WO2019000240A1 - Question answering system and question answering method - Google Patents
Question answering system and question answering methodDownload PDFInfo
- Publication number
- WO2019000240A1 WO2019000240A1PCT/CN2017/090401CN2017090401WWO2019000240A1WO 2019000240 A1WO2019000240 A1WO 2019000240A1CN 2017090401 WCN2017090401 WCN 2017090401WWO 2019000240 A1WO2019000240 A1WO 2019000240A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- question
- candidate answer
- answer
- candidate
- sub
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation
Definitions
- the embodiments of the present inventionrelate to the field of artificial intelligence and natural language processing (NLP), and in particular, to a question answering system and a question and answer method.
- NLPnatural language processing
- Question answering systemis an advanced form of information retrieval system, which can answer the questions raised by users in natural language with accurate and concise natural language to meet people's needs for fast and accurate information acquisition.
- the usersubmits a question to the Q&A system: "When was the phone invented?", the system should return a streamlined answer: "1867".
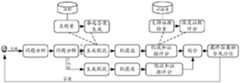
- FIG. 1is a schematic diagram of the DeepQA architecture.
- the deep question answering systemcan include the following processes: receiving user input questions ⁇ problem analysis ⁇ Problem decomposition ⁇ main search ⁇ alternative answer generation ⁇ generation hypothesis ⁇ soft filtering ⁇ hypothesis and evidence scoring ⁇ fusion of final answer and ranking ⁇ feedback the correct answer with the highest ranking to the user.
- each sub-processis executed in series. If an error occurs in the previous sub-process, the error will be accumulated in the subsequent sub-process, thereby reducing the final answer of the deep question answering system.
- the embodiment of the inventionprovides a question answering system and a question and answer method. Solved the problem that the accuracy of the answer obtained by the existing DeepQA is not high.
- the embodiment of the present inventionadopts the following technical solutions:
- an embodiment of the present inventionprovides a question and answer system, including:
- a user interaction modulefor receiving a question raised by a user
- the chapter structure analysis moduleis configured to obtain a first candidate answer set corresponding to the problem received by the user interaction module based on the chapter structure analysis algorithm; the chapter structure analysis algorithm is used to obtain the syntax structure or the defined grammar rule or the structured knowledge base a candidate answer corresponding to the question, the first candidate answer set includes at least one first candidate answer corresponding to the question, and a score of the first candidate answer;
- the feature statistics moduleis configured to obtain a second candidate answer set corresponding to the problem received by the user interaction module based on the feature statistics algorithm;
- the feature statistics algorithmis configured to obtain a candidate answer corresponding to the question by using a word frequency statistics, and the second candidate answer set Having at least one second candidate answer corresponding to the question, and a score of the second candidate answer;
- a combination processing modulefor using the first candidate answer set and the feature statistical model obtained by the chapter structure analysis module
- the second candidate answer set obtained by the blockis combined, and the candidate answer with the highest score after the combination processing is taken as the correct answer of the question;
- the user interaction moduleis also used to feed back the correct answer to the user.
- the question answering systemCompared with the existing question answering system, the question answering system provided by the embodiment of the present invention combines the text structure analysis algorithm and the feature statistical algorithm to obtain the correct answer of the question, because the chapter structure analysis is a grammatical rule or structuring analyzed or defined by the syntax structure.
- an algorithm for selecting candidate answersis selected.
- the feature statistical algorithmis an algorithm for selecting candidate answers based on the word frequency statistical method. The manner in which the candidate answers are selected is different, so that the selected candidate answer types are selected. For example, the inaccurate answers included in the candidate answer set returned by the text structure analysis algorithm generally do not appear in the candidate answer set selected based on the feature statistics algorithm. Therefore, the embodiments of the present invention can utilize the two algorithms.
- the complementarity of the returned candidate answer setsgreatly removes the incorrect answers of the top scores and improves the accuracy of the question and answer system.
- the chapter structure analysis modulemay specifically include:
- a problem analysis unitconfigured to perform word segmentation, syntax parsing, and named entity recognition on the problem, obtain at least one sub-question, and at least one keyword corresponding to the sub-question;
- a searching unitconfigured to input, to any one of the at least one sub-question, at least one keyword corresponding to the sub-question into the first corpus, and retrieve a related document set of each keyword;
- An alternative answer generating unitconfigured to extract, for any one of the at least one sub-question, at least one candidate answer corresponding to the sub-question from the related document set of all the keywords corresponding to the sub-question, and at least one candidate answer Generating a hypothesis, soft filtering process to obtain an alternative answer set corresponding to the sub-question; the alternative answer set includes at least one alternative answer;
- the evidence retrieval scoring unitis configured to generate, for any one of the at least one sub-question, the at least one candidate answer corresponding to the sub-question into the sub-question to generate at least one statement, and input each sentence into the evidence database for retrieval. , the candidate answers corresponding to the statement are scored according to the number of related documents retrieved;
- An answer synthesis and sorting unitis configured to synthesize an alternative answer set corresponding to each sub-question, and use the candidate answer of the pre-score M in the synthesized candidate answer set as the first candidate answer set, and M is an integer greater than or equal to 1.
- the text structure analysis modulecan generate the first candidate by means of the first corpus, through analysis of the problem, related document set retrieval based on the first corpus, alternative answer generation, candidate answer score, and alternative answer synthesis and sorting.
- the answer setcan be generated by means of the first corpus, through analysis of the problem, related document set retrieval based on the first corpus, alternative answer generation, candidate answer score, and alternative answer synthesis and sorting. The answer set.
- the feature statistics modulemay specifically include:
- a search unitconfigured to input the problem received by the user interaction module into the second corpus, and search for a related document set that obtains the problem
- a feature extraction unitconfigured to perform feature extraction from a related document set obtained by the search unit search based on the feature statistical algorithm, to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
- a feature rating and answer sorting unitconfigured to score each candidate answer in the candidate answer set determined by the feature extracting unit, and use the candidate answer of the N before the score as the second candidate answer set, where N is greater than or equal to 1 Integer
- the first corpusis different from the second corpus.
- the feature statistics modulecan pass the problem by means of a second corpus different from the first corpus. Searching for related documents, extracting candidate answers based on feature statistics, and selecting candidate answer scores to generate a second set of candidate answers.
- the second corpuscontains a number of corpora greater than the number of corpora contained in the first corpus.
- the first corpusmay include at least one of the following corpora: Wikipedia, knowledge map, professional literature, manual corpus.
- the second corpuscan be the first corpus and at least one of the following corpora: Baidu, Forum Post, Portal, Blog, Weibo.
- a formal, high-quality corpuscan be configured for the chapter structure analysis module to ensure the purity of the candidate answers determined by the chapter structure analysis module; meanwhile, in order to exploit the advantages of feature statistics, a large-scale corpus is configured for the feature statistics module.
- the search scope of the corpusis expanded, and the feature statistics module determines the candidate answers different from the answers determined by the chapter structure analysis, and improves the accuracy of the answers determined by the question and answer system.
- the feature statistics modulemay specifically include:
- a feature extraction unitconfigured to perform feature extraction on all related documents retrieved from the retrieval unit based on the feature statistics algorithm to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
- a feature ranking and answer sorting unitconfigured to score each candidate answer in the candidate answer set determined by the feature extracting unit, and use the candidate answer of the pre-score O as the second candidate answer set, where O is greater than or equal to 1 The integer.
- the feature statistics modulemay extract the candidate document set from the related document set based on the feature statistics by using the related document set retrieved by the chapter structure analysis module, and generate a second candidate answer set for the candidate answer score. In this way, the feature statistics module is not required to search the related document set, which greatly reduces the design complexity of the feature statistics module.
- the feature statistics modulemay specifically include:
- a search unitconfigured to input a question received by the user interaction module into the evidence base, and search for a related document set that obtains the problem
- a feature extraction unitconfigured to perform feature extraction from a related document set obtained by the search unit search based on the feature statistical algorithm, to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
- a feature ranking and answer sorting unitconfigured to score each candidate answer in the candidate answer set determined by the feature extracting unit, and use the candidate answer of the pre-score P as the second candidate answer set, P is greater than or equal to 1 The integer.
- the feature statistics modulecan generate the second candidate answer set by searching the related documents of the question, extracting the candidate answer based on the feature statistics, and the candidate answer score by means of the evidence base, and does not need to separately configure the corpus for the feature statistics module, thereby greatly reducing the corpus.
- the overall complexity of the question and answer systemprovided by the embodiment of the present invention.
- the processing modulemay be specifically configured to:
- the same candidate answer in the second candidate answer set of the first candidate answer setis weighted, and the candidate answer with the highest score after the weighting process is used as the correct answer to the question.
- the candidate answer with the highest score in the intersection of the candidate answer set and the candidate answer set obtained based on the feature statistical algorithm based on the chapter structure analysis algorithmcan be used as the final answer, or the candidate answer set and the feature based on the chapter structure analysis algorithm can be obtained.
- the candidate answers in the intersection of the candidate answer sets obtained by the statistical algorithmare weighted and processed, and the candidate answers with the highest score are taken as the final answer.
- an embodiment of the present inventionprovides a question and answer method, including:
- Receiving a question raised by the userobtaining a first candidate answer set corresponding to the question based on the chapter structure analysis algorithm, obtaining a second candidate answer set corresponding to the question based on the feature statistics algorithm, and setting the first candidate answer set and the second candidate answer set Perform a combination process, and use the candidate answer with the highest score after the combination process as the correct answer of the question; feed the correct answer to the user;
- the text structure analysis algorithmis used to obtain a candidate answer corresponding to the question by syntactic structure analysis or a defined grammar rule or a structured knowledge base
- the feature statistics algorithmis used to obtain a candidate answer corresponding to the question by using word frequency statistics.
- the specific implementation process of the foregoing question and answer methodmay refer to the process performed by each module or unit in the first aspect or the possible implementation manner of the first aspect, and details are not repeatedly described herein. Therefore, the question answering system provided by this aspect can achieve the same beneficial effects as the first aspect.
- the embodiment of the present applicationprovides a question answering system, which can implement the functions performed by the question answering system element in the foregoing method embodiment, and the functions can be implemented by hardware or by executing corresponding software through hardware.
- the hardware or softwareincludes one or more modules corresponding to the above functions.
- the structure of the question answering systemincludes a processor and a communication unit configured to support the question answering system to perform the corresponding functions of the above methods.
- the communication unitis used to support communication between the question and answer system and a user or other network element.
- the question answering systemcan also include a memory for coupling with the processor that holds the program instructions and data necessary for the question answering system.
- an embodiment of the present applicationprovides a computer storage medium for storing computer software instructions for use in the above question answering system, the computer software instructions including a program designed to perform the above aspects.
- an embodiment of the present applicationprovides a computer program product, which stores computer software instructions for use in the above question and answer system, the computer software instructions including a program designed to perform the above aspects.
- the embodiment of the present applicationprovides a device, which is in the form of a product of a chip.
- the deviceincludes a processor and a memory, and the memory is coupled to the processor to save necessary program instructions of the device. And data, the processor is operative to execute program instructions stored in the memory such that the apparatus performs the functions corresponding to the question answering system in the above method.
- FIG. 1is a schematic diagram of a network architecture of a DeepQA provided by the prior art
- FIG. 2is a simplified schematic diagram of a question answering system according to an embodiment of the present invention.
- FIG. 3is a schematic structural diagram of a question answering system according to an embodiment of the present invention.
- FIG. 4is a schematic structural diagram of a question answering system according to an embodiment of the present invention.
- FIG. 5is a schematic structural diagram of a question answering system according to an embodiment of the present invention.
- FIG. 6is a flowchart of a question and answer method according to an embodiment of the present invention.
- FIG. 7is a schematic structural diagram of a question and answer system according to an embodiment of the present invention.
- An embodiment of the present inventionprovides a question answering system.
- the basic principleis: after receiving a question raised by a user, acquiring a set of candidate answers corresponding to the question based on the chapter structure analysis algorithm, and acquiring another candidate corresponding to the problem based on the feature statistics algorithm The candidate answers are combined, and the candidate answers of the two groups are combined, and the candidate answers with the highest scores are processed as the final correct answers to the user.
- the complementarity of the two algorithmsis used to determine the answer and improve the accuracy of the question and answer system.
- FIG. 2is a simplified schematic diagram of a question answering system 10 according to an embodiment of the present invention.
- the question answering system 10can be set on the user terminal in the form of application software (application, APP).
- applicationapplication
- APPapplication software
- the usercan interact with the question answering system 10 by clicking the APP corresponding to the question answering system 10 on the user terminal, and the user terminal can be: a mobile phone. , tablet, ultra-mobile personal computer (UMPC), laptop, netbook, personal digital assistant (PDA) and other devices; the question and answer system 10 can also be used as a stand-alone device
- UMPCultra-mobile personal computer
- PDApersonal digital assistant
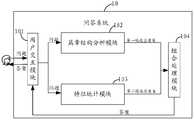
- the question answering system 10may include: a user interaction module 101, a chapter structure analysis module 102, a feature statistics module 103, and a combination processing module 104.
- the user interaction module 101can be configured to receive a question raised by the user and feed back the correct correct answer to the user.
- the question raised by the usermay be: the question expressed by the user in natural language, and the correct answer to the question may be: an answer described in a concise natural language such as "word”, "phrase” or "list”.
- the user interaction module 101can include an image interface, and the image interface is designed with an input box for the user to input a question through an input unit such as a keyboard or a microphone.
- the user interaction module 101can be used to receive the user through the input box.
- the proposed problem, and the correct answer to the questionis fed back to the user in the form of text through the image interface of the user interaction module 101; or the user interaction module 101 of the question answering system 10 may include an audio unit, and the audio unit may include
- the microphone and the player, the microphonecan be used to receive the sound emitted by the user, and the player can be used to feed the answer determined by the question answering system 10 to the user in the form of sound.
- the user interaction module 101can be used to receive the user through the audio unit.
- the question asked and the correct answer to the questionare played to the user in the form of sound.
- the chapter structure analysis module 102can be configured to obtain a question raised by the user from the user interaction module 101, and obtain a first candidate answer set corresponding to the problem based on the chapter structure analysis algorithm.
- syntactic structure analysisor defined grammar rules or structured knowledge base
- syntactic structure analysis, defined grammar rules, structured knowledge baseare the existing chapter structures Common means in the analysis algorithm are not detailed here.
- the first candidate answer setmay include at least one candidate answer, each candidate answer corresponding to a score, the score is used to represent the credibility of the candidate answer as the correct answer, and the higher the score, the more likely the correct answer is, the more likely it is to be the correct answer,
- the scorecan be expressed in percentage.
- the score of the candidate answermay be The results obtained by combining multiple scoring algorithms; some typical scoring algorithms may include but are not limited to the following: 1.
- the type of the candidate answeris the same as the answer type of the question. If they are the same, the score of the candidate answer is relatively higher. High, if different, the score of the candidate answer is relatively low; for example, if the user asks "what city” question, the corresponding answer type is city type, then "Beijing", "Tianjin", etc. are the candidate answers of the city type.
- Candidate answers that do not belong to the city typesuch as "Tiananmen” should be scored high; 2.
- the candidate answerappears in an important position of the article or encyclopedia (such as the title, article or the first paragraph of the encyclopedia, etc.), if the candidate answer appears in If the article or the important position of the encyclopedia is relatively high, the score of the candidate answer is relatively high. Otherwise, the score of the candidate answer is relatively low. 3.
- the candidate answeris substituted into the evidence database for retrieval, if the returned document If the number is large, the candidate answer has a higher score, otherwise, the candidate answer has a lower score.
- the feature statistics module 103may be configured to obtain a problem raised by the user from the user interaction module 101, and obtain a second candidate answer set corresponding to the problem according to the feature statistics algorithm;
- the feature statistical algorithmis used to obtain a candidate answer corresponding to the question by using word frequency statistics, and the second candidate answer set may include at least one candidate answer, and each candidate answer corresponds to one score. Similarly, the score is also used to represent the candidate answer. Becoming the credibility of the correct answer, the higher the candidate answer, the higher the probability of becoming the correct answer.
- the weight of a word in an articlecan be used to indicate the score of the word as a candidate answer.
- the industry's methods for calculating word weightsmay include word frequency, relative word frequency, word frequency--inverted file frequency and the like.
- the combination processing module 104is configured to perform a combination process on the first candidate answer set of the chapter structure analysis module 101 and the second candidate answer set acquired by the feature statistics module 103, and use the candidate answer with the highest score after the combination process as the problem corresponding to the problem. The correct answer.
- the combination processing module 104extracts an intersection of the first candidate answer set and the second candidate answer set, and uses the candidate answer with the highest score in the extracted intersection as the correct answer of the question; or
- the same candidate answer in the second candidate answer set of the first candidate answer setis weighted, and the candidate answer with the highest score after the weighting process is used as the correct answer to the question.
- the weighting processrefers to: for the same word, the scores of the words in the two candidate answer sets are respectively multiplied by one weight (ie, coefficients), and then added to obtain a total score, which is used as the score of the word. If a word does not appear in a candidate answer set, the word can be considered to have a score of 0 in the candidate answer set.
- the first candidate answer set and the scoreare (Beijing 0.86, Tianjin 0.80), the second candidate answer set and the score are ( Tiananmen Square 0.81, Beijing 0.78), the intersection of the two candidate answer sets is only Beijing, then “Beijing” is the correct answer to “Which city is China's capital”; or, the weight of the first candidate answer set is 2, The weight of the second candidate answer set is 1.
- the question answering system shown in FIG. 2can use the complementarity of the two algorithms to largely remove the incorrect answer before the score and improve the accuracy of the question and answer system.
- the chapter structure analysis module 102may include: a problem analysis unit 1021a, a retrieval unit 1022a, an alternative answer generation unit 1023a, an evidence retrieval and scoring unit 1024a, and an answer.
- the composition and ranking unit 1025a; the feature statistics module 103may include a search unit 1031a, a feature extraction unit 1032a, and a feature rating and answer sorting unit 1033a.
- the problem analysis unit 1021ais configured to perform word segmentation, syntax analysis, and named entity recognition on the question raised by the user, and obtain at least one sub-question and at least one keyword corresponding to the sub-question.
- the keywordsare generally words that modify the interrogative words and can be obtained by analyzing the results of the syntactic analysis. For example, in the above example, the keyword and its modified question word are [Huawei - President - (Who)].
- the search unit 1022ais configured to input a keyword of the sub-question into the first corpus for each sub-question, and obtain a related document set of the keyword.
- the related document setmay include at least one document related to the keyword.
- the word extraction related document setcan be implemented by a general search engine, and the description is not extended here; for example, the search unit 1022a can be used to input keywords into the input box of the first corpus, and click the search button to perform the search.
- the alternative answer generating unit 1023ais configured to extract, for each sub-question, the at least one candidate answer corresponding to the sub-question from the related document set of the keyword corresponding to the sub-question acquired from the retrieving unit 1022a, at least one The alternative answer is generated by a hypothesis and soft filtering to obtain an alternative answer set corresponding to the sub-question.
- the alternative answer setmay include: at least one alternative answer.
- the alternative answer generating unit 1023amay be configured to extract an alternative answer set from the related document set by using a syntax structure analysis or a defined grammar rule or a structured knowledge base (ie, a knowledge map).
- the generation hypothesis and soft filteringare common processes of the existing question answering system and will not be described in detail here.
- the generation hypothesiscan be a process of substituting an alternative answer into the original question to generate a statement. For example, suppose the question is “Which city is China's capital?” There are two alternative answers, namely “Beijing” and “Tiananmen”, the hypothesis is “China's capital is Beijing” and “China's capital is Tiananmen Square”.
- Soft filteringis to filter out alternative answers that do not meet the requirements through some lightweight scoring algorithms, type matching algorithms, and so on.
- the question “Which city is the capital of China?”should be “city”; then among the two alternative answers, “Beijing” is a city, so it is a possible correct answer; “Tiananmen” is not a city, so it is probably not the right answer. In this way, soft filtering can filter out the alternative answer of "Tiananmen”.
- the evidence retrieval scoring unit 1024ais configured to generate, for each sub-question acquired by the candidate answer generating unit 1023a, each candidate answer in the candidate answer set corresponding to the sub-question into a sub-question to generate a statement, and input the statement into the evidence base.
- a searchis performed to score the alternate answer based on the number of related documents retrieved.
- the evidence retrieval scoring unit 1024acan be used not only for scoring according to the number of related documents returned, but also for scoring alternative answers by using other scoring algorithms (such as the scoring algorithm mentioned above). The embodiment does not limit this.
- An answer synthesis and sorting unit 1025aconfigured to synthesize an alternative answer set corresponding to each of the sub-questions, and use the candidate answer of the pre-score M in the synthesized candidate answer set as the first candidate answer set, the M Is an integer greater than or equal to 1.
- Mis an integer greater than or equal to 1, and M can be set as needed, which is not limited by the embodiment of the present invention; for example, the candidate answer of M before the score may be an alternative with a score greater than or equal to the preset score.
- the answer, the preset scorecan be set as needed, which is not limited by the embodiment of the present invention.
- the searching unit 1031ais configured to input the question received by the user interaction module into the second corpus, and search for a related document set that obtains the problem.
- the feature extraction unit 1032ais configured to perform feature extraction from the related document set searched by the search unit 1031a based on the feature statistics algorithm to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question.
- the feature extractionmay include: a feature extraction method based on word frequency, an information gain based method and other feature extraction methods, and a feature extraction method based on word frequency may refer to: word frequency, relative word frequency, word frequency appearing in the document set--reverse Transfer file frequency.
- Feature score and answer sorting unit 1033afor determining alternative answers to feature extracting unit 1032a
- Each candidate answer in the setis scored, and an alternative answer of N before the score is taken as the second set of candidate answers, and N is an integer greater than or equal to 1.
- the general feature extraction unit 1032ahas included a process of calculating a score (ie, a weight) of each candidate answer (ie, a feature) at the time of feature extraction, and therefore, an algorithm for calculating a score of each candidate answer may be based on the word frequency described above. , relative word frequency, word frequency - reverse file frequency and other algorithms.
- the two processes of feature extraction and the calculation of the score of each candidate answerare also separated, and are calculated by different algorithms, which is not limited in the embodiment of the present invention.
- the first corpus and the second corpus used by the chapter structure analysis module 102 and the feature statistic module 103are different, the first corpus is a corpus with relatively high purity, and the second corpus is the first corpus.
- a corpus expanded by a corpus, relative to the first corpus, the second corpusis a large document library, containing a wide corpus, that is, the second corpus contains more corpus than the corpus contained in the first corpus.
- the first corpusmay include: Wikipedia, knowledge map, professional literature, manual corpus and other professional and relatively small-scale corpus
- the second corpusmay include: first corpus, Baidu know, forum post, portal Large-scale corpus currently searchable, such as websites and other web pages.
- the evidence baseis generally a large document library, which can contain a wide range of corpora.
- the evidence basecan include web pages, encyclopedias, Baidu knows, forum posts, portals, and other web pages. Similar to the general general search engine, there is no special requirement. From the corpus contained in the evidence base, the evidence base is similar to the second corpus. In the industry and academia, the evidence base is often used in the chapter structure analysis module. Named after the search.
- the evidence base and the second corpusmay be set to the same corpus, and in another achievable manner, the evidence base and the first may be respectively set according to the specific uses of the two. Second language library.
- a prompt for setting a corpusmay be sent to the user through the user interaction interface of the question answering system 10, and at this time, the user may press the prompt in the input box of the user interaction interface.
- the corpusis input and stored in the question answering system 10 by clicking the store button on the user interaction interface; or the first corpus and the second corpus are set in a database, and the question answering system can access the corpus when needed.
- the chapter structure analysis module 102uses the canonical corpus to obtain candidate answers
- the feature statistics module 103uses a wide range of corpora to obtain candidate answers, and while ensuring the purity of the answers, the search range of the candidate answers is expanded, and the question answering system is improved. Precision.
- the feature statistics module 103may not need to set the search unit, but use the relevant document set retrieved by the text structure analysis module 102 to determine The candidate answer, that is, only the first corpus is set for the question answering system 10.
- the chapter structure analysis module 102 in the question answering system 10may include: a question analysis unit 1021b, a retrieval unit 1022b, an alternative answer generation unit 1023b, an evidence retrieval scoring unit 1024b, an answer synthesis and sorting unit 1025b.
- the feature statistics module 103can include a feature extraction unit 1031b, and a feature rating and answer sorting unit 1032b.
- the problem analysis unit 1021bhas the same function as the problem analysis unit 1021a shown in FIG. 3.
- the retrieval unit 1022bhas the same function as the retrieval unit 1022a shown in FIG. 3, and the alternative answer generation unit 1023b and the alternative shown in FIG.
- the function of the answer generating unit 1023ais the same, the evidence retrieval scoring unit 1024b and FIG.
- the functions of the evidence retrieval scoring unit 1024aare the same, and the functions of the answer synthesizing and sorting unit 1025b and the answer synthesizing and sorting unit 1025a shown in FIG. 3 are the same, and will not be repeated here.
- the feature extraction unit 1031bis configured to perform feature extraction from the document set acquired by the retrieval unit 1022b based on the feature statistical algorithm to obtain an alternative answer set.
- the function extracting unit 1031bhas the same function as the feature extracting unit 1032a shown in FIG. 3, and details are not repeated herein.
- the feature score and answer sorting unit 1032bhas the same functions as the feature score and answer sorting unit 1033a shown in FIG. 3, and details are not repeated herein.
- the feature statistics module in the question and answer systemcan perform feature extraction from the related documents retrieved from the chapter structure analysis module without setting the search unit, determine the candidate answer set, and reduce the design complexity of the feature statistics module, thereby reducing the complexity.
- the chapter structure analysis module 102may include: a problem analysis unit 1021c, a retrieval unit 1022c, an alternative answer generation unit 1023c, an evidence retrieval scoring unit 1024c, and an answer.
- the composition and ranking unit 1025c; the feature statistics module 103may include a search unit 1031c, a feature extraction unit 1032c, and a feature rating and answer sorting unit 1033c.
- the problem analysis unit 1021chas the same function as the problem analysis unit 1021a shown in FIG. 3.
- the retrieval unit 1022chas the same function as the retrieval unit 1022a shown in FIG. 3, and the alternative answer generation unit 1023c and the candidate shown in FIG.
- the function of the answer generating unit 1023ais the same
- the evidence retrieval scoring unit 1024chas the same function as the evidence retrieval scoring unit 1024a shown in FIG. 3
- the answer synthesizing and sorting unit 1025chas the same function as the answer synthesizing and sorting unit 1025a shown in FIG. I will not repeat them here.
- a searching unit 1031cconfigured to input a question into the evidence base, and search for a related document set that obtains the problem
- the function extracting unit 1032chas the same function as the feature extracting unit 1032a shown in FIG. 3, and details are not repeatedly described herein.
- the feature score and answer sorting unit 1032chas the same functions as the feature score and answer sorting unit 1033a shown in FIG. 3, and details are not repeated herein.
- the evidence base used by the search unit 1031c and the evidence base used by the evidence search scoring unitmay be the same corpus.
- the existing question and answer system design scheme for the friend(including only the user interaction module 101 and the chapter structure structure analysis module 102 shown in FIG. 2 to FIG. 5), in order to modify the existing question and answer system design scheme Smaller.
- the units in the feature statistics module 102 shown in FIG. 5can be integrated with the evidence retrieval scoring unit 1024c in the chapter structure analysis module 10 to improve the accuracy of the "evidence search" step in the chapter structure analysis module 102.
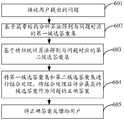
- FIG. 6is a method for question and answer according to an embodiment of the present invention. As shown in FIG. 6, the method may include:
- Step 601Receive a question raised by the user.
- Step 602Obtain a first candidate answer set corresponding to the question based on the chapter structure analysis algorithm.
- the text structure analysis algorithmis used to obtain a candidate answer corresponding to the question by using a syntax structure analysis or a defined grammar rule or a structured knowledge base, and the first candidate answer set includes at least one corresponding to the problem.
- the first candidate answer, and the score of the first candidate answerare used to obtain a candidate answer corresponding to the question by using a syntax structure analysis or a defined grammar rule or a structured knowledge base, and the first candidate answer set includes at least one corresponding to the problem.
- the first candidate answer, and the score of the first candidate answeris used to obtain a candidate answer corresponding to the question by using a syntax structure analysis or a defined grammar rule or a structured knowledge base, and the first candidate answer set includes at least one corresponding to the problem.
- the first candidate answer setcan be determined by:
- the at least one keyword corresponding to the sub-questionis respectively input into the first corpus, and the related document set of each keyword is retrieved;
- At least one candidate answer corresponding to the sub-questionis extracted from the related document set of all the keywords corresponding to the sub-question, and at least one candidate answer is obtained by generating a hypothesis and soft filtering.
- the at least one alternative answer corresponding to the sub-questionis substituted into the sub-question to generate at least one statement, and each sentence is input into the evidence base for retrieval, according to the retrieved related document The number ranks the alternative answers corresponding to the statement;
- the candidate answer set corresponding to each sub-questionis synthesized, and the candidate answer of the pre-score M in the synthesized candidate answer set is used as the first candidate answer set, and M is an integer greater than or equal to 1.
- Step 603Obtain a second candidate answer set corresponding to the question based on the feature statistics algorithm.
- the feature statistics algorithmis used to obtain a candidate answer corresponding to the question by using a word frequency statistic, and the second candidate answer set includes at least one second candidate answer corresponding to the question, and a score of the second candidate answer.
- the second candidate answer setcan be obtained by the following manner 1 or mode 2 or mode 3:
- Method 1Enter the question into the second corpus and search for the relevant document set for the question;
- feature extractionis performed from the relevant document set of the question, and an alternative answer set is obtained, and the candidate answer set includes at least one candidate answer corresponding to the question;
- Nis an integer greater than or equal to 1;
- the first corpusis different from the second corpus.
- Method 2Perform feature extraction from a related document set of all keywords corresponding to at least one sub-question based on the feature statistics algorithm to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
- Each candidate answer in the candidate answer set obtained after the feature extractionis scored, and the candidate answer of the score before O is taken as the second candidate answer set, and O is an integer greater than or equal to 1.
- the related document set of all the keywords corresponding to the at least one sub-questioncan be obtained through step 602.
- Method 3Enter the question into the evidence base and search for the relevant document set for the problem
- feature extractionis performed from the relevant document set of the question, and an alternative answer set is obtained, and the candidate answer set includes at least one candidate answer corresponding to the question;
- Each candidate answer in the candidate answer set obtained after the feature extractionis scored, and the candidate answer of the pre-score P is taken as the second candidate answer set, and P is an integer greater than or equal to 1.
- the evidence base used in this stepmay be the same as the evidence base used in step 602.
- Step 604Combine the first candidate answer set and the second candidate answer set, and select the candidate answer with the highest score after the combination process as the correct answer of the question.
- an intersection of the first candidate answer set and the second candidate answer setmay be extracted, and the candidate answer with the highest score in the extracted intersection set is used as the correct answer to the question.
- Step 605Feed the correct answer to the user.
- the question and answer methodcan use the complementarity of the two algorithms to largely remove the non-correct score.
- the correct answeris to improve the accuracy of the question and answer system.
- the solution provided by the embodiment of the present applicationis mainly introduced from the perspective of the question answering system. It can be understood that the Q&A system includes corresponding hardware structures and/or software modules for performing various functions in order to implement the above functions.
- the present applicationcan be implemented in a combination of hardware or hardware and computer software in combination with the algorithmic steps of the various examples described in the embodiments disclosed herein. Whether a function is implemented in hardware or computer software to drive hardware depends on the specific application and design constraints of the solution. A person skilled in the art can use different methods to implement the described functions for each particular application, but such implementation should not be considered to be beyond the scope of the present application.
- the embodiment of the present applicationmay divide the function module into the question answering system according to the foregoing method example.
- each function modulemay be divided according to each function (such as the question answering system shown in FIG. 2 to FIG. 5), or two or two may be used.
- the above functionsare integrated in one processing module.
- the above integrated modulescan be implemented in the form of hardware or in the form of software functional modules. It should be noted that the division of the module in the embodiment of the present application is schematic, and is only a logical function division, and the actual implementation may have another division manner.
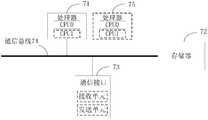
- FIG. 7shows another possible composition diagram of the question answering system involved in the above embodiment.
- the question answering systemcan include at least one processor 71, a memory 72, a communication unit 73, and a communication bus 74.
- the processor 71is a control center of the question answering system, and may be a processor or a collective name of a plurality of processing elements.
- the processor 71is a central processing unit (CPU), may be an application specific integrated circuit (ASIC), or one or more integrated circuits configured to implement the embodiments of the present application.
- ASICapplication specific integrated circuit
- DSPsdigital signal processors
- FPGAsfield programmable gate arrays
- the processor 71can perform various functions of the question answering system by running or executing a software program stored in the memory 72 and calling data stored in the memory 72.
- processor 71may include one or more CPUs, such as CPU0 and CPU1 shown in FIG.
- the question answering systemcan include multiple processors, such as processor 71 and processor 75 shown in FIG.
- processorscan be a single core processor (CPU) or a multi-core processor (multi-CPU).
- a processor hereinmay refer to one or more devices, circuits, and/or processing data (eg, computer program instructions) Processing core.
- the memory 72can be a read-only memory (ROM) or other type of static storage device that can store static information and instructions, a random access memory (RAM) or other type that can store information and instructions.
- the dynamic storage devicecan also be an electrically erasable programmable read-only memory (EEPROM), a compact disc read-only memory (CD-ROM) or other optical disc storage, and a disc storage device. (including compact discs, laser discs, optical discs, digital versatile discs, Blu-ray discs, etc.), magnetic disk storage media or other magnetic storage devices, or can be used to carry or store desired program code in the form of instructions or data structures and can be Any other media accessed, but not limited to this.
- the memory 72can exist independently and is coupled to the processor 71 via a communication bus 74.
- the memory 72can also be integrated with the processor 71.
- the memory 72is used to store a software program that executes the solution provided by the embodiment of the present application, and is controlled by the processor 71 for execution.
- the communication unit 73is configured to interact with a user or other device.
- the communication unit 73can be a user interaction interface of the question answering system.
- the communication bus 74may be an industry standard architecture (ISA) bus, a peripheral component (PCI) bus, or an extended industry standard architecture (EISA) bus.
- ISAindustry standard architecture
- PCIperipheral component
- EISAextended industry standard architecture
- the buscan be divided into an address bus, a data bus, a control bus, and the like. For ease of representation, only one thick line is shown in Figure 7, but it does not mean that there is only one bus or one type of bus.
- the question answering system shown in FIG. 7can perform the operations performed by the question answering system in the question and answer method provided by the embodiment of the present application. Therefore, all related content of the steps involved in the method embodiments may be referred to the function description of the corresponding function module, and details are not described herein.
- the processor 71may be configured to support the question answering system to perform steps 602 to 604, and the communication unit. 73 is used to support the question answering system to perform step 601 and step 605.
- the question answering system provided by the embodiment of the present inventionis used to execute the above question and answer method, so that the same effect as the above question and answer method can be achieved.
- the disclosed apparatus and methodmay be implemented in other manners.
- the device embodiments described aboveare merely illustrative.
- the division of the modules or unitsis only a logical function division.
- there may be another division mannerfor example, multiple units or components may be used.
- the combinationmay be integrated into another device, or some features may be ignored or not performed.
- the mutual coupling or direct coupling or communication connection shown or discussedmay be an indirect coupling or communication connection through some interface, device or unit, and may be in an electrical, mechanical or other form.
- the units described as separate componentsmay or may not be physically separated, and the components displayed as units may be one physical unit or multiple physical units, that is, may be located in one place, or may be distributed to multiple different places. . Some or all of the units may be selected according to actual needs to achieve the purpose of the solution of the embodiment.
- each functional unit in each embodiment of the present inventionmay be integrated into one processing unit, or each unit may exist physically separately, or two or more units may be integrated into one unit.
- the above integrated unitcan be implemented in the form of hardware or in the form of a software functional unit.
- the integrated unitis implemented in the form of a software functional unit and sold or used as a standalone product It can be stored in a readable storage medium.
- the technical solution of the embodiments of the present inventionmay contribute to the prior art or all or part of the technical solution may be embodied in the form of a software product stored in a storage medium.
- a number of instructionsare included to cause a device (which may be a microcontroller, chip, etc.) or a processor to perform all or part of the steps of the methods described in various embodiments of the present invention.
- the foregoing storage mediumincludes various media that can store program codes, such as a USB flash drive, a mobile hard disk, a ROM, a RAM, a magnetic disk, or an optical disk.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Theoretical Computer Science (AREA)
- Artificial Intelligence (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese本发明实施例涉及人工智能和自然语言处理(natural language processing,NLP)领域,尤其涉及一种问答系统及问答方法。The embodiments of the present invention relate to the field of artificial intelligence and natural language processing (NLP), and in particular, to a question answering system and a question and answer method.
问答系统(question answering system,QA)是信息检索系统中的一种高级形式,它能够用准确、简洁的自然语言回答用户用自然语言提出的问题,以满足人们对快速、准确地获取信息的需求。例如,用户向问答系统提交一个问题:“电话是什么时候发明的?”,系统应该返回一个精简的答案:“1867”。Question answering system (QA) is an advanced form of information retrieval system, which can answer the questions raised by users in natural language with accurate and concise natural language to meet people's needs for fast and accurate information acquisition. . For example, the user submits a question to the Q&A system: "When was the phone invented?", the system should return a streamlined answer: "1867".
目前,业界最具代表性的问答系统为深度问答系统(DeepQA),图1为DeepQA架构示意图,如图1所示,该深度问答系统可以包括以下处理过程:接收用户输入的问题→问题分析→问题分解→主搜索→备选答案生成→生成假说→软滤波→假设和证据评分→最终答案的融合及排位→将排位最高的正确答案反馈给用户。At present, the most representative question and answer system in the industry is the deep question answering system (DeepQA). Figure 1 is a schematic diagram of the DeepQA architecture. As shown in Figure 1, the deep question answering system can include the following processes: receiving user input questions → problem analysis → Problem decomposition → main search → alternative answer generation → generation hypothesis → soft filtering → hypothesis and evidence scoring → fusion of final answer and ranking → feedback the correct answer with the highest ranking to the user.
由图1可知,在DeepQA的处理过程中,各个子过程之间是串联执行的,若前一子过程出现误差,则该误差会累计到后续的子过程中,进而减低该深度问答系统最终答案的准确率,如:假设每个子过程的准确率为95%,则9个子过程串联后的准确率为:0.95^9=0.63;其次,对于现有的DeepQA而言,其对语料库的质量要求非常高,通常局限于百科辞典、专业文献或者专门手工编写等小规模的专业语料库,基于该小规模的语料库得到的候选答案有限,误差大,严重影响了最终答案的准确率。It can be seen from Fig. 1 that during the processing of DeepQA, each sub-process is executed in series. If an error occurs in the previous sub-process, the error will be accumulated in the subsequent sub-process, thereby reducing the final answer of the deep question answering system. The accuracy rate, for example, assumes that the accuracy of each sub-process is 95%, then the accuracy of the nine sub-processes after concatenation is: 0.95^9=0.63; secondly, for the existing DeepQA, its quality requirements for the corpus Very high, usually limited to encyclopedia dictionaries, professional literature or specialized hand-written small-scale professional corpus, based on the small-scale corpus, the candidate answers are limited, the error is large, seriously affecting the accuracy of the final answer.
发明内容Summary of the invention
本发明实施例提供一种问答系统及问答方法。解决了现有DeepQA得到的答案准确率不高的问题。The embodiment of the invention provides a question answering system and a question and answer method. Solved the problem that the accuracy of the answer obtained by the existing DeepQA is not high.
为达到上述目的,本发明实施例采用如下技术方案:To achieve the above objective, the embodiment of the present invention adopts the following technical solutions:
第一方面,本发明实施例提供了一种问答系统,包括:In a first aspect, an embodiment of the present invention provides a question and answer system, including:
用户交互模块,用于接收用户提出的问题;a user interaction module for receiving a question raised by a user;
篇章结构分析模块,用于基于篇章结构分析算法得到与用户交互模块接收到的问题对应的第一候选答案集;篇章结构分析算法用于采用句法结构分析或者定义的语法规则或者结构化知识库得到与问题对应的候选答案,第一候选答案集包含至少一个与问题对应的第一候选答案、以及第一候选答案的评分;The chapter structure analysis module is configured to obtain a first candidate answer set corresponding to the problem received by the user interaction module based on the chapter structure analysis algorithm; the chapter structure analysis algorithm is used to obtain the syntax structure or the defined grammar rule or the structured knowledge base a candidate answer corresponding to the question, the first candidate answer set includes at least one first candidate answer corresponding to the question, and a score of the first candidate answer;
特征统计模块,用于基于特征统计算法得到与用户交互模块接收到的问题对应的第二候选答案集;特征统计算法用于采用词频统计的方式得到与问题对应的候选答案,第二候选答案集包含至少一个与问题对应的第二候选答案、以及第二候选答案的评分;The feature statistics module is configured to obtain a second candidate answer set corresponding to the problem received by the user interaction module based on the feature statistics algorithm; the feature statistics algorithm is configured to obtain a candidate answer corresponding to the question by using a word frequency statistics, and the second candidate answer set Having at least one second candidate answer corresponding to the question, and a score of the second candidate answer;
组合处理模块,用于将篇章结构分析模块得到的第一候选答案集和特征统计模块得到的第二候选答案集进行组合处理,将组合处理后评分最高的候选答案作为问题的正确答案;a combination processing module for using the first candidate answer set and the feature statistical model obtained by the chapter structure analysis moduleThe second candidate answer set obtained by the block is combined, and the candidate answer with the highest score after the combination processing is taken as the correct answer of the question;
用户交互模块,还用于将正确答案反馈给用户。The user interaction module is also used to feed back the correct answer to the user.
与现有问答系统相比,本发明实施例提供的问答系统结合篇章结构分析算法和特征统计算法得到问题的正确答案,由于篇章结构分析是一种以句法结构分析或定义的语法规则或结构化知识库为基础选择出候选答案的算法,特征统计算法是一种以词频统计方式为基础选择出候选答案的算法,二者选择候选答案时采用的方式是不同的,使得选择出的候选答案类型大大不同,如:基于篇章结构分析算法返回的候选答案集中所包含的非正确答案,一般不会出现在基于特征统计算法选择出的候选答案集中,因此,本发明实施例可以借助这两种算法返回的候选答案集的互补性,很大程度地去掉评分靠前的非正确答案,提高问答系统的准确率。Compared with the existing question answering system, the question answering system provided by the embodiment of the present invention combines the text structure analysis algorithm and the feature statistical algorithm to obtain the correct answer of the question, because the chapter structure analysis is a grammatical rule or structuring analyzed or defined by the syntax structure. Based on the knowledge base, an algorithm for selecting candidate answers is selected. The feature statistical algorithm is an algorithm for selecting candidate answers based on the word frequency statistical method. The manner in which the candidate answers are selected is different, so that the selected candidate answer types are selected. For example, the inaccurate answers included in the candidate answer set returned by the text structure analysis algorithm generally do not appear in the candidate answer set selected based on the feature statistics algorithm. Therefore, the embodiments of the present invention can utilize the two algorithms. The complementarity of the returned candidate answer sets greatly removes the incorrect answers of the top scores and improves the accuracy of the question and answer system.
结合第一方面,在一种可能的实现方式中,篇章结构分析模块,具体可以包括:With reference to the first aspect, in a possible implementation manner, the chapter structure analysis module may specifically include:
问题分析单元,用于对问题进行分词、句法解析以及命名实体识别,获得至少一个子问题、以及与子问题对应的至少一个关键词;a problem analysis unit, configured to perform word segmentation, syntax parsing, and named entity recognition on the problem, obtain at least one sub-question, and at least one keyword corresponding to the sub-question;
检索单元,用于对于至少一个子问题中的任一子问题,将子问题对应的至少一个关键词分别输入第一语料库,检索得到每个关键字的相关文档集;a searching unit, configured to input, to any one of the at least one sub-question, at least one keyword corresponding to the sub-question into the first corpus, and retrieve a related document set of each keyword;
备选答案生成单元,用于对于至少一个子问题中的任一子问题,从子问题对应的所有关键字的相关文档集中提取至少一个与子问题对应的备选答案,将至少一个备选答案经生成假说、软滤波处理得到与子问题对应的备选答案集;备选答案集包含至少一个备选答案;An alternative answer generating unit, configured to extract, for any one of the at least one sub-question, at least one candidate answer corresponding to the sub-question from the related document set of all the keywords corresponding to the sub-question, and at least one candidate answer Generating a hypothesis, soft filtering process to obtain an alternative answer set corresponding to the sub-question; the alternative answer set includes at least one alternative answer;
证据检索评分单元,用于对于至少一个子问题中的任一子问题,将子问题对应的备选答案集中至少一个备选答案代入子问题生成至少一个语句,将每个语句输入证据库进行检索,根据检索出的相关文档数量对语句对应的备选答案进行评分;The evidence retrieval scoring unit is configured to generate, for any one of the at least one sub-question, the at least one candidate answer corresponding to the sub-question into the sub-question to generate at least one statement, and input each sentence into the evidence database for retrieval. , the candidate answers corresponding to the statement are scored according to the number of related documents retrieved;
答案合成和排序单元,用于合成每个子问题对应的备选答案集,将合成后的备选答案集中评分前M的备选答案作为第一候选答案集,M为大于或等于1的整数。An answer synthesis and sorting unit is configured to synthesize an alternative answer set corresponding to each sub-question, and use the candidate answer of the pre-score M in the synthesized candidate answer set as the first candidate answer set, and M is an integer greater than or equal to 1.
如此,篇章结构分析模块可以借助于第一语料库,通过对问题的分析、基于第一语料库的相关文档集检索、备选答案生成、备选答案评分、备选答案的合成和排序生成第一候选答案集。In this way, the text structure analysis module can generate the first candidate by means of the first corpus, through analysis of the problem, related document set retrieval based on the first corpus, alternative answer generation, candidate answer score, and alternative answer synthesis and sorting. The answer set.
结合上述可能的实现方式,在一种可能的实现方式中,特征统计模块,具体可以包括:In combination with the foregoing possible implementation manners, in a possible implementation manner, the feature statistics module may specifically include:
搜索单元,用于将用户交互模块接收到的问题输入第二语料库,搜索得到问题的相关文档集;a search unit, configured to input the problem received by the user interaction module into the second corpus, and search for a related document set that obtains the problem;
特征提取单元,用于基于特征统计算法,从搜索单元搜索得到的相关文档集中进行特征提取,获得备选答案集,备选答案集包含至少一个与问题对应的备选答案;a feature extraction unit, configured to perform feature extraction from a related document set obtained by the search unit search based on the feature statistical algorithm, to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
特征评分和答案排序单元,用于对特征提取单元确定出的备选答案集中的每个备选答案进行评分,将评分前N的备选答案作为第二候选答案集,N为大于或等于1的整数;And a feature rating and answer sorting unit, configured to score each candidate answer in the candidate answer set determined by the feature extracting unit, and use the candidate answer of the N before the score as the second candidate answer set, where N is greater than or equal to 1 Integer
第一语料库和第二语料库不同。The first corpus is different from the second corpus.
如此,特征统计模块可以借助于不同于第一语料库的第二语料库,通过对问题的相关文档的搜索、基于特征统计提取候选答案、候选答案评分生成第二候选答案集。In this way, the feature statistics module can pass the problem by means of a second corpus different from the first corpus.Searching for related documents, extracting candidate answers based on feature statistics, and selecting candidate answer scores to generate a second set of candidate answers.
结合上述可能的实现方式,在一种可能的实现方式中,In combination with the above possible implementation manners, in a possible implementation manner,
所述第二语料库包含的语料的数量大于所述第一语料库包含的语料的数量。The second corpus contains a number of corpora greater than the number of corpora contained in the first corpus.
可选的,第一语料库可以包含下述至少一种语料:维基百科、知识图谱、专业文献、手工语料。第二语料库可以第一语料库以及下述至少一种语料:百度知道、论坛贴吧、门户网站、博客、微博。Optionally, the first corpus may include at least one of the following corpora: Wikipedia, knowledge map, professional literature, manual corpus. The second corpus can be the first corpus and at least one of the following corpora: Baidu, Forum Post, Portal, Blog, Weibo.
如此,可以为篇章结构分析模块配置正式的、高质量的语料库,保证了篇章结构分析模块确定出的候选答案的纯净度;同时,为了发挥特征统计的优势,为特征统计模块配置大规模语料库,扩大了语料库的搜索范围,使特征统计模块确定出不同于篇章结构分析确定的答案的候选答案,提高了问答系统确定出的答案的精度。In this way, a formal, high-quality corpus can be configured for the chapter structure analysis module to ensure the purity of the candidate answers determined by the chapter structure analysis module; meanwhile, in order to exploit the advantages of feature statistics, a large-scale corpus is configured for the feature statistics module. The search scope of the corpus is expanded, and the feature statistics module determines the candidate answers different from the answers determined by the chapter structure analysis, and improves the accuracy of the answers determined by the question and answer system.
结合上述可能的实现方式,在一种可能的实现方式中,特征统计模块,具体可以包括:In combination with the foregoing possible implementation manners, in a possible implementation manner, the feature statistics module may specifically include:
特征提取单元,用于基于特征统计算法,从检索单元检索得到的所有相关文档集中进行特征提取,获得备选答案集,备选答案集包含至少一个与问题对应的备选答案;a feature extraction unit, configured to perform feature extraction on all related documents retrieved from the retrieval unit based on the feature statistics algorithm to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
特征评分和答案排序单元,用于对特征提取单元确定出的备选答案集中的每个备选答案进行评分,将评分前O的备选答案作为第二候选答案集,O为大于或等于1的整数。And a feature ranking and answer sorting unit, configured to score each candidate answer in the candidate answer set determined by the feature extracting unit, and use the candidate answer of the pre-score O as the second candidate answer set, where O is greater than or equal to 1 The integer.
在该可能的实现方式中,特征统计模块可以借助于篇章结构分析模块检索出的相关文档集,基于特征统计从该相关文档集中提取候选答案,并对候选答案评分生成第二候选答案集。如此,不需要特征统计模块进行相关文档集的搜索,大大降低了特征统计模块的设计复杂度。In this possible implementation manner, the feature statistics module may extract the candidate document set from the related document set based on the feature statistics by using the related document set retrieved by the chapter structure analysis module, and generate a second candidate answer set for the candidate answer score. In this way, the feature statistics module is not required to search the related document set, which greatly reduces the design complexity of the feature statistics module.
结合上述可能的实现方式,在一种可能的实现方式中,特征统计模块,具体可以包括:In combination with the foregoing possible implementation manners, in a possible implementation manner, the feature statistics module may specifically include:
搜索单元,用于将用户交互模块接收到的问题输入证据库,搜索得到问题的相关文档集;a search unit, configured to input a question received by the user interaction module into the evidence base, and search for a related document set that obtains the problem;
特征提取单元,用于基于特征统计算法,从搜索单元搜索得到的相关文档集中进行特征提取,获得备选答案集,备选答案集包含至少一个与问题对应的备选答案;a feature extraction unit, configured to perform feature extraction from a related document set obtained by the search unit search based on the feature statistical algorithm, to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
特征评分和答案排序单元,用于对特征提取单元确定出的备选答案集中的每个备选答案进行评分,将评分前P的备选答案作为第二候选答案集,P为大于或等于1的整数。And a feature ranking and answer sorting unit, configured to score each candidate answer in the candidate answer set determined by the feature extracting unit, and use the candidate answer of the pre-score P as the second candidate answer set, P is greater than or equal to 1 The integer.
如此,特征统计模块可以借助于证据库,通过对问题的相关文档的搜索、基于特征统计提取候选答案、候选答案评分生成第二候选答案集,不需要单独为特征统计模块配置语料库,大大降低了本发明实施例提供的问答系统的整体复杂度。In this way, the feature statistics module can generate the second candidate answer set by searching the related documents of the question, extracting the candidate answer based on the feature statistics, and the candidate answer score by means of the evidence base, and does not need to separately configure the corpus for the feature statistics module, thereby greatly reducing the corpus. The overall complexity of the question and answer system provided by the embodiment of the present invention.
结合上述可能的实现方式,在一种可能的实现方式中,组合处理模块,具体可以用于:In combination with the foregoing possible implementation manners, in a possible implementation manner, the processing module may be specifically configured to:
提取第一候选答案集和第二候选答案集的交集,将提取的交集中评分最高的候选答案作为问题的正确答案;或者Extracting an intersection of the first candidate answer set and the second candidate answer set, and using the candidate answer with the highest score in the extracted intersection as the correct answer to the question; or
对第一候选答案集合第二候选答案集中的同一候选答案进行加权处理,将加权处理后评分最高的候选答案作为问题的正确答案。The same candidate answer in the second candidate answer set of the first candidate answer set is weighted, and the candidate answer with the highest score after the weighting process is used as the correct answer to the question.
如此,可以将基于篇章结构分析算法得到候选答案集和基于特征统计算法得到的候选答案集的交集中的评分最高的候选答案作为最终答案,或者将基于篇章结构分析算法得到候选答案集和基于特征统计算法得到的候选答案集的交集中的候选答案加权处理后评分最高的候选答案作为最终答案。In this way, the candidate answer with the highest score in the intersection of the candidate answer set and the candidate answer set obtained based on the feature statistical algorithm based on the chapter structure analysis algorithm can be used as the final answer, or the candidate answer set and the feature based on the chapter structure analysis algorithm can be obtained. The candidate answers in the intersection of the candidate answer sets obtained by the statistical algorithm are weighted and processed, and the candidate answers with the highest score are taken as the final answer.
第二方面,本发明实施例提供了一种问答方法,包括:In a second aspect, an embodiment of the present invention provides a question and answer method, including:
接收用户提出的问题,基于篇章结构分析算法得到与问题对应的第一候选答案集,基于特征统计算法得到与问题对应的第二候选答案集,将第一候选答案集、以及第二候选答案集进行组合处理,将组合处理后评分最高的候选答案作为问题的正确答案;将正确答案反馈给用户;Receiving a question raised by the user, obtaining a first candidate answer set corresponding to the question based on the chapter structure analysis algorithm, obtaining a second candidate answer set corresponding to the question based on the feature statistics algorithm, and setting the first candidate answer set and the second candidate answer set Perform a combination process, and use the candidate answer with the highest score after the combination process as the correct answer of the question; feed the correct answer to the user;
其中,篇章结构分析算法用于采用句法结构分析或者定义的语法规则或者结构化知识库得到与问题对应的候选答案,特征统计算法用于采用词频统计的方式得到与问题对应的候选答案。The text structure analysis algorithm is used to obtain a candidate answer corresponding to the question by syntactic structure analysis or a defined grammar rule or a structured knowledge base, and the feature statistics algorithm is used to obtain a candidate answer corresponding to the question by using word frequency statistics.
具体的,上述问答方法的具体实现过程可以参照第一方面或第一方面的可能的实现方式中各模块或单元执行的过程,在此不再重复赘述。因此,该方面提供的问答系统可以达到与第一方面相同的有益效果。Specifically, the specific implementation process of the foregoing question and answer method may refer to the process performed by each module or unit in the first aspect or the possible implementation manner of the first aspect, and details are not repeatedly described herein. Therefore, the question answering system provided by this aspect can achieve the same beneficial effects as the first aspect.
又一方面,本申请实施例提供了一种问答系统,该问答系统可以实现上述方法实施例中问答系统元所执行的功能,所述功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。硬件或软件包括一个或多个上述功能相应的模块。In another aspect, the embodiment of the present application provides a question answering system, which can implement the functions performed by the question answering system element in the foregoing method embodiment, and the functions can be implemented by hardware or by executing corresponding software through hardware. . The hardware or software includes one or more modules corresponding to the above functions.
在一种可能的设计中,该问答系统的结构中包括处理器和通信单元,该处理器被配置为支持该问答系统执行上述方法中相应的功能。该通信单元用于支持该问答系统与用户或者其他网元之间的通信。该问答系统还可以包括存储器,该存储器用于与处理器耦合,其保存该问答系统必要的程序指令和数据。In one possible design, the structure of the question answering system includes a processor and a communication unit configured to support the question answering system to perform the corresponding functions of the above methods. The communication unit is used to support communication between the question and answer system and a user or other network element. The question answering system can also include a memory for coupling with the processor that holds the program instructions and data necessary for the question answering system.
再一方面,本申请实施例提供了一种计算机存储介质,用于储存为上述问答系统所用的计算机软件指令,该计算机软件指令包含用于执行上述方面所设计的程序。In still another aspect, an embodiment of the present application provides a computer storage medium for storing computer software instructions for use in the above question answering system, the computer software instructions including a program designed to perform the above aspects.
再一方面,本申请实施例提供了一种计算机程序产品,该程序产品储存有上述问答系统所用的计算机软件指令,该计算机软件指令包含用于执行上述方面所设计的程序。In still another aspect, an embodiment of the present application provides a computer program product, which stores computer software instructions for use in the above question and answer system, the computer software instructions including a program designed to perform the above aspects.
再一方面,本申请实施例提供了一种装置,该装置以芯片的产品形态存在,该装置的结构中包括处理器和存储器,该存储器用于与处理器耦合,保存该装置必要的程序指令和数据,该处理器用于执行存储器中存储的程序指令,使得该装置执行上述方法中与问答系统相应的功能。In a further aspect, the embodiment of the present application provides a device, which is in the form of a product of a chip. The device includes a processor and a memory, and the memory is coupled to the processor to save necessary program instructions of the device. And data, the processor is operative to execute program instructions stored in the memory such that the apparatus performs the functions corresponding to the question answering system in the above method.
图1为现有技术提供的一种DeepQA的网络架构示意图;1 is a schematic diagram of a network architecture of a DeepQA provided by the prior art;
图2为本发明实施例提供的一种问答系统的简化示意图;2 is a simplified schematic diagram of a question answering system according to an embodiment of the present invention;
图3为本发明实施例提供的一种问答系统的组成示意图;3 is a schematic structural diagram of a question answering system according to an embodiment of the present invention;
图4为本发明实施例提供的一种问答系统的组成示意图;4 is a schematic structural diagram of a question answering system according to an embodiment of the present invention;
图5为本发明实施例提供的一种问答系统的组成示意图;FIG. 5 is a schematic structural diagram of a question answering system according to an embodiment of the present invention;
图6为本发明实施例提供的一种问答方法的流程图;FIG. 6 is a flowchart of a question and answer method according to an embodiment of the present invention;
图7为本发明实施例提供的一种问答系统的组成示意图。FIG. 7 is a schematic structural diagram of a question and answer system according to an embodiment of the present invention.
本发明实施例提供一种问答系统,其基本原理是:接收用户提出的问题后,基于篇章结构分析算法获取与该问题对应的一组候选答案,基于特征统计算法获取与该问题对应的另一组候选答案,并对两组候选答案组合处理,将处理后评分最高的候选答案作为最终正确答案反馈给用户,如此,利用两种算法的互补性确定出答案,提高问答系统的准确性。An embodiment of the present invention provides a question answering system. The basic principle is: after receiving a question raised by a user, acquiring a set of candidate answers corresponding to the question based on the chapter structure analysis algorithm, and acquiring another candidate corresponding to the problem based on the feature statistics algorithm The candidate answers are combined, and the candidate answers of the two groups are combined, and the candidate answers with the highest scores are processed as the final correct answers to the user. Thus, the complementarity of the two algorithms is used to determine the answer and improve the accuracy of the question and answer system.
下面结合附图对本发明实施例的实施方式进行详细描述。The embodiments of the present invention are described in detail below with reference to the accompanying drawings.
图2为本发明实施例提供的问答系统10的简化示意图。该问答系统10可以以应用软件(application,APP)的形式设置在用户终端上,用户可以通过点击用户终端上与该问答系统10对应APP与该问答系统10进行交互,该用户终端可以为:手机、平板电脑、超级移动个人计算机(ultra-mobile personal computer,UMPC)、笔记本电脑、上网本、无个人数字处理(personal digital assistant,PDA)等设备;该问答系统10还也可以作为一个独立的设备与用户直接进行交互,本发明对此不进行限定。FIG. 2 is a simplified schematic diagram of a
具体的,如图2所示,该问答系统10可以包括:用户交互模块101、篇章结构分析模块102、特征统计模块103、以及组合处理模块104。Specifically, as shown in FIG. 2, the
其中,用户交互模块101,可以用于接收用户提出的问题、以及将该问题的正确正确答案反馈给用户。The user interaction module 101 can be configured to receive a question raised by the user and feed back the correct correct answer to the user.
用户提出的问题可以为:用户用自然语言表述的问题,该问题的正确答案可以为:以“词语”、“词组”或者“列表”等简洁的自然语言描述的答案。The question raised by the user may be: the question expressed by the user in natural language, and the correct answer to the question may be: an answer described in a concise natural language such as "word", "phrase" or "list".
用户交互模块101:可以包含一图像界面,该图像界面上设计有输入框,该输入框用于用户通过键盘、麦克风等输入单元输入问题,如:用户交互模块101可以用于接收用户通过输入框提出的问题,以及将该问题的正确答案通过该用户交互模块101的图像界面、以文字的形式反馈给用户;或者,该问答系统10的用户交互模块101可以包含音频单元,该音频单元可以包含麦克风和播放器,麦克风可以用于接收用户发出的声音,播放器可以用于将问答系统10确定出的答案以声音的形式反馈给用户,如:用户交互模块101可以用于接收用户通过音频单元提出的问题、以及将该问题的正确答案以声音的形式播放给用户。The user interaction module 101 can include an image interface, and the image interface is designed with an input box for the user to input a question through an input unit such as a keyboard or a microphone. For example, the user interaction module 101 can be used to receive the user through the input box. The proposed problem, and the correct answer to the question, is fed back to the user in the form of text through the image interface of the user interaction module 101; or the user interaction module 101 of the
篇章结构分析模块102,可以用于从用户交互模块101获取用户提出的问题,基于篇章结构分析算法得到与该问题对应的第一候选答案集。The chapter
其中,篇章结构分析算法用于采用句法结构分析或者定义的语法规则或者结构化知识库得到与问题对应的候选答案;句法结构分析、定义的语法规则、结构化知识库这些方式是现有篇章结构分析算法中的常用手段,在此不再详述。Among them, the text structure analysis algorithm is used to obtain candidate answers corresponding to the problem by syntactic structure analysis or defined grammar rules or structured knowledge base; syntactic structure analysis, defined grammar rules, structured knowledge base are the existing chapter structures Common means in the analysis algorithm are not detailed here.
第一候选答案集可以包含至少一个候选答案,每个候选答案对应一个评分,该评分用于表征候选答案称为正确答案的可信度,评分越高的候选答案,越可能是正确答案,该评分可以以百分数的形式来表示。The first candidate answer set may include at least one candidate answer, each candidate answer corresponding to a score, the score is used to represent the credibility of the candidate answer as the correct answer, and the higher the score, the more likely the correct answer is, the more likely it is to be the correct answer, The score can be expressed in percentage.
可选的,在本发明实施例基于篇章结构分析算法中,候选答案的评分,可能是综合多种评分算法得到的结果;其中,一些典型的评分算法可以包括但不限于下述几种:1、候选答案的类型是否与问题的答案类型相同,若相同,则候选答案的评分相对较高,若不同,则候选答案的评分相对较低;例如若用户提问“哪个城市”的问题,其对应的答案类型为城市类型,则“北京”、“天津”等属于城市类型的候选答案比“天安门”等不属于城市类型的候选答案评分要高;2、候选答案是否出现在文章或者百科全书的重要位置(如标题、文章或者百科全书的第一个段落等),若候选答案出现在文章或者百科全书的重要位置,则该候选答案的评分相对较高,否则,该候选答案的评分相对较低;3、候选答案代入问题后的语句输入到证据库中进行检索,若返回的文档数量较多,则该候选答案的评分较高,否则,该候选答案的评分较低。Optionally, in the chapter structure analysis algorithm according to the embodiment of the present invention, the score of the candidate answer may beThe results obtained by combining multiple scoring algorithms; some typical scoring algorithms may include but are not limited to the following: 1. The type of the candidate answer is the same as the answer type of the question. If they are the same, the score of the candidate answer is relatively higher. High, if different, the score of the candidate answer is relatively low; for example, if the user asks "what city" question, the corresponding answer type is city type, then "Beijing", "Tianjin", etc. are the candidate answers of the city type. Candidate answers that do not belong to the city type such as "Tiananmen" should be scored high; 2. Whether the candidate answer appears in an important position of the article or encyclopedia (such as the title, article or the first paragraph of the encyclopedia, etc.), if the candidate answer appears in If the article or the important position of the encyclopedia is relatively high, the score of the candidate answer is relatively high. Otherwise, the score of the candidate answer is relatively low. 3. The candidate answer is substituted into the evidence database for retrieval, if the returned document If the number is large, the candidate answer has a higher score, otherwise, the candidate answer has a lower score.
特征统计模块103,可以用于从用户交互模块101获取用户提出的问题,基于特征统计算法得到与该问题对应的第二候选答案集;The
其中,特征统计算法用于采用词频统计的方式得到与问题对应的候选答案,第二候选答案集可以包含至少一个候选答案,每个候选答案对应一个评分,同样,该评分也用于表征候选答案成为正确答案的可信度,评分越高的候选答案,成为正确答案的可能性越高。一般在基于特征统计算法中,可以用词语在文章中的权重表示这个词语作为候选答案的评分。业界的计算词语权重的方法可以包括词频、相对词频、词频--反转文件频率等算法。The feature statistical algorithm is used to obtain a candidate answer corresponding to the question by using word frequency statistics, and the second candidate answer set may include at least one candidate answer, and each candidate answer corresponds to one score. Similarly, the score is also used to represent the candidate answer. Becoming the credibility of the correct answer, the higher the candidate answer, the higher the probability of becoming the correct answer. Generally, in a feature-based statistical algorithm, the weight of a word in an article can be used to indicate the score of the word as a candidate answer. The industry's methods for calculating word weights may include word frequency, relative word frequency, word frequency--inverted file frequency and the like.
组合处理模块104:用于对篇章结构分析模块101的第一候选答案集和特征统计模块103获取到的第二候选答案集进行组合处理,将组合处理后评分最高的候选答案作为所述问题对应的正确答案。The
可选的,组合处理模块104,提取第一候选答案集和第二候选答案集的交集,将提取的交集中评分最高的候选答案作为问题的正确答案;或者Optionally, the
对第一候选答案集合第二候选答案集中的同一候选答案进行加权处理,将加权处理后评分最高的候选答案作为问题的正确答案。The same candidate answer in the second candidate answer set of the first candidate answer set is weighted, and the candidate answer with the highest score after the weighting process is used as the correct answer to the question.
其中,加权处理是指:对于同一词语,将该词语在两个候选答案集中的评分分别乘于一个权重(即系数),然后相加得到总分,将该总分作为该词语的评分。如果一个词语没出现在某个候选答案集中,则可认为该词语在该候选答案集中的评分为0。The weighting process refers to: for the same word, the scores of the words in the two candidate answer sets are respectively multiplied by one weight (ie, coefficients), and then added to obtain a total score, which is used as the score of the word. If a word does not appear in a candidate answer set, the word can be considered to have a score of 0 in the candidate answer set.
例如,假设对于“中国的首都是哪个城市?”这个问题,得到两个候选答案集:第一个候选答案集及评分为(北京0.86,天津0.80),第二个候选答案集及评分为(天安门0.81,北京0.78),两个候选答案集的交集仅为北京,则将“北京”作为“中国的首都是哪个城市”的正确答案;或者,设置第一个候选答案集的权重为2,第二个候选答案集的权重为1,对这两组候选答案集加权处理,则北京的加权得分为:0.86*2+0.78*1=2.5;天津的加权得分为:0.80*2+0*1=1.6;天安门的得分为:0*2+0.81*1=0.81,北京的得分最高,则将“北京”作为“中国的首都是哪个城市”的正确答案。For example, suppose that for the question "Which city is China's capital?", two candidate answer sets are obtained: the first candidate answer set and the score are (Beijing 0.86, Tianjin 0.80), the second candidate answer set and the score are ( Tiananmen Square 0.81, Beijing 0.78), the intersection of the two candidate answer sets is only Beijing, then “Beijing” is the correct answer to “Which city is China's capital”; or, the weight of the first candidate answer set is 2, The weight of the second candidate answer set is 1. For the weighted processing of the two sets of candidate answers, the weighted score of Beijing is: 0.86*2+0.78*1=2.5; the weighted score of Tianjin is: 0.80*2+0* 1 = 1.6; Tiananmen's score is: 0 * 2 + 0.81 * 1 = 0.81, Beijing's highest score, then "Beijing" as the "China's capital is the city" the correct answer.
如此,结合篇章结构分析算法和特征统计算法得到与问题的正确答案,由于二者选择候选答案时采用的方式不同,选择出的候选答案类型大大不同,通常情况下,基于篇章结构分析算法返回的候选答案集中所包含的非正确答案,一般不会出现在基于特征统计算法选择出的候选答案集中,因此,图2所示的问答系统可以借助这两种算法互补性,很大程度地去掉评分靠前的非正确答案,提高问答系统的准确率。In this way, combined with the text structure analysis algorithm and the feature statistical algorithm to get the correct answer to the question, because the two choose different candidate answers in different ways, the selected candidate answer types are greatly different, usually, based on the text structure analysis algorithm returns The incorrect answer contained in the candidate answer set does not generally appear inThe candidate answer set is selected based on the feature statistical algorithm. Therefore, the question answering system shown in FIG. 2 can use the complementarity of the two algorithms to largely remove the incorrect answer before the score and improve the accuracy of the question and answer system.
下面结合图3、图4以及图5分别对图2所示问答系统10中的各功能模块进一步介绍。The functional modules in the
在本发明实施例的一种可行性方案中,如图3所示,篇章结构分析模块102可以包括:问题分析单元1021a、检索单元1022a、备选答案生成单元1023a、证据检索评分单元1024a、答案合成和排序单元1025a;特征统计模块103可以包括:搜索单元1031a、特征提取单元1032a、以及特征评分和答案排序单元1033a。In a feasible solution of the embodiment of the present invention, as shown in FIG. 3, the chapter
问题分析单元1021a,用于对用户提出的问题进行分词、句法解析以及命名实体识别,获得至少一个子问题、以及与子问题对应的至少一个关键词。The
其中,分词、句法解析是中文自然语言处理的业界通用流程,在此不再详述。例如:把“华为的总裁是谁?”这一问题输入到开源的斯坦福NLP包中,输出结果如下:Among them, word segmentation and syntactic parsing are common processes in Chinese natural language processing, and will not be described in detail here. For example: Enter the question "Who is the president of Huawei?" into the open source Stanford NLP package. The output is as follows:
分词结果:Word segmentation results:
华为的总裁是谁?Who is the president of Huawei?
句法分析结果:Syntactic analysis results:
(ROOT(ROOT
(IP(IP
(NP(NP
(DNP(DNP
(NP(NR华为))(NP (NR Huawei))
(DEG的))(DEG))
(NP(NN总裁)))(NP (NN President)))
(VP(VC是)(VP (VC is)
(NP(PN谁)))(NP (PN)))
(PU?)))(PU?)))
命名实体识别结果:Named entity recognition results:
<ORG>华为</ORG>的总裁是谁?Who is the president of <ORG>Huawei</ORG>?
在英语中,可以通过who、when、where等疑问词来确定答案类型分别为人、时间、地点等。汉语的情形会复杂一些,因为汉语的疑问词非常多样,比如问人可以是“谁”、“哪位”等;甚至可以不用疑问词,比如直接说“不知这位是?”用于问人。但汉语中确定答案类型的方法与英语类似,都是通过词语、句式规则进行匹配,按规则确定答案类型。In English, you can use the question words such as who, when, and so on to determine the type of answer as person, time, place, etc. The situation in Chinese will be more complicated, because Chinese questions are very diverse. For example, ask people who can be “who”, “who”, etc.; even without question words, such as saying “I don’t know if this is?” . However, the method of determining the type of answer in Chinese is similar to that of English. It is matched by words and sentence rules, and the answer type is determined according to the rules.
确定疑问词(包括省略的疑问词)后,可以进一步确定关键词。关键词一般为修饰疑问词的词,可以对句法分析的结果进行分析而得到。例如,上面的例子中,关键词及其修饰的疑问词为[华为-总裁-(谁)]。After identifying the question words (including the omitted question words), the keywords can be further determined. The keywords are generally words that modify the interrogative words and can be obtained by analyzing the results of the syntactic analysis. For example, in the above example, the keyword and its modified question word are [Huawei - President - (Who)].
检索单元1022a,用于对每个子问题,将该子问题的关键词输入到第一语料库中进行检索,获取与该关键词的相关文档集。The search unit 1022a is configured to input a keyword of the sub-question into the first corpus for each sub-question, and obtain a related document set of the keyword.
其中,相关文档集可以包含至少一个与关键词相关的文档。可选的,根据关键词提取相关文档集可以由通用的搜索引擎实现,这里不再展开描述;如:检索单元1022a可以用于将关键词输入到第一语料库的输入框内,点击搜索按钮进行检索。The related document set may include at least one document related to the keyword. Optional, according to the keyThe word extraction related document set can be implemented by a general search engine, and the description is not extended here; for example, the search unit 1022a can be used to input keywords into the input box of the first corpus, and click the search button to perform the search.
备选答案生成单元1023a,用于对每个子问题,从检索单元1022a获取到的与该子问题对应的关键词的相关文档集中提取至少一个与所述子问题对应的备选答案,将至少一个备选答案经生成假说、软滤波处理得到与该子问题对应的备选答案集。The alternative answer generating unit 1023a is configured to extract, for each sub-question, the at least one candidate answer corresponding to the sub-question from the related document set of the keyword corresponding to the sub-question acquired from the retrieving unit 1022a, at least one The alternative answer is generated by a hypothesis and soft filtering to obtain an alternative answer set corresponding to the sub-question.
其中,备选答案集可以包含:至少一个备选答案。The alternative answer set may include: at least one alternative answer.
可选的,备选答案生成单元1023a,可以用于采用句法结构分析或者定义的语法规则或者结构化知识库(即知识图谱)从相关文档集中提取备选答案集。Optionally, the alternative answer generating unit 1023a may be configured to extract an alternative answer set from the related document set by using a syntax structure analysis or a defined grammar rule or a structured knowledge base (ie, a knowledge map).
生成假说、软滤波为现有问答系统通用流程,在此不再详述。例如:生成假说可以为把备选答案代入到原问题中,生成一个陈述句的过程。例如,假设问题是“中国的首都是哪个城市?”,有两个备选答案,分别为“北京”、“天安门”,则生成假说分别为“中国的首都是北京”、“中国的首都是天安门”。软滤波,是通过一些轻量级评分算法、类型匹配算法等,过滤掉不符合要求的备选答案。例如,前面的例子中,问题“中国的首都是哪个城市?”的答案的类型,应该为“城市”;那么两个备选答案中,“北京”是城市,因此为一个可能正确的答案;“天安门”不是城市,因此很可能不是正确的答案。这样,软滤波就可以把“天安门”这个备选答案过滤掉。The generation hypothesis and soft filtering are common processes of the existing question answering system and will not be described in detail here. For example, the generation hypothesis can be a process of substituting an alternative answer into the original question to generate a statement. For example, suppose the question is “Which city is China's capital?” There are two alternative answers, namely “Beijing” and “Tiananmen”, the hypothesis is “China's capital is Beijing” and “China's capital is Tiananmen Square". Soft filtering is to filter out alternative answers that do not meet the requirements through some lightweight scoring algorithms, type matching algorithms, and so on. For example, in the previous example, the question “Which city is the capital of China?” should be “city”; then among the two alternative answers, “Beijing” is a city, so it is a possible correct answer; “Tiananmen” is not a city, so it is probably not the right answer. In this way, soft filtering can filter out the alternative answer of "Tiananmen".
证据检索评分单元1024a,用于对备选答案生成单元1023a获取到的每个子问题,将该子问题对应的候选答案集中的每个候选答案代入子问题生成一个语句,将该语句输入证据库中进行搜索,根据检索出的相关文档数量对该备选答案进行评分。The evidence
需要说明的是,证据检索评分单元1024a不仅可以用于根据返回的相关文档数量进行评分,也可以用于结合采用其他评分算法(如前面提到的评分算法)对备选答案进行评分,本发明实施例对此不进行限定。It should be noted that the evidence
答案合成和排序单元1025a,用于合成每个所述子问题对应的备选答案集,将合成后的备选答案集中评分前M的备选答案作为所述第一候选答案集,所述M为大于或等于1的整数。An answer synthesis and
其中,M为大于等于1的整数,可以根据需要对M进行设置,本发明实施例对此不进行限定;如:评分前M的备选答案可以为评分大于或等于预设分值的备选答案,预设分值可以根据需要进行设置,本发明实施例对此不进行限定。Wherein, M is an integer greater than or equal to 1, and M can be set as needed, which is not limited by the embodiment of the present invention; for example, the candidate answer of M before the score may be an alternative with a score greater than or equal to the preset score. The answer, the preset score can be set as needed, which is not limited by the embodiment of the present invention.
搜索单元1031a,用于将用户交互模块接收到的问题输入第二语料库,搜索得到问题的相关文档集。The searching unit 1031a is configured to input the question received by the user interaction module into the second corpus, and search for a related document set that obtains the problem.
特征提取单元1032a,用于基于特征统计算法,从搜索单元1031a搜索得到的相关文档集中进行特征提取,获得备选答案集,备选答案集包含至少一个与问题对应的备选答案。The feature extraction unit 1032a is configured to perform feature extraction from the related document set searched by the search unit 1031a based on the feature statistics algorithm to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question.
其中,特征提取可以包括:基于词频的特征提取方法、基于信息增益的方法以及其他的特征提取方法,基于词频的特征提取方法可以指:特征在文档集中出现的词频、相对词频、词频--反转文件频率。这些算法及上面提到的基于信息增益的方法,都是业界通用的算法,这里不再展开描述。The feature extraction may include: a feature extraction method based on word frequency, an information gain based method and other feature extraction methods, and a feature extraction method based on word frequency may refer to: word frequency, relative word frequency, word frequency appearing in the document set--reverse Transfer file frequency. These algorithms and the above-mentioned information gain-based methods are all common algorithms in the industry and will not be described here.
特征评分和答案排序单元1033a,用于对特征提取单元1032a确定出的备选答案集中的每个备选答案进行评分,将评分前N的备选答案作为所述第二候选答案集,所述N为大于或等于1的整数。Feature score and answer sorting unit 1033a for determining alternative answers to feature extracting unit 1032aEach candidate answer in the set is scored, and an alternative answer of N before the score is taken as the second set of candidate answers, and N is an integer greater than or equal to 1.
一般特征提取单元1032a在特征提取时,已经包含了计算每个备选答案(即特征)的评分(即权重)的过程,因此,计算每个备选答案的评分的算法可以是上述的基于词频、相对词频、词频--反转文件频等算法。也可以把特征提取和计算每个备选答案的评分这两个过程分开,分别用不同的算法进行计算,本发明实施例对此不进行限定。The general feature extraction unit 1032a has included a process of calculating a score (ie, a weight) of each candidate answer (ie, a feature) at the time of feature extraction, and therefore, an algorithm for calculating a score of each candidate answer may be based on the word frequency described above. , relative word frequency, word frequency - reverse file frequency and other algorithms. The two processes of feature extraction and the calculation of the score of each candidate answer are also separated, and are calculated by different algorithms, which is not limited in the embodiment of the present invention.
其中,在本发明实施例中,篇章结构分析模块102、以及特征统计模块103用到的第一语料库和第二语料库是不同的,第一语料库为纯净度比较高的语料库,第二语料库为第一语料库扩展后的语料库,相对于第一语料库而言,第二语料库为一个较大的文档库,包含广泛的语料,即第二语料库包含的语料的数量大于第一语料库包含的语料的数量。具体的,第一语料库可以包含:维基百科、知识图谱、专业文献、手工语料等专业性较强、较规范的小规模语料,第二语料库可以包含:第一语料库、百度知道、论坛贴吧、门户网站以及其他网页等目前可搜索的大规模语料。In the embodiment of the present invention, the first corpus and the second corpus used by the chapter
证据库一般为一个较大的文档库,可以包含广泛的语料,如:证据库可以包含网页、百科全书、百度知道、论坛贴吧、门户网站以及其他网页等目前可搜索的大规模语料,其语料与一般通用搜索引擎类似,并没有特殊的要求,从证据库包含的语料来看,证据库与第二语料库比较类似,在业界和学术界,该证据库因常用于篇章结构分析模块中的证据检索而得名。可选的,在一种可实现方式中,可以将证据库和第二语料库设置为同一语料库,在另一种可实现方式中,还可以将根据二者的具体用途,分别设置证据库和第二语料库。The evidence base is generally a large document library, which can contain a wide range of corpora. For example, the evidence base can include web pages, encyclopedias, Baidu knows, forum posts, portals, and other web pages. Similar to the general general search engine, there is no special requirement. From the corpus contained in the evidence base, the evidence base is similar to the second corpus. In the industry and academia, the evidence base is often used in the chapter structure analysis module. Named after the search. Optionally, in an implementable manner, the evidence base and the second corpus may be set to the same corpus, and in another achievable manner, the evidence base and the first may be respectively set according to the specific uses of the two. Second language library.
可选的,在启动该问答系统10的问答功能时,可以通过该问答系统10的用户交互界面向用户发送设置语料库的提示,此时,用户可以根据该提示,在用户交互界面的输入框内输入语料,并点击用户交互界面上的存储按钮,存储在问答系统10中;或者,将该第一语料库和第二语料库设置在一数据库中,当需要时该问答系统访问该语料库即可。Optionally, when the question and answer function of the
如此,篇章结构分析模块102采用规范的语料库得到候选答案,特征统计模块103采用大范围的语料库得到候选答案,在保证答案的纯净度的同时,扩大了候选答案的搜索范围,提高了问答系统的精度。In this way, the chapter
在本发明实施例的又一可行性方案中,为了降低问答系统10的设计复杂度,特征统计模块103可以不需要设置搜索单元,而是采用篇章结构分析模块102检索出的相关文档集来确定候选答案,即仅设置第一语料库为问答系统10所用。In a further feasible solution of the embodiment of the present invention, in order to reduce the design complexity of the
具体的,如图4所示,问答系统10中的篇章结构分析模块102可以包括:问题分析单元1021b、检索单元1022b、备选答案生成单元1023b、证据检索评分单元1024b、答案合成和排序单元1025b;特征统计模块103可以包括:特征提取单元1031b、以及特征评分和答案排序单元1032b。Specifically, as shown in FIG. 4, the chapter
其中,问题分析单元1021b与图3所示的问题分析单元1021a的功能相同,检索单元1022b与图3所示的检索单元1022a的功能相同,备选答案生成单元1023b与图3所示的备选答案生成单元1023a的功能相同,证据检索评分单元1024b与图3所示的证据检索评分单元1024a的功能相同,答案合成和排序单元1025b和图3所示的答案合成和排序单元1025a的功能相同,在此不再一一重复赘述。The
特征提取单元1031b,用于基于特征统计算法,从检索单元1022b获取到的文档集中进行特征提取,获得备选答案集。The
特征提取单元1031b与图3所示的特征提取单元1032a的功能相同,在此不再重复赘述。The
特征评分和答案排序单元1032b与图3所示的特征评分和答案排序单元1033a的功能相同,在此不再重复赘述。The feature score and answer sorting
如此,该问答系统中的特征统计模块可以不用设置搜索单元,而是从篇章结构分析模块检索出的相关文档集中进行特征提取,确定候选答案集,降低了特征统计模块的设计复杂度,进而降低了整个问答系统的设计复杂度。In this way, the feature statistics module in the question and answer system can perform feature extraction from the related documents retrieved from the chapter structure analysis module without setting the search unit, determine the candidate answer set, and reduce the design complexity of the feature statistics module, thereby reducing the complexity. The design complexity of the entire question and answer system.
在本发明实施例的再一可行性方案中,如图5所示,篇章结构分析模块102可以包括:问题分析单元1021c、检索单元1022c、备选答案生成单元1023c、证据检索评分单元1024c、答案合成和排序单元1025c;特征统计模块103可以包括:搜索单元1031c、特征提取单元1032c、以及特征评分和答案排序单元1033c。In still another feasible solution of the embodiment of the present invention, as shown in FIG. 5, the chapter
其中,问题分析单元1021c与图3所示的问题分析单元1021a的功能相同,检索单元1022c与图3所示的检索单元1022a的功能相同,备选答案生成单元1023c与图3所示的备选答案生成单元1023a的功能相同,证据检索评分单元1024c与图3所示的证据检索评分单元1024a的功能相同,答案合成和排序单元1025c和图3所示的答案合成和排序单元1025a的功能相同,在此不再一一重复赘述。The
搜索单元1031c,用于将问题输入到证据库,搜索得到问题的相关文档集;a searching
特征提取单元1032c与图3所示的特征提取单元1032a的功能相同,在此不再重复赘述。特征评分和答案排序单元1032c与图3所示的特征评分和答案排序单元1033a的功能相同,在此不再重复赘述。The function extracting unit 1032c has the same function as the feature extracting unit 1032a shown in FIG. 3, and details are not repeatedly described herein. The feature score and answer sorting unit 1032c has the same functions as the feature score and answer sorting unit 1033a shown in FIG. 3, and details are not repeated herein.
其中,搜索单元1031c用到的证据库与上述证据检索评分单元用到的证据库可以为同一语料库。The evidence base used by the
可选的,针对友商的现有问答系统设计方案(仅包含图2~图5所示的用户交互模块101、篇章结构结构分析模块102的设计方案),为了对现有问答系统设计方案改动较小。图5所示特征统计模块102中的各单元可以与篇章结构分析模块10中证据检索评分单元1024c集成在一起,以提高篇章结构分析模块102中“证据检索”这个步骤的准确率。Optionally, the existing question and answer system design scheme for the friend (including only the user interaction module 101 and the chapter structure
下面结合图2~图5所示的问答系统,对本发明实施例提供的问答方法进行介绍。需要说明的是,虽然在下述方法流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。The question and answer method provided by the embodiment of the present invention will be described below with reference to the question answering system shown in FIG. 2 to FIG. It should be noted that although the logical order is shown in the method flow diagrams described below, in some cases, the steps shown or described may be performed in a different order than the ones described herein.
图6为本发明实施例提供的问答方法,如图6所示,该方法可以包括:FIG. 6 is a method for question and answer according to an embodiment of the present invention. As shown in FIG. 6, the method may include:
步骤601:接收用户提出的问题。Step 601: Receive a question raised by the user.
步骤602:基于篇章结构分析算法得到与问题对应的第一候选答案集。Step 602: Obtain a first candidate answer set corresponding to the question based on the chapter structure analysis algorithm.
其中,篇章结构分析算法用于采用句法结构分析或者定义的语法规则或者结构化知识库得到与问题对应的候选答案,第一候选答案集包含至少一个与问题对应的第一候选答案、以及第一候选答案的评分。The text structure analysis algorithm is used to obtain a candidate answer corresponding to the question by using a syntax structure analysis or a defined grammar rule or a structured knowledge base, and the first candidate answer set includes at least one corresponding to the problem.The first candidate answer, and the score of the first candidate answer.
可选的,可以通过下述方式确定第一候选答案集:Optionally, the first candidate answer set can be determined by:
对问题进行分词、句法解析以及命名实体识别,获得至少一个子问题、以及与子问题对应的至少一个关键词;Performing word segmentation, syntactic parsing, and named entity recognition on the problem, obtaining at least one sub-question, and at least one keyword corresponding to the sub-question;
对于至少一个子问题中的任一子问题,将子问题对应的至少一个关键词分别输入第一语料库,检索得到每个关键字的相关文档集;For any one of the at least one sub-question, the at least one keyword corresponding to the sub-question is respectively input into the first corpus, and the related document set of each keyword is retrieved;
对于至少一个子问题中的任一子问题,从子问题对应的所有关键字的相关文档集中提取至少一个与子问题对应的备选答案,将至少一个备选答案经生成假说、软滤波处理得到与子问题对应的备选答案集;备选答案集包含至少一个备选答案;For any one of the at least one sub-problems, at least one candidate answer corresponding to the sub-question is extracted from the related document set of all the keywords corresponding to the sub-question, and at least one candidate answer is obtained by generating a hypothesis and soft filtering. An alternative answer set corresponding to the sub-question; the alternative answer set includes at least one alternative answer;
对于至少一个子问题中的任一子问题,将子问题对应的备选答案集中至少一个备选答案代入子问题生成至少一个语句,将每个语句输入证据库进行检索,根据检索出的相关文档数量对语句对应的备选答案进行评分;For any one of the at least one sub-question, the at least one alternative answer corresponding to the sub-question is substituted into the sub-question to generate at least one statement, and each sentence is input into the evidence base for retrieval, according to the retrieved related document The number ranks the alternative answers corresponding to the statement;
合成每个子问题对应的备选答案集,将合成后的备选答案集中评分前M的备选答案作为第一候选答案集,M为大于或等于1的整数。The candidate answer set corresponding to each sub-question is synthesized, and the candidate answer of the pre-score M in the synthesized candidate answer set is used as the first candidate answer set, and M is an integer greater than or equal to 1.
步骤603:基于特征统计算法得到与问题对应的第二候选答案集。Step 603: Obtain a second candidate answer set corresponding to the question based on the feature statistics algorithm.
其中,特征统计算法用于采用词频统计的方式得到与问题对应的候选答案,第二候选答案集包含至少一个与问题对应的第二候选答案、以及第二候选答案的评分。The feature statistics algorithm is used to obtain a candidate answer corresponding to the question by using a word frequency statistic, and the second candidate answer set includes at least one second candidate answer corresponding to the question, and a score of the second candidate answer.
可选的,可以通过下述方式1或者方式2或者方式3得到第二候选答案集:Optionally, the second candidate answer set can be obtained by the following manner 1 or mode 2 or mode 3:
方式1:将问题输入第二语料库,搜索得到问题的相关文档集;Method 1: Enter the question into the second corpus and search for the relevant document set for the question;
基于特征统计算法,从问题的相关文档集中进行特征提取,获得备选答案集,备选答案集包含至少一个与问题对应的备选答案;Based on the feature statistics algorithm, feature extraction is performed from the relevant document set of the question, and an alternative answer set is obtained, and the candidate answer set includes at least one candidate answer corresponding to the question;
对特征提取后获得的备选答案集中的每个备选答案进行评分,将评分前N的备选答案作为第二候选答案集,N为大于或等于1的整数;Each candidate answer in the candidate answer set obtained after the feature extraction is scored, and the candidate answer of the N before the score is taken as the second candidate answer set, and N is an integer greater than or equal to 1;
其中,第一语料库和第二语料库不同。Among them, the first corpus is different from the second corpus.
方式2:基于特征统计算法,从至少一个子问题对应的所有关键词的相关文档集中进行特征提取,获得备选答案集,备选答案集包含至少一个与问题对应的备选答案;Method 2: Perform feature extraction from a related document set of all keywords corresponding to at least one sub-question based on the feature statistics algorithm to obtain an alternative answer set, where the candidate answer set includes at least one candidate answer corresponding to the question;
对特征提取后获得的备选答案集中的每个备选答案进行评分,将评分前O的备选答案作为第二候选答案集,O为大于或等于1的整数。Each candidate answer in the candidate answer set obtained after the feature extraction is scored, and the candidate answer of the score before O is taken as the second candidate answer set, and O is an integer greater than or equal to 1.
其中,至少一个子问题对应的所有关键词的相关文档集可以通过步骤602获取得到。The related document set of all the keywords corresponding to the at least one sub-question can be obtained through
方式3:将问题输入到证据库,搜索得到问题的相关文档集;Method 3: Enter the question into the evidence base and search for the relevant document set for the problem;
基于特征统计算法,从问题的相关文档集中进行特征提取,获得备选答案集,备选答案集包含至少一个与问题对应的备选答案;Based on the feature statistics algorithm, feature extraction is performed from the relevant document set of the question, and an alternative answer set is obtained, and the candidate answer set includes at least one candidate answer corresponding to the question;
对特征提取后获得的备选答案集中的每个备选答案进行评分,将评分前P的备选答案作为第二候选答案集,P为大于或等于1的整数。Each candidate answer in the candidate answer set obtained after the feature extraction is scored, and the candidate answer of the pre-score P is taken as the second candidate answer set, and P is an integer greater than or equal to 1.
其中,该步骤用到的证据库可以与步骤602中用到的证据库相同。The evidence base used in this step may be the same as the evidence base used in
步骤604:将第一候选答案集和第二候选答案集进行组合处理,将组合处理后评分最高的候选答案作为问题的正确答案。Step 604: Combine the first candidate answer set and the second candidate answer set, and select the candidate answer with the highest score after the combination process as the correct answer of the question.
可选的的,可以提取第一候选答案集和第二候选答案集的交集,将提取的交集中评分最高的候选答案作为问题的正确答案。Optionally, an intersection of the first candidate answer set and the second candidate answer set may be extracted, and the candidate answer with the highest score in the extracted intersection set is used as the correct answer to the question.
还可以对第一候选答案集合第二候选答案集中的同一候选答案进行加权处理,将加权处理后评分最高的候选答案作为问题的正确答案。It is also possible to perform weighting processing on the same candidate answer in the second candidate answer set of the first candidate answer set, and use the candidate answer with the highest score after the weighting process as the correct answer of the question.
步骤605:将正确答案反馈给用户。Step 605: Feed the correct answer to the user.
如此,结合篇章结构分析算法和特征统计算法得到与问题的正确答案,由于二者选择候选答案时采用的方式不同,选择出的候选答案类型大大不同,通常情况下,基于篇章结构分析算法返回的候选答案集中所包含的非正确答案,一般不会出现在基于特征统计算法选择出的候选答案集中,因此,该问答方法可以借助这两种算法互补性,很大程度地去掉评分靠前的非正确答案,提高问答系统的准确率。In this way, combined with the text structure analysis algorithm and the feature statistical algorithm to get the correct answer to the question, because the two choose different candidate answers in different ways, the selected candidate answer types are greatly different, usually, based on the text structure analysis algorithm returns The incorrect answers included in the candidate answer set generally do not appear in the candidate answer set selected based on the feature statistics algorithm. Therefore, the question and answer method can use the complementarity of the two algorithms to largely remove the non-correct score. The correct answer is to improve the accuracy of the question and answer system.
上述主要从问答系统的角度对本申请实施例提供的方案进行了介绍。可以理解的是,问答系统为了实现上述功能,其包含了执行各个功能相应的硬件结构和/或软件模块。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的算法步骤,本申请能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。The solution provided by the embodiment of the present application is mainly introduced from the perspective of the question answering system. It can be understood that the Q&A system includes corresponding hardware structures and/or software modules for performing various functions in order to implement the above functions. Those skilled in the art will readily appreciate that the present application can be implemented in a combination of hardware or hardware and computer software in combination with the algorithmic steps of the various examples described in the embodiments disclosed herein. Whether a function is implemented in hardware or computer software to drive hardware depends on the specific application and design constraints of the solution. A person skilled in the art can use different methods to implement the described functions for each particular application, but such implementation should not be considered to be beyond the scope of the present application.
本申请实施例可以根据上述方法示例对问答系统进行功能模块的划分,例如,可以对应各个功能划分各个功能模块(如图2~图5所示的问答系统),也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。需要说明的是,本申请实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。The embodiment of the present application may divide the function module into the question answering system according to the foregoing method example. For example, each function module may be divided according to each function (such as the question answering system shown in FIG. 2 to FIG. 5), or two or two may be used. The above functions are integrated in one processing module. The above integrated modules can be implemented in the form of hardware or in the form of software functional modules. It should be noted that the division of the module in the embodiment of the present application is schematic, and is only a logical function division, and the actual implementation may have another division manner.
在采用集成的单元的情况下,图7示出了上述实施例中所涉及的问答系统的另一种可能的组成示意图。如图7所示,该问答系统可以包括至少一个处理器71,存储器72、通信单元73、通信总线74。下面结合图7对问答系统的各个构成部件进行具体的介绍:In the case of an integrated unit, FIG. 7 shows another possible composition diagram of the question answering system involved in the above embodiment. As shown in FIG. 7, the question answering system can include at least one
处理器71是问答系统的控制中心,可以是一个处理器,也可以是多个处理元件的统称。例如,处理器71是一个中央处理器(central processing unit,CPU),也可以是特定集成电路(application specific integrated circuit,ASIC),或者是被配置成实施本申请实施例的一个或多个集成电路,例如:一个或多个微处理器(digital signal processor,DSP),或,一个或者多个现场可编程门阵列(field programmable gate array,FPGA)。其中,处理器71可以通过运行或执行存储在存储器72内的软件程序,以及调用存储在存储器72内的数据,执行问答系统的各种功能。The
在具体的实现中,作为一种实施例,处理器71可以包括一个或多个CPU,例如图7中所示的CPU0和CPU1。在具体实现中,作为一种实施例,问答系统可以包括多个处理器,例如图7中所示的处理器71和处理器75。这些处理器中的每一个可以是一个单核处理器(single-CPU),也可以是一个多核处理器(multi-CPU)。这里的处理器可以指一个或多个设备、电路、和/或用于处理数据(例如计算机程序指令)的处理核。In a particular implementation, as an embodiment,
存储器72可以是只读存储器(read-only memory,ROM)或可存储静态信息和指令的其他类型的静态存储设备,随机存取存储器(random access memory,RAM)或者可存储信息和指令的其他类型的动态存储设备,也可以是电可擦可编程只读存储器(electrically erasable programmable read-only memory,EEPROM)、只读光盘(compact disc read-only memory,CD-ROM)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器72可以独立存在,通过通信总线74与处理器71相连接。存储器72也可以和处理器71集成在一起。其中,所述存储器72用于存储执行本申请实施例提供的方案的软件程序,并由处理器71来控制执行。The
通信单元73,用于与用户或者其他设备进行交互,如:通信单元73可以为问答系统的用户交互界面。The
通信总线74,可以是工业标准体系结构(industry standard architecture,ISA)总线、外部设备互连(peripheral component,PCI)总线或扩展工业标准体系结构(extended industry standard architecture,EISA)总线等。该总线可以分为地址总线、数据总线、控制总线等。为便于表示,图7中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。The communication bus 74 may be an industry standard architecture (ISA) bus, a peripheral component (PCI) bus, or an extended industry standard architecture (EISA) bus. The bus can be divided into an address bus, a data bus, a control bus, and the like. For ease of representation, only one thick line is shown in Figure 7, but it does not mean that there is only one bus or one type of bus.
图7所示的问答系统可以执行本申请实施例提供的问答方法中问答系统执行的操作。因此,方法实施例涉及的各步骤的所有相关内容均可以援引到对应功能模块的功能描述,在此不再赘述,如:处理器71可以用于支持问答系统执行步骤602~步骤604,通信单元73用于支持问答系统执行步骤601、步骤605。本发明实施例提供的问答系统,用于执行上述问答方法,因此可以达到与上述问答方法相同的效果。The question answering system shown in FIG. 7 can perform the operations performed by the question answering system in the question and answer method provided by the embodiment of the present application. Therefore, all related content of the steps involved in the method embodiments may be referred to the function description of the corresponding function module, and details are not described herein. For example, the
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个装置,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided by the present application, it should be understood that the disclosed apparatus and method may be implemented in other manners. For example, the device embodiments described above are merely illustrative. For example, the division of the modules or units is only a logical function division. In actual implementation, there may be another division manner, for example, multiple units or components may be used. The combination may be integrated into another device, or some features may be ignored or not performed. In addition, the mutual coupling or direct coupling or communication connection shown or discussed may be an indirect coupling or communication connection through some interface, device or unit, and may be in an electrical, mechanical or other form.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是一个物理单元或多个物理单元,即可以位于一个地方,或者也可以分布到多个不同地方。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and the components displayed as units may be one physical unit or multiple physical units, that is, may be located in one place, or may be distributed to multiple different places. . Some or all of the units may be selected according to actual needs to achieve the purpose of the solution of the embodiment.
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present invention may be integrated into one processing unit, or each unit may exist physically separately, or two or more units may be integrated into one unit. The above integrated unit can be implemented in the form of hardware or in the form of a software functional unit.
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该软件产品存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。The integrated unit is implemented in the form of a software functional unit and sold or used as a standalone productIt can be stored in a readable storage medium. Based on such understanding, the technical solution of the embodiments of the present invention may contribute to the prior art or all or part of the technical solution may be embodied in the form of a software product stored in a storage medium. A number of instructions are included to cause a device (which may be a microcontroller, chip, etc.) or a processor to perform all or part of the steps of the methods described in various embodiments of the present invention. The foregoing storage medium includes various media that can store program codes, such as a USB flash drive, a mobile hard disk, a ROM, a RAM, a magnetic disk, or an optical disk.
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何在本发明揭露的技术范围内的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。The above is only the specific embodiment of the present invention, but the scope of the present invention is not limited thereto, and any changes or substitutions within the technical scope of the present invention should be covered by the scope of the present invention. . Therefore, the scope of the invention should be determined by the scope of the appended claims.
Claims (21)
Translated fromChinesePriority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201780092702.9ACN110799970A (en) | 2017-06-27 | 2017-06-27 | Question-answering system and question-answering method |
| PCT/CN2017/090401WO2019000240A1 (en) | 2017-06-27 | 2017-06-27 | Question answering system and question answering method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2017/090401WO2019000240A1 (en) | 2017-06-27 | 2017-06-27 | Question answering system and question answering method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019000240A1true WO2019000240A1 (en) | 2019-01-03 |
Family
ID=64740209
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2017/090401CeasedWO2019000240A1 (en) | 2017-06-27 | 2017-06-27 | Question answering system and question answering method |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN110799970A (en) |
| WO (1) | WO2019000240A1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111353290A (en)* | 2020-02-28 | 2020-06-30 | 支付宝(杭州)信息技术有限公司 | Method and system for automatically responding to user inquiry |
| CN111782790A (en)* | 2020-07-03 | 2020-10-16 | 阳光保险集团股份有限公司 | A document analysis method, device, electronic device and storage medium |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114942986B (en)* | 2022-06-21 | 2024-03-19 | 平安科技(深圳)有限公司 | Text generation method, text generation device, computer equipment and computer readable storage medium |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6154720A (en)* | 1995-06-13 | 2000-11-28 | Sharp Kabushiki Kaisha | Conversational sentence translation apparatus allowing the user to freely input a sentence to be translated |
| CN1952928A (en)* | 2005-10-20 | 2007-04-25 | 梁威 | Computer system to constitute natural language base and automatic dialogue retrieve |
| CN103605781A (en)* | 2013-11-29 | 2014-02-26 | 苏州大学 | Implicit expression chapter relationship type inference method and system |
| CN105159996A (en)* | 2015-09-07 | 2015-12-16 | 百度在线网络技术(北京)有限公司 | Deep question-and-answer service providing method and device based on artificial intelligence |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101329683A (en)* | 2008-07-25 | 2008-12-24 | 华为技术有限公司 | Recommendation system and method |
| EP2622510A4 (en)* | 2010-09-28 | 2017-04-05 | International Business Machines Corporation | Providing answers to questions using logical synthesis of candidate answers |
| US9613317B2 (en)* | 2013-03-29 | 2017-04-04 | International Business Machines Corporation | Justifying passage machine learning for question and answer systems |
| CN104572797A (en)* | 2014-05-12 | 2015-04-29 | 深圳市智搜信息技术有限公司 | Individual service recommendation system and method based on topic model |
| US9471689B2 (en)* | 2014-05-29 | 2016-10-18 | International Business Machines Corporation | Managing documents in question answering systems |
| CN104536991B (en)* | 2014-12-10 | 2017-12-08 | 乐娟 | answer extracting method and device |
| US20160196336A1 (en)* | 2015-01-02 | 2016-07-07 | International Business Machines Corporation | Cognitive Interactive Search Based on Personalized User Model and Context |
| CN104615724B (en)* | 2015-02-06 | 2018-01-23 | 百度在线网络技术(北京)有限公司 | The foundation of knowledge base and the information search method and device in knowledge based storehouse |
| CN106649258A (en)* | 2016-09-22 | 2017-05-10 | 北京联合大学 | Intelligent question and answer system |
| CN106649786B (en)* | 2016-12-28 | 2020-04-07 | 北京百度网讯科技有限公司 | Answer retrieval method and device based on deep question answering |
| CN106874441B (en)* | 2017-02-07 | 2024-03-05 | 腾讯科技(上海)有限公司 | Intelligent question and answer method and device |
- 2017
- 2017-06-27CNCN201780092702.9Apatent/CN110799970A/enactivePending
- 2017-06-27WOPCT/CN2017/090401patent/WO2019000240A1/ennot_activeCeased
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6154720A (en)* | 1995-06-13 | 2000-11-28 | Sharp Kabushiki Kaisha | Conversational sentence translation apparatus allowing the user to freely input a sentence to be translated |
| CN1952928A (en)* | 2005-10-20 | 2007-04-25 | 梁威 | Computer system to constitute natural language base and automatic dialogue retrieve |
| CN103605781A (en)* | 2013-11-29 | 2014-02-26 | 苏州大学 | Implicit expression chapter relationship type inference method and system |
| CN105159996A (en)* | 2015-09-07 | 2015-12-16 | 百度在线网络技术(北京)有限公司 | Deep question-and-answer service providing method and device based on artificial intelligence |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111353290A (en)* | 2020-02-28 | 2020-06-30 | 支付宝(杭州)信息技术有限公司 | Method and system for automatically responding to user inquiry |
| CN111353290B (en)* | 2020-02-28 | 2023-07-14 | 支付宝(杭州)信息技术有限公司 | Method and system for automatically responding to user inquiry |
| CN111782790A (en)* | 2020-07-03 | 2020-10-16 | 阳光保险集团股份有限公司 | A document analysis method, device, electronic device and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110799970A (en) | 2020-02-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9223779B2 (en) | Text segmentation with multiple granularity levels | |
| CN111581949B (en) | Method and device for disambiguating name of learner, storage medium and terminal | |
| JPH1145241A (en) | Kana-kanji conversion system and computer-readable recording medium storing a program for causing a computer to function as each means of the system | |
| CN118296120A (en) | Large-scale language model retrieval enhancement generation method for multi-mode multi-scale multi-channel recall | |
| CN106257455B (en) | A kind of Bootstrapping method extracting viewpoint evaluation object based on dependence template | |
| CN104008126A (en) | Method and device for segmentation on basis of webpage content classification | |
| CN109815390B (en) | Method, device, computer equipment and computer storage medium for retrieving multilingual information | |
| JP2011118689A (en) | Retrieval method and system | |
| CN109840255A (en) | Reply document creation method, device, equipment and storage medium | |
| WO2019000240A1 (en) | Question answering system and question answering method | |
| CN103226601B (en) | A kind of method and apparatus of picture searching | |
| CN100454294C (en) | Equipment for translating Japanese into Chinese | |
| CN112905752A (en) | Intelligent interaction method, device, equipment and storage medium | |
| Li et al. | Complex query recognition based on dynamic learning mechanism | |
| Ung et al. | Combination of features for vietnamese news multi-document summarization | |
| KR101662399B1 (en) | Apparatus and method for question-answering using user interest information based on keyword input | |
| CN103577397A (en) | Computer translation data processing method and computer translation data processing device | |
| JPH1145254A (en) | Document retrieval apparatus and computer-readable recording medium recording a program for causing a computer to function as the apparatus | |
| JP4484957B1 (en) | Retrieval expression generation device, retrieval expression generation method, and program | |
| CN117493585B (en) | A data retrieval system based on large language models | |
| JP5541124B2 (en) | Language processing device, speech synthesis device, language processing method, and language processing program | |
| Duan et al. | Mutual‐Attention Net: A Deep Attentional Neural Network for Keyphrase Generation | |
| Wu et al. | Retrieving Tables via Inter-and Intra-Content Contrastive Representation Learning | |
| JP2019211884A (en) | Information search system | |
| Jiang et al. | Chinese Short Text Fusion Algorithm |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| NENP | Non-entry into the national phase | Ref country code:DE | |
| 122 | Ep: pct application non-entry in european phase | Ref document number:17915618 Country of ref document:EP Kind code of ref document:A1 |