US9275631B2 - Speech synthesis system, speech synthesis program product, and speech synthesis method - Google Patents
Speech synthesis system, speech synthesis program product, and speech synthesis methodDownload PDFInfo
- Publication number
- US9275631B2 US9275631B2US13/731,268US201213731268AUS9275631B2US 9275631 B2US9275631 B2US 9275631B2US 201213731268 AUS201213731268 AUS 201213731268AUS 9275631 B2US9275631 B2US 9275631B2
- Authority
- US
- United States
- Prior art keywords
- cost
- speech
- speech segment
- prosody
- segment sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active, expires
Links
Images







Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/06—Elementary speech units used in speech synthesisers; Concatenation rules
- G10L13/07—Concatenation rules
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
Definitions
- the present inventionrelates to a speech synthesis technology for synthesizing speech by computer processing and particularly to a technology for synthesizing the speech with high sound quality.
- This technologygenerates synthesized speech by selecting speech segments having similar prosody to the target prosody predicted using a prosody model from a speech segment database and concatenating them.
- the first advantage of this technologyis that it can provide high sound quality and naturalness close to those of a recorded human voice in a portion where appropriate speech segments are selected.
- the fine tuning (smoothing) of prosodyis unnecessary in a portion where originally continuous speech segments (continuous speech segments) in speakers original speech can be used for the synthesized speech directly in the concatenated sequence, and therefore the best sound quality with natural accent is achieved.
- the frequency of speechmay be different according to the context even if the accent is the same, and the prosody may become unnatural at the connection of the accent as a whole in the case of poor consistency with outer portions of the continuous speech segments.
- Japanese Unexamined Patent Publication (Kokai) No. 2005-292433discloses a technology for: acquiring a prosody sequence for target speech to be speech-synthesized with respect to a plurality of respective segments, each of which is a synthesis unit of speech synthesis; associating a fused speech segment obtained by fusing a plurality of speech segments, which are intended for the same speech unit and different in prosody of the speech unit from each other, with fused speech segment prosody information indicating the prosody of the fused speech segment and holding them; estimating a degree of distortion between segment prosody information indicating the prosody of segments obtained by division and the fused speech segment prosody information; selecting a fused speech segment based on the degree of the estimated distortion; and generating synthesized speech by concatenating the fused speech segments selected for the respective segments.
- Japanese Unexamined Patent Publication (Kokai) No. 2005-292433does not suggest a technique for treating continuous speech segments.
- a speech segment sequence having the maximum likelihoodis obtained by learning the distribution of absolute values and relative values of a fundamental frequency (F0) in a prosody model for use in waveform concatenation speech synthesis. Also in the technique disclosed in this document, however, unnatural prosody is produced by the synthesis without speech segments. Although it is possible to use a F0 curve having the maximum likelihood forcibly as the prosody of synthesized speech, the naturalness only possible in the waveform concatenation speech synthesis is lost.
- F0fundamental frequency
- the following document [2]discloses that speech segment prosody is used directly for continuous speech segments since discontinuity never occurs in the continuous speech segments.
- the synthesized speechis used after smoothing the speech segment prosody in the portions other than the continuous speech segments.
- Patent Document 1
- synthesized speechis produced with high sound quality where accents are naturally connected in the case where there are large quantities of speech segments, while synthesized speech can be produced with accurate accents even if the above is not the case.
- a sentence having a similar content to recorded speaker's speechis synthesized with high sound quality, while any other sentence can be synthesized with accurate accents.
- the present inventionhas been provided to solve the above problem and it provides prosody with high accuracy and high sound quality by performing a two-path search including a speech segment search and a prosody modification value search.
- an accurate accentis secured by evaluating the consistency of prosody by using a statistical model of prosody variations (the slope of fundamental frequency) for both of two paths of the speech segment selection and the modification value search.
- a prosody modification value searcha prosody modification value sequence that minimizes a modified prosody cost is searched for. This allows a search for a modification value sequence that can increase the likelihood of absolute values or variations of the prosody to the statistical model as high as possible with minimum modification values.
- continuous speech segmentsan evaluation is made to determine whether they keep the consistency by using the statistical model of prosody variations similarly and only correct continuous speech segments are treated on a priority basis.
- the term “treated on a priority basis”means that the best sound quality is achieved by leaving the fine tuning undone in the corresponding portion, first.
- the prosody of other speech segmentsis modified with the priority continuous speech segments particularly weighted in the modification value search so as to ensure that other speech segments have correct consistency in the relationship with the prior continuous speech segments.
- the consistency of the fundamental frequencyis evaluated by modeling the slope of the fundamental frequency using the statistical model and calculating the likelihood for the model.
- Stable valuescan be observed independently of a mora length and the consistency can be evaluated in consideration of all parts of the fundamental frequency within the range by using the slope obtained by linear-approximating the fundamental frequency within a certain time interval, instead of a difference from the fundamental frequency in a position in an adjacent mora, which contributes to the reproduction of an accent that sounds accurate to a human ear.
- the slope of the fundamental frequencyis calculated during learning, for example, by linear-approximating a curve generated by interpolating pitch marks in a silent section by linear interpolation first and then smoothing the entire curve, preferably within a range from a point obtained by equally dividing each mora to a point traced back for a certain time period.
- FIG. 1is an outline block diagram illustrating a learning process which is the premise of the present invention and an entire speech synthesis process;
- FIG. 2is a block diagram of hardware for practicing the present invention
- FIG. 3is a flowchart of the main process of the present invention.
- FIG. 4is a diagram illustrating an example of a decision tree
- FIG. 5is a flowchart of the process for determining priority continuous speech segments
- FIG. 6is a diagram illustrating the state of applying prosody modification values to speech segments.
- FIG. 7is a diagram illustrating a difference in the process between the case where continuous speech segments are priority continuous speech segments and a case other than that.
- FIG. 1there is shown an outline block diagram illustrating the overview of speech processing which is the premise of the present invention.
- the left part of FIG. 1is a processing block diagram illustrating a learning step of preparing necessary information such as a speech segment database and a prosody model necessary for speech synthesis.
- the right part of FIG. 1is a processing block diagram illustrating a speech synthesis step.
- a recorded script 102includes at least several hundred sentences corresponding to various fields and situations in a text file format.
- the recorded script 102is read aloud by a plurality of narrators preferably including men and women, the readout speech is converted to a speech analog signal through a microphone (not shown) and then A/D-converted, and the A/D-converted speech is stored preferably in PCM format into the hard disk of a computer.
- a recording process 104is performed.
- Digital speech signals stored in the hard diskconstitute a speech corpus 106 .
- the speech corpus 106can include analytical data such as classes of recorded speeches.
- a language processing unit 108performs processing specific to the language of the recorded script 102 . More specifically, it obtains the reading (phonemes), accents, and word classes of the input text. Since no space is left between words in some languages, there may also be a need to divide the sentence in word units. Therefore, a parsing technique is used, if necessary.
- a reading and accentare assigned to each of the divided words. It is performed with reference to a prepared dictionary in which a reading is associated with an accent for each word.
- the speechis divided into speech segments (an alignment of speech segments is obtained).
- the waveform editing and synthesis unit 114observes the fundamental frequency preferably at three equally spaced points of each mora on the basis of speech segment data generated in the building block 112 by the waveform editing and synthesis unit and constructs a decision tree for predicting this. Furthermore, the distribution is modeled by the Gaussian mixture model (GMM) for each node of the decision tree. More specifically, the decision tree is used to cluster the input feature values so as to associate the probability distribution determined by the Gaussian mixture model with each cluster.
- GMMGaussian mixture model
- a speech segment database 116 and a prosody model 118 constructed as described aboveare stored in the hard disk of the computer. Data of the speech segment database 116 and that of the prosody model 118 prepared in this manner can be copied to another speech synthesis system and used for an actual speech synthesis process.
- the speech synthesis processis basically to read aloud a sentence provided in a text format via text-to-speech (US).
- This type of input text 120is typically generated by an application program of the computer.
- a typical computer application programdisplays a message in a popup window format for a user, and the message can be used as an input text.
- an instructionsuch as, for example, “Turn to the right at the intersection located 200 meters ahead” is used as text to be read aloud.
- a language processing unit 122obtains the reading (phonemes), accents, and word classes of the input text, similarly to the above processing of the language processing unit 108 .
- the sentenceis divided into words in this process, too.
- a reading and accentare assigned to each of the divided words similarly to the text analysis result block 110 in response to a processing output of the language processing unit 122 .
- a synthesis block 126 by the waveform editing and synthesis unittypically the following processes are sequentially performed:
- the synthesized speech 128is obtained.
- the signal of the synthesized speech 128is converted to an analog signal by DA conversion and is output from a speaker.
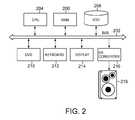
- FIG. 2there is shown a block diagram illustrating a basic structure of the speech synthesis system (text-to-speech synthesis system) according to the present invention.
- this embodimentwill be described under the assumption that the configuration in FIG. 2 is applied to a car navigation system, it should be appreciated that the present invention is not limited thereto, but the invention may be applied to an arbitrary information processor having a speech synthesis function such as a vending machine or any other arbitrary built-in device and an ordinary personal computer.
- a bus 202is connected to a CPU 204 , a main storage (RAM) 206 , a hard disk drive (HDD) 208 , a DVD drive 210 , a keyboard 212 , a display 214 , and a DA converter 216 .
- the DA converter 216is connected to the speaker 218 and thus speech synthesized by the speech synthesis system according to the present invention is output from the speaker 218 .
- the car navigation systemis equipped with a GPS function and a GPS antenna, though they are not shown.
- the CPU 204has a 32-bit or 64-bit architecture that enables the execution of an operating system such as TRON, Windows® Automotive, and Linux®.
- the HDD 208stores data of the speech segment database 116 generated by the learning process in FIG. 1 and data of the prosody model 118 .
- the HDD 208further stores an operating system, a program for generating information related to a location detected by the GPS function or other text data to be speech-synthesized, and a speech synthesis program according to the present invention.
- these programscan be stored in an EEPROM (not shown) so as to be loaded into the main storage 206 from the EEPROM at power on.
- the DVD drive 210is for use in mounting a DVD having map information for navigation.
- the DVDcan store a text file to be read aloud by the speech synthesis function.
- the keyboard 212substantially includes operation buttons provided on the front of the car navigation system.
- the display 214is preferably a liquid crystal display and is used for displaying a navigation map in conjunction with the GPS function. Moreover, the display 214 appropriately displays a control panel or a control menu to be operated through the keyboard 212 .
- the DA converter 216is for use in converting a digital signal of the speech synthesized by the speech synthesis system according to the present invention to an analog signal for driving the speaker 218 .
- FIG. 3there is shown a flowchart illustrating processing of the speech segment search and the prosody modification value search according to the present invention.
- a processing module for this processingis included in the synthesis block 126 by the waveform editing and synthesis unit in the configuration shown in FIG. 1 .
- FIG. 2it is stored in the hard disk drive 208 and executable loaded into the RAM 206 .
- a plurality of types of prosody to be used during processingwill be described below.
- Prosody predicted using a prosody model for an input sentence in the runtime of a conventional approachProsody predicted using a prosody model for an input sentence in the runtime of a conventional approach.
- speech segments having speech segment prosody close to this valueare selected.
- the target prosodyis basically not used in the approach of the present invention. More specifically, speech segments are selected because of its speech segment prosody having a high likelihood to the model stochastically representing the features of the speaker's prosody, instead of being selected because of the similar prosody to the target prosody.
- Prosodyfinally assigned to the synthesized speech. There are pluralities of options available for a value therefore.
- discontinuous prosodymay occur between the speech segments and speech segments adjacent thereto, which leads to deterioration of the sound quality on the contrary in some cases. Since such discontinuous prosody never occurs in continuous speech segments, this method is used only in such a portion in the conventional approach.
- the speech segment prosodyis smoothed in adjacent speech segments to obtain the final prosody. This eliminates discontinuity in accent and thereby the speech sounds smooth In the conventional approach, this method is generally used in the portions other than the continuous speech segments. In that case, however, an inaccurate accent may be produced unless there are any speech segments having the similar speech segment prosody to the target prosody.
- the target prosodyis forcibly used.
- the target prosodyis determined by predicting the target prosody using the prosody model for the input sentence as described above. If this method is used, a major modification is required for the speech segments in a portion where there are no speech segments having the similar speech segment prosody to the target prosody, and the sound quality significantly deteriorates in that portion.
- this methodis one of the conventional technologies, it is an undesirable method since it impairs the advantage of the high sound quality of the waveform concatenation speech synthesis.
- the speech segment prosodyis basically used, while the likelihood is evaluated to use calculations of the final prosody depending on each part.
- the speech segment prosodyis directly used similarly to 3-1 for a portion where the likelihood is sufficiently high in the continuous speech segments (priority continuous speech segments). The best sound quality is achieved by directly using the speech segment prosody for the portion sufficiently high in likelihood.
- the speech segment prosodyis smoothed before it is used similarly to 3-2 for a portion whose likelihood is relatively high regarding other speech segments than the continuous speech segments. Thereby, considerably high sound quality is obtained.
- the prosodyis modified with the minimum modification values so as to increase the likelihood and then the modified prosody is used as the final prosody.
- the sound qualityis not as high as the above one. We can say that this case is similar to the case of 3-3.
- the GMM (Gaussian mixture model) decisionis made using a decision tree.
- the decision treeis, for example, as shown in FIG. 4 and questions are associated with respective nodes.
- the controlreaches an end-point by following the tree according to the determination of yes or no on the basis of the input feature value.
- FIG. 4illustrates an example of the decision tree based on the questions related to the positions of moras within a sentence.
- the decision treeis used for the GMM decision and a GMM ID number is associated with its end-point.
- the GMM parameteris obtained by checking the table using the ID number.
- the term “GMM,” namely “the Gaussian mixture distribution”is the superposition of a plurality of weighted normal distributions, and the GMM parameter includes an average, dispersion, and a weighting factor.
- the input feature values to the decision treeinclude a word class, the type of speech segment, and the position of mora within the sentence.
- the term “output parameter”means a GMM parameter of a frequency slope or an absolute frequency. The combination of the decision tree and GMM is used to predict the output parameter based on the input feature values.
- the related technologyis conventionally known and therefore a more detailed description is omitted here. For example, refer to the above document [1] or the specification of Japanese Patent Application No. 2006-320890 filed by the present applicant.
- the speech segment database 116contains a speech segment list and actual voices of respective speech segments. Moreover, in the speech segment database 116 , each speech segment is associated with information such as a start-edge frequency, end-edge frequency, sound volume, length, and tone (cep strum vector) at the start edge or end edge. In step 306 , the above information is used to obtain a speech segment sequence having the minimum cost.
- the spectrum continuity costis applied as a cost (penalty) to a difference across the spectrum so that the tones (spectrum) are smoothly connected in the selection of the speech segments.
- the frequency continuity costis applied as a cost to a difference of the fundamental frequency so that the fundamental frequencies are smoothly connected in the selection of the speech segments.
- the duration error costis applied as a cost to a difference between target duration and speech segment duration so that the speech segment duration (length) is close to duration predicted using the prosody model in the selection of the speech segments.
- the volume error costis applied as a cost to a difference between a target sound volume and a speech segment volume.
- the frequency error costis applied as a cost to an error of a speech segment frequency (speech segment prosody) from a target frequency, where the target frequency (target prosody) is previously obtained.
- the frequency error cost and the frequency continuity costare omitted among the above costs as a result of reconsidering the costs of the conventional technology. Instead, an absolute frequency likelihood cost (Cla), a frequency slope likelihood cost (Cld), and a frequency linear approximation error cost (Cf) are introduced.
- Caabsolute frequency likelihood cost
- Cldfrequency slope likelihood cost
- Cffrequency linear approximation error cost
- the absolute frequency likelihood cost (Cla)will be described below.
- the fundamental frequencyis observed at three equally spaced points of each mora and a decision tree for predicting it is constructed during learning.
- the distributionis modeled by the Gaussian mixture model (GMM) for the nodes of the decision tree.
- GMMGaussian mixture model
- the decision tree and GMMare used to calculate the likelihood of the speech segment prosody of the speech segments currently under consideration.
- its log likelihoodis positive-negative reversed and an external weighting factor is applied thereto to obtain the cost.
- GMMis employed with the aim of increasing the choices of speech segments here.
- the frequency slope likelihood cost(Cld) will be described below.
- the slope of the fundamental frequencyis observed at three equally spaced points of each mora and a decision tree for predicting it is constructed.
- the distributionis modeled by GMM for the nodes of the decision tree.
- the decision tree and GMMare used to calculate the likelihood of the slope of the speech segment sequence currently under consideration. Then, its log likelihood is positive-negative reversed and an external weighting factor is applied thereto to obtain the cost.
- the slopeis calculated during learning within a range from the position under consideration to a point going back, for example, 0.15 sec.
- the slope of the speech segmentsis calculated within a range from the speech segment under consideration to a point going back 0.15 sec similarly to calculate the likelihood.
- the slopeis calculated by obtaining an approximate straight line having the minimum square error.
- the frequency linear approximation error cost (Cf)will be described below. While a change in the log frequency within the above range of 0.15 sec is approximated by a straight line when the frequency slope likelihood is calculated, the external weighting factor is applied to its approximation error to obtain the frequency linear approximation error cost (Cf). This cost is used due to the following two reasons: (1) If the approximation error is too large, the calculation of the frequency slope cost becomes meaningless; and (2) The prosody of the concatenated speech segments should change smoothly to the extent that the change can be approximated by the first-order approximation during the short time period of 0.15 sec.
- the speech segment sequenceis determined by a beam search so as to minimize the spectrum continuity cost, the duration error cost, the volume error cost, the absolute frequency likelihood cost, the frequency slope likelihood cost, and the frequency linear approximation error cost.
- the beam searchis to limit the number of steps in the best-first search for rationalization of the search space.
- different decision treesare used for the spectrum continuity cost, the duration error cost, the volume error cost, the absolute frequency likelihood cost, the frequency slope likelihood cost, and the frequency linear approximation error cost, respectively.
- the volume, frequency, and durationare combined as a vector and a value of the vector can be estimated at a time using a single decision tree.
- the likelihood evaluation in step 310is intended for a continuous speech segment portion including continuous speech segments selected by the number exceeding an externally provided threshold value Tc in the selected speech segment sequence:
- the frequency slope likelihood cost Cld of that portionis compared with another externally provided threshold value Td. Only the portion exceeding the threshold value is handled as “priority continuous speech segments” as shown in step 312 in the subsequent processes. Handling of the priority continuous speech segments will be described later with reference to the flowchart of FIG. 5 .
- an appropriate modification value sequence for the speech segment prosody sequenceis obtained by a Viterbi search.
- the Viterbi searchis used to find the prosody modification value sequence so as to maximize the likelihood estimation of the speech segment prosody sequence through the dynamic programming.
- the GMM parameter obtained in step 304is used.
- the beam searchcan be used, instead of the Viterbi search, to obtain the prosody modification value sequence in this step, too.
- One modification valueis selected out of candidates determined discretely within the previously determined range from the lower limit to the upper limit (For example, from ⁇ 100 Hz to +100 Hz at intervals of 10 Hz).
- the modified speech segment prosodyis evaluated by the sum of the following costs, namely modified prosody cost:
- absolute frequency likelihood cost“absolute frequency likelihood cost,” “frequency slope likelihood cost,” and “frequency linear approximation error cost” are the same as those of the above speech segment search, but different decision trees from those of the calculation of the costs for the speech segment search are used to calculate the modified prosody cost.
- Input variables used for the decision treesare the same as existing input variables used for the decision tree of the frequency error cost. Note here that it is also possible to estimate a two-dimensional vector which is the combination of the absolute frequency likelihood cost and the frequency slope likelihood cost through one decision tree at a time.
- the prosody modification costmeans a cost (penalty) for a modification value for the modification of a speech segment F0.
- the reason why it is referred to as penaltyis because the sound quality deteriorates as the modification value increases.
- the prosody modification costis calculated by multiplying the modification value of the prosody by an external weight. Note that, however, for the priority continuous speech segments, the prosody modification cost is calculated by multiplying the cost by another external large weight or the cost is set to an extremely large constant to inhibit the modification value to be other than zero. Thereby, a modification value is selected so as to be consistent with the prosody of the priority continuous speech segments in the vicinity of the priority continuous speech segments. Thus, in step 316 , the prosody modification value for each speech segment is determined.
- no decision treeis used to calculate the prosody modification cost (Cm). It is based on a concept that the prosody modification should be small for all phonemes equally. If, however, it is expected that the sound quality of some phonemes does not deteriorate even after the prosody modification while the sound quality of other phonemes significantly deteriorates after the prosody modification and it is desirable to perform different prosody modification for them, the use of a decision tree is appropriate for the prosody modification cost, too.
- step 318the prosody modification value obtained in step 316 is applied to each speech segment to smooth the prosody.
- step 320the prosody to be finally applied to the synthesized speech is determined.
- FIG. 5there is shown a flowchart of processing for determining a weight for the modification value cost, which is used in the modification value search 314 shown in FIG. 3 .
- the speech segmentsare checked one by one in step 502 .
- continuous speech segmentsmeans a sequence of speech segments that have been originally continuous in the original speaker's speech and can be used for the synthesized speech directly in the concatenated sequence. If the number of continuous speech segments is smaller than the intended threshold value Tc, the speech segments are immediately determined to be ordinary speech segments in 510 .
- step 504it is determined whether the number of continuous speech segments is greater than the intended threshold value Tc in step 504 .
- the Tc valueis 10 in one example.
- the speech segment sequenceis not treated specially only for this reason.
- step 508it is determined whether the slope likelihood Ld of the continuous speech segment portion is greater than the given threshold value Td in step 508 : If it is not so, the control progresses to step 510 to consider it to be ordinary speech segments after all; and only after the slope likelihood Ld is determined to be greater than the given threshold value Td in step 508 , the speech segment sequence is considered to be priority continuous speech segments.
- the frequency slope likelihood cost (Cld)is obtained by assigning a negative weight to the log of the slope likelihood Ld.
- the consideration of the priority continuous speech segmentscorresponds to step 312 shown in FIG. 3 .
- a large weightis used as shown in step 516 in a prosody modification value search 514 .
- the large weight used for the priority continuous speech segmentssubstantially or completely inhibits the prosody modification to be applied to the priority continuous speech segments.
- a normal weightis used as shown in step 518 in the prosody modification value search 514 .
- a weight of 1.0 or 2.0is used for the ordinary speech segments, and a weight that is twice to 10 times larger than the weight for the ordinary speech segments is used for the priority continuous speech segments.
- the onset or codamay be omitted.
- the observation pointsare placed at three equally spaced points of the syllable when the coda includes a voiceless consonant such as /s/ or /t/, the third point comes behind the coda which is the voiceless consonant.
- the fundamental frequencydoes not exist in a voiceless consonant and therefore the third point may be meaningless.
- the use of the observation point for the codamay reduce the important observation points for use in modeling the fundamental frequency of a vowel.
- the codaincludes only a voiced consonant and therefore the same problem as English does not occur.
- the forms of the fundamental frequencies of the four tonesare very important, and they have important implications only in vowels.
- consonantsare voiceless consonants or plosive sounds in Chinese and they do not have a fundamental frequency, and therefore modeling of the corresponding portion is unnecessary.
- the ups and downs of the fundamental frequency in Chineseare very significant, and therefore the frequency slope cannot be modeled successfully by observation at three points.
- FIG. 6there is shown a diagram illustrating the state of modifying speech segment prosody.
- the ordinate axisrepresents a frequency axis and an abscissa axis represents a time axis.
- a graph 602shows the concatenated state of the speech segments determined by the speech segment search in step 306 of the flowchart in FIG. 3 : a plurality of vertical lines represent boundaries between the speech segments. At this time point, the prosody of the original speech segments is shown as it is.
- a graph 604shows prosody modification values for the respective speech segments, which are determined in the prosody modification value search in step 314 of the flowchart in FIG. 3 .
- a graph 606illustrates modified speech segment prosody as a result of application of the modification values in the graph 604 .
- a graph 702 of FIG. 7shows the speech segment prosody which has not been modified yet.
- a speech segment before the modificationis indicated by a dashed line and a speech segment after the modification is indicated by a solid line.
- the speech segment sequenceincludes continuous speech segments 705 .
- the continuous speech segmentscan be recognized by no level difference in the prosody at the joint between the speech segments.
- the continuous speech segmentsare not immediately considered as priority continuous speech segments, but only in the case where the likelihood Ld of the slope of the continuous speech segments is greater than the threshold value Td, they are considered as priority continuous speech segments.
- the continuous speech segmentsare considered as priority continuous speech segments as a consequence, they are treated as ordinary speech segments and therefore the continuous speech segments 705 are also modified into the phone segments 705 ′ as shown in a graph 704 .
- the continuous speech segmentsare considered as priority continuous speech segments
- a large weightis used for the priority continuous speech segments in the prosody modification value search as shown in FIG. 5 , and therefore the prosody modification values are not substantially applied to the continuous speech segments as shown by the waveform 707 of a graph 706 .
- the prosody modification valuesneed to be applied so as to maximize the likelihood of the slope as a whole, and therefore the graph 706 shows that larger prosody modification values than in the graph 704 are applied to the portions other than the priority continuous speech segments.
- the valueindicates a prosody modification value of a speech segment by a root mean square: it is thought that the greater the value is, the more the sound quality is deteriorated by the prosody modification.
- the prosody modification valueis 10 Hz or more smaller than in the application of target prosody, though it is slightly greater than in the application of speech segment prosody, which proved that the present invention achieves a high accent precision with a high sound quality.
- the comparison objectsare as follows: the present invention; a case where the prosody modification of the present invention is not performed; and a case where all continuous speech segments are treated as priority continuous speech segments with Td of the present invention set to an extremely small value.
- the samples used for the evaluationare synthesized speeches each of which is composed of 75 sentences (approx. 200 breath groups) and the number of subjects is one. As a result, it has been proved that both of the prosody modification and Td are contributed to the improvement of the accent precision as shown in the following table:
- a model using the fundamental frequency slope of the present inventionhas been compared with a model [1] using a fundamental frequency difference under the same conditions without prosody modification in order to verify the superiority of the model using the fundamental frequency slope to the model [1] using the fundamental frequency difference.
- This evaluationhas been performed simultaneously with the above evaluation. Therefore, the number of subjects and the number of samples are the same as those of the above. In consequence, it has been proved that the model using the fundamental frequency slope of the present invention is superior in accent precision as shown below.
- the prosody modification valuehas been used in the frequency as an example in the above embodiment, the same method is also applicable to the duration. If so, the first path for the speech segment search is shared with the case of the frequency and the second path for the modification value search is used to perform the modification value search only for the duration separately from the pitch.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Machine Translation (AREA)
Abstract
Description
- Obtaining prosody modification values using the
prosody model 118; - Reading candidates of speech segments from the
speech segment database 116; - Getting a speech segment sequence;
- Applying prosody modification appropriately; and
- Generating synthesized speech by concatenating speech segments.
- Obtaining prosody modification values using the
- 1. Absolute frequency likelihood cost (Cla)
- 2. Frequency slope likelihood cost (Cld)
- 3. Frequency linear approximation error cost (Cf)
- 4. Prosody modification cost (Cm)
| TABLE 1 | |||
| Accent precision | |||
| Unnatural | Prosody | ||||
| though accent | Incorrect | modification | |||
| Natural | type is correct | accent type | value [Hz] | ||
| Application of | 57.6% | 16.7% | 25.7% | 11.3 Hz |
| speech segment | ||||
| prosody | ||||
| Application of | 74.2% | 13.9% | 12.0% | 30.5 Hz |
| target prosody | ||||
| Present invention | 91.2% | 5.88% | 2.94% | 17.7 Hz |
| TABLE 2 | ||||
| Unnatural though | Incorrect | |||
| Natural | accent type is correct | accent type | ||
| No modification | 78.8% | 11.6% | 9.53% |
| Low Td value | 85.7% | 7.41% | 6.88% |
| Present invention | 91.0% | 4.76% | 2.35% |
| TABLE 3 | ||||
| Unnatural though | Incorrect | |||
| Natural | accent type is correct | accent type | ||
| Delta pitch | 65.8% | 10.7% | 23.5% |
| without prosody | |||
| modification | |||
| Present invention | 78.8% | 11.6% | 9.53% |
| without prosody | |||
| modification | |||
Claims (15)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/731,268US9275631B2 (en) | 2007-09-07 | 2012-12-31 | Speech synthesis system, speech synthesis program product, and speech synthesis method |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007-232395 | 2007-09-07 | ||
| JP2007232395AJP5238205B2 (en) | 2007-09-07 | 2007-09-07 | Speech synthesis system, program and method |
| US12/192,510US8370149B2 (en) | 2007-09-07 | 2008-08-15 | Speech synthesis system, speech synthesis program product, and speech synthesis method |
| US13/731,268US9275631B2 (en) | 2007-09-07 | 2012-12-31 | Speech synthesis system, speech synthesis program product, and speech synthesis method |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/192,510ContinuationUS8370149B2 (en) | 2007-09-07 | 2008-08-15 | Speech synthesis system, speech synthesis program product, and speech synthesis method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20130268275A1 US20130268275A1 (en) | 2013-10-10 |
| US9275631B2true US9275631B2 (en) | 2016-03-01 |
Family
ID=40432832
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/192,510Active2030-09-23US8370149B2 (en) | 2007-09-07 | 2008-08-15 | Speech synthesis system, speech synthesis program product, and speech synthesis method |
| US13/731,268Active2028-09-28US9275631B2 (en) | 2007-09-07 | 2012-12-31 | Speech synthesis system, speech synthesis program product, and speech synthesis method |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/192,510Active2030-09-23US8370149B2 (en) | 2007-09-07 | 2008-08-15 | Speech synthesis system, speech synthesis program product, and speech synthesis method |
Country Status (2)
| Country | Link |
|---|---|
| US (2) | US8370149B2 (en) |
| JP (1) | JP5238205B2 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20160365085A1 (en)* | 2015-06-11 | 2016-12-15 | Interactive Intelligence Group, Inc. | System and method for outlier identification to remove poor alignments in speech synthesis |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101617359B (en)* | 2007-02-20 | 2012-01-18 | 日本电气株式会社 | Speech synthesizing device, and method |
| JP5238205B2 (en) | 2007-09-07 | 2013-07-17 | ニュアンス コミュニケーションズ,インコーポレイテッド | Speech synthesis system, program and method |
| US8583438B2 (en)* | 2007-09-20 | 2013-11-12 | Microsoft Corporation | Unnatural prosody detection in speech synthesis |
| WO2010119534A1 (en)* | 2009-04-15 | 2010-10-21 | 株式会社東芝 | Speech synthesizing device, method, and program |
| EP2357646B1 (en)* | 2009-05-28 | 2013-08-07 | International Business Machines Corporation | Apparatus, method and program for generating a synthesised voice based on a speaker-adaptive technique. |
| US8332225B2 (en)* | 2009-06-04 | 2012-12-11 | Microsoft Corporation | Techniques to create a custom voice font |
| RU2421827C2 (en)* | 2009-08-07 | 2011-06-20 | Общество с ограниченной ответственностью "Центр речевых технологий" | Speech synthesis method |
| US8965768B2 (en) | 2010-08-06 | 2015-02-24 | At&T Intellectual Property I, L.P. | System and method for automatic detection of abnormal stress patterns in unit selection synthesis |
| JP5717097B2 (en)* | 2011-09-07 | 2015-05-13 | 独立行政法人情報通信研究機構 | Hidden Markov model learning device and speech synthesizer for speech synthesis |
| US20140074465A1 (en)* | 2012-09-11 | 2014-03-13 | Delphi Technologies, Inc. | System and method to generate a narrator specific acoustic database without a predefined script |
| US20140236602A1 (en)* | 2013-02-21 | 2014-08-21 | Utah State University | Synthesizing Vowels and Consonants of Speech |
| JP5807921B2 (en)* | 2013-08-23 | 2015-11-10 | 国立研究開発法人情報通信研究機構 | Quantitative F0 pattern generation device and method, model learning device for F0 pattern generation, and computer program |
| JP2015125681A (en)* | 2013-12-27 | 2015-07-06 | パイオニア株式会社 | Information providing device |
| GB2524505B (en)* | 2014-03-24 | 2017-11-08 | Toshiba Res Europe Ltd | Voice conversion |
| US9997154B2 (en) | 2014-05-12 | 2018-06-12 | At&T Intellectual Property I, L.P. | System and method for prosodically modified unit selection databases |
| US9990916B2 (en)* | 2016-04-26 | 2018-06-05 | Adobe Systems Incorporated | Method to synthesize personalized phonetic transcription |
| CN106356052B (en)* | 2016-10-17 | 2019-03-15 | 腾讯科技(深圳)有限公司 | Phoneme synthesizing method and device |
| US10347238B2 (en)* | 2017-10-27 | 2019-07-09 | Adobe Inc. | Text-based insertion and replacement in audio narration |
| CN108364632B (en)* | 2017-12-22 | 2021-09-10 | 东南大学 | Emotional Chinese text voice synthesis method |
| US10770063B2 (en) | 2018-04-13 | 2020-09-08 | Adobe Inc. | Real-time speaker-dependent neural vocoder |
| JP6698789B2 (en)* | 2018-11-05 | 2020-05-27 | パイオニア株式会社 | Information provision device |
| WO2020101263A1 (en)* | 2018-11-14 | 2020-05-22 | Samsung Electronics Co., Ltd. | Electronic apparatus and method for controlling thereof |
| CN109841216B (en)* | 2018-12-26 | 2020-12-15 | 珠海格力电器股份有限公司 | Voice data processing method and device and intelligent terminal |
| US11062691B2 (en)* | 2019-05-13 | 2021-07-13 | International Business Machines Corporation | Voice transformation allowance determination and representation |
| JP2020144890A (en)* | 2020-04-27 | 2020-09-10 | パイオニア株式会社 | Information provision device |
| US11335324B2 (en)* | 2020-08-31 | 2022-05-17 | Google Llc | Synthesized data augmentation using voice conversion and speech recognition models |
Citations (96)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3828132A (en)* | 1970-10-30 | 1974-08-06 | Bell Telephone Labor Inc | Speech synthesis by concatenation of formant encoded words |
| US5664050A (en)* | 1993-06-02 | 1997-09-02 | Telia Ab | Process for evaluating speech quality in speech synthesis |
| US5913193A (en)* | 1996-04-30 | 1999-06-15 | Microsoft Corporation | Method and system of runtime acoustic unit selection for speech synthesis |
| US5999900A (en)* | 1993-06-21 | 1999-12-07 | British Telecommunications Public Limited Company | Reduced redundancy test signal similar to natural speech for supporting data manipulation functions in testing telecommunications equipment |
| US6173263B1 (en)* | 1998-08-31 | 2001-01-09 | At&T Corp. | Method and system for performing concatenative speech synthesis using half-phonemes |
| US6233544B1 (en)* | 1996-06-14 | 2001-05-15 | At&T Corp | Method and apparatus for language translation |
| US6240384B1 (en)* | 1995-12-04 | 2001-05-29 | Kabushiki Kaisha Toshiba | Speech synthesis method |
| US6253182B1 (en)* | 1998-11-24 | 2001-06-26 | Microsoft Corporation | Method and apparatus for speech synthesis with efficient spectral smoothing |
| US6266637B1 (en)* | 1998-09-11 | 2001-07-24 | International Business Machines Corporation | Phrase splicing and variable substitution using a trainable speech synthesizer |
| US20010021906A1 (en)* | 2000-03-03 | 2001-09-13 | Keiichi Chihara | Intonation control method for text-to-speech conversion |
| JP2001282282A (en) | 2000-03-31 | 2001-10-12 | Canon Inc | Voice information processing method and apparatus, and storage medium |
| US20010039492A1 (en)* | 2000-05-02 | 2001-11-08 | International Business Machines Corporation | Method, system, and apparatus for speech recognition |
| US20010056347A1 (en)* | 1999-11-02 | 2001-12-27 | International Business Machines Corporation | Feature-domain concatenative speech synthesis |
| US6366883B1 (en)* | 1996-05-15 | 2002-04-02 | Atr Interpreting Telecommunications | Concatenation of speech segments by use of a speech synthesizer |
| US6377917B1 (en)* | 1997-01-27 | 2002-04-23 | Microsoft Corporation | System and methodology for prosody modification |
| US20020152073A1 (en)* | 2000-09-29 | 2002-10-17 | Demoortel Jan | Corpus-based prosody translation system |
| US20030046079A1 (en)* | 2001-09-03 | 2003-03-06 | Yasuo Yoshioka | Voice synthesizing apparatus capable of adding vibrato effect to synthesized voice |
| US20030088417A1 (en)* | 2001-09-19 | 2003-05-08 | Takahiro Kamai | Speech analysis method and speech synthesis system |
| US20030112987A1 (en)* | 2001-12-18 | 2003-06-19 | Gn Resound A/S | Hearing prosthesis with automatic classification of the listening environment |
| US20030158721A1 (en)* | 2001-03-08 | 2003-08-21 | Yumiko Kato | Prosody generating device, prosody generating method, and program |
| US20030195743A1 (en)* | 2002-04-10 | 2003-10-16 | Industrial Technology Research Institute | Method of speech segment selection for concatenative synthesis based on prosody-aligned distance measure |
| US20030208355A1 (en)* | 2000-05-31 | 2003-11-06 | Stylianou Ioannis G. | Stochastic modeling of spectral adjustment for high quality pitch modification |
| US6665641B1 (en)* | 1998-11-13 | 2003-12-16 | Scansoft, Inc. | Speech synthesis using concatenation of speech waveforms |
| US20040030555A1 (en)* | 2002-08-12 | 2004-02-12 | Oregon Health & Science University | System and method for concatenating acoustic contours for speech synthesis |
| US6701295B2 (en)* | 1999-04-30 | 2004-03-02 | At&T Corp. | Methods and apparatus for rapid acoustic unit selection from a large speech corpus |
| US20040059568A1 (en)* | 2002-08-02 | 2004-03-25 | David Talkin | Method and apparatus for smoothing fundamental frequency discontinuities across synthesized speech segments |
| JP2004109535A (en) | 2002-09-19 | 2004-04-08 | Nippon Hoso Kyokai <Nhk> | Speech synthesis method, speech synthesis device, and speech synthesis program |
| JP2004139033A (en) | 2002-09-25 | 2004-05-13 | Nippon Hoso Kyokai <Nhk> | Speech synthesis method, speech synthesis device, and speech synthesis program |
| US20040148171A1 (en)* | 2000-12-04 | 2004-07-29 | Microsoft Corporation | Method and apparatus for speech synthesis without prosody modification |
| US20040172249A1 (en)* | 2001-05-25 | 2004-09-02 | Taylor Paul Alexander | Speech synthesis |
| US20040220813A1 (en)* | 2003-04-30 | 2004-11-04 | Fuliang Weng | Method for statistical language modeling in speech recognition |
| US6823309B1 (en)* | 1999-03-25 | 2004-11-23 | Matsushita Electric Industrial Co., Ltd. | Speech synthesizing system and method for modifying prosody based on match to database |
| US6829581B2 (en)* | 2001-07-31 | 2004-12-07 | Matsushita Electric Industrial Co., Ltd. | Method for prosody generation by unit selection from an imitation speech database |
| US6839670B1 (en)* | 1995-09-11 | 2005-01-04 | Harman Becker Automotive Systems Gmbh | Process for automatic control of one or more devices by voice commands or by real-time voice dialog and apparatus for carrying out this process |
| US20050119890A1 (en)* | 2003-11-28 | 2005-06-02 | Yoshifumi Hirose | Speech synthesis apparatus and speech synthesis method |
| JP2005164749A (en) | 2003-11-28 | 2005-06-23 | Toshiba Corp | Speech synthesis method, speech synthesizer, and speech synthesis program |
| US20050182629A1 (en)* | 2004-01-16 | 2005-08-18 | Geert Coorman | Corpus-based speech synthesis based on segment recombination |
| JP2005292433A (en) | 2004-03-31 | 2005-10-20 | Toshiba Corp | Speech synthesis apparatus, speech synthesis method, and speech synthesis program |
| US6980955B2 (en)* | 2000-03-31 | 2005-12-27 | Canon Kabushiki Kaisha | Synthesis unit selection apparatus and method, and storage medium |
| US6988069B2 (en)* | 2003-01-31 | 2006-01-17 | Speechworks International, Inc. | Reduced unit database generation based on cost information |
| US20060020473A1 (en)* | 2004-07-26 | 2006-01-26 | Atsuo Hiroe | Method, apparatus, and program for dialogue, and storage medium including a program stored therein |
| US20060041429A1 (en) | 2004-08-11 | 2006-02-23 | International Business Machines Corporation | Text-to-speech system and method |
| US20060074674A1 (en) | 2004-09-30 | 2006-04-06 | International Business Machines Corporation | Method and system for statistic-based distance definition in text-to-speech conversion |
| US20060074678A1 (en)* | 2004-09-29 | 2006-04-06 | Matsushita Electric Industrial Co., Ltd. | Prosody generation for text-to-speech synthesis based on micro-prosodic data |
| US20060085194A1 (en)* | 2000-03-31 | 2006-04-20 | Canon Kabushiki Kaisha | Speech synthesis apparatus and method, and storage medium |
| US20060229877A1 (en)* | 2005-04-06 | 2006-10-12 | Jilei Tian | Memory usage in a text-to-speech system |
| US7124083B2 (en)* | 2000-06-30 | 2006-10-17 | At&T Corp. | Method and system for preselection of suitable units for concatenative speech |
| US7136816B1 (en)* | 2002-04-05 | 2006-11-14 | At&T Corp. | System and method for predicting prosodic parameters |
| US20060259303A1 (en)* | 2005-05-12 | 2006-11-16 | Raimo Bakis | Systems and methods for pitch smoothing for text-to-speech synthesis |
| US7165030B2 (en)* | 2001-09-17 | 2007-01-16 | Massachusetts Institute Of Technology | Concatenative speech synthesis using a finite-state transducer |
| US20070073542A1 (en)* | 2005-09-23 | 2007-03-29 | International Business Machines Corporation | Method and system for configurable allocation of sound segments for use in concatenative text-to-speech voice synthesis |
| US7280967B2 (en)* | 2003-07-30 | 2007-10-09 | International Business Machines Corporation | Method for detecting misaligned phonetic units for a concatenative text-to-speech voice |
| US7280969B2 (en)* | 2000-12-07 | 2007-10-09 | International Business Machines Corporation | Method and apparatus for producing natural sounding pitch contours in a speech synthesizer |
| US20070264010A1 (en)* | 2006-05-09 | 2007-11-15 | Aegis Lightwave, Inc. | Self Calibrated Optical Spectrum Monitor |
| US20070276666A1 (en)* | 2004-09-16 | 2007-11-29 | France Telecom | Method and Device for Selecting Acoustic Units and a Voice Synthesis Method and Device |
| US20080027727A1 (en)* | 2006-07-31 | 2008-01-31 | Kabushiki Kaisha Toshiba | Speech synthesis apparatus and method |
| US20080046247A1 (en)* | 2006-08-21 | 2008-02-21 | Gakuto Kurata | System And Method For Supporting Text-To-Speech |
| US20080059190A1 (en)* | 2006-08-22 | 2008-03-06 | Microsoft Corporation | Speech unit selection using HMM acoustic models |
| US7349847B2 (en)* | 2004-10-13 | 2008-03-25 | Matsushita Electric Industrial Co., Ltd. | Speech synthesis apparatus and speech synthesis method |
| US7369994B1 (en)* | 1999-04-30 | 2008-05-06 | At&T Corp. | Methods and apparatus for rapid acoustic unit selection from a large speech corpus |
| US20080132178A1 (en)* | 2006-09-22 | 2008-06-05 | Shouri Chatterjee | Performing automatic frequency control |
| JP2008134475A (en) | 2006-11-28 | 2008-06-12 | Internatl Business Mach Corp <Ibm> | Technique for recognizing accent of input voice |
| US20080177548A1 (en)* | 2005-05-31 | 2008-07-24 | Canon Kabushiki Kaisha | Speech Synthesis Method and Apparatus |
| US20080195391A1 (en)* | 2005-03-28 | 2008-08-14 | Lessac Technologies, Inc. | Hybrid Speech Synthesizer, Method and Use |
| US20080243511A1 (en)* | 2006-10-24 | 2008-10-02 | Yusuke Fujita | Speech synthesizer |
| US7447635B1 (en)* | 1999-10-19 | 2008-11-04 | Sony Corporation | Natural language interface control system |
| US7454343B2 (en)* | 2005-06-16 | 2008-11-18 | Panasonic Corporation | Speech synthesizer, speech synthesizing method, and program |
| US20080288256A1 (en)* | 2007-05-14 | 2008-11-20 | International Business Machines Corporation | Reducing recording time when constructing a concatenative tts voice using a reduced script and pre-recorded speech assets |
| US20090055188A1 (en)* | 2007-08-21 | 2009-02-26 | Kabushiki Kaisha Toshiba | Pitch pattern generation method and apparatus thereof |
| US20090083036A1 (en)* | 2007-09-20 | 2009-03-26 | Microsoft Corporation | Unnatural prosody detection in speech synthesis |
| US20090112596A1 (en)* | 2007-10-30 | 2009-04-30 | At&T Lab, Inc. | System and method for improving synthesized speech interactions of a spoken dialog system |
| US20090204405A1 (en)* | 2005-09-06 | 2009-08-13 | Nec Corporation | Method, apparatus and program for speech synthesis |
| US20090234652A1 (en)* | 2005-05-18 | 2009-09-17 | Yumiko Kato | Voice synthesis device |
| US20090254349A1 (en)* | 2006-06-05 | 2009-10-08 | Yoshifumi Hirose | Speech synthesizer |
| US7617105B2 (en)* | 2004-05-31 | 2009-11-10 | Nuance Communications, Inc. | Converting text-to-speech and adjusting corpus |
| US7630896B2 (en)* | 2005-03-29 | 2009-12-08 | Kabushiki Kaisha Toshiba | Speech synthesis system and method |
| US7643990B1 (en)* | 2003-10-23 | 2010-01-05 | Apple Inc. | Global boundary-centric feature extraction and associated discontinuity metrics |
| US20100004931A1 (en)* | 2006-09-15 | 2010-01-07 | Bin Ma | Apparatus and method for speech utterance verification |
| US20100076768A1 (en) | 2007-02-20 | 2010-03-25 | Nec Corporation | Speech synthesizing apparatus, method, and program |
| US7702510B2 (en)* | 2007-01-12 | 2010-04-20 | Nuance Communications, Inc. | System and method for dynamically selecting among TTS systems |
| US7716052B2 (en)* | 2005-04-07 | 2010-05-11 | Nuance Communications, Inc. | Method, apparatus and computer program providing a multi-speaker database for concatenative text-to-speech synthesis |
| US7761296B1 (en)* | 1999-04-02 | 2010-07-20 | International Business Machines Corporation | System and method for rescoring N-best hypotheses of an automatic speech recognition system |
| US7801725B2 (en)* | 2006-03-30 | 2010-09-21 | Industrial Technology Research Institute | Method for speech quality degradation estimation and method for degradation measures calculation and apparatuses thereof |
| US7912719B2 (en)* | 2004-05-11 | 2011-03-22 | Panasonic Corporation | Speech synthesis device and speech synthesis method for changing a voice characteristic |
| US7916799B2 (en)* | 2006-04-03 | 2011-03-29 | Realtek Semiconductor Corp. | Frequency offset correction for an ultrawideband communication system |
| US8015011B2 (en)* | 2007-01-30 | 2011-09-06 | Nuance Communications, Inc. | Generating objectively evaluated sufficiently natural synthetic speech from text by using selective paraphrases |
| US8024193B2 (en)* | 2006-10-10 | 2011-09-20 | Apple Inc. | Methods and apparatus related to pruning for concatenative text-to-speech synthesis |
| US8041569B2 (en)* | 2007-03-14 | 2011-10-18 | Canon Kabushiki Kaisha | Speech synthesis method and apparatus using pre-recorded speech and rule-based synthesized speech |
| US8055501B2 (en)* | 2007-06-23 | 2011-11-08 | Industrial Technology Research Institute | Speech synthesizer generating system and method thereof |
| US20120059654A1 (en)* | 2009-05-28 | 2012-03-08 | International Business Machines Corporation | Speaker-adaptive synthesized voice |
| US8155964B2 (en)* | 2007-06-06 | 2012-04-10 | Panasonic Corporation | Voice quality edit device and voice quality edit method |
| US8175881B2 (en)* | 2007-08-17 | 2012-05-08 | Kabushiki Kaisha Toshiba | Method and apparatus using fused formant parameters to generate synthesized speech |
| US8249874B2 (en)* | 2007-03-07 | 2012-08-21 | Nuance Communications, Inc. | Synthesizing speech from text |
| US8255222B2 (en)* | 2007-08-10 | 2012-08-28 | Panasonic Corporation | Speech separating apparatus, speech synthesizing apparatus, and voice quality conversion apparatus |
| US20120321016A1 (en)* | 2002-07-12 | 2012-12-20 | Alcatel-Lucent Usa Inc | Communicating Over Single- or Multiple- Antenna Channels Having Both Temporal and Spectral Fluctuations |
| US8370149B2 (en) | 2007-09-07 | 2013-02-05 | Nuance Communications, Inc. | Speech synthesis system, speech synthesis program product, and speech synthesis method |
- 2007
- 2007-09-07JPJP2007232395Apatent/JP5238205B2/ennot_activeExpired - Fee Related
- 2008
- 2008-08-15USUS12/192,510patent/US8370149B2/enactiveActive
- 2012
- 2012-12-31USUS13/731,268patent/US9275631B2/enactiveActive
Patent Citations (109)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3828132A (en)* | 1970-10-30 | 1974-08-06 | Bell Telephone Labor Inc | Speech synthesis by concatenation of formant encoded words |
| US5664050A (en)* | 1993-06-02 | 1997-09-02 | Telia Ab | Process for evaluating speech quality in speech synthesis |
| US5999900A (en)* | 1993-06-21 | 1999-12-07 | British Telecommunications Public Limited Company | Reduced redundancy test signal similar to natural speech for supporting data manipulation functions in testing telecommunications equipment |
| US6839670B1 (en)* | 1995-09-11 | 2005-01-04 | Harman Becker Automotive Systems Gmbh | Process for automatic control of one or more devices by voice commands or by real-time voice dialog and apparatus for carrying out this process |
| US6240384B1 (en)* | 1995-12-04 | 2001-05-29 | Kabushiki Kaisha Toshiba | Speech synthesis method |
| US5913193A (en)* | 1996-04-30 | 1999-06-15 | Microsoft Corporation | Method and system of runtime acoustic unit selection for speech synthesis |
| US6366883B1 (en)* | 1996-05-15 | 2002-04-02 | Atr Interpreting Telecommunications | Concatenation of speech segments by use of a speech synthesizer |
| US6233544B1 (en)* | 1996-06-14 | 2001-05-15 | At&T Corp | Method and apparatus for language translation |
| US6377917B1 (en)* | 1997-01-27 | 2002-04-23 | Microsoft Corporation | System and methodology for prosody modification |
| US6173263B1 (en)* | 1998-08-31 | 2001-01-09 | At&T Corp. | Method and system for performing concatenative speech synthesis using half-phonemes |
| US6266637B1 (en)* | 1998-09-11 | 2001-07-24 | International Business Machines Corporation | Phrase splicing and variable substitution using a trainable speech synthesizer |
| US6665641B1 (en)* | 1998-11-13 | 2003-12-16 | Scansoft, Inc. | Speech synthesis using concatenation of speech waveforms |
| US7219060B2 (en)* | 1998-11-13 | 2007-05-15 | Nuance Communications, Inc. | Speech synthesis using concatenation of speech waveforms |
| US6253182B1 (en)* | 1998-11-24 | 2001-06-26 | Microsoft Corporation | Method and apparatus for speech synthesis with efficient spectral smoothing |
| US6823309B1 (en)* | 1999-03-25 | 2004-11-23 | Matsushita Electric Industrial Co., Ltd. | Speech synthesizing system and method for modifying prosody based on match to database |
| US7761296B1 (en)* | 1999-04-02 | 2010-07-20 | International Business Machines Corporation | System and method for rescoring N-best hypotheses of an automatic speech recognition system |
| US7369994B1 (en)* | 1999-04-30 | 2008-05-06 | At&T Corp. | Methods and apparatus for rapid acoustic unit selection from a large speech corpus |
| US6701295B2 (en)* | 1999-04-30 | 2004-03-02 | At&T Corp. | Methods and apparatus for rapid acoustic unit selection from a large speech corpus |
| US7447635B1 (en)* | 1999-10-19 | 2008-11-04 | Sony Corporation | Natural language interface control system |
| US20010056347A1 (en)* | 1999-11-02 | 2001-12-27 | International Business Machines Corporation | Feature-domain concatenative speech synthesis |
| US20010021906A1 (en)* | 2000-03-03 | 2001-09-13 | Keiichi Chihara | Intonation control method for text-to-speech conversion |
| US6980955B2 (en)* | 2000-03-31 | 2005-12-27 | Canon Kabushiki Kaisha | Synthesis unit selection apparatus and method, and storage medium |
| US7039588B2 (en)* | 2000-03-31 | 2006-05-02 | Canon Kabushiki Kaisha | Synthesis unit selection apparatus and method, and storage medium |
| US20060085194A1 (en)* | 2000-03-31 | 2006-04-20 | Canon Kabushiki Kaisha | Speech synthesis apparatus and method, and storage medium |
| JP2001282282A (en) | 2000-03-31 | 2001-10-12 | Canon Inc | Voice information processing method and apparatus, and storage medium |
| US7155390B2 (en)* | 2000-03-31 | 2006-12-26 | Canon Kabushiki Kaisha | Speech information processing method and apparatus and storage medium using a segment pitch pattern model |
| US20010039492A1 (en)* | 2000-05-02 | 2001-11-08 | International Business Machines Corporation | Method, system, and apparatus for speech recognition |
| US20030208355A1 (en)* | 2000-05-31 | 2003-11-06 | Stylianou Ioannis G. | Stochastic modeling of spectral adjustment for high quality pitch modification |
| US7124083B2 (en)* | 2000-06-30 | 2006-10-17 | At&T Corp. | Method and system for preselection of suitable units for concatenative speech |
| US7069216B2 (en)* | 2000-09-29 | 2006-06-27 | Nuance Communications, Inc. | Corpus-based prosody translation system |
| US20020152073A1 (en)* | 2000-09-29 | 2002-10-17 | Demoortel Jan | Corpus-based prosody translation system |
| US20040148171A1 (en)* | 2000-12-04 | 2004-07-29 | Microsoft Corporation | Method and apparatus for speech synthesis without prosody modification |
| US7280969B2 (en)* | 2000-12-07 | 2007-10-09 | International Business Machines Corporation | Method and apparatus for producing natural sounding pitch contours in a speech synthesizer |
| US20030158721A1 (en)* | 2001-03-08 | 2003-08-21 | Yumiko Kato | Prosody generating device, prosody generating method, and program |
| US20040172249A1 (en)* | 2001-05-25 | 2004-09-02 | Taylor Paul Alexander | Speech synthesis |
| US6829581B2 (en)* | 2001-07-31 | 2004-12-07 | Matsushita Electric Industrial Co., Ltd. | Method for prosody generation by unit selection from an imitation speech database |
| US20030046079A1 (en)* | 2001-09-03 | 2003-03-06 | Yasuo Yoshioka | Voice synthesizing apparatus capable of adding vibrato effect to synthesized voice |
| US7165030B2 (en)* | 2001-09-17 | 2007-01-16 | Massachusetts Institute Of Technology | Concatenative speech synthesis using a finite-state transducer |
| US20030088417A1 (en)* | 2001-09-19 | 2003-05-08 | Takahiro Kamai | Speech analysis method and speech synthesis system |
| US20030112987A1 (en)* | 2001-12-18 | 2003-06-19 | Gn Resound A/S | Hearing prosthesis with automatic classification of the listening environment |
| US7136816B1 (en)* | 2002-04-05 | 2006-11-14 | At&T Corp. | System and method for predicting prosodic parameters |
| US20030195743A1 (en)* | 2002-04-10 | 2003-10-16 | Industrial Technology Research Institute | Method of speech segment selection for concatenative synthesis based on prosody-aligned distance measure |
| US20120321016A1 (en)* | 2002-07-12 | 2012-12-20 | Alcatel-Lucent Usa Inc | Communicating Over Single- or Multiple- Antenna Channels Having Both Temporal and Spectral Fluctuations |
| US7286986B2 (en)* | 2002-08-02 | 2007-10-23 | Rhetorical Systems Limited | Method and apparatus for smoothing fundamental frequency discontinuities across synthesized speech segments |
| US20040059568A1 (en)* | 2002-08-02 | 2004-03-25 | David Talkin | Method and apparatus for smoothing fundamental frequency discontinuities across synthesized speech segments |
| US20040030555A1 (en)* | 2002-08-12 | 2004-02-12 | Oregon Health & Science University | System and method for concatenating acoustic contours for speech synthesis |
| JP2004109535A (en) | 2002-09-19 | 2004-04-08 | Nippon Hoso Kyokai <Nhk> | Speech synthesis method, speech synthesis device, and speech synthesis program |
| JP2004139033A (en) | 2002-09-25 | 2004-05-13 | Nippon Hoso Kyokai <Nhk> | Speech synthesis method, speech synthesis device, and speech synthesis program |
| US6988069B2 (en)* | 2003-01-31 | 2006-01-17 | Speechworks International, Inc. | Reduced unit database generation based on cost information |
| US20040220813A1 (en)* | 2003-04-30 | 2004-11-04 | Fuliang Weng | Method for statistical language modeling in speech recognition |
| US7280967B2 (en)* | 2003-07-30 | 2007-10-09 | International Business Machines Corporation | Method for detecting misaligned phonetic units for a concatenative text-to-speech voice |
| US7643990B1 (en)* | 2003-10-23 | 2010-01-05 | Apple Inc. | Global boundary-centric feature extraction and associated discontinuity metrics |
| JP2005164749A (en) | 2003-11-28 | 2005-06-23 | Toshiba Corp | Speech synthesis method, speech synthesizer, and speech synthesis program |
| US20050137870A1 (en) | 2003-11-28 | 2005-06-23 | Tatsuya Mizutani | Speech synthesis method, speech synthesis system, and speech synthesis program |
| US7668717B2 (en)* | 2003-11-28 | 2010-02-23 | Kabushiki Kaisha Toshiba | Speech synthesis method, speech synthesis system, and speech synthesis program |
| US20050119890A1 (en)* | 2003-11-28 | 2005-06-02 | Yoshifumi Hirose | Speech synthesis apparatus and speech synthesis method |
| US7856357B2 (en)* | 2003-11-28 | 2010-12-21 | Kabushiki Kaisha Toshiba | Speech synthesis method, speech synthesis system, and speech synthesis program |
| US7567896B2 (en)* | 2004-01-16 | 2009-07-28 | Nuance Communications, Inc. | Corpus-based speech synthesis based on segment recombination |
| US20050182629A1 (en)* | 2004-01-16 | 2005-08-18 | Geert Coorman | Corpus-based speech synthesis based on segment recombination |
| JP2005292433A (en) | 2004-03-31 | 2005-10-20 | Toshiba Corp | Speech synthesis apparatus, speech synthesis method, and speech synthesis program |
| US7912719B2 (en)* | 2004-05-11 | 2011-03-22 | Panasonic Corporation | Speech synthesis device and speech synthesis method for changing a voice characteristic |
| US7617105B2 (en)* | 2004-05-31 | 2009-11-10 | Nuance Communications, Inc. | Converting text-to-speech and adjusting corpus |
| US20060020473A1 (en)* | 2004-07-26 | 2006-01-26 | Atsuo Hiroe | Method, apparatus, and program for dialogue, and storage medium including a program stored therein |
| US7869999B2 (en)* | 2004-08-11 | 2011-01-11 | Nuance Communications, Inc. | Systems and methods for selecting from multiple phonectic transcriptions for text-to-speech synthesis |
| US20060041429A1 (en) | 2004-08-11 | 2006-02-23 | International Business Machines Corporation | Text-to-speech system and method |
| US20070276666A1 (en)* | 2004-09-16 | 2007-11-29 | France Telecom | Method and Device for Selecting Acoustic Units and a Voice Synthesis Method and Device |
| US20060074678A1 (en)* | 2004-09-29 | 2006-04-06 | Matsushita Electric Industrial Co., Ltd. | Prosody generation for text-to-speech synthesis based on micro-prosodic data |
| US20060074674A1 (en) | 2004-09-30 | 2006-04-06 | International Business Machines Corporation | Method and system for statistic-based distance definition in text-to-speech conversion |
| US7590540B2 (en)* | 2004-09-30 | 2009-09-15 | Nuance Communications, Inc. | Method and system for statistic-based distance definition in text-to-speech conversion |
| US7349847B2 (en)* | 2004-10-13 | 2008-03-25 | Matsushita Electric Industrial Co., Ltd. | Speech synthesis apparatus and speech synthesis method |
| US20080195391A1 (en)* | 2005-03-28 | 2008-08-14 | Lessac Technologies, Inc. | Hybrid Speech Synthesizer, Method and Use |
| US7630896B2 (en)* | 2005-03-29 | 2009-12-08 | Kabushiki Kaisha Toshiba | Speech synthesis system and method |
| US20060229877A1 (en)* | 2005-04-06 | 2006-10-12 | Jilei Tian | Memory usage in a text-to-speech system |
| US7716052B2 (en)* | 2005-04-07 | 2010-05-11 | Nuance Communications, Inc. | Method, apparatus and computer program providing a multi-speaker database for concatenative text-to-speech synthesis |
| US20060259303A1 (en)* | 2005-05-12 | 2006-11-16 | Raimo Bakis | Systems and methods for pitch smoothing for text-to-speech synthesis |
| US20090234652A1 (en)* | 2005-05-18 | 2009-09-17 | Yumiko Kato | Voice synthesis device |
| US20080177548A1 (en)* | 2005-05-31 | 2008-07-24 | Canon Kabushiki Kaisha | Speech Synthesis Method and Apparatus |
| US7454343B2 (en)* | 2005-06-16 | 2008-11-18 | Panasonic Corporation | Speech synthesizer, speech synthesizing method, and program |
| US20090204405A1 (en)* | 2005-09-06 | 2009-08-13 | Nec Corporation | Method, apparatus and program for speech synthesis |
| US20070073542A1 (en)* | 2005-09-23 | 2007-03-29 | International Business Machines Corporation | Method and system for configurable allocation of sound segments for use in concatenative text-to-speech voice synthesis |
| US7801725B2 (en)* | 2006-03-30 | 2010-09-21 | Industrial Technology Research Institute | Method for speech quality degradation estimation and method for degradation measures calculation and apparatuses thereof |
| US7916799B2 (en)* | 2006-04-03 | 2011-03-29 | Realtek Semiconductor Corp. | Frequency offset correction for an ultrawideband communication system |
| US20070264010A1 (en)* | 2006-05-09 | 2007-11-15 | Aegis Lightwave, Inc. | Self Calibrated Optical Spectrum Monitor |
| US20090254349A1 (en)* | 2006-06-05 | 2009-10-08 | Yoshifumi Hirose | Speech synthesizer |
| US20080027727A1 (en)* | 2006-07-31 | 2008-01-31 | Kabushiki Kaisha Toshiba | Speech synthesis apparatus and method |
| US20080046247A1 (en)* | 2006-08-21 | 2008-02-21 | Gakuto Kurata | System And Method For Supporting Text-To-Speech |
| US7921014B2 (en)* | 2006-08-21 | 2011-04-05 | Nuance Communications, Inc. | System and method for supporting text-to-speech |
| US20080059190A1 (en)* | 2006-08-22 | 2008-03-06 | Microsoft Corporation | Speech unit selection using HMM acoustic models |
| US20100004931A1 (en)* | 2006-09-15 | 2010-01-07 | Bin Ma | Apparatus and method for speech utterance verification |
| US20080132178A1 (en)* | 2006-09-22 | 2008-06-05 | Shouri Chatterjee | Performing automatic frequency control |
| US8024193B2 (en)* | 2006-10-10 | 2011-09-20 | Apple Inc. | Methods and apparatus related to pruning for concatenative text-to-speech synthesis |
| US20080243511A1 (en)* | 2006-10-24 | 2008-10-02 | Yusuke Fujita | Speech synthesizer |
| US20080177543A1 (en)* | 2006-11-28 | 2008-07-24 | International Business Machines Corporation | Stochastic Syllable Accent Recognition |
| JP2008134475A (en) | 2006-11-28 | 2008-06-12 | Internatl Business Mach Corp <Ibm> | Technique for recognizing accent of input voice |
| US7702510B2 (en)* | 2007-01-12 | 2010-04-20 | Nuance Communications, Inc. | System and method for dynamically selecting among TTS systems |
| US8015011B2 (en)* | 2007-01-30 | 2011-09-06 | Nuance Communications, Inc. | Generating objectively evaluated sufficiently natural synthetic speech from text by using selective paraphrases |
| US20100076768A1 (en) | 2007-02-20 | 2010-03-25 | Nec Corporation | Speech synthesizing apparatus, method, and program |
| US8249874B2 (en)* | 2007-03-07 | 2012-08-21 | Nuance Communications, Inc. | Synthesizing speech from text |
| US8041569B2 (en)* | 2007-03-14 | 2011-10-18 | Canon Kabushiki Kaisha | Speech synthesis method and apparatus using pre-recorded speech and rule-based synthesized speech |
| US20080288256A1 (en)* | 2007-05-14 | 2008-11-20 | International Business Machines Corporation | Reducing recording time when constructing a concatenative tts voice using a reduced script and pre-recorded speech assets |
| US8155964B2 (en)* | 2007-06-06 | 2012-04-10 | Panasonic Corporation | Voice quality edit device and voice quality edit method |
| US8055501B2 (en)* | 2007-06-23 | 2011-11-08 | Industrial Technology Research Institute | Speech synthesizer generating system and method thereof |
| US8255222B2 (en)* | 2007-08-10 | 2012-08-28 | Panasonic Corporation | Speech separating apparatus, speech synthesizing apparatus, and voice quality conversion apparatus |
| US8175881B2 (en)* | 2007-08-17 | 2012-05-08 | Kabushiki Kaisha Toshiba | Method and apparatus using fused formant parameters to generate synthesized speech |
| US20090055188A1 (en)* | 2007-08-21 | 2009-02-26 | Kabushiki Kaisha Toshiba | Pitch pattern generation method and apparatus thereof |
| US8370149B2 (en) | 2007-09-07 | 2013-02-05 | Nuance Communications, Inc. | Speech synthesis system, speech synthesis program product, and speech synthesis method |
| US20090083036A1 (en)* | 2007-09-20 | 2009-03-26 | Microsoft Corporation | Unnatural prosody detection in speech synthesis |
| US20090112596A1 (en)* | 2007-10-30 | 2009-04-30 | At&T Lab, Inc. | System and method for improving synthesized speech interactions of a spoken dialog system |
| US20120059654A1 (en)* | 2009-05-28 | 2012-03-08 | International Business Machines Corporation | Speaker-adaptive synthesized voice |
Non-Patent Citations (5)
| Title |
|---|
| Black, A. W., Taylor, P., "Automatically clustering similar units for unit selection in speech synthesis," Proc. Eurospeech '97, Rhodes, pp. 601-604, 1997. |
| Donovan, R. E., et al., "Current status of the IBM trainable speech synthesis system," Proc. 4th ISCA Tutorial and Research Workshop on Speech Synthesis. Atholl Palace Hotel, Scotland, 2001. |
| E. Eide, A. Aaron, R. Bakis, R. Cohen, R. Donovan, W. Hamza, T. Mathes, M. Picheny, M. Polkosky, M. Smith, and M. Viswanathan, "Recent improvements to the IBM trainable speech synthesis system," in Proc. of ICASSP, 2003, pp. 1-708-I-711. |
| Office Action mailed Feb. 28, 2012 in corresponding Japanese Application No. 2007-232395. |
| Xi Jun Ma, Wei Zhang, Weibin Zhu, Qin Shi and Ling Jin, "Probability based prosody model for unit selection," Proc. ICASSP, Montreal, 2004. |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20160365085A1 (en)* | 2015-06-11 | 2016-12-15 | Interactive Intelligence Group, Inc. | System and method for outlier identification to remove poor alignments in speech synthesis |
| US9972300B2 (en)* | 2015-06-11 | 2018-05-15 | Genesys Telecommunications Laboratories, Inc. | System and method for outlier identification to remove poor alignments in speech synthesis |
| US10497362B2 (en) | 2015-06-11 | 2019-12-03 | Interactive Intelligence Group, Inc. | System and method for outlier identification to remove poor alignments in speech synthesis |
Also Published As
| Publication number | Publication date |
|---|---|
| US8370149B2 (en) | 2013-02-05 |
| US20090070115A1 (en) | 2009-03-12 |
| JP2009063869A (en) | 2009-03-26 |
| JP5238205B2 (en) | 2013-07-17 |
| US20130268275A1 (en) | 2013-10-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9275631B2 (en) | Speech synthesis system, speech synthesis program product, and speech synthesis method | |
| JP4054507B2 (en) | Voice information processing method and apparatus, and storage medium | |
| JP4080989B2 (en) | Speech synthesis method, speech synthesizer, and speech synthesis program | |
| US6778962B1 (en) | Speech synthesis with prosodic model data and accent type | |
| US10692484B1 (en) | Text-to-speech (TTS) processing | |
| US9484012B2 (en) | Speech synthesis dictionary generation apparatus, speech synthesis dictionary generation method and computer program product | |
| US20060259303A1 (en) | Systems and methods for pitch smoothing for text-to-speech synthesis | |
| US20040215459A1 (en) | Speech information processing method and apparatus and storage medium | |
| JP4406440B2 (en) | Speech synthesis apparatus, speech synthesis method and program | |
| Gutkin et al. | TTS for low resource languages: A Bangla synthesizer | |
| US20160189705A1 (en) | Quantitative f0 contour generating device and method, and model learning device and method for f0 contour generation | |
| JP4648878B2 (en) | Style designation type speech synthesis method, style designation type speech synthesis apparatus, program thereof, and storage medium thereof | |
| Gutkin et al. | Building statistical parametric multi-speaker synthesis for bangladeshi bangla | |
| JP4532862B2 (en) | Speech synthesis method, speech synthesizer, and speech synthesis program | |
| JP5007401B2 (en) | Pronunciation rating device and program | |
| JP4247289B1 (en) | Speech synthesis apparatus, speech synthesis method and program thereof | |
| US20130117026A1 (en) | Speech synthesizer, speech synthesis method, and speech synthesis program | |
| JP3854593B2 (en) | Speech synthesis apparatus, cost calculation apparatus therefor, and computer program | |
| JP2006084854A (en) | Speech synthesis apparatus, speech synthesis method, and speech synthesis program | |
| EP1589524B1 (en) | Method and device for speech synthesis | |
| EP1640968A1 (en) | Method and device for speech synthesis | |
| Dzibela et al. | Hidden-Markov-Model Based Speech Enhancement | |
| JP4603290B2 (en) | Speech synthesis apparatus and speech synthesis program | |
| Janicki et al. | Taking advantage of pronunciation variation in unit selection speech synthesis for Polish | |
| CN115798452A (en) | End-to-end voice splicing synthesis method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment | Owner name:INTERNATIONAL BUSINESS MACHINES CORPORATION, NEW Y Free format text:ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:TACHIBANA, RYUKI;NISHIMURA, MASAFUMI;REEL/FRAME:029666/0218 Effective date:20080630 | |
| AS | Assignment | Owner name:NUANCE COMMUNICATIONS, INC., MASSACHUSETTS Free format text:ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:INTERNATIONAL BUSINESS MACHINES CORPORATION;REEL/FRAME:029683/0432 Effective date:20090331 | |
| STCF | Information on status: patent grant | Free format text:PATENTED CASE | |
| MAFP | Maintenance fee payment | Free format text:PAYMENT OF MAINTENANCE FEE, 4TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1551); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment:4 | |
| AS | Assignment | Owner name:CERENCE INC., MASSACHUSETTS Free format text:INTELLECTUAL PROPERTY AGREEMENT;ASSIGNOR:NUANCE COMMUNICATIONS, INC.;REEL/FRAME:050836/0191 Effective date:20190930 | |
| AS | Assignment | Owner name:CERENCE OPERATING COMPANY, MASSACHUSETTS Free format text:CORRECTIVE ASSIGNMENT TO CORRECT THE ASSIGNEE NAME PREVIOUSLY RECORDED AT REEL: 050836 FRAME: 0191. ASSIGNOR(S) HEREBY CONFIRMS THE INTELLECTUAL PROPERTY AGREEMENT;ASSIGNOR:NUANCE COMMUNICATIONS, INC.;REEL/FRAME:050871/0001 Effective date:20190930 | |
| AS | Assignment | Owner name:BARCLAYS BANK PLC, NEW YORK Free format text:SECURITY AGREEMENT;ASSIGNOR:CERENCE OPERATING COMPANY;REEL/FRAME:050953/0133 Effective date:20191001 | |
| AS | Assignment | Owner name:CERENCE OPERATING COMPANY, MASSACHUSETTS Free format text:RELEASE BY SECURED PARTY;ASSIGNOR:BARCLAYS BANK PLC;REEL/FRAME:052927/0335 Effective date:20200612 | |
| AS | Assignment | Owner name:WELLS FARGO BANK, N.A., NORTH CAROLINA Free format text:SECURITY AGREEMENT;ASSIGNOR:CERENCE OPERATING COMPANY;REEL/FRAME:052935/0584 Effective date:20200612 | |
| AS | Assignment | Owner name:CERENCE OPERATING COMPANY, MASSACHUSETTS Free format text:CORRECTIVE ASSIGNMENT TO CORRECT THE REPLACE THE CONVEYANCE DOCUMENT WITH THE NEW ASSIGNMENT PREVIOUSLY RECORDED AT REEL: 050836 FRAME: 0191. ASSIGNOR(S) HEREBY CONFIRMS THE ASSIGNMENT;ASSIGNOR:NUANCE COMMUNICATIONS, INC.;REEL/FRAME:059804/0186 Effective date:20190930 | |
| MAFP | Maintenance fee payment | Free format text:PAYMENT OF MAINTENANCE FEE, 8TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1552); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment:8 | |
| AS | Assignment | Owner name:CERENCE OPERATING COMPANY, MASSACHUSETTS Free format text:RELEASE (REEL 052935 / FRAME 0584);ASSIGNOR:WELLS FARGO BANK, NATIONAL ASSOCIATION;REEL/FRAME:069797/0818 Effective date:20241231 |