WO2021139262A1 - Document mesh term aggregation method and apparatus, computer device, and readable storage medium - Google Patents
Document mesh term aggregation method and apparatus, computer device, and readable storage mediumDownload PDFInfo
- Publication number
- WO2021139262A1 WO2021139262A1PCT/CN2020/118699CN2020118699WWO2021139262A1WO 2021139262 A1WO2021139262 A1WO 2021139262A1CN 2020118699 WCN2020118699 WCN 2020118699WWO 2021139262 A1WO2021139262 A1WO 2021139262A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- document
- phrase
- noun
- citation
- similarity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2465—Query processing support for facilitating data mining operations in structured databases
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
- G06F18/232—Non-hierarchical techniques
- G06F18/2321—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions
- G06F18/23213—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions with fixed number of clusters, e.g. K-means clustering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Definitions
- This applicationrelates to the field of digital medical technology, and in particular to a method, device, computer equipment, and computer-readable storage medium for document subject word aggregation.
- the selected topic representative wordsoften contain a large number of synonymous or synonymous professional terms, resulting in redundant and inaccurate information, such as non- small cell lung cancer, non-small cell lung cancer, non-small cell cancer, non-small cell lung cancer cells, human non-small cell lung cancer, should be standardized to the same subject term non-small cell lung cancer.
- This applicationprovides a method, device, computer equipment, and computer-readable storage medium for document subject word aggregation, which can solve the problem of low accuracy of document subject word aggregation in traditional technology.
- this applicationprovides a method for aggregation of document subject terms, the method comprising: obtaining document data, the document data including the document title, document abstract, and the corresponding information of each document. Citation information; using a preset natural language processing tool to extract the noun phrases contained in the document title and the document abstract; based on the citation information and the noun phrases, clustering the noun phrases to obtain A set of synonymous words; the target noun phrase with the highest word frequency is selected from the set of synonymous words as the subject words of the document.
- this applicationalso provides a document subject word aggregation device, including: an acquisition unit for acquiring document data, the document data including the document title, document abstract, and each document contained in each document Corresponding citation information; an extraction unit for extracting noun phrases contained in the document title and the document abstract by using a preset natural language processing tool; a clustering unit for extracting noun phrases contained in the document title and the document abstract based on the citation information and the A noun phrase clusters the noun phrase to obtain a set of synonyms; a screening unit is used to filter the target noun phrase with the highest word frequency from the set of synonyms as the subject word of the document.
- the present applicationalso provides a computer device, which includes a memory and a processor, the memory stores a computer program, and the processor executes the following steps when running the computer program: acquiring document data, The document data includes the document title, document abstract, and citation information corresponding to each document; preset natural language processing tools are used to extract the noun phrases contained in the document title and the document abstract Based on the citation information and the noun phrase, cluster the noun phrase to obtain a set of synonyms; select the target noun phrase with the highest word frequency from the set of synonyms as the subject words of the document.
- the present applicationalso provides a computer-readable storage medium, the computer-readable storage medium stores a computer program, and when the computer program is executed by a processor, the processor implements the following steps: Obtain document data , The document data includes the document title, document abstract, and citation information corresponding to each document; the preset natural language processing tool is used to extract the document title and the document abstract. Based on the citation information and the noun phrase, cluster the noun phrase to obtain a set of synonyms; select the target noun phrase with the highest word frequency from the set of synonyms as the subject words of the literature.
- the embodiment of this applicationobtains document data including the document title, document abstract and citation information corresponding to each document contained in each document, and uses a preset natural language processing tool to obtain the document title and Extracting the noun phrases contained in the document abstract, clustering the noun phrases based on the citation information and the noun phrases to obtain a set of synonyms, and selecting the target with the highest word frequency from the set of synonyms
- Noun phrasesare the subject words of the literature. Due to the combination of noun phrases and citation information, the phrase-level synonym processing method is used for the scene of document mining, and the citation information is combined to represent the similarity of noun phrases. Compared with the traditional technology , Only word-level semantic similarity is used for characterization, while only sentence-level information is considered.
- the characterization method in the embodiment of this applicationfully represents the similarity between the topics represented by two noun phrases, so that the aggregated The subject words can accurately describe the subject of the document, which improves the accuracy of the subject word aggregation of the document.
- FIG. 1is a schematic flowchart of a method for aggregation of document subject words provided by an embodiment of the application;
- FIG. 2is a schematic diagram of a sub-process in the method for document subject word aggregation provided by an embodiment of the application;
- FIG. 3is a schematic diagram of an example of a document co-citation network in a document subject word aggregation method provided by an embodiment of the application;
- FIG. 4is a schematic diagram of another sub-flow of the method for document subject word aggregation provided by an embodiment of the application;
- FIG. 5is a schematic diagram of an aggregation process of a method for aggregation of document subject words provided by an embodiment of the application;
- Fig. 6is a schematic block diagram of a document subject word aggregation device provided by an embodiment of the application.
- FIG. 7is a schematic block diagram of a computer device provided by an embodiment of the application.
- FIG. 1is a schematic flowchart of a method for aggregation of document subject words provided by an embodiment of the application. As shown in Figure 1, the method includes the following steps S101-S104:
- the document data corresponding to the documentcan be retrieved from the preset database by means of keywords.
- the document dataincludes the document title, document abstract and citation information corresponding to each document contained in each document.
- the citation informationis the mutual citation relationship between the documents.
- the Pubmed databaseis generally used to search for documents. By searching keywords, you can obtain the document titles, document abstracts, and mutual citation relationships between documents in a specific field contained in the Pubmed database, for example, by searching for "lung cancer" ", download the titles, abstracts, and citation relationships of articles related to lung cancer.
- natural language processing toolsinclude Stanford nlp, TextBlob, Polyglot and other natural language processing tools that can extract noun phrases.
- the specific process of extracting noun phrasesis as follows: 1) Use a preset natural language processing tool to extract noun phrases contained in the document title and the document abstract, for example, use Stanford nlp to extract noun phrases. 2) Processing word phrases, you can delete the words and words with the highest frequency. For example, delete the words and words in the 2000 words with the highest frequency in the Wikipedia corpus. The phrase "cancer" will be deleted to avoid high-frequency general vocabulary. Affect the aggregation of keywords.
- a co-citation network between the documentsis constructed, and the co-citation relationship between the noun phrases is obtained according to the co-citation network between the documents, and then the co-citation relationship between the noun phrases is obtained.
- Predict the semantic similarity of noun phrasesso as to cluster the noun phrases according to the co-citation relationship and semantic similarity between the noun phrases to obtain a set of synonyms.
- the target noun phrase that meets the requirementsis selected from the synonym set, and the target noun phrase is used as the subject word of the document, for example, the noun phrase with the highest frequency in the synonym set is used as the target noun Phrases, etc., to get the subject words of the literature.
- a phrase-level synonym processing methodis used for document mining scenarios, and citation information is combined to characterize the similarity of noun phrases.
- citation informationis combined to characterize the similarity of noun phrases.
- Only word-level semantic similarityis used for characterization, while only sentence-level information is considered.
- the characterization method of the embodiment of the present applicationfully represents the similarity between the topics represented by two noun phrases, so that the aggregated topics The word can accurately describe the subject of the document, which improves the accuracy of the subject word aggregation of the document.
- FIG. 2is a schematic diagram of a sub-process in the method for aggregation of document subject words provided by an embodiment of the application.
- the step of clustering the noun phrases based on the citation information and the noun phrases to obtain a set of synonymsincludes:
- the semantic similarityis used to describe the language meaning similarity between noun phrases, and the semantic similarity can be measured by cosine similarity, Euclidean distance, or Minkowski distance (English: Minkowski distance).
- the similarity between two noun phrasescan be calculated by vectorizing the noun phrase, and the similarity between the two noun phrases can be obtained by quantifying the similarity.
- the step of establishing a semantic similarity based on the noun phrase according to the noun phraseincludes: inputting the noun phrase into a preset Biobert model to obtain the semantic vector corresponding to the noun phrase; and calculating; The cosine similarity between the semantic vectors is used to obtain the semantic similarity corresponding to the noun phrase.
- Biobertis a Bert model trained on a huge medical corpus, which can effectively represent the semantics of medical-related words and phrases. Input the extracted noun phrases into the Biobert model to obtain the semantic vector representation at the noun phrase level.
- each Noun phrasesare transformed into 768-dimensional vectors, that is, the latitude is 768-dimensional, and then the cosine similarity is used to calculate the similarity between the vectors, that is, the semantic similarity between phrases can be obtained.
- a deep learning model based on the Biobert modelcan be pre-trained to represent contextual features and semantic information of the noun phrase itself, so as to realize the aggregation of topic words in the embodiment of this application, combining phrase-level synonyms, Fully characterize the similarity between the topics represented by two noun phrases through the similarity of the noun phrase level.
- phrase-level datatrain a deep learning model based on the pre-trained Biobert model to represent the contextual features and the semantics of the phrase itself. Information, which improves the semantic similarity corresponding to noun phrases extracted based on co-citation information, and improves the accuracy of semantic similarity statistics.
- co-cited documentsrefer to a document at the same time, and co-cited documents are referred to by a document at the same time, and co-cited as co-cited.
- the corresponding literature citation relationship networkcan be constructed. From the perspective of the cited literature, it is the literature cited network. If it is multiple documents The co-cited network among the documents is the document co-cited network.
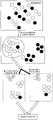
- Figure 3is a schematic diagram of a document co-citation network example in the document keyword aggregation method provided by the embodiment of this application.
- a and B in Figure 3are both cited by C, and there is a similarity between A and B. Therefore, a co-citation network citing A and B can be constructed to obtain the relationship between A and B.
- the co-citation network of CDE cited in Document Ais constructed.
- the weight of the edgeis the co-citation similarity between the two nodes (for example, the node is A1
- the nodeis A1
- the two documents of A1 and A2, the two documents A1 and A2cite the same document and there is a citation intersection, which can be used to measure the similarity between A1 and A2.
- Ais cited by CDE.
- Bis cited by CD and AB is cited by CD.
- the statistical measure of the similarity between the twois called co-cited similarity), the calculation formula as follows:
- M and Nrepresent the collection of documents citing document i and document j, respectively.
- Fig. 3Take Fig. 3 as an example.
- Fig. 3there are a total of five documents ABCDE, in which the direction of the arrow indicates the citation relationship, and the dotted line between AB is used to describe AB as a co-cited object, for example, arrows C to A indicate Document C quotes document A.
- the three CDE documentsall quote document A, and the citing document set of A is ⁇ C, D, E ⁇ , the same can be obtained, the citing document set of B Is ⁇ C, D ⁇ , the co-citation similarity between AB is:
- the noun phraseis used to describe the document, that is, the noun phrase co-citation similarity can be established
- the default co-citation similarity between document i and itselfis 1.
- the co-citation similarity of the documentis used to characterize the similarity between the extracted noun phrases corresponding to the document. The calculation formula is as follows:
- X and Yrespectively represent the collection of documents containing phrases x and y. So far, a co-citation similarity network between phrases can be obtained. According to the phrase co-citation similarity network, the noun phrase is obtained. Corresponding phrase co-citation similarity, and then based on the phrase co-citation similarity and the semantic similarity, clustering the noun phrases to obtain a set of synonyms, the embodiment of this application introduces based on the document co-citation Phrases with similarity are cited as similarity, which can better learn the professional knowledge in the field of phrase segmentation, and can better express the similarity between topics.
- FIG. 4is a schematic diagram of another sub-process of the method for aggregation of document subject words provided by an embodiment of the application.
- the methodbefore the step of clustering the noun phrases according to the phrase co-citation similarity and the semantic similarity to obtain a set of synonyms, the method further includes:
- community detectionalso known as community detection
- Englishis Community Detection
- communitiesusually finds out the closely connected parts of the network, these parts are called communities, then it can also be considered that the internal connections of the communities are dense, and the connections between the communities Sparse
- community detection algorithmsinclude Louvain algorithm, Newman fast algorithm, CNM algorithm and MSG-MV algorithm.
- community detectionis performed through a preset community detection algorithm, so that phrases are clustered according to the similarity network to obtain several communities, and each community contains similar words.
- the phrase co-citation networkis clustered into small communities, and the Louvain community detection algorithm is used to perform community mining on the obtained phrase co-citation similarity network, and finally a series of communities (Clusters) are obtained.
- the phrase co-citation similarity network of the phraseis used to perform community detection using the preset community detection method to obtain a series of communities, and then perform hierarchical clustering of each community to obtain a set of synonyms, due to the combination of citation information and semantic information. Synonyms of, construct a phrase similarity network based on co-citation information, and realize the use of phrase similarity network for community detection.
- the candidate set of synonymsis recalled first, which can greatly reduce the calculation amount of the clustering department. At the same time, it does not rely on annotated data and specific corpus, has good versatility, is more in line with the scene of topic mining, and improves the accuracy of topic word screening.
- the step of clustering the noun phrases according to the co-citation similarity of the phrases and the semantic similarity to obtain a set of synonymsincludes:
- cluster analysisis also called cluster analysis. It is a statistical analysis method for studying (sample or index) classification problems, and it is also an important algorithm for data mining.
- Cluster analysisis composed of several patterns. Usually, a pattern is a vector of measurement, or a point in a multi-dimensional space. Cluster analysis is based on similarity, and there are more similarities between patterns in a cluster than patterns that are not in the same cluster.
- Clustering algorithmsinclude K-means clustering algorithm, Mean-Shift clustering and Expectation Maximization (EM) clustering based on Gaussian Mixture Model (GMM).
- phrase co-citation similarity networkAfter clustering the phrase co-citation similarity network through community detection, hierarchical clustering is performed on each community, assuming that synonyms will only appear in the same community, and each phrase in each community is separately clustered.
- phrase co-citation similarity and semantic similarityyou can set the threshold of hierarchical clustering, and at the same time, the words that are clustered together in both clusters are considered as synonyms.
- two types of bottom-up hierarchical clusteringare carried out, one is clustering based on the co-citation similarity of noun phrases, and the other is clustering based on the mentioned semantic similarity, for example based on Biobert’s semantic similarity is used as the standard for clustering.
- FIG. 5is a schematic diagram of an example of the aggregation process of the document subject word aggregation method provided by an embodiment of the application.
- the white circlesrepresent the same document
- the black circlerepresents the noun phrase extracted from the same document
- the gray circlerepresents the noun phrase extracted from the third document
- the different white circles, black circles and gray circlesrepresent different noun phrases, because A A and B are clustered together in the two hierarchical clusters. Therefore, A and B can be combined into synonyms.
- a synonym miningcombining two types of information of citation information and semantic information is proposed to construct a co-citation information-based approach.
- the phrase similarity networkclusters the phrase community based on the co-cited similarity of the phrases corresponding to the noun phrase, and clusters the phrase community based on the semantic similarity corresponding to the phrase.
- the community detectionis used in the phrase similarity network to recall the set of possible synonyms, which greatly reduces the candidate range of synonyms.
- the two noun phrasesare synonyms, and can be combined to obtain a set of synonyms, using semantic similarity and co-citation similarity respectively Clustering, instead of using the usual strategy of weighted addition of different similarities, avoids the influence of similarity weights on the results, and ensures that the obtained synonyms can have similar semantics and similar topics at the same time, without relying on labeled data and specific
- the corpushas good versatility, is more in line with the scene of topic mining, and improves the accuracy of topic word selection.
- the step of selecting the target noun phrase with the highest word frequency from the synonym set as the subject word of the documentincludes: selecting TF-IDF from the synonym set according to a preset TF-IDF algorithm.
- the noun phrase with the highest IDF valueis used as the target noun phrase; the target noun phrase is used as the subject word of the document.
- TF-IDFthe English term frequency-inverse document frequency
- term frequencyrefers to the number of times a given word appears in the document. This number is usually normalized (the numerator is generally smaller than the denominator, which distinguishes it from IDF) To prevent it from favoring long files. (The same word may have a higher word frequency in a long document than in a short document, regardless of the importance of the word.)
- IDFInverse document frequency
- the IDF of a particular wordcan be obtained by dividing the total number of documents by the number of documents containing the word, and then taking the logarithm of the obtained quotient. A high word frequency in a particular document and a low document frequency of the word in the entire document collection can produce a high-weight TF-IDF. Therefore, TF-IDF tends to filter out common words and keep important words.
- the TF-IDF valueis calculated, and the phrase with the highest TF-IDF value is selected as the standard subject word.
- a weighted TF-IDF valuecan be used.
- the cited amount of the literatureis used as the importance index of the literature, and the importance of the literature is standardized to 0-1.
- the importanceis equal to the average value of the importance of all documents in which the phrase appears, and then multiplied by the TF-IDF of the phrase, as the final TF-IDF value of each phrase.
- a preset community detection methodis used to perform community detection to obtain a series of communities, hierarchical clustering is performed on each community, and the obtained synonymous word set is selected, The phrase with the largest TF-IDF value is used as the standard subject word.
- a phrase similarity network based on co-citation informationis constructed, and the phrase similarity network is used for community detection for the first time.
- the obtained synonymscan have similar semantics and similar topics at the same time, which is more in line with the topic mining scenario, does not rely on labeled data and specific corpus, has good versatility, and improves the accuracy of topic word selection.
- FIG. 6is a schematic block diagram of a document subject word aggregation device provided by an embodiment of the application.
- an embodiment of the present applicationalso provides a document subject word aggregation device.
- the document topic word aggregation deviceincludes a unit for executing the above-mentioned document topic word aggregation method, and the document topic word aggregation device may be configured in a computer device.
- the document subject word aggregation device 600includes an acquisition unit 601, an extraction unit 602, a clustering unit 603 and a screening unit 604.
- the acquiring unit 601is configured to acquire document data, the document data including the document title, document abstract, and citation information corresponding to each document contained in each document;
- the extracting unit 602is configured to use the preset nature
- the language processing toolextracts the noun phrases contained in the document title and the document abstract;
- the clustering unit 603is configured to cluster the noun phrases based on the citation information and the noun phrases to obtain A set of synonyms;
- the screening unit 604is used to filter the target noun phrase with the highest word frequency from the set of synonyms as the subject words of the document.
- the clustering unit 603includes: a establishing subunit for establishing a semantic similarity based on the noun phrase according to the noun phrase; a first constructing subunit for establishing a semantic similarity based on the noun phrase; , Construct the document co-citation network corresponding to the document; the first calculation subunit is used to calculate the document co-citation similarity corresponding to the document according to the document co-citation network; the second construction subunit uses According to the co-citation similarity of the documents, construct the phrase co-citation similarity network corresponding to the noun phrase; the first acquisition subunit is used to obtain the noun based on the co-citation similarity network of the phrase Phrases corresponding to the phrase co-citation similarity; the first clustering subunit is used to cluster the noun phrases according to the phrase co-citation similarity and the semantic similarity to obtain a set of synonyms.
- the establishment subunitincludes: an input subunit for inputting the noun phrase into a preset Biobert model to obtain the semantic vector corresponding to the noun phrase; a second calculation subunit, using To calculate the cosine similarity between the semantic vectors to obtain the semantic similarity corresponding to the noun phrase.
- the document topic word aggregation device 600further includes: a detection unit, configured to perform community detection using a preset community detection method based on the phrase co-citation similarity network to obtain several phrase communities;
- the first clustering subunitincludes: a second clustering subunit, configured to cluster the phrase community according to the co-citation similarity of the phrases corresponding to the noun phrase to obtain the first cluster;
- the third clustering subunitis used to cluster the phrase community according to the semantic similarity corresponding to the phrase to obtain the second cluster;
- the judgment subunitis used to judge every two of the Whether noun phrases are both included in the first cluster and the second cluster;
- a determination subunitfor determining if every two of the noun phrases are included in the first cluster and the second cluster , Determine that the two noun phrases are synonymous words, thereby obtaining synonymous word phrases;
- the combination subunitis used to combine all the synonymous word phrases into a set to obtain a synonymous word set.
- the screening unit 604includes: a screening subunit, configured to select a noun phrase with the highest TF-IDF value from the set of synonyms according to a preset TF-IDF algorithm as a target noun phrase; second The acquiring subunit is used to use the target noun phrase as the subject word of the document.
- the document topic word aggregation devicecan be divided into different units as needed, or the document topic words can be aggregated.
- Each unit in the deviceadopts different connection sequences and methods to complete all or part of the functions of the above-mentioned document subject word aggregation device.
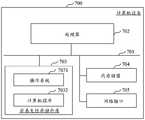
- the above-mentioned document subject word aggregation apparatusmay be implemented in the form of a computer program, and the computer program may run on the computer device as shown in FIG. 7.
- FIG. 7is a schematic block diagram of a computer device according to an embodiment of the present application.
- the computer device 700may be a computer device such as a desktop computer or a server, or may be a component or component in other devices.
- the computer device 700includes a processor 702, a memory, and a network interface 705 connected through a system bus 701, where the memory may include a non-volatile storage medium 703 and an internal memory 704.
- the non-volatile storage medium 703can store an operating system 7031 and a computer program 7032.
- the processor 702can execute the above-mentioned method for aggregation of document subject terms.
- the processor 702is used to provide calculation and control capabilities to support the operation of the entire computer device 700.
- the internal memory 704provides an environment for the operation of the computer program 7032 in the non-volatile storage medium 703.
- the processor 702can execute the above-mentioned method for aggregating literature subject terms.
- the network interface 705is used for network communication with other devices.
- the specific computer device 700may include more or fewer components than shown in the figure, or combine certain components, or have a different component arrangement.
- the computer devicemay only include a memory and a processor. In such an embodiment, the structure and function of the memory and the processor are consistent with the embodiment shown in FIG. 7 and will not be repeated here.
- the processor 702is configured to run a computer program 7032 stored in a memory to implement the method for aggregation of document subject terms described in the embodiment of the present application.
- the processor 702may be a central processing unit (Central Processing Unit, CPU), and the processor 702 may also be other general-purpose processors, digital signal processors (Digital Signal Processors, DSPs), Application Specific Integrated Circuit (ASIC), Field-Programmable Gate Array (FPGA) or other programmable logic devices, discrete gates or transistor logic devices, discrete hardware components, etc.
- the general-purpose processormay be a microprocessor or the processor may also be any conventional processor.
- the embodiment of the present applicationalso provides a computer-readable storage medium.
- the computer-readable storage mediummay be a non-volatile computer-readable storage medium, or may be a volatile computer-readable storage medium, the computer-readable storage medium stores a computer program, and the computer program is executed by the processor At this time, the processor is made to execute the steps of the method for aggregation of the document subject words described in the above embodiments.
- the storage mediumis a physical, non-transitory storage medium, such as a U disk, a mobile hard disk, a read-only memory (Read-Only Memory, ROM), a magnetic disk, or an optical disk, etc., which can store computer programs. medium.
- a physical, non-transitory storage mediumsuch as a U disk, a mobile hard disk, a read-only memory (Read-Only Memory, ROM), a magnetic disk, or an optical disk, etc., which can store computer programs. medium.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Computational Linguistics (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Probability & Statistics with Applications (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- General Health & Medical Sciences (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Fuzzy Systems (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese本申请要求于2020年07月29日提交中国专利局、申请号为202010744556.7、申请名称为“文献主题词聚合方法、装置、计算机设备及可读存储介质”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。This application claims the priority of the Chinese patent application filed with the Chinese Patent Office on July 29, 2020, the application number is 202010744556.7, and the application name is "the method, device, computer equipment and readable storage medium for document subject term aggregation", all of which The content is incorporated in this application by reference.
本申请涉及数字医疗技术领域,尤其涉及一种文献主题词聚合方法、装置、计算机设备及计算机可读存储介质。This application relates to the field of digital medical technology, and in particular to a method, device, computer equipment, and computer-readable storage medium for document subject word aggregation.
在对技术进行研究的过程中,把握一个领域的研究热点变化动态或者最新的研究热点是十分重要的,尽管文献库存在对文献的主题进行了打标签,但很多情况下,对主题的描述所对应的标签存在不准确的情形。例如,对于医学研究者,把握一个领域的研究热点变化动态或者最新的研究热点是十分重要的,不仅可以提高科研的效率也对诊断治疗疑难病症有巨大的帮助。尽管医学文献库PUBMED,绝大部分文献均有专家打的标签(即Mesh Term方式)或者关键词,但是Mesh Term耗费人力巨大,而且Mesh Term是从多种不同角度(如疾病、药物、物种等)进行标记,在大多数情况下,并不能代表该文献具体的研究热点所在,而关键词也同样存在较泛指并且会偏向于作者自己主观的选择。所以在多数的科学计量分析中,选择标题和摘要里面的名词短语作为一篇文章主题词的候选项,这样蕴含的信息会更加贴近文献的真正研究内容。但是直接适用标题和摘要中的短语进行主题分析,同义词会带来极大的噪音。尤其是对于细分领域,如肺癌,现有的主流主题模型,如LDA等,选出的主题代表词往往包含了大量近义或同义专业术语,造成信息冗余、不准确,例如non-small cell lung cancer,non-small cell lung carcinoma,non-small cell carcinoma,non-small cell lung cancer cells,human non-small cell lung cancer,应该标准化到同一个主题词non-small cell lung cancer中。In the process of researching technology, it is very important to grasp the changing dynamics of research hotspots or the latest research hotspots in a field. Although the literature library labels the subject of the literature, in many cases, the description of the subject is very important. The corresponding label is inaccurate. For example, for medical researchers, it is very important to grasp the changing dynamics of research hotspots or the latest research hotspots in a field, which can not only improve the efficiency of scientific research, but also greatly help the diagnosis and treatment of difficult diseases. Although the medical literature database PUBMED, most of the literature has tags (namely Mesh Term) or keywords marked by experts, but Mesh Term consumes a lot of manpower, and Mesh Term is based on many different perspectives (such as diseases, drugs, species, etc.). ) To mark, in most cases, it does not represent the specific research hotspot of the document, and the keywords also have more general references and will be biased towards the author's own subjective choice. Therefore, in most scientometric analysis, noun phrases in the title and abstract are selected as candidates for the subject words of an article, so that the information contained will be closer to the true research content of the literature. However, if you directly apply the phrases in the title and abstract for thematic analysis, synonyms will bring great noise. Especially for sub-fields, such as lung cancer, the existing mainstream topic models, such as LDA, etc., the selected topic representative words often contain a large number of synonymous or synonymous professional terms, resulting in redundant and inaccurate information, such as non- small cell lung cancer, non-small cell lung cancer, non-small cell cancer, non-small cell lung cancer cells, human non-small cell lung cancer, should be standardized to the same subject term non-small cell lung cancer.
发明人发现,对文献近义词术语处理过程中,尤其对于医学文献近义词术语处理过程中,由于一般使用单词级别的语义相似度进行表征,并且,一般的近义词获取只能考虑到句子级别的信息,如上下文及词性等,对于文献的主题词聚合的准确性较低。The inventor found that in the process of processing synonymous terms in documents, especially in the processing of synonymous terms in medical documents, the semantic similarity of the word level is generally used for characterization, and the general synonym acquisition can only consider the sentence-level information, such as Context and part-of-speech, etc., are less accurate for the subject word aggregation of documents.
发明内容Summary of the invention
本申请提供了一种文献主题词聚合方法、装置、计算机设备及计算机可读存储介质,能够解决传统技术中对文献的主题词聚合的准确性较低的问题。This application provides a method, device, computer equipment, and computer-readable storage medium for document subject word aggregation, which can solve the problem of low accuracy of document subject word aggregation in traditional technology.
第一方面,本申请提供了一种文献主题词聚合方法,所述方法包括:获取文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息;采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语;基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合;从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词。In the first aspect, this application provides a method for aggregation of document subject terms, the method comprising: obtaining document data, the document data including the document title, document abstract, and the corresponding information of each document. Citation information; using a preset natural language processing tool to extract the noun phrases contained in the document title and the document abstract; based on the citation information and the noun phrases, clustering the noun phrases to obtain A set of synonymous words; the target noun phrase with the highest word frequency is selected from the set of synonymous words as the subject words of the document.
第二方面,本申请还提供了一种文献主题词聚合装置,包括:获取单元,用于获取文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息;提取单元,用于采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语;聚类单元,用于基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合;筛选单元,用于从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词。In the second aspect, this application also provides a document subject word aggregation device, including: an acquisition unit for acquiring document data, the document data including the document title, document abstract, and each document contained in each document Corresponding citation information; an extraction unit for extracting noun phrases contained in the document title and the document abstract by using a preset natural language processing tool; a clustering unit for extracting noun phrases contained in the document title and the document abstract based on the citation information and the A noun phrase clusters the noun phrase to obtain a set of synonyms; a screening unit is used to filter the target noun phrase with the highest word frequency from the set of synonyms as the subject word of the document.
第三方面,本申请还提供了一种计算机设备,其包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器运行所述计算机程序时执行如下步骤:获取文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息;采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语;基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合;从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词。In a third aspect, the present application also provides a computer device, which includes a memory and a processor, the memory stores a computer program, and the processor executes the following steps when running the computer program: acquiring document data, The document data includes the document title, document abstract, and citation information corresponding to each document; preset natural language processing tools are used to extract the noun phrases contained in the document title and the document abstract Based on the citation information and the noun phrase, cluster the noun phrase to obtain a set of synonyms; select the target noun phrase with the highest word frequency from the set of synonyms as the subject words of the document.
第四方面,本申请还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如下步骤:获取文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息;采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语;基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合;从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词。In a fourth aspect, the present application also provides a computer-readable storage medium, the computer-readable storage medium stores a computer program, and when the computer program is executed by a processor, the processor implements the following steps: Obtain document data , The document data includes the document title, document abstract, and citation information corresponding to each document; the preset natural language processing tool is used to extract the document title and the document abstract. Based on the citation information and the noun phrase, cluster the noun phrase to obtain a set of synonyms; select the target noun phrase with the highest word frequency from the set of synonyms as the subject words of the literature.
本申请实施例通过获取文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息,采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语,基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合,从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词,由于结合了名词短语及引文信息,针对文献挖掘的场景,使用了短语级别的近义词处理方式,且结合了引文信息进行名词短语相似度的表征,相比传统技术中,仅使用单词级别的语义相似度进行表征,同时仅考虑到句子级别的信息,本申请实施例的表征方式充分表征了两个名词短语所代表的主题之间的相似度,从而使聚合后的主题词能够准确描述文献的主题,提高了文献的主题词聚合的准确性。The embodiment of this application obtains document data including the document title, document abstract and citation information corresponding to each document contained in each document, and uses a preset natural language processing tool to obtain the document title and Extracting the noun phrases contained in the document abstract, clustering the noun phrases based on the citation information and the noun phrases to obtain a set of synonyms, and selecting the target with the highest word frequency from the set of synonyms Noun phrases are the subject words of the literature. Due to the combination of noun phrases and citation information, the phrase-level synonym processing method is used for the scene of document mining, and the citation information is combined to represent the similarity of noun phrases. Compared with the traditional technology , Only word-level semantic similarity is used for characterization, while only sentence-level information is considered. The characterization method in the embodiment of this application fully represents the similarity between the topics represented by two noun phrases, so that the aggregated The subject words can accurately describe the subject of the document, which improves the accuracy of the subject word aggregation of the document.
为了更清楚地说明本申请实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to explain the technical solutions of the embodiments of the present application more clearly, the following will briefly introduce the drawings used in the description of the embodiments. Obviously, the drawings in the following description are some embodiments of the present application. Ordinary technicians can obtain other drawings based on these drawings without creative work.
图1为本申请实施例提供的文献主题词聚合方法的一个流程示意图;FIG. 1 is a schematic flowchart of a method for aggregation of document subject words provided by an embodiment of the application;
图2为本申请实施例提供的文献主题词聚合方法中一个子流程的示意图;FIG. 2 is a schematic diagram of a sub-process in the method for document subject word aggregation provided by an embodiment of the application;
图3为本申请实施例提供的文献主题词聚合方法中一个文献共被引网络示例示意图;FIG. 3 is a schematic diagram of an example of a document co-citation network in a document subject word aggregation method provided by an embodiment of the application;
图4为本申请实施例提供的文献主题词聚合方法的另一个子流程示意图;FIG. 4 is a schematic diagram of another sub-flow of the method for document subject word aggregation provided by an embodiment of the application;
图5为本申请实施例提供的文献主题词聚合方法的聚合流程示意图;FIG. 5 is a schematic diagram of an aggregation process of a method for aggregation of document subject words provided by an embodiment of the application; FIG.
图6为本申请实施例提供的文献主题词聚合装置的一个示意性框图;以及Fig. 6 is a schematic block diagram of a document subject word aggregation device provided by an embodiment of the application; and
图7为本申请实施例提供的计算机设备的示意性框图。FIG. 7 is a schematic block diagram of a computer device provided by an embodiment of the application.
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。The technical solutions in the embodiments of the present application will be described clearly and completely in conjunction with the accompanying drawings in the embodiments of the present application. Obviously, the described embodiments are part of the embodiments of the present application, rather than all of them. Based on the embodiments in this application, all other embodiments obtained by those of ordinary skill in the art without creative work shall fall within the protection scope of this application.
请参阅图1,图1为本申请实施例提供的文献主题词聚合方法的一个流程示意图。如图1所示,该方法包括以下步骤S101-S104:Please refer to FIG. 1. FIG. 1 is a schematic flowchart of a method for aggregation of document subject words provided by an embodiment of the application. As shown in Figure 1, the method includes the following steps S101-S104:
S101、获取文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息。S101. Obtain document data, where the document data includes a document title, a document abstract, and citation information corresponding to each document contained in each document.
具体地,可以通过关键字方式从预设数据库中检索出文献所对应的文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息,引文信息为所述文献之间的相互引用关系。针对文献,一般使用Pubmed数据库来检索文献,通过搜索关键词,获取Pubmed数据库中所包含的具体领域的所有文献的文献标题、文献摘要以及文献之间的互相引用的关系,例如通过检索“lung cancer”,下载与肺癌相关的文献的标题、摘要以及引用关系。Specifically, the document data corresponding to the document can be retrieved from the preset database by means of keywords. The document data includes the document title, document abstract and citation information corresponding to each document contained in each document. The citation information is the mutual citation relationship between the documents. For documents, the Pubmed database is generally used to search for documents. By searching keywords, you can obtain the document titles, document abstracts, and mutual citation relationships between documents in a specific field contained in the Pubmed database, for example, by searching for "lung cancer" ", download the titles, abstracts, and citation relationships of articles related to lung cancer.
S102、采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语。S102. Use a preset natural language processing tool to extract noun phrases contained in the document title and the document abstract.
其中,自然语言处理工具包括Stanford nlp、TextBlob及Polyglot等能够提取名词短语的自然语言处理工具。Among them, natural language processing tools include Stanford nlp, TextBlob, Polyglot and other natural language processing tools that can extract noun phrases.
具体地,检索出预设具体领域的所有文献的标题、摘要以及互相引用的关系后,采用预 设自然语言处理工具从标题和摘要中抽取出名词短语,例如使用Stanford core NLP工具中的词性标注,抽取出名词短语,进一步地,还可以使用SciScapy中的缩写检查,将抽取出的名词短语中的缩写词映射成全称,例如,抽出的文献描述为A,最终文献A会被表示成一个短语的集合{P1,P2,P3,…Pn}。Specifically, after retrieving the titles, abstracts, and mutual citation relationships of all documents in a preset specific field, use a preset natural language processing tool to extract noun phrases from the titles and abstracts, such as using part-of-speech tagging in the Stanford core NLP tool , Extract noun phrases, and further, you can use the abbreviation check in SciScapy to map the abbreviations in the extracted noun phrases into full names. For example, the extracted document is described as A, and the final document A will be expressed as a phrase The set {P1, P2, P3,...Pn}.
进一步地,抽取名词短语的具体过程如下:1)采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语,例如使用Stanford nlp抽取出名词短语。2)处理单词短语,可以删除出现词频最高的单词词语,例如删除维基百科语料中出现词频最高的2000个单词中的单词词语,如“cancer”这一短语会被删除,以避免高频率通用词汇影响主题词的聚合。3)检测所述名词短语中是否包含缩写词,若所述名词短语中包含缩写词,根据预设替换词库,将所述缩写词替换为所述缩写词所对应的全称,例如使用SciScapy工具抽取文章出现的缩写与全称,如{QOL:quality of life},将出现的缩写词全部替换成全称,从而得到一个短语集合。Further, the specific process of extracting noun phrases is as follows: 1) Use a preset natural language processing tool to extract noun phrases contained in the document title and the document abstract, for example, use Stanford nlp to extract noun phrases. 2) Processing word phrases, you can delete the words and words with the highest frequency. For example, delete the words and words in the 2000 words with the highest frequency in the Wikipedia corpus. The phrase "cancer" will be deleted to avoid high-frequency general vocabulary. Affect the aggregation of keywords. 3) Detect whether the noun phrase contains an abbreviation, if the noun phrase contains an abbreviation, replace the abbreviation with the full name corresponding to the abbreviation according to the preset replacement dictionary, for example, use the SciScapy tool Extract the abbreviations and full names that appear in the article, such as {QOL:quality of life}, and replace all the abbreviations that appear with the full names to obtain a set of phrases.
S103、基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合。S103. Based on the citation information and the noun phrase, cluster the noun phrase to obtain a set of synonyms.
具体地,根据检索出的文献之间的引文信息,构建文献之间的共被引网络,根据文献之间的共被引网络,得到所述名词短语之间的共被引关系,再获取所述名词短语的语义相似度,从而根据所述名词短语之间的共被引关系及语义相似度,对所述名词短语进行聚类,从而得到近义词集合。Specifically, according to the citation information between the retrieved documents, a co-citation network between the documents is constructed, and the co-citation relationship between the noun phrases is obtained according to the co-citation network between the documents, and then the co-citation relationship between the noun phrases is obtained. Predict the semantic similarity of noun phrases, so as to cluster the noun phrases according to the co-citation relationship and semantic similarity between the noun phrases to obtain a set of synonyms.
S104、从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词。S104. Select the target noun phrase with the highest word frequency from the synonymous word set as the subject word of the document.
具体地,得到近义词集合之后,从近义词集合中筛选出符合要求的目标名词短语,将所述目标名词短语作为文献的主题词,例如,将所述近义词集合中出现频率最高的名词短语作为目标名词短语等,从而得到文献的主题词。Specifically, after the synonym set is obtained, the target noun phrase that meets the requirements is selected from the synonym set, and the target noun phrase is used as the subject word of the document, for example, the noun phrase with the highest frequency in the synonym set is used as the target noun Phrases, etc., to get the subject words of the literature.
在本申请实施例中,由于结合了名词短语及引文信息,针对文献挖掘的场景,使用了短语级别的近义词处理方式,且结合了引文信息进行名词短语相似度的表征,相比传统技术中,仅使用单词级别的语义相似度进行表征,同时仅考虑到句子级别的信息,本申请实施例的表征方式充分表征了两个名词短语所代表的主题之间的相似度,从而使聚合后的主题词能够准确描述文献的主题,提高了文献的主题词聚合的准确性。In the embodiments of this application, since noun phrases and citation information are combined, a phrase-level synonym processing method is used for document mining scenarios, and citation information is combined to characterize the similarity of noun phrases. Compared with traditional technologies, Only word-level semantic similarity is used for characterization, while only sentence-level information is considered. The characterization method of the embodiment of the present application fully represents the similarity between the topics represented by two noun phrases, so that the aggregated topics The word can accurately describe the subject of the document, which improves the accuracy of the subject word aggregation of the document.
请参阅图2,图2为本申请实施例提供的文献主题词聚合方法中一个子流程的示意图。在该实施例中,所述基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合的步骤包括:Please refer to FIG. 2. FIG. 2 is a schematic diagram of a sub-process in the method for aggregation of document subject words provided by an embodiment of the application. In this embodiment, the step of clustering the noun phrases based on the citation information and the noun phrases to obtain a set of synonyms includes:
S201、根据所述名词短语,建立基于所述名词短语的语义相似度。S201. Establish a semantic similarity based on the noun phrase according to the noun phrase.
其中,语义相似度用于描述名词短语之间的语言意思相似性,对于语义相似度可以通过余弦相似度、欧氏距离或者明可夫斯基距离(英文为Minkowski distance)等衡量。Among them, the semantic similarity is used to describe the language meaning similarity between noun phrases, and the semantic similarity can be measured by cosine similarity, Euclidean distance, or Minkowski distance (English: Minkowski distance).
具体地,可以通过将名词短语向量化来计算两个名词短语之间的相似性,将相似性进行量化即可得到两个名词短语之间的相似度。Specifically, the similarity between two noun phrases can be calculated by vectorizing the noun phrase, and the similarity between the two noun phrases can be obtained by quantifying the similarity.
进一步地,所述根据所述名词短语,建立基于所述名词短语的语义相似度的步骤包括:将所述名词短语输入至预设Biobert模型,以得到所述名词短语所对应的语义向量;计算所述语义向量之间的余弦相似度,以得到所述名词短语所对应的语义相似度。Further, the step of establishing a semantic similarity based on the noun phrase according to the noun phrase includes: inputting the noun phrase into a preset Biobert model to obtain the semantic vector corresponding to the noun phrase; and calculating; The cosine similarity between the semantic vectors is used to obtain the semantic similarity corresponding to the noun phrase.
具体地,基于提取的名词短语,建立基于Biobert的语义相似度,使用经预训练的Biobert模型的输出向量表征短语语义,再计算向量之间的余弦相似度,即可得到所述名词短语所对应的语义相似度。其中,Biobert是基于庞大的医学语料训练的Bert模型,可以有效表示医学相关的单词及短语的语义,将提取的名词短语输入Biobert模型,即可获得名词短语级别的语义向量表示,例如将每个名词短语转化为768维向量,即纬度为768维,再使用余弦相似度计算向量之间的相似度,即可以得到短语之间的语义相似度。针对短语级别的数据,可以预先训练基于Biobert模型的深度学习模型,分别表征上下文特征及名词短语本身的语义信息,从而实现在本申请实施例中对主题词进行聚合时,结合短语级别的近义词,通过名词短语级 别的相似度来充分表征两个名词短语所代表的主题之间的相似度,针对短语级别的数据,训练基于预训练Biobert模型的深度学习模型,分别表征上下文特征及短语本身的语义信息,提高了基于共被引信息的抽取的名词短语所对应的语义相似度,提高了进行语义相似度统计的准确性。Specifically, based on the extracted noun phrases, a Biobert-based semantic similarity is established, the output vector of the pre-trained Biobert model is used to represent the semantics of the phrase, and the cosine similarity between the vectors is calculated to obtain the corresponding noun phrase The semantic similarity of. Among them, Biobert is a Bert model trained on a huge medical corpus, which can effectively represent the semantics of medical-related words and phrases. Input the extracted noun phrases into the Biobert model to obtain the semantic vector representation at the noun phrase level. For example, each Noun phrases are transformed into 768-dimensional vectors, that is, the latitude is 768-dimensional, and then the cosine similarity is used to calculate the similarity between the vectors, that is, the semantic similarity between phrases can be obtained. For phrase-level data, a deep learning model based on the Biobert model can be pre-trained to represent contextual features and semantic information of the noun phrase itself, so as to realize the aggregation of topic words in the embodiment of this application, combining phrase-level synonyms, Fully characterize the similarity between the topics represented by two noun phrases through the similarity of the noun phrase level. For phrase-level data, train a deep learning model based on the pre-trained Biobert model to represent the contextual features and the semantics of the phrase itself. Information, which improves the semantic similarity corresponding to noun phrases extracted based on co-citation information, and improves the accuracy of semantic similarity statistics.
S202、基于所述引文信息,构建文献所对应的文献共被引网络。S202: Based on the citation information, construct a document co-citation network corresponding to the document.
S203、根据所述文献共被引网络,计算所述文献所对应的文献共被引相似度。S203: Calculate the co-citation similarity of the documents corresponding to the documents according to the document co-citation network.
其中,共引文献为同时参考了一篇文献,共被引文献就是同时被一篇文献所参考,共被引为共同被引用。Among them, co-cited documents refer to a document at the same time, and co-cited documents are referred to by a document at the same time, and co-cited as co-cited.
具体地,获取文献的引文信息后,根据文献之间的引用关系,即可构建所对应的文献引用关系网络,从被引用的文献角度来看,即为文献被引网络,若为多篇文献之间的共同被引用网络,即为文献共被引网络。Specifically, after obtaining the citation information of the literature, based on the citation relationship between the documents, the corresponding literature citation relationship network can be constructed. From the perspective of the cited literature, it is the literature cited network. If it is multiple documents The co-cited network among the documents is the document co-cited network.
在科学计量分析中,被同一篇文章引用的两篇文章具有一定的主题相似性,请参阅图3,图3为本申请实施例提供的文献主题词聚合方法中一个文献共被引网络示例示意图,如图3所示,图中3的A和B均被C引用,则A和B之间具有主题相似性,因此,可以构建引用A和B的共被引网络以得到A和B之间的相似性,如图3中,构建引用文献A的CDE的共被引网络。若构建的共被引网络由A1,A2,…,Am组成,其中文献A1,A2,…,Am为节点,边的权重为两个节点之间的共被引相似度(例如,节点为A1和A2的两篇文献,两篇文献A1和A2由于共同引用了同一篇文献而存在引用交集,可以以此衡量A1和A2两者之间的相似度,如图3中,A被CDE引用,B被CD引用,AB共同被CD引用,计算AB被CD共同引用,所以AB两者之间存在的相似度,衡量两者之间的相似度的统计称为共被引相似度),计算公式如下:In scientometric analysis, two articles cited by the same article have a certain topic similarity. Please refer to Figure 3. Figure 3 is a schematic diagram of a document co-citation network example in the document keyword aggregation method provided by the embodiment of this application. As shown in Figure 3, A and B in Figure 3 are both cited by C, and there is a similarity between A and B. Therefore, a co-citation network citing A and B can be constructed to obtain the relationship between A and B. As shown in Figure 3, the co-citation network of CDE cited in Document A is constructed. If the constructed co-citation network consists of A1, A2,..., Am, where documents A1, A2,..., Am are nodes, the weight of the edge is the co-citation similarity between the two nodes (for example, the node is A1 The two documents of A1 and A2, the two documents A1 and A2 cite the same document and there is a citation intersection, which can be used to measure the similarity between A1 and A2. As shown in Figure 3, A is cited by CDE. B is cited by CD and AB is cited by CD. Calculate the similarity between AB and CD, so the similarity between AB is calculated. The statistical measure of the similarity between the two is called co-cited similarity), the calculation formula as follows:

其中,M与N分别代表引用了文献i和引用了文献j的文献集。以图3为例,在图3中,共包含五篇文献ABCDE,其中,箭头指向的方向表示引用关系,AB之间的虚线用于描述AB为共被引对象,例如,箭头C至A表示文献C引用了文献A,可知,在图3中,CDE三篇文献均引用了文献A,A的施引文献集为{C,D,E},同理可得,B的施引文献集为{C,D},AB之间的共被引相似度为:Among them, M and N represent the collection of documents citing document i and document j, respectively. Take Fig. 3 as an example. In Fig. 3, there are a total of five documents ABCDE, in which the direction of the arrow indicates the citation relationship, and the dotted line between AB is used to describe AB as a co-cited object, for example, arrows C to A indicate Document C quotes document A. It can be seen that in Figure 3, the three CDE documents all quote document A, and the citing document set of A is {C, D, E}, the same can be obtained, the citing document set of B Is {C, D}, the co-citation similarity between AB is:

S204、根据所述文献共被引相似度,构建所述名词短语所对应的短语共被引相似度网络。S204: According to the document co-citation similarity, construct a phrase co-citation similarity network corresponding to the noun phrase.
S205、根据所述短语共被引相似度网络,得到所述名词短语所对应的短语共被引相似度。S205: According to the phrase co-citation similarity network, obtain the phrase co-citation similarity corresponding to the noun phrase.
S206、根据所述短语共被引相似度及所述语义相似度,对所述名词短语进行聚类,以得到近义词集合。S206. Cluster the noun phrases according to the co-citation similarity of the phrases and the semantic similarity to obtain a set of synonyms.
具体地,构建文献被共引网络后,通过文献共被引相似度,基于文献的引用关系和抽取出的名词短语,通过名词短语用于描述该文献,即可以建立名词短语共被引相似度默认文献i和自身的共被引相似度为1,使用文献共被引相似度表征文献所对应的抽取的名词短语之间的相似度,计算公式如下:Specifically, after constructing a document co-citation network, based on the document co-citation similarity, based on the citation relationship of the document and the extracted noun phrases, the noun phrase is used to describe the document, that is, the noun phrase co-citation similarity can be established The default co-citation similarity between document i and itself is 1. The co-citation similarity of the document is used to characterize the similarity between the extracted noun phrases corresponding to the document. The calculation formula is as follows:

其中,X,Y分别表示包含短语x,y的文献集合,至此,可以得到一个短语之间的共被引相似度网络,根据所述短语共被引相似度网络,即得到所述名词短语所对应的短语共被引相似度,再根据所述短语共被引相似度及所述语义相似度,对所述名词短语进行聚类,以得到近义词集合,本申请实施例引入基于文献共被引相似度的短语共被引相似度,可以更好地学习到短语细分领域的专业知识,可以更好地表示主题之间的相似度。Among them, X and Y respectively represent the collection of documents containing phrases x and y. So far, a co-citation similarity network between phrases can be obtained. According to the phrase co-citation similarity network, the noun phrase is obtained. Corresponding phrase co-citation similarity, and then based on the phrase co-citation similarity and the semantic similarity, clustering the noun phrases to obtain a set of synonyms, the embodiment of this application introduces based on the document co-citation Phrases with similarity are cited as similarity, which can better learn the professional knowledge in the field of phrase segmentation, and can better express the similarity between topics.
进一步地,请参阅图4,图4为本申请实施例提供的文献主题词聚合方法的另一个子流 程示意图。在该实施例中,所述根据所述短语共被引相似度及所述语义相似度,对所述名词短语进行聚类,以得到近义词集合的步骤之前,还包括:Further, please refer to FIG. 4, which is a schematic diagram of another sub-process of the method for aggregation of document subject words provided by an embodiment of the application. In this embodiment, before the step of clustering the noun phrases according to the phrase co-citation similarity and the semantic similarity to obtain a set of synonyms, the method further includes:
S401、基于所述短语共被引相似度网络,采用预设社团检测方式进行社团检测,以得到若干个短语社团。S401: Based on the phrase co-citation similarity network, perform community detection using a preset community detection method to obtain several phrase communities.
其中,社团检测,又称为社区检测,英文为Community Detection,通常为将网络中联系紧密的部分找出来,这些部分就称之为社团,那么也可以认为社团内部联系稠密,而社团之间联系稀疏,社团检测算法包括Louvain算法、Newman快速算法、CNM算法及MSG-MV算法等。Among them, community detection, also known as community detection, English is Community Detection, usually finds out the closely connected parts of the network, these parts are called communities, then it can also be considered that the internal connections of the communities are dense, and the connections between the communities Sparse, community detection algorithms include Louvain algorithm, Newman fast algorithm, CNM algorithm and MSG-MV algorithm.
具体地,基于所述短语共被引相似度网络,通过预设社团检测算法进行社团检测,从而将短语根据相似度网络进行聚类,从而得到若干个社团,每个社团中包含有近似词,例如,使用社团检测,将短语共被引网络聚类成一个个小社团,使用Louvain社团检测算法,将得到的短语共被引相似度网络进行社团挖掘,最终得到一系列的社团(Cluster),默认近似词出现在同一社团中,从而在本申请实施例中,将社团检测结合到本申请实施例中的名词短语聚类中,将抽取的名词短语通过社团检测进行初步聚类,从而基于得到的短语共被引相似度网络,采用预设社团检测方式进行社团检测,以得到一系列社团,再对每个社团进行层次聚类,获得近义词集合,由于结合了引文信息和语义信息两类信息的近义词,构建基于共被引信息的短语相似度网络,实现将社团检测用到短语相似度网络,使用社团检测的算法,将近义词先进行候选集合召回,可以极大地降低聚类部的计算量,同时不依赖标注数据和特定语料,具有很好的通用性,更加符合主题挖掘这一场景,提高了主题词筛选的准确性。Specifically, based on the phrase co-citation similarity network, community detection is performed through a preset community detection algorithm, so that phrases are clustered according to the similarity network to obtain several communities, and each community contains similar words. For example, using community detection, the phrase co-citation network is clustered into small communities, and the Louvain community detection algorithm is used to perform community mining on the obtained phrase co-citation similarity network, and finally a series of communities (Clusters) are obtained. The default similar words appear in the same community, so in this embodiment of the application, the community detection is combined with the noun phrase clustering in the embodiment of this application, and the extracted noun phrases are initially clustered through the community detection, so as to obtain The phrase co-citation similarity network of the phrase is used to perform community detection using the preset community detection method to obtain a series of communities, and then perform hierarchical clustering of each community to obtain a set of synonyms, due to the combination of citation information and semantic information. Synonyms of, construct a phrase similarity network based on co-citation information, and realize the use of phrase similarity network for community detection. Using the community detection algorithm, the candidate set of synonyms is recalled first, which can greatly reduce the calculation amount of the clustering department. At the same time, it does not rely on annotated data and specific corpus, has good versatility, is more in line with the scene of topic mining, and improves the accuracy of topic word screening.
进一步地,所述根据所述短语共被引相似度及所述语义相似度,对所述名词短语进行聚类,以得到近义词集合的步骤包括:Further, the step of clustering the noun phrases according to the co-citation similarity of the phrases and the semantic similarity to obtain a set of synonyms includes:
S402、根据所述名词短语所对应的短语共被引相似度,对所述短语社团进行聚类,以得到第一聚类;S403、根据所述短语所对应的所述语义相似度,对所述短语社团进行聚类,以得到第二聚类;S404、判断每两个所述名词短语是否均包含于所述第一聚类和所述第二聚类;S405、若每两个所述名词短语均包含于所述第一聚类和所述第二聚类,判定该两个所述名词短语为近义词,从而得到近义词短语;S406、若每两个所述名词短语未均包含于所述第一聚类和所述第二聚类,判定该两个所述名词短语不为近义词;S407、将所有所述近义词短语组合成集合以得到近义词集合。S402. Cluster the phrase community according to the co-citation similarity of the phrases corresponding to the noun phrase to obtain a first cluster; S403, perform a comparison of the semantic similarity corresponding to the phrase. Clustering the predicate phrase community to obtain a second cluster; S404. Determine whether every two of the noun phrases are included in the first cluster and the second cluster; S405, if every two of the noun phrases are included in the first cluster and the second cluster; Noun phrases are included in the first cluster and the second cluster, and the two noun phrases are determined to be synonyms, so as to obtain the synonym phrases; S406, if every two of the noun phrases are not included in all the noun phrases. According to the first cluster and the second cluster, it is determined that the two noun phrases are not synonymous words; S407. Combine all the synonymous word phrases into a set to obtain a synonymous word set.
其中,聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。聚类(Cluster)分析是由若干模式(Pattern)组成的,通常,模式是一个度量(Measurement)的向量,或者是多维空间中的一个点。聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。聚类算法包括K-means聚类算法、Mean-Shift聚类及基于高斯混合模型(GMM)的期望最大化(EM)聚类。Among them, cluster analysis is also called cluster analysis. It is a statistical analysis method for studying (sample or index) classification problems, and it is also an important algorithm for data mining. Cluster analysis is composed of several patterns. Usually, a pattern is a vector of measurement, or a point in a multi-dimensional space. Cluster analysis is based on similarity, and there are more similarities between patterns in a cluster than patterns that are not in the same cluster. Clustering algorithms include K-means clustering algorithm, Mean-Shift clustering and Expectation Maximization (EM) clustering based on Gaussian Mixture Model (GMM).
具体地,通过社团检测对所述短语共被引相似度网络进行聚类后,再对每个社团进行层次聚类,以近义词只会出现在同一社团内的假设,对每个社团内短语分别使用短语共被引相似度和语义相似度分别进行层次聚类,可以设置层次聚类的阈值,同时在两种聚类中均被聚在一起的,被认为是近义词。对于每个社团,分别进行两种从下而上的层次聚类,一是以名词短语共被引相似度为相似度进行聚类,二是以提到的语义相似度进行聚类,例如基于Biobert的语义相似度为标准进行聚类,其中,这里使用从下而上的层次聚类,最终分析两个名词短语是否为近义词的依据是,若在两种类型的聚类中,均被聚类在一起,判定该两个名词短语为近义词,请参阅图5,图5为本申请实施例提供的文献主题词聚合方法的聚合流程示例示意图,如图5所示,白色圆圈代表同一文献中提取的名词短语,黑色圆圈代表另同一文献中提取出的名词短语,灰色圆圈代表第三文献中提取出的名词短语,不同的白色圆圈、黑色圆圈及灰色圆圈分别代表不同的名词短语,由于A和B在两次层次聚类中均被聚在了一起,因此,A和B可以合并为近义词。Specifically, after clustering the phrase co-citation similarity network through community detection, hierarchical clustering is performed on each community, assuming that synonyms will only appear in the same community, and each phrase in each community is separately clustered. Using phrase co-citation similarity and semantic similarity to perform hierarchical clustering separately, you can set the threshold of hierarchical clustering, and at the same time, the words that are clustered together in both clusters are considered as synonyms. For each community, two types of bottom-up hierarchical clustering are carried out, one is clustering based on the co-citation similarity of noun phrases, and the other is clustering based on the mentioned semantic similarity, for example based on Biobert’s semantic similarity is used as the standard for clustering. Here, bottom-up hierarchical clustering is used here. The basis for the final analysis of whether two noun phrases are synonyms is that if in both types of clusters, both are clustered. To determine the two noun phrases as synonyms, please refer to Figure 5. Figure 5 is a schematic diagram of an example of the aggregation process of the document subject word aggregation method provided by an embodiment of the application. As shown in Figure 5, the white circles represent the same document The extracted noun phrase, the black circle represents the noun phrase extracted from the same document, the gray circle represents the noun phrase extracted from the third document, and the different white circles, black circles and gray circles represent different noun phrases, because A A and B are clustered together in the two hierarchical clusters. Therefore, A and B can be combined into synonyms.
在本申请实施例中,针对某一细分领域的文献主题挖掘遇到的同义及近义主题词,提出了结合引文信息和语义信息两类信息的近义词挖掘,构建基于共被引信息的短语相似度网络,根据所述名词短语所对应的短语共被引相似度,对所述短语社团进行聚类,并且根据所述短语所对应的所述语义相似度,对所述短语社团进行聚类,首次将社团检测用到短语相似度网络中,召回可能的近义词集合,极大地缩小了近义词候选范围。In the embodiment of this application, for the synonymous and similar subject words encountered in document subject mining in a certain subdivision field, a synonym mining combining two types of information of citation information and semantic information is proposed to construct a co-citation information-based approach. The phrase similarity network clusters the phrase community based on the co-cited similarity of the phrases corresponding to the noun phrase, and clusters the phrase community based on the semantic similarity corresponding to the phrase. For the first time, the community detection is used in the phrase similarity network to recall the set of possible synonyms, which greatly reduces the candidate range of synonyms.
若每两个所述名词短语均包含于两种类型的聚类中,判定该两个所述名词短语为近义词,可以进行合并,以得到近义词集合,分别使用语义相似度及共被引相似度进行聚类,而不是使用惯用的不同相似度加权相加的策略,避免了相似度权重对结果的影响,保证了得到的近义词可以同时具有相似的语义和相似的主题,不依赖标注数据和特定语料,具有很好的通用性,更加符合主题挖掘这一场景,提高了主题词筛选的准确性,If every two of the noun phrases are included in two types of clusters, it is determined that the two noun phrases are synonyms, and can be combined to obtain a set of synonyms, using semantic similarity and co-citation similarity respectively Clustering, instead of using the usual strategy of weighted addition of different similarities, avoids the influence of similarity weights on the results, and ensures that the obtained synonyms can have similar semantics and similar topics at the same time, without relying on labeled data and specific The corpus has good versatility, is more in line with the scene of topic mining, and improves the accuracy of topic word selection.
在一实施例中,所述从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词的步骤包括:根据预设TF-IDF算法,从所述近义词集合中筛选出TF-IDF值最高的名词短语作为目标名词短语;将所述目标名词短语作为文献的主题词。In one embodiment, the step of selecting the target noun phrase with the highest word frequency from the synonym set as the subject word of the document includes: selecting TF-IDF from the synonym set according to a preset TF-IDF algorithm. The noun phrase with the highest IDF value is used as the target noun phrase; the target noun phrase is used as the subject word of the document.
其中,其中,TF-IDF,英文为Term frequency–inverse document frequency,是一种常用加权方法。在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的次数,这个数字通常会被归一化(分子一般小于分母区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。Among them, TF-IDF, the English term frequency-inverse document frequency, is a commonly used weighting method. In a given document, term frequency (TF) refers to the number of times a given word appears in the document. This number is usually normalized (the numerator is generally smaller than the denominator, which distinguishes it from IDF) To prevent it from favoring long files. (The same word may have a higher word frequency in a long document than in a short document, regardless of the importance of the word.) Inverse document frequency (IDF) is a measure of the universal importance of a word. The IDF of a particular word can be obtained by dividing the total number of documents by the number of documents containing the word, and then taking the logarithm of the obtained quotient. A high word frequency in a particular document and a low document frequency of the word in the entire document collection can produce a high-weight TF-IDF. Therefore, TF-IDF tends to filter out common words and keep important words.
具体地,对于得到的近义词集合,计算TF-IDF值,并选取TF-IDF值最高的短语作为标准的主题词。Specifically, for the obtained set of synonyms, the TF-IDF value is calculated, and the phrase with the highest TF-IDF value is selected as the standard subject word.
进一步地,如果可以对文献的重要程度打分,可以使用加权的TF-IDF值,比如使用文献的被引量作为文献的重要性指标,标准化到0-1之后作为文献的重要程度。对于每个短语,重要程度等于该短语出现的所有文献的重要程度的均值,再乘以短语的TF-IDF,作为每个短语最终的TF-IDF值。Further, if the importance of the literature can be scored, a weighted TF-IDF value can be used. For example, the cited amount of the literature is used as the importance index of the literature, and the importance of the literature is standardized to 0-1. For each phrase, the importance is equal to the average value of the importance of all documents in which the phrase appears, and then multiplied by the TF-IDF of the phrase, as the final TF-IDF value of each phrase.
在本申请实施例中,基于得到的短语共被引相似度网络,采用预设社团检测方式进行社团检测,以得到一系列社团,对每个社团进行层次聚类,选取获得的近义词集合中,TF-IDF值最大的短语作为标准主题词,由于结合了引文信息和语义信息两类信息的近义词,构建基于共被引信息的短语相似度网络,首次将社团检测用到短语相似度网络,保证了得到的近义词可以同时具有相似的语义和相似的主题,更加符合主题挖掘这一场景,不依赖标注数据和特定语料,具有很好的通用性,提高了主题词筛选的准确性,In the embodiment of this application, based on the obtained phrase co-citation similarity network, a preset community detection method is used to perform community detection to obtain a series of communities, hierarchical clustering is performed on each community, and the obtained synonymous word set is selected, The phrase with the largest TF-IDF value is used as the standard subject word. As the synonymous words of two types of information are combined with citation information and semantic information, a phrase similarity network based on co-citation information is constructed, and the phrase similarity network is used for community detection for the first time. The obtained synonyms can have similar semantics and similar topics at the same time, which is more in line with the topic mining scenario, does not rely on labeled data and specific corpus, has good versatility, and improves the accuracy of topic word selection.
需要说明的是,上述各个实施例所述的文献主题词聚合方法,可以根据需要将不同实施例中包含的技术特征重新进行组合,以获取组合后的实施方案,但都在本申请要求的保护范围之内。It should be noted that the document subject word aggregation methods described in the above embodiments can recombine the technical features contained in different embodiments as needed to obtain combined implementation schemes, but they are all protected by this application. Within range.
请参阅图6,图6为本申请实施例提供的文献主题词聚合装置的一个示意性框图。对应于上述所述文献主题词聚合方法,本申请实施例还提供一种文献主题词聚合装置。如图6所示,该文献主题词聚合装置包括用于执行上述所述文献主题词聚合方法的单元,该文献主题词聚合装置可以被配置于计算机设备中。具体地,请参阅图6,该文献主题词聚合装置600包括获取单元601、提取单元602、聚类单元603及筛选单元604。Please refer to FIG. 6. FIG. 6 is a schematic block diagram of a document subject word aggregation device provided by an embodiment of the application. Corresponding to the above-mentioned document subject word aggregation method, an embodiment of the present application also provides a document subject word aggregation device. As shown in FIG. 6, the document topic word aggregation device includes a unit for executing the above-mentioned document topic word aggregation method, and the document topic word aggregation device may be configured in a computer device. Specifically, referring to FIG. 6, the document subject
其中,获取单元601,用于获取文献数据,所述文献数据包括每篇文献所包含的文献标题、文献摘要及所述每篇文献所对应的引文信息;提取单元602,用于采用预设自然语言处理工具从所述文献标题和所述文献摘要中提取所包含的名词短语;聚类单元603,用于基于所述引文信息及所述名词短语,对所述名词短语进行聚类,以得到近义词集合;筛选单元604,用于从所述近义词集合中筛选出词频频率最高的目标名词短语作为文献的主题词。Wherein, the acquiring
在一实施例中,所述聚类单元603包括:建立子单元,用于根据所述名词短语,建立基于所述名词短语的语义相似度;第一构建子单元,用于基于所述引文信息,构建文献所对应的文献共被引网络;第一计算子单元,用于根据所述文献共被引网络,计算所述文献所对应的文献共被引相似度;第二构建子单元,用于根据所述文献共被引相似度,构建所述名词短语所对应的短语共被引相似度网络;第一获取子单元,用于根据所述短语共被引相似度网络,得到所述名词短语所对应的短语共被引相似度;第一聚类子单元,用于根据所述短语共被引相似度及所述语义相似度,对所述名词短语进行聚类,以得到近义词集合。In one embodiment, the
在一实施例中,所述建立子单元包括:输入子单元,用于将所述名词短语输入至预设Biobert模型,以得到所述名词短语所对应的语义向量;第二计算子单元,用于计算所述语义向量之间的余弦相似度,以得到所述名词短语所对应的语义相似度。In one embodiment, the establishment subunit includes: an input subunit for inputting the noun phrase into a preset Biobert model to obtain the semantic vector corresponding to the noun phrase; a second calculation subunit, using To calculate the cosine similarity between the semantic vectors to obtain the semantic similarity corresponding to the noun phrase.
在一实施例中,所述文献主题词聚合装置600还包括:检测单元,用于基于所述短语共被引相似度网络,采用预设社团检测方式进行社团检测,以得到若干个短语社团;In an embodiment, the document topic
所述第一聚类子单元包括:第二聚类子单元,用于根据所述名词短语所对应的短语共被引相似度,对所述短语社团进行聚类,以得到第一聚类;第三聚类子单元,用于根据所述短语所对应的所述语义相似度,对所述短语社团进行聚类,以得到第二聚类;判断子单元,用于判断每两个所述名词短语是否均包含于所述第一聚类和所述第二聚类;判定子单元,用于若每两个所述名词短语均包含于所述第一聚类和所述第二聚类,判定该两个所述名词短语为近义词,从而得到近义词短语;组合子单元,用于将所有所述近义词短语组合成集合以得到近义词集合。The first clustering subunit includes: a second clustering subunit, configured to cluster the phrase community according to the co-citation similarity of the phrases corresponding to the noun phrase to obtain the first cluster; The third clustering subunit is used to cluster the phrase community according to the semantic similarity corresponding to the phrase to obtain the second cluster; the judgment subunit is used to judge every two of the Whether noun phrases are both included in the first cluster and the second cluster; a determination subunit for determining if every two of the noun phrases are included in the first cluster and the second cluster , Determine that the two noun phrases are synonymous words, thereby obtaining synonymous word phrases; the combination subunit is used to combine all the synonymous word phrases into a set to obtain a synonymous word set.
在一实施例中,所述筛选单元604包括:筛选子单元,用于根据预设TF-IDF算法,从所述近义词集合中筛选出TF-IDF值最高的名词短语作为目标名词短语;第二获取子单元,用于将所述目标名词短语作为文献的主题词。In an embodiment, the screening unit 604 includes: a screening subunit, configured to select a noun phrase with the highest TF-IDF value from the set of synonyms according to a preset TF-IDF algorithm as a target noun phrase; second The acquiring subunit is used to use the target noun phrase as the subject word of the document.
需要说明的是,所属领域的技术人员可以清楚地了解到,上述文献主题词聚合装置和各单元的具体实现过程,可以参考前述方法实施例中的相应描述,为了描述的方便和简洁,在此不再赘述。It should be noted that those skilled in the art can clearly understand that the specific implementation process of the above-mentioned document subject word aggregation device and each unit can refer to the corresponding description in the foregoing method embodiment. For the convenience and brevity of the description, No longer.
同时,上述文献主题词聚合装置中各个单元的划分和连接方式仅用于举例说明,在其他实施例中,可将文献主题词聚合装置按照需要划分为不同的单元,也可将文献主题词聚合装置中各单元采取不同的连接顺序和方式,以完成上述文献主题词聚合装置的全部或部分功能。At the same time, the division and connection of the various units in the above-mentioned document topic word aggregation device are only for illustration. In other embodiments, the document topic word aggregation device can be divided into different units as needed, or the document topic words can be aggregated. Each unit in the device adopts different connection sequences and methods to complete all or part of the functions of the above-mentioned document subject word aggregation device.
上述文献主题词聚合装置可以实现为一种计算机程序的形式,该计算机程序可以在如图7所示的计算机设备上运行。The above-mentioned document subject word aggregation apparatus may be implemented in the form of a computer program, and the computer program may run on the computer device as shown in FIG. 7.
请参阅图7,图7是本申请实施例提供的一种计算机设备的示意性框图。该计算机设备700可以是台式机电脑或者服务器等计算机设备,也可以是其他设备中的组件或者部件。Please refer to FIG. 7, which is a schematic block diagram of a computer device according to an embodiment of the present application. The
参阅图7,该计算机设备700包括通过系统总线701连接的处理器702、存储器和网络接口705,其中,存储器可以包括非易失性存储介质703和内存储器704。Referring to FIG. 7, the
该非易失性存储介质703可存储操作系统7031和计算机程序7032。该计算机程序7032被执行时,可使得处理器702执行一种上述文献主题词聚合方法。The
该处理器702用于提供计算和控制能力,以支撑整个计算机设备700的运行。The
该内存储器704为非易失性存储介质703中的计算机程序7032的运行提供环境,该计算机程序7032被处理器702执行时,可使得处理器702执行一种上述文献主题词聚合方法。The
该网络接口705用于与其它设备进行网络通信。本领域技术人员可以理解,图7中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备700的限定,具体的计算机设备700可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。例如,在一些实施例中,计算机设备可以仅包括存储器及处理器,在这样的实施例中,存储器及处理器的结构及功能与图7所示实施例一致,在此不再赘述。The
其中,所述处理器702用于运行存储在存储器中的计算机程序7032,以实现本申请实施 例所描述的文献主题词聚合方法。Wherein, the
应当理解,在本申请实施例中,处理器702可以是中央处理单元(Central Processing Unit,CPU),该处理器702还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。其中,通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。It should be understood that, in this embodiment of the application, the
本领域普通技术人员可以理解的是实现上述实施例的方法中的全部或部分流程,是可以通过计算机程序来完成,该计算机程序可存储于一计算机可读存储介质。该计算机程序被该计算机系统中的至少一个处理器执行,以实现上述方法的实施例的流程步骤。A person of ordinary skill in the art can understand that all or part of the processes in the methods of the foregoing embodiments can be implemented by a computer program, and the computer program can be stored in a computer-readable storage medium. The computer program is executed by at least one processor in the computer system to implement the process steps of the foregoing method embodiment.
因此,本申请实施例还提供一种计算机可读存储介质。该计算机可读存储介质可以为非易失性的计算机可读存储介质,也可以为易失性的计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时使处理器执行以上各实施例中所描述的所述文献主题词聚合方法的步骤。Therefore, the embodiment of the present application also provides a computer-readable storage medium. The computer-readable storage medium may be a non-volatile computer-readable storage medium, or may be a volatile computer-readable storage medium, the computer-readable storage medium stores a computer program, and the computer program is executed by the processor At this time, the processor is made to execute the steps of the method for aggregation of the document subject words described in the above embodiments.
所述存储介质为实体的、非瞬时性的存储介质,例如可以是U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、磁碟或者光盘等各种可以存储计算机程序的实体存储介质。The storage medium is a physical, non-transitory storage medium, such as a U disk, a mobile hard disk, a read-only memory (Read-Only Memory, ROM), a magnetic disk, or an optical disk, etc., which can store computer programs. medium.
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。A person of ordinary skill in the art may be aware that the units and algorithm steps of the examples described in the embodiments disclosed herein can be implemented by electronic hardware, computer software, or a combination of both, in order to clearly illustrate the hardware and software Interchangeability, in the above description, the composition and steps of each example have been generally described in accordance with the function. Whether these functions are executed by hardware or software depends on the specific application and design constraint conditions of the technical solution. Professionals and technicians can use different methods for each specific application to implement the described functions, but such implementation should not be considered beyond the scope of this application.
以上所述,仅为本申请的具体实施方式,但本申请明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以权利要求的保护范围为准。The above are only specific implementations of this application, but the scope of protection stated in this application is not limited to this. Any person skilled in the art can easily think of various equivalents within the technical scope disclosed in this application. Modifications or replacements, these modifications or replacements shall be covered within the scope of protection of this application. Therefore, the protection scope of this application shall be subject to the protection scope of the claims.
Claims (20)
Translated fromChineseApplications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010744556.7 | 2020-07-29 | ||
| CN202010744556.7ACN111898366B (en) | 2020-07-29 | 2020-07-29 | Document subject word aggregation method and device, computer equipment and readable storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021139262A1true WO2021139262A1 (en) | 2021-07-15 |
Family
ID=73182439
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2020/118699CeasedWO2021139262A1 (en) | 2020-07-29 | 2020-09-29 | Document mesh term aggregation method and apparatus, computer device, and readable storage medium |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN111898366B (en) |
| WO (1) | WO2021139262A1 (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113705217A (en)* | 2021-09-01 | 2021-11-26 | 国网江苏省电力有限公司电力科学研究院 | Literature recommendation method and device for knowledge learning in power field |
| CN114528390A (en)* | 2022-02-22 | 2022-05-24 | 黄河勘测规划设计研究院有限公司 | Yellow river basin evolution analysis method based on text mining |
| CN115658851A (en)* | 2022-12-27 | 2023-01-31 | 药融云数字科技(成都)有限公司 | Medical literature retrieval method, system, storage medium and terminal based on theme |
| CN116975281A (en)* | 2023-06-26 | 2023-10-31 | 华侨大学 | Topic detection method and device based on BERT model and seed LDA model |
| CN117391073A (en)* | 2023-09-22 | 2024-01-12 | 北京工业大学 | Document identification method, device, electronic equipment and storage medium |
| CN118069851A (en)* | 2024-04-18 | 2024-05-24 | 中国标准化研究院 | Intelligent document information intelligent classification retrieval method and system |
| CN118797027A (en)* | 2024-07-03 | 2024-10-18 | 吉林师范大学 | A method for processing English text data based on data analysis |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112667810B (en)* | 2020-12-25 | 2024-07-23 | 平安科技(深圳)有限公司 | Document clustering, device, electronic equipment and storage medium |
| CN114691861A (en)* | 2020-12-28 | 2022-07-01 | 北京市博汇科技股份有限公司 | Topic clustering method based on subject term semantic similarity |
| CN113111180B (en)* | 2021-03-22 | 2022-01-25 | 杭州祺鲸科技有限公司 | Chinese medical synonym clustering method based on deep pre-training neural network |
| CN113392072B (en)* | 2021-06-25 | 2022-08-02 | 中国标准化研究院 | Standard knowledge service method, device, electronic equipment and storage medium |
| CN113704412B (en)* | 2021-08-31 | 2023-05-02 | 交通运输部科学研究院 | Early identification method for revolutionary research literature in transportation field |
| CN113806237B (en)* | 2021-11-18 | 2022-03-08 | 杭州费尔斯通科技有限公司 | Language understanding model evaluation method and system based on dictionary |
| CN114201962B (en)* | 2021-12-03 | 2023-07-25 | 中国中医科学院中医药信息研究所 | Method, device, medium and equipment for analyzing paper novelty |
| CN115017315A (en)* | 2022-06-09 | 2022-09-06 | 北京市科学技术研究院 | A cutting-edge subject identification method, system and computer equipment |
| CN115713085B (en)* | 2022-10-31 | 2023-11-07 | 北京市农林科学院 | Method and device for analyzing literature topic content |
| CN116644338B (en)* | 2023-06-01 | 2024-01-30 | 北京智谱华章科技有限公司 | Document subject classification method, device, equipment and media based on hybrid similarity |
| CN118052225A (en)* | 2024-02-28 | 2024-05-17 | 中国科学院文献情报中心 | Method, device, equipment and medium for extracting research question phrases |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110295903A1 (en)* | 2010-05-28 | 2011-12-01 | Drexel University | System and method for automatically generating systematic reviews of a scientific field |
| CN105956130A (en)* | 2016-05-09 | 2016-09-21 | 浙江农林大学 | Multi-information fusion scientific research literature theme discovering and tracking method and system thereof |
| CN110020034A (en)* | 2018-06-29 | 2019-07-16 | 程宇镳 | A kind of information citation analysis method and system |
| CN110349632A (en)* | 2019-06-28 | 2019-10-18 | 广州序科码生物技术有限责任公司 | A method of from PubMed document screening-gene keyword |
| CN111143511A (en)* | 2019-12-16 | 2020-05-12 | 北京工业大学 | Emerging technology prediction method, emerging technology prediction device, electronic equipment and medium |
| CN111259156A (en)* | 2020-02-18 | 2020-06-09 | 北京航空航天大学 | A Time Series Oriented Hotspot Clustering Method |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6978274B1 (en)* | 2001-08-31 | 2005-12-20 | Attenex Corporation | System and method for dynamically evaluating latent concepts in unstructured documents |
| JP4462014B2 (en)* | 2004-11-15 | 2010-05-12 | 日本電信電話株式会社 | Topic word combination method, apparatus, and program |
| JP5474704B2 (en)* | 2010-08-16 | 2014-04-16 | Kddi株式会社 | Binary relation classification program, method, and apparatus for classifying semantically similar situation pairs into binary relations |
| CN106897436B (en)* | 2017-02-28 | 2018-08-07 | 北京邮电大学 | A kind of academic research hot keyword extracting method inferred based on variation |
| CN109117436A (en)* | 2017-06-26 | 2019-01-01 | 上海新飞凡电子商务有限公司 | Synonym automatic discovering method and its system based on topic model |
| CN108920454A (en)* | 2018-06-13 | 2018-11-30 | 北京信息科技大学 | A kind of theme phrase extraction method |
| US20200117751A1 (en)* | 2018-10-10 | 2020-04-16 | Twinword Inc. | Context-aware computing apparatus and method of determining topic word in document using the same |
| CN110321553B (en)* | 2019-05-30 | 2023-01-17 | 平安科技(深圳)有限公司 | Short text topic identification method and device and computer readable storage medium |
| CN110489745B (en)* | 2019-07-31 | 2020-12-22 | 北京大学 | Paper text similarity detection method based on citation network |
| CN110851602A (en)* | 2019-11-13 | 2020-02-28 | 精硕科技(北京)股份有限公司 | Method and device for topic clustering |
| CN111079422B (en)* | 2019-12-13 | 2023-07-14 | 北京小米移动软件有限公司 | Keyword extraction method, device and storage medium |
- 2020
- 2020-07-29CNCN202010744556.7Apatent/CN111898366B/enactiveActive
- 2020-09-29WOPCT/CN2020/118699patent/WO2021139262A1/ennot_activeCeased
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110295903A1 (en)* | 2010-05-28 | 2011-12-01 | Drexel University | System and method for automatically generating systematic reviews of a scientific field |
| CN105956130A (en)* | 2016-05-09 | 2016-09-21 | 浙江农林大学 | Multi-information fusion scientific research literature theme discovering and tracking method and system thereof |
| CN110020034A (en)* | 2018-06-29 | 2019-07-16 | 程宇镳 | A kind of information citation analysis method and system |
| CN110349632A (en)* | 2019-06-28 | 2019-10-18 | 广州序科码生物技术有限责任公司 | A method of from PubMed document screening-gene keyword |
| CN111143511A (en)* | 2019-12-16 | 2020-05-12 | 北京工业大学 | Emerging technology prediction method, emerging technology prediction device, electronic equipment and medium |
| CN111259156A (en)* | 2020-02-18 | 2020-06-09 | 北京航空航天大学 | A Time Series Oriented Hotspot Clustering Method |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113705217A (en)* | 2021-09-01 | 2021-11-26 | 国网江苏省电力有限公司电力科学研究院 | Literature recommendation method and device for knowledge learning in power field |
| CN113705217B (en)* | 2021-09-01 | 2024-05-28 | 国网江苏省电力有限公司电力科学研究院 | A literature recommendation method and device for knowledge learning in the electric power field |
| CN114528390A (en)* | 2022-02-22 | 2022-05-24 | 黄河勘测规划设计研究院有限公司 | Yellow river basin evolution analysis method based on text mining |
| CN115658851A (en)* | 2022-12-27 | 2023-01-31 | 药融云数字科技(成都)有限公司 | Medical literature retrieval method, system, storage medium and terminal based on theme |
| CN116975281A (en)* | 2023-06-26 | 2023-10-31 | 华侨大学 | Topic detection method and device based on BERT model and seed LDA model |
| CN117391073A (en)* | 2023-09-22 | 2024-01-12 | 北京工业大学 | Document identification method, device, electronic equipment and storage medium |
| CN118069851A (en)* | 2024-04-18 | 2024-05-24 | 中国标准化研究院 | Intelligent document information intelligent classification retrieval method and system |
| CN118797027A (en)* | 2024-07-03 | 2024-10-18 | 吉林师范大学 | A method for processing English text data based on data analysis |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111898366B (en) | 2022-08-09 |
| CN111898366A (en) | 2020-11-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021139262A1 (en) | Document mesh term aggregation method and apparatus, computer device, and readable storage medium | |
| CN111581949B (en) | Method and device for disambiguating name of learner, storage medium and terminal | |
| CN108509474B (en) | Synonym expansion method and device for search information | |
| US9613024B1 (en) | System and methods for creating datasets representing words and objects | |
| US10394851B2 (en) | Methods and systems for mapping data items to sparse distributed representations | |
| WO2021189951A1 (en) | Text search method and apparatus, and computer device and storage medium | |
| WO2019091026A1 (en) | Knowledge base document rapid search method, application server, and computer readable storage medium | |
| CN111694823B (en) | Institutional standardization method, device, electronic device and storage medium | |
| JP5057474B2 (en) | Method and system for calculating competition index between objects | |
| CN106547739A (en) | A kind of text semantic similarity analysis method | |
| WO2020232898A1 (en) | Text classification method and apparatus, electronic device and computer non-volatile readable storage medium | |
| US20240111956A1 (en) | Nested named entity recognition method based on part-of-speech awareness, device and storage medium therefor | |
| WO2020107835A1 (en) | Sample data processing method and device | |
| CN110019474B (en) | Automatic synonymy data association method and device in heterogeneous database and electronic equipment | |
| CN116881436A (en) | Literature retrieval methods, systems, terminals and storage media based on knowledge graphs | |
| EP4091063A1 (en) | Systems and methods for mapping a term to a vector representation in a semantic space | |
| CN116848490A (en) | Document analysis using model intersection | |
| CN114461783B (en) | Keyword generation method, device, computer equipment, storage medium and product | |
| CN114330335A (en) | Keyword extraction method, device, equipment and storage medium | |
| Shakhovska et al. | Methods and tools for text analysis of publications to study the functioning of scientific schools | |
| CN113468890B (en) | Sedimentology literature mining method based on NLP information extraction and part-of-speech rules | |
| CN113535938B (en) | Standard data construction method, system, equipment and medium based on content identification | |
| CN117633180A (en) | Question-answer matching method and device, electronic equipment and storage medium | |
| CN113032573A (en) | Large-scale text classification method and system combining theme semantics and TF-IDF algorithm | |
| CN107885875A (en) | Synonymous transform method, device and the server of term |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | Ref document number:20912252 Country of ref document:EP Kind code of ref document:A1 | |
| NENP | Non-entry into the national phase | Ref country code:DE | |
| 122 | Ep: pct application non-entry in european phase | Ref document number:20912252 Country of ref document:EP Kind code of ref document:A1 |