TWI813358B - Memory device and data searching method thereof - Google Patents
Memory device and data searching method thereofDownload PDFInfo
- Publication number
- TWI813358B TWI813358BTW111124082ATW111124082ATWI813358BTW I813358 BTWI813358 BTW I813358BTW 111124082 ATW111124082 ATW 111124082ATW 111124082 ATW111124082 ATW 111124082ATW I813358 BTWI813358 BTW I813358B
- Authority
- TW
- Taiwan
- Prior art keywords
- search
- data
- memory
- database
- vector
- Prior art date
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription26
- 239000013598vectorSubstances0.000claimsabstractdescription211
- 238000007906compressionMethods0.000claimsabstractdescription31
- 230000006835compressionEffects0.000claimsabstractdescription31
- 238000010586diagramMethods0.000description31
- 238000004364calculation methodMethods0.000description10
- 238000004458analytical methodMethods0.000description9
- 238000013144data compressionMethods0.000description6
- 230000008901benefitEffects0.000description3
- 230000002093peripheral effectEffects0.000description3
- 230000011218segmentationEffects0.000description3
- 238000013473artificial intelligenceMethods0.000description2
- 230000009286beneficial effectEffects0.000description2
- 238000001514detection methodMethods0.000description2
- 238000012986modificationMethods0.000description2
- 230000004048modificationEffects0.000description2
- 238000009825accumulationMethods0.000description1
- 230000008859changeEffects0.000description1
- 238000006243chemical reactionMethods0.000description1
- 238000007418data miningMethods0.000description1
- 230000000694effectsEffects0.000description1
- 238000005516engineering processMethods0.000description1
- 230000001815facial effectEffects0.000description1
- 230000006870functionEffects0.000description1
- 230000000873masking effectEffects0.000description1
- 238000005065miningMethods0.000description1
- 238000005192partitionMethods0.000description1
- 230000009467reductionEffects0.000description1
- 238000011524similarity measureMethods0.000description1
Images

























Landscapes
- Debugging And Monitoring (AREA)
- Radar Systems Or Details Thereof (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
Translated fromChinese本發明是有關於一種記憶體裝置及其資料搜尋方法。The present invention relates to a memory device and a data search method thereof.
目前已進入資訊時代,對於相似性分析有極為廣泛的需求。例如,文字探勘(text mining)、資料探勘(data mining)、抄襲檢測、推薦系統、人臉辨識、聲紋辨識、指紋辨識等。Now that we have entered the information age, there is an extremely wide range of needs for similarity analysis. For example, text mining, data mining, plagiarism detection, recommendation system, face recognition, voiceprint recognition, fingerprint recognition, etc.
相似度分析經常是以向量分析來進行,常見的向量相似性度量包括但不限於,歐幾里得距離(Euclidean distance)、餘弦相似性(Cosine similarity)、漢明距離(Hamming distance)等。Similarity analysis is often performed by vector analysis. Common vector similarity measures include, but are not limited to, Euclidean distance, Cosine similarity, Hamming distance, etc.
為了做上述分析,先汲取物件特徵,將之向量化。例如,在龐大的資料庫中做人工智慧(AI)訓練,訓練完成後,模型可對所輸入的人臉資訊進行向量化。好的模型可將同一人的不同照片,輸出成相似度高的向量。之後,將欲搜尋物件向量化後,與資料庫中的向量進行相似性分析,以搜尋資料庫內的資料是否相似於欲搜尋物件。In order to do the above analysis, first extract the object characteristics and vectorize them. For example, artificial intelligence (AI) training is done in a huge database. After the training is completed, the model can vectorize the input face information. A good model can output different photos of the same person into vectors with high similarity. Afterwards, the object to be searched is vectorized, and similarity analysis is performed with the vectors in the database to search whether the data in the database is similar to the object to be searched.
故而,目前需要有一種能達成計算簡單但分析結果可信度高的記憶體裝置及其資料搜尋方法。Therefore, there is currently a need for a memory device and a data search method that can achieve simple calculations but high reliability of analysis results.
根據本案一實施例,提出一種記憶體裝置之資料搜尋方法,包括:根據所記錄的一壓縮模式,對一搜尋資料進行向量化以得到一搜尋資料向量,以及,根據該壓縮模式,對該搜尋資料與一資料庫的複數個物件進行壓縮;設定一搜尋條件;以該搜尋資料向量去搜尋該資料庫的該些物件,以判斷該搜尋資料是否匹配於該資料庫中的該些物件;以及記錄並輸出與該搜尋資料匹配的該資料庫中的至少一匹配物件。According to an embodiment of the present invention, a data search method for a memory device is proposed, including: vectorizing a search data according to a recorded compression mode to obtain a search data vector, and performing the search data vector according to the compression mode. Compressing data with multiple objects in a database; setting a search condition; using the search data vector to search for the objects in the database to determine whether the search data matches the objects in the database; and Record and output at least one matching object in the database that matches the search data.
根據本案另一實施例,提出一種記憶體裝置,包括:複數個記憶平面,各該些記憶平面包括一記憶體陣列,該記憶體陣列包括複數個記憶區塊、複數條字元線與複數條位元線,各該記憶區塊包括複數個記憶體晶胞,位於該些字元線與該些位元線之複數個交叉處;其中,於各該些記憶區塊中,該些m個記憶體晶胞組成一記憶體晶胞群組,該些m個記憶體晶胞中之n個記憶體晶胞被程式化為一第一臨界電壓,該些m個記憶體晶胞中之(m-n)個記憶體晶胞被程式化為一第二臨界電壓,m為大於等於2的正整數,n為大於等於1的正整數,該記憶體晶胞群組儲存一第一物件之一第一特徵向量;於進行資料搜尋時,一搜尋資料編碼成m個搜尋電壓,該些m個搜尋電壓中之n個搜尋電壓為一第一搜尋電壓,該些m個搜尋電壓中之(m-n)個搜尋電壓為一第二搜尋電壓;於進行資料搜尋時,耦接至一第一位元線的p個記憶區塊同時被打開,p為大於等於2的正整數;以及根據該第一位元線上之一電流感應結果,以判斷該搜尋資料是否匹配於該記憶體晶胞群組之該第一物件之該第一特徵向量。According to another embodiment of the present invention, a memory device is proposed, including: a plurality of memory planes, each of the memory planes including a memory array, and the memory array includes a plurality of memory blocks, a plurality of character lines and a plurality of character lines. Bit lines, each memory block includes a plurality of memory unit cells, located at a plurality of intersections of the word lines and the bit lines; wherein, in each of the memory blocks, the m The memory unit cells form a memory unit cell group, n memory unit cells among the m memory unit cells are programmed to a first critical voltage, and ( m-n) memory cells are programmed to a second critical voltage, m is a positive integer greater than or equal to 2, n is a positive integer greater than or equal to 1, and the memory cell group stores one of the first objects. A feature vector; when performing data search, a search data is encoded into m search voltages, n search voltages among the m search voltages are a first search voltage, and (m-n) among the m search voltages The search voltage is a second search voltage;When performing data search, p memory blocks coupled to a first element line are opened at the same time, p is a positive integer greater than or equal to 2; and based on a current sensing result on the first element line, it is determined Whether the search data matches the first eigenvector of the first object of the memory cell group.
根據本案更一實施例,提出一種記憶體裝置,包括:一記憶體陣列,以及一控制器,耦接至該記憶體陣列,其中,該控制器架構成:根據所記錄的一壓縮模式,對一搜尋資料進行向量化以得到一搜尋資料向量,以及,根據該壓縮模式,對該搜尋資料與一資料庫的複數個物件進行壓縮,該資料庫的該些物件係儲存於該記憶體陣列內;設定一搜尋條件;以該搜尋資料向量去搜尋儲存於該記憶體陣列內的該資料庫的該些物件,以判斷該搜尋資料是否匹配於該資料庫中的該些物件;以及記錄並輸出與該搜尋資料匹配的該資料庫中的至少一匹配物件。According to a further embodiment of the present case, a memory device is proposed, including: a memory array, and a controller coupled to the memory array, wherein the controller is configured to: according to a recorded compression mode, Vectorizing a search data to obtain a search data vector, and compressing the search data and a plurality of objects of a database stored in the memory array according to the compression mode ; Set a search condition; use the search data vector to search for the objects in the database stored in the memory array to determine whether the search data matches the objects in the database; and record and output At least one matching object in the database that matches the search data.
為了對本發明之上述及其他方面有更佳的瞭解,下文特舉實施例,並配合所附圖式詳細說明如下:In order to have a better understanding of the above and other aspects of the present invention, examples are given below and are described in detail with reference to the accompanying drawings:
105-170:步驟105-170: Steps
705-770:步驟705-770: Steps
805-870:步驟805-870: Steps
900:記憶體裝置900: Memory device
900A:記憶體陣列900A: Memory Array
900B:頁緩衝器900B: Page buffer
900C:周邊電路900C: Peripheral circuit
B0~BN:記憶區塊B0~BN: memory block
MC:記憶體晶胞MC: memory cell
BL0~BL7:位元線BL0~BL7: bit lines
WL0~WL7:字元線WL0~WL7: character lines
BLT:位元線電晶體BLT: bit line transistor
GST:接地選擇電晶體GST: ground selector transistor
1200、1500、1600、1700:記憶體晶胞群組1200, 1500, 1600, 1700: memory cell group
MC0、MC1:記憶體晶胞MC0, MC1: memory unit cell
1800:記憶體裝置1800: Memory device
1810:記憶體陣列1810:Memory array
1820:控制器1820:Controller
第1A圖繪示根據本案第一實施例之架構向量資料庫之流程圖。Figure 1A illustrates a flow chart of a vector database architecture according to the first embodiment of the present invention.
第1B圖繪示根據本案第一實施例之記憶體裝置之資料搜尋方法之流程圖。Figure 1B illustrates a flow chart of a data search method in a memory device according to the first embodiment of the present invention.
第2圖顯示根據本案第一實施例的資料庫的向量數值分析之一例。Figure 2 shows vector numerical analysis of the database according to the first embodiment of the present case.An example.
第3圖顯示根據本案第一實施例之向量壓縮示意圖。Figure 3 shows a schematic diagram of vector compression according to the first embodiment of the present invention.
第4A圖與第4B圖顯示根據本案一實施例之向量壓縮示意圖,其中以維度來做分割。Figures 4A and 4B show a schematic diagram of vector compression according to an embodiment of the present invention, in which dimensions are used for segmentation.
第5圖顯示根據本案第一實施例之維度等量切割的資料壓縮結果。Figure 5 shows the data compression result of equal dimension cutting according to the first embodiment of this case.
第6圖顯示根據本案第一實施例之資料等量切割的資料壓縮結果。Figure 6 shows the data compression result of equal cutting of data according to the first embodiment of this case.
第7A圖繪示根據本案第二實施例之架構向量資料庫之流程圖。Figure 7A illustrates a flow chart of a vector database architecture according to the second embodiment of the present invention.
第7B圖繪示根據本案第二實施例之記憶體裝置之資料搜尋方法之流程圖。Figure 7B illustrates a flow chart of a data search method of a memory device according to the second embodiment of the present invention.
第8A圖繪示根據本案第三實施例之架構向量資料庫之流程圖。Figure 8A illustrates a flow chart of a vector database architecture according to the third embodiment of the present invention.
第8B圖繪示根據本案第三實施例之記憶體裝置之資料搜尋方法之流程圖。Figure 8B illustrates a flow chart of a data search method of a memory device according to the third embodiment of the present invention.
第9圖顯示根據本案一實施例之記憶體裝置之示意圖。Figure 9 shows a schematic diagram of a memory device according to an embodiment of the present invention.
第10圖顯示根據本案一實施例之記憶區塊的電路架構圖。Figure 10 shows a circuit structure diagram of a memory block according to an embodiment of the present invention.
第11圖顯示根據本案一實施例之2個記憶區塊之示意圖。Figure 11 shows a schematic diagram of two memory blocks according to an embodiment of the present invention.
第12圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0與儲存狀態為1的示意圖。Figure 12 shows a schematic diagram of the storage state of the memory unit cell group being 0 and the storage state being 1 in an embodiment of the present invention.
第13圖顯示在本案一實施例中,對記憶體晶胞群組進行讀取的示意圖。Figure 13 shows that in one embodiment of the present case, the memory unit cell group is read.schematic diagram.
第14A圖顯示根據本案一實施例之儲存特徵向量於記憶體陣列內的示意圖。Figure 14A shows a schematic diagram of storing feature vectors in a memory array according to an embodiment of the present invention.
第14B圖顯示根據本案一實施例之資料搜尋的一步驟示意圖。Figure 14B shows a schematic diagram of a step of data search according to an embodiment of this case.
第14C圖顯示根據本案一實施例之資料搜尋的另一步驟示意圖。Figure 14C shows another step diagram of data search according to an embodiment of the present case.
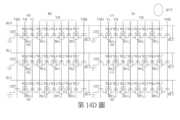
第14D圖顯示根據本案一實施例之資料搜尋的更一步驟示意圖。Figure 14D shows a further step diagram of data search according to an embodiment of the present case.
第14E圖顯示根據本案一實施例之資料搜尋結果。Figure 14E shows the data search results according to an embodiment of this case.
第15圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0~2的示意圖。Figure 15 shows a schematic diagram showing that the storage states of the memory unit cell group are 0~2 in an embodiment of this case.
第16圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0~3的示意圖。Figure 16 shows a schematic diagram showing that the storage states of the memory unit cell group are 0~3 in an embodiment of this case.
第17圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0~5的示意圖。Figure 17 shows a schematic diagram showing that the storage states of the memory unit cell group are 0~5 in an embodiment of this case.
第18圖顯示根據本案一實施例之記憶體裝置之功能方塊圖。Figure 18 shows a functional block diagram of a memory device according to an embodiment of the present invention.
本說明書的技術用語係參照本技術領域之習慣用語,如本說明書對部分用語有加以說明或定義,該部分用語之解釋係以本說明書之說明或定義為準。本揭露之各個實施例分別具有一或多個技術特徵。在可能實施的前提下,本技術領域具有通常知識者可選擇性地實施任一實施例中部分或全部的技術特徵,或者選擇性地將這些實施例中部分或全部的技術特徵加以組合。The technical terms in this specification refer to the idioms in the technical field. If there are explanations or definitions for some terms in this specification, the explanation or definition of this part of the terms shall prevail. Each embodiment of the present disclosure has one or more technical features. Under the premise that it is possible to implement, there are generally known people in this technical field.The skilled person may selectively implement some or all of the technical features in any embodiment, or selectively combine some or all of the technical features in these embodiments.
第一實施例First embodiment
第1A圖繪示根據本案第一實施例之架構向量資料庫之流程圖。第1B圖繪示根據本案第一實施例之記憶體裝置之資料搜尋方法之流程圖。Figure 1A illustrates a flow chart of a vector database architecture according to the first embodiment of the present invention. Figure 1B illustrates a flow chart of a data search method in a memory device according to the first embodiment of the present invention.
現請參照第1A圖。於步驟105中,訓練模型M。在此,訓練模型M的細節可不特別限定之。Please refer now to Figure 1A. In
於步驟110中,判斷資料的維度是否大於或等於維度門檻值。例如但不受限於,維度門檻值是64。通常而言,當資料的維度愈大時,有利於計算精細度;以及,當資料的維度愈小時,有利於減少運算資源。故而,維度門檻值的選擇是為在「計算精細度」與「減少運算資源」之間取得平衡點。In
於步驟115中,利用訓練好的模型M對資料庫(為方便稱呼,在底下將該資料庫稱為資料庫B)內的複數個物件(資料)進行向量化,以得到各該些物件(資料)的個別向量數值。資料庫儲存有複數個物件。例如但不受限於,利用訓練好的模型M對其中一個物件A向量化,以得到A的向量數值A=(A1,A2,…An),其中,n為正整數,代表維度。在進行人臉辨識、聲紋辨識、指紋辨識等時,需要對人臉資料、聲紋資料與指紋資料的資訊進行向量化。通常來說,當維度n為較大值時,有利於精細計算;當維度n為較小值時,有利於減少運算資源。故而,維度n的設定通常為平衡上述需求。In
物件A可以是,例如但不受限於,人臉影像(用於人臉辨識),或者是,人物聲紋(用於聲紋辨識),或者是,人物指紋(用於指紋辨識)等。Object A may be, for example, but not limited to, a face image (used for face recognition), a person's voiceprint (used for voiceprint recognition), or a person's fingerprint (used for fingerprint recognition), etc.
於步驟120中,判斷解析度是否等於或小於一解析度門檻值。例如但不受限於,解析度門檻值為3位元。當步驟120為否時,則壓縮資料庫的該些物件之該些向量數值(步驟125)。當步驟120為是時,則儲存所得到的各該些物件的該些向量數值(步驟135)。在本實施例中,解析度等於或低於3位元(8個狀態(states))可得到較理想的運算結果。In
在本案一可能例中,步驟125中的資料壓縮例如但不受限於,為資料等量切割或維度等量切割,其細節將於底下說明之。In a possible example of this case, the data compression in
於步驟130中,記錄壓縮模式(資料等量切割或維度等量切割)。In
此外,於本案一實施例中,當有新物件加入至資料庫時,如果原有物件的資料量遠大於新物件的資料量,則可依現有壓縮模式來壓縮新物件。如果原有物件的資料量遠小於新物件的資料量,仍可依現有壓縮模式來壓縮新物件,但若檢測到新物件造成整體資料分布有相當變化,這代表目前資料庫含有相當與原有物件不一致的資訊,則將重新壓縮資料庫。在重新壓縮資料庫,可以繼續用資料等量切割或是維度等量切割,然而,切割點將有所移動。In addition, in an embodiment of this case, when a new object is added to the database, if the data amount of the original object is much larger than the data amount of the new object, the new object can be compressed according to the existing compression mode. If the data amount of the original object is much smaller than the data amount of the new object, the new object can still be compressed according to the existing compression mode. However, if the detection of the new object causes a considerable change in the overall data distribution, this means that the current database contains an equivalent amount of data to the original object. If the object has inconsistent information, the database will be recompressed. When recompressing the database, you can continue to use data equal cutting or dimension equal cutting. However, the cutting pointThere will be some movement.
現請參照第1B圖。現將說明,以搜尋資料(待比對資料、待辨識資料)來搜尋資料庫,找出資料庫中相似於此搜尋資料的物件。例如但不受限於,資料庫為人臉影像資料庫,則可以將攝影機所擷取的待辨識人臉影像當成搜尋資料,來搜尋人臉影像資料庫,以找出人臉影像資料庫中相似於此待辨識人臉影像的物件(人臉影像)。Please refer to Figure 1B now. It will now be explained that the search data (data to be compared, data to be identified) is used to search the database to find objects in the database that are similar to the search data. For example, but not limited to, if the database is a face image database, the face image to be identified captured by the camera can be used as search data to search the face image database to find out the faces in the face image database. An object similar to the face image to be recognized (face image).
於步驟140中,依據訓練模型M來對搜尋資料進行向量化,並根據於步驟130中所記錄的壓縮模式(資料等量切割或維度等量切割),來對搜尋資料的向量化資料進行壓縮。也就是說,在本案實施例中,例如但不受限於,當解析度為3位元時,於壓縮之後,將資料庫的該些物件之各維度向量與搜尋資料的各維度向量壓縮在3位元或8個狀態之內。In
於步驟145中,設定搜尋條件(例如但不受限於,匹配維度的數量或比例等)。In
於步驟150中,以搜尋資料的壓縮後向量化資料去搜尋資料庫中的所有物件,以判斷搜尋資料是否匹配於資料庫中的該些物件。例如但不受限於,當搜尋資料與資料庫的匹配物件之間匹配維度符合搜尋條件時,則判斷搜尋資料相似於資料庫中的匹配物件,反之亦然。In
例如但不受限於,物件資料的維度是512,則搜尋資料與一資料庫物件之間的匹配維度要高於搜尋條件(例如但不受限於,300維度),則視為搜尋資料匹配於此資料庫物件。For example, but not limited to, if the dimension of the object data is 512, then the matching dimension between the search data and a database object is higher than the search condition (for example, but not limited toLimited to 300 dimensions), the search data is considered to match this database object.
當步驟150的判斷為是時,則記錄匹配於搜尋資料的資料庫物件(步驟155);以及,當步驟150的判斷為否時,則判斷是否已搜尋到最後一筆資料(步驟160)。When the determination in
在步驟155中,所記錄的物件資訊可包括,例如但不受限於,物件標號、名稱、匹配數值等。In
當步驟160的判斷為否時,則以此搜尋資料的壓縮後向量化資料去搜尋資料庫中的下一筆物件(步驟165)。當步驟160的判斷為是時,則輸出符合搜尋條件的匹配物件(步驟170)。When the determination in
於步驟170中,所輸出的匹配物件資訊可以是,例如但不受限於,物件的原始資料(raw data),物件的排序後資料,匹配程度較高的數筆物件的資料,或者,信號強度最強(匹配程度最高)的物件資料等。In
現將詳細說明本案第一實施例之架構向量資料庫與資料搜尋方法之細節。以漢明距離做相似性計算的話,可以有計算快速的好處。故而,漢明距離可適用於高維度低解析度的情況。高維度有助於減少低解析度導致的精準度問題,而低解析度有關於計算快速、儲存資料量低、資料庫讀取快等好處。以下將說明漢明距離可以達成快速又精準的計算。但當知本案並不受限於此。The details of the structured vector database and the data search method of the first embodiment of this case will now be described in detail. If you use Hamming distance to calculate similarity, you can have the advantage of fast calculation. Therefore, Hamming distance can be applied to high-dimensional and low-resolution situations. High dimensionality helps reduce accuracy problems caused by low resolution, while low resolution has benefits such as fast calculation, low amount of data stored, and fast database reading. The following will illustrate that Hamming distance can achieve fast and accurate calculations. But it should be noted that this case is not limited to this.
下表1顯示資料庫之一例。在此,以資料庫B為人臉影像資料庫為例做說明,但當知本案並不受限於此。該人臉影像資料庫儲存有多個人的人臉照片,每一個人有多張人臉照片。此外,在此以維度為512維度為例做說明,但當知本案並不受限於此。Table 1 below shows an example of a database. Here, the database B is a face image database as an example for explanation, but it should be noted that this case is not limited to this. The person's faceFor example, a database stores face photos of multiple people, and each person has multiple face photos. In addition, the dimension 512 is used as an example for explanation, but it should be noted that this case is not limited to this.

在上表1中,“a”與“b”乃是代表不同人,而“1”與“2”乃是代表不同照片,所以,Ba1乃是人物a的第1張照片,Ba2乃是人物a的第2張照片,Bb2乃是人物b的第2張照片,其餘可依此類推。In Table 1 above, "a" and "b" represent different people, while "1" and "2" represent different photos. Therefore, Ba1 is the first photo of person a, and Ba2 is the person. The second photo of a, Bb2 is the second photo of person b, and so on.
由訓練好的AI模型對人物a的第1張照片Ba1進行向量化後,可以得到向量:(Ba11,Ba12,Ba13,...,Ba1510,Ba1511,Ba1512)。向量“Ba11”代表人物a的第1張照片Ba1的第1維向量,其餘可依此類推。After the first photo Ba1 of person a is vectorized by the trained AI model, the vector can be obtained: (Ba11 , Ba12 , Ba13 ,..., Ba1510 , Ba1511 , Ba1512 ). The vector "Ba11 " represents the 1st dimension vector of the first photo Ba1 of person a, and the rest can be deduced in the same way.
下表2顯示上表1的一個示範例子。Table 2 below shows an exemplary example of Table 1 above.

在上表2中,向量乃是經過正規化,所以,正規化向量的值介於+0.16~-0.16之間,但當知本案並不受限於此。In Table 2 above, the vector is normalized, so the value of the normalized vector is between +0.16~-0.16, but it should be noted that this case is not limited to this.
第2圖顯示根據本案第一實施例的資料庫的向量數值分析之一例,但當知本案並不受限於此。於第2圖中,橫軸代表向量數值,縱軸代表向量數值在資料庫中的佔比(density)。假設資料庫中有19955張照片,該些19955張照片屬於不同人,每個人有數張照片。每張照片被模型向量化為512個數值。資料有512維度,故而,資料向量有32狀態(state)。舉例而言,向量數值0.05的佔比為1.9%,代表,在所有向量中,數值為0.05的向量佔整體資料的1.9%。Figure 2 shows an example of vector numerical analysis of the database according to the first embodiment of the present case, but it should be understood that the present case is not limited thereto. In Figure 2, the horizontal axis represents the vector value, and the vertical axis represents the density of the vector value in the database. Suppose there are 19955 photos in the database. These 19955 photos belong to different people, and each person has several photos. Each photo is vectorized by the model into 512 numerical values. The information is512 dimensions, therefore, the data vector has 32 states. For example, the vector value 0.05 accounts for 1.9%, which means that among all vectors, the vector with a value of 0.05 accounts for 1.9% of the entire data.
現將說明本案第一實施例之資料搜尋。以人臉影像辨識為例做說明,但當知本案並不受限於此。在人臉影像資料庫中,如上述,經模型向量化後,人物a的第1張人臉照片Ba1的向量可表示為:(Ba11,Ba12,Ba13,...,Ba1510,Ba1511,Ba1512)。對於攝影機所擷取到的人物x的人臉照片,經模型向量化後,人物x的人臉照片Bx的向量可表示為:(Bx11,Bx12,Bx13,...,Bx1510,Bx1511,Bx1512)。在步驟150中,以搜尋資料的向量(Bx11,Bx12,Bx13,...,Bx1510,Bx1511,Bx1512)去搜尋/比對此人臉影像資料庫中的人物a的第1張人臉照片Ba1的向量:(Ba11,Ba12,Ba13,...,Ba1510,Ba1511,Ba1512)。當Bx11匹配於Ba11時,則稱為第1維匹配;以及,當Bx11不匹配於Ba11時,則稱為第1維不匹配。將所有維度向量逐一比對後,可得到匹配的維度數量。當人物x的人臉照片Bx的向量與人物a的第1張人臉照片Ba1的向量之間的匹配維度高於搜尋條件(例如但不受限於,300個維度),則視為人物x匹配於人物a,亦即,經人臉辨識後,人物x與人物a視為同一個人。反之亦然。The data search in the first embodiment of this case will now be described. Face image recognition is used as an example for explanation, but it should be noted that this case is not limited to this. In the face image database, as mentioned above, after model vectorization, the vector of the first face photo Ba1 of person a can be expressed as: (Ba11 , Ba12 , Ba13 ,..., Ba1510 , Ba1511 , Ba1512 ). Forthe facial photo of person x captured by the camera, after vectorization bythe model, thevectorof the face photo Bx of person Bx1511 , Bx1512 ). In
現將說明本案對向量進行壓縮(數位化)的細節。於本案第一實施例中,降低解析度對漢明距離的計算有相當好處,故而,壓縮資料以將解析度降低。The details of vector compression (digitization) in this case will now be explained. In the first embodiment of this case, reducing the resolution is of great benefit to the calculation of the Hamming distance. Therefore, the data is compressed to reduce the resolution.
在此以解析度為1位元且0為切割點為例做說明。當Bn(向量數值)小於等於0,則Bn被設為0;以及,當Bn(向量數值)大於0,則Bn被設為1。Here, the resolution is 1 bit and 0 is the cutting point as an example. When Bn (vector value) is less than or equal to 0, Bn is set to 0; and when Bn (vector value) is greater than 0, Bn is set to 1.
或者是,於另一可能例中,以解析度為1位元且以中間值middle(Bn)為切割點為例做說明。中間值middle(Bn)代表所有向量數值的中間值。當Bn(向量數值)小於等於middle(Bn),則Bn被設為0;以及,當Bn(向量數值)大於middle(Bn),則Bn被設為1。Or, in another possible example, the resolution is 1 bit and the middle value middle (Bn) is used as the cutting point. The middle value middle(Bn) represents the middle value of all vector values. When Bn (vector value) is less than or equal to middle(Bn), then Bn is set to 0; and when Bn (vector value) is greater than middle(Bn), then Bn is set to 1.
或者是,於另一可能例中,以解析度為1位元且以平均值avg(Bn)為切割點為例做說明。平均值avg(Bn)代表所有向量數值的平均值。當Bn(向量數值)小於等於avg(Bn),則Bn被設為0;以及,當Bn(向量數值)大於avg(Bn),則Bn被設為1。Or, in another possible example, the resolution is 1 bit and the average avg(Bn) is used as the cutting point. Average avg(Bn) represents the average of all vector values. When Bn (vector value) is less than or equal to avg(Bn), Bn is set to 0; and when Bn (vector value) is greater than avg(Bn), Bn is set to 1.
第3圖顯示根據本案第一實施例之向量壓縮示意圖。於第3圖中,以解析度為1位元且0為切割點為例做說明,但當知本案並不受限於此。Figure 3 shows a schematic diagram of vector compression according to the first embodiment of the present invention. In Figure 3, the resolution is 1 bit and 0 is the cutting point as an example, but it should be noted that the present case is not limited to this.
經過壓縮後,若模型未做正規化...等原因,造成資料庫的向量數值分布呈現不對稱分布,則以中間值middle(B)切割可得到較佳效果。在本案說明書中,資料切割與資料壓縮具有相似意思。After compression, if the model is not regularized... and other reasons cause the vector numerical distribution of the database to show an asymmetric distribution, then cutting with the intermediate value middle (B) can achieve better results. In this case specification, data cutting and data compression have similar meanings.
第4A圖與第4B圖顯示根據本案一實施例之向量壓縮示意圖,其中以維度來做分割。第4A圖顯示資料庫在維度15(D15)的資料分布(總維度為512);以及,第4B圖顯示資料庫在維度109(D109)的資料分布(總維度為512)。由第4A圖與第4B圖可以看出,0為切割點與中間值middle(Bn)為切割點,所得到的壓縮結果有明顯差異。Figures 4A and 4B show a schematic diagram of vector compression according to an embodiment of the present invention, in which dimensions are used for segmentation. Figure 4A shows the data distribution of the database in dimension 15 (D15) (the total dimension is 512); and Figure 4B shows the databaseData distribution in dimension 109 (D109) (total dimensions are 512). It can be seen from Figure 4A and Figure 4B that 0 is the cutting point and the middle value middle (Bn) is the cutting point, and the obtained compression results are significantly different.
第5圖顯示根據本案第一實施例之維度等量切割的資料壓縮結果。如第5圖所示,資料可以依維度等量切割為m等分(m可以是2、3、4、5…等任意正整數)。當m=2時,則壓縮結果是2狀態(state)(0或1),且其為1位元解析度。當m=3時,則壓縮結果是3狀態(0或1或2)。當m=4時,則壓縮結果是4狀態(0或1或2或3),且其為2位元解析度。其餘可依此類推。第5圖顯示將該些資料向量以維度等量切割為3狀態(0或1或2),且切割點分別為-0.05與+0.05。亦即,當向量小於-0.05時,該向量被壓縮為0;當向量介於-0.05與+0.05之間時,該向量被壓縮為1;以及,當向量大於+0.05時,該向量被壓縮為2。Figure 5 shows the data compression result of equal dimension cutting according to the first embodiment of this case. As shown in Figure 5, the data can be cut into m equal parts according to the dimensions (m can be any positive integer such as 2, 3, 4, 5...). When m=2, the compression result is 2 states (0 or 1), and it has 1-bit resolution. When m=3, the compression result is 3 states (0 or 1 or 2). When m=4, the compression result is 4 states (0 or 1 or 2 or 3), and it is 2-bit resolution. The rest can be deduced in this way. Figure 5 shows that these data vectors are cut into 3 states (0 or 1 or 2) with equal dimensions, and the cutting points are -0.05 and +0.05 respectively. That is, when a vector is less than -0.05, the vector is compressed to 0; when the vector is between -0.05 and +0.05, the vector is compressed to 1; and when the vector is greater than +0.05, the vector is compressed is 2.
第6圖顯示根據本案第一實施例之資料等量切割的資料壓縮結果。如第6圖所示,資料可以依據資料等量切割為m等分(m可以是2、3、4、5…等任意正整數)。第6圖顯示將該些資料向量以資料等量壓縮為3狀態(0或1或2)。經資料等量切割後,約有1/3的向量被壓縮為0,約有1/3的向量被壓縮為1,約有1/3的向量被壓縮為2。其切割點則視資料分布而決定。第6圖的資料分布更為均勻。Figure 6 shows the data compression result of equal cutting of data according to the first embodiment of this case. As shown in Figure 6, the data can be cut into m equal parts according to the data (m can be any positive integer such as 2, 3, 4, 5...). Figure 6 shows that these data vectors are compressed into 3 states (0 or 1 or 2) with equal amounts of data. After the data is cut equally, about 1/3 of the vectors are compressed to 0, about 1/3 of the vectors are compressed to 1, and about 1/3 of the vectors are compressed to 2. The cutting point is determined by the data distribution. The data in Figure 6 is more evenly distributed.
由上述可知,在本案第一實施例中,資料等量切割可使得資料分布更為均勻。It can be seen from the above that in the first embodiment of this case, equal cutting of data can make the data distribution more uniform.
在本案第一實施例中,維度法採漢明距離計算,適用於解析度低的資料庫。通常而言,維度法在解析度3位元以下會有更好的結果(8個狀態或更低的狀態)。在本案第一實施例中,系統儲存需求大幅降低,計算速度提升。In the first embodiment of this case, the dimensional method uses Hamming distance calculation, which is suitable for databases with low resolution. Generally speaking, the dimensional method will give better results at resolutions below 3 bits (8 states or less). In the first embodiment of this case, the system storage requirements are significantly reduced and the computing speed is increased.
此外,在本案第一實施例中,藉由分割資料(Data Partition)來降低解析度。如上述般,資料分割可以是資料等量切割或維度等量切割或其他切割方式(例如以指數距離切割)。在進行分割資料時,可以將資料向量分割成m個狀態,m小於等於8(3位元解析度)。In addition, in the first embodiment of this case, the resolution is reduced by dividing data (Data Partition). As mentioned above, the data segmentation may be data equal-amount cutting or dimension equal-amount cutting or other cutting methods (for example, exponential distance cutting). When dividing data, the data vector can be divided into m states, m is less than or equal to 8 (3-bit resolution).
在本案第一實施例中,進行資料等量切割可以得到較大的適用範圍與穩定性,與較佳效果。In the first embodiment of this case, equal cutting of data can achieve a larger application range, stability, and better effects.
第二實施例Second embodiment
第7A圖繪示根據本案第二實施例之架構向量資料庫之流程圖。第7B圖繪示根據本案第二實施例之記憶體裝置之資料搜尋方法之流程圖。Figure 7A illustrates a flow chart of a vector database architecture according to the second embodiment of the present invention. Figure 7B illustrates a flow chart of a data search method of a memory device according to the second embodiment of the present invention.
第7A圖的步驟705-735原則上相同或相似於第1A圖的步驟105-135,故其細節在此省略。Steps 705-735 in Figure 7A are in principle the same or similar to steps 105-135 in Figure 1A, so their details are omitted here.
於步驟736中,找出各物件的個別特徵向量(亦可稱為代表向量),其細節如下。In
在本案第二實施例中,在運用維度法時,以人臉影像資料庫為例做說明,但當知本案並不受限於此。在人臉影像資料庫中,每個人可以有多張照片。用訓練好的模型對同一個人的每張照片進行向量化得到多維向量。對於屬於同一個人的該些照片的多維向量之中,找出各維度中最常出現的值(MODE),作為此人的特徵向量。In the second embodiment of this case, when applying the dimensional method, the face image database is used as an example for explanation, but it should be noted that this case is not limited to this. In the face image database, each person can have multiple photos. Use the trained model to compare the same person’sEach photo is vectorized to obtain a multidimensional vector. For the multi-dimensional vectors of the photos belonging to the same person, find the most frequently occurring value (MODE) in each dimension as the feature vector of the person.
例如,以資料庫B中的人物a為例,則該人物a的特徵向量可表示為:(Ba1,Ba2,...Ban),其中Bai=MODE(Ba1i,Ba2i,Ba3i...),i=1~n。函數MODE代表是該些數值中,最常出現的值。當某一維度有多個數值同樣有最多計次時,可以任取其一當成特徵向量;在其他可能例中,可取較小數值者當成特徵向量。搜尋資料的特徵向量可以相同或相似方法產生。For example, taking character a in database B as an example, the feature vector of character a can be expressed as: (Ba1 ,Ba2 ,...Ban ), where Bai =MODE(Ba1i ,Ba2i , Ba3i ...), i=1~n. The function MODE represents the most frequently occurring value among these values. When there are multiple values in a certain dimension that also have the most counts, any one of them can be used as the feature vector; in other possible cases, the smaller value can be used as the feature vector. The feature vectors of the search data can be generated by the same or similar methods.
為方便了解,下表3舉例一例來說明如何找出特徵向量,但當知本案並不受限於此。For ease of understanding, Table 3 below gives an example to illustrate how to find the eigenvector, but it should be noted that this case is not limited to this.


以表3而言,人物a的5張照片,經模型向量化後,第1張照片的向量:(0,2,1,...,2,3,0),其餘可依此類推。Taking Table 3 as an example, after vectorization of the five photos of person a by the model, the vector of the first photo is: (0, 2, 1,..., 2, 3, 0), and the rest can be deduced in this way.
人物a的這5張照片的向量1(D1)分別為:0、0、0、1與0,數值“0”有最多計數次數,故而,人物a的特徵向量的第一個元件(第一維特徵向量)Ba1為0。依此,人物a的特徵向量的第二個元件(第二維特徵向量)Ba2為2;人物a的特徵向量的第三個元件(第三維特徵向量)Ba3為2或3;人物a的特徵向量的第510個元件(第510維特徵向量)Ba510為1;人物a的特徵向量的第511個元件(第511維特徵向量)Ba511為2;人物a的特徵向量的第512個元件(第512維特徵向量)Ba512為3。The vectors 1 (D1) of these five photos of person a are: 0, 0, 0, 1 and 0 respectively. The value "0" has the largest number of counts. Therefore, the first component (the first element) of the feature vector of person a dimensional eigenvector) Ba1 is 0. According to this, the second element of the eigenvector of person a (second-dimensional eigenvector) Ba2 is 2; the third element of the eigenvector of person a (third-dimensional eigenvector) Ba3 is 2 or 3; person a The 510th element (510th-dimensional feature vector) Ba510 of the feature vector of person a is 1; the 511th element (511th-dimensional feature vector) Ba511 of the feature vector of person a is 2; the 512th element of the feature vector of person a is 2 element (512th dimension eigenvector) Ba512 is 3.
故而,依此可得到,人物a(物件a)的特徵向量:(Ba1,Ba2,...Ban)=(0,2,(2或3),…,1,2,3)。Therefore, according to this, the eigenvector of person a (object a) can be obtained: (Ba1 , Ba2 ,...Ban )=(0, 2, (2 or 3),..., 1, 2, 3) .
於步驟737中,儲存在步驟736中所找出的各物件的個別特徵向量,並將該資料庫命名為BM,以有別於原始資料庫B。In
第7B圖的步驟740-770原則上相同或相似於第1B圖的步驟140-170,故其細節在此省略。不同處在於,於步驟740中,依據訓練模型M來對搜尋資料進行向量化,並根據所記錄的壓縮模式(資料等量切割或維度等量切割),來對搜尋資料的向量化資料進行壓縮,再依上述方式來找出搜尋資料的特徵向量。於之後的步驟中,則是以搜尋資料的特徵向量對資料庫BM進行搜尋。Steps 740-770 in Figure 7B are in principle the same or similar to steps 140-170 in Figure 1B, so their details are omitted here. The difference is that in
現將說明本案第二實施例之資料搜尋。以人臉影像辨識為例做說明,但當知本案並不受限於此。在人臉影像資料庫中,如上述,經模型向量化與求出特徵向量後,人物a的特徵向量為(Ba1,Ba2,...Ban)。對於攝影機所擷取到的人物x的人臉照片,經模型向量化與找出特徵向量後,人物x的特徵向量可表示為:(Bx1,Bx2,...Bxn)。在步驟750中,以人物x的特徵向量(Bx1,Bx2,...Bxn)去搜尋/比對此人臉影像資料庫中的人物a的特徵向量(Ba1,Ba2,...Ban)。當Bx1匹配於Ba1時,則稱為第1維匹配;以及,當Bx1不匹配於Ba1時,則稱為第1維不匹配。將所有維度向量逐一比對後,可得到匹配的維度數量。當人物x的特徵向量與人物a的特徵向量之間的匹配維度高於搜尋條件(例如但不受限於,300個維度),則視為人物x匹配於人物a,亦即,經人臉辨識後,人物x與人物a視為同一個人。反之亦然。The data search in the second embodiment of this case will now be described. Face image recognition is used as an example for explanation, but it should be noted that this case is not limited to this. In the face image database, as mentioned above, after model vectorization and finding the feature vector, the feature vector of person a is (Ba1 , Ba2 ,...Ban ). For the face photo of person x captured by the camera, after model vectorization and finding the feature vector, the feature vector of person x can be expressed as: (Bx1 , Bx2 ,...Bxn ). In
在本案一實施例中,搜尋資料的特徵向量的每一維度係具有多向量狀態,該多向量狀態之數量係等於或低於3位元或8狀態;以及資料庫物件之該特徵向量的每一維度係具有多向量狀態,該多向量狀態之數量係等於或低於3位元或8狀態。In one embodiment of this case, each dimension of the feature vector of the search data has multiple vector states, and the number of the multiple vector states is equal to or less than 3 bits or 8 states; and each dimension of the feature vector of the database object A one-dimensional system has multiple vector states, the number of which is equal to or lower than 3 bits or 8 states.
第三實施例Third embodiment
第8A圖繪示根據本案第三實施例之記憶體裝置之架構向量資料庫之流程圖。第8B圖繪示根據本案第三實施例之記憶體裝置之資料搜尋方法之流程圖。Figure 8A illustrates a flow chart of a vector database architecture of a memory device according to the third embodiment of the present invention. Figure 8B illustrates the record according to the third embodiment of this caseFlowchart of the data search method of the memory device.
第8A圖的步驟805-836原則上相同或相似於第7A圖的步驟705-736,故其細節在此省略。Steps 805-836 in Figure 8A are in principle the same or similar to steps 705-736 in Figure 7A, so their details are omitted here.
於步驟838中,設定遮罩(mask)比例。在本案第三實施例中,將根據遮罩比例對特徵向量的元件給予遮罩,以提高匹配信心度。In
為更加了解步驟838的細節,茲說明如下。In order to better understand the details of
舉例說明,資料庫有物件a的19筆資料(例如是人物a的19張人臉照片),經向量化後,該物件a的19個向量維度如下表4。For example, the database contains 19 pieces of information about object a (for example, 19 face photos of person a). After vectorization, the 19 vector dimensions of object a are as shown in Table 4.


以上表4來做說明。在本案第三實施例中,人物a的特徵向量為(1,0,1,1,1,0,1,0,1,0)。此特徵向量的10個元件的個別出現次數分別為12,17,18,10,15,15,11,11,14與18。亦即,人物a的特徵向量的第一個元件(第一維特徵向量)Ba1為1,其在這19個第一維向量(D1)中的出現次數為12,其餘可依此類推。Table 4 above is used for illustration. In the third embodiment of this case, the feature vector of person a is (1, 0, 1, 1, 1, 0, 1, 0, 1, 0). The individual occurrence times of the 10 elements of this feature vector are 12, 17, 18, 10, 15, 15, 11, 11, 14 and 18 respectively. That is, the first component (first-dimensional feature vector) Ba1 of the character a's feature vector is 1, and its number of occurrences in these 19 first-dimensional vectors (D1) is 12, and the rest can be deduced in the same way.
若將遮罩比例設為40%。則代表特徵向量的所有元件中,有40%要被遮罩。在上表4中,特徵向量包括10個元件,10*40%=4。亦即,要從特徵向量的所有元件找到「出現次數前4低」的4個元件,並給於遮罩。在上表4中,出現次數前4低的4個元件是D1(出現12次)、D4(出現10次)、D7(出現11次)、D8(出現11次)。故而,將該些維度(D1、D4、D7與D8)的遮罩位元設為0,其餘維度的遮罩位元設為1。故而,可得到物件a的遮罩向量為:(0,1,1,0,1,1,0,0,1,1)。如果向量被遮罩,則該向量不會被用於後續的匹配中。If the mask ratio is set to 40%. Then 40% of all components representing feature vectors will be masked. In Table 4 above, the feature vector includes 10 components, 10*40%=4. That is, we need to find the "top 4 occurrences" from all components of the feature vector."Low" 4 components and give them masks. In Table 4 above, the four components with the top four lowest occurrences are D1 (appeared 12 times), D4 (appeared 10 times), D7 (appeared 11 times), and D8 (appeared 11 times). Therefore, the mask bits of these dimensions (D1, D4, D7, and D8) are set to 0, and the mask bits of the other dimensions are set to 1. Therefore, the mask vector of object a can be obtained as: (0, 1, 1, 0, 1, 1, 0, 0, 1, 1). If a vector is masked, it will not be used in subsequent matches.
也就是說,在本案第三實施例中,將出現次數低、信心度低的向量遮罩掉。That is to say, in the third embodiment of this case, vectors with low occurrence frequency and low confidence are masked out.
於步驟839A中,根據遮罩比例及特徵向量中的各向量的出現次數,來得到各物件的遮罩向量。In
於步驟839B中,將各物件的遮罩向量與特徵向量存於資料庫BM中,以成為資料庫BMM。In
第8B圖的步驟840-870原則上相同或相似於第7B圖的步驟740-770,故其細節在此省略。不同處在於,於步驟840中,依據訓練模型M來對搜尋資料進行向量化,並根據所記錄的壓縮模式,來對搜尋資料的向量化資料進行壓縮,並找出搜尋資料的特徵向量。於之後的步驟中,則是以搜尋資料的特徵向量對資料庫BMM進行搜尋。Steps 840-870 in Figure 8B are in principle the same or similar to steps 740-770 in Figure 7B, so their details are omitted here. The difference is that in
現將說明本案第三實施例之資料搜尋。以人臉影像辨識為例做說明,但當知本案並不受限於此。在人臉影像資料庫中,如上述,經模型向量化與求出特徵向量與遮罩向量後,人物a的特徵向量為(Ba1,Ba2,...Ban),且人物a的遮罩向量為(Ba1M,Ba2M,...BanM)。對於攝影機所擷取到的人物x的人臉照片,經模型向量化與找出特徵向量與遮罩向量後,人物x的特徵向量可表示為:(Bx1,Bx2,...Bxn)。在步驟850中,以人物x的特徵向量(Bx1,Bx2,...Bxn)去搜尋/比對此人臉影像資料庫中的人物a的特徵向量(Ba1,Ba2,...Ban),且需考量人物a的遮罩向量。當Bx1匹配於Ba1且此向量Ba1不被遮罩時,則稱為第1維匹配;當Bx1不匹配於Ba1(不論此向量Ba1是否要被遮罩)時,則稱為第1維不匹配;以及,當此向量Ba1要被遮罩(不論Bx1是否匹配於Ba1)時,則稱為第1維不匹配。將所有維度向量逐一比對後,可得到匹配的維度數量。在考量到遮罩向量後,當人物x的特徵向量與人物a的特徵向量之間的匹配維度高於搜尋條件(例如但不受限於,300個維度),則視為人物x匹配於人物a,亦即,經人臉辨識後,人物x與人物a視為同一個人。反之亦然。The data search in the third embodiment of this case will now be described. Face image recognition is used as an example for explanation, but it should be noted that this case is not limited to this. In the face image database, as mentioned above, after model vectorization and finding the feature vector and mask vector, the feature vector of person a is (Ba1 , Ba2 ,...Ban ), and the feature vector of person a is The mask vector is (Ba1M , Ba2M ,...BanM ). For the face photo of person x captured by the camera, after model vectorization and finding the feature vector and mask vector, the feature vector of person x can be expressed as: (Bx1 , Bx2 ,...Bxn ). In
在本案第三實施例中,透過遮罩信心度的向量,可以提高信心度,且加速搜尋速度並減少所需的儲存空間。In the third embodiment of this case, by masking the confidence vector, the confidence can be improved, the search speed can be accelerated, and the required storage space can be reduced.
現將說明根據本案一實施例的記憶體裝置如何實現上述的資料搜尋方法。How the memory device according to an embodiment of the present invention implements the above data search method will now be described.
在本案一實施例中,將向量資料(特徵向量)儲存於記憶體晶胞內。In one embodiment of this case, vector data (eigenvectors) are stored in a memory unit cell.
第9圖顯示根據本案一實施例之記憶體裝置之示意圖。記憶體裝置可包括複數個記憶平面900。如第9圖所示,記憶平面900包括:記憶體陣列900A、頁緩衝器(page buffer)900B與周邊電路900C。周邊電路900C耦接至記憶體陣列900A與頁緩衝器900B。頁緩衝器900B耦接至記憶體陣列900A的該些位元線。頁緩衝器900B包含用於執行邏輯運算的複數個運算單元(operation unit)。頁緩衝器900B包含用於執行電流感應的感應放大器,以根據電流感應結果而判斷資料搜尋是否匹配。此外,頁緩衝器900B可選擇性包含類比數位轉換器,將感應放大器的類比電流感應結果轉換成數位信號,以判斷資料搜尋是否匹配。Figure 9 shows a schematic diagram of a memory device according to an embodiment of the present invention. A memory device may include a plurality of memory planes 900 . As shown in Figure 9, the
在此以512維度為例做說明,當知本案並不受限於此。人物a的特徵向量有512個維度,故而,可將人物a的特徵向量沿著字元線上存放於512個記憶體晶胞內。之後,下一個人物b的特徵向量也有512個維度,故而,可將人物b的特徵向量沿著字元線上存放於後續的512個記憶體晶胞(未顯示)內。其餘可依此類推。Here, the 512 dimension is used as an example. It should be noted that this case is not limited to this. The eigenvector of person a has 512 dimensions. Therefore, the eigenvector of person a can be stored in 512 memory cells along the character line. After that, the eigenvector of the next character b also has 512 dimensions. Therefore, the eigenvector of character b can be stored in the subsequent 512 memory unit cells (not shown) along the character line. The rest can be deduced in this way.
此外,記憶體陣列900A包括多個記憶區塊(block)B0~BN(N為正整數,例如但不受限於,N介於500-20000之間)。每個記憶區塊包括複數個記憶體晶胞,位於複數條字元線與複數條位元線之交叉處。例如但不受限於,當每一條字元線上有128k個記憶體晶胞時,則每一條字元線可以存放128k/512=256個人的特徵向量。In addition, the
在習知記憶體技術中,當要進行資料讀寫時,一次選定一個記憶區塊來進行資料讀寫。In conventional memory technology, when data is to be read and written, one memory block is selected at a time to read and write data.
然而,在本案一實施例中,當要進行資料搜尋時,可以一次選定多個記憶區塊及選定多條字元線,以電流累加來進行記憶體內計算(in memory computing,IMC)。However, in one embodiment of this case, when data search is to be performed,Multiple memory blocks and multiple word lines can be selected at one time, and current accumulation is used to perform in-memory computing (IMC).
為方便解說,在此下以顯示2個記憶區塊的資料搜尋為例做說明,但當知本案並不受限於此。For convenience of explanation, a data search that displays two memory blocks is used as an example below for explanation, but it should be noted that this case is not limited to this.
第10圖顯示根據本案一實施例之記憶區塊的電路架構圖。在此以記憶區塊B0為例做說明,該電路架構圖可應用至其他記憶區塊。如第10圖所示,記憶區塊B0包括複數個記憶體晶胞MC、複數個位元線電晶體BLT與複數個接地選擇電晶體GST。在此以顯示8條字元線WL0~WL7與8條位元線BL0~BL7為例做說明,但當知本案並不受限於此。Figure 10 shows a circuit structure diagram of a memory block according to an embodiment of the present invention. Here, memory block B0 is used as an example for illustration. This circuit architecture diagram can be applied to other memory blocks. As shown in FIG. 10 , the memory block B0 includes a plurality of memory cells MC, a plurality of bit line transistors BLT and a plurality of ground selection transistors GST. Here, the display of 8 word lines WL0~WL7 and 8 bit lines BL0~BL7 is used as an example for explanation, but it should be noted that the present case is not limited to this.
該些記憶體晶胞MC位於該些字元線WL0~WL7與該些位元線BL0~BL7之交叉處。該些位元線電晶體BLT之閘極接收串選擇線(string select line)信號SSL,該些位元線電晶體BLT之一端耦接至該些位元線BL0~BL7,該些位元線電晶體BLT之另一端耦接至該些記憶體晶胞MC。The memory unit cells MC are located at the intersections of the word lines WL0 ~ WL7 and the bit lines BL0 ~ BL7. The gates of the bit line transistors BLT receive the string select line signal SSL. One end of the bit line transistors BLT is coupled to the bit lines BL0~BL7. The bit lines The other end of the transistor BLT is coupled to the memory cells MC.
該些接地選擇電晶體GST之閘極接收接地選擇線(ground select line)信號GSL,該些接地選擇電晶體GST之一端耦接至接地端GND,該些接地選擇電晶體GST之另一端耦接至該些記憶體晶胞MC。The gates of the ground select transistors GST receive the ground select line signal GSL. One end of the ground select transistors GST is coupled to the ground terminal GND, and the other end of the ground select transistors GST is coupled to these memory unit cells MC.
在本案一實施例中,該些記憶體晶胞MC可用於儲存資料庫物件的特徵向量。而搜尋資料則可由位元線輸入至該些記憶體晶胞MC,以進行資料比對與搜尋。In an embodiment of this case, the memory cells MC can be used to store feature vectors of database objects. The search data can be input to the memory cells MC through bit lines for data comparison and search.
第11圖顯示根據本案一實施例之2個記憶區塊之示意圖。如第11圖所示,當記憶區塊的位元線電晶體BLT被導通時,可以選擇該記憶區塊。如第11圖所示,可以同時選擇此2個記憶區塊。在本案其他可能實施例中,可以同時選擇多於2個的記憶區塊。Figure 11 shows a schematic diagram of two memory blocks according to an embodiment of the present invention. As shown in Figure 11, when the bit line transistor BLT of the memory block is turned on, the memory block can be selected. As shown in Figure 11, these two memory blocks can be selected at the same time. In other possible embodiments of this case, more than 2 memory blocks can be selected at the same time.
第12圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0與儲存狀態為1的示意圖。在此,記憶體晶胞群組1200包括耦接至同一位元線的2個相鄰或不相鄰記憶體晶胞。第12圖顯示記憶體晶胞群組1200包括2個相鄰記憶體晶胞MC0與MC1,但當知本案並不受限於此。Figure 12 shows a schematic diagram of the storage state of the memory unit cell group being 0 and the storage state being 1 in an embodiment of the present invention. Here, the
當記憶體晶胞MC0與MC1分別被程式化為高臨界電壓(HVT)與低臨界電壓(LVT)時,記憶體晶胞群組1200的儲存狀態為0。相反地,當記憶體晶胞MC0與MC1分別被程式化為低臨界電壓(LVT)與高臨界電壓(HVT)時,記憶體晶胞群組1200的儲存狀態為1。When the memory cells MC0 and MC1 are programmed to high threshold voltage (HVT) and low threshold voltage (LVT) respectively, the storage state of the
第13圖顯示在本案一實施例中,對記憶體晶胞群組進行讀取的示意圖。於進行資料搜尋(讀取)時,當搜尋資料為1而儲存狀態為1時,則為匹配;當搜尋資料為0而儲存狀態為0時,則為匹配;反之,當搜尋資料為1而儲存狀態為0時,則為不匹配;當搜尋資料為0而儲存狀態為1時,則為不匹配。Figure 13 shows a schematic diagram of reading a memory unit cell group in an embodiment of the present invention. When performing data search (reading), when the search data is 1 and the storage status is 1, it is a match; when the search data is 0 and the storage status is 0, it is a match; conversely, when the search data is 1 and the storage status is 0, it is a match. When the storage status is 0, it means no match; when the search data is 0 and the storage status is 1, it means no match.
在本案一實施例中,對搜尋資料進行編碼以得到一組搜尋電壓(至少包括第一搜尋電壓與第二搜尋電壓)。例如但不受限於,對搜尋資料0進行編碼以得到第一搜尋電壓為高電壓VH與第二搜尋電壓為低電壓VR;以及,對搜尋資料1進行編碼以得到第一搜尋電壓為低電壓VR與第二搜尋電壓為高電壓VH。其中,第一搜尋電壓與第二搜尋電壓分別透過不同字元線而施加至記憶體晶胞群組1200的2個記憶體晶胞的閘極。在底下的說明中,第一搜尋電壓施加至記憶體晶胞MC0的閘極,而第二搜尋電壓施加至記憶體晶胞MC1的閘極。In one embodiment of this case, the search data is encoded to obtain a set of search voltages (including at least a first search voltage and a second search voltage). For example but notThe
於記憶體晶胞群組1200的儲存狀態為0時,(1)當高電壓VH的第一搜尋電壓與低電壓VR的第二搜尋電壓分別施加至記憶體晶胞MC0的閘極與記憶體晶胞MC1的閘極時,記憶體晶胞MC0與MC1皆為導通,故而,記憶體晶胞群組1200有電流;以及,(2)當低電壓VR的第一搜尋電壓與高電壓VH的第二搜尋電壓分別施加至記憶體晶胞MC0的閘極與記憶體晶胞MC1的閘極時,記憶體晶胞MC0與MC1皆為關閉,故而,記憶體晶胞群組1200沒有電流。When the storage state of the
也就是說,於記憶體晶胞群組1200的儲存狀態為0時,當搜尋資料為0時,記憶體晶胞群組1200有電流(此為匹配);以及,當搜尋資料為1時,記憶體晶胞群組1200沒有電流(此為不匹配)。That is to say, when the storage state of the
於記憶體晶胞群組1200的儲存狀態為1時,(1)當高電壓VH的第一搜尋電壓與低電壓VR的第二搜尋電壓分別施加至記憶體晶胞MC0的閘極與記憶體晶胞MC1的閘極時,記憶體晶胞MC0與MC1皆為關閉,故而,記憶體晶胞群組1200沒有電流;以及,(2)當低電壓VR的第一搜尋電壓與高電壓VH的第二搜尋電壓分別施加至記憶體晶胞MC0的閘極與記憶體晶胞MC1的閘極時,記憶體晶胞MC0與MC1皆為導通,故而,記憶體晶胞群組1200有電流。When the storage state of the
也就是說,於記憶體晶胞群組1200的儲存狀態為1時,當搜尋資料為0時,記憶體晶胞群組1200沒有電流(此為不匹配);以及,當搜尋資料為1時,記憶體晶胞群組1200有電流(此為匹配)。That is to say, when the storage state of the
第14A圖顯示根據本案一實施例之儲存特徵向量於記憶體陣列內的示意圖。於第14圖中,“Ba1”代表物件a的第一張照片的特徵向量,“Ba11”代表物件a的第一張照片的特徵向量的第一維特徵向量,“Ba12”代表物件a的第一張照片的特徵向量的第二維特徵向量,其餘可依此類推。Figure 14A shows a schematic diagram of storing feature vectors in a memory array according to an embodiment of the present invention. In Figure 14, “Ba1” represents the eigenvector of the first photo of object a, “Ba11 ” represents the first-dimensional eigenvector of the eigenvector of the first photo of object a, and “Ba12 ” represents the feature vector of object a. The second-dimensional eigenvector of the first photo's eigenvector, and so on for the rest.
於儲存時,耦接至位元線BL0的該些記憶體晶胞可以儲存物件a、物件b、物件d與物件f的特徵向量。其餘可依此類推。During storage, the memory cells coupled to the bit line BL0 can store the characteristic vectors of object a, object b, object d, and object f. The rest can be deduced in this way.
此外,如上所述,2個記憶體晶胞用於儲存物件的特徵向量的一維特徵向量。例如,於第14A圖中,記憶體晶胞MC0與MC1儲存物件a的特徵向量的一維特徵向量Ba11,其中,記憶體晶胞MC0為高臨界電壓(HVT)而記憶體晶胞MC1為低臨界電壓(LVT),亦即物件a的第一張照片的特徵向量的第一維特徵向量Ba11為儲存狀態0。其餘可依此類推。In addition, as mentioned above, two memory unit cells are used to store the one-dimensional eigenvectors of the object's eigenvectors. For example, in Figure 14A, the memory cells MC0 and MC1 store the one-dimensional eigenvector Ba11 of the eigenvector of object a, where the memory cell MC0 is the high threshold voltage (HVT) and the memory cell MC1 is The low threshold voltage (LVT), that is, the first-dimensional feature vector Ba11 of the feature vector of the first photo of object a is the
第14B圖顯示根據本案一實施例之資料搜尋的一步驟示意圖。如第14B圖所示,於進行資料搜尋之前,施加參考電壓VHB至該些位元線電晶體BLT以導通該些位元線電晶體BLT,以及施加參考電壓VHG至該些接地選擇電晶體GST以導通該些接地選擇電晶體GST。當相關的位元線電晶體BLT與接地選擇電晶體GST被導通時,則該相關記憶區塊被選擇。Figure 14B shows a schematic diagram of a step of data search according to an embodiment of this case. As shown in Figure 14B, before performing a data search, a reference voltage VHB is applied to the bit line transistors BLT to turn on the bit line transistors BLT, and a reference voltage VHG is applied to the ground selection transistors GST. to turn on the ground selection transistors GST. When the relevant bit line transistor BLT and ground selection transistor GST are turned on, the relevant memory block is selected.
由第14B圖可知,在本案一實施例中,於進行資料搜尋時,可以同時選擇複數個記憶區塊,及同時導通複數個位元線電晶體BLT與複數個接地選擇電晶體GST。As can be seen from Figure 14B, in one embodiment of this case, when performing data search, multiple memory blocks can be selected simultaneously, and multiple bit line transistors BLT and multiple ground selection transistors GST can be turned on simultaneously.
假設物件的特徵向量有512維度,則於進行資料搜尋時,至少有512記憶區塊可以被同時選擇。Assuming that the object's feature vector has 512 dimensions, at least 512 memory blocks can be selected simultaneously during data search.
第14C圖顯示根據本案一實施例之資料搜尋的另一步驟示意圖。第14D圖顯示根據本案一實施例之資料搜尋的更一步驟示意圖。於第14C圖中,施加參考電壓VH至未選字元線,以將該些未選字元線全部導通。於第14D圖中,根據該搜尋資料,施加搜尋電壓VH與VR至被選字元線。於一可能實施例中,搜尋電壓VH與VR可分別是通過電壓與讀取電壓,但本案並不受限於此。Figure 14C shows another step diagram of data search according to an embodiment of the present case. Figure 14D shows a further step diagram of data search according to an embodiment of the present case. In Figure 14C, the reference voltage VH is applied to the unselected word lines to turn on all the unselected word lines. In Figure 14D, search voltages VH and VR are applied to the selected word lines based on the search data. In a possible embodiment, the search voltages VH and VR may be the passing voltage and the reading voltage respectively, but the present case is not limited thereto.
例如,於第一次資料搜尋中,比對物件a的第一張照片的特徵向量“Ba1”、物件a的第二張照片的特徵向量“Ba2”與物件b的第一張照片的特徵向量“Bb1”,則被選字元線是字元線WL0、WL1,而未選字元線則是字元線WL2~WL7。For example, in the first data search, compare the feature vector "Ba1" of the first photo of object a, the feature vector "Ba2" of the second photo of object a, and the feature vector of the first photo of object b. "Bb1", then the selected character line is the characterLines WL0 and WL1, and the unselected word lines are word lines WL2~WL7.
如第14C圖與第14D圖所示,於第一次資料搜尋中,搜尋電壓VH與VR(搜尋資料為0)施加至記憶區塊B0的被選字元線WL0、WL1;以及,搜尋電壓VR與VH(搜尋資料為1)施加至記憶區塊B1的被選字元線WL0、WL1。As shown in Figures 14C and 14D, in the first data search, the search voltages VH and VR (the search data is 0) are applied to the selected word lines WL0 and WL1 of the memory block B0; and, the search voltages VR and VH (search data is 1) are applied to selected word lines WL0, WL1 of memory block B1.
第14E圖顯示根據本案一實施例之資料搜尋結果。Figure 14E shows the data search results according to an embodiment of this case.
在此假設“Ba11”=0、“Ba12”=0,“Ba21”=0、“Ba22”=1,“Bb11”=0、“Bb12”=0。則位元線BL0上,記憶區塊B0的記憶體晶胞群組1200為導通,記憶區塊B1的記憶體晶胞群組1200為不導通,所以位元線BL0上的電流為1單位電流;於位元線BL1上,記憶區塊B0的記憶體晶胞群組1200為導通,記憶區塊B1的記憶體晶胞群組1200為導通,所以位元線BL1上的電流為2單位電流;位元線BL2上,記憶區塊B0的記憶體晶胞群組1200為導通,記憶區塊B1的記憶體晶胞群組1200為不導通,所以位元線BL2上的電流為1單位電流。It is assumed here that "Ba11 "=0, "Ba12 "=0, "Ba21 "=0, "Ba22 "=1, "Bb11 "=0, "Bb12 "=0. Then, on the bit line BL0, the
依此,將各位元線上的512記憶區塊的電流加總(將頁緩衝器900B上的感應放大器的電流感應結果相加),以得到匹配結果。亦即,位元線BL0上的總電流代表物件a的第一張照片的特徵向量“Ba1”的資料搜尋結果;位元線BL1上的總電流代表物件a的第二張照片的特徵向量“Ba2”的資料搜尋結果;以及,位元線BL2上的總電流代表物件b的第一張照片的特徵向量“Bb1”的資料搜尋結果。Accordingly, the currents of the 512 memory blocks on each bit line are summed (the current sensing results of the sense amplifiers on the page buffer 900B are summed) to obtain the matching result. That is, the total current on bit line BL0 represents the data search result of the feature vector "Ba1" of the first photo of object a; the total current on bit line BL1 represents the feature vector "Ba1" of the second photo of object a. The data search results of "Ba2"; and, the total current on bit line BL2 represents the data search results of the feature vector "Bb1" of the first photo of object b.
當位元線上的電流加總結果超過電流閥值時,代表資料搜尋結果為匹配,反之亦然。When the sum of the currents on the bit lines exceeds the current threshold, it means that the data search result is a match, and vice versa.
於本案另一可能實施例中,頁緩衝器900B可以更選擇性包括類比數位轉換器,將位元線上的電流加總結果進行類比數位轉換。當頁緩衝器900B的類比數位轉換器的數位輸出信號為1時,代表資料搜尋結果為匹配,反之亦然。In another possible embodiment of this case, the page buffer 900B may optionally include an analog-to-digital converter to perform analog-to-digital conversion on the summed result of the currents on the bit lines. When the digital output signal of the analog-to-digital converter of the page buffer 900B is 1, it means that the data search result is a match, and vice versa.
第15圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0~2的示意圖。在此,記憶體晶胞群組1500包括耦接至同一位元線的3個相鄰或不相鄰記憶體晶胞MC0~MC2。Figure 15 shows a schematic diagram showing that the storage states of the memory unit cell group are 0~2 in an embodiment of this case. Here, the
記憶體晶胞群組1500的其中1個記憶體晶胞被程式化為高臨界電壓(HVT),而其餘2個記憶體晶胞被程式化為低臨界電壓(LVT)。例如但不受限於,記憶體晶胞MC0被程式化為高臨界電壓(HVT),而其餘2個記憶體晶胞MC1~MC2被程式化為低臨界電壓(LVT),則記憶體晶胞群組1500的儲存狀態為0。記憶體晶胞MC1被程式化為高臨界電壓(HVT),而其餘2個記憶體晶胞MC0與MC2被程式化為低臨界電壓(LVT),則記憶體晶胞群組1500的儲存狀態為1。記憶體晶胞MC2被程式化為高臨界電壓(HVT),而其餘2個記憶體晶胞MC0~MC1被程式化為低臨界電壓(LVT),則記憶體晶胞群組1500的儲存狀態為2。所以,記憶體晶胞群組1500最多有
至於資料搜尋(讀取)記憶體晶胞群組1500,則類似於第13圖的電壓設定。例如但不受限於,在本案一實施例中,對搜尋資料進行編碼以得到一組搜尋電壓(包括3個搜尋電壓)。對搜尋資料0進行編碼以得到第一搜尋電壓為高電壓VH,第二搜尋電壓與第三搜尋電壓為低電壓VR;對搜尋資料1進行編碼以得到第二搜尋電壓為高電壓VH,第一搜尋電壓與第三搜尋電壓為低電壓VR;對搜尋資料2進行編碼以得到第三搜尋電壓為高電壓VH,第一搜尋電壓與第二搜尋電壓為低電壓VR。其中,第一搜尋電壓至第三搜尋電壓分別透過不同字元線而施加至記憶體晶胞群組1500的3個記憶體晶胞的閘極。As for the data search (read)
同樣地,於進行資料搜尋時,當搜尋資料匹配於儲存資料時,記憶體晶胞群組1500產生電流,反之亦然。Similarly, during data search, when the search data matches the stored data, the
第16圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0~3的示意圖。在此,記憶體晶胞群組1600包括耦接至同一位元線的4個相鄰或不相鄰記憶體晶胞。記憶體晶胞群組1600的其中1個記憶體晶胞被程式化為高臨界電壓(HVT),而其餘3個記憶體晶胞被程式化為低臨界電壓(LVT)。其儲存狀態的細節可如上所述,於此不重述。記憶體晶胞群組1600最多有
至於資料搜尋(讀取)記憶體晶胞群組1600,則類似於第13圖的電壓設定。例如但不受限於,在本案一實施例中,對搜尋資料進行編碼以得到一組搜尋電壓(包括4個搜尋電壓),其中,1個搜尋電壓是高電壓VH,而其餘3個搜尋電壓是低電壓VR。搜尋資料轉換成搜尋電壓的細節可如上所述,於此不重述。As for the data search (read)
同樣地,於進行資料搜尋(讀取)時,當搜尋資料匹配於儲存資料時,記憶體晶胞群組1600產生電流,反之亦然。Similarly, during data search (reading), when the search data matches the stored data, the
第17圖顯示在本案一實施例中,記憶體晶胞群組的儲存狀態為0~5的示意圖。在此,記憶體晶胞群組1700包括耦接至同一位元線的4個相鄰或不相鄰記憶體晶胞。記憶體晶胞群組1700的其中2個記憶體晶胞被程式化為高臨界電壓(HVT),而其餘2個記憶體晶胞被程式化為低臨界電壓(LVT)。其儲存狀態的細節可如上所述,於此不重述。記憶體晶胞群組1700最多有
至於資料搜尋(讀取)記憶體晶胞群組1700,則類似於第13圖的電壓設定。例如但不受限於,在本案一實施例中,對搜尋資料進行編碼以得到一組搜尋電壓(包括4個搜尋電壓),其中,2個搜尋電壓是高電壓VH,而其餘2個搜尋電壓是低電壓VR。搜尋資料轉換成搜尋電壓的細節可如上所述,於此不重述。As for the data search (read)
同樣地,於進行讀取時,當搜尋資料匹配於儲存資料時,記憶體晶胞群組1700產生電流,反之亦然。Likewise, during reading, the
於本案其他可能實施例中,第17圖亦可用於記憶體晶胞群組的儲存狀態為0~4,其亦在本案精神範圍內。In other possible embodiments of this case, Figure 17 can also be used to store the storage states of the memory unit cell group from 0 to 4, which is also within the spirit of this case.
綜上所述,於本案上述實施例中,當將資料寫入至記憶體晶胞群組的記憶體晶胞時,以m(m為正整數,m≧2)條字元線為一組(亦即,以m個記憶體晶胞為一個記憶體晶胞群組,且該些m個記憶體晶胞耦接至同一位元線),其中,該m個記憶體晶胞中有n(n為正整數,n≧1)個記憶體晶胞被程式化為高臨界電壓且有(m-n)個記憶體晶胞被程式化為低臨界電壓,則該m個記憶體晶胞最多可以有
至於資料搜尋時,則將搜尋資料編碼為m個搜尋電壓,該m個搜尋電壓透過m條字元線輸入至記憶體晶胞群組,其中,有n個搜尋電壓為高電壓VH而有(m-n)個搜尋電壓為低電壓VR。故而,從該搜尋資料所編碼得到的搜尋電壓共有
於資料搜尋時,耦接至同一條位元線的p個(p為大於等於2的正整數)記憶區塊同時被打開,耦接至同一條位元線的該些p個記憶區塊的感應電流從該位元線流至頁緩衝器的感應放大器以得到搜尋結果。當感應電流愈大時,代表搜尋資料與儲存資料之間的相似度(similarity)愈高,故而,可利用感應電流來判斷相似度。例如但不受限於,當資料庫物件的特徵向量有512個維度時,於搜尋資料庫物件時,p至少大於等於512。亦即,p之值相關於資料庫物件的特徵向量的維度數量。During data search, p (p is a positive integer greater than or equal to 2) memory blocks coupled to the same bit line are opened at the same time. The p memory blocks coupled to the same bit line are opened at the same time. A sense current flows from the bit line to the sense amplifier of the page buffer to obtain the search result. When the induced current is larger, it means that the similarity between the search data and the stored data is higher. Therefore, the induced current can be used to determine the similarity. For example, but not limited to, when the feature vector of a database object has 512 dimensions, p is at least greater than or equal to 512 when searching for the database object. That is, pThe value relates to the number of dimensions of the database object's feature vector.
進一步說,一記憶平面包括q個記憶區塊,則p<(q/2),亦即,該記憶平面可儲存資料庫物件的至少2個特徵向量。Furthermore, if a memory plane includes q memory blocks, then p<(q/2), that is, the memory plane can store at least 2 feature vectors of database objects.
第18圖顯示根據本案一實施例之記憶體裝置之功能方塊圖。該記憶體裝置1800包括:一記憶體陣列1810,以及一控制器1820,耦接至該記憶體陣列1810。其中,該控制器1820架構成:根據所記錄的一壓縮模式,對一搜尋資料進行向量化以得到一搜尋資料向量,其中,該搜尋資料與一資料庫的複數個物件皆由該壓縮模式所壓縮,該資料庫的複數個物件儲存於該記憶體陣列1810內;設定一搜尋條件;以該搜尋資料向量去搜尋儲存於該記憶體陣列1810內的該資料庫的該些物件,以判斷該搜尋資料是否匹配於該資料庫中的該些物件;以及記錄並輸出與該搜尋資料匹配的該資料庫中的至少一匹配物件。Figure 18 shows a functional block diagram of a memory device according to an embodiment of the present invention. The memory device 1800 includes: a
在本案上述實施例中,資料庫中的複數個物件資料被模型進行向量化以得到物件向量(或特徵向量),該些物件向量(或特徵向量)符合高維度低解析度,以簡化計算及減少所需的儲存空間。此外,更可以對該些物件向量進行切割(亦即壓縮),例如但不受限於,維度等量切割。In the above embodiment of this case, multiple object data in the database are vectorized by the model to obtain object vectors (or feature vectors). These object vectors (or feature vectors) conform to high dimensions and low resolution to simplify calculations and Reduce required storage space. In addition, these object vectors can be cut (that is, compressed), for example, but not limited to, cutting by equal dimensions.
在本案上述實施例中,透過導入遮罩向量,可以遮罩信心度較低的向量元件,以提高匹配信心度。In the above embodiment of this case, by importing mask vectors, vector elements with low confidence can be masked to improve matching confidence.
在本案上述實施例中,該記憶體裝置可為非揮發性記憶體,或者是,揮發性NAND快閃記憶體。In the above embodiment of this case, the memory device can be a non-volatilememory, or volatile NAND flash memory.
本案上述實施例的記憶體裝置及其資料搜尋/比對方法可應用於車載裝置、行動裝置、邊緣裝置(edge device)等。The memory device and its data search/comparison method in the above embodiments of this case can be applied to vehicle-mounted devices, mobile devices, edge devices, etc.
本案上述實施例的記憶體裝置及其資料搜尋方法可以達成計算簡單但高分析信心度。The memory device and its data search method in the above embodiments of this case can achieve simple calculation but high analysis confidence.
綜上所述,雖然本發明已以實施例揭露如上,然其並非用以限定本發明。本發明所屬技術領域中具有通常知識者,在不脫離本發明之精神和範圍內,當可作各種之更動與潤飾。因此,本發明之保護範圍當視後附之申請專利範圍所界定者為準。In summary, although the present invention has been disclosed above through embodiments, they are not intended to limit the present invention. Those with ordinary knowledge in the technical field to which the present invention belongs can make various modifications and modifications without departing from the spirit and scope of the present invention. Therefore, the protection scope of the present invention shall be determined by the appended patent application scope.
105-135:步驟105-135: Steps
Claims (10)
Translated fromChinese

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| TW111124082ATWI813358B (en) | 2022-06-28 | 2022-06-28 | Memory device and data searching method thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| TW111124082ATWI813358B (en) | 2022-06-28 | 2022-06-28 | Memory device and data searching method thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| TWI813358Btrue TWI813358B (en) | 2023-08-21 |
| TW202401275A TW202401275A (en) | 2024-01-01 |
Family
ID=88585858
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW111124082ATWI813358B (en) | 2022-06-28 | 2022-06-28 | Memory device and data searching method thereof |
Country Status (1)
| Country | Link |
|---|---|
| TW (1) | TWI813358B (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2008133898A1 (en)* | 2007-04-23 | 2008-11-06 | Aptina Imaging Corporation | Compressed domain image summation apparatus, systems, and methods |
| TW200912680A (en)* | 2007-05-31 | 2009-03-16 | Yahoo Inc | System and method for providing vector terms related to a search query |
| CN101290545B (en)* | 2007-04-17 | 2011-10-26 | 霍奂雯 | Matrix Chinese character input method and device |
| CN105706155B (en)* | 2013-09-27 | 2019-01-15 | 英特尔公司 | The memory access of vector index adds arithmetic and/or logical operation processor, method, system and instruction |
| TW201931163A (en)* | 2017-10-10 | 2019-08-01 | 香港商阿里巴巴集團服務有限公司 | Image search and index building |
| TWI749691B (en)* | 2019-08-28 | 2021-12-11 | 美商美光科技公司 | Error correction for content-addressable memory |
- 2022
- 2022-06-28TWTW111124082Apatent/TWI813358B/enactive
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101290545B (en)* | 2007-04-17 | 2011-10-26 | 霍奂雯 | Matrix Chinese character input method and device |
| WO2008133898A1 (en)* | 2007-04-23 | 2008-11-06 | Aptina Imaging Corporation | Compressed domain image summation apparatus, systems, and methods |
| TW200912680A (en)* | 2007-05-31 | 2009-03-16 | Yahoo Inc | System and method for providing vector terms related to a search query |
| CN105706155B (en)* | 2013-09-27 | 2019-01-15 | 英特尔公司 | The memory access of vector index adds arithmetic and/or logical operation processor, method, system and instruction |
| TW201931163A (en)* | 2017-10-10 | 2019-08-01 | 香港商阿里巴巴集團服務有限公司 | Image search and index building |
| TWI749691B (en)* | 2019-08-28 | 2021-12-11 | 美商美光科技公司 | Error correction for content-addressable memory |
Also Published As
| Publication number | Publication date |
|---|---|
| TW202401275A (en) | 2024-01-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Jégou et al. | On the burstiness of visual elements | |
| US11294624B2 (en) | System and method for clustering data | |
| Jain et al. | Online metric learning and fast similarity search | |
| CN107562938B (en) | A Court Intelligent Judgment Method | |
| Beecks et al. | Modeling image similarity by gaussian mixture models and the signature quadratic form distance | |
| Wei et al. | Projected residual vector quantization for ANN search | |
| CN105718960A (en) | Image ordering model based on convolutional neural network and spatial pyramid matching | |
| WO2023246337A1 (en) | Unsupervised semantic retrieval method and apparatus, and computer-readable storage medium | |
| CN115795065A (en) | Multimedia data cross-modal retrieval method and system based on weighted hash code | |
| CN113553326A (en) | Spreadsheet data processing method, device, computer equipment and storage medium | |
| CN115617985A (en) | Automatic matching and classifying method and system for digital personnel file titles | |
| CN117352032A (en) | Memory device and data search method | |
| TWI813358B (en) | Memory device and data searching method thereof | |
| CN107704872A (en) | A kind of K means based on relatively most discrete dimension segmentation cluster initial center choosing method | |
| CN108536772B (en) | An Image Retrieval Method Based on Multi-feature Fusion and Diffusion Process Reordering | |
| Torkkola | Learning discriminative feature transforms to low dimensions in low dimentions | |
| CN117131196B (en) | Text processing method and system | |
| TWI868456B (en) | Memory device and data searching method thereof | |
| Tseng et al. | In-memory approximate computing architecture based on 3D-NAND flash memories | |
| CN108280485A (en) | A kind of non-rigid method for searching three-dimension model based on spectrogram Wavelet Descriptor | |
| Zhang et al. | Automatic image region annotation through segmentation based visual semantic analysis and discriminative classification | |
| CN117290535A (en) | Memory device and data searching method thereof | |
| CN112465024A (en) | Image pattern mining method based on feature clustering | |
| TWI875591B (en) | Database circuit and data matching method | |
| CN113486176B (en) | News classification method based on secondary feature amplification |