WO2020197256A1 - Electronic device for detecting extorted user utterance and method for operating same - Google Patents
Electronic device for detecting extorted user utterance and method for operating sameDownload PDFInfo
- Publication number
- WO2020197256A1 WO2020197256A1PCT/KR2020/004044KR2020004044WWO2020197256A1WO 2020197256 A1WO2020197256 A1WO 2020197256A1KR 2020004044 WKR2020004044 WKR 2020004044WWO 2020197256 A1WO2020197256 A1WO 2020197256A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sound
- electronic device
- speech
- synthesized sound
- frequency band
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





















Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L9/00—Cryptographic mechanisms or cryptographic arrangements for secret or secure communications; Network security protocols
- H04L9/40—Network security protocols
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/02—Preprocessing operations, e.g. segment selection; Pattern representation or modelling, e.g. based on linear discriminant analysis [LDA] or principal components; Feature selection or extraction
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/06—Decision making techniques; Pattern matching strategies
Definitions
- Various embodiments of the present disclosurerelate to an electronic device for detecting a hijacked user utterance, and a method of operating the same.
- portable digital communication devicesFor many people living in modern times, portable digital communication devices have become an essential element. Consumers want to receive a variety of high-quality services they want anytime, anywhere by using portable digital communication devices.
- the voice recognition serviceis a service for providing various content services to consumers in response to a user's voice received based on a voice recognition interface implemented in portable digital communication devices.
- portable digital transmittersinclude technologies that recognize and analyze human language (eg, automatic speech recognition, natural language understanding, natural language generation, machine translation, dialogue system, question and answer, speech recognition/synthesis, Etc.) is implemented.
- the electronic devicemay receive a speech from a user while an intelligent voice service application is being executed, and provide a service corresponding to the received speech using the intelligent voice service application.
- the user utterancemay be stolen (or recorded) by another recording device in the vicinity of the electronic device.
- the user of the recording deviceie, the hijacker
- personal information of a genuine user of the electronic deviceis leaked to the hijacker while receiving a service from the electronic device, thereby making the security of the personal information vulnerable.
- the electronic device and its operating methodoutput various types of sounds (eg, sound having an inaudible frequency band) each time a user speech is received, and include user speech and various types of sounds. Synthetic sound can be obtained. According to various embodiments, the electronic device and its operation method determine whether or not the currently received user utterance is stolen based on the result of comparing the obtained synthesized sound and the previously stored synthesized sound. It can solve the problem of weak information security.
- soundseg, sound having an inaudible frequency band
- a microphone, a memory, and at least one processorare included, and when instructions stored in the memory are executed, the at least one processor executes an intelligent voice service application, and during execution of the intelligent voice service application Receives a first speech through the microphone, obtains a first synthesized sound based on the first speech and a first sound having an inaudible frequency band, and a first speech related to the first speech among a plurality of pre-stored sounds A comparison result of the second synthesized sound and the first synthesized sound is obtained, and the second synthesized sound includes a second sound having an inaudible frequency band different from that of the first sound, and based on the comparison result, the An electronic device may be provided that enables a service corresponding to the first speech to be provided by an intelligent voice service application.
- a method of operating an electronic deviceexecuting an intelligent voice service application, receiving a first speech through a microphone of the electronic device during execution of the intelligent voice service application, and the first speech And obtaining a first synthesized sound based on the first sound having an inaudible frequency band, obtaining a comparison result of the second synthesized sound related to the first speech among a plurality of pre-stored sounds and the first synthesized sound.
- the second synthesized soundincludes a second sound having an inaudible frequency band different from the first sound, and based on the comparison result, the first speech by the intelligent voice service application
- a method of operationmay be provided, further comprising the step of providing a service corresponding to.
- a databaseat least one processor, and when instructions stored in the memory are executed, the at least one processor obtains a first synthesized sound, and the first synthesized sound is an intelligent voice Confirming a second synthesized sound related to the first utterance among a plurality of sounds obtained based on the first utterance and the first sound having an inaudible frequency band received during execution of the service application, and stored in advance in the database,
- the second synthesized soundincludes a second sound having an inaudible frequency band different from that of the first sound, and the first synthesized sound and the second synthesized sound are compared, and the first synthesized sound and the second
- An electronic devicemay be provided that checks a degree of similarity between synthesized sounds and, based on the confirmed degree of similarity, provides a service corresponding to the first speech by the intelligent voice service application.
- the electronic deviceoutputs various types of sounds (e.g., sounds having an inaudible frequency band) each time a user speech is received, and obtains a synthesized sound including the user speech and various types of sounds. can do.
- the security of the voice recognition service and the security of personal informationare weakened by checking whether the currently received user utterance is stolen based on the result of comparing the obtained synthesized sound and the previously stored synthesized sound.
- FIG. 1is a block diagram illustrating an integrated intelligence system according to various embodiments.
- FIG. 2is a diagram illustrating a form in which relationship information between a concept and an operation is stored in a database according to various embodiments.
- FIG. 3is a diagram illustrating a screen in which a user terminal processes a voice input received through an intelligent app, according to various embodiments.
- FIG. 4is a diagram illustrating an example of a configuration of an intelligent system according to various embodiments.
- FIG. 5is a diagram for describing an example of a configuration of an intelligent system according to various embodiments.
- FIG. 6is a flowchart illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- FIG. 7is a diagram illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- FIG. 8is a flowchart illustrating an example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- FIG. 9is a diagram illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- FIG. 10is another diagram illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- 11is a diagram illustrating a comparison result between synthesized sounds according to whether or not utterance is deodorized according to various embodiments.
- FIG. 12is a flowchart illustrating another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- FIG. 13is a diagram for describing an example of an operation of outputting sound having an inaudible frequency band of an electronic device according to various embodiments of the present disclosure.
- FIG. 14is a diagram illustrating an example of an inaudible frequency band of a captured speech when randomly outputting a sound having an inaudible frequency band according to various embodiments.
- 15is a flowchart illustrating an example of an operation of randomly outputting a sound having an inaudible frequency band of an electronic device according to various embodiments of the present disclosure.
- 16is a diagram for describing an example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
- 17is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
- 18is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
- 19is a flowchart illustrating an example of an operation of an external electronic device according to various embodiments of the present disclosure.
- 20is a diagram for describing an example of an operation of an external electronic device according to various embodiments.
- 21is a flowchart illustrating still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- 22is a diagram for describing still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- FIG 23is another diagram for describing still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- 24is a flowchart illustrating another example of an operation of an electronic device according to various embodiments.
- 25is a block diagram of an electronic device in a network environment according to various embodiments of the present disclosure.
- FIG. 1is a block diagram illustrating an integrated intelligence system, according to various embodiments.
- an integrated intelligent system 10may include a user terminal 100, an intelligent server 200, and a service server 300.
- the user terminal 100may be a terminal device (or electronic device) capable of connecting to the Internet.
- the user terminal 100may be a mobile phone, a smart phone, a personal digital assistant (PDA), or a notebook computer.
- PDApersonal digital assistant
- the user terminal 100may include a communication interface 110, a microphone 120, a speaker 130, a display 140, a memory 150, or a processor 160.
- the components listed abovemay be operatively or electrically connected to each other.
- the communication interface 110may be configured to transmit and receive data by being connected to an external device.
- the microphone 120may receive sound (eg, user speech) and convert it into an electrical signal.
- the speaker 130 of an embodimentmay output an electrical signal as sound (eg, voice).
- the display 140may be configured to display an image or video.
- the display 140 according to an exemplary embodimentmay also display a graphic user interface (GUI) of an executed app (or application program).
- GUIgraphic user interface
- the memory 150may store a client module 151, a software development kit (SDK) 153, and a plurality of apps 155.
- the client module 151 and the SDK 153may constitute a framework (or a solution program) for performing a general function.
- the client module 151 or the SDK 153may configure a framework for processing voice input.
- the plurality of apps 155may be programs for performing a specified function.
- the plurality of apps 155may include a first app 155_1 and a second app 155_3.
- each of the plurality of apps 155may include a plurality of operations for performing a specified function.
- the appsmay include an alarm app, a message app, and/or a schedule app.
- the plurality of apps 155may be executed by the processor 160 to sequentially execute at least some of the plurality of operations.
- the processor 160may control the overall operation of the user terminal 100.
- the processor 160may be electrically connected to and connected to the communication interface 110, the microphone 120, the speaker 130, and the display 140 to perform a designated operation.
- the processor 160may also execute a program stored in the memory 150 to perform a designated function.
- the processor 160may execute at least one of the client module 151 and the SDK 153 to perform the following operation for processing a voice input.
- the processor 160may control the operation of the plurality of apps 155 through, for example, the SDK 153.
- the following operation described as the operation of the client module 151 or the SDK 153may be an operation by execution of the processor 160.
- the client module 151 of an embodimentmay receive a voice input.
- the client module 151may receive a voice signal corresponding to a user's speech sensed through the microphone 120.
- the client module 151may transmit the received voice input to the intelligent server 200.
- the client module 151may transmit state information of the user terminal 100 to the intelligent server 200 together with the received voice input.
- the status informationmay be, for example, information on an execution status of an app.
- the client module 151may receive a result corresponding to the received voice input. For example, when the intelligent server 200 can calculate a result corresponding to the received voice input, the client module 151 may receive a result corresponding to the received voice input. The client module 151 may display the received result on the display 140.
- the client module 151may receive a plan corresponding to the received voice input.
- the client module 151may display a result of executing a plurality of operations of the app on the display 140 according to the plan.
- the client module 151may sequentially display execution results of a plurality of operations on the display, for example.
- the user terminal 100may display only a partial result of executing a plurality of operations (eg, a result of the last operation) on the display.
- the client module 151may receive a request from the intelligent server 200 to obtain information necessary to calculate a result corresponding to a voice input. According to an embodiment, the client module 151 may transmit the necessary information to the intelligent server 200 in response to the request.
- the client module 151may transmit information as a result of executing a plurality of operations according to a plan to the intelligent server 200.
- the intelligent server 200may confirm that the received voice input is correctly processed using the result information.
- the client module 151may include a voice recognition module. According to an embodiment, the client module 151 may recognize a voice input performing a limited function through the voice recognition module. For example, the client module 151 may perform an intelligent app for processing a voice input for performing an organic operation through a designated input (eg, wake up!).
- a voice recognition modulemay recognize a voice input performing a limited function through the voice recognition module. For example, the client module 151 may perform an intelligent app for processing a voice input for performing an organic operation through a designated input (eg, wake up!).
- the intelligent server 200may receive information related to a user voice input from the user terminal 100 through a communication network. According to an embodiment, the intelligent server 200 may change data related to the received voice input into text data. According to an embodiment, the intelligent server 200 may generate a plan for performing a task corresponding to a user voice input based on the text data.
- the planmay be created by an artificial intelligent (AI) system.
- the artificial intelligence systemmay be a rule-based system, or a neural network-based system (e.g., a feedforward neural network (FNN)), a recurrent neural network (RNN). It may be ))). Alternatively, it may be a combination of the above or another artificial intelligence system.
- the planmay be selected from a set of predefined plans, or may be generated in real time in response to a user request. For example, the artificial intelligence system may select at least one of a plurality of predefined plans.
- the intelligent server 200may transmit a result according to the generated plan to the user terminal 100 or may transmit the generated plan to the user terminal 100.
- the user terminal 100may display a result according to the plan on the display.
- the user terminal 100may display a result of executing an operation according to a plan on a display.
- the intelligent server 200 of one embodimentincludes a front end 210, a natural language platform 220, a capsule DB 230, an execution engine 240, and It may include an end user interface 250, a management platform 260, a big data platform 270, or an analytic platform 280.
- the front end 210 of an embodimentmay receive a voice input received from the user terminal 100.
- the front end 210may transmit a response corresponding to the voice input.
- the natural language platform 220includes an automatic speech recognition module (ASR module) 221, a natural language understanding module (NLU module) 223, a planner module ( A planner module 225, a natural language generator module (NLG module) 227, or a text to speech module (TTS module) 229 may be included.
- ASR moduleautomatic speech recognition module
- NLU modulenatural language understanding module
- NTL modulenatural language generator module
- TTS moduletext to speech module
- the automatic speech recognition module 221may convert a voice input received from the user terminal 100 into text data.
- the natural language understanding module 223may determine the user's intention by using text data of voice input. For example, the natural language understanding module 223 may grasp a user's intention by performing syntactic analysis or semantic analysis.
- the natural language understanding module 223 of an embodimentgrasps the meaning of the word extracted from the voice input using the linguistic features (eg, grammatical elements) of a morpheme or phrase, and matches the meaning of the identified word with the intention of the user. You can determine your intentions.
- the planner module 225may generate a plan using the intention and parameters determined by the natural language understanding module 223. According to an embodiment, the planner module 225 may determine a plurality of domains necessary to perform a task based on the determined intention. The planner module 225 may determine a plurality of operations included in each of a plurality of domains determined based on the intention. According to an embodiment, the planner module 225 may determine a parameter required to execute the determined plurality of operations or a result value output by executing the plurality of operations. The parameter and the result value may be defined as a concept of a designated format (or class). Accordingly, the plan may include a plurality of operations and a plurality of concepts determined by the intention of the user.
- the planner module 225may determine a relationship between the plurality of operations and the plurality of concepts in stages (or hierarchical). For example, the planner module 225 may determine an execution order of a plurality of operations determined based on a user's intention based on a plurality of concepts. In other words, the planner module 225 may determine the execution order of the plurality of operations based on parameters required for execution of the plurality of operations and a result output by the execution of the plurality of operations. Accordingly, the planner module 225 may generate a plan including a plurality of operations and related information (eg, ontology) between a plurality of concepts. The planner module 225 may generate a plan using information stored in the capsule database 230 in which a set of relationships between concept and operation is stored.
- the planner module 225may determine an execution order of a plurality of operations determined based on a user's intention based on a plurality of concepts. In other words, the planner module 225 may determine the execution order of the plurality of operations based on parameters required
- the natural language generation module 227may change designated information into a text format.
- the information changed in the text formmay be in the form of natural language speech.
- the text-to-speech module 229may change information in text form into information in voice form.
- some or all functions of the functions of the natural language platform 220may be implemented in the user terminal 100 as well.
- the capsule database 230may store information on a relationship between a plurality of concepts and operations corresponding to a plurality of domains.
- a capsulemay include a plurality of action objects (action objects or action information) and concept objects (concept objects or concept information) included in a plan.
- the capsule database 230may store a plurality of capsules in the form of a concept action network (CAN).
- CANconcept action network
- a plurality of capsulesmay be stored in a function registry included in the capsule database 230.
- the capsule database 230may include a strategy registry in which strategy information necessary for determining a plan corresponding to the voice input is stored.
- the strategy informationmay include reference information for determining one plan when there are a plurality of plans corresponding to the voice input.
- the capsule database 230may include a follow up registry in which information on a follow-up operation for suggesting a follow-up operation to a user in a specified situation is stored.
- the subsequent operationmay include, for example, a subsequent speech.
- the capsule database 230may include a layout registry that stores layout information of information output through the user terminal 100.
- the capsule database 230may include a vocabulary registry in which vocabulary information included in capsule information is stored.
- the capsule database 230may include a dialog registry in which information about a conversation (or interaction) with a user is stored.
- the capsule database 230may update an object stored through a developer tool.
- the developer toolmay include, for example, a function editor for updating an action object or a concept object.
- the developer toolmay include a vocabulary editor for updating vocabulary.
- the developer toolmay include a strategy editor for creating and registering a strategy for determining a plan.
- the developer toolmay include a dialog editor that creates a dialog with a user.
- the developer toolmay include a follow up editor capable of activating a follow-up goal and editing subsequent utterances that provide hints.
- the subsequent targetmay be determined based on a currently set target, user preference, or environmental conditions.
- the capsule database 230may be implemented in the user terminal 100 as well.
- the execution engine 240 of an embodimentmay calculate a result using the generated plan.
- the end user interface 250may transmit the calculated result to the user terminal 100. Accordingly, the user terminal 100 may receive the result and provide the received result to the user.
- the management platform 260may manage information used in the intelligent server 200.
- the big data platform 270according to an embodiment may collect user data.
- the analysis platform 280 of an embodimentmay manage the quality of service (QoS) of the intelligent server 200. For example, the analysis platform 280 may manage components and processing speed (or efficiency) of the intelligent server 200.
- QoSquality of service
- the service server 300may provide a designated service (eg, food order or hotel reservation) to the user terminal 100.
- the service server 300may be a server operated by a third party.
- the service server 300may provide information for generating a plan corresponding to the received voice input to the intelligent server 200.
- the provided informationmay be stored in the capsule database 230.
- the service server 300may provide result information according to the plan to the intelligent server 200.
- the user terminal 100may provide various intelligent services to a user in response to a user input.
- the user inputmay include, for example, an input through a physical button, a touch input, or a voice input.
- the user terminal 100may provide a voice recognition service through an intelligent app (or voice recognition app) stored therein.
- the user terminal 100may recognize a user utterance or voice input received through the microphone, and provide a service corresponding to the recognized voice input to the user. .
- the user terminal 100may perform a specified operation alone or together with the intelligent server and/or service server based on the received voice input. For example, the user terminal 100 may execute an app corresponding to the received voice input and perform a specified operation through the executed app.
- the user terminal 100when the user terminal 100 provides a service together with the intelligent server 200 and/or the service server, the user terminal detects the user's speech using the microphone 120, and A signal (or voice data) corresponding to the detected user's speech may be generated. The user terminal may transmit the voice data to the intelligent server 200 using the communication interface 110.
- the intelligent server 200is a plan for performing a task corresponding to the voice input as a response to a voice input received from the user terminal 100, or performing an operation according to the plan. Can produce results.
- the planmay include, for example, a plurality of operations for performing a task corresponding to a user's voice input, and a plurality of concepts related to the plurality of operations.
- the conceptmay be a parameter input to execution of the plurality of operations or a result value outputted by execution of the plurality of operations.
- the planmay include a plurality of operations and association information between a plurality of concepts.
- the user terminal 100may receive the response using the communication interface 110.
- the user terminal 100outputs a voice signal generated inside the user terminal 100 to the outside using the speaker 130, or externally outputs an image generated inside the user terminal 100 using the display 140.
- FIG. 2is a diagram illustrating a form in which relationship information between a concept and an operation is stored in a database according to various embodiments.
- the capsule database (eg, capsule database 230) of the intelligent server 200may store capsules in the form of a concept action network (CAN) 400.
- the capsule databasemay store an operation for processing a task corresponding to a user's voice input and a parameter necessary for the operation in the form of a concept action network (CAN) 400.
- the capsule databasemay store a plurality of capsules (capsule(A) 401, capsule(B) 404) corresponding to each of a plurality of domains (eg, applications).
- one capsuleeg, capsule(A) 401 may correspond to one domain (eg, location (geo), application).
- one capsuleincludes at least one service provider (eg, CP 1 (402), CP 2 (403), CP 3 (406), or CP 4 (405)) for performing a function for a domain related to the capsule) Can be matched.
- one capsulemay include at least one or more operations 410 and at least one concept 420 for performing a specified function.
- the natural language platform 220may generate a plan for performing a task corresponding to a received voice input using a capsule stored in a capsule database.
- the planner module 225 of the natural language platformmay create a plan using capsules stored in the capsule database. For example, using the actions 4011 and 4013 and concepts 4012 and 4014 of capsule A 410 and the action 4041 and concept 4042 of capsule B 404 to create a plan 407 can do.
- FIG. 3is a diagram illustrating a screen in which a user terminal processes a voice input received through an intelligent app, according to various embodiments.
- the user terminal 100may execute an intelligent app to process user input through the intelligent server 200.
- the user terminal 100processes the voice input.
- You can run intelligent apps for The user terminal 100may, for example, run the intelligent app while running the schedule app.
- the user terminal 100may display an object (eg, an icon) 311 corresponding to an intelligent app on the display 140.
- the user terminal 100may receive a voice input by user utterance. For example, the user terminal 100 may receive a voice input “Tell me about this week's schedule!”.
- the user terminal 100may display a user interface (UI) 313 (eg, an input window) of an intelligent app displaying text data of a received voice input on the display.
- UIuser interface
- the user terminal 100may display a result corresponding to the received voice input on the display.
- the user terminal 100may receive a plan corresponding to the received user input, and display a “this week schedule” on the display according to the plan.
- the intelligent systemis not limited to the configurations illustrated in FIG. 4, and may include more devices than the devices illustrated in FIG. 4, or may include at least one fewer devices.
- the intelligent systemmay include an electronic device 410 and an intelligent server 420 as shown in FIG. 4.
- the electronic device 410 and the intelligent server 420may be implemented like the electronic devices 410 shown in FIG. 1 (eg, 100, 200, 300), and the network environment shown in FIG. 25 ( Since it may be implemented like the electronic device 2501 in 2500), a redundant description will be omitted.
- the electronic device 410may receive the user utterance 412 from the user 411 and provide a service to the received user utterance 412.
- the electronic device 410is based on an input for executing an intelligent voice service application (eg, an intelligent app) (eg, a voice input for calling an intelligent voice service application, a button input, etc.), Service application can be executed.
- the electronic device 410may acquire the user utterance 412 while the intelligent voice service application is being executed.
- the electronic device 410may transmit information on the user utterance to the intelligent server 420 and receive an analysis result of the user utterance 412 in response thereto.
- the information on the user utterancerefers to various types of information representing the received user utterance 412, and is processed as information of a speech signal type in which the user utterance is not processed, or a text corresponding to the received user utterance (e.g. : User utterance is processed by ASR) information of text type, etc. may be included.
- the electronic device 410may receive various additional information together with the user utterance 412.
- Various additional informationmay include context information and/or user information.
- the context informationmay include information on an application or program executed in the electronic device 410, information on a current location, and the like.
- the user informationis analyzed from the user's 411's electronic device usage pattern (eg, application usage pattern), the user's personal information (eg, age, etc.), and the user 411 ) And related unique phonetic information (eg, information related to the fundamental frequency FO), and the like.
- the electronic device 410may provide a service corresponding to the user utterance 412 based on the received analysis result. For example, the electronic device 410 may display content corresponding to the user utterance 412 on the display based on the received analysis result (eg, UI/UX including content corresponding to the user utterance 412). Can be displayed. In addition, for example, the electronic device 410 performs an operation of the application corresponding to the user utterance on the electronic device 410 based on the analysis result (eg, a deep link for executing an application corresponding to the user utterance 412). You can provide the services you provide. In addition, for example, the electronic device 410 may have at least one intelligent server 420 (e.g.: IOT things devices) can be provided.
- IOT things devicese.g.: IOT things devices
- the intelligent server 420will be described.
- the intelligent server 420processes the user utterance 412 received from the electronic device 410 to provide a service corresponding to the user utterance 412. Information can be obtained.
- the intelligent server 420may refer to additional information received along with the user utterance received from the electronic device 410 to process the user utterance 412.
- the intelligent server 420may cause a user utterance to be processed by a voice assistant (eg, capsules).
- a voice assistanteg, capsules
- the intelligent server 420allows the user utterance 412 to be processed by the voice assistant provided in the intelligent server 420 to obtain processing result information from the voice assistant, or interlock with the intelligent server 420
- processing result informationcan be obtained from an external server. Since the voice assistant can perform the same operation as the capsules described above, a redundant description will be omitted.
- the processing result information obtained according to the processing of the speech by the voice assistantmay be a plan for performing the above-described task or a result of performing an operation according to the plan, a duplicate description will be omitted.
- the processing result informationmay further include at least one of a deep link including an access mechanism for accessing a specific screen of a designated application or visual information (UI/UX) for providing a service.
- the intelligent server 420may obtain a voice assistant for processing user utterances from the developer server.
- the intelligent server 420may obtain a capsule for processing user utterances from the developer server.
- a developer of the developer servermay register voice assistants with the intelligent server 420.
- the present inventionis not limited to the above description, and the intelligent server 420 may store voice assistants produced by the intelligent server 420 by itself.
- the hijacker 440 in the vicinity of the electronic device 410performs a recording function while the electronic device 410 receives the utterance from the sincere user 411 in the stolen speech 430. It may be an utterance recorded using another electronic device 410 that is present.
- the captured speech 430may include user speech 412 and various types of sounds (eg, sound having an inaudible frequency band) output through a speaker of the electronic device 410.
- an utterance other than the stolen utterance 430may be defined as an authentic user utterance
- a user 411 of the electronic device 410 from which the utterance is stolenmay be defined as an authentic user.
- the electronic device 410repeatedly outputs various types of sounds (eg, sounds having an inaudible frequency band) each time an utterance is received, and acquires various types of sounds together with the utterance.
- soundseg, sounds having an inaudible frequency band
- the electronic device 410By acquiring the synthesized sound and comparing the obtained synthesized sound with the previously acquired synthesized sound, it is possible to check whether the sound is a hijacked speech.
- various phonetic information added to the soundeg, sound having an inaudible frequency band
- the electronic device 410 and the intelligent server 420are not limited to the configurations illustrated in FIG. 5, and include more or less than the configurations illustrated in FIG. 5. It may also include the composition of. Modules described in this document (for example, the sound output module 506 shown in FIG. 5, the speech analysis module 512, and the speech comparison module 513) are coded so that a specific electronic device can perform a specified operation. It may be a program, computer code, or instructions.
- the electronic device 410stores a plurality of modules (eg, a sound output module 506) in the memory 503, and a plurality of modules included in the stored memory 503 (eg, a sound output module ( 506)) may cause the processor 505 to perform a specified operation.
- the intelligent server 420stores a plurality of modules (eg, speech analysis module 512, speech comparison module 513) in a memory, and a plurality of modules included in the stored memory (eg, speech analysis module) At 512, the utterance comparison module 513 may cause the processor 511 to perform a designated operation.
- the electronic device 410includes a processor 505 including a speaker 501, a microphone 502, a memory 503, and a sound output module 506, as shown in FIG. 5. can do.
- the speaker, microphone 502, memory 503, and processorare the same as those included in the user terminal 100 of FIG. 1 or the electronic device 2501 included in the network environment 2500 shown in FIG. 25 to be described later. Since it can be implemented, duplicate descriptions are omitted.
- the speaker 501may output various types of sounds.
- the electronic device 410may control the speaker 501 to output various types of sounds (eg, sound having an inaudible frequency band) while an intelligent voice service application is being executed.
- various types of sounds output through the speaker 501 of the electronic device 410may be applied to sounds (eg, user speech) received by the electronic device 410 through the microphone 502 from the outside. It may be a sound that has little or no effect (or does not degrade). In other words, when various types of sounds output through the speaker 501 of the electronic device 410 are received together with the sound output to the electronic device 410 from the outside, various types of sounds are transmitted from the external device 410 ) May be a sound that does not significantly affect the intensity of each frequency. For example, when the sound output to the electronic device 410 from the outside is user speech, the sound output through the speaker 501 may include sound or music in an inaudible frequency band.
- the inaudible frequency bandmay mean a frequency band that the user cannot hear.
- the inaudible frequency bandmay be a frequency band included in the 10HZ to 300GHZ band.
- the audible frequency bandmay mean a frequency band that a user can listen to.
- itis not limited to the above-described types (e.g., sound in an inaudible frequency band, music), but affects the sound (e.g., user utterance) output to the electronic device 410 from the outside output through the speaker 501
- various embodimentsare described by taking the case of outputting sound in an inaudible frequency band through the speaker 501 as an example. However, the following various embodiments apply mutatis mutandis to the case of outputting various types of phonetic sounds that do not affect sound (eg, user speech) output from the outside to the electronic device 410 through the speaker 501 Can be.
- the microphone 502may receive various types of sounds received by the electronic device 410.
- the electronic device 410may receive a user's speech through the microphone 502.
- the electronic device 410may receive various types of sounds (eg, sound having an inaudible frequency band) output through the speaker 501 of the electronic device 410 through the microphone 502.
- the electronic device 410may receive various types of synthesized sounds through the microphone 502.
- the synthesized soundmay be a sound including two or more sounds received through the microphone 502.
- the synthesized soundmay be a sound including a user's speech received through the microphone 502 and various kinds of sounds output through the speaker 501.
- the memory 503may store various types of data 504 for generating various types of sounds output through the speaker 501 of the electronic device 410.
- the electronic device 410acquires various types of data 504 stored in the memory 503, generates various types of sounds based on the various types of data 504, and generates various types of sounds.
- the speaker 501can be controlled to output. An operation of outputting various types of sounds (eg, sound having an inaudible frequency band) of the electronic device 410 will be described later with reference to FIGS. 8 to 11.
- the various types of data 504may include text data.
- the various types of data 504may include various types of electronic data for generating various types of sounds in addition to the text data.
- the various types of data 504may include various types of sound source files. Music corresponding to the sound source file based on the sound source file may be output through the speaker 501 of the electronic device 410.
- the sound output module 506may generate various types of sounds based on various types of data 504 stored in the above-described memory 503. For example, the sound output module 506 acquires at least one text data stored in the memory 503, converts the obtained text data into sound data, and modulates the frequency band of the converted sound data to obtain an inaudible frequency. You can create a sound with a band. Also, for example, the sound output module 506 may generate music based on the sound source file stored in the above-described memory 503. The sound generation operation by the sound output module 506 will be described later in FIGS. 8 to 12.
- the intelligent server 420includes a speech analysis module 512, a speech comparison module 513, and a processor 511 including a natural language platform 514, as shown in FIG. 5, and a speech database. (515) may be included.
- the speech analysis module 512may check a sound corresponding to the received sound.
- the speech analysis module 512may check a synthesized sound corresponding to the synthesized sound received from the electronic device 410 among a plurality of sounds stored in the database 515 of the intelligent server 420.
- the comparison operation between the two sounds to identify sounds corresponding to each othermay be performed based on auto speech recognition (ASR) or semantic analysis (NLU analysis) of the sound.
- ASRauto speech recognition
- NLU analysissemantic analysis
- the utterance comparison module 513may compare a sound received from the electronic device 410 with a sound stored in the database 515 corresponding to the received sound, and check similarity between the two sounds. For example, the utterance comparison module 513 may compare the characteristics (eg, intensity, etc.) of two sounds according to time to check the similarity of the two sounds. Techniques for checking the similarity between the two sounds may include linear alignment analysis including Euclidean distance analysis, and the like, and non-linear alignment analysis including dynamic time wrapping (DTW). According to various embodiments, the natural language platform 514 may process a sound received from the electronic device 410 and generate processing result information for providing a service corresponding to the received sound based on the processing result. . Redundant description of the processing result information will be omitted.
- the characteristicseg, intensity, etc.
- the utterance database 515may store a plurality of sounds.
- the utterance database 515includes sounds obtained by the electronic device 410 (eg, user device) received from the electronic device 410 by the intelligent server 420 (eg, the intelligent server 420). You can save 516.
- the intelligent server 420may receive the user utterance from the electronic device 410 and store the received user utterance in the database 515. have.
- the electronic device 410acquires a synthesized sound including user utterances and various types of sounds (eg, sound having an inaudible frequency band)
- the electronic device 410acquires a synthesized sound including user utterances and various types of sounds (eg, sound having an inaudible frequency band)
- the electronic device 410acquires a synthesized sound including user utterances and various types of sounds (eg, sound having an inaudible frequency band)
- the electronic device 410acquires a synthesized sound including user utterances and various types of sounds (eg, sound having an inaudible frequency band)
- the utterance database 515is not limited to those described above, and may store various types of sounds provided from a developer server or a cloud server other than a user device.
- the above-described components of the electronic device 410may be implemented in the intelligent server 420, or the above-described components of the intelligent server 420 may be implemented in the electronic device 410.
- the electronic device 410may include a speech analysis module 512, a speech comparison module 513, and a speech database 515 implemented in the intelligent server 420. Accordingly, the electronic device 410 checks the sound corresponding to the received user's speech among the plurality of sounds 516 stored in the speech database 515 by the speech analysis module 512, and the speech comparison module 513 ), you can compare the sounds.
- the electronic device 410may be implemented as an on-device type device that is implemented to perform operations performed by the intelligent server 420 described below.
- the intelligent server 420may be implemented as an on-device type device that is implemented to perform operations performed by the electronic device 410 described below.
- the electronic device 410may provide a service according to whether or not an utterance is captured based on a comparison result of a synthesized sound currently received and a previously stored synthesized sound.
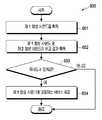
- FIG. 6is a flowchart 600 illustrating an example of operations of the electronic device 410 and the intelligent server 420 according to various embodiments. According to various embodiments, the operations illustrated in FIG. 6 are not limited to the illustrated order and may be performed in various orders. Further, according to various embodiments, more operations may be performed than the operations illustrated in FIG. 6, or at least one less operation may be performed. Hereinafter, FIG. 6 will be described with reference to FIG. 7.
- FIG. 7is a diagram illustrating an example of operations of the electronic device 410 and the intelligent server 420 according to various embodiments.
- a "+" symbolindicates that each sound is combined and received by the microphone 502 of the electronic device.
- the electronic device 410may obtain the first synthesized sound in operation 601.
- the electronic device 410may provide a sound output from the outside during execution of an intelligent voice service application through the microphone 502 (eg, "Tell me the weather") (eg, 701, Sounds (eg, 702 and 712) output through the speaker 501 of the electronic device 410 and 711 may be received together.
- the electronic device 410includes user speech 701 output from the user 411 and sound output through the speaker 501 while the intelligent voice service application is being executed (eg, a high frequency band). Eggplant sound) 702 may be received together through the microphone 502.
- the electronic device 410is captured by the hijacker 440 during execution of the intelligent voice service application and output from the recording device 441 through the speech 711 and the speaker 501.
- the output sound (eg, sound having a high frequency band) 712may be received together through the microphone 502.
- the electronic device 410may obtain a result of comparing the first synthesized sound and the second synthesized sound in operation 602.
- the electronic device 410obtains a result of comparing the previously stored second synthesized sound and the first synthesized sound corresponding to the currently received first synthesized sound. (Eg, received from the intelligent server 420 or obtained by analyzing the electronic device 410).
- the second synthesized soundmay be an utterance including a second utterance corresponding to the first utterance included in the first synthesized sound.
- the first synthesized soundincludes a first utterance 701 of “tell me the weather”
- the second synthesized soundalso includes a second utterance 711 of “tell me the weather”. It can be sound.
- a second synthesized sound corresponding to the first synthesized soundmay be identified based on an analysis result of the ASR module (ie, analysis of a user speech portion (or audible portion) of the synthesized sound) among a plurality of pre-stored sounds. The operation of confirming the second synthesized sound corresponding to the first synthesized sound among the plurality of sounds will be described later with reference to FIGS. 8 to 10.
- the electronic device 410may obtain a comparison result including various information according to the similarity between the first synthesized sound and the second synthesized sound. . If the similarity between the first synthesized sound and the second synthesized sound is greater than or equal to a preset value, the first utterance 701 is a user utterance, and if the similarity between the first synthesized sound and the second synthesized sound is less than a preset value, It could be an ignition. That is, the comparison result may include various types of information depending on whether the first speech included in the currently received first synthesized sound is a stolen speech. The comparison of the first synthesized sound and the second synthesized sound and the operation of determining whether to take off according to the similarity between the two synthesized sounds will be described later with reference to FIGS. 8 to 10.
- the comparison resultindicates a service corresponding to the first speech.
- Processing result information to be providedeg, UI/UX for indicating information related to the first utterance 701
- Redundant descriptions related to processing result information for providing a servicewill be omitted.
- the comparison resultis the currently received first speech 701 May include information for indicating that is a stolen ignition.
- the electronic device 410(eg, at least one processor 505) has a degree of similarity between the first synthesized sound and the second synthesized sound equal to or greater than a preset value (ie, the first speech is In the case of user speech), a service corresponding to the first synthesized sound may be provided in operation 604.
- the electronic device 410may provide a service corresponding to the first speech based on processing result information included in the above-described comparison result.
- the electronic device 410provides a UI/UX for displaying today's weather information in response to the utterance 701 of “tell me the weather” received from the user. 410).
- the electronic device 410(for example, at least one processor 505) has a similarity between the first synthesized sound and the second synthesized sound less than a preset value in operation 603 (i.e., the utterance from which the first utterance is captured). In this case, in operation 605, provision of a service corresponding to the first synthesized sound may be prohibited.
- the electronic device 410provides an utterance including a specific keyword in order to check whether the user currently using the electronic device 410 is a genuine user. Can be requested. An operation of requesting the provision of speech including a specific keyword will be described later with reference to FIGS. 21 to 23.
- the electronic device 410when the electronic device 410 acquires additional information along with the user's speech, and it is determined that the user providing the current speech based on the additional information is not a genuine user, the above-described synthetic sound Provision of a service corresponding to an utterance can be prohibited without the need to perform a comparison operation.
- the electronic device 410outputs various types of sounds (for example, sounds in an inaudible frequency band) and compares the synthesized sounds obtained accordingly, By prohibiting the provision of the voice service, the security of the voice service and the security of personal information may be improved.
- soundsfor example, sounds in an inaudible frequency band
- the electronic device 410performs an analysis operation for comparing the phonetic characteristics of the actual speech of the user of true intention with the phonetic characteristics of the currently received speech ( Example: An analysis operation based on a learning model using deep learning, etc.) can be performed.
- the electronic device 410stores various data (for example, a learning model) for performing an analysis operation, and determines whether the speech is stolen by performing an operation to check the data. May increase the operational burden.
- whether or not it is a hijacked speechis determined by a relatively small number of processors due to various types of sounds (eg, sound having an inaudible frequency band) added to the currently received speech. Can be confirmed, the relative operational burden can be reduced.
- soundseg, sound having an inaudible frequency band
- the electronic device 410may transmit the currently received synthesized sound to the intelligent server 420.
- the intelligent server 420compares the received synthesized sound with the previously stored synthesized sound to check whether the utterance is deodorized (that is, whether the utterance is an authentic user utterance), and according to whether the utterance is deodorized, the electronic device 410 is It is possible to provide a service corresponding to the speech.
- FIG. 8is a flowchart 800 illustrating an example of operations of the electronic device 410 and the intelligent server 420 according to various embodiments. According to various embodiments, the operations illustrated in FIG. 8 are not limited to the illustrated order and may be performed in various orders. In addition, according to various embodiments, more operations than the operations illustrated in FIG. 8 may be performed, or at least one less operation may be performed. Hereinafter, FIG. 8 will be described with reference to FIGS. 9 to 11.
- FIG. 9is a diagram illustrating an example of operations of the electronic device 410 and the intelligent server 420 according to various embodiments.
- a "+" symbolindicates that each sound is combined and received by the microphone 502 of the electronic device.
- 10is another diagram illustrating an example of operations of the electronic device 410 and the intelligent server 420 according to various embodiments.
- 11is a diagram illustrating a comparison result between synthesized sounds according to whether or not utterance is deodorized according to various embodiments.
- the electronic device 410may execute an intelligent voice service application in operation 801.
- the electronic device 410may control the display to display an execution screen of the intelligent service application based on the execution of the intelligent service application, as illustrated in 901 of FIG. 9.
- the electronic device 410receives a user's wake-up command through the microphone 502, and based on the received wake-up command, a user input (eg, : You can run an intelligent voice service application to receive user speech).
- a user inputeg, : You can run an intelligent voice service application to receive user speech.
- the wakeup commandmay be a user utterance including a designated voice (eg, wake up!, Hi Bixby!) received through the microphones 502 and 111 of the electronic device 410.
- the electronic device 410may store at least one designated voice in the memory 503 and execute an intelligent voice service application when the voice received through the microphone 502 corresponds to at least one designated voice stored therein.
- the wakeup commandmay be a user input received through a hardware key 910 implemented in the electronic device 410.
- the wakeup commandmay be a user input for selecting an icon for executing an intelligent voice service application.
- the electronic device 410(for example, the sound output module 506 of the at least one processor 505) transmits the first sound having an inaudible frequency band through the speaker 501 in operation 802. Can be printed.
- the sound having the inaudible frequency bandmay be a sound including not only sound in the inaudible frequency band, but also in other audible frequency bands. Since the inaudible frequency band has been described above, redundant descriptions will be omitted.
- the electronic device 410determines that the first sound having an inaudible frequency band is
- the speaker 501can be controlled to output. Satisfaction of the various conditions is when the intelligent voice service application is executed, a preset time elapses after the execution of the intelligent voice service application, or a specific event (for example, the microphone 502 of the electronic device 410) during execution of the intelligent application. ), the user's input for activating) is generated.
- the electronic device 410may control the speaker 501 to output a first sound having an inaudible frequency band in response to execution of an intelligent voice service application.
- the electronic device 410controls the speaker 501 to output a first sound having an inaudible frequency band for a specified time. Can be controlled.
- the designated timemay be set to a time period in which the electronic device 410 is likely to receive a speech while the intelligent voice service application is being executed. For example, after the intelligent voice service application is executed, the electronic device 410 may have an inaudible frequency band only for a period of time (for example, 3 seconds) that a speech is likely to be received from the execution time of the intelligent voice service application. 1
- the speaker 501can be controlled to output sound.
- the electronic device 410(for example, the sound output module 506 of the at least one processor 505) generates the first sound having an inaudible frequency band while the intelligent voice service application is being executed.
- At least one of a plurality of data stored in the memory 503may be obtained.
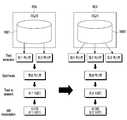
- the electronic device 410may include at least one text data 911 (for example, at least one text data 911) stored in the memory 503 for generating a first sound having an inaudible frequency band.
- First text data, second text datamay be obtained.
- the electronic device 410may randomly obtain data from among the plurality of data 504 in order to randomly generate a sound (eg, a first sound) having an inaudible frequency band. Accordingly, whenever sound having an inaudible frequency band is output, the electronic device 410 may output sounds having different inaudible frequency bands, which will be described later with reference to FIGS. 13 to 19.
- the electronic device 410(for example, the sound output module 506 of the at least one processor 505) generates at least one acquired data as sound data, and makes the generated sound data inaudible. It can be converted to a sound having a frequency band.
- the electronic device 410may convert at least one acquired text data into sound data. Since the operation of generating sound data from the data may be performed by a conventional text-to-speech (TTS) technology, a detailed description thereof will be omitted. In this case, when the number of acquired data is plural, the electronic device 410 may merge the plurality of data and generate sound data based on the merged data.
- TTStext-to-speech
- the electronic device 410may randomly combine texts with the acquired text data or may merge each text by arranging it in a line.
- the electronic device 410may merge them to obtain the text NucleicFloyd.
- the electronic device 410combines them to obtain each preset unit (eg, letter), such as NuclFloydeic. (one letter)) can be combined in any order.
- the acquired datamay be converted into various types of sounds that do not affect speech (eg, user speech) received through the microphone 502. Since various types of sounds are the same as described above, overlapping descriptions will be omitted.
- the electronic device 410(for example, the sound output module 506 of the at least one processor 505) outputs the same sound or a different sound whenever it outputs a sound having an inaudible frequency. Sound can be output. For example, whenever a sound having an inaudible frequency is output, the electronic device 410 may generate and output a sound having an inaudible frequency based on the same data. Also, for example, the electronic device 410 may randomly output a sound having an inaudible frequency so that the second sound and the first sound are different from each other.
- the electronic device 410may receive the first speech through the microphone 502 while the intelligent voice service application is being executed in operation 803. For example, while an intelligent voice service application is being executed, the electronic device 410 may acquire a user utterance for requesting provision of a specific service from the user. In addition, for example, while the intelligent voice service application is being executed, the electronic device 410 may acquire the stolen speech output from the speaker 501 of another intelligent server 420.
- the electronic device 410may obtain a first synthesized sound based on a first sound having a first speech and an inaudible frequency band in operation 804.
- the electronic device 410may obtain a first synthesized sound based on a first sound having a first speech and an inaudible frequency band in operation 804.
- the electronic device 410may obtain a first synthesized sound based on a first sound having a first speech and an inaudible frequency band in operation 804.
- the electronic device 410as shown in 903 of FIG. 9, through the speaker 501 together with the first speech (eg, user speech or hijacked user speech) 913 through the microphone 502
- the first sound 912 of the output inaudible frequency bandmay be received together.
- the first synthesized sound 914may be a sound including a first speech 913 and a first sound 914 in an inaudible frequency band.
- the electronic device 410may transmit information on the first synthesized sound 914 obtained as shown in 904 of FIG. 9. It can be transmitted to the intelligent server 420.
- the information on the first synthesized sound 914may refer to electronic information for indicating the first synthesized sound.
- the information on the first synthesized sound 914may be information obtained as the first synthesized sound 914 is converted into electronic data.
- the intelligent server 420(for example, the speech analysis module 512 of the at least one processor 511) is related to the first speech among a plurality of sounds stored in the memory 503 in operation 806. You can check the second synthesized sound.
- the second synthesized soundmay be a sound including a user speech and a second sound in an inaudible frequency band. Since the plurality of sounds stored in the database 515 of the data of the intelligent server 420 are the same as described above in FIG. 5, a duplicate description will be omitted.
- the second soundmay be the same as, similar to, or different from the first sound having an inaudible frequency band included in the first synthesized sound.
- the synthesized sounds stored in the database 515 of the intelligent server 420have the same or similar ratio. It may include sound having a blue frequency band.
- the synthesized sounds stored in the database 515 of the intelligent server 420are each different in audible frequency bands. It may include a sound with. In this case, as the first sound and the second sound are different, the accuracy of the operation of determining whether the currently received first utterance is a hijacked utterance may be improved. This will be described later in FIGS. 13 to 18.
- the intelligent server 420(for example, the speech analysis module 512 of the at least one processor 511) performs a plurality of sounds stored in the database 515 and the received first synthesized sound. By comparison, the second synthesized sound can be confirmed.
- the intelligent server 420as shown in 1001 of FIG. 10, the first speech included in the first synthesized sound 914 among a plurality of sounds 516 stored in the database 515 ( A second synthesized sound 1001 including an utterance (eg, a second utterance) corresponding to 913 may be identified.
- the second synthesized sound 1011is a plurality of pieces stored in the database 515 of the intelligent server 420 Among the sounds, it may be a synthesized sound including a user utterance of "volume up"
- the intelligent server 420(for example, the speech analysis module 512 of the at least one processor 511) the sound of the audible frequency band of the plurality of synthesized sounds 516 stored in the database 515 By comparing the sound of the audible frequency band of the first synthesized sound 914, the audible frequency band corresponding to the sound of the audible frequency band of the first synthesized sound 914 (for example, having the same or similarity equal to or greater than a preset value) A second synthesized sound 1011 having sound can be identified.
- the intelligent server 420compares semantic information of the plurality of synthesized sounds 516 stored in the database 515 with semantic information of the first synthesized sound 914 Thus, the second synthesized sound 1011 having semantic information corresponding to the semantic information of the first synthesized sound 914 may be identified.
- the intelligent server 420(eg, the speech comparison module 513 of the at least one processor 511) checks the similarity by comparing the first synthesized sound with the second synthesized sound in operation 807. Then, in operation 808, the similarity and the threshold may be compared. The degree of similarity between the first synthesized sound 914 and the second synthesized sound 1011 is determined by comparing the first synthesized sound 914 and the second synthesized sound 1011 with time-specific characteristics (eg, phonetic characteristics such as intensity). Can be confirmed by comparison. For example, the intelligent server 420 may compare the similarity between the first synthesized sound 914 and the second synthesized sound 1011 based on a linear analysis method. In addition, for example, the intelligent server 420, as shown in 1002 of FIG. 10, based on a nonlinear analysis method such as DTW, the similarity between the first synthesized sound 914 and the second synthesized sound 1011 Can be compared.
- a nonlinear analysis methodsuch as DTW
- the intelligent server 420may determine the electronic device 410 according to a comparison result of a similarity and a threshold value between the first synthesized sound and the second synthesized sound. It is possible to check whether the first utterance 913 received in is a stolen utterance. For example, if the similarity between the first synthesized sound 914 and the second synthesized sound is greater than or equal to the threshold value, the intelligent server 420 determines that the first utterance is not a stolen utterance, and the first synthesized sound and the second synthesized sound When the similarity between the synthesized sounds is less than the threshold value, the first utterance may be identified as a deodorized utterance.
- the similarity between the first synthesized sound 914 and the second synthesized sound 1011is determined by the sound 913 and the second synthesized sound 1011 in an inaudible frequency band of the first synthesized sound 914.
- whether the first utterance 913 is a hijacked utteranceis determined between the sound 912 of the inaudible frequency band of the first synthesized sound 914 and the sound of the inaudible frequency band of the second synthesized sound 1011 It can be determined based on the similarity of.
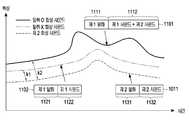
- the first synthesized sound 1101(first synthesized sound 914 in the case of deodorization) and the first synthesized sound 1101 disclosed in FIG. 11 for explaining different characteristics of the first synthesized sound 914 depending on whether or not deodorization
- the synthesized sound 1102(the first synthesized sound 914 if not stolen)
- the inaudible frequency band of the currently received first synthesized sound 914 according to whether the first utterance 913 is stolene.g. : 1112 or 1122
- itmay be determined whether or not at least two or more sounds are superimposed (eg, two or more sounds are superimposed in an inaudible frequency band when deodorizing).
- the degree of similarity between the first synthesized sound 914 and the second synthesized sound 1011may decrease according to whether at least two or more sounds are overlapped in the inaudible frequency band of the first synthesized sound 914.
- a synthesized sound selected for determining similarityis a second sound corresponding to a first utterance in an audible frequency band portion 1131. It may include speech and may include a second sound in the inaudible frequency band portion 1132.
- the synthesized sound 1101 comprising the hijacked utterancecomprises a first utterance in the audible frequency band portion 1111 and a second sound previously recorded by the hijacker in the inaudible frequency band portion 1112 and the current electronic device ( The first sound output through the speaker 501 of 410 may be included.
- the synthesized sound 1102 containing the utterances of the true userincludes the first utterance in the audible frequency band portion 1121 and through the speaker 501 of the current electronic device 410 in the inaudible frequency band portion 1122 It may include the output first sound.
- the intelligent server 420has a similarity k2 between the currently received synthesized sound 1101 and the second synthesized sound 1011. It can be identified as being below the threshold (i.e., determined by a captured ignition).
- the intelligent server 420since only the first sound currently output in the inaudible frequency band 1122 of the synthesized sound 1102 that does not include the deodorized speech exists, the inaudible frequency band 1122 of the synthesized sound 1102 ) And the inaudible frequency band 1132 of the second synthesized sound 1011 are maintained at a certain level, so that the intelligent server 420 has a similarity k1 between the synthesized sound 1102 and the second synthesized sound 1011. ) Is greater than or equal to the threshold (i.e., determined by a captured ignition).
- the threshold valuemay be set to determine whether to deodorize speech according to whether sounds overlap in an inaudible frequency band. That is, referring to FIG. 11, the similarity between the synthesized sound 1101 and the second synthesized sound 1011, which is found when the sound overlaps in the inaudible frequency band of the synthesized sound 1101 including the deodorized speech (
- the threshold valuemay be set higher than k2).
- the intelligent server 420processes to provide a service corresponding to the first utterance based on the result of comparing the similarity and the threshold value in operation 809. Result information can be obtained.
- the intelligent server 420may include various types of processing result information depending on whether the first speech 913 is a stolen speech. .
- the intelligent server 420may be ) Process (e.g., processing using the natural language platform 514 described above), and obtain processing result information including information (e.g., UI/UX, etc.) for providing a service corresponding to the first speech. have. Since the operation of acquiring the processing result information may be performed in the same manner as the operation based on the natural language platform 514 described above, a duplicate description will be omitted.
- the intelligent server 420(for example, at least one processor 511) may be ) Can generate information to indicate that the service cannot be provided.
- the intelligent server 420may transmit processing result information to the electronic device 410 in operation 810 as illustrated in 1003 of FIG. 10. .
- the processing result information including information (eg, UI/UX, etc.) for providing a service corresponding to the first speech 913is received from the intelligent server 420 and the first speech ( 913) can be provided.
- the electronic device 410may display a UI/UX for providing today's weather information in response to a currently received speech (eg, how is today's weather). .
- the electronic device 410receives information indicating that the first utterance 913 is a stolen speech. can do.
- the electronic device 410may display a notification message on the execution screen of the intelligent voice service application based on the received information.
- the notification messagemay include a graphic object (eg, text, image, etc.) for indicating that the currently received speech is a stolen speech, or a graphic object for re-requesting the speech.
- the electronic device 410may re-request the utterance including a specific keyword to re-check whether the user is true or not. This will be described later with reference to FIGS. 22 to 24.
- the electronic device 410may randomly output sound having an inaudible frequency band.
- the electronic device 410may control the speaker 501 to output a sound having an inaudible frequency band generated based on different data whenever sound having an inaudible frequency band is output.
- the intelligent server 420receives from the electronic device 410 synthesized sounds, each of which includes sounds having an inaudible frequency band randomly output from the electronic device 410, and receives the received synthesized sounds from the database ( 515).
- FIG. 12is a flowchart 1200 illustrating another example of operations of the electronic device 410 and the intelligent server 420 according to various embodiments. According to various embodiments, the operations illustrated in FIG. 12 are not limited to the illustrated order and may be performed in various orders. Further, according to various embodiments, more operations may be performed than the operations illustrated in FIG. 12, or at least one less operation may be performed. Hereinafter, FIG. 12 will be described with reference to FIGS. 13 to 14.
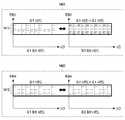
- FIG. 13is a diagram illustrating an example of an operation of outputting a sound having an inaudible frequency band of the electronic device 410 according to various embodiments.
- a "+" symbolindicates that each sound is combined and received by the microphone 502 of the electronic device.
- 14is a diagram illustrating an example of an inaudible frequency band of a captured speech when randomly outputting a sound having an inaudible frequency band according to various embodiments. "-" shown in the graph of FIG. 14 may indicate the intensity at the characteristic frequency for each time.
- the electronic device 410executes an intelligent voice service application in operation 1201, and the first sound 1312 having an inaudible frequency band in operation 1202. Can be output through the microphone 502.
- the electronic device 410may include at least one first data 1311 (eg, first text data) among a plurality of data 504 during execution of an intelligent voice service application. And second text data), and control the speaker 501 to generate and output the first sound 1312 having an inaudible frequency band based on the obtained at least one first data 1311. .
- the electronic device 410(for example, at least one processor 505), as shown in 1302 of FIG. 13 in operation 1203, has a first utterance 1313 and an inaudible frequency band.
- a first synthesized sound 1314 including one sound 1312may be obtained, and information on the first synthesized sound 1314 may be transmitted to the intelligent server 420 in operation 1204. Since operations 1203 and 1204 of the electronic device 410 may be performed in the same manner as operations 903 to 905 of the electronic device 410 described above, redundant descriptions will be omitted.
- the intelligent server 420may store the second synthesized sound 1318 in the database 515 in operation 1305.
- the electronic device 410executes an intelligent voice service application in operation 1206 and the first sound 1312 having an inaudible frequency band in operation 1207. Can be output through the microphone 502.
- the electronic device 410may perform at least one second data 1315 (eg, third text data and fourth data) among a plurality of pieces of data during execution of the intelligent voice service application. Text data), and generating and outputting a second sound 1316 having an inaudible frequency band based on the at least one second data 1315 obtained as shown in 1304 of FIG. 13. ) Can be controlled.
- the first sound 1312 having an inaudible frequency band output from the electronic device 410 and the second sound 1316 having an inaudible frequency bandmay be different from each other.
- the first sound 1312 and the second sound 1316may be sounds having different phonetic characteristics in an inaudible frequency band.
- the first sound 1312 and the second sound 1316may be sounds having different intensities for each inaudible frequency band. That is, the first sound 1312 may be a sound having a first intensity in an inaudible frequency band of the first band, and the second sound 1316 may be a sound having a second intensity in the inaudible frequency band of the first band. have.
- the first sound 1312 and the second sound 1316may be sounds having different inaudible frequency bands. That is, the first sound 1312 may be a sound having an inaudible frequency band of the first band, and the second sound 1316 may be a sound having an inaudible frequency band of a second band different from the first band.
- the first sound 1312 and the second sound 1316may be sounds having different intensities in different inaudible frequency bands. That is, the first sound 1312 is a sound having a first intensity in an inaudible frequency band of the first band, and the second sound 1316 is a second intensity in an inaudible frequency band of a second band different from the first band. It may be a sound with.
- the first sound 1312 and the second sound 1316may have different phonetic characteristics in an audible frequency band other than the inaudible frequency band.
- the first sound 1312may be a music sound from a first sound source
- the second sound 1316may be a music sound from a second sound source.
- each time the electronic device 410(for example, at least one processor 505) outputs a sound having an inaudible frequency band
- a plurality of data 504 stored in the memory 503At least one piece of data may be obtained at random from among them.
- the electronic device 410may output sounds having different inaudible frequency bands based on at least one randomly acquired data among the plurality of data 504.
- the electronic device 410(eg, at least one processor 505) manages and/or stores the usage history of data, and uses managed data among a plurality of data 504. By selecting data based on the history, sound having an inaudible frequency band can be generated.
- the electronic device 410stores identification information for each of a plurality of pieces of data 504, and includes identification numbers of data used to generate a sound going in an inaudible frequency band among the plurality of pieces of data 504. Information indicating whether to use or not can be stored.
- the electronic device 410When generating a sound having an inaudible frequency band, the electronic device 410 checks the identification number stored for each of the plurality of data 504 and information indicating whether to use it, and uses it before among the plurality of data 504 You can check the data you did not. The electronic device 410 generates a sound having an inaudible frequency band based on the identified previously unused data, thereby generating a sound having a previously output inaudible frequency band (for example, the first sound 1312). A sound having an inaudible frequency band different from that (eg, the second sound 1316) may be output.
- the electronic device 410(eg, at least one processor 505) includes a first speech 1313 and a first sound 1312 having an inaudible frequency band.
- the synthesized sound 1314may be obtained, and information on the first synthesized sound 1314 may be transmitted to the intelligent server 420 in operation 1209.
- the intelligent server 420may store the second synthesized sound 1318 in the database 515 in operation 1310.
- the electronic device 410includes a second sound 1316 and a second speech 1317 having an inaudible frequency band currently output through the speaker 501, as shown in 1304 of FIG. 13.
- the second synthesized sound 1318may be acquired, and the obtained second synthesized sound 1318 may be transmitted to the intelligent server 420 so that the intelligent server 420 may store the second synthesized sound 1318.
- the electronic device 410randomly has a sound having an inaudible frequency band (for example, the first sound 1312 and the second sound 1316). As is output, the accuracy of the detection operation of whether or not the currently received utterance is stolen may be improved.
- the type of sound (that is, overlapping) in the inaudible frequency band (1411 or 1412) of the synthesized soundfor example, the second synthesized sound
- the similarity between the currently received synthesized sound (eg, the second synthesized sound) and the previously stored synthesized sound (eg, the first synthesized sound)may significantly differ.
- the inaudible frequency band 1411 of the second synthesized sound including the captured speechincludes different sounds (eg, the first sound 1312 and the second sound 1316).
- the similarity between the sound in the inaudible frequency band 1411 of the previously stored first synthesized sound and the inaudible frequency band 1411 of the second synthesized soundmay be significantly lowered.
- a first synthesized sound previously storedincludes a first sound 1312 having a first inaudible frequency band
- the second synthesized soundincludes a first sound 1312 having a first inaudible frequency band
- a second sound 1316 having a second inaudible frequency bandmay be included.
- a first synthesized sound previously storedincludes a first sound 1312 having a first inaudible frequency band
- a second synthesized soundincludes a first sound having a first intensity in a first non-audible frequency band.
- the sound 1312 and the second sound 1316 having a second intensity in the first non-audible frequency bandmay be included.
- the same soundsoverlap each other in the inaudible frequency band 1412 shown in 1402 of FIG.
- the similarity between the first synthesized sound and the second synthesized soundmay be relatively low compared to the similarity in the case of the case.
- the electronic device 410may randomly acquire data from among a plurality of data based on various variables, and output sounds of different inaudible frequency bands based on the randomly acquired data. have.
- FIG. 15is a flowchart 1500 for explaining an example of an operation of randomly outputting a sound having an inaudible frequency band by the electronic device 410 according to various embodiments.
- the operations illustrated in FIG. 15are not limited to the illustrated order and may be performed in various orders. Further, according to various embodiments, more operations may be performed, or at least one less operation may be performed than the operations illustrated in FIG. 15.
- FIG. 15will be described with reference to FIGS. 16 to 18.
- 16is a diagram for describing an example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
- 17is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
- 18is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
- the electronic device 410may execute an intelligent voice service application in operation 1501. Since operation 1501 of the electronic device 410 may be performed similarly to operation 801 of the electronic device 410 described above, a redundant description will be omitted.
- the electronic device 410(for example, at least one processor 505) checks at least one parameter among various types of parameters in operation 1502 and determines a value related to the identified at least one variable. Then, text data may be obtained based on a value associated with at least one variable identified in operation 1503. For example, whenever the electronic device 410 outputs a sound having an inaudible frequency band, the electronic device 410 checks at least one parameter among various types of parameters, and sets a value related to the identified parameter to a value different from the previous one. By changing, text data can be obtained based on the changed value. In other words, in order to improve the accuracy of the operation of detecting whether the received utterance is a stolen utterance, the electronic device 410 outputs a sound having a different inaudible frequency band. Can be output.
- the various kinds of parametersare used for selecting data for generating sounds having an inaudible frequency band so that similarity between sounds having an inaudible frequency band output from an electronic device is lowered.
- various types of parametersmay include the number of acquired data, a data group having one characteristic from which data is acquired, and the like.
- the electronic devicemay store values related to various types of parameters and refer to values related to various types of parameters whenever sound having an inaudible frequency band is output. For example, if the parameter is the number of data, the electronic device stores the number of data previously acquired to output a sound having an inaudible frequency, and then stores the number of data previously acquired each time a sound having an inaudible frequency band is output. You can check the number of data and make the number of previously acquired data different from the number of currently acquired data.
- the electronic device 410eg, at least one processor 505 outputs sound having an inaudible frequency band, as shown in FIG. 16, it checks the number of data as a parameter and , Data may be acquired with a number different from the number of previously acquired data.
- the electronic device 410acquires a first number (eg, two) of text data (eg, first to second text data) among a plurality of data 1601 stored as illustrated in FIG. 16.
- a first synthesized soundmay be output based on the acquired first number of text data.
- the electronic deviceWhen generating a second synthesized sound after outputting the first synthesized sound, the electronic device includes a second number (eg, three) of text data different from the previously acquired first number among a plurality of stored data 1601 (Eg, first to third text data) may be acquired and a second synthesized sound may be output based on the acquired second number of text data.
- a second numbereg, three
- a second synthesized soundmay be output based on the acquired second number of text data.
- the electronic device 410(eg, at least one processor 505) stores a plurality of text data groups 1701 and 1702 having different characteristics, as shown in FIG. Whenever sound having a blue frequency band is output, text data may be obtained from different text data groups.
- the different characteristicsmay include the length of the text and a frequency band related to the text.
- the electronic device 410may store a text data group related to a first length and a text data group related to a second length.
- the text data group related to the specific lengthmay mean a group including texts of a specific length as well as texts of a specific length range.
- the electronic devicemay obtain at least one text data (eg, a1a1a1, a2a2a2) from a text data group (eg, 1701) related to the first length, and output a first synthesized sound based on the obtained at least one text data. have.
- the electronic deviceacquires at least one text data (eg, b1b1b1, b2b2b2) from a text data group (eg, 1702) related to the second length when generating a second synthesized sound after outputting the first synthesized sound, and A second synthesized sound may be output based on at least one piece of text data. Accordingly, when the two synthesized sounds are compared, the similarity between the sound in the inaudible frequency band included in one synthesized sound and the sound in the inaudible frequency band included in the synthesized sound including the deodorized speech may be significantly lowered. This has been described above with reference to FIG. 14, so a redundant description will be omitted.
- a redundant descriptionwill be omitted.
- the electronic device 410may store a text data group related to a first frequency band and a text data group related to a second frequency band.
- the text data group related to the specific frequency bandmay mean that the corresponding sound has a specific frequency band when texts included in the text data group are converted to sound.
- the electronic deviceobtains at least one text data (eg, a1a1a1, a2a2a2) from a text data group (eg, 1701) related to the first frequency band, and outputs a first synthesized sound based on the obtained at least one text data.
- a1a1a1, a2a2a2a2eg, 1701
- the electronic deviceobtains and acquires at least one text data (eg, b1b1b1, b2b2b2) from a text data group (eg, 1702) related to the second frequency band when generating a second synthesized sound after outputting the first synthesized sound.
- a second synthesized soundmay be output based on the at least one piece of text data. Accordingly, when the two synthesized sounds are compared, the similarity between the sound in the inaudible frequency band included in one synthesized sound and the sound in the inaudible frequency band included in the synthesized sound including the deodorized speech may be significantly lowered. This has been described above with reference to FIG. 14, so a redundant description will be omitted.
- the electronic device 410(eg, at least one processor 505) stores a plurality of text data groups 1801, 1802, 1803 having different characteristics, as shown in FIG. 18
- datamay be obtained from different text data groups with a number different from the number of previously obtained data.
- the electronic device 410(for example, at least one processor 505) outputs a sound having an inaudible frequency band based on text data obtained in operation 1504, and utters a user in operation 1505. And a synthesized sound based on sound having an inaudible frequency band. Since operations 1504 and 1505 of the electronic device 410 may be performed in the same manner as operations 802 to 803 of the electronic device 410 described above, a duplicate description will be omitted.
- the intelligent server 420may compare only sounds of an inaudible frequency band included in the two synthesized sounds.
- FIG. 19is a flowchart 1800 for explaining an example of an operation of the intelligent server 420 according to various embodiments.
- the operations illustrated in FIG. 19are not limited to the illustrated order and may be performed in various orders. Further, according to various embodiments, more operations may be performed than the operations illustrated in FIG. 19, or at least one less operation may be performed.
- FIG. 19will be described with reference to FIG. 20.
- FIG. 20is a diagram illustrating an example of an operation of an intelligent server 420 according to various embodiments. "-" shown in the graph of FIG. 20 may indicate the intensity at the characteristic frequency for each time.
- the intelligent server 420obtains a first synthesized sound in operation 1901 and checks a second synthesized sound corresponding to the first synthesized sound in operation 1902. I can. Since operations 1901 and 1902 of the intelligent server 420 may be performed in the same manner as operations 805 and 806 of the intelligent server 420 described above, a duplicate description will be omitted.
- the intelligent server 420obtains a first synthesized sound in operation 1901 and a second synthesized sound corresponding to the first synthesized sound in operation 1902. I can confirm. Since operations 1901 and 1902 of the intelligent server 420 may be performed in the same manner as operations 805 and 806 of the intelligent server 420 described above, a duplicate description will be omitted.
- the intelligent server 420may compare the inaudible frequency band of the first synthesized sound and the inaudible frequency band of the second synthesized sound in operation 1903. .
- the intelligent server 420includes an inaudible frequency band 2001 of the first synthesized sound (for example, a first non-audible frequency band) and an inaudible frequency of the second synthesized sound.
- the band 2001(for example, the second inaudible frequency band) is compared, and the degree of similarity can be checked according to whether or not the inaudible frequency bands of each synthesized sound match.
- the intelligent server 420may have a sound intensity (eg, first sound intensity) of the inaudible frequency band 2001 of the first synthesized sound and the inaudible frequency band 2001 of the second synthesized sound.
- the sound intensityeg, the second sound intensity
- the similaritymay be determined according to whether the sound intensity of the inaudible frequency band of each synthesized sound is similar.
- the intelligent server 420may check similarity by comparing the inaudible frequency band of each synthesized sound and the sound intensity of the non-audible frequency band coincident with each other.
- the intelligent server 420may only provide a specific frequency band among the inaudible frequency bands of two synthesized sounds (e.g., the first synthesized sound and the second synthesized sound). You can compare the sound of For example, when a specific type of speaker is provided in the electronic device 410 (eg, a general speaker or an ultra sonic sound speaker), an available non-audible frequency band may vary according to the type of speaker 501. In other words, the electronic device 410 corresponds to the type of the speaker 501 provided in the electronic device 410 (that is, based on the type of speaker 501) when comparing the sound in the inaudible frequency band of the two synthesized sounds. It is possible to compare only the sounds of a specific frequency band). As described above, as the sound of only a specific frequency band is compared among the inaudible frequency bands, the operational burden of the intelligent server 420 for comparing sounds of other frequency bands may be reduced.
- the intelligent server 420checks only the sound in the stored inaudible frequency band and It is possible to check whether the utterance included in the synthesized sound is a deodorant utterance.
- the intelligent server 420may store only sound in an inaudible frequency band previously output from the electronic device 410 in the database 515.
- the intelligent server 420receives the synthesized sound from the electronic device 410, the intelligent server 420 corresponds to the first sound in the non-audible frequency band included in the received synthesized sound among sounds of a plurality of non-audible frequency bands (the same or , It is possible to check whether or not the second sound in the inaudible frequency band) has a similarity greater than or equal to a preset value.
- the intelligent server 420may determine that the utterance included in the currently received synthesized sound is the utterance that has not been captured.
- the intelligent server 420compares only the sound in the inaudible frequency band, only the sound in the inaudible frequency band is stored in the database 515.
- the operational burden for storing various types of synthetic sounds in the basscan be alleviated.
- the intelligent server 420may obtain processing result information for providing a service corresponding to the first utterance based on the comparison result in operation 1904. I can. Since operation 1904 of the intelligent server 420 may be performed as the operation 809 of the intelligent server 420 described above, a duplicate description will be omitted.
- the operational burden of the intelligent server 420 required to perform an operation of comparing the two synthesized soundscan be reduced.
- the electronic devicemay request the speech including a specific keyword.
- the electronic devicemay determine whether or not the authenticity of a user providing the current utterance is based on a result of comparing the received synthesized sound including the utterance including the specific keyword and the synthesized sound associated with the specific keyword previously stored.
- FIG. 21is a flowchart 2100 illustrating still another example of operations of an electronic device and an external electronic device according to various embodiments.
- the operations illustrated in FIG. 21are not limited to the illustrated order and may be performed in various orders. Further, according to various embodiments, more operations may be performed, or at least one less operation may be performed than the operations illustrated in FIG. 21.
- FIG. 21will be described with reference to FIGS. 22 to 23.
- FIG. 22is a diagram for describing still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- a "+" symbolindicates that each sound is combined and received by the microphone 502 of the electronic device.
- 23is another diagram for describing still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
- the electronic device 410obtains the first synthesized sound 2213 in operation 2101, and the first synthesized sound 2213 obtained in operation 2102. May be transmitted to the intelligent server 420.
- the electronic device 410includes a first sound 2211 and a first utterance 2212 having an inaudible frequency band received through the microphone 502 as shown in 2201 of FIG. 22.
- One synthesized sound 2213may be obtained, and information on the first synthesized sound 2213 may be transmitted to the intelligent server 420 as shown in 2202 of FIG. 22. Since operations 2101 and 2102 of the electronic device 410 may be performed in the same manner as operations 801 to 805 of the electronic device 410 described above, redundant descriptions will be omitted.
- the intelligent server 420(eg, at least one processor 511) is based on the first synthesized sound 2213 received in operation 2103, as shown in 2203 of FIG. Whether an error event related to the first synthesized sound 2213 received by the device 410 has occurred may be detected.
- the error event related to the first synthesized sound 2213is when the first speech 2212 included in the first synthesized sound 2213 is identified as a stolen speech, or the intelligent server 420 This may include a case where it is determined that there is no synthesized sound corresponding to the first synthesized sound 2213 in the database 515 of. In other words, when the first speech 2212 included in the first synthesized sound 2213 is a captured speech, the intelligent server 420 may confirm that an error event related to the first synthesized sound 2213 occurs. In addition, when the intelligent server 420 determines that there is no synthesized sound corresponding to the first synthesized sound 2213 in the database 515, it can be confirmed that an error event occurs.
- the intelligent server 420(for example, at least one processor 511) checks the second synthesized sound corresponding to the first synthesized sound 2213, and synthesizes the first synthesized sound 2213 and the second synthesized sound. It is possible to determine whether the first speech 2212 included in the first synthesized sound 2213 is a captured speech by comparing the similarity of the sound.
- the operation of determining whether the first utterance 2212 of the intelligent server 420 is a hijacked utterancemay be performed in the same manner as operations 806 to 809 of the intelligent server 420 described above, and thus a duplicate description will be omitted.
- the intelligent server 420(eg, at least one processor 511) checks a synthesized sound corresponding to the first synthesized sound 2213 among a plurality of sounds stored in the database 515 Then, it can be confirmed that there is no synthesized sound corresponding to the first synthesized sound 2213 based on the check operation. For example, as the electronic device 410 first receives the first utterance 2212, the database 515 of the intelligent server 420 does not store the synthesized sound including the utterance corresponding to the first utterance 2212. May not.
- the intelligent server 420may transmit result information according to whether an error event occurs in operation 2014 to the electronic device 410.
- the result informationmay include information indicating that an error event related to the first synthesized sound 2213 occurs.
- the electronic device 410requests a second utterance 2213 including a specific keyword in operation 2015 as shown in 2204 of FIG. ,
- a second speech 2213may be obtained, and a second synthesized sound may be obtained based on the second sound 2211 having an inaudible frequency band.
- a second utterance 2213 including a keywordmay be requested.
- the specific keywordmay include a keyword for calling an intelligent voice service application (eg, Hi Bixby), a user's name, or other preset keyword.
- the electronic device 410(for example, at least one processor 505) transmits a second sound 2211 having an inaudible frequency band with a speech including a specific keyword through the microphone 502. You can receive it through. For example, as shown in 2104 of FIG. 21, the electronic device 410 displays a notification message for requesting a keyword for calling an intelligent voice service application, and rains through the speaker 501 while the notification message is displayed. A second sound 2211 having a blue frequency band may be output. The electronic device 410 may receive a second speech 2213 including a specific keyword and a second sound 2211 output through the speaker 501 through the microphone 502.
- the electronic device 410may transmit the second synthesized sound obtained in operation 2107 to the intelligent server 420.
- the intelligent server 420compares the second synthesized sound in operation 2108 with a third synthesized sound previously stored related to a specific keyword, and compares in operation 2109. Based on the results, the identified similarity and threshold can be compared. For example, the intelligent server 420 identifies a third synthesized sound including a specific keyword among a plurality of sounds 516 stored in the database 515 as shown in 2301 of FIG. 23, and As shown in 2302, a similarity between a third synthesized sound including a specific keyword and a currently received synthesized sound may be checked. Since operations 2108 and 2109 of the intelligent server 420 may be performed in the same manner as operations 806 to 808 of the intelligent server 420 described above, a duplicate description will be omitted.
- the database 515 of the intelligent server 420may store a synthesized sound including a speech including the above-described specific keyword and a sound having an inaudible frequency band.
- the electronic device 410initially executes an intelligent voice service application, through the microphone 502, the user's speech including a specific keyword and a synthesized sound including sound having an inaudible frequency band are obtained, and acquired.
- the synthesized soundmay be transmitted to the intelligent server 420.
- the intelligent server 420may store the synthesized sound including the user's speech including the received specific keyword in the database 515.
- the user's utterance including a specific keywordis stored in the database 515 of the intelligent server 420 in advance, it may be determined whether the user is a hijacker according to a request for the utterance including the specific keyword.
- the intelligent server 420(for example, at least one processor 511) provides processing result information for providing a service corresponding to the first utterance 2212 based on the comparison result in operation 2110. It is obtained, and in operation 2111, the processing result information may be transmitted to the electronic device 410.
- the intelligent server 420transmits the processing result information as shown in 2303 of FIG. 23, and the electronic device 410 is based on the received processing result information as shown in 2304 of FIG. 1
- a service corresponding to the utterance 2212can be provided.
- Operations 2110 and 2111 of the intelligent server 420may be performed in the same manner as operations 809 and 810 of the intelligent server 420 described above, and thus redundant descriptions will be omitted.
- the accuracy of the operation of confirming the authentic useris improved by re-requesting the utterance including a specific keyword and reconfirming whether the user is a hijacker.
- the deodorization of the ignitioncan be accurately confirmed by reconfirming whether the ignition is deodorized
- the electronic device 410may obtain the synthesized sound and determine whether the utterance included in the synthesized sound is a stolen speech based on a plurality of sounds stored in the database of the electronic device 410. have.
- FIG. 24is a flowchart 2300 for describing another example of an operation of the electronic device 410 according to various embodiments.
- the operations illustrated in FIG. 24are not limited to the illustrated order and may be performed in various orders. In addition, according to various embodiments, more operations than the operations illustrated in FIG. 24 may be performed, or at least one less operation may be performed.
- the electronic device 410executes an intelligent voice service application in operation 2401, and transmits a first sound having an inaudible frequency band to a microphone 502 in operation 2402. ), and receiving the first speech through the microphone 502 during execution of the intelligent voice service application in operation 2403, and receiving the first speech in operation 2404 and the first sound based on the first sound having an inaudible frequency band. Synthetic sound can be obtained. Since operations 2401 to 2404 of the electronic device 410 may be performed as operations 801 to 804 of the electronic device 410, redundant descriptions will be omitted.
- the electronic device 410in operation 2405, the electronic device 410 (eg, at least one processor 505) checks a second synthesized sound related to the first speech among a plurality of sounds stored in the memory 503, In operation 2406, the first synthesized sound and the second synthesized sound are compared to determine a similarity, and whether the similarity determined in operation 2407 is greater than or equal to a threshold value may be determined. Since operations 2405 to 2407 of the electronic device 410 may be performed as operations 805 to 807 of the intelligent server 420, redundant descriptions will be omitted. In other words, the electronic device 410 includes the above-described database and may check whether the currently received first utterance is a hijacked utterance based on a plurality of sounds stored in the database.
- the electronic device 410(for example, at least one processor 505) transmits the first speech to the intelligent server 420 in operation 2408, and receives processing result information from the intelligent server 420. can do. For example, when it is determined that the first utterance is not the stolen utterance, the electronic device 410 transmits the first utterance to the intelligent server 420 and provides a service for the first utterance from the intelligent server 420 It is possible to receive processing result information for processing.
- the configuration of the electronic device 410 and the intelligent server 420may be implemented as the configuration of the electronic device 2501 in the network environment 2500 described below.
- 25is a block diagram of an electronic device 2501 in a network environment 2500 according to various embodiments.
- the electronic device 2501communicates with the electronic device 2502 through a first network 2598 (for example, a short-range wireless communication network) or a second network 2599. It is possible to communicate with the electronic device 2504 or the server 2508 through (eg, a long-distance wireless communication network).
- the electronic device 2501may communicate with the electronic device 2504 through the server 2508.
- the electronic device 2501includes a processor 2520, a memory 2530, an input device 2550, an audio output device 2555, a display device 2560, an audio module 2570, and a sensor module ( 2576), interface 2577, haptic module 2579, camera module 2580, power management module 2588, battery 2589, communication module 2590, subscriber identification module 2596, or antenna module 2597 ) Can be included.
- at least one of these components(for example, the display device 2560 or the camera module 2580) may be omitted or one or more other components may be added to the electronic device 2501.
- some of these componentsmay be implemented as one integrated circuit.
- the sensor module 2576eg, a fingerprint sensor, an iris sensor, or an illuminance sensor
- the display device 2560eg, a display.
- the processor 2520for example, executes software (eg, a program 2540) to implement at least one other component (eg, a hardware or software component) of the electronic device 2501 connected to the processor 2520. It can be controlled and can perform various data processing or operations. According to an embodiment, as at least part of data processing or operation, the processor 2520 may transfer commands or data received from other components (eg, the sensor module 2576 or the communication module 2590) to the volatile memory 2532. The command or data stored in the volatile memory 2532 may be processed, and result data may be stored in the nonvolatile memory 2534.
- softwareeg, a program 2540
- the processor 2520may transfer commands or data received from other components (eg, the sensor module 2576 or the communication module 2590) to the volatile memory 2532.
- the command or data stored in the volatile memory 2532may be processed, and result data may be stored in the nonvolatile memory 2534.
- the processor 2520includes a main processor 2521 (eg, a central processing unit or an application processor), and a coprocessor 2523 (eg, a graphics processing unit, an image signal processor) that can be operated independently or together. , A sensor hub processor, or a communication processor). Additionally or alternatively, the coprocessor 2523 may be configured to use less power than the main processor 2521 or to be specialized for a designated function.
- the secondary processor 2523may be implemented separately from the main processor 2521 or as a part thereof.
- the coprocessor 2523is, for example, in place of the main processor 2521 while the main processor 2521 is in an inactive (eg, sleep) state, or the main processor 2521 is active (eg, an application is executed). ) While in the state, together with the main processor 2521, at least one of the components of the electronic device 2501 (for example, the display device 2560, the sensor module 2576, or the communication module 2590) It is possible to control at least some of the functions or states related to. According to an embodiment, the coprocessor 2523 (eg, an image signal processor or a communication processor) may be implemented as part of another functionally related component (eg, a camera module 2580 or a communication module 2590). have.
- the memory 2530may store various data used by at least one component of the electronic device 2501 (for example, the processor 2520 or the sensor module 2576).
- the datamay include, for example, software (eg, the program 2540) and input data or output data for commands related thereto.
- the memory 2530may include a volatile memory 2532 or a nonvolatile memory 2534.
- the program 2540may be stored as software in the memory 2530 and may include, for example, an operating system 2542, middleware 2544, or an application 2546.
- the input device 2550may receive a command or data to be used for a component of the electronic device 2501 (eg, the processor 2520) from an external device (eg, a user) of the electronic device 2501.
- the input device 2550may include, for example, a microphone, a mouse, a keyboard, or a digital pen (eg, a stylus pen).
- the sound output device 2555may output an sound signal to the outside of the electronic device 2501.
- the sound output device 2555may include, for example, a speaker or a receiver.
- the speakercan be used for general purposes such as multimedia playback or recording playback, and the receiver can be used to receive incoming calls. According to one embodiment, the receiver may be implemented separately from the speaker or as part of it.
- the display device 2560may visually provide information to the outside of the electronic device 2501 (eg, a user).
- the display device 2560may include, for example, a display, a hologram device, or a projector and a control circuit for controlling the device.
- the display device 2560may include a touch circuitry set to sense a touch, or a sensor circuit (eg, a pressure sensor) set to measure the strength of a force generated by the touch. have.
- the audio module 2570may convert sound into an electrical signal, or conversely, may convert an electrical signal into sound. According to an embodiment, the audio module 2570 acquires sound through the input device 2550, the sound output device 2555, or an external electronic device (for example, an external electronic device directly or wirelessly connected to the electronic device 2501). Sound may be output through the electronic device 2502) (for example, a speaker or headphones).
- the sensor module 2576detects an operating state (eg, power or temperature) of the electronic device 2501, or an external environmental state (eg, a user state), and generates an electrical signal or data value corresponding to the detected state. can do.
- the sensor module 2576includes, for example, a gesture sensor, a gyro sensor, an atmospheric pressure sensor, a magnetic sensor, an acceleration sensor, a grip sensor, a proximity sensor, a color sensor, an infrared (IR) sensor, a biometric sensor, It may include a temperature sensor, a humidity sensor, or an illuminance sensor.
- the interface 2577may support one or more designated protocols that may be used to connect the electronic device 2501 directly or wirelessly to an external electronic device (eg, the electronic device 2502 ).
- the interface 2577may include, for example, a high definition multimedia interface (HDMI), a universal serial bus (USB) interface, an SD card interface, or an audio interface.
- HDMIhigh definition multimedia interface
- USBuniversal serial bus
- SD card interfaceSecure Digital Card
- connection terminal 2578may include a connector through which the electronic device 2501 can be physically connected to an external electronic device (eg, the electronic device 2502).
- the connection terminal 2578may include, for example, an HDMI connector, a USB connector, an SD card connector, or an audio connector (eg, a headphone connector).
- the haptic module 2579may convert an electrical signal into a mechanical stimulus (eg, vibration or movement) or an electrical stimulus that a user can perceive through a tactile or motor sense.
- the haptic module 2579may include, for example, a motor, a piezoelectric element, or an electrical stimulation device.
- the camera module 2580may capture a still image and a video.
- the camera module 2580may include one or more lenses, image sensors, image signal processors, or flashes.
- the power management module 2588may manage power supplied to the electronic device 2501. According to an embodiment, the power management module 2588 may be implemented as at least a part of a power management integrated circuit (PMIC), for example.
- PMICpower management integrated circuit
- the battery 2589may supply power to at least one component of the electronic device 2501.
- the battery 2589may include, for example, a non-rechargeable primary cell, a rechargeable secondary cell, or a fuel cell.
- the communication module 2590is a direct (eg, wired) communication channel or a wireless communication channel between the electronic device 2501 and an external electronic device (eg, electronic device 2502, electronic device 2504, or server 2508). It is possible to support establishment and communication through the established communication channel.
- the communication module 2590operates independently of the processor 2520 (eg, an application processor) and may include one or more communication processors supporting direct (eg, wired) communication or wireless communication.
- the communication module 2590is a wireless communication module 2592 (eg, a cellular communication module, a short-range wireless communication module, or a global navigation satellite system (GNSS) communication module) or a wired communication module 2594 (eg : A LAN (local area network) communication module, or a power line communication module) may be included.
- a corresponding communication moduleis a first network 2598 (for example, a short-range communication network such as Bluetooth, WiFi direct or IrDA (infrared data association)) or a second network 2599 (for example, a cellular network, the Internet, or It can communicate with external electronic devices through a computer network (for example, a telecommunication network such as a LAN or WAN).
- the wireless communication module 2592uses subscriber information stored in the subscriber identification module 2596 (eg, International Mobile Subscriber Identifier (IMSI)) within a communication network such as the first network 2598 or the second network 2599.
- IMSIInternational Mobile Subscriber Identifier
- the electronic device 2501may be checked and authenticated.
- the antenna module 2597may transmit a signal or power to the outside (eg, an external electronic device) or receive from the outside.
- the antenna modulemay include one antenna including a conductor formed on a substrate (eg, a PCB) or a radiator formed of a conductive pattern.
- the antenna module 2597may include a plurality of antennas. In this case, at least one antenna suitable for a communication method used in a communication network such as the first network 2598 or the second network 2599 is, for example, provided by the communication module 2590 from the plurality of antennas. Can be chosen. Signal or power may be transmitted or received between the communication module 2590 and an external electronic device through the at least one selected antenna.
- other componentseg, RFIC
- other than the radiatormay be additionally formed as part of the antenna module 2597.
- At least some of the componentsare connected to each other through a communication method (e.g., a bus, general purpose input and output (GPIO), serial peripheral interface (SPI), or mobile industry processor interface (MIPI))) between peripheral devices and signals ( E.g. commands or data) can be exchanged with each other.
- a communication methode.g., a bus, general purpose input and output (GPIO), serial peripheral interface (SPI), or mobile industry processor interface (MIPI)
- GPIOgeneral purpose input and output
- SPIserial peripheral interface
- MIPImobile industry processor interface
- commands or datamay be transmitted or received between the electronic device 2501 and an external electronic device 2504 through the server 2508 connected to the second network 2599.
- Each of the electronic devices 2502 and 2504may be the same or different types of devices as the electronic device 2501.
- all or some of the operations executed by the electronic device 2501may be executed by one or more of the external electronic devices 2502, 2504, or 2508.
- the electronic device 2501needs to perform a function or service automatically or in response to a request from a user or another device, the electronic device 2501 does not execute the function or service by itself.
- One or more external electronic devices receiving the requestmay execute at least a part of the requested function or service, or an additional function or service related to the request, and transmit a result of the execution to the electronic device 2501.
- the electronic device 2501may process the result as it is or additionally and provide it as at least part of a response to the request.
- cloud computing, distributed computing, or client-server computing technologyCan be used.
- Electronic devicesmay be devices of various types.
- the electronic devicemay include, for example, a portable communication device (eg, a smart phone), a computer device, a portable multimedia device, a portable medical device, a camera, a wearable device, or a home appliance.
- a portable communication deviceeg, a smart phone
- a computer devicee.g., a smart phone
- a portable multimedia devicee.g., a portable medical device
- a camerae.g., a portable medical device
- a camerae.g., a portable medical device
- a camerae.g., a portable medical device
- a wearable devicee.g., a smart bracelet
- phrases such as “at least one of, B, or C”may include any one of the items listed together in the corresponding one of the phrases, or all possible combinations thereof.
- Terms such as “first”, “second”, or “first” or “second”may be used simply to distinguish the component from other corresponding components, and the components may be referred to in other aspects (eg, importance or Order) is not limited.
- Some (eg, first) componentis referred to as “coupled” or “connected” to another (eg, second) component, with or without the terms “functionally” or “communicatively”. When mentioned, it means that any of the above components can be connected to the other components directly (eg by wire), wirelessly, or via a third component.
- moduleused in this document may include a unit implemented in hardware, software, or firmware, and may be used interchangeably with terms such as logic, logic blocks, parts, or circuits.
- the modulemay be an integrally configured component or a minimum unit of the component or a part thereof that performs one or more functions.
- the modulemay be implemented in the form of an application-specific integrated circuit (ASIC).
- ASICapplication-specific integrated circuit
- Various embodiments of the present documentinclude one or more instructions stored in a storage medium (eg, internal memory 2536 or external memory 2538) that can be read by a machine (eg, electronic device 2501). It may be implemented as software (for example, the program 2540) including them.
- the processoreg, the processor 2520 of the device (eg, the electronic device 2501) may call and execute at least one command among one or more commands stored from a storage medium. This makes it possible for the device to be operated to perform at least one function according to the at least one command invoked.
- the one or more instructionsmay include code generated by a compiler or code executable by an interpreter.
- a storage medium that can be read by a devicemay be provided in the form of a non-transitory storage medium.
- non-transientonly means that the storage medium is a tangible device and does not contain a signal (e.g., electromagnetic wave), and this term refers to the case where data is semi-permanently stored in the storage medium. It does not distinguish between temporary storage cases.
- a signale.g., electromagnetic wave
- a method according to various embodiments disclosed in the present documentmay be provided by being included in a computer program product.
- Computer program productscan be traded between sellers and buyers as commodities.
- Computer program productsare distributed in the form of a device-readable storage medium (e.g. compact disc read only memory (CD-ROM)), or through an application store (e.g. Play StoreTM) or two user devices (e.g. It can be distributed (e.g., downloaded or uploaded) directly between, e.g. smartphones).
- a devicee.g. compact disc read only memory (CD-ROM)
- an application storee.g. Play StoreTM
- two user devicese.g. It can be distributed (e.g., downloaded or uploaded) directly between, e.g. smartphones).
- at least some of the computer program productsmay be temporarily stored or temporarily generated in a storage medium that can be read by a device such as a server of a manufacturer, a server of an application store, or a memory of a relay server.
- each component (eg, module or program) of the above-described componentsmay include a singular number or a plurality of entities.
- one or more components or operations among the above-described corresponding componentsmay be omitted, or one or more other components or operations may be added.
- a plurality of componentseg, a module or a program
- the integrated componentmay perform one or more functions of each component of the plurality of components in the same or similar to that performed by the corresponding component among the plurality of components prior to the integration. .
- operations performed by a module, program, or other componentare sequentially, parallel, repeatedly, or heuristically executed, or one or more of the above operations are executed in a different order or omitted. Or one or more other actions may be added.
- a microphone 502, a memory 503, and at least one processorare included, and when instructions stored in the memory 503 are executed, the at least one processor executes an intelligent voice service application. , Receiving a first speech through the microphone 502 during execution of the intelligent voice service application, obtaining a first synthesized sound based on the first speech and a first sound having an inaudible frequency band, and pre-stored A second sound obtained by comparing a second synthesized sound related to the first speech among a plurality of sounds and the first synthesized sound, and wherein the second synthesized sound has a different inaudible frequency band from the first sound And, based on the comparison result, the electronic device 410 for providing a service corresponding to the first speech by the intelligent voice service application may be provided.
- the at least one processorwhen the instructions stored in the memory 503 are executed, the at least one processor causes the first speech to be uttered when the similarity between the first synthesized sound and the second synthesized sound is greater than or equal to a threshold value.
- An electronic device 410that allows a service corresponding to to be provided may be provided.
- a speakerfurther includes a speaker, and when instructions stored in the memory 503 are executed, the at least one processor causes the at least one processor to perform through the microphone 502 based on the execution of the intelligent voice service application.
- An electronic device 410may be provided that outputs the first sound and receives the first speech and the outputted first sound through the microphone 502.
- a speakerfurther includes a speaker, and when instructions stored in the memory 503 are executed, the at least one processor determines an inaudible frequency band through the speaker before receiving the first speech. Outputting a second sound having a second sound, receiving a second speech and the second sound through the microphone 502, obtaining the second synthesized sound based on the second speech and the second sound, and the An electronic device 410 for storing the second synthesized sound in the memory 503 may be provided.
- a plurality of first text datais checked from the memory 503, the first sound is obtained based on the plurality of first text data, and a plurality of first sounds are obtained from the memory 503. 2
- An electronic device 410 that checks text data and acquires the second sound based on the plurality of second text datamay be provided.
- the electronic device 410may be provided, characterized in that the number of the plurality of first text data and the number of the plurality of second text data are different from each other.
- the memory 503stores a first text data group and a second text group, and a first text length related to the first text data group and a first text length related to the second text data group. 2 Text lengths are different from each other, and when instructions stored in the memory 503 are executed, the at least one processor obtains the plurality of first text data from the first text data group, and the second text data group An electronic device 410 may be provided to obtain the plurality of second text data from a.
- the memory 503stores a first text data group and a second text group, and a first frequency band related to the first text data group and a second frequency band related to the second text data group. Frequency bands are different from each other, and when the instructions stored in the memory 503 are executed, the at least one processor obtains the plurality of first text data from the first text data group, and from the second text data group An electronic device 410 for acquiring the plurality of second text data may be provided.
- the first frequency band related to the first text data group and the second frequency band related to the second text data groupare included in a preset frequency band among inaudible frequency bands. 410 may be provided.
- the at least one processorwhen instructions stored in the memory 503 are executed, causes the at least one processor to receive a third speech including a specific keyword when a synthesized sound related to the first speech is not identified. And obtaining a third synthesized sound based on a third sound having a third utterance and an inaudible frequency band including the specific keyword, and combining a fourth synthesized sound related to the specific keyword and the obtained third synthesized sound.
- the electronic device 410may be provided to obtain a comparison result and to provide a service corresponding to the first utterance based on the comparison result.
- the intelligent voice service applicationin a method of operating the electronic device 410, executing an intelligent voice service application, and making a first speech through the microphone 502 of the electronic device 410 during execution of the intelligent voice service application Receiving, acquiring a first synthesized sound based on a first sound having the first utterance and an inaudible frequency band, a second synthesized sound related to the first utterance among a plurality of pre-stored sounds and the Obtaining a comparison result of the first synthesized sound, wherein the second synthesized sound includes a second sound having an inaudible frequency band different from that of the first sound, and based on the comparison result, the intelligent An operation method may be provided, further comprising the step of providing a service corresponding to the first speech by a voice service application.
- the operation methodwhen the similarity between the first synthesized sound and the second synthesized sound is greater than or equal to a threshold value, the operation method further comprises providing a service corresponding to the first utterance. I can.
- An operation methodmay be provided, further comprising the step of receiving the outputted first sound.
- outputting a second sound having an inaudible frequency band through the speaker before receiving the first utterance, the second utterance and the second sound through the microphone 502Receiving, based on the second speech and the second sound, obtaining the second synthesized sound, and storing the second synthesized sound in the memory (503), the method of operation Can be provided.
- the steps of checking a plurality of first text data from the memory 503, acquiring the first sound based on the plurality of first text data, and receiving the first sound from the memory 503An operation method may be provided, further comprising the step of confirming the second text data, and obtaining the second sound based on the plurality of second text data.
- an operation methodmay be provided, characterized in that the number of the plurality of first text data and the number of the plurality of second text data are different from each other.
- the memory 503 of the electronic device 410stores a first text data group and a second text group, and includes a first text length and the second text associated with the first text data group.
- the second text lengths related to the data groupare different from each other, and the operation method includes obtaining the plurality of first text data from the first text data group, and the plurality of second text data from the second text data group.
- a method of operationmay be provided, further comprising the step of obtaining data.
- the memory 503 of the electronic device 410stores a first text data group and a second text group, and includes a first frequency band and the second text related to the first text data group.
- the second frequency bands associated with the data groupare different from each other, and the operation method includes obtaining the plurality of first text data from the first text data group, and the plurality of second text data from the second text data group.
- the method of operationmay be provided, further comprising the step of obtaining.
- the first frequency band associated with the first text data group and the second frequency band associated with the second text data groupare included in a preset frequency band among inaudible frequency bands. Can be provided.
- the database 515includes at least one processor, and when instructions stored in the memory 503 are executed, the at least one processor obtains a first synthesized sound, and 1 The synthesized sound is obtained based on a first sound having a first utterance and an inaudible frequency band received during execution of an intelligent voice service application, and the first utterance and the first utterance among a plurality of sounds previously stored in the database 515 Checking a related second synthesized sound, wherein the second synthesized sound includes a second sound having an inaudible frequency band different from the first sound, and compares the first synthesized sound with the second synthesized sound, The electronic device 410, which checks a similarity between the first synthesized sound and the second synthesized sound, and provides a service corresponding to the first speech by the intelligent voice service application based on the checked similarity. ) Can be provided.
Landscapes
- Engineering & Computer Science (AREA)
- Computer Security & Cryptography (AREA)
- Human Computer Interaction (AREA)
- Signal Processing (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computer Networks & Wireless Communication (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Business, Economics & Management (AREA)
- Game Theory and Decision Science (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
Description
Translated fromKorean본 개시의 다양한 실시예는 탈취된 사용자 발화를 검출하기 위한 전자 장치 및 그 동작 방법에 관한 것이다.Various embodiments of the present disclosure relate to an electronic device for detecting a hijacked user utterance, and a method of operating the same.
현대를 살아가는 많은 사람들에게 휴대용 디지털 통신기기들은 하나의 필수 요소가 되었다. 소비자들은 휴대용 디지털 통신기기들을 이용하여 언제 어디서나 자신이 원하는 다양한 고품질의 서비스를 제공받고 싶어한다.For many people living in modern times, portable digital communication devices have become an essential element. Consumers want to receive a variety of high-quality services they want anytime, anywhere by using portable digital communication devices.
다양한 고품질의 서비스 중 음성 인식 서비스는, 휴대용 디지털 통신기기들에 구현되는 음성인식 인터페이스를 기반으로, 수신되는 사용자 음성에 대응하여 다양한 컨텐츠 서비스를 소비자들에게 제공하기 위한 서비스이다. 음성 인식 서비스의 제공을 위해 휴대용 디지털 통시기기들에는 인간의 언어를 인식하고 분석하는 기술들(예: 자동 음성 인식, 자연어 이해, 자연어 생성, 기계 번역, 대화시스템, 질의 응답, 음성 인식/합성, 등)이 구현된다.Among various high-quality services, the voice recognition service is a service for providing various content services to consumers in response to a user's voice received based on a voice recognition interface implemented in portable digital communication devices. In order to provide speech recognition services, portable digital transmitters include technologies that recognize and analyze human language (eg, automatic speech recognition, natural language understanding, natural language generation, machine translation, dialogue system, question and answer, speech recognition/synthesis, Etc.) is implemented.
근래에, 탈취자는 음성 인식 서비스를 이용하는 사용자들의 발화를 탈취하여, 탈취된 발화를 이용하여 음성 인식 서비스의 보안성을 저해하고 있다. 따라서 소비자들에게 보안성 높은 음성 인식 서비스를 제공하기 위해서는, 휴대용 디지털 통신 기기들로 수신되는 발화의 탈취 여부를 확인하는 기술의 구현이 필요하다.In recent years, hijackers have hijacked the utterances of users who use the voice recognition service, and use the stolen utterances to hinder the security of the voice recognition service. Therefore, in order to provide a highly secure voice recognition service to consumers, it is necessary to implement a technology to check whether speech received by portable digital communication devices is stolen.
전자 장치는 지능형 음성 서비스 어플리케이션의 실행 중에 사용자로부터 발화를 수신하고, 지능형 음성 서비스 어플리케이션을 이용하여 수신된 발화에 대응하는 서비스를 제공할 수 있다. 그러나, 전자 장치가 사용자로부터 발화를 수신하는 동안, 전자 장치의 근처의 다른 녹음 장치에 의해 사용자 발화가 탈취(또는, 녹음)될 수 있다. 녹음 장치의 사용자(즉, 탈취자)는 탈취된 사용자 발화에 기반해서, 탈취된 사용자 발화에 대응하는 서비스를 요청하고 제공 받게 되어, 음성 인식 서비스의 보안이 취약하게 될 수 있다. 또, 탈취자가 탈취된 사용자 발화에 기반해서, 전자 장치로부터 서비스를 제공받는 중에 전자 장치의 진의의 사용자의 개인 정보가 탈취자에게 유출되어 개인 정보의 보안이 취약해지는 문제점이 발생될 수 있다.The electronic device may receive a speech from a user while an intelligent voice service application is being executed, and provide a service corresponding to the received speech using the intelligent voice service application. However, while the electronic device receives the utterance from the user, the user utterance may be stolen (or recorded) by another recording device in the vicinity of the electronic device. The user of the recording device (ie, the hijacker) requests and receives a service corresponding to the hijacked user utterance based on the hijacked user utterance, so that the security of the voice recognition service may be weak. In addition, based on the user's utterances that the hijacker is stolen, personal information of a genuine user of the electronic device is leaked to the hijacker while receiving a service from the electronic device, thereby making the security of the personal information vulnerable.
다양한 실시예들에 따르면, 전자 장치 및 그 동작 방법은 사용자 발화를 수신할 때 마다 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 출력하고, 사용자 발화 및 다양한 종류의 사운드를 포함하는 합성 사운드를 획득할 수 있다. 다양한 실시예들에 따르면, 전자 장치 및 그 동작 방법은 획득한 합성 사운드 및 이전에 저장된 합성 사운드의 비교 결과에 기반하여, 현재 수신된 사용자 발화의 탈취 여부를 확인함으로써 음성 인식 서비스의 보안성 및 개인 정보의 보안성이 취약해지는 문제점을 해결할 수 있다.According to various embodiments, the electronic device and its operating method output various types of sounds (eg, sound having an inaudible frequency band) each time a user speech is received, and include user speech and various types of sounds. Synthetic sound can be obtained. According to various embodiments, the electronic device and its operation method determine whether or not the currently received user utterance is stolen based on the result of comparing the obtained synthesized sound and the previously stored synthesized sound. It can solve the problem of weak information security.
다양한 실시예들에 따르면, 마이크, 메모리, 적어도 하나의 프로세서를 포함하고, 상기 메모리에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 지능형 음성 서비스 어플리케이션를 실행하고, 상기 지능형 음성 서비스 어플리케이션의 실행 중에 상기 마이크를 통해 제 1 발화를 수신하고, 상기 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 제 1 합성 사운드를 획득하고, 미리 저장된 복수 개의 사운드들 중 상기 제 1 발화와 관련된 제 2 합성 사운드와 상기 제 1 합성 사운드의 비교 결과를 획득하고, 상기 제 2 합성 사운드는 상기 제 1 사운드와는 다른 비가청 주파수 대역을 갖는 제 2 사운드를 포함하고, 상기 비교 결과에 기반하여, 상기 지능형 음성 서비스 어플리케이션에 의해 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는, 전자 장치가 제공될 수 있다.According to various embodiments, a microphone, a memory, and at least one processor are included, and when instructions stored in the memory are executed, the at least one processor executes an intelligent voice service application, and during execution of the intelligent voice service application Receives a first speech through the microphone, obtains a first synthesized sound based on the first speech and a first sound having an inaudible frequency band, and a first speech related to the first speech among a plurality of pre-stored sounds A comparison result of the second synthesized sound and the first synthesized sound is obtained, and the second synthesized sound includes a second sound having an inaudible frequency band different from that of the first sound, and based on the comparison result, the An electronic device may be provided that enables a service corresponding to the first speech to be provided by an intelligent voice service application.
다양한 실시예들에 따르면, 전자 장치의 동작 방법에 있어서, 지능형 음성 서비스 어플리케이션를 실행하는 단계, 상기 지능형 음성 서비스 어플리케이션의 실행 중에 상기 전자 장치의 마이크를 통해 제 1 발화를 수신하는 단계, 상기 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 제 1 합성 사운드를 획득하는 단계, 미리 저장된 복수 개의 사운드들 중 상기 제 1 발화와 관련된 제 2 합성 사운드와 상기 제 1 합성 사운드의 비교 결과를 획득하는 단계를 포함하고, 상기 제 2 합성 사운드는 상기 제 1 사운드와는 다른 비가청 주파수 대역을 갖는 제 2 사운드를 포함하고, 상기 비교 결과에 기반하여, 상기 지능형 음성 서비스 어플리케이션에 의해 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, in a method of operating an electronic device, executing an intelligent voice service application, receiving a first speech through a microphone of the electronic device during execution of the intelligent voice service application, and the first speech And obtaining a first synthesized sound based on the first sound having an inaudible frequency band, obtaining a comparison result of the second synthesized sound related to the first speech among a plurality of pre-stored sounds and the first synthesized sound. Including the step of, wherein the second synthesized sound includes a second sound having an inaudible frequency band different from the first sound, and based on the comparison result, the first speech by the intelligent voice service application A method of operation may be provided, further comprising the step of providing a service corresponding to.
다양한 실시예들에 따르면, 데이터베이스, 적어도 하나의 프로세서,를 포함하고, 상기 메모리에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 제 1 합성 사운드를 획득하고, 상기 제 1 합성 사운드는 지능형 음성 서비스 어플리케이션의 실행 중에 수신된 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 획득되고, 상기 데이터베이스에 미리 저장된 복수 개의 사운드들 중 상기 제 1 발화와 관련된 제 2 합성 사운드를 확인하고, 상기 제 2 합성 사운드는 상기 제 1 사운드와는 다른 비가청 주파수 대역을 갖는 제 2 사운드를 포함하고, 상기 제 1 합성 사운드와 상기 제 2 합성 사운드를 비교하여, 상기 제 1 합성 사운드와 상기 제 2 합성 사운드 사이의 유사도를 확인하고, 상기 확인된 유사도에 기반하여, 상기 지능형 음성 서비스 어플리케이션에 의해 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는, 전자 장치가 제공될 수 있다.According to various embodiments, a database, at least one processor, and when instructions stored in the memory are executed, the at least one processor obtains a first synthesized sound, and the first synthesized sound is an intelligent voice Confirming a second synthesized sound related to the first utterance among a plurality of sounds obtained based on the first utterance and the first sound having an inaudible frequency band received during execution of the service application, and stored in advance in the database, The second synthesized sound includes a second sound having an inaudible frequency band different from that of the first sound, and the first synthesized sound and the second synthesized sound are compared, and the first synthesized sound and the second An electronic device may be provided that checks a degree of similarity between synthesized sounds and, based on the confirmed degree of similarity, provides a service corresponding to the first speech by the intelligent voice service application.
다양한 실시예들에 따른, 과제의 해결 수단이 상술한 해결 수단들로 제한되는 것은 아니며, 언급되지 아니한 해결 수단들은 본 명세서 및 첨부된 도면으로부터 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.The solution means of the problem according to various embodiments is not limited to the above-described solution means, and solutions that are not mentioned are from the present specification and the accompanying drawings to those of ordinary skill in the art to which the present invention pertains. It can be clearly understood.
다양한 실시예들에 따르면, 전자 장치는 사용자 발화를 수신할 때 마다 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 출력하고, 사용자 발화 및 다양한 종류의 사운드를 포함하는 합성 사운드를 획득할 수 있다. 다양한 실시예들에 따르면, 획득한 합성 사운드 및 이전에 저장된 합성 사운드의 비교 결과에 기반하여, 현재 수신된 사용자 발화의 탈취 여부를 확인함으로써 음성 인식 서비스의 보안성 및 개인 정보의 보안성이 취약해지는 문제점을 해결하는 전자 장치 및 그 동작 방법이 제공될 수 있다.According to various embodiments, the electronic device outputs various types of sounds (e.g., sounds having an inaudible frequency band) each time a user speech is received, and obtains a synthesized sound including the user speech and various types of sounds. can do. According to various embodiments, the security of the voice recognition service and the security of personal information are weakened by checking whether the currently received user utterance is stolen based on the result of comparing the obtained synthesized sound and the previously stored synthesized sound. An electronic device that solves a problem and a method of operating the same may be provided.
도 1은 다양한 실시예들에 따른, 통합 지능(integrated intelligence) 시스템을 나타낸 블록도이다.1 is a block diagram illustrating an integrated intelligence system according to various embodiments.
도 2는 다양한 실시예들에 따른, 컨셉과 동작의 관계 정보가 데이터베이스에 저장된 형태를 나타낸 도면이다.2 is a diagram illustrating a form in which relationship information between a concept and an operation is stored in a database according to various embodiments.
도 3은 다양한 실시예들에 따른, 사용자 단말이 지능형 앱을 통해 수신된 음성 입력을 처리하는 화면을 나타낸 도면이다.3 is a diagram illustrating a screen in which a user terminal processes a voice input received through an intelligent app, according to various embodiments.
도 4는 다양한 실시예들에 따른 지능형 시스템의 구성의 일 예를 나타내는 도면이다.4 is a diagram illustrating an example of a configuration of an intelligent system according to various embodiments.
도 5는 다양한 실시예들에 따른 지능형 시스템의 구성의 일 예를 설명하기 위한 도면이다.5 is a diagram for describing an example of a configuration of an intelligent system according to various embodiments.
도 6은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 일 예를 설명하기 위한 흐름도이다.6 is a flowchart illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 7은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 일 예를 설명하기 위한 도면이다.7 is a diagram illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 8은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 일 예를 설명하기 위한 흐름도이다.8 is a flowchart illustrating an example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 9는 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 일 예를 설명하기 위한 도면이다.9 is a diagram illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 10은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 일 예를 설명하기 위한 다른 도면이다.10 is another diagram illustrating an example of an operation of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 11은 다양한 실시예들에 따른 발화의 탈취 여부에 따른 합성 사운드 간의 비교 결과를 설명하기 위한 도면이다.11 is a diagram illustrating a comparison result between synthesized sounds according to whether or not utterance is deodorized according to various embodiments.
도 12는 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 다른 예를 설명하기 위한 흐름도이다.12 is a flowchart illustrating another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 13은 다양한 실시예들에 따른 전자 장치의 비가청 주파수 대역을 갖는 사운드를 출력하는 동작의 일 예를 설명하기 위한 도면이다.13 is a diagram for describing an example of an operation of outputting sound having an inaudible frequency band of an electronic device according to various embodiments of the present disclosure.
도 14는 다양한 실시예들에 따른 랜덤하게 비가청 주파수 대역을 갖는 사운드를 출력하는 경우 탈취된 발화의 비가청 주파수 대역의 일 예를 설명하기 위한 도면이다.14 is a diagram illustrating an example of an inaudible frequency band of a captured speech when randomly outputting a sound having an inaudible frequency band according to various embodiments.
도 15는 다양한 실시예들에 따른 전자 장치의 랜덤하게 비가청 주파수 대역을 갖는 사운드를 출력하는 동작의 일 예를 설명하기 위한 흐름도이다.15 is a flowchart illustrating an example of an operation of randomly outputting a sound having an inaudible frequency band of an electronic device according to various embodiments of the present disclosure.
도 16은 다양한 실시예들에 따른 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력하기 위해 데이터를 획득하는 동작의 일 예를 설명하기 위한 도면이다.16 is a diagram for describing an example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
도 17은 다양한 실시예들에 따른 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력하기 위해 데이터를 획득하는 동작의 다른 예를 설명하기 위한 도면이다.17 is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
도 18은 다양한 실시예들에 따른 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력하기 위해 데이터를 획득하는 동작의 또 다른 예를 설명하기 위한 도면이다.18 is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
도 19는 다양한 실시예들에 따른 외부 전자 장치의 동작의 일 예를 설명하기 위한 흐름도이다.19 is a flowchart illustrating an example of an operation of an external electronic device according to various embodiments of the present disclosure.
도 20은 다양한 실시예들에 따른 외부 전자 장치의 동작의 일 예를 설명하기 위한 도면이다.20 is a diagram for describing an example of an operation of an external electronic device according to various embodiments.
도 21은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 또 다른 예를 설명하기 위한 흐름도이다.21 is a flowchart illustrating still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 22는 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 또 다른 예를 설명하기 위한 도면이다.22 is a diagram for describing still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 23은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 또 다른 예를 설명하기 위한 다른 도면이다.23 is another diagram for describing still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure.
도 24는 다양한 실시예들에 따른 전자 장치의 동작의 다른 예를 설명하기 위한 흐름도이다.24 is a flowchart illustrating another example of an operation of an electronic device according to various embodiments.
도 25는 다양한 실시예들에 따른, 네트워크 환경 내의 전자 장치의 블럭도이다.25 is a block diagram of an electronic device in a network environment according to various embodiments of the present disclosure.
다양한 실시예들을 서술하기에 앞서, 통합 지능 시스템에 대해 설명한다.Before describing various embodiments, an integrated intelligent system will be described.
도 1은 다양한 실시예들에 따른, 통합 지능 (integrated intelligence) 시스템을 나타낸 블록도이다.1 is a block diagram illustrating an integrated intelligence system, according to various embodiments.
도 1을 참조하면, 일 실시예의 통합 지능 시스템(10)은 사용자 단말(100), 지능형 서버(200), 및 서비스 서버(300)를 포함할 수 있다.Referring to FIG. 1, an integrated
일 실시 예의 사용자 단말(100)은, 인터넷에 연결 가능한 단말 장치(또는, 전자 장치)일 수 있으며, 예를 들어, 사용자 단말(100)은 휴대폰, 스마트폰, PDA(personal digital assistant), 노트북 컴퓨터, TV, 백색 가전, 웨어러블 장치, HMD, 또는 스마트 스피커일 수 있다.The
도시된 실시 예에 따르면, 사용자 단말(100)은 통신 인터페이스(110), 마이크(120), 스피커(130), 디스플레이(140), 메모리(150), 또는 프로세서(160)를 포함할 수 있다. 상기 열거된 구성요소들은 서로 작동적으로 또는 전기적으로 연결될 수 있다.According to the illustrated embodiment, the
일 실시 예의 통신 인터페이스(110)는 외부 장치와 연결되어 데이터를 송수신하도록 구성될 수 있다. 일 실시 예의 마이크(120)는 소리(예: 사용자 발화)를 수신하여, 전기적 신호로 변환할 수 있다. 일 실시예의 스피커(130)는 전기적 신호를 소리(예: 음성)으로 출력할 수 있다. 일 실시 예의 디스플레이(140)는 이미지 또는 비디오를 표시하도록 구성될 수 있다. 일 실시 예의 디스플레이(140)는 또한 실행되는 앱(app)(또는, 어플리케이션 프로그램(application program))의 그래픽 사용자 인터페이스(graphic user interface)(GUI)를 표시할 수 있다.The
일 실시 예의 메모리(150)는 클라이언트 모듈(151), SDK(software development kit)(153), 및 복수의 앱들(155)을 저장할 수 있다. 상기 클라이언트 모듈(151), 및 SDK(153)는 범용적인 기능을 수행하기 위한 프레임워크(framework)(또는, 솔루션 프로그램)를 구성할 수 있다. 또한, 클라이언트 모듈(151) 또는 SDK(153)는 음성 입력을 처리하기 위한 프레임워크를 구성할 수 있다.The
일 실시 예의 메모리(150)는 상기 복수의 앱들(155)은 지정된 기능을 수행하기 위한 프로그램일 수 있다. 일 실시 예에 따르면, 복수의 앱(155)은 제1 앱(155_1), 제2 앱(155_3) 을 포함할 수 있다. 일 실시 예에 따르면, 복수의 앱(155) 각각은 지정된 기능을 수행하기 위한 복수의 동작들을 포함할 수 있다. 예를 들어, 상기 앱들은, 알람 앱, 메시지 앱, 및/또는 스케줄 앱을 포함할 수 있다. 일 실시 예에 따르면, 복수의 앱들(155)은 프로세서(160)에 의해 실행되어 상기 복수의 동작들 중 적어도 일부를 순차적으로 실행할 수 있다.In the
일 실시 예의 프로세서(160)는 사용자 단말(100)의 전반적인 동작을 제어할 수 있다. 예를 들어, 프로세서(160)는 통신 인터페이스(110), 마이크(120), 스피커(130), 및 디스플레이(140)와 전기적으로 연결되어 연결되어 지정된 동작을 수행할 수 있다.The
일 실시 예의 프로세서(160)는 또한 상기 메모리(150)에 저장된 프로그램을 실행시켜 지정된 기능을 수행할 수 있다. 예를 들어, 프로세서(160)는 클라이언트 모듈(151) 또는 SDK(153) 중 적어도 하나를 실행하여, 음성 입력을 처리하기 위한 이하의 동작을 수행할 수 있다. 프로세서(160)는, 예를 들어, SDK(153)를 통해 복수의 앱(155)의 동작을 제어할 수 있다. 클라이언트 모듈(151) 또는 SDK(153)의 동작으로 설명된 이하의 동작은 프로세서(160)의 실행에 의한 동작일 수 있다.The
일 실시 예의 클라이언트 모듈(151)은 음성 입력을 수신할 수 있다. 예를 들어, 클라이언트 모듈(151)은 마이크(120)를 통해 감지된 사용자 발화에 대응되는 음성 신호를 수신할 수 있다. 상기 클라이언트 모듈(151)은 수신된 음성 입력을 지능형 서버(200)로 송신할 수 있다. 클라이언트 모듈(151)은 수신된 음성 입력과 함께, 사용자 단말(100)의 상태 정보를 지능형 서버(200)로 송신할 수 있다. 상기 상태 정보는, 예를 들어, 앱의 실행 상태 정보일 수 있다.The
일 실시 예의 클라이언트 모듈(151)은 수신된 음성 입력에 대응되는 결과를 수신할 수 있다. 예를 들어, 클라이언트 모듈(151)은 지능형 서버(200)에서 상기 수신된 음성 입력에 대응되는 결과를 산출할 수 있는 경우, 수신된 음성 입력에 대응되는 결과를 수신할 수 있다. 클라이언트 모듈(151)은 상기 수신된 결과를 디스플레이(140)에 표시할 수 있다.The
일 실시 예의 클라이언트 모듈(151)은 수신된 음성 입력에 대응되는 플랜을 수신할 수 있다. 클라이언트 모듈(151)은 플랜에 따라 앱의 복수의 동작을 실행한 결과를 디스플레이(140)에 표시할 수 있다. 클라이언트 모듈(151)은, 예를 들어, 복수의 동작의 실행 결과를 순차적으로 디스플레이에 표시할 수 있다. 사용자 단말(100)은, 다른 예를 들어, 복수의 동작을 실행한 일부 결과(예: 마지막 동작의 결과)만을 디스플레이에 표시할 수 있다.The
일 실시 예에 따르면, 클라이언트 모듈(151)은 지능형 서버(200)로부터 음성 입력에 대응되는 결과를 산출하기 위해 필요한 정보를 획득하기 위한 요청을 수신할 수 있다. 일 실시 예에 따르면, 클라이언트 모듈(151)은 상기 요청에 대응하여 상기 필요한 정보를 지능형 서버(200)로 송신할 수 있다.According to an embodiment, the
일 실시 예의 클라이언트 모듈(151)은 플랜에 따라 복수의 동작을 실행한 결과 정보를 지능형 서버(200)로 송신할 수 있다. 지능형 서버(200)는 상기 결과 정보를 이용하여 수신된 음성 입력이 올바르게 처리된 것을 확인할 수 있다.The
일 실시 예의 클라이언트 모듈(151)은 음성 인식 모듈을 포함할 수 있다. 일 실시 예에 따르면, 클라이언트 모듈(151)은 상기 음성 인식 모듈을 통해 제한된 기능을 수행하는 음성 입력을 인식할 수 있다. 예를 들어, 클라이언트 모듈(151)은 지정된 입력(예: 웨이크 업!)을 통해 유기적인 동작을 수행하기 위한 음성 입력을 처리하기 위한 지능형 앱을 수행할 수 있다.The
일 실시 예의 지능형 서버(200)는 통신 망을 통해 사용자 단말(100)로부터 사용자 음성 입력과 관련된 정보를 수신할 수 있다. 일 실시 예에 따르면, 지능형 서버(200)는 수신된 음성 입력과 관련된 데이터를 텍스트 데이터(text data)로 변경할 수 있다. 일 실시 예에 따르면, 지능형 서버(200)는 상기 텍스트 데이터에 기초하여 사용자 음성 입력과 대응되는 태스크(task)를 수행하기 위한 플랜(plan)을 생성할 수 있다The
일 실시 예에 따르면, 플랜은 인공 지능(artificial intelligent)(AI) 시스템에 의해 생성될 수 있다. 인공지능 시스템은 룰 베이스 시스템(rule-based system) 일 수도 있고, 신경망 베이스 시스템(neual network-based system)(예: 피드포워드 신경망(feedforward neural network(FNN)), 순환 신경망(recurrent neural network(RNN))) 일 수도 있다. 또는, 전술한 것의 조합 또는 이와 다른 인공지능 시스템일 수도 있다. 일 실시 예에 따르면, 플랜은 미리 정의된 플랜의 집합에서 선택될 수 있거나, 사용자 요청에 응답하여 실시간으로 생성될 수 있다. 예를 들어, 인공지능 시스템은 미리 정의 된 복수의 플랜 중 적어도 하나의 플랜을 선택할 수 있다.According to an embodiment, the plan may be created by an artificial intelligent (AI) system. The artificial intelligence system may be a rule-based system, or a neural network-based system (e.g., a feedforward neural network (FNN)), a recurrent neural network (RNN). It may be ))). Alternatively, it may be a combination of the above or another artificial intelligence system. According to an embodiment, the plan may be selected from a set of predefined plans, or may be generated in real time in response to a user request. For example, the artificial intelligence system may select at least one of a plurality of predefined plans.
일 실시 예의 지능형 서버(200)는 생성된 플랜에 따른 결과를 사용자 단말(100)로 송신하거나, 생성된 플랜을 사용자 단말(100)로 송신할 수 있다. 일 실시 예에 따르면, 사용자 단말(100)은 플랜에 따른 결과를 디스플레이에 표시할 수 있다. 일 실시 예에 따르면, 사용자 단말(100)은 플랜에 따른 동작을 실행한 결과를 디스플레이에 표시할 수 있다.The
일 실시 예의 지능형 서버(200)는 프론트 엔드(front end)(210), 자연어 플랫폼(natual language platform)(220), 캡슐 데이터베이스(capsule DB)(230), 실행 엔진(execution engine)(240), 엔드 유저 인터페이스(end user interface)(250), 매니지먼트 플랫폼(management platform)(260), 빅 데이터 플랫폼(big data platform)(270), 또는 분석 플랫폼(analytic platform)(280)을 포함할 수 있다.The
일 실시 예의 프론트 엔드(210)는 사용자 단말(100)로부터 수신된 음성 입력을 수신할 수 있다. 프론트 엔드(210)는 상기 음성 입력에 대응되는 응답을 송신할 수 있다.The
일 실시 예에 따르면, 자연어 플랫폼(220)은 자동 음성 인식 모듈(automatic speech recognition module)(ASR module)(221), 자연어 이해 모듈(natural language understanding module)(NLU module)(223), 플래너 모듈(planner module)(225), 자연어 생성 모듈(natural language generator module)(NLG module)(227)또는 텍스트 음성 변환 모듈(text to speech module)(TTS module)(229)를 포함할 수 있다.According to an embodiment, the
일 실시 예의 자동 음성 인식 모듈(221)은 사용자 단말(100)로부터 수신된 음성 입력을 텍스트 데이터로 변환할 수 있다. 일 실시 예의 자연어 이해 모듈(223)은 음성 입력의 텍스트 데이터를 이용하여 사용자의 의도를 파악할 수 있다. 예를 들어, 자연어 이해 모듈(223)은 문법적 분석(syntactic analyze) 또는 의미적 분석(semantic analyze)을 수행하여 사용자의 의도를 파악할 수 있다. 일 실시 예의 자연어 이해 모듈(223)은 형태소 또는 구의 언어적 특징(예: 문법적 요소)을 이용하여 음성 입력으로부터 추출된 단어의 의미를 파악하고, 상기 파악된 단어의 의미를 의도에 매칭시켜 사용자의 의도를 결정할 수 있다.The automatic
일 실시 예의 플래너 모듈(225)은 자연어 이해 모듈(223)에서 결정된 의도 및 파라미터를 이용하여 플랜을 생성할 수 있다. 일 실시 예에 따르면, 플래너 모듈(225)은 상기 결정된 의도에 기초하여 태스크를 수행하기 위해 필요한 복수의 도메인을 결정할 수 있다. 플래너 모듈(225)은 상기 의도에 기초하여 결정된 복수의 도메인 각각에 포함된 복수의 동작을 결정할 수 있다. 일 실시 예에 따르면, 플래너 모듈(225)은 상기 결정된 복수의 동작을 실행하는데 필요한 파라미터나, 상기 복수의 동작의 실행에 의해 출력되는 결과 값을 결정할 수 있다. 상기 파라미터, 및 상기 결과 값은 지정된 형식(또는, 클래스)의 컨셉으로 정의될 수 있다. 이에 따라, 플랜은 사용자의 의도에 의해 결정된 복수의 동작, 및 복수의 컨셉을 포함할 수 있다. 상기 플래너 모듈(225)은 상기 복수의 동작, 및 상기 복수의 컨셉 사이의 관계를 단계적(또는, 계층적)으로 결정할 수 있다. 예를 들어, 플래너 모듈(225)은 복수의 컨셉에 기초하여 사용자의 의도에 기초하여 결정된 복수의 동작의 실행 순서를 결정할 수 있다. 다시 말해, 플래너 모듈(225)은 복수의 동작의 실행에 필요한 파라미터, 및 복수의 동작의 실행에 의해 출력되는 결과에 기초하여, 복수의 동작의 실행 순서를 결정할 수 있다. 이에 따라, 플래너 모듈(225)는 복수의 동작, 및 복수의 컨셉 사이의 연관 정보(예: 온톨로지(ontology))가 포함된 플랜를 생성할 수 있다. 상기 플래너 모듈(225)은 컨셉과 동작의 관계들의 집합이 저장된 캡슐 데이터베이스(230)에 저장된 정보를 이용하여 플랜을 생성할 수 있다.The
일 실시 예의 자연어 생성 모듈(227)은 지정된 정보를 텍스트 형태로 변경할 수 있다. 상기 텍스트 형태로 변경된 정보는 자연어 발화의 형태일 수 있다. 일 실시 예의 텍스트 음성 변환 모듈(229)은 텍스트 형태의 정보를 음성 형태의 정보로 변경할 수 있다.The natural
일 실시 예에 따르면, 자연어 플랫폼(220)의 기능의 일부 기능 또는 전체 기능은 사용자 단말(100)에서도 구현가능 할 수 있다.According to an embodiment, some or all functions of the functions of the
상기 캡슐 데이터베이스(230)는 복수의 도메인에 대응되는 복수의 컨셉과 동작들의 관계에 대한 정보를 저장할 수 있다. 일 실시예에 따른 캡슐은 플랜에 포함된 복수의 동작 오브젝트(action object 또는, 동작 정보) 및 컨셉 오브젝트(concept object 또는 컨셉 정보)를 포함할 수 있다. 일 실시 예에 따르면, 캡슐 데이터베이스(230)는 CAN(concept action network)의 형태로 복수의 캡슐을 저장할 수 있다. 일 실시 예에 따르면, 복수의 캡슐은 캡슐 데이터베이스(230)에 포함된 기능 저장소(function registry)에 저장될 수 있다.The
상기 캡슐 데이터베이스(230)는 음성 입력에 대응되는 플랜을 결정할 때 필요한 전략 정보가 저장된 전략 레지스트리(strategy registry)를 포함할 수 있다. 상기 전략 정보는 음성 입력에 대응되는 복수의 플랜이 있는 경우, 하나의 플랜을 결정하기 위한 기준 정보를 포함할 수 있다. 일 실시 예에 따르면, 캡슐 데이터베이스(230)는 지정된 상황에서 사용자에게 후속 동작을 제안하기 위한 후속 동작의 정보가 저장된 후속 동작 레지스트리(follow up registry)를 포함할 수 있다. 상기 후속 동작은, 예를 들어, 후속 발화를 포함할 수 있다. 일 실시 예에 따르면, 캡슐 데이터베이스(230)는 사용자 단말(100)을 통해 출력되는 정보의 레이아웃(layout) 정보를 저장하는 레이아웃 레지스트리(layout registry)를 포함할 수 있다. 일 실시 예에 따르면, 캡슐 데이터베이스(230)는 캡슐 정보에 포함된 어휘(vocabulary) 정보가 저장된 어휘 레지스트리(vocabulary registry)를 포함할 수 있다. 일 실시 예에 따르면, 캡슐 데이터베이스(230)는 사용자와의 대화(dialog)(또는, 인터렉션(interaction)) 정보가 저장된 대화 레지스트리(dialog registry)를 포함할 수 있다. 상기 캡슐 데이터베이스(230)는 개발자 툴(developer tool)을 통해 저장된 오브젝트를 업데이트(update)할 수 있다. 상기 개발자 툴은, 예를 들어, 동작 오브젝트 또는 컨셉 오브젝트를 업데이트하기 위한 기능 에디터(function editor)를 포함할 수 있다. 상기 개발자 툴은 어휘를 업데이트하기 위한 어휘 에디터(vocabulary editor)를 포함할 수 있다. 상기 개발자 툴은 플랜을 결정하는 전략을 생성 및 등록 하는 전략 에디터(strategy editor)를 포함할 수 있다. 상기 개발자 툴은 사용자와의 대화를 생성하는 대화 에디터(dialog editor)를 포함할 수 있다. 상기 개발자 툴은 후속 목표를 활성화하고, 힌트를 제공하는 후속 발화를 편집할 수 있는 후속 동작 에디터(follow up editor)를 포함할 수 있다. 상기 후속 목표는 현재 설정된 목표, 사용자의 선호도 또는 환경 조건에 기초하여 결정될 수 있다. 일 실시 예에서는 캡슐 데이터베이스(230) 은 사용자 단말(100) 내에도 구현이 가능할 수 있다.The
일 실시 예의 실행 엔진(240)은 상기 생성된 플랜을 이용하여 결과를 산출할 수 있다. 엔드 유저 인터페이스(250)는 산출된 결과를 사용자 단말(100)로 송신할 수 있다. 이에 따라, 사용자 단말(100)은 상기 결과를 수신하고, 상기 수신된 결과를 사용자에게 제공할 수 있다. 일 실시 예의 매니지먼트 플랫폼(260)은 지능형 서버(200)에서 이용되는 정보를 관리할 수 있다. 일 실시 예의 빅 데이터 플랫폼(270)은 사용자의 데이터를 수집할 수 있다. 일 실시 예의 분석 플랫폼(280)을 지능형 서버(200)의 QoS(quality of service)를 관리할 수 있다. 예를 들어, 분석 플랫폼(280)은 지능형 서버(200)의 구성 요소 및 처리 속도(또는, 효율성)를 관리할 수 있다.The
일 실시 예의 서비스 서버(300)는 사용자 단말(100)에 지정된 서비스(예: 음식 주문 또는 호텔 예약)를 제공할 수 있다. 일 실시 예에 따르면, 서비스 서버(300)는 제3 자에 의해 운영되는 서버일 수 있다. 일 실시 예의 서비스 서버(300)는 수신된 음성 입력에 대응되는 플랜을 생성하기 위한 정보를 지능형 서버(200)에 제공할 수 있다. 상기 제공된 정보는 캡슐 데이터베이스(230)에 저장될 수 있다. 또한, 서비스 서버(300)는 플랜에 따른 결과 정보를 지능형 서버(200)에 제공할 수 있다.The
위에 기술된 통합 지능 시스템(10)에서, 상기 사용자 단말(100)은, 사용자 입력에 응답하여 사용자에게 다양한 인텔리전트 서비스를 제공할 수 있다. 상기 사용자 입력은, 예를 들어, 물리적 버튼을 통한 입력, 터치 입력 또는 음성 입력을 포함할 수 있다.In the integrated
일 실시 예에서, 상기 사용자 단말(100)은 내부에 저장된 지능형 앱(또는, 음성 인식 앱)을 통해 음성 인식 서비스를 제공할 수 있다. 이 경우, 예를 들어, 사용자 단말(100)은 상기 마이크를 통해 수신된 사용자 발화(utterance) 또는 음성 입력(voice input)를 인식하고, 인식된 음성 입력에 대응되는 서비스를 사용자에게 제공할 수 있다.In an embodiment, the
일 실시 예에서, 사용자 단말(100)은 수신된 음성 입력에 기초하여, 단독으로 또는 상기 지능형 서버 및/또는 서비스 서버와 함께 지정된 동작을 수행할 수 있다. 예를 들어, 사용자 단말(100)은 수신된 음성 입력에 대응되는 앱을 실행시키고, 실행된 앱을 통해 지정된 동작을 수행할 수 있다.In an embodiment, the
일 실시 예에서, 사용자 단말(100)이 지능형 서버(200) 및/또는 서비스 서버와 함께 서비스를 제공하는 경우에는, 상기 사용자 단말은, 상기 마이크(120)를 이용하여 사용자 발화를 감지하고, 상기 감지된 사용자 발화에 대응되는 신호(또는, 음성 데이터)를 생성할 수 있다. 상기 사용자 단말은, 상기 음성 데이터를 통신 인터페이스(110)를 이용하여 지능형 서버(200)로 송신할 수 있다.In one embodiment, when the
일 실시 예에 따른 지능형 서버(200)는 사용자 단말(100)로부터 수신된 음성 입력에 대한 응답으로써, 음성 입력에 대응되는 태스크(task)를 수행하기 위한 플랜, 또는 상기 플랜에 따라 동작을 수행한 결과를 생성할 수 있다. 상기 플랜은, 예를 들어, 사용자의 음성 입력에 대응되는 태스크(task)를 수행하기 위한 복수의 동작, 및 상기 복수의 동작과 관련된 복수의 컨셉을 포함할 수 있다. 상기 컨셉은 상기 복수의 동작의 실행에 입력되는 파라미터나, 복수의 동작의 실행에 의해 출력되는 결과 값을 정의한 것일 수 있다. 상기 플랜은 복수의 동작, 및 복수의 컨셉 사이의 연관 정보를 포함할 수 있다.The
일 실시 예의 사용자 단말(100)은, 통신 인터페이스(110)를 이용하여 상기 응답을 수신할 수 있다. 사용자 단말(100)은 상기 스피커(130)를 이용하여 사용자 단말(100) 내부에서 생성된 음성 신호를 외부로 출력하거나, 디스플레이(140)를 이용하여 사용자 단말(100) 내부에서 생성된 이미지를 외부로 출력할 수 있다.The
도 2는 다양한 실시예들에 따른, 컨셉과 동작의 관계 정보가 데이터베이스에 저장된 형태를 나타낸 도면이다.2 is a diagram illustrating a form in which relationship information between a concept and an operation is stored in a database according to various embodiments.
상기 지능형 서버(200)의 캡슐 데이터베이스(예: 캡슐 데이터베이스(230))는 CAN(concept action network)(400) 형태로 캡슐을 저장할 수 있다. 상기 캡슐 데이터베이스는 사용자의 음성 입력에 대응되는 태스크를 처리하기 위한 동작, 및 상기 동작을 위해 필요한 파라미터를 CAN(concept action network)(400) 형태로 저장될 수 있다.The capsule database (eg, capsule database 230) of the
상기 캡슐 데이터베이스는 복수의 도메인(예: 어플리케이션) 각각에 대응되는 복수의 캡슐(capsule(A)(401), capsule(B)(404))을 저장할 수 있다. 일 실시 예에 따르면, 하나의 캡슐(예:capsule(A)(401))은 하나의 도메인(예: 위치(geo), 어플리케이션)에 대응될 수 있다. 또한, 하나의 캡슐에는 캡슐과 관련된 도메인에 대한 기능을 수행하기 위한 적어도 하나의 서비스 제공자(예: CP 1(402), CP 2(403), CP 3(406), 또는 CP 4(405))가 대응될 수 있다. 일 실시 예에 따르면, 하나의 캡슐은 지정된 기능을 수행하기 위한 적어도 하나 이상의 동작(410) 및 적어도 하나 이상의 컨셉(420)을 포함할 수 있다.The capsule database may store a plurality of capsules (capsule(A) 401, capsule(B) 404) corresponding to each of a plurality of domains (eg, applications). According to an embodiment, one capsule (eg, capsule(A) 401) may correspond to one domain (eg, location (geo), application). In addition, one capsule includes at least one service provider (eg, CP 1 (402), CP 2 (403), CP 3 (406), or CP 4 (405)) for performing a function for a domain related to the capsule) Can be matched. According to an embodiment, one capsule may include at least one or
상기, 자연어 플랫폼(220)은 캡슐 데이터베이스에 저장된 캡슐을 이용하여 수신된 음성 입력에 대응하는 태스크를 수행하기 위한 플랜을 생성할 수 있다. 예를 들어, 자연어 플랫폼의 플래너 모듈(225)은 캡슐 데이터베이스에 저장된 캡슐을 이용하여 플랜을 생성할 수 있다. 예를 들어, 캡슐 A (410) 의 동작들(4011,4013) 과 컨셉들(4012,4014) 및 캡슐 B(404)의 동작(4041) 과 컨셉(4042) 를 이용하여 플랜(407)을 생성할 수 있다.The
도 3은 다양한 실시예들에 따른, 사용자 단말이 지능형 앱을 통해 수신된 음성 입력을 처리하는 화면을 나타낸 도면이다.3 is a diagram illustrating a screen in which a user terminal processes a voice input received through an intelligent app, according to various embodiments.
사용자 단말(100)은 지능형 서버(200)를 통해 사용자 입력을 처리하기 위해 지능형 앱을 실행할 수 있다.The
일 실시 예에 따르면, 310 화면에서, 사용자 단말(100)은 지정된 음성 입력(예: 웨이크 업!)를 인식하거나 하드웨어 키(예: 전용 하드웨어 키)를 통한 입력을 수신하면, 음성 입력을 처리하기 위한 지능형 앱을 실행할 수 있다. 사용자 단말(100)은, 예를 들어, 스케줄 앱을 실행한 상태에서 지능형 앱을 실행할 수 있다. 일 실시 예에 따르면, 사용자 단말(100)은 지능형 앱에 대응되는 오브젝트(예: 아이콘)(311)를 디스플레이(140)에 표시할 수 있다. 일 실시 예에 따르면, 사용자 단말(100)은 사용자 발화에 의한 음성 입력을 수신할 수 있다. 예를 들어, 사용자 단말(100)은 “이번주 일정 알려줘!”라는 음성 입력을 수신할 수 있다. 일 실시 예에 따르면, 사용자 단말(100)은 수신된 음성 입력의 텍스트 데이터가 표시된 지능형 앱의 UI(user interface)(313)(예: 입력창)를 디스플레이에 표시할 수 있다.According to an embodiment, on
일 실시 예에 따르면, 320 화면에서, 사용자 단말(100)은 수신된 음성 입력에 대응되는 결과를 디스플레이에 표시할 수 있다. 예를 들어, 사용자 단말(100)은 수신된 사용자 입력에 대응되는 플랜을 수신하고, 플랜에 따라 ‘이번주 일정’을 디스플레이에 표시할 수 있다.According to an embodiment, on
이하에서는, 다양한 실시예들에 따른 지능형 시스템에 대해서 설명한다.Hereinafter, an intelligent system according to various embodiments will be described.
도 4는 다양한 실시예들에 따른 지능형 시스템의 구성의 일 예를 나타내는 도면이다. 다양한 실시예들에 따르면, 지능형 시스템은 도 4에 도시된 구성들에 국한되지 않고, 도 4에 도시되는 장치들 보다 더 많은 장치들을 포함하거나, 더 적은 적어도 하나의 장치를 포함할 수도 있다.4 is a diagram illustrating an example of a configuration of an intelligent system according to various embodiments. According to various embodiments, the intelligent system is not limited to the configurations illustrated in FIG. 4, and may include more devices than the devices illustrated in FIG. 4, or may include at least one fewer devices.
다양한 실시예들에 다르면, 지능형 시스템은 도 4에 도시된 바와 같이 전자 장치(410) 및 지능형 서버(420)를 포함할 수 있다. 전자 장치(410) 및 지능형 서버(420)는 도 1에 도시되는 전자 장치(410)들(예: 100, 200, 300)과 같이 구현될 수 있고, 또 후술할 도 25에 도시되는 네트워크 환경(2500) 내의 전자 장치(2501)와 같이 구현될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the intelligent system may include an
이하에서는 전자 장치(410)에 대해서 설명한다.Hereinafter, the
다양한 실시예들에 따르면, 전자 장치(410)는 사용자(411)로부터 사용자 발화(412)를 수신하고, 수신된 사용자 발화(412)에 서비스가 제공되도록 할 수 있다. 예를 들어, 전자 장치(410)는 지능형 음성 서비스 어플리케이션(예: 지능형 앱)을 실행하기 위한 입력(예: 지능형 음성 서비스 어플리케이션을 호출하기 위한 음성 입력, 또는 버튼 입력 등)에 기반하여, 지능형 음성 서비스 어플리케이션을 실행할 수 있다. 전자 장치(410)는 지능형 음성 서비스 어플리케이션의 실행 중에 사용자 발화(412)를 획득 할 수 있다. 전자 장치(410)는 사용자 발화에 대한 정보를 지능형 서버(420)로 송신하고, 이에 대한 응답으로 사용자 발화(412)의 분석 결과를 수신할 수 있다. 여기서, 사용자 발화에 대한 정보는 수신된 사용자 발화(412)를 나타내는 다양한 종류의 정보를 의미하며, 사용자 발화가 처리되지 않은 음성 신호 타입의 정보, 또는 수신된 사용자 발화가 대응하는 텍스트로 처리(예: ASR에 의해 사용자 발화가 처리됨)된 텍스트 타입의 정보 등을 포함할 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 전자 장치(410)는 사용자 발화(412)와 함께 다양한 부가 정보를 수신할 수 있다. 다양한 부가 정보는 컨텍스트 정보 및/또는 사용자 정보를 포함할 수 있다. 예를 들어, 컨텍스트 정보는 전자 장치(410)에서 실행되는 어플리케이션 내지는 프로그램에 대한 정보, 현재 위치에 대한 정보 등을 포함할 수 있다. 예를 들어, 사용자 정보는 사용자(411)의 전자 장치 사용 패턴(예: 어플리케이션 사용 패턴 등), 사용자(411)의 개인 정보(예: 나이 등), 사용자 발화(412)로부터 분석되는 사용자(411)와 관련된 고유의 음성학적인 정보(예: 기본 주파수 FO와 관련된 정보) 등을 포함할 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 전자 장치(410)는 수신된 분석 결과에 기반하여, 사용자 발화(412)에 대응하는 서비스를 제공할 수 있다. 예를 들어, 전자 장치(410)는 수신된 분석 결과(예: 사용자 발화(412)에 대응하는 컨텐트를 포함하는 UI/UX)에 기반하여, 디스플레이 상에 사용자 발화(412)에 대응하는 컨텐트를 표시할 수 있다. 또 예를 들어, 전자 장치(410)는 분석 결과 (예: 사용자 발화(412)에 대응하는 어플리케이션을 실행하기 위한 딥 링크)를 기반으로 전자 장치(410) 상에서 사용자 발화에 대응하는 어플리케이션의 동작을 제공하는 서비스를 제공할 수 있다. 또 예를 들어, 전자 장치(410)는 분석 결과(예: IOT 사물 기기의 ID 정보 및 패스 룰)를 기반으로, 상기 전자 장치(410)에 통신 연결된 적어도 하나의 지능형 서버(420)(예: IOT 사물 기기들)를 제어하는 서비스를 제공할 수 있다.According to various embodiments, the
이하에서는 지능형 서버(420)에 대해서 설명한다.Hereinafter, the
다양한 실시예들에 따르면 지능형 서버(420)(예: 지능형 서버(420))는 전자 장치(410)로부터 수신된 사용자 발화(412)를 처리하여, 사용자 발화(412)에 대응하는 서비스를 제공하기 위한 정보를 획득할 수 있다. 지능형 서버(420)는 사용자 발화(412)를 처리하는 데에 전자 장치(410)로부터 수신된 사용자 발화와 함께 수신된 부가 정보를 참조할 수 있다.According to various embodiments, the intelligent server 420 (for example, the intelligent server 420) processes the
다양한 실시예들에 따르면 지능형 서버(420)(예: 지능형 서버(420))는 사용자 발화를 보이스 어시스턴트(예: 캡슐들)에 의해 처리되도록 할 수 있다. 일 예를 들어, 지능형 서버(420)는 사용자 발화(412)가 지능형 서버(420)에 구비되는 보이스 어시스턴트에 의해 처리되도록 하여 처리 결과 정보를 보이스 어시스턴트로부터 획득하거나, 지능형 서버(420)에 연동되는 외부 서버에 의해 처리되도록 하여 처리 결과 정보를 외부 서버로부터 획득 할 수 있다. 상기 보이스 어시스턴트는 상술한 캡슐들과 같은 동작을 수행할 수 있기 때문에, 중복되는 설명은 생략한다. 상기 보이스 어시스턴트의 발화의 처리에 따라 획득되는 처리 결과 정보는 상술한 태스크(task)를 수행하기 위한 플랜, 또는 상기 플랜에 따라 동작을 수행한 결과가 될 수 있으므로, 중복되는 설명은 생략한다. 아울러, 상기 처리 결과 정보는 지정된 어플리케이션의 특정 화면에 접근하기 위한 액세스 메카니즘을 포함하는 딥 링크 또는 서비스를 제공하기 위한 시각적인 정보(UI/UX) 중 적어도 하나를 더 포함할 수 있다.According to various embodiments, the intelligent server 420 (eg, the intelligent server 420) may cause a user utterance to be processed by a voice assistant (eg, capsules). For example, the
다양한 실시예들에 따르면 지능형 서버(420)(예: 지능형 서버(420))는 사용자 발화를 처리하기 위한 보이스 어시스턴트를 개발자 서버로부터 획득할 수 있다. 예를 들어, 지능형 서버(420)는 사용자 발화를 처리하기 위한 캡슐을 개발자 서버로부터 획득할 수 있다. 예를 들어, 개발자 서버의 개발자는 보이스 어시스턴트들을 지능형 서버(420)에 등록할 수 있다. 한편, 상기 기재에 국한되지 않고, 지능형 서버(420)는 지능형 서버(420)에서 자체적으로 제작된 보이스 어시스턴트들을 저장할 수도 있다.According to various embodiments, the intelligent server 420 (eg, the intelligent server 420) may obtain a voice assistant for processing user utterances from the developer server. For example, the
이하에서는 탈취된 발화에 대해서 설명한다.Hereinafter, the deodorized ignition will be described.
다양한 실시예들에 따르면, 탈취된 발화(430)는 전자 장치(410)가 진의의 사용자(411)로부터 발화를 수신하는 중에 전자 장치(410)의 주변에 있는 탈취자(440)가 녹음 기능이 있는 다른 전자 장치(410)를 이용하여 녹음한 발화일 수 있다. 이 때, 탈취된 발화(430)는 사용자 발화(412) 및 전자 장치(410)의 스피커를 통해 출력되는 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 포함할 수 있다. 이하에서 설명의 편의를 위해, 탈취된 발화(430)가 아닌 발화는 진의의 사용자 발화, 그리고 발화가 탈취된 전자 장치(410)의 사용자(411)는 진의의 사용자로 정의될 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 전자 장치(410)는 발화를 수신할 때마다 반복적으로 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 출력하여, 발화와 함께 다양한 종류의 사운드를 획득하여 합성 사운드를 획득하고, 획득된 합성 사운드와 이전에 획득된 합성 사운드를 비교함으로써 사운드가 탈취된 발화인지 여부를 확인할 수 있다. 다시 말해, 사운드에 부가되는 다양한 음성학적인 정보(예: 비가청 주파수 대역을 갖는 사운드)에 의해, 현재 전자 장치(410)로 수신되는 발화가 탈취된 발화인지 여부가 확인될 수 있다. 이에 대해서는 이하에서 구체적으로 후술한다.According to various embodiments, the
이하에서는, 다양한 실시예들에 따른 지능형 시스템에 구현되는 전자 장치(410)의 구성의 일 예 및 지능형 서버(420)의 구성의 일 예에 대해서 설명한다.Hereinafter, an example of the configuration of the
도 5는 다양한 실시예들에 따른 지능형 시스템의 구성의 일 예를 설명하기 위한 도면이다. 다양한 실시예들에 따르면, 전자 장치(410) 및 지능형 서버(420)는 도 5에 도시된 구성들에 국한되지 않고, 도 5에 도시되는 구성들 보다 더 많은 구성들을 포함하거나, 더 적은 적어도 하나의 구성을 포함할 수도 있다. 본 문서에서 설명되는 모듈들(예: 도 5에 도시되는 사운드 출력 모듈(506), 발화 분석 모듈(512), 발화 비교 모듈(513))은 특정 전자 장치가 지정된 동작을 수행할 수 있도록 코딩된 프로그램, 컴퓨터 코드 내지는 인스터력션들일 수 있다. 즉, 전자 장치(410)는 복수 개의 모듈들(예: 사운드 출력 모듈(506))을 메모리(503)에 저장하고, 저장된 메모리(503)에 포함된 복수 개의 모듈들(예: 사운드 출력 모듈(506))은 프로세서(505)가 지정된 동작을 수행하도록 할 수 있다. 또, 지능형 서버(420)는 복수 개의 모듈들(예: 발화 분석 모듈(512), 발화 비교 모듈(513))을 메모리에 저장하고, 저장된 메모리에 포함된 복수 개의 모듈들(예: 발화 분석 모듈(512), 발화 비교 모듈(513))은 프로세서(511)가 지정된 동작을 수행하도록 할 수 있다.5 is a diagram for describing an example of a configuration of an intelligent system according to various embodiments. According to various embodiments, the
이하에서는 전자 장치(410)의 구성에 대해서 설명한다.Hereinafter, the configuration of the
다양한 실시예들에 따르면, 전자 장치(410)는 도 5에 도시된 바와 같이 스피커(501), 마이크(502), 메모리(503) 및 사운드 출력 모듈(506)을 포함하는 프로세서(505)를 포함할 수 있다. 스피커, 마이크(502), 메모리(503) 및 프로세서는 도 1의 사용자 단말(100) 또는 후술할 도 25에 도시되는 네트워크 환경(2500)에 포함되는 전자 장치(2501)에 포함된 구성들과 같이 구현될 수 있으므로, 중복되는 설명은 생략한다.According to various embodiments, the
다양한 실시예들에 따르면, 스피커(501)는 다양한 종류의 사운드를 출력할 수 있다. 예를 들어, 전자 장치(410)는 지능형 음성 서비스 어플리케이션 실행 중에 다양한 종류의 사운드(예: 비가청 주파수 대역을 가지는 사운드)를 출력하도록 스피커(501)를 제어할 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 전자 장치(410)의 스피커(501)를 통해 출력되는 다양한 종류의 사운드는 외부로부터 전자 장치(410)가 마이크(502)를 통해 수신하는 사운드(예: 사용자 발화)에 영향을 거의 주지 않거나(또는, 열화 되지 않도록 하는) 사운드일 수 있다. 다시 말해, 전자 장치(410)의 스피커(501)를 통해 출력되는 다양한 종류의 사운드가 외부로부터 전자 장치(410)로 출력되는 사운드와 함께 수신되는 경우, 다양한 종류의 사운드는 외부로부터 전자 장치(410)로 출력되는 사운드의 주파수 별 세기에 큰 영향을 주지 않는 사운드일 수 있다. 일 예로, 외부로부터 전자 장치(410)로 출력되는 사운드가 사용자 발화인 경우, 상기 스피커(501)를 통해 출력되는 사운드는 비가청 주파수 대역의 사운드, 음악 등을 포함할 수 있다. 상기 비가청 주파수 대역은 사용자가 청취할 수 없는 주파수 대역을 의미할 수 있다. 예를 들어, 비가청 주파수 대역은 10HZ 내지 300GHZ 대역 내에 포함되는 주파수 대역일 수 있다. 가청 주파수 대역은 사용자가 청취할 수 있는 주파수 대역을 의미할 수 있다. 한편, 상기 기재된 종류(예: 비가청 주파수 대역의 사운드, 음악)에 국한되지 않고, 상기 스피커(501)를 통해 출력되는 외부로부터 전자 장치(410)로 출력되는 사운드(예: 사용자 발화)에 영향을 주지 않는 음성학적인 사운드가 될 수 있다. 이하에서는, 설명의 편의를 위해, 스피커(501)를 통해, 비가청 주파수 대역의 사운드를 출력하는 경우를 예로 들어 다양한 실시예들이 설명된다. 그러나, 이하의 다양한 실시예들은, 스피커(501)를 통해, 외부로부터 전자 장치(410)로 출력되는 사운드(예: 사용자 발화)에 영향을 주지 않는 다양한 종류의 음성학적인 사운드를 출력하는 경우에도 준용될 수 있다.According to various embodiments, various types of sounds output through the
다양한 실시예들에 따르면, 마이크(502)는 전자 장치(410)로 수신되는 다양한 종류의 사운드를 수신할 수 있다. 예를 들어, 전자 장치(410)는 마이크(502)를 통해서 사용자 발화를 수신할 수 있다. 또 예를 들어. 전자 장치(410)는 마이크(502)를 통해서 전자 장치(410)의 스피커(501)를 통해서 출력되는 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 수신할 수 있다. 또 예를 들어, 전자 장치(410)는 마이크(502)를 통해서 다양한 종류의 합성 사운드를 수신할 수 있다.According to various embodiments, the
다양한 실시예들에 따르면 합성 사운드는 상기 마이크(502)를 통해서 수신되는 둘 이상의 사운드를 포함하는 사운드일 수 있다. 예를 들어, 합성 사운드는 마이크(502)를 통해 수신되는 사용자 발화 및 스피커(501)를 통해 출력된 다양한 종류의 사운드를 포함하는 사운드일 수 있다.According to various embodiments, the synthesized sound may be a sound including two or more sounds received through the
다양한 실시예들에 따르면, 메모리(503)는 상기 전자 장치(410)의 스피커(501)를 통해 출력되는 다양한 종류의 사운드를 생성하기 위한 다양한 종류의 데이터(504)를 저장할 수 있다. 다시 말해, 전자 장치(410)는 메모리(503)에 저장된 다양한 종류의 데이터(504)를 획득하고, 다양한 종류의 데이터(504)를 기반으로 다양한 종류의 사운드를 생성하여, 생성된 다양한 종류의 사운드를 스피커(501)가 출력하도록 제어할 수 있다. 전자 장치(410)의 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 출력하는 동작은 도 8 내지 11에서 후술한다.According to various embodiments, the
다양한 실시예들에 따르면 상기 다양한 종류의 데이터(504)는 텍스트 데이터를 포함할 수 있다. 상기 다양한 종류의 데이터(504)는 상기 텍스트 데이터 이외에도 다양한 종류의 사운드를 생성하기 위한 다양한 종류의 전자적 데이터를 포함할 수 있다. 일 예로, 상기 다양한 종류의 데이터(504)는 다양한 종류의 음원 파일을 포함할 수 있다. 상기 음원 파일에 기반해서 음원 파일에 대응하는 음악이 전자 장치(410)의 스피커(501)를 통해 출력될 수 있다.According to various embodiments, the various types of
다양한 실시예들에 따르면, 사운드 출력 모듈(506)은 상술한 메모리(503)에 저장된 다양한 종류의 데이터(504)를 기반으로 다양한 종류의 사운드를 생성할 수 있다. 예를 들어, 사운드 출력 모듈(506)은 메모리(503)에 저장된 적어도 하나의 텍스트 데이터를 획득하고, 획득된 텍스트 데이터를 사운드 데이터로 변환하고, 변환된 사운드 데이터의 주파수 대역을 변조하여 비가청 주파수 대역을 가지는 사운드를 생성할 수 있다. 또 예를 들어, 사운드 출력 모듈(506)은 상술한 메모리(503)에 저장된 음원 파일을 기반으로 음악을 생성할 수 있다. 사운드 출력 모듈(506)에 의한 사운드 생성 동작에 대해서는 도 8 내지 12에서 후술한다.According to various embodiments, the
이하에서는 지능형 서버(420)의 구성에 대해서 설명한다.Hereinafter, the configuration of the
다양한 실시예들에 따르면 지능형 서버(420)는 도 5에 도시된 바와 같이 발화 분석 모듈(512), 발화 비교 모듈(513), 및 자연어 플랫폼(514)를 포함하는 프로세서(511) 및 발화 데이터 베이스(515)를 포함할 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 발화 분석 모듈(512)은 수신된 사운드에 대응하는 사운드를 확인할 수 있다. 예를 들어, 발화 분석 모듈(512)은 지능형 서버(420)의 데이터 베이스(515)에 저장된 복수 개의 사운드들 중 전자 장치(410)로부터 수신된 합성 사운드에 대응하는 합성 사운드를 확인할 수 있다. 서로 대응하는 사운드를 확인하기 위한 상기 두 사운드들 간의 비교 동작은 ASR(auto speech recognition) 또는 사운드의 의미 분석(NLU 분석)을 기반으로 수행될 수 있다. 발화 분석 모듈(512)의 수신된 사운드에 대응하는 사운드를 확인하는 동작은 도 8 내지 도 11에서 후술한다.According to various embodiments, the
다양한 실시예들에 따르면, 발화 비교 모듈(513)은 전자 장치(410)로부터 수신된 사운드와 수신된 사운드에 대응하는 데이터베이스(515)에 저장된 사운드를 비교하여, 두 사운드 간의 유사도를 확인할 수 있다. 예를 들어, 발화 비교 모듈(513)은 두 사운드 각각의 시간 별 특성(예: 세기 등)을 비교하여, 두 사운드의 유사도를 확인할 수 있다. 상기 두 사운드의 유사도를 확인하는 기술은 Euclidean distance 분석 등을 포함하는 선형 분석(linear alignment analysis), 및 DTW(Dynamic time wrapping)를 포함하는 비선형 분석(non-linear alignment analysis)를 포함할 수 있다.다양한 실시예들에 따르면, 자연어 플랫폼(514)은 전자 장치(410)로부터 수신된 사운드를 처리하고, 처리 결과에 기반하여 수신된 사운드에 대응하는 서비스를 제공하기 위한 처리 결과 정보를 생성할 수 있다. 처리 결과 정보에 대한 중복되는 설명은 생략한다.According to various embodiments, the
다양한 실시예들에 따르면, 발화 데이터 베이스(515)는 복수 개의 사운드들을 저장할 수 있다.According to various embodiments, the
예를 들어, 발화 데이터 베이스(515)는 전자 장치(410)로부터 지능형 서버(420)(예: 지능형 서버(420)) 수신된 전자 장치(410)(예: 사용자 장치)에 의해 획득된 사운드들(516)을 저장할 수 있다. 일 예로, 지능형 서버(420)는, 전자 장치(410)가 사용자로부터 사용자 발화를 수신하는 경우, 전자 장치(410)로부터 사용자 발화를 수신하고, 수신된 사용자 발화를 데이터 베이스(515)에 저장할 수 있다. 또 일 예로, 지능형 서버(420)는, 전자 장치(410)가 사용자 발화 및 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 포함하는 합성 사운드를 획득하는 경우, 전자 장치(410)로부터 합성 사운드를 수신하고, 수신된 합성 사운드를 데이터베이스(515)에 저장할 수 있다.For example, the
또 예를 들어, 발화 데이터 베이스(515)는 상기 기재된 바에 국한되지 않고, 사용자 장치 이외의 다른 개발자 서버 또는 클라우드 서버로부터 제공되는 다양한 종류의 사운드를 저장할 수 있다.Further, for example, the
다양한 실시예들에 따르면, 상술한 전자 장치(410)의 구성들은 지능형 서버(420)에 구현되거나, 상술한 지능형 서버(420)의 구성들은 전자 장치(410)에 구현될 수 있다. 예를 들어, 전자 장치(410)는 지능형 서버(420)에 구현되는 발화 분석 모듈(512), 발화 비교 모듈(513), 및 발화 데이터 베이스(515)를 포함할 수 있다. 이에 따라, 전자 장치(410)는 발화 분석 모듈(512)에 의해 발화 데이터 베이스(515)에 저장된 복수 개의 사운드들(516) 중 수신된 사용자 발화에 대응하는 사운드를 확인하고, 발화 비교 모듈(513)에 의해 사운드들을 비교할 수 있다.According to various embodiments, the above-described components of the
다시 말해, 전자 장치(410)은 이하에서 설명되는 지능형 서버(420)에서 수행되는 동작들을 수행하도록 구현되는 On-device 타입의 장치로 구현될 수 있다. 또, 지능형 서버(420)가 이하에서 설명되는 전자 장치(410)에서 수행되는 동작들을 수행하도록 구현되는 On-device 타입의 장치로 구현될 수도 있다.In other words, the
이하에서는, 전자 장치(410)의 동작의 일 예에 대해서 설명한다.Hereinafter, an example of the operation of the
다양한 실시예들에 따르면, 전자 장치(410)는 현재 수신된 합성 사운드와 미리 저장된 합성 사운드의 비교 결과에 기반해서 확인되는 발화 탈취 여부에 따라 서비스를 제공할 수 있다.According to various embodiments, the
도 6은 다양한 실시예들에 따른 전자 장치(410) 및 지능형 서버(420)의 동작의 일 예를 설명하기 위한 흐름도(600)이다. 다양한 실시예들에 따르면, 도 6에 도시되는 동작들은 도시되는 순서에 국한되지 않고 다양한 순서로 수행될 수 있다. 또한, 다양한 실시예들에 따르면 도 6에 도시되는 동작들 보다 더 많은 동작들이 수행되거나, 더 적은 적어도 하나의 동작이 수행될 수도 있다. 이하에서는, 도 7을 참조하여 도 6에 대해서 설명한다.6 is a
도 7은 다양한 실시예들에 따른 전자 장치(410) 및 지능형 서버(420)의 동작의 일 예를 설명하기 위한 도면이다. 도 7에서 "+" 기호는 각각의 사운드가 결합되어 전자 장치의 마이크(502)에 수신됨을 나타내는 기호이다.7 is a diagram illustrating an example of operations of the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 601 동작에서 제 1 합성 사운드를 획득할 수 있다. 예를 들어, 전자 장치(410)는, 도 7에 도시된 바와 같이, 마이크(502)를 통해 지능형 음성 서비스 어플리케이션의 실행 중에 외부로부터 출력되는 사운드(예: "날씨 알려줘")(예: 701, 711) 및 전자 장치(410)의 스피커(501)를 통해 출력되는 사운드(예: 702, 712)를 함께 수신할 수 있다. 일 예로, 전자 장치(410)는 도 7을 참조하면, 지능형 음성 서비스 어플리케이션의 실행 중에 사용자(411)로부터 출력되는 사용자 발화(701) 및 스피커(501)를 통해 출력되는 사운드(예: 고주파수 대역을 가지는 사운드)(702)를 마이크(502)를 통해 함께 수신 할 수 있다. 또 일 예로, 전자 장치(410)는 도 7을 참조하면 지능형 음성 서비스 어플리케이션의 실행 중에 탈취자(440)에 의해 탈취되어 녹음 장치(441)로부터 출력되는 발화(711) 및 스피커(501)를 통해 출력되는 사운드(예: 고주파수 대역을 가지는 사운드)(712)를 마이크(502)를 통해 함께 수신할 수 있다.According to various embodiments, the electronic device 410 (eg, at least one processor 505) may obtain the first synthesized sound in
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 602 동작에서 제 1 합성 사운드 및 제 2 합성 사운드의 비교 결과를 획득할 수 있다.According to various embodiments, the electronic device 410 (eg, at least one processor 505) may obtain a result of comparing the first synthesized sound and the second synthesized sound in
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 현재 수신된 제 1 합성 사운드에 대응하는 미리 저장된 제 2 합성 사운드와 제 1 합성 사운드의 비교 결과를 획득(예: 지능형 서버(420)로부터 수신, 또는 전자 장치(410)가 분석하여 획득)할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) obtains a result of comparing the previously stored second synthesized sound and the first synthesized sound corresponding to the currently received first synthesized sound. (Eg, received from the
다양한 실시예들에 따르면, 제 2 합성 사운드는 제 1 합성 사운드에 포함된 제 1 발화에 대응하는 제 2 발화를 포함하는 발화일 수 있다. 일 예로, 도 7에 도시된 바와 같이 제 1 합성 사운드가 "날씨 알려줘"라는 제 1 발화(701)를 포함하는 경우, 제 2 합성 사운드 또한 "날씨 알려줘 "라는 제 2 발화(711)를 포함하는 사운드일 수 있다. 미리 저장된 복수 개의 사운드들 중에서 ASR 모듈의 분석 결과(즉, 합성 사운드의 사용자 발화 부분(또는, 가청 부분) 분석)에 기반해서 제 1 합성 사운드에 대응하는 제 2 합성 사운드가 확인될 수 있다. 복수 개의 사운드들 중 제 1 합성 사운드에 대응하는 제 2 합성 사운드가 확인되는 동작에 대해서는 도 8 내지 도 10에서 더 후술한다.According to various embodiments, the second synthesized sound may be an utterance including a second utterance corresponding to the first utterance included in the first synthesized sound. For example, as shown in FIG. 7, when the first synthesized sound includes a
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 제 1 합성 사운드와 제 2 합성 사운드 사이의 유사도에 따라서 다양한 정보를 포함하는 비교 결과를 획득할 수 있다. 상기 제 1 합성 사운드와 제 2 합성 사운드 사이의 유사도가 기설정된 값 이상인 경우 제 1 발화(701)는 사용자 발화이고, 제 1 합성 사운드와 제 2 합성 사운드 사이의 유사도가 기설정된 값 미만인 경우 탈취된 발화일 수 있다. 즉, 상기 비교 결과는 현재 수신된 제 1 합성 사운드에 포함된 제 1 발화가 탈취된 발화인지 여부에 따른 다양한 종류의 정보를 포함할 수 있다. 제 1 합성 사운드와 제 2 합성 사운드의 비교 및 두 합성 사운드 사이의 유사도에 따라 탈취 여부를 결정하는 동작에 대해서는 도 8 내지 도 10에서 더 후술한다.According to various embodiments, the electronic device 410 (eg, at least one processor 505) may obtain a comparison result including various information according to the similarity between the first synthesized sound and the second synthesized sound. . If the similarity between the first synthesized sound and the second synthesized sound is greater than or equal to a preset value, the
예를 들어, 상기 제 1 합성 사운드와 상기 제 2 합성 사운드의 유사도가 임계 값 이상인 경우(즉, 제 1 발화(701)가 사용자 발화인 경우), 상기 비교 결과는 제 1 발화에 대응하는 서비스를 제공하기 위한 처리 결과 정보(예: 제 1 발화(701)와 관련된 정보를 나타내기 위한 UI/UX)를 포함할 수 있다. 서비스를 제공하기 위한 처리 결과 정보와 관련된 중복되는 설명은 생략한다.For example, when the similarity between the first synthesized sound and the second synthesized sound is greater than or equal to a threshold value (that is, when the
또 예를 들어, 상기 제 1 합성 사운드와 상기 제 2 합성 사운드의 유사도가 임계 값 미만인 경우(즉, 제 1 발화가 탈취된 발화인 경우), 상기 비교 결과는 현재 수신된 제 1 발화(701)가 탈취된 발화임을 나타내기 위한 정보를 포함할 수 있다.Also, for example, when the similarity between the first synthesized sound and the second synthesized sound is less than a threshold value (that is, if the first speech is a captured speech), the comparison result is the currently received
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 603 동작에서 제 1 합성 사운드 및 제 2 합성 사운드의 유사도가 기설정된 값 이상(즉, 제 1 발화가 사용자 발화)인 경우, 604 동작에서 제 1 합성 사운드에 대응하는 서비스를 제공할 수 있다. 예를 들어, 전자 장치(410)는 상술한 비교 결과에 포함된 처리 결과 정보에 기반하여 제 1 발화에 대응하는 서비스를 제공할 수 있다. 일 예로, 전자 장치(410)는 도 7의 701에 도시된 바와 같이, 사용자로부터 수신된 "날씨 알려줘"라는 발화(701)에 대응하여, 오늘 날씨 정보를 표시하기 위한 UI/UX를 전자 장치(410)의 디스플레이에 표시할 수 있다.According to various embodiments, in
또, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 603 동작에서 제 1 합성 사운드 및 제 2 합성 사운드의 유사도가 기설정된 값 미만(즉, 제 1 발화가 탈취된 발화)인 경우, 605 동작에서 제 1 합성 사운드에 대응하는 서비스를 제공을 금지할 수 있다. 또는, 전자 장치(410)는 제 1 발화가 탈취된 발화인 경우, 다시 한 번 현재 전자 장치(410)를 사용하는 사용자가 진의의 사용자인지 여부를 확인하기 위해 특정 키워드를 포함하는 발화의 제공을 요청할 수 있다. 특정 키워드를 포함하는 발화의 제공을 요청하는 동작에 대해서는 도 21 내지 도 23에서 후술한다.In addition, the electronic device 410 (for example, at least one processor 505) has a similarity between the first synthesized sound and the second synthesized sound less than a preset value in operation 603 (i.e., the utterance from which the first utterance is captured). In this case, in operation 605, provision of a service corresponding to the first synthesized sound may be prohibited. Alternatively, when the first utterance is a stolen utterance, the
다양한 실시예들에 따르면, 전자 장치(410)가 사용자 발화와 함께 부가 정보를 획득하고, 부가 정보에 기반하여 현재 발화를 제공하는 사용자가 진의의 사용자가 아닌 것으로 확인되는 경우에는 상술한 합성 사운드 간의 비교 동작을 수행할 필요 없이 발화에 대응하는 서비스의 제공을 금지할 수 있다.According to various embodiments, when the
상술한 바와 같이, 전자 장치(410)가 다양한 종류의 사운드(예: 비가청 주파수 대역의 사운드)를 출력하고, 이에 따라 획득되는 합성 사운드들 사이의 비교하는 동작을 수행함에 따라 탈취되 발화에 의한 음성 서비스 제공이 금지됨으로써, 음성 서비스의 보안성 및 개인 정보의 보안성이 향상될 수 있다.As described above, as the
아울러, 전자 장치(410)가 탈취된 발화인지 여부를 확인하기 위해 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)를 수신되는 발화에 부가되도록 함으로써, 전자 장치(410)의 탈취된 발화를 검출하기 위한 운용 부담이 경감될 수 있다. 예를 들어, 전자 장치(410)는 수신된 발화가 탈취된 발화인지 여부를 확인하기 위해, 진의의 사용자의 실제 발화의 음성학적인 특성과 현재 수신된 발화의 음성학적인 특성을 비교하기 위한 분석 동작(예: 딥 러닝 등을 이용한 학습 모델에 기반한 분석 동작)을 수행할 수 있다. 이 경우, 전자 장치(410)는 분석 동작을 수행하기 위한 다양한 데이터들(예: 학습 모델)을 저장하고, 이를 확인하는 동작을 수행함에 따라 탈취된 발화인지 여부를 확인하기 위한 전자 장치(410)의 운용 부담이 증가될 수 있다. 다양한 실시예들에 따른 전자 장치(410)의 경우, 탈취된 발화인지 여부가 현재 수신되는 발화에 부가되는 다양한 종류의 사운드(예: 비가청 주파수 대역을 갖는 사운드)에 의해 상대적으로 적은 프로세서에 의해 확인될 수 있어, 상대적인 운용 부담이 경감될 수 있다.In addition, by adding various types of sounds (eg, sound having an inaudible frequency band) to the received utterance in order to check whether the
이하에서는, 전자 장치(410) 및 지능형 서버(420)의 동작의 일 예에 대해서 설명한다.Hereinafter, an example of operations of the
다양한 실시예들에 따르면, 전자 장치(410)는 현재 수신되는 합성 사운드를 지능형 서버(420)로 송신할 수 있다. 지능형 서버(420)는 수신된 합성 사운드와 미리 저장된 합성 사운드를 비교하여 발화의 탈취 여부(즉, 발화가 진의의 사용자 발화인지 여부)를 확인하고, 발화 탈취 여부에 따라서 전자 장치(410)가 사용자 발화에 대응하는 서비스를 제공하도록 할 수 있다.According to various embodiments, the
도 8은 다양한 실시예들에 따른 전자 장치(410) 및 지능형 서버(420)의 동작의 일 예를 설명하기 위한 흐름도(800)이다. 다양한 실시예들에 따르면, 도 8에 도시되는 동작들은 도시되는 순서에 국한되지 않고 다양한 순서로 수행될 수 있다. 또한, 다양한 실시예들에 따르면 도 8에 도시되는 동작들 보다 더 많은 동작들이 수행되거나, 더 적은 적어도 하나의 동작이 수행될 수도 있다. 이하에서는, 도 9 내지 11을 참조하여 도 8에 대해서 설명한다.8 is a flowchart 800 illustrating an example of operations of the
도 9는 다양한 실시예들에 따른 전자 장치(410) 및 지능형 서버(420)의 동작의 일 예를 설명하기 위한 도면이다. 도 9에서 "+" 기호는 각각의 사운드가 결합되어 전자 장치의 마이크(502)에 수신됨을 나타내는 기호이다. 도 10은 다양한 실시예들에 따른 전자 장치(410) 및 지능형 서버(420)의 동작의 일 예를 설명하기 위한 다른 도면이다. 도 11은 다양한 실시예들에 따른 발화의 탈취 여부에 따른 합성 사운드 간의 비교 결과를 설명하기 위한 도면이다.9 is a diagram illustrating an example of operations of the
다양한 실시예들에 따르면, 전자 장치(410)는 801 동작에서 지능형 음성 서비스 어플리케이션을 실행할 수 있다. 전자 장치(410)는 도 9의 901에 도시된 바와 같이, 지능형 서비스 어플리케이션의 실행에 기반하여 지능형 서비스 어플리케이션의 실행 화면을 표시하도록 디스플레이를 제어할 수 있다.According to various embodiments, the
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 마이크(502)를 통해 사용자의 웨이크 업 명령을 수신하고, 수신된 웨이크 업 명령에 기반하여 사용자 입력(예: 사용자 발화)을 수신하기 위한 지능형 음성 서비스 어플리케이션을 실행시킬 수 있다.According to various embodiments, the electronic device 410 (eg, at least one processor 505) receives a user's wake-up command through the
예를 들어, 상기 웨이크업 명령은 전자 장치(410)의 마이크(502)(111)를 통해 수신되는 지정된 음성(예: 일어나!, 하이 빅스비!)을 포함하는 사용자 발화일 수 있다. 전자 장치(410)는 메모리(503)에 적어도 하나의 지정된 음성을 저장하고, 마이크(502)를 통해 수신된 음성이 저장된 적어도 하나의 지정된 음성에 대응하는 경우 지능형 음성 서비스 어플리케이션을 실행할 수 있다.For example, the wakeup command may be a user utterance including a designated voice (eg, wake up!, Hi Bixby!) received through the
또 예를 들어, 상기 웨이크업 명령은 전자 장치(410)에 구현되는 하드웨어 키(910)를 통해 수신되는 사용자 입력일 수 있다.Further, for example, the wakeup command may be a user input received through a
또 다른 예를 들어, 상기 웨이크업 명령은 지능형 음성 서비스 어플리케이션을 실행하기 위한 아이콘을 선택하기 위한 사용자 입력일 수 있다.For another example, the wakeup command may be a user input for selecting an icon for executing an intelligent voice service application.
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505)의 사운드 출력 모듈(506))는 802 동작에서 비가청 주파수 대역을 갖는 제 1 사운드를 스피커(501)를 통해 출력할 수 있다. 상기 비가청 주파수 대역을 갖는 사운드는 비가청 주파수 대역의 사운드 뿐만 아니라, 다른 가청 주파수 대역의 사운드를 포함하는 사운드일 수 있다. 비가청 주파수 대역에 대해서는 상술하였으므로, 중복되는 설명은 생략한다.According to various embodiments, the electronic device 410 (for example, the
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505)의 사운드 출력 모듈(506))는 다양한 조건의 만족을 확인한 것에 기반하여, 비가청 주파수 대역을 갖는 제 1 사운드의 출력하도록 스피커(501)를 제어할 수 있다. 상기 다양한 조건의 만족은 지능형 음성 서비스 어플리케이션이 실행되는 경우, 지능형 음성 서비스 어플리케이션의 실행 이후 기설정된 시간이 경과되는 경우, 또는 지능형 어플리케이션의 실행 중 특정 이벤트(예: 전자 장치(410)의 마이크(502)를 활성화하기 위한 사용자의 입력)가 발생되는 경우 등을 포함할 수 있다. 예를 들어, 전자 장치(410)는 지능형 음성 서비스 어플리케이션의 실행에 대한 응답으로, 비가청 주파수 대역을 갖는 제 1 사운드를 출력하도록 스피커(501)를 제어할 수 있다.According to various embodiments, the electronic device 410 (eg, the
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505)의 사운드 출력 모듈(506))는 지정된 시간 동안 비가청 주파수 대역을 갖는 제 1 사운드를 출력하도록 스피커(501)를 제어할 수 있다. 지정된 시간은 지능형 음성 서비스 어플리케이션의 실행 중에 전자 장치(410)로 발화가 수신될 가능성이 높은 시구간으로 설정될 수 있다. 예를 들어, 전자 장치(410)는 지능형 음성 서비스 어플리케이션이 실행된 이후, 지능형 음성 서비스 어플리케이션의 실행 시점으로부터 발화가 수신될 가능성이 높은 시간 동안(예: 3초)만 비가청 주파수 대역을 갖는 제 1 사운드를 출력하도록 스피커(501)를 제어할 수 있다.According to various embodiments, the electronic device 410 (for example, the
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505)의 사운드 출력 모듈(506))는 지능형 음성 서비스 어플리케이션의 실행 중에, 비가청 주파수 대역을 갖는 제 1 사운드의 생성을 위해 메모리(503)에 저장된 복수 개의 데이터들 중 적어도 하나의 데이터를 획득할 수 있다. 예를 들어, 전자 장치(410)는 도 9의 902에 도시된 바와 같이, 비가청 주파수 대역을 갖는 제 1 사운드의 생성을 위해 메모리(503)에 저장된 적어도 하나의 텍스트 데이터(911)(예: 제 1 텍스트 데이터, 제 2 텍스트 데이터) 를 획득할 수 있다. 전자 장치(410)는 비가청 주파수 대역을 갖는 사운드(예: 제 1 사운드)를 랜덤하게 생성하기 위해, 복수 개의 데이터들(504) 중에서 데이터를 랜덤하게 획득할 수 있다. 이에 따라, 전자 장치(410)는 비가청 주파수 대역을 갖는 사운드를 출력할 때마다, 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력할 수 있는데, 이에 대해서는 도 13 내지 도 19에서 후술한다.According to various embodiments, the electronic device 410 (for example, the
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505)의 사운드 출력 모듈(506))는 획득된 적어도 하나의 데이터를 사운드 데이터로 생성하고, 생성된 사운드 데이터를 비가청 주파수 대역을 갖는 사운드로 변환할 수 있다. 예를 들어, 전자 장치(410)는 획득된 적어도 하나의 텍스트 데이터를 사운드 데이터로 변환할 수 있다. 상기 데이터를 사운드 데이터를 생성하는 동작은 종래의 TTS(Text-to-Speech) 기술에 의해 수행될 수 있으므로, 이와 관련된 구체적인 설명은 생략한다. 이 때, 전자 장치(410)는 획득된 데이터의 수가 복수 개인 경우, 복수 개의 데이터들을 병합하고 병합된 데이터를 기반으로 사운드 데이터를 생성할 수 있다. 예를 들어, 전자 장치(410)는 복수 개의 텍스트 데이터들을 획득하는 경우, 획득된 복수 개의 텍스트 데이터들을 텍스트들을 랜덤하게 조합하거나 또는 각각의 텍스트들을 일렬로 나열하여 병합할 수 있다. 일 예로, 전자 장치(410)는 Nucleic이라는 텍스트를 포함하는 제 1 텍스트 데이터와 Floyd라는 텍스트를 포함하는 제 2 텍스트 데이터를 획득한 경우, 이를 병합하여 NucleicFloyd라는 텍스트를 획득할 수 있다. 다른 예로, 전자 장치(410)는 Nucleic이라는 텍스트를 포함하는 제 1 텍스트 데이터와 Floyd라는 텍스트를 포함하는 제 2 텍스트 데이터를 획득한 경우, 이를 조합하여 NuclFloydeic과 같이 각각의 기설정된 단위(예: 레터(one letter))의 텍스트를 임의의 순서대로 조합할 수도 있다.According to various embodiments, the electronic device 410 (for example, the
또 기재된 바에 국한되지 않고, 획득된 데이터를 마이크(502)를 통해 수신되는 발화(예: 사용자 발화)에 영향을 주지 않는 다양한 종류의 사운드로 변환할 수 있다. 다양한 종류의 사운드에 대해서는 상술한 바와 같으므로 중복되는 설명은 생략한다.In addition, it is not limited to what is described, and the acquired data may be converted into various types of sounds that do not affect speech (eg, user speech) received through the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505)의 사운드 출력 모듈(506))는 비가청 주파수를 갖는 사운드를 출력할 때마다, 같은 사운드를 출력하거나 또는 상이한 사운드를 출력할 수 있다. 예를 들어, 전자 장치(410)는 비가청 주파수를 갖는 사운드를 출력할 때마다, 같은 데이터를 기반으로 비가청 주파수를 갖는 사운드를 생성하여 출력할 수 있다. 또 예를 들어, 전자 장치(410)는 제 2 사운드와 제 1 사운드가 상이하도록 비가청 주파수를 갖는 사운드를 랜덤하게 출력할 수 있다.According to various embodiments, the electronic device 410 (for example, the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 803 동작에서 지능형 음성 서비스 어플리케이션의 실행 중에 마이크(502)를 통해 제 1 발화를 수신할 수 있다. 예를 들어, 전자 장치(410)는 지능형 음성 서비스 어플리케이션의 실행 중에, 사용자로부터 특정 서비스를 제공을 요청하기 위한 사용자 발화를 획득할 수 있다. 또 예를 들어, 전자 장치(410)는 지능형 음성 서비스 어플리케이션의 실행 중에, 다른 지능형 서버(420)의 스피커(501)로부터 출력되는 탈취된 발화를 획득할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) may receive the first speech through the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 804 동작에서 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 제 1 합성 사운드를 획득할 수 있다. 예를 들어, 전자 장치(410)는 도 9의 903에 도시된 바와 같이 마이크(502)를 통해서 제 1 발화(예: 사용자 발화 또는 탈취된 사용자 발화)(913)와 함께 스피커(501)를 통해 출력되는 비가청 주파수 대역의 제 1 사운드(912)를 함께 수신할 수 있다. 다시 말해, 상기 제 1 합성 사운드(914)는 제 1 발화(913) 및 비가청 주파수 대역의 제 1 사운드(914)를 포함하는 사운드일 수 있다.According to various embodiments, the electronic device 410 (eg, at least one processor 505) may obtain a first synthesized sound based on a first sound having a first speech and an inaudible frequency band in
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 805 동작에서, 도 9의 904에 도시된 바와 같이 획득된 제 1 합성 사운드(914)에 관한 정보를 지능형 서버(420)로 전송할 수 있다. 상기 제 1 합성 사운드(914)에 관한 정보는 제 1 합성 사운드를 나타내기 위한 전자적인 정보를 의미할 수 있다. 예를 들어, 제 1 합성 사운드(914)에 관한 정보는 제 1 합성 사운드(914)가 전자적인 데이터로 변환됨에 따라 획득되는 정보일 수 있다.According to various embodiments, in operation 805, the electronic device 410 (for example, at least one processor 505) may transmit information on the first
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511)의 발화 분석 모듈(512))는 806 동작에서 메모리(503)에 저장된 복수 개의 사운드들 중 제 1 발화와 관련된 제 2 합성 사운드를 확인할 수 있다. 상기 제 2 합성 사운드는 사용자 발화 및 비가청 주파수 대역의 제 2 사운드를 포함하는 사운드일 수 있다. 지능형 서버(420)의 데이터의 데이터 베이스(515)에 저장된 복수 개의 사운드들은 도 5에서 상술한 바와 같으므로, 중복되는 설명은 생략한다. 상기 제 2 사운드는, 제 1 합성 사운드에 포함된 비가청 주파수 대역을 갖는 제 1 사운드와 같거나 또는 유사하거나, 또는 상이할 수 있다. 예를 들어, 상술한 바와 같이 전자 장치(410)가 같은 비가청 주파수 대역을 갖는 사운드만을 출력함에 따라, 지능형 서버(420)의 데이터 베이스(515)에 저장된 합성 사운드는 각각이 서로 같거나 유사한 비가청 주파수 대역을 갖는 사운드를 포함할 수 있다. 또는, 상술한 바와 같이 전자 장치(410)가 랜덤하게 비가청 주파수 대역을 갖는 사운드만을 출력함에 따라, 지능형 서버(420)의 데이터 베이스(515)에 저장된 합성 사운드들은 각각이 서로 다른 비가청 주파수 대역을 갖는 사운드를 포함할 수 있다. 이 때, 제 1 사운드와 제 2 사운드가 상이하게 됨에 따라, 현재 수신된 제 1 발화의 탈취된 발화인지 여부를 확인하는 동작의 정확도가 향상될 수 있다. 이에 대해서는, 도 13 내지 도 18에서 후술한다.According to various embodiments, the intelligent server 420 (for example, the
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511)의 발화 분석 모듈(512))는 데이터 베이스(515)에 저장된 복수 개의 사운드들과 수신된 제 1 합성 사운드를 비교하여, 제 2 합성 사운드를 확인할 수 있다. 예를 들어, 지능형 서버(420)는, 도 10의 1001에 도시된 바와 같이, 데이터 베이스(515)에 저장된 복수 개의 사운드들(516) 중 제 1 합성 사운드(914)에 포함된 제 1 발화(913)에 대응하는 발화(예: 제 2 발화)를 포함하는 제 2 합성 사운드(1001)를 확인할 수 있다. 일 예로, 제 1 합성 사운드(914)가 "볼륨 키워줘"라는 제 1 발화(913)를 포함하는 경우, 제 2 합성 사운드(1011)는 지능형 서버(420)의 데이터 베이스(515)에 저장된 복수 개의 사운드들 중 "볼륨 키워줘"라는 사용자 발화 또는 이와 유사한 의미(또는, NLU 가 동일한)의 사용자 발화를 포함하는 합성 사운드일 수 있다.According to various embodiments, the intelligent server 420 (for example, the
다양한 실시예들에 따르면 지능형 서버(420)(예: 적어도 하나의 프로세서(511)의 발화 분석 모듈(512))데이터 베이스(515)에 저장된 복수 개의 합성 사운드들(516)의 가청 주파수 대역의 사운드와 제 1 합성 사운드(914)의 가청 주파수 대역의 사운드를 비교하여, 제 1 합성 사운드(914)의 가청 주파수 대역의 사운드에 대응하는(예: 동일한 또는 유사도가 기설정된 값 이상인) 가청 주파수 대역의 사운드를 가지는 제 2 합성 사운드(1011)를 확인할 수 있다.According to various embodiments, the intelligent server 420 (for example, the
상기 기재된 바에 국한되지 않고, 다양한 실시예들에 따르면 지능형 서버(420)는 데이터 베이스(515)에 저장된 복수 개의 합성 사운드들(516)의 의미 정보와 제 1 합성 사운드(914)의 의미 정보를 비교하여, 제 1 합성 사운드(914)의 의미 정보에 대응하는 의미 정보를 가지는 제 2 합성 사운드(1011)를 확인할 수도 있다.Without being limited to the above description, according to various embodiments, the
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511)의 발화 비교 모듈(513))는 807 동작에서 제 1 합성 사운드와 상기 제 2 합성 사운드를 비교하여 유사도를 확인하고, 808 동작에서 유사도와 임계값을 비교할 수 있다. 상기 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도는 제 1 합성 사운드(914)와 제 2 합성 사운드(1011)를 시간 별 특성(예: 세기 등의 음성학적 특성)의 비교에 따라 확인될 수 있다. 예를 들어, 지능형 서버(420)는 선형 분석 방법에 기반하여 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도를 비교할 수 있다. 또 예를 들어, 지능형 서버(420)는, 도 10의 1002에 도시된 바와 같이, DTW와 같은 비선형 분석 방법에 기반해서 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도를 비교할 수 있다.According to various embodiments, the intelligent server 420 (eg, the
상술한 바와 같이, 수신된 사운드를 분석하기 위한 복잡한 프로세스가 수행될 필요 없이, 단순히 두 합성 사운드를 시간 순서대로 비교함에 따라 지능형 서버(420)의 발화 탈취 여부를 판단하기 위한 운용 부담이 경감될 수 있다.As described above, it is not necessary to perform a complicated process for analyzing the received sound, and simply comparing the two synthesized sounds in chronological order, thereby reducing the operational burden for determining whether the
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 제 1 합성 사운드와 제 2 합성 사운드 사이의 유사도와 임계 값의 비교 결과에 따라, 전자 장치(410)에 수신된 제 1 발화(913)가 탈취된 발화인지 여부를 확인할 수 있다. 예를 들어, 지능형 서버(420)는 제 1 합성 사운드(914)와 제 2 합성 사운드 사이의 유사도가 임계값 이상인 경우 제 1 발화가 탈취된 발화가 아닌 것으로 확인하고, 제 1 합성 사운드와 제 2 합성 사운드 사이의 유사도가 임계값 미만인 경우 제 1 발화가 탈취된 발화로 확인할 수 있다.According to various embodiments, the intelligent server 420 (for example, the at least one processor 511) may determine the
다양한 실시예들에 따르면, 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도는 제 1 합성 사운드(914)의 비가청 주파수 대역의 사운드(913)와 제 2 합성 사운드(1011)의 비가청 주파수 대역의 사운드 사이의 유사도에 기반하여 결정될 수 있다. 다시 말해, 제 1 발화(913)가 탈취된 발화인지 여부는, 제 1 합성 사운드(914)의 비가청 주파수 대역의 사운드(912)와 제 2 합성 사운드(1011)의 비가청 주파수 대역의 사운드 사이의 유사도에 기반하여 결정될 수 있다.According to various embodiments, the similarity between the first
예를 들어, 탈취 여부에 따라 제 1 합성 사운드(914)의 서로 다른 특성을 설명하기 위한, 도 11에 개시되는 제 1 합성 사운드(1101)(탈취 경우 제 1 합성 사운드(914))과 제 1 합성 사운드(1102)(탈취되지 않은 경우 제 1 합성 사운드(914))를 참조하면, 제 1 발화(913)의 탈취 여부에 따라서 현재 수신되는 제 1 합성 사운드(914)의 비가청 주파수 대역(예: 1112 또는 1122)에서의 적어도 둘 이상의 사운드의 중첩 여부가 결정될 수 있다(예: 탈취 시 비가청 주파수 대역에서 둘 이상의 사운드가 중첩됨). 상기 제 1 합성 사운드(914)의 비가청 주파수 대역에서의 적어도 둘 이상의 사운드의 중첩 여부에 따라, 제 1 합성 사운드(914)와 제 2 합성 사운드(1011)의 유사도가 낮아질 수 있다.For example, the first synthesized sound 1101 (first synthesized
도 11을 참조하면, 복수 개의 사운드들(516) 중 유사도의 판단을 위해 선택된 합성 사운드(예: 제 2 합성 사운드(1011))는 가청 주파수 대역 부분(1131)에서 제 1 발화에 대응하는 제 2 발화를 포함하고 비가청 주파수 대역 부분(1132)에서 제 2 사운드를 포함할 수 있다. 탈취된 발화를 포함하는 합성 사운드(1101)는 가청 주파수 대역 부분(1111)에서 제 1 발화 및 비가청 주파수 대역 부분(1112)에서 이전에 이미 탈취자에 의해 녹음된 제 2 사운드 및 현재 전자 장치(410)의 스피커(501)를 통해 출력된 제 1 사운드를 포함할 수 있다. 진의의 사용자의 발화를 포함하는 합성 사운드(1102)는 가청 주파수 대역 부분(1121)에서 제 1 발화를 포함하고 비가청 주파수 대역 부분(1122)에서 현재 전자 장치(410)의 스피커(501)를 통해 출력된 제 1 사운드를 포함할 수 있다.Referring to FIG. 11, among a plurality of
이 경우, 탈취된 발화를 포함하는 합성 사운드(1101)의 비가청 주파수 대역(1112)에서 현재 출력된 제 1 사운드 및 녹음된 제 2 사운드가 중첩됨에 기인하여, 합성 사운드(1101)의 비가청 주파수 대역과 제 2 합성 사운드(1011)의 비가청 주파수 대역의 유사도가 현저하게 낮아져, 지능형 서버(420)는 현재 수신된 합성 사운드(1101)와 제 2 합성 사운드(1011) 사이의 유사도(k2)가 임계값 미만인 것으로 확인(즉, 탈취된 발화로 결정)할 수 있다.In this case, due to the superimposition of the first sound currently output and the recorded second sound in the
또 이 경우, 탈취된 발화를 포함하지 않는 합성 사운드(1102)의 비가청 주파수 대역(1122)에서 현재 출력된 제 1 사운드만이 존재하게 됨에 따라, 합성 사운드(1102)의 비가청 주파수 대역(1122)과 제 2 합성 사운드(1011)의 비가청 주파수 대역(1132)의 유사도가 일정 수준으로 유지됨으로써, 지능형 서버(420)는 합성 사운드(1102)와 제 2 합성 사운드(1011) 사이의 유사도(k1)가 임계값 이상인 것으로 확인(즉, 탈취된 발화로 결정)할 수 있다.Further, in this case, since only the first sound currently output in the
다양한 실시예들에 따르면 상기 임계값은 비가청 주파수 대역에서의 사운드의 중첩 여부에 따라 발화의 탈취 여부가 결정되도록 설정될 수 있다. 즉, 도 11을 참조하면, 탈취된 발화를 포함하는 합성 사운드(1101)의 비가청 주파수 대역에서 사운드가 중첩되는 경우에 확인되는 합성 사운드(1101)와 제 2 합성 사운드(1011) 사이의 유사도(k2) 보다 임계값이 높도록 설정될 수 있다.According to various embodiments, the threshold value may be set to determine whether to deodorize speech according to whether sounds overlap in an inaudible frequency band. That is, referring to FIG. 11, the similarity between the
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 809 동작에서 유사도와 임계값의 비교 결과에 기반하여, 제 1 발화에 대응하는 서비스를 제공하기 위한 처리 결과 정보를 획득할 수 있다.According to various embodiments, the intelligent server 420 (eg, at least one processor 511) processes to provide a service corresponding to the first utterance based on the result of comparing the similarity and the threshold value in
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 제 1 발화(913)가 탈취된 발화인지 여부에 따라서, 다양한 종류의 처리 결과 정보를 포함할 수 있다.According to various embodiments, the intelligent server 420 (eg, at least one processor 511) may include various types of processing result information depending on whether the
예를 들어, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도가 임계값 이상인 경우, 제 1 발화(913)를 처리(예: 상술한 자연어 플랫폼(514)을 이용한 처리)하고, 제 1 발화에 대응하는 서비스를 제공하기 위한 정보들(예: UI/UX 등)을 포함하는 처리 결과 정보를 획득할 수 있다. 처리 결과 정보를 획득하는 동작은 상술한 자연어 플랫폼(514)에 기반한 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.For example, when the similarity between the first
예를 들어, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도가 임계값 미만인 경우, 제 1 발화(913)에 의해 서비스가 제공될 수 없음을 나타내기 위한 정보를 생성할 수 있다.For example, when the similarity between the first
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 810 동작에서 도 10의 1003에 도시된 바와 같이 처리 결과 정보를 전자 장치(410)로 송신할 수 있다.According to various embodiments, the intelligent server 420 (eg, at least one processor 511) may transmit processing result information to the
예를 들어, 전자 장치(410)는 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도가 임계값 이상인 경우(즉, 제 1 발화(913)가 진의의 사용자 발화인 경우), 제 1 발화(913)에 대응하는 서비스를 제공하기 위한 정보들(예: UI/UX 등)을 포함하는 처리 결과 정보를 지능형 서버(420)로부터 수신하고 획득된 정보에 기반하여 제 1 발화(913)에 대응하는 서비스를 제공할 수 있다. 일 예로, 전자 장치(410)는 도 10의 1003에 도시된 바와 같이, 현재 수신된 발화(예: 오늘 날씨는 어떠니)에 대한 응답으로 오늘 날씨 정보를 제공하기 위한 UI/UX를 표시할 수 있다.For example, when the
또 예를 들어, 전자 장치(410)는 제 1 합성 사운드(914)와 제 2 합성 사운드(1011) 사이의 유사도가 임계값 미만인 경우, 제 1 발화(913)가 탈취된 발화임을 나타내는 정보를 수신할 수 있다. 전자 장치(410)는 수신된 정보에 기반해서 지능형 음성 서비스 어플리케이션의 실행 화면 상에 알림 메시지를 표시할 수 있다. 상기 알림 메시지는, 현재 수신된 발화가 탈취된 발화임을 나타내기 위한 그래픽 오브젝트(예: 텍스트, 이미지 등), 또는 발화를 재요청하기 위한 그래픽 오브젝트를 포함할 수 있다. 전자 장치(410)는 발화를 재요청하는 경우, 특정 키워드를 포함하는 발화를 재요청하여 사용자의 진의 여부를 재확인할 수 있는데 이에 대해서는 도 22 내지 도 24에서 후술한다.Also, for example, when the similarity between the first
이하에서는 전자 장치(410) 및 지능형 서버(420)의 동작의 다른 예에 대해서 설명한다.Hereinafter, another example of the operation of the
다양한 실시예들에 따르면, 전자 장치(410)는 랜덤하게 비가청 주파수 대역을 갖는 사운드를 출력할 수 있다. 예를 들어, 전자 장치(410)는 비가청 주파수 대역을 갖는 사운드의 출력 시 마다, 서로 다른 데이터를 기반으로 생성되는 비가청 주파수 대역을 갖는 사운드를 출력하도록 스피커(501)를 제어할 수 있다. 이에 따라, 지능형 서버(420)는 각각이 전자 장치(410)로부터 랜덤하게 출력되는 비가청 주파수 대역을 갖는 사운드를 포함하는 합성 사운드들을 전자 장치(410)로부터 수신하고, 수신된 합성 사운드들을 데이터베이스(515)에 저장할 수 있다.According to various embodiments, the
도 12는 다양한 실시예들에 따른 전자 장치(410) 및 지능형 서버(420)의 동작의 다른 예를 설명하기 위한 흐름도(1200)이다. 다양한 실시예들에 따르면, 도 12에 도시되는 동작들은 도시되는 순서에 국한되지 않고 다양한 순서로 수행될 수 있다. 또한, 다양한 실시예들에 따르면 도 12에 도시되는 동작들 보다 더 많은 동작들이 수행되거나, 더 적은 적어도 하나의 동작이 수행될 수도 있다. 이하에서는, 도 13 내지 14를 참조하여 도 12에 대해서 설명한다.12 is a
도 13은 다양한 실시예들에 따른 전자 장치(410)의 비가청 주파수 대역을 갖는 사운드를 출력하는 동작의 일 예를 설명하기 위한 도면이다. 도 13에서 "+" 기호는 각각의 사운드가 결합되어 전자 장치의 마이크(502)에 수신됨을 나타내는 기호이다. 도 14는 다양한 실시예들에 따른 랜덤하게 비가청 주파수 대역을 갖는 사운드를 출력하는 경우 탈취된 발화의 비가청 주파수 대역의 일 예를 설명하기 위한 도면이다. 도 14의 그래프에 도시되는 "-"는 시간 별 특성 주파수에서의 세기를 나타낼 수 있다.13 is a diagram illustrating an example of an operation of outputting a sound having an inaudible frequency band of the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 1201 동작에서 지능형 음성 서비스 어플리케이션을 실행하고, 1202 동작에서 비가청 주파수 대역을 갖는 제 1 사운드(1312)를 마이크(502)를 통해 출력할 수 있다. 예를 들어, 전자 장치(410)는 도 13의 1301에 도시된 바와 같이 지능형 음성 서비스 어플리케이션의 실행 중 복수 개의 데이터들(504) 중 적어도 하나의 제 1 데이터(1311)(예: 제 1 텍스트 데이터 및 제 2 텍스트 데이터)를 획득하고, 획득된 적어도 하나의 제 1 데이터(1311)에 기반하여 비가청 주파수 대역을 갖는 제 1 사운드(1312)를 생성하여 출력하도록 스피커(501)를 제어할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) executes an intelligent voice service application in
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 1203 동작에서 도 13의 1302에 도시된 바와 같이 제 1 발화(1313) 및 비가청 주파수 대역을 갖는 제 1 사운드(1312)를 포함하는 제 1 합성 사운드(1314)를 획득하고, 1204 동작에서 제 1 합성 사운드(1314)에 대한 정보를 지능형 서버(420)로 전송할 수 있다. 전자 장치(410)의 1203 동작 및 1204 동작은 상술한 전자 장치(410)의 903 동작 내지 905 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다. 이에 따라, 지능형 서버(420)는 1305 동작에서 제 2 합성 사운드(1318)를 데이터베이스(515)에 저장할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505), as shown in 1302 of FIG. 13 in
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 1206 동작에서 지능형 음성 서비스 어플리케이션을 실행하고, 1207 동작에서 비가청 주파수 대역을 갖는 제 1 사운드(1312)를 마이크(502)를 통해 출력할 수 있다. 예를 들어, 전자 장치(410)는 도 13의 1303에 도시된 바와 같이 지능형 음성 서비스 어플리케이션의 실행 중 복수 개 데이터들 중 적어도 하나의 제 2 데이터(1315)(예: 제 3 텍스트 데이터 및 제 4 텍스트 데이터)를 획득하고, 도 13의 1304에 도시된 바와 같이 획득된 적어도 하나의 제 2 데이터(1315)에 기반하여 비가청 주파수 대역을 갖는 제 2 사운드(1316)를 생성하여 출력하도록 스피커(501)를 제어할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) executes an intelligent voice service application in
다양한 실시예들에 따르면, 전자 장치(410)로부터 출력되는 비가청 주파수 대역을 갖는 제 1 사운드(1312)와 비가청 주파수 대역을 갖는 제 2 사운드(1316)는 서로 다를 수 있다.According to various embodiments, the
예를 들어, 제 1 사운드(1312)와 제 2 사운드(1316)는 비가청 주파수 대역에서의 음성학적 특성이 서로 다른 사운드일 수 있다.For example, the
일 예로, 제 1 사운드(1312)와 제 2 사운드(1316)는 비가청 주파수 대역 별로 서로 다른 세기를 가지는 사운드일 수 있다. 즉, 제 1 사운드(1312)는 제 1 대역의 비가청 주파수 대역에서 제 1 세기를 가지는 사운드이고, 제 2 사운드(1316)는 제 1 대역의 비가청 주파수 대역에서 제 2 세기를 가지는 사운드일 수 있다.As an example, the
다른 예로, 제 1 사운드(1312)와 제 2 사운드(1316)는 서로 다른 비가청 주파수 대역을 가지는 사운드일 수 있다. 즉, 제 1 사운드(1312)는 제 1 대역의 비가청 주파수 대역을 가지는 사운드이고 제 2 사운드(1316)는 제 1 대역과는 다른 제 2 대역의 비가청 주파수 대역을 가지는 사운드일 수 있다.As another example, the
또 다른 예로, 제 1 사운드(1312)와 제 2 사운드(1316)는 서로 다른 비가청 주파수 대역에서 서로 다른 세기를 가지는 사운드일 수 있다. 즉, 제 1 사운드(1312)는 제 1 대역의 비가청 주파수 대역에서 제 1 세기를 가지는 사운드이고 제 2 사운드(1316)는 제 1 대역과는 다른 제 2 대역의 비가청 주파수 대역에서 제 2 세기를 가지는 사운드일 수 있다.As another example, the
상기 기재된 바에 국한되지 않고, 제 1 사운드(1312)와 제 2 사운드(1316)는 비가청 주파수 대역이 아닌 다른 가청 주파수 대역에서의 음성학적 특성이 서로 다를 수도 있다. 예를 들어, 제 1 사운드(1312)는 제 1 음원에 의한 음악 사운드이고, 제 2 사운드(1316)는 제 2 음원에 의한 음악 사운드일 수 있다.Not limited to the above description, the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 비가청 주파수 대역을 갖는 사운드를 출력할 때마다, 메모리(503)에 저장된 복수 개의 데이터들(504) 중에서 랜덤하게 적어도 하나의 데이터를 획득할 수 있다. 전자 장치(410)는, 복수 개의 데이터들(504) 중에서 랜덤하게 획득된 적어도 하나의 데이터에 기반하여, 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력할 수 있다.According to various embodiments, each time the electronic device 410 (for example, at least one processor 505) outputs a sound having an inaudible frequency band, a plurality of
또 다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 데이터들의 사용 이력을 관리 및/또는 저장하고, 복수 개의 데이터들(504) 중 관리되는 데이터들의 사용 이력을 기반으로 데이터를 선택하여 비가청 주파수 대역을 갖는 사운드를 생성할 수 있다. 예를 들어, 전자 장치(410)는 복수 개의 데이터들(504) 별로 식별 정보를 저장하고, 복수 개의 데이터들(504) 중 비가청 주파수 대역을 가는 사운드를 생성하기 위해 사용된 데이터들의 식별 번호와 사용 여부를 나타내는 정보를 저장할 수 있다. 전자 장치(410)는 비가청 주파수 대역을 갖는 사운드를 생성하는 경우, 복수 개의 데이터들(504) 별로 저장된 식별 번호와 사용 여부를 나타내는 정보를 확인하고, 복수 개의 데이터들(504) 중 이전에 사용하지 않은 데이터를 확인할 수 있다. 전자 장치(410)는, 확인된 이전에 사용하지 않은 데이터를 기반으로 비가청 주파수 대역을 갖는 사운드를 생성함으로써, 이전에 출력된 비가청 주파수 대역을 갖는 사운드(예: 제 1 사운드(1312))와는 다른 비가청 주파수 대역을 갖는 사운드(예: 제 2 사운드(1316))를 출력할 수 있다.In addition, according to various embodiments, the electronic device 410 (eg, at least one processor 505) manages and/or stores the usage history of data, and uses managed data among a plurality of
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 1208 동작에서 제 1 발화(1313) 및 비가청 주파수 대역을 갖는 제 1 사운드(1312)를 포함하는 제 1 합성 사운드(1314)를 획득하고, 1209 동작에서 제 1 합성 사운드(1314)에 대한 정보를 지능형 서버(420)로 전송할 수 있다. 이에 따라, 지능형 서버(420)는 1310 동작에서 제 2 합성 사운드(1318)를 데이터베이스(515)에 저장할 수 있다. 예를 들어, 전자 장치(410)는 도 13의 1304에 도시된 바와 같이, 현재 스피커(501)를 통해 출력되는 비가청 주파수 대역을 갖는 제 2 사운드(1316) 및 제 2 발화(1317)를 포함하는 제 2 합성 사운드(1318)를 획득하고, 획득된 제 2 합성 사운드(1318)를 지능형 서버(420)로 전달하여 지능형 서버(420)가 제 2 합성 사운드(1318)를 저장하도록 할 수 있다.According to various embodiments, in
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))가 랜덤하게 비가청 주파수 대역을 갖는 사운드(예: 제 1 사운드(1312) 및 제 2 사운드(1316))를 출력함에 따라, 현재 수신된 발화의 탈취 여부의 탐지 동작의 정확도가 향상될 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) randomly has a sound having an inaudible frequency band (for example, the
예를 들어, 도 14의 1401 및 1402를 참조하면, 탈취된 발화를 포함하는 합성 사운드(예: 제 2 합성 사운드)의 비가청 주파수 대역(1411 또는 1412)에 중첩되는 사운드의 종류(즉, 중첩되는 사운드가 상이한지 여부)에 따라, 현재 수신된 합성 사운드(예: 제 2 합성 사운드)와 이전에 저장된 합성 사운드(예: 제 1 합성 사운드)의 유사도가 현저하게 달라질 수 있다.For example, referring to 1401 and 1402 of FIG. 14, the type of sound (that is, overlapping) in the inaudible frequency band (1411 or 1412) of the synthesized sound (for example, the second synthesized sound) including the captured speech Depending on whether the resulting sound is different), the similarity between the currently received synthesized sound (eg, the second synthesized sound) and the previously stored synthesized sound (eg, the first synthesized sound) may significantly differ.
도 14의 1401을 참조하면, 탈취된 발화를 포함하는 제 2 합성 사운드의 비가청 주파수 대역(1411)이 서로 다른 사운드(예: 제 1 사운드(1312)와 제 2 사운드(1316))를 포함하는 경우, 이전에 저장된 제 1 합성 사운드의 비가청 주파수 대역(1411)의 사운드와 제 2 합성 사운드의 비가청 주파수 대역(1411)의 유사도가 현저하게 낮아질 수 있다. 예를 들어, 이전에 저장된 제 1 합성 사운드에는 제 1 비가청 주파수 대역을 갖는 제 1 사운드(1312)가 포함되고, 제 2 합성 사운드에는 제 1 비가청 주파수 대역을 갖는 제 1 사운드(1312) 및 제 2 비가청 주파수 대역을 갖는 제 2 사운드(1316)가 포함될 수 있다. 이 경우, 제 2 합성 사운드의 제 2 비가청 주파수 대역을 갖는 제 2 사운드에 의한 사운드의 세기에 기반하여, 도 14의 1402에 도시된 비가청 주파수 대역(1412)에서 서로 같은 사운드가 중첩되는 경우의 유사도에 비해서, 상대적으로 제 1 합성 사운드와 제 2 합성 사운드의 유사도가 낮을 수 있다. 또 예를 들어, 이전에 저장된 제 1 합성 사운드에는 제 1 비가청 주파수 대역을 갖는 제 1 사운드(1312)가 포함되고, 제 2 합성 사운드에는 제 1 비가청 주파수 대역에서 제 1 세기를 갖는 제 1 사운드(1312) 및 제 1 비가청 주파수 대역에서 제 2 세기를 갖는 제 2 사운드(1316)가 포함될 수 있다. 이 경우, 제 2 합성 사운드의 제 1 비가청 주파수 대역을 갖는 제 2 사운드(1316)의 제 2 세기에 기반하여, 도 14의 1402에 도시된 비가청 주파수 대역(1412)에서 서로 같은 사운드가 중첩되는 경우의 유사도에 비해서 상대적으로 제 1 합성 사운드와 제 2 합성 사운드의 유사도가 낮을 수 있다.Referring to 1401 of FIG. 14, the
이하에서는 전자 장치(410)의 동작의 일 예에 대해서 설명한다.Hereinafter, an example of the operation of the
다양한 실시예들에 따르면, 전자 장치(410)는 다양한 변수에 기반하여 복수 개의 데이터들 중에서 랜덤하게 데이터를 획득하고, 랜덤하게 획득된 데이터에 기반하여 서로 다른 비가청 주파수 대역의 사운드를 출력할 수 있다.According to various embodiments, the
도 15는 다양한 실시예들에 따른 전자 장치(410)의 랜덤하게 비가청 주파수 대역을 갖는 사운드를 출력하는 동작의 일 예를 설명하기 위한 흐름도(1500)이다. 다양한 실시예들에 따르면, 도 15에 도시되는 동작들은 도시되는 순서에 국한되지 않고 다양한 순서로 수행될 수 있다. 또한, 다양한 실시예들에 따르면 도 15에 도시되는 동작들 보다 더 많은 동작들이 수행되거나, 더 적은 적어도 하나의 동작이 수행될 수도 있다. 이하에서는, 도 16 내지 도 18을 참조하여 도 15에 대해서 설명한다.15 is a
도 16은 다양한 실시예들에 따른 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력하기 위해 데이터를 획득하는 동작의 일 예를 설명하기 위한 도면이다. 도 17은 다양한 실시예들에 따른 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력하기 위해 데이터를 획득하는 동작의 다른 예를 설명하기 위한 도면이다. 도 18은 다양한 실시예들에 따른 서로 다른 비가청 주파수 대역을 갖는 사운드를 출력하기 위해 데이터를 획득하는 동작의 또 다른 예를 설명하기 위한 도면이다.16 is a diagram for describing an example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments. 17 is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments. 18 is a diagram for describing another example of an operation of acquiring data to output sounds having different inaudible frequency bands according to various embodiments.
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 1501 동작에서 지능형 음성 서비스 어플리케이션을 실행할 수 있다. 전자 장치(410)의 1501 동작은 상술한 전자 장치(410)의 801 동작과 같이 수행될 수 있으므로, 중복되는 설명은 생략한다.According to various embodiments, the electronic device 410 (eg, at least one processor 505) may execute an intelligent voice service application in
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 1502 동작에서 다양한 종류의 파라미터들 중 적어도 하나의 파라미터를 확인하고 확인된 적어도 하나의 변수와 관련된 값을 변경하고, 1503 동작에서 확인된 적어도 하나의 변수와 관련된 값에 기반하여 텍스트 데이터를 획득할 수 있다. 예를 들어, 전자 장치(410)는 비가청 주파수 대역을 갖는 사운드를 출력할 때마다, 다양한 종류의 파라미터들 중 적어도 하나의 파라미터를 확인하고, 확인된 파라미터와 관련된 값을 이전과는 다른 값으로 변경하여 변경된 값에 기반하여 텍스트 데이터를 획득할 수 있다. 다시 말해, 전자 장치(410)는 수신되는 발화가 탈취된 발화인지 여부를 탐지하는 동작의 정확도를 향상하기 위해, 비가청 주파수 대역을 갖는 사운드를 출력할 때마다, 상이한 비가청 주파수 대역을 갖는 사운드가 출력되도록 할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) checks at least one parameter among various types of parameters in
다양한 실시예들에 따르면 상기 다양한 종류의 파라미터들은 전자 장치로부터 출력되는 비가청 주파수 대역을 갖는 사운드들 사이의 유사도가 낮아지도록, 비가청 주파수 대역을 갖는 사운드들 사운드들을 생성하기 위한 데이터의 선택을 위한 변수들이 될 수 있다. 예를 들어, 도 16 내지 도 18을 참조하면, 다양한 종류의 파라미터들은 획득되는 데이터의 수, 데이터가 획득되는 일 특성을 갖는 데이터 그룹 등을 포함할 수 있다. 전자 장치는 다양한 종류의 파라미터와 관련된 값들을 저장하고, 비가청 주파수 대역을 갖는 사운드의 출력 시 마다 다양한 종류의 파라미터와 관련된 값을 참조할 수 있다. 예를 들어, 전자 장치는 파라미터가 데이터의 수인 경우, 이전에 비가청 주파수를 갖는 사운드를 출력하기 위해 획득한 데이터의 수를 저장하고, 이후 비가청 주파수 대역을 갖는 사운드의 출력 시마다 이전에 획득된 데이터의 수를 확인하고 이전에 획득된 데이터의 수와 현재 획득하는 데이터의 수를 다르게 할 수 있다.According to various embodiments, the various kinds of parameters are used for selecting data for generating sounds having an inaudible frequency band so that similarity between sounds having an inaudible frequency band output from an electronic device is lowered. Can be variables. For example, referring to FIGS. 16 to 18, various types of parameters may include the number of acquired data, a data group having one characteristic from which data is acquired, and the like. The electronic device may store values related to various types of parameters and refer to values related to various types of parameters whenever sound having an inaudible frequency band is output. For example, if the parameter is the number of data, the electronic device stores the number of data previously acquired to output a sound having an inaudible frequency, and then stores the number of data previously acquired each time a sound having an inaudible frequency band is output. You can check the number of data and make the number of previously acquired data different from the number of currently acquired data.
예를 들어, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 도 16에 도시된 바와 같이, 비가청 주파수 대역을 갖는 사운드를 출력할 때마다, 파라미터로서 데이터의 수를 확인하고, 이전에 획득된 데이터의 수와는 다른 수로 데이터를 획득할 수 있다. 일 예로 전자 장치(410)는 도 16에 도시된 바와 같이 저장된 복수 개의 데이터들(1601) 중 제 1 갯수(예: 2 개)의 텍스트 데이터(예: 제 1 내지 제 2 텍스트 데이터)를 획득하고 획득된 제 1 갯수의 텍스트 데이터에 기반하여 제 1 합성 사운드를 출력할 수 있다. 전자 장치는, 제 1 합성 사운드의 출력 이후 제 2 합성 사운드의 생성 시, 저장된 복수 개의 데이터들(1601) 중 이전에 획득한 제 1 갯수와는 다른 제 2 갯수(예: 3 개)의 텍스트 데이터(예: 제 1 내지 제 3 텍스트 데이터)를 획득하고 획득된 제 2 갯수의 텍스트 데이터에 기반하여 제 2 합성 사운드를 출력할 수 있다.For example, whenever the electronic device 410 (eg, at least one processor 505) outputs sound having an inaudible frequency band, as shown in FIG. 16, it checks the number of data as a parameter and , Data may be acquired with a number different from the number of previously acquired data. As an example, the
또 예를 들어, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 도 17에 도시된 바와 같이, 서로 다른 특성을 가지는 복수 개의 텍스트 데이터 그룹(1701, 1702)을 저장하고, 비가청 주파수 대역을 갖는 사운드를 출력할 때마다 서로 다른 텍스트 데이터 그룹으로부터 텍스트 데이터를 획득할 수 있다. 상기 서로 다른 특성은, 텍스트의 길이, 텍스트와 관련된 주파수 대역 등을 포함할 수 있다.Also, for example, the electronic device 410 (eg, at least one processor 505) stores a plurality of
일 예로, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 제 1 길이와 관련된 텍스트 데이터 그룹 및 제 2 길이와 관련된 텍스트 데이터 그룹을 저장할 수 있다. 상기 특정 길이와 관련된 텍스트 데이터 그룹은 특정 길이의 텍스트들만을 포함하는 그룹 뿐만 아니라, 특정 길이 범위의 텍스트들을 포함하는 텍스트들을 포함하는 그룹을 의미할 수 있다. 전자 장치는 제 1 길이와 관련된 텍스트 데이터 그룹(예: 1701)로부터 적어도 하나의 텍스트 데이터(예: a1a1a1, a2a2a2)를 획득하고 획득된 적어도 하나의 텍스트 데이터에 기반하여 제 1 합성 사운드를 출력할 수 있다. 전자 장치는, 제 1 합성 사운드의 출력 이후 제 2 합성 사운드의 생성 시, 제 2 길이와 관련된 텍스트 데이터 그룹(예: 1702)로부터 적어도 하나의 텍스트 데이터(예: b1b1b1, b2b2b2)를 획득하고 획득된 적어도 하나의 텍스트 데이터에 기반하여 제 2 합성 사운드를 출력할 수 있다. 이에 따라, 두 합성 사운드가 비교되는 경우, 일 합성 사운드에 포함된 비가청 주파수 대역의 사운드와 탈취된 발화를 포함하는 합성 사운드에 포함된 비가청 주파수 대역의 사운드의 유사도가 현저하게 낮아질 수 있다. 이는, 도 14에서 상술하였으므로 중복되는 설명은 생략한다.For example, the electronic device 410 (for example, at least one processor 505) may store a text data group related to a first length and a text data group related to a second length. The text data group related to the specific length may mean a group including texts of a specific length as well as texts of a specific length range. The electronic device may obtain at least one text data (eg, a1a1a1, a2a2a2) from a text data group (eg, 1701) related to the first length, and output a first synthesized sound based on the obtained at least one text data. have. The electronic device acquires at least one text data (eg, b1b1b1, b2b2b2) from a text data group (eg, 1702) related to the second length when generating a second synthesized sound after outputting the first synthesized sound, and A second synthesized sound may be output based on at least one piece of text data. Accordingly, when the two synthesized sounds are compared, the similarity between the sound in the inaudible frequency band included in one synthesized sound and the sound in the inaudible frequency band included in the synthesized sound including the deodorized speech may be significantly lowered. This has been described above with reference to FIG. 14, so a redundant description will be omitted.
또 다른 예로, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 제 1 주파수 대역과 관련된 텍스트 데이터 그룹 및 제 2 주파수 대역과 관련된 텍스트 데이터 그룹을 저장할 수 있다. 상기 특정 주파수 대역과 관련된 텍스트 데이터 그룹은 텍스트 데이터 그룹에 포함된 텍스트들의 사운드 변환 시, 해당 사운드가 특정 주파수 대역을 갖는 다는 것을 의미할 수 있다. 전자 장치는 제 1 주파수 대역과 관련된 텍스트 데이터 그룹(예: 1701)로부터 적어도 하나의 텍스트 데이터(예: a1a1a1, a2a2a2)를 획득하고 획득된 적어도 하나의 텍스트 데이터에 기반하여 제 1 합성 사운드를 출력할 수 있다. 전자 장치는, 제 1 합성 사운드의 출력 이후 제 2 합성 사운드의 생성 시, 제 2 주파수 대역과 관련된 텍스트 데이터 그룹(예: 1702)로부터 적어도 하나의 텍스트 데이터(예: b1b1b1, b2b2b2)를 획득하고 획득된 적어도 하나의 텍스트 데이터에 기반하여 제 2 합성 사운드를 출력할 수 있다. 이에 따라, 두 합성 사운드가 비교되는 경우, 일 합성 사운드에 포함된 비가청 주파수 대역의 사운드와 탈취된 발화를 포함하는 합성 사운드에 포함된 비가청 주파수 대역의 사운드의 유사도가 현저하게 낮아질 수 있다. 이는, 도 14에서 상술하였으므로 중복되는 설명은 생략한다.As another example, the electronic device 410 (for example, at least one processor 505) may store a text data group related to a first frequency band and a text data group related to a second frequency band. The text data group related to the specific frequency band may mean that the corresponding sound has a specific frequency band when texts included in the text data group are converted to sound. The electronic device obtains at least one text data (eg, a1a1a1, a2a2a2) from a text data group (eg, 1701) related to the first frequency band, and outputs a first synthesized sound based on the obtained at least one text data. I can. The electronic device obtains and acquires at least one text data (eg, b1b1b1, b2b2b2) from a text data group (eg, 1702) related to the second frequency band when generating a second synthesized sound after outputting the first synthesized sound. A second synthesized sound may be output based on the at least one piece of text data. Accordingly, when the two synthesized sounds are compared, the similarity between the sound in the inaudible frequency band included in one synthesized sound and the sound in the inaudible frequency band included in the synthesized sound including the deodorized speech may be significantly lowered. This has been described above with reference to FIG. 14, so a redundant description will be omitted.
또 다른 예를 들어, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 도 18에 도시된 바와 같이, 서로 다른 특성을 가지는 복수 개의 텍스트 데이터 그룹(1801, 1802, 1803)을 저장하고, 비가청 주파수 대역을 갖는 사운드를 출력할 때마다 서로 다른 텍스트 데이터 그룹으로부터 이전에 이전에 획득된 데이터의 수와는 다른 수로 데이터를 획득할 수도 있다.As another example, the electronic device 410 (eg, at least one processor 505) stores a plurality of
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 1504 동작에서 획득된 텍스트 데이터에 기반하여 비가청 주파수 대역을 갖는 사운드를 출력하고, 1505 동작에서 사용자 발화 및 비가청 주파수 대역을 갖는 사운드에 기반하여 합성 사운드를 획득할 수 있다. 전자 장치(410)의 1504 동작 및 1505 동작은, 상술한 전자 장치(410)의 802 동작 내지 803 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) outputs a sound having an inaudible frequency band based on text data obtained in
이하에서는 지능형 서버(420)의 동작의 다른 예에 대해서 설명한다.Hereinafter, another example of the operation of the
다양한 실시예들에 따르면, 지능형 서버(420)(예: 지능형 서버(420))는 두 합성 사운드에 포함된 비가청 주파수 대역의 사운드들만을 비교할 수 있다.According to various embodiments, the intelligent server 420 (for example, the intelligent server 420) may compare only sounds of an inaudible frequency band included in the two synthesized sounds.
도 19는 다양한 실시예들에 따른 지능형 서버(420)의 동작의 일 예를 설명하기 위한 흐름도(1800)이다. 도 19에 도시되는 동작들은 도시되는 순서에 국한되지 않고 다양한 순서로 수행될 수 있다. 또한, 다양한 실시예들에 따르면 도 19에 도시되는 동작들 보다 더 많은 동작들이 수행되거나, 더 적은 적어도 하나의 동작이 수행될 수도 있다. 이하에서는, 도 20을 참조하여 도 19에 대해서 설명한다.19 is a flowchart 1800 for explaining an example of an operation of the
도 20은 다양한 실시예들에 따른 지능형 서버(420)의 동작의 일 예를 설명하기 위한 도면이다. 도 20의 그래프에 도시되는 "-"는 시간 별 특성 주파수에서의 세기를 나타낼 수 있다.20 is a diagram illustrating an example of an operation of an
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 1901 동작에서 제 1 합성 사운드를 획득하고 1902 동작에서 제 1 합성 사운드에 대응하는 제 2 합성 사운드를 확인할 수 있다. 지능형 서버(420)의 1901 동작 및 1902 동작은 상술한 지능형 서버(420)의 805 동작 및 806 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the intelligent server 420 (eg, at least one processor 511) obtains a first synthesized sound in
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 1901 동작에서 제 1 합성 사운드를 획득하고, 1902 동작에서 제 1 합성 사운드에 대응하는 제 2 합성 사운드를 확인할 수 있다. 지능형 서버(420)의 1901 동작 및 1902 동작은 상술한 지능형 서버(420)의 805 동작 및 806 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the intelligent server 420 (for example, at least one processor 511) obtains a first synthesized sound in
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 1903 동작에서 제 1 합성 사운드의 비가청 주파수 대역과 제 2 합성 사운드의 비가청 주파수 대역을 비교할 수 있다. 예를 들어, 지능형 서버(420)는 도 20에 도시된 바와 같이 제 1 합성 사운드가 갖는 비가청 주파수 대역(2001)(예: 제 1 비가청 주파수 대역)과 제 2 합성 사운드가 갖는 비가청 주파수 대역(2001) (예: 제 2 비가청 주파수 대역)을 비교하고, 각각의 합성 사운드가 갖는 비가청 주파수 대역의 일치 여부에 따라서 유사도를 확인할 수 있다. 또 예를 들어, 지능형 서버(420)는 제 1 합성 사운드가 갖는 비가청 주파수 대역(2001)의 사운드 세기(예: 제 1 사운드 세기)와 제 2 합성 사운드가 갖는 비가청 주파수 대역(2001)의 사운드 세기(예: 제 2 사운드 세기)를 비교하고, 각각의 합성 사운드가 갖는 비가청 주파수 대역의 사운드 세기의 유사 여부에 따라서 유사도를 확인할 수 있다. 또 예를 들어, 지능형 서버(420)는 각의 합성 사운드가 갖는 비가청 주파수 대역 및 서로 일치하는 비가청 주파수 대역의 사운드 세기를 비교하여, 유사도를 확인할 수도 있다.According to various embodiments, the intelligent server 420 (eg, at least one processor 511) may compare the inaudible frequency band of the first synthesized sound and the inaudible frequency band of the second synthesized sound in
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 두 합성 사운드(예: 제 1 합성 사운드 및 제 2 합성 사운드)의 비가청 주파수 대역 중 특정 주파수 대역만의 사운드를 비교할 수 있다. 예를 들어, 전자 장치(410)에 특정 종류의 스피커가 구비(예: 일반 스피커, 또는 울트라 소닉 사운드 스피커)되는 경우, 스피커(501)의 종류에 따라서 이용 가능한 비가청 주파수 대역이 달라질 수 있다. 다시 말해, 전자 장치(410)는 두 합성 사운드의 비가청 주파수 대역의 사운드의 비교 시 전자 장치(410)에 구비된 스피커(501)의 종류에 대응하는(즉, 스피커(501)의 종류에 기반하여 이용 가능한) 특정 주파수 대역의 사운드만을 비교할 수 있다. 상술한 바와 같이, 비가청 주파수 대역 중에서도 특정 주파수 대역만의 사운드를 비교함에 따라 다른 주파수 대역의 사운드를 비교하기 위한 지능형 서버(420)의 운용 부담이 경감될 수 있다.According to various embodiments, the intelligent server 420 (e.g., at least one processor 511) may only provide a specific frequency band among the inaudible frequency bands of two synthesized sounds (e.g., the first synthesized sound and the second synthesized sound). You can compare the sound of For example, when a specific type of speaker is provided in the electronic device 410 (eg, a general speaker or an ultra sonic sound speaker), an available non-audible frequency band may vary according to the type of
다양한 실시예들에 따르면, 상기 기재된 바에 국한되지 않고 상술한 바와 같이 두 사운드의 비가청 주파수 대역의 사운드만을 비교하는 경우, 지능형 서버(420)는 저장된 비가청 주파수 대역의 사운드만을 확인하여 현재 수신된 합성 사운드에 포함된 발화가 탈취 발화인지 여부를 확인할 수 있다.According to various embodiments, when comparing only the sound in the inaudible frequency band of the two sounds as described above, but not limited to the above, the
예를 들어, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 데이터베이스(515)에 이전에 전자 장치(410)로부터 출력된 비가청 주파수 대역의 사운드만을 저장할 수 있다. 지능형 서버(420)는 전자 장치(410)로부터 합성 사운드를 수신하는 경우, 복수 개의 비가청 주파수 대역의 사운드들 중에서 수신된 합성 사운드에 포함된 비가청 주파수 대역의 제 1 사운드에 대응하는(동일하거나, 유사도가 기설정된 값 이상인) 비가청 주파수 대역의 제 2 사운드의 존재 여부를 확인할 수 있다. 지능형 서버(420)는, 제 2 사운드가 존재하는 경우 현재 수신된 합성 사운드에 포함된 발화가 탈취되지 않은 발화인 것으로 확인할 수 있다.For example, the intelligent server 420 (for example, at least one processor 511) may store only sound in an inaudible frequency band previously output from the
상술한 바와 같이, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))가 비가청 주파수 대역의 사운드만을 비교함에 따라, 비가청 주파수 대역의 사운드 만을 데이터베이스(515)에 저장하게 됨에 따라 데이터 베이스에 다양한 종류의 합성 사운드의 저장을 위한 운용 부담이 경감될 수 있다.As described above, as the intelligent server 420 (for example, at least one processor 511) compares only the sound in the inaudible frequency band, only the sound in the inaudible frequency band is stored in the
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 1904 동작에서 비교 결과에 기반하여, 제 1 발화에 대응하는 서비스를 제공하기 위한 처리 결과 정보를 획득할 수 있다. 지능형 서버(420)의 1904 동작은 상술한 지능형 서버(420)의 809 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the intelligent server 420 (eg, at least one processor 511) may obtain processing result information for providing a service corresponding to the first utterance based on the comparison result in
상술한 바와 같이, 두 합성 사운드의 비가청 주파수 대역의 사운드만을 비교함으로써, 두 합성 사운드를 비교하는 동작을 수행하는 데 소요되는 지능형 서버(420)의 운용 부담이 경감될 수 있다.As described above, by comparing only the sound of the inaudible frequency band of the two synthesized sounds, the operational burden of the
이하에서는 외부 전자 장치의 동작의 다른 예에 대해서 설명한다.Hereinafter, another example of the operation of the external electronic device will be described.
다양한 실시예들에 따르면, 전자 장치는 현재 수신된 발화에 대한 에러가 검출되는 경우, 특정 키워드를 포함하는 발화를 요청할 수 있다. 전자 장치는 수신된 특정 키워드를 포함하는 발화를 포함하는 합성 사운드와 미리 저장된 특정 키워드와 연관된 합성 사운드의 비교 결과에 기반하여, 현재 발화를 제공하는 사용자의 진위 여부를 판단할 수 있다.According to various embodiments, when an error with respect to the currently received speech is detected, the electronic device may request the speech including a specific keyword. The electronic device may determine whether or not the authenticity of a user providing the current utterance is based on a result of comparing the received synthesized sound including the utterance including the specific keyword and the synthesized sound associated with the specific keyword previously stored.
도 21은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 또 다른 예를 설명하기 위한 흐름도(2100)이다. 도 21에 도시되는 동작들은 도시되는 순서에 국한되지 않고 다양한 순서로 수행될 수 있다. 또한, 다양한 실시예들에 따르면 도 21에 도시되는 동작들 보다 더 많은 동작들이 수행되거나, 더 적은 적어도 하나의 동작이 수행될 수도 있다. 이하에서는, 도 22 내지 도 23을 참조하여 도 21에 대해서 설명한다.21 is a
도 22는 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 또 다른 예를 설명하기 위한 도면이다. 도 22에서 "+" 기호는 각각의 사운드가 결합되어 전자 장치의 마이크(502)에 수신됨을 나타내는 기호이다. 도 23은 다양한 실시예들에 따른 전자 장치 및 외부 전자 장치의 동작의 또 다른 예를 설명하기 위한 다른 도면이다.22 is a diagram for describing still another example of operations of an electronic device and an external electronic device according to various embodiments of the present disclosure. In FIG. 22, a "+" symbol indicates that each sound is combined and received by the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 2101 동작에서 제 1 합성 사운드(2213)를 획득하고, 2102 동작에서 획득된 제 1 합성 사운드(2213)를 지능형 서버(420)로 전송할 수 있다. 예를 들어, 전자 장치(410)는 도 22의 2201에 도시된 바와 같이 마이크(502)를 통해서 수신되는 비가청 주파수 대역을 갖는 제 1 사운드(2211) 및 제 1 발화(2212)를 포함하는 제 1 합성 사운드(2213)를 획득하고, 도 22의 2202에 도시된 바와 같이 제 1 합성 사운드(2213)에 대한 정보를 지능형 서버(420)로 전송할 수 있다. 전자 장치(410)의 2101 동작 및 2102 동작은 상술한 전자 장치(410)의 801 동작 내지 805 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) obtains the first
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 2103 동작에서 수신된 제 1 합성 사운드(2213)에 기반하여, 도 22의 2203에 도시된 바와 같이 전자 장치(410)에 수신된 제 1 합성 사운드(2213)와 관련된 에러 이벤트의 발생 여부를 검출할 수 있다.According to various embodiments, the intelligent server 420 (eg, at least one processor 511) is based on the first
다양한 실시예들에 따르면 상기 제 1 합성 사운드(2213)와 관련된 에러 이벤트는 제 1 합성 사운드(2213)에 포함된 제 1 발화(2212)가 탈취된 발화로 확인되는 경우, 또는 지능형 서버(420)의 데이터 베이스(515)에 제 1 합성 사운드(2213)에 대응하는 합성 사운드가 없는 것으로 확인되는 경우를 포함할 수 있다. 다시 말해, 지능형 서버(420)는 제 1 합성 사운드(2213)에 포함된 제 1 발화(2212)가 탈취된 발화인 경우 제 1 합성 사운드(2213)와 관련된 에러 이벤트가 발생됨을 확인할 수 있다. 또, 지능형 서버(420)는 데이터 베이스(515)에 제 1 합성 사운드(2213)에 대응하는 합성 사운드가 없음을 확인하는 경우 에러 이벤트가 발생됨을 확인할 수 있다.According to various embodiments, the error event related to the first
예를 들어, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 제 1 합성 사운드(2213)에 대응하는 제 2 합성 사운드를 확인하고, 제 1 합성 사운드(2213)와 제 2 합성 사운드의 유사도를 비교하여 제 1 합성 사운드(2213)에 포함된 제 1 발화(2212)가 탈취된 발화인지 여부를 확인할 수 있다. 지능형 서버(420)의 제 1 발화(2212)가 탈취된 발화인지 여부를 확인하는 동작은, 상술한 지능형 서버(420)의 806 동작 내지 809 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.For example, the intelligent server 420 (for example, at least one processor 511) checks the second synthesized sound corresponding to the first
또 예를 들어, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 데이터 베이스(515)에 저장된 복수 개의 사운드들 중 제 1 합성 사운드(2213)에 대응하는 합성 사운드를 확인하는 동작을 수행하고, 확인 동작에 기반해서 제 1 합성 사운드(2213)에 대응하는 합성 사운드가 없음을 확인할 수 있다. 일 예로, 전자 장치(410)는 제 1 발화(2212)를 최초로 수신함에 따라, 지능형 서버(420)의 데이터베이스(515)는 제 1 발화(2212)에 대응하는 발화를 포함하는 합성 사운드를 저장하지 않을 수 있다.In addition, for example, the intelligent server 420 (eg, at least one processor 511) checks a synthesized sound corresponding to the first
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 2014 동작에서 에러 이벤트의 발생 여부에 따른 결과 정보를 전자 장치(410)로 송신할 수 있다. 상기 결과 정보는 제 1 합성 사운드(2213)와 관련된 에러 이벤트가 발생됨을 나타내는 정보를 포함할 수 있다.According to various embodiments, the intelligent server 420 (for example, at least one processor 511) may transmit result information according to whether an error event occurs in operation 2014 to the
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 도 22의 2204에 도시된 바와 같이 2015 동작에서 특정 키워드를 포함하는 제 2 발화(2213)를 요청하고, 2016 동작에서 제 2 발화(2213)를 획득하고 및 비가청 주파수 대역을 갖는 제 2 사운드(2211)에 기반하여 제 2 합성 사운드를 획득할 수 있다.According to various embodiments, the electronic device 410 (eg, at least one processor 505) requests a
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 수신된 결과 정보를 기반으로 제 1 합성 사운드(2213)와 관련된 에러 이벤트가 발생됨을 확인하는 경우, 특정 키워드를 포함하는 제 2 발화(2213)를 요청할 수 있다. 예를 들어, 특정 키워드는 지능형 음성 서비스 어플리케이션을 호출하기 위한 키워드(예: 하이 빅스비), 사용자의 이름, 또는 그 밖의 기설정된 키워드를 포함할 수 있다.According to various embodiments, when the electronic device 410 (eg, at least one processor 505) determines that an error event related to the first
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 특정 키워드를 포함하는 발화와 함께 비가청 주파수 대역을 갖는 제 2 사운드(2211)를 마이크(502)를 통해 수신할 수 있다. 예를 들어, 전자 장치(410)는 도 21의 2104에 도시된 바와 같이 지능형 음성 서비스 어플리케이션을 호출하기 위한 키워드를 요청하기 위한 알림 메시지를 표시하고, 알림 메시지의 표시 중에 스피커(501)를 통해 비가청 주파수 대역을 갖는 제 2 사운드(2211)를 출력할 수 있다. 전자 장치(410)는 특정 키워드를 포함하는 제 2 발화(2213) 및 스피커(501)를 통해 출력되는 제 2 사운드(2211)를 마이크(502)를 통해 수신할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) transmits a
다양한 실시예들에 따르면, 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 2107 동작에서 획득된 제 2 합성 사운드를 지능형 서버(420)로 송신할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) may transmit the second synthesized sound obtained in
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 2108 동작에서 제 2 합성 사운드와 특정 키워드와 관련된 미리 저장된 제 3 합성 사운드를 비교하고, 2109 동작에서 비교 결과에 기반해서 확인된 유사도와 임계값을 비교할 수 있다. 예를 들어, 지능형 서버(420)는 도 23의 2301에 도시된 바와 같이 데이터 베이스(515)에 저장된 복수 개의 사운드들(516) 중 특정 키워드를 포함하는 제 3 합성 사운드를 식별하고, 도 23의 2302에 도시된 바와 같이 특정 키워드를 포함하는 제 3 합성 사운드와 현재 수신된 합성 사운드의 유사도를 확인할 수 있다. 지능형 서버(420)의 2108 동작 및 2109 동작은 상술한 지능형 서버(420)의 806 동작 내지 808 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the intelligent server 420 (for example, at least one processor 511) compares the second synthesized sound in operation 2108 with a third synthesized sound previously stored related to a specific keyword, and compares in
다양한 실시예들에 따르면, 지능형 서버(420)의 데이터 베이스(515)는 상술한 특정 키워드를 포함하는 발화 및 비가청 주파수 대역을 갖는 사운드를 포함하는 합성 사운드를 저장할 수 있다. 예를 들어, 전자 장치(410)는 최초 지능형 음성 서비스 어플리케이션의 실행 시 마이크(502)를 통해 특정 키워드를 포함하는 사용자의 발화 및 비가청 주파수 대역을 갖는 사운드를 포함하는 합성 사운드를 획득하고, 획득된 합성 사운드를 지능형 서버(420)로 송신할 수 있다. 지능형 서버(420)는 수신된 특정 키워드를 포함하는 사용자 발화를 포함하는 합성 사운드를 데이터 베이스(515)에 저장할 수 있게 된다. 다시 말해, 특정 키워드를 포함하는 사용자의 발화가 지능형 서버(420)의 데이터 베이스(515)에 미리 저장됨으로써, 특정 키워드를 포함하는 발화의 요청에 따라 사용자가 탈취자인지 여부가 결정될 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 지능형 서버(420)(예: 적어도 하나의 프로세서(511))는 2110 동작에서 비교 결과에 기반하여 제 1 발화(2212)에 대응하는 서비스를 제공하기 위한 처리 결과 정보를 획득하고, 2111 동작에서 처리 결과 정보를 전자 장치(410)로 송신할 수 있다. 예를 들어, 지능형 서버(420)는 도 23의 2303에 도시된 바와 같이 처리 결과 정보를 송신하고, 전자 장치(410)는 도 23의 2304에 도시된 바와 같이 수신된 처리 결과 정보에 기반하여 제 1 발화(2212)에 대응하는 서비스를 제공할 수 있다. 지능형 서버(420)의 2110 동작 및 2111 동작은, 상술한 지능형 서버(420)의 809 동작 및 810 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the intelligent server 420 (for example, at least one processor 511) provides processing result information for providing a service corresponding to the
상술한 바와 같이, 제 1 발화(2212)와 관련된 에러 이벤트가 발생되는 경우 특정 키워드를 포함하는 발화를 재요청하고 사용자가 탈취자인지 여부를 재확인함으로써, 진의의 사용자를 확인하는 동작의 정확도가 향상(예: 제 1 발화(2212)가 탈취된 발화로 오인되는 경우, 탈취 여부를 재확인함으로써 발화의 탈취 여부가 정확하게 확인됨)될 수 있다.As described above, when an error event related to the
이하에서는 전자 장치(410)의 동작의 다른 예에 대해서 설명한다.Hereinafter, another example of the operation of the
다양한 실시예들에 따르면, 전자 장치(410)는 합성 사운드를 획득하고, 전자 장치(410)의 데이터 베이스에 저장된 복수 개의 사운드들을 기반으로 합성 사운드에 포함된 발화가 탈취된 발화인지 여부를 확인할 수 있다.According to various embodiments, the
도 24는 다양한 실시예들에 따른 전자 장치(410)의 동작의 다른 예를 설명하기 위한 흐름도(2300)이다. 도 24에 도시되는 동작들은 도시되는 순서에 국한되지 않고 다양한 순서로 수행될 수 있다. 또한, 다양한 실시예들에 따르면 도 24에 도시되는 동작들 보다 더 많은 동작들이 수행되거나, 더 적은 적어도 하나의 동작이 수행될 수도 있다.24 is a flowchart 2300 for describing another example of an operation of the
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 2401 동작에서 지능형 음성 서비스 어플리케이션을 실행하고, 2402 동작에서 비가청 주파수 대역을 갖는 제 1 사운드를 마이크(502)를 통해 출력하고, 2403 동작에서 지능형 음성 서비스 어플리케이션의 실행 중에 마이크(502)를 통해 제 1 발화를 수신하고, 2404 동작에서 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 제 1 합성 사운드를 획득할 수 있다. 전자 장치(410)의 2401 동작 내지 2404 동작은 전자 장치(410)의 801 동작 내지 804 동작과 같이 수행될 수 있으므로 중복되는 설명은 생략한다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) executes an intelligent voice service application in
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 2405 동작에서 메모리(503)에 저장된 복수 개의 사운드들 중 제 1 발화와 관련된 제 2 합성 사운드를 확인하고, 2406 동작에서 제 1 합성 사운드와 상기 제 2 합성 사운드를 비교하여 유사도를 확인하고, 2407 동작에서 확인된 유사도가 임계값 이상인지 여부를 확인할 수 있다. 전자 장치(410)의 2405 동작 내지 2407 동작은 지능형 서버(420)의 805 동작 내지 807 동작과 같이 수행될 수 있으므로, 중복되는 설명은 생략한다. 다시 말해, 전자 장치(410)는 상술한 데이터 베이스를 포함하고, 데이터 베이스에 저장된 복수 개의 사운드들을 기반으로 현재 수신된 제 1 발화가 탈취된 발화인지 여부를 확인할 수 있다.According to various embodiments, in
다양한 실시예들에 따르면 전자 장치(410)(예: 적어도 하나의 프로세서(505))는 2408 동작에서 제 1 발화를 지능형 서버(420)로 송신하고, 지능형 서버(420)로부터 처리 결과 정보를 수신할 수 있다. 예를 들어, 전자 장치(410)는 제 1 발화가 탈취된 발화가 아닌 것으로 확인된 경우 지능형 서버(420)로 제 1 발화를 송신하고, 지능형 서버(420)로부터 제 1 발화에 대한 서비스를 제공하기 위한 처리 결과 정보를 수신할 수 있다.According to various embodiments, the electronic device 410 (for example, at least one processor 505) transmits the first speech to the
이하에서는 상술한, 전자 장치(410) 및 지능형 서버(420)의 구현 예에 대해서 설명한다. 전자 장치(410) 및 지능형 서버(420)의 구성은 아래에서 설명되는 네트워크 환경(2500) 내의 전자 장치(2501)의 구성과 같이 구현될 수 있다.Hereinafter, an implementation example of the
도 25는, 다양한 실시예들에 따른, 네트워크 환경(2500) 내의 전자 장치(2501)의 블럭도이다. 도 25을 참조하면, 네트워크 환경(2500)에서 전자 장치(2501)는 제 1 네트워크(2598)(예: 근거리 무선 통신 네트워크)를 통하여 전자 장치(2502)와 통신하거나, 또는 제 2 네트워크(2599)(예: 원거리 무선 통신 네트워크)를 통하여 전자 장치(2504) 또는 서버(2508)와 통신할 수 있다. 일실시예에 따르면, 전자 장치(2501)는 서버(2508)를 통하여 전자 장치(2504)와 통신할 수 있다. 일실시예에 따르면, 전자 장치(2501)는 프로세서(2520), 메모리(2530), 입력 장치(2550), 음향 출력 장치(2555), 표시 장치(2560), 오디오 모듈(2570), 센서 모듈(2576), 인터페이스(2577), 햅틱 모듈(2579), 카메라 모듈(2580), 전력 관리 모듈(2588), 배터리(2589), 통신 모듈(2590), 가입자 식별 모듈(2596), 또는 안테나 모듈(2597)을 포함할 수 있다. 어떤 실시예에서는, 전자 장치(2501)에는, 이 구성요소들 중 적어도 하나(예: 표시 장치(2560) 또는 카메라 모듈(2580))가 생략되거나, 하나 이상의 다른 구성 요소가 추가될 수 있다. 어떤 실시예에서는, 이 구성요소들 중 일부들은 하나의 통합된 회로로 구현될 수 있다. 예를 들면, 센서 모듈(2576)(예: 지문 센서, 홍채 센서, 또는 조도 센서)은 표시 장치(2560)(예: 디스플레이)에 임베디드된 채 구현될 수 있다25 is a block diagram of an electronic device 2501 in a
프로세서(2520)는, 예를 들면, 소프트웨어(예: 프로그램(2540))를 실행하여 프로세서(2520)에 연결된 전자 장치(2501)의 적어도 하나의 다른 구성요소(예: 하드웨어 또는 소프트웨어 구성요소)을 제어할 수 있고, 다양한 데이터 처리 또는 연산을 수행할 수 있다. 일실시예에 따르면, 데이터 처리 또는 연산의 적어도 일부로서, 프로세서(2520)는 다른 구성요소(예: 센서 모듈(2576) 또는 통신 모듈(2590))로부터 수신된 명령 또는 데이터를 휘발성 메모리(2532)에 로드하고, 휘발성 메모리(2532)에 저장된 명령 또는 데이터를 처리하고, 결과 데이터를 비휘발성 메모리(2534)에 저장할 수 있다. 일실시예에 따르면, 프로세서(2520)는 메인 프로세서(2521)(예: 중앙 처리 장치 또는 어플리케이션 프로세서), 및 이와는 독립적으로 또는 함께 운영 가능한 보조 프로세서(2523)(예: 그래픽 처리 장치, 이미지 시그널 프로세서, 센서 허브 프로세서, 또는 커뮤니케이션 프로세서)를 포함할 수 있다. 추가적으로 또는 대체적으로, 보조 프로세서(2523)은 메인 프로세서(2521)보다 저전력을 사용하거나, 또는 지정된 기능에 특화되도록 설정될 수 있다. 보조 프로세서(2523)는 메인 프로세서(2521)와 별개로, 또는 그 일부로서 구현될 수 있다.The
보조 프로세서(2523)는, 예를 들면, 메인 프로세서(2521)가 인액티브(예: 슬립) 상태에 있는 동안 메인 프로세서(2521)를 대신하여, 또는 메인 프로세서(2521)가 액티브(예: 어플리케이션 실행) 상태에 있는 동안 메인 프로세서(2521)와 함께, 전자 장치(2501)의 구성요소들 중 적어도 하나의 구성요소(예: 표시 장치(2560), 센서 모듈(2576), 또는 통신 모듈(2590))와 관련된 기능 또는 상태들의 적어도 일부를 제어할 수 있다. 일실시예에 따르면, 보조 프로세서(2523)(예: 이미지 시그널 프로세서 또는 커뮤니케이션 프로세서)는 기능적으로 관련 있는 다른 구성 요소(예: 카메라 모듈(2580) 또는 통신 모듈(2590))의 일부로서 구현될 수 있다. The
메모리(2530)는, 전자 장치(2501)의 적어도 하나의 구성요소(예: 프로세서(2520) 또는 센서모듈(2576))에 의해 사용되는 다양한 데이터를 저장할 수 있다. 데이터는, 예를 들어, 소프트웨어(예: 프로그램(2540)) 및, 이와 관련된 명령에 대한 입력 데이터 또는 출력 데이터를 포함할 수 있다. 메모리(2530)는, 휘발성 메모리(2532) 또는 비휘발성 메모리(2534)를 포함할 수 있다.The
프로그램(2540)은 메모리(2530)에 소프트웨어로서 저장될 수 있으며, 예를 들면, 운영 체제(2542), 미들 웨어(2544) 또는 어플리케이션(2546)을 포함할 수 있다.The
입력 장치(2550)는, 전자 장치(2501)의 구성요소(예: 프로세서(2520))에 사용될 명령 또는 데이터를 전자 장치(2501)의 외부(예: 사용자)로부터 수신할 수 있다. 입력 장치(2550)은, 예를 들면, 마이크, 마우스, 키보드, 또는 디지털 펜(예:스타일러스 펜)을 포함할 수 있다.The
음향 출력 장치(2555)는 음향 신호를 전자 장치(2501)의 외부로 출력할 수 있다. 음향 출력 장치(2555)는, 예를 들면, 스피커 또는 리시버를 포함할 수 있다. 스피커는 멀티미디어 재생 또는 녹음 재생과 같이 일반적인 용도로 사용될 수 있고, 리시버는 착신 전화를 수신하기 위해 사용될 수 있다. 일실시예에 따르면, 리시버는 스피커와 별개로, 또는 그 일부로서 구현될 수 있다.The sound output device 2555 may output an sound signal to the outside of the electronic device 2501. The sound output device 2555 may include, for example, a speaker or a receiver. The speaker can be used for general purposes such as multimedia playback or recording playback, and the receiver can be used to receive incoming calls. According to one embodiment, the receiver may be implemented separately from the speaker or as part of it.
표시 장치(2560)는 전자 장치(2501)의 외부(예: 사용자)로 정보를 시각적으로 제공할 수 있다. 표시 장치(2560)은, 예를 들면, 디스플레이, 홀로그램 장치, 또는 프로젝터 및 해당 장치를 제어하기 위한 제어 회로를 포함할 수 있다. 일실시예에 따르면, 표시 장치(2560)는 터치를 감지하도록 설정된 터치 회로(touch circuitry), 또는 상기 터치에 의해 발생되는 힘의 세기를 측정하도록 설정된 센서 회로(예: 압력 센서)를 포함할 수 있다.The
오디오 모듈(2570)은 소리를 전기 신호로 변환시키거나, 반대로 전기 신호를 소리로 변환시킬 수 있다. 일실시예에 따르면, 오디오 모듈(2570)은, 입력 장치(2550) 를 통해 소리를 획득하거나, 음향 출력 장치(2555), 또는 전자 장치(2501)와 직접 또는 무선으로 연결된 외부 전자 장치(예: 전자 장치(2502)) (예: 스피커 또는 헤드폰))를 통해 소리를 출력할 수 있다.The
센서 모듈(2576)은 전자 장치(2501)의 작동 상태(예: 전력 또는 온도), 또는 외부의 환경 상태(예: 사용자 상태)를 감지하고, 감지된 상태에 대응하는 전기 신호 또는 데이터 값을 생성할 수 있다. 일실시예에 따르면, 센서 모듈(2576)은, 예를 들면, 제스처 센서, 자이로 센서, 기압 센서, 마그네틱 센서, 가속도 센서, 그립 센서, 근접 센서, 컬러 센서, IR(infrared) 센서, 생체 센서, 온도 센서, 습도 센서, 또는 조도 센서를 포함할 수 있다.The
인터페이스(2577)는 전자 장치(2501)이 외부 전자 장치(예: 전자 장치(2502))와 직접 또는 무선으로 연결되기 위해 사용될 수 있는 하나 이상의 지정된 프로토콜들을 지원할 수 있다. 일실시예에 따르면, 인터페이스(2577)는, 예를 들면, HDMI(high definition multimedia interface), USB(universal serial bus) 인터페이스, SD카드 인터페이스, 또는 오디오 인터페이스를 포함할 수 있다.The
연결 단자(2578)는, 그를 통해서 전자 장치(2501)가 외부 전자 장치(예: 전자 장치(2502))와 물리적으로 연결될 수 있는 커넥터를 포함할 수 있다. 일실시예에 따르면, 연결 단자(2578)은, 예를 들면, HDMI 커넥터, USB 커넥터, SD 카드 커넥터, 또는 오디오 커넥터(예: 헤드폰 커넥터)를 포함할 수 있다.The
햅틱 모듈(2579)은 전기적 신호를 사용자가 촉각 또는 운동 감각을 통해서 인지할 수 있는 기계적인 자극(예: 진동 또는 움직임) 또는 전기적인 자극으로 변환할 수 있다. 일실시예에 따르면, 햅틱 모듈(2579)은, 예를 들면, 모터, 압전 소자, 또는 전기 자극 장치를 포함할 수 있다.The
카메라 모듈(2580)은 정지 영상 및 동영상을 촬영할 수 있다. 일실시예에 따르면, 카메라 모듈(2580)은 하나 이상의 렌즈들, 이미지 센서들, 이미지 시그널 프로세서들, 또는 플래시들을 포함할 수 있다.The
전력 관리 모듈(2588)은 전자 장치(2501)에 공급되는 전력을 관리할 수 있다. 일실시예에 따르면, 전력 관리 모듈(2588)은, 예를 들면, PMIC(power management integrated circuit)의 적어도 일부로서 구현될 수 있다.The
배터리(2589)는 전자 장치(2501)의 적어도 하나의 구성 요소에 전력을 공급할 수 있다. 일실시예에 따르면, 배터리(2589)는, 예를 들면, 재충전 불가능한 1차 전지, 재충전 가능한 2차 전지 또는 연료 전지를 포함할 수 있다.The
통신 모듈(2590)은 전자 장치(2501)와 외부 전자 장치(예: 전자 장치(2502), 전자 장치(2504), 또는 서버(2508))간의 직접(예: 유선) 통신 채널 또는 무선 통신 채널의 수립, 및 수립된 통신 채널을 통한 통신 수행을 지원할 수 있다. 통신 모듈(2590)은 프로세서(2520)(예: 어플리케이션 프로세서)와 독립적으로 운영되고, 직접(예: 유선) 통신 또는 무선 통신을 지원하는 하나 이상의 커뮤니케이션 프로세서를 포함할 수 있다. 일실시예에 따르면, 통신 모듈(2590)은 무선 통신 모듈(2592)(예: 셀룰러 통신 모듈, 근거리 무선 통신 모듈, 또는 GNSS(global navigation satellite system) 통신 모듈) 또는 유선 통신 모듈(2594)(예: LAN(local area network) 통신 모듈, 또는 전력선 통신 모듈)을 포함할 수 있다. 이들 통신 모듈 중 해당하는 통신 모듈은 제 1 네트워크(2598)(예: 블루투스, WiFi direct 또는 IrDA(infrared data association) 같은 근거리 통신 네트워크) 또는 제 2 네트워크(2599)(예: 셀룰러 네트워크, 인터넷, 또는 컴퓨터 네트워크(예: LAN 또는 WAN)와 같은 원거리 통신 네트워크)를 통하여 외부 전자 장치와 통신할 수 있다. 이런 여러 종류의 통신 모듈들은 하나의 구성 요소(예: 단일 칩)으로 통합되거나, 또는 서로 별도의 복수의 구성 요소들(예: 복수 칩들)로 구현될 수 있다. 무선 통신 모듈(2592)은 가입자 식별 모듈(2596)에 저장된 가입자 정보(예: 국제 모바일 가입자 식별자(IMSI))를 이용하여 제 1 네트워크(2598) 또는 제 2 네트워크(2599)와 같은 통신 네트워크 내에서 전자 장치(2501)를 확인 및 인증할 수 있다.The
안테나 모듈(2597)은 신호 또는 전력을 외부(예: 외부 전자 장치)로 송신하거나 외부로부터 수신할 수 있다. 일실시예에 따르면, 안테나 모듈은 서브스트레이트(예: PCB) 위에 형성된 도전체 또는 도전성 패턴으로 이루어진 방사체를 포함하는 하나의 안테나를 포함할 수 있다. 일실시예에 따르면, 안테나 모듈(2597)은 복수의 안테나들을 포함할 수 있다. 이런 경우, 제 1 네트워크(2598) 또는 제 2 네트워크(2599)와 같은 통신 네트워크에서 사용되는 통신 방식에 적합한 적어도 하나의 안테나가, 예를 들면, 통신 모듈(2590)에 의하여 상기 복수의 안테나들로부터 선택될 수 있다. 신호 또는 전력은 상기 선택된 적어도 하나의 안테나를 통하여 통신 모듈(2590)과 외부 전자 장치 간에 송신되거나 수신될 수 있다. 어떤 실시예에 따르면, 방사체 이외에 다른 부품(예: RFIC)이 추가로 안테나 모듈(2597)의 일부로 형성될 수 있다.The
상기 구성요소들 중 적어도 일부는 주변 기기들간 통신 방식(예: 버스, GPIO(general purpose input and output), SPI(serial peripheral interface), 또는 MIPI(mobile industry processor interface))를 통해 서로 연결되고 신호(예: 명령 또는 데이터)를 상호간에 교환할 수 있다.At least some of the components are connected to each other through a communication method (e.g., a bus, general purpose input and output (GPIO), serial peripheral interface (SPI), or mobile industry processor interface (MIPI))) between peripheral devices and signals ( E.g. commands or data) can be exchanged with each other.
일실시예에 따르면, 명령 또는 데이터는 제 2 네트워크(2599)에 연결된 서버(2508)를 통해서 전자 장치(2501)와 외부의 전자 장치(2504)간에 송신 또는 수신될 수 있다. 전자 장치(2502, 2504) 각각은 전자 장치(2501)와 동일한 또는 다른 종류의 장치일 수 있다. 일실시예에 따르면, 전자 장치(2501)에서 실행되는 동작들의 전부 또는 일부는 외부 전자 장치들(2502, 2504, 또는 2508) 중 하나 이상의 외부 장치들에서 실행될 수 있다. 예를 들면, 전자 장치(2501)가 어떤 기능이나 서비스를 자동으로, 또는 사용자 또는 다른 장치로부터의 요청에 반응하여 수행해야 할 경우에, 전자 장치(2501)는 기능 또는 서비스를 자체적으로 실행시키는 대신에 또는 추가적으로, 하나 이상의 외부 전자 장치들에게 그 기능 또는 그 서비스의 적어도 일부를 수행하라고 요청할 수 있다. 상기 요청을 수신한 하나 이상의 외부 전자 장치들은 요청된 기능 또는 서비스의 적어도 일부, 또는 상기 요청과 관련된 추가 기능 또는 서비스를 실행하고, 그 실행의 결과를 전자 장치(2501)로 전달할 수 있다. 전자 장치(2501)는 상기 결과를, 그대로 또는 추가적으로 처리하여, 상기 요청에 대한 응답의 적어도 일부로서 제공할 수 있다.. 이를 위하여, 예를 들면, 클라우드 컴퓨팅, 분산 컴퓨팅, 또는 클라이언트-서버 컴퓨팅 기술이 이용될 수 있다. According to an embodiment, commands or data may be transmitted or received between the electronic device 2501 and an external
본 문서에 개시된 다양한 실시예들에 따른 전자 장치는 다양한 형태의 장치가 될 수 있다. 전자 장치는, 예를 들면, 휴대용 통신 장치 (예: 스마트폰), 컴퓨터 장치, 휴대용 멀티미디어 장치, 휴대용 의료 기기, 카메라, 웨어러블 장치, 또는 가전 장치를 포함할 수 있다. 본 문서의 실시예에 따른 전자 장치는 전술한 기기들에 한정되지 않는다.Electronic devices according to various embodiments disclosed in this document may be devices of various types. The electronic device may include, for example, a portable communication device (eg, a smart phone), a computer device, a portable multimedia device, a portable medical device, a camera, a wearable device, or a home appliance. The electronic device according to the embodiment of the present document is not limited to the above-described devices.
본 문서의 다양한 실시예들 및 이에 사용된 용어들은 본 문서에 기재된 기술적 특징들을 특정한 실시예들로 한정하려는 것이 아니며, 해당 실시예의 다양한 변경, 균등물, 또는 대체물을 포함하는 것으로 이해되어야 한다. 도면의 설명과 관련하여, 유사한 또는 관련된 구성요소에 대해서는 유사한 참조 부호가 사용될 수 있다. 아이템에 대응하는 명사의 단수 형은 관련된 문맥상 명백하게 다르게 지시하지 않는 한, 상기 아이템 한 개 또는 복수 개를 포함할 수 있다. 본 문서에서, "A 또는 B", "A 및 B 중 적어도 하나",“A 또는 B 중 적어도 하나,”"A, B 또는 C," "A, B 및 C 중 적어도 하나,”및 “A, B, 또는 C 중 적어도 하나"와 같은 문구들 각각은 그 문구들 중 해당하는 문구에 함께 나열된 항목들 중 어느 하나, 또는 그들의 모든 가능한 조합을 포함할 수 있다. "제 1", "제 2", 또는 "첫째" 또는 "둘째"와 같은 용어들은 단순히 해당 구성요소를 다른 해당 구성요소와 구분하기 위해 사용될 수 있으며, 해당 구성요소들을 다른 측면(예: 중요성 또는 순서)에서 한정하지 않는다. 어떤(예: 제 1) 구성요소가 다른(예: 제 2) 구성요소에, “기능적으로” 또는 “통신적으로”라는 용어와 함께 또는 이런 용어 없이, “커플드” 또는 “커넥티드”라고 언급된 경우, 그것은 상기 어떤 구성요소가 상기 다른 구성요소에 직접적으로(예: 유선으로), 무선으로, 또는 제 3 구성요소를 통하여 연결될 수 있다는 것을 의미한다.Various embodiments of the present document and terms used therein are not intended to limit the technical features described in this document to specific embodiments, and should be understood to include various modifications, equivalents, or substitutes of the corresponding embodiments. In connection with the description of the drawings, similar reference numerals may be used for similar or related components. The singular form of a noun corresponding to an item may include one or a plurality of the items unless clearly indicated otherwise in a related context. In this document, “A or B”, “at least one of A and B”, “at least one of A or B,” “A, B or C,” “at least one of A, B and C,” and “A Each of phrases such as "at least one of, B, or C" may include any one of the items listed together in the corresponding one of the phrases, or all possible combinations thereof. Terms such as "first", "second", or "first" or "second" may be used simply to distinguish the component from other corresponding components, and the components may be referred to in other aspects (eg, importance or Order) is not limited. Some (eg, first) component is referred to as “coupled” or “connected” to another (eg, second) component, with or without the terms “functionally” or “communicatively”. When mentioned, it means that any of the above components can be connected to the other components directly (eg by wire), wirelessly, or via a third component.
본 문서에서 사용된 용어 "모듈"은 하드웨어, 소프트웨어 또는 펌웨어로 구현된 유닛을 포함할 수 있으며, 예를 들면, 로직, 논리 블록, 부품, 또는 회로 등의 용어와 상호 호환적으로 사용될 수 있다. 모듈은, 일체로 구성된 부품 또는 하나 또는 그 이상의 기능을 수행하는, 상기 부품의 최소 단위 또는 그 일부가 될 수 있다. 예를 들면, 일실시예에 따르면, 모듈은 ASIC(application-specific integrated circuit)의 형태로 구현될 수 있다.The term "module" used in this document may include a unit implemented in hardware, software, or firmware, and may be used interchangeably with terms such as logic, logic blocks, parts, or circuits. The module may be an integrally configured component or a minimum unit of the component or a part thereof that performs one or more functions. For example, according to an embodiment, the module may be implemented in the form of an application-specific integrated circuit (ASIC).
본 문서의 다양한 실시예들은 기기(machine)(예: 전자 장치(2501)) 의해 읽을 수 있는 저장 매체(storage medium)(예: 내장 메모리(2536) 또는 외장 메모리(2538))에 저장된 하나 이상의 명령어들을 포함하는 소프트웨어(예: 프로그램(2540))로서 구현될 수 있다. 예를 들면, 기기(예: 전자 장치(2501))의 프로세서(예: 프로세서(2520))는, 저장 매체로부터 저장된 하나 이상의 명령어들 중 적어도 하나의 명령을 호출하고, 그것을 실행할 수 있다. 이것은 기기가 상기 호출된 적어도 하나의 명령어에 따라 적어도 하나의 기능을 수행하도록 운영되는 것을 가능하게 한다. 상기 하나 이상의 명령어들은 컴파일러에 의해 생성된 코드 또는 인터프리터에 의해 실행될 수 있는 코드를 포함할 수 있다. 기기로 읽을 수 있는 저장매체 는, 비일시적(non-transitory) 저장매체의 형태로 제공될 수 있다. 여기서, ‘비일시적’은 저장매체가 실재(tangible)하는 장치이고, 신호(signal)(예: 전자기파)를 포함하지 않는다는 것을 의미할 뿐이며, 이 용어는 데이터가 저장매체에 반영구적으로 저장되는 경우와 임시적으로 저장되는 경우를 구분하지 않는다.Various embodiments of the present document include one or more instructions stored in a storage medium (eg,
일실시예에 따르면, 본 문서에 개시된 다양한 실시예들에 따른 방법은 컴퓨터 프로그램 제품(computer program product)에 포함되어 제공될 수 있다. 컴퓨터 프로그램 제품은 상품으로서 판매자 및 구매자 간에 거래될 수 있다. 컴퓨터 프로그램 제품은 기기로 읽을 수 있는 저장 매체(예: compact disc read only memory (CD-ROM))의 형태로 배포되거나, 또는 어플리케이션 스토어(예: 플레이 스토어TM)를 통해 또는 두개의 사용자 장치들(예: 스마트폰들) 간에 직접, 온라인으로 배포(예: 다운로드 또는 업로드)될 수 있다. 온라인 배포의 경우에, 컴퓨터 프로그램 제품의 적어도 일부는 제조사의 서버, 어플리케이션 스토어의 서버, 또는 중계 서버의 메모리와 같은 기기로 읽을 수 있는 저장 매체에 적어도 일시 저장되거나, 임시적으로 생성될 수 있다.According to an embodiment, a method according to various embodiments disclosed in the present document may be provided by being included in a computer program product. Computer program products can be traded between sellers and buyers as commodities. Computer program products are distributed in the form of a device-readable storage medium (e.g. compact disc read only memory (CD-ROM)), or through an application store (e.g. Play StoreTM) or two user devices (e.g. It can be distributed (e.g., downloaded or uploaded) directly between, e.g. smartphones). In the case of online distribution, at least some of the computer program products may be temporarily stored or temporarily generated in a storage medium that can be read by a device such as a server of a manufacturer, a server of an application store, or a memory of a relay server.
다양한 실시예들에 따르면, 상기 기술한 구성요소들의 각각의 구성요소(예: 모듈 또는 프로그램)는 단수 또는 복수의 개체를 포함할 수 있다. 다양한 실시예들에 따르면, 전술한 해당 구성요소들 중 하나 이상의 구성요소들 또는 동작들이 생략되거나, 또는 하나 이상의 다른 구성요소들 또는 동작들이 추가될 수 있다. 대체적으로 또는 추가적으로, 복수의 구성요소들(예: 모듈 또는 프로그램)은 하나의 구성요소로 통합될 수 있다. 이런 경우, 통합된 구성요소는 상기 복수의 구성요소들 각각의 구성요소의 하나 이상의 기능들을 상기 통합 이전에 상기 복수의 구성요소들 중 해당 구성요소에 의해 수행되는 것과 동일 또는 유사하게 수행할 수 있다. 다양한 실시예들에 따르면, 모듈, 프로그램 또는 다른 구성요소에 의해 수행되는 동작들은 순차적으로, 병렬적으로, 반복적으로, 또는 휴리스틱하게 실행되거나, 상기 동작들 중 하나 이상이 다른 순서로 실행되거나, 생략되거나, 또는 하나 이상의 다른 동작들이 추가될 수 있다.According to various embodiments, each component (eg, module or program) of the above-described components may include a singular number or a plurality of entities. According to various embodiments, one or more components or operations among the above-described corresponding components may be omitted, or one or more other components or operations may be added. Alternatively or additionally, a plurality of components (eg, a module or a program) may be integrated into one component. In this case, the integrated component may perform one or more functions of each component of the plurality of components in the same or similar to that performed by the corresponding component among the plurality of components prior to the integration. . According to various embodiments, operations performed by a module, program, or other component are sequentially, parallel, repeatedly, or heuristically executed, or one or more of the above operations are executed in a different order or omitted. Or one or more other actions may be added.
다양한 실시예들에 따르면, 마이크(502), 메모리(503), 적어도 하나의 프로세서를 포함하고, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 지능형 음성 서비스 어플리케이션를 실행하고, 상기 지능형 음성 서비스 어플리케이션의 실행 중에 상기 마이크(502)를 통해 제 1 발화를 수신하고, 상기 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 제 1 합성 사운드를 획득하고, 미리 저장된 복수 개의 사운드들 중 상기 제 1 발화와 관련된 제 2 합성 사운드와 상기 제 1 합성 사운드의 비교 결과를 획득하고, 상기 제 2 합성 사운드는 상기 제 1 사운드와는 다른 비가청 주파수 대역을 갖는 제 2 사운드를 포함하고, 상기 비교 결과에 기반하여, 상기 지능형 음성 서비스 어플리케이션에 의해 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, a
다양한 실시예들에 따르면, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 상기 제 1 합성 사운드와 상기 제 2 합성 사운드 사이의 유사도가 임계값 이상인 경우, 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, when the instructions stored in the
다양한 실시예들에 따르면, 스피커를 더 포함하고, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 상기 지능형 음성 서비스 어플리케이션의 실행에 기반하여, 상기 마이크(502)를 통해 상기 제 1 사운드를 출력하고, 상기 마이크(502)를 통해 상기 제 1 발화 및 상기 출력된 제 1 사운드를 수신하도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, a speaker further includes a speaker, and when instructions stored in the
다양한 실시예들에 따르면, 스피커를 더 포함하고, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 상기 제 1 발화를 수신하기 이전에 상기 스피커를 통해 비가청 주파수 대역을 갖는 제 2 사운드를 출력하고, 상기 마이크(502)를 통해 제 2 발화 및 상기 제 2 사운드를 수신하고, 상구 제 2 발화 및 상기 제 2 사운드에 기반하여, 상기 제 2 합성 사운드를 획득하고, 상기 제 2 합성 사운드를 상기 메모리(503)에 저장하도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, a speaker further includes a speaker, and when instructions stored in the
다양한 실시예들에 따르면, 상기 메모리(503)로부터 복수 개의 제 1 텍스트 데이터를 확인하고, 상기 복수 개의 제 1 텍스트 데이터를 기반으로 상기 제 1 사운드를 획득하고, 상기 메모리(503)로부터 복수 개의 제 2 텍스트 데이터를 확인하고, 상기 복수 개의 제 2 텍스트 데이터를 기반으로 상기 제 2 사운드를 획득하도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, a plurality of first text data is checked from the
다양한 실시예들에 따르면, 상기 복수 개의 제 1 텍스트 데이터의 개수와 상기 복수 개의 제 2 텍스트 데이터의 개수는 서로 다른 것을 특징으로 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 상기 메모리(503)는 제 1 텍스트 데이터 그룹과 제 2 텍스트 그룹을 저장하고, 상기 제 1 텍스트 데이터 그룹과 관련된 제 1 텍스트 길이와 상기 제 2 텍스트 데이터 그룹에 과 관련된 제 2 텍스트 길이는 서로 다르고, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 상기 제 1 텍스트 데이터 그룹으로부터 상기 복수 개의 제 1 텍스트 데이터를 획득하고, 상기 제 2 텍스트 데이터 그룹으로부터 상기 복수 개의 제 2 텍스트 데이터를 획득하도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 상기 메모리(503)는 제 1 텍스트 데이터 그룹과 제 2 텍스트 그룹을 저장하고, 상기 제 1 텍스트 데이터 그룹과 관련된 제 1 주파수 대역과 상기 제 2 텍스트 데이터 그룹과 관련된 제 2 주파수 대역은 서로 다르고, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 상기 제 1 텍스트 데이터 그룹으로부터 상기 복수 개의 제 1 텍스트 데이터를 획득하고, 상기 제 2 텍스트 데이터 그룹으로부터 상기 복수 개의 제 2 텍스트 데이터를 획득하도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 상기 제 1 텍스트 데이터 그룹과 관련된 상기 제 1 주파수 대역과 상기 제 2 텍스트 데이터 그룹과 관련된 상기 제 2 주파수 대역은 비가청 주파수 대역 중에서 기설정된 주파수 대역 내에 포함되는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, the first frequency band related to the first text data group and the second frequency band related to the second text data group are included in a preset frequency band among inaudible frequency bands. 410 may be provided.
다양한 실시예들에 따르면, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 상기 제 1 발화와 관련된 합성 사운드가 식별되지 않는 경우, 특정 키워드를 포함하는 제 3 발화를 수신하고, 상기 특정 키워드를 포함하는 제 3 발화 및 비가청 주파수 대역을 갖는 제 3 사운드에 기반하여 제 3 합성 사운드를 획득하고, 상기 특정 키워드와 관련된 제 4 합성 사운드와 상기 획득된 제 3 합성 사운드의 비교 결과를 획득하고, 상기 비교 결과에 기반하여, 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, when instructions stored in the
다양한 실시예들에 따르면, 전자 장치(410)의 동작 방법에 있어서, 지능형 음성 서비스 어플리케이션를 실행하는 단계, 상기 지능형 음성 서비스 어플리케이션의 실행 중에 상기 전자 장치(410)의 마이크(502)를 통해 제 1 발화를 수신하는 단계, 상기 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 제 1 합성 사운드를 획득하는 단계, 미리 저장된 복수 개의 사운드들 중 상기 제 1 발화와 관련된 제 2 합성 사운드와 상기 제 1 합성 사운드의 비교 결과를 획득하는 단계를 포함하고, 상기 제 2 합성 사운드는 상기 제 1 사운드와는 다른 비가청 주파수 대역을 갖는 제 2 사운드를 포함하고, 상기 비교 결과에 기반하여, 상기 지능형 음성 서비스 어플리케이션에 의해 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, in a method of operating the
다양한 실시예들에 따르면, 상기 제 1 합성 사운드와 상기 제 2 합성 사운드 사이의 유사도가 임계값 이상인 경우, 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, when the similarity between the first synthesized sound and the second synthesized sound is greater than or equal to a threshold value, the operation method further comprises providing a service corresponding to the first utterance. I can.
다양한 실시예들에 따르면, 상기 지능형 음성 서비스 어플리케이션의 실행에 기반하여, 상기 전자 장치(410)의 스피커를 통해 상기 제 1 사운드를 출력하는 단계, 및 상기 마이크(502)를 통해 상기 제 1 발화 및 상기 출력된 제 1 사운드를 수신하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, based on the execution of the intelligent voice service application, outputting the first sound through a speaker of the
다양한 실시예들에 따르면, 상기 제 1 발화를 수신하기 이전에 상기 스피커를 통해 비가청 주파수 대역을 갖는 제 2 사운드를 출력하는 단계, 상기 마이크(502)를 통해 제 2 발화 및 상기 제 2 사운드를 수신하는 단계, 상구 제 2 발화 및 상기 제 2 사운드에 기반하여, 상기 제 2 합성 사운드를 획득하는 단계, 및 상기 제 2 합성 사운드를 상기 메모리(503)에 저장하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, outputting a second sound having an inaudible frequency band through the speaker before receiving the first utterance, the second utterance and the second sound through the
다양한 실시예들에 따르면, 상기 메모리(503)로부터 복수 개의 제 1 텍스트 데이터를 확인하는 단계, 상기 복수 개의 제 1 텍스트 데이터를 기반으로 상기 제 1 사운드를 획득하는 단계, 상기 메모리(503)로부터 복수 개의 제 2 텍스트 데이터를 확인하는 단계, 및 상기 복수 개의 제 2 텍스트 데이터를 기반으로 상기 제 2 사운드를 획득하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, the steps of checking a plurality of first text data from the
다양한 실시예들에 따르면, 상기 복수 개의 제 1 텍스트 데이터의 개수와 상기 복수 개의 제 2 텍스트 데이터의 개수는 서로 다른 것을 특징으로 하는, 동작 방법이 제공될 수 있다.According to various embodiments, an operation method may be provided, characterized in that the number of the plurality of first text data and the number of the plurality of second text data are different from each other.
다양한 실시예들에 따르면, 상기 전자 장치(410)의 메모리(503)는 제 1 텍스트 데이터 그룹과 제 2 텍스트 그룹을 저장하고, 상기 제 1 텍스트 데이터 그룹과 관련된 제 1 텍스트 길이와 상기 제 2 텍스트 데이터 그룹에 과 관련된 제 2 텍스트 길이는 서로 다르고, 상기 동작 방법은 상기 제 1 텍스트 데이터 그룹으로부터 상기 복수 개의 제 1 텍스트 데이터를 획득하는 단계, 및 상기 제 2 텍스트 데이터 그룹으로부터 상기 복수 개의 제 2 텍스트 데이터를 획득하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 상기 전자 장치(410)의 메모리(503)는 제 1 텍스트 데이터 그룹과 제 2 텍스트 그룹을 저장하고, 상기 제 1 텍스트 데이터 그룹과 관련된 제 1 주파수 대역과 상기 제 2 텍스트 데이터 그룹과 관련된 제 2 주파수 대역은 서로 다르고, 상기 동작 방법은 상기 제 1 텍스트 데이터 그룹으로부터 상기 복수 개의 제 1 텍스트 데이터를 획득하는 단계, 및 상기 제 2 텍스트 데이터 그룹으로부터 상기 복수 개의 제 2 텍스트 데이터를 획득하는 단계를 더 포함하는, 동작 방법이 제공될 수 있다.According to various embodiments, the
다양한 실시예들에 따르면, 상기 제 1 텍스트 데이터 그룹과 관련된 상기 제 1 주파수 대역과 상기 제 2 텍스트 데이터 그룹과 관련된 상기 제 2 주파수 대역은 비가청 주파수 대역 중에서 기설정된 주파수 대역 내에 포함되는, 동작 방법이 제공될 수 있다.According to various embodiments, the first frequency band associated with the first text data group and the second frequency band associated with the second text data group are included in a preset frequency band among inaudible frequency bands. Can be provided.
다양한 실시예들에 따르면, 데이터베이스(515), 적어도 하나의 프로세서,를 포함하고, 상기 메모리(503)에 저장된 인스트럭션들이 실행되는 경우 상기 적어도 하나의 프로세서로 하여금 제 1 합성 사운드를 획득하고, 상기 제 1 합성 사운드는 지능형 음성 서비스 어플리케이션의 실행 중에 수신된 제 1 발화 및 비가청 주파수 대역을 갖는 제 1 사운드에 기반하여 획득되고, 상기 데이터베이스(515)에 미리 저장된 복수 개의 사운드들 중 상기 제 1 발화와 관련된 제 2 합성 사운드를 확인하고, 상기 제 2 합성 사운드는 상기 제 1 사운드와는 다른 비가청 주파수 대역을 갖는 제 2 사운드를 포함하고, 상기 제 1 합성 사운드와 상기 제 2 합성 사운드를 비교하여, 상기 제 1 합성 사운드와 상기 제 2 합성 사운드 사이의 유사도를 확인하고, 상기 확인된 유사도에 기반하여, 상기 지능형 음성 서비스 어플리케이션에 의해 상기 제 1 발화에 대응하는 서비스가 제공되도록 하는, 전자 장치(410)가 제공될 수 있다.According to various embodiments, the
Claims (15)
Translated fromKoreanApplications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20190033954 | 2019-03-25 | ||
| KR10-2019-0033954 | 2019-03-25 | ||
| KR1020200035833AKR20200115259A (en) | 2019-03-25 | 2020-03-24 | Electronic device for detecting an stolen user utterances and method for operating thereof |
| KR10-2020-0035833 | 2020-03-24 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020197256A1true WO2020197256A1 (en) | 2020-10-01 |
Family
ID=72609065
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/KR2020/004044CeasedWO2020197256A1 (en) | 2019-03-25 | 2020-03-25 | Electronic device for detecting extorted user utterance and method for operating same |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2020197256A1 (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180063106A1 (en)* | 2016-08-25 | 2018-03-01 | International Business Machines Corporation | User authentication using audiovisual synchrony detection |
| US20180374487A1 (en)* | 2017-06-27 | 2018-12-27 | Cirrus Logic International Semiconductor Ltd. | Detection of replay attack |
| US20190013033A1 (en)* | 2016-08-19 | 2019-01-10 | Amazon Technologies, Inc. | Detecting replay attacks in voice-based authentication |
- 2020
- 2020-03-25WOPCT/KR2020/004044patent/WO2020197256A1/ennot_activeCeased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190013033A1 (en)* | 2016-08-19 | 2019-01-10 | Amazon Technologies, Inc. | Detecting replay attacks in voice-based authentication |
| US20180063106A1 (en)* | 2016-08-25 | 2018-03-01 | International Business Machines Corporation | User authentication using audiovisual synchrony detection |
| US20180374487A1 (en)* | 2017-06-27 | 2018-12-27 | Cirrus Logic International Semiconductor Ltd. | Detection of replay attack |
Non-Patent Citations (2)
| Title |
|---|
| CEMAL HANILCI: "Spoofing Detection Goes Noisy: An Analysis of Synthetic Speech Detection in the Presence of Additive Noise", ARXIV.ORG , ARXIV:1603.03947V3, 14 September 2016 (2016-09-14), pages 1 - 23, XP055744027, Retrieved from the Internet <URL:htt://arxiv.or/abs/1603.03947v3>> [retrieved on 20200617]* |
| HYE-JIN SHIM: "Replay spoofing detection system for automatic speaker verification using multi-task learning of noise classes", ARXIV.ORG , ARXIV:1808.09638, 29 August 2018 (2018-08-29), pages 1 - 6, XP033478478, Retrieved from the Internet <URL:http://arxiv.org/abs/1808.09638> [retrieved on 20200617]* |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2019039834A1 (en) | Voice data processing method and electronic device supporting the same | |
| WO2020197166A1 (en) | Electronic device providing response and method of operating same | |
| WO2021025350A1 (en) | Electronic device managing plurality of intelligent agents and operation method thereof | |
| WO2019013510A1 (en) | Voice processing method and electronic device supporting the same | |
| WO2020122677A1 (en) | Method of performing function of electronic device and electronic device using same | |
| WO2020032563A1 (en) | System for processing user voice utterance and method for operating same | |
| WO2021075736A1 (en) | Electronic device and method for sharing voice command thereof | |
| WO2021060728A1 (en) | Electronic device for processing user utterance and method for operating same | |
| WO2020040595A1 (en) | Electronic device for processing user utterance, and control method therefor | |
| WO2020032568A1 (en) | Electronic device for performing task including call in response to user utterance and operation method thereof | |
| WO2020050475A1 (en) | Electronic device and method for executing task corresponding to shortcut command | |
| WO2019190062A1 (en) | Electronic device for processing user voice input | |
| WO2022010157A1 (en) | Method for providing screen in artificial intelligence virtual secretary service, and user terminal device and server for supporting same | |
| WO2020167006A1 (en) | Method of providing speech recognition service and electronic device for same | |
| WO2020263016A1 (en) | Electronic device for processing user utterance and operation method therefor | |
| WO2019039873A1 (en) | System and electronic device for generating tts model | |
| WO2019235878A1 (en) | Voice recognition service operating method and electronic device supporting same | |
| WO2020032381A1 (en) | Electronic apparatus for processing user utterance and controlling method thereof | |
| WO2020101389A1 (en) | Electronic device for displaying voice recognition-based image | |
| WO2020153720A1 (en) | Electronic device for processing user voice and control method therefor | |
| WO2019164191A1 (en) | Method for processing voice input, and electronic device supporting same | |
| WO2022010187A1 (en) | Electronic device and authentication operation method of electronic device | |
| WO2021187956A1 (en) | Electronic device and method for processing user input | |
| WO2022220559A1 (en) | Electronic device for processing user utterance and control method thereof | |
| WO2019177377A1 (en) | Apparatus for processing user voice input |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | Ref document number:20778374 Country of ref document:EP Kind code of ref document:A1 | |
| NENP | Non-entry into the national phase | Ref country code:DE | |
| 122 | Ep: pct application non-entry in european phase | Ref document number:20778374 Country of ref document:EP Kind code of ref document:A1 |