WO2021164147A1 - Artificial intelligence-based service evaluation method and apparatus, device and storage medium - Google Patents
Artificial intelligence-based service evaluation method and apparatus, device and storage mediumDownload PDFInfo
- Publication number
- WO2021164147A1 WO2021164147A1PCT/CN2020/093342CN2020093342WWO2021164147A1WO 2021164147 A1WO2021164147 A1WO 2021164147A1CN 2020093342 WCN2020093342 WCN 2020093342WWO 2021164147 A1WO2021164147 A1WO 2021164147A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- recognized
- recognition
- voice stream
- target
- emotion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/02—Marketing; Price estimation or determination; Fundraising
- G06Q30/0282—Rating or review of business operators or products
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/01—Customer relationship services
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
- G10L25/63—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination for estimating an emotional state
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M3/00—Automatic or semi-automatic exchanges
- H04M3/42—Systems providing special services or facilities to subscribers
- H04M3/50—Centralised arrangements for answering calls; Centralised arrangements for recording messages for absent or busy subscribers ; Centralised arrangements for recording messages
- H04M3/51—Centralised call answering arrangements requiring operator intervention, e.g. call or contact centers for telemarketing
- H04M3/5175—Call or contact centers supervision arrangements
Definitions
- This applicationrelates to the field of artificial intelligence technology, and in particular to an artificial intelligence-based service evaluation method, device, equipment and storage medium.
- the enterpriseIn order to improve the service capabilities of the enterprise and fully meet the different requirements of customers, the enterprise establishes a corresponding seat center, and the seat staff of the seat center provide customers with corresponding services to improve service efficiency and avoid the inconvenience of customers going to the counter to handle business. Since the agent is an important link between the customer and the company, the service quality of the agent will greatly affect the customer's satisfaction with the company.
- the inventorrealizes that the current service evaluation of the agents in the enterprise is mainly based on the customer's manual scoring of the agent's services. Whether the customer scores and the specific evaluation scores are subjectively determined by the customer, which makes the service evaluation process objective and accurate. not tall.
- the embodiments of the present applicationprovide an artificial intelligence-based service evaluation method, device, equipment, and storage medium to solve the problem of low objectivity and accuracy in the current service evaluation process.
- a service evaluation method based on artificial intelligenceincluding:
- Fusion processingis performed on the text analysis result and the emotion analysis result corresponding to the voice stream to be recognized, and the service quality score corresponding to the target identity information is obtained.
- a service evaluation device based on artificial intelligenceincluding:
- To-be-recognized voice stream acquisition moduleused to acquire the to-be-recognized voice stream collected in real time during the service process
- the target identity information acquisition moduleis configured to perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized;
- a text analysis result obtaining moduleconfigured to perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized;
- An emotion analysis result obtaining moduleconfigured to perform emotion analysis on the voice stream to be recognized, and obtain the emotion analysis result corresponding to the voice stream to be recognized;
- the service quality score obtaining moduleis configured to perform fusion processing on the text analysis result and the sentiment analysis result corresponding to the voice stream to be recognized, and obtain the service quality score corresponding to the target identity information.
- a computer deviceincludes a memory, a processor, and computer-readable instructions that are stored in the memory and can run on the processor, and the processor implements the following steps when the processor executes the computer-readable instructions:
- One or more readable storage mediastoring computer readable instructions
- the computer readable storage mediumstoring computer readable instructions
- the one Or multiple processorsperform the following steps:
- Fusion processingis performed on the text analysis result and the emotion analysis result corresponding to the voice stream to be recognized, and the service quality score corresponding to the target identity information is obtained.
- the voice stream to be recognizedis identified to determine its corresponding target identity information, so as to realize the identity recognition of the voice stream to be recognized corresponding to the unknown speaker .
- the text analysis results and sentiment analysis resultsare obtained respectively, and then the text analysis results and sentiment analysis results are fused to obtain the service quality score corresponding to the target identity information, so as to realize the use of artificial intelligence
- the technical meansto realize the objective analysis of the service quality of the speaker in the speech stream to be recognized, to ensure the objectivity and accuracy of the target analysis results obtained, and to avoid the lack of subjective evaluation by people.
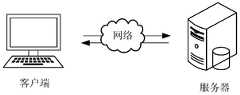
- FIG. 1is a schematic diagram of an application environment of an artificial intelligence-based service evaluation method in an embodiment of the present application
- FIG. 2is a flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application
- FIG. 3is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application
- FIG. 4is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application
- FIG. 5is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application
- FIG. 6is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application.
- FIG. 7is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application.
- FIG. 8is a schematic diagram of a service evaluation device based on artificial intelligence in an embodiment of the present application.
- Fig. 9is a schematic diagram of a computer device in an embodiment of the present application.
- the artificial intelligence-based service evaluation methodcan be applied to the application environment as shown in FIG. 1.
- the artificial intelligence-based service evaluation methodis applied in an artificial intelligence-based service evaluation system.
- the artificial intelligence-based service evaluation systemincludes a client and a server as shown in FIG. 1, and the client and the server communicate through a network. It is used to objectively analyze the recordings collected during the process of providing services to customers by the agents to ensure the objectivity and accuracy of service evaluation.
- the clientis also called the client, which refers to the program that corresponds to the server and provides local services to the client.
- the clientcan be installed on, but not limited to, various personal computers, notebook computers, smart phones, tablet computers, and portable wearable devices.
- the servercan be implemented as an independent server or a server cluster composed of multiple servers.
- an artificial intelligence-based service evaluation methodis provided.
- the artificial intelligence-based service evaluation methodis applied to the server shown in FIG. 1, and includes the following steps:
- S201Obtain a voice stream to be recognized that is collected in real time during the service process.
- the voice stream to be recognizedrefers to the voice stream used for service evaluation.
- the to-be-recognized voice streammay be a voice stream recorded in real time during the process of providing a service to a customer by an agent, and is specifically an object of information processing for service evaluation.
- the agentprovides services to customers through the telemarketing system.
- the recording module on the telemarketing systemcollects the voice stream to be recognized in the process of providing services to the customer in real time, and sends the voice stream to be recognized
- the server of the service evaluation systemcan receive the to-be-recognized voice stream recorded by the recording module in real time, and can also obtain the to-be-recognized voice stream that needs to be evaluated for the service from the database, so that the seat personnel’s For each service, the corresponding voice stream to be recognized can be collected and the follow-up service evaluation can be performed.
- the serverobtains the real-time recorded voice stream to be recognized during the service provided by the agent to the customer and conducts follow-up service evaluation, so that the service evaluation process is not limited to whether the customer scores or not, and ensures that the object used for service evaluation Completeness, to ensure the objectivity and accuracy of the service evaluation process.
- S202Perform identity recognition on the voice stream to be recognized, and determine target identity information corresponding to the voice stream to be recognized.
- the identification of the voice stream to be recognizedis used to identify the identity of the speaker corresponding to the voice stream to be recognized.
- the target identity informationis based on the identity information of the speaker identified by the voice stream to be recognized.
- performing identity recognition on the voice stream to be recognized and determining the target identity information corresponding to the voice stream to be recognizedmay specifically include the following steps: performing voiceprint feature extraction on the voice stream to be recognized, acquiring voiceprint features to be recognized, and recognizing the voice
- the similarity of the fingerprint feature and the standard voiceprint feature corresponding to each seat in the databaseis calculated to obtain the voiceprint similarity, and the identity information corresponding to the standard voiceprint feature with the largest voiceprint similarity is determined as the target identity information.
- the voiceprint feature to be recognizedis the voiceprint feature obtained by using a pre-trained voiceprint extraction model to perform voiceprint extraction on the voice stream to be recognized.
- the standard voiceprint featureis the voiceprint feature obtained by using a pre-trained voiceprint extraction model to extract the voiceprint of a standard voice stream of an agent.
- the standard voice streamis a voice stream that carries the identity information of the seat personnel, so that the extracted standard voiceprint features are associated with the identity information of the seat personnel.
- the voiceprint extraction modelcan be, but is not limited to, a Gaussian mixture model.
- the serverAfter the server acquires the voice stream to be recognized in real time during the service process, it performs identity recognition on the voice stream to be recognized to determine the target identity information corresponding to the voice stream to be recognized, so that the machine can analyze the corresponding voice stream to be recognized.
- the identity information of the targetto ensure the consistency of the voice stream to be recognized corresponding to the seat personnel and the target identity information, which can realize the identity recognition of the seat personnel with unknown identities.
- S203Perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized.
- the text analysis resultis a result reflecting the service quality obtained by analyzing the text content corresponding to the voice stream to be recognized.
- the servermay pre-train a text analysis model for analyzing speaker emotions corresponding to the text content.
- the text analysis modelmay be a model obtained after model training is performed on training text data carrying different emotion labels using a neural network model.
- the text analysis modelcan be used to perform sentiment analysis on the text information to be recognized extracted from the speech stream to be recognized to obtain text analysis results. The processing process is more efficient and the analysis results are more objective.
- S204Perform sentiment analysis on the voice stream to be recognized, and obtain a sentiment analysis result corresponding to the voice stream to be recognized.
- the sentiment analysis resultis the result obtained by the sentiment analysis for the speech stream to be recognized.
- a voice emotion recognition modelis pre-stored in the service evaluation system, and the voice emotion recognition model is a pre-trained model for emotion recognition of a voice stream.
- the serveruses a pre-trained voice emotion recognition model to recognize the emotion of the voice stream to be recognized collected in real time by the recording module on the telemarketing system.
- the processcan be realized by a machine to ensure the objectivity and accuracy of the identified target analysis result .
- S205Perform fusion processing on the text analysis result and the emotion analysis result corresponding to the voice stream to be recognized, and obtain the service quality score corresponding to the target identity information.
- the service quality scoreis a service score determined based on analysis of the voice stream to be recognized.
- the fusion processing of the text analysis result and the emotion analysis result corresponding to the voice stream to be recognizedrefers to combining the text analysis result and the emotion analysis result to obtain a service quality score that can objectively reflect the service quality of the agent corresponding to the voice stream to be recognized.
- the results of text analysis and sentiment analysiscan include at least two types of results, such as positive and negative reviews, or 1-star to 5-star ratings, etc.
- the service evaluation systempre-stores different text analysis results and sentiment analysis results corresponding The scoring score comparison table. After obtaining the text analysis result and sentiment analysis result corresponding to each voice stream to be recognized, the server can query the score comparison table based on the text analysis result and sentiment analysis result to determine its corresponding service quality score, so that the obtained The service quality score comprehensively considers the text analysis results and sentiment analysis results corresponding to the voice stream to be recognized, which helps to ensure the objectivity and accuracy of the service quality score.
- the voice stream to be recognizedis identified to determine its corresponding target identity information, so as to realize the identity recognition of the voice stream to be recognized corresponding to the unknown speaker.
- the text analysis results and sentiment analysis resultsare obtained respectively, and then the text analysis results and sentiment analysis results are fused to obtain the service quality score corresponding to the target identity information, so as to realize the use of artificial intelligence.
- the technical meansto realize the objective analysis of the service quality of the speaker in the speech stream to be recognized, to ensure the objectivity and accuracy of the target analysis results obtained, and to avoid the lack of subjective evaluation by people.
- the agentmay collect "um", "good” or other short speech streams to be recognized. These short speech streams to be recognized are used in identification and In the emotion recognition process, the recognition accuracy is low. Therefore, after step S201, that is, after the voice stream to be recognized is collected in real time in the process of obtaining the service, the service evaluation method based on artificial intelligence further includes: obtaining the corresponding voice stream to be recognized Voice duration, if the voice duration is greater than the duration threshold, perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized.
- the voice duration corresponding to the voice stream to be recognizedrefers to the speaking duration corresponding to the voice stream to be recognized.
- the voice durationis the speaking duration corresponding to the to-be-recognized voice stream recorded in real time during the process of providing services to the customer by the agent, and is the service duration for the agent to provide services to the customer.
- the duration thresholdrefers to a preset threshold for evaluating whether the duration reaches the target of service evaluation.
- the serverafter the server acquires the voice stream to be recognized in real time during the service process, it needs to determine the voice duration corresponding to each voice stream to be recognized, and compare the voice duration with the preset duration threshold of the system; if the voice duration is If the duration is greater than the duration threshold, then perform the identification of the voice stream to be recognized, determine the target identity information corresponding to the voice stream to be recognized and the subsequent steps, that is, perform steps S202-S205; if the voice duration is not greater than the duration threshold, do not perform the recognition to be recognized
- the voice streamperforms identity recognition, and the target identity information corresponding to the voice stream to be recognized and the subsequent steps are determined, that is, the subsequent steps S202-S205 are not executed.
- the subsequent identity recognition and emotion recognitionare only performed on the to-be-recognized speech stream whose speech duration is greater than the duration threshold, so as to ensure the accuracy of subsequent identity recognition and emotion recognition and avoid speech
- the recognition result of the short-duration voice stream to be recognizedis inaccurate and affects the service evaluation; understandably, if the voice duration of the voice stream to be recognized is not greater than the duration threshold, the server does not perform subsequent recognition processing on the voice stream to be recognized, which can be effective Reduce the amount of data for subsequent identification and improve the processing efficiency of subsequent identification.
- step S202that is, performing identity recognition on the voice stream to be recognized, and determining the target identity information corresponding to the voice stream to be recognized, specifically includes the following steps:
- S301Perform feature extraction on the voice stream to be recognized, and obtain the MFCC feature and the pitch feature corresponding to the voice stream to be recognized.
- MFCCMel-scale Frequency Cepstral Coefficients
- the Mel scaledescribes the non-linear characteristics of the human ear frequency, and its relationship with frequency is available
- the serverperforms pre-emphasis, framing, windowing, fast Fourier transform, triangular bandpass filter filtering, logarithmic operation, and logarithmic operation on the to-be-recognized speech stream collected in real time during the process of obtaining the service.
- Discrete cosine transform processingto obtain MFCC features.
- the Pitch featureis a feature related to the fundamental frequency (F0) of the sound, which reflects the information of the pitch, that is, the tone.
- F0fundamental frequency
- Calculating F0is also called pitch detection algorithms (PDA).
- PDApitch detection algorithms
- the systempre-stores a pitch detection algorithm (Pitch detection algorithm), which can estimate the pitch or fundamental frequency of periodic signals, and is widely used in voice signals and music signals.
- the algorithmscan be divided into time domains. And frequency domain two methods.
- the serveracquires the voice stream to be recognized in real time during the service process, it uses a pre-stored pitch detection algorithm to perform feature extraction on the voice stream to be recognized to obtain the pitch feature.
- MFCC featurescan better reflect the tone and prosody information of the speaker, making voices of the same sex more distinguishable, and helping to improve subsequent extraction based on the voice stream to be recognized The characteristics of the accuracy of identification.
- S302Perform splicing processing on the MFCC feature and the Pitch feature to obtain a target feature vector.
- concatenating the MFCC feature and the Pitch featurerefers to concatenating all the dimensions of the MFCC feature and the Pitch feature to form a target feature vector.
- the target feature vectorrefers to the feature vector formed after the MFCC feature and the Pitch feature are spliced.
- the serveris performing feature extraction on the voice stream to be recognized to obtain 32-dimensional MFCC features and 32-dimensional pitch features; then, the 32-dimensional MFCC features and 32-dimensional pitch features are spliced to form a 64-dimensional target feature vector.
- the target feature vector after splicingcontains both the information of the MFCC feature and the information of the Pitch feature, which makes the information of the target feature vector larger, which is more helpful to improve the accuracy of subsequent identification.
- S303Use a time-delay neural network-based identity feature recognition model to process the target feature vector to obtain identity feature information.
- the identity feature recognition modelis equipped with a summary pool for calculating the mean and standard deviation of the features input to the hidden layer Floor.
- the identity feature recognition model based on the time-delay neural networkis a model obtained by pre-training the training samples with the time-delay neural network.
- the Time-Delay Neural Network(TDNN) can adapt to the dynamic time domain changes in the speech signal, and the structural parameters are less, and the speech recognition does not need to align the phonetic symbols with the audio in advance on the timeline.
- the training samplesinclude training speech and speaker labels corresponding to the training speech.
- a traditional TDNNincludes an input layer, a first hidden layer, a second hidden layer and an output layer.
- the input layer, the first hidden layer, the second hidden layer, and the output layerare constructed in advance according to the requirements of the service evaluation system, and the second hidden layer and the output layer are set up between the second hidden layer and the output layer for matching the hidden layer.
- the statistical pooling layer(Stattistic Pooling) where the mean and standard deviation of the input features are calculated.
- the mean vector Standard deviation vector ⁇is the same or operator.
- the identification feature recognition model obtained by the time-delayed neural network training with a summary pooling layer set between the second hidden layer and the output layeris used to process the target feature vector to obtain the identification feature information, so that the summary pool
- the transformation layercan process the mean vector ⁇ and standard deviation vector ⁇ obtained by processing the target feature vector through the first hidden layer and the second hidden layer, so as to process the mean vector ⁇ and standard deviation vector ⁇ in the output layer to The accuracy of the extracted identity feature information.
- S304Perform similarity calculation between the identity feature information and the standard feature information corresponding to each agent in the database, obtain feature similarity, and determine the target identity information corresponding to the voice stream to be recognized based on the feature similarity.
- the databaseis a database used to store data used or generated in the service evaluation process, and the database is connected to the server so that the server can access the database.
- the standard feature informationis the feature information corresponding to the identity tag of the seat personnel stored in the database in advance.
- the standard voice stream corresponding to each agentcan be input in advance into the time-delay neural network-based identity feature recognition model in step S303 for processing, so as to obtain corresponding standard feature information.
- the corresponding identity tag associationcan be used for subsequent identity recognition based on the obtained standard feature information.
- the feature similarityrefers to the specific value obtained by calculating the similarity between the identity feature information and the standard feature information using a preset similarity algorithm.
- the similarity algorithmincludes but is not limited to the cosine similarity algorithm.
- determining the target identity information corresponding to the voice stream to be recognized based on the feature similarityrefers to at least one feature similarity obtained by performing similarity calculations between the identity feature information and at least one standard feature information in the database, based on the feature similarity
- the identity tag corresponding to the largest standard feature informationis determined as the target identity information corresponding to the voice stream to be recognized.
- the MFCC feature and the pitch feature extracted from the speech stream to be recognizedare spliced, so that the obtained target feature vector has a larger amount of information, which is more helpful to ensure subsequent identity Accuracy of recognition;
- the identification feature recognition model based on time-delay neural networkis used to process the target feature vector, and the identification feature recognition model is equipped with a summary pooling layer for calculating the mean and standard deviation of the features input to the hidden layer , So that its processing process fully considers the context information of the target feature vector, and the output layer processes the output after the mean and standard deviation processing, which not only helps to ensure the processing efficiency of the recognition result, but also the accuracy of the recognition result.
- the similarity calculationis performed based on the identity feature information and the standard feature information to determine the target identity information corresponding to the voice stream to be recognized according to the feature similarity, so as to ensure the objectivity of the target identity information determination.
- step S203which is to perform text analysis on the voice stream to be recognized, and obtain the text analysis result corresponding to the voice stream to be recognized, specifically includes the following steps:
- S401Use a voice recognition model to perform text recognition on a voice stream to be recognized, and obtain text information to be recognized.
- the speech recognition modelis a pre-trained model for recognizing text content in speech.
- the speech recognition modelmay be a static speech decoding network for recognizing text content in speech, which is obtained by using training speech data and training text data for model training. Therefore, the decoding speed is fast during text recognition, and the speech static decoding network is used to perform text recognition on the speech stream to be recognized, and the corresponding text information to be recognized can be quickly obtained.
- the text information to be recognizedis the text content recognized from the voice stream to be recognized.
- S402Perform sensitive word analysis on the text information to be recognized, and obtain a sensitive word analysis result.
- the sensitive word analysis resultis a result used to reflect whether there are sensitive words in the text information to be recognized and the impact of the existing sensitive words on the service evaluation.
- the sensitive word analysis process of the text information to be recognizedincludes the following steps: query a sensitive word database based on the text information to be recognized, obtain the number of sensitive words in the text information to be recognized, and determine the sensitive word analysis result according to the number of sensitive words.
- the sensitive word databasepre-stores the sensitive words of the agents in the service process, so that the sensitive word analysis can be performed on the text information to be recognized in the service evaluation process, and the sensitive word analysis results can be obtained.
- the sensitive word analysis resultcan be determined based on the comparison between the number of sensitive words and the first number threshold preset by the system.
- the first number thresholdis a preset value used to evaluate the quality of sensitive word analysis.
- the sensitive word score tablecan be queried based on the number of sensitive words to determine the sensitive word analysis result.
- the sensitive word score tableis a pre-stored information table used to reflect the number of sensitive words and the corresponding scoring score or scoring result.
- the tone analysis resultis used to reflect the analysis result corresponding to the speaker's tone in the text information to be recognized.
- the tone analysis of the text information to be recognizedincludes the following steps: using a voice analyzer to analyze the text information to be recognized to obtain the recognition tone, query the service evaluation information table based on the recognition tone, and obtain the tone analysis result.
- the tone analyzeris an analyzer used to analyze the language and text to determine the tone contained therein.
- the tone analyzercan use IBM's Watson tone analyzer.
- the recognition toneis the tone of the speaker recognized from the text information to be recognized using a tone analyzer.
- the corresponding relationship between different scoring standards and corresponding emotion recognition resultsis stored in the service evaluation information table in advance.
- the scoring standardcontains multiple judgment conditions related to the tone, such as plain tone, no passion, rigid tone, showing indifference and disdain, dissatisfaction In the tone of the client, such as "Didn’t I tell you this question just now?" and "Do you even need me to explain this?” etc., the server is using a tone analyzer to analyze the recognized text information After confirming the recognition tone, query the service evaluation information table based on the recognition tone to obtain the corresponding tone analysis result.
- the text analysis comparison table stored in the systemcan be queried based on the sensitive word analysis results and the tone analysis results, and collected in real time during the service process The text analysis result corresponding to the voice stream to be recognized.
- the text analysis comparison tableis a data table preset by the system to reflect the corresponding relationship between the combination of different sensitive word analysis results and tone analysis results and the analysis results, so that after determining the sensitive word analysis results and the tone analysis results, you can Quickly look up the table to determine the corresponding text analysis results.
- the sensitive word analysis results and the tone analysis resultscan be analyzed Normalization processing to obtain the normalization result of sensitive words and the normalization result of the tone, so as to change the dimensional expression into a dimensionless expression; then use the text analysis weighting algorithm to normalize the result of the sensitive word and the tone Calculate the transformation results, and obtain the text analysis results corresponding to the voice stream to be recognized collected in real time during the service process, so that the text analysis results can be represented by quantitative features.
- the sensitive word analysis weight w1 and the tone analysis weight w2are the weights preset by the service evaluation system.
- a speech recognition modelis used to perform text recognition on the speech stream to be recognized, so as to convert speech information into text information, and provide technical support for subsequent sensitive word and tone analysis; Perform sensitive word analysis and tone analysis on the text information to be recognized. According to the obtained sensitive word analysis results and tone analysis results, determine the text analysis results corresponding to the voice stream to be recognized, so that the text analysis results comprehensively consider the sensitive words and the tone in the text information to be recognized.
- the two dimensions of the speaker's toneevaluate the quality of service and ensure the objectivity and accuracy of the obtained text analysis results.
- step S403that is, using the voice emotion recognition model to analyze the voice stream to be recognized to obtain the emotion analysis result, specifically includes the following steps:
- S501Perform voice segmentation on the voice stream to be recognized, and obtain at least two target voice segments.
- the target speech segmentis a speech segment formed by segmenting the speech stream to be recognized.
- the serveruses a voice activation detection algorithm to detect the voice stream to be recognized, to detect the pause time corresponding to each pause point in the voice stream to be recognized, and determine the pause point whose pause time is greater than the preset duration threshold as the voice segment point , Perform voice segmentation on the to-be-recognized voice stream based on the voice segmentation point, and obtain at least two target voice segments for subsequent emotion recognition and speech rate calculations based on the target voice segments, which provides a technical basis for parallel processing and helps Ensure the efficiency of subsequent analysis and processing.
- S502Perform emotion recognition on each target speech segment using a voice emotion recognition model, and obtain the recognition emotion corresponding to each target speech segment.
- the speech emotion recognition modelis a model that is pre-trained to recognize the speaker's emotion in the speech.
- the speech emotion recognition modelmay specifically be a PAD emotion model, which will have three dimensions of pleasure, activation and dominance for emotions, where P stands for Pleasure-displeasure, which represents the individual's emotional state Positive and negative characteristics; A stands for activation (Arousal-nonarousal), which represents the individual's neurophysiological activation level; D stands for Dominance-submissiveness, which represents the individual's control over the situation and others. Recognizing emotions is the output result of emotion recognition for each target speech segment using a speech emotion recognition model.
- S503Calculate the recognition speech rate corresponding to each target speech segment.
- the recognition speech rate corresponding to the target speech segmentrefers to the quotient of the number of spoken words corresponding to the target speech segment and the speech duration, which is used to reflect the number of spoken words per unit time.
- the voice recognition modelhas been used to perform text recognition on the voice stream to be recognized, and the text information to be recognized corresponding to the entire voice stream to be recognized is obtained.
- the speech durationcan be determined based on the timestamps corresponding to the first frame of data and the last frame of data in each target speech segment; and the text information to be recognized can be determined based on the timestamps corresponding to the first frame of data and the last frame of data
- the number of spoken words and the speech durationare used to determine the recognition speech rate corresponding to each target speech segment. Understandably, based on the to-be-recognized text information obtained in the text analysis process, the recognition speech rate corresponding to the target speech segment can be quickly calculated, and the efficiency of obtaining the recognition speech rate can be improved.
- the agentspeaks faster, it means that the agent is more impatient, which makes the customer's satisfaction with the service provided by the agent worse. Therefore, the agent speaks faster It can be used as a sentiment analysis dimension to evaluate its service quality, so it is necessary to calculate the recognition speech rate corresponding to each target speech segment.
- S504Obtain an emotion analysis result corresponding to the voice stream to be recognized based on the recognition speech rate and the recognition emotion corresponding to the at least two target speech segments.
- the servermay perform sentiment analysis based on the two sentiment analysis dimensions of the recognition speech rate and the sentiment recognition corresponding to the at least two target speech segments, and obtain the sentiment analysis result corresponding to the to-be-recognized voice stream composed of the at least two target speech segments.
- the recognition speech rate and recognition emotion corresponding to at least two target speech segmentscan be converted into corresponding scores respectively, and then weighted processing can be performed to obtain the emotion analysis corresponding to the voice stream to be recognized collected in real time during the service process. result.
- the service evaluation method based on artificial intelligenceby dividing the to-be-recognized speech stream into at least two target speech segments, a technical basis is provided for subsequent analysis of the speech rate changes and mood changes corresponding to the at least two target speech segments. Then analyze each target speech segment to determine its corresponding recognition speech speed and recognition emotion. Use the two dimensions of recognition speech speed and recognition emotion to evaluate the service quality to ensure the objectivity and objectivity of the sentiment analysis results obtained. accuracy.
- step S502which uses a speech emotion recognition model to perform emotion recognition on each target speech segment, and obtains the recognition emotion corresponding to each target speech segment, specifically includes the following steps:
- S601Perform feature extraction on each target speech segment, and obtain the spectrogram feature and TEO feature corresponding to the target speech segment.
- the spectrogramis a speech spectrogram, which is a spectrum analysis view obtained by processing time domain signals with sufficient time length.
- the abscissa of the spectrogramis time, the ordinate is frequency, and the coordinate point value Energy for voice data.
- the spectrogram featuresare based on the features extracted from the spectrogram.
- the serverobtains the corresponding spectrogram based on the target speech segment; then normalizes the spectrogram to obtain the normalized spectrogram grayscale image; then, calculate Gabor maps of different scales and directions, and local binary patterns are used to extract the texture features of the Gabor maps; finally, the texture features corresponding to the local binary patterns extracted from the Gabor maps of different scales and directions are cascaded to obtain the corresponding The characteristics of the spectrogram.
- the spectrogram featureis a voice emotion feature. Compared with the traditional prosody feature, frequency domain feature and voice quality feature, the emotion recognition result is more accurate when performing emotion recognition.
- TEOTag Energy Operator
- HMTeager Energy Operatoris a nonlinear operator that can track the instantaneous energy of the signal. It is a simple signal analysis algorithm proposed by the scientist HMTeager when he is studying nonlinear speech modeling.
- the TEO featureis the fundamental frequency feature obtained by using TEO to analyze the target speech segment. Due to the characteristics of the Teager energy operator, the TEO feature extracted from the target speech segment has better stability in a noisy environment and improves its distinguishability. Therefore, the anti-noise performance of the TEO feature is good.
- S602Splicing the spectrogram feature and the TEO feature to obtain the target recognition feature corresponding to the target speech segment.
- the splicing processing of the spectrogram feature and the TEO featurerefers to splicing all the dimensions of the spectrogram feature and the TEO feature to form the target recognition feature.
- the target recognition featurerefers to the feature formed after the splicing process of the spectrogram feature and the TEO feature.
- the serverwhen it performs feature extraction on the target speech segment, it can obtain 1024-dimensional spectrogram features and 20-dimensional TEO features; and then splice the 1024-dimensional spectrogram features and 20-dimensional TEO features into 1044 dimensions.
- Target recognition featureso that the spliced target recognition feature contains not only the information of the spectrogram feature, but also the information of the TEO feature, so that the amount of information of the target recognition feature is larger. Since the target recognition feature contains the information of the TEO feature, It has good stability in a noisy environment, so that the final target recognition feature also has corresponding anti-noise performance. It helps to improve the accuracy of subsequent recognition.
- S603Use the voice emotion recognition model to perform emotion recognition on the target recognition feature corresponding to each target speech segment, and obtain the recognition emotion corresponding to each target speech segment.
- the speech emotion recognition modelis a model that is pre-trained to recognize the speaker's emotion in the speech.
- the process of pre-training a speech emotion recognition modelincludes the following steps: (1) Obtain original speeches whose speech duration is greater than a preset duration, and each original speech carries a corresponding emotion label, wherein the preset duration is a spectrogram The minimum duration for feature processing, the voice duration of the original speech is longer than the preset time, which can ensure the feasibility of subsequent spectrogram feature extraction. (2) Perform feature extraction on the original speech, obtain the spectrogram feature and TEO feature corresponding to the original speech, and stitch the spectrogram feature and TEO feature corresponding to the original speech to form a training sample.
- the training samplerefers to a training feature formed by splicing the spectrogram feature corresponding to the original speech and the TEO feature, and the training feature corresponds to the emotion label of the original speech.
- the process of feature extraction and feature splicing in the process of acquiring training samplesis consistent with the foregoing steps S602 and S603, and in order to avoid repetition, details are not repeated here.
- the training samples of the speech emotion recognition modelcombine the information of the spectrogram feature and the TEO feature Compared with the traditional prosodic features, frequency domain features, and voice quality features, the emotion recognition results are more accurate when performing emotion recognition; moreover, it has the anti-noise characteristics of TEO features, so that the subsequent use of voice emotion recognition models for target recognition When the feature is used for emotion recognition, the anti-noise performance is good, which helps to improve the accuracy of the emotion recognition.
- the spectrogram features and TEO features extracted from the target speech segmentare spliced, so that the acquired target
- the greater amount of information in the recognition featurehelps to ensure the accuracy and noise resistance of subsequent emotion recognition.
- the target recognition feature determined by the target speech segmentis input into the speech emotion recognition model for recognition, and the recognition emotion corresponding to the target speech segment can be quickly obtained, so that the accuracy of the obtained recognition emotion is higher and the noise resistance is higher.
- step S504which is to obtain the emotion analysis result corresponding to the voice stream to be recognized based on the recognition speech rate and the recognition emotion corresponding to at least two target speech segments, specifically includes the following steps:
- S701Obtain the target emotion corresponding to the current target speech segment based on the recognition speech rate of the current target speech segment, the recognition speech rate of the previous target speech segment, and the recognition emotion of the current target speech segment.
- the current target speech segmentrefers to the target speech segment that needs to be analyzed at the current moment.
- the last target speech segmentrefers to a target speech segment before the current target speech segment among at least two target speech segments after voice segmentation of the speech stream to be recognized.
- the target emotion corresponding to the current target speech segmentrefers to the target emotion corresponding to the current target speech segment that is determined for subsequent analysis by considering the recognition speech rate of the two target speech segments before and after and the recognition emotion corresponding to the current target recognition speech segment.
- the above step S701specifically includes the following steps: (1) If there is no previous target speech segment, obtain the target emotion corresponding to the current target speech segment based on the recognition emotion corresponding to the current speech segment. That is, the current target speech segment is the first target speech segment. At this time, if the current target speech segment is negative emotion, then the target emotion of the current target speech segment is negative emotion; if the current target speech segment is positive emotion, then the current target speech The target emotion of the segment is positive emotion. (2) If there is a previous target speech segment, when the recognition rate of the current target speech segment is greater than the recognition rate of the last target speech segment, and the recognition emotion of the current target speech segment is a negative emotion, the current target speech segment The corresponding target emotion is determined to be a negative emotion.
- the recognition rate of the current target speech segmentis not greater than the recognition rate of the previous target speech segment, or the recognition rate of the current target speech segment is greater than the previous target speech segment
- the recognition rate of speech and the recognition emotion of the current target speech segmentis a positive emotion
- the target emotion corresponding to the current target speech segmentis a positive emotion.
- the target emotion of the current target speech segmentis determined to be negative Emotions and other emotions are all positive emotions, so that the determined target emotion comprehensively considers information such as emotions and speaking speed, which helps to improve the accuracy of subsequent analysis.
- S702Obtain the number of negative emotions corresponding to the voice stream to be recognized based on the target emotions corresponding to at least two current target speech segments.
- the target emotioncan be positive emotion and negative emotion.
- Positive emotionrefers to the emotion corresponding to the positive mental attitude or state. It is the emotion corresponding to a benign, positive, stable and constructive mental state, including but not Limited to emotions such as love, happiness, optimism, trust, acceptance and surprise.
- Negative emotionsrefer to emotions that are generated by external or internal factors in a specific behavior that are not conducive to continuing to complete work or normal thinking. It is opposite to positive emotions, including but not limited to disgust, dislike, opposition, dissatisfaction, ignorance And contempt and other emotions.
- the number of negative emotionsrefers to the number of at least two current target speech segments whose target emotions are negative emotions.
- S703Obtain a sentiment analysis result corresponding to the voice stream to be recognized based on the number of negative emotions corresponding to the voice stream to be recognized.
- obtaining the emotion analysis result corresponding to the voice stream to be recognizedincludes: if the number of negative emotions corresponding to the voice stream to be recognized is greater than the second number threshold, then the obtained emotion analysis result Is a negative emotion; if the number of negative emotions corresponding to the voice stream to be recognized is not greater than the second number threshold, the obtained emotion analysis result is a positive emotion.
- the second number thresholdis a preset value.
- obtaining the emotion analysis result corresponding to the voice stream to be recognizedincludes: calculating the probability of the negative emotion based on the number of negative emotions corresponding to the voice stream to be recognized, if the probability of the negative emotion is greater than a preset Probability threshold, the obtained sentiment analysis result is a negative sentiment; if the probability of the negative sentiment is not greater than the preset probability threshold, the obtained sentiment analysis result is a positive sentiment.
- the probability of negative emotionrefers to the ratio of the number of negative emotions to the number of all target speech segments.
- the preset probability thresholdis a preset probability value.
- obtaining the emotion analysis result corresponding to the speech stream to be recognizedincludes: querying the emotion score comparison table based on the number of negative emotions corresponding to the speech stream to be recognized, and obtaining the speech stream to be recognized
- the sentiment score comparison tableis a data table used to store sentiment scores corresponding to different amounts of negative emotions.
- the target emotion corresponding to each current target voiceneeds to comprehensively consider the recognition emotion and the recognition speed of the two target speech segments, which helps to improve the accuracy of subsequent analysis.
- the target emotions corresponding to at least two current target speech segmentsdetermine the number of negative emotions corresponding to the voice stream to be recognized, and obtain the sentiment analysis results based on the number of negative emotions, so that the sentiment analysis results comprehensively consider the two effects of speech speed and negative emotions.
- the key dimension of qualityhelps to improve the objectivity and accuracy of service evaluation.
- an artificial intelligence-based service evaluation devicecorresponds to the artificial intelligence-based service evaluation method in the foregoing embodiment in a one-to-one correspondence.
- the artificial intelligence-based service evaluation deviceincludes a voice stream acquisition module 801 to be recognized, a target identity information acquisition module 802, a text analysis result acquisition module 803, a sentiment analysis result acquisition module 804, and a service quality score acquisition module 805 .
- the detailed description of each functional moduleis as follows:
- the to-be-recognized voice stream acquisition module 801is used to acquire the to-be-recognized voice stream collected in real time during the service process.
- the target identity information acquisition module 802is configured to perform identity recognition on the voice stream to be recognized and determine the target identity information corresponding to the voice stream to be recognized.
- the text analysis result obtaining module 803is configured to perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized.
- the emotion analysis result obtaining module 804is configured to perform emotion analysis on the voice stream to be recognized, and obtain the emotion analysis result corresponding to the voice stream to be recognized.
- the service quality score obtaining module 805is configured to perform fusion processing on the text analysis result and the sentiment analysis result corresponding to the voice stream to be recognized, and obtain the service quality score corresponding to the target identity information.
- the artificial intelligence-based service evaluation devicefurther includes: a voice duration judgment processing module for acquiring the voice duration corresponding to the voice stream to be recognized, if the voice duration is greater than the duration Threshold, perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized.
- a voice duration judgment processing modulefor acquiring the voice duration corresponding to the voice stream to be recognized, if the voice duration is greater than the duration Threshold, perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized.
- the target identity information acquisition module 802includes:
- the voice stream feature extraction unitis used to perform feature extraction on the voice stream to be recognized, and obtain the MFCC feature and pitch feature corresponding to the voice stream to be recognized.
- the target feature vector obtaining unitis used for splicing the MFCC feature and the pitch feature to obtain the target feature vector.
- the identity feature information acquisition unitis used to process the target feature vector using the identity feature recognition model based on the time-delay neural network to obtain the identity feature information.
- the identity feature recognition modelis equipped with the average value and standard for the hidden layer input features Aggregate pooling layer for difference calculation.
- the target identity information acquisition unitis used to calculate the similarity between the identity characteristic information and the standard characteristic information corresponding to each agent in the database, obtain the characteristic similarity, and determine the target identity information corresponding to the voice stream to be recognized based on the characteristic similarity.
- the text analysis result obtaining module 803includes:
- the text information acquisition unitis configured to use a voice recognition model to perform text recognition on the voice stream to be recognized, and obtain text information to be recognized.
- the sensitive word analysis result obtaining unitis used to perform sensitive word analysis on the text information to be recognized and obtain the sensitive word analysis result.
- the tone analysis result obtaining unitis used to perform tone analysis on the text information to be recognized and obtain the tone analysis result.
- the text analysis result obtaining unitis used to obtain the text analysis result corresponding to the voice stream to be recognized based on the sensitive word analysis result and the tone analysis result.
- the sentiment analysis result obtaining module 804includes:
- the target speech segment acquisition unitis configured to perform speech segmentation on the speech stream to be recognized to acquire at least two target speech segments.
- the recognition emotion acquisition unitis used for using a voice emotion recognition model to perform emotion recognition on each target speech segment, and obtain the recognition emotion corresponding to each target speech segment.
- the recognition speech rate calculation unitis used to calculate the recognition speech rate corresponding to each target speech segment.
- the emotion analysis result obtaining unitis configured to obtain the emotion analysis result corresponding to the speech stream to be recognized based on the recognition speech rate and the recognition emotion corresponding to the at least two target speech segments.
- the recognition emotion acquiring unitincludes:
- the voice segment feature extraction subunitis used to perform feature extraction on each target voice segment to obtain the spectrogram features and TEO features corresponding to the target voice segment.
- the target recognition feature acquisition subunitis used to splice the spectrogram features and TEO features to acquire the target recognition features corresponding to the target speech segment.
- the recognition emotion acquisition sub-unitis used for using the voice emotion recognition model to perform emotion recognition on the target recognition feature corresponding to each target speech segment, and obtain the recognition emotion corresponding to each target speech segment.
- the sentiment analysis result obtaining unitincludes:
- the target emotion acquisition subunitis used to obtain the target emotion corresponding to the current target speech segment based on the recognition speech rate of the current target speech segment, the recognition speech speed of the previous target speech segment, and the recognition emotion of the current target speech segment.
- the negative emotion quantity obtaining subunitis used to obtain the negative emotion quantity corresponding to the voice stream to be recognized based on the target emotion corresponding to at least two current target speech segments.
- the emotion analysis result obtaining subunitis used to obtain the emotion analysis result corresponding to the voice stream to be recognized based on the number of negative emotions corresponding to the voice stream to be recognized.
- Each module in the above artificial intelligence-based service evaluation devicecan be implemented in whole or in part by software, hardware, and a combination thereof.
- the above-mentioned modulesmay be embedded in the form of hardware or independent of the processor in the computer equipment, or may be stored in the memory of the computer equipment in the form of software, so that the processor can call and execute the operations corresponding to the above-mentioned modules.
- a computer deviceis provided.
- the computer devicemay be a server, and its internal structure diagram may be as shown in FIG. 9.
- the computer equipmentincludes a processor, a memory, a network interface, and a database connected through a system bus. Among them, the processor of the computer device is used to provide calculation and control capabilities.
- the memory of the computer deviceincludes a non-volatile storage medium and an internal memory.
- the non-volatile storage mediumstores an operating system, computer readable instructions, and a database.
- the internal memoryprovides an environment for the operation of the operating system and computer-readable instructions in the non-volatile storage medium.
- the database of the computer equipmentis used to store data used or generated during the execution of the artificial intelligence-based service evaluation method.
- the network interface of the computer deviceis used to communicate with an external terminal through a network connection. When the computer-readable instructions are executed by the processor, an artificial intelligence-based service evaluation method is realized.
- a computer deviceincluding a memory, a processor, and computer-readable instructions stored in the memory and capable of running on the processor.
- the processorexecutes the computer-readable instructions to implement the Artificial intelligence service evaluation methods, such as S201-S205 shown in Fig. 2, or shown in Figs. 2-7, are not repeated here to avoid repetition.
- the functions of the modules/units in the embodiment of the artificial intelligence-based service evaluation deviceare realized, for example, the to-be-recognized voice stream acquisition module 801 and the target identity information acquisition module shown in FIG. 8 802.
- the functions of the text analysis result acquisition module 803, the sentiment analysis result acquisition module 804, and the service quality score acquisition module 805are not repeated here in order to avoid repetition.
- one or more readable storage media storing computer readable instructionsare provided.
- the computer readable storage mediumstores computer readable instructions, and the computer readable instructions are executed by one or more processors.
- the one or more processorsare executed to implement the artificial intelligence-based service evaluation method in the foregoing embodiment, such as S201-S205 shown in FIG. 2, or shown in FIG. 2 to FIG. 7, in order to avoid repetition, I won't repeat it here.
- the computer-readable instructionis executed by the processor, the function of each module/unit in the embodiment of the above-mentioned artificial intelligence-based service evaluation device is realized, for example, the to-be-recognized voice stream acquisition module 801 and the target identity shown in FIG.
- the functions of the information acquisition module 802, the text analysis result acquisition module 803, the sentiment analysis result acquisition module 804, and the service quality score acquisition module 805are not repeated here in order to avoid repetition.
- the readable storage medium in this embodimentincludes a non-volatile readable storage medium and a volatile readable storage medium.
- Non-volatile memorymay include read only memory (ROM), programmable ROM (PROM), electrically programmable ROM (EPROM), electrically erasable programmable ROM (EEPROM), or flash memory.
- Volatile memorymay include random access memory (RAM) or external cache memory.
- RAMis available in many forms, such as static RAM (SRAM), dynamic RAM (DRAM), synchronous DRAM (SDRAM), double data rate SDRAM (DDRSDRAM), enhanced SDRAM (ESDRAM), synchronous chain Channel (Synchlink) DRAM (SLDRAM), memory bus (Rambus) direct RAM (RDRAM), direct memory bus dynamic RAM (DRDRAM), and memory bus dynamic RAM (RDRAM), etc.
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Strategic Management (AREA)
- Accounting & Taxation (AREA)
- Marketing (AREA)
- Development Economics (AREA)
- Physics & Mathematics (AREA)
- Finance (AREA)
- General Business, Economics & Management (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Economics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- Acoustics & Sound (AREA)
- Entrepreneurship & Innovation (AREA)
- Human Computer Interaction (AREA)
- Game Theory and Decision Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Psychiatry (AREA)
- Hospice & Palliative Care (AREA)
- General Health & Medical Sciences (AREA)
- Child & Adolescent Psychology (AREA)
- Telephonic Communication Services (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese本申请以2020年2月19日提交的申请号为202010102176.3,名称为“基于人工智能的服务评价方法、装置、设备及存储介质”的中国发明申请为基础,并要求其优先权。This application is based on the Chinese invention application with the application number 202010102176.3 and the title of "artificial intelligence-based service evaluation method, device, equipment and storage medium" filed on February 19, 2020, and claims its priority.
本申请涉及人工智能技术领域,尤其涉及一种基于人工智能的服务评价方法、装置、设备及存储介质。This application relates to the field of artificial intelligence technology, and in particular to an artificial intelligence-based service evaluation method, device, equipment and storage medium.
为了提升企业服务能力,充分满足客户的不同要求,企业建立相应的坐席中心,由坐席中心的坐席人员给客户提供相应的服务,以提高服务效率,避免客户到柜台办理业务存在的不便。由于坐席人员是连接客户与企业的重要纽带,坐席人员的服务质量很大程度上会影响客户对企业的满意度。发明人意识到当前企业内部对坐席人员的服务评价主要是根据客户对坐席人员的服务进行手动评分,客户是否评分以及具体评多少分均由客户主观决定,使得服务评价过程中客观性和准确率不高。In order to improve the service capabilities of the enterprise and fully meet the different requirements of customers, the enterprise establishes a corresponding seat center, and the seat staff of the seat center provide customers with corresponding services to improve service efficiency and avoid the inconvenience of customers going to the counter to handle business. Since the agent is an important link between the customer and the company, the service quality of the agent will greatly affect the customer's satisfaction with the company. The inventor realizes that the current service evaluation of the agents in the enterprise is mainly based on the customer's manual scoring of the agent's services. Whether the customer scores and the specific evaluation scores are subjectively determined by the customer, which makes the service evaluation process objective and accurate. not tall.
发明内容Summary of the invention
本申请实施例提供一种基于人工智能的服务评价方法、装置、设备及存储介质,以解决当前服务评价过程中客观性和准确率不高的问题。The embodiments of the present application provide an artificial intelligence-based service evaluation method, device, equipment, and storage medium to solve the problem of low objectivity and accuracy in the current service evaluation process.
一种基于人工智能的服务评价方法,包括:A service evaluation method based on artificial intelligence, including:
获取服务过程中实时采集的待识别语音流;The voice stream to be recognized collected in real time during the process of obtaining the service;
对所述待识别语音流进行身份识别,确定所述待识别语音流对应的目标身份信息;Perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized;
对所述待识别语音流进行文本分析,获取所述待识别语音流对应的文本分析结果;Perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized;
对所述待识别语音流进行情绪分析,获取所述待识别语音流对应的情绪分析结果;Perform sentiment analysis on the voice stream to be recognized, and obtain a sentiment analysis result corresponding to the voice stream to be recognized;
对所述待识别语音流对应的所述文本分析结果和所述情绪分析结果进行融合处理,获取所述目标身份信息对应的服务质量评分。Fusion processing is performed on the text analysis result and the emotion analysis result corresponding to the voice stream to be recognized, and the service quality score corresponding to the target identity information is obtained.
一种基于人工智能的服务评价装置,包括:A service evaluation device based on artificial intelligence, including:
待识别语音流获取模块,用于获取服务过程中实时采集的待识别语音流;To-be-recognized voice stream acquisition module, used to acquire the to-be-recognized voice stream collected in real time during the service process;
目标身份信息获取模块,用于对所述待识别语音流进行身份识别,确定所述待识别语音流对应的目标身份信息;The target identity information acquisition module is configured to perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized;
文本分析结果获取模块,用于对所述待识别语音流进行文本分析,获取所述待识别语音流对应的文本分析结果;A text analysis result obtaining module, configured to perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized;
情绪分析结果获取模块,用于对所述待识别语音流进行情绪分析,获取所述待识别语音流对应的情绪分析结果;An emotion analysis result obtaining module, configured to perform emotion analysis on the voice stream to be recognized, and obtain the emotion analysis result corresponding to the voice stream to be recognized;
服务质量评分获取模块,用于对所述待识别语音流对应的所述文本分析结果和所述情绪分析结果进行融合处理,获取所述目标身份信息对应的服务质量评分。The service quality score obtaining module is configured to perform fusion processing on the text analysis result and the sentiment analysis result corresponding to the voice stream to be recognized, and obtain the service quality score corresponding to the target identity information.
一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机可读指令,所述处理器执行所述计算机可读指令时实现如下步骤:A computer device includes a memory, a processor, and computer-readable instructions that are stored in the memory and can run on the processor, and the processor implements the following steps when the processor executes the computer-readable instructions:
获取服务过程中实时采集的待识别语音流;The voice stream to be recognized collected in real time during the process of obtaining the service;
对所述待识别语音流进行身份识别,确定所述待识别语音流对应的目标身份信息;Perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized;
对所述待识别语音流进行文本分析,获取所述待识别语音流对应的文本分析结果;Perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized;
对所述待识别语音流进行情绪分析,获取所述待识别语音流对应的情绪分析结果;Perform sentiment analysis on the voice stream to be recognized, and obtain a sentiment analysis result corresponding to the voice stream to be recognized;
对所述待识别语音流对应的所述文本分析结果和所述情绪分析结果进行融合处理,获 取所述目标身份信息对应的服务质量评分。Perform fusion processing on the text analysis result and the sentiment analysis result corresponding to the voice stream to be recognized, and obtain a service quality score corresponding to the target identity information.
一个或多个存储有计算机可读指令的可读存储介质,所述计算机可读存储介质存储有计算机可读指令,所述计算机可读指令被一个或多个处理器执行时,使得所述一个或多个处理器执行如下步骤:One or more readable storage media storing computer readable instructions, the computer readable storage medium storing computer readable instructions, and when the computer readable instructions are executed by one or more processors, the one Or multiple processors perform the following steps:
获取服务过程中实时采集的待识别语音流;The voice stream to be recognized collected in real time during the process of obtaining the service;
对所述待识别语音流进行身份识别,确定所述待识别语音流对应的目标身份信息;Perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized;
对所述待识别语音流进行文本分析,获取所述待识别语音流对应的文本分析结果;Perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized;
对所述待识别语音流进行情绪分析,获取所述待识别语音流对应的情绪分析结果;Perform sentiment analysis on the voice stream to be recognized, and obtain a sentiment analysis result corresponding to the voice stream to be recognized;
对所述待识别语音流对应的所述文本分析结果和所述情绪分析结果进行融合处理,获取所述目标身份信息对应的服务质量评分。Fusion processing is performed on the text analysis result and the emotion analysis result corresponding to the voice stream to be recognized, and the service quality score corresponding to the target identity information is obtained.
上述基于人工智能的服务评价方法、装置、设备及存储介质中,通过对待识别语音流进行身份识别,以确定其对应的目标身份信息,从而实现对未知说话人对应的待识别语音流进行身份识别。通过对待识别语音流进行文本分析和情绪分析,分别获取文本分析结果和情绪分析结果,再对文本分析结果和情绪分析结果进行融合处理,获取目标身份信息对应的服务质量评分,以实现采用人工智能的技术手段实现对待识别语音流中说话人的服务质量进行客观分析,以保证获取的目标分析结果的客观性和准确性,避免人为主观评价的不足。In the above artificial intelligence-based service evaluation method, device, equipment and storage medium, the voice stream to be recognized is identified to determine its corresponding target identity information, so as to realize the identity recognition of the voice stream to be recognized corresponding to the unknown speaker . Through text analysis and sentiment analysis of the voice stream to be recognized, the text analysis results and sentiment analysis results are obtained respectively, and then the text analysis results and sentiment analysis results are fused to obtain the service quality score corresponding to the target identity information, so as to realize the use of artificial intelligence The technical means to realize the objective analysis of the service quality of the speaker in the speech stream to be recognized, to ensure the objectivity and accuracy of the target analysis results obtained, and to avoid the lack of subjective evaluation by people.
为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to explain the technical solutions of the embodiments of the present application more clearly, the following will briefly introduce the drawings that need to be used in the description of the embodiments of the present application. Obviously, the drawings in the following description are only some embodiments of the present application. For those of ordinary skill in the art, other drawings can be obtained based on these drawings without creative labor.
图1是本申请一实施例中基于人工智能的服务评价方法的一应用环境示意图;FIG. 1 is a schematic diagram of an application environment of an artificial intelligence-based service evaluation method in an embodiment of the present application;
图2是本申请一实施例中基于人工智能的服务评价方法的一流程图;FIG. 2 is a flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application;
图3是本申请一实施例中基于人工智能的服务评价方法的另一流程图;FIG. 3 is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application;
图4是本申请一实施例中基于人工智能的服务评价方法的另一流程图;FIG. 4 is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application;
图5是本申请一实施例中基于人工智能的服务评价方法的另一流程图;FIG. 5 is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application;
图6是本申请一实施例中基于人工智能的服务评价方法的另一流程图;FIG. 6 is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application;
图7是本申请一实施例中基于人工智能的服务评价方法的另一流程图;FIG. 7 is another flowchart of a service evaluation method based on artificial intelligence in an embodiment of the present application;
图8是本申请一实施例中基于人工智能的服务评价装置的一示意图;FIG. 8 is a schematic diagram of a service evaluation device based on artificial intelligence in an embodiment of the present application;
图9是本申请一实施例中计算机设备的一示意图。Fig. 9 is a schematic diagram of a computer device in an embodiment of the present application.
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。The technical solutions in the embodiments of the present application will be described clearly and completely in conjunction with the accompanying drawings in the embodiments of the present application. Obviously, the described embodiments are part of the embodiments of the present application, rather than all of them. Based on the embodiments in this application, all other embodiments obtained by those of ordinary skill in the art without creative work shall fall within the protection scope of this application.
本申请实施例提供的基于人工智能的服务评价方法,该基于人工智能的服务评价方法可应用如图1所示的应用环境中。具体地,该基于人工智能的服务评价方法应用在基于人工智能的服务评价系统中,该基于人工智能的服务评价系统包括如图1所示的客户端和服务器,客户端与服务器通过网络进行通信,用于对坐席人员给客户提供服务过程中采集的录音进行客观分析,以保证服务评价的客观性和准确性。其中,客户端又称为用户端,是指与服务器相对应,为客户提供本地服务的程序。客户端可安装在但不限于各种个人计算机、笔记本电脑、智能手机、平板电脑和便携式可穿戴设备上。服务器可以用独立的服务 器或者是多个服务器组成的服务器集群来实现。According to the artificial intelligence-based service evaluation method provided by the embodiments of the present application, the artificial intelligence-based service evaluation method can be applied to the application environment as shown in FIG. 1. Specifically, the artificial intelligence-based service evaluation method is applied in an artificial intelligence-based service evaluation system. The artificial intelligence-based service evaluation system includes a client and a server as shown in FIG. 1, and the client and the server communicate through a network. It is used to objectively analyze the recordings collected during the process of providing services to customers by the agents to ensure the objectivity and accuracy of service evaluation. Among them, the client is also called the client, which refers to the program that corresponds to the server and provides local services to the client. The client can be installed on, but not limited to, various personal computers, notebook computers, smart phones, tablet computers, and portable wearable devices. The server can be implemented as an independent server or a server cluster composed of multiple servers.
在一实施例中,如图2所示,提供一种基于人工智能的服务评价方法,该基于人工智能的服务评价方法应用在图1所示的服务器中,包括如下步骤:In one embodiment, as shown in FIG. 2, an artificial intelligence-based service evaluation method is provided. The artificial intelligence-based service evaluation method is applied to the server shown in FIG. 1, and includes the following steps:
S201:获取服务过程中实时采集的待识别语音流。S201: Obtain a voice stream to be recognized that is collected in real time during the service process.
其中,待识别语音流是指进行服务评价所采用的语音流。该待识别语音流可以是坐席人员给客户提供服务过程中实时录制的语音流,具体是服务评价进行信息处理的对象。Among them, the voice stream to be recognized refers to the voice stream used for service evaluation. The to-be-recognized voice stream may be a voice stream recorded in real time during the process of providing a service to a customer by an agent, and is specifically an object of information processing for service evaluation.
作为一示例,坐席人员通过电话销售系统给客户提供服务,在服务过程中,电话销售系统上的录音模块实时采集坐席人员给客户提供服务过程中的待识别语音流,将该待识别语音流发送给服务评价系统或者存储在数据库中;相应地,服务评价系统的服务器可接收录音模块实时录制的待识别语音流,也可以从数据库中获取需要进行服务评价的待识别语音流,使得坐席人员的每一次服务均可采集到相应的待识别语音流并进行后续服务评价。As an example, the agent provides services to customers through the telemarketing system. During the service process, the recording module on the telemarketing system collects the voice stream to be recognized in the process of providing services to the customer in real time, and sends the voice stream to be recognized To the service evaluation system or stored in the database; correspondingly, the server of the service evaluation system can receive the to-be-recognized voice stream recorded by the recording module in real time, and can also obtain the to-be-recognized voice stream that needs to be evaluated for the service from the database, so that the seat personnel’s For each service, the corresponding voice stream to be recognized can be collected and the follow-up service evaluation can be performed.
可以理解地,服务器获取坐席人员给客户提供服务过程中实时录制的待识别语音流并进行后续服务评价,使得其服务评价过程不受限于客户是否进行评分,保证用于进行服务评价的对象的完整性,保证服务评价过程的客观性和准确性。Understandably, the server obtains the real-time recorded voice stream to be recognized during the service provided by the agent to the customer and conducts follow-up service evaluation, so that the service evaluation process is not limited to whether the customer scores or not, and ensures that the object used for service evaluation Completeness, to ensure the objectivity and accuracy of the service evaluation process.
S202:对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息。S202: Perform identity recognition on the voice stream to be recognized, and determine target identity information corresponding to the voice stream to be recognized.
其中,对待识别语音流进行身份识别是用于识别待识别语音流对应的说话人的身份。目标身份信息是基于待识别语音流识别出的说话人的身份信息。Among them, the identification of the voice stream to be recognized is used to identify the identity of the speaker corresponding to the voice stream to be recognized. The target identity information is based on the identity information of the speaker identified by the voice stream to be recognized.
作为一示例,对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息,具体可以包括如下步骤:对待识别语音流进行声纹特征提取,获取待识别声纹特征,将待识别声纹特征与数据库中每一坐席人员对应的标准声纹特征进行相似度计算,获取声纹相似度,将声纹相似度最大的标准声纹特征对应的身份信息确定为目标身份信息。其中,待识别声纹特征是采用预先训练好的声纹提取模型对待识别语音流进行声纹提取所获取的声纹特征。标准声纹特征是采用预先训练好的声纹提取模型对某一坐席人员的标准语音流进行声纹提取所获取的声纹特征。标准语音流是携带坐席人员的身份信息的语音流,使得所提取的标准声纹特征与坐席人员的身份信息相关联。该声纹提取模型可以是但不限于高斯混合模型。As an example, performing identity recognition on the voice stream to be recognized and determining the target identity information corresponding to the voice stream to be recognized may specifically include the following steps: performing voiceprint feature extraction on the voice stream to be recognized, acquiring voiceprint features to be recognized, and recognizing the voice The similarity of the fingerprint feature and the standard voiceprint feature corresponding to each seat in the database is calculated to obtain the voiceprint similarity, and the identity information corresponding to the standard voiceprint feature with the largest voiceprint similarity is determined as the target identity information. Among them, the voiceprint feature to be recognized is the voiceprint feature obtained by using a pre-trained voiceprint extraction model to perform voiceprint extraction on the voice stream to be recognized. The standard voiceprint feature is the voiceprint feature obtained by using a pre-trained voiceprint extraction model to extract the voiceprint of a standard voice stream of an agent. The standard voice stream is a voice stream that carries the identity information of the seat personnel, so that the extracted standard voiceprint features are associated with the identity information of the seat personnel. The voiceprint extraction model can be, but is not limited to, a Gaussian mixture model.
可以理解地,服务器在获取服务过程中实时采集的待识别语音流之后,对待识别语音流进行身份识别,以确定该待识别语音流对应的目标身份信息,以实现机器分析该待识别语音流对应的目标身份信息,保证坐席人员对应的待识别语音流与其目标身份信息的一致性,可实现对未知身份的坐席人员进行身份识别。Understandably, after the server acquires the voice stream to be recognized in real time during the service process, it performs identity recognition on the voice stream to be recognized to determine the target identity information corresponding to the voice stream to be recognized, so that the machine can analyze the corresponding voice stream to be recognized. The identity information of the target to ensure the consistency of the voice stream to be recognized corresponding to the seat personnel and the target identity information, which can realize the identity recognition of the seat personnel with unknown identities.
S203:对待识别语音流进行文本分析,获取待识别语音流对应的文本分析结果。S203: Perform text analysis on the voice stream to be recognized, and obtain a text analysis result corresponding to the voice stream to be recognized.
其中,文本分析结果是用于对待识别语音流对应的文本内容进行分析所得到的反映服务质量的结果。Among them, the text analysis result is a result reflecting the service quality obtained by analyzing the text content corresponding to the voice stream to be recognized.
作为一示例,服务器可预先训练一用于分析文本内容对应的说话人情绪的文本分析模型,文本分析模型可以是采用神经网络模型对携带不同情绪标签的训练文本数据进行模型训练后获取的模型,可采用该文本分析模型对待识别语音流提取出的待识别文本信息进行情绪分析,以获取文本分析结果,其处理过程效率较高,其分析结果客观性较强。As an example, the server may pre-train a text analysis model for analyzing speaker emotions corresponding to the text content. The text analysis model may be a model obtained after model training is performed on training text data carrying different emotion labels using a neural network model. The text analysis model can be used to perform sentiment analysis on the text information to be recognized extracted from the speech stream to be recognized to obtain text analysis results. The processing process is more efficient and the analysis results are more objective.
S204:对待识别语音流进行情绪分析,获取待识别语音流对应的情绪分析结果。S204: Perform sentiment analysis on the voice stream to be recognized, and obtain a sentiment analysis result corresponding to the voice stream to be recognized.
其中,情绪分析结果是用于对待识别语音流进行情绪分析所获取的结果。作为一示例,服务评价系统中预先存储有语音情绪识别模型,该语音情绪识别模型是预先训练好的用于对语音流进行情绪识别的模型。服务器采用预先训练好的语音情绪识别模型对电话销售系统上的录音模块实时采集的待识别语音流进行情绪识别,其过程可通过机器实现,以保证识别出的目标分析结果的客观性和准确性。Among them, the sentiment analysis result is the result obtained by the sentiment analysis for the speech stream to be recognized. As an example, a voice emotion recognition model is pre-stored in the service evaluation system, and the voice emotion recognition model is a pre-trained model for emotion recognition of a voice stream. The server uses a pre-trained voice emotion recognition model to recognize the emotion of the voice stream to be recognized collected in real time by the recording module on the telemarketing system. The process can be realized by a machine to ensure the objectivity and accuracy of the identified target analysis result .
S205:对待识别语音流对应的文本分析结果和情绪分析结果进行融合处理,获取目标身份信息对应的服务质量评分。S205: Perform fusion processing on the text analysis result and the emotion analysis result corresponding to the voice stream to be recognized, and obtain the service quality score corresponding to the target identity information.
其中,服务质量评分是基于待识别语音流进行分析所确定的服务评分。对待识别语音流对应的文本分析结果和情绪分析结果进行融合处理是指将文本分析结果和情绪分析结果结合,获取可客观反应待识别语音流对应的坐席人员的服务质量的服务质量评分。Among them, the service quality score is a service score determined based on analysis of the voice stream to be recognized. The fusion processing of the text analysis result and the emotion analysis result corresponding to the voice stream to be recognized refers to combining the text analysis result and the emotion analysis result to obtain a service quality score that can objectively reflect the service quality of the agent corresponding to the voice stream to be recognized.
作为一示例,文本分析结果和情绪分析结果匀可以包括至少两种结果类型,如好评和差评,或者1星评分至5星评分等,服务评价系统预先存储不同文本分析结果和情绪分析结果对应的评分分值对照表。服务器在获取每一待识别语音流对应的文本分析结果和情绪分析结果之后,可基于该文本分析结果和情绪分析结果查询评分分值对照表,以确定其对应的服务质量评分,使得所获取的服务质量评分综合考虑待识别语音流对应的文本分析结果和情绪分析结果,有利于保障服务质量评分的客观性和准确性。As an example, the results of text analysis and sentiment analysis can include at least two types of results, such as positive and negative reviews, or 1-star to 5-star ratings, etc. The service evaluation system pre-stores different text analysis results and sentiment analysis results corresponding The scoring score comparison table. After obtaining the text analysis result and sentiment analysis result corresponding to each voice stream to be recognized, the server can query the score comparison table based on the text analysis result and sentiment analysis result to determine its corresponding service quality score, so that the obtained The service quality score comprehensively considers the text analysis results and sentiment analysis results corresponding to the voice stream to be recognized, which helps to ensure the objectivity and accuracy of the service quality score.
本实施例所提供的基于人工智能的服务评价方法中,通过对待识别语音流进行身份识别,以确定其对应的目标身份信息,从而实现对未知说话人对应的待识别语音流进行身份识别。通过对待识别语音流进行文本分析和情绪分析,分别获取文本分析结果和情绪分析结果,再对文本分析结果和情绪分析结果进行融合处理,获取目标身份信息对应的服务质量评分,以实现采用人工智能的技术手段实现对待识别语音流中说话人的服务质量进行客观分析,以保证获取的目标分析结果的客观性和准确性,避免人为主观评价的不足。In the service evaluation method based on artificial intelligence provided in this embodiment, the voice stream to be recognized is identified to determine its corresponding target identity information, so as to realize the identity recognition of the voice stream to be recognized corresponding to the unknown speaker. Through text analysis and sentiment analysis of the voice stream to be recognized, the text analysis results and sentiment analysis results are obtained respectively, and then the text analysis results and sentiment analysis results are fused to obtain the service quality score corresponding to the target identity information, so as to realize the use of artificial intelligence The technical means to realize the objective analysis of the service quality of the speaker in the speech stream to be recognized, to ensure the objectivity and accuracy of the target analysis results obtained, and to avoid the lack of subjective evaluation by people.
在一实施例中,在坐席人员给客户提供服务过程中,其可能采集到“嗯”、“好的”或者其他较简短的待识别语音流,这些较简短的待识别语音流在身份识别和情绪识别过程中,识别准确性较低,因此,在步骤S201之后,即在获取服务过程中实时采集的待识别语音流之后,基于人工智能的服务评价方法还包括:获取待识别语音流对应的语音时长,若语音时长大于时长阈值,则执行对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息。In one embodiment, in the process of providing services to customers, the agent may collect "um", "good" or other short speech streams to be recognized. These short speech streams to be recognized are used in identification and In the emotion recognition process, the recognition accuracy is low. Therefore, after step S201, that is, after the voice stream to be recognized is collected in real time in the process of obtaining the service, the service evaluation method based on artificial intelligence further includes: obtaining the corresponding voice stream to be recognized Voice duration, if the voice duration is greater than the duration threshold, perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized.
其中,待识别语音流对应的语音时长是指待识别语音流对应的说话时长。作为一示例,该语音时长是坐席人员给客户提供服务过程中实时录制的待识别语音流对应的说话时长,是坐席人员给客户提供服务的服务时长。时长阈值是指预先设置的用于评估时长是否达到作为服务评价的对象的阈值。Wherein, the voice duration corresponding to the voice stream to be recognized refers to the speaking duration corresponding to the voice stream to be recognized. As an example, the voice duration is the speaking duration corresponding to the to-be-recognized voice stream recorded in real time during the process of providing services to the customer by the agent, and is the service duration for the agent to provide services to the customer. The duration threshold refers to a preset threshold for evaluating whether the duration reaches the target of service evaluation.
本实施例中,服务器在获取服务过程中实时采集的待识别语音流后,需确定每一待识别语音流对应的语音时长,将该语音时长与系统预先设置的时长阈值进行比较;若语音时长大于时长阈值,则执行对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息及以后的步骤,即执行步骤S202-S205;若语音时长不大于时长阈值,则不执行执行对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息及以后的步骤,即不执行后续步骤S202-S205。In this embodiment, after the server acquires the voice stream to be recognized in real time during the service process, it needs to determine the voice duration corresponding to each voice stream to be recognized, and compare the voice duration with the preset duration threshold of the system; if the voice duration is If the duration is greater than the duration threshold, then perform the identification of the voice stream to be recognized, determine the target identity information corresponding to the voice stream to be recognized and the subsequent steps, that is, perform steps S202-S205; if the voice duration is not greater than the duration threshold, do not perform the recognition to be recognized The voice stream performs identity recognition, and the target identity information corresponding to the voice stream to be recognized and the subsequent steps are determined, that is, the subsequent steps S202-S205 are not executed.
本实施例所提供的基于人工智能的服务评价方法中,只对语音时长大于时长阈值的待识别语音流进行后续的身份识别和情绪识别,以保证后续身份识别和情绪识别的准确性,避免语音时长较短的待识别语音流的识别结果不准确而影响服务评价;可以理解地,若待识别语音流的语音时长不大于时长阈值,则服务器不对该待识别语音流进行后续识别处理,可有效减少后续识别的数据量,提高后续识别的处理效率。In the service evaluation method based on artificial intelligence provided in this embodiment, the subsequent identity recognition and emotion recognition are only performed on the to-be-recognized speech stream whose speech duration is greater than the duration threshold, so as to ensure the accuracy of subsequent identity recognition and emotion recognition and avoid speech The recognition result of the short-duration voice stream to be recognized is inaccurate and affects the service evaluation; understandably, if the voice duration of the voice stream to be recognized is not greater than the duration threshold, the server does not perform subsequent recognition processing on the voice stream to be recognized, which can be effective Reduce the amount of data for subsequent identification and improve the processing efficiency of subsequent identification.
在一实施例中,步骤S202,即对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息,具体包括如下步骤:In one embodiment, step S202, that is, performing identity recognition on the voice stream to be recognized, and determining the target identity information corresponding to the voice stream to be recognized, specifically includes the following steps:
S301:对待识别语音流进行特征提取,获取待识别语音流对应的MFCC特征和Pitch特征。S301: Perform feature extraction on the voice stream to be recognized, and obtain the MFCC feature and the pitch feature corresponding to the voice stream to be recognized.
其中,MFCC(Mel-scale Frequency Cepstral Coefficients,梅尔倒谱系数)是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性,它与频率的关系可用下式近似表示
Pitch特征是与声音的基频fundamental frequency(F0)有关的特征,反应的是音高的信息,即声调。计算F0也被称为pitch detection algorithms(PDA)。作为一示例,系统预先存储有基音检测算法(Pitch detection algorithm),该基音检测算法可以估计周期性信号的音高或基本频率,广泛地应用于语音信号与音乐信号中,算法可分为时域和频域两种方法。服务器在获取服务过程中实时采集的待识别语音流之后,采用预先存储的基音检测算法对待识别语音流进行特征提取,以获取Pitch特征。The Pitch feature is a feature related to the fundamental frequency (F0) of the sound, which reflects the information of the pitch, that is, the tone. Calculating F0 is also called pitch detection algorithms (PDA). As an example, the system pre-stores a pitch detection algorithm (Pitch detection algorithm), which can estimate the pitch or fundamental frequency of periodic signals, and is widely used in voice signals and music signals. The algorithms can be divided into time domains. And frequency domain two methods. After the server acquires the voice stream to be recognized in real time during the service process, it uses a pre-stored pitch detection algorithm to perform feature extraction on the voice stream to be recognized to obtain the pitch feature.
在实际测试过程中,研发人员发现相同性别的人说话所形成的语音较难区分,若仅提取MFCC特征进行后续身份识别,可能使得其识别结果不够准确;因此,在对待识别语音流进行特征提取时,服务器不仅提取MFCC特征,还提取Pitch特征,Pitch特征可以较好地体现说话人的声调和韵律信息,使得同性之间的语音更有区分度,有助于提高后续基于待识别语音流提取的特征进行身份识别的准确性。In the actual test process, R&D personnel found that the speech formed by people of the same gender is difficult to distinguish. If only MFCC features are extracted for subsequent identification, the recognition results may be inaccurate; therefore, feature extraction is performed on the voice stream to be recognized. At the same time, the server not only extracts MFCC features, but also Pitch features. Pitch features can better reflect the tone and prosody information of the speaker, making voices of the same sex more distinguishable, and helping to improve subsequent extraction based on the voice stream to be recognized The characteristics of the accuracy of identification.
S302:对MFCC特征和Pitch特征进行拼接处理,获取目标特征向量。S302: Perform splicing processing on the MFCC feature and the Pitch feature to obtain a target feature vector.
其中,对MFCC特征和Pitch特征进行拼接处理是指将MFCC特征和Pitch特征所有维度进行拼接,以形成目标特征向量。目标特征向量是指MFCC特征和Pitch特征经过拼接处理后形成的特征向量。Among them, concatenating the MFCC feature and the Pitch feature refers to concatenating all the dimensions of the MFCC feature and the Pitch feature to form a target feature vector. The target feature vector refers to the feature vector formed after the MFCC feature and the Pitch feature are spliced.
作为一示例,服务器在对待识别语音流进行特征提取,获取32维的MFCC特征和32维的Pitch特征;再将32维的MFCC特征和32维的Pitch特征拼接形成64维度的目标特征向量,以使拼接之后的目标特征向量既包含MFCC特征的信息,又包含Pitch特征的信息,使得目标特征向量的信息量更大,更有助于提高后续身份识别的准确率。As an example, the server is performing feature extraction on the voice stream to be recognized to obtain 32-dimensional MFCC features and 32-dimensional pitch features; then, the 32-dimensional MFCC features and 32-dimensional pitch features are spliced to form a 64-dimensional target feature vector. The target feature vector after splicing contains both the information of the MFCC feature and the information of the Pitch feature, which makes the information of the target feature vector larger, which is more helpful to improve the accuracy of subsequent identification.
S303:采用基于时延神经网络的身份特征识别模型对目标特征向量进行处理,获取身份特征信息,身份特征识别模型上设有用于对隐含层输入的特征进行均值和标准差计算的汇总池化层。S303: Use a time-delay neural network-based identity feature recognition model to process the target feature vector to obtain identity feature information. The identity feature recognition model is equipped with a summary pool for calculating the mean and standard deviation of the features input to the hidden layer Floor.
其中,基于时延神经网络的身份特征识别模型是预先采用时延神经网络对训练样本进行模型训练后得到的模型。其中,时延神经网络(Time-Delay Neural Network,简称TDNN)可适应语音信号中的动态时域变化,并且该结构参数较少,进行语音识别不需要预先将音标与音频在时间线上进行对齐,主要考虑时序信号的上下文信息,有助于保障识别结果的准确性和处理效率。训练样本包括训练语音和与训练语音相对应的说话人标签。Among them, the identity feature recognition model based on the time-delay neural network is a model obtained by pre-training the training samples with the time-delay neural network. Among them, the Time-Delay Neural Network (TDNN) can adapt to the dynamic time domain changes in the speech signal, and the structural parameters are less, and the speech recognition does not need to align the phonetic symbols with the audio in advance on the timeline. , Mainly consider the context information of the time sequence signal, which helps to ensure the accuracy of the recognition result and processing efficiency. The training samples include training speech and speaker labels corresponding to the training speech.
传统的TDNN包括输入层、第一隐含层、第二隐含层和输出层。本实施例中,预先根据服务评价系统的需求搭建输入层、第一隐含层、第二隐含层和输出层,并在第二隐含层与输出层之间搭建用于对隐含层输入的特征进行均值和标准差计算的汇总池化层(Stattistic Pooling)。该汇总池化层计算均值向量μ以及二阶统计量作为帧级特征ht(t=1,...,T)上的标准差向量σ,将标准差向量σ作为汇总池化层的输出,输出层的输入。其中,均值向量

本实施例中,采用在第二隐含层与输出层之间设置有汇总池化层的时延神经网络训练所得的身份特征识别模型对目标特征向量进行处理,获取身份特征信息,使得汇总池化层可对目标特征向量经过第一隐含层和第二隐含层进行处理所获取的均值向量μ和标准差向量σ,以便在输出层对均值向量μ和标准差向量σ进行处理,以提取输出的身份特征信息的准确性。In this embodiment, the identification feature recognition model obtained by the time-delayed neural network training with a summary pooling layer set between the second hidden layer and the output layer is used to process the target feature vector to obtain the identification feature information, so that the summary pool The transformation layer can process the mean vector μ and standard deviation vector σ obtained by processing the target feature vector through the first hidden layer and the second hidden layer, so as to process the mean vector μ and standard deviation vector σ in the output layer to The accuracy of the extracted identity feature information.
S304:将身份特征信息与数据库中每一坐席人员对应的标准特征信息进行相似度计算,获取特征相似度,基于特征相似度确定待识别语音流对应的目标身份信息。S304: Perform similarity calculation between the identity feature information and the standard feature information corresponding to each agent in the database, obtain feature similarity, and determine the target identity information corresponding to the voice stream to be recognized based on the feature similarity.
其中,数据库是用于存储服务评价过程中采用或生成的数据的数据库,该数据库与服务器相连,以使服务器可访问数据库。Among them, the database is a database used to store data used or generated in the service evaluation process, and the database is connected to the server so that the server can access the database.
标准特征信息是预先存储在数据库中的与坐席人员的身份标签相对应的特征信息。作为一示例,可预先将每一坐席人员对应的标准语音流输入到步骤S303中的基于时延神经网络的身份特征识别模型进行处理,以获取相应的标准特征信息,该标准特征信息与坐席人员对应的身份标签关联,可基于获取的标准特征信息进行后续的身份识别。The standard feature information is the feature information corresponding to the identity tag of the seat personnel stored in the database in advance. As an example, the standard voice stream corresponding to each agent can be input in advance into the time-delay neural network-based identity feature recognition model in step S303 for processing, so as to obtain corresponding standard feature information. The corresponding identity tag association can be used for subsequent identity recognition based on the obtained standard feature information.
其中,特征相似度是指采用预先设置的相似度算法对身份特征信息和标准特征信息进行相似度计算所获得的具体值。作为一示例,该相似度算法包括但不限于余弦相似度算法。Among them, the feature similarity refers to the specific value obtained by calculating the similarity between the identity feature information and the standard feature information using a preset similarity algorithm. As an example, the similarity algorithm includes but is not limited to the cosine similarity algorithm.
其中,基于特征相似度确定待识别语音流对应的目标身份信息,是指从身份特征信息与数据库中至少一个标准特征信息分别进行相似度计算所获取的至少一个特征相似度中,基于特征相似度最大的一个标准特征信息对应的身份标签,确定为待识别语音流对应的目标身份信息。Among them, determining the target identity information corresponding to the voice stream to be recognized based on the feature similarity refers to at least one feature similarity obtained by performing similarity calculations between the identity feature information and at least one standard feature information in the database, based on the feature similarity The identity tag corresponding to the largest standard feature information is determined as the target identity information corresponding to the voice stream to be recognized.
本实施例所提供的基于人工智能的服务评价方法中,对待识别语音流提取出的MFCC特征和Pitch特征进行拼接处理,使得所获取的目标特征向量信息量更大,更有助于保障后续身份识别的准确性;采用基于时延神经网络的身份特征识别模型对目标特征向量进行处理,且身份特征识别模型上设有用于对隐含层输入的特征进行均值和标准差计算的汇总池化层,使得其处理过程充分考虑目标特征向量的上下文信息,且输出层对均值和标准差处理后的输出进行处理,既有助于保障识别结果的处理效率,又保障其识别结果的准确性。在基于身份特征信息与标准特征信息进行相似度计算,以根据特征相似度确定待识别语音流对应的目标身份信息,以保证目标身份信息确定的客观性。In the artificial intelligence-based service evaluation method provided in this embodiment, the MFCC feature and the pitch feature extracted from the speech stream to be recognized are spliced, so that the obtained target feature vector has a larger amount of information, which is more helpful to ensure subsequent identity Accuracy of recognition; the identification feature recognition model based on time-delay neural network is used to process the target feature vector, and the identification feature recognition model is equipped with a summary pooling layer for calculating the mean and standard deviation of the features input to the hidden layer , So that its processing process fully considers the context information of the target feature vector, and the output layer processes the output after the mean and standard deviation processing, which not only helps to ensure the processing efficiency of the recognition result, but also the accuracy of the recognition result. The similarity calculation is performed based on the identity feature information and the standard feature information to determine the target identity information corresponding to the voice stream to be recognized according to the feature similarity, so as to ensure the objectivity of the target identity information determination.
在一实施例中,如图4所示,步骤S203,即对待识别语音流进行文本分析,获取待识别语音流对应的文本分析结果,具体包括如下步骤:In one embodiment, as shown in FIG. 4, step S203, which is to perform text analysis on the voice stream to be recognized, and obtain the text analysis result corresponding to the voice stream to be recognized, specifically includes the following steps:
S401:采用语音识别模型对待识别语音流进行文本识别,获取待识别文本信息。S401: Use a voice recognition model to perform text recognition on a voice stream to be recognized, and obtain text information to be recognized.
其中,语音识别模型是预先训练好的用于识别语音中文本内容的模型。作为一示例,该语音识别模型可以是预先采用训练语音数据和训练文本数据进行模型训练获取的用于识别语音中文本内容的语音静态解码网络,该语音静态解码网络在解码过程中将搜索空间全部展开,因此,其在文本识别时,解码速度快,采用该语音静态解码网络对待识别语音流进行文本识别,可快速获取对应的待识别文本信息。该待识别文本信息是从待识别语音流中识别出的文本内容。Among them, the speech recognition model is a pre-trained model for recognizing text content in speech. As an example, the speech recognition model may be a static speech decoding network for recognizing text content in speech, which is obtained by using training speech data and training text data for model training. Therefore, the decoding speed is fast during text recognition, and the speech static decoding network is used to perform text recognition on the speech stream to be recognized, and the corresponding text information to be recognized can be quickly obtained. The text information to be recognized is the text content recognized from the voice stream to be recognized.
S402:对待识别文本信息进行敏感词分析,获取敏感词分析结果。S402: Perform sensitive word analysis on the text information to be recognized, and obtain a sensitive word analysis result.
其中,该敏感词分析结果是用于反映待识别文本信息中是否存在敏感词以及存在的敏感词对服务评价的影响的结果。Among them, the sensitive word analysis result is a result used to reflect whether there are sensitive words in the text information to be recognized and the impact of the existing sensitive words on the service evaluation.
具体地,对待识别文本信息进行敏感词分析过程包括如下步骤:基于待识别文本信息查询敏感词库,获取待识别文本信息中的敏感词数量,根据敏感词数量确定敏感词分析结果。敏感词库中预先存储坐席人员在服务过程中的敏感词,以便在服务评价过程中对待识别文本信息进行敏感词分析,获取敏感词分析结果。Specifically, the sensitive word analysis process of the text information to be recognized includes the following steps: query a sensitive word database based on the text information to be recognized, obtain the number of sensitive words in the text information to be recognized, and determine the sensitive word analysis result according to the number of sensitive words. The sensitive word database pre-stores the sensitive words of the agents in the service process, so that the sensitive word analysis can be performed on the text information to be recognized in the service evaluation process, and the sensitive word analysis results can be obtained.
作为一示例,可基于敏感词数量与系统预先设置的第一数量阈值进行比较,确定敏感词分析结果。该第一数量阈值是预先设置的用于评估敏感词分析好坏结果的数值。作为另一示例,可基于敏感词数量查询敏感词分值表,确定敏感词分析结果。该敏感词分值表是预先存储的用于反应敏感词数量及对应的评分分值或评分结果的信息表。As an example, the sensitive word analysis result can be determined based on the comparison between the number of sensitive words and the first number threshold preset by the system. The first number threshold is a preset value used to evaluate the quality of sensitive word analysis. As another example, the sensitive word score table can be queried based on the number of sensitive words to determine the sensitive word analysis result. The sensitive word score table is a pre-stored information table used to reflect the number of sensitive words and the corresponding scoring score or scoring result.
S403:对待识别文本信息进行语气分析,获取语气分析结果。S403: Perform tone analysis on the text information to be recognized, and obtain a tone analysis result.
其中,语气分析结果是用于反映待识别文本信息中说话人语气对应的分析结果。Among them, the tone analysis result is used to reflect the analysis result corresponding to the speaker's tone in the text information to be recognized.
具体地,对待识别文本信息进行语气分析包括如下步骤:采用语音分析器对待识别文 本信息进行分析,获取识别语气,基于识别语气查询服务评价信息表,获取语气分析结果。其中,语气分析器(Tone Analyzer)是用于分析语言文字,以确定其中蕴含的语气的分析器。该语气分析器可以采用IBM的Watson语气分析器。该识别语气是采用语气分析器从待识别文本信息中识别出的说话人语气。服务评价信息表中预先存储不同评分标准及对应的情绪识别结果的对应关系,该评分标准包含多个与语气相关的评判条件,如语气平淡,无激情、语气僵硬,显示冷淡和以不屑、不满的语气向客户发出提问,例如“这个问题我刚才不是给您说过了吗?”和“您难道连这都需要我再解释吗?”等,服务器在采用语气分析器对待识别文本信息进行分析,确定识别语气之后,基于识别语气查询服务评价信息表,以获取相应的语气分析结果。Specifically, the tone analysis of the text information to be recognized includes the following steps: using a voice analyzer to analyze the text information to be recognized to obtain the recognition tone, query the service evaluation information table based on the recognition tone, and obtain the tone analysis result. Among them, the tone analyzer is an analyzer used to analyze the language and text to determine the tone contained therein. The tone analyzer can use IBM's Watson tone analyzer. The recognition tone is the tone of the speaker recognized from the text information to be recognized using a tone analyzer. The corresponding relationship between different scoring standards and corresponding emotion recognition results is stored in the service evaluation information table in advance. The scoring standard contains multiple judgment conditions related to the tone, such as plain tone, no passion, rigid tone, showing indifference and disdain, dissatisfaction In the tone of the client, such as "Didn’t I tell you this question just now?" and "Do you even need me to explain this?" etc., the server is using a tone analyzer to analyze the recognized text information After confirming the recognition tone, query the service evaluation information table based on the recognition tone to obtain the corresponding tone analysis result.
S404:基于敏感词分析结果和语气分析结果,获取待识别语音流对应的文本分析结果。S404: Obtain a text analysis result corresponding to the voice stream to be recognized based on the sensitive word analysis result and the tone analysis result.
作为一示例,若敏感词分析结果和语气分析结果均为不同评价等级对应的分析结果,则可基于敏感词分析结果和语气分析结果查询系统预先存储的文本分析对照表,获取服务过程中实时采集的待识别语音流对应的文本分析结果。其中,文本分析对照表是系统预先设置的用于反映不同敏感词分析结果和语气分析结果的组合与分析结果之间对应关系的数据表,以便在确定敏感词分析结果和语气分析结果之后,可快速查表确定相应的文本分析结果。As an example, if both the sensitive word analysis results and the tone analysis results are the analysis results corresponding to different evaluation levels, the text analysis comparison table stored in the system can be queried based on the sensitive word analysis results and the tone analysis results, and collected in real time during the service process The text analysis result corresponding to the voice stream to be recognized. Among them, the text analysis comparison table is a data table preset by the system to reflect the corresponding relationship between the combination of different sensitive word analysis results and tone analysis results and the analysis results, so that after determining the sensitive word analysis results and the tone analysis results, you can Quickly look up the table to determine the corresponding text analysis results.
作为另一示例,若敏感词分析结果和语气分析结果均为具体分值时,如敏感词分析结果为80分,而语气分析结果为76分时,可对敏感词分析结果和语气分析结果进行归一化处理,以获取敏感词归一化结果和语气归一化结果,以将有量纲表达式变为无量纲表达式;再采用文本分析加权算法对敏感词归一结果和语气归一化结果进行计算,获取服务过程中实时采集的待识别语音流对应的文本分析结果,使得文本分析结果可采用量化特征表示。例如,文本分析加权算法为P=p1*w1+p2*w2,P为文本分析结果,p1为敏感词分析结果,w1为敏感词分析权重,p2为语气分析结果,w2为语气分析权重。该敏感词分析权重w1和语气分析权重w2为服务评价系统预先设置的权重。As another example, if both the sensitive word analysis result and the tone analysis result are specific scores, such as the sensitive word analysis result is 80 points, and the tone analysis result is 76 points, the sensitive word analysis results and the tone analysis results can be analyzed Normalization processing to obtain the normalization result of sensitive words and the normalization result of the tone, so as to change the dimensional expression into a dimensionless expression; then use the text analysis weighting algorithm to normalize the result of the sensitive word and the tone Calculate the transformation results, and obtain the text analysis results corresponding to the voice stream to be recognized collected in real time during the service process, so that the text analysis results can be represented by quantitative features. For example, the text analysis weighting algorithm is P=p1*w1+p2*w2, P is the text analysis result, p1 is the sensitive word analysis result, w1 is the sensitive word analysis weight, p2 is the mood analysis result, and w2 is the mood analysis weight. The sensitive word analysis weight w1 and the tone analysis weight w2 are the weights preset by the service evaluation system.
本实施例所提供的基于人工智能的服务评价方法中,采用语音识别模型对待识别语音流进行文本识别,以将语音信息转换成文本信息,为后续进行敏感词和语气分析提供技术保障;再分析对待识别文本信息进行敏感词分析和语气分析,根据获取的敏感词分析结果和语气分析结果,确定待识别语音流对应的文本分析结果,使得文本分析结果综合考虑待识别文本信息中的敏感词和说话人语气这两个维度对服务质量进行评价,保障获取的文本分析结果的客观性和准确性。In the service evaluation method based on artificial intelligence provided in this embodiment, a speech recognition model is used to perform text recognition on the speech stream to be recognized, so as to convert speech information into text information, and provide technical support for subsequent sensitive word and tone analysis; Perform sensitive word analysis and tone analysis on the text information to be recognized. According to the obtained sensitive word analysis results and tone analysis results, determine the text analysis results corresponding to the voice stream to be recognized, so that the text analysis results comprehensively consider the sensitive words and the tone in the text information to be recognized. The two dimensions of the speaker's tone evaluate the quality of service and ensure the objectivity and accuracy of the obtained text analysis results.
在一实施例中,如图5所示,步骤S403,即采用语音情绪识别模型对待识别语音流分析,获取情绪分析结果,具体包括如下步骤:In one embodiment, as shown in FIG. 5, step S403, that is, using the voice emotion recognition model to analyze the voice stream to be recognized to obtain the emotion analysis result, specifically includes the following steps:
S501:对待识别语音流进行语音分段,获取至少两个目标语音段。S501: Perform voice segmentation on the voice stream to be recognized, and obtain at least two target voice segments.
其中,目标语音段是对待识别语音流进行分段所形成的语音片段。Among them, the target speech segment is a speech segment formed by segmenting the speech stream to be recognized.
作为一示例,服务器采用语音激活检测算法对待识别语音流进行检测,以检测待识别语音流中每一个停顿点对应的停顿时间,将停顿时间大于预设时长阈值的停顿点确定为语音分段点,基于语音分段点对待识别语音流进行语音分段,获取至少两个目标语音段,以便后续基于目标语音段进行后续的情绪识别和语速计算,为并行处理提供技术基础,且有助于保障后续分析处理的效率。As an example, the server uses a voice activation detection algorithm to detect the voice stream to be recognized, to detect the pause time corresponding to each pause point in the voice stream to be recognized, and determine the pause point whose pause time is greater than the preset duration threshold as the voice segment point , Perform voice segmentation on the to-be-recognized voice stream based on the voice segmentation point, and obtain at least two target voice segments for subsequent emotion recognition and speech rate calculations based on the target voice segments, which provides a technical basis for parallel processing and helps Ensure the efficiency of subsequent analysis and processing.
S502:采用语音情绪识别模型对每一目标语音段进行情绪识别,获取每一目标语音段对应的识别情绪。S502: Perform emotion recognition on each target speech segment using a voice emotion recognition model, and obtain the recognition emotion corresponding to each target speech segment.
其中,语音情绪识别模型是预先训练好用于识别语音中说话人情绪的模型。作为一示例,该语音情绪识别模型具体可以是PAD情感模型,该模型将为情感具有愉悦度、激活度 和优势度3个维度,其中P代表愉悦度(Pleasure-displeasure),表示个体情感状态的正负特性;A代表激活度(Arousal-nonarousal),表示个体的神经生理激活水平;D代表优势度(Dominance-submissiveness),表示个体对情景和他人的控制状态。识别情绪是采用语音情绪识别模型对每一目标语音段进行情绪识别所输出的结果。Among them, the speech emotion recognition model is a model that is pre-trained to recognize the speaker's emotion in the speech. As an example, the speech emotion recognition model may specifically be a PAD emotion model, which will have three dimensions of pleasure, activation and dominance for emotions, where P stands for Pleasure-displeasure, which represents the individual's emotional state Positive and negative characteristics; A stands for activation (Arousal-nonarousal), which represents the individual's neurophysiological activation level; D stands for Dominance-submissiveness, which represents the individual's control over the situation and others. Recognizing emotions is the output result of emotion recognition for each target speech segment using a speech emotion recognition model.
S503:计算每一目标语音段对应的识别语速。S503: Calculate the recognition speech rate corresponding to each target speech segment.
其中,目标语音段对应的识别语速是指目标语音段对应的说话字数和语音时长的商,用于反应单位时间内说话字数的多少。作为一示例,由于对待识别语音流进行文本分析时,已经采用语音识别模型对待识别语音流进行文本识别,获取整个待识别语音流对应的待识别文本信息,因此,在对待识别语音流进行语音分段时,可基于每一目标语音段中的第一帧数据和最后一帧数据对应的时间戳,确定语音时长;并基于第一帧数据和最后一帧数据对应的时间戳确定待识别文本信息中的相应位置,从而确定目标语音段对应的说话字数,以便利用说话字数与语音时长,确定每一目标语音段对应的识别语速。可以理解地,根据文本分析过程中获取的待识别文本信息,可快速计算目标语音段对应的识别语速,提高识别语速的获取效率。Among them, the recognition speech rate corresponding to the target speech segment refers to the quotient of the number of spoken words corresponding to the target speech segment and the speech duration, which is used to reflect the number of spoken words per unit time. As an example, when performing text analysis on the voice stream to be recognized, the voice recognition model has been used to perform text recognition on the voice stream to be recognized, and the text information to be recognized corresponding to the entire voice stream to be recognized is obtained. During segment time, the speech duration can be determined based on the timestamps corresponding to the first frame of data and the last frame of data in each target speech segment; and the text information to be recognized can be determined based on the timestamps corresponding to the first frame of data and the last frame of data In order to determine the number of spoken words corresponding to the target speech segment, the number of spoken words and the speech duration are used to determine the recognition speech rate corresponding to each target speech segment. Understandably, based on the to-be-recognized text information obtained in the text analysis process, the recognition speech rate corresponding to the target speech segment can be quickly calculated, and the efficiency of obtaining the recognition speech rate can be improved.
一般来说,坐席人员在给客户提供服务过程中,若说话语速越快,则说明坐席人员越急躁,使得客户对坐席人员提供的服务的满意度越差,因此,坐席人员的说话语速可以作为评价其服务质量的一个情绪分析维度,所以需计算每一目标语音段对应的识别语速。Generally speaking, in the process of providing services to customers, if the agent speaks faster, it means that the agent is more impatient, which makes the customer's satisfaction with the service provided by the agent worse. Therefore, the agent speaks faster It can be used as a sentiment analysis dimension to evaluate its service quality, so it is necessary to calculate the recognition speech rate corresponding to each target speech segment.
S504:基于至少两个目标语音段对应的识别语速和识别情绪,获取待识别语音流对应的情绪分析结果。S504: Obtain an emotion analysis result corresponding to the voice stream to be recognized based on the recognition speech rate and the recognition emotion corresponding to the at least two target speech segments.
具体地,服务器可基于至少两个目标语音段对应的识别语速和识别情绪这两个情绪分析维度进行情绪分析,获取由至少两个目标语音段组成的待识别语音流对应的情绪分析结果,使得所获取的情绪分析结果更具有客观性和准确性。作为一示例,可以将至少两个目标语音段对应的识别语速和识别情绪分别转换为相应的分值,再进行加权处理,即可获取服务过程中实时采集的待识别语音流对应的情绪分析结果。Specifically, the server may perform sentiment analysis based on the two sentiment analysis dimensions of the recognition speech rate and the sentiment recognition corresponding to the at least two target speech segments, and obtain the sentiment analysis result corresponding to the to-be-recognized voice stream composed of the at least two target speech segments. This makes the obtained sentiment analysis results more objective and accurate. As an example, the recognition speech rate and recognition emotion corresponding to at least two target speech segments can be converted into corresponding scores respectively, and then weighted processing can be performed to obtain the emotion analysis corresponding to the voice stream to be recognized collected in real time during the service process. result.
本实施例所提供的基于人工智能的服务评价方法中,通过将待识别语音流划分至少两个目标语音段,为后续分析至少两个目标语音段对应的语速变化和情绪变化提供技术基础。再对每一目标语音段进行分析,以确定其对应的识别语速和识别情绪,利用识别语速和识别情绪这两个维度数据对服务质量进行评价,保障获取的情绪分析结果的客观性和准确性。In the service evaluation method based on artificial intelligence provided in this embodiment, by dividing the to-be-recognized speech stream into at least two target speech segments, a technical basis is provided for subsequent analysis of the speech rate changes and mood changes corresponding to the at least two target speech segments. Then analyze each target speech segment to determine its corresponding recognition speech speed and recognition emotion. Use the two dimensions of recognition speech speed and recognition emotion to evaluate the service quality to ensure the objectivity and objectivity of the sentiment analysis results obtained. accuracy.
在一实施例中,如图6所示,步骤S502,即采用语音情绪识别模型对每一目标语音段进行情绪识别,获取每一目标语音段对应的识别情绪,具体包括如下步骤:In one embodiment, as shown in FIG. 6, step S502, which uses a speech emotion recognition model to perform emotion recognition on each target speech segment, and obtains the recognition emotion corresponding to each target speech segment, specifically includes the following steps:
S601:对每一目标语音段进行特征提取,获取目标语音段对应的语谱图特征和TEO特征。S601: Perform feature extraction on each target speech segment, and obtain the spectrogram feature and TEO feature corresponding to the target speech segment.
其中,语谱图就是语音频谱图,是对有足够时间长度的时域信号进行处理进行处理所获得的一种频谱分析视图,语谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量。语谱图特征是基于语谱图提取的特征。Among them, the spectrogram is a speech spectrogram, which is a spectrum analysis view obtained by processing time domain signals with sufficient time length. The abscissa of the spectrogram is time, the ordinate is frequency, and the coordinate point value Energy for voice data. The spectrogram features are based on the features extracted from the spectrogram.
作为一示例,服务器在获取目标语音段后,基于目标语音段获取相应的语谱图;再对语谱图进行归一化处理,得到归一化后的语谱图灰度图像;然后,计算不同尺度、不同方向的Gabor图谱,并采用局部二值模式提取Gabor图谱的纹理特征;最后,将不同尺度、不同方向Gabor图谱提取到的局部二值模式对应的纹理特征进行级联,以获取相应的语谱图特征。该语谱图特征作为一种语音情感特征,相比传统的韵律特征、频域特征和音质特征,在进行情感识别时,情感识别结果更准确。As an example, after obtaining the target speech segment, the server obtains the corresponding spectrogram based on the target speech segment; then normalizes the spectrogram to obtain the normalized spectrogram grayscale image; then, calculate Gabor maps of different scales and directions, and local binary patterns are used to extract the texture features of the Gabor maps; finally, the texture features corresponding to the local binary patterns extracted from the Gabor maps of different scales and directions are cascaded to obtain the corresponding The characteristics of the spectrogram. The spectrogram feature is a voice emotion feature. Compared with the traditional prosody feature, frequency domain feature and voice quality feature, the emotion recognition result is more accurate when performing emotion recognition.
其中,TEO(Teager Energy Operator,即Teager能量算子)是一个非线性算子,能够跟踪信号的瞬时能量,是科学家H.M.Teager在研究非线性语音建模时,提出的一种简单的信号分析算法。TEO特征是采用TEO对目标语音段进行分析获取的基频特征,由于 Teager能量算子的特性使得目标语音段所提取的TEO特征在噪声环境下具有较好的稳定性,提高其可区分度,因此,TEO特征的抗噪声性能良好。Among them, TEO (Teager Energy Operator) is a nonlinear operator that can track the instantaneous energy of the signal. It is a simple signal analysis algorithm proposed by the scientist HMTeager when he is studying nonlinear speech modeling. . The TEO feature is the fundamental frequency feature obtained by using TEO to analyze the target speech segment. Due to the characteristics of the Teager energy operator, the TEO feature extracted from the target speech segment has better stability in a noisy environment and improves its distinguishability. Therefore, the anti-noise performance of the TEO feature is good.
S602:对语谱图特征和TEO特征进行拼接,获取目标语音段对应的目标识别特征。S602: Splicing the spectrogram feature and the TEO feature to obtain the target recognition feature corresponding to the target speech segment.
其中,对语谱图特征和TEO特征进行拼接处理是指将语谱图特征和TEO特征的所有维度进行拼接,以形成目标识别特征。目标识别特征是指语谱图特征和TEO特征经过拼接处理后形成的特征。Among them, the splicing processing of the spectrogram feature and the TEO feature refers to splicing all the dimensions of the spectrogram feature and the TEO feature to form the target recognition feature. The target recognition feature refers to the feature formed after the splicing process of the spectrogram feature and the TEO feature.
作为一示例,服务器在对目标语音段进行特征提取时,可获取1024维的语谱图特征和20维的TEO特征;再将1024维的语谱图特征和20维的TEO特征拼接成1044维的目标识别特征,以使拼接之后的目标识别特征既包含语谱图特征的信息,又包含TEO特征的信息,使得目标识别特征的信息量更大,由于目标识别特征包含TEO特征的信息,使其在噪声环境下具有较好的稳定性,使得最终形成的目标识别特征也具有相应的抗噪声性能。有助于提高后续识别的准确性。As an example, when the server performs feature extraction on the target speech segment, it can obtain 1024-dimensional spectrogram features and 20-dimensional TEO features; and then splice the 1024-dimensional spectrogram features and 20-dimensional TEO features into 1044 dimensions. Target recognition feature, so that the spliced target recognition feature contains not only the information of the spectrogram feature, but also the information of the TEO feature, so that the amount of information of the target recognition feature is larger. Since the target recognition feature contains the information of the TEO feature, It has good stability in a noisy environment, so that the final target recognition feature also has corresponding anti-noise performance. It helps to improve the accuracy of subsequent recognition.
S603:采用语音情绪识别模型对每一目标语音段对应的目标识别特征进行情绪识别,获取每一目标语音段对应的识别情绪。S603: Use the voice emotion recognition model to perform emotion recognition on the target recognition feature corresponding to each target speech segment, and obtain the recognition emotion corresponding to each target speech segment.
其中,语音情绪识别模型是预先训练好用于识别语音中说话人情绪的模型。作为一示例,预先训练语音情绪识别模型的过程包括如下步骤:(1)获取语音时长大于预设时长的原始语音,每一原始语音携带相应的情绪标签,其中,预设时长是采用语谱图进行特征处理的最小时长,原始语音的语音时长大于预设时间,可保证后续进行语谱图特征提取的可行性。(2)对原始语音进行特征提取,获取原始语音对应的语谱图特征和TEO特征,并将原始语音对应的语谱图特征和TEO特征拼接形成训练样本。该训练样本是指将原始语音对应的语谱图特征和TEO特征拼接后形成的训练特征,该训练特征与原始语音的情绪标签相对应。训练样本获取过程中的特征提取和特征拼接处理过程与上述步骤S602和S603一致,为避免重复,此处不一一赘述。(3)将训练样本输入到神经网络模型进行模型训练,以更新神经网络模型中的网络参数,从而获取语音情绪识别模型,该语音情绪识别模型的训练样本结合语谱图特征和TEO特征的信息,使其相比于传统的韵律特征、频域特征和音质特征,在进行情感识别时,情感识别结果更准确;而且,具备TEO特征的抗噪声性,使得后续采用语音情绪识别模型对目标识别特征进行情绪识别时,抗噪声性能良好,有助于提高出的识别情绪的准确性。Among them, the speech emotion recognition model is a model that is pre-trained to recognize the speaker's emotion in the speech. As an example, the process of pre-training a speech emotion recognition model includes the following steps: (1) Obtain original speeches whose speech duration is greater than a preset duration, and each original speech carries a corresponding emotion label, wherein the preset duration is a spectrogram The minimum duration for feature processing, the voice duration of the original speech is longer than the preset time, which can ensure the feasibility of subsequent spectrogram feature extraction. (2) Perform feature extraction on the original speech, obtain the spectrogram feature and TEO feature corresponding to the original speech, and stitch the spectrogram feature and TEO feature corresponding to the original speech to form a training sample. The training sample refers to a training feature formed by splicing the spectrogram feature corresponding to the original speech and the TEO feature, and the training feature corresponds to the emotion label of the original speech. The process of feature extraction and feature splicing in the process of acquiring training samples is consistent with the foregoing steps S602 and S603, and in order to avoid repetition, details are not repeated here. (3) Input the training samples into the neural network model for model training to update the network parameters in the neural network model to obtain the speech emotion recognition model. The training samples of the speech emotion recognition model combine the information of the spectrogram feature and the TEO feature Compared with the traditional prosodic features, frequency domain features, and voice quality features, the emotion recognition results are more accurate when performing emotion recognition; moreover, it has the anti-noise characteristics of TEO features, so that the subsequent use of voice emotion recognition models for target recognition When the feature is used for emotion recognition, the anti-noise performance is good, which helps to improve the accuracy of the emotion recognition.
本实施例所提供的基于人工智能的服务评价方法中,在对每一目标语音段进行情绪识别时,对目标语音段提取出的语谱图特征和TEO特征进行拼接处理,使得所获取的目标识别特征的信息量更大,有助于保障后续情绪识别的准确性和抗噪声性。将目标语音段确定的目标识别特征输入语音情绪识别模型进行识别,可快速获取该目标语音段对应的识别情绪,使得所获取的识别情绪的准确性更高且抗噪声性更高。In the artificial intelligence-based service evaluation method provided in this embodiment, when emotion recognition is performed on each target speech segment, the spectrogram features and TEO features extracted from the target speech segment are spliced, so that the acquired target The greater amount of information in the recognition feature helps to ensure the accuracy and noise resistance of subsequent emotion recognition. The target recognition feature determined by the target speech segment is input into the speech emotion recognition model for recognition, and the recognition emotion corresponding to the target speech segment can be quickly obtained, so that the accuracy of the obtained recognition emotion is higher and the noise resistance is higher.
在一实施例中,如图7所示,步骤S504,即基于至少两个目标语音段对应的识别语速和识别情绪,获取待识别语音流对应的情绪分析结果,具体包括如下步骤:In one embodiment, as shown in FIG. 7, step S504, which is to obtain the emotion analysis result corresponding to the voice stream to be recognized based on the recognition speech rate and the recognition emotion corresponding to at least two target speech segments, specifically includes the following steps:
S701:基于当前目标语音段的识别语速、上一目标语音段的识别语速和当前目标语音段的识别情绪,获取当前目标语音段对应的目标情绪。S701: Obtain the target emotion corresponding to the current target speech segment based on the recognition speech rate of the current target speech segment, the recognition speech rate of the previous target speech segment, and the recognition emotion of the current target speech segment.
其中,当前目标语音段是指当前时刻需要进行分析的目标语音段。上一目标语音段是指对待识别语音流进行语音分段后的至少两个目标语音段中,在当前目标语音段之前的一个目标语音段。当前目标语音段对应的目标情绪是指综合考虑前后两个目标语音段的识别语速以及当前目标识别语音段对应的识别情绪,确定的用于进行后续分析的当前目标语音段对应的目标情绪。Among them, the current target speech segment refers to the target speech segment that needs to be analyzed at the current moment. The last target speech segment refers to a target speech segment before the current target speech segment among at least two target speech segments after voice segmentation of the speech stream to be recognized. The target emotion corresponding to the current target speech segment refers to the target emotion corresponding to the current target speech segment that is determined for subsequent analysis by considering the recognition speech rate of the two target speech segments before and after and the recognition emotion corresponding to the current target recognition speech segment.
作为一示例,上述步骤S701具体包括如下步骤:(1)若不存在上一目标语音段,则基于当前语音段对应的识别情绪,获取当前目标语音段对应的目标情绪。即当前目标语音段为第一个目标语音段,此时,若当前目标语音段为消极情绪,则当前目标语音段的目标 情绪为消极情绪;若当前目标语音段为积极情绪,则当前目标语音段的目标情绪为积极情绪。(2)若存在上一目标语音段,则在当前目标语音段的识别语速大于上一目标语音段的识别语速,且当前目标语音段的识别情绪为消极情绪时,将当前目标语音段对应的目标情绪确定为为消极情绪。(2)若存在上一目标语音段,则在当前目标语音段的识别语速不大于上一目标语音段的识别语速时,或者在当前目标语音段的识别语速大于上一目标语音段的识别语速,且当前目标语音段的识别情绪为积极情绪时,将当前目标语音段对应的目标情绪为积极情绪。本示例中,只将目前目标语音段的识别语速比上一目标识别语音段稳步上升,且当前目标语音段的识别情绪为消极情绪时,才将该当前目标语音段的目标情绪确定为消极情绪,其他情绪均为积极情绪,使得所确定的目标情绪综合考虑识别情绪及语速等信息,有助于提高后续分析的准确性。As an example, the above step S701 specifically includes the following steps: (1) If there is no previous target speech segment, obtain the target emotion corresponding to the current target speech segment based on the recognition emotion corresponding to the current speech segment. That is, the current target speech segment is the first target speech segment. At this time, if the current target speech segment is negative emotion, then the target emotion of the current target speech segment is negative emotion; if the current target speech segment is positive emotion, then the current target speech The target emotion of the segment is positive emotion. (2) If there is a previous target speech segment, when the recognition rate of the current target speech segment is greater than the recognition rate of the last target speech segment, and the recognition emotion of the current target speech segment is a negative emotion, the current target speech segment The corresponding target emotion is determined to be a negative emotion. (2) If the previous target speech segment exists, the recognition rate of the current target speech segment is not greater than the recognition rate of the previous target speech segment, or the recognition rate of the current target speech segment is greater than the previous target speech segment When the recognition rate of speech and the recognition emotion of the current target speech segment is a positive emotion, the target emotion corresponding to the current target speech segment is a positive emotion. In this example, only when the recognition rate of the current target speech segment is steadily increased compared to the previous target recognition speech segment, and the recognition emotion of the current target speech segment is negative emotion, the target emotion of the current target speech segment is determined to be negative Emotions and other emotions are all positive emotions, so that the determined target emotion comprehensively considers information such as emotions and speaking speed, which helps to improve the accuracy of subsequent analysis.
S702:基于至少两个当前目标语音段对应的目标情绪,获取待识别语音流对应的消极情绪数量。S702: Obtain the number of negative emotions corresponding to the voice stream to be recognized based on the target emotions corresponding to at least two current target speech segments.
一般来说,目标情绪可以是积极情绪和消极情绪,积极情绪是指积极的心理态度或状态对应的情绪,是一种良性、正向、稳定和建设性的心理状态对应的情绪,包括但不限于喜爱、开心、乐观、信任、可接受和惊喜等情绪。消极情绪是指在某种具体行为中,由外因或内因影响而产生的不利于继续完成工作或者正常的思考的情感,其与积极情绪相对,包括但不限于厌恶、讨厌、反对、不满、无视和蔑视等情绪。Generally speaking, the target emotion can be positive emotion and negative emotion. Positive emotion refers to the emotion corresponding to the positive mental attitude or state. It is the emotion corresponding to a benign, positive, stable and constructive mental state, including but not Limited to emotions such as love, happiness, optimism, trust, acceptance and surprise. Negative emotions refer to emotions that are generated by external or internal factors in a specific behavior that are not conducive to continuing to complete work or normal thinking. It is opposite to positive emotions, including but not limited to disgust, dislike, opposition, dissatisfaction, ignorance And contempt and other emotions.
在坐席人员给客户提供服务过程中,若通话过程中坐席人员的情绪为消极情绪,容易使得其说话时携带相应的消极情绪,影响客户对坐席人员的服务满意度,因此,在对坐席人员进行服务评价时,需考核坐席人员在给客户提供服务过程中是否传递消极情绪,故需统计每一待识别语音流对应的消极情绪数量。该消极情绪数量是指至少两个当前目标语音段的目标情绪为消极情绪的数量。In the process of providing services to customers by agents, if the emotions of the agents are negative during the call, it is easy for them to carry the corresponding negative emotions when speaking, which will affect the customer’s service satisfaction with the agents. During service evaluation, it is necessary to assess whether the agents convey negative emotions in the process of providing services to customers, so it is necessary to count the number of negative emotions corresponding to each voice stream to be recognized. The number of negative emotions refers to the number of at least two current target speech segments whose target emotions are negative emotions.
S703:基于待识别语音流对应的消极情绪数量,获取待识别语音流对应的情绪分析结果。S703: Obtain a sentiment analysis result corresponding to the voice stream to be recognized based on the number of negative emotions corresponding to the voice stream to be recognized.
作为一示例,基于待识别语音流对应的消极情绪数量,获取待识别语音流对应的情绪分析结果,包括:若待识别语音流对应的消极情绪数量大于第二数量阈值,则获取的情绪分析结果为消极情绪;若待识别语音流对应的消极情绪数量不大于第二数量阈值,则获取的情绪分析结果为积极情绪。该第二数量阈值是预先设置的数值。As an example, based on the number of negative emotions corresponding to the voice stream to be recognized, obtaining the emotion analysis result corresponding to the voice stream to be recognized includes: if the number of negative emotions corresponding to the voice stream to be recognized is greater than the second number threshold, then the obtained emotion analysis result Is a negative emotion; if the number of negative emotions corresponding to the voice stream to be recognized is not greater than the second number threshold, the obtained emotion analysis result is a positive emotion. The second number threshold is a preset value.
作为一示例,基于待识别语音流对应的消极情绪数量,获取待识别语音流对应的情绪分析结果,包括:基于待识别语音流对应的消极情绪数量计算消极情绪概率,若消极情绪概率大于预设概率阈值,则获取的情绪分析结果为消极情绪;若消极情绪概率不大于预设概率阈值,则获取的情绪分析结果为积极情绪。其中,消极情绪概率是指消极情绪数量与所有目标语音段的数量的比值。预设概率阈值是预先设置的概率值。As an example, based on the number of negative emotions corresponding to the voice stream to be recognized, obtaining the emotion analysis result corresponding to the voice stream to be recognized includes: calculating the probability of the negative emotion based on the number of negative emotions corresponding to the voice stream to be recognized, if the probability of the negative emotion is greater than a preset Probability threshold, the obtained sentiment analysis result is a negative sentiment; if the probability of the negative sentiment is not greater than the preset probability threshold, the obtained sentiment analysis result is a positive sentiment. Among them, the probability of negative emotion refers to the ratio of the number of negative emotions to the number of all target speech segments. The preset probability threshold is a preset probability value.
作为一示例,基于待识别语音流对应的消极情绪数量,获取待识别语音流对应的情绪分析结果,包括:基于待识别语音流对应的消极情绪数量查询情绪分值对照表,获取待识别语音流对应的情绪分析结果,该情绪分值对照表是用于存储不同消极情绪数量对应的情绪评分值的数据表。As an example, based on the number of negative emotions corresponding to the speech stream to be recognized, obtaining the emotion analysis result corresponding to the speech stream to be recognized includes: querying the emotion score comparison table based on the number of negative emotions corresponding to the speech stream to be recognized, and obtaining the speech stream to be recognized Corresponding to the sentiment analysis result, the sentiment score comparison table is a data table used to store sentiment scores corresponding to different amounts of negative emotions.
本实施例所提供的基于人工智能的服务评价方法中,每一当前目标语音对应的目标情绪需综合考虑识别情绪和前后两个目标语音段的识别语速,有助于提高后续分析的准确性。依据至少两个当前目标语音段对应的目标情绪,确定待识别语音流对应的消极情绪数量,基于消极情绪数量获取情绪分析结果,使得其情绪分析结果综合考虑语速和消极情绪这两种影响服务质量的关键维度,有助于提高服务评价的客观性和准确性。In the service evaluation method based on artificial intelligence provided in this embodiment, the target emotion corresponding to each current target voice needs to comprehensively consider the recognition emotion and the recognition speed of the two target speech segments, which helps to improve the accuracy of subsequent analysis. . According to the target emotions corresponding to at least two current target speech segments, determine the number of negative emotions corresponding to the voice stream to be recognized, and obtain the sentiment analysis results based on the number of negative emotions, so that the sentiment analysis results comprehensively consider the two effects of speech speed and negative emotions. The key dimension of quality helps to improve the objectivity and accuracy of service evaluation.
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。It should be understood that the size of the sequence number of each step in the foregoing embodiment does not mean the order of execution. The execution sequence of each process should be determined by its function and internal logic, and should not constitute any limitation on the implementation process of the embodiment of the present application.
在一实施例中,提供一种基于人工智能的服务评价装置,该基于人工智能的服务评价 装置与上述实施例中基于人工智能的服务评价方法一一对应。如图8所示,该基于人工智能的服务评价装置包括待识别语音流获取模块801、目标身份信息获取模块802、文本分析结果获取模块803、情绪分析结果获取模块804和服务质量评分获取模块805。各功能模块详细说明如下:In one embodiment, an artificial intelligence-based service evaluation device is provided, and the artificial intelligence-based service evaluation device corresponds to the artificial intelligence-based service evaluation method in the foregoing embodiment in a one-to-one correspondence. As shown in FIG. 8, the artificial intelligence-based service evaluation device includes a voice
待识别语音流获取模块801,用于获取服务过程中实时采集的待识别语音流。The to-be-recognized voice
目标身份信息获取模块802,用于对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息。The target identity
文本分析结果获取模块803,用于对待识别语音流进行文本分析,获取待识别语音流对应的文本分析结果。The text analysis
情绪分析结果获取模块804,用于对待识别语音流进行情绪分析,获取待识别语音流对应的情绪分析结果。The emotion analysis
服务质量评分获取模块805,用于对待识别语音流对应的文本分析结果和情绪分析结果进行融合处理,获取目标身份信息对应的服务质量评分。The service quality score obtaining
优选地,在获取服务过程中实时采集的待识别语音流之后,基于人工智能的服务评价装置还包括:语音时长判断处理模块,用于获取待识别语音流对应的语音时长,若语音时长大于时长阈值,则执行对待识别语音流进行身份识别,确定待识别语音流对应的目标身份信息。Preferably, after acquiring the voice stream to be recognized in real time during the process of acquiring the service, the artificial intelligence-based service evaluation device further includes: a voice duration judgment processing module for acquiring the voice duration corresponding to the voice stream to be recognized, if the voice duration is greater than the duration Threshold, perform identity recognition on the voice stream to be recognized, and determine the target identity information corresponding to the voice stream to be recognized.
优选地,目标身份信息获取模块802包括:Preferably, the target identity
语音流特征提取单元,用于对待识别语音流进行特征提取,获取待识别语音流对应的MFCC特征和Pitch特征。The voice stream feature extraction unit is used to perform feature extraction on the voice stream to be recognized, and obtain the MFCC feature and pitch feature corresponding to the voice stream to be recognized.
目标特征向量获取单元,用于对MFCC特征和Pitch特征进行拼接处理,获取目标特征向量。The target feature vector obtaining unit is used for splicing the MFCC feature and the pitch feature to obtain the target feature vector.
身份特征信息获取单元,用于采用基于时延神经网络的身份特征识别模型对目标特征向量进行处理,获取身份特征信息,身份特征识别模型上设有用于对隐含层输入的特征进行均值和标准差计算的汇总池化层。The identity feature information acquisition unit is used to process the target feature vector using the identity feature recognition model based on the time-delay neural network to obtain the identity feature information. The identity feature recognition model is equipped with the average value and standard for the hidden layer input features Aggregate pooling layer for difference calculation.
目标身份信息获取单元,用于将身份特征信息与数据库中每一坐席人员对应的标准特征信息进行相似度计算,获取特征相似度,基于特征相似度确定待识别语音流对应的目标身份信息。The target identity information acquisition unit is used to calculate the similarity between the identity characteristic information and the standard characteristic information corresponding to each agent in the database, obtain the characteristic similarity, and determine the target identity information corresponding to the voice stream to be recognized based on the characteristic similarity.
优选地,文本分析结果获取模块803包括:Preferably, the text analysis
文本信息获取单元,用于采用语音识别模型对待识别语音流进行文本识别,获取待识别文本信息。The text information acquisition unit is configured to use a voice recognition model to perform text recognition on the voice stream to be recognized, and obtain text information to be recognized.
敏感词分析结果获取单元,用于对待识别文本信息进行敏感词分析,获取敏感词分析结果。The sensitive word analysis result obtaining unit is used to perform sensitive word analysis on the text information to be recognized and obtain the sensitive word analysis result.
语气分析结果获取单元,用于对待识别文本信息进行语气分析,获取语气分析结果。The tone analysis result obtaining unit is used to perform tone analysis on the text information to be recognized and obtain the tone analysis result.
文本分析结果获取单元,用于基于敏感词分析结果和语气分析结果,获取待识别语音流对应的文本分析结果。The text analysis result obtaining unit is used to obtain the text analysis result corresponding to the voice stream to be recognized based on the sensitive word analysis result and the tone analysis result.
优选地,情绪分析结果获取模块804包括:Preferably, the sentiment analysis
目标语音段获取单元,用于对待识别语音流进行语音分段,获取至少两个目标语音段。The target speech segment acquisition unit is configured to perform speech segmentation on the speech stream to be recognized to acquire at least two target speech segments.
识别情绪获取单元,用于采用语音情绪识别模型对每一目标语音段进行情绪识别,获取每一目标语音段对应的识别情绪。The recognition emotion acquisition unit is used for using a voice emotion recognition model to perform emotion recognition on each target speech segment, and obtain the recognition emotion corresponding to each target speech segment.
识别语速计算单元,用于计算每一目标语音段对应的识别语速。The recognition speech rate calculation unit is used to calculate the recognition speech rate corresponding to each target speech segment.
情绪分析结果获取单元,用于基于至少两个目标语音段对应的识别语速和识别情绪,获取待识别语音流对应的情绪分析结果。The emotion analysis result obtaining unit is configured to obtain the emotion analysis result corresponding to the speech stream to be recognized based on the recognition speech rate and the recognition emotion corresponding to the at least two target speech segments.
优选地,识别情绪获取单元包括:Preferably, the recognition emotion acquiring unit includes:
语音段特征提取子单元,用于对每一目标语音段进行特征提取,获取目标语音段对应 的语谱图特征和TEO特征。The voice segment feature extraction subunit is used to perform feature extraction on each target voice segment to obtain the spectrogram features and TEO features corresponding to the target voice segment.
目标识别特征获取子单元,用于对语谱图特征和TEO特征进行拼接,获取目标语音段对应的目标识别特征。The target recognition feature acquisition subunit is used to splice the spectrogram features and TEO features to acquire the target recognition features corresponding to the target speech segment.
识别情绪获取子单元,用于采用语音情绪识别模型对每一目标语音段对应的目标识别特征进行情绪识别,获取每一目标语音段对应的识别情绪。The recognition emotion acquisition sub-unit is used for using the voice emotion recognition model to perform emotion recognition on the target recognition feature corresponding to each target speech segment, and obtain the recognition emotion corresponding to each target speech segment.
优选地,情绪分析结果获取单元包括:Preferably, the sentiment analysis result obtaining unit includes:
目标情绪获取子单元,用于基于当前目标语音段的识别语速、上一目标语音段的识别语速和当前目标语音段的识别情绪,获取当前目标语音段对应的目标情绪。The target emotion acquisition subunit is used to obtain the target emotion corresponding to the current target speech segment based on the recognition speech rate of the current target speech segment, the recognition speech speed of the previous target speech segment, and the recognition emotion of the current target speech segment.
消极情绪数量获取子单元,用于基于至少两个当前目标语音段对应的目标情绪,获取待识别语音流对应的消极情绪数量。The negative emotion quantity obtaining subunit is used to obtain the negative emotion quantity corresponding to the voice stream to be recognized based on the target emotion corresponding to at least two current target speech segments.
情绪分析结果获取子单元,用于基于待识别语音流对应的消极情绪数量,获取待识别语音流对应的情绪分析结果。The emotion analysis result obtaining subunit is used to obtain the emotion analysis result corresponding to the voice stream to be recognized based on the number of negative emotions corresponding to the voice stream to be recognized.
关于基于人工智能的服务评价装置的具体限定可以参见上文中对于基于人工智能的服务评价方法的限定,在此不再赘述。上述基于人工智能的服务评价装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。Regarding the specific limitation of the artificial intelligence-based service evaluation device, please refer to the above limitation on the artificial intelligence-based service evaluation method, which will not be repeated here. Each module in the above artificial intelligence-based service evaluation device can be implemented in whole or in part by software, hardware, and a combination thereof. The above-mentioned modules may be embedded in the form of hardware or independent of the processor in the computer equipment, or may be stored in the memory of the computer equipment in the form of software, so that the processor can call and execute the operations corresponding to the above-mentioned modules.
在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图9所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机可读指令和数据库。该内存储器为非易失性存储介质中的操作系统和计算机可读指令的运行提供环境。该计算机设备的数据库用于存储执行基于人工智能的服务评价方法过程中采用或生成的数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机可读指令被处理器执行时以实现一种基于人工智能的服务评价方法。In one embodiment, a computer device is provided. The computer device may be a server, and its internal structure diagram may be as shown in FIG. 9. The computer equipment includes a processor, a memory, a network interface, and a database connected through a system bus. Among them, the processor of the computer device is used to provide calculation and control capabilities. The memory of the computer device includes a non-volatile storage medium and an internal memory. The non-volatile storage medium stores an operating system, computer readable instructions, and a database. The internal memory provides an environment for the operation of the operating system and computer-readable instructions in the non-volatile storage medium. The database of the computer equipment is used to store data used or generated during the execution of the artificial intelligence-based service evaluation method. The network interface of the computer device is used to communicate with an external terminal through a network connection. When the computer-readable instructions are executed by the processor, an artificial intelligence-based service evaluation method is realized.
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机可读指令,处理器执行计算机可读指令时实现上述实施例中基于人工智能的服务评价方法,例如图2所示S201-S205,或者图2至图7中所示,为避免重复,这里不再赘述。或者,处理器执行计算机可读指令时实现基于人工智能的服务评价装置这一实施例中的各模块/单元的功能,例如图8所示的待识别语音流获取模块801、目标身份信息获取模块802、文本分析结果获取模块803、情绪分析结果获取模块804和服务质量评分获取模块805的功能,为避免重复,这里不再赘述。In one embodiment, a computer device is provided, including a memory, a processor, and computer-readable instructions stored in the memory and capable of running on the processor. The processor executes the computer-readable instructions to implement the Artificial intelligence service evaluation methods, such as S201-S205 shown in Fig. 2, or shown in Figs. 2-7, are not repeated here to avoid repetition. Or, when the processor executes the computer-readable instructions, the functions of the modules/units in the embodiment of the artificial intelligence-based service evaluation device are realized, for example, the to-be-recognized voice
在一实施例中,提供一个或多个存储有计算机可读指令的可读存储介质,所述计算机可读存储介质存储有计算机可读指令,所述计算机可读指令被一个或多个处理器执行时,使得所述一个或多个处理器执行时实现上述实施例中基于人工智能的服务评价方法,例如图2所示S201-S205,或者图2至图7中所示,为避免重复,这里不再赘述。或者,该计算机可读指令被处理器执行时实现上述基于人工智能的服务评价装置这一实施例中的各模块/单元的功能,例如图8所示的待识别语音流获取模块801、目标身份信息获取模块802、文本分析结果获取模块803、情绪分析结果获取模块804和服务质量评分获取模块805的功能,为避免重复,这里不再赘述。本实施例中的可读存储介质包括非易失性可读存储介质和易失性可读存储介质。In an embodiment, one or more readable storage media storing computer readable instructions are provided. The computer readable storage medium stores computer readable instructions, and the computer readable instructions are executed by one or more processors. When executed, the one or more processors are executed to implement the artificial intelligence-based service evaluation method in the foregoing embodiment, such as S201-S205 shown in FIG. 2, or shown in FIG. 2 to FIG. 7, in order to avoid repetition, I won't repeat it here. Or, when the computer-readable instruction is executed by the processor, the function of each module/unit in the embodiment of the above-mentioned artificial intelligence-based service evaluation device is realized, for example, the to-be-recognized voice
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机可读指令来指令相关的硬件来完成,该计算机可读指令可存储于一非易失性可读存储介质也可以存储在易失性可读存储介质中,该计算机可读指令在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数 据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。A person of ordinary skill in the art can understand that all or part of the processes in the above-mentioned embodiment methods can be implemented by instructing relevant hardware through computer-readable instructions, which can be stored in a non-volatile readable storage. The medium may also be stored in a volatile readable storage medium, and when the computer readable instructions are executed, they may include the processes of the above-mentioned method embodiments. Wherein, any reference to memory, storage, database or other media used in the embodiments provided in this application may include non-volatile and/or volatile memory. Non-volatile memory may include read only memory (ROM), programmable ROM (PROM), electrically programmable ROM (EPROM), electrically erasable programmable ROM (EEPROM), or flash memory. Volatile memory may include random access memory (RAM) or external cache memory. As an illustration and not a limitation, RAM is available in many forms, such as static RAM (SRAM), dynamic RAM (DRAM), synchronous DRAM (SDRAM), double data rate SDRAM (DDRSDRAM), enhanced SDRAM (ESDRAM), synchronous chain Channel (Synchlink) DRAM (SLDRAM), memory bus (Rambus) direct RAM (RDRAM), direct memory bus dynamic RAM (DRDRAM), and memory bus dynamic RAM (RDRAM), etc.
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将所述装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。Those skilled in the art can clearly understand that, for the convenience and conciseness of description, only the division of the above functional units and modules is used as an example. In practical applications, the above functions can be allocated to different functional units and modules as needed. Module completion, that is, the internal structure of the device is divided into different functional units or modules to complete all or part of the functions described above.
以上所述实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围,均应包含在本申请的保护范围之内。The above-mentioned embodiments are only used to illustrate the technical solutions of the present application, not to limit them; although the present application has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that they can still implement the foregoing The technical solutions recorded in the examples are modified, or some of the technical features are equivalently replaced; these modifications or replacements do not cause the essence of the corresponding technical solutions to deviate from the spirit and scope of the technical solutions of the embodiments of the application, and should be included in Within the scope of protection of this application.
Claims (20)
Translated fromChineseApplications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010102176.3 | 2020-02-19 | ||
| CN202010102176.3ACN111311327A (en) | 2020-02-19 | 2020-02-19 | Service evaluation method, device, equipment and storage medium based on artificial intelligence |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021164147A1true WO2021164147A1 (en) | 2021-08-26 |
Family
ID=71148448
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2020/093342CeasedWO2021164147A1 (en) | 2020-02-19 | 2020-05-29 | Artificial intelligence-based service evaluation method and apparatus, device and storage medium |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN111311327A (en) |
| WO (1) | WO2021164147A1 (en) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113808622A (en)* | 2021-09-17 | 2021-12-17 | 青岛大学 | Emotion recognition system and method based on Chinese voice and text |
| CN113889081A (en)* | 2021-10-12 | 2022-01-04 | 杭州网易智企科技有限公司 | Speech recognition method, medium, apparatus and computing device |
| CN113903358A (en)* | 2021-10-15 | 2022-01-07 | 北京房江湖科技有限公司 | Voice quality inspection method, readable storage medium and computer program product |
| CN114242048A (en)* | 2021-12-17 | 2022-03-25 | 音数汇元(上海)智能科技有限公司 | A voice-based home service quality assessment method and system |
| CN115086283A (en)* | 2022-05-18 | 2022-09-20 | 阿里巴巴(中国)有限公司 | Voice stream processing method and unit |
| CN115187070A (en)* | 2022-07-12 | 2022-10-14 | 中国工商银行股份有限公司 | Processing method and device for evaluating customer service quality |
| CN115273854A (en)* | 2022-07-27 | 2022-11-01 | 上海数策软件股份有限公司 | Service quality determination method and device, electronic equipment and storage medium |
| CN115545799A (en)* | 2022-11-04 | 2022-12-30 | 北京赛西科技发展有限责任公司 | Information technology service quality evaluation method, device, equipment and medium |
| CN117271753A (en)* | 2023-11-20 | 2023-12-22 | 深圳市数商时代科技有限公司 | Intelligent property question-answering method and related products |
| CN118536848A (en)* | 2024-03-05 | 2024-08-23 | 北方工业大学 | Public occasion service quality evaluation method and system based on multi-mode fusion |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111899763B (en)* | 2020-07-18 | 2022-06-10 | 浙江嘉科智慧养老服务有限公司 | Nursing identification and evaluation method based on audio analysis |
| CN112308379A (en)* | 2020-09-30 | 2021-02-02 | 音数汇元(上海)智能科技有限公司 | Home care service order evaluation method, device, equipment and storage medium |
| CN112221162B (en)* | 2020-10-15 | 2021-05-14 | 武汉卧友网络科技有限公司 | Network game interaction method based on artificial intelligence recognition and intelligent game platform |
| CN112700795B (en)* | 2020-12-15 | 2024-11-29 | 深圳市声希科技有限公司 | Spoken language pronunciation quality evaluation method, device, equipment and storage medium |
| CN112837702A (en)* | 2020-12-31 | 2021-05-25 | 萨孚凯信息系统(无锡)有限公司 | Voice emotion distributed system and voice signal processing method |
| CN112837693A (en)* | 2021-01-29 | 2021-05-25 | 上海钧正网络科技有限公司 | User experience tendency identification method, device, equipment and readable storage medium |
| CN113011159A (en)* | 2021-03-23 | 2021-06-22 | 中国建设银行股份有限公司 | Artificial seat monitoring method and device, electronic equipment and storage medium |
| CN113192537B (en)* | 2021-04-27 | 2024-04-09 | 深圳市优必选科技股份有限公司 | Awakening degree recognition model training method and voice awakening degree acquisition method |
| CN114157758A (en)* | 2021-09-25 | 2022-03-08 | 南方电网数字电网研究院有限公司 | Voice intelligent customer service character quality inspection method and system |
| CN114267340A (en)* | 2021-12-27 | 2022-04-01 | 科大讯飞股份有限公司 | Method, device, storage medium and equipment for evaluating service quality of 4S shop |
| CN114519638A (en)* | 2022-02-16 | 2022-05-20 | 平安普惠企业管理有限公司 | Post-loan payment urging method, post-loan payment urging device, electronic equipment and storage medium |
| CN114666618B (en)* | 2022-03-15 | 2023-10-13 | 广州欢城文化传媒有限公司 | Audio auditing method, device, equipment and readable storage medium |
| CN114783420A (en)* | 2022-06-22 | 2022-07-22 | 成都博点科技有限公司 | Data processing method and system |
| CN115101053B (en)* | 2022-06-23 | 2025-09-26 | 平安银行股份有限公司 | Dialogue processing method, device, terminal and storage medium based on emotion recognition |
| CN115841823A (en)* | 2022-11-17 | 2023-03-24 | 武汉海微科技有限公司 | Audio device detection method, device, equipment and storage medium |
| CN116108177A (en)* | 2023-02-01 | 2023-05-12 | 中国第一汽车股份有限公司 | Evaluation method and device for voice interaction and brand positioning relation |
| CN117649141A (en)* | 2023-11-28 | 2024-03-05 | 广州方舟信息科技有限公司 | Customer service quality evaluation method, customer service quality evaluation device, customer service quality evaluation equipment and storage medium |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007004001A (en)* | 2005-06-27 | 2007-01-11 | Tokyo Electric Power Co Inc:The | Operator response capability diagnostic device, operator response capability diagnostic program, program storage medium |
| CN101662549A (en)* | 2009-09-09 | 2010-03-03 | 中兴通讯股份有限公司 | Customer evaluation system and customer evaluation method based on voice |
| CN103811009A (en)* | 2014-03-13 | 2014-05-21 | 华东理工大学 | Smart phone customer service system based on speech analysis |
| CN107154257A (en)* | 2017-04-18 | 2017-09-12 | 苏州工业职业技术学院 | Customer service quality evaluating method and system based on customer voice emotion |
| CN107452385A (en)* | 2017-08-16 | 2017-12-08 | 北京世纪好未来教育科技有限公司 | A kind of voice-based data evaluation method and device |
| CN108564968A (en)* | 2018-04-26 | 2018-09-21 | 广州势必可赢网络科技有限公司 | Method and device for evaluating customer service |
| CN109151218A (en)* | 2018-08-21 | 2019-01-04 | 平安科技(深圳)有限公司 | Call voice quality detecting method, device, computer equipment and storage medium |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107818798B (en)* | 2017-10-20 | 2020-08-18 | 百度在线网络技术(北京)有限公司 | Customer service quality evaluation method, device, equipment and storage medium |
| US11768979B2 (en)* | 2018-03-23 | 2023-09-26 | Sony Corporation | Information processing device and information processing method |
| CN109448730A (en)* | 2018-11-27 | 2019-03-08 | 广州广电运通金融电子股份有限公司 | A kind of automatic speech quality detecting method, system, device and storage medium |
| CN109346088A (en)* | 2018-12-06 | 2019-02-15 | 泰康保险集团股份有限公司 | Personal identification method, device, medium and electronic equipment |
- 2020
- 2020-02-19CNCN202010102176.3Apatent/CN111311327A/enactivePending
- 2020-05-29WOPCT/CN2020/093342patent/WO2021164147A1/ennot_activeCeased
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007004001A (en)* | 2005-06-27 | 2007-01-11 | Tokyo Electric Power Co Inc:The | Operator response capability diagnostic device, operator response capability diagnostic program, program storage medium |
| CN101662549A (en)* | 2009-09-09 | 2010-03-03 | 中兴通讯股份有限公司 | Customer evaluation system and customer evaluation method based on voice |
| CN103811009A (en)* | 2014-03-13 | 2014-05-21 | 华东理工大学 | Smart phone customer service system based on speech analysis |
| CN107154257A (en)* | 2017-04-18 | 2017-09-12 | 苏州工业职业技术学院 | Customer service quality evaluating method and system based on customer voice emotion |
| CN107452385A (en)* | 2017-08-16 | 2017-12-08 | 北京世纪好未来教育科技有限公司 | A kind of voice-based data evaluation method and device |
| CN108564968A (en)* | 2018-04-26 | 2018-09-21 | 广州势必可赢网络科技有限公司 | Method and device for evaluating customer service |
| CN109151218A (en)* | 2018-08-21 | 2019-01-04 | 平安科技(深圳)有限公司 | Call voice quality detecting method, device, computer equipment and storage medium |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113808622A (en)* | 2021-09-17 | 2021-12-17 | 青岛大学 | Emotion recognition system and method based on Chinese voice and text |
| CN113889081A (en)* | 2021-10-12 | 2022-01-04 | 杭州网易智企科技有限公司 | Speech recognition method, medium, apparatus and computing device |
| CN113903358A (en)* | 2021-10-15 | 2022-01-07 | 北京房江湖科技有限公司 | Voice quality inspection method, readable storage medium and computer program product |
| CN113903358B (en)* | 2021-10-15 | 2022-11-04 | 贝壳找房(北京)科技有限公司 | Voice quality inspection method, readable storage medium and computer program product |
| CN114242048A (en)* | 2021-12-17 | 2022-03-25 | 音数汇元(上海)智能科技有限公司 | A voice-based home service quality assessment method and system |
| CN115086283B (en)* | 2022-05-18 | 2024-02-06 | 阿里巴巴(中国)有限公司 | Voice stream processing method and device |
| CN115086283A (en)* | 2022-05-18 | 2022-09-20 | 阿里巴巴(中国)有限公司 | Voice stream processing method and unit |
| CN115187070A (en)* | 2022-07-12 | 2022-10-14 | 中国工商银行股份有限公司 | Processing method and device for evaluating customer service quality |
| CN115273854A (en)* | 2022-07-27 | 2022-11-01 | 上海数策软件股份有限公司 | Service quality determination method and device, electronic equipment and storage medium |
| CN115545799B (en)* | 2022-11-04 | 2023-03-24 | 北京赛西科技发展有限责任公司 | Information technology service quality evaluation method, device, equipment and medium |
| CN115545799A (en)* | 2022-11-04 | 2022-12-30 | 北京赛西科技发展有限责任公司 | Information technology service quality evaluation method, device, equipment and medium |
| CN117271753A (en)* | 2023-11-20 | 2023-12-22 | 深圳市数商时代科技有限公司 | Intelligent property question-answering method and related products |
| CN117271753B (en)* | 2023-11-20 | 2024-03-19 | 深圳市数商时代科技有限公司 | Smart property question and answer methods and related products |
| CN118536848A (en)* | 2024-03-05 | 2024-08-23 | 北方工业大学 | Public occasion service quality evaluation method and system based on multi-mode fusion |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111311327A (en) | 2020-06-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021164147A1 (en) | Artificial intelligence-based service evaluation method and apparatus, device and storage medium | |
| CN112259106B (en) | Voiceprint recognition method and device, storage medium and computer equipment | |
| US10771627B2 (en) | Personalized support routing based on paralinguistic information | |
| WO2019210557A1 (en) | Voice quality inspection method and device, computer device and storage medium | |
| US20130325470A1 (en) | System and method for identification of a speaker by phonograms of spontaneous oral speech and by using formant equalization | |
| WO2021047319A1 (en) | Voice-based personal credit assessment method and apparatus, terminal and storage medium | |
| Drygajlo | Automatic speaker recognition for forensic case assessment and interpretation | |
| CN114155460B (en) | User type identification method, device, computer equipment and storage medium | |
| WO2021012495A1 (en) | Method and device for verifying speech recognition result, computer apparatus, and medium | |
| CN113763992B (en) | Voice evaluation method, device, computer equipment and storage medium | |
| CN115631772A (en) | Method and device for evaluating risk of suicide injury, electronic equipment and storage medium | |
| Xu et al. | Speaker recognition and speech emotion recognition based on GMM | |
| CN114220419B (en) | A method, device, medium and equipment for speech evaluation | |
| Babu et al. | Forensic speaker recognition system using machine learning | |
| Lopez‐Otero et al. | Influence of speaker de‐identification in depression detection | |
| Leuzzi et al. | A statistical approach to speaker identification in forensic phonetics | |
| CN114333848B (en) | Voiceprint recognition method and device, electronic equipment and storage medium | |
| Akinrinmade et al. | Creation of a Nigerian voice corpus for indigenous speaker recognition | |
| CN116631450A (en) | Multi-mode voice emotion recognition method, device, equipment and storage medium | |
| Singh | Speaker Identification Using MFCC Feature Extraction ANN Classification Technique | |
| Beigi | Effects of time lapse on speaker recognition results | |
| Sarhan | Smart voice search engine | |
| Nguyen et al. | Speaker diarization for vietnamese conversations using deep neural network embeddings | |
| CN118588112B (en) | Alternating current state analysis method, equipment and medium for nonverbal signals | |
| SUCIU et al. | SPEECH RECOGNITION SYSTEM. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | Ref document number:20919610 Country of ref document:EP Kind code of ref document:A1 | |
| NENP | Non-entry into the national phase | Ref country code:DE | |
| 32PN | Ep: public notification in the ep bulletin as address of the adressee cannot be established | Free format text:NOTING OF LOSS OF RIGHTS PURSUANT TO RULE 112(1) EPC (EPO FORM 1205A DATED 09/12/2022) | |
| 122 | Ep: pct application non-entry in european phase | Ref document number:20919610 Country of ref document:EP Kind code of ref document:A1 |