the drinking rank and the drinking volume, and the drinking advice corresponding to the drinking rank in the drinking volume prediction model;
- the display module 5is connected with the drinking suggestion database module 3, and is used for displaying the user's genetic data, the prediction result of the drinking amount, and the drinking suggestion.
- the user's genetic datais obtained, and the user's genetic data is input into the alcohol consumption prediction model to predict the user's alcohol consumption, wherein the alcohol consumption prediction model adopts a decision tree classification model Construct, get the first prediction result of drinking amount, give drinking suggestion according to the first prediction result of user's drinking amount through the drinking suggestion database module, and finally display the user's genetic data, the predicted result of drinking amount, and drinking suggestion through the display module , according to the user's physical condition, it will give more intuitive and valuable alcohol evaluation and drinking suggestions to improve the user's experience.
- the query moduleis used to query the relationship between alcohol consumption-related genes, drinking grades and alcohol consumption, and drinking recommendations corresponding to drinking grades based on the alcohol consumption prediction model. related information.
- Fig. 2is a block diagram of a user gene acquisition module according to an embodiment of the present invention. As shown in Fig. 2, the user gene acquisition module 1 includes:
- the first obtaining module 11is used to obtain the saliva of the user
- the first processing module 12connected with the first acquisition module 11, is used to extract DNA from the saliva of the user, and perform gene sequencing on the extracted DNA;
- the second processing module 13is connected to the first processing module 12, and is used to perform bioinformatics analysis after gene sequencing, obtain the genotype of the specified site, and format the genotype data of the specified site rs1229984 and rs671 .
- DNA extraction and chip sequencingare performed according to the saliva of the user, the rs1229984 gene locus and the rs671 gene locus of the user are found out, and the genotype data of the designated loci rs1229984 and rs671 are formatted and processed , to obtain the genetic data related to the user's alcohol consumption, which is convenient and fast.
- Fig. 3is a flow chart of a method for constructing an alcohol consumption prediction model according to an embodiment of the present invention. As shown in Fig. 3, the alcohol consumption prediction model is constructed by selecting a machine learning model, including:
- the working principle and beneficial effects of the above technical solutionsobtain the relationship between the drinking ability and the drinking amount of the sample through a questionnaire survey method, and carry out data analysis, divide the drinking amount into a first preset number of drinking grades, and establish a first database. Dividing alcohol consumption into drinking grades and quantifying alcohol consumption can help to give more valuable drinking advice.
- the genetic data of the sampleis formatted, and the alcohol consumption prediction model is constructed according to the genetic data of the formatted sample and the first database.
- FIG. 4is a flowchart of processing genetic data of a sample according to an embodiment of the present invention. As shown in FIG. 4 , the acquiring and formatting the genetic data of the sample includes:
- S23Process the gene data after gene sequencing to obtain the genotype of the locus related to the alcohol consumption of each sample;
- DNA extraction, gene sequencing, and genotypingare performed on the saliva of the sample to obtain the genetic data of the sample; the gene sequencing methods include: chip sequencing, second-generation sequencing, third-generation sequencing, PCR sequencing, At least one of panel sequencing.
- the genotypes of the loci related to the alcohol consumption of each sampleare obtained.
- the lociare formatted into numbers according to the genotype. Illustratively, wild type is 0, heterozygous mutant is 1, and homozygous mutant is 2.
- CCis a homozygous mutant, formatted as a number 2;
- TTis a wild type, formatted as a number 0;
- CTis a heterozygous mutant, formatted as a number 1; such as at the rs671 locus
- AAis a homozygous mutant, formatted as a number 2;
- GGis a wild type, formatted as a number 0;
- AGis a heterozygous mutant, formatted as a number 1.
- Fig. 5is a flow chart of the screening of gene loci related to alcohol consumption according to an embodiment of the present invention. As shown in Fig. 5, the gene locus screening is performed on the gene data of the formatted sample, including:
- the method for measuring the purity and uncertainty of the data set before and after dividing the data setincludes calculating at least one parameter in the information gain, the information gain rate, and the Gini coefficient. Specifically, the method is determined according to the Gini coefficient. In the method of purity and uncertainty, the larger the Gini coefficient, the higher the uncertainty of the data, and the lower the sample purity, indicating that the proportion of the target sample in the data set to the total sample is smaller; the smaller the Gini coefficient, the uncertainty of the data.
- the Gini coefficientis equal to 0, all samples in the dataset are of the same class.
- the result of the rs671 locus of the sampleis GG, that is, it is determined whether the format of the rs671 locus of the sample is 0, and according to whether the rs671 locus is 0, the first
- the databaseis divided into two data sets, the first data set and the second data set, wherein the rs671 gene locus of the samples in the first data set is GG, and the rs671 gene locus results of the samples in the second data set are AA and AG; Calculate the Gini coefficient of the eigenvalues of each gene locus in the first data set and the second data set, and select the gene locus A with the smallest calculated Gini coefficient and the eigenvalue a of the gene locus A, wherein the all The gene locus A is used as a child node, and the data set is split again according to the grouping of the characteristic value a of the gene locus A; for example, in the first data set, it is judged
- the drinking segmentis 8 segments.
- each groupis a sample of the same type, that is, the Gini coefficient is 0.
- the splittingis stopped, and the gene loci related to the amount of drinking and the relationship between the gene locus and the drinking rank are finally obtained.
- the genes related to alcohol consumptionare divided into corresponding drinking grades according to their gene types, which is convenient for memory, and can accurately reflect the corresponding relationship between gene types and alcohol consumption, which is clear at a glance and improves user experience.
- the loci related to alcohol consumptioninclude the rs1229984 locus and the rs671 locus, wherein the rs1229984 locus is located on the ADH1B gene, and when the result of the rs1229984 locus is TT type, The activity of alcohol dehydrogenase is strong, and the metabolism of ethanol is fast; the result is CT type, the activity of alcohol dehydrogenase is moderate, and the rate of alcohol metabolism is moderate; the result is that the activity of alcohol dehydrogenase is weak, and the rate of alcohol metabolism is slow; the rs671 gene locus is located in In the ALDH2 gene, when the rs671 gene locus was GG type, the activity of acetaldehyde dehydrogenase was strong, and the acetaldehyde metabolism was fast; when the result was GA ⁇ AA type, the activity of acetaldehyde dehydrogenase was weak, and the metabolism of acetalde
- a decision tree classification modelis selected to construct a drinking quantity prediction model.
- a decision tree classification modelwas used to construct a drinking consumption prediction model
- Algorithmsinclude:
- DecisionTreeClassifier modulemain parameter settings:
- criterion'gini': select the Gini coefficient as the metric for the quality of node division;
- splitter'best': find the best split point among all features
- max_depthNone: Set the maximum depth of the decision tree, None means that the maximum depth of the decision tree is not constrained until the samples on each leaf node belong to the same class;
- min_samples_split2: When dividing an internal node, the minimum number of samples on the node is required to be 2;
- min_samples_leaf1: Set the minimum number of samples on the leaf node to 1;
- the first preset numberis 7, and the drinking rank is 7 ranks, and the relationship between the rs1229984 locus and the rs671 locus and the drinking amount is obtained as shown in Table 2.
- the working principle and beneficial effects of the above technical solutionswhen the drinking rank is 0, there are three situations: 1.
- the rs1229984 locusis CC, and the rs671 locus is AA; 2.
- the rs1229984 locusis TT and the rs671 locus 3.
- the rs1229984 locusis CT, and the rs671 locus is AA.
- the naming of drinking tiersis done in a discontinuous way. If 3 and 6 tiers are missing, the discontinuous naming can match the drinking tier with the specific amount of alcohol consumed. For example, when the drinking tier is 9, the user The amount of alcohol consumed is 9 taels or more.
- Fig. 6is a block diagram of a system for predicting alcohol consumption based on genetic screening according to yet another embodiment of the present invention; as shown in Fig. 6 , it further includes: a user terminal 6, connected to the display module, for receiving relevant information sent by the display module Data information is convenient for users to view.
- a second obtaining module 7configured to obtain second information that affects the drinking amount of the user, where the second information includes: disease history, drinking type, drinking degree, and drinking frequency;
- the calculation module 8is connected with the interface module of the drinking quantity prediction model, the second acquisition module, and the drinking suggestion database module, and is used for calculating the drinking alcohol according to the first prediction result and the second information according to a preset algorithm. the second prediction result of the quantity;
- the drinking suggestion database module 3is further configured to give drinking suggestions according to the second prediction result of the drinking amount of the user.
- the first prediction result of the drinking amount output by the drinking amount prediction model based on the user's genetic datais combined with the second information that affects the drinking amount of the user to modify the prediction of the drinking amount,
- the second informationincludes: disease history, drinking type, drinking degree, drinking frequency; for example, as shown in Table 2, if the user's genetic data is rs1229984 locus CC, rs671 locus is GG, then the user's drinking The volume is predicted to be 7 segments, that is, the user can drink more than 7 taels of wine (take 50° liquor as an example), but the user has recently suffered from stomach problems and cannot drink alcohol. Drinking alcohol can easily cause gastric perforation, which seriously endangers health.
- the prediction of the user's drinking amountwill also be affected.
- the second prediction result of drinking amountis calculated and obtained, which can make more effective drinking amount prediction according to the actual situation of the user, and the prediction result is more accurate.
- the preset algorithmincludes:
- V 1A ⁇ c
- Ais the drinking volume (ml) output by the alcohol volume prediction model based on the user's genetic data
- cis the preset alcohol concentration (%vol) in the alcohol volume prediction model
- V 2V 1 ⁇ d ⁇ t ⁇ f
- dis the correlation coefficient between the user's disease history and drinking amount
- tis the correlation coefficient between drinking type and drinking amount
- fis the correlation coefficient between drinking frequency and drinking amount
- cuis the drinking degree input by the user.
- the correlation coefficient d between the user's disease history and alcohol consumptionis 0, that is, the user cannot drink alcohol; other users' disease history
- the value of the correlation coefficient d with the amount of drinkingis between 0 and 1; the value of the correlation coefficient t between the type of drinking and the amount of drinking is shown in Table 3; the value of the correlation coefficient f between the frequency of drinking and the amount of drinking is shown in Table 4.
- the first prediction result of drinking quantityis revised, and the second prediction result of drinking quantity is calculated, which can make more effective prediction of drinking quantity according to the actual situation of the user, the prediction result is more accurate, and the most correct user is given. drinking recommendations to improve user experience.
- FIG. 8is a block diagram of an SOA system architecture according to an embodiment of the present invention. As shown in FIG. 8 , the genetic screening-based alcohol consumption prediction system uses the SOA system architecture; including:
- the data layer 9is used to obtain user data according to the data source
- a data platform layer 10, connected to the data layer 9,is used to provide a development environment for data management;
- the service layer 14, connected to the data platform layer 10,is used for receiving data information sent by the data platform, and providing services for data consumers according to the data information.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- Business, Economics & Management (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- General Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Physics & Mathematics (AREA)
- Economics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Human Resources & Organizations (AREA)
- Strategic Management (AREA)
- Game Theory and Decision Science (AREA)
- General Engineering & Computer Science (AREA)
- Operations Research (AREA)
- Quality & Reliability (AREA)
- Tourism & Hospitality (AREA)
- Entrepreneurship & Innovation (AREA)
- General Business, Economics & Management (AREA)
- Development Economics (AREA)
- Public Health (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Primary Health Care (AREA)
- Computing Systems (AREA)
- Marketing (AREA)
- Mathematical Physics (AREA)
- Epidemiology (AREA)
- Chemical & Material Sciences (AREA)
- Analytical Chemistry (AREA)
- Nutrition Science (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Bioinformatics & Computational Biology (AREA)
Abstract
Description
Translated fromChinese本发明涉及生物基因技术领域,特别涉及一种基于基因筛选的饮酒量预测系统。The invention relates to the technical field of biological genes, in particular to a system for predicting alcohol consumption based on genetic screening.
酒精进入人体后经口腔、食道、胃、肠等器官直接通过生物膜进入血液循环,迅速的被运输到全身各组织器官进行代谢利用。人体内有两种酶来进行酒精代谢:在乙醇脱氢酶催化下,乙醇被氧化成乙醛;乙醛经过乙醛脱氢酶转化为乙酸。在酒精代谢主要由两种酶(乙醇脱氢酶和乙醛脱氢酶)共同完成,个体之间的饮酒能力(酒量)差异主要由这两种酶的活性决定,而酶的多少活性由基因决定,归根结底人的酒量由基因决定。After alcohol enters the human body, it enters the blood circulation directly through the biofilm through the oral cavity, esophagus, stomach, intestine and other organs, and is quickly transported to various tissues and organs of the body for metabolism and utilization. There are two enzymes in the human body for alcohol metabolism: ethanol is oxidized to acetaldehyde under the catalysis of alcohol dehydrogenase; acetaldehyde is converted to acetic acid by acetaldehyde dehydrogenase. Alcohol metabolism is mainly completed by two enzymes (alcohol dehydrogenase and aldehyde dehydrogenase), and the difference in drinking ability (alcohol amount) between individuals is mainly determined by the activities of these two enzymes, and the activity of the enzymes is determined by the gene In the final analysis, the amount of alcohol a person can drink is determined by genetics.
酒作为部分人们生活中重要的饮品,衍生出各种酒文化,成为特定场合不可或缺的存在。但研究表明不是人人适宜饮酒,饮酒过度对身体的危害极大;且不同的人的饮酒能力也有较大区别,正确认知自我的酒精代谢能力,有一个健康的饮酒标准就非常重要了。As an important drink in some people's lives, wine has derived various wine cultures and has become an indispensable existence in specific occasions. However, studies have shown that drinking is not suitable for everyone, and excessive drinking is extremely harmful to the body; and the drinking ability of different people is also quite different. It is very important to have a correct understanding of one's ability to metabolize alcohol and have a healthy drinking standard.
目前市面上的类似产品都是检测用户的酒精代谢能力,而没有对饮酒能力进行量化,对用户的指导作用不强,不能根据用户的身体情况给出针对性的饮酒建议。At present, similar products on the market test the user's ability to metabolize alcohol, but do not quantify the drinking ability. They are not strong enough to guide users, and cannot give targeted drinking advice based on the user's physical condition.
发明内容SUMMARY OF THE INVENTION
本发明旨在至少一定程度上解决上述技术中的技术问题之一。为此,本发明的目的在于提出一种基于基因筛选的饮酒量预测系统,提供饮酒量判断标准,量化个体的饮酒能力,根据用户的身体情况给出给出更直观有价值的酒量 评价及饮酒建议,提高用户的体验。The present invention aims to solve one of the technical problems in the above technologies at least to a certain extent. To this end, the purpose of the present invention is to propose a drinking quantity prediction system based on genetic screening, which provides a drinking quantity judgment standard, quantifies an individual's drinking ability, and gives a more intuitive and valuable alcohol quantity evaluation and drinking according to the user's physical condition. Recommendations to improve user experience.
为达到上述目的,本发明实施例提出了一种基于基因筛选的饮酒量预测系统,包括:In order to achieve the above purpose, the embodiment of the present invention proposes a system for predicting alcohol consumption based on genetic screening, including:
用户基因获取模块,用于获取用户的基因数据;The user gene acquisition module is used to obtain the user's genetic data;
饮酒量预测模型接口模块,与所述用户基因获取模块连接,将用户的基因数据输入饮酒量预测模型对用户的饮酒量进行预测,得到饮酒量的第一预测结果;The drinking volume prediction model interface module is connected with the user gene acquisition module, and inputs the user's genetic data into the drinking volume prediction model to predict the drinking volume of the user, and obtains the first prediction result of the drinking volume;
饮酒建议数据库模块,与所述饮酒量预测模型接口模块连接,用于根据用户的饮酒量的第一预测结果给出饮酒建议;a drinking suggestion database module, connected with the drinking quantity prediction model interface module, and used for giving drinking suggestions according to the first prediction result of the drinking quantity of the user;
查询模块,与所述饮酒量预测模型接口模块连接,用于查询基于饮酒量预测模型中与饮酒量相关基因、饮酒段位及饮酒量的关系、饮酒段位对应的饮酒建议;a query module, connected with the interface module of the drinking volume prediction model, and used for querying the relationship between the drinking volume-related genes, the drinking rank and the drinking volume, and the drinking advice corresponding to the drinking tier in the drinking volume prediction model;
展示模块,与所述饮酒建议数据库模块连接,用于将用户基因数据、饮酒量的预测结果、饮酒建议展示出来。The display module is connected with the drinking suggestion database module, and is used for displaying the user's genetic data, the prediction result of drinking amount, and the drinking suggestion.
根据本发明提出的一种基于基因筛选的饮酒量预测系统,获取用户的基因数据,将用户的基因数据输入饮酒量预测模型对用户的饮酒量进行预测,其中饮酒量预测模型通过决策树分类模型构建,得到饮酒量的第一预测结果,通过饮酒建议数据库模块根据用户的饮酒量的第一预测结果给出饮酒建议,最后通过展示模块将用户基因数据、饮酒量的预测结果、饮酒建议展示出来,根据用户的身体情况给出给出更直观有价值的酒量评价及饮酒建议,提高用户的体验。查询模块用于查询基于饮酒量预测模型中与饮酒量相关基因、饮酒段位及饮酒量的关系、饮酒段位对应的饮酒建议;提供饮酒量判断标准,量化个体的饮酒能力,方便用户进行查询,了解相关知识。According to a genetic screening-based alcohol consumption prediction system proposed by the present invention, the user's genetic data is obtained, and the user's genetic data is input into the alcohol consumption prediction model to predict the user's alcohol consumption, wherein the alcohol consumption prediction model adopts a decision tree classification model Construct, get the first prediction result of drinking amount, give drinking suggestion according to the first prediction result of user's drinking amount through the drinking suggestion database module, and finally display the user's genetic data, the predicted result of drinking amount, and drinking suggestion through the display module , according to the user's physical condition, it will give more intuitive and valuable alcohol evaluation and drinking suggestions to improve the user's experience. The query module is used to query the relationship between alcohol consumption-related genes, drinking grades and alcohol consumption, and drinking recommendations corresponding to drinking grades based on the alcohol consumption prediction model. related information.
根据本发明的一些实施例,所述用户基因获取模块包括:According to some embodiments of the present invention, the user gene acquisition module includes:
第一获取模块,用于获取用户的唾液;a first obtaining module, used to obtain the saliva of the user;
第一处理模块,与所述第一获取模块连接,用于将所述用户的唾液进行 DNA提取,对提取DNA进行基因测序;a first processing module, connected to the first acquisition module, for extracting DNA from the saliva of the user, and performing gene sequencing on the extracted DNA;
第二处理模块,与所述第一处理模块连接,用于在基因测序后进行生信分析,获取指定位点的基因型,对指定位点rs1229984和rs671的基因型数据进行格式化处理。The second processing module is connected to the first processing module, and is used to perform bioinformatics analysis after gene sequencing, obtain the genotype of the specified site, and format the genotype data of the specified site rs1229984 and rs671.
根据本发明的一些实施例,所述饮酒量预测模型选用机器学习模型进行构建,包括:According to some embodiments of the present invention, the alcohol consumption prediction model is constructed by selecting a machine learning model, including:
S1、获取样本的饮酒能力与饮酒量的关系,根据所述饮酒量分为第一预设数量个饮酒段位,并根据所述样本的饮酒能力与饮酒量的关系、饮酒段位建立第一数据库;S1. Obtain the relationship between the drinking ability and the drinking amount of the sample, divide the sample into a first preset number of drinking rank according to the drinking amount, and establish a first database according to the relationship between the drinking ability and the drinking amount of the sample, and the drinking rank;
S2、获取样本的基因数据并进行基因数据格式化;S2. Obtain the genetic data of the sample and format the genetic data;
S3、根据格式化后的样本的基因数据和所述第一数据库构建饮酒量预测模型。S3. Build a drinking amount prediction model according to the gene data of the formatted sample and the first database.
根据本发明的一些实施例,所述获取样本的基因数据并进行基因数据格式化包括:According to some embodiments of the present invention, the acquiring genetic data of the sample and formatting the genetic data includes:
S21、采集样本的唾液;S21, collecting saliva from the sample;
S22、根据所述样本的唾液进行DNA提取,对提取DNA进行基因测序;S22, performing DNA extraction according to the saliva of the sample, and performing gene sequencing on the extracted DNA;
S23、对基因测序后的基因数据进行处理,得到每个样本饮酒量相关的基因位点的基因型;S23. Process the gene data after gene sequencing to obtain the genotype of the locus related to the alcohol consumption of each sample;
S24、将所述基因位点按照基因型格式化成数字。S24. Format the gene loci into numbers according to the genotype.
根据本发明的一些实施例,对所述格式化后的样本的基因数据进行基因位点筛选,包括:According to some embodiments of the present invention, genetic locus screening is performed on the genetic data of the formatted sample, including:
S241、分别计算每个基因位点的特征值对所述第一数据库进行划分后得到的各数据子集与划分前的数据集的纯度提升值或不确定性降低值;S241, respectively calculating the characteristic value of each gene locus and dividing the first database to obtain the purity improvement value or uncertainty reduction value of each data subset and the data set before division;
S242、选取最大纯度提升值或最大不确定性降低值的基因位点N和所述基因位点N的特征值n,其中,将所述基因位点N作为节点,按照所述基因位点N的特征值n的分组将所述第一数据库拆分成两个子数据集;S242. Select the gene locus N with the maximum purity improvement value or the maximum uncertainty reduction value and the characteristic value n of the gene locus N, wherein the gene locus N is used as a node, according to the gene locus N The grouping of the eigenvalue n splits the first database into two sub-data sets;
S243、依次在两个子数据集中,计算各基因位点的特征值在子数据集中的纯度提升值或不确定性降低值;选取最大纯度提升值或最大不确定性降低值的基因位点M和所述基因位点M的特征值m,其中,将所述基因位点M作为子节点,按照所述基因位点M的特征值m的分组对子数据集再次拆分;S243. In the two sub-data sets in turn, calculate the purity improvement value or the uncertainty reduction value of the characteristic value of each gene locus in the sub-data set; select the gene locus M and the uncertainty reduction value with the largest purity improvement value or the largest uncertainty reduction value. The eigenvalue m of the gene locus M, wherein the gene locus M is used as a sub-node, and the sub-data set is split again according to the grouping of the eigenvalue m of the gene locus M;
S244、在确定划分后的子数据集的纯度大于预设纯度阈值或不确定性值小于预设不确定性阈值时,停止拆分,最终得到与饮酒量相关的基因位点及基因位点与饮酒段位的关系。S244. When it is determined that the purity of the divided sub-data set is greater than the preset purity threshold or the uncertainty value is less than the preset uncertainty threshold, stop the splitting, and finally obtain the gene locus related to the alcohol consumption and the gene locus and the gene locus The relationship between drinking grades.
根据本发明的一些实施例,还包括:用户终端,与所述展示模块连接,用于接收展示模块发送的相关数据信息方便用户进行查看。According to some embodiments of the present invention, the method further includes: a user terminal, connected to the display module, for receiving relevant data information sent by the display module to facilitate viewing by the user.
根据本发明的一些实施例,还包括:第二获取模块,用于获取影响用户饮酒量的第二信息,所述第二信息包括:疾病史、饮酒种类、饮酒度数、饮酒频率;According to some embodiments of the present invention, it further includes: a second obtaining module, configured to obtain second information that affects the drinking amount of the user, the second information including: disease history, drinking type, drinking degree, and drinking frequency;
计算模块,与所述饮酒量预测模型接口模块、所述第二获取模块、饮酒建议数据库模块连接,用于根据所述第一预测结果和所述第二信息按照预设算法,计算得到饮酒量的第二预测结果;The calculation module is connected with the interface module of the drinking volume prediction model, the second acquisition module, and the drinking recommendation database module, and is used for calculating the drinking volume according to the first prediction result and the second information according to a preset algorithm The second prediction result of ;
所述饮酒建议数据库模块,还用于根据用户的饮酒量的第二预测结果给出饮酒建议。The drinking suggestion database module is further configured to give drinking suggestions according to the second prediction result of the drinking amount of the user.
根据本发明的一些实施例,所述预设算法包括:According to some embodiments of the present invention, the preset algorithm includes:
计算饮酒量第一预测结果中的乙醇量:Calculate the amount of ethanol in the first prediction of alcohol consumption:
V1=A×cV1 =A×c
其中,A为酒量预测模型基于用户的基因数据输出的饮酒量(ml);c为酒量预测模型中预设酒精浓度(%vol);Among them, A is the drinking volume (ml) output by the alcohol volume prediction model based on the user's genetic data; c is the preset alcohol concentration (%vol) in the alcohol volume prediction model;
计算饮酒量第二预测结果中的乙醇量:Calculate the amount of ethanol in the second predictor of alcohol consumption:
V2=V1×d×t×fV2 =V1 ×d×t×f
其中,d为用户疾病史与饮酒量的相关系数;t为饮酒种类与饮酒量的相关系数;f为饮酒频率与饮酒量的相关系数;Among them, d is the correlation coefficient between the user's disease history and drinking amount; t is the correlation coefficient between drinking type and drinking amount; f is the correlation coefficient between drinking frequency and drinking amount;
第二预测结果的饮酒量:Alcohol consumption for the second predictor:

其中,cu为用户输入的饮酒度数。Among them,cu is the drinking degree input by the user.
根据本发明的一些实施例,所述基于基因筛选的饮酒量预测系统运用SOA系统架构;包括:According to some embodiments of the present invention, the genetic screening-based alcohol consumption prediction system uses SOA system architecture; including:
数据层,用于根据数据源获取用户数据;The data layer is used to obtain user data according to the data source;
数据平台层,与所述数据层连接,用于为数据管理提供开发环境;a data platform layer, connected to the data layer, for providing a development environment for data management;
服务层,与所述数据平台层连接,用于接收数据平台发送的数据信息,根据所述数据信息为数据消费者提供服务。The service layer, connected with the data platform layer, is used for receiving data information sent by the data platform, and providing services for data consumers according to the data information.
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。Other features and advantages of the present invention will be set forth in the description which follows, and in part will be apparent from the description, or may be learned by practice of the invention. The objectives and other advantages of the invention may be realized and attained by the structure particularly pointed out in the written description and drawings.
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。The technical solutions of the present invention will be further described in detail below through the accompanying drawings and embodiments.
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:The accompanying drawings are used to provide a further understanding of the present invention, and constitute a part of the specification, and are used to explain the present invention together with the embodiments of the present invention, and do not constitute a limitation to the present invention. In the attached image:
图1是根据本发明一个实施例的一种基于基因筛选的饮酒量预测系统的框图;1 is a block diagram of a genetic screening-based alcohol consumption prediction system according to an embodiment of the present invention;
图2是根据本发明一个实施例的用户基因获取模块的框图;2 is a block diagram of a user gene acquisition module according to an embodiment of the present invention;
图3是根据本发明一个实施例的一种构建饮酒量预测模型的方法的流程图;3 is a flowchart of a method for constructing a drinking quantity prediction model according to an embodiment of the present invention;
图4是根据本发明一个实施例的对样本的基因数据的处理的流程图;FIG. 4 is a flowchart of processing genetic data of a sample according to an embodiment of the present invention;
图5是根据本发明一个实施例的对于饮酒量相关的基因位点筛选的流程图;Fig. 5 is a flow chart of the screening of genetic loci related to alcohol consumption according to an embodiment of the present invention;
图6是根据本发明又一个实施例的基于基因筛选的饮酒量预测系统的框 图;6 is a block diagram of a genetic screening-based alcohol consumption prediction system according to yet another embodiment of the present invention;
图7是根据本发明一个实施例的SOA系统架构的框图;7 is a block diagram of an SOA system architecture according to an embodiment of the present invention;
图8是根据本发明一个实施例的饮酒量相关基因与饮酒段位的决策树的示意图。FIG. 8 is a schematic diagram of a decision tree of drinking quantity-related genes and drinking rank according to an embodiment of the present invention.
附图标记:Reference number:
用户基因获取模块1、第一获取模块11、第一处理模块12、第二处理模块13、饮酒量预测模型接口模块2、饮酒建议数据库模块3、查询模块4、展示模块5、用户终端6、第二获取模块7、计算模块8、数据层9、数据平台层10、服务层14。User
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。The preferred embodiments of the present invention will be described below with reference to the accompanying drawings. It should be understood that the preferred embodiments described herein are only used to illustrate and explain the present invention, but not to limit the present invention.
下面参考图1至图8来描述本发明实施例提出的一种基于基因筛选的饮酒量预测系统。The following describes a system for predicting the amount of alcohol consumption based on genetic screening proposed in an embodiment of the present invention with reference to FIG. 1 to FIG. 8 .
图1是根据本发明一个实施例的一种基于基因筛选的饮酒量预测系统的框图;如图1所示,本发明实施例提出了一种基于基因筛选的饮酒量预测系统,包括:Fig. 1 is a block diagram of a system for predicting alcohol consumption based on genetic screening according to an embodiment of the present invention; as shown in Fig. 1, an embodiment of the present invention proposes a system for predicting alcohol consumption based on genetic screening, including:
用户基因获取模块1,用于获取用户的基因数据;User
饮酒量预测模型接口模块2,与所述用户基因获取模块1连接,将用户的基因数据输入饮酒量预测模型对用户的饮酒量进行预测,得到饮酒量的第一预测结果;The drinking volume prediction model interface module 2 is connected to the user
饮酒建议数据库模块3,与所述饮酒量预测模型接口模块2连接,用于根据用户的饮酒量的第一预测结果给出饮酒建议;The drinking suggestion database module 3 is connected with the drinking quantity prediction model interface module 2, and is used for giving drinking suggestions according to the first prediction result of the drinking quantity of the user;
查询模块4,与所述饮酒量预测模型接口模块2连接,用于查询基于饮酒量预测模型中与饮酒量相关基因、饮酒段位及饮酒量的关系、饮酒段位对应的 饮酒建议;A query module 4, connected with the drinking volume prediction model interface module 2, is used to query the relationship between the drinking volume-related genes, the drinking rank and the drinking volume, and the drinking advice corresponding to the drinking rank in the drinking volume prediction model;
展示模块5,与所述饮酒建议数据库模块3连接,用于将用户基因数据、饮酒量的预测结果、饮酒建议展示出来。The display module 5 is connected with the drinking suggestion database module 3, and is used for displaying the user's genetic data, the prediction result of the drinking amount, and the drinking suggestion.
根据本发明提出的一种基于基因筛选的饮酒量预测系统,获取用户的基因数据,将用户的基因数据输入饮酒量预测模型对用户的饮酒量进行预测,其中饮酒量预测模型通过决策树分类模型构建,得到饮酒量的第一预测结果,通过饮酒建议数据库模块根据用户的饮酒量的第一预测结果给出饮酒建议,最后通过展示模块将用户基因数据、饮酒量的预测结果、饮酒建议展示出来,根据用户的身体情况给出给出更直观有价值的酒量评价及饮酒建议,提高用户的体验。查询模块用于查询基于饮酒量预测模型中与饮酒量相关基因、饮酒段位及饮酒量的关系、饮酒段位对应的饮酒建议;提供饮酒量判断标准,量化个体的饮酒能力,方便用户进行查询,了解相关知识。According to a genetic screening-based alcohol consumption prediction system proposed by the present invention, the user's genetic data is obtained, and the user's genetic data is input into the alcohol consumption prediction model to predict the user's alcohol consumption, wherein the alcohol consumption prediction model adopts a decision tree classification model Construct, get the first prediction result of drinking amount, give drinking suggestion according to the first prediction result of user's drinking amount through the drinking suggestion database module, and finally display the user's genetic data, the predicted result of drinking amount, and drinking suggestion through the display module , according to the user's physical condition, it will give more intuitive and valuable alcohol evaluation and drinking suggestions to improve the user's experience. The query module is used to query the relationship between alcohol consumption-related genes, drinking grades and alcohol consumption, and drinking recommendations corresponding to drinking grades based on the alcohol consumption prediction model. related information.
图2是根据本发明一个实施例的用户基因获取模块的框图;如图2所示,所述用户基因获取模块1包括:Fig. 2 is a block diagram of a user gene acquisition module according to an embodiment of the present invention; as shown in Fig. 2, the user
第一获取模块11,用于获取用户的唾液;The first obtaining module 11 is used to obtain the saliva of the user;
第一处理模块12,与所述第一获取模块11连接,用于将所述用户的唾液进行DNA提取,对提取DNA进行基因测序;The first processing module 12, connected with the first acquisition module 11, is used to extract DNA from the saliva of the user, and perform gene sequencing on the extracted DNA;
第二处理模块13,与所述第一处理模块12连接,用于在基因测序后进行生信分析,获取指定位点的基因型,对指定位点rs1229984和rs671的基因型数据进行格式化处理。The second processing module 13 is connected to the first processing module 12, and is used to perform bioinformatics analysis after gene sequencing, obtain the genotype of the specified site, and format the genotype data of the specified site rs1229984 and rs671 .
上述技术方案的工作原理及有益效果:根据用户的唾液进行DNA提取、芯片测序、找出用户的rs1229984基因位点和rs671基因位点,对指定位点rs1229984和rs671的基因型数据进行格式化处理,获取用户与饮酒量相关的基因数据,方便快捷。The working principle and beneficial effects of the above technical solutions: DNA extraction and chip sequencing are performed according to the saliva of the user, the rs1229984 gene locus and the rs671 gene locus of the user are found out, and the genotype data of the designated loci rs1229984 and rs671 are formatted and processed , to obtain the genetic data related to the user's alcohol consumption, which is convenient and fast.
图3是根据本发明一个实施例的一种构建饮酒量预测模型的方法的流程图;如图3所示,所述饮酒量预测模型选用机器学习模型进行构建,包括:Fig. 3 is a flow chart of a method for constructing an alcohol consumption prediction model according to an embodiment of the present invention; as shown in Fig. 3, the alcohol consumption prediction model is constructed by selecting a machine learning model, including:
S1、获取样本的饮酒能力与饮酒量的关系,根据所述饮酒量分为第一预设数量个饮酒段位,并根据所述样本的饮酒能力与饮酒量的关系、饮酒段位建立第一数据库;S1. Obtain the relationship between the drinking ability and the drinking amount of the sample, divide the sample into a first preset number of drinking rank according to the drinking amount, and establish a first database according to the relationship between the drinking ability and the drinking amount of the sample, and the drinking rank;
S2、获取样本的基因数据并进行基因数据格式化;S2. Obtain the genetic data of the sample and format the genetic data;
S3、根据格式化后的样本的基因数据和所述第一数据库构建饮酒量预测模型。S3. Build a drinking amount prediction model according to the gene data of the formatted sample and the first database.
上述技术方案的工作原理及有益效果:通过问卷调查方法,获取样本的饮酒能力与饮酒量的关系,并进行数据分析,将饮酒量分为第一预设数量个饮酒段位,建立第一数据库,对饮酒量划分饮酒等级,对饮酒量进行具体量化,有利于给出更有价值的饮酒建议。对样本的基因数据并进行基因数据格式化,根据格式化后的样本的基因数据和第一数据库构建饮酒量预测模型。The working principle and beneficial effects of the above technical solutions: obtain the relationship between the drinking ability and the drinking amount of the sample through a questionnaire survey method, and carry out data analysis, divide the drinking amount into a first preset number of drinking grades, and establish a first database. Dividing alcohol consumption into drinking grades and quantifying alcohol consumption can help to give more valuable drinking advice. The genetic data of the sample is formatted, and the alcohol consumption prediction model is constructed according to the genetic data of the formatted sample and the first database.
图4是根据本发明一个实施例的对样本的基因数据的处理的流程图;如图4所示,所述获取样本的基因数据并进行基因数据格式化包括:FIG. 4 is a flowchart of processing genetic data of a sample according to an embodiment of the present invention; as shown in FIG. 4 , the acquiring and formatting the genetic data of the sample includes:
S21、采集样本的唾液;S21, collecting saliva from the sample;
S22、根据所述样本的唾液进行DNA提取,对提取DNA进行基因测序;S22, performing DNA extraction according to the saliva of the sample, and performing gene sequencing on the extracted DNA;
S23、对基因测序后的基因数据进行处理,得到每个样本饮酒量相关的基因位点的基因型;S23. Process the gene data after gene sequencing to obtain the genotype of the locus related to the alcohol consumption of each sample;
S24、将所述基因位点按照基因型格式化成数字。S24. Format the gene loci into numbers according to the genotype.
上述技术方案的工作原理及有益效果:获取样本的基因数据通过对样本的唾液进行DNA提取、基因测序、基因分型;基因测序的方法包括:芯片测序、二代测序、三代测序、PCR测序、panel测序中的至少一种。最终得到每个样本饮酒量相关的基因位点的基因型,为了对基因位点对饮酒量的影响进行有效计算,将基因位点按照基因型格式化成数字。示例的,野生型为0、杂合突变型为1、纯合突变型为2。如在rs1229984基因位点上,CC为纯合突变型,格式化成数字为2;TT为野生型,格式化成数字为0;CT为杂合突变型,格式化成数字为1;如在rs671基因位点上,AA为纯合突变型,格式化成数字为2; GG为野生型,格式化成数字为0;AG为杂合突变型,格式化成数字为1。The working principle and beneficial effects of the above technical solutions: DNA extraction, gene sequencing, and genotyping are performed on the saliva of the sample to obtain the genetic data of the sample; the gene sequencing methods include: chip sequencing, second-generation sequencing, third-generation sequencing, PCR sequencing, At least one of panel sequencing. Finally, the genotypes of the loci related to the alcohol consumption of each sample are obtained. In order to effectively calculate the influence of the loci on the alcohol consumption, the loci are formatted into numbers according to the genotype. Illustratively, wild type is 0, heterozygous mutant is 1, and homozygous mutant is 2. For example, at the rs1229984 locus, CC is a homozygous mutant, formatted as a number 2; TT is a wild type, formatted as a number 0; CT is a heterozygous mutant, formatted as a
图5是根据本发明一个实施例的对于饮酒量相关的基因位点筛选的流程图;如图5所示,对所述格式化后的样本的基因数据进行基因位点筛选,包括:Fig. 5 is a flow chart of the screening of gene loci related to alcohol consumption according to an embodiment of the present invention; as shown in Fig. 5, the gene locus screening is performed on the gene data of the formatted sample, including:
S241、分别计算每个基因位点的特征值对所述第一数据库进行划分后得到的各数据子集与划分前的数据集的纯度提升值或不确定性降低值;S241, respectively calculating the characteristic value of each gene locus and dividing the first database to obtain the purity improvement value or uncertainty reduction value of each data subset and the data set before division;
S242、选取最大纯度提升值或最大不确定性降低值的基因位点N和所述基因位点N的特征值n,其中,将所述基因位点N作为节点,按照所述基因位点N的特征值n的分组将所述第一数据库拆分成两个子数据集;S242. Select the gene locus N with the maximum purity improvement value or the maximum uncertainty reduction value and the characteristic value n of the gene locus N, wherein the gene locus N is used as a node, according to the gene locus N The grouping of the eigenvalue n splits the first database into two sub-data sets;
S243、依次在两个子数据集中,计算各基因位点的特征值在子数据集中的纯度提升值或不确定性降低值;选取最大纯度提升值或最大不确定性降低值的基因位点M和所述基因位点M的特征值m,其中,将所述基因位点M作为子节点,按照所述基因位点M的特征值m的分组对子数据集再次拆分;S243. In the two sub-data sets in turn, calculate the purity improvement value or the uncertainty reduction value of the characteristic value of each gene locus in the sub-data set; select the gene locus M and the uncertainty reduction value with the largest purity improvement value or the largest uncertainty reduction value. The eigenvalue m of the gene locus M, wherein the gene locus M is used as a sub-node, and the sub-data set is split again according to the grouping of the eigenvalue m of the gene locus M;
S244、在确定划分后的子数据集的纯度大于预设纯度阈值或不确定性值小于预设不确定性阈值时,停止拆分,最终得到与饮酒量相关的基因位点及基因位点与饮酒段位的关系。S244. When it is determined that the purity of the divided sub-data set is greater than the preset purity threshold or the uncertainty value is less than the preset uncertainty threshold, stop the splitting, and finally obtain the gene locus related to the alcohol consumption and the gene locus and the gene locus The relationship between drinking grades.
上述技术方案的工作原理及有益效果:度量划分数据集前后的数据集的纯度以及不确定性的方法包括计算信息增益、信息增益率、基尼系数中的至少一个参数,具体的在根据基尼系数确定纯度及不确定性的方法中,基尼系数越大,数据的不确定性越高,样本纯度越低,表示数据集中目标样本所占总样本的比例越小;基尼系数越小,数据的不确定性越低,样本纯度越高,表示数据集中目标样本所占总样本的比例越高;在基尼系数小于预设数值时,表示划分后的子数据集的纯度大于预设纯度阈值或不确定性值小于预设不确定性阈值时,停止拆分,最终得到与饮酒量相关的基因位点及基因位点与饮酒段位的关系。示例的,在基尼系数等于0时,数据集中的所有样本都是同一类别。The working principle and beneficial effect of the above technical solution: the method for measuring the purity and uncertainty of the data set before and after dividing the data set includes calculating at least one parameter in the information gain, the information gain rate, and the Gini coefficient. Specifically, the method is determined according to the Gini coefficient. In the method of purity and uncertainty, the larger the Gini coefficient, the higher the uncertainty of the data, and the lower the sample purity, indicating that the proportion of the target sample in the data set to the total sample is smaller; the smaller the Gini coefficient, the uncertainty of the data. The lower the stability, the higher the sample purity, which means that the proportion of the target sample in the total sample is higher; when the Gini coefficient is less than the preset value, it means that the purity of the divided sub-data set is greater than the preset purity threshold or uncertainty When the value is less than the preset uncertainty threshold, the splitting is stopped, and the gene locus related to the drinking amount and the relationship between the locus and the drinking rank are finally obtained. Exemplarily, when the Gini coefficient is equal to 0, all samples in the dataset are of the same class.
在一实施例中,如图8所示,判断样本的rs671基因位点结果是否为GG,即判断样本的rs671基因位点格式化是否为0,根据rs671基因位点是否为0, 将第一数据库分成两个数据集,为第一数据集和第二数据集,其中,第一数据集中样本的rs671基因位点结果为GG,第二数据集中样本的rs671基因位点结果为AA、AG;在第一数据集和第二数据集中计算各基因位点的特征值的基尼系数,选取计算出的基尼系数最小的基因位点A和所述基因位点A的特征值a,其中,将所述基因位点A作为子节点,按照所述基因位点A的特征值a的分组将数据集再次进行拆分;示例的,在第一数据集中,判断样本rs1229984基因位点是否为CC或CT,在判断为False时,样本rs1229984基因位点为TT,即该分组中样本rs671基因位点结果为GG,样本rs1229984基因位点为TT,如表一所示,饮酒段位为8段。在确定每个分组都为同一类型的样本即基尼系数为0时,停止拆分,最终得到与饮酒量相关的基因位点及基因位点与饮酒段位的关系。将与饮酒量相关的基因根据其基因类型,划分相对应的饮酒段位,方便记忆,且能准确的反应出基因类型与饮酒量的对应关系,一目了然,提高用户体验。In one embodiment, as shown in FIG. 8 , it is determined whether the result of the rs671 locus of the sample is GG, that is, it is determined whether the format of the rs671 locus of the sample is 0, and according to whether the rs671 locus is 0, the first The database is divided into two data sets, the first data set and the second data set, wherein the rs671 gene locus of the samples in the first data set is GG, and the rs671 gene locus results of the samples in the second data set are AA and AG; Calculate the Gini coefficient of the eigenvalues of each gene locus in the first data set and the second data set, and select the gene locus A with the smallest calculated Gini coefficient and the eigenvalue a of the gene locus A, wherein the all The gene locus A is used as a child node, and the data set is split again according to the grouping of the characteristic value a of the gene locus A; for example, in the first data set, it is judged whether the rs1229984 gene locus of the sample is CC or CT , when the judgment is False, the sample rs1229984 locus is TT, that is, the sample rs671 locus in this grouping is GG, and the sample rs1229984 locus is TT. As shown in Table 1, the drinking segment is 8 segments. When it is determined that each group is a sample of the same type, that is, the Gini coefficient is 0, the splitting is stopped, and the gene loci related to the amount of drinking and the relationship between the gene locus and the drinking rank are finally obtained. The genes related to alcohol consumption are divided into corresponding drinking grades according to their gene types, which is convenient for memory, and can accurately reflect the corresponding relationship between gene types and alcohol consumption, which is clear at a glance and improves user experience.
根据本发明的一些实施例,所述与饮酒量相关的基因位点包括rs1229984基因位点和rs671基因位点,其中,rs1229984基因位点位于ADH1B基因上,rs1229984基因位点结果为TT型时,乙醇脱氢酶活性强,乙醇代谢快;结果为CT型时乙醇脱氢酶活性中等,乙醇代谢速度中等;结果为CC型时乙醇脱氢酶活性弱,乙醇代谢速度慢;rs671基因位点位于ALDH2基因上,rs671基因位点结果为GG型时乙醛脱氢酶活性强,乙醛代谢快;结果为GA\AA型时乙醛脱氢酶活性弱,乙醛代谢慢。According to some embodiments of the present invention, the loci related to alcohol consumption include the rs1229984 locus and the rs671 locus, wherein the rs1229984 locus is located on the ADH1B gene, and when the result of the rs1229984 locus is TT type, The activity of alcohol dehydrogenase is strong, and the metabolism of ethanol is fast; the result is CT type, the activity of alcohol dehydrogenase is moderate, and the rate of alcohol metabolism is moderate; the result is that the activity of alcohol dehydrogenase is weak, and the rate of alcohol metabolism is slow; the rs671 gene locus is located in In the ALDH2 gene, when the rs671 gene locus was GG type, the activity of acetaldehyde dehydrogenase was strong, and the acetaldehyde metabolism was fast; when the result was GA\AA type, the activity of acetaldehyde dehydrogenase was weak, and the metabolism of acetaldehyde was slow.
根据本发明的一些实施例,选用决策树分类模型构建饮酒量预测模型。According to some embodiments of the present invention, a decision tree classification model is selected to construct a drinking quantity prediction model.
选用决策树分类模型构建饮酒量预测模型;A decision tree classification model was used to construct a drinking consumption prediction model;
算法包括:Algorithms include:
使用Python进行编程调用Sklearn的DecisionTreeClassifier模块进行数据挖掘和构建饮酒量预测模型;Use Python to program and call the DecisionTreeClassifier module of Sklearn to perform data mining and build a drinking volume prediction model;
DecisionTreeClassifier模块主要参数设置:DecisionTreeClassifier module main parameter settings:
criterion='gini':选用基尼系数作为节点划分质量的度量标准;criterion='gini': select the Gini coefficient as the metric for the quality of node division;
splitter=’best’:在所有特征中找最好的切分点;splitter='best': find the best split point among all features;
max_depth=None:设置决策树的最大深度,None表示不对决策树的最大深度作约束,直到每个叶子节点上的样本均属于同一类;max_depth=None: Set the maximum depth of the decision tree, None means that the maximum depth of the decision tree is not constrained until the samples on each leaf node belong to the same class;
min_samples_split=2:当对一个内部节点划分时,要求该节点上的最小样本数为2;min_samples_split=2: When dividing an internal node, the minimum number of samples on the node is required to be 2;
min_samples_leaf=1:设置叶子节点上的最小样本数为1;min_samples_leaf=1: Set the minimum number of samples on the leaf node to 1;
最终得到rs1229984基因位点和rs671基因位点与饮酒量的关系,在第一预设数量为9时,如表一所示。Finally, the relationship between the rs1229984 locus and the rs671 locus and alcohol consumption was obtained, when the first preset number was 9, as shown in Table 1.
表一Table I

在一实施例中,第一预设数量为7,饮酒段位为7个段位,得到rs1229984基因位点和rs671基因位点与饮酒量的关系如表二所示。In one embodiment, the first preset number is 7, and the drinking rank is 7 ranks, and the relationship between the rs1229984 locus and the rs671 locus and the drinking amount is obtained as shown in Table 2.
表二Table II

上述技术方案的工作原理及有益效果:饮酒段位为0段时包括3种情形:1、rs1229984基因位点为CC,rs671基因位点为AA;2、rs1229984基因位点为TT、rs671基因位点为AA;3、rs1229984基因位点为CT,rs671基因位点为AA。饮酒段位的命名使用不连续的方式进行命名,如缺少3段及6段,该不连续方式命名可以将饮酒段位与饮酒量的具体酒量进行相匹配,示例的,饮酒段位为9段时,用户饮酒量为9两以上。The working principle and beneficial effects of the above technical solutions: when the drinking rank is 0, there are three situations: 1. The rs1229984 locus is CC, and the rs671 locus is AA; 2. The rs1229984 locus is TT and the rs671 locus 3. The rs1229984 locus is CT, and the rs671 locus is AA. The naming of drinking tiers is done in a discontinuous way. If 3 and 6 tiers are missing, the discontinuous naming can match the drinking tier with the specific amount of alcohol consumed. For example, when the drinking tier is 9, the user The amount of alcohol consumed is 9 taels or more.
图6是根据本发明又一个实施例的基于基因筛选的饮酒量预测系统的框图;如图6所示,还包括:用户终端6,与所述展示模块连接,用于接收展示模块发送的相关数据信息方便用户进行查看。Fig. 6 is a block diagram of a system for predicting alcohol consumption based on genetic screening according to yet another embodiment of the present invention; as shown in Fig. 6 , it further includes: a user terminal 6, connected to the display module, for receiving relevant information sent by the display module Data information is convenient for users to view.
根据本发明的一些实施例,还包括:第二获取模块7,用于获取影响用户饮酒量的第二信息,所述第二信息包括:疾病史、饮酒种类、饮酒度数、饮酒频率;According to some embodiments of the present invention, it further includes: a second obtaining module 7, configured to obtain second information that affects the drinking amount of the user, where the second information includes: disease history, drinking type, drinking degree, and drinking frequency;
计算模块8,与所述饮酒量预测模型接口模块、所述第二获取模块、饮酒建议数据库模块连接,用于根据所述第一预测结果和所述第二信息按照预设算法,计算得到饮酒量的第二预测结果;The calculation module 8 is connected with the interface module of the drinking quantity prediction model, the second acquisition module, and the drinking suggestion database module, and is used for calculating the drinking alcohol according to the first prediction result and the second information according to a preset algorithm. the second prediction result of the quantity;
所述饮酒建议数据库模块3,还用于根据用户的饮酒量的第二预测结果给出饮酒建议。The drinking suggestion database module 3 is further configured to give drinking suggestions according to the second prediction result of the drinking amount of the user.
上述技术方案的工作原理及有益效果:将经饮酒量预测模型基于用户的基因数据输出的饮酒量的第一预测结果,结合实际情况影响用户饮酒量的第二信息对饮酒量的预测进行修正,第二信息包括:疾病史、饮酒种类、饮酒度数、饮酒频率;示例的,如表二所示,用户的基因数据为rs1229984基因位点为CC、rs671基因位点为GG,则对用户的饮酒量预测为7段,即用户能饮用7两以上的酒(以50°的白酒为例),但是用户最近在犯胃病,不能喝酒,喝酒容易引发胃穿孔,严重危害身体健康。同样的,根据用户饮酒种类、饮酒度数、饮酒频率的不同也会影响对用户饮酒量的预测。按照预设算法,计算得到饮酒量的第二预测结果,能根据用户的实际情况进行更加有效的饮酒量预测,预测结果 更加精准。The working principle and beneficial effects of the above technical solutions: the first prediction result of the drinking amount output by the drinking amount prediction model based on the user's genetic data is combined with the second information that affects the drinking amount of the user to modify the prediction of the drinking amount, The second information includes: disease history, drinking type, drinking degree, drinking frequency; for example, as shown in Table 2, if the user's genetic data is rs1229984 locus CC, rs671 locus is GG, then the user's drinking The volume is predicted to be 7 segments, that is, the user can drink more than 7 taels of wine (take 50° liquor as an example), but the user has recently suffered from stomach problems and cannot drink alcohol. Drinking alcohol can easily cause gastric perforation, which seriously endangers health. Similarly, according to the user's drinking type, drinking degree, and drinking frequency, the prediction of the user's drinking amount will also be affected. According to the preset algorithm, the second prediction result of drinking amount is calculated and obtained, which can make more effective drinking amount prediction according to the actual situation of the user, and the prediction result is more accurate.
根据本发明的一些实施例,所述预设算法包括:According to some embodiments of the present invention, the preset algorithm includes:
计算饮酒量第一预测结果中的乙醇量:Calculate the amount of ethanol in the first prediction of alcohol consumption:
V1=A×cV1 =A×c
其中,A为酒量预测模型基于用户的基因数据输出的饮酒量(ml);c为酒量预测模型中预设酒精浓度(%vol);Among them, A is the drinking volume (ml) output by the alcohol volume prediction model based on the user's genetic data; c is the preset alcohol concentration (%vol) in the alcohol volume prediction model;
计算饮酒量第二预测结果中的乙醇量:Calculate the amount of ethanol in the second predictor of alcohol consumption:
V2=V1×d×t×fV2 =V1 ×d×t×f
其中,d为用户疾病史与饮酒量的相关系数;t为饮酒种类与饮酒量的相关系数;f为饮酒频率与饮酒量的相关系数;Among them, d is the correlation coefficient between the user's disease history and drinking amount; t is the correlation coefficient between drinking type and drinking amount; f is the correlation coefficient between drinking frequency and drinking amount;
第二预测结果的饮酒量:Alcohol consumption for the second predictor:

其中,cu为用户输入的饮酒度数。Among them,cu is the drinking degree input by the user.
用户在属于胃病患者、肝病患者、心脑血管疾病患者、孕妇、服用感冒药、安眠药、镇定药时,用户疾病史与饮酒量的相关系数d为0,即用户不能够饮酒;其他用户疾病史与饮酒量的相关系数d的取值在0-1之间;饮酒种类与饮酒量的相关系数t取值如表三所示;饮酒频率与饮酒量的相关系数f取值如表四所示;通过预设算法,将饮酒量的第一预测结果进行修正,计算得到饮酒量第二预测结果,能根据用户的实际情况进行更加有效的饮酒量预测,预测结果更加精准,给出用户最正确的饮酒建议,提升用户体验。When the user belongs to stomach disease patients, liver disease patients, cardiovascular and cerebrovascular disease patients, pregnant women, taking cold medicine, sleeping pills, and tranquilizers, the correlation coefficient d between the user's disease history and alcohol consumption is 0, that is, the user cannot drink alcohol; other users' disease history The value of the correlation coefficient d with the amount of drinking is between 0 and 1; the value of the correlation coefficient t between the type of drinking and the amount of drinking is shown in Table 3; the value of the correlation coefficient f between the frequency of drinking and the amount of drinking is shown in Table 4. ; Through the preset algorithm, the first prediction result of drinking quantity is revised, and the second prediction result of drinking quantity is calculated, which can make more effective prediction of drinking quantity according to the actual situation of the user, the prediction result is more accurate, and the most correct user is given. drinking recommendations to improve user experience.
表三Table 3
表四Table 4
图8是根据本发明一个实施例的SOA系统架构的框图;如图8所示,所述基于基因筛选的饮酒量预测系统运用SOA系统架构;包括:8 is a block diagram of an SOA system architecture according to an embodiment of the present invention; as shown in FIG. 8 , the genetic screening-based alcohol consumption prediction system uses the SOA system architecture; including:
数据层9,用于根据数据源获取用户数据;The data layer 9 is used to obtain user data according to the data source;
数据平台层10,与所述数据层9连接,用于为数据管理提供开发环境;A data platform layer 10, connected to the data layer 9, is used to provide a development environment for data management;
服务层14,与所述数据平台层10连接,用于接收数据平台发送的数据信息,根据所述数据信息为数据消费者提供服务。The service layer 14, connected to the data platform layer 10, is used for receiving data information sent by the data platform, and providing services for data consumers according to the data information.
上述技术方案的工作原理及有益效果:基于面向服务(SOA)系统架构,可以实现系统的先进性、安全性和可靠性,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和契约联系起来,提高工作效率,实现系统的可行性、伸缩性和扩展性。这些服务以松耦合的方式连接在一起,运用SOA系统架构,管理这些各种各样的服务,协调服务之间的交互,同时使用户能方便地存取这些服务。The working principle and beneficial effects of the above technical solutions: Based on the service-oriented (SOA) system architecture, the advanced nature, security and reliability of the system can be realized. Through well-defined interfaces and contracts between these services, work efficiency is improved, and the feasibility, scalability and extensibility of the system are realized. These services are connected together in a loosely coupled manner, using the SOA system architecture to manage these various services, coordinate the interaction between services, and enable users to easily access these services.
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。It will be apparent to those skilled in the art that various modifications and variations can be made in the present invention without departing from the spirit and scope of the invention. Thus, provided that these modifications and variations of the present invention fall within the scope of the claims of the present invention and their equivalents, the present invention is also intended to include these modifications and variations.
Claims (9)
Translated fromChinese
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010748006.2ACN112102920B (en) | 2020-07-30 | 2020-07-30 | Drinking volume prediction system based on gene screening |
| CN202010748006.2 | 2020-07-30 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022022667A1true WO2022022667A1 (en) | 2022-02-03 |
Family
ID=73749886
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2021/109457CeasedWO2022022667A1 (en) | 2020-07-30 | 2021-07-30 | Gene screening-based alcohol tolerance prediction system |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN112102920B (en) |
| WO (1) | WO2022022667A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120199493A (en)* | 2025-03-14 | 2025-06-24 | 中国人民解放军总医院第二医学中心 | A method for constructing a prognostic model for non-small cell lung cancer |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112102920B (en)* | 2020-07-30 | 2023-11-10 | 苏州因顿医学检验实验室有限公司 | Drinking volume prediction system based on gene screening |
| CN114908146A (en)* | 2022-05-31 | 2022-08-16 | 因顿健康科技(苏州)有限公司 | Method for rapidly detecting and judging alcohol content by gene |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180209955A1 (en)* | 2017-01-17 | 2018-07-26 | Giner, Inc. | Method and system for assessing drinking behavior |
| CN111312396A (en)* | 2020-02-21 | 2020-06-19 | 光瀚健康咨询管理(上海)有限公司 | Individual wine capacity evaluation method and system based on wine capacity related factors |
| CN112002375A (en)* | 2020-07-30 | 2020-11-27 | 苏州因顿医学检验实验室有限公司 | Construction method of alcohol capacity prediction model |
| CN112037855A (en)* | 2020-07-30 | 2020-12-04 | 苏州因顿医学检验实验室有限公司 | Method for predicting alcohol consumption based on gene screening |
| CN112102920A (en)* | 2020-07-30 | 2020-12-18 | 苏州因顿医学检验实验室有限公司 | Alcohol consumption prediction system based on gene screening |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20130138447A1 (en)* | 2010-07-19 | 2013-05-30 | Pathway Genomics | Genetic based health management apparatus and methods |
| CN110046179B (en)* | 2018-12-25 | 2023-09-08 | 创新先进技术有限公司 | Mining method, device and equipment for alarm dimension |
| GB2591115A (en)* | 2020-01-16 | 2021-07-21 | Congenica Ltd | Screening system and method for acquiring and processing genomic information for generating gene variant interpretations |
| CN111272988B (en)* | 2020-02-27 | 2021-04-02 | 广州逆熵电子科技有限公司 | Alcohol concentration prediction method and system and alcohol degradation assessment instrument |
- 2020
- 2020-07-30CNCN202010748006.2Apatent/CN112102920B/enactiveActive
- 2021
- 2021-07-30WOPCT/CN2021/109457patent/WO2022022667A1/ennot_activeCeased
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180209955A1 (en)* | 2017-01-17 | 2018-07-26 | Giner, Inc. | Method and system for assessing drinking behavior |
| CN111312396A (en)* | 2020-02-21 | 2020-06-19 | 光瀚健康咨询管理(上海)有限公司 | Individual wine capacity evaluation method and system based on wine capacity related factors |
| CN112002375A (en)* | 2020-07-30 | 2020-11-27 | 苏州因顿医学检验实验室有限公司 | Construction method of alcohol capacity prediction model |
| CN112037855A (en)* | 2020-07-30 | 2020-12-04 | 苏州因顿医学检验实验室有限公司 | Method for predicting alcohol consumption based on gene screening |
| CN112102920A (en)* | 2020-07-30 | 2020-12-18 | 苏州因顿医学检验实验室有限公司 | Alcohol consumption prediction system based on gene screening |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120199493A (en)* | 2025-03-14 | 2025-06-24 | 中国人民解放军总医院第二医学中心 | A method for constructing a prognostic model for non-small cell lung cancer |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112102920A (en) | 2020-12-18 |
| CN112102920B (en) | 2023-11-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022022667A1 (en) | Gene screening-based alcohol tolerance prediction system | |
| Schena et al. | Development and testing of an artificial intelligence tool for predicting end-stage kidney disease in patients with immunoglobulin A nephropathy | |
| WO2022022663A1 (en) | Method for constructing alcohol tolerance prediction model | |
| Ruijter et al. | Statistical evaluation of SAGE libraries: consequences for experimental design | |
| Nelson et al. | The Population Reference Sample, POPRES: a resource for population, disease, and pharmacological genetics research | |
| US12387816B2 (en) | Processes for genetic and clinical data evaluation and classification of complex human traits | |
| WO2022022665A1 (en) | Method for predicting alcohol consumption amount on the basis of gene screening | |
| Beretta et al. | Genome-wide whole blood transcriptome profiling in a large European cohort of systemic sclerosis patients | |
| JP2022028907A (en) | Detection and diagnosis of cancer evolution | |
| CN116895334A (en) | Methods and compositions for estimating or predicting genotypes and phenotypes | |
| Sayres et al. | Cell‐free fetal DNA testing: a pilot study of obstetric healthcare provider attitudes toward clinical implementation | |
| CN113012761B (en) | Method and device for constructing stroke polygene genetic risk comprehensive score and application | |
| CN116486913B (en) | System, apparatus and medium for de novo predictive regulatory mutations based on single cell sequencing | |
| CN108682457B (en) | Patient long-term prognosis quantitative prediction and intervention system and method | |
| CN111312334A (en) | Method for analyzing receptor-ligand system influencing intercellular communication | |
| Taylor et al. | Genetic and BMI risks for predicting blood pressure in three generations of West African Dogon women | |
| CN115424728A (en) | Method for constructing tumor malignant cell gene prognosis risk model | |
| CN108345768A (en) | A kind of method and marker combination of determining infant's intestinal flora maturity | |
| Gu et al. | TALLSorts: a T-cell acute lymphoblastic leukemia subtype classifier using RNA-seq expression data | |
| JP6737519B1 (en) | Program, learning model, information processing device, information processing method, and learning model generation method | |
| Grill et al. | A simple-to-use method incorporating genomic markers into prostate cancer risk prediction tools facilitated future validation | |
| CN116936101A (en) | Evaluation gene set, prediction model and risk stratification decision system and application thereof in acute myeloid leukemia | |
| Thomas et al. | Alcohol metabolizing polygenic risk for alcohol consumption in European American college students | |
| CN115662622A (en) | Hepatic fibrosis molecular typing system | |
| Jung et al. | Machine Learning Model for Predicting Mortality in Heart Failure Patients Using Electronic Health Records and Exome Sequencing Data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | Ref document number:21851457 Country of ref document:EP Kind code of ref document:A1 | |
| NENP | Non-entry into the national phase | Ref country code:DE | |
| 122 | Ep: pct application non-entry in european phase | Ref document number:21851457 Country of ref document:EP Kind code of ref document:A1 |